
Scott H. Young's Blog, page 20
May 3, 2022
More Recent Reading
About a year ago, I started a research project focused on the transfer of learning. Given the often disappointing evidence for learning transfer between the classroom and the real world, I was eager to dig into the research on apprenticeships and learning by doing.
But the research turned out to be more complicated (and interesting!) than I had expected. I wrote a little about some of the difficulties with my original hypothesis here. Since then, I’ve been exploring broadly to build a more coherent picture of how we think and learn.
The following books are from my most recent batch. (If you want to see more, here are some previous entries in my research reading list series.)
1. Descartes’ Error by Antonio DamasioThe mind is not separate from the body. Emotions are essential to reason. Descartes’ error was assuming that our sense of self is grounded in our ability to think and that the flesh we inhabit is a mere appendage.
Damasio is a neuroscientist most famous for his somatic marker hypothesis. This theory argues that we unconsciously integrate perceptions of our emotional and physical state. These bodily cues serve to “mark” out decisions for risk and reward, allowing us to make intelligent “gut” decisions.
Damasio’s principal evidence comes from brain-damaged patients. Those with damage to the limbic system exhibit normal intelligence but are utterly useless in their personal lives. They can’t make decisions, in part, because they lack the emotions that would help them prioritize.
In the Iowa Gambling Task participants choose cards from decks. Some have high rewards but occasionally big losses. Other decks are safe choices, and they have lower rewards but fewer big dips. Control participants without brain damage learn to sense which decks are risky and avoid them. Brain-damaged patients continue to choose risky cards.
I found the book persuasive, but the somatic marker hypothesis remains controversial.
2. Greatness by Dean SimontonWho makes history and why? Psychologist Dean Simonton surveys a vast scientific literature on the contributions of famous artists, scientists, politicians and leaders.
Simonton finds that career productivity exhibits a characteristic shape. Output rapidly accelerates starting at career onset, followed by a peak and more gradual decline. The sharpness of the peak is field-specific, with poets and mathematicians both rising and falling faster than novelists or biologists.

Quality and quantity are highly correlated in creative work. The best scientists, authors and artists are also the most prolific. Price’s Law puts this observation in mathematical language: half of the creative output will be produced by the square root of the number of researchers. To illustrate, in a group of 100 scientists, this equation predicts half of the papers will be published by only ten researchers.
3. Secret Knowledge by David HockneyHow did Renaissance-era painters go from this to this in just a few decades?

Artist David Hockney amasses compelling evidence that Renaissance-era painters made use of mirrors and lenses much earlier than previously suspected. He argues that the old masters’ adoption of optics caused not only the rapid increase in realism, but led to signature distortions that a careful eye can detect.
4. Will College Pay Off? by Peter CappelliWharton professor Peter Cappelli reviews the evidence on the financial payoff of going to college. What he finds is confusing, and that’s sort of his point.
Cappelli finds that the return on a college degree varies wildly. Majors that are “hot” now may not be after graduation. Schools that offer more vocational training often have worse returns than traditional liberal arts institutions. Financial aid, student loans, and the fact that few people pay the sticker price make it even harder to evaluate the return on higher education.
Cappelli argues against the idea of a skills gap that claims there’s a deficit of highly-skilled workers. Instead, he argues there is a training gap. Employers want new workers to be job-ready, but they don’t want to invest any time getting new hires up to speed. Unfortunately, employers don’t seem to care much about the academic skills offered in school, so the direct value of such preparation is questionable.
This book is not very helpful if you want a clear answer to the titular question. But if you want to understand how the labor market “works” and who gets hired, it is a fascinating overview.
5. Exploring Science by David KlahrHow do scientists think? Klahr, drawing on the pioneering work of Herbert Simon and Allen Newell, views scientific cognition as an act of problem solving. Discovery is a search through the space of possible hypotheses, as well as possible experiments for testing whether they’re right.
In contrast to sociological studies of science, Klahr looks at discovery processes in the laboratory. Students were given programmable gadgets with mysterious functions and asked to figure them out. From that, Klahr and others deduce the cognitive processes involved in scientific work.
The book is full of interesting tidbits, but one that stood out to me was an alternative explanation of the famous 2-4-6 task. In this experiment, subjects are given numbers, “2, 4, 6,” that follow a rule, and they can ask if other numbers follow the rule. Experimenters typically find confirmation bias in this task. People come up with a theory (e.g., “1x, 2x, 3x”) and then only test examples which seek to confirm that theory, such as “3, 6, 9” or “10, 20, 30”. These students typically fail since the actual rule, “any ascending sequence,” is broader. Klahr, in contrast, argues that students instead rely on a “positive test strategy,” which is rational if you assume that most of the tests you try won’t work.
6. Working Minds by Beth Crandall, Gary Klein and Robert HoffmanTacit knowledge is a major barrier to informal learning. When you see an accomplished artist paint a masterpiece, how do they do it? If you’re lucky, you might be able to see their brushstrokes, but you can’t see why they made those strokes. What factors did they consider? What heuristics, skills and intuitions did they use?
Since Schneider and Shiffrin’s theory of controlled and automatic processing, it’s been argued that skills proceed through phases. In the beginning, performing any skill is deliberate and effortful. With time it becomes invisible and automatic. Figuring out how experts perform the skill is hard. This isn’t because they hoard secrets, but because the right thing to do is so apparent to them that it becomes difficult to express.
Cognitive task analysis is family of methods designed to tease out this kind of knowledge. It includes concept mapping, structured interviews, and retelling critical incidents. While extracting expert knowledge is itself a skill that requires considerable training, I found the basic framework helpful for thinking about developing skills.
7. Cognition and Reality by Ulric NeisserThe cognitive revolution in psychology is often dated to Neisser’s text Cognitive Psychology. This revolution brought with it a renewed interest in hidden mental processes that were considered unscientific in the age of American behaviorism.
In this book, Neisser turns against some of the new distortions the revolution brought about. In particular, he criticizes the computer model espoused by researchers like Herbert Simon and Allen Newell. He calls for greater ecological validity of psychological experiments (i.e., experiment findings or predictions should mirror real-life behavior).
The importance of schema is a central idea. These are mental patterns you have that allow you to “pick out” information from the environment. Your schema for English words, for instance, enables you to make sense of these squiggles you’re reading right now.
There is an ongoing debate between “constructivist” and “positivist” visions of psychology. Constructivists see the world top-down: prior knowledge, context, and culture limit what we are able to see. Positivists see the world bottom-up: we gain knowledge directly from our senses and science.
The reality is probably both. As I discuss in my review of Walter Kintsch’s Construction-Integration theory, we have stimulus-driven rules for understanding text, but apply prior knowledge to make inferences and assemble complex meanings. Both schemas in our head and stimuli in the outside world combine to determine our thoughts.
8. Noise by Daniel Kahneman, Olivier Sibony and Cass SunsteinEverybody worries about bias. Not enough people worry about noise.
Using the authors’ analogy, imagine firing at a target. Bias means the center of your shots misses the bulls-eye in a consistent way. Noise means your shots have a large spread. Both are bad, but the latter often gets overlooked.

The authors point out that noise can be worse than bias. Judges set wildly different sentences for the same crimes. Insurance underwriters have large ranges in the quotes they offer for particular risks. Employers’ impressions of candidates vary significantly from interviews.
To avoid bias, the authors suggest a few decision hygiene strategies:
Use mechanical rules over human judgements.Aggregate independent ratings.Use ranked comparisons rather than absolute scales.Use structured, analytical assessments before holistic evaluations.Take the outside view. Use base rates to judge likelihood.My interest in this book stems from the limits of learning and expertise. Kahneman is famously skeptical of expertise, arguing that many so-called experts simply aren’t very good. Why are we so noisy and fallible in our judgement, even with years of training and experience? What does the answer say about the path to self-improvement?
9. Administrative Behavior by Herbert SimonHerbert Simon won a Nobel prize for his work on bounded rationality. In Administrative Behavior, based on his doctoral dissertation, he argues that many “principles” of management are contradictory.
Instead, he views management as being an issue of information and influence. Individual decision-making suffers under the constraints of limited attention and processing capacity. The existence of firms, Simon argues, is predicated on the enhanced ability of organizations to channel flows of information that enable cooperation.
I found this book interesting because it identifies organizational learning problems, essentially, as network problems. Only when you see the work of organizations in such a light can you make sense of both their powers and dysfunctions.
10. Scientific Elite by Harriet ZuckermanWho becomes a Nobel prize winner? How do they differ from rank-and-file scientists?
Zuckerman’s classic work takes a comprehensive look at the lives of American Nobel laureates. She systematically combed over their family backgrounds (typically wealthy, professional), their educational path (invariably elite), and scientific careers (prolific, concentrated in highly productive networks).
Zuckerman, with the great sociologist Robert Merton, argues in favor of the Matthew Effect in science. Alluding to the Biblical passage, this argues that elite research is a self-reinforcing cycle. The best talents get the best mentors, the most funding, and access to cutting edge problems. Researchers outside this illustrious circle struggle to compete.
I’m fascinated by data-driven accounts of how elite success “works” in various fields. While few of us will ever reach such heights, the knowledge of how to achieve that success is unevenly distributed. As one Nobel laureate remarked on the “obvious” truth of finding good scientific mentors:
“Many of the students were just silly about the way they chose professors. They just didn’t know the professors of real quality.”
Certainly, some part of success is due to innate talent and sheer chance. But it seems more than coincidental how those who eventually win so often exhibit shrewd analysis of the often obscure rules of success in their field.
===
I’ve done several of these book reviews, but I’ve spent a similar amount of time reading scientific papers. Perhaps I should put together a list sharing some of the more interesting ones I’ve read? Let me know what you think!
The post More Recent Reading appeared first on Scott H Young.


April 25, 2022
Rapid Learner is Now Open for a New Session
Rapid Learner, my six week course designed to make you a better student, professional and lifelong learner is now open:
Click here to sign up for Rapid Learner.
This is the new edition of the course, which includes 20+ newly recorded lessons, deep dives, walkthroughs and more. If you’re looking to get better at learning difficult things, this course is the place to start.
Registration will only remain open until midnight on Friday, April 29th, 2022 (Pacific time).
The post Rapid Learner is Now Open for a New Session appeared first on Scott H Young.
April 21, 2022
See-Do-Feedback: The Right Way To Practice
Next week, I’m opening a new session of my popular course, Rapid Learner. Registration will begin on Monday, April 25th and closes on Friday, April 29th. Below is a lesson drawn from the material I teach in Rapid Learner. If you find it helpful, be sure to check out the full course.
The foundation for effective learning is practice. You get good at things by doing them. Yet within this simple observation is a maze of complexity. How should you practice to get the most improvement with the least time and effort?
Good practice has three components:
See. Look for an example of how to solve a problem.Do. Solve the problem yourself.Feedback. Check whether you got the right answer.
These basic steps form a loop that can allow you to learn any skill or subject. Much of effective learning is about optimizing the details of the see-do-feedback loop. Let’s look at each part.
1. See: The Power of ExamplesPeople don’t solve problems by building general-purpose problem-solving skills. Instead, decades of research shows that experts in domains as diverse as chess, programming, and medical reasoning get good by acquiring tons of specific patterns of knowledge.
What’s the best way to acquire these patterns? Graham Cooper and John Sweller examined this in high-school students learning algebra in a now-famous study. Half the students were given a set of problems and asked to solve them. The other half were given examples where the problems were worked step-by-step and the solutions were provided. After this, both groups took the same test. Who did better?
The group given worked examples ended up doing better than those who solved the problems themselves—even when the problem-solving group correctly answered every question in the practice session.
The authors explain their results in terms of cognitive load. When faced with a question where you don’t know the pattern for finding the answer, people engage in a mentally taxing process of problem solving. This process is efficient for finding the solution to the problem in front of you, but it doesn’t leave much capacity for learning the pattern you use to answer that type of problem.

Sweller’s results show why seeing examples and getting explicit instructions for performing a task are so beneficial—the pattern can be learned correctly rather than guessed at.
2. Do: The Need for RetrievalOf course, if watching alone led to skill, we wouldn’t need to practice at all. We could watch cooking shows and instantly become chefs or see a football (soccer) match and pick up dribbling skills. Acquiring patterns isn’t enough—the knowledge needs to become an automatic skill in order to be useful.
A study by Jeffrey Karpicke and Janelle Blunt shows that practice isn’t just for physical skills. They had students learn from a text. Some read the passage once and then tried to recall everything they had learned. Others read the same passage multiple times.
Before the test, re-readers thought they had mastered the material. Those who only read it once and then recalled the material expected to do poorly. Yet the test results were the reverse. Those who practiced recall did better than re-readers.

How do we reconcile this study with the previous one, where those solving problems did worse than those who just looked at examples?
There are two answers here. First, even in Karpicke and Blunt’s study, subjects who practiced recall still read the text once. The disadvantage was for re-reading, not avoiding reading altogether. This makes sense—how could you possibly recall anything from a text you didn’t read?
The second is that the power of practice depends on task complexity. Solving algebra problems was still an unfamiliar task for the participants in Sweller and Cooper’s study. This meant answering a question required active problem solving, not just retrieving a pattern from memory. In contrast, Karpicke and Blunt were only asking students to recall anything they could—an activity that doesn’t require holding a lot of information in working memory while you’re trying to arrive at an answer.
Therefore, the best approach to learning is to see a few examples of the pattern to be learned. If the pattern is complicated and you can’t remember it all at once, doing it once or twice with examples on hand is helpful. Later, however, you should switch to practicing without the examples so you can perform it from memory.
3. Feedback: Check Your WorkFinally, you need to get feedback on your practice. If the problem is something with a straightforward, unique answer, seeing the correct solution is enough. For skills with gradations of performance or more subjective measures of success, a teacher, tutor or coach can give you the feedback you need.

Feedback is vital for a few reasons. First, it can correct for errors. Making mistakes when learning can actually be beneficial—if there is quick feedback. Students whose expectations were violated by an answer remembered the correct answer better.
Second, feedback can train your unconscious learning system. The procedural learning system of the brain operates through rewards. It strengthens past actions that led to success and weakens those that led to failure. While this kind of reinforcement learning isn’t suited to some types of problems, it can help you develop an intuition for skills beyond what you can consciously recognize.
Finally, feedback directs your attention and motivation for future learning. By pointing out areas of weakness in your performance, you can spend more energy on the next see-do-feedback loop to fix things. Without feedback, we waste a lot of energy focusing on the wrong things.
Implementing the LoopA loop like this can be applied to many different skills and subjects:
Programming: See a particular command, data structure or design pattern; implement it yourself; then check to see that it works properly.Languages: See vocabulary, phrases and grammar; test it out in a conversation, and check whether you are properly understood.History: Read a book, write a passage explaining the main points, and check back to see what you’ve missed.Business: Learn a new management technique, implement it within your company, and see how it performs.Getting this loop right involves subtly tweaking a lot of variables. One concerns the level of granularity: how much of your focus should go to big projects (programming projects, full conversations in another language) versus component parts (individual commands, exact vocabulary). Another variable is the trade-offs between tighter loops and more realistic practice. Flashcards may give quick feedback when learning a language, but they won’t teach many of the skills needed for fluent conversations.
In Rapid Learner, I’ll go into far more detail about how to develop and optimize your learning practice. Until then, start asking yourself how you might convert more of your current learning activities into a see-do-feedback loop?
Leave a comment below and tell me one thing you could do to make your learning more effective applying this approach.
The post See-Do-Feedback: The Right Way To Practice appeared first on Scott H Young.
April 12, 2022
Reader Mailbag: Sustaining Motivation, Judging Experts and the Meanings of Life
Last week, I asked readers to send me their questions about learning, life, or… anything really. I got over one hundred replies! Here are a few I’d like to share:

Gary asks:
“What are your morning and evening routines?”
I don’t have anything fancy in terms of routines.
My mornings, these days, usually start at seven. I have coffee, my wife and I get our son ready for daycare, and I go to the office. My evenings are usually dinner and family time until my son goes to bed, then I watch a television show with my wife and read a bit before going to sleep.
As a meta-point, I’m somewhat against the idea of focusing too much on routines. While good habits are important, they’re not a magic sauce for getting results. People with wildly different habits can reach similar levels of success. In contrast, others who have identical routines can have totally different outcomes.
Perhaps that isn’t the motivation behind your question. Still, it’s worth stating because sometimes people overanalyze things like routines and under analyze more direct contributors to someone’s outcomes (e.g. what projects they work on, what skills and assets they possess, etc.).
Michael asks:
“How do you balance growth with sustainability? I recently started a full time job, in addition to a rigorous virtual conservatory (16+ hours a week) in addition to part time work and an increasingly busy creative freelance career. After two months of near-burnout I left the virtual conservatory. Did I make the right choice?”
Burnout isn’t good. It sounds like you made the right choice to me.
Doing a ton of things and being hyper-busy is one of the most overrated ideas to infect productivity writing. If this is what “productivity” means, then I’m hardly the person to be offering advice. I take quite a bit of vacation time, and my working hours are pretty reasonable.
To me, the aim of productivity is to get bigger outcomes for fewer inputs, including time. Even when you need to pour tons of time into one pursuit, that’s often best handled by being able to drastically cut other kinds of competing work.
Ene asks:
“What’s in your opinion, the best theory so far on how to sustain motivation?”
I believe motivation is a (somewhat) rational signal about the value of your activity. To feel motivated, the project needs to be high value with high certainty.
On top of that there are experiential concerns. A project can be frustrating because there are problem-solving steps with large, unbounded problem spaces that don’t allow tractable progress. Emotional issues arising because of people you need to work with or the intrinsic interestingness (or lack thereof) of the subject can also affect the motivational “costs” of pursuing it.
This rationalistic perspective doesn’t suggest a simple “hack” you can do to improve your motivation. But I think it does help diagnose why motivation can succeed or fail. The answer is to design projects that have a high expected value, that you have confidence you can achieve, and design them to minimize the friction you experience when pursuing them.
When it comes to projects with low value, low confidence, and lots of friction, I’m not sure there’s a way to motivate yourself to pursue them. In part because without fixing those underlying problems, I’m not sure you should motivate yourself to do them.
Cort asks:
“I have a question for you. I am an older student (39 years old) and have encountered a lot of pushback when I tell people I want to get a PhD in quantum physics because I’m told math skills peak in one’s 20s. I know there’s evidence that the age of receiving the Fields Medal has increased, but is there any neuroscience or other evidence that you are aware of disproving this thesis?”
Fluid intelligence probably does peak a little younger, but I think the idea that there are massive declines in fluid intelligence is overstated. You’re probably roughly as intelligent as you were at 18 for most of your adult life. Fluid intelligence mostly seems to decline in very old age, and even then, there is considerable variability.
Put another way, I don’t think the difference in intelligence level between yourself at 20, and 39 even reaches the top ten factors that will influence your success in getting a Ph.D.
I suspect the skew to younger success in fields like math is less due to the advantage of young people, but their comparative lack of disadvantage. Math doesn’t need the huge knowledge base required in, say, history. Productivity probably declines after one’s youth for non-cognitive reasons. Ambition may be lower, you may have more family/admin responsibilities, etc.
If you have the energy to pursue a Ph.D., I wouldn’t let age stop you.
Michael asks:
“What are you most glad that you stopped doing?”
Social media, particularly Twitter. Every now and then, I get glimpses of it from links in blog posts. I forget how angry and toxic a place it is.
Parth asks:
“Are there any tips you have on how Ultralearning’s methodology can be applied at scale to an organization? I work at a software R&D centre.”
I think it’s up to organizations to give people the means to become better at their work. The major barriers to ultralearning are (a) a lack of good resources and (b) a lack of credible signals that these skills matter within the organization.
People want to invest in learning, but they often aren’t sure which skills are worth investing in, nor whether those investments will be recognized. Employers can solve both of those problems.
Adrian asks:
“How do you judge expertise? It seems like most fake news detection is done on a case-by-case basis. Is there an algorithm for evaluating experts?”
Expertise is a social phenomenon.
To be an expert means that other experts of the same “type” recognize you as such. This is a social mechanism that does pretty well because, relative to the standards of a discipline, other experts are much harder to bs than lay audiences. But it often fails because the standard itself isn’t tied to any objective result. Hence, you can have “experts” that make pretty bad predictions, like political pundits or many supposed foreign policy experts during the lead-up to the Iraq War.
I think it is useful to measure performance against some kind of real-world benchmark, but it seems clear to me that this isn’t what we generally mean when we say someone is an expert.
Sneha asks:
“I have 2 little kids- 3 and 7 years old. I want them to be good learners and develop a passion for learning from childhood. How do I get them to do that?”
My little one is only two, so I don’t have a lot of first-hand experience here.
My overall philosophy is that the best thing you can do is embody what you try to teach. It’s hard to encourage kids to be lifelong learners if you aren’t one yourself. So my focus would be on improving my own self-education and then trying to share that with my kids.
Calvin asks:
“I would like to know your opinion on when you should build a skill versus when you should delegate it and focus on someone else doing it.”
I don’t think there’s a general answer. My model of the situation is that whenever the skill you’re learning is highly integrated with the main value you provide through an activity, learning is better than delegation. However, delegation usually works better when the new skill is decoupled from your performance.
For me, research is an example of an integrated activity. I experimented with having a researcher help with essays. While he did a great job, the knowledge wasn’t my knowledge. I couldn’t assimilate it easily it to come up with new ideas or better advice.
This is additionally complicated by the opportunity cost of time investment and the level of expertise you need to acquire to recoup that cost. Learning everything myself made more sense when I started out because my effective wage rate was low. The opportunity cost of, say, learning programming to the $25/hour level of expertise was low. But if I wanted to get my skills to a $200/hour level, then the costs of difficulty and time needed to learn the skill become much steeper, and it’s less worthwhile.
All of this economic analysis omits the intrinsic dimension of things. I like learning Chinese, but it patently fails this cost-benefit calculation, so I’m forced to admit it’s just a hobby. The same is probably true of my doodling.
Jeremy asks:
“What are your thoughts about spirituality and the meaning of life?”
I tend to think there is no meaning of life, only meanings in life. I think the idea that you can stand outside of life and ask what it is “for” is a category error. Instead of a meaning for life, as a whole, there are meanings in life—good relationships, work that helps people, creative accomplishment, novel experiences and intellectual understandings.
Don’t get me wrong, I’m not making the claim that life is pointless or that there are no meanings greater than ourselves. I think it’s a mistake to imagine some vantage point that stands above our lives and evaluates them. But such a vantage point is not actually possible to experience. The most we can do is reflect back on our memories and assign them meaning, which isn’t exactly the same question.
Thus, I tend to think the “meaning of life” is a problematic philosophical question owing to this cognitive illusion. I think a better question is how you can have more plentiful meanings in your life. It may seem less profound because the answer tends to be less surprising: help people, have good relationships, fulfill creative and intellectual ambitions, be a good person, etc.
Sam asks:
“How has your relationship with productivity changed over time?”
Theoretically, I think I’m less interested in systems than I used to be. Part of this is simply because my work has shifted from checking off a lot of relatively easy tasks that nonetheless need to be done, to mostly working on really hard things (all the straightforward work got delegated away).
Kalpana asks:
“If you could design an education system, what would it look like?”
My thoughts on the education system have bounced around a lot.
I like academic topics. I think the world would be a better place if people knew more of them.
Yet I also think our current system is enormously wasteful. People invest enormous energy and cost into acquiring academic skills that have minimal relevance to their eventual work. They do so for the near-mandatory signals of intellectual ability and work ethic. This vocationalism also tends to undercut genuine interest as students grind through coursework to pass courses and exams that they don’t care about.
I think, in a perfect world, education would be nearly free. It would be delivered online and allow participation via voluntary communities of those interested in the subjects. Work skills would be mainly learned via apprenticeship processes. Necessary book learning could be provided through cheap testing/certification methods. In such a world, anyone could learn any skill they want to free of charge, only paying when they need tutoring or testing certification.
Yet I’m also pessimistic about such a world coming about. It’s not that this is economically or pedagogically impossible. It’s that we’ve gotten into a bad signaling equilibrium where doing well in a traditional, four-year academic program is considered the only way to get started professionally. Most professional licensing organizations exacerbate the problem by also requiring those credentials.
Given that my vision is somewhat utopian, I’m happy to settle for self-directed learning of the kind I espouse in Ultralearning for now. It’s harder than it should be due to a lack of institutional support. Still, it’s definitely doable for someone who actually cares about educating themselves.
===
Thanks to everyone who asked a question. Hopefully, we can do it again sometime!
The post Reader Mailbag: Sustaining Motivation, Judging Experts and the Meanings of Life appeared first on Scott H Young.
March 28, 2022
Book Review: Human Problem Solving
How do we solve hard problems? What are we thinking about as we work? What influences whether we find an answer or remain stuck forever?
These are the questions Allen Newell and Herbert Simon set out to address in their landmark 1972 book, Human Problem Solving. Their work has had an enormous influence on psychology, artificial intelligence, and economics.

How do you get reliable data for complicated problems? Here’s the basic strategy behind HPS:
Find a category of problems you want to study.1Write a computer program to solve the problem.Get participants to solve the problem while verbalizing their thought processes.Compare the computer program to the transcripts of real people solving the problem and look for similarities and differences.While all models are imperfect, computer programs have some distinct advantages as theories of human performance. For starters, they can solve the problems proposed. Since we know how computers work, but not how minds work, using a known process—the computer program—as a model avoids the issue of trying to explain one mysterious phenomenon with another.
However, Newell and Simon go further than this theoretical convenience. They argue that human thinking is an information processing system, just as a computer is. This remains a controversial thesis, but nonetheless, it makes strong and interesting predictions about how we think.2
Key Idea: Problem Solving is Searching a Problem SpaceNewell and Simon argue problem solving is essentially a search through an abstract problem space. We navigate through this space using operators, and those operators transform our current information state into a new one. We evaluate this state, and if it matches our answer (or is good enough for our purposes), the problem is solved.
We can liken this to finding our way in a physical space. Compare problem solving to finding the exit of a maze:
The problem space is the physical space in the maze. You have some current location, and you want to be at the exit. Solving the problem means finding your way out.Operators are the physical movements you can make. You can go left, right, forward or backward. After each movement, you’re in a different place. You evaluate your new state and decide if you have found the solution or if you should move again.
Now consider solving a Rubik’s Cube. How does this perspective on problem solving apply?
The problem space is all the possible configurations of the cube. Given there are over 43 quintillion possibilities, the space is enormous.The operators are your ability to rotate the cube in various directions. Even though the space is vast, the operators available at each moment are quite limited.Solving the puzzle involves moving through this abstract problem space, ending in a configuration where the colors are properly segregated to each side of the cube.
In a Rubik’s Cube, the operators on the problem space are physical, but they need not be. Consider Sudoku, where there might be other ways of conceptualizing the problem, resulting in different problem spaces:
A basic space might just be the set of all possible assignments of numbers to squares. Most of these would fail to fit the constraints of the numbers 1-9 being used uniquely in each subgrid, row, and column. Search in this space might look like trying out a random combination and seeing if it is correct.A better space would be augmented. Instead of allowing only fixed numbers at each square, you might have information about sets of “possible” numbers. Operators would consist of fixing a particular square and eliminating possibilities from those that remain via other constraints. This is closer to how experts solve Sudoku puzzles, as the basic problem space is unwieldy.
The difficulty of solving a problem isn’t always in searching the problem space. Sometimes, the hard part is choosing the correct space to work in in the first place. Insight-based puzzles, such as the nine-dot puzzle, fit this pattern. In this puzzle, you must cross all nine dots using four straight lines, drawn without lifting your pencil from the paper.

What makes this puzzle difficult is finding the problem space where the solution exists. (Answer here for those interested.)
What Determines Problem Solving Difficulty?I’ve already mentioned two factors that influence the difficulty of problems: the size of the problem space and how strongly the task itself suggests the best space. Newell and Simon found others in their research.
A simple one is the role memory has on problem solving. Human cognition depends far more on memory than most of us realize. Because working memory is limited, we lean heavily on past experience to solve new problems.
For instance, subjects universally prefer evaluating chess positions one sequence of moves at a time rather than pursuing multiple sequences simultaneously. For computers, the difference between breadth-first and depth-first search is a technical choice. For humans, depth-first is necessary because we don’t have the working memory capacity to hold multiple intermediate positions in our mind’s eye.

Conversely, many problems cease to be problems at all once we have the correct procedure in memory. As we learn new things, we develop memorized answers and algorithms that eliminate the need for problem solving altogether. Tic-tac-toe is a fun puzzle when you’re a kid, but it’s boring as an adult because the game always leads to a stalemate.
To see something as a problem, then, means it must occupy a strange middle-ground. It must be unfamiliar enough so that the correct answer is not routine, yet not so vast and inscrutable that searching the problem space feels pointless.
Is There a Programming Language of Thought?Given Newell and Simon frame their theories of human cognition in terms of computer programs, this raises a question: what sorts of programs fit best?
Newell and Simon argue in favor of production systems. A production system is a collection of IF-THEN patterns, each independent from one another. The collection of productions fires when the “IF” part of the observed pattern matches the contents of short-term memory. The “THEN” part corresponds to an operator—you do something to move yourself through the problem space.
This remains a popular choice. ACT-R theory, which continues to be influential in psychological research, is also based on the production system framework.
Productions have a few characteristics that make them plausible for modeling aspects of human thought:
Their modularity means that parts of what has been learned can transfer to new skills. While transfer research has often been pessimistic, it’s clear that humans transfer acquired skills much better than most computer programs. They extend the basic behaviorist notions of stimulus-response. Productions are like habits except, because they can operate on both internal and external states, they are far more powerful. They can incorporate goals, desires and memories.They force serial order on human thinking. The brain’s underlying architecture is massively parallel—billions of independently firing neurons. But human thinking is remarkably serial. Productions, processed in parallel but acted on in sequence, suggest a resolution to the paradox.Can We Solve Problems Better?Human Problem Solving articulates a theory of cognition, not practical advice. Yet it has implications for the kinds of problems we face in life:
1. The Power of Prior KnowledgePrior knowledge exerts an enormous influence on problem solving. While raw intelligence—often construed as processing speed or working memory capacity—does play a role, it is often far less important than having key knowledge.
Consider the ways prior knowledge influences your thinking:
Prior knowledge determines your choice of problem space. This is clear in the cryptarithmetic puzzles used by Newell and Simon. Subjects who already knew a lot about multi-digit addition were able to form a problem space consisting of letter values, odd-even parities and carries. In contrast, less-knowledgeable subjects struggled. Some worked in a more basic problem space, trying out random combinations before giving up. Others attempted dozens of different problem spaces, none of which were particularly suited to the task.Prior knowledge determines which operators are available to you. A sophisticated library of operators can make the problem much easier to solve. In some cases, it can eliminate the problem entirely as search is no longer required—you simply proceed with an algorithm that gets the answer directly. Much of what we do in life is routine action, not problem-solving.Prior knowledge creates memories of specific patterns, reducing analysis required. In chess, for instance, dynamic patterns require a player to simulate how play will unfold over time. This difficult-to-process task can be replaced by learning static patterns whose outcomes are understood just by looking at them. Consider a pattern such as a “forking attack” where a knight attacks two pieces simultaneously. While this pattern can be discovered through searching the possible future moves of the pieces in play, good players recognize it visually on the board. Simple recognition eliminates the need to formally analyze the implications of each piece, sparing precious working memory capacity.All of this suggests that knowledge is more important than intelligence for particular classes of problems. Of course, the two factors are often correlated. Intelligence speeds learning, which allows you to have more knowledge. However the intelligence-as-accelerated-knowledge-acquisition picture suggests different implications than the intelligence-as-raw-insight picture we often associate with genius. Geniuses are smart, in large part, because they know more things.
2. The Only Solvable Problems are Tractable OnesThis is an area where I’ve changed my thinking. Previously, I had written about what I called “tractability bias.” We tend to work on solvable, less important problems rather than harder problems that don’t suggest any solutions.
There is some truth to this account: we do tend to avoid impossible-seeming problems, even if they’re more worthy of our efforts. Yet HPS points to an obvious difficulty: the importance of a problem has nothing to do with our ability to solve it. Even for well-defined challenges, problem spaces can be impossibly vast. Finding a solution, even something that is “good enough,” can be impractical for many classes of problems.
I suspect our emotional aversion to hard problems comes from this place. Unless we have reasonable confidence our problem solving search will arrive at an answer we don’t invest any effort. Because the size of problem spaces can often be enormous, this is shrewd, not lazy.
To be successful we need to work on important problems. But, we also need to find ways to make those problems tractable. The intersection of these two requirements is what makes much of life so intriguing—and challenging.
The post Book Review: Human Problem Solving appeared first on Scott H Young.
March 21, 2022
How to Decide What to Work On
Working hard all day doesn’t matter if it’s on the wrong tasks. The most critical factor in your productivity is what you decide to work on.
The question of what to work on is under-discussed. There’s plenty of advice on getting work done: setting up good habits, creating productivity systems, project management and planning. Yet, there’s relative silence for the crucial decision of which projects to pursue.
Choosing what to work on is hard because you can’t know in advance how any project will turn out. If you knew what perspective was most worthwhile, the right choice would be obvious. It would simply be a matter of doing the work. But these choices exist outside of any particular vantage point. We don’t have this information, and we have to choose anyway.
 Ruling Out, Ruling In
Ruling Out, Ruling InA fundamental distinction is between having too many ideas or too few.
Too many ideas creates the problem of prioritization. You need to find reasons to disqualify projects. Evaluate your current activities and cull those that don’t make the cut.
Too few ideas can leave you feeling stuck. You want things to be better, but nothing pops out as worth pursuing. As a result, you put half-hearted efforts into tasks you’re not sure will work.

The “right” quantity of ideas isn’t a given. Instead, it’s a mental threshold for what’s worth pursuing. Dialing it up forces you to focus, and dialing it down lets you explore more options. Plans often generate ongoing or future commitments. Thus, there’s often a lag between when you realize your threshold is off and when you can adjust it. Whether you’re set too far in one direction may feel obvious, even as you struggle to change it.
Both reason and intuition factor into your settings here. Feeling burned out or bored can cause you to adjust. But so can looking at your calendar and realizing, actually no, you can’t take on another client.
Coming Up With IdeasThe origin of ideas often seems mysterious. How can you force yourself to have a creative spark?
Except, in practice, most ideas—even groundbreaking ones—tend to be derivative or incremental. Even ideas that look original usually start out as a permutation on something already extant. Given background and context, even the most radical suggestions look like incremental steps.

This suggests that the best way to have better ideas is to expose yourself to more ideas. Which ideas? The ones used by people who are accomplishing things in roughly the direction you’d like to go.
Find people who are achieving the sorts of success you’d like for yourself then ask what type of projects they pursue. If you can extract the general idea behind these projects, and why they worked, you’ll narrow the space of possibilities considerably.
Making the ChoiceA threshold for action is a crude way for filtering your projects. Advice to “do less” or “do more” misses the crux of the issue. Which efforts should you drop? Which ones should you undertake?
Having adjusted your threshold, and hopefully immersed yourself in a range of possible idea templates, now you need to cross over from a notion to a commitment.
A commitment can come from either direction. You can lower your threshold for action, generate a new idea and decide to pursue it. Or you can tighten your standards and commit to focusing on a pursuit you are already engaged in. Either way, the decision remains.
I find it useful to separate deciding from executing. The act of deciding needs to be realistic, perhaps even somewhat pessimistic. Executing that decision needs an almost irrational confidence and headstrong spirit. Failure to separate the two tends to result in impulsive choices and irresolute action.
For instance, the decision to start a business needs to be clear-eyed about the risks, your plan, and your odds of success. However, once you start that business, you need to be zealously committed to doing everything you can to make it work.
One way to help manage these two conflicting mental states is to separate them in time. Make a decision, and don’t let yourself change it for a month. The delay forces you to stop second-guessing yourself when you need to work. The nearby offramp helps you avoid worrying that you’re committing indefinitely to a potentially ruinous choice.
 Finding a Path and Walking It
Finding a Path and Walking ItMuch of life boils down to figuring out a path for yourself and then getting yourself to actually walk it.
It’s easy to dismiss either half of the problem. If the path seems obvious, you might think everyone who fails to walk it is simply lazy. Or perhaps you can’t find the path, so it seems everyone walking forward is a delusional striver.
But both halves of the problem interact. We often fail to stick to our plans because we’re not confident in our chosen path. And we fail to find paths forward because we don’t try enough things to find our footing.
Decision and action are always combined. The challenge is taking the next step.
The post How to Decide What to Work On appeared first on Scott H Young.
March 15, 2022
Desirable Difficulties: When Harder is Better for Learning
A key strategy for getting better at things is hill-climbing. The idea is simple: try different things, keep doing the things that work, stop doing those that don’t.
The strategy is named because you can envision it as finding the highest spot in a landscape filled with fog. You can’t necessarily see the highest point, but you can always walk uphill.
Most of the time, this approach works fairly well. It likely explains how we get better at many things simply by doing them repeatedly. Where this strategy runs into trouble, however, is when you need to do something worse before you can do it better.
Interestingly, learning itself seems to be one of these situations. The actions that improve your short-term performance on a task don’t always create much long-term improvement. Since short-term effects are easier to notice, this can create a trap. Students choose strategies that make them feel like they’re learning the material but fail miserably when the exam comes.
Psychologist Robert Bjork addresses this issue by calling for desirable difficulties: actions that appear to work worse in the short-term but work better in the long run. These include:
Spacing. Imagine you have to choose between practicing something ten times in a row vs. ten times spaced out (over hours or days). The first feels easier—you will perform better immediately after practice. The second is harder but results in more permanent memory. Yet students avoid spacing, in part, because it feels like it doesn’t work as well as cramming.1Variability. Say you’re learning tennis shots. Should you perfect your forehand swing before moving onto the backhand? Or mix both up at the same time? Intuition argues for mastering one thing before moving onto the next, but research suggests otherwise. Variable practice tends to result in better retention and transfer than blocked practice.Testing. Should you re-read or do practice questions? Students overwhelmingly favor re-reading as a learning strategy. However, practice testing is one of the most effective learning methods that has been systematically studied, while re-reading is one of the worst. What Makes Difficulties Desirable?
What Makes Difficulties Desirable?The exact mechanisms behind the value of desirable difficulties are still being debated.
Bjork argues that the benefits come from the difference between storage strength and retrieval strength in memory. In his theory, what we learn is never erased from our minds. Instead, we forget things as our ability to retrieve them becomes weaker through competition with other memories.

This theory says that successful access to hard-to-recall memory boosts retrieval strength more than if the memory was easier to access. It’s as if your brain is saying, “Whoa! That was important and I barely remembered it! Better strengthen that connection.” Easy memory access (say because you just immediately learned it or had the answer in front of you) sends the opposite signal, with correspondingly less benefit.
Even a failure to remember isn’t always a bad thing. Mistakes and errors made while learning can be damaging to long-term performance. Still, they may also contribute to eventual learning provided the correct answer is given promptly.
Contextual Interference and Noticing ContrastsWhile Bjork’s theory of retrieval vs. storage strengths helps explain the three main desirable difficulties mentioned above, there’s another possible benefit to practice variability. When you mix practice between two similar ideas or concepts, you’re better able to notice the difference between the two.
I can remember a good example of this when I was learning Chinese via flashcards. Some characters are very similar. Learned separately, it’s tough to notice the actual distinctions between, say, 已 and 己. However, the difference emerges if you put the cards right next to each other, and it becomes much easier to focus your attention on it.
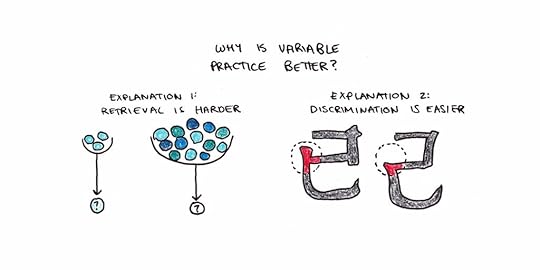
This discriminative account in favor of variable practice holds true for many problem-solving skills. Math problems are often taught in a blocked fashion. You learn some problem type and do it repeatedly until you’re good at it. Then, you move onto a different type of problem and repeat the same process. The issue with this blocked approach is that it doesn’t let you practice telling apart the different types of problems because, in each case, it’s obvious.
We can zoom out even further. When taking an exam in a high-school math class, you know that whatever questions you are asked must be from one of the topics you studied that semester. However, you don’t know whether a real-world problem you face can be answered with math you’ve learned from classes. This is why transferring math skills to real life is so tricky.
Are All Difficulties Desirable?Some difficulties contribute to greater learning. But not all do.
Work on cognitive load theory points out that many activities which increase the effort involved in learning tend to result in worse outcomes for typical students. These activities include solving problems you haven’t taught how to solve, having to split your attention between different sources of information to understand an idea, or having redundant information you need to ignore to get at the answer.
The value of desirable difficulties seems to lie on a continuum. When you’re new to a subject or idea, you need clear explanations, examples and immediate feedback to get the initial pattern into your head. Once in memory, however, desirable difficulties make practice more efficient.
This suggests that there exists a zone of optimal learning. This zone would be challenging, using up nearly all of your available mental bandwidth. But it wouldn’t be so difficult that you consistently fail in applying what you had learned.
The challenge of learning is that our reward system tends to push us away from this zone of optimal improvement through its simple pattern of maximizing immediate performance,. Instead, we find ways to make things easier for ourselves now, even though this limits our growth in the long term.
The post Desirable Difficulties: When Harder is Better for Learning appeared first on Scott H Young.
March 8, 2022
What I’ve Been Reading
It’s been almost a year since I started my current research project. My initial starting point was the intriguing, if somewhat pessimistic, research on learning transfer. However, crawling through citations has gotten me to some of the more interesting science on how people think the mind works.
Having now read over 70 books and 250 papers, a picture is emerging of how it all connects. My views have definitely evolved since the project started, which is probably a good thing—if reading books only reconfirmed everything you already knew, there’d be no point in reading them.
Here are a few picks from my most recent batch:
1. Apprentice to Genius by Robert KanigelHow is elite level science produced? Kanigel offers a fascinating portrait of one scientific dynasty, working at Johns Hopkins, that has produced Nobel and Lasker prize-winning scientists.
I found this portrait fascinating because it suggests to me that there is a hidden, tacit knowledge involved in producing elite level work. While the scientific foundations learned in school are clearly important, this crucial knowledge is still transmitted mainly via the master-apprentice relationship.
My leading explanation for the effect Kanigel observes is that, through a lifetime of experience, elite scientists build an incredible skill for identifying fruitful scientific opportunities. Since they can’t personally pursue all of them, they attract intelligent students and assign these problems to them. By achieving success, the novices eventually adopt the same pattern recognition abilities of the masters and hone their scientific “style.”
This book illustrates the incredible importance of mentors and guidance in doing elite level work. It also indicates why there is so much inequality in output. The knowledge learned in school is necessary—but rarely sufficient—to perform at the highest levels. Those who lack access to these mentor networks are often excluded from doing groundbreaking science.
2. A Cognitive Approach to Language Learning by Peter SkehanLanguage learning is a topic where I have a lot more hands-on experience than theoretical backing. Having learned several languages to middling proficiency, I have lots of intuitions about what works best, but fewer rigorous experiments.
Skehan’s book both shed light on some experiences I have had while learning a language and challenged some of my preconceptions.
Skehan sketches language learning as a process of acquiring vocabulary and grammar while bound by the constraints of a limited working-memory system. A few of his key findings:
Memory plays a much larger role than most realize in language learning. Linguists are obsessed with how we acquire the rules and usage of a language. It seems like people not only memorize words but entire “chunks” of phrases to reduce processing burdens.In speaking, we are overwhelmingly focused on getting our point across. This aids our communication goals, but can conflict with learning more complex and correct forms of the language, since less capacity is available to focus on those aspects.Speed, correctness, and complexity must all trade-off under such a system. Good language learning involves a mix of practice opportunities that give chances to strengthen each aspect.While I wouldn’t change my language learning strategy at the early stage, Skehan’s work shows why just having conversations eventually stalls further progress. You need practice opportunities that stretch you because speaking becomes easy long before you become really good.
3. The Sweet Spot by Paul BloomSuffering is part of a meaningful life. I enjoyed this book because it pushes back against the hedonic emphasis of so much of positive psychology.
Meaningfulness is not all that related to momentary happiness. Self-chosen challenges are an essential part of the good life. This is obvious to any student of philosophy. Still, it seems to have been largely ignored by social psychology interested in measuring positive well-being.
Bloom’s book surveys the research landscape, which, to put it mildly, is mixed and confusing. Thus, I found it provided an interesting window into how science has tried to tackle the problem of meaning, yet I was left with the impression that we haven’t made much progress.
4. Productive Thinking by Max WertheimerMax Wertheimer was the founder of gestalt psychology. Productive Thinking, published posthumously, is one of his most important works. Productive thinking refers to “creative” thinking rather than mere habit or routine thinking.
Wertheimer explores a number of intriguing puzzles. My favorite is the process people use while trying to figure out how to solve for the area of a parallelogram. The abstract insight people manage to draw from this determines, in large part, what other types of problems they can solve.

Wertheimer distinguishes between A and B processes. A processes are those where the same principle underlies two problems, even if they are superficially distinct. B processes are problems that look similar, but applying the same principle to both won’t work.
Consider the process for solving the area of a parallelogram: “rearranging” the shape allows us to find the area using a simple formula. This same process can be used to find the area of the A shape because the protrusion on one side matches the indentation on the other. Yet, this process won’t work on the B shape, where the principle is violated.

In many ways, Wertheimer’s book foreshadowed the cognitive revolution, back in a time when behaviorist principles were dominant.
5. Word Problems by Stephen ReedThe psychology of solving algebra word problems might seem an unimportant topic. However, I am interested in it because it seems to be an example of the difficulty observed with transferring what we learn in school to real-life problems.
Word problems are hard, yes, but they’re hard precisely because they ask us to transform real situations to be solvable with methods learned in school. How do we do this?
Reed explores many different factors that contribute to the difficulty of word problems. For elementary arithmetic problems such as, “Bob has eight marbles, and Jim has six. How many do they have altogether?” it seems like a central stumbling point for young children is linguistic. They may not understand what “altogether” means or that it implies addition.
For algebra word problems, the problem seems different. Looking at their errors, students don’t struggle with the algebra but with correctly mapping the situation onto the set of equations implied by the problem. It seems disappointing how bad most people are at this. Most college freshmen, for instance, get wrong “There are six times as many students as professors.” Most people map this as 6S = P, when it should be 6P = S.

Word Problems illustrates both the importance of mastering mathematics knowledge for solving quantitative problems and how we do students a disservice when we don’t equip them with tools for translating this mathematics knowledge to real life.
6. Self-Insight by David DunningDunning is most famous for the Dunning-Kruger effect, which comes from a study showing that most students over-predicted their relative performance on a test. The only exception was the best students, who slightly under-predicted their score.
In Self-Insight, Dunning marshals a large body of evidence showing that we’re terrible at knowing ourselves. We misjudge our competencies, choices and character. My favorite factoid was that people were about as good at judging someone else’s IQ after watching a 90-second video of them talking, as people are at judging their own IQ.
What explains our dismal self-assessment abilities? Dunning prefers a cognitive explanation. He argues that we misjudge ourselves not because we’re lazy or lying, just that self-assessment is a very hard problem. We get inconsistent feedback, struggle to imagine ourselves in different situations, and have little to go on when assessing our aptitude.
I wasn’t entirely convinced. It seems unlikely that we can systematically assess others much better than ourselves for merely cognitive reasons. Instead, I believe social desirability bias plays a much bigger role. Much of our reasoning aims not to solve problems, but to create justifications for our social selves. Thus, many cognitive biases don’t seem like genuine mistakes, but areas where evolution distorts our beliefs to improve our self-presentation.
That said, Dunning does give some interesting counter-evidence to this view. For instance, we seem far more accurate at judging our athletic ability than our intellectual skills. Monetary payments don’t seem to make much difference in our accuracy either.
Regardless of the cause, the difficulty we have in forming accurate self-beliefs seems like a major problem on the road to self-improvement.
The post What I’ve Been Reading appeared first on Scott H Young.
February 28, 2022
Cultural Literacy: Does Knowledge Need to Be Deep to Be Useful?
A common critique of school is that it leads to shallow memorization of facts. Deep understanding and practical skills are often pushed aside in favor of trivia, quickly forgotten after the final exam.
The most typical reaction, at least from those endorsing the value of education, is to deny the charge. Yes, we all remember dull or seemingly pointless classes. But school provides the necessary foundation for deeper thinking.
What makes E. D. Hirsch’s controversial bestseller, Cultural Literacy, interesting is how it inverts this defense of education. The shallowness of school isn’t a failing but a virtue! Deep understanding and mastery of universal skills are overrated. Instead, we need to supply students with a large supply of background knowledge, often shallow, that allows them to participate in literate culture.
 Why I Enjoyed This Book (Even If I Don’t Entirely Agree)
Why I Enjoyed This Book (Even If I Don’t Entirely Agree)I enjoyed this book, in part, because my intuitions run directly counter to it. I’ve always felt that deep understanding and practical skills are the principal reason to learn anything. That schooling focuses on so much useless, high-culture knowledge has been a major source of my ambivalence towards it.
Most educational proponents defend studying superficially useless topics on the dubious basis that this work will later transfer to other skills. Thus, we have people arguing that reading Shakespeare makes you more empathetic, listening to classical music makes you smarter, or studying military history will sharpen your business acumen.
Yet we now have mountains of psychological evidence that suggest no such thing happens. There are no “mental muscles” that strengthen through general practice. For learning to be useful, the content needs to be useful.
What makes Hirsch’s book surprising and insightful is that he strenuously agrees. Most skills won’t transfer. Most school learning withers to a hazy association in the years after graduation. Reading Shakespeare and memorizing dates won’t ever help you fix a car, program a computer or decide on a corporate strategy.
If school knowledge tends to be shallow and impractical, why learn it? Hirsch argues that such knowledge is needed to participate in literate culture. You need to learn these things because they allow you to read publications like The New York Times or The Atlantic. You need it to understand the allusions embedded in business memos and corporate speeches.
In short, the value of useless, poorly remembered trivia is that it enables access to the social realm of educated society. Those who lack this knowledge, primarily those whose family background provides less of it, are handicapped in participating in elite culture, thus shutting off their economic advancement.
Why Knowledge MattersSay you wanted to start reading in another language, which words should you learn? The obvious answer is that you should start by learning the most common words. You’d also want to prioritize volume over depth. Knowing the origins, connotations, and usage quirks of a single word wouldn’t help nearly as much as having tons of shallower word associations at your fingertips.
Every word you don’t already know impedes your understanding of a text. If you have to look up one or two terms in an essay, that might be tolerable. But twenty? Fifty? Reading might not be worth the effort if you have to look up half the words. Better to watch television instead.

