
Robert H. Edwards's Blog: Great 20th century mysteries, page 4
May 19, 2024
Voynich Reconsidered: Exon Domesday (part 3)
In a previous article on this platform, I reported on my reconstruction of the Latin abbreviations in the English manuscript Exon Domesday, probably written in 1087. I worked from the expanded transcription by Dr Frank Thorn, Visiting Fellow at King's College London. My sample so far has 5,498 characters including letters and abbreviation symbols.
Although the sample is small, the frequency distributions of the abbreviated Exon Domesday are already shaping up to be very different from those of the Voynich manuscript.
In the frequencies of the characters, we see an egregious presence of the lower-case “i”, largely as a result of its occurrence as a vowel within words, and also as the Roman numeral for 1 (which, as far as I can tell from the manuscript, is written identically). If the Voynich producer had given the scribes a set of Latin documents containing “i” as both letter and number, I imagine that he or she would have instructed them to treat both forms the same way. Any other instruction, I think, would have increased the requirement for quality control; I imagine the producer as desiring the scribes to work with minimal supervision.
So far, among my alternative transliterations of the Voynich manuscript, the best statistical fit with Exon Domesday is v102, for which the correlation between glyph frequencies and character frequencies is 85.0 percent. This is relatively low by comparison with the results that I have obtained for texts in unabbreviated natural languages.
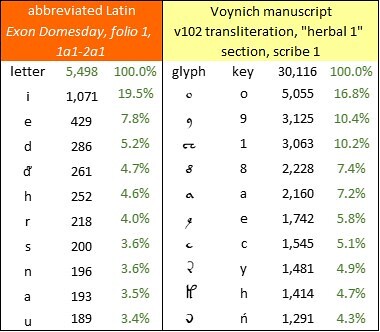
The ten most frequent characters in the abbreviated Exon Domesday, sections 1a1-2a1; and the ten most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As for the frequencies of the "words": in Exon Domesday the single-letter “word” “&” is by far the most frequent. This seems to me partly the consequence of the natural frequency of the precursor word “et” in medieval Latin, as illustrated by the LatinISE subcorpus. The second most frequent “word” is “hiᵭ”, the abbreviation for “hidas” or “hidis” (from “hida”, a measure of land area). In both cases, the frequencies are partly a reflection of the highly repetitive nature of Exon Domesday.
The ”words” in Exon Domesday conform closely to Zipf’s Law, with a correlation of 94.1 percent between the actual word counts and those predicted by the Zipf sequence. The incidence of hapax legomena (“words” occurring only once) is 65.1 percent of the vocabulary, which in my understanding is normal for a medieval document in a natural language.
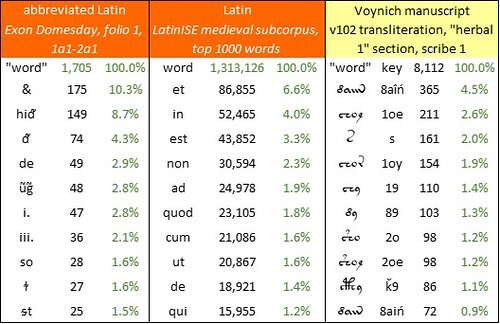
The ten most frequent "words" in the abbreviated Exon Domesday, sections 1a1-2a1 (written in 1087?); in the LatinISE corpus, medieval subcorpus (seventh to fourteenth centuries); and in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As to whether any plausible mapping exists between common “words” in Exon Domesday and in the Voynich manuscript: this hypothesis will have to await a larger sample of text.
Although the sample is small, the frequency distributions of the abbreviated Exon Domesday are already shaping up to be very different from those of the Voynich manuscript.
In the frequencies of the characters, we see an egregious presence of the lower-case “i”, largely as a result of its occurrence as a vowel within words, and also as the Roman numeral for 1 (which, as far as I can tell from the manuscript, is written identically). If the Voynich producer had given the scribes a set of Latin documents containing “i” as both letter and number, I imagine that he or she would have instructed them to treat both forms the same way. Any other instruction, I think, would have increased the requirement for quality control; I imagine the producer as desiring the scribes to work with minimal supervision.
So far, among my alternative transliterations of the Voynich manuscript, the best statistical fit with Exon Domesday is v102, for which the correlation between glyph frequencies and character frequencies is 85.0 percent. This is relatively low by comparison with the results that I have obtained for texts in unabbreviated natural languages.
The ten most frequent characters in the abbreviated Exon Domesday, sections 1a1-2a1; and the ten most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As for the frequencies of the "words": in Exon Domesday the single-letter “word” “&” is by far the most frequent. This seems to me partly the consequence of the natural frequency of the precursor word “et” in medieval Latin, as illustrated by the LatinISE subcorpus. The second most frequent “word” is “hiᵭ”, the abbreviation for “hidas” or “hidis” (from “hida”, a measure of land area). In both cases, the frequencies are partly a reflection of the highly repetitive nature of Exon Domesday.
The ”words” in Exon Domesday conform closely to Zipf’s Law, with a correlation of 94.1 percent between the actual word counts and those predicted by the Zipf sequence. The incidence of hapax legomena (“words” occurring only once) is 65.1 percent of the vocabulary, which in my understanding is normal for a medieval document in a natural language.
The ten most frequent "words" in the abbreviated Exon Domesday, sections 1a1-2a1 (written in 1087?); in the LatinISE corpus, medieval subcorpus (seventh to fourteenth centuries); and in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As to whether any plausible mapping exists between common “words” in Exon Domesday and in the Voynich manuscript: this hypothesis will have to await a larger sample of text.


May 17, 2024
Voynich Reconsidered: the Latin “qu”
In Voynich Reconsidered (Schiffer Books, 2024), and in previous articles on this platform, I explored the idea that the scribes of the Voynich manuscript had worked from precursor documents in medieval Latin. I conjectured that the producer had given the scribes a set of Latin documents, and a mapping from Latin letters to glyphs. As a simple assumption that conformed to Occam’s Razor, I supposed that the mapping had been one-to-one. In other words, I assumed that the scribes had mapped each Latin letter uniquely to a Voynich glyph. (Reasonable people may disagree.)
The question then arose: how would the Voynich scribes have dealt with the Latin bigram “qu”? In Latin as in most medieval and modern European languages, the letter “q” is almost invariably followed by the letter “u”. In fact, we could think of the bigram “qu” as a single letter.
The frequency of “q”
We may observe first that in Latin, “q” is not a very common letter. For example, in my copy of Dante Alighieri’s Monarchia, written in 1312-13, there are 111,691 characters excluding punctuation. The letter “q” (equivalently, the bigram “qu”) occurs 1,742 times; its frequency, relative to the character count, is 1.6 percent.
If the Voynich scribes mapped Latin letters to glyphs one-to-one, then any glyph which represents “q” should have an approximately similar frequency: say in the range 1 to 3 percent, with allowance for the natural divergences between one precursor document and another. Therefore, to my mind, the glyphs that are most likely to represent “q” are the following:
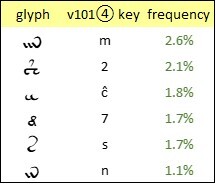
Voynich manuscript, v101④ transliteration: glyphs with frequencies between 1 and 3 percent. Author’s analysis.
If, as I suspect, {7} is a simply a handwriting variant of the far more frequent glyph {8}, then it should be excluded as a transcription of “q”. I am inclined to think that {s} also is improbable, since it occurs pervasively as a single-letter “word”. That seems to leave (2} and {ĉ} as the most probable candidates. (I write {ĉ} for the v101 glyph {C}, simply to avoid any confusion between upper and lower case. )
Separate “q” and “u”
If the scribes had mapped "q" and "u" separately, then I can think of two possibilities regarding the resultant glyphs:
If we now advance the hypothesis that {4o} is a transcription of “qu”: the downside is that the frequencies are not a very good match. In the v101④ transliteration, the glyph ④ has a frequency of 3.3 percent. This does not exclude the hypothesis: we could conjecture that the presumed precursor text of the Voynich manuscript had an unusually high incidence of “qu”.
As to whether there are any two glyphs that always co-occur within Voynich “words”: this is a more complex hypothesis. Testing it would require more programming skills than I possess. However, as a low-tech test, I would venture that we could at least investigate the bigrams starting with {2} or {ĉ}.
{2} and its companions
With regard to the glyph {2}, I found a remarkable and somewhat unexpected phenomenon. In my v101④ transliteration, I counted all the bigrams that started with {2}. In 48.7 percent of these bigrams, {2} was followed by {c}. But among the other glyphs that followed the {2}, there was a vast preponderance of glyphs that seemed to have an embedded {c}. That is, they contained the quill stroke for {c}, but added further quill strokes which, conventionally, are seen as resulting in another glyph. I calculated that of the bigrams that started with {2}, 97.1 percent followed the {2} either with a {c} or with an embedded {c}.
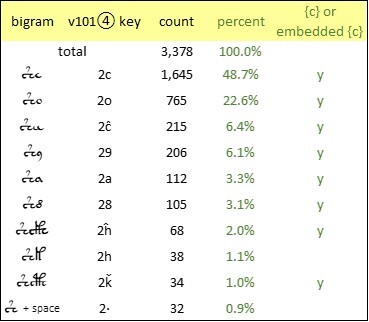
Voynich manuscript, v101④ transliteration: the ten most frequent bigrams starting with {2}. Author’s analysis.
Accordingly, we might hypothesise that, for example, the sequence {2o} is not a bigram, but a trigram of the nature {2cↄ}, in which {ↄ} is a (so far) undefined glyph which is merged with the preceding {c}. If so, that would help explain the extremely high frequency of the glyph {o), by comparison with the most common letter in most European languages. Likewise, (29} might be a trigram which we could express as (2c,}, and {2a} might be expressed as {2c\}.
{ĉ} and its companions
We see a similar phenomenon with the glyph {ĉ}. This glyph also has a favorite companion, namely {9}. In 42.7 percent of the bigrams starting with {c}, the next glyph (perhaps we should say: the next grapheme) is {9}. Furthermore, we see also here a proliferation of the “embedded” {c}. In 98.1 percent of the bigrams starting with {ĉ}, the next glyph or grapheme is written with an initial quill stroke that forms a {c}.
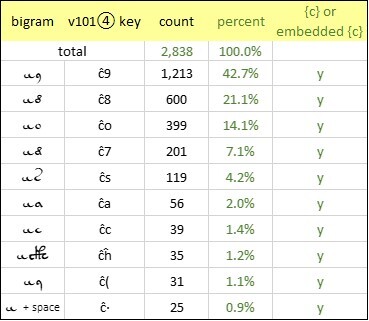
Voynich manuscript, v101④ transliteration: the ten most frequent bigrams starting with {ĉ}. Author’s analysis.
Again, if {9} is sometimes not one glyph but two, that would help explain the egregiously high frequency of the {9} in comparison with common letters in European languages.
So, both with {2} and with {ĉ}, we have approximately the right frequency to represent the Latin “q”, and the possibility that the glyph has a constant companion, even if sometimes concealed, which could represent the Latin “u”.
Visual similarities
As an alternative to statistical analysis, we could consider visual similarities. Given that the Latin “qu” is effectively a single letter written as two, we might be tempted to look for a counterpart glyph with complex quill strokes, or a glyph that seems bifurcate in some way. That is, writing the glyph should require at least one lift of the quill between strokes.
By way of a counterpoint: we should observe that several common Voynich glyphs seem to resemble Latin letters; and it is tempting to infer that they do indeed represent the respective letters. However, the frequencies are largely wrong. The following table juxtaposes the frequencies of the “Latin-looking” glyphs with those of the Latin letters that they resemble.
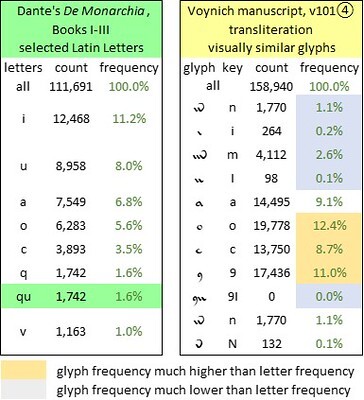
A selection of lower-case Latin letters for which visually similar glyphs exist in the Voynich manuscript; and the corresponding frequencies. Author's analysis.
With this reservation: to my mind, there are several glyphs which look as if they could have been mapped from bigrams. They include ④; {1}; {2} and its variants; and the “gallows” glyphs {f}, {g}, {h} and {k}. Their frequencies, in each of the main thematic sections of the manuscript, are summarised below.

Voynich manuscript, v101④ transliteration, main thematic sections: frequencies of selected glyphs with complex or bifurcate quill strokes. Author’s analysis. Higher resolution at https://flic.kr/p/2pRK9H9
Here again, to my mind we see some possibilities that the glyphs {2} and {ĉ}, and possibly ④, could represent “qu”, both in terms of the complexity of the quill strokes and in terms of frequencies; also, that if the Voynich manuscript was transcribed from Latin precursors, that the rules of transcription could have been different from one thematic section to another.
Postscript
If the source documents were in natural languages other than Latin, the same analysis would be applicable; but the letter frequencies would change, and therefore the putative letter-to-glyph mapping would be different.
For example, we might select Dante's La Divina Commedia to represent medieval Italian, or more precisely, the medieval Tuscan which became modern Italian. In my copy, in which, following Adriano Cappelli, I abbreviated certain prefixes, the bigram "qu" accounts for just 0.8 percent of the overall letter count. In this case the glyphs that suggest the best mapping for "qu" would be different from those for Latin.
The question then arose: how would the Voynich scribes have dealt with the Latin bigram “qu”? In Latin as in most medieval and modern European languages, the letter “q” is almost invariably followed by the letter “u”. In fact, we could think of the bigram “qu” as a single letter.
The frequency of “q”
We may observe first that in Latin, “q” is not a very common letter. For example, in my copy of Dante Alighieri’s Monarchia, written in 1312-13, there are 111,691 characters excluding punctuation. The letter “q” (equivalently, the bigram “qu”) occurs 1,742 times; its frequency, relative to the character count, is 1.6 percent.
If the Voynich scribes mapped Latin letters to glyphs one-to-one, then any glyph which represents “q” should have an approximately similar frequency: say in the range 1 to 3 percent, with allowance for the natural divergences between one precursor document and another. Therefore, to my mind, the glyphs that are most likely to represent “q” are the following:
Voynich manuscript, v101④ transliteration: glyphs with frequencies between 1 and 3 percent. Author’s analysis.
If, as I suspect, {7} is a simply a handwriting variant of the far more frequent glyph {8}, then it should be excluded as a transcription of “q”. I am inclined to think that {s} also is improbable, since it occurs pervasively as a single-letter “word”. That seems to leave (2} and {ĉ} as the most probable candidates. (I write {ĉ} for the v101 glyph {C}, simply to avoid any confusion between upper and lower case. )
Separate “q” and “u”
If the scribes had mapped "q" and "u" separately, then I can think of two possibilities regarding the resultant glyphs:
• If the scribes retained the order of the letters within the Latin words, the two glyphs would always be adjacent to one another.With regard to the first possibility: in the v101 transliteration, there is only one glyph with a constant companion: that is the glyph {4), which in 96 percent of its occurrences is followed by {o}. Indeed, to my eye, the {4) and the {o} appear to be conjoined; and to my mind, {4o} is not two glyphs but one, which I have represented in my v101④ transliteration by the Unicode symbol ④.
• If the scribes re-ordered the glyphs after transcription, as Mary D’Imperio’s and Massimiliano Zattera’s work encourages us to believe, then the two glyphs would co-occur within Voynich “words”. They would not necessarily be adjacent.
If we now advance the hypothesis that {4o} is a transcription of “qu”: the downside is that the frequencies are not a very good match. In the v101④ transliteration, the glyph ④ has a frequency of 3.3 percent. This does not exclude the hypothesis: we could conjecture that the presumed precursor text of the Voynich manuscript had an unusually high incidence of “qu”.
As to whether there are any two glyphs that always co-occur within Voynich “words”: this is a more complex hypothesis. Testing it would require more programming skills than I possess. However, as a low-tech test, I would venture that we could at least investigate the bigrams starting with {2} or {ĉ}.
{2} and its companions
With regard to the glyph {2}, I found a remarkable and somewhat unexpected phenomenon. In my v101④ transliteration, I counted all the bigrams that started with {2}. In 48.7 percent of these bigrams, {2} was followed by {c}. But among the other glyphs that followed the {2}, there was a vast preponderance of glyphs that seemed to have an embedded {c}. That is, they contained the quill stroke for {c}, but added further quill strokes which, conventionally, are seen as resulting in another glyph. I calculated that of the bigrams that started with {2}, 97.1 percent followed the {2} either with a {c} or with an embedded {c}.
Voynich manuscript, v101④ transliteration: the ten most frequent bigrams starting with {2}. Author’s analysis.
Accordingly, we might hypothesise that, for example, the sequence {2o} is not a bigram, but a trigram of the nature {2cↄ}, in which {ↄ} is a (so far) undefined glyph which is merged with the preceding {c}. If so, that would help explain the extremely high frequency of the glyph {o), by comparison with the most common letter in most European languages. Likewise, (29} might be a trigram which we could express as (2c,}, and {2a} might be expressed as {2c\}.
{ĉ} and its companions
We see a similar phenomenon with the glyph {ĉ}. This glyph also has a favorite companion, namely {9}. In 42.7 percent of the bigrams starting with {c}, the next glyph (perhaps we should say: the next grapheme) is {9}. Furthermore, we see also here a proliferation of the “embedded” {c}. In 98.1 percent of the bigrams starting with {ĉ}, the next glyph or grapheme is written with an initial quill stroke that forms a {c}.
Voynich manuscript, v101④ transliteration: the ten most frequent bigrams starting with {ĉ}. Author’s analysis.
Again, if {9} is sometimes not one glyph but two, that would help explain the egregiously high frequency of the {9} in comparison with common letters in European languages.
So, both with {2} and with {ĉ}, we have approximately the right frequency to represent the Latin “q”, and the possibility that the glyph has a constant companion, even if sometimes concealed, which could represent the Latin “u”.
Visual similarities
As an alternative to statistical analysis, we could consider visual similarities. Given that the Latin “qu” is effectively a single letter written as two, we might be tempted to look for a counterpart glyph with complex quill strokes, or a glyph that seems bifurcate in some way. That is, writing the glyph should require at least one lift of the quill between strokes.
By way of a counterpoint: we should observe that several common Voynich glyphs seem to resemble Latin letters; and it is tempting to infer that they do indeed represent the respective letters. However, the frequencies are largely wrong. The following table juxtaposes the frequencies of the “Latin-looking” glyphs with those of the Latin letters that they resemble.
A selection of lower-case Latin letters for which visually similar glyphs exist in the Voynich manuscript; and the corresponding frequencies. Author's analysis.
With this reservation: to my mind, there are several glyphs which look as if they could have been mapped from bigrams. They include ④; {1}; {2} and its variants; and the “gallows” glyphs {f}, {g}, {h} and {k}. Their frequencies, in each of the main thematic sections of the manuscript, are summarised below.
Voynich manuscript, v101④ transliteration, main thematic sections: frequencies of selected glyphs with complex or bifurcate quill strokes. Author’s analysis. Higher resolution at https://flic.kr/p/2pRK9H9
Here again, to my mind we see some possibilities that the glyphs {2} and {ĉ}, and possibly ④, could represent “qu”, both in terms of the complexity of the quill strokes and in terms of frequencies; also, that if the Voynich manuscript was transcribed from Latin precursors, that the rules of transcription could have been different from one thematic section to another.
Postscript
If the source documents were in natural languages other than Latin, the same analysis would be applicable; but the letter frequencies would change, and therefore the putative letter-to-glyph mapping would be different.
For example, we might select Dante's La Divina Commedia to represent medieval Italian, or more precisely, the medieval Tuscan which became modern Italian. In my copy, in which, following Adriano Cappelli, I abbreviated certain prefixes, the bigram "qu" accounts for just 0.8 percent of the overall letter count. In this case the glyphs that suggest the best mapping for "qu" would be different from those for Latin.
May 15, 2024
Voynich Reconsidered: Exon Domesday (Part 2)
Many researchers of the Voynich manuscript have remarked on the similarities between certain glyphs and some abbreviation symbols used in medieval Latin texts. The work of the archivist Adriano Cappelli lends support to this observation. This permits us to advance the hypothesis that the Voynich scribes worked from precursor documents in abbreviated Latin.
To test this hypothesis: as with other possible precursor languages that I have investigated, to my mind the first step is to look for statistical relationships.
If we could find a machine-readable text in abbreviated Latin, of at least 50,000 characters, we could test its statistical correlation with the Voynich manuscript. In my search for such a text, I considered the Exon Domesday, a part of the Domesday Book commissioned in 1086 by King William of England. In my attempt to process the Exon Domesday, I ran into an obstacle in terms of the sheer labor-intensity of the work.
My starting point was the excellent Exon Domesday website at https://www.exondomesday.ac.uk/. The site includes images of the original manuscript; scans of the 1816 printed edition transcribed by Ralph Barnes and published by Sir Henry Ellis; and a modern transcription into expanded conventional Latin (I believe, by Dr Frank Thorn).
The manuscript is not machine-readable (at least, not with any software to which I have access). The 1816 edition reproduces the original abbreviations in a modern typeface, but can only be downloaded one page at a time, then subjected to optical character recognition which yields a multitude of errors.
Dr Thorn’s transcription is fully machine-readable, but replaces the abbreviations with expanded strings of letters. Fortunately, the expanded strings are written in italics. Microsoft Word has a find-and-replace function which can distinguish italics from regular font. Thus, it should be possible to reconstruct the abbreviations while preserving the machine-readability of the text.
Accordingly, I devised the following process for restoring the abbreviations:
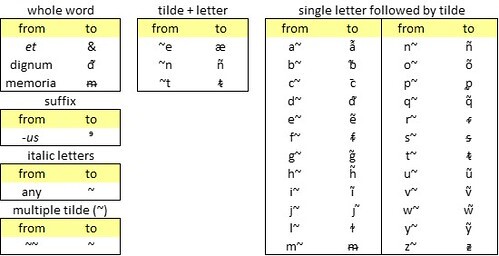
An experimental algorithm for restoring Latin abbreviations to a expanded Latin text in which abbreviations are represented by text strings in italics (~). Author’s analysis.
The following is an example of this process, applied to a short extract from Dr Thorn’s transliteration:

Exon Domesday, folio 1, lines 1-5. (above) An algorithmic restoration of the Latin abbreviation symbols, applied to sections 1a1 and 1a2 of Dr Frank Thorn’s transcription; (below) the same lines from the Barnes-Ellis printed edition published in 1816. Author’s analysis.
Thus, with an objective algorithm, we are able to create a close approximation of the Barnes-Ellis edition of 1816, and what is better, one which is machine-readable and is not subject to the errors inherent in optical character recognition.
Next steps
As an experiment, I applied my algorithm to sections 1a1 through 2a1 of Dr Thorn's transcription. My reconstructed text has 6,557 characters, of which 5,498 are letters or abbreviation signs represented by Unicode symbols. This sample is still too small for robust statistical analysis.
A logical next step would be to assemble a longer extract from Dr Thorn’s transcription, say of at least 10,000 characters, and apply the same algorithm for the restoration of the Latin abbreviation signs. If the result is a satisfactory approximation of the Barnes-Ellis transcription, the frequency distribution of the characters should have greater statistical significance (as compared to those of the shorter extracts that I have produced).
We could then attempt another comparison of the frequency distribution with those of conventional Latin corpora, and with those of selected transliterations of the Voynich manuscript.
To test this hypothesis: as with other possible precursor languages that I have investigated, to my mind the first step is to look for statistical relationships.
If we could find a machine-readable text in abbreviated Latin, of at least 50,000 characters, we could test its statistical correlation with the Voynich manuscript. In my search for such a text, I considered the Exon Domesday, a part of the Domesday Book commissioned in 1086 by King William of England. In my attempt to process the Exon Domesday, I ran into an obstacle in terms of the sheer labor-intensity of the work.
My starting point was the excellent Exon Domesday website at https://www.exondomesday.ac.uk/. The site includes images of the original manuscript; scans of the 1816 printed edition transcribed by Ralph Barnes and published by Sir Henry Ellis; and a modern transcription into expanded conventional Latin (I believe, by Dr Frank Thorn).
The manuscript is not machine-readable (at least, not with any software to which I have access). The 1816 edition reproduces the original abbreviations in a modern typeface, but can only be downloaded one page at a time, then subjected to optical character recognition which yields a multitude of errors.
Dr Thorn’s transcription is fully machine-readable, but replaces the abbreviations with expanded strings of letters. Fortunately, the expanded strings are written in italics. Microsoft Word has a find-and-replace function which can distinguish italics from regular font. Thus, it should be possible to reconstruct the abbreviations while preserving the machine-readability of the text.
Accordingly, I devised the following process for restoring the abbreviations:
• replace certain whole words such as et (in italics) with the corresponding standard abbreviations (in regular font)The algorithm is summarised below.
• replace the suffix -us (in italics) with the abbreviation ⁹ (in regular font)
• replace all other letters in italics with the Unicode symbol ~ (tilde); for example hundreto becomes hund~~~~
• replace all resulting strings of ~ with a single ~; for example ~~~ becomes ~
• replace all occurrences of, ~e with æ, ~n with ñ, and ~t with ᵵ; for example h~nt (from habent) becomes hñt
• in any other occurrence of a letter followed by ~, replace it with the same letter with embedded tilde.
An experimental algorithm for restoring Latin abbreviations to a expanded Latin text in which abbreviations are represented by text strings in italics (~). Author’s analysis.
The following is an example of this process, applied to a short extract from Dr Thorn’s transliteration:
Exon Domesday, folio 1, lines 1-5. (above) An algorithmic restoration of the Latin abbreviation symbols, applied to sections 1a1 and 1a2 of Dr Frank Thorn’s transcription; (below) the same lines from the Barnes-Ellis printed edition published in 1816. Author’s analysis.
Thus, with an objective algorithm, we are able to create a close approximation of the Barnes-Ellis edition of 1816, and what is better, one which is machine-readable and is not subject to the errors inherent in optical character recognition.
Next steps
As an experiment, I applied my algorithm to sections 1a1 through 2a1 of Dr Thorn's transcription. My reconstructed text has 6,557 characters, of which 5,498 are letters or abbreviation signs represented by Unicode symbols. This sample is still too small for robust statistical analysis.
A logical next step would be to assemble a longer extract from Dr Thorn’s transcription, say of at least 10,000 characters, and apply the same algorithm for the restoration of the Latin abbreviation signs. If the result is a satisfactory approximation of the Barnes-Ellis transcription, the frequency distribution of the characters should have greater statistical significance (as compared to those of the shorter extracts that I have produced).
We could then attempt another comparison of the frequency distribution with those of conventional Latin corpora, and with those of selected transliterations of the Voynich manuscript.
May 13, 2024
Voynich Reconsidered: multiple alphabets
In the final chapter of Voynich Reconsidered (Schiffer Books, 2024), I attempted to imagine the workplace where the Voynich manuscript was produced. Undoubtedly there was a team of scribes: Dr Lisa Fagin Davis has identified five distinct hands, though we have no way of knowing whether they worked together or separately. In my imagination, I saw a producer: a wealthy individual who conceived the project, paid for the labor and materials, and gave instructions to the scribes as to how they should proceed.
In previous articles on this platform, I expressed the view that the producer would have wished to give the scribes a simple set of instructions, whereby they could write the text with minimal supervision. Furthermore, such instructions had to yield a text in which, within nearly every “word”, the glyphs followed a relatively strict sequence, of the kind that Mary D'Imperio and Massimiliano Zattera observed.
As a working assumption, I conjectured that the producer provided the scribes with source documents in natural languages, together with a simple system for mapping letters to glyphs. A relatively undemanding rule could be as follows: take one word at a time, first transcribe the letters to glyphs, then re-order the glyphs in each "word" according to a "Voynich alphabet".
Zattera's "alphabet"
Zattera's "slot alphabet" describes a process for such a re-ordering. However, with Zattera's alphabet, the scribes would need to know where to place the "nomadic glyphs". For example, should a v101 glyph {8} be in slot 0, 7 or10? In Zattera’s alphabet, all three are permitted.

Zattera’s "slot alphabet". Glyphs which can be in multiple "slots" are marked in cells with solid borders. Graphics by author. Higher resolution at https://flic.kr/p/2oj1sYr.
Trying to step into the Voynich producer's shoes, I could imagine that he or she might define two or more "slot alphabets". Perhaps in one alphabet, {8} is always in slot 0; in the second, always in slot 7; in a third, always in slot 10.
We might see evidence of such multiplicity if we subdivide the manuscript in various ways. There are at least three such ways, as follows.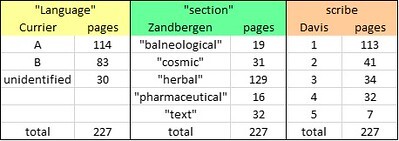
Three ways to subdivide the Voynich manuscript: by "language" (after Prescott Currier); by thematic "section" (after René Zandbergen); and by scribe (after Dr. Lisa Fagin Davis). Author's analysis.
To test this hypothesis, we could invite Mr Zattera to re-run his program on Language A and B separately; on each of the themed sections; and on the pages written by each of the five scribes.
As a low-tech alternative to re-running Mr Zattera’s program: it occurred to me that we could subdivide the Voynich manuscript in the three ways proposed above; in each subdivision, select the most frequent “words” (say, the top five or ten); test each of these “words” for conformity with Zattera’s “slot alphabet”; and examine whether there is any version of the “slot alphabet” that best fits the subdivision.
"Languages"
Below are my results for the subdivision by “language”.
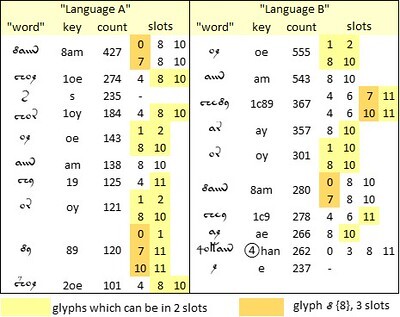
The ten most frequent "words" in the "Language A" and "Language B" pages of the Voynich manuscript, as defined by Currier. Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQLeDP.
Here we can see that in both “languages”, at least among the top ten “words”:
"Sections
However, the same exercise on the thematic sections reveals a substantial differentiation in vocabulary and in conformity to the “slot alphabet”.
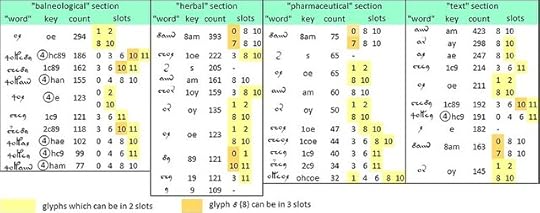
The ten most frequent "words" in the four major thematic sections of the Voynich manuscript; and the conformity of each "word" to Zattera's "slot alphabet". Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQSf8d.
Here we see that the “balneological” section has a distinctive vocabulary, in which the top ten “words” are dominated by “words” beginning with ④, and only two “words” are in common with the other three sections. This result suggests that in this section, either the precursor documents were in a different language, or the rules for transcribing letters to glyphs were in some sense unique. That is, the “balneological” section may have a different alphabet from the others.
It is as if the producer specifically allocated the glyph ④ to the “balneological” section, with the instruction that it be used only at the beginning of a “word”. If so, we might conjecture that in other sections where there are “words” beginning with ④, such as {④c89} in the “text” section, they are references to the “balneological” section.
Furthermore, in the "balneological" section we rarely see the ubiquitous "word" {8am}; and therefore we rarely see the glyph {8} in slot 0. Again, it is as if for this section, the producer specified {8} in a different way from that for the other sections.
Scribes
Finally the same exercise, applied to the pages written by each major scribe, yields mixed results.

The ten most frequent "words" written by each of the four major scribes of the Voynich manuscript, as identified by Dr Lisa Fagin Davis; and for each "word", the corresponding slots in Massimiliano Zattera's "slot alphabet". Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQSU9h
Here, we can detect the following differences between the scribes:
Next steps
From these relatively low-tech exercises, I have the impression that the division of the Voynich manuscript into thematic sections is the most important differentiation. In particular, the “balneological” section seems to stand alone. These results tend to reinforce my feeling that in any attempt at mapping from the Voynich text to natural languages, it is advisable to work with a single thematic section. My preference is the “herbal” section, which is the largest; and within that section, the pages written by scribe 1.
In previous articles on this platform, I expressed the view that the producer would have wished to give the scribes a simple set of instructions, whereby they could write the text with minimal supervision. Furthermore, such instructions had to yield a text in which, within nearly every “word”, the glyphs followed a relatively strict sequence, of the kind that Mary D'Imperio and Massimiliano Zattera observed.
As a working assumption, I conjectured that the producer provided the scribes with source documents in natural languages, together with a simple system for mapping letters to glyphs. A relatively undemanding rule could be as follows: take one word at a time, first transcribe the letters to glyphs, then re-order the glyphs in each "word" according to a "Voynich alphabet".
Zattera's "alphabet"
Zattera's "slot alphabet" describes a process for such a re-ordering. However, with Zattera's alphabet, the scribes would need to know where to place the "nomadic glyphs". For example, should a v101 glyph {8} be in slot 0, 7 or10? In Zattera’s alphabet, all three are permitted.
Zattera’s "slot alphabet". Glyphs which can be in multiple "slots" are marked in cells with solid borders. Graphics by author. Higher resolution at https://flic.kr/p/2oj1sYr.
Trying to step into the Voynich producer's shoes, I could imagine that he or she might define two or more "slot alphabets". Perhaps in one alphabet, {8} is always in slot 0; in the second, always in slot 7; in a third, always in slot 10.
We might see evidence of such multiplicity if we subdivide the manuscript in various ways. There are at least three such ways, as follows.
• “Language”. At Mary D’Imperio’s seminar in 1976, Captain Prescott Currier identified two “languages” in the Voynich manuscript. He called them “Language A” and “Language B”. Currier was clear that they were not different languages in the vernacular sense; simply that they had different (but overlapping) vocabularies. The downside of this concept is that Currier never defined the difference between A and B; he said only that it was statistical. Therefore, there is no objective algorithm by which, today, we can classify a Voynich page as A or B.
• “Section”. We are on stronger ground if we subdivide the manuscript by thematic sections, on the basis of the illustrations. Conventionally in Voynich research (and here I defer to René Zandbergen), we can recognise four major sections, which we can call “balneological”, “herbal”, “pharmaceutical” and “text”; and one small section, which we could call “cosmic”. The producer might have defined a "slot alphabet" for each section of the manuscript.
• Scribes. Another differentiation in the manuscript is between the hands of the various scribes. Here I acknowledge the work of Dr Lisa Fagin Davis, who in 2020 extended Currier’s earlier work and identified five individual scribes. Here we might conjecture that each scribe had his or her own “slot alphabet”.
Three ways to subdivide the Voynich manuscript: by "language" (after Prescott Currier); by thematic "section" (after René Zandbergen); and by scribe (after Dr. Lisa Fagin Davis). Author's analysis.
To test this hypothesis, we could invite Mr Zattera to re-run his program on Language A and B separately; on each of the themed sections; and on the pages written by each of the five scribes.
As a low-tech alternative to re-running Mr Zattera’s program: it occurred to me that we could subdivide the Voynich manuscript in the three ways proposed above; in each subdivision, select the most frequent “words” (say, the top five or ten); test each of these “words” for conformity with Zattera’s “slot alphabet”; and examine whether there is any version of the “slot alphabet” that best fits the subdivision.
"Languages"
Below are my results for the subdivision by “language”.
The ten most frequent "words" in the "Language A" and "Language B" pages of the Voynich manuscript, as defined by Currier. Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQLeDP.
Here we can see that in both “languages”, at least among the top ten “words”:
• the “nomadic” glyph {8} can be in slots 0, 7 or 10So, to my mind, this test yields no evidence that “Language A” and “Language B” have different alphabets.
• the “flexible” glyph {o} can be in slots 1 or 8
• the “flexible” glyphs {e} and {y} can be in slots 2 or 10.
"Sections
However, the same exercise on the thematic sections reveals a substantial differentiation in vocabulary and in conformity to the “slot alphabet”.
The ten most frequent "words" in the four major thematic sections of the Voynich manuscript; and the conformity of each "word" to Zattera's "slot alphabet". Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQSf8d.
Here we see that the “balneological” section has a distinctive vocabulary, in which the top ten “words” are dominated by “words” beginning with ④, and only two “words” are in common with the other three sections. This result suggests that in this section, either the precursor documents were in a different language, or the rules for transcribing letters to glyphs were in some sense unique. That is, the “balneological” section may have a different alphabet from the others.
It is as if the producer specifically allocated the glyph ④ to the “balneological” section, with the instruction that it be used only at the beginning of a “word”. If so, we might conjecture that in other sections where there are “words” beginning with ④, such as {④c89} in the “text” section, they are references to the “balneological” section.
Furthermore, in the "balneological" section we rarely see the ubiquitous "word" {8am}; and therefore we rarely see the glyph {8} in slot 0. Again, it is as if for this section, the producer specified {8} in a different way from that for the other sections.
Scribes
Finally the same exercise, applied to the pages written by each major scribe, yields mixed results.
The ten most frequent "words" written by each of the four major scribes of the Voynich manuscript, as identified by Dr Lisa Fagin Davis; and for each "word", the corresponding slots in Massimiliano Zattera's "slot alphabet". Keyboard assignments are from author's v101④ transliteration. Author's analysis. Higher resolution at https://flic.kr/p/2pQSU9h
Here, we can detect the following differences between the scribes:
• Scribes 2 and 3 used what we might call the “④ vocabulary”; and scribes 1 and 4 did not.On the whole, it does not seem that scribes 1, 2, 3 and 4 had different alphabets, or more precisely, different rules for ordering the glyphs within “words”.
• Scribes 1, 3 and 4 used the "word" {8am} extensively; this “word” requires the glyph {8} to be in slot 0. Scribe 2 used {8am} less frequently, and therefore had less occasion to place {8} in slot 0.
• All four scribes used the extremely common "word" {oe}, in which both {o} and {e} have two choices of slot.
Next steps
From these relatively low-tech exercises, I have the impression that the division of the Voynich manuscript into thematic sections is the most important differentiation. In particular, the “balneological” section seems to stand alone. These results tend to reinforce my feeling that in any attempt at mapping from the Voynich text to natural languages, it is advisable to work with a single thematic section. My preference is the “herbal” section, which is the largest; and within that section, the pages written by scribe 1.
May 12, 2024
Mallory, Irvine, Everest: reviews
Here are extracts from some kind reviews of Mallory, Irvine and Everest: The Last Step But One on NetGalley.

Image credit: Balázs Petheő
Francis Tapon
 on FrancisTapon.com
on FrancisTapon.com
Image credit: Balázs Petheő
Francis Tapon
Wow. If you want the most comprehensive study of George Mallory's 3rd and final climb up Mt. Everest, read this book!Gail Hanlon
The book Mallory, Irvine and Everest: The Last Step But One by Dr. Robert Edwards examines the mystery surrounding George Mallory and Andrew Irvine's 1924 attempt to reach the summit of Mount Everest.
The book provides a fresh and original perspective on this historical event, as the author is a mathematician who has applied modern analysis techniques to the available evidence. Dr. Edwards has thoroughly researched the contemporary accounts, letters, and artifacts related to the climb and has identified inconsistencies in previous narratives.
I always enjoy books about those who conquer mountains. Here is an ambitious attempt to solve the mystery of the last climb on Mount Everest of George Mallory and Andrew Irvine, on 8 June 1924. Mallory’s body was found in 1999 but it didn’t reveal whether or not he and Irvine made it to the summit.Jay Freer
On the 100th anniversary of the climb Dr Edwards, a mathematician, combines meticulous research with a scholarly approach to provide his assessment.
I have a lot of mountaineering books, and this has to rate as one of the best ones.Jennifer Ruth
Meticulously researched and beautifully written Mr Edwards has gone to extreme lengths to detail what he thinks mathematically happened to Irvine and Mallory.
This is absolutely fascinating and will have pride of place on my bookshelf
I enjoyed this! … I found how he laid out all the expeditions and the information to be very different and it really helps call out what “is known” and what “is speculation”. I also loved the artist rendering of so many of the photographs and images. I’ve not seen that used before.Katherine McCrea
If you are new to a fascination about Mallory/Irvine and Everest or just looking for a new overview, this is the rare book that could cover both!
This book is a great read if you love history, especially adventure history. Mt. Everest has held a place in my heart for years and I love reading about the great climbers. If you love mountain lore, history, and how Everest impacted Mallory, Irvine, the British Empire, and everyone around it, you'll love this story.Kathryn McLeer
It was interesting to go on this path with the hikers and try to figure out what happened to the them. It really added to the suspense in this and the respect for this. Robert H Edwards has a great writing style and worked with the historical element.Sophie L
... Everest has held a long-standing fascination with people since its discovery in the late 1800s as the world’s tallest mountain, it's summit the highest place on earth. Edmund Hillary and Tenzing Norgay have been accredited with being the first climbers to reach its top in 1953 on the ninth British expedition to take place. But one question remains: were they really the first?
Several decades earlier, another British expedition took place in 1924, in which George Mallory and Andrew Irvine attempted to be the first people on earth to summit the great Mount Everest. As anyone with any mountaineering experience or knowledge knows, tragedy befell them both. But for exactly 100 years, the same questions remain. Did they make it to the top? Did they die on their ascent or descent? What clues remain on the mountain? Edwards seeks not to answer this categorically (for no one as of yet truly can) but to eliminate certain lines of inquiry and expose what was probable and improbable, therefore divulging what was likely to have happened.
Edwards’ research is extensive and meticulous, and it was fascinating to see so many details of that expedition revealed, from letters and photographs, to sketches and maps. The facts of the 1924 expedition are so vast that any text on the subject could easily become a tangled web, but Edwards’ narration is measured, factual, and straightforward. His lack of bias towards the events that might or might not have taken place is also refreshing. It is a great addition to companion pieces about Mallory and the great mystery of 1924.
All in all, this was a deeply fascinating read. For those interested in Everest, particularly the early expeditions, this book is a must read, for it only deals in facts, and they really do speak for themselves.
May 11, 2024
Voynich Reconsidered: Domesday
In an earlier article on this platform, I reported on my ongoing search for a machine-readable text in abbreviated Latin. Such a text, of sufficient length, would permit a statistical comparison with the Voynich manuscript, and thereby an objective evaluation of abbreviated Latin as a precursor language.
I found another candidate document, in the form of the complete Domesday Book, in the 1783 edition, which also transcribes the original manuscript into a modern typeface (I think, Record font). The edition is available from https://archive.org/details/gri_33125... and can be downloaded as a single pdf file of 780 pages.
The Domesday Book, being essentially a census of lands and properties in England, is a highly repetitive text. It occurred to me therefore that a short extract might be representative, in statistical terms, of the whole volume. To this end, as an experiment, I randomly selected page 119, which covers a number of farms and villages in the county of Hampshire. After applying optical character recognition and cleaning up the errors, I had a text file with 512 “words” (including single-letter abbreviations) and 1,727 characters.
Below is an extract from the original manuscript, with the corresponding transcription from 1783 and my OCR output for comparison.

Three versions of an extract from the Domesday Book. (Left) from the original manuscript, probably written in 1087; (middle) from the printed transcription published by Abraham Farley in 1783, page 119; (right) my transcription in Unicode symbols. Image credits: public domain and author's work. Higher resolution at https://flic.kr/p/2pQtUUF
Even on such a small sample, some statistical tests seemed worthwhile. The average “word” length was 2.86 characters, compared to 3.78 glyphs in my v101④ transliteration of the Voynich manuscript. If the Voynich text had precursor documents in abbreviated Latin, the Domesday Book is even more radically abbreviated. The vocabulary is highly condensed: just 137 “words”, of which 40 are abbreviations. The top ten “words” account for 31 percent of the “word” count.
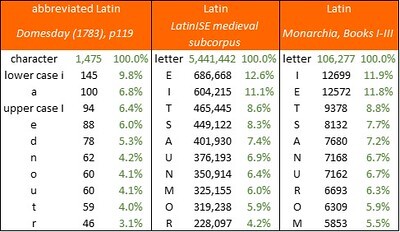
Running this sample through the Browserling character counter yielded the frequency distribution, which I could then compare with those in conventional corpora of unabbreviated Latin. An extract from the results is below. As with Exon Domesday, the character frequencies do not closely match up with those in the LatinISE medieval subcorpus or in Monarchia.
The top ten characters in the "Domesday Book", 1783 edition, page 119; and for comparison, the top ten letters in the LatinISE medieval subcorpus and in Dante's "Monarchia". Author's analysis.
I ventured one more test, without any expectation of statistical significance. This was to compare the Domesday sample with the glyph frequencies in my various transliterations of the Voynich manuscript. In this test, the following transliterations had the best statistical fit with Domesday:
The top ten characters in the "Domesday Book", 1783 edition, page 119; and for comparison, the top ten glyphs in my v101④ and v102 transliterations of the Voynich manuscript. Author's analysis.
These statistical results are not brilliant. I would not propose to attach much significance to them, pending development of a much larger sample of text in abbreviated Latin; and ideally, a sample much closer in time to the fifteenth century.
I found another candidate document, in the form of the complete Domesday Book, in the 1783 edition, which also transcribes the original manuscript into a modern typeface (I think, Record font). The edition is available from https://archive.org/details/gri_33125... and can be downloaded as a single pdf file of 780 pages.
The Domesday Book, being essentially a census of lands and properties in England, is a highly repetitive text. It occurred to me therefore that a short extract might be representative, in statistical terms, of the whole volume. To this end, as an experiment, I randomly selected page 119, which covers a number of farms and villages in the county of Hampshire. After applying optical character recognition and cleaning up the errors, I had a text file with 512 “words” (including single-letter abbreviations) and 1,727 characters.
Below is an extract from the original manuscript, with the corresponding transcription from 1783 and my OCR output for comparison.
Three versions of an extract from the Domesday Book. (Left) from the original manuscript, probably written in 1087; (middle) from the printed transcription published by Abraham Farley in 1783, page 119; (right) my transcription in Unicode symbols. Image credits: public domain and author's work. Higher resolution at https://flic.kr/p/2pQtUUF
Even on such a small sample, some statistical tests seemed worthwhile. The average “word” length was 2.86 characters, compared to 3.78 glyphs in my v101④ transliteration of the Voynich manuscript. If the Voynich text had precursor documents in abbreviated Latin, the Domesday Book is even more radically abbreviated. The vocabulary is highly condensed: just 137 “words”, of which 40 are abbreviations. The top ten “words” account for 31 percent of the “word” count.
Running this sample through the Browserling character counter yielded the frequency distribution, which I could then compare with those in conventional corpora of unabbreviated Latin. An extract from the results is below. As with Exon Domesday, the character frequencies do not closely match up with those in the LatinISE medieval subcorpus or in Monarchia.
The top ten characters in the "Domesday Book", 1783 edition, page 119; and for comparison, the top ten letters in the LatinISE medieval subcorpus and in Dante's "Monarchia". Author's analysis.
I ventured one more test, without any expectation of statistical significance. This was to compare the Domesday sample with the glyph frequencies in my various transliterations of the Voynich manuscript. In this test, the following transliterations had the best statistical fit with Domesday:
• v101④, that is, Glen Claston’s v101 with all occurrences of {4o} replaced by the Unicode symbol ④; "herbal" sectionA juxtaposition of the most frequent Domesday characters and the most frequent Voynich glyphs is presented below.
- average absolute difference between glyph frequencies and character frequencies: 0.77 percent
• v102, that is, v101④ with merging of various groups of visually similar glyphs; "herbal" section, Scribe 1
- correlation between glyph frequencies and character frequencies: 97.7 percent.
The top ten characters in the "Domesday Book", 1783 edition, page 119; and for comparison, the top ten glyphs in my v101④ and v102 transliterations of the Voynich manuscript. Author's analysis.
These statistical results are not brilliant. I would not propose to attach much significance to them, pending development of a much larger sample of text in abbreviated Latin; and ideally, a sample much closer in time to the fifteenth century.
May 9, 2024
Voynich Reconsidered: Adriano Cappelli and the Exon Domesday
In Voynich Reconsidered (Schiffer Books, 2024), I devoted a chapter to the idea of Latin as a precursor language of the Voynich manuscript, with a particular focus on abbreviated Latin as written in the fifteenth century. I drew upon Adriano Cappelli’s Lexicon Abbreviaturarum (Ulrico Hoepli, 1929), which reproduces thousands of examples of the abbreviation symbols used in medieval documents in both Latin and Italian. I have continued to explore the hypothesis that the Voynich scribes worked with documents in abbreviated Latin.

The cover of Adriano Cappelli's "Lexicon Abbreviaturarum", third edition, published by Hoepli in 1929. Image credit: Ulrico Hoepli. Inset is a portrait of Cappelli (author unknown).
In my imagining of the Voynich workplace, I feel that if the Voynich producer had instructed the scribes to work from abbreviated Latin, he or she would have told them to transcribe the abbreviations as written: not to expand them. I do not imagine the scribes as authors or content creators; and I believe that the producer’s instructions had to be sufficiently simple that the scribes could complete the project with minimal supervision.
These assumptions (and they are no more than that) would help explain phenomena such as the Voynich glyph {9}, which is ubiquitous as the initial or final glyph of a Voynich “word”. As Cappelli demonstrated, a symbol resembling a 9 was used pervasively in medieval manuscripts to represent a wide range of prefixes and suffixes. In fact, in Lexicon Abbreviaturarum he included an eighteen-page section titled “Abbreviature comincianti coi segni 9 o Ↄ” (“Abbreviations beginning with the signs 9 or Ↄ”).
As with other languages that I have considered, the first step was to find a corpus of documents written in abbreviated Latin: preferably from the fifteenth century.
This task was tough.
Cappelli himself reproduced several facsimiles of documents in abbreviated Latin. In the accompanying text, he set out his interpretation of their meaning, but with the abbreviations expanded to conventional Latin. So it proved with most of the Latin documents and corpora that I found. The LatinISE medieval subcorpus, for example, is a wonderful resource for the analysis of conventional Latin; but all of the words are written in full.
After much searching, I found a document which retains the medieval abbreviations and, at least in principle, is amenable to machine-reading. The title is simply Exon Domesday; it is available online at https://www.exondomesday.ac.uk/.
The term “Exon” is shorthand for “Exonia”, the Latin name for Exeter in England; and “Domesday” refers to the great survey of lands, buildings and livestock in England, ordered by King William in 1086. The website includes images of all the surviving pages of the original manuscript; transcriptions of the pages to expanded conventional Latin; and most importantly for my purposes, the transcription by Ralph Barnes, edited by Sir Henry Ellis and published in 1816, which retains the Latin abbreviations.
Extracts from the first folio, which bears page number 290, are reproduced below.

The first five lines of folio 1 of “Exon Domesday”. (top) in the original manuscript; (middle) as transcribed in the 1816 Ellis edition; (bottom) as expanded to conventional Latin. Image credits: "Exon: The Domesday Survey of South-West England", edited by P. A. Stokes, "Studies in Domesday", general editor J. Crick (London, 2018), available at http://www.exondomesday.ac.uk.
Here, the great obstacle that I encountered is that the Ellis edition, although it can be downloaded one page at a time, can be saved only as a series of png images. These images then have to be subjected to optical character recognition in order to yield machine-readable text. Each page of the Ellis edition contains about 2,000 characters including punctuation and abbreviation signs; for comparability with the approximately 150,000 glyphs in the Voynich manuscript, it would be necessary to download and apply OCR to about seventy-five pages. That already shapes up as a massive manual job.
The second obstacle is that the Ellis pages do not lend themselves to optical character recognition. Ralph Barnes used a special typeface (I think it was Record) to recreate the Latin abbreviation symbols. He included symbols approximating the modern Unicode characters đ, ł, ñ, and ⁹. OCR software, even when set to Latin as the language to be identified, does not deal well with such a diversity of symbols.
As a test, I downloaded the first thirteen lines of folio 1 of the Ellis edition, and applied my favorite OCR software. An extract from the results is below.
I persevered with a manual cleaning of the OCR text file, by reference to the Ellis edition and the manuscript, using Unicode symbols as approximations to the abbreviation signs. After much effort, the first thirteen lines bore a close resemblance to the Ellis edition. Again, an example is below.
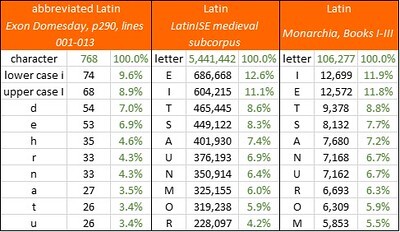
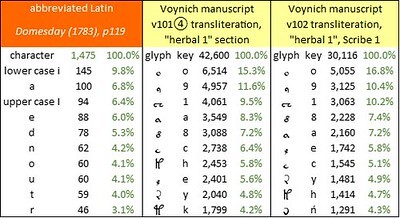
The top ten characters in “Exon Domesday”, p290, lines 1-13 (1086); the LatinISE medieval subcorpus, top 1,000 words, (7th-14th centuries); and Dante’s “Monarchia”, Books I-III (1312-13). Author’s analysis.
The sample is too small to take this analysis any further; but I note that the character frequencies in the sample from Exon Domesday are substantially different from those in LatinISE and Monarchia. Also, the Exon Domesday uses the lower-case i as a letter, and the upper-case I pervasively as the Roman numeral 1, which is atypical in relation to Latin narrative text.
Next steps
To entertain any hope of a robust statistical comparison between abbreviated Latin and the Voynich manuscript, we would need a machine-readable Latin text of at least 100,000 characters, which preserved the abbreviation symbols.
In terms of length, about fifty pages of the Ellis edition of Exon Domesday would serve the purpose. However, I am conscious that between the execution of Exon Domesday and the most recent carbon dates of samples from the Voynich manuscript, the best part of four centuries elapsed. I imagine that such an asynchronicity would render Exon Domesday an archaic document compared to anything that the Voynich scribes might have held in their hands.
May I invite readers to propose or direct me to documents in abbreviated Latin, of suitable length and with the abbreviation signs preserved, that might be more contemporary with the Voynich manuscript.
The cover of Adriano Cappelli's "Lexicon Abbreviaturarum", third edition, published by Hoepli in 1929. Image credit: Ulrico Hoepli. Inset is a portrait of Cappelli (author unknown).
In my imagining of the Voynich workplace, I feel that if the Voynich producer had instructed the scribes to work from abbreviated Latin, he or she would have told them to transcribe the abbreviations as written: not to expand them. I do not imagine the scribes as authors or content creators; and I believe that the producer’s instructions had to be sufficiently simple that the scribes could complete the project with minimal supervision.
These assumptions (and they are no more than that) would help explain phenomena such as the Voynich glyph {9}, which is ubiquitous as the initial or final glyph of a Voynich “word”. As Cappelli demonstrated, a symbol resembling a 9 was used pervasively in medieval manuscripts to represent a wide range of prefixes and suffixes. In fact, in Lexicon Abbreviaturarum he included an eighteen-page section titled “Abbreviature comincianti coi segni 9 o Ↄ” (“Abbreviations beginning with the signs 9 or Ↄ”).
As with other languages that I have considered, the first step was to find a corpus of documents written in abbreviated Latin: preferably from the fifteenth century.
This task was tough.
Cappelli himself reproduced several facsimiles of documents in abbreviated Latin. In the accompanying text, he set out his interpretation of their meaning, but with the abbreviations expanded to conventional Latin. So it proved with most of the Latin documents and corpora that I found. The LatinISE medieval subcorpus, for example, is a wonderful resource for the analysis of conventional Latin; but all of the words are written in full.
After much searching, I found a document which retains the medieval abbreviations and, at least in principle, is amenable to machine-reading. The title is simply Exon Domesday; it is available online at https://www.exondomesday.ac.uk/.
The term “Exon” is shorthand for “Exonia”, the Latin name for Exeter in England; and “Domesday” refers to the great survey of lands, buildings and livestock in England, ordered by King William in 1086. The website includes images of all the surviving pages of the original manuscript; transcriptions of the pages to expanded conventional Latin; and most importantly for my purposes, the transcription by Ralph Barnes, edited by Sir Henry Ellis and published in 1816, which retains the Latin abbreviations.
Extracts from the first folio, which bears page number 290, are reproduced below.
The first five lines of folio 1 of “Exon Domesday”. (top) in the original manuscript; (middle) as transcribed in the 1816 Ellis edition; (bottom) as expanded to conventional Latin. Image credits: "Exon: The Domesday Survey of South-West England", edited by P. A. Stokes, "Studies in Domesday", general editor J. Crick (London, 2018), available at http://www.exondomesday.ac.uk.
Here, the great obstacle that I encountered is that the Ellis edition, although it can be downloaded one page at a time, can be saved only as a series of png images. These images then have to be subjected to optical character recognition in order to yield machine-readable text. Each page of the Ellis edition contains about 2,000 characters including punctuation and abbreviation signs; for comparability with the approximately 150,000 glyphs in the Voynich manuscript, it would be necessary to download and apply OCR to about seventy-five pages. That already shapes up as a massive manual job.
The second obstacle is that the Ellis pages do not lend themselves to optical character recognition. Ralph Barnes used a special typeface (I think it was Record) to recreate the Latin abbreviation symbols. He included symbols approximating the modern Unicode characters đ, ł, ñ, and ⁹. OCR software, even when set to Latin as the language to be identified, does not deal well with such a diversity of symbols.
As a test, I downloaded the first thirteen lines of folio 1 of the Ellis edition, and applied my favorite OCR software. An extract from the results is below.
Iu HUND FERSTESFELT st. xr. hid& dimidia üg. De his hfit barones regis t dnio, stIt was apparent that my software had correctly identified most of the standard Latin letters but had failed to reproduce accurately the abbreviation symbols.
hid'&. r uirg. Inde ht hunfrid? de 1 fula, rt. hid. Ricard? eftormit. 1. hid. otre, r. hi, — Aldret
1. üg. À p. vir. bid dimid uirga min? habuit rex. xlr. fol. & 11. d. Illi etii q collegeft
geldü reddidert m denaf. 1. c; remanferat. ? 7 In hund dolesfelt st, Ixvzt. hid
& dim. 7 d.üg. Inde híit barones t dnio. xxxv. hid, & r üg & dfi, Eduuard? ui& vir.
I persevered with a manual cleaning of the OCR text file, by reference to the Ellis edition and the manuscript, using Unicode symbols as approximations to the abbreviation signs. After much effort, the first thirteen lines bore a close resemblance to the Ellis edition. Again, an example is below.
IN HUND⁴ FERSTESFELT sť XI · hid⁴ & dimidia ũg̃ · De his hñt barones regis ĩ dnĩo · IIII ·At this juncture, I had produced a small machine-readable sample of abbreviated Latin text, with 885 characters, of which 768 were Latin letters or abbreviation signs. The sample was entirely too small to be comparable with the Voynich manuscript; but I thought that it justified an experiment in frequency analysis. Running the sample through the Browserling character counter yielded a letter frequency distribution, in which for the time being, I combined upper and lower case letters. This distribution could then be compared with the letter frequencies in the LatinISE medieval subcorpus, and in Dante’s Monarchia. An extract from the results is below.
hid⁴ & · I uirg̃ · Inde hť hunfrid⁹ de ĩſula · II · hid⁴ · Ricard⁹ eſtormit · I · hiđ · otre · I · hid · Aldret
I · ũg̃ · & p · VII · hiđ dimiđ uirga min⁹ habuit rex · XlI · foł · & II · đ · Illi etiā q collegeřt
geldũ reddideřt mᵒ denař · I · q¹ remanſerat · ⑦ In hund dolesfelt sť IXVII hiđ
& dim⁴ · 7 đ · ũg̃ · Inde hñt barones ĩ dnĩo · XXXV · hiđ · & · I · ũg̃ & dḿ · Eduuard⁹ uić · VII ·
The top ten characters in “Exon Domesday”, p290, lines 1-13 (1086); the LatinISE medieval subcorpus, top 1,000 words, (7th-14th centuries); and Dante’s “Monarchia”, Books I-III (1312-13). Author’s analysis.
The sample is too small to take this analysis any further; but I note that the character frequencies in the sample from Exon Domesday are substantially different from those in LatinISE and Monarchia. Also, the Exon Domesday uses the lower-case i as a letter, and the upper-case I pervasively as the Roman numeral 1, which is atypical in relation to Latin narrative text.
Next steps
To entertain any hope of a robust statistical comparison between abbreviated Latin and the Voynich manuscript, we would need a machine-readable Latin text of at least 100,000 characters, which preserved the abbreviation symbols.
In terms of length, about fifty pages of the Ellis edition of Exon Domesday would serve the purpose. However, I am conscious that between the execution of Exon Domesday and the most recent carbon dates of samples from the Voynich manuscript, the best part of four centuries elapsed. I imagine that such an asynchronicity would render Exon Domesday an archaic document compared to anything that the Voynich scribes might have held in their hands.
May I invite readers to propose or direct me to documents in abbreviated Latin, of suitable length and with the abbreviation signs preserved, that might be more contemporary with the Voynich manuscript.
May 7, 2024
Voynich Reconsidered: the Voynich alphabet
In Voynich Reconsidered (Schiffer Publishing, 2024), and in articles on this platform, I have proposed a strategy for discovering meaning in the text of the Voynich manuscript. As part of this strategy, I have proposed the following working assumptions:
If we accept these assumptions, there are objective processes whereby we can attempt to identify the precursor language or languages. However, to my mind there is one important respect in which the Voynich text does not behave like a natural language. Within the Voynich "words", the glyphs largely conform to a sequence, a kind of marching order. In a natural language, we would call it an alphabetical order. Mary D’Imperio described the sequence as the "five states"; Massimiliano Zattera called it the "slot alphabet".
This sequence invites us to conjecture that the Voynich scribes re-ordered either letters within the precursor words, or glyphs within the transcribed glyph strings.
In this article, I want to consider the hypothesis that they first transcribed the letters, and then re-ordered the glyphs in each string. My question is: how might they do this? To put it another way, what was the Voynich alphabet?
The "slot alphabet"
Zattera’s “slot alphabet” is a starting point. In his paper at the Voynich 2022 conference, Zattera made a persuasive argument that the glyphs could be grouped into twelve “slots”, which he numbered 0 to 11. His term "slot" refers to the position of a glyph within a "word": with 0 being the leftmost and 11 the rightmost.
The rules of the “slot alphabet” are essentially as follows:

Zattera’s "slot alphabet". Data from Zattera (2022), except v101 {m} and {n} based on author's assumption; graphics by author.
As an example: the most common "word" in the v101 transliteration of the Voynich manuscript is {8am}. Here, we could assign (8} to slot 0 or slot 7; {a} can only be in slot 8; {m} can only be in slot 10. In either case, the "word" conforms to the "slot alphabet".
(As an aside: I think Zattera’s placement of {o} in slot 1 is partly a consequence of treating {4o} as two glyphs. I believe that {4o} is a single glyph. However, {o} is a very common initial glyph; I think that there is a case for placing [o} in slot 0 rather than slot 1.)
We can therefore imagine the Voynich producer providing the scribes with a wall chart or desk chart looking somewhat like Zattera’s slot alphabet, with instructions in whatever language the scribes spoke or used.
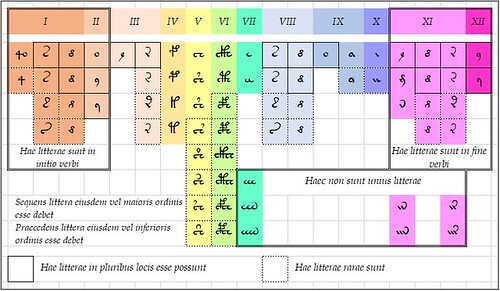
A hypothetical wall chart for the Voynich scribes. The inscriptions are in Latin. Data from Zattera (2022) except {m} and {n} by author; graphic by author.
That would only be part of the job. The Voynich scribes would have had at least two decisions to make before committing quill to parchment. One would be how to place the “flexible” glyphs like {8} in the right slot. Of the criteria for that decision, at the moment I have no idea; I will have to return to them. The second would be: how to order two glyphs which were in the same slot. Zattera’s slot alphabet has twelve slots, but the scribes had at least thirty glyphs to place in the right order, if we exclude rare glyphs like the v101 {F} and {G}. They needed instructions on how to do this: in short, a glyph alphabet.
The glyph alphabet
It occurred to me that we could make a stab at reconstructing that alphabet. The process would be to consider each of Zattera’s slots; to list the possible digraphs of the glyphs in the slot; and to count the occurrences of each of those digraphs.
For example, Zattera’s slot 0, as I interpret it, comprises the glyphs {4o}, {8} and {s}. These three glyphs have six possible digraphs. Using the v101 transliteration as a corpus of reference (and readers are free to use EVA or other transliterations if they prefer), my counts of the digraphs in the initial position were as follows:
I did similar counts of digraphs for each of Zattera’s slots; and to cut to the chase, my provisional proposal for the glyph alphabet is as follows:
Next steps
In another article on this platform, I will look at the hypothesis that the sorting occurred prior to transcription; and might therefore have been based on the alphabets of the source documents, which might have been Latin, Cyrillic, Glagolitic, Greek or something else.
a) that the Voynich scribes worked from precursor documents in natural languagesThese are not the only possible assumptions. Alternative scenarios include:
b) that they transcribed the precursor letters to glyphs, on a one-to-one basis (i.e. each letter was mapped uniquely to a corresponding glyph)
c) that they retained the word breaks (i.e. a word in the source document became a "word" in the Voynich manuscript).
* that there was transcription of letters to glyphs, but it was not one-to-one;But a one-to-one transcription of letters is a simple hypothesis and allows testing by frequency analysis.
* or that there was transcription but it was based on digraphs, words or other text elements;
* or that the word breaks were changed;
* or that the manuscript was created by a process other than transcription.
If we accept these assumptions, there are objective processes whereby we can attempt to identify the precursor language or languages. However, to my mind there is one important respect in which the Voynich text does not behave like a natural language. Within the Voynich "words", the glyphs largely conform to a sequence, a kind of marching order. In a natural language, we would call it an alphabetical order. Mary D’Imperio described the sequence as the "five states"; Massimiliano Zattera called it the "slot alphabet".
This sequence invites us to conjecture that the Voynich scribes re-ordered either letters within the precursor words, or glyphs within the transcribed glyph strings.
In this article, I want to consider the hypothesis that they first transcribed the letters, and then re-ordered the glyphs in each string. My question is: how might they do this? To put it another way, what was the Voynich alphabet?
The "slot alphabet"
Zattera’s “slot alphabet” is a starting point. In his paper at the Voynich 2022 conference, Zattera made a persuasive argument that the glyphs could be grouped into twelve “slots”, which he numbered 0 to 11. His term "slot" refers to the position of a glyph within a "word": with 0 being the leftmost and 11 the rightmost.
The rules of the “slot alphabet” are essentially as follows:
• A glyph can be followed by a glyph in the same or a higher-numbered slot.Zattera, working from the EVA transliteration, defined the “slot alphabet” as follows.
• A glyph can be preceded by a glyph in the same or a lower-numbered slot.
• Five glyphs – namely the v101 glyphs {o}, {9}, {e}, {y} and {s} – can be in one or both of two slots: a low slot and a high slot.
• One glyph – the v101 glyph {8} – can be in any or all of three slots.
Zattera’s "slot alphabet". Data from Zattera (2022), except v101 {m} and {n} based on author's assumption; graphics by author.
As an example: the most common "word" in the v101 transliteration of the Voynich manuscript is {8am}. Here, we could assign (8} to slot 0 or slot 7; {a} can only be in slot 8; {m} can only be in slot 10. In either case, the "word" conforms to the "slot alphabet".
(As an aside: I think Zattera’s placement of {o} in slot 1 is partly a consequence of treating {4o} as two glyphs. I believe that {4o} is a single glyph. However, {o} is a very common initial glyph; I think that there is a case for placing [o} in slot 0 rather than slot 1.)
We can therefore imagine the Voynich producer providing the scribes with a wall chart or desk chart looking somewhat like Zattera’s slot alphabet, with instructions in whatever language the scribes spoke or used.
A hypothetical wall chart for the Voynich scribes. The inscriptions are in Latin. Data from Zattera (2022) except {m} and {n} by author; graphic by author.
That would only be part of the job. The Voynich scribes would have had at least two decisions to make before committing quill to parchment. One would be how to place the “flexible” glyphs like {8} in the right slot. Of the criteria for that decision, at the moment I have no idea; I will have to return to them. The second would be: how to order two glyphs which were in the same slot. Zattera’s slot alphabet has twelve slots, but the scribes had at least thirty glyphs to place in the right order, if we exclude rare glyphs like the v101 {F} and {G}. They needed instructions on how to do this: in short, a glyph alphabet.
The glyph alphabet
It occurred to me that we could make a stab at reconstructing that alphabet. The process would be to consider each of Zattera’s slots; to list the possible digraphs of the glyphs in the slot; and to count the occurrences of each of those digraphs.
For example, Zattera’s slot 0, as I interpret it, comprises the glyphs {4o}, {8} and {s}. These three glyphs have six possible digraphs. Using the v101 transliteration as a corpus of reference (and readers are free to use EVA or other transliterations if they prefer), my counts of the digraphs in the initial position were as follows:
{4o8} {4os} {84o} {8s} {s4o} {s8}
92 9 0 5 2 0
When I included {o} as a member of slot 0, which Zattera does not, the counts of the additional digraphs in the initial position were as follows:
{4oo} {8o} {so} {o4o} {o8} {os}
20 324 296 16 232 59
From these counts, we see that among the glyphs in slot 0, if {4o} is followed by another such glyph, it is very likely to be {8}; {8} can only precede {s); and both {8} and {s} are likely to precede {o}. So for slot 0, my proposed alphabetical order is {4o-8-s-o}.I did similar counts of digraphs for each of Zattera’s slots; and to cut to the chase, my provisional proposal for the glyph alphabet is as follows:
• slot 0: {4o-8-s-o}With this or a similar alphabet, the Voynich producer would have been able to instruct the scribes on the desired writing order of nearly all of the glyphs, subject only or mainly to rules for where to place the nomadic {8} and the other "flexible" glyphs.
• slot 1: {9}
• slot 2: {e-y}
• slot 3: {f-g-h-k} in any order; digraphs of these gallows glyphs practically never occur
• slot 4: {2-1} or alternatively {1-2}; the counts are not much different
• slot 5: {F-G-H-K} in any order; digraphs of these pedestal glyphs never occur
• slot 6: {C-d-c}
• slot 7: {8-s} or {s-8}; the counts are similar
• slot 8: {o-a}
• slot 9: {i} or {I}
• slot 10: {e-y-8-p-N}
• slot 11: {9}.
Next steps
In another article on this platform, I will look at the hypothesis that the sorting occurred prior to transcription; and might therefore have been based on the alphabets of the source documents, which might have been Latin, Cyrillic, Glagolitic, Greek or something else.
May 6, 2024
Voynich Reconsidered: Latin as precursor
In Voynich Reconsidered (Schiffer Publishing, 2024), I devoted a chapter to the proposition that one of the precursor languages of the Voynich manuscript might have been Latin. I titled the chapter “Cappelli”, in homage to Adriano Cappelli, the great chronicler of abbreviations in Latin and Italian manuscripts. It seemed to me that if Latin had been a precursor, the source documents quite probably had been in a pervasively abbreviated Latin.
There were two reasons for this conjecture. One was simply that, assuming that parchment and ink were valuable commodities, it would be logical to suppose that scribes abbreviated in order to conserve materials. The second reason was more pragmatic. Latin is a language with a tendency for long words. In Dante Alighieri’s Monarchia, written between 1312 and 1313, the average length of words is 5.77 letters. By comparison, in my v101④ transliteration of the Voynich manuscript, in which I replace the v101 {4o} with the Unicode ④, the average length of a “word” is 3.78 glyphs.
So far, I have not found a machine-readable Latin text incorporating abbreviations. As an experiment, therefore, I created a version of Monarchia with abbreviations of my own devising. Drawing upon Cappelli’s work, I replaced selected text strings with Unicode symbols which resembled Cappelli’s abbreviations, as follows:

Here is an example, based on the first seven words of Monarchia:
Undoubtedly, a real scribe would have abbreviated even more rigorously. As an example: the University of Zurich has developed a wonderful crowd-sourced compilation of Cappelli's abbreviations at https://www.adfontes.uzh.ch/en/ressou.... Using this resource, I constructed a radical abbreviation of the above phrase from Monarchia, as follows:
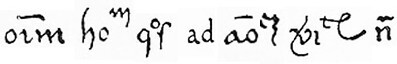
The first seven words of Dante's "Monarchia", radically abbreviated. Image credits: Adriano Cappelli. Author's analysis.
The abbreviated phrase has 19 characters; the average word length is just 2.71 characters. We can see that Cappelli's abbreviations could easily generate a text that matched the average "word" length of the Voynich manuscript. However, this was a manual exercise; we need a mechanism for creating machine-readable renditions of abbreviated Latin texts. To this issue, I shall return.
Unabbreviated Latin
Here, I would like to back up a little, and present the results of some tests on unabbreviated Latin as a precursor language of the Voynich manuscript.
The average word length is already a downside of this hypothesis. The next test is the statistical fit between letter frequencies and glyph frequencies. Among the multiple transliterations that I had developed, I found the best fits with unabbreviated Latin as follows.
For the LatinISE medieval subcorpus, which comprises texts from the seventh to the fourteenth century, the best-fitting transliteration is:

The most common letters in the LatinISE medieval subcorpus and in Dante’s “Monarchia”; and the most common glyphs in my v103 and v171 transliterations of the Voynich manuscript. Author’s analysis.
As suitable samples of the Voynich text for mapping, I selected the most common “words” of one to four glyphs in the v103 and v171 transliterations.
To cut to the chase: the v103 transliteration yielded very few Latin words. The v171 transliteration did not work very well when mapping on the frequencies in Monarchia. However, when mapping on the frequencies in the LatinISE medieval subcorpus, v171 produced a sprinkling of common Latin words, such as “eo”, “si” and “quem”.
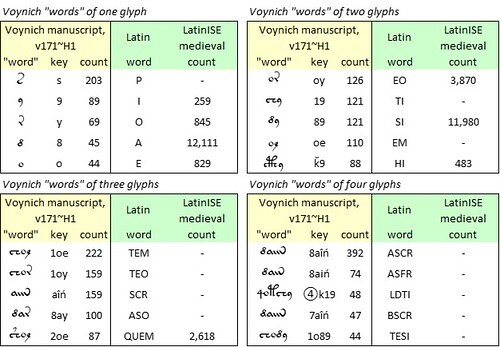
Test mappings from common “words” of one to four glyphs in the v171 transliteration, "herbal 1" section, to Latin as represented by the LatinISE medieval subcorpus. LatinISE count "-" means the string is not among the top 1,000 words. Author’s analysis.
Alternatives
The above results do not strongly support the hypothesis that Latin is a precursor language of the Voynich manuscript. However, they do not exclude the hypothesis. I can think of a number of alternative approaches to an extrication of Latin text from the Voynich manuscript, including the following:
There were two reasons for this conjecture. One was simply that, assuming that parchment and ink were valuable commodities, it would be logical to suppose that scribes abbreviated in order to conserve materials. The second reason was more pragmatic. Latin is a language with a tendency for long words. In Dante Alighieri’s Monarchia, written between 1312 and 1313, the average length of words is 5.77 letters. By comparison, in my v101④ transliteration of the Voynich manuscript, in which I replace the v101 {4o} with the Unicode ④, the average length of a “word” is 3.78 glyphs.
So far, I have not found a machine-readable Latin text incorporating abbreviations. As an experiment, therefore, I created a version of Monarchia with abbreviations of my own devising. Drawing upon Cappelli’s work, I replaced selected text strings with Unicode symbols which resembled Cappelli’s abbreviations, as follows:
Here is an example, based on the first seven words of Monarchia:
original: "omnium hominum quos ad amorem veritatis natura ..."My algorithmic abbreviation process reduced the average word length to 5.23 letters: still far too long, compared to the Voynich manuscript.
abbreviated: "omniᵐ hominᵐ qu⁹ ad amorem veritat⁹ natura ..."
Undoubtedly, a real scribe would have abbreviated even more rigorously. As an example: the University of Zurich has developed a wonderful crowd-sourced compilation of Cappelli's abbreviations at https://www.adfontes.uzh.ch/en/ressou.... Using this resource, I constructed a radical abbreviation of the above phrase from Monarchia, as follows:
The first seven words of Dante's "Monarchia", radically abbreviated. Image credits: Adriano Cappelli. Author's analysis.
The abbreviated phrase has 19 characters; the average word length is just 2.71 characters. We can see that Cappelli's abbreviations could easily generate a text that matched the average "word" length of the Voynich manuscript. However, this was a manual exercise; we need a mechanism for creating machine-readable renditions of abbreviated Latin texts. To this issue, I shall return.
Unabbreviated Latin
Here, I would like to back up a little, and present the results of some tests on unabbreviated Latin as a precursor language of the Voynich manuscript.
The average word length is already a downside of this hypothesis. The next test is the statistical fit between letter frequencies and glyph frequencies. Among the multiple transliterations that I had developed, I found the best fits with unabbreviated Latin as follows.
For the LatinISE medieval subcorpus, which comprises texts from the seventh to the fourteenth century, the best-fitting transliteration is:
• the v170 transliteration, “herbal 1” section:For Monarchia, the best-fitting transliterations are:* variations from v101④: m => iiń, M => iiiń, n => iń
* correlation between letter frequencies and glyph frequencies: 98.2 percent
* average absolute difference between letter frequencies and glyph frequencies: 0.37 percent.
• the v103 transliteration, "herbal 1" section:The most frequent letters in the Latin sources, and the most frequent glyphs in the best-fitting transliterations, are as follows.* variations from v101④: 2, 3, 5, !, %, +, # => 1'; 6, 7, & => 8; ( => 9; C => cc; F => f1 etc; I => ii; m => iiń, M => iiiń, n => iń; A => o; *, Q => p; P => ip• the v170 transliteration, “herbal 1” section:
* correlation between letter frequencies and glyph frequencies: 98.1 percent* average absolute difference between letter frequencies and glyph frequencies: 0.42 percent.
The most common letters in the LatinISE medieval subcorpus and in Dante’s “Monarchia”; and the most common glyphs in my v103 and v171 transliterations of the Voynich manuscript. Author’s analysis.
As suitable samples of the Voynich text for mapping, I selected the most common “words” of one to four glyphs in the v103 and v171 transliterations.
To cut to the chase: the v103 transliteration yielded very few Latin words. The v171 transliteration did not work very well when mapping on the frequencies in Monarchia. However, when mapping on the frequencies in the LatinISE medieval subcorpus, v171 produced a sprinkling of common Latin words, such as “eo”, “si” and “quem”.
Test mappings from common “words” of one to four glyphs in the v171 transliteration, "herbal 1" section, to Latin as represented by the LatinISE medieval subcorpus. LatinISE count "-" means the string is not among the top 1,000 words. Author’s analysis.
Alternatives
The above results do not strongly support the hypothesis that Latin is a precursor language of the Voynich manuscript. However, they do not exclude the hypothesis. I can think of a number of alternative approaches to an extrication of Latin text from the Voynich manuscript, including the following:
• We could try another corpus of medieval Latin, which might have a different style or vocabulary from the LatinISE medieval subcorpus or from De Monarchia, and consequently a different set of letter frequencies.
• We could conjecture that the Voynich scribes worked from a text in abbreviated Latin. We can readily imagine that the producer would instruct the scribes not to expand the abbreviations, but simply to transcribe what they saw. In this case, the letter frequencies would be significantly different from those of the unabbreviated text.
• We could conjecture, as D'Imperio's and Zattera's papers seem to imply, and as I have suggested in previous articles, that after transcription of each precursor word, the Voynich scribes re-ordered the glyphs within each Voynich "word". In this case, our raw transliteration to Latin is just the beginning, and for each string of Latin letters, we have to look for predecessors that make sense as words and as parts of sentences.
May 5, 2024
Voynich Reconsidered: Currier's dilemma
In 1976, the US National Security Agency hosted a seminar in Washington, D.C. The subject was the enigmatic Voynich manuscript. I have the impression that the agency thought that the manuscript might be an advanced implementation of encryption; and that its decipherment might have benefits to the security of the USA. For forty-one years, the proceedings were secret; the NSA declassified them in 2017.
I have no idea why anyone should suppose the Voynich manuscript to be encrypted; it is simply written in unknown symbols. If we had no knowledge of, say, Chinese characters, we might equally suppose that any text in Chinese was encrypted.
Mary D’Imperio, at that time an employee of the National Security Agency, hosted the seminar. She later wrote the classic book An Elegant Enigma,, as well as two analytical articles on the manuscript. Her entire work on the Voynich manuscript was likewise classified till 2017.
Captain Prescott Currier, a US Navy officer with a background in cryptanalysis, was one of the key speakers in the seminar. In his presentation, he made the following statement::
Capt. Prescott Currier. Image credit: Station Hypo.
We may be permitted one observation. Currier was treating a {9} at the end of a glyph string as a suffix, and an initial {4o} as a prefix. But these were assumptions. They could only hold true if a glyph string was a word as we understand it: that is, a string of characters which appear in the order that they are spoken.
In fact, elsewhere in the seminar, Currier himself referred to the "words" in the Voyich manuscript as follows:
The glyph sequence
As Mary D’Imperio demonstrated in a technical paper for the National Security Agency around 1978, and as Massimiliano Zattera confirmed quantitatively in his presentation to the Voynich 2022 conference, in nearly all of the Voynich “words”, the glyphs follow a sequence. Certain glyphs appear predominantly at the beginning of a “word”; others, generally in the middle; yet others, nearly always at the end.
D’Imperio called the sequence the “five states”; in fact, in her paper she implied that there were as many as seven positions for which glyphs had preferences. Zattera called it the “slot alphabet”, with twelve slots where D’Imperio had found five. However, neither D’Imperio nor Zattera presented control studies of natural languages.
So I am not sure that Currier was correct: I suspect that there may be natural languages in which this phenomenon occurs. For example, in modern English (with thanks to Emory Oxford College), the letters t and a account for 31 percent of all initial letters; and the letters e and s account for 34 percent of all final letters. So we should not be surprised to see a word ending in s to be followed by a word beginning with t.
Even if Currier was correct in saying that the Voynich “words” are not words, we do not have to conclude that the Voynich manuscript is meaningless. We only have to look at the following sequence of letters

Abraham Lincoln, speaking perfect English words at Gettysburg. Image credit: Library of Congress.
In the re-ordered sequence, “words” that end in “s”, “v” or “y” are likely to be followed by “words” beginning with “a”. That is a consequence of the order of the English alphabet.
Next steps
In my ongoing research, I have tried to explore the following issues:
I have no idea why anyone should suppose the Voynich manuscript to be encrypted; it is simply written in unknown symbols. If we had no knowledge of, say, Chinese characters, we might equally suppose that any text in Chinese was encrypted.
Mary D’Imperio, at that time an employee of the National Security Agency, hosted the seminar. She later wrote the classic book An Elegant Enigma,, as well as two analytical articles on the manuscript. Her entire work on the Voynich manuscript was likewise classified till 2017.
Captain Prescott Currier, a US Navy officer with a background in cryptanalysis, was one of the key speakers in the seminar. In his presentation, he made the following statement::
‘''Words" ending in the {9} sort of symbol, which is very frequent, are followed about four times as often by "words" beginning with {4o}. … These phenomena are consistent, statistically significant, and hold true throughout those areas of text where they are found.
I can think of no linguistic explanation for this sort of phenomenon, not if we are dealing with words or phrases, or the syntax of a language where suffixes are present. In no language I know of does the suffix of a word have anything to do with the beginning of the next word.’
Capt. Prescott Currier. Image credit: Station Hypo.
We may be permitted one observation. Currier was treating a {9} at the end of a glyph string as a suffix, and an initial {4o} as a prefix. But these were assumptions. They could only hold true if a glyph string was a word as we understand it: that is, a string of characters which appear in the order that they are spoken.
In fact, elsewhere in the seminar, Currier himself referred to the "words" in the Voyich manuscript as follows:
'That's just the point - they're not words!’Here, I believe, Currier touched on the essence of the Voynich manuscript. The glyph strings that look like words are possibly not words; at least, not words as we understand them.
The glyph sequence
As Mary D’Imperio demonstrated in a technical paper for the National Security Agency around 1978, and as Massimiliano Zattera confirmed quantitatively in his presentation to the Voynich 2022 conference, in nearly all of the Voynich “words”, the glyphs follow a sequence. Certain glyphs appear predominantly at the beginning of a “word”; others, generally in the middle; yet others, nearly always at the end.
D’Imperio called the sequence the “five states”; in fact, in her paper she implied that there were as many as seven positions for which glyphs had preferences. Zattera called it the “slot alphabet”, with twelve slots where D’Imperio had found five. However, neither D’Imperio nor Zattera presented control studies of natural languages.
So I am not sure that Currier was correct: I suspect that there may be natural languages in which this phenomenon occurs. For example, in modern English (with thanks to Emory Oxford College), the letters t and a account for 31 percent of all initial letters; and the letters e and s account for 34 percent of all final letters. So we should not be surprised to see a word ending in s to be followed by a word beginning with t.
Even if Currier was correct in saying that the Voynich “words” are not words, we do not have to conclude that the Voynich manuscript is meaningless. We only have to look at the following sequence of letters
"foru ceors adn eensv aersy ago".The strings that look like words are not words in English, and probably not in any natural language, with the exception of "ago". The initial "a" of several strings is not a prefix. Nevertheless, the sequence contains meaning, which is this:
"four score and seven years ago"which is the opening phrase of Abraham Lincoln’s “Gettysburg Address”.
Abraham Lincoln, speaking perfect English words at Gettysburg. Image credit: Library of Congress.
In the re-ordered sequence, “words” that end in “s”, “v” or “y” are likely to be followed by “words” beginning with “a”. That is a consequence of the order of the English alphabet.
Next steps
In my ongoing research, I have tried to explore the following issues:
* If the glyph strings are the result of a re-ordering process, did the re-ordering happen before or after the transcription?
* If the scribes re-ordered the letters in the source words before the transcription, did they use the source alphabet (for example the Latin, Cyrillic, Glagolitic, Greek or another alphabet)?
* If the scribes first transcribed from letters to glyphs, and then re-ordered the transcribed glyphs), what were the rules for the re-ordering? Did the producer provide them with a "Voynich alphabet"?
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

