
Robert H. Edwards's Blog: Great 20th century mysteries, page 5
May 5, 2024
Voynich Reconsidered: Bohemian as precursor
Wilfrid Voynich was said to have bought the Voynich manuscript in central Italy. In my ongoing search for the underlying languages of the manuscript, and with a view to radiating the search outwards from Italy, I considered the languages of neighboring countries. One such language is Old Bohemian (the precursor of the modern Czech language).
The first step was to find documents in Old Bohemian, from which I could calculate the letter frequencies.
One interesting candidate document was Dalimilova kronika (The Chronicle of Dalimil), which is said to be the earliest manuscript in Bohemian. The manuscript is richly illustrated; the text is in verse; the author is unknown. In its original version, it relates events in the land of Croatia (which then encompassed what is now Czechia) up to the year 1314. It is therefore assumed to have been composed early in the fourteenth century.
My first problem was that every electronic full text that I could find was written in what appeared to be the modern Czech language. For example, in one popular version the first three lines are as follows:
The first page of text of the original Dalimilova kronika. Image by courtesy of Petar B. Bogunovic.
As I read it, the modern “ě” was written “ie”, “v” was written “w”, “j” was written “g”, and many modern accents were absent. The letter frequencies would therefore be substantially different in Bohemian from those in modern Czech.
In the absence of an electronic full text in Bohemian, I created my own version of Dalimilova kronika, starting with the modern version and making as many substitutions as I could identify from the first page of the original. This reduced the alphabet from forty letters in Czech to twenty-five in Bohemian. After converting all letters to lower case and removing punctuation, I had a flat text file with 25,460 words and 131,200 characters excluding spaces.
As I have reported in previous posts on this platform, I have been using four tests for the hypothesis that a given language could be an underlying language of the Voynich manuscript:
In my rendition of Dalimilova kronika, the average word length was 5.15 letters, which was substantially longer than the average of 3.78 glyphs in my v101④ transliteration of the Voynich manuscript. So there was already some discouragement of the idea that the Voynich scribes had worked from documents in Old Bohemian.
Alternative transliterations
Among my thirty-seven alternative transliterations of the Voynich manuscript, those that had the best statistical fit with Dalimilova kronika were as follows:
Letter and glyph frequencies
The most frequent letters in Dalimilova kronika, and the most frequent glyphs in the v104 and v171 transliterations, were as follows:
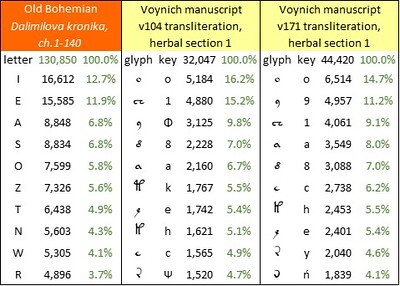
The ten most frequent letters in the Old Bohemian language, represented by "Dalimilova kronika"; and the ten most frequent glyphs in my v104 and v171 transliterations of the Voynich manuscript. Author's analysis.
Test mappings
The crucial test was to attempt mappings to Old Bohemian from selected extracts from the Voynich text, for which purpose I again used the most frequent “words” of one to four glyphs in the v104 and v171 transliterations.
Here, the v104 transliteration yielded no Old Bohemian words longer than one letter; the v171 transliteration yielded no words longer than two letters.
In summary, my comparisons of word length and frequencies, and my test mappings of glyphs to letters, have not supported the hypothesis that Old Bohemian was an underlying language of the Voynich manuscript.
As with the other languages that we have investigated: it remains to be considered that, as Mary D’Imperio’s “five states” and Massimiliano Zattera's "slot alphabet" suggest, the Voynich scribes re-ordered the glyphs in every "word". We can imagine that the producer gave them a prescribed sequence that the glyphs had to follow. If that is so, our mappings might not be the last step. Each of the mapped strings might have a predecessor, with the same letters but in a different order - in effect, an anagram. However, I have tested all of the text strings in this way, without finding any common Bohemian word.
The first step was to find documents in Old Bohemian, from which I could calculate the letter frequencies.
One interesting candidate document was Dalimilova kronika (The Chronicle of Dalimil), which is said to be the earliest manuscript in Bohemian. The manuscript is richly illustrated; the text is in verse; the author is unknown. In its original version, it relates events in the land of Croatia (which then encompassed what is now Czechia) up to the year 1314. It is therefore assumed to have been composed early in the fourteenth century.
My first problem was that every electronic full text that I could find was written in what appeared to be the modern Czech language. For example, in one popular version the first three lines are as follows:
Mnozí pověstí hledajú,However, the Old Bohemian language was substantially different from modern Czech. Notably, Old Bohemian had fewer accents. My reading of the first three lines in the original is approximately as follows:
v tom múdřě i dvorně činie,
ale ţe své země netbajú …
Mnozy powiesti hledagi
wtom diwnie y mudře čyni
ale že sivezemie nedbagy …
The first page of text of the original Dalimilova kronika. Image by courtesy of Petar B. Bogunovic.
As I read it, the modern “ě” was written “ie”, “v” was written “w”, “j” was written “g”, and many modern accents were absent. The letter frequencies would therefore be substantially different in Bohemian from those in modern Czech.
