
Robert H. Edwards's Blog: Great 20th century mysteries, page 6
March 25, 2024
Voynich Reconsidered: the "truncation effect"
In the course of my research for Voynich Reconsidered (Schiffer Publishing, 2024), I made a series of statistical tests on the Voynich manuscript, based on the incidence of hapax legomena: that is, words that occur only once.
As Alexander Boxer demonstrated in his presentation to the Voynich 2022 conference, the prevalence of hapax legomena can be an indicator of the presence or absence of semantic meaning. Specifically, for a document of a given length, a lower incidence of hapax legomena is indicative of meaningful content. A higher incidence is a "fingerprint" of gibberish.
Below is a summary of the incidence of hapax legomena in the major thematic sections of the manuscript; in the two "languages" identified by Prescott Currier; and in the pages written by the five scribes identified by Dr Lisa Fagin Davis.
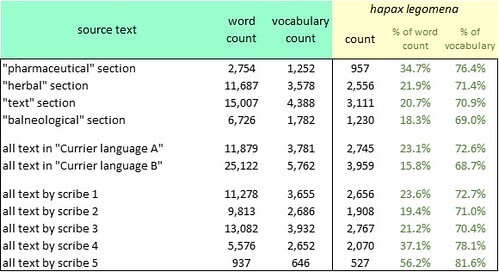
The incidence of hapax legomena in the Voynich manuscript, by section, "language" and scribe. Author's analysis.
These calculations show that the incidence of hapax legomena, as a percentage of the word count, is generally in the range 15 to 37 percent, depending on which element of the manuscript we measure. The longer the chunk of text, the lower the incidence of hapax legomena. This is as we should expect, since a longer text gives more opportunity for a word to be re-used.
The outlier is the work of Scribe 5, who wrote five pages of the "herbal" section and one page of the "text" section.
As a comparator, I have only one example of presumed gibberish: the compilation of "angelic messages" written by John Dee and Edward Kelley between 1581 and 1583 (as cited by Boxer). This document, of about 4,000 words, has an incidence of hapax legomena of about 57 percent of the word count.
Against this, the Voynich manuscript generally gives the impression of meaningful content, however we slice it: with the possible exception of the contribution of Scribe 5.
The "truncation effect"
In one set of tests, on the text in Language B, I examined the impact of removing the initial and final glyphs of every "word". This made all the "words" of one or two glyphs disappear; and shortened all the remaining "words" by two glyphs. An example is shown below.

Voynich manuscript, page f1r, lines 1-6: identification of hapax legomena. Author's analysis.
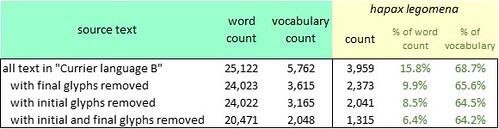
Voynich manuscript: the incidence of hapax legomena after removing initial or final glyphs. Author's analysis.
The removal of initial or final glyphs, or both, had the effect of reducing the incidence of hapax legomena: that is, increasing the probability that there was meaning in the remaining text. I was inclined to call this phenomenon "the truncation effect".
In a natural language, to some extent this effect should be expected. For example if a document in English contained the words "fonder", "wonder" and "yonder", after removal of the initial letter the three would become "onder". If any of these three words had been a hapax legomenon, it would cease to be so; and the incidence of hapax legomena would probably decrease.
The order of the letters
I thought that perhaps we could use the "truncation effect" for another purpose. Perhaps we could determine whether, when the Voynich scribes mapped from the presumed natural languages to glyphs, they preserved the order of the letters within words.
In natural languages, what we call a meaningful text is made up of words in which the letters are in their original order. In the Voynich manuscript, we have reason to suspect that this is not the case. This will be evident from a reading of two technical papers on the Voynich manuscript:
Them's not the breaks
With regard to the Voynich manuscript, we have seen that we can remove all the initial glyphs, and all the final glyphs, and the text somehow appears to retain whatever meaning it may possess. My first reaction was that the interior glyphs held the meaning of the text, and that the initial and final glyphs were something like punctuation, or maybe junk.
But removing glyphs from Voynich "words" makes those "words" impossibly short, by comparison with natural languages. In the v101 transliteration, the average length of "words" is 3.90 glyphs; if we remove two glyphs from each "word", the average drops to 2.44 glyphs. To my knowledge, there is no natural language in which the words are that short.
If the initial and final glyphs are really punctuation or junk, it is an inescapable inference that the Voynich "words" are not words. Prescott Currier said as much, at Mary D'Imperio's seminar in 1976. Specifically, the spaces are not word breaks.
By analogy, let's imagine that we wished to hide the Gettysburg Address within brackets of junk letters. Firstly we would insert spaces at random points between the letters. Thus, the first two words:
An alphabetic cipher?
If the initial and final glyphs are not punctuation or junk, then another possibility is that they are indicators of an alphabetic sorting, of the kind that D'Imperio's and Zattera’s papers imply. In English, we expect that after an alphabetic sorting, words will often begin with a or e, and will often end in t or u.
Likewise, in the Voynich manuscript, "words" often begin with the v101 glyphs {4o} or {o} or {9}, and often end with the glyph {9}. This would be the case if {4o} and {o} were among the first letters of the Voynich “alphabet” and {9} was both among the first and among the last; and if the glyphs in every word were in “alphabetic” order. This phenomenon found expression in Zattera's "slot alphabet", in which, for example, {4} is invariably in slot 0, {o} is usually in slot 1, and {9} can be in slot 1 or slot 11.
Further research
To me it seems that the "truncation effect" needs testing on an appropriate document. We need a document of a comparable length to the Voynich manuscript, say at least 40,000 words. Also, as long as we assume a medieval European provenance for the text (which I think is a reasonable assumption), we might start with a document in medieval Latin or Italian. I am working on Dante’s La Divina Commedia and will report in another post.
As Alexander Boxer demonstrated in his presentation to the Voynich 2022 conference, the prevalence of hapax legomena can be an indicator of the presence or absence of semantic meaning. Specifically, for a document of a given length, a lower incidence of hapax legomena is indicative of meaningful content. A higher incidence is a "fingerprint" of gibberish.
Below is a summary of the incidence of hapax legomena in the major thematic sections of the manuscript; in the two "languages" identified by Prescott Currier; and in the pages written by the five scribes identified by Dr Lisa Fagin Davis.
The incidence of hapax legomena in the Voynich manuscript, by section, "language" and scribe. Author's analysis.
These calculations show that the incidence of hapax legomena, as a percentage of the word count, is generally in the range 15 to 37 percent, depending on which element of the manuscript we measure. The longer the chunk of text, the lower the incidence of hapax legomena. This is as we should expect, since a longer text gives more opportunity for a word to be re-used.
The outlier is the work of Scribe 5, who wrote five pages of the "herbal" section and one page of the "text" section.
As a comparator, I have only one example of presumed gibberish: the compilation of "angelic messages" written by John Dee and Edward Kelley between 1581 and 1583 (as cited by Boxer). This document, of about 4,000 words, has an incidence of hapax legomena of about 57 percent of the word count.
Against this, the Voynich manuscript generally gives the impression of meaningful content, however we slice it: with the possible exception of the contribution of Scribe 5.
The "truncation effect"
In one set of tests, on the text in Language B, I examined the impact of removing the initial and final glyphs of every "word". This made all the "words" of one or two glyphs disappear; and shortened all the remaining "words" by two glyphs. An example is shown below.
Voynich manuscript, page f1r, lines 1-6: identification of hapax legomena. Author's analysis.
Voynich manuscript: the incidence of hapax legomena after removing initial or final glyphs. Author's analysis.
The removal of initial or final glyphs, or both, had the effect of reducing the incidence of hapax legomena: that is, increasing the probability that there was meaning in the remaining text. I was inclined to call this phenomenon "the truncation effect".
In a natural language, to some extent this effect should be expected. For example if a document in English contained the words "fonder", "wonder" and "yonder", after removal of the initial letter the three would become "onder". If any of these three words had been a hapax legomenon, it would cease to be so; and the incidence of hapax legomena would probably decrease.
The order of the letters
I thought that perhaps we could use the "truncation effect" for another purpose. Perhaps we could determine whether, when the Voynich scribes mapped from the presumed natural languages to glyphs, they preserved the order of the letters within words.
In natural languages, what we call a meaningful text is made up of words in which the letters are in their original order. In the Voynich manuscript, we have reason to suspect that this is not the case. This will be evident from a reading of two technical papers on the Voynich manuscript:
• Mary D'Imperio's paper "An Application of PTAH to the Voynich Manuscript", written for the National Security Agency around 1978 but classified until 2009;D'Imperio and Zattera made a compelling case that the "words" in the Voynich manuscript had a specific interior sequence of glyphs: what D'Imperio called "the five states"; what Zattera called a “slot alphabet”; and what, in a natural language, we would call an alphabetical order.
• Massimilano Zattera’s paper “A New Transliteration Alphabet Brings New Evidence of Word Structure and Multiple "Languages" in the Voynich Manuscript”, presented at the Voynich 2022 conference.
Them's not the breaks
With regard to the Voynich manuscript, we have seen that we can remove all the initial glyphs, and all the final glyphs, and the text somehow appears to retain whatever meaning it may possess. My first reaction was that the interior glyphs held the meaning of the text, and that the initial and final glyphs were something like punctuation, or maybe junk.
But removing glyphs from Voynich "words" makes those "words" impossibly short, by comparison with natural languages. In the v101 transliteration, the average length of "words" is 3.90 glyphs; if we remove two glyphs from each "word", the average drops to 2.44 glyphs. To my knowledge, there is no natural language in which the words are that short.
If the initial and final glyphs are really punctuation or junk, it is an inescapable inference that the Voynich "words" are not words. Prescott Currier said as much, at Mary D'Imperio's seminar in 1976. Specifically, the spaces are not word breaks.
By analogy, let's imagine that we wished to hide the Gettysburg Address within brackets of junk letters. Firstly we would insert spaces at random points between the letters. Thus, the first two words:
four scorewould become, for example:
f ou rs c or eWe would then add random letters before and after each block of letters. We would choose the initial letter randomly from the first five letters of the Latin alphabet (a through e) and the final letter randomly from the last five (v through z). The result would be somewhat as follows:
cfy douy crsw acv borx aey.Something like this could be occurring in the Voynich manuscript, where a small set of glyphs predominates as initial glyphs, and another small set predominates as final glyphs.
An alphabetic cipher?
If the initial and final glyphs are not punctuation or junk, then another possibility is that they are indicators of an alphabetic sorting, of the kind that D'Imperio's and Zattera’s papers imply. In English, we expect that after an alphabetic sorting, words will often begin with a or e, and will often end in t or u.
Likewise, in the Voynich manuscript, "words" often begin with the v101 glyphs {4o} or {o} or {9}, and often end with the glyph {9}. This would be the case if {4o} and {o} were among the first letters of the Voynich “alphabet” and {9} was both among the first and among the last; and if the glyphs in every word were in “alphabetic” order. This phenomenon found expression in Zattera's "slot alphabet", in which, for example, {4} is invariably in slot 0, {o} is usually in slot 1, and {9} can be in slot 1 or slot 11.
Further research
To me it seems that the "truncation effect" needs testing on an appropriate document. We need a document of a comparable length to the Voynich manuscript, say at least 40,000 words. Also, as long as we assume a medieval European provenance for the text (which I think is a reasonable assumption), we might start with a document in medieval Latin or Italian. I am working on Dante’s La Divina Commedia and will report in another post.


March 21, 2024
Voynich Reconsidered: La Divina Commedia
Any mapping of the Voynich text to natural languages is necessarily based on the assumption that the Voynich scribes created the manuscript by some kind of process based on precursor documents in such languages. To my mind, the text gives little clue as to what those languages might have been. (The illustrations possibly yield clues, but I have no expertise in that area.)
However, the distance-decay hypothesis (to which I have alluded in other posts) gives us some reason to think that a manuscript found in Frascati, Italy, might have some link with the languages spoken or written in Italy.
In my early research for my book Voynich Reconsidered (Schiffer Publishing, 2024), I experimented with mapping from the Voynich text to medieval Italian. The mapping was based on the frequencies of the Voynich glyphs (in various transliterations of my own devising) and the frequencies of the letters in medieval Italian (as represented by the OVI corpus). This mapping yielded a sequence of Italian text strings. Nearly all of the strings could be found as real words in the corpus.
The OVI corpus is intended primarily for speakers of Italian (of whom, I am not one), and does not include translations of Italian words into any other language. I was not able to determine the meanings of all of the words that I found; nor to judge whether the words, in the mapped sequence, made any sense.
The home page of the OVI corpus of medieval Italian at http://gattoweb.ovi.cnr.it. Image credit: Istituto Opera del Vocabulario Italiano.
In any case, I wondered whether the OVI corpus was an accurate reflection of the presumed source documents that the Voynich scribes had on their walls or tables. My reasons for doubt included the following:

The first nine lines of La Divina Commedia, Foligno edition of 1472. Image credit: Biblioteca Europea di Informazione e Cultura; public domain.
The full text of La Divina Commedia is available online, from Project Gutenberg and elsewhere; but as far as I can tell, all the online versions are written in (what appears to be) a modernised Italian which diverges from that of the 1472 edition. To take just one example, namely the first line:
Of the twenty-one letters in the alphabet of the reconstructed Commedia, nine had the same rankings as those in the OVI corpus. For example, the seven most frequent letters in OVI and in the Commedia were E, A, I, O, N, R, and L, in that order. Only from the eighth letter onwards were there some slight divergences in the rankings. In particular the letter U, which in the 1472 edition was also used in place of V, moved into the top ten.
Having generated a frequency table for Italian letters, I then tested a range of alternative transliterations of the Voynich manuscript, which I numbered from v101④ to v202. As I have mentioned in other posts, the ④ reflects my view that the v101 glyph pair {4o} is a single glyph; in all my transliterations, I assigned this glyph the Unicode symbol ④.
In prioritising my transliterations vis-à-vis any presumed precursor language, I used two metrics, as follows:
On this metric, the transliteration which best fitted the Italian language of 1472 (as represented by my reconstruction of the Foligno edition of La Divina Commedia) was the one that I numbered v121.mF. This transliteration yielded both the highest frequency correlation (98.3 percent) and the lowest average frequency difference (0.30 percent).
What I call v121 is in fact a family of transliterations, with some variations. The differences between v121 and v101 are as follows:
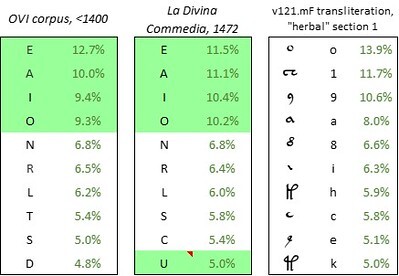
The top ten letters in the OVI corpus and in La Divina Commedia (reconstructed 1472 edition), and the top ten glyphs in the Voynich manuscript, v121.mF transliteration, “herbal” section. Author’s analysis.
The next heroic step was to explore these juxtapositions as correspondences or mappings: in other words, to conjecture that the Voynich scribes mapped the Italian E to the glyph {o}, the Italian A to the glyph {1}, and so on.
It was simple enough to test this conjecture. We could take, say, the five most common Voynich “words” and see whether they map to real words in Italian. In order to see to what extent such a mapping might hold water, I selected the most common Voynich “words” of one, two, three and four glyphs. The results were as follows.
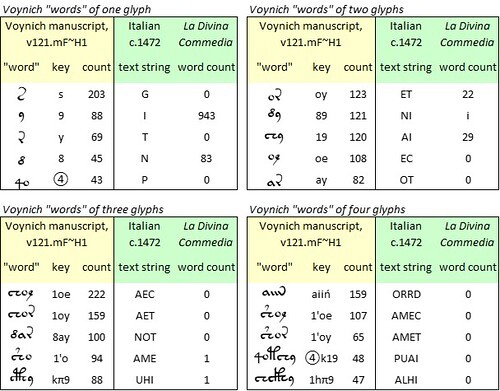
The five most common "words" of one, two, three and four glyphs in the Voynich manuscript, v121.mF transliteration, "herbal" section; and test mappings of these "words" to Italian as written in 1472. Author's analysis.
Notwithstanding the good statistical fit between the v121.mF transliteration and La Divina Commedia, this test did not produce many real Italian words, apart from a few words of one or two letters.
We may draw a number of possible conclusions: that the precursor languages of the Voynich manuscript do not include Italian; or that they do, but not Italian as it appeared in printed books around 1472; or that the period is about right, but that La Divina Commedia is a not a good representation of the precursor documents. Alternatively: that the v121.mF transliteration is not the best one; or that, as Prescott Currier said in 1976, the Voynich “words” are not really words.
Finally, we could recall Massimiliano’s concept of the “slot” alphabet” and conjecture that the Voynich scribes re-ordered the glyphs in each Voynich “word”. In that case, we could conceive the possibility that at some point, a scribe came across the real Italian word TEMA, which he mapped to the glyph string {yo’1}. Since the “slot alphabet” did not permit this sequence, he re-ordered it to {1’oy}, or {2oy} as it is written in v101: which is a real Voynich “word”.
However, the distance-decay hypothesis (to which I have alluded in other posts) gives us some reason to think that a manuscript found in Frascati, Italy, might have some link with the languages spoken or written in Italy.
In my early research for my book Voynich Reconsidered (Schiffer Publishing, 2024), I experimented with mapping from the Voynich text to medieval Italian. The mapping was based on the frequencies of the Voynich glyphs (in various transliterations of my own devising) and the frequencies of the letters in medieval Italian (as represented by the OVI corpus). This mapping yielded a sequence of Italian text strings. Nearly all of the strings could be found as real words in the corpus.
The OVI corpus is intended primarily for speakers of Italian (of whom, I am not one), and does not include translations of Italian words into any other language. I was not able to determine the meanings of all of the words that I found; nor to judge whether the words, in the mapped sequence, made any sense.
The home page of the OVI corpus of medieval Italian at http://gattoweb.ovi.cnr.it. Image credit: Istituto Opera del Vocabulario Italiano.
In any case, I wondered whether the OVI corpus was an accurate reflection of the presumed source documents that the Voynich scribes had on their walls or tables. My reasons for doubt included the following:
• The OVI corpus consists of texts written before the year 1400.For these reasons, I thought it worthwhile to calculate the Italian letter frequencies on the basis of another corpus, from a slightly later period than the OVI. For this purpose, I again turned to Dante Alighieri’s La Divina Commedia, specifically the first printed edition, launched by Johann Neumeister in the city of Foligno in the year 1472.
• Of five samples from the parchment of the Voynich manuscript, the most recent (from folio 8) was carbon-dated to the period 1394 to 1458 with 92.2 percent probability.
• We might reasonably assume that the scribes wrote the manuscript after the latest date of production of the parchment.
• We might conjecture that the scribes worked from printed source documents (as opposed to manuscripts). Since Johannes Gutenberg introduced commercial printing in Europe around 1455, this assumption would date the Voynich text to about 1455 at the earliest.
• The Italian language (like any language) surely evolved over time, and must have undergone changes in the letter frequencies.
The first nine lines of La Divina Commedia, Foligno edition of 1472. Image credit: Biblioteca Europea di Informazione e Cultura; public domain.
The full text of La Divina Commedia is available online, from Project Gutenberg and elsewhere; but as far as I can tell, all the online versions are written in (what appears to be) a modernised Italian which diverges from that of the 1472 edition. To take just one example, namely the first line:
The 1472 edition reads: Nel mezo delcamin dinrã uitaI wanted to reconstruct the text that the Voynich scribes would have seen if, hypothetically, they had had the 1472 edition of the Commedia on their work table. Accordingly, working from the Gutenberg version, I restored the abbreviations and spelling conventions that I could detect in the 1472 edition. Having done so, I recalculated the letter frequencies.
The Gutenberg version reads: Nel mezzo del cammin di nostra vita.
Of the twenty-one letters in the alphabet of the reconstructed Commedia, nine had the same rankings as those in the OVI corpus. For example, the seven most frequent letters in OVI and in the Commedia were E, A, I, O, N, R, and L, in that order. Only from the eighth letter onwards were there some slight divergences in the rankings. In particular the letter U, which in the 1472 edition was also used in place of V, moved into the top ten.
Having generated a frequency table for Italian letters, I then tested a range of alternative transliterations of the Voynich manuscript, which I numbered from v101④ to v202. As I have mentioned in other posts, the ④ reflects my view that the v101 glyph pair {4o} is a single glyph; in all my transliterations, I assigned this glyph the Unicode symbol ④.
In prioritising my transliterations vis-à-vis any presumed precursor language, I used two metrics, as follows:
• The statistical correlation (R-squared} between the glyph frequencies in the transliteration and the letter frequencies in the precursor language;The frequency correlations do not differ much from one transliteration to another, and are typically well over 90 percent for any pairing of transliteration and precursor language. I am inclined therefore to use the average frequency difference as the more powerful metric.
• The average frequency difference, defined as the average of the absolute differences between glyph frequencies and equally-ranked letter frequencies in the precursor language.
On this metric, the transliteration which best fitted the Italian language of 1472 (as represented by my reconstruction of the Foligno edition of La Divina Commedia) was the one that I numbered v121.mF. This transliteration yielded both the highest frequency correlation (98.3 percent) and the lowest average frequency difference (0.30 percent).
What I call v121 is in fact a family of transliterations, with some variations. The differences between v121 and v101 are as follows:
• As mentioned above, I replaced the v101 {4o} with the single glyph ④.The differences between v121.mF and v121 are as follows:
• I redefined the v101 glyph {2} and all its variants {3}, {5}, {!}, {%}, {+} and {#} as 1', in other words as the glyph {1} plus a catch-all accent {‘}.
• I disaggregated the v101 glyph {m} into the string iiN; but allowed the v101 {M} and {n} to remain as distinct glyphs from {N}.As an illustration, a juxtaposition of the frequencies of the top ten letters in the 1472 La Divina Commedia, and those of the top ten glyphs in v121.mF, looks like this:
• I disaggregated each of the “bench gallows” glyphs into its vertical component and its “bench”. The “bench” resembles an elongated {1}, but I did not wish to assume that it was the same as {1}; so I assigned it a new key, π (the Greek letter pi). Under this process, {F} became fπ, {G} became gπ, and so on.
The top ten letters in the OVI corpus and in La Divina Commedia (reconstructed 1472 edition), and the top ten glyphs in the Voynich manuscript, v121.mF transliteration, “herbal” section. Author’s analysis.
The next heroic step was to explore these juxtapositions as correspondences or mappings: in other words, to conjecture that the Voynich scribes mapped the Italian E to the glyph {o}, the Italian A to the glyph {1}, and so on.
It was simple enough to test this conjecture. We could take, say, the five most common Voynich “words” and see whether they map to real words in Italian. In order to see to what extent such a mapping might hold water, I selected the most common Voynich “words” of one, two, three and four glyphs. The results were as follows.
The five most common "words" of one, two, three and four glyphs in the Voynich manuscript, v121.mF transliteration, "herbal" section; and test mappings of these "words" to Italian as written in 1472. Author's analysis.
Notwithstanding the good statistical fit between the v121.mF transliteration and La Divina Commedia, this test did not produce many real Italian words, apart from a few words of one or two letters.
We may draw a number of possible conclusions: that the precursor languages of the Voynich manuscript do not include Italian; or that they do, but not Italian as it appeared in printed books around 1472; or that the period is about right, but that La Divina Commedia is a not a good representation of the precursor documents. Alternatively: that the v121.mF transliteration is not the best one; or that, as Prescott Currier said in 1976, the Voynich “words” are not really words.
Finally, we could recall Massimiliano’s concept of the “slot” alphabet” and conjecture that the Voynich scribes re-ordered the glyphs in each Voynich “word”. In that case, we could conceive the possibility that at some point, a scribe came across the real Italian word TEMA, which he mapped to the glyph string {yo’1}. Since the “slot alphabet” did not permit this sequence, he re-ordered it to {1’oy}, or {2oy} as it is written in v101: which is a real Voynich “word”.
March 20, 2024
Voynich Reconsidered: Persian as precursor
In the sourse of my ongoing search for meaning in the text of the Voynich manuscript, I have investigated the hypothesis that the underlying or precursor language was Persian.
Persian, like Arabic, Hebrew and Ottoman Turkish, uses an abjad script in which the long vowels are written but the short vowels usually are not. The pronunciation of a written Persian word therefore has to be inferred from the context, or from diacritics which the writer may have placed above or below the consonants.
Pareidolia
In any exercise of mapping from the Voynich manuscript to a language in an abjad script, there is a risk of pareidolia: of seeing words that are not necessarily there. This is because of what I am inclined to call the abjad effect: in the absence of short vowels, any short string of letters is quite likely to be a real word.
A classic example of pareidolia: the “Face on Mars”. Image credit: NASA.
Here is an example.
The modern Persian alphabet has thirty-three letters, as follows, with acknowledgement to Dr Mehrzad Mansouri, “Examining the frequency of Persian characters and their suitability on the computer keyboard” (Journal of Linguistics and Khorasan Dialects, No. 7, fall and winter 2013).

We can use the =RAND() function in Microsoft Excel to generate three random numbers between 1 and 33. My first run of this function yielded the following numbers:
To my mind it follows that, if we wish to map the Voynich manuscript to Persian (or to any other language which uses an abjad script), we cannot be satisfied with finding individual words. We must seek to map at least a whole line, or a paragraph, or a whole page, and the result must make sense.
Upsides of abjad
The upside of any abjad script proposed as a precursor to the Voynich text is that the words are typically short.
For example, I have a corpus of Persian, drawn from the works of forty-eight Persian poets. It contains 8,102,157 words with 26,572,744 letters. The average length of words is 3.27 letters.
In Arabic, Dr Jiří Milička of Charles University has studied a large diachronic corpus (Corpus Linguae Arabicae Universalis Diachronicus, or CLAUDia), with about 420 million words. He found that in the fifteenth century, the average length of Arabic words was 4.12 letters.
The Voynich manuscript, in the v101 transliteration, has an average of 3.90 glyphs per "word". Thus in terms of length, Persian and Arabic words match Voynich "words" much better than those in most European languages.
A Voynich-Persian mapping
The researcher on the Voynich Ninja forum proposed a mapping from Voynich glyphs to Persian letters based (in my understanding) on visual similarities. For example, the v101 glyphs {m} and {N} were proposed to map (as I understand, interchangeably) to the Persian letters ﻡ (m) and ﻥ (n).
A consequence of this proposed mapping is that in the resulting Persian text, the letters have a frequency distribution which is greatly different from that of the Persian language as a whole.
With thanks to bi3mw of the Voynich ninja forum, I was able to calculate that in my Persian corpus, the letters ﻡ (m) and ﻥ (n) together accounted for 13.7 percent of the total. In the Voynich manuscript, if we use the v101 transliteration, the glyphs {m} and {N}, and their variants {M} and {n}, together account for 4.5 percent of all the glyphs.
The proposed mapping would therefore create a Persian text in which the letters ﻡ (m) and ﻥ (n) were unusually rare: a text quite unlike the corpus of written Persian.
In any language, individual documents can have letter frequency distributions that diverge from that the language as a whole. In my experience, these divergences are not large, and are typically evident from around the tenth most common letter onwards. For example, in the OVI corpus of medieval Italian, and in Dante’s La Divina Commedia, the nine most common letters are the same, and in the same order. The tenth and eleventh most common letters in OVI are respectively D and C; in La Divina Commedia, they are C and D.
Likewise, we can make a comparison of my corpus of Persian poets with the Ruba’iyat of Omar Khayyam, which in my copy has 19,876 letters. The top ten letters are the same in the Ruba’iyat as in the larger corpus, although in a slightly different order. For the whole Persian alphabet, the correlation of letter frequencies between the Ruba’iyat and the corpus is 98.6 percent. In short, we do not expect an individual document to have a greatly different letter frequency from that of the language as a whole.
There can of course be exceptions, such as lipograms: texts which intentionally omit a selected letter or letters. For example, in the English language we have the novel Gadsby by Ernest Vincent Wright, and in French La Disparition by Georges Perec, neither of which contains the letter e, the most common letter in both English and French. We have to hope that the Voynich manuscript is not a lipogram.
Letter frequencies
My own predilection is to ignore any visual similarities that may exist between Voynich glyphs and letters in natural languages, and to focus on glyph and letter frequencies. This was a device used by Edgar Allen Poe in his short story The Gold Bug, and by Sir Arthur Conan Doyle in his Sherlock Holmes tale The Adventure of the Dancing Men. In both cases the protagonist used frequency comparisons to solve enciphered messages.
In the case of the Voynich manuscript, following Occam’s Razor, we could adopt the simplest assumptions: that the scribes worked from a precursor document or documents in a natural language or languages; and that they chose to use, or the producer instructed them to use, a one-to-one mapping between letters and glyphs. If so, the frequencies of the precursor letters should have been preserved. If the precursor language was Persian, then the frequencies of the Persian letters should match, in some respect, the frequencies of the glyphs that the scribes committed to vellum.
As a start, we could look at the ten most common symbols in Persian and in Voynich.
For Persian, I used the above-mentioned corpus of the works of forty-eight poets: for which my colleague bi3mw kindly calculated the letter frequencies. For the Voynich manuscript, I used a range of alternative transliterations to Glen Claston’s classic v101 transliteration. To select the best-fitting transliteration, I used the average frequency difference (which I defined in another post on this platform). The best fit was the transliteration which I numbered v170. This had the following differences from v101:
The results are as follows.
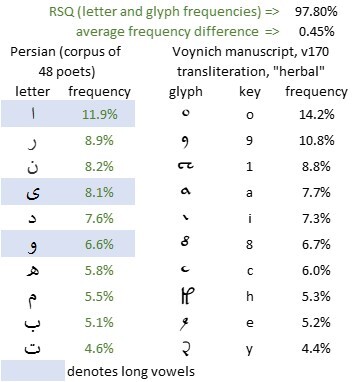
The Voynich manuscript, v170 transliteration, “herbal” section, the ten most frequent glyphs; and the ten most frequent letters in a corpus of the works of forty-eight Persian poets (frequencies by courtesy of bi3mw)
Here it is tempting to see not merely a visual resemblance but a correspondence between the v101 glyph {9} and the Persian letter و. But to minimise the element of subjectivity, I felt that it would be better to stay with the frequencies, and to see where that led.
The correlation between the v170 glyph frequencies and the Persian letter frequencies is 97.8 percent. This correlation is comparable with my results for many modern and medieval European languages. They do not, in themselves, imply that Persian is more or less likely than a European language to be a precursor of the Voynich manuscript.
The common “words”
If the above juxtapositions of frequencies have any merit as correspondences (we might say: mappings), then we should be able to map some of the common “words” in the Voynich manuscript to letter strings in Persian, and see whether this process yields any real Persian words.
In the v170 transliteration, "herbal" section, I identified the top five "words" of one, two, three and four glyphs, and mapped each of them to Persian, one glyph at a time, according to the rankings in the frequency tables.
The results were as follows:
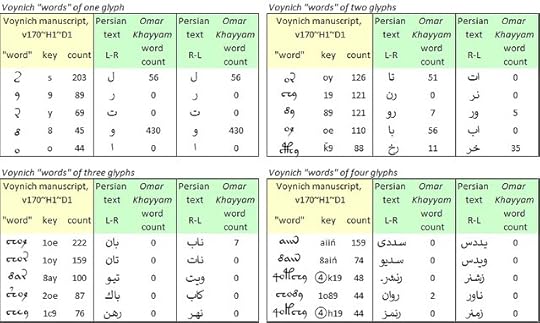
Voynich manuscript, v170 transliteration, “herbal” section: the five most frequent “words” of one, two, three and four glyphs; and test mappings to Persian. Author's analysis.
In short, the results are weak. Notwithstanding the abjad effect, few of the Voynich “words” map to real words in Persian, whether we read the glyphs from left to right or from right to left.
Postscript: the scribes
Persian is, and always has been, written from right to left; and by (I think) universal agreement, the Voynich manuscript is written from left to right. Therefore, if the manuscript is in Persian, we are compelled to conjecture that the Voynich scribes did not work directly from written documents. I imagine them, rather, taking dictation.
If so (and this would apply to dictation in any language), I could imagine that they would not always be sure where words began and ended. That might help us understand why the "word" breaks are so irregular, and why there are so many instances of what Zattera calls "separable words".
Finally: the quality and consistency of the Voynich script leads us to believe that the scribes were professionals. They made a living by writing what other people wanted written. If they wrote from dictation, is it possible they wrote phonetically from a language that they did not themselves understand?
Separable “words”
In any phonetic language, as George Zipf observed when he formulated Zipf’s Law, the most frequent words are short: like "the" and "and" in English. In an abjad language, with short vowels omitted, the most frequent words will be even shorter. The top ten words in medieval Persian have two letters, or one: for example و ("and").
Some of the top ten Voynich "words" are too long to match the top ten Persian words. Examples, in the v170 transliteration, are the "words" {1oe}, {1oy} and {8ay}.
It seems to me possible that Voynich “words” do not map very well to Persian words because the “words” are not words. As Preston Currier remarked at Mary D’Imperio’s Voynich seminar in 1976:
Zattera, in his paper at Voynich 2022, did not specify the "separable words" that he had identified. I have not yet formulated a systematic approach to the identification of "separable words". For any given transliteration, my provisional process has the following steps: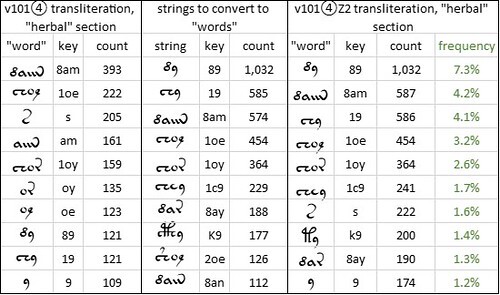
A sequence of steps to identify the “separable words” in the Voynich manuscript, v101 transliteration. Author’s analysis.
If the Voynich manuscript has a Persian precursor, we may need to apply Zattera's concept of "separable words", and break up some of the common Voynich “words”. That is a line of research that seems worth some effort.
Other languages
The approach that I outlined above would apply equally to a mapping from Voynich to any phonetic natural language.
I have already tested mappings from corpora and selected documents in several medieval languages including Albanian, Arabic, Bohemian, English, French, Galician-Portuguese, German, Italian, Latin and Ottoman Turkish. Some of my results are reported in Voynich Reconsidered: others have appeared elsewhere on this platform, or may appear in due course. Readers who would like me to test other languages are invited to send me examples of the respective corpora, preferably as .txt files.
Persian, like Arabic, Hebrew and Ottoman Turkish, uses an abjad script in which the long vowels are written but the short vowels usually are not. The pronunciation of a written Persian word therefore has to be inferred from the context, or from diacritics which the writer may have placed above or below the consonants.
Pareidolia
In any exercise of mapping from the Voynich manuscript to a language in an abjad script, there is a risk of pareidolia: of seeing words that are not necessarily there. This is because of what I am inclined to call the abjad effect: in the absence of short vowels, any short string of letters is quite likely to be a real word.
A classic example of pareidolia: the “Face on Mars”. Image credit: NASA.
Here is an example.
The modern Persian alphabet has thirty-three letters, as follows, with acknowledgement to Dr Mehrzad Mansouri, “Examining the frequency of Persian characters and their suitability on the computer keyboard” (Journal of Linguistics and Khorasan Dialects, No. 7, fall and winter 2013).
We can use the =RAND() function in Microsoft Excel to generate three random numbers between 1 and 33. My first run of this function yielded the following numbers:
5, 12, 23.The fifth, twelfth and twenty-third letters in the Persian alphabet are ف, ر, ث. These three letters, read from right to left, form the string
فرثwhich is a real word in Persian, according to the Dehkhoda dictionary, maintained by the Dehkhoda Lexicon Institute and International Centre for Persian Studies at the University of Tehran. Thus we are able by a random process to create a real word.
To my mind it follows that, if we wish to map the Voynich manuscript to Persian (or to any other language which uses an abjad script), we cannot be satisfied with finding individual words. We must seek to map at least a whole line, or a paragraph, or a whole page, and the result must make sense.
Upsides of abjad
The upside of any abjad script proposed as a precursor to the Voynich text is that the words are typically short.
For example, I have a corpus of Persian, drawn from the works of forty-eight Persian poets. It contains 8,102,157 words with 26,572,744 letters. The average length of words is 3.27 letters.
In Arabic, Dr Jiří Milička of Charles University has studied a large diachronic corpus (Corpus Linguae Arabicae Universalis Diachronicus, or CLAUDia), with about 420 million words. He found that in the fifteenth century, the average length of Arabic words was 4.12 letters.
The Voynich manuscript, in the v101 transliteration, has an average of 3.90 glyphs per "word". Thus in terms of length, Persian and Arabic words match Voynich "words" much better than those in most European languages.
A Voynich-Persian mapping
The researcher on the Voynich Ninja forum proposed a mapping from Voynich glyphs to Persian letters based (in my understanding) on visual similarities. For example, the v101 glyphs {m} and {N} were proposed to map (as I understand, interchangeably) to the Persian letters ﻡ (m) and ﻥ (n).
A consequence of this proposed mapping is that in the resulting Persian text, the letters have a frequency distribution which is greatly different from that of the Persian language as a whole.
With thanks to bi3mw of the Voynich ninja forum, I was able to calculate that in my Persian corpus, the letters ﻡ (m) and ﻥ (n) together accounted for 13.7 percent of the total. In the Voynich manuscript, if we use the v101 transliteration, the glyphs {m} and {N}, and their variants {M} and {n}, together account for 4.5 percent of all the glyphs.
The proposed mapping would therefore create a Persian text in which the letters ﻡ (m) and ﻥ (n) were unusually rare: a text quite unlike the corpus of written Persian.
In any language, individual documents can have letter frequency distributions that diverge from that the language as a whole. In my experience, these divergences are not large, and are typically evident from around the tenth most common letter onwards. For example, in the OVI corpus of medieval Italian, and in Dante’s La Divina Commedia, the nine most common letters are the same, and in the same order. The tenth and eleventh most common letters in OVI are respectively D and C; in La Divina Commedia, they are C and D.
Likewise, we can make a comparison of my corpus of Persian poets with the Ruba’iyat of Omar Khayyam, which in my copy has 19,876 letters. The top ten letters are the same in the Ruba’iyat as in the larger corpus, although in a slightly different order. For the whole Persian alphabet, the correlation of letter frequencies between the Ruba’iyat and the corpus is 98.6 percent. In short, we do not expect an individual document to have a greatly different letter frequency from that of the language as a whole.
There can of course be exceptions, such as lipograms: texts which intentionally omit a selected letter or letters. For example, in the English language we have the novel Gadsby by Ernest Vincent Wright, and in French La Disparition by Georges Perec, neither of which contains the letter e, the most common letter in both English and French. We have to hope that the Voynich manuscript is not a lipogram.
Letter frequencies
My own predilection is to ignore any visual similarities that may exist between Voynich glyphs and letters in natural languages, and to focus on glyph and letter frequencies. This was a device used by Edgar Allen Poe in his short story The Gold Bug, and by Sir Arthur Conan Doyle in his Sherlock Holmes tale The Adventure of the Dancing Men. In both cases the protagonist used frequency comparisons to solve enciphered messages.
In the case of the Voynich manuscript, following Occam’s Razor, we could adopt the simplest assumptions: that the scribes worked from a precursor document or documents in a natural language or languages; and that they chose to use, or the producer instructed them to use, a one-to-one mapping between letters and glyphs. If so, the frequencies of the precursor letters should have been preserved. If the precursor language was Persian, then the frequencies of the Persian letters should match, in some respect, the frequencies of the glyphs that the scribes committed to vellum.
As a start, we could look at the ten most common symbols in Persian and in Voynich.
For Persian, I used the above-mentioned corpus of the works of forty-eight poets: for which my colleague bi3mw kindly calculated the letter frequencies. For the Voynich manuscript, I used a range of alternative transliterations to Glen Claston’s classic v101 transliteration. To select the best-fitting transliteration, I used the average frequency difference (which I defined in another post on this platform). The best fit was the transliteration which I numbered v170. This had the following differences from v101:
• I replaced the v101 glyph pair {4o} by the single Unicode symbol ④Furthermore, since the Voynich manuscript has evidence of multiple languages, I thought it advisable to work with only the “herbal” section, which appeared to use a single homogenous language. I followed Rene Zandbergen’s definition of the “herbal” section: that is, the folios which contain full-page drawings of objects that resemble plants. We do not need to assume that the text of this section has anything to do with plants or herbs.
• I disaggregated three related v101 glyphs as follows: m => iiN, M= iiiN, n => iN.
The results are as follows.
The Voynich manuscript, v170 transliteration, “herbal” section, the ten most frequent glyphs; and the ten most frequent letters in a corpus of the works of forty-eight Persian poets (frequencies by courtesy of bi3mw)
Here it is tempting to see not merely a visual resemblance but a correspondence between the v101 glyph {9} and the Persian letter و. But to minimise the element of subjectivity, I felt that it would be better to stay with the frequencies, and to see where that led.
The correlation between the v170 glyph frequencies and the Persian letter frequencies is 97.8 percent. This correlation is comparable with my results for many modern and medieval European languages. They do not, in themselves, imply that Persian is more or less likely than a European language to be a precursor of the Voynich manuscript.
The common “words”
If the above juxtapositions of frequencies have any merit as correspondences (we might say: mappings), then we should be able to map some of the common “words” in the Voynich manuscript to letter strings in Persian, and see whether this process yields any real Persian words.
In the v170 transliteration, "herbal" section, I identified the top five "words" of one, two, three and four glyphs, and mapped each of them to Persian, one glyph at a time, according to the rankings in the frequency tables.
The results were as follows:
Voynich manuscript, v170 transliteration, “herbal” section: the five most frequent “words” of one, two, three and four glyphs; and test mappings to Persian. Author's analysis.
In short, the results are weak. Notwithstanding the abjad effect, few of the Voynich “words” map to real words in Persian, whether we read the glyphs from left to right or from right to left.
Postscript: the scribes
Persian is, and always has been, written from right to left; and by (I think) universal agreement, the Voynich manuscript is written from left to right. Therefore, if the manuscript is in Persian, we are compelled to conjecture that the Voynich scribes did not work directly from written documents. I imagine them, rather, taking dictation.
If so (and this would apply to dictation in any language), I could imagine that they would not always be sure where words began and ended. That might help us understand why the "word" breaks are so irregular, and why there are so many instances of what Zattera calls "separable words".
Finally: the quality and consistency of the Voynich script leads us to believe that the scribes were professionals. They made a living by writing what other people wanted written. If they wrote from dictation, is it possible they wrote phonetically from a language that they did not themselves understand?
Separable “words”
In any phonetic language, as George Zipf observed when he formulated Zipf’s Law, the most frequent words are short: like "the" and "and" in English. In an abjad language, with short vowels omitted, the most frequent words will be even shorter. The top ten words in medieval Persian have two letters, or one: for example و ("and").
Some of the top ten Voynich "words" are too long to match the top ten Persian words. Examples, in the v170 transliteration, are the "words" {1oe}, {1oy} and {8ay}.
It seems to me possible that Voynich “words” do not map very well to Persian words because the “words” are not words. As Preston Currier remarked at Mary D’Imperio’s Voynich seminar in 1976:
“That’s just the point – they’re not words!”I am mindful that, as Massimiliano Zattera demonstrated at the Voynich 2022 conference, the Voynich manuscript contains thousands of “words” that look like compound “words”. To take just one example: the v101 “word” {2coehcc89} can be disaggregated into {2coe} {hcc89} or {2co} {ehcc89} or {2co} {e} {hcc89}, and in each case the components are Voynich “words”. As I observed in a previous post, Zattera estimated that such “separable words” accounted for 10.4 percent of the text and for 37.1 percent of the vocabulary of the manuscript.
Zattera, in his paper at Voynich 2022, did not specify the "separable words" that he had identified. I have not yet formulated a systematic approach to the identification of "separable words". For any given transliteration, my provisional process has the following steps:
* to identify the twenty most common “words” (delimited by spaces or line breaks), by means of an online word frequency counter such as https://www.browserling.com/tools/wor...
* to exclude single-glyph "words" such as {s}: by analogy with single-letter words such as "e" in Italian, which do not carry the implication that other occurrences of such letters are words
* to exclude "words" which are parts of other frequent "words": for example, to exclude {am} which is part of {8am}
* for each of the remaining "words", to search for other occurrences of those “words” as strings within “words”;
* to select the ten most frequent such strings;
* to convert such strings to “words” by adding a preceding and following space.
A sequence of steps to identify the “separable words” in the Voynich manuscript, v101 transliteration. Author’s analysis.
If the Voynich manuscript has a Persian precursor, we may need to apply Zattera's concept of "separable words", and break up some of the common Voynich “words”. That is a line of research that seems worth some effort.
Other languages
The approach that I outlined above would apply equally to a mapping from Voynich to any phonetic natural language.
I have already tested mappings from corpora and selected documents in several medieval languages including Albanian, Arabic, Bohemian, English, French, Galician-Portuguese, German, Italian, Latin and Ottoman Turkish. Some of my results are reported in Voynich Reconsidered: others have appeared elsewhere on this platform, or may appear in due course. Readers who would like me to test other languages are invited to send me examples of the respective corpora, preferably as .txt files.
March 18, 2024
Voynich Reconsidered: Arabic as precursor
In my ongoing search for meaning in the text of the Voynich manuscript, I have considered Arabic as a possible precursor language.
In order to assess Arabic as a precursor, we could start by examining whether there are any statistical similarities between the Voynich manuscript and Arabic documents of its era (which we may reasonably assume to be the fifteenth century). One useful metric is the frequency distribution of Arabic letters as written at that time.
An example is the letter frequency distribution in البداية والنهاية (The Beginning and the End), by Abulfida' ibn Kathir (1300-1373).