We all intuitively understand that basic literacy requires a vast amount of verbal knowledge. Depth in a handful of chosen words won’t substitute. Neither will the ability to look things up on the fly.
But understanding texts depends not just on word knowledge but on world knowledge. You can’t read an article about American politics, for instance, without some idea of what the Senate is, why people care about who is on the Supreme Court, or that “the White House” refers to the president.
Hirsch’s argument is that we underrate how much knowledge is needed to understand a newspaper or popular nonfiction book. Just as fluent reading requires knowledge of tens of thousands of words, fluent understanding requires thousands of cultural facts that cannot be derived from direct experience.
What Knowledge Matters?What background knowledge do we need? Hirsch’s answer is empirical: look around and see what knowledge writers assume everyone already knows. That’s what you need to teach.
Hirsch also argues that curricula need to be standardized at the national level. He writes fondly of previous efforts to stamp out linguistic diversity within early nation states and argues that a similar cultural assimilation process needs to continue. Ultimately, Hirsch thinks we need a strong national culture based on shared references if we are to cooperate effectively.
This focus on deliberately cultivating a shared, jingoistic mythology in America has attracted Hirsch the most criticism. Certainly, some have argued that it’s exactly this stamping out of diverse perspectives that is one of modern education’s greatest sins.
I’m not an American, and so I read this section with detached bemusement. In interacting with some Americans, I’ve often been disappointed at how sparse and distorted their knowledge of the broader world is. This isn’t any American’s fault. A side-effect of being from a large country with a dominant media presence is that it’s rarely necessary to consume information not explicitly prepared for a domestic perspective. In this circumstance, unless you take active steps to inform yourself of international views, you won’t encounter them.
While I found the nationalism embedded in Hirsch’s argument distasteful, I thought his idea of making this knowledge explicit to be very interesting.
One challenge I’ve had in learning other languages is, inevitably, you lack not just linguistic knowledge, but cultural knowledge. I find it much easier to read Chinese science fiction than period novels. In part, this is because the average Chinese reader is expected to know quite a bit about medieval China already, which I don’t. In contrast, science fiction relies mostly on the scientific knowledge that I already possess.
I would love to see a list of Chinese (or Korean, or Spanish) common knowledge, such as that presented in the back of Hirsch’s book for an American audience. Even an imperfect list would help clarify what most people can be expected to know already, and what knowledge would need to be spelled out for even a literate audience.
Final Thoughts on Cultural LiteracyIn high school, I read Shakespeare. Each year, a chunk of the English curriculum was devoted to going through, in detail, one of his plays. If I recall correctly, I think I studied A Midsummer Night’s Dream, Romeo and Juliet, Othello, and Hamlet.
I’m not a huge Shakespeare fan. I don’t feel like I learned much about human nature or life in any broader sense from those works. If that had been the goal, I would have preferred a course on psychology or philosophy. But, I can say that if a reference is made to one of those four plays, I have a reasonable chance of remembering it.
But here’s the problem: Shakespeare wrote a lot of plays. I never studied The Tempest, King Lear, or Julius Caesar. I think I’ve watched movie versions of Macbeth and Much Ado About Nothing. Beyond this, my knowledge of Shakespeare references is limited. This, in turn, limits my ability to see through opaque cultural references that allude to them.
Hirsch’s solution in this case seems practical. A crash course in Shakespeare reviewing the main plot points, characters, themes and sayings from the most commonly read plays would benefit me. We could skip the painful group readings, with high-schoolers stumbling through sixteenth-century English, and get straight to the point.
Something similar has been a goal of mine for awhile. As I’ve spent most of my learning time in the sciences, my humanities knowledge is often weaker. One of my favorite ways to rectify this problem is to listen to survey courses on history, philosophy and literature. These overviews aren’t sufficient for reaching any deep insights. Still, they serve their purpose in providing the background knowledge needed for further reading.
In my mind, Hirsch has done a service in pointing out the value of this kind of knowledge.
However, in other respects, I depart from Hirsch. Half-remembered factoids might be good for filling out the Sunday crossword puzzle, but it’s inert for any other practical problem. Useful skills necessitate depth, detail, and hands-on experience in a way that book learning rarely makes sufficient.
I also think Hirsch neglects the dynamic effects of literate knowledge. Hirsch argues that high-brow publications presume background knowledge because it smooths communication. But I think it’s equally likely that writers use opaque metaphors and allusions as a way of restricting their audience.
There’s an associative quality between writers and their audiences. A writer is keen to be not just widely read, but to be read by the right kind of people. Literary allusions are not neutral facilitators of conversation, but tools for restricting text to certain audiences.
This restriction isn’t necessarily conscious snobbery. In-groups of all sorts constantly invent slang, inside jokes and references in order to separate themselves from outsiders. Members show off by conspicuously displaying their mastery of in-group lore. This can create an arms race where in-group texts become increasingly impenetrable to outsiders, on purpose—anyone who doubts this need only to browse some Continental philosophy or fanfiction subreddits.

When considering skills and knowledge that are directly useful for solving problems, this arms race seems less relevant. Yes, escalating knowledge requirements to be an effective programmer can make it harder for programmers to keep up. But at least we get better-written code as a result.
In contrast, when the knowledge learned is known, in advance, to be useless, it risks simply moving the goal-posts. If the goal is to maintain cultural exclusivity, the “literate” will define a new stratum of discourse that is intentionally elevated beyond the masses.
The signaling theory of education remains underrated, in my view, because few educational theorists seriously grapple with it. Hirsch does an excellent job pointing to the value of mastering shared cultural knowledge, regardless of its direct utility for solving problems. But I still believe usefulness should be the benchmark for education as a whole.
What are your thoughts? What role do you think education has in forming the necessary, shared background knowledge of a culture versus deeper understanding or practical skills? Share your thoughts in the comments.
The post Cultural Literacy: Does Knowledge Need to Be Deep to Be Useful? appeared first on Scott H Young.
February 22, 2022
How Does Understanding Work? A Look at the Construction-Integration Model of Comprehension
Last week, I discussed John Anderson’s ACT-R theory of cognitive skill acquisition. ACT-R is an ambitious theory tackling a big question: how do we learn things? Anderson’s theory makes compelling predictions and has quite a bit of evidence to back it up.
Yet understanding the mind is like the story of the blind men and the elephant. One touches the tusk and says that elephants are hard and smooth. Another touches the leg and says they’re rough and thick. A third touches the tail and says they’re thin and hairy. What theory you arrive at depends on what you choose to grasp.
ACT-R was developed using a paradigm of problem-solving, particularly in well-defined domains like algebra or programming. This relatively simple paradigm is then assumed to represent all of the broader, messier kinds of intellectual skills that people apply to real-life situations.
But what if we take a different paradigm as our starting point?
In this essay, I take a deeper look at Walter Kintsch’s Construction-Integration (CI) theory. This theory uses the process of understanding text as its starting point for a broader view of cognition. As I’ll show, it both complements and contrasts the ACT-R model we discussed previously.1
 How Do We Comprehend What We Read?
How Do We Comprehend What We Read?What is going on right now, in your head, so that you can understand the words I’ve typed?
At a basic level, we understand that the brain has to convert these black squiggles into letters and words. But what happens next? How do we actually make sense of it? We are pretty good at getting machines to recognize text from a photo. But we’re a lot worse at getting these machines to understand what they read in ways that closely resemble human beings.
Part of the reason this is so hard is that language is ambiguous. Take the phrase, “time flies like an arrow.” What does it mean? For most of us, the expression is a metaphor—it evokes an idea of time passing forward in a straight line. Except, taken literally, there are several possible situations this sentence could refer to.
The joke in linguistics is “time flies like an arrow, fruit flies like a banana.”
How, then, do we know when reading that there isn’t a species of fly called the “time fly,” and they happen to be particularly fond of a kind of projectile?

The vague, but correct, answer is that we use our world knowledge to constrain which interpretation is the most reasonable. We merge the literal words of the text with what we already know to effortlessly form a picture of what the sentence means. Walter Kintsch’s Construction-Integration theory is a hypothesis about how we do this.
Fundamental Concept: PropositionsThe basic building blocks of Kintsch’s theory are propositions. A proposition is a way of rewriting an English sentence that makes clear a single, literal meaning. Propositions are useful because English sentences can be ambiguous, or they may be arbitrarily complicated (and thus contain many propositions).
A sentence like “they are flying planes” could be interpreted as two propositional structures: FLY[THEY, PLANES] or ISA[THEY, FLYING[PLANE]]. The first roughly translates to the idea that there are some people (they) who are piloting (flying) planes. The second is a statement that there are some things (they) which happen to be planes for flying.

Think of a proposition as a fundamental building block of meaning. We can even form complex meaning by connecting together a network of these atomic propositions.
Propositions are a useful tool, but do they have any psychological reality? Kintsch argues that they do:
Propositions tend to be recalled entirely or not at all.People tend to recall things based on their proximity in the propositional structure rather than the actual text. For example, given the sentence “The mausoleum that enshrined the tzar overlooked the square,” subjects who are given the cue “overlooked” are more able to recall “square” than “tzar.” This happens even though “tzar” and “overlooked” are closer together in the actual text.Recall of a text depends on the number of propositions, not the number of words. This is another clue that we use something like propositions to think at the level of meaning.Is all knowledge propositional? Probably not. We have mental imagery, bodily sensations, and far more than we can express in words. Experiments on mental rotation showed conclusively that the idea of a “mind’s eye” is not just a convenient metaphor. What things look like when we imagine them does impact our reasoning.
However, Kintsch argues persuasively that we can treat knowledge as propositional. The benefit of this approximation is that it allows us to represent diverse types of knowledge in the same way, to make it easier to model.
Step One: Convert Text to PropositionsThe first step in Construction-Integration is to construct a more-or-less literal representation of the text. This involves transforming patterns of dark and light hitting our eyeballs into letters and words. We then need to convert those words into propositions that represent what the text is saying. Kintsch’s model omits the details of this visual transformation and parsing function. However we manage to do it, the theory assumes we read text and develop a few propositions in our working memory, each literally derived from the text.
At this stage, we are not yet using context to disambiguate meanings. So the phrase “they are flying planes” would activate both FLY[THEY, PLANES] and ISA[THEY, FLYING[PLANE]]. Both meanings are activated, but the degree of activation may depend on its overall likelihood, independent of the current situation.
This is the “construction” phase of the Construction-Integration model. Text is converted into the propositions it literally implies. If the sentence is ambiguous, this will include multiple, contradictory meanings.
Step Two: Build Propositions into a TextbaseThese atomic, literal propositions now must be linked together. This network of propositions is called the textbase.
Kintsch provides the following text, and its associated network of a textbase, as an example:
“The snow was deep on the mountain. The skiers were lost, so they dug a snow cave, which provided them shelter.”
Becomes the following textbase:
 Step Three: Link Textbase to Prior Knowledge
Step Three: Link Textbase to Prior KnowledgeA proposition on its own doesn’t mean very much. The sentences “the snow is deep” and “the glarb is snarf” are both interpretable as DEEP[SNOW] and SNARF[GLARB]. The difference is that “snarf” and “glarb” don’t activate anything in prior knowledge, so they’re essentially meaningless.
It is the link to prior understanding that gives words their meaning. This understanding itself is also assumed to be a network of propositions. Instead of just the momentary network created by reading the text, this deeper understanding is thought to be a vast, dormant network of connections in long-term memory.

As we read, we activate prior knowledge. The likelihood of retrieving this prior knowledge depends on the retrieval strength for the concept, given the cue word. This may be near 100% for familiar words, but obviously, it will be lower if the word is new or unfamiliar.
Thus, creating a textbase is not just creating a new network. We must then overlay this textbase network on top of a mostly dormant network created from past experience.
Step Four: Stabilize the Network of PropositionsFinally, the network of propositions will stabilize. This is the “integration” phase of Construction-Integration theory. This happens because some of the possible meanings will not match with other information in the text, and also because prior world knowledge constrains which meanings are activated in the network.
We can see how this might happen with the ambiguous phrase, “they are flying planes”:
Initially, both senses are active, although one may be more active than the other depending on its prior likelihood. (For me, the sense that “they” referred to pilots and not planes came first.)Another sentence follows, “They recently graduated from flight school.”This new information activates other nodes which are connected through our prior knowledge. We know planes can’t graduate from flight school, which suppresses the inappropriate meaning.In contrast, you might have the unexpected sentence, “They are really noisy when they pass by overhead.” The idea of pilots being noisy seems less plausible, so the alternative meaning that those objects were flying planes becomes more likely.
Stabilization happens between nodes simultaneously as they activate or weaken their connected neighbors. The “channels” through which this activation/suppression flows are a combination of the textbase given by the environment and our prior world knowledge. If the text makes the meaning explicit, a good reader will rely on the textbase over their prior world knowledge. However, if the text does not provide many inferential steps, we will fill in the meaning using our prior world knowledge.
Putting the Steps TogetherLet’s recap the basics of how Construction-Integration says we make sense of text:
We convert English sentences into propositions. These are the atomic, unambiguous meanings in the text.As we read, we link the propositions together to form a textbase. This network of propositions forms the literal interpretation(s) of the text.The nodes of the textbase activate corresponding nodes in our prior world knowledge. Thus we have two networks—a momentarily activated one consisting of the text’s literal meaning(s), and a vast, mostly dormant network of prior knowledge.Nodes activate related meanings and suppress contradictory ones. The textbase drives this activation, but it flows through our existing world knowledge. This allows us to make obvious inferences that aren’t literally in the text. It’s also how we suppress inappropriate meanings given the context.This jostling of activation and suppression eventually stabilizes into a coherent structure. That structure is the meaning of the text.Although I’ve presented this as a series of steps, these processes are likely acting in parallel. Each word you read simultaneously updates the textbase, activates prior knowledge, and stabilizes the structure.
Getting the GistWe often remember the gist of what we read, even as the literal contents rapidly fade from memory. Consider the following text:
“Jane drove to Alfalfa’s, picked up some fresh fruit, a halibut steak, and some Italian cheese for dessert, and paid with her credit card.”
Although it’s nowhere in the text, the proposition “Jane bought groceries” would be highly active for this sentence. Because of our world knowledge, when we read a series of propositions we associate with grocery shopping, the central theme of the sentence becomes more and more active. The overall meaning may be more retrievable from our long-term memory than any of the details because of this flow of activation.

This pattern also helps explain why we generally seem to recall meaningful patterns better than arbitrary details and why prior knowledge is crucial for learning.
Implications of the CI Model for CognitionThe idea of a vast network of simultaneously firing nodes that suppress and activate each other may seem difficult to imagine, let alone draw any conclusions from. But I’ll do my best to share what the CI model implies.
1. Meaning is ShallowOne implication of the CI model for comprehension is that meaning is relatively shallow. When you read a word, its meaning is defined by the network of related activation. What words mean in a situation will often be quite limited compared to all their potential meanings.
Research on transfer-appropriate processing bears this out. Researchers gave participants stories about a piano that were the context of either moving furniture or playing music. The result was that whether “heavy” or “loud” was a better retrieval cue depended on which story they heard.

This is related to Nick Chater’s argument in The Mind is Flat. Our conscious awareness is a few spots of light on a broader tapestry. Our moment-to-moment experience is surprisingly impoverished, but we have an illusion of depth because we can access our existing knowledge as soon as we want to think about it.
The meaning of a word, sentence or even an entire book isn’t inherent to the text. It’s a collaboration between literal words and an active reader.
2. Working Memory Isn’t Limited for Familiar TasksIn addition to his CI model, Kintsch worked with Anders Ericsson to explain how experts are seemingly not hampered by working memory limitations. They propose that experts develop long-term working memory.
To briefly recap, working memory is what you can keep in mind simultaneously. It is famously limited, perhaps to as little as four chunks of information. Yet experts seem to be free of this limitation in performing tasks.
This is particularly relevant to a theory of text comprehension because, for familiar texts, we are all experts. In one experiment, subjects read a passage about the invention of the steam engine, presented one sentence at a time. Except in-between they were presented distractor sentences not about the story. The result was that comprehension was barely affected.
This may not seem too surprising—after all, we regularly read stories while having our attention flit back and forth. However, if you tried the same thing with phone numbers or nonsense syllables the distraction would most likely erase whatever you were previously paying attention to.
Ericsson and Kintch’s answer is that we overcome working memory limitations by creating retrieval structures. This means that, through practice, we can remove the constraint of our working memory—effectively becoming smarter. However there’s a big catch: these retrieval structures only help for the material we’ve practiced. Thus you can get smarter, but don’t expect it to transfer to unfamiliar tasks.
3. Problem-Solving or Problem Understanding?Last week, I suggested that ACT-R and CI offer different accounts for how we think. How do the two compare?
In many ways, the two theories sit together nicely. ACT-R is simply a more elaborate description of the procedural memory system, whereas CI offers a more detailed account of declarative memory.
Yet there are contrasts. ACT-R sees thinking as problem-solving, but CI sees thinking as comprehension. ACT-R bases the learning of skills on acquiring and strengthening IF-THEN production rules. CI bases learning on a process of spreading activation that allows us to understand a situation effortlessly.
These different frameworks suggest different pictures of transfer. ACT-R is more pessimistic. Skills transfer to the extent they share productions, and most productions are highly specific. In contrast, CI argues that world knowledge forms a background for interpreting tasks. Every little bit of knowledge adds to that background, even if none of it is decisive.
Despite these contrasts, I shouldn’t exaggerate the differences. Both models paint a picture in which learning is domain-specific, and extensive experience is required for expertise. Both models are firmly within cognitive science, assume a limited working memory capacity and an information-processing model for thinking.
Both may be true, but they emphasize different parts of the mind. Like the blind men and the elephant, we shouldn’t be misled to think either paints a complete picture.
Final Thoughts on Construction-IntegrationI’ve barely scratched the surface of implications from Kintsch’s CI theory. In later chapters, he explores how we solve word problems in mathematics, the source of cognitive biases that lead to irrational decisions, and even how such a model might support a sense of self. I highly recommend his book, Comprehension: A Paradigm for Cognition, for those who want to learn more.
The post How Does Understanding Work? A Look at the Construction-Integration Model of Comprehension appeared first on Scott H Young.



{kind=link}