
Voynich Reconsidered: the glyphs re-ordered?
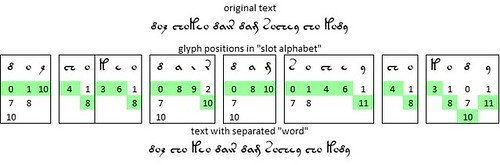
At the Voynich conference hosted by the University of Malta in 2022, Massimiliano Zattera presented his finding that in 97 percent of the “words” in the Voynich manuscript, the glyphs conformed to a specific sequence. within the "word".
He called this sequence the “slot alphabet”.
Zattera was using the term “alphabet” in the same sense that we use with reference to the Latin script, or any phonetic script. That is, an alphabet is not merely a collection of letters but a sequence of letters. An alphabet permits the concept of "alphabetic order". In the case of the Latin script, we agree that the alphabet has a fixed order, starting with A, B, C and ending with X, Y, Z. The "slot alphabet" is more complex: it has twelve slots. The first is slot 0 which consists of the v101 glyphs {4}, initial {8} and initial {s}, in no fixed order. The last is slot 11 which consists of the final glyph {9}.
Zattera demonstrated that in the Voynich "words", with few exceptions, a glyph can only be followed by a glyph in the same or a higher slot; and can only be preceded by a glyph in the same or a lower slot. For example, since {h} is in slot 3 and {1} is in slot 4, {1} can follow {h}, but {1} cannot precede {h}.
Unlike the Latin alphabet, the "slot alphabet" has some flexibility. For example, the glyph {8} can be in any of three slots. It is as if in the Latin alphabet, the letter B were between A and C; again between L and M; and again between T and U. Alternatively, we could think of the {8} as three different glyphs; one in the initial position, one in a medial position, and one in the penultimate or final position.
My intuition (which may be wrong) makes me think that in a written natural language, the letters are not bound to a specific sequence. For example in English words, A can precede B (as in "able"), or follow B (as in "back").
What we see in the Voynich manuscript is akin to what a person with no knowledge of the English language or the Latin script would see in the following sequence:
Zattera's "slot alphabet", with the v101 glyphs {m} and {n} added in their presumed slots, and the rare v101 glyphs {F} and {G} removed. Graphics by author.
Therefore, to my mind, Zattera’s findings convey a powerful argument (though one that he himself did not express), that if the glyphs represent letters in natural languages, then in each Voynich “word” the scribes re-ordered the glyphs according to some predefined sequence.
An alphabetic cipher
If that is what the scribes of the Voynich did, it was a form of encipherment: easy to implement, but difficult to decode. In effect, it implies that nearly every Voynich “word” is an anagram. That does not make the Voynich text impossible to decipher; but the process involves at least the following steps:
1. Candidate languages
In my forthcoming book Voynich Reconsidered, and in several posts on this platform, I have argued that we could draw a series of concentric circles centred on Frascati, Italy, where Wilfred Voynich discovered or purchased the manuscript; and in each of these circles, identify the languages most widely spoken and written in the fifteenth century. To my mind, by the distance-decay hypothesis, it is more probable that the manuscript arrived in Frascati from a nearer location than from one more distant. If so, we can assign higher probabilities to the languages of the inner circles, than those of the peripheral circles.
By this process, we would be encouraged to think of Romance languages as probable precursors, followed by Slavic and Germanic languages, thereafter Albanian, Hellenic, Uralic and perhaps Arabic. Within the Romance language group, I am inclined to favour Italian and Latin, followed by French.
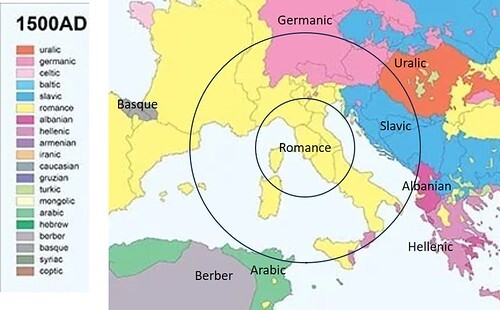
The two innermost concentric circles centred on Frascati, Italy. Image credit: "blogen"; graphics and annotations by author.