A modern edition of Al bidayah wal nihayah by ibn Kathir, in twenty-one volumes. Image credit: amazon.
For the Voynich manuscript, Glen Claston’s v101 transliteration is a starting point, The frequencies of the glyphs in the v101 transliteration, in descending order, and the frequencies of the letters in the works of ibn Kathir, have a correlation of 94.4 percent. That in itself is not remarkable: with two short sequences in descending order, it's easy to obtain a correlation of over 90 percent. Many European languages, as well as Hebrew, Persian and Ottoman Turkish, yield a similar correlation with the v101 transliteration.
However, it seems to me that the juxtaposition of these frequency tables opens the possibility of a provisional mapping of any chunk of Voynich text to Arabic. Having done so, it would probably be necessary to reverse the order of the letters in each transliterated word (for which there exist online tools such as https://onlinetexttools.com/reverse-text).
If the resulting text contained any recognisable Arabic words, we might be on the right track. If not, it might be necessary to try different approaches.
Here it should be remembered that Arabic uses an abjad script, in which the long vowels are written but the short vowels usually are not.
Alternative transliterations
One necessary consideration is whether the v101 transliteration is the right one to use.
v101 has a basic character set of seventy-one glyphs, which is far more than the number of letters in any alphabet of a phonetic natural language. There are several groups of visually similar glyphs such as {6}, {7}, {8} and {&}; it makes sense to combine each such group into a single glyph. We can disaggregate glyphs that look like strings, e.g. {m} => {iN}, {n} => {iN}. In both cases, that will reduce the size of the character set and make v101 more like a representation of a natural language.
Conversely, we can make distinctions between initial, interior, final and isolated glyphs. That will increase the size of the character set.
In all cases, these variants change the frequency table and consequently change the mapping from glyphs to any natural language.
In exploring Arabic and other natural languages as possible precursors to the Voynich manuscript, I felt it advisable to examine alternatives to v101. Accordingly, I developed a range of alternative transliterations of the Voynich text, all based on v101 but differing from v101 in one or more respects. I numbered these transliterations v101④ through v202. The ④ signifies that in all the transliterations, I treated the v101 glyph pair {4o} as a single glyph, to which I assigned the Unicode symbol ④.
For comparison of the Voynich text with the Arabic language, I used letter frequencies derived from the works of Ibn Kathir.
To prioritize my Voynich transliterations, I started by calculating the statistical correlations between the glyph frequencies and the Arabic letter frequencies, using the R-squared function (RSQ in Microsoft Excel). However, as expected with two short descending sequences, most of the correlations were well in excess of 90 percent. Substantial differences between transliterations, for example combining the {2} group of glyphs, resulted in quite small changes in the frequency correlations.
Frequency differences
I therefore adopted an alternative metric, namely the average frequency difference. Mathematically, this is the average of the absolute differences between the frequency of a precursor letter and the frequency of the equally ranked Voynich glyph. My idea was that the lowest average frequency difference should represent the best fit between a transliteration and the presumed precursor language.
On this metric, I found that the transliteration which I had numbered v171 was the best fit for ibn Kathir's Arabic alphabet. Apart from the treatment of {4o}, the v171 transliteration has the following differences from v101:
Below is a juxtaposition of the frequencies of the top ten glyphs in the v171 transliteration, and of those of the top ten Arabic letters. The average frequency difference between v171 and Ibn Kathir's Arabic (calculated on all 43 letters) is 0.64 percent.
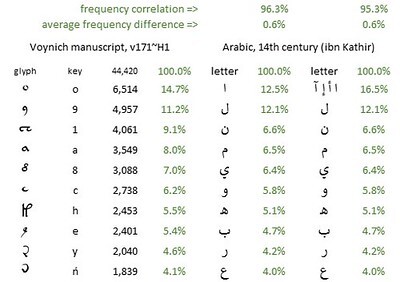
The frequencies of the ten most common glyphs in the Voynich manuscript; and those of the ten most common letters in fourteenth-century Arabic. The glyph frequencies are from author's v171 transliteration, "herbal" section. The Arabic letter frequencies are based on the works of Ibn Kathir, with the variants of alef (ﺍ ﺃ ﺇ ﺁ) shown separately or combined. Author's analysis.
The next step is to explore the potential of these juxtapositions as correspondences or mappings. For example, the Voynich {o} could map to and from the Arabic ا (alef). Thereby, we could map some of the most common Voynich "words", such as {8am}, {oe} and {1oe}, to text strings in Arabic. We could then search appropriate corpora of the Arabic language to determine whether these strings are real words.
Test mappings
Below is a summary of my test mappings of the top five Voynich "words" of one, two, three and four glyphs.
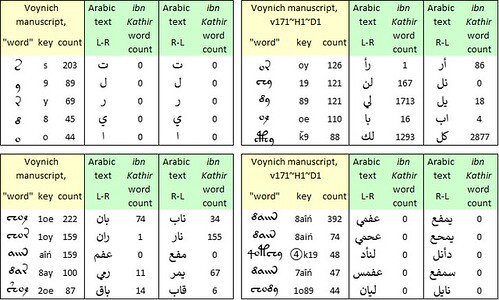
Test mappings of the top five "words" of one, two, three and four glyphs in the Voynich manuscript, v171 transliteration, "herbal" section, to text strings in medieval Arabic. Author's analysis.
We see here what I am inclined to call the abjad effect, which I had already observed with Hebrew, Persian and Ottoman Turkish. Most of the Voynich "words" of two or three glyphs map to real Arabic words. They do so whether the glyphs are read from left to right, or from right to left. But in an abjad script, almost any random string of two or three letters will be a real word. At the levels of one glyph and four glyphs, the mapping breaks down.
An alphabetic cipher?
These test mappings do not entirely exclude Arabic as a precursor language of the Voynich manuscript.
As Massimiliano Zattera demonstrated at the Voynich 2022 conference, in almost every Voynich "word" the glyphs follow a sequence, a kind of alphabetic order. Indeed, Zattera called the sequence a "slot alphabet". We are compelled to imagine that if the Voynich scribes mapped their manuscript from precursor documents, they re-ordered the glyphs in every "word". That would imply that we could take any one of our Arabic text strings, scramble the letters, and reverse-engineer it to the same Voynich "word" from which we started.
For example, in the above tests I mapped the Voynich "word" {1o89} to the Arabic strings ليان and نايل which are not real words. However, both strings have an anagram الين which is rare, occurring just six times in ibn Kathir. According to our mapping, if the Voynich scribes had read it from right to left, they would have mapped it to {o981}. If read from left to right, it would map to {189o}. The slot alphabet does not permit either of these sequences, so the scribes would have re-ordered them to {1o89}.
To take this idea further would require a good knowledge of Arabic (preferably medieval Arabic), a head for anagrams or Scrabble, and plenty of computing power (or patience).
In order to assess Arabic as a precursor, we could start by examining whether there are any statistical similarities between the Voynich manuscript and Arabic documents of its era (which we may reasonably assume to be the fifteenth century). One useful metric is the frequency distribution of Arabic letters as written at that time.
An example is the letter frequency distribution in البداية والنهاية (The Beginning and the End), by Abulfida' ibn Kathir (1300-1373).
A modern edition of Al bidayah wal nihayah by ibn Kathir, in twenty-one volumes. Image credit: amazon.
For the Voynich manuscript, Glen Claston’s v101 transliteration is a starting point, The frequencies of the glyphs in the v101 transliteration, in descending order, and the frequencies of the letters in the works of ibn Kathir, have a correlation of 94.4 percent. That in itself is not remarkable: with two short sequences in descending order, it's easy to obtain a correlation of over 90 percent. Many European languages, as well as Hebrew, Persian and Ottoman Turkish, yield a similar correlation with the v101 transliteration.
However, it seems to me that the juxtaposition of these frequency tables opens the possibility of a provisional mapping of any chunk of Voynich text to Arabic. Having done so, it would probably be necessary to reverse the order of the letters in each transliterated word (for which there exist online tools such as https://onlinetexttools.com/reverse-text).
If the resulting text contained any recognisable Arabic words, we might be on the right track. If not, it might be necessary to try different approaches.
Here it should be remembered that Arabic uses an abjad script, in which the long vowels are written but the short vowels usually are not.
Alternative transliterations
One necessary consideration is whether the v101 transliteration is the right one to use.
v101 has a basic character set of seventy-one glyphs, which is far more than the number of letters in any alphabet of a phonetic natural language. There are several groups of visually similar glyphs such as {6}, {7}, {8} and {&}; it makes sense to combine each such group into a single glyph. We can disaggregate glyphs that look like strings, e.g. {m} => {iN}, {n} => {iN}. In both cases, that will reduce the size of the character set and make v101 more like a representation of a natural language.
Conversely, we can make distinctions between initial, interior, final and isolated glyphs. That will increase the size of the character set.
In all cases, these variants change the frequency table and consequently change the mapping from glyphs to any natural language.
In exploring Arabic and other natural languages as possible precursors to the Voynich manuscript, I felt it advisable to examine alternatives to v101. Accordingly, I developed a range of alternative transliterations of the Voynich text, all based on v101 but differing from v101 in one or more respects. I numbered these transliterations v101④ through v202. The ④ signifies that in all the transliterations, I treated the v101 glyph pair {4o} as a single glyph, to which I assigned the Unicode symbol ④.
For comparison of the Voynich text with the Arabic language, I used letter frequencies derived from the works of Ibn Kathir.
To prioritize my Voynich transliterations, I started by calculating the statistical correlations between the glyph frequencies and the Arabic letter frequencies, using the R-squared function (RSQ in Microsoft Excel). However, as expected with two short descending sequences, most of the correlations were well in excess of 90 percent. Substantial differences between transliterations, for example combining the {2} group of glyphs, resulted in quite small changes in the frequency correlations.
Frequency differences
I therefore adopted an alternative metric, namely the average frequency difference. Mathematically, this is the average of the absolute differences between the frequency of a precursor letter and the frequency of the equally ranked Voynich glyph. My idea was that the lowest average frequency difference should represent the best fit between a transliteration and the presumed precursor language.
On this metric, I found that the transliteration which I had numbered v171 was the best fit for ibn Kathir's Arabic alphabet. Apart from the treatment of {4o}, the v171 transliteration has the following differences from v101:
• m=INTo have some assurance of mapping from a single Voynich “language”, I used the text of the “herbal” section only.
• M=iIN
• n=iN.
Below is a juxtaposition of the frequencies of the top ten glyphs in the v171 transliteration, and of those of the top ten Arabic letters. The average frequency difference between v171 and Ibn Kathir's Arabic (calculated on all 43 letters) is 0.64 percent.
The frequencies of the ten most common glyphs in the Voynich manuscript; and those of the ten most common letters in fourteenth-century Arabic. The glyph frequencies are from author's v171 transliteration, "herbal" section. The Arabic letter frequencies are based on the works of Ibn Kathir, with the variants of alef (ﺍ ﺃ ﺇ ﺁ) shown separately or combined. Author's analysis.
The next step is to explore the potential of these juxtapositions as correspondences or mappings. For example, the Voynich {o} could map to and from the Arabic ا (alef). Thereby, we could map some of the most common Voynich "words", such as {8am}, {oe} and {1oe}, to text strings in Arabic. We could then search appropriate corpora of the Arabic language to determine whether these strings are real words.
Test mappings
Below is a summary of my test mappings of the top five Voynich "words" of one, two, three and four glyphs.
Test mappings of the top five "words" of one, two, three and four glyphs in the Voynich manuscript, v171 transliteration, "herbal" section, to text strings in medieval Arabic. Author's analysis.
We see here what I am inclined to call the abjad effect, which I had already observed with Hebrew, Persian and Ottoman Turkish. Most of the Voynich "words" of two or three glyphs map to real Arabic words. They do so whether the glyphs are read from left to right, or from right to left. But in an abjad script, almost any random string of two or three letters will be a real word. At the levels of one glyph and four glyphs, the mapping breaks down.
An alphabetic cipher?
These test mappings do not entirely exclude Arabic as a precursor language of the Voynich manuscript.
As Massimiliano Zattera demonstrated at the Voynich 2022 conference, in almost every Voynich "word" the glyphs follow a sequence, a kind of alphabetic order. Indeed, Zattera called the sequence a "slot alphabet". We are compelled to imagine that if the Voynich scribes mapped their manuscript from precursor documents, they re-ordered the glyphs in every "word". That would imply that we could take any one of our Arabic text strings, scramble the letters, and reverse-engineer it to the same Voynich "word" from which we started.
For example, in the above tests I mapped the Voynich "word" {1o89} to the Arabic strings ليان and نايل which are not real words. However, both strings have an anagram الين which is rare, occurring just six times in ibn Kathir. According to our mapping, if the Voynich scribes had read it from right to left, they would have mapped it to {o981}. If read from left to right, it would map to {189o}. The slot alphabet does not permit either of these sequences, so the scribes would have re-ordered them to {1o89}.
To take this idea further would require a good knowledge of Arabic (preferably medieval Arabic), a head for anagrams or Scrabble, and plenty of computing power (or patience).
March 9, 2024
Voynich Reconsidered: Turkish as precursor
According to Ethel Lilian Voynich, her husband Wilfred Voynich discovered or purchased his eponymous manuscript in Frascati, Italy. In recent posts on this platform, I advanced the idea that wherever the manuscript was produced, it was more likely to have had a shorter journey to Frascati than a longer one. This is simply an example of the well-documented distance-decay hypothesis, whereby human interactions are more probable over short distances than over long ones.
Accordingly, I thought that if the Voynich manuscript had had precursor documents in natural languages, the most probable languages were those written and spoken within a specifiable geographical radius of Italy. Among such languages, those of the Romance group seemed the most promising; followed by those of the Germanic and Slavic groups. If we chose to cast our net wider within Europe, we could include languages of the Hellenic and Uralic groups.
The purpose of this article is to cast the net farther afield, to the periphery of medieval Europe, and to assess the possibility that the precursor language, or one of the precursor languages, of the Voynich manuscript was Turkish.
Radio-carbon analysis, performed on four samples of the vellum, yielded dates between 1400 and 1461, with standard errors of between 35 and 38 years. We might reasonably make the assumption (and it is no more than that) that the manuscript was written sometime in the fifteenth century. If so, and if its precursor documents were in Turkish, those documents would have been written in Ottoman Turkish.
The letters in Ottoman Turkish, like those in Persian, were written in a variant of the Arabic script. This script was an abjad, in which the long vowels were written but the short vowels were not (except sometimes as diacritics above or below the letters).
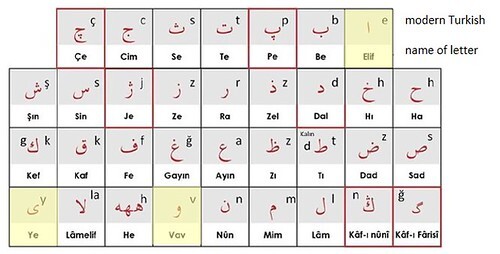
The Ottoman Turkish alphabet. Image by courtesy of Bedrettin Yazan. Highlighted letters are long vowels, which can sometimes also serve as consonants.
In order to assess whether documents in Ottoman Turkish could have been a precursor of the Voynich text, I followed a variant of a strategy which I have outlined in other articles on this platform. The elements of the strategy were as follows:
Corpora of reference
My friend Mustafa Kamel Sen kindly provided a link to an archive of documents in Ottoman Turkish, held by Ataturk University, at https://archive.org/details/dulturk?&.... Among these were a number of documents by authors who lived in the fifteenth or sixteenth centuries.
These documents had been scanned by OCR software and required some cleaning to remove Latin letters and punctuation marks, as well as Arabic numerals, which had been misidentified by the software. A less tractable problem was that some of the original manuscripts had been written in a cramped or compact style, and the software often did not recognise the word breaks. For example, the OCR “word” فرآنوسنت is recognisable as two words by the final ن, and should have been فرآن وسنت. A consequence is that the average length of words, and the incidence of hapax legomena, are overstated.
From these archives I selected, as a corpus of reference, Kitab-I Minhac ul-Fukara by Ismail Ankaravi. Although the title is an Arabic phrase, meaning approximately The Book of the Path of the Poor, the text is in Ottoman Turkish. Ankaravi wrote the book around 1624. The digitised edition, after my cleaning, has 71,232 words with 376,150 characters: equivalent to an average word length of 5.28 characters (as noted above, probably an over-estimate).

The first page of Kitab-i Minhac ul-Fukara. Image by courtesy of Duke University Libraries.
Transliterations and correlations
I calculated the Ottoman letter frequencies on the basis of the full text of Kitab-i Minhac ul-Fukara; and compared these with the glyph frequencies in twenty alternative transliterations of the Voynich manuscript. In terms of correlations with the letter frequencies, the most promising transliterations were the following:

Correspondences
As a trial, I took the v102 transliteration as the best fit with Ottoman Turkish (this does not exclude alternative trials with other transliterations). As in my experiments with other languages, in order to have a reasonable assurance of mapping from a single language, I calculated the glyph frequencies on the basis of the “herbal” section of the Voynich manuscript.
The mappings of the five most frequent glyphs and letters, for example, were as follows:
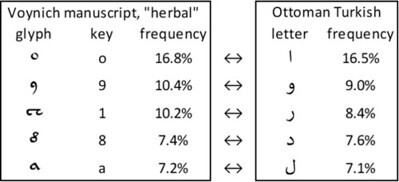
The five most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal” section; and the five most frequent letters in Kitab-I Minhac ul-Fukara. Author’s analysis.
Trial mappings
The next step was to select a suitable sample of Voynich text for the trial mappings.
One possible approach was to take a randomly selected line from the Voynich manuscript. However, I felt that this process was uncertain, since we do not know whether the whole of the manuscript contains meaning; it could be that some small or large part of the text is meaningless filler or junk. I thought it preferable, therefore, to take the most frequent “words”, map them to text strings in Ottoman Turkish, and see, by reference to the corpus, whether the resulting strings were real words.
In order to assess the abjad effect (of which, more below), I selected the most frequent Voynich “words” of one, two, three and four glyphs.
The results, in summary, are below.

The five most frequent “words” of one, two, three and four glyphs in the Voynich manuscript, v102 transliteration, “herbal” section; and trial mappings to text strings in Ottoman Turkish on the basis of frequency rankings. Author’s analysis.
We can see that the top five “words” of one glyph, the top five “words” of two glyphs, and the top two “words” of three glyphs, map to text strings which are real words in Kitab-I Minhac ul-Fukara. But thereafter the mapping breaks down. None of the less frequent “words” of three glyphs, and none of the “words” of four glyphs, maps to words in Ottoman Turkish.
In these results, I detect the abjad effect. Ottoman Turkish, like Arabic, Hebrew and Persian, is an abjad language, with no written short vowels. As I have demonstrated in my forthcoming book Voynich Reconsidered (Schiffer, 2024), in such a language, almost any random string of up to three letters is quite likely to be a real word.
With regard to the apparent words that I found: not being a speaker of Turkish, I do not know the English equivalents. I established only that these strings existed as words in Kitab-i Minhac ul-Fukara. Google Translate is no help, since it only works on modern Turkish. Readers of Turkish who also know the Ottoman script would be able to confirm whether these words are real.
In this light, I was not motivated to pursue a possible further step: namely, to attempt a mapping of a whole line of Voynich text to Ottoman Turkish. If “words” of four glyphs do not map to words, there is not much chance that lines of text will produce meaningful phrases.
In summary, I do not have an expectation that, through a systematic and objective process, it is possible to extract meaningful content in the Ottoman Turkish language from the Voynich manuscript.
Where next?
It would be possible to refine this process by selecting other corpora of reference than Kitab-i Minhac ul-Fukara; by testing other transliterations than v102, with comparable correlations; and by selecting other samples of Voynich text for mapping. I do not have much confidence that these variations would yield meaningful narrative text in Ottoman Turkish.
An alternative would be to recall Massimiliano Zattera’s discovery of the “slot alphabet”, with its quasi-rigid marching order of the glyphs within the Voynich “words”. We would then consider its near-inescapable corollary, that in nearly every Voynich “word”, the scribes mapped letters in some natural language to glyphs, and then re-ordered the glyphs from their original sequence. If so, the mapped text strings in Ottoman Turkish are not the last step; we would have to look for anagrams, which the Voynich scribes would have mapped to the identical Voynich “words”.
Here again, only speakers or readers of Ottoman Turkish could take this analysis to the next level.
Accordingly, I thought that if the Voynich manuscript had had precursor documents in natural languages, the most probable languages were those written and spoken within a specifiable geographical radius of Italy. Among such languages, those of the Romance group seemed the most promising; followed by those of the Germanic and Slavic groups. If we chose to cast our net wider within Europe, we could include languages of the Hellenic and Uralic groups.
The purpose of this article is to cast the net farther afield, to the periphery of medieval Europe, and to assess the possibility that the precursor language, or one of the precursor languages, of the Voynich manuscript was Turkish.
Radio-carbon analysis, performed on four samples of the vellum, yielded dates between 1400 and 1461, with standard errors of between 35 and 38 years. We might reasonably make the assumption (and it is no more than that) that the manuscript was written sometime in the fifteenth century. If so, and if its precursor documents were in Turkish, those documents would have been written in Ottoman Turkish.
The letters in Ottoman Turkish, like those in Persian, were written in a variant of the Arabic script. This script was an abjad, in which the long vowels were written but the short vowels were not (except sometimes as diacritics above or below the letters).
The Ottoman Turkish alphabet. Image by courtesy of Bedrettin Yazan. Highlighted letters are long vowels, which can sometimes also serve as consonants.
In order to assess whether documents in Ottoman Turkish could have been a precursor of the Voynich text, I followed a variant of a strategy which I have outlined in other articles on this platform. The elements of the strategy were as follows:
• to identify a suitable corpus of reference, in the form of a digitised text in Ottoman Turkish, of at least 40,000 words and ideally much more, preferably written in the fifteenth century;A further (but optional) step, in the event that real Ottoman words could be identified, would be to examine whether a line of Voynich text could be thus mapped to a sequence of words in Ottoman Turkish, and if so, whether the result would make any sense.
• to calculate the frequency distribution of the letters in the reference corpus;
• to calculate the correlations between the letter frequencies in the Ottoman Turkish and the glyph frequencies in a range of alternative transliterations of the Voynich manuscript; to select the best-fitting transliteration; and thereby to develop a provisional mapping between Ottoman letters and Voynich glyphs;
• to identify the most frequent “words” in the selected Voynich transliteration, and to map them, letter by letter, to text strings in Ottoman Turkish;
• to search for those text strings in the Ottoman corpus of reference, with a view to identifying whole words.
Corpora of reference
My friend Mustafa Kamel Sen kindly provided a link to an archive of documents in Ottoman Turkish, held by Ataturk University, at https://archive.org/details/dulturk?&.... Among these were a number of documents by authors who lived in the fifteenth or sixteenth centuries.
These documents had been scanned by OCR software and required some cleaning to remove Latin letters and punctuation marks, as well as Arabic numerals, which had been misidentified by the software. A less tractable problem was that some of the original manuscripts had been written in a cramped or compact style, and the software often did not recognise the word breaks. For example, the OCR “word” فرآنوسنت is recognisable as two words by the final ن, and should have been فرآن وسنت. A consequence is that the average length of words, and the incidence of hapax legomena, are overstated.
From these archives I selected, as a corpus of reference, Kitab-I Minhac ul-Fukara by Ismail Ankaravi. Although the title is an Arabic phrase, meaning approximately The Book of the Path of the Poor, the text is in Ottoman Turkish. Ankaravi wrote the book around 1624. The digitised edition, after my cleaning, has 71,232 words with 376,150 characters: equivalent to an average word length of 5.28 characters (as noted above, probably an over-estimate).
The first page of Kitab-i Minhac ul-Fukara. Image by courtesy of Duke University Libraries.
Transliterations and correlations
I calculated the Ottoman letter frequencies on the basis of the full text of Kitab-i Minhac ul-Fukara; and compared these with the glyph frequencies in twenty alternative transliterations of the Voynich manuscript. In terms of correlations with the letter frequencies, the most promising transliterations were the following:
Correspondences
As a trial, I took the v102 transliteration as the best fit with Ottoman Turkish (this does not exclude alternative trials with other transliterations). As in my experiments with other languages, in order to have a reasonable assurance of mapping from a single language, I calculated the glyph frequencies on the basis of the “herbal” section of the Voynich manuscript.
The mappings of the five most frequent glyphs and letters, for example, were as follows:
The five most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal” section; and the five most frequent letters in Kitab-I Minhac ul-Fukara. Author’s analysis.
Trial mappings
The next step was to select a suitable sample of Voynich text for the trial mappings.
One possible approach was to take a randomly selected line from the Voynich manuscript. However, I felt that this process was uncertain, since we do not know whether the whole of the manuscript contains meaning; it could be that some small or large part of the text is meaningless filler or junk. I thought it preferable, therefore, to take the most frequent “words”, map them to text strings in Ottoman Turkish, and see, by reference to the corpus, whether the resulting strings were real words.
In order to assess the abjad effect (of which, more below), I selected the most frequent Voynich “words” of one, two, three and four glyphs.
The results, in summary, are below.
The five most frequent “words” of one, two, three and four glyphs in the Voynich manuscript, v102 transliteration, “herbal” section; and trial mappings to text strings in Ottoman Turkish on the basis of frequency rankings. Author’s analysis.
We can see that the top five “words” of one glyph, the top five “words” of two glyphs, and the top two “words” of three glyphs, map to text strings which are real words in Kitab-I Minhac ul-Fukara. But thereafter the mapping breaks down. None of the less frequent “words” of three glyphs, and none of the “words” of four glyphs, maps to words in Ottoman Turkish.
In these results, I detect the abjad effect. Ottoman Turkish, like Arabic, Hebrew and Persian, is an abjad language, with no written short vowels. As I have demonstrated in my forthcoming book Voynich Reconsidered (Schiffer, 2024), in such a language, almost any random string of up to three letters is quite likely to be a real word.
With regard to the apparent words that I found: not being a speaker of Turkish, I do not know the English equivalents. I established only that these strings existed as words in Kitab-i Minhac ul-Fukara. Google Translate is no help, since it only works on modern Turkish. Readers of Turkish who also know the Ottoman script would be able to confirm whether these words are real.
In this light, I was not motivated to pursue a possible further step: namely, to attempt a mapping of a whole line of Voynich text to Ottoman Turkish. If “words” of four glyphs do not map to words, there is not much chance that lines of text will produce meaningful phrases.
In summary, I do not have an expectation that, through a systematic and objective process, it is possible to extract meaningful content in the Ottoman Turkish language from the Voynich manuscript.
Where next?
It would be possible to refine this process by selecting other corpora of reference than Kitab-i Minhac ul-Fukara; by testing other transliterations than v102, with comparable correlations; and by selecting other samples of Voynich text for mapping. I do not have much confidence that these variations would yield meaningful narrative text in Ottoman Turkish.
An alternative would be to recall Massimiliano Zattera’s discovery of the “slot alphabet”, with its quasi-rigid marching order of the glyphs within the Voynich “words”. We would then consider its near-inescapable corollary, that in nearly every Voynich “word”, the scribes mapped letters in some natural language to glyphs, and then re-ordered the glyphs from their original sequence. If so, the mapped text strings in Ottoman Turkish are not the last step; we would have to look for anagrams, which the Voynich scribes would have mapped to the identical Voynich “words”.
Here again, only speakers or readers of Ottoman Turkish could take this analysis to the next level.
March 4, 2024
Voynich Reconsidered: them’s the breaks
Dante’s La Divina Commedia, in the Gutenberg edition, has 97,332 words. There are 8,083 words that occur just once in the entire narrative. Linguists refer to such words by the Greek term hapax legomenon, "said once" (plural: hapax legomena).
These words are not necessarily long, complex or obscure. In La Divina Commedia, some are quite short: examples are “acra”, “isso” and “rara”. In the first printed edition, dated 1472, on the first page, examples include “delcamin”, “diricta” and “pertractar”.
The incidence of hapax legomena in La Divina Commedia is 8.3 percent of the total word count.

Three instances of hapax legomena in La Divina Commedia, Canto I, lines 1-9. Author’s analysis
In the v101 transliteration of the Voynich manuscript, there are 40,704 “words”. Here I am using the term “word” to refer to a glyph string delimited by spaces, “uncertain spaces” or line breaks. There are 6,714 “words” which occur exactly once. In the first eight lines, there are at least sixteen cases of hapax legomena. The incidence of hapax legomena in the Voynich manuscript is 16.5 percent of the total "word" count: almost double that in La Divina Commedia.
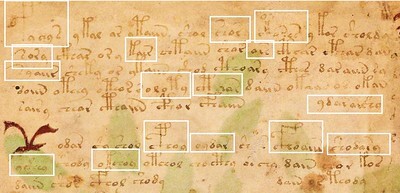
Sixteen examples of hapax legomena in the Voynich manuscript, page f1r, lines 1-8. Author’s analysis.
An anomalous vocabulary
As Prescott Currier said in 1976, at Mary D’Imperio’s Voynich seminar (although in a different context):
As Alexander Boxer observed in his presentation at the Voynich 2022 conference, the incidence of hapax legomena is linked to the length of the document. Other things being equal, a longer document will give more opportunities for a word to be re-used, and therefore will generally have a lower incidence of hapax legomena. Therefore, to assess whether the Voynich manuscript is anomalous, we need to look at documents of a similar length.
Below is a summary of the incidence of hapax legomena in the Voynich manuscript, and in extracts of about 40,000 words from a selection of medieval European documents.

Incidence of hapax legomena in the Voynich manuscript and in selected medieval European documents. Author's analysis.
We can see that the Voynich manuscript is an outlier, with a notably greater prevalence of hapax legomena than any of the comparator documents.
Separable "words"
One example may illustrate what a hapax legomenon looks like in the Voynich manuscript. The v101 “word” {8amo89} occurs just once: on line 8 of page f089r2. In English, if we see an uncommon word like "herein", we instinctively recognise the two components, "here" and "in". Likewise, if the researcher has a passing familiarity with the Voynich vocabulary, he or she will observe that the “word” {8amo89} has two parts: {8am} and {o89}. Both are common “words” in the Voynich manuscript: in the v101 transliteration, {8am} occurs 739 times and {o89} forty-five times.

We have to wonder if a construction like {8amo89} is not one “word” but two: in which the scribe chose to omit, or was instructed to omit, the space which would have marked a “word” break.
Here we return to Massimiliano Zattera’s presentation at the Voynich 2022 conference, and his concept of “separable words”: that is, “words” which can be divided into two (or maybe more) parts, each of which is a Voynich “word”. Zattera took a computational approach to the text, and worked with an abridged version of the EVA transliteration, in which he counted 31,317 “words”. He identified 3,249 occurrences of “words” which were separable. Each of these “words” could be split into two parts, each of at least two glyphs, and each of which was a real Voynich “word”.
Zattera required a "word" to have at least two glyphs. But among the v101 glyphs, there are at least forty-seven that sometimes occur with preceding and following spaces: that is, as “words”. If we allow one of the parts of a “word” to be a single glyph, the number of “separable words” will be substantially greater than Zattera’s estimate. If we also allow more than two parts of the “word”, the number of “separable words” will further increase.
The “slot alphabet” revisited
If our objective is mapping the glyphs to text in natural languages, and if the glyphs are in their original order, it will not much matter whether the “word” breaks are identifiable or not. For example, if miraculously we could map a line of Voynich text to the sequence “nelm ezode lcam indinr auita”, it would not take us long to see the medieval Italian phrase “nel mezo delcamin dinra uita”.
But Zattera’s principal finding was that in nearly all of the Voynich “words”, the glyphs followed a specific sequence, which he called the “slot alphabet”. In natural languages, to the best of my knowledge, a comparable marching order of letters within words is unknown. Therefore, as I have observed elsewhere on this platform, we have a powerful argument that within each Voynich “word”, the scribes re-ordered the glyphs.
To take an illustration from the English language: the first two words of the Gettysburg Address are “four score”. If in each word, we sort the letters alphabetically, the result is “foru ceors”: from which we can easily extract the original words. But if Abraham Lincoln had written “fourscore”, and an imaginary scribe had sorted the letters alphabetically, the result would be “cefoorrsu”. It would not be self-evident to reconstruct Lincoln’s “four score”: although with patience and a head for anagrams, we might do so.
If the glyphs have been re-ordered, we have to know where the “word” breaks are.
The breaks
In a previous article on this platform, I set out my ideas on a procedure for trial mappings of Voynich glyphs to text in natural languages. The first step was to identify the best fits between alternative transliterations and candidate languages; and to select suitable chunks of Voynich text for mapping. We now turn to the second step: establishing the “word” breaks.
Here, our ally is Zattera’s “slot alphabet”. There are twelve slots, numbered from 0 to 11. The rule is that within a Voynich “word”, a glyph can only be followed by a glyph in the same or a higher slot.
Among the lines of Voynich text that I selected for the trial mappings, one line contained the v101 “word” {soeham}. This “word” occurs only three times in the manuscript: it is not quite a hapax legomenon, but close. We therefore suspect it to be a “separable word”. We can check each glyph, and see what slots it can occupy; identify a sequence that conforms to the “slot” alphabet; and break the “word” at any point where it can be separated and maintain conformity. The result is as follows:

In this instance, the whole “word” conforms to the “slot alphabet”; there are five breakdowns that also conform. We can break after the {s), leaving {oeham} which occurs 28 times. We can break after {so}, leaving {eham} which is a more common “word”. If we break into {soe} and {ham}, these are even more common “words”. The breaks into {soeh} and {am}, and into {soeha} and {m}, do not work, since {soeh} and {soeha} are not “words”. We are encouraged to believe that the “word” {soeham} is actually two “words”: most probably {soe} and {ham}.
“Word” separation
Having constructed an algorithm for breaking down “separable words”, we may now return to the second step. We might capitalise it as the Second Step, since our task is akin to climbing Mount Everest.
To cut to the chase: below is an analysis of one of the eleven lines of text that I selected for the trial mappings, with “word” breaks inserted at the points where I saw the highest probability of generating the basic Voynich “words”: what we might call the building blocks of the manuscript.

These words are not necessarily long, complex or obscure. In La Divina Commedia, some are quite short: examples are “acra”, “isso” and “rara”. In the first printed edition, dated 1472, on the first page, examples include “delcamin”, “diricta” and “pertractar”.
The incidence of hapax legomena in La Divina Commedia is 8.3 percent of the total word count.
Three instances of hapax legomena in La Divina Commedia, Canto I, lines 1-9. Author’s analysis
In the v101 transliteration of the Voynich manuscript, there are 40,704 “words”. Here I am using the term “word” to refer to a glyph string delimited by spaces, “uncertain spaces” or line breaks. There are 6,714 “words” which occur exactly once. In the first eight lines, there are at least sixteen cases of hapax legomena. The incidence of hapax legomena in the Voynich manuscript is 16.5 percent of the total "word" count: almost double that in La Divina Commedia.
Sixteen examples of hapax legomena in the Voynich manuscript, page f1r, lines 1-8. Author’s analysis.
An anomalous vocabulary
As Prescott Currier said in 1976, at Mary D’Imperio’s Voynich seminar (although in a different context):
“That’s just the point … they’re not words!”Considerations such as these encourage us to conjecture that the Voynich manuscript possesses an anomalous vocabulary. We might wonder, for example, if this vocabulary uses rare or obscure "words" to a much greater extent than other comparable documents of a similar time and place.
As Alexander Boxer observed in his presentation at the Voynich 2022 conference, the incidence of hapax legomena is linked to the length of the document. Other things being equal, a longer document will give more opportunities for a word to be re-used, and therefore will generally have a lower incidence of hapax legomena. Therefore, to assess whether the Voynich manuscript is anomalous, we need to look at documents of a similar length.
Below is a summary of the incidence of hapax legomena in the Voynich manuscript, and in extracts of about 40,000 words from a selection of medieval European documents.
Incidence of hapax legomena in the Voynich manuscript and in selected medieval European documents. Author's analysis.
We can see that the Voynich manuscript is an outlier, with a notably greater prevalence of hapax legomena than any of the comparator documents.
Separable "words"
One example may illustrate what a hapax legomenon looks like in the Voynich manuscript. The v101 “word” {8amo89} occurs just once: on line 8 of page f089r2. In English, if we see an uncommon word like "herein", we instinctively recognise the two components, "here" and "in". Likewise, if the researcher has a passing familiarity with the Voynich vocabulary, he or she will observe that the “word” {8amo89} has two parts: {8am} and {o89}. Both are common “words” in the Voynich manuscript: in the v101 transliteration, {8am} occurs 739 times and {o89} forty-five times.
We have to wonder if a construction like {8amo89} is not one “word” but two: in which the scribe chose to omit, or was instructed to omit, the space which would have marked a “word” break.
Here we return to Massimiliano Zattera’s presentation at the Voynich 2022 conference, and his concept of “separable words”: that is, “words” which can be divided into two (or maybe more) parts, each of which is a Voynich “word”. Zattera took a computational approach to the text, and worked with an abridged version of the EVA transliteration, in which he counted 31,317 “words”. He identified 3,249 occurrences of “words” which were separable. Each of these “words” could be split into two parts, each of at least two glyphs, and each of which was a real Voynich “word”.
Zattera required a "word" to have at least two glyphs. But among the v101 glyphs, there are at least forty-seven that sometimes occur with preceding and following spaces: that is, as “words”. If we allow one of the parts of a “word” to be a single glyph, the number of “separable words” will be substantially greater than Zattera’s estimate. If we also allow more than two parts of the “word”, the number of “separable words” will further increase.
The “slot alphabet” revisited
If our objective is mapping the glyphs to text in natural languages, and if the glyphs are in their original order, it will not much matter whether the “word” breaks are identifiable or not. For example, if miraculously we could map a line of Voynich text to the sequence “nelm ezode lcam indinr auita”, it would not take us long to see the medieval Italian phrase “nel mezo delcamin dinra uita”.
But Zattera’s principal finding was that in nearly all of the Voynich “words”, the glyphs followed a specific sequence, which he called the “slot alphabet”. In natural languages, to the best of my knowledge, a comparable marching order of letters within words is unknown. Therefore, as I have observed elsewhere on this platform, we have a powerful argument that within each Voynich “word”, the scribes re-ordered the glyphs.
To take an illustration from the English language: the first two words of the Gettysburg Address are “four score”. If in each word, we sort the letters alphabetically, the result is “foru ceors”: from which we can easily extract the original words. But if Abraham Lincoln had written “fourscore”, and an imaginary scribe had sorted the letters alphabetically, the result would be “cefoorrsu”. It would not be self-evident to reconstruct Lincoln’s “four score”: although with patience and a head for anagrams, we might do so.
If the glyphs have been re-ordered, we have to know where the “word” breaks are.
The breaks
In a previous article on this platform, I set out my ideas on a procedure for trial mappings of Voynich glyphs to text in natural languages. The first step was to identify the best fits between alternative transliterations and candidate languages; and to select suitable chunks of Voynich text for mapping. We now turn to the second step: establishing the “word” breaks.
Here, our ally is Zattera’s “slot alphabet”. There are twelve slots, numbered from 0 to 11. The rule is that within a Voynich “word”, a glyph can only be followed by a glyph in the same or a higher slot.
Among the lines of Voynich text that I selected for the trial mappings, one line contained the v101 “word” {soeham}. This “word” occurs only three times in the manuscript: it is not quite a hapax legomenon, but close. We therefore suspect it to be a “separable word”. We can check each glyph, and see what slots it can occupy; identify a sequence that conforms to the “slot” alphabet; and break the “word” at any point where it can be separated and maintain conformity. The result is as follows:
In this instance, the whole “word” conforms to the “slot alphabet”; there are five breakdowns that also conform. We can break after the {s), leaving {oeham} which occurs 28 times. We can break after {so}, leaving {eham} which is a more common “word”. If we break into {soe} and {ham}, these are even more common “words”. The breaks into {soeh} and {am}, and into {soeha} and {m}, do not work, since {soeh} and {soeha} are not “words”. We are encouraged to believe that the “word” {soeham} is actually two “words”: most probably {soe} and {ham}.
“Word” separation
Having constructed an algorithm for breaking down “separable words”, we may now return to the second step. We might capitalise it as the Second Step, since our task is akin to climbing Mount Everest.
To cut to the chase: below is an analysis of one of the eleven lines of text that I selected for the trial mappings, with “word” breaks inserted at the points where I saw the highest probability of generating the basic Voynich “words”: what we might call the building blocks of the manuscript.
March 2, 2024
Voynich Reconsidered: alternative transliterations
During the late 1990s, Timothy Rayhel developed a new transliteration of the complete text of the Voynich manuscript. He made it available online under the pseudonym Glen Claston. He called the transliteration v101. Rayhel passed away in 2014, aged only fifty-six; but the v101 transliteration lived on. Of the several widely used (and very different) transliterations of the Voynich manuscript, it is my personal favourite.
The v101 transliteration identifies far more glyphs than there are letters in any modern or medieval phonetic alphabet. Rayhel’s basic character set had seventy-one glyphs: for which he had to assign the following keys:
In many cases, Rayhel assigned different keys to glyphs that seemed to differ in minor respects. For example:
Nevertheless, like any transliteration of an unknown set of symbols, v101 incorporates certain assumptions, as to what constitutes a glyph. The most consequential of these assumptions relate to the following groups of glyphs, which other transliterations such as EVA treat as glyph strings:
I like to think that Rayhel anticipated these concerns; and that he did not intend his v101 to be definitive. Indeed, the appellation v101 invites us to imagine further transliterations, numbered v102, v103 and so on.
A final reason why I like v101 is that, thanks to Rebecca Bettencourt of KreativeKorp, the glyphs are available as a Unicode font. Thereby, in Microsoft Word or Excel, we can write a line of v101 characters, change the font to Voynich v101, and see the glyphs in a form close to that which appears in the original document MS408 at the Beinecke Rare Book and Manuscript Library.
Considerations such as these prompted me, when writing Voynich Reconsidered, to work from the v101 transliteration and to depart from it whenever it was necessary for the statistical testing of hypotheses. Indeed, in the book I presented three alternative transliterations, which I numbered v102, v103 and v104.
In subsequent research, I started by developing twenty additional transliterations, currently numbered from v120 to v202. Their main characteristics are summarised below.

A summary of transliterations v101④ (i.e. v101 with 4o replaced by ④) to v202. Included but not shown in the F group: v101 glyphs {j}, {J}, {l}, {L}, [r}, {R}, {u}, {U}. Author’s analysis.
There were two common characteristics of these transliterations, as follows:
Examples of variant transliterations
An example may illustrate the differences between the transliterations. I selected page f1r, line 13, as a line of Voynich text which could be transliterated in many different ways. It includes some “gallows” glyphs, some “pedestal” glyphs, and some occurrences of the {2} group, the {8} group, {m} and {n}. It does not have any occurrences of {4o}, {A}, {C} or {cc}.
Below is a summary of my transliterations of this line in v101④ through v104.

Prioritising the transliterations
The issue then arose: was it possible to rank or prioritise these transliterations, in terms of their probability of a sensible mapping from a precursor language?
For any given transliteration, a natural and objective test would be to compare the glyph frequencies with the letter frequencies in selected precursor languages.
However, we do not know the precursor languages; we can only assign probabilities to various plausible candidates. In other posts on this platform, I have argued that, given that Voynich found the manuscript in Italy, the languages spoken and written in or near medieval Italy are more probable precursors than those more geographically distant. Therefore, I thought it reasonable to begin with medieval Italian, represented broadly by the OVI corpus, or more narrowly by Dante’s La Divina Commedia; with other Romance languages such as French, Galician-Portuguese and Latin; and with other European languages such as Bohemian and German.
If one or another transliteration produced a good correlation, we could then plan on some trial mappings.
In calculating the letter frequencies, I made no distinction between vowels and consonants. In other posts on this platform, I have advanced the hypothesis that the Voynich scribes, after mapping letters to glyphs, re-ordered the glyphs in each "word". If they did, the typical alternation of consonants and vowels, which is familiar to us in European languages, would disappear; and we would have no way of knowing which glyphs represented consonants and which vowels.
The correlations are simply the correlation coefficients calculated by the R-squared function (RSQ in Microsoft Excel). The coefficient is only calculated on the data for which matches can be made in both datasets. For example, Glen Claston’s basic v101 glyph set has seventy-one glyphs, while medieval Italian (in the OVI corpus) has only thirty-one letters, including accented letters. If we are matching v101 with medieval Italian, the correlation is calculated only for the thirty-one most frequent glyphs; the forty least frequent glyphs are ignored. Fortunately, those last forty glyphs have frequencies of less than 0.1 percent; and most of them can be combined with other glyphs which they resemble.
In each case, in order to have some confidence of using Voynich text containing (or derived from) a single language, I used the glyph frequencies from the “herbal” section of the manuscript.
Without further ado, below is a summary of the correlations between the glyph frequencies in my transliterations v101④ to v202, and the letter frequencies in ten candidate medieval languages (eight European, plus Arabic and Persian).

Correlations between glyph frequencies (v101④ through v202) and letter frequencies in potential precursor languages. I made no distinction between vowels and consonants (i.e., no implementation of the Sukhotin algorithm. Author’s analysis.
For each potential precursor language, we find that there is one transliteration (or sometimes two) that is a best fit for the letter frequencies in the language in question.
The logical next step is to select the best-fitting pairings of transliteration and language, and to attempt some trial mappings. My provisional procedure is as follows:
The v101 transliteration identifies far more glyphs than there are letters in any modern or medieval phonetic alphabet. Rayhel’s basic character set had seventy-one glyphs: for which he had to assign the following keys:
• the twenty-six lower-case letters of the Latin alphabet;In addition, Rayhel defined an extended character set with eighty-one additional glyphs, each of which occurs only once or a few times in the whole manuscript.
• plus twenty-five upper-case letters (all except O);
• plus the numbers from 1 to 9;
• plus eleven special characters such as $.
In many cases, Rayhel assigned different keys to glyphs that seemed to differ in minor respects. For example:
• His glyphs {2}, {3}, {5} and four others differ only in the shape and position of a small accent or diacritic.However, none of this matters. The researcher is free to treat any group of similar glyphs as one glyph; v101 places no constraint on doing so.
• His glyphs {6}, {7}, {8} and {&} are sufficiently similar that we might ascribe their differences to styles of handwriting.
• The differences between {f} and {u}, and between {g} and {j}, are tiny hooks or flourishes.
Nevertheless, like any transliteration of an unknown set of symbols, v101 incorporates certain assumptions, as to what constitutes a glyph. The most consequential of these assumptions relate to the following groups of glyphs, which other transliterations such as EVA treat as glyph strings:
• the v101 glyphs {m} and {n}; for example, the v101 {m} is {iin} in EVA;In cases such as these, the researcher who suspects the single glyphs in v101 to be strings must be prepared to break them up, as EVA does.
• the v101 “pedestal” glyphs {F}, {G}, {H} and {K}, and their relatives; for example, v101 {K} is {cth} in EVA;
• the v101 “multiple” glyphs {C} and its relatives, and {I}; the v101 glyph {C} is {ee} in EVA, and the v101 {I} is {ii} in EVA.
I like to think that Rayhel anticipated these concerns; and that he did not intend his v101 to be definitive. Indeed, the appellation v101 invites us to imagine further transliterations, numbered v102, v103 and so on.
A final reason why I like v101 is that, thanks to Rebecca Bettencourt of KreativeKorp, the glyphs are available as a Unicode font. Thereby, in Microsoft Word or Excel, we can write a line of v101 characters, change the font to Voynich v101, and see the glyphs in a form close to that which appears in the original document MS408 at the Beinecke Rare Book and Manuscript Library.
Considerations such as these prompted me, when writing Voynich Reconsidered, to work from the v101 transliteration and to depart from it whenever it was necessary for the statistical testing of hypotheses. Indeed, in the book I presented three alternative transliterations, which I numbered v102, v103 and v104.
In subsequent research, I started by developing twenty additional transliterations, currently numbered from v120 to v202. Their main characteristics are summarised below.
A summary of transliterations v101④ (i.e. v101 with 4o replaced by ④) to v202. Included but not shown in the F group: v101 glyphs {j}, {J}, {l}, {L}, [r}, {R}, {u}, {U}. Author’s analysis.
There were two common characteristics of these transliterations, as follows:
• In all cases, I redefined the v101 glyph string {4o} as a single glyph, to which I assigned the Unicode symbol ④. The v101 glyph {4}, in 96 percent of its occurrences, is followed by, and indeed joined to, what appears to be a v101 {o}; I felt that this pairing could not be two glyphs.I grouped the alternative transliterations from v120 to v191 in series, each characterised by a specific divergence from v101. For example, the v160 series shared a disaggregation of the “pedestal” glyphs, which I called the “F group”. In the v200 series, I experimented with combining several divergences from v101.
• In all cases, I assumed that a glyph retained its meaning (that is, its presumed precursor letter) independently of its position within the Voynich “word”.
Examples of variant transliterations
An example may illustrate the differences between the transliterations. I selected page f1r, line 13, as a line of Voynich text which could be transliterated in many different ways. It includes some “gallows” glyphs, some “pedestal” glyphs, and some occurrences of the {2} group, the {8} group, {m} and {n}. It does not have any occurrences of {4o}, {A}, {C} or {cc}.
Below is a summary of my transliterations of this line in v101④ through v104.
Prioritising the transliterations
The issue then arose: was it possible to rank or prioritise these transliterations, in terms of their probability of a sensible mapping from a precursor language?
For any given transliteration, a natural and objective test would be to compare the glyph frequencies with the letter frequencies in selected precursor languages.
However, we do not know the precursor languages; we can only assign probabilities to various plausible candidates. In other posts on this platform, I have argued that, given that Voynich found the manuscript in Italy, the languages spoken and written in or near medieval Italy are more probable precursors than those more geographically distant. Therefore, I thought it reasonable to begin with medieval Italian, represented broadly by the OVI corpus, or more narrowly by Dante’s La Divina Commedia; with other Romance languages such as French, Galician-Portuguese and Latin; and with other European languages such as Bohemian and German.
If one or another transliteration produced a good correlation, we could then plan on some trial mappings.
In calculating the letter frequencies, I made no distinction between vowels and consonants. In other posts on this platform, I have advanced the hypothesis that the Voynich scribes, after mapping letters to glyphs, re-ordered the glyphs in each "word". If they did, the typical alternation of consonants and vowels, which is familiar to us in European languages, would disappear; and we would have no way of knowing which glyphs represented consonants and which vowels.
The correlations are simply the correlation coefficients calculated by the R-squared function (RSQ in Microsoft Excel). The coefficient is only calculated on the data for which matches can be made in both datasets. For example, Glen Claston’s basic v101 glyph set has seventy-one glyphs, while medieval Italian (in the OVI corpus) has only thirty-one letters, including accented letters. If we are matching v101 with medieval Italian, the correlation is calculated only for the thirty-one most frequent glyphs; the forty least frequent glyphs are ignored. Fortunately, those last forty glyphs have frequencies of less than 0.1 percent; and most of them can be combined with other glyphs which they resemble.
In each case, in order to have some confidence of using Voynich text containing (or derived from) a single language, I used the glyph frequencies from the “herbal” section of the manuscript.
Without further ado, below is a summary of the correlations between the glyph frequencies in my transliterations v101④ to v202, and the letter frequencies in ten candidate medieval languages (eight European, plus Arabic and Persian).
Correlations between glyph frequencies (v101④ through v202) and letter frequencies in potential precursor languages. I made no distinction between vowels and consonants (i.e., no implementation of the Sukhotin algorithm. Author’s analysis.
For each potential precursor language, we find that there is one transliteration (or sometimes two) that is a best fit for the letter frequencies in the language in question.
The logical next step is to select the best-fitting pairings of transliteration and language, and to attempt some trial mappings. My provisional procedure is as follows:
• select (preferably randomly) a chunk of Voynich text, consisting of at least a whole line
• check the selected text for Zattera’s “separable words”; for this purpose, each “word” needs to be tested against Zattera’s “slot alphabet”, to see whether it conforms; and if not, separate the word with a space or spaces at appropriate points;
• map the text to the target precursor language, with a straight frequency mapping, without distinguishing vowels and consonants;
• check the resultant text strings against a suitable corpus or text of the target language, as to whether they are real words in the language;
• and in cases where a text string is not a real word, or is a rare word, examine the possibilities of re-arranging vowels and consonants in the string, with a view to finding a common real word (again by reference to the corpus or text)
• and finally, if a whole line is thus mapped to real words, examine whether the result makes any sense.
February 17, 2024
Voynich Reconsidered: the glyphs re-ordered?
At the Voynich conference hosted by the University of Malta in 2022, Massimiliano Zattera presented his finding that in 97 percent of the “words” in the Voynich manuscript, the glyphs conformed to a specific sequence. within the "word".
He called this sequence the “slot alphabet”.
Zattera was using the term “alphabet” in the same sense that we use with reference to the Latin script, or any phonetic script. That is, an alphabet is not merely a collection of letters but a sequence of letters. An alphabet permits the concept of "alphabetic order". In the case of the Latin script, we agree that the alphabet has a fixed order, starting with A, B, C and ending with X, Y, Z. The "slot alphabet" is more complex: it has twelve slots. The first is slot 0 which consists of the v101 glyphs {4}, initial {8} and initial {s}, in no fixed order. The last is slot 11 which consists of the final glyph {9}.
Zattera demonstrated that in the Voynich "words", with few exceptions, a glyph can only be followed by a glyph in the same or a higher slot; and can only be preceded by a glyph in the same or a lower slot. For example, since {h} is in slot 3 and {1} is in slot 4, {1} can follow {h}, but {1} cannot precede {h}.
Unlike the Latin alphabet, the "slot alphabet" has some flexibility. For example, the glyph {8} can be in any of three slots. It is as if in the Latin alphabet, the letter B were between A and C; again between L and M; and again between T and U. Alternatively, we could think of the {8} as three different glyphs; one in the initial position, one in a medial position, and one in the penultimate or final position.
My intuition (which may be wrong) makes me think that in a written natural language, the letters are not bound to a specific sequence. For example in English words, A can precede B (as in "able"), or follow B (as in "back").
What we see in the Voynich manuscript is akin to what a person with no knowledge of the English language or the Latin script would see in the following sequence:
Zattera's "slot alphabet", with the v101 glyphs {m} and {n} added in their presumed slots, and the rare v101 glyphs {F} and {G} removed. Graphics by author.
Therefore, to my mind, Zattera’s findings convey a powerful argument (though one that he himself did not express), that if the glyphs represent letters in natural languages, then in each Voynich “word” the scribes re-ordered the glyphs according to some predefined sequence.
An alphabetic cipher
If that is what the scribes of the Voynich did, it was a form of encipherment: easy to implement, but difficult to decode. In effect, it implies that nearly every Voynich “word” is an anagram. That does not make the Voynich text impossible to decipher; but the process involves at least the following steps:
1. Candidate languages
In my forthcoming book Voynich Reconsidered, and in several posts on this platform, I have argued that we could draw a series of concentric circles centred on Frascati, Italy, where Wilfred Voynich discovered or purchased the manuscript; and in each of these circles, identify the languages most widely spoken and written in the fifteenth century. To my mind, by the distance-decay hypothesis, it is more probable that the manuscript arrived in Frascati from a nearer location than from one more distant. If so, we can assign higher probabilities to the languages of the inner circles, than those of the peripheral circles.
By this process, we would be encouraged to think of Romance languages as probable precursors, followed by Slavic and Germanic languages, thereafter Albanian, Hellenic, Uralic and perhaps Arabic. Within the Romance language group, I am inclined to favour Italian and Latin, followed by French.
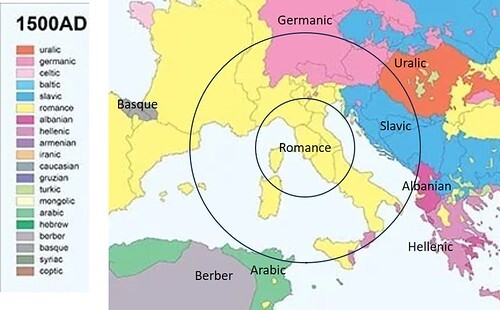
The two innermost concentric circles centred on Frascati, Italy. Image credit: "blogen"; graphics and annotations by author.
2. Mapping between glyphs and letters
To my mind, the most objective mapping between glyphs and letters would be based on, or at least derived from, frequency analysis. That is, the most frequent letters in the precursor documents should map to the most frequent glyphs in the Voynich manuscript, with approximately the same rankings.
Since at this stage we cannot identify the precursor documents, we are obliged to refer to corpora of the candidate languages, or at least to reasonably lengthy documents in those languages. For example, to test the medieval Bohemian language, I referred to Dalimilova kronika, an epic historical narrative written at the beginning of the fourteenth century.

Frequency comparisons between v101 glyphs and Bohemian letters in Dalimilova kronika; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
It has to be kept in mind that whatever corpus or reference document we use, the precursor documents of the Voynich manuscript cannot be expected to have identical rankings of the letters. For example, the letter frequencies in Dante’s La Divina Commedia differ slightly from those in the broader OVI corpus of medieval Italian. From comparisons such as these, I think that the best we can hope for is that in the precursor documents, the top nine or ten letters will be the same as in the language as a whole, and in the same order. For less common letters, we have to be prepared to make swaps in the rankings.
3(a). Glyph definitions
In other posts on this platform, I have set out some ideas on what constitutes a glyph. My thinking is that various assumptions are reasonable, and that to test these assumptions, it is necessary to develop multiple transliterations of the Voynich manuscript.
In Voynich Reconsidered, as possible alternatives to v101, I presented three new transliterations which I numbered v102, v103 and v104. In subsequent research, I have developed about twenty further transliterations, numbered from v120 to v216. Most of them differ from v101 in just one respect; for example, in one case the only change was to replace {C} with {cc}. Some differ in several respects.
In another post, I may set out some ideas for ranking or prioritizing alternative transliterations. One possible criterion is the extent of correlation between the glyph frequencies and the letter frequencies in selected medieval languages. In this respect, some of my transliterations have higher correlations than others. In that sense, they encourage further testing.
3(b). “Word” definitions
Elsewhere on this platform, I have written that there is considerable uncertainty as to how the Voynich manuscript establishes breaks between “words”. Where the text is horizontal, we can see line breaks; within the lines, we often see clear spaces between text strings. The v101 transliteration also distinguishes “uncertain spaces”, which might be “word” breaks or might simply be elongations of “words”. There is nothing resembling punctuation, that might guide us as to where “words” begin and end.
As shown in the image below, we also often see text run up against an illustration and continue on the other side. Sometimes the "words" to left and right of the break are unique. In such cases, we may wonder whether the illustration broke a “word” into two fragments, neither necessarily a “word”; or whether in the text to left or right of the illustration, the scribe omitted some "word" breaks.

An extract from page f026r, showing presumed "word" breaks. The "words" highlighted in light yellow occur nowhere else in the manuscript. Image credit: Beinecke Rare Book and Manuscript Library; graphics and legend by author.
Furthermore, at the Voynich 2022 conference Zattera demonstrated that there are thousands of Voynich “words” which can be split into two parts, each of which is a “word”. He called them “separable words”. We could think of them as analogous to compound words in natural languages, like "oversee" in English; alternatively, we could think of them as cases in which the scribe simply omitted a space.
If we did not suspect the Voynich text to have been subject to a re-ordering of glyphs within “words”, the “word” breaks would not much matter. For example, if in English we saw the sequence:
It seems to me therefore that it is important to make explicit and objective assumptions on the word breaks in the Voynich manuscript. My working assumption is that all line breaks, v101 spaces and v101 “uncertain spaces” are “word" breaks; and that all of Zattera’s “separable words” need to have spaces inserted at the appropriate places.
(As a footnote: Zattera did not identify the “separable words”, nor did he define the algorithm whereby he had identified them. In another post on this platform, I have set out some ideas for that identification.)
4. Mapping and re-ordering
If we think that there was a re-ordering process, it makes a big difference whether it preceded or followed the mapping.
An example may illustrate this issue. Let us imagine ourselves somewhere in Italy in the year 1472. At the Annunciation Fair in Foligno, the entrepreneur Johann Neumeister has launched the first printed edition of Dante’s beloved La Divina Commedia. A wealthy person, whom we will call "the producer", has purchased several copies. He or she distributes the copies to a team of scribes, engaged for this purpose. He or she instructs them to transliterate the book, word by word and letter by letter, into an invented script. He or she prescribes the mapping from Latin letters to the inscrutable glyphs. The scribes speak and read Italian, and they are free to parse the printed words as they see fit.
The producer has one further instruction. In mapping each Italian word, the scribes are to do one of the following (and we do not know which):

Two alternative mappings of Dante's La Divina Commedia (1472 edition), Canto 1, line 1, to Voynich glyphs, on the basis of frequency matching and re-ordering processes. Author's analysis. (The three alternative results in column 2 reflect the flexible positioning of the glyphs {o}, {8} and {9} within Zattera’s “slot alphabet”. The glyph strings in blue are real Voynich "words".)
Column 2, which conforms to the “slot alphabet”, contains two glyph strings which exist as real "words" in the Voynich manuscript. Column 1 has only one such string. The sequences of glyph strings in Columns 1 and 2 are somewhat different.
It seems to me that the process represented in Column 1 is less probable. For example, if we sort alphabetically the letters in European words, many words will begin with A. Therefore A should map to one of the glyphs in Zattera's slot 0: that is, either {4}, the initial {8} or the initial {s}. But in the medieval European languages that I have studied, the letter A has a frequency of between 7 and 11 percent. In the Voynich v101 transliteration, the frequencies of {4}, initial {8} and initial {s} do not exceed 3.2 percent.
If the glyphs have been re-ordered, I am inclined to view process 2 (mapping and then re-ordering) as the more probable process.
5(a). Selecting the Voynich text
Elsewhere on this platform, I have argued that any serious attempt at mapping the Voynich text must be based on a reasonably long chunk of text: at least a whole line, better a paragraph, better still a whole page. We cannot be content with single "words".
Since we are taking aim at a natural language, to my mind we need to select a chunk of text which appears to be in a uniform language.
Here, we could start with Prescott Currier's Language A and Language B. The downside is that Currier never explained how he had identified Languages A and B. In the 1976 conference, he said that the differences were statistical; we might guess that those differences were in glyph frequencies, or "word" frequencies. For example, the v101 glyph {c} is much more common in the {B} pages than in the {A} pages; also, "words" beginning with {4o} are more common in B than in A.
My own preference is to work with the thematic sections of the manuscript. Here at least, we have the illustrations as a basis for defining the section. For example, we can follow the conventional definition of the "herbal" section as the set of pages containing illustrations of complete plants. There is no necessity to assume that the text corresponds to the illustrations.
If we select a single thematic section, we can run statistical tests on sub-sections to see whether the section is in a uniform language. Sub-sections can be defined by reference to the scribes. In the case of the "herbal" section, Dr Lisa Fagin Davis has proposed that there were four scribes: she numbered them 1, 2, 3 and 5. I have found some evidence that the four scribes used four different languages. To have some assurance of mapping from a single language, I am inclined to work with only the 95 pages written by Scribe 1.
5(b). Reverse mapping
If we then leave the re-ordering process aside and simply attempt some reverse glyph-to-letter mappings, we will generate text strings in the presumed precursor languages. For example, let us say that we want to test medieval Italian as a possible precursor.
We select the first page of the "herbal" section, f1v, which Currier assigned to Language A, and which, according to Dr Davis, was written by Scribe 1. Randomly we select line 4, which appears to contain seven "words". However, before we do the mapping, we need to confirm the "word" breaks. Here we apply Zattera's "slot alphabet", with the following result:
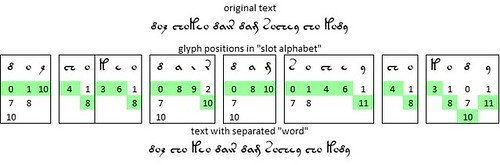
We infer that all the "words" conform to the "slot alphabet", except the second "word", which is a "separable word" and needs to have a space inserted.
We now have eight "words", which we map to medieval Italian with a straight frequency analysis, making no distinction between vowels and consonants, as shown in the right-hand mapping below:
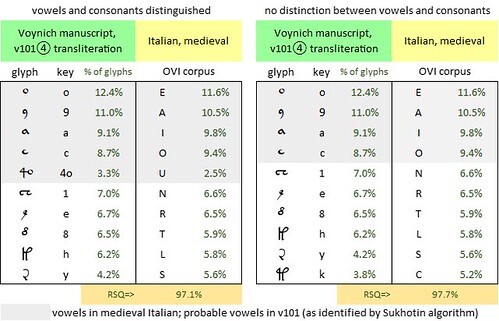
Frequency comparisons between v101 glyphs and Italian letters in the OVI corpus; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
We thereby generate the sequence:
[As a footnote: we can also try alternative transliterations of the Voynich manuscript. The v101 transliteration has too many glyphs to map to a typical European alphabet; it makes sense to combine some of them. In my v102 and subsequent transliterations, I have explored this avenue, and others: for example:
5(c). Finding real words
For sure, to non-Italian speakers (of whom, I am one), only GENOA is a recognisable Italian word: indeed, the name of an Italian city. This could be pure coincidence. However, here is where we can refer to the respective corpora. In the case of medieval Italian, I use the OVI corpus (Opera del Vocabolario Italiano) at https://gattoweb.ovi.cnr.it/. Here we find that LETA, NE and TER are words in medieval Italian. Only NE is a common word; but at least we establish that the mapping is not producing nonsense.
6. Reconstructing words from letter strings
In the last part of the process, we start with our mapped strings of letters in a natural language, which may often look as if they possess no meaning. Above, I gave the example of the sequence:
Here we may recall that the average length of a Voynich “word” is four glyphs. If the mapping is one-to-one, a four-glyph “word” maps to a four-letter string. There are 24 possible anagrams of such a string. For a five-letter string, the number of anagrams rises to 120. If, starting with a whole line of Voynich text; we hope to find meaningful anagrams for each word; and to construct a meaningful phrase or sentence from the whole: our task is large but, with computing power, not impossible.
In Step 5(c) above, we found that LETA was a real word in medieval Italian, but a rare one (with only thirty occurrences in the OVI corpus). However, if the glyphs had been re-ordered after the mapping, the string ALTE would have generated the same Voynich “word”. If we now search for ALTE in the OVI corpus, we find that it is also a real Italian word, and a much more common one, with 1,200 occurrences. It translates to the English "high" (feminine plural). An example of its occurrence in the OVI corpus is this:
From these examples, we might be permitted to think that if in our raw mapping, we do not find satisfactory words in the presumed precursor language, some re-arrangements of vowels or consonants might yield better words. We do not have to work through all the permutations; in natural languages, as Sukhotin observed, vowels and consonants tend to alternate.
Finally, even if we can find a sequence of satisfactory words in the precursor language, we still have to extract meaning from the phrase, line, paragraph or page that we selected. That is where the real work begins.
He called this sequence the “slot alphabet”.
Zattera was using the term “alphabet” in the same sense that we use with reference to the Latin script, or any phonetic script. That is, an alphabet is not merely a collection of letters but a sequence of letters. An alphabet permits the concept of "alphabetic order". In the case of the Latin script, we agree that the alphabet has a fixed order, starting with A, B, C and ending with X, Y, Z. The "slot alphabet" is more complex: it has twelve slots. The first is slot 0 which consists of the v101 glyphs {4}, initial {8} and initial {s}, in no fixed order. The last is slot 11 which consists of the final glyph {9}.
Zattera demonstrated that in the Voynich "words", with few exceptions, a glyph can only be followed by a glyph in the same or a higher slot; and can only be preceded by a glyph in the same or a lower slot. For example, since {h} is in slot 3 and {1} is in slot 4, {1} can follow {h}, but {1} cannot precede {h}.
Unlike the Latin alphabet, the "slot alphabet" has some flexibility. For example, the glyph {8} can be in any of three slots. It is as if in the Latin alphabet, the letter B were between A and C; again between L and M; and again between T and U. Alternatively, we could think of the {8} as three different glyphs; one in the initial position, one in a medial position, and one in the penultimate or final position.
My intuition (which may be wrong) makes me think that in a written natural language, the letters are not bound to a specific sequence. For example in English words, A can precede B (as in "able"), or follow B (as in "back").
What we see in the Voynich manuscript is akin to what a person with no knowledge of the English language or the Latin script would see in the following sequence:
elt eehrt be ghilt adn eehrt asw ghilt.How would such a person know that this is a phrase from the King James Bible, namely:
Let there be light; and there was light.
Zattera's "slot alphabet", with the v101 glyphs {m} and {n} added in their presumed slots, and the rare v101 glyphs {F} and {G} removed. Graphics by author.
Therefore, to my mind, Zattera’s findings convey a powerful argument (though one that he himself did not express), that if the glyphs represent letters in natural languages, then in each Voynich “word” the scribes re-ordered the glyphs according to some predefined sequence.
An alphabetic cipher
If that is what the scribes of the Voynich did, it was a form of encipherment: easy to implement, but difficult to decode. In effect, it implies that nearly every Voynich “word” is an anagram. That does not make the Voynich text impossible to decipher; but the process involves at least the following steps:
1. making reasonable assumptions about the precursor natural languages (and to my mind, there are at least ten plausible candidates);We may take these steps in order.
2. for each such language, constructing an objective mapping between Voynich glyphs and letters in the language (here at least, we have frequency analysis and the Sukhotin algorithm as useful tools);
3(a). deciding what constitutes a glyph (since the various transliterations of the Voynich manuscript use differing assumptions on whether some symbols are one glyph or several);
3(b). deciding whether the “word” breaks in the Voynich manuscript are word breaks in the precursor documents (we hope that they are, for if not, our task is greater);
4. testing the hypotheses that the letters were first re-ordered and then mapped, or first mapped to glyphs which were then re-ordered;
5(a). selecting suitable passages of Voynich text for reverse mapping;
5(b). mapping the selected Voynich text to strings in precursor languages;
5(c). comparing the resulting text strings with corpora of the respective languages, in a search for real words;
6. and if no or few real words are found (which is probable if the glyphs have been re-ordered), then we have to reconstruct the original order of the letters: which requires a knowledge of the precursor language, the skills of a crossword puzzle or Scrabble enthusiast, and the patience to work through the permutations.
1. Candidate languages
In my forthcoming book Voynich Reconsidered, and in several posts on this platform, I have argued that we could draw a series of concentric circles centred on Frascati, Italy, where Wilfred Voynich discovered or purchased the manuscript; and in each of these circles, identify the languages most widely spoken and written in the fifteenth century. To my mind, by the distance-decay hypothesis, it is more probable that the manuscript arrived in Frascati from a nearer location than from one more distant. If so, we can assign higher probabilities to the languages of the inner circles, than those of the peripheral circles.
By this process, we would be encouraged to think of Romance languages as probable precursors, followed by Slavic and Germanic languages, thereafter Albanian, Hellenic, Uralic and perhaps Arabic. Within the Romance language group, I am inclined to favour Italian and Latin, followed by French.
The two innermost concentric circles centred on Frascati, Italy. Image credit: "blogen"; graphics and annotations by author.
2. Mapping between glyphs and letters
To my mind, the most objective mapping between glyphs and letters would be based on, or at least derived from, frequency analysis. That is, the most frequent letters in the precursor documents should map to the most frequent glyphs in the Voynich manuscript, with approximately the same rankings.
Since at this stage we cannot identify the precursor documents, we are obliged to refer to corpora of the candidate languages, or at least to reasonably lengthy documents in those languages. For example, to test the medieval Bohemian language, I referred to Dalimilova kronika, an epic historical narrative written at the beginning of the fourteenth century.
Frequency comparisons between v101 glyphs and Bohemian letters in Dalimilova kronika; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
It has to be kept in mind that whatever corpus or reference document we use, the precursor documents of the Voynich manuscript cannot be expected to have identical rankings of the letters. For example, the letter frequencies in Dante’s La Divina Commedia differ slightly from those in the broader OVI corpus of medieval Italian. From comparisons such as these, I think that the best we can hope for is that in the precursor documents, the top nine or ten letters will be the same as in the language as a whole, and in the same order. For less common letters, we have to be prepared to make swaps in the rankings.
3(a). Glyph definitions
In other posts on this platform, I have set out some ideas on what constitutes a glyph. My thinking is that various assumptions are reasonable, and that to test these assumptions, it is necessary to develop multiple transliterations of the Voynich manuscript.
In Voynich Reconsidered, as possible alternatives to v101, I presented three new transliterations which I numbered v102, v103 and v104. In subsequent research, I have developed about twenty further transliterations, numbered from v120 to v216. Most of them differ from v101 in just one respect; for example, in one case the only change was to replace {C} with {cc}. Some differ in several respects.
In another post, I may set out some ideas for ranking or prioritizing alternative transliterations. One possible criterion is the extent of correlation between the glyph frequencies and the letter frequencies in selected medieval languages. In this respect, some of my transliterations have higher correlations than others. In that sense, they encourage further testing.
3(b). “Word” definitions
Elsewhere on this platform, I have written that there is considerable uncertainty as to how the Voynich manuscript establishes breaks between “words”. Where the text is horizontal, we can see line breaks; within the lines, we often see clear spaces between text strings. The v101 transliteration also distinguishes “uncertain spaces”, which might be “word” breaks or might simply be elongations of “words”. There is nothing resembling punctuation, that might guide us as to where “words” begin and end.
As shown in the image below, we also often see text run up against an illustration and continue on the other side. Sometimes the "words" to left and right of the break are unique. In such cases, we may wonder whether the illustration broke a “word” into two fragments, neither necessarily a “word”; or whether in the text to left or right of the illustration, the scribe omitted some "word" breaks.
An extract from page f026r, showing presumed "word" breaks. The "words" highlighted in light yellow occur nowhere else in the manuscript. Image credit: Beinecke Rare Book and Manuscript Library; graphics and legend by author.
Furthermore, at the Voynich 2022 conference Zattera demonstrated that there are thousands of Voynich “words” which can be split into two parts, each of which is a “word”. He called them “separable words”. We could think of them as analogous to compound words in natural languages, like "oversee" in English; alternatively, we could think of them as cases in which the scribe simply omitted a space.
If we did not suspect the Voynich text to have been subject to a re-ordering of glyphs within “words”, the “word” breaks would not much matter. For example, if in English we saw the sequence:
fo ursc orea ndsev enye arsa go,we would not have much difficulty in recognising it as the opening phrase of the Gettysburg Address. But if we saw the same sequence with the letters sorted alphabetically within the strings, that is:
fo crsu aeor densv eeny aars go,we would have a hard time in reaching the same interpretation.
It seems to me therefore that it is important to make explicit and objective assumptions on the word breaks in the Voynich manuscript. My working assumption is that all line breaks, v101 spaces and v101 “uncertain spaces” are “word" breaks; and that all of Zattera’s “separable words” need to have spaces inserted at the appropriate places.
(As a footnote: Zattera did not identify the “separable words”, nor did he define the algorithm whereby he had identified them. In another post on this platform, I have set out some ideas for that identification.)
4. Mapping and re-ordering
If we think that there was a re-ordering process, it makes a big difference whether it preceded or followed the mapping.
An example may illustrate this issue. Let us imagine ourselves somewhere in Italy in the year 1472. At the Annunciation Fair in Foligno, the entrepreneur Johann Neumeister has launched the first printed edition of Dante’s beloved La Divina Commedia. A wealthy person, whom we will call "the producer", has purchased several copies. He or she distributes the copies to a team of scribes, engaged for this purpose. He or she instructs them to transliterate the book, word by word and letter by letter, into an invented script. He or she prescribes the mapping from Latin letters to the inscrutable glyphs. The scribes speak and read Italian, and they are free to parse the printed words as they see fit.
The producer has one further instruction. In mapping each Italian word, the scribes are to do one of the following (and we do not know which):
1. sort the letters according to the Latin alphabet, and then apply the letter-to-glyph mapping; orOne of the scribes begins by parsing the first line of Canto 1: "Nel mezo delcamin dinra uita". We now try to reconstruct what he did. Not knowing what mapping the producer specified, we use our own mapping based on glyph and letter frequencies (which is not intended to be definitive). The results are shown below.
2. apply the letter-to-glyph mapping, and then in each “word”, sort the glyphs according to a sequence which the producer has specified (and which, over 500 years later, Zattera will call the “slot alphabet”).
Two alternative mappings of Dante's La Divina Commedia (1472 edition), Canto 1, line 1, to Voynich glyphs, on the basis of frequency matching and re-ordering processes. Author's analysis. (The three alternative results in column 2 reflect the flexible positioning of the glyphs {o}, {8} and {9} within Zattera’s “slot alphabet”. The glyph strings in blue are real Voynich "words".)
Column 2, which conforms to the “slot alphabet”, contains two glyph strings which exist as real "words" in the Voynich manuscript. Column 1 has only one such string. The sequences of glyph strings in Columns 1 and 2 are somewhat different.
It seems to me that the process represented in Column 1 is less probable. For example, if we sort alphabetically the letters in European words, many words will begin with A. Therefore A should map to one of the glyphs in Zattera's slot 0: that is, either {4}, the initial {8} or the initial {s}. But in the medieval European languages that I have studied, the letter A has a frequency of between 7 and 11 percent. In the Voynich v101 transliteration, the frequencies of {4}, initial {8} and initial {s} do not exceed 3.2 percent.
If the glyphs have been re-ordered, I am inclined to view process 2 (mapping and then re-ordering) as the more probable process.
5(a). Selecting the Voynich text
Elsewhere on this platform, I have argued that any serious attempt at mapping the Voynich text must be based on a reasonably long chunk of text: at least a whole line, better a paragraph, better still a whole page. We cannot be content with single "words".
Since we are taking aim at a natural language, to my mind we need to select a chunk of text which appears to be in a uniform language.
Here, we could start with Prescott Currier's Language A and Language B. The downside is that Currier never explained how he had identified Languages A and B. In the 1976 conference, he said that the differences were statistical; we might guess that those differences were in glyph frequencies, or "word" frequencies. For example, the v101 glyph {c} is much more common in the {B} pages than in the {A} pages; also, "words" beginning with {4o} are more common in B than in A.
My own preference is to work with the thematic sections of the manuscript. Here at least, we have the illustrations as a basis for defining the section. For example, we can follow the conventional definition of the "herbal" section as the set of pages containing illustrations of complete plants. There is no necessity to assume that the text corresponds to the illustrations.
If we select a single thematic section, we can run statistical tests on sub-sections to see whether the section is in a uniform language. Sub-sections can be defined by reference to the scribes. In the case of the "herbal" section, Dr Lisa Fagin Davis has proposed that there were four scribes: she numbered them 1, 2, 3 and 5. I have found some evidence that the four scribes used four different languages. To have some assurance of mapping from a single language, I am inclined to work with only the 95 pages written by Scribe 1.
5(b). Reverse mapping
If we then leave the re-ordering process aside and simply attempt some reverse glyph-to-letter mappings, we will generate text strings in the presumed precursor languages. For example, let us say that we want to test medieval Italian as a possible precursor.
We select the first page of the "herbal" section, f1v, which Currier assigned to Language A, and which, according to Dr Davis, was written by Scribe 1. Randomly we select line 4, which appears to contain seven "words". However, before we do the mapping, we need to confirm the "word" breaks. Here we apply Zattera's "slot alphabet", with the following result:
We infer that all the "words" conform to the "slot alphabet", except the second "word", which is a "separable word" and needs to have a space inserted.
We now have eight "words", which we map to medieval Italian with a straight frequency analysis, making no distinction between vowels and consonants, as shown in the right-hand mapping below:
Frequency comparisons between v101 glyphs and Italian letters in the OVI corpus; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
We thereby generate the sequence:
TER NE LOE TIKS TIF GENOA NE LETA.This mapping is not set in stone. If we had used a specific medieval Italian document instead of the OVI corpus, the frequencies would be slightly different and the mapping would change. For example, if we had mapped on the basis of La Divina Commedia, the T and L would swap places, and the sequence would become
LER NE TOE LIKS LIF GENOA NE TELA.Likewise, the K, mapped from the infrequent v101 glyph {i}, is an uncertain result; it could just as well be J or X.
[As a footnote: we can also try alternative transliterations of the Voynich manuscript. The v101 transliteration has too many glyphs to map to a typical European alphabet; it makes sense to combine some of them. In my v102 and subsequent transliterations, I have explored this avenue, and others: for example:
* combining the v101 glyphs {2}, {3}, {5} and their many variantsThese modifications change the glyph frequencies, and thereby change some parts of the mapping.]
* merging the similar-looking glyphs {6}, {7}, {8} and {&}
* redefining {I} as {ii}, and {C} as {cc}
* redefining {m} as {iiN}, and {n} as {iN}.
5(c). Finding real words
For sure, to non-Italian speakers (of whom, I am one), only GENOA is a recognisable Italian word: indeed, the name of an Italian city. This could be pure coincidence. However, here is where we can refer to the respective corpora. In the case of medieval Italian, I use the OVI corpus (Opera del Vocabolario Italiano) at https://gattoweb.ovi.cnr.it/. Here we find that LETA, NE and TER are words in medieval Italian. Only NE is a common word; but at least we establish that the mapping is not producing nonsense.
6. Reconstructing words from letter strings
In the last part of the process, we start with our mapped strings of letters in a natural language, which may often look as if they possess no meaning. Above, I gave the example of the sequence:
eln emoz del acimn di anr aituwhich is not self-evidently meaningful. But it can be re-ordered to make the phrase:
nel mezo del camin di nra uita,which, as we saw, is the first line of Canto 1 in the 1472 edition of La Divina Commedia.
Here we may recall that the average length of a Voynich “word” is four glyphs. If the mapping is one-to-one, a four-glyph “word” maps to a four-letter string. There are 24 possible anagrams of such a string. For a five-letter string, the number of anagrams rises to 120. If, starting with a whole line of Voynich text; we hope to find meaningful anagrams for each word; and to construct a meaningful phrase or sentence from the whole: our task is large but, with computing power, not impossible.
In Step 5(c) above, we found that LETA was a real word in medieval Italian, but a rare one (with only thirty occurrences in the OVI corpus). However, if the glyphs had been re-ordered after the mapping, the string ALTE would have generated the same Voynich “word”. If we now search for ALTE in the OVI corpus, we find that it is also a real Italian word, and a much more common one, with 1,200 occurrences. It translates to the English "high" (feminine plural). An example of its occurrence in the OVI corpus is this:
"e vedemo e llo cielo stelle alte e stelle basse"Likewise, one of our mappings yielded the rare and archaic word TER; but in our re-ordering scenario, the word TRE would map to the same Voynich "word". In the OVI corpus, TRE occurs 22,418 times. The English translation is "three".
("and we saw in the sky high stars and low stars")
[Restoro d'Arezzo, 1282]
From these examples, we might be permitted to think that if in our raw mapping, we do not find satisfactory words in the presumed precursor language, some re-arrangements of vowels or consonants might yield better words. We do not have to work through all the permutations; in natural languages, as Sukhotin observed, vowels and consonants tend to alternate.
Finally, even if we can find a sequence of satisfactory words in the precursor language, we still have to extract meaning from the phrase, line, paragraph or page that we selected. That is where the real work begins.
February 14, 2024
Voynich Reconsidered: a research strategy
In my book Voynich Reconsidered (Schiffer Publishing, 2024), I proposed that in any attempt to find meaning in the Voynich manuscript, the researcher should adopt a strategy.
My approach to the formulation of a research strategy was as follows:
A map of the main language groups in Western Europe in the year 1500, with concentric circles of arbitrary radius centred on Frascati, Italy. Image credit: blogen, www.theapricity.com; graphics and annotations by author.
Permutations
The implementation of the strategy that I outlined above requires the testing of multiple mappings. The permutations that I have conceptualised so far are as follows:
My approach to the formulation of a research strategy was as follows:
• I attempted no interpretation of the illustrations, nor of any visual similarity between the Voynich text and known medieval scripts such as Uncial or Beneventan. I believe that professional medievalists, such as Dr Lisa Fagin Davis and D N O'Donovan, have approached the manuscript from this perspective, but I have no expertise in this area.
• I focussed on the text, as a database permitting a computational and statistical approach.
• I adopted the hypothesis that the text possessed meaning (since I think that the converse is not amenable to proof).
• I adopted the hypothesis that the text had a precursor document or documents in a natural human language or languages.
• I thought it a reasonable assumption that (by the distance-decay hypothesis) those languages were more likely to be used within certain concentric geographical radii of Italy, where Wilfred Voynich claimed to have discovered the document.
• I assumed that the producer or author of the manuscript had been sufficiently wealthy to employ a team of professional scribes for months or years, and to pay for the materials and supplies. As such, that person would have had other interests which would preclude detailed supervision of the scribes. Therefore, I thought it probable that the producer had given the scribes a set of simple instructions which they could follow until completion of the manuscript.
• My objective (with due recognition of Occam's Razor) was to reconstruct those instructions, as simply as possible.
A map of the main language groups in Western Europe in the year 1500, with concentric circles of arbitrary radius centred on Frascati, Italy. Image credit: blogen, www.theapricity.com; graphics and annotations by author.
Permutations
The implementation of the strategy that I outlined above requires the testing of multiple mappings. The permutations that I have conceptualised so far are as follows:
• glyph definitionsTo my mind, the researcher who wishes to pursue a computational approach to the text needs a sufficient number of permutations, and as a corollary, sufficient computing power, to be able to test a wide range of assumptions. I have in mind a matrix of, say, ten sets of glyph definitions; three definitions of “word” breaks; and maybe ten potential precursor languages: implying at least 300 permutations. In each case, the researcher needs to do the following:
The widely used transliterations of the Voynich manuscript (for example EVA and v101) embody assumptions about what is a glyph. For example, the v101 glyph {m} is three glyphs in EVA, namely {iin}. Conversely, the three-glyph string {cth} in EVA is the single glyph {K} in v101. These are reasonable interpretations of the symbols, but they cannot be the only ones. The researcher needs multiple transliterations in which various definitions of the glyphs are applied.
• “word” definitions
All transliterations assume that glyph strings delimited by spaces or line breaks are “words” in the sense that we use the term “word” in a natural language. That is, a Voynich “word” represents an object or a concept, and can be spoken and understood. EVA seems to treat any obvious space as a word break. The v101 transliteration makes a distinction between “spaces” and “uncertain spaces”, wherein glyphs are closely spaced and we are not sure whether or not a word break is present. At the Voynich 2022 conference, Massimiliano Zattera introduced a third concept: that of “separable words”: those "words" which have no discernible internal spaces, yet can be broken up into two or more Voynich “words”. In natural languages, an analogy can be seen in compound words such as, in English, “battlefield”.
• precursor languages
Since the Voynich script is not the script of any known language, we have a multitude of possible precursor languages. I have proposed that we could apply some filters on the basis of probabilities. For example, we might assign higher probabilities to languages used within some specified geographical radii of Italy. Likewise, since the material of the manuscript is calfskin, we could assign higher probabilities to the languages of countries or regions where cattle have been widely domesticated.
• take a sufficiently large chunk of Voynich text (at least a paragraph, or a page, or longer)
• map the Voynich text (using an objective and consistent algorithm such as frequency analysis) to the candidate language
• test the resulting text strings against appropriate corpora of the candidate language, and see whether there is any clear narrative meaning
• and if not, explore the possibilities that re-ordering of the letters within words might produce narrative meaning.
Voynich Reconsidered: an alphabetic cipher?
In other articles on this platform, I have referred to my working assumptions on the Voynich manuscript (with which reasonable people may disagree), which include the following:
In 1978 Mary D’Imperio wrote a technical article (not published until decades later) in which she observed that the Voynich glyphs could be classified by their position within the "word". She identified between five and seven classes of glyph, to which she gave labels like "beginners", "middles" and "enders".
Massimiliano Zattera's paper at the Voynich 2022 conference, on what he called the "slot alphabet", confirmed and elaborated D'Imperio's findings. With much more computing power at his disposal than D'Imperio could have dreamed of, Zattera identified twelve classes of glyph. He demonstrated that there was an almost inflexible order in which the glyphs could appear within a Voynich "word": like soldiers grouped by their rank in the army.
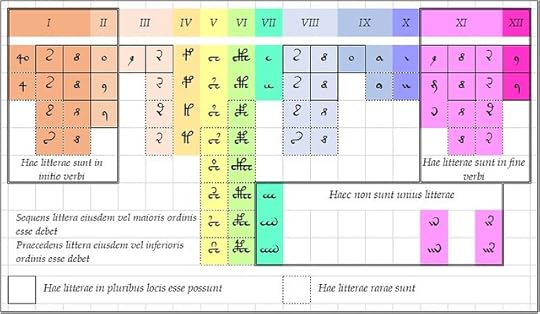
An imagined wall chart for the scribes of the Voynich manuscript. Image credit: author, based on Zattera's "slot alphabet".
To my mind, D'Imperio's and Zattera's findings encourage us to imagine an encipherment based on a simple and practicable instruction to the scribes: that after the transcription from precursor letters to glyphs, they should re-order the glyphs in each "word", according to a prescribed sequence.
The Ozymandias manuscript
In English, for example, if we take the first line of Shelley's Ozymandias:
Our hypothetical decoders of the Ozymandias manuscript would surely notice that "words" often began with the glyph "a", and often ended with the glyph "u" or "v". They would wonder, as Prescott Currier wondered in 1976, whether the ending of a "word" somehow influenced the beginning of the next "word". They would observe, as Currier observed, that there was no natural language in which this phenomenon occurred. They would be wrong: that phenomenon was a correlation but not an influence.
But if we had a reverse mapping of Voynich text to any natural language, lovers of crossword puzzles or Scrabble (in that language) could probably determine quickly whether there was any embedded meaning or narrative.
The Sukhotin algorithm
In other posts on this platform, I have proposed that, if the Voynich "words" correspond to precursor words, and if the Voynich glyphs are in the same order as the presumed precursor letters, we could use the Sukhotin algorithm to identify vowels. More precisely, we could identify the glyphs that most probably represent vowels in the precursor documents.
The algorithm is based on Sukhotin's insight that in natural languages, vowels and consonants alternate more often than not.
But if the glyphs have undergone re-ordering, the juxtaposition of vowels and consonants has been lost, and the Sukhotin algorithm will break down.
In this case, what is preserved is only the frequency distribution of the glyphs; and at best, we could hope to match five of the seven or eight most frequent glyphs with the five vowels typically found in European languages. Once we have identified five vowel-glyphs, we can assume that the remaining glyphs represent consonants, and we can match them with precursor consonants, using tools such as frequency analysis.
Recurring letters
However, a re-ordering of the glyphs within "words" will still preserve the number of glyphs in each "word"; and specifically, the number of glyphs which recur within the "word".
As we saw in the example above from Ozymandias, an alphabetic sorting of letters within words will assemble the recurring letters, and will often produce strings of double or triple letters. For example, the word "traveller" yielded the strings "ee", "ll" and "rr".
We see a similar phenomenon in the Voynich manuscript. In the v101 transliteration, there are at least eleven glyphs, conventionally viewed as single glyphs, that look as if they could represent or contain doubled or tripled letters. There are four that are actually viewed in v101 as doubled or tripled.

v101 glyphs or glyph strings that could be interpreted as doubled or tripled letters. Author's analysis.
In these cases, we have to wonder if these apparent doubles and triples are simply a consequence of a re-ordering of the glyphs.
This hypothesis should be amenable to testing. We can select some large texts in medieval natural languages, for example Dante's La Divina Commedia; apply an alphabetic re-ordering of the letters in each word (for which online tools exist); in the re-ordered text, count the occurrences of double and triple letters; and see how the frequencies compare with those in the Voynich manuscript.
Below is a very small example, drawn from the first nine lines of La Divina Commedia, Gutenberg edition. This is written in a somewhat modernised Italian; in the first printed edition of 1472, the first line was "Nel mezo delcamin dinrã uita". In the Gutenberg version, there are no occurrences of the string "aa"; in the sorted version, there are six. If medieval Italian had been a precursor of the Voynich manuscript, we might suspect that the glyph {c} represented the letter "a"; and that glyphs or glyph strings such as {1}, {C} or {cc} had been mapped from words containing multiple "a"s.

La Divina Commedia, Canto 1, lines 1-9: Gutenberg version, and with letters sorted alphabetically within words. Author's analysis.
On my further testing of this hypothesis, more later.
* that the manuscript was derived from precursor documents in a natural language or languagesI considered the possibility that the producer's instructions to the scribes included some form of encipherment. I like the idea of Dr Jiří Milička, of the Faculty of Comparative Linguistics at Charles University, that any system for enciphering a fifteenth-century document should be relatively simple. I have therefore thought about ciphers which would be easy to administer, but difficult to decode.
* that the author or producer of the manuscript engaged a team of scribes, to whom he or she gave simple instructions for the transliteration from letters to glyphs.
In 1978 Mary D’Imperio wrote a technical article (not published until decades later) in which she observed that the Voynich glyphs could be classified by their position within the "word". She identified between five and seven classes of glyph, to which she gave labels like "beginners", "middles" and "enders".
Massimiliano Zattera's paper at the Voynich 2022 conference, on what he called the "slot alphabet", confirmed and elaborated D'Imperio's findings. With much more computing power at his disposal than D'Imperio could have dreamed of, Zattera identified twelve classes of glyph. He demonstrated that there was an almost inflexible order in which the glyphs could appear within a Voynich "word": like soldiers grouped by their rank in the army.
An imagined wall chart for the scribes of the Voynich manuscript. Image credit: author, based on Zattera's "slot alphabet".
To my mind, D'Imperio's and Zattera's findings encourage us to imagine an encipherment based on a simple and practicable instruction to the scribes: that after the transcription from precursor letters to glyphs, they should re-order the glyphs in each "word", according to a prescribed sequence.
The Ozymandias manuscript
In English, for example, if we take the first line of Shelley's Ozymandias:
I met a traveller from an antique land,a simple alphabetic re-ordering of the letters produces the following sequence:
I emt a aeellrrtv fmor an aeinqtu adln.Someone who did not know the English language or the Latin script, and who sought meaning in this sequence, would have a task comparable with that which we face with the Voynich manuscript.
Our hypothetical decoders of the Ozymandias manuscript would surely notice that "words" often began with the glyph "a", and often ended with the glyph "u" or "v". They would wonder, as Prescott Currier wondered in 1976, whether the ending of a "word" somehow influenced the beginning of the next "word". They would observe, as Currier observed, that there was no natural language in which this phenomenon occurred. They would be wrong: that phenomenon was a correlation but not an influence.
But if we had a reverse mapping of Voynich text to any natural language, lovers of crossword puzzles or Scrabble (in that language) could probably determine quickly whether there was any embedded meaning or narrative.
The Sukhotin algorithm
In other posts on this platform, I have proposed that, if the Voynich "words" correspond to precursor words, and if the Voynich glyphs are in the same order as the presumed precursor letters, we could use the Sukhotin algorithm to identify vowels. More precisely, we could identify the glyphs that most probably represent vowels in the precursor documents.
The algorithm is based on Sukhotin's insight that in natural languages, vowels and consonants alternate more often than not.
But if the glyphs have undergone re-ordering, the juxtaposition of vowels and consonants has been lost, and the Sukhotin algorithm will break down.
In this case, what is preserved is only the frequency distribution of the glyphs; and at best, we could hope to match five of the seven or eight most frequent glyphs with the five vowels typically found in European languages. Once we have identified five vowel-glyphs, we can assume that the remaining glyphs represent consonants, and we can match them with precursor consonants, using tools such as frequency analysis.
Recurring letters
However, a re-ordering of the glyphs within "words" will still preserve the number of glyphs in each "word"; and specifically, the number of glyphs which recur within the "word".
As we saw in the example above from Ozymandias, an alphabetic sorting of letters within words will assemble the recurring letters, and will often produce strings of double or triple letters. For example, the word "traveller" yielded the strings "ee", "ll" and "rr".
We see a similar phenomenon in the Voynich manuscript. In the v101 transliteration, there are at least eleven glyphs, conventionally viewed as single glyphs, that look as if they could represent or contain doubled or tripled letters. There are four that are actually viewed in v101 as doubled or tripled.
v101 glyphs or glyph strings that could be interpreted as doubled or tripled letters. Author's analysis.
In these cases, we have to wonder if these apparent doubles and triples are simply a consequence of a re-ordering of the glyphs.
This hypothesis should be amenable to testing. We can select some large texts in medieval natural languages, for example Dante's La Divina Commedia; apply an alphabetic re-ordering of the letters in each word (for which online tools exist); in the re-ordered text, count the occurrences of double and triple letters; and see how the frequencies compare with those in the Voynich manuscript.
Below is a very small example, drawn from the first nine lines of La Divina Commedia, Gutenberg edition. This is written in a somewhat modernised Italian; in the first printed edition of 1472, the first line was "Nel mezo delcamin dinrã uita". In the Gutenberg version, there are no occurrences of the string "aa"; in the sorted version, there are six. If medieval Italian had been a precursor of the Voynich manuscript, we might suspect that the glyph {c} represented the letter "a"; and that glyphs or glyph strings such as {1}, {C} or {cc} had been mapped from words containing multiple "a"s.
La Divina Commedia, Canto 1, lines 1-9: Gutenberg version, and with letters sorted alphabetically within words. Author's analysis.
On my further testing of this hypothesis, more later.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

