
Voynich Reconsidered: Zattera's "separable words"
In my book Voynich Reconsidered (Schiffer Publishing, August 2024), I outlined Massimilano Zattera's concepts of the "slot alphabet" and "separable words" in the Voynich manuscript. Zattera presented these concepts at the Voynich 2022 conference. His intriguing paper had the title “A New Transliteration Alphabet Brings New Evidence of Word Structure and Multiple "Languages" in the Voynich Manuscript”.
In this article, I had the idea of returning to Zattera's concepts.
Zattera’s main objective, as I understood it, was to demonstrate that most of the “words” in the Voynich manuscript conformed to a sequence which he called the “slot alphabet”. This alphabet was based on the following concepts:
I have assumed that Zattera used the term "word" to mean a glyph string delimited in EVA by spaces or line breaks. I think that in EVA there is no distinction (as there is in v101) between spaces and "uncertain spaces".

Zattera's "slot alphabet", setting out an order in which glyphs can appear in a Voynich "word". Graphics by author. Higher resolution at https://flic.kr/p/2odKsKz
Separable “words”
Here, my interest is in what Zattera called “separable words”. By this he meant “words” which could be divided into two parts, each of which was a Voynich “word”. In his paper, he stated that “separable words” accounted for an additional 10.4% of the text, and for 37.1% of the vocabulary; and that the components of the "separable words" conformed to the "slot alphabet".
For example, the v101 “word” {2coehcc89}, which occurs only once, can be separated into two parts: {2coe} which occurs 50 times as a “word”, and {hcc89} with 18 occurrences as a “word”. This is not the only way to separate the “word”: {2co} occurs 26 times and {ehcc89} occurs 14 times. Both separations conform to the "slot alphabet".
In "separable words", we might conjecture that there is a word break, but it is not a space; it is invisible, or implied (as in "battlefield" or any other compound word in English).
Zattera did not provide a list of the separable words that he had identified. But we can have a shot at doing so. I approached this task with several basic assumptions, as follows:
In Glen Claston's v101 transliteration, the "herbal" section has 11,687 “words” with an average “word” length of 3.73 glyphs. The vocabulary consists of 3,790 distinct “words”. The ten most common “words”, including the isolated {s} and {9} which may or may not function as “words”, are as follows:
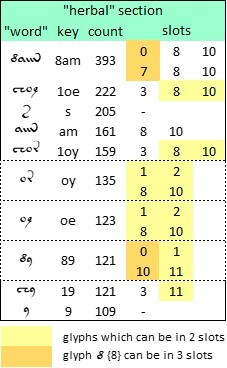
The ten most frequent “words”, including the isolated glyphs {s} and {9}, in the "herbal" section of the Voynich manuscript. Source: author’s analysis. Higher resolution at https://flic.kr/p/2prgAMA
Here, it seemed noteworthy that the text did not have a brilliant fit with Zipf’s Law. The correlation of the glyph frequencies with the expected Zipf sequence (for a natural language) was just 81.9 percent.
The second step in the process was to import the v101 transliteration into Microsoft Word, and using the “find-and-replace” function, replace each of the top ten “words” with the same string preceded and followed by a space. It seemed advisable to leave the isolated {s} and {9} alone. This step converted all occurrences of the selected strings to “words”. For example, any occurrence of the string {8am}, even when interior to a glyph string, became the “word” {8am}. This step produced a new transliteration, with a smaller vocabulary.
The third step was to make some alternative conversions of frequent glyph strings to “words”, as follows:

Some alternative rankings of the ten most frequent "words" in the "herbal" section of the Voynich manuscript. Source: author’s analysis. RSQ denotes correlation coefficient for frequencies of all words in the section’s vocabulary, against the expected frequencies as per Zipf’s Law.
Of these tests, the one which gave the best fit with Zipf’s Law was the first, in which the top ten “words”, whether occurring as strings or as “words”, were converted to “words”. Here the correlation with the Zipf sequence was 98.8 percent.
Thus, it appears that by converting the top ten glyph strings to “words”, but ignoring single-glyph “words”, we can identify a vocabulary which is highly consistent with Zipf’s Law. This conversion made the “herbal” section resemble much more closely a text in a natural language.
The first three lines
We can illustrate the process of word separability by applying it to an extract from the text of the “herbal” section: for example, the first three lines on the first page of the section (f001v). In the v101 transliteration, these lines are as follows:

With word separability, these three lines become as follows:
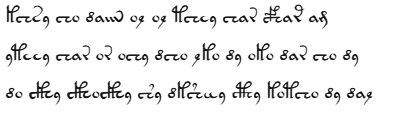
Vowel recognition
The next step was to identify vowels, using the Sukhotin algorithm as implemented by Dr Mans Hulden’s Python code. In the v101 transliteration, the algorithm identifies the following glyphs as the five most probable vowels, in descending order of probability:
Mapping to precursor languages
The logical next step is to select a chunk of the “herbal” section, or alternatively the most frequent “words” of the “herbal” section, and map the glyphs to letters in some potential precursor languages, as follows:
In this article, I had the idea of returning to Zattera's concepts.
Zattera’s main objective, as I understood it, was to demonstrate that most of the “words” in the Voynich manuscript conformed to a sequence which he called the “slot alphabet”. This alphabet was based on the following concepts:
• twelve “slots”, which Zattera numbered 0 to 11;Zattera’s principal thesis was that in a Voynich “word”, each glyph could only be preceded by a glyph in a lower “slot”, and could only be followed by a glyph in a higher “slot”. He stated that this was the case in 86.6 percent of the text in the manuscript.
• twenty-six distinct glyphs, based on the EVA transliteration (Zattera ignored the profuse variations and “rare glyphs” that occur in Glen Claston's v101 transliteration);
• the allocation of each glyph to one or more slots
• a rule that in most cases, a given glyph could occupy only one slot; in a few cases it could be in either of two slots; and in one case (EVA-d or v101-8) it could be in any of three slots.
I have assumed that Zattera used the term "word" to mean a glyph string delimited in EVA by spaces or line breaks. I think that in EVA there is no distinction (as there is in v101) between spaces and "uncertain spaces".
Zattera's "slot alphabet", setting out an order in which glyphs can appear in a Voynich "word". Graphics by author. Higher resolution at https://flic.kr/p/2odKsKz
Separable “words”
Here, my interest is in what Zattera called “separable words”. By this he meant “words” which could be divided into two parts, each of which was a Voynich “word”. In his paper, he stated that “separable words” accounted for an additional 10.4% of the text, and for 37.1% of the vocabulary; and that the components of the "separable words" conformed to the "slot alphabet".
For example, the v101 “word” {2coehcc89}, which occurs only once, can be separated into two parts: {2coe} which occurs 50 times as a “word”, and {hcc89} with 18 occurrences as a “word”. This is not the only way to separate the “word”: {2co} occurs 26 times and {ehcc89} occurs 14 times. Both separations conform to the "slot alphabet".
In "separable words", we might conjecture that there is a word break, but it is not a space; it is invisible, or implied (as in "battlefield" or any other compound word in English).
Zattera did not provide a list of the separable words that he had identified. But we can have a shot at doing so. I approached this task with several basic assumptions, as follows:
• that, rather than use the v101 transliteration with its many variations, I might elect to use one of my own transliterations, which aggregates several v101 glyphs that seem to be similar, such as {1} and {2};To this end, as a first step, I selected the “herbal” section as defined by René Zandbergen. This section is visually identifiable by the full-page drawings of plants. I take no position on whether the text is related to the drawings; however, the text appears to have a uniform vocabulary which is different from that in other parts of the manuscript.
• that I should regard certain glyphs as having different meanings (or mappings) in the initial, interior, final and isolated positions; in other words, for example, an initial {9} was not the same as a final {9};
• that the most probable building blocks of Zattera’s “separable words” were the most frequent “words”;
• that, rather than use the whole Voynich manuscript with its (probable) multiple languages, I should work with a single thematic section that seemed to have a homogenous language.
In Glen Claston's v101 transliteration, the "herbal" section has 11,687 “words” with an average “word” length of 3.73 glyphs. The vocabulary consists of 3,790 distinct “words”. The ten most common “words”, including the isolated {s} and {9} which may or may not function as “words”, are as follows:
The ten most frequent “words”, including the isolated glyphs {s} and {9}, in the "herbal" section of the Voynich manuscript. Source: author’s analysis. Higher resolution at https://flic.kr/p/2prgAMA
Here, it seemed noteworthy that the text did not have a brilliant fit with Zipf’s Law. The correlation of the glyph frequencies with the expected Zipf sequence (for a natural language) was just 81.9 percent.
The second step in the process was to import the v101 transliteration into Microsoft Word, and using the “find-and-replace” function, replace each of the top ten “words” with the same string preceded and followed by a space. It seemed advisable to leave the isolated {s} and {9} alone. This step converted all occurrences of the selected strings to “words”. For example, any occurrence of the string {8am}, even when interior to a glyph string, became the “word” {8am}. This step produced a new transliteration, with a smaller vocabulary.
The third step was to make some alternative conversions of frequent glyph strings to “words”, as follows:
• the top ten “words”, including the isolated {s}The results of the second and third steps are shown below.
• the top twenty “words”, excluding the isolated glyphs {s}, {9} and {y}
• the top thirty “words”, excluding the isolated glyphs {s}, {9} and {y}.
Some alternative rankings of the ten most frequent "words" in the "herbal" section of the Voynich manuscript. Source: author’s analysis. RSQ denotes correlation coefficient for frequencies of all words in the section’s vocabulary, against the expected frequencies as per Zipf’s Law.
Of these tests, the one which gave the best fit with Zipf’s Law was the first, in which the top ten “words”, whether occurring as strings or as “words”, were converted to “words”. Here the correlation with the Zipf sequence was 98.8 percent.
Thus, it appears that by converting the top ten glyph strings to “words”, but ignoring single-glyph “words”, we can identify a vocabulary which is highly consistent with Zipf’s Law. This conversion made the “herbal” section resemble much more closely a text in a natural language.
The first three lines
We can illustrate the process of word separability by applying it to an extract from the text of the “herbal” section: for example, the first three lines on the first page of the section (f001v). In the v101 transliteration, these lines are as follows:
With word separability, these three lines become as follows:
Vowel recognition
The next step was to identify vowels, using the Sukhotin algorithm as implemented by Dr Mans Hulden’s Python code. In the v101 transliteration, the algorithm identifies the following glyphs as the five most probable vowels, in descending order of probability:
{o}, {a}, {9}, {c}, {A}.The Sukhotin algorithm identifies probable vowels and probable consonants by the frequency with which they alternate. In the v211 transliteration with position-dependent glyphs and "word" separability, the "word" breaks have changed; so, not all the glyphs have the same neighbors as in v101. Therefore, the vowel-glyphs will not necessarily be the same. Applied to the “herbal” section, the five most probable vowels are now identified as follows:
interior {o} [ô], interior {a} [â], interior {1} [1], final {9} [⁹], initial {o} [ó].In a natural language, especially a medieval European language, we generally expect only five vowels. If so, we may adopt a working assumption that these five glyphs in all other positions, and all other glyphs, represent consonants in the presumed precursor languages. Alternatively, some of the non-vowel glyphs may represent punctuation, abbreviations, markers or other devices without phonetic significance.
Mapping to precursor languages
The logical next step is to select a chunk of the “herbal” section, or alternatively the most frequent “words” of the “herbal” section, and map the glyphs to letters in some potential precursor languages, as follows:
• vowel-glyphs to vowels in the precursor language, in order of frequency;This step requires a detailed recalculation of glyph frequencies in the word-separated Voynich text: not because the gross frequencies have changed, but because the position-dependent frequencies have changed. For example, within the separated words, some interior glyphs may have become initial or final glyphs. More on this in another article.
• consonant-glyphs to consonants in the precursor language, in order of frequency;
• as for precursor languages, to my mind we have nothing to lose by starting with medieval Italian and medieval Latin.


No comments have been added yet.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

