
Robert H. Edwards's Blog: Great 20th century mysteries, page 2
August 12, 2024
Voynich Reconsidered: review
Here is a kind review of Voynich Reconsidered by Richard SantaColoma, creator of the voynich.net forum:
Extracts from the home page of the Voynich Net Forum at voynich.net/forum/index.php, and (inset) Richard SantaColoma, creator and administrator of the forum. Image credits: Richard SantaColoma.

A detail from the cover of Voynich Reconsidered (Schiffer Books, August 2024). Image credit: Schiffer Books.
“In his book, author Edwards brilliantly and patiently dissects many of the previous attempts at plumbing the secrets of the mysterious Voynich Manuscript. These stories read like a literary detective novel, and are interesting in their own right.
But by offering insights into the wide range of possible methods for tackling this most enigmatic problem, and detailing both their failures and possible achievements, it will help the next wave of hopefuls attempting to solve it. They will not need to reinvent the wheel, nor repeat old mistakes, and so will have a much better chance of avoiding previous pitfalls and failures.
Voynich Reconsidered would be a valuable asset to anyone’s literary history, cipher, or Voynich Manuscript Library”.
Extracts from the home page of the Voynich Net Forum at voynich.net/forum/index.php, and (inset) Richard SantaColoma, creator and administrator of the forum. Image credits: Richard SantaColoma.
A detail from the cover of Voynich Reconsidered (Schiffer Books, August 2024). Image credit: Schiffer Books.


August 7, 2024
Mallory, Irvine, Everest: reviews
Five-star reviews of Mallory, Irvine and Everest: The Last Step But One from readers in the UK, USA and (I think) Ireland, on Amazon and Goodreads:

Five-star reviews of "Mallory: Irvine, Everest: The Last Step But One". Image credit: Balázs Petheő; additional graphics by author.
Five-star reviews of "Mallory: Irvine, Everest: The Last Step But One". Image credit: Balázs Petheő; additional graphics by author.
• "Amazing re-evaluation of a 100 year old mystery ... a work of scholarship ... could easily be submitted for a second Ph D thesis to the one the author already has ... It studies in careful and forensic detail all the circumstances surrounding the disappearance of Mallory and Irvine on the 1924 Everest expediton."
https://www.amazon.co.uk/gp/customer-...
• "The book is brilliant. I can't recommend it highly enough."
• "Meticulously researched and beautifully written ... absolutely fascinating ..."
• "Excellent read ... Excellent book on an enduring mystery."
• "Riveting read ... Tells it like it is with plenty of background information none of which is superfluous."
• "Great Insight ... I was delighted to read this excellent book."
• "Edwards’ research is extensive and meticulous ... narration is measured, factual, and straightforward. .., this was a deeply fascinating read."
• "... brilliantly researched and eloquently written book ... A fantastically fascinating journey ..."
• "ANOTHER OUTSTANDING STUDY BY DR. EDWARDS ... Meticulously researched and fascinating to read ..."
July 31, 2024
Voynich Reconsidered: review
Here is a kind review of my new book Voynich Reconsidered (Schiffer Books, August 2024), by Dr Andrew Steckley, CEO of Steckley and Associates and QuantumLynx Research:
Steckley and Associates is a leading consultancy in the fields of data science, predictive analytics and machine learning. Image credit: Steckley and Associates.
"In his aptly titled new book, "Voynich Reconsidered," Bob Edwards offers a refreshing and unbiased exploration of the enigmatic Voynich Manuscript. Although the main focus is the manuscript's unique Voynichese script, the book also provides an excellent overview of the broader aspects of the manuscript and the key results of previous research.
Edwards' valuable insights, along with plenty of original analytical results, make this book an excellent starting point for anyone hoping to decode this mysterious text. I would recommend this book as a must-read resource for both experienced cryptographers and amateur researchers."
Steckley and Associates is a leading consultancy in the fields of data science, predictive analytics and machine learning. Image credit: Steckley and Associates.
July 16, 2024
Voynich Reconsidered: the {8am} strategy revisited
In my new book Voynich Reconsidered (Schiffer Books, August 2024), one of my objectives was to engage the reader in a quest for the underlying meaning of the inscrutable Voynich manuscript; and to provide him or her with the tools to do so.
In an earlier article on this platform, I set out my idea of an efficient strategy for identifying the presumed precursor languages of the Voynich manuscript. The strategy is based on testing whether any given transliteration of the manuscript, and any potential precursor language, together yield a mapping from Voynich “words” to real words. I proposed to focus on the v101 “word” {8am}, the most common “word” in the manuscript. For that reason, I called this approach the {8am} strategy.
My subsequent work on what I call “leaf words” has instilled a doubt in my mind as to whether {8am} is a “word” at all. I found some evidence that {8am} might be an arbitrary, and possibly meaningless, filler for gaps between intervening illustrations, like the plants in the “herbal” section. However, {8am} occurs hundreds of times outside the “herbal” section, and in locations which are not adjacent to illustrations. I thought it worthwhile, therefore, to persevere with the {8am} strategy.

The Voynich “word” {8am}, rendered in the Voynich v101 font. Image credit: Rebecca G Bettencourt / KreativeKorp.
The {8am} strategy is, in essence, to try multiple transliterations of the Voynich manuscript, in permutations with multiple precursor languages; for each permutation, to map {8am} to a text string in the target language; and to search a suitable corpus of the target language for that string as a real word.
My transliterations, all derived from v101, are currently numbered from v101④ to v226. Some of my transliterations allow for {8am} to be not three glyphs, as it is in v101; but four glyphs, which I write as [8aîń], or five, which I write as [8aiiń].
Following Mary D’Imperio and Massimiliano Zattera, I allowed for the possibility of re-ordering the letters in the text string: even of reversing the order, to allow for target languages which are written from right to left (as is the case with Arabic, Hebrew, Persian and Ottoman Turkish)
In cases where {8am} could be mapped to a real word, it might be a common word, or a rare word. It seemed to me that, the more common the word, the more encouragement we might feel for our permutation of transliteration and language.
The first mappings
As reported earlier: in my first implementation of the {8am} strategy, I started with three potential precursor languages and four corpora, as follows:
The most encouraging result came from the mappings to medieval Italian using the letter frequencies in the OVI corpus. Allowing for re-ordering or reversing the text string, it seemed possible to map {8am} to either of the following words:
In the next stage of mapping, I tested the following potential precursor languages:
Selected mappings of the "word" [8am} to words in some medieval European languages. Author's analysis. Higher resolution at https://flic.kr/p/2q4ow8z
In each case, there were multiple transliterations which yielded the same mapping. I was inclined to prioritise the transliterations according to what I call the AFD metric (the average absolute frequency difference), as outlined in previous articles on this platform. What I identified as the “best transliteration” is not necessarily the right one. To narrow down the choices will require mapping of other Voynich “words”.
Next steps
The next step would be to map some other ubiquitous “words” in the Voynich manuscript. To avoid possible “filler words”, I am inclined to look at “words” of at least three glyphs, such as {1oe}, {2oe} and {1oy}. Again, the objective would be to map these “words” to text strings in selected target languages, and to see whether those strings are real words. If we can map several common Voynich “words” to real words in some medieval languages, we might continue towards mappings of whole lines. We will be looking for such mappings to make grammatical sense.
In an earlier article on this platform, I set out my idea of an efficient strategy for identifying the presumed precursor languages of the Voynich manuscript. The strategy is based on testing whether any given transliteration of the manuscript, and any potential precursor language, together yield a mapping from Voynich “words” to real words. I proposed to focus on the v101 “word” {8am}, the most common “word” in the manuscript. For that reason, I called this approach the {8am} strategy.
My subsequent work on what I call “leaf words” has instilled a doubt in my mind as to whether {8am} is a “word” at all. I found some evidence that {8am} might be an arbitrary, and possibly meaningless, filler for gaps between intervening illustrations, like the plants in the “herbal” section. However, {8am} occurs hundreds of times outside the “herbal” section, and in locations which are not adjacent to illustrations. I thought it worthwhile, therefore, to persevere with the {8am} strategy.
The Voynich “word” {8am}, rendered in the Voynich v101 font. Image credit: Rebecca G Bettencourt / KreativeKorp.
The {8am} strategy is, in essence, to try multiple transliterations of the Voynich manuscript, in permutations with multiple precursor languages; for each permutation, to map {8am} to a text string in the target language; and to search a suitable corpus of the target language for that string as a real word.
My transliterations, all derived from v101, are currently numbered from v101④ to v226. Some of my transliterations allow for {8am} to be not three glyphs, as it is in v101; but four glyphs, which I write as [8aîń], or five, which I write as [8aiiń].
Following Mary D’Imperio and Massimiliano Zattera, I allowed for the possibility of re-ordering the letters in the text string: even of reversing the order, to allow for target languages which are written from right to left (as is the case with Arabic, Hebrew, Persian and Ottoman Turkish)
In cases where {8am} could be mapped to a real word, it might be a common word, or a rare word. It seemed to me that, the more common the word, the more encouragement we might feel for our permutation of transliteration and language.
The first mappings
As reported earlier: in my first implementation of the {8am} strategy, I started with three potential precursor languages and four corpora, as follows:
• Finnish as written around 1548, represented by Uusi Testamentti (The New Testament)and with thirty-seven alternative transliterations of the Voynich manuscript, which I had numbered from v101④ to v202.
• Early New High German as written around 1401, represented by von Tepl's Der Ackerman aus Böhmen (The Ploughman from Bohemia)
• vernacular Italian (perhaps I should say Tuscan-Italian) as written around 1308-21, represented by Dante's La Divina Commedia (The Divine Comedy)
• Italian as written prior to 1400, represented by the OVI corpus, or Opera del Vocabolario Italiano,
The most encouraging result came from the mappings to medieval Italian using the letter frequencies in the OVI corpus. Allowing for re-ordering or reversing the text string, it seemed possible to map {8am} to either of the following words:
• “con”, which occurs 135,186 times in OVI and translates to English as “with”The second stage of mapping
• “dio”, which occurs 55,550 times in OVI and translates to English as “God”.
In the next stage of mapping, I tested the following potential precursor languages:
• Albanian as written in 1555, as represented by Gjon Buzuku’s Meshari (Missals)To cut to the chase: in addition to the previously identified mappings to medieval Italian, these tests yielded just two languages in which {8am} could be mapped to real words:
• Arabic as written in the fourteenth century, represented mainly by Ibn Kathir’s البداية والنهاية (The Beginning and the End), by courtesy of Dr Mohsen Madi
• Arabic as written in the eighth through fifteenth centuries, represented by three corpora: Grammarians, Medieval Philosophy and Science, and The Thousand and One Nights, by courtesy of Dr Dilworth Parkinson
• Bohemian as written prior to 1314, represented by Dalimilova Kronika (The Chronicles of Dalimil)
• English as written in the 1330s, represented by the Auchinleck manuscript, lines 1 to 2330
• English as written between 1488 and 1500, represented by the Ashmole 61 manuscript, parts 1 to 27
• French as written around 1440, represented by La Farce de Maistre Pathelin
• Galician-Portuguese as written between 1220 and 1300, represented by Cantigas d'Amigo (Songs of a Friend)
• Latin as written in the seventh through fourteenth centuries, represented by the LatinISE medieval subcorpus, by courtesy of Barbara McGillivray
• Latin as written in 1312-13, represented by Dante’s Monarchia
• Persian, represented by a predominantly medieval corpus of the works of forty-eight poets, by courtesy of https://github.com/amnghd/Persian_poe...
• Ottoman Turkish as written prior to 1631, represented by Ismail Ankaravi’s كتاب منهاج الفقراء Kitabi Minhac ul-Fukara
• Welsh as written in the mid-fourteenth century, represented by The White Book of Mabinogion.
* Arabic as written in the fourteenth century: the words منع (“prevention” or “it prevents”), أمي (“my mother” or “maternal”), أيم (“widow” or “widowed”)
* English as written in the 1330s: the word “and”.
Selected mappings of the "word" [8am} to words in some medieval European languages. Author's analysis. Higher resolution at https://flic.kr/p/2q4ow8z
In each case, there were multiple transliterations which yielded the same mapping. I was inclined to prioritise the transliterations according to what I call the AFD metric (the average absolute frequency difference), as outlined in previous articles on this platform. What I identified as the “best transliteration” is not necessarily the right one. To narrow down the choices will require mapping of other Voynich “words”.
Next steps
The next step would be to map some other ubiquitous “words” in the Voynich manuscript. To avoid possible “filler words”, I am inclined to look at “words” of at least three glyphs, such as {1oe}, {2oe} and {1oy}. Again, the objective would be to map these “words” to text strings in selected target languages, and to see whether those strings are real words. If we can map several common Voynich “words” to real words in some medieval languages, we might continue towards mappings of whole lines. We will be looking for such mappings to make grammatical sense.
July 15, 2024
Voynich Reconsidered: Zattera's "separable words"
In my book Voynich Reconsidered (Schiffer Publishing, August 2024), I outlined Massimilano Zattera's concepts of the "slot alphabet" and "separable words" in the Voynich manuscript. Zattera presented these concepts at the Voynich 2022 conference. His intriguing paper had the title “A New Transliteration Alphabet Brings New Evidence of Word Structure and Multiple "Languages" in the Voynich Manuscript”.
In this article, I had the idea of returning to Zattera's concepts.
Zattera’s main objective, as I understood it, was to demonstrate that most of the “words” in the Voynich manuscript conformed to a sequence which he called the “slot alphabet”. This alphabet was based on the following concepts:
I have assumed that Zattera used the term "word" to mean a glyph string delimited in EVA by spaces or line breaks. I think that in EVA there is no distinction (as there is in v101) between spaces and "uncertain spaces".

Zattera's "slot alphabet", setting out an order in which glyphs can appear in a Voynich "word". Graphics by author. Higher resolution at https://flic.kr/p/2odKsKz
Separable “words”
Here, my interest is in what Zattera called “separable words”. By this he meant “words” which could be divided into two parts, each of which was a Voynich “word”. In his paper, he stated that “separable words” accounted for an additional 10.4% of the text, and for 37.1% of the vocabulary; and that the components of the "separable words" conformed to the "slot alphabet".
For example, the v101 “word” {2coehcc89}, which occurs only once, can be separated into two parts: {2coe} which occurs 50 times as a “word”, and {hcc89} with 18 occurrences as a “word”. This is not the only way to separate the “word”: {2co} occurs 26 times and {ehcc89} occurs 14 times. Both separations conform to the "slot alphabet".
In "separable words", we might conjecture that there is a word break, but it is not a space; it is invisible, or implied (as in "battlefield" or any other compound word in English).
Zattera did not provide a list of the separable words that he had identified. But we can have a shot at doing so. I approached this task with several basic assumptions, as follows:
In Glen Claston's v101 transliteration, the "herbal" section has 11,687 “words” with an average “word” length of 3.73 glyphs. The vocabulary consists of 3,790 distinct “words”. The ten most common “words”, including the isolated {s} and {9} which may or may not function as “words”, are as follows:
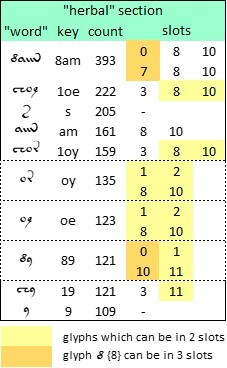
The ten most frequent “words”, including the isolated glyphs {s} and {9}, in the "herbal" section of the Voynich manuscript. Source: author’s analysis. Higher resolution at https://flic.kr/p/2prgAMA
Here, it seemed noteworthy that the text did not have a brilliant fit with Zipf’s Law. The correlation of the glyph frequencies with the expected Zipf sequence (for a natural language) was just 81.9 percent.
The second step in the process was to import the v101 transliteration into Microsoft Word, and using the “find-and-replace” function, replace each of the top ten “words” with the same string preceded and followed by a space. It seemed advisable to leave the isolated {s} and {9} alone. This step converted all occurrences of the selected strings to “words”. For example, any occurrence of the string {8am}, even when interior to a glyph string, became the “word” {8am}. This step produced a new transliteration, with a smaller vocabulary.
The third step was to make some alternative conversions of frequent glyph strings to “words”, as follows:

Some alternative rankings of the ten most frequent "words" in the "herbal" section of the Voynich manuscript. Source: author’s analysis. RSQ denotes correlation coefficient for frequencies of all words in the section’s vocabulary, against the expected frequencies as per Zipf’s Law.
Of these tests, the one which gave the best fit with Zipf’s Law was the first, in which the top ten “words”, whether occurring as strings or as “words”, were converted to “words”. Here the correlation with the Zipf sequence was 98.8 percent.
Thus, it appears that by converting the top ten glyph strings to “words”, but ignoring single-glyph “words”, we can identify a vocabulary which is highly consistent with Zipf’s Law. This conversion made the “herbal” section resemble much more closely a text in a natural language.
The first three lines
We can illustrate the process of word separability by applying it to an extract from the text of the “herbal” section: for example, the first three lines on the first page of the section (f001v). In the v101 transliteration, these lines are as follows:

With word separability, these three lines become as follows:
Vowel recognition
The next step was to identify vowels, using the Sukhotin algorithm as implemented by Dr Mans Hulden’s Python code. In the v101 transliteration, the algorithm identifies the following glyphs as the five most probable vowels, in descending order of probability:
Mapping to precursor languages
The logical next step is to select a chunk of the “herbal” section, or alternatively the most frequent “words” of the “herbal” section, and map the glyphs to letters in some potential precursor languages, as follows:
In this article, I had the idea of returning to Zattera's concepts.
Zattera’s main objective, as I understood it, was to demonstrate that most of the “words” in the Voynich manuscript conformed to a sequence which he called the “slot alphabet”. This alphabet was based on the following concepts:
• twelve “slots”, which Zattera numbered 0 to 11;Zattera’s principal thesis was that in a Voynich “word”, each glyph could only be preceded by a glyph in a lower “slot”, and could only be followed by a glyph in a higher “slot”. He stated that this was the case in 86.6 percent of the text in the manuscript.
• twenty-six distinct glyphs, based on the EVA transliteration (Zattera ignored the profuse variations and “rare glyphs” that occur in Glen Claston's v101 transliteration);
• the allocation of each glyph to one or more slots
• a rule that in most cases, a given glyph could occupy only one slot; in a few cases it could be in either of two slots; and in one case (EVA-d or v101-8) it could be in any of three slots.
I have assumed that Zattera used the term "word" to mean a glyph string delimited in EVA by spaces or line breaks. I think that in EVA there is no distinction (as there is in v101) between spaces and "uncertain spaces".
Zattera's "slot alphabet", setting out an order in which glyphs can appear in a Voynich "word". Graphics by author. Higher resolution at https://flic.kr/p/2odKsKz
Separable “words”
Here, my interest is in what Zattera called “separable words”. By this he meant “words” which could be divided into two parts, each of which was a Voynich “word”. In his paper, he stated that “separable words” accounted for an additional 10.4% of the text, and for 37.1% of the vocabulary; and that the components of the "separable words" conformed to the "slot alphabet".
For example, the v101 “word” {2coehcc89}, which occurs only once, can be separated into two parts: {2coe} which occurs 50 times as a “word”, and {hcc89} with 18 occurrences as a “word”. This is not the only way to separate the “word”: {2co} occurs 26 times and {ehcc89} occurs 14 times. Both separations conform to the "slot alphabet".
In "separable words", we might conjecture that there is a word break, but it is not a space; it is invisible, or implied (as in "battlefield" or any other compound word in English).
Zattera did not provide a list of the separable words that he had identified. But we can have a shot at doing so. I approached this task with several basic assumptions, as follows:
• that, rather than use the v101 transliteration with its many variations, I might elect to use one of my own transliterations, which aggregates several v101 glyphs that seem to be similar, such as {1} and {2};To this end, as a first step, I selected the “herbal” section as defined by René Zandbergen. This section is visually identifiable by the full-page drawings of plants. I take no position on whether the text is related to the drawings; however, the text appears to have a uniform vocabulary which is different from that in other parts of the manuscript.
• that I should regard certain glyphs as having different meanings (or mappings) in the initial, interior, final and isolated positions; in other words, for example, an initial {9} was not the same as a final {9};
• that the most probable building blocks of Zattera’s “separable words” were the most frequent “words”;
• that, rather than use the whole Voynich manuscript with its (probable) multiple languages, I should work with a single thematic section that seemed to have a homogenous language.
In Glen Claston's v101 transliteration, the "herbal" section has 11,687 “words” with an average “word” length of 3.73 glyphs. The vocabulary consists of 3,790 distinct “words”. The ten most common “words”, including the isolated {s} and {9} which may or may not function as “words”, are as follows:
The ten most frequent “words”, including the isolated glyphs {s} and {9}, in the "herbal" section of the Voynich manuscript. Source: author’s analysis. Higher resolution at https://flic.kr/p/2prgAMA
Here, it seemed noteworthy that the text did not have a brilliant fit with Zipf’s Law. The correlation of the glyph frequencies with the expected Zipf sequence (for a natural language) was just 81.9 percent.
The second step in the process was to import the v101 transliteration into Microsoft Word, and using the “find-and-replace” function, replace each of the top ten “words” with the same string preceded and followed by a space. It seemed advisable to leave the isolated {s} and {9} alone. This step converted all occurrences of the selected strings to “words”. For example, any occurrence of the string {8am}, even when interior to a glyph string, became the “word” {8am}. This step produced a new transliteration, with a smaller vocabulary.
The third step was to make some alternative conversions of frequent glyph strings to “words”, as follows:
• the top ten “words”, including the isolated {s}The results of the second and third steps are shown below.
• the top twenty “words”, excluding the isolated glyphs {s}, {9} and {y}
• the top thirty “words”, excluding the isolated glyphs {s}, {9} and {y}.
Some alternative rankings of the ten most frequent "words" in the "herbal" section of the Voynich manuscript. Source: author’s analysis. RSQ denotes correlation coefficient for frequencies of all words in the section’s vocabulary, against the expected frequencies as per Zipf’s Law.
Of these tests, the one which gave the best fit with Zipf’s Law was the first, in which the top ten “words”, whether occurring as strings or as “words”, were converted to “words”. Here the correlation with the Zipf sequence was 98.8 percent.
Thus, it appears that by converting the top ten glyph strings to “words”, but ignoring single-glyph “words”, we can identify a vocabulary which is highly consistent with Zipf’s Law. This conversion made the “herbal” section resemble much more closely a text in a natural language.
The first three lines
We can illustrate the process of word separability by applying it to an extract from the text of the “herbal” section: for example, the first three lines on the first page of the section (f001v). In the v101 transliteration, these lines are as follows:
With word separability, these three lines become as follows:
Vowel recognition
The next step was to identify vowels, using the Sukhotin algorithm as implemented by Dr Mans Hulden’s Python code. In the v101 transliteration, the algorithm identifies the following glyphs as the five most probable vowels, in descending order of probability:
{o}, {a}, {9}, {c}, {A}.The Sukhotin algorithm identifies probable vowels and probable consonants by the frequency with which they alternate. In the v211 transliteration with position-dependent glyphs and "word" separability, the "word" breaks have changed; so, not all the glyphs have the same neighbors as in v101. Therefore, the vowel-glyphs will not necessarily be the same. Applied to the “herbal” section, the five most probable vowels are now identified as follows:
interior {o} [ô], interior {a} [â], interior {1} [1], final {9} [⁹], initial {o} [ó].In a natural language, especially a medieval European language, we generally expect only five vowels. If so, we may adopt a working assumption that these five glyphs in all other positions, and all other glyphs, represent consonants in the presumed precursor languages. Alternatively, some of the non-vowel glyphs may represent punctuation, abbreviations, markers or other devices without phonetic significance.
Mapping to precursor languages
The logical next step is to select a chunk of the “herbal” section, or alternatively the most frequent “words” of the “herbal” section, and map the glyphs to letters in some potential precursor languages, as follows:
• vowel-glyphs to vowels in the precursor language, in order of frequency;This step requires a detailed recalculation of glyph frequencies in the word-separated Voynich text: not because the gross frequencies have changed, but because the position-dependent frequencies have changed. For example, within the separated words, some interior glyphs may have become initial or final glyphs. More on this in another article.
• consonant-glyphs to consonants in the precursor language, in order of frequency;
• as for precursor languages, to my mind we have nothing to lose by starting with medieval Italian and medieval Latin.
Voynich Reconsidered: the blind men and the elephant
Correspondents on internet forums have enquired about the theme, direction and scope of my book Voynich Reconsidered, which was published by Schiffer Books of Atglen, Pennsylvania on August 28, 2024.

Regarding the cover concept which appears on my Flickr page at https://www.flickr.com/photos/roberti... that is my own design. I used the elephant as a gentle reference to the parable of the six blind men and the elephant. https://en.wikipedia.org/wiki/Blind_m.... In the parable, which is probably of Indian origin, the six blind men touch the elephant in different places but cannot agree on what it is.
However, the real cover is Schiffer's design.
The subject of the book is document MS408 at the Beinecke Rare Book and Manuscript Library at Yale University, popularly known as the Voynich manuscript.
This document consists of 102 folios made of calfskin vellum, dated by radiocarbon analysis to the early fifteenth century. It contains hundreds of bizarre illustrations, but its greatest mystery lies in its thousands of lines of what appears to be text. If it is text, it is written in symbols which, for the most part, belong to no known human language. Since inorganic ink cannot be dated, we cannot say that the text was necessarily written in the fifteenth century.
The purpose of my book is to investigate, primarily from a perspective of a mathematician:
Regarding the cover concept which appears on my Flickr page at https://www.flickr.com/photos/roberti... that is my own design. I used the elephant as a gentle reference to the parable of the six blind men and the elephant. https://en.wikipedia.org/wiki/Blind_m.... In the parable, which is probably of Indian origin, the six blind men touch the elephant in different places but cannot agree on what it is.
However, the real cover is Schiffer's design.
The subject of the book is document MS408 at the Beinecke Rare Book and Manuscript Library at Yale University, popularly known as the Voynich manuscript.
This document consists of 102 folios made of calfskin vellum, dated by radiocarbon analysis to the early fifteenth century. It contains hundreds of bizarre illustrations, but its greatest mystery lies in its thousands of lines of what appears to be text. If it is text, it is written in symbols which, for the most part, belong to no known human language. Since inorganic ink cannot be dated, we cannot say that the text was necessarily written in the fifteenth century.
The purpose of my book is to investigate, primarily from a perspective of a mathematician:
* whether the text of the Voynich manuscript has an underlying meaning, or none;A forum member asked if I had considered cryptographic possibilities. Wilfrid Voynich thought it contained an encrypted text. In fact, he called it the "Cipher Manuscript"; the Beinecke Library uses the same term. But to my mind, it is simply a document written in unfamiliar symbols. If we had no knowledge of, for example, Chinese characters, and we saw a text in such characters, we might suppose it to be encrypted. My working assumption is that the Voynich manuscript is a plaintext; but I think it a real possibility that within the Voynich "words", the glyphs have been re-ordered in some way.
* if it has meaning, whether there is an underlying natural language or languages, and if so, what are the most probable languages;
* and what analytical tools could be applied to identifying the meaning of the text (if meaning is there to be found).
July 13, 2024
Voynich Reconsidered: “leaf words” revisited
In the context of the Voynich manuscript, I use the term “leaf words” to denote “words” that occur immediately before (to the left of), or immediately after (to the right of) an intervening illustration. These illustrations are in most cases of plants, hence my expression “leaf word”.

Examples of "leaf words" on line 1, page f26r of the Voynich manuscript. Image credit: Beinecke Rare Book and Manuscript Library.
To my mind, there is no doubt that in the Voynich manuscript, someone (or more than one person) drew the illustrations first, and later the scribes wrote the text around and within the illustrations, taking care not to overwrite an illustration. Therefore, the “leaf words” may tell us something about how the scribes managed the text in relation to the available space; and possibly, about the instructions that the producer gave them.
Dr Steckley’s database contains 625 lines. Each line contains at least two “leaf words” (a left “word” and a right “word”); a few contain as many as nine. I counted a total of 1,508 occurrences of “leaf words”.
As I had expected, most of the “leaf words” occur in the “herbal” section, which accounts for 531 of the 625 lines. Other thematic sections represented are the “balneological” section (56 lines), the “pharmaceutical” section (25 lines) and the “cosmic” section (13 lines). The database represents all five of the scribes identified by Dr Lisa Fagin Davis. Of the lines in the database, 436 were written by Scribe 1, 127 by Scribe 2, 22 by Scribe 3, 13 by Scribe 4 and 27 by Scribe 5.

Examples of "leaf words" in the Voynich manuscript, page f75r, line 17. Image credit: Beinecke Rare Book and Manuscript Library.
It seemed to me that this database would permit testing of the following hypotheses:
Short “words” to the left
The left “leaf words” had an average length of 3.49 glyphs; the right “leaf words” had an average length of 3.92 glyphs.
Dr. Steckley, in his recent paper with Noah Steckley, “Subtle Signs of Scribal Intent in the Voynich Manuscript”, found a similar result. Working with the pages of the “herbal” section written by Scribe 1, the Steckleys found that left “leaf words” (in their terminology, “before” tokens) had an average length of 4.24 glyphs; and right “leaf words” (“after” tokens) had an average length of 4.66 glyphs.
The Steckleys applied the chi-squared test of statistical significance, and concluded that there was some underlying causal mechanism that distinguished left “leaf words” from right “leaf words”. I have not performed an equivalent test; but the difference in the lengths of “words” seems to me significant.
From these results, we are encouraged to think that the left “leaf words” were inserted simply to fill the space that was available as the text approached the illustration.
For me, this is an unexpected and somewhat counter-intuitive inference. I have imagined the scribes as copyists. That is, they were professional writers, paid by the page, and working from documents that the producer or client had provided. In this scenario, the producer instructed the scribes to transliterate from letters in a (presumed) natural script to what we now call the Voynich glyphs; but did not give them authority or instructions to add or insert anything that did not represent the original documents.
Yet, in the left “leaf words” at least, we see some evidence of the scribe as author: that is, the scribe appearing to insert “words” or strings that the producer did not provide, in order to achieve a certain visual or artistic effect.
This result, in itself, did not imply that the “leaf words” were either meaningful, or what we might call junk. For that, I needed another test.
The top “leaf words”
Using the word counter at https://www.browserling.com/tools/wor..., I assembled rankings of the “leaf words” in descending order of frequency. These rankings could then be compared with the frequencies of the same “words” in the Voynich manuscript as a whole. A summary of the results is below.

The top ten left “leaf words”; the top ten right “leaf words”; and their frequencies in the Voynich manuscript as a whole. Highlighted frequencies denote cases where the “word” is much more common as a “leaf word” than in the manuscript as a whole. Author’s analysis, based on data kindly provided by Dr Andrew Steckley. Higher resolution at https://flic.kr/p/2q3TgRu
I am inclined to read these frequency comparisons as follows.
One way to test this would be to remove all occurrences of, for example, {8am} from the transliteration; to recalculate the frequencies of the glyphs that remain; and to test whether the remaining common “words” can be mapped to real words in natural languages.
For the moment, I am not inclined to attempt such tests: if only because, as I have reported in other articles on this platform, the “word” {8am} seems capable of mapping to real words in several medieval natural languages that I have examined. For example, {8am} can be mapped to منع (“prevention”) in Arabic; or “and” in English; or “con” or “dio” in Italian.
Next steps
I think that the true test of the function of “leaf words” will come when, or if, it becomes possible to map whole lines of Voynich text. As noted above, I have had some encouraging results in mapping {8am} to real words in some natural languages. I envisage a subsequent step of attempting mappings of other common “words”: probably “words" of at least three glyphs, such as the v101 "words" {1oe}, {1oy} or {2c9). If these mappings yield real words in any language, we may have enough correspondence of Voynich glyphs to letters to attempt a whole line. At that point, it may become more clear whether the “leaf words” represent words or junk.
Examples of "leaf words" on line 1, page f26r of the Voynich manuscript. Image credit: Beinecke Rare Book and Manuscript Library.
To my mind, there is no doubt that in the Voynich manuscript, someone (or more than one person) drew the illustrations first, and later the scribes wrote the text around and within the illustrations, taking care not to overwrite an illustration. Therefore, the “leaf words” may tell us something about how the scribes managed the text in relation to the available space; and possibly, about the instructions that the producer gave them.
Dr Steckley’s database contains 625 lines. Each line contains at least two “leaf words” (a left “word” and a right “word”); a few contain as many as nine. I counted a total of 1,508 occurrences of “leaf words”.
As I had expected, most of the “leaf words” occur in the “herbal” section, which accounts for 531 of the 625 lines. Other thematic sections represented are the “balneological” section (56 lines), the “pharmaceutical” section (25 lines) and the “cosmic” section (13 lines). The database represents all five of the scribes identified by Dr Lisa Fagin Davis. Of the lines in the database, 436 were written by Scribe 1, 127 by Scribe 2, 22 by Scribe 3, 13 by Scribe 4 and 27 by Scribe 5.
Examples of "leaf words" in the Voynich manuscript, page f75r, line 17. Image credit: Beinecke Rare Book and Manuscript Library.
It seemed to me that this database would permit testing of the following hypotheses:
• that the “leaf words” are the equivalent of hyphenated words: that is, fragments of longer “words” that were broken up by the illustrations (as if, when writing Shelley’s Ozymandias around an existing drawing, we had to write: “I met a traveller fro<->m an antique land”)Accordingly, I parsed Dr Steckley’s 625 lines into their component parts, breaking the lines where an illustration intervened; and built a database of the “leaf words” to left and to right of the “plant breaks”. Working with just the first two “leaf words” on each line, my first test was to calculate the average lengths of the “words”. The results were as follows.
• that the “leaf words” are complete “words”, inserted to match the available space and remaining grammatically correct (as in: “I met a traveller far <-> from an antique land”)
• that the “leaf words” are complete “words” but are not grammatically correct (as in: “I met a traveller sky <-> from an antique land”)
• that the “leaf words” are not “words” but meaningless strings, inserted to fill the available space (as in “I met a traveller xkz <-> from an antique land”).
Short “words” to the left
The left “leaf words” had an average length of 3.49 glyphs; the right “leaf words” had an average length of 3.92 glyphs.
Dr. Steckley, in his recent paper with Noah Steckley, “Subtle Signs of Scribal Intent in the Voynich Manuscript”, found a similar result. Working with the pages of the “herbal” section written by Scribe 1, the Steckleys found that left “leaf words” (in their terminology, “before” tokens) had an average length of 4.24 glyphs; and right “leaf words” (“after” tokens) had an average length of 4.66 glyphs.
The Steckleys applied the chi-squared test of statistical significance, and concluded that there was some underlying causal mechanism that distinguished left “leaf words” from right “leaf words”. I have not performed an equivalent test; but the difference in the lengths of “words” seems to me significant.
From these results, we are encouraged to think that the left “leaf words” were inserted simply to fill the space that was available as the text approached the illustration.
For me, this is an unexpected and somewhat counter-intuitive inference. I have imagined the scribes as copyists. That is, they were professional writers, paid by the page, and working from documents that the producer or client had provided. In this scenario, the producer instructed the scribes to transliterate from letters in a (presumed) natural script to what we now call the Voynich glyphs; but did not give them authority or instructions to add or insert anything that did not represent the original documents.
Yet, in the left “leaf words” at least, we see some evidence of the scribe as author: that is, the scribe appearing to insert “words” or strings that the producer did not provide, in order to achieve a certain visual or artistic effect.
This result, in itself, did not imply that the “leaf words” were either meaningful, or what we might call junk. For that, I needed another test.
The top “leaf words”
Using the word counter at https://www.browserling.com/tools/wor..., I assembled rankings of the “leaf words” in descending order of frequency. These rankings could then be compared with the frequencies of the same “words” in the Voynich manuscript as a whole. A summary of the results is below.
The top ten left “leaf words”; the top ten right “leaf words”; and their frequencies in the Voynich manuscript as a whole. Highlighted frequencies denote cases where the “word” is much more common as a “leaf word” than in the manuscript as a whole. Author’s analysis, based on data kindly provided by Dr Andrew Steckley. Higher resolution at https://flic.kr/p/2q3TgRu
I am inclined to read these frequency comparisons as follows.
• Both the left “leaf words” and the right “leaf words” seem to have a relatively compact vocabulary, in which certain “words” are used again and again; for example, among the left “leaf words”, the top five account for 14.5 percent of all occurrences of such “words”. This is consistent with natural language. For example, in the Brown corpus of modern American English, the top five words (“the”, “of”, “and”, “to” and “a”) account for 15.7 percent of all words in the corpus.Finally, if we are starting to suspect that the “leaf words” are junk, we have to ask the question: are they junk only next to illustrations, or are they junk wherever they occur? For example, is the v101 “word” {8am}, which is the most common “word” in the manuscript, just a filler, and not a meaningful “word”?
• There is some overlap in the vocabularies of the left and right “leaf words”. For example, the v101 “words” {s}, {8am} and {8an} occur frequently both as left and as right “leaf words”. This encourages us to think that they are not fragments of “words”: they are not evidence of a form of hyphenation.
• Nearly all of the common “leaf words” are common in the Voynich manuscript as a whole. Again, they do not look like fragments or parts of hyphenated “words”.
• Of the top ten “leaf words”, most are vastly more frequent as “leaf words” than in the manuscript as a whole. For example, the v101 “word” {89} accounts for 4.6 percent of all the left “leaf words”. To my mind, this encourages the inference that the “leaf words”, or some of them, are arbitrary fillers, or junk. We might expect a left “leaf word” to be a filler, as the text approaches the illustration and the available space contracts. But it is more surprising that the right “leaf words”, or some of them, although less constrained by space, should also seem to be junk.
One way to test this would be to remove all occurrences of, for example, {8am} from the transliteration; to recalculate the frequencies of the glyphs that remain; and to test whether the remaining common “words” can be mapped to real words in natural languages.
For the moment, I am not inclined to attempt such tests: if only because, as I have reported in other articles on this platform, the “word” {8am} seems capable of mapping to real words in several medieval natural languages that I have examined. For example, {8am} can be mapped to منع (“prevention”) in Arabic; or “and” in English; or “con” or “dio” in Italian.
Next steps
I think that the true test of the function of “leaf words” will come when, or if, it becomes possible to map whole lines of Voynich text. As noted above, I have had some encouraging results in mapping {8am} to real words in some natural languages. I envisage a subsequent step of attempting mappings of other common “words”: probably “words" of at least three glyphs, such as the v101 "words" {1oe}, {1oy} or {2c9). If these mappings yield real words in any language, we may have enough correspondence of Voynich glyphs to letters to attempt a whole line. At that point, it may become more clear whether the “leaf words” represent words or junk.
June 30, 2024
Voynich Reconsidered: scribes and languages
To my mind, the central mystery of the Voynich manuscript is whether there is a language underlying the strings of glyphs which have the appearance of text. That is the focus of my book Voynich Reconsidered (Schiffer Books, August 2024). A corollary of that issue is whether there is more than one such language.
To my knowledge, the first proposition to this effect was made by Captain Prescott Currier, in Mary D’Imperio’s seminar in Washington, DC, in 1976. Currier told his audience:
Currier made it clear that he did not consider the difference between “languages” to be equivalent to the vernacular difference between, say, English and French. Nevertheless, his concept of two “languages” has passed into the canon of Voynich research. This concept encourages the researcher to imagine that part of the manuscript is derived from (say) Latin and another part from (say) Greek. I do not think that Currier intended that inference.
However, on the basis of Currier's assignment of pages to "languages", we can at least assess the overall statistical divergence between his "languages" A and B. I calculated the frequencies of the glyphs in his A and B pages, and juxtaposed the results. An extract, showing just the top ten glyphs in the B pages, is below.
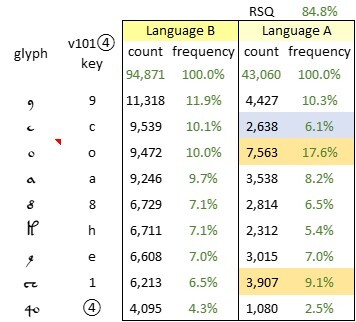
The ten most frequent glyphs in the pages of the Voynich manuscript which Currier assigned to "language" B; and the frequencies of the same glyphs in "language" A. Counts and frequencies based on v101④ transliteration. Author's analysis.
Here I observed that across the whole glyph alphabet, the correlation between the glyph frequencies in the A pages and the B pages was 84.8 percent. The question then arose: was this correlation a sign of two different languages as we understand them today? Or did it simply represent two dissimilar source documents in a single language?
Corpora and texts
To elucidate this question, I selected two corpora and several texts in medieval European languages which used the Latin (or a mainly Latin) alphabet. The corpora contain thousands of texts; for example, the OVI corpus of medieval Italian, as of April 2024, included 3,512 texts with 30,443,280 words. For each corpus, I calculated the correlations between the letter frequencies in the corpus and those in selected texts, in the same language or another. An initial summary is below.
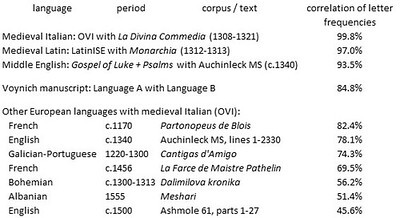
Correlations of the letter frequencies between two medieval European corpora and selected texts in the Latin (or mainly Latin) script. Author's analysis. Higher resolution at https://flic.kr/p/2q1Ckwo
From these results, it seemed to me that documents in a common language were likely to have a correlation of letter frequencies in excess of 90 percent. On the other hand, documents in different languages were likely to have correlations in the range 50 to 80 percent.
The Voynich A-B correlation seemed to suggest that, if there were natural languages underlying the text, there could well be at least two.
Dr Davis and the five scribes
To the best of my knowledge, forty-four years passed before anyone reconsidered Currier’s concept of “languages”, and his related concept of “hands” or scribes. In 2020, Dr Lisa Fagin Davis, Executive Director of the Medieval Academy of America, presented her paper ”How Many Glyphs and How Many Scribes? Digital Paleography and the Voynich Manuscript”, which I think was the first elaboration and extension of Currier’s work.
As far as I can determine, Dr Davis did not substantively challenge Currier’s assignment of pages to “languages”; except that she preferred the term “dialect” rather than “language”. As I understood her paper, she accepted Currier's assignments of pages to A and B, with two exceptions; and the thirty pages which Currier had not assigned, she allocated to “dialect B”.
However, Dr Davis presented a significantly different view of the “hands” or scribes. Where Currier had identified seven scribes, she identified five. Her identifications included 67 pages which Currier had left unclassified, and differed from Currier’s in 32 other cases. Like Currier, she identified a principal scribe, whom I call “Scribe D1”, who was the single most prolific writer of the text; in her analysis, Scribe D1 wrote 113 of the 227 pages.
To my mind, Dr Davis’s view of the scribes is a springboard from which we can further reconstruct the statistical basis for Currier’s concept of “languages”.
Starting from Dr Davis’s assignment of pages to scribes, I divided the text into five sections, each representing the work of a single scribe. I ran each section through the character frequency counter at browserling.com; this yielded a tabulation of glyph frequencies for each scribe. I then juxtaposed the five scribes’ glyph frequencies in a single Excel spreadsheet. An extract, showing just the top ten glyphs used by Scribe D1, is below.
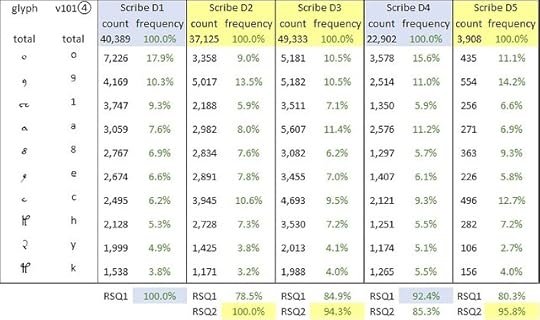
The counts and frequencies of the top ten glyphs used by Scribe D1; and the counts and frequencies of the same glyphs as used by Scribes D2 through D5. Counts based on v101④ transliteration. RSQ1 denotes correlation with frequencies of Scribe D1. RSQ2 denotes correlation with frequencies of Scribe D2. Author’s analysis. Higher resolution at https://flic.kr/p/2q1oHrR
As shown in the table above, I calculated the correlation coefficients (as expressed by the RSQ function in Excel) between the glyph frequencies of the five scribes. To my mind, this yielded two results that might be significant in mapping from the Voynich text to natural languages, as follows:
The vocabularies of the scribes
Given that we have five distinct bodies of text, corresponding to Dr Davis’s five scribes, we can also start thinking about the vocabularies of the five sections. The extent to which the vocabularies differ may inform our view as to whether the sections represent languages or dialects, in the modern vernacular sense.
Running the five texts through the word counter at browserling.com produced complete listings of all the “words” used by each of the five scribes. I noted that differences between visually similar v101 glyphs such as (6}, {7}, {8} and {&} would create distinct “words”; therefore, it is entirely possible that the scribes’ vocabularies are overstated. With that reservation, their vocabularies were as follows:
Looking at the most frequent “words” used by each scribe, it became apparent that the five scribes had some commonalities in vocabulary, and also some divergences. For example, the “words” {am} and {oe} were among the top ten of all five scribes; the "word" {8am} was among the top ten of four scribes. But each scribe had between three and eight common vocabulary “words” that were less commonly used (but used nonetheless) by the others.
To my mind, these differences cannot represent different languages as we understand them today. But perhaps, as Dr Davis preferred to say, they represent different dialects of a common language with a substantial shared vocabulary.
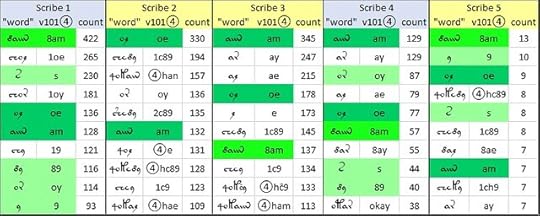
The ten most frequent “words” used by each of the five scribes of the Voynich manuscript, as identified by Dr Lisa Fagin Davis. Counts based on v101④ transliteration. Author’s analysis. Higher resolution at https://flic.kr/p/2q1nwZD
I am aware of at least two modern instances (I imagine that there are more) in which a regional language or dialect is officially recognised as a national language. In the Scottish Parliament, any communication may be made in the Scots language, which is differentiated from English as in the following example:
And in Catalonia, the equivalent phrases in Catalan and Spanish are as follows:
More than this: perhaps scholars of linguistics could identify pairs of medieval languages or dialects that differ in letter frequencies and word frequencies in approximately the ways that we see among the five Voynich scribes. If so, that might greatly focus the search for the underlying languages of the manuscript.
To my knowledge, the first proposition to this effect was made by Captain Prescott Currier, in Mary D’Imperio’s seminar in Washington, DC, in 1976. Currier told his audience:
“The first twenty-five folios in the herbal section are obviously in one hand and one "language," which I called "A." … the text of this second portion of the herbal section (that is, the next twenty-five or thirty folios) is in two “languages” and each "language" is in its own hand.And that is all that we know about Currier’s “languages” A and B. Currier never defined the two “languages”, or specified the statistical mechanism or algorithm whereby he had distinguished A from B. He did however assign, for 197 of the 227 pages in the manuscript, the “language” of that page. He listed 114 pages in “language” A and 83 pages in “language” B. Implicitly, he was saying that each page contained only one “language”.
… my use of the word “language” is convenient, but it does not have the same connotations as it would have in normal use.
… the characteristics of "languages" A and B are obviously statistical. (I can't show you what they are here, as I don’t have slides prepared …) … There are two different series of agglomerations of symbols or letters, so that there are in fact two statistically distinguishable "languages”.”
Currier made it clear that he did not consider the difference between “languages” to be equivalent to the vernacular difference between, say, English and French. Nevertheless, his concept of two “languages” has passed into the canon of Voynich research. This concept encourages the researcher to imagine that part of the manuscript is derived from (say) Latin and another part from (say) Greek. I do not think that Currier intended that inference.
However, on the basis of Currier's assignment of pages to "languages", we can at least assess the overall statistical divergence between his "languages" A and B. I calculated the frequencies of the glyphs in his A and B pages, and juxtaposed the results. An extract, showing just the top ten glyphs in the B pages, is below.
The ten most frequent glyphs in the pages of the Voynich manuscript which Currier assigned to "language" B; and the frequencies of the same glyphs in "language" A. Counts and frequencies based on v101④ transliteration. Author's analysis.
Here I observed that across the whole glyph alphabet, the correlation between the glyph frequencies in the A pages and the B pages was 84.8 percent. The question then arose: was this correlation a sign of two different languages as we understand them today? Or did it simply represent two dissimilar source documents in a single language?
Corpora and texts
To elucidate this question, I selected two corpora and several texts in medieval European languages which used the Latin (or a mainly Latin) alphabet. The corpora contain thousands of texts; for example, the OVI corpus of medieval Italian, as of April 2024, included 3,512 texts with 30,443,280 words. For each corpus, I calculated the correlations between the letter frequencies in the corpus and those in selected texts, in the same language or another. An initial summary is below.
Correlations of the letter frequencies between two medieval European corpora and selected texts in the Latin (or mainly Latin) script. Author's analysis. Higher resolution at https://flic.kr/p/2q1Ckwo
From these results, it seemed to me that documents in a common language were likely to have a correlation of letter frequencies in excess of 90 percent. On the other hand, documents in different languages were likely to have correlations in the range 50 to 80 percent.
The Voynich A-B correlation seemed to suggest that, if there were natural languages underlying the text, there could well be at least two.
Dr Davis and the five scribes
To the best of my knowledge, forty-four years passed before anyone reconsidered Currier’s concept of “languages”, and his related concept of “hands” or scribes. In 2020, Dr Lisa Fagin Davis, Executive Director of the Medieval Academy of America, presented her paper ”How Many Glyphs and How Many Scribes? Digital Paleography and the Voynich Manuscript”, which I think was the first elaboration and extension of Currier’s work.
As far as I can determine, Dr Davis did not substantively challenge Currier’s assignment of pages to “languages”; except that she preferred the term “dialect” rather than “language”. As I understood her paper, she accepted Currier's assignments of pages to A and B, with two exceptions; and the thirty pages which Currier had not assigned, she allocated to “dialect B”.
However, Dr Davis presented a significantly different view of the “hands” or scribes. Where Currier had identified seven scribes, she identified five. Her identifications included 67 pages which Currier had left unclassified, and differed from Currier’s in 32 other cases. Like Currier, she identified a principal scribe, whom I call “Scribe D1”, who was the single most prolific writer of the text; in her analysis, Scribe D1 wrote 113 of the 227 pages.
To my mind, Dr Davis’s view of the scribes is a springboard from which we can further reconstruct the statistical basis for Currier’s concept of “languages”.
Starting from Dr Davis’s assignment of pages to scribes, I divided the text into five sections, each representing the work of a single scribe. I ran each section through the character frequency counter at browserling.com; this yielded a tabulation of glyph frequencies for each scribe. I then juxtaposed the five scribes’ glyph frequencies in a single Excel spreadsheet. An extract, showing just the top ten glyphs used by Scribe D1, is below.
The counts and frequencies of the top ten glyphs used by Scribe D1; and the counts and frequencies of the same glyphs as used by Scribes D2 through D5. Counts based on v101④ transliteration. RSQ1 denotes correlation with frequencies of Scribe D1. RSQ2 denotes correlation with frequencies of Scribe D2. Author’s analysis. Higher resolution at https://flic.kr/p/2q1oHrR
As shown in the table above, I calculated the correlation coefficients (as expressed by the RSQ function in Excel) between the glyph frequencies of the five scribes. To my mind, this yielded two results that might be significant in mapping from the Voynich text to natural languages, as follows:
• Scribes D1 and D4 appeared to write in a common “language” or dialect.To my mind, these results seemed to underpin one of the processes that I have been using in all my attempted mappings from the Voynich text to natural languages: namely, to work with the text of a single scribe at a time. My preference has been to work with the text of Scribe D1 who, as I observed above, was the lead scribe.
• Scribes D2, D3 and D5 appeared to write in a common “language” or dialect, which was different from that of Scribes D1 and D4.
The vocabularies of the scribes
Given that we have five distinct bodies of text, corresponding to Dr Davis’s five scribes, we can also start thinking about the vocabularies of the five sections. The extent to which the vocabularies differ may inform our view as to whether the sections represent languages or dialects, in the modern vernacular sense.
Running the five texts through the word counter at browserling.com produced complete listings of all the “words” used by each of the five scribes. I noted that differences between visually similar v101 glyphs such as (6}, {7}, {8} and {&} would create distinct “words”; therefore, it is entirely possible that the scribes’ vocabularies are overstated. With that reservation, their vocabularies were as follows:
• Scribe 1: text 11,278 “words”, vocabulary, 3,655 “words”, hapax legomena 2,655 “words”The incidence of hapax legomena (“words” used only once) was in the range 19 to 24 percent for Scribes D1, D2 and D3. These percentages were comparable with those in medieval documents of similar length that I have examined. For example, in Der Ackerman aus Böhmen (Early Modern High German, c.1401), with 10,232 words, the incidence of hapax legomena is 20.6 percent.
• Scribe 2: text 9,813 “words”, vocabulary 2,686 “words”, hapax legomena 1,908 “words”
• Scribe 3: text 13,082 “words”, vocabulary 3,932 “words”, hapax legomena 2,767 “words”
• Scribe 4: text 5,576 “words”, vocabulary 2,652 “words”, hapax legomena 2,070 “words”
• Scribe 5: text 937 “words”, vocabulary 646 “words”, hapax legomena 527 “words”.
Looking at the most frequent “words” used by each scribe, it became apparent that the five scribes had some commonalities in vocabulary, and also some divergences. For example, the “words” {am} and {oe} were among the top ten of all five scribes; the "word" {8am} was among the top ten of four scribes. But each scribe had between three and eight common vocabulary “words” that were less commonly used (but used nonetheless) by the others.
To my mind, these differences cannot represent different languages as we understand them today. But perhaps, as Dr Davis preferred to say, they represent different dialects of a common language with a substantial shared vocabulary.
The ten most frequent “words” used by each of the five scribes of the Voynich manuscript, as identified by Dr Lisa Fagin Davis. Counts based on v101④ transliteration. Author’s analysis. Higher resolution at https://flic.kr/p/2q1nwZD
I am aware of at least two modern instances (I imagine that there are more) in which a regional language or dialect is officially recognised as a national language. In the Scottish Parliament, any communication may be made in the Scots language, which is differentiated from English as in the following example:
• “The Scots language is an important part of Scotland's culture and heritage, appearing in songs, poetry and literature, as well as daily use in our communities.”Here, the words “leid”, “pairt”, “o”, “kythin”, “heirship”, “sang”, “poyems”, “leetratur”, “an”, “ilka”, “uiss”, “oor” and “forby” are Scots words which either do not exist, or do not have the same spelling or meaning, in English.
• “The Scots leid is a important pairt o Scotland's cultural heirship, kythin in sang, poyems an leetratur, an in ilka day uiss in oor communities forby.”
And in Catalonia, the equivalent phrases in Catalan and Spanish are as follows:
• “La llengua catalana és una part important de la cultura i el patrimoni de Catalunya, apareix en cançons, poesia i literatura, així com en l'ús quotidià a les nostres comunitats.”It seems to me possible that in the fourteenth and fifteenth centuries (and scholars of linguistics may correct me), regional languages or dialects had commonalities and divergences of the kind that we see in the writings of the five scribes of the Voynich manuscript.
• “La lengua catalana es una parte importante de la cultura y el patrimonio de Cataluña, apareciendo en canciones, poesía y literatura, así como en el uso diario en nuestras comunidades.”
More than this: perhaps scholars of linguistics could identify pairs of medieval languages or dialects that differ in letter frequencies and word frequencies in approximately the ways that we see among the five Voynich scribes. If so, that might greatly focus the search for the underlying languages of the manuscript.
June 27, 2024
Voynich Reconsidered: Arabic revisited
In a previous article on this platform, I started to explore this concept of Arabic as a possible precursor language to the text of the Voynich manuscript.
Arabic is an abjad language, in which the long vowels are written and the short vowels are either omitted, or represented by diacritics known as hamza. If hamza are used, they are placed above or below the preceding consonant, or above or below an initial vowel alef (ا), or both. If a hamza is linked with an alef, it changes the sound of the vowel: for example, alef kasra (إ) is pronounced somewhat like the English short “u”, as in “put”. However, in many medieval Arabic texts, the hamza are omitted, leaving the reader to understand or to pronounce the words by reference to the context.
In order to assess Arabic as a precursor language, I had to make a number of assumptions. Some of my assumptions were common to my analysis of other languages, for example:
My assumptions that were specific to the Arabic language included the following:
I therefore assumed that the scribes could distinguish the initial, medial and final forms of Arabic letters; and crucially, that they did not carry over these distinctions to the Voynich glyphs. For example, they would map an initial or medial kaf (ک) and a final kaf (ك) to the same glyph.
Right to left?
One consideration remained unresolved. Arabic is written from right to left. The Voynich text has every appearance of having been written from left to right. The questions arose: did the Voynich scribes reverse the order of the Arabic words? Or did they reverse the order of the letters within the words? Or both? To my mind, it did not seem possible to make an a priori judgement. I felt that if I attempted some mappings, and if some of these mappings yielded recognisable Arabic words in some order, or strings that could be reversed to make recognisable Arabic words, only then it might be possible to fathom what the scribes had done.
Letter and glyph frequencies
As with other languages that I have investigated, I started by examining the frequencies of Arabic letters as written in the fifteenth century, or the preceding centuries. I found a number of relevant corpora, including the following:
For the Voynich manuscript, I took Glen Claston’s v101 transliteration as a starting point. As I have reported in other articles on this platform, I have developed a series of alternative transliterations based on v101. Most of my alternative transliterations make a single change with reference to a group of related v101 glyphs; for example, my v130 transliteration merges the v101 glyphs {6}, {7} and {&} with the glyph {8). Currently, the alternative transliterations are numbered from v101④ to v226.
For any given precursor language to be tested, I have developed two metrics by which to prioritise the alternative transliterations. One is the correlation coefficient between letter frequencies in the precursor language and glyph frequencies in the Voynich transliteration (expressed by the RSQ function in Excel). The other is the average absolute difference between letter frequencies and equally-ranked glyph frequencies. In any case, my usual procedure is to test all of the transliterations.
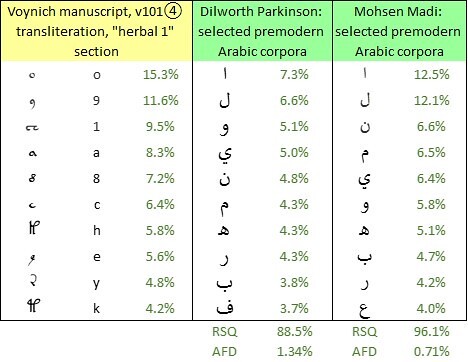
The frequencies of the ten most common glyphs in the Voynich manuscript, v101④ transliteration, "herbal" section, and the ten most common letters in Dr Dilworth Parkinson’s corpora of 8th to 15th century Arabic, and Mohsen Madi’s corpus of (mainly) fourteenth-century Arabic. Author's analysis.
Mappings
The next step was to explore the potential of these juxtapositions as correspondences or mappings. For example, the most frequent Voynich glyph {o} could plausibly map to and from the most frequent Arabic letter, alef (ا).
As I proposed in another article on this platform, to my mind an efficient test of such mappings is to try the “word” {8am}, which is the most common “word” in the Voynich manuscript. If (8am} maps to a recognisable word, we may be encouraged to try the same mapping with other Voynich “words”.
Again, I have kept in mind that, if the precursor documents were in Arabic, we do not know whether the Voynich scribes reversed the order of the words, or of the letters within words. Therefore, it seemed to me that if a mapping did not yield a common Arabic word, we could try reversing the order of the Arabic letters and see whether that yielded a more common word.
For each of my alternative transliterations, I mapped {8am} to a string of Arabic letters, using frequency comparisons based on both Dr Parkinson’s three corpora and Mohsen Madi’s (mainly) fourteenth-century corpus. To test whether the resulting text strings were real Arabic words, I took word counts from the full range of Dr Parkinson’s premodern corpora, including the Holy Quran, the Hadith and the Adab literature.
With Dr Parkinson’s corpora, the mappings yielded a few recognisable Arabic words, none of them common, including the following:
Next steps
The mapping of {8am} to منع was an outcome of three alternative transliterations - v221, v223 and v225 – all of which make a distinction between the glyph {9} in the final position of a Voynich “word”, and the {9} in any other position. The v225 transliteration also distinguishes the initial {o} from the medial, final and isolated {o}. These distinctions have the effect of reducing the extremely high frequencies of {9} and {o} in the conventional transliterations, and thereby making the Voynich manuscript more statistically similar to a natural language.
The logical next step would be to try mappings of other common Voynich “words”, such as {oe} and {1c9}, to text strings in medieval Arabic.
Arabic is an abjad language, in which the long vowels are written and the short vowels are either omitted, or represented by diacritics known as hamza. If hamza are used, they are placed above or below the preceding consonant, or above or below an initial vowel alef (ا), or both. If a hamza is linked with an alef, it changes the sound of the vowel: for example, alef kasra (إ) is pronounced somewhat like the English short “u”, as in “put”. However, in many medieval Arabic texts, the hamza are omitted, leaving the reader to understand or to pronounce the words by reference to the context.
In order to assess Arabic as a precursor language, I had to make a number of assumptions. Some of my assumptions were common to my analysis of other languages, for example:
• that the Voynich producer provided the scribes with source documents in the precursor languages, and that these documents were approximately contemporary with the production of the manuscriptReasonable persons may of course disagree; but to my mind these instructions would be sufficiently simple to enable the producer to commission the work and to trust the scribes to proceed with minimal supervision.
• that the producer gave the scribes instructions as to how to map those documents to the symbols that we now know as the Voynich glyphs
• that the instructions were based on letters (rather than, say, words, parts of speech, sounds, or other aspects of the source documents)
• that the instructions specified a mapping of each source letter (objectively defined) uniquely to a corresponding glyph.
My assumptions that were specific to the Arabic language included the following:
• that the scribes knew the Arabic script (indeed, it would be logical to assume that the producer hired them for this knowledge)I made one additional, and major, assumption. Written Arabic is mainly cursive: that is, most letters are joined to the preceding and following letters. Therefore, most letters have initial, medial and final forms. For example, the initial and medial kaf are written (ک); the final kaf is written (ك). However, the Voynich text does not appear to be cursive; to my mind, the glyphs are separated by distinct gaps. (Here I will restate my belief that the symbol represented in the v101 transliteration by the two-glyph string {4o} is a single glyph.)
• that they knew the functions of the hamza, and could pronounce a word and understand its meaning even if the hamza were not present
• that in the absence of a hamza, if necessary to preserve meaning, they could add the appropriate hamza and map it in some objective way to the Voynich glyphs.
I therefore assumed that the scribes could distinguish the initial, medial and final forms of Arabic letters; and crucially, that they did not carry over these distinctions to the Voynich glyphs. For example, they would map an initial or medial kaf (ک) and a final kaf (ك) to the same glyph.
Right to left?
One consideration remained unresolved. Arabic is written from right to left. The Voynich text has every appearance of having been written from left to right. The questions arose: did the Voynich scribes reverse the order of the Arabic words? Or did they reverse the order of the letters within the words? Or both? To my mind, it did not seem possible to make an a priori judgement. I felt that if I attempted some mappings, and if some of these mappings yielded recognisable Arabic words in some order, or strings that could be reversed to make recognisable Arabic words, only then it might be possible to fathom what the scribes had done.
Letter and glyph frequencies
As with other languages that I have investigated, I started by examining the frequencies of Arabic letters as written in the fifteenth century, or the preceding centuries. I found a number of relevant corpora, including the following:
• by courtesy of Mohsen Madi: a compilation of three major works:A priori, I saw no compelling reason to select one corpus over another; it seemed advisable to try all of them, and to see where that led.
* The Beginning and the End, Volumes 1-7, by Abulfida' ibn Kathir (1300-1373), containing 4,326,031 letters;
* The Sealed Nectar, a compilation of the Prophet’s sayings (therefore dating to the 7th century) by Safiur Rahman Mubarakpuri, containing 553,740 letters;
* The Masterpiece of the Brides by Al-shuri, containing 242,361 letters in old Arabic
• by courtesy of Dr Dilworth Parkinson of Brigham Young University:
* the Grammarians corpus, dating from the 8th through 13th centuries, with 2,537,462 letters;
* the Medieval Philosophy and Science corpus, dating from the 9th through 15th centuries, with 4,554,954 letters;
* the Thousand and One Nights, first referenced in Arabic in the 12th century, with 2,326,696 letters.
For the Voynich manuscript, I took Glen Claston’s v101 transliteration as a starting point. As I have reported in other articles on this platform, I have developed a series of alternative transliterations based on v101. Most of my alternative transliterations make a single change with reference to a group of related v101 glyphs; for example, my v130 transliteration merges the v101 glyphs {6}, {7} and {&} with the glyph {8). Currently, the alternative transliterations are numbered from v101④ to v226.
For any given precursor language to be tested, I have developed two metrics by which to prioritise the alternative transliterations. One is the correlation coefficient between letter frequencies in the precursor language and glyph frequencies in the Voynich transliteration (expressed by the RSQ function in Excel). The other is the average absolute difference between letter frequencies and equally-ranked glyph frequencies. In any case, my usual procedure is to test all of the transliterations.
The frequencies of the ten most common glyphs in the Voynich manuscript, v101④ transliteration, "herbal" section, and the ten most common letters in Dr Dilworth Parkinson’s corpora of 8th to 15th century Arabic, and Mohsen Madi’s corpus of (mainly) fourteenth-century Arabic. Author's analysis.
Mappings
The next step was to explore the potential of these juxtapositions as correspondences or mappings. For example, the most frequent Voynich glyph {o} could plausibly map to and from the most frequent Arabic letter, alef (ا).
As I proposed in another article on this platform, to my mind an efficient test of such mappings is to try the “word” {8am}, which is the most common “word” in the Voynich manuscript. If (8am} maps to a recognisable word, we may be encouraged to try the same mapping with other Voynich “words”.
Again, I have kept in mind that, if the precursor documents were in Arabic, we do not know whether the Voynich scribes reversed the order of the words, or of the letters within words. Therefore, it seemed to me that if a mapping did not yield a common Arabic word, we could try reversing the order of the Arabic letters and see whether that yielded a more common word.
For each of my alternative transliterations, I mapped {8am} to a string of Arabic letters, using frequency comparisons based on both Dr Parkinson’s three corpora and Mohsen Madi’s (mainly) fourteenth-century corpus. To test whether the resulting text strings were real Arabic words, I took word counts from the full range of Dr Parkinson’s premodern corpora, including the Holy Quran, the Hadith and the Adab literature.
With Dr Parkinson’s corpora, the mappings yielded a few recognisable Arabic words, none of them common, including the following:
نيت - word count: 486 - Neet (name of queen)With Mohsen Madi’s corpus, I found mappings to several recognisable, and considerably more frequent, Arabic words, of which the following topped the lists:
منت - word count: 288 - English: she afflicted
ينت - word count: 184 - English: he/it swayed.
منع - word count: 5,277 - English: prevention/preventsFrom these results, I was inclined to think firstly that, if medieval Arabic was a precursor language of the Voynich manuscript, it was better represented by fourteenth-century corpora than by earlier texts. Secondly, the most satisfactory mapping of the “word” {8am} was منع (as a noun, “prevention”, or as a verb, “he, she or it prevents”); this required the Voynich scribes to write the first (rightmost) Arabic letter first (that is, leftmost in the Voynich text).
يمٲ - reversed: أمي - word count: 4,130 - English: my mother/maternal
ميٲ - reversed: أيم - word count: 3,914 - English: widow/widowed.
Next steps
The mapping of {8am} to منع was an outcome of three alternative transliterations - v221, v223 and v225 – all of which make a distinction between the glyph {9} in the final position of a Voynich “word”, and the {9} in any other position. The v225 transliteration also distinguishes the initial {o} from the medial, final and isolated {o}. These distinctions have the effect of reducing the extremely high frequencies of {9} and {o} in the conventional transliterations, and thereby making the Voynich manuscript more statistically similar to a natural language.
The logical next step would be to try mappings of other common Voynich “words”, such as {oe} and {1c9}, to text strings in medieval Arabic.
June 21, 2024
Voynich Reconsidered: upper and lower case
In the search for meaning in the text of the Voynich manuscript, to my mind the researcher is well-advised to start with a strategy and a clearly defined set of assumptions. In the light of the results that emerge, those assumptions may change. As I have reported in previous articles on this platform, my working assumptions include the following:
I like to be guided by Occam’s Razor. Ockham is a village in Surrey, England. William of Ockham (later Occam) was a philosopher who lived from about 1287 to 1347. The principle to which he gave his name has been stated in many ways, among them the following: “It is futile to do with more, that which can be done with less”.
Since I expected simplicity in the Voynich producer’s instructions, and bearing Occam’s Razor in mind, I felt that an instruction of sufficient simplicity should map each distinct letter in the source documents uniquely to a distinct glyph in the Voynich manuscript. Reasonable persons may disagree; but to my mind, an instruction of this nature would enable the scribes to complete their work with minimal supervision.
The issue then arose: what alphabet could contain sufficient letters to yield mappings to at least 35 glyphs?
It seemed to me that such an alphabet must include all or most of the lower-case letters in the underlying script (whether Arabic, Cyrillic, Glagolitic, Greek, Latin or another). In addition, it must include either a number of accented letters (viewed as distinct from their unadorned counterparts); or a number of upper-case letters (if such existed in the alphabet); or both.
This consideration, to my mind, reduced the probability of precursor languages based on the Arabic alphabet, which has no cases. My corpora of medieval Arabic and Persian, for example, do not contain enough distinct letters to yield a mapping of the 35 most frequent Voynich glyphs, from {o} down to {M}. Ottoman Turkish has more variations on the Arabic alphabet, and remains a possibility, which I will investigate.
With regard to European languages: of the corpora and texts that I have investigated so far, all contain some proportion of upper case.
It seems to me that in works of prose, upper case is more frequent, either as a marker of the start of a sentence, or as the initial of a proper name. In German, upper case also denotes a noun, as in Der Ackermann aus Böhmen: “Ich bin genannt ein Ackermann” (“I was born a ploughman”). In poetry, upper case seems to be less common: for example in Dante’s La Divina Commedia, only the first letter of each three-line stanza is capitalised. As yet, we do not know whether the precursor documents of the Voynich manuscript were works of prose of poetry: although, as I wrote in Voynich Reconsidered, there is evidence of a poetic structure in the manuscript.

Counts of the more common letters in selected medieval languages, with and without case-sensitivity. Author's analysis. Higher resolution at https://flic.kr/p/2pYJJXj
These considerations led me to think about how the Voynich scribes might have dealt with upper and lower case. It seemed to be a simple assumption, of which Occam would have approved, that the scribes knew the languages of the source documents (and indeed, that they would have been hired on that criterion). Therefore, they would recognise the upper and lower cases of each letter.
I could think of several scenarios, including the following (and surely there are others):
In the second scenario, we could start by looking for visual resemblances between pairs of glyphs, in which one glyph (representing the lower case) is much more common than the other (representing the upper case).
Selected "core glyphs", and possible variants with apparently embedded {i}, {E} or {c}. Author's analysis.
For example, I wondered whether the glyph {i} might be a marker of upper case. In the v101 transliteration, {i} on its own is not a common glyph; it has a frequency of 0.1 percent. However, we often see it apparently embedded in other glyphs. One example is {m} which could be read as {in}; but the frequencies are wrong, since {m} is much more common than {n}. Other examples, with the right frequency differentials, are {A} which could be {oi}; {7} which could be {8i}; and {I} which could be {ii}. We might conjecture that an {i} added to, or blended into, the right-hand side of the glyph is a marker of something; maybe of upper case.
Along the same lines, we might wonder whether what I call the “grand piano” glyphs are variants of their cousins the "gallows glyphs" and “bench glyphs”. For example {l} could be {Ehc} or {Hc}, and {L} could be {Ekc} or {Kc}. If so, the embedded {E} and {c} might be markers of something; again, maybe of upper case.
These are simply initial thoughts, which I think merit further investigation. More later.
• that there was a producer of the manuscript: possibly more than one, but there is no harm in imagining a single personI am inclined to see in these assumptions the following consequences:
• that the producer was sufficiently wealthy or (equivalently) powerful to engage a team of scribes and other artisans, and to pay for their work and supplies for a period of months or years
• that he or she provided the scribes with source documents in natural languages, and instructions whereby they were to create the sequences of symbols that we now call the Voynich glyphs.
• that the languages of the precursor documents are more likely to be European than not, and more likely to be medieval than modernIn previous articles on this platform, I examined three short sequences of glyphs on page f1r of the Voynich manuscript, which appear to be right-justified. I wanted to explore the hypothesis that these sequences might represent proper names. In the course of this work, I observed that one of these sequences contained the glyph that, in the v101 transliteration, is denoted by {M}. This glyph is not common: it is the 35th most frequent glyph in the Voynich manuscript.
• that the languages of the precursor documents are more likely to be alphabetic than not
• that the producer’s instructions to the scribes are more likely to be simple than complex.
I like to be guided by Occam’s Razor. Ockham is a village in Surrey, England. William of Ockham (later Occam) was a philosopher who lived from about 1287 to 1347. The principle to which he gave his name has been stated in many ways, among them the following: “It is futile to do with more, that which can be done with less”.
Since I expected simplicity in the Voynich producer’s instructions, and bearing Occam’s Razor in mind, I felt that an instruction of sufficient simplicity should map each distinct letter in the source documents uniquely to a distinct glyph in the Voynich manuscript. Reasonable persons may disagree; but to my mind, an instruction of this nature would enable the scribes to complete their work with minimal supervision.
The issue then arose: what alphabet could contain sufficient letters to yield mappings to at least 35 glyphs?
It seemed to me that such an alphabet must include all or most of the lower-case letters in the underlying script (whether Arabic, Cyrillic, Glagolitic, Greek, Latin or another). In addition, it must include either a number of accented letters (viewed as distinct from their unadorned counterparts); or a number of upper-case letters (if such existed in the alphabet); or both.
This consideration, to my mind, reduced the probability of precursor languages based on the Arabic alphabet, which has no cases. My corpora of medieval Arabic and Persian, for example, do not contain enough distinct letters to yield a mapping of the 35 most frequent Voynich glyphs, from {o} down to {M}. Ottoman Turkish has more variations on the Arabic alphabet, and remains a possibility, which I will investigate.
With regard to European languages: of the corpora and texts that I have investigated so far, all contain some proportion of upper case.
It seems to me that in works of prose, upper case is more frequent, either as a marker of the start of a sentence, or as the initial of a proper name. In German, upper case also denotes a noun, as in Der Ackermann aus Böhmen: “Ich bin genannt ein Ackermann” (“I was born a ploughman”). In poetry, upper case seems to be less common: for example in Dante’s La Divina Commedia, only the first letter of each three-line stanza is capitalised. As yet, we do not know whether the precursor documents of the Voynich manuscript were works of prose of poetry: although, as I wrote in Voynich Reconsidered, there is evidence of a poetic structure in the manuscript.
Counts of the more common letters in selected medieval languages, with and without case-sensitivity. Author's analysis. Higher resolution at https://flic.kr/p/2pYJJXj
These considerations led me to think about how the Voynich scribes might have dealt with upper and lower case. It seemed to be a simple assumption, of which Occam would have approved, that the scribes knew the languages of the source documents (and indeed, that they would have been hired on that criterion). Therefore, they would recognise the upper and lower cases of each letter.
I could think of several scenarios, including the following (and surely there are others):
• The producer gave the scribes an explicit mapping of every upper-case and lower-case letter to a corresponding glyph, with no necessary visual resemblance between the two glyphs; as a completely hypothetical example, “e” could map to {o} and “E” could map to {8}.In the first scenario, we could use frequency analysis as a guide, as indeed I have in all of my attempts at mapping glyphs to letters. For example, in medieval Italian as represented by La Divina Commedia, the lower-case “e” has a frequency of 11.4 percent and has a good chance of mapping to the Voynich {o}; the upper-case “E” has a frequency of 0.2 percent and could plausibly map to any of the glyphs {z}, {f}, {u}, {*} or {(}.
• The producer gave the scribes more autonomy, in the form of a mapping of every lower-case letter to a corresponding glyph, and an algorithm for mapping the equivalent upper-case letter in some systematic way.
In the second scenario, we could start by looking for visual resemblances between pairs of glyphs, in which one glyph (representing the lower case) is much more common than the other (representing the upper case).
Selected "core glyphs", and possible variants with apparently embedded {i}, {E} or {c}. Author's analysis.
For example, I wondered whether the glyph {i} might be a marker of upper case. In the v101 transliteration, {i} on its own is not a common glyph; it has a frequency of 0.1 percent. However, we often see it apparently embedded in other glyphs. One example is {m} which could be read as {in}; but the frequencies are wrong, since {m} is much more common than {n}. Other examples, with the right frequency differentials, are {A} which could be {oi}; {7} which could be {8i}; and {I} which could be {ii}. We might conjecture that an {i} added to, or blended into, the right-hand side of the glyph is a marker of something; maybe of upper case.
Along the same lines, we might wonder whether what I call the “grand piano” glyphs are variants of their cousins the "gallows glyphs" and “bench glyphs”. For example {l} could be {Ehc} or {Hc}, and {L} could be {Ekc} or {Kc}. If so, the embedded {E} and {c} might be markers of something; again, maybe of upper case.
These are simply initial thoughts, which I think merit further investigation. More later.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