2. Mapping between glyphs and letters
To my mind, the most objective mapping between glyphs and letters would be based on, or at least derived from, frequency analysis. That is, the most frequent letters in the precursor documents should map to the most frequent glyphs in the Voynich manuscript, with approximately the same rankings.
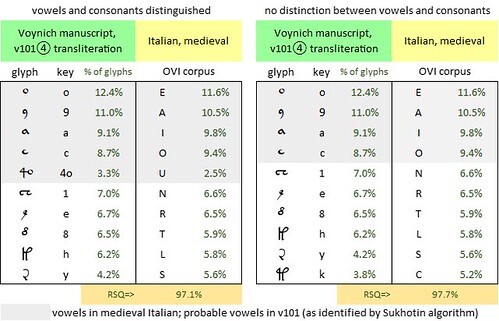
Since at this stage we cannot identify the precursor documents, we are obliged to refer to corpora of the candidate languages, or at least to reasonably lengthy documents in those languages. For example, to test the medieval Bohemian language, I referred to Dalimilova kronika, an epic historical narrative written at the beginning of the fourteenth century.

Frequency comparisons between v101 glyphs and Bohemian letters in Dalimilova kronika; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
It has to be kept in mind that whatever corpus or reference document we use, the precursor documents of the Voynich manuscript cannot be expected to have identical rankings of the letters. For example, the letter frequencies in Dante’s La Divina Commedia differ slightly from those in the broader OVI corpus of medieval Italian. From comparisons such as these, I think that the best we can hope for is that in the precursor documents, the top nine or ten letters will be the same as in the language as a whole, and in the same order. For less common letters, we have to be prepared to make swaps in the rankings.
3(a). Glyph definitions
In other posts on this platform, I have set out some ideas on what constitutes a glyph. My thinking is that various assumptions are reasonable, and that to test these assumptions, it is necessary to develop multiple transliterations of the Voynich manuscript.
In Voynich Reconsidered, as possible alternatives to v101, I presented three new transliterations which I numbered v102, v103 and v104. In subsequent research, I have developed about twenty further transliterations, numbered from v120 to v216. Most of them differ from v101 in just one respect; for example, in one case the only change was to replace {C} with {cc}. Some differ in several respects.
In another post, I may set out some ideas for ranking or prioritizing alternative transliterations. One possible criterion is the extent of correlation between the glyph frequencies and the letter frequencies in selected medieval languages. In this respect, some of my transliterations have higher correlations than others. In that sense, they encourage further testing.
3(b). “Word” definitions
Elsewhere on this platform, I have written that there is considerable uncertainty as to how the Voynich manuscript establishes breaks between “words”. Where the text is horizontal, we can see line breaks; within the lines, we often see clear spaces between text strings. The v101 transliteration also distinguishes “uncertain spaces”, which might be “word” breaks or might simply be elongations of “words”. There is nothing resembling punctuation, that might guide us as to where “words” begin and end.
As shown in the image below, we also often see text run up against an illustration and continue on the other side. Sometimes the "words" to left and right of the break are unique. In such cases, we may wonder whether the illustration broke a “word” into two fragments, neither necessarily a “word”; or whether in the text to left or right of the illustration, the scribe omitted some "word" breaks.

An extract from page f026r, showing presumed "word" breaks. The "words" highlighted in light yellow occur nowhere else in the manuscript. Image credit: Beinecke Rare Book and Manuscript Library; graphics and legend by author.
Furthermore, at the Voynich 2022 conference Zattera demonstrated that there are thousands of Voynich “words” which can be split into two parts, each of which is a “word”. He called them “separable words”. We could think of them as analogous to compound words in natural languages, like "oversee" in English; alternatively, we could think of them as cases in which the scribe simply omitted a space.
If we did not suspect the Voynich text to have been subject to a re-ordering of glyphs within “words”, the “word” breaks would not much matter. For example, if in English we saw the sequence:
It seems to me therefore that it is important to make explicit and objective assumptions on the word breaks in the Voynich manuscript. My working assumption is that all line breaks, v101 spaces and v101 “uncertain spaces” are “word" breaks; and that all of Zattera’s “separable words” need to have spaces inserted at the appropriate places.
(As a footnote: Zattera did not identify the “separable words”, nor did he define the algorithm whereby he had identified them. In another post on this platform, I have set out some ideas for that identification.)
4. Mapping and re-ordering
If we think that there was a re-ordering process, it makes a big difference whether it preceded or followed the mapping.
An example may illustrate this issue. Let us imagine ourselves somewhere in Italy in the year 1472. At the Annunciation Fair in Foligno, the entrepreneur Johann Neumeister has launched the first printed edition of Dante’s beloved La Divina Commedia. A wealthy person, whom we will call "the producer", has purchased several copies. He or she distributes the copies to a team of scribes, engaged for this purpose. He or she instructs them to transliterate the book, word by word and letter by letter, into an invented script. He or she prescribes the mapping from Latin letters to the inscrutable glyphs. The scribes speak and read Italian, and they are free to parse the printed words as they see fit.
The producer has one further instruction. In mapping each Italian word, the scribes are to do one of the following (and we do not know which):

Two alternative mappings of Dante's La Divina Commedia (1472 edition), Canto 1, line 1, to Voynich glyphs, on the basis of frequency matching and re-ordering processes. Author's analysis. (The three alternative results in column 2 reflect the flexible positioning of the glyphs {o}, {8} and {9} within Zattera’s “slot alphabet”. The glyph strings in blue are real Voynich "words".)
Column 2, which conforms to the “slot alphabet”, contains two glyph strings which exist as real "words" in the Voynich manuscript. Column 1 has only one such string. The sequences of glyph strings in Columns 1 and 2 are somewhat different.
It seems to me that the process represented in Column 1 is less probable. For example, if we sort alphabetically the letters in European words, many words will begin with A. Therefore A should map to one of the glyphs in Zattera's slot 0: that is, either {4}, the initial {8} or the initial {s}. But in the medieval European languages that I have studied, the letter A has a frequency of between 7 and 11 percent. In the Voynich v101 transliteration, the frequencies of {4}, initial {8} and initial {s} do not exceed 3.2 percent.
If the glyphs have been re-ordered, I am inclined to view process 2 (mapping and then re-ordering) as the more probable process.
5(a). Selecting the Voynich text
Elsewhere on this platform, I have argued that any serious attempt at mapping the Voynich text must be based on a reasonably long chunk of text: at least a whole line, better a paragraph, better still a whole page. We cannot be content with single "words".
Since we are taking aim at a natural language, to my mind we need to select a chunk of text which appears to be in a uniform language.
Here, we could start with Prescott Currier's Language A and Language B. The downside is that Currier never explained how he had identified Languages A and B. In the 1976 conference, he said that the differences were statistical; we might guess that those differences were in glyph frequencies, or "word" frequencies. For example, the v101 glyph {c} is much more common in the {B} pages than in the {A} pages; also, "words" beginning with {4o} are more common in B than in A.
My own preference is to work with the thematic sections of the manuscript. Here at least, we have the illustrations as a basis for defining the section. For example, we can follow the conventional definition of the "herbal" section as the set of pages containing illustrations of complete plants. There is no necessity to assume that the text corresponds to the illustrations.
If we select a single thematic section, we can run statistical tests on sub-sections to see whether the section is in a uniform language. Sub-sections can be defined by reference to the scribes. In the case of the "herbal" section, Dr Lisa Fagin Davis has proposed that there were four scribes: she numbered them 1, 2, 3 and 5. I have found some evidence that the four scribes used four different languages. To have some assurance of mapping from a single language, I am inclined to work with only the 95 pages written by Scribe 1.
5(b). Reverse mapping
If we then leave the re-ordering process aside and simply attempt some reverse glyph-to-letter mappings, we will generate text strings in the presumed precursor languages. For example, let us say that we want to test medieval Italian as a possible precursor.
We select the first page of the "herbal" section, f1v, which Currier assigned to Language A, and which, according to Dr Davis, was written by Scribe 1. Randomly we select line 4, which appears to contain seven "words". However, before we do the mapping, we need to confirm the "word" breaks. Here we apply Zattera's "slot alphabet", with the following result:
We infer that all the "words" conform to the "slot alphabet", except the second "word", which is a "separable word" and needs to have a space inserted.
We now have eight "words", which we map to medieval Italian with a straight frequency analysis, making no distinction between vowels and consonants, as shown in the right-hand mapping below:
Frequency comparisons between v101 glyphs and Italian letters in the OVI corpus; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
We thereby generate the sequence:
[As a footnote: we can also try alternative transliterations of the Voynich manuscript. The v101 transliteration has too many glyphs to map to a typical European alphabet; it makes sense to combine some of them. In my v102 and subsequent transliterations, I have explored this avenue, and others: for example:
5(c). Finding real words
For sure, to non-Italian speakers (of whom, I am one), only GENOA is a recognisable Italian word: indeed, the name of an Italian city. This could be pure coincidence. However, here is where we can refer to the respective corpora. In the case of medieval Italian, I use the OVI corpus (Opera del Vocabolario Italiano) at https://gattoweb.ovi.cnr.it/. Here we find that LETA, NE and TER are words in medieval Italian. Only NE is a common word; but at least we establish that the mapping is not producing nonsense.
6. Reconstructing words from letter strings
In the last part of the process, we start with our mapped strings of letters in a natural language, which may often look as if they possess no meaning. Above, I gave the example of the sequence:
Here we may recall that the average length of a Voynich “word” is four glyphs. If the mapping is one-to-one, a four-glyph “word” maps to a four-letter string. There are 24 possible anagrams of such a string. For a five-letter string, the number of anagrams rises to 120. If, starting with a whole line of Voynich text; we hope to find meaningful anagrams for each word; and to construct a meaningful phrase or sentence from the whole: our task is large but, with computing power, not impossible.
In Step 5(c) above, we found that LETA was a real word in medieval Italian, but a rare one (with only thirty occurrences in the OVI corpus). However, if the glyphs had been re-ordered after the mapping, the string ALTE would have generated the same Voynich “word”. If we now search for ALTE in the OVI corpus, we find that it is also a real Italian word, and a much more common one, with 1,200 occurrences. It translates to the English "high" (feminine plural). An example of its occurrence in the OVI corpus is this:
From these examples, we might be permitted to think that if in our raw mapping, we do not find satisfactory words in the presumed precursor language, some re-arrangements of vowels or consonants might yield better words. We do not have to work through all the permutations; in natural languages, as Sukhotin observed, vowels and consonants tend to alternate.
Finally, even if we can find a sequence of satisfactory words in the precursor language, we still have to extract meaning from the phrase, line, paragraph or page that we selected. That is where the real work begins.
He called this sequence the “slot alphabet”.
Zattera was using the term “alphabet” in the same sense that we use with reference to the Latin script, or any phonetic script. That is, an alphabet is not merely a collection of letters but a sequence of letters. An alphabet permits the concept of "alphabetic order". In the case of the Latin script, we agree that the alphabet has a fixed order, starting with A, B, C and ending with X, Y, Z. The "slot alphabet" is more complex: it has twelve slots. The first is slot 0 which consists of the v101 glyphs {4}, initial {8} and initial {s}, in no fixed order. The last is slot 11 which consists of the final glyph {9}.
Zattera demonstrated that in the Voynich "words", with few exceptions, a glyph can only be followed by a glyph in the same or a higher slot; and can only be preceded by a glyph in the same or a lower slot. For example, since {h} is in slot 3 and {1} is in slot 4, {1} can follow {h}, but {1} cannot precede {h}.
Unlike the Latin alphabet, the "slot alphabet" has some flexibility. For example, the glyph {8} can be in any of three slots. It is as if in the Latin alphabet, the letter B were between A and C; again between L and M; and again between T and U. Alternatively, we could think of the {8} as three different glyphs; one in the initial position, one in a medial position, and one in the penultimate or final position.
My intuition (which may be wrong) makes me think that in a written natural language, the letters are not bound to a specific sequence. For example in English words, A can precede B (as in "able"), or follow B (as in "back").
What we see in the Voynich manuscript is akin to what a person with no knowledge of the English language or the Latin script would see in the following sequence:
elt eehrt be ghilt adn eehrt asw ghilt.How would such a person know that this is a phrase from the King James Bible, namely:
Let there be light; and there was light.
Zattera's "slot alphabet", with the v101 glyphs {m} and {n} added in their presumed slots, and the rare v101 glyphs {F} and {G} removed. Graphics by author.
Therefore, to my mind, Zattera’s findings convey a powerful argument (though one that he himself did not express), that if the glyphs represent letters in natural languages, then in each Voynich “word” the scribes re-ordered the glyphs according to some predefined sequence.
An alphabetic cipher
If that is what the scribes of the Voynich did, it was a form of encipherment: easy to implement, but difficult to decode. In effect, it implies that nearly every Voynich “word” is an anagram. That does not make the Voynich text impossible to decipher; but the process involves at least the following steps:
1. making reasonable assumptions about the precursor natural languages (and to my mind, there are at least ten plausible candidates);We may take these steps in order.
2. for each such language, constructing an objective mapping between Voynich glyphs and letters in the language (here at least, we have frequency analysis and the Sukhotin algorithm as useful tools);
3(a). deciding what constitutes a glyph (since the various transliterations of the Voynich manuscript use differing assumptions on whether some symbols are one glyph or several);
3(b). deciding whether the “word” breaks in the Voynich manuscript are word breaks in the precursor documents (we hope that they are, for if not, our task is greater);
4. testing the hypotheses that the letters were first re-ordered and then mapped, or first mapped to glyphs which were then re-ordered;
5(a). selecting suitable passages of Voynich text for reverse mapping;
5(b). mapping the selected Voynich text to strings in precursor languages;
5(c). comparing the resulting text strings with corpora of the respective languages, in a search for real words;
6. and if no or few real words are found (which is probable if the glyphs have been re-ordered), then we have to reconstruct the original order of the letters: which requires a knowledge of the precursor language, the skills of a crossword puzzle or Scrabble enthusiast, and the patience to work through the permutations.
1. Candidate languages
In my forthcoming book Voynich Reconsidered, and in several posts on this platform, I have argued that we could draw a series of concentric circles centred on Frascati, Italy, where Wilfred Voynich discovered or purchased the manuscript; and in each of these circles, identify the languages most widely spoken and written in the fifteenth century. To my mind, by the distance-decay hypothesis, it is more probable that the manuscript arrived in Frascati from a nearer location than from one more distant. If so, we can assign higher probabilities to the languages of the inner circles, than those of the peripheral circles.
By this process, we would be encouraged to think of Romance languages as probable precursors, followed by Slavic and Germanic languages, thereafter Albanian, Hellenic, Uralic and perhaps Arabic. Within the Romance language group, I am inclined to favour Italian and Latin, followed by French.
The two innermost concentric circles centred on Frascati, Italy. Image credit: "blogen"; graphics and annotations by author.
2. Mapping between glyphs and letters
To my mind, the most objective mapping between glyphs and letters would be based on, or at least derived from, frequency analysis. That is, the most frequent letters in the precursor documents should map to the most frequent glyphs in the Voynich manuscript, with approximately the same rankings.
Since at this stage we cannot identify the precursor documents, we are obliged to refer to corpora of the candidate languages, or at least to reasonably lengthy documents in those languages. For example, to test the medieval Bohemian language, I referred to Dalimilova kronika, an epic historical narrative written at the beginning of the fourteenth century.
Frequency comparisons between v101 glyphs and Bohemian letters in Dalimilova kronika; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
It has to be kept in mind that whatever corpus or reference document we use, the precursor documents of the Voynich manuscript cannot be expected to have identical rankings of the letters. For example, the letter frequencies in Dante’s La Divina Commedia differ slightly from those in the broader OVI corpus of medieval Italian. From comparisons such as these, I think that the best we can hope for is that in the precursor documents, the top nine or ten letters will be the same as in the language as a whole, and in the same order. For less common letters, we have to be prepared to make swaps in the rankings.
3(a). Glyph definitions
In other posts on this platform, I have set out some ideas on what constitutes a glyph. My thinking is that various assumptions are reasonable, and that to test these assumptions, it is necessary to develop multiple transliterations of the Voynich manuscript.
In Voynich Reconsidered, as possible alternatives to v101, I presented three new transliterations which I numbered v102, v103 and v104. In subsequent research, I have developed about twenty further transliterations, numbered from v120 to v216. Most of them differ from v101 in just one respect; for example, in one case the only change was to replace {C} with {cc}. Some differ in several respects.
In another post, I may set out some ideas for ranking or prioritizing alternative transliterations. One possible criterion is the extent of correlation between the glyph frequencies and the letter frequencies in selected medieval languages. In this respect, some of my transliterations have higher correlations than others. In that sense, they encourage further testing.
3(b). “Word” definitions
Elsewhere on this platform, I have written that there is considerable uncertainty as to how the Voynich manuscript establishes breaks between “words”. Where the text is horizontal, we can see line breaks; within the lines, we often see clear spaces between text strings. The v101 transliteration also distinguishes “uncertain spaces”, which might be “word” breaks or might simply be elongations of “words”. There is nothing resembling punctuation, that might guide us as to where “words” begin and end.
As shown in the image below, we also often see text run up against an illustration and continue on the other side. Sometimes the "words" to left and right of the break are unique. In such cases, we may wonder whether the illustration broke a “word” into two fragments, neither necessarily a “word”; or whether in the text to left or right of the illustration, the scribe omitted some "word" breaks.
An extract from page f026r, showing presumed "word" breaks. The "words" highlighted in light yellow occur nowhere else in the manuscript. Image credit: Beinecke Rare Book and Manuscript Library; graphics and legend by author.
Furthermore, at the Voynich 2022 conference Zattera demonstrated that there are thousands of Voynich “words” which can be split into two parts, each of which is a “word”. He called them “separable words”. We could think of them as analogous to compound words in natural languages, like "oversee" in English; alternatively, we could think of them as cases in which the scribe simply omitted a space.
If we did not suspect the Voynich text to have been subject to a re-ordering of glyphs within “words”, the “word” breaks would not much matter. For example, if in English we saw the sequence:
fo ursc orea ndsev enye arsa go,we would not have much difficulty in recognising it as the opening phrase of the Gettysburg Address. But if we saw the same sequence with the letters sorted alphabetically within the strings, that is:
fo crsu aeor densv eeny aars go,we would have a hard time in reaching the same interpretation.
It seems to me therefore that it is important to make explicit and objective assumptions on the word breaks in the Voynich manuscript. My working assumption is that all line breaks, v101 spaces and v101 “uncertain spaces” are “word" breaks; and that all of Zattera’s “separable words” need to have spaces inserted at the appropriate places.
(As a footnote: Zattera did not identify the “separable words”, nor did he define the algorithm whereby he had identified them. In another post on this platform, I have set out some ideas for that identification.)
4. Mapping and re-ordering
If we think that there was a re-ordering process, it makes a big difference whether it preceded or followed the mapping.
An example may illustrate this issue. Let us imagine ourselves somewhere in Italy in the year 1472. At the Annunciation Fair in Foligno, the entrepreneur Johann Neumeister has launched the first printed edition of Dante’s beloved La Divina Commedia. A wealthy person, whom we will call "the producer", has purchased several copies. He or she distributes the copies to a team of scribes, engaged for this purpose. He or she instructs them to transliterate the book, word by word and letter by letter, into an invented script. He or she prescribes the mapping from Latin letters to the inscrutable glyphs. The scribes speak and read Italian, and they are free to parse the printed words as they see fit.
The producer has one further instruction. In mapping each Italian word, the scribes are to do one of the following (and we do not know which):
1. sort the letters according to the Latin alphabet, and then apply the letter-to-glyph mapping; orOne of the scribes begins by parsing the first line of Canto 1: "Nel mezo delcamin dinra uita". We now try to reconstruct what he did. Not knowing what mapping the producer specified, we use our own mapping based on glyph and letter frequencies (which is not intended to be definitive). The results are shown below.
2. apply the letter-to-glyph mapping, and then in each “word”, sort the glyphs according to a sequence which the producer has specified (and which, over 500 years later, Zattera will call the “slot alphabet”).
Two alternative mappings of Dante's La Divina Commedia (1472 edition), Canto 1, line 1, to Voynich glyphs, on the basis of frequency matching and re-ordering processes. Author's analysis. (The three alternative results in column 2 reflect the flexible positioning of the glyphs {o}, {8} and {9} within Zattera’s “slot alphabet”. The glyph strings in blue are real Voynich "words".)
Column 2, which conforms to the “slot alphabet”, contains two glyph strings which exist as real "words" in the Voynich manuscript. Column 1 has only one such string. The sequences of glyph strings in Columns 1 and 2 are somewhat different.
It seems to me that the process represented in Column 1 is less probable. For example, if we sort alphabetically the letters in European words, many words will begin with A. Therefore A should map to one of the glyphs in Zattera's slot 0: that is, either {4}, the initial {8} or the initial {s}. But in the medieval European languages that I have studied, the letter A has a frequency of between 7 and 11 percent. In the Voynich v101 transliteration, the frequencies of {4}, initial {8} and initial {s} do not exceed 3.2 percent.
If the glyphs have been re-ordered, I am inclined to view process 2 (mapping and then re-ordering) as the more probable process.
5(a). Selecting the Voynich text
Elsewhere on this platform, I have argued that any serious attempt at mapping the Voynich text must be based on a reasonably long chunk of text: at least a whole line, better a paragraph, better still a whole page. We cannot be content with single "words".
Since we are taking aim at a natural language, to my mind we need to select a chunk of text which appears to be in a uniform language.
Here, we could start with Prescott Currier's Language A and Language B. The downside is that Currier never explained how he had identified Languages A and B. In the 1976 conference, he said that the differences were statistical; we might guess that those differences were in glyph frequencies, or "word" frequencies. For example, the v101 glyph {c} is much more common in the {B} pages than in the {A} pages; also, "words" beginning with {4o} are more common in B than in A.
My own preference is to work with the thematic sections of the manuscript. Here at least, we have the illustrations as a basis for defining the section. For example, we can follow the conventional definition of the "herbal" section as the set of pages containing illustrations of complete plants. There is no necessity to assume that the text corresponds to the illustrations.
If we select a single thematic section, we can run statistical tests on sub-sections to see whether the section is in a uniform language. Sub-sections can be defined by reference to the scribes. In the case of the "herbal" section, Dr Lisa Fagin Davis has proposed that there were four scribes: she numbered them 1, 2, 3 and 5. I have found some evidence that the four scribes used four different languages. To have some assurance of mapping from a single language, I am inclined to work with only the 95 pages written by Scribe 1.
5(b). Reverse mapping
If we then leave the re-ordering process aside and simply attempt some reverse glyph-to-letter mappings, we will generate text strings in the presumed precursor languages. For example, let us say that we want to test medieval Italian as a possible precursor.
We select the first page of the "herbal" section, f1v, which Currier assigned to Language A, and which, according to Dr Davis, was written by Scribe 1. Randomly we select line 4, which appears to contain seven "words". However, before we do the mapping, we need to confirm the "word" breaks. Here we apply Zattera's "slot alphabet", with the following result:
We infer that all the "words" conform to the "slot alphabet", except the second "word", which is a "separable word" and needs to have a space inserted.
We now have eight "words", which we map to medieval Italian with a straight frequency analysis, making no distinction between vowels and consonants, as shown in the right-hand mapping below:
Frequency comparisons between v101 glyphs and Italian letters in the OVI corpus; glyphs representing vowels and consonants are identified on the basis of the Sukhotin algorithm. (left) vowels and consonants distinguished (right) no distinction between vowels and consonants. Author's analysis.
We thereby generate the sequence:
TER NE LOE TIKS TIF GENOA NE LETA.This mapping is not set in stone. If we had used a specific medieval Italian document instead of the OVI corpus, the frequencies would be slightly different and the mapping would change. For example, if we had mapped on the basis of La Divina Commedia, the T and L would swap places, and the sequence would become
LER NE TOE LIKS LIF GENOA NE TELA.Likewise, the K, mapped from the infrequent v101 glyph {i}, is an uncertain result; it could just as well be J or X.
[As a footnote: we can also try alternative transliterations of the Voynich manuscript. The v101 transliteration has too many glyphs to map to a typical European alphabet; it makes sense to combine some of them. In my v102 and subsequent transliterations, I have explored this avenue, and others: for example:
* combining the v101 glyphs {2}, {3}, {5} and their many variantsThese modifications change the glyph frequencies, and thereby change some parts of the mapping.]
* merging the similar-looking glyphs {6}, {7}, {8} and {&}
* redefining {I} as {ii}, and {C} as {cc}
* redefining {m} as {iiN}, and {n} as {iN}.
5(c). Finding real words
For sure, to non-Italian speakers (of whom, I am one), only GENOA is a recognisable Italian word: indeed, the name of an Italian city. This could be pure coincidence. However, here is where we can refer to the respective corpora. In the case of medieval Italian, I use the OVI corpus (Opera del Vocabolario Italiano) at https://gattoweb.ovi.cnr.it/. Here we find that LETA, NE and TER are words in medieval Italian. Only NE is a common word; but at least we establish that the mapping is not producing nonsense.
6. Reconstructing words from letter strings
In the last part of the process, we start with our mapped strings of letters in a natural language, which may often look as if they possess no meaning. Above, I gave the example of the sequence:
eln emoz del acimn di anr aituwhich is not self-evidently meaningful. But it can be re-ordered to make the phrase:
nel mezo del camin di nra uita,which, as we saw, is the first line of Canto 1 in the 1472 edition of La Divina Commedia.
Here we may recall that the average length of a Voynich “word” is four glyphs. If the mapping is one-to-one, a four-glyph “word” maps to a four-letter string. There are 24 possible anagrams of such a string. For a five-letter string, the number of anagrams rises to 120. If, starting with a whole line of Voynich text; we hope to find meaningful anagrams for each word; and to construct a meaningful phrase or sentence from the whole: our task is large but, with computing power, not impossible.
In Step 5(c) above, we found that LETA was a real word in medieval Italian, but a rare one (with only thirty occurrences in the OVI corpus). However, if the glyphs had been re-ordered after the mapping, the string ALTE would have generated the same Voynich “word”. If we now search for ALTE in the OVI corpus, we find that it is also a real Italian word, and a much more common one, with 1,200 occurrences. It translates to the English "high" (feminine plural). An example of its occurrence in the OVI corpus is this:
"e vedemo e llo cielo stelle alte e stelle basse"Likewise, one of our mappings yielded the rare and archaic word TER; but in our re-ordering scenario, the word TRE would map to the same Voynich "word". In the OVI corpus, TRE occurs 22,418 times. The English translation is "three".
("and we saw in the sky high stars and low stars")
[Restoro d'Arezzo, 1282]
From these examples, we might be permitted to think that if in our raw mapping, we do not find satisfactory words in the presumed precursor language, some re-arrangements of vowels or consonants might yield better words. We do not have to work through all the permutations; in natural languages, as Sukhotin observed, vowels and consonants tend to alternate.
Finally, even if we can find a sequence of satisfactory words in the precursor language, we still have to extract meaning from the phrase, line, paragraph or page that we selected. That is where the real work begins.


No comments have been added yet.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