In the absence of an electronic full text in Bohemian, I created my own version of Dalimilova kronika, starting with the modern version and making as many substitutions as I could identify from the first page of the original. This reduced the alphabet from forty letters in Czech to twenty-five in Bohemian. After converting all letters to lower case and removing punctuation, I had a flat text file with 25,460 words and 131,200 characters excluding spaces.
As I have reported in previous posts on this platform, I have been using four tests for the hypothesis that a given language could be an underlying language of the Voynich manuscript:
• The average length of words should be similar to that of the Voynich "words": that is, about 4.0 letters or less.Word lengths
• There should be a good correlation between the frequencies of the letters and the frequencies of the Voynich glyphs: preferably, at least 95 per cent.
• There should be a low average absolute difference between the frequencies of the letters and the frequencies of the equally-ranked Voynich glyphs: preferably, at most 0.4 per cent.
• A test mapping of Voynich glyph strings to letters (in the candidate language) should produce at least some intelligible words: preferably words of at least four letters.
In my rendition of Dalimilova kronika, the average word length was 5.15 letters, which was substantially longer than the average of 3.78 glyphs in my v101④ transliteration of the Voynich manuscript. So there was already some discouragement of the idea that the Voynich scribes had worked from documents in Old Bohemian.
Alternative transliterations
Among my thirty-seven alternative transliterations of the Voynich manuscript, those that had the best statistical fit with Dalimilova kronika were as follows:
v104, which differs from v101④ in the following respects:However, the statistical fits are not brilliant. The v104 transliteration has the best correlation of glyph frequencies with Old Bohemian letter frequencies, but it is only 93.0 percent. The v171 transliteration has the best absolute frequency difference, but it is 0.92 percent which is high by comparison with my results for other medieval European languages. At this stage it already seems that the Old Bohemian language has a substantially different “shape” (as represented by the letter frequencies) from the “shape” of the Voynich manuscript.
• The glyphs {2}, {3}, {5}, {!}, {%}, {+} and {#} are all equated with {1} plus a catch-all accent {‘};
• The glyphs {6}, {7}, and {&} are all equated with {8}
• The “bench gallows” glyphs are redefined as “gallows” + “bench”, and the “bench” is assumed to be the glyph {1}: so {F} = {f1} and so on;
• The “double glyph” {I} is disaggregated: {I} = {ii};
• The glyphs {m}, {M} and {n} are disaggregated into strings, so that {m} = {iiΩ}, {M} = {iiiΩ}, {n} = {iΩ};
• A few less common glyphs are equated with more common ones: {( }= {Φ}; {A} = {o}; {*}, {Q} = {Π}; {P} = {iΠ}.
v171, which has the following variations from v101④:
• The glyphs {m}, {M} and {n} are disaggregated into strings, so that {m} => {îń}, {M} => {iîń}, {n} => {iń}.
Letter and glyph frequencies
The most frequent letters in Dalimilova kronika, and the most frequent glyphs in the v104 and v171 transliterations, were as follows:
The ten most frequent letters in the Old Bohemian language, represented by "Dalimilova kronika"; and the ten most frequent glyphs in my v104 and v171 transliterations of the Voynich manuscript. Author's analysis.
Test mappings
The crucial test was to attempt mappings to Old Bohemian from selected extracts from the Voynich text, for which purpose I again used the most frequent “words” of one to four glyphs in the v104 and v171 transliterations.
Here, the v104 transliteration yielded no Old Bohemian words longer than one letter; the v171 transliteration yielded no words longer than two letters.
In summary, my comparisons of word length and frequencies, and my test mappings of glyphs to letters, have not supported the hypothesis that Old Bohemian was an underlying language of the Voynich manuscript.
As with the other languages that we have investigated: it remains to be considered that, as Mary D’Imperio’s “five states” and Massimiliano Zattera's "slot alphabet" suggest, the Voynich scribes re-ordered the glyphs in every "word". We can imagine that the producer gave them a prescribed sequence that the glyphs had to follow. If that is so, our mappings might not be the last step. Each of the mapped strings might have a predecessor, with the same letters but in a different order - in effect, an anagram. However, I have tested all of the text strings in this way, without finding any common Bohemian word.


May 4, 2024
Voynich Reconsidered: Welsh as precursor
In my research for Voynich Reconsidered (Schiffer Publishing, 2024), I prioritised the languages spoken in or near medieval Italy as potential precursors of the Voynich text. The languages of northern Europe seemed geographically rather remote. However, I thought it prudent to widen the net. In so doing, I investigated the Middle Welsh language.
I am using the term "Middle Welsh" to refer to the Welsh language as spoken and written from the twelfth to the fifteenth centuries.
As with other languages that I have examined, the first step in this process was to identify a suitable corpus of documents of the right time period. For this purpose, I thought of the Peniarth Manuscripts.
At the National Library of Wales, the Peniarth Manuscripts are the single most important collection. These manuscripts were collected by Robert Vaughan (c.1592-1667), whose library was in Hengwrt, Meirioneth county. Among the collection there are several manuscripts in Middle Welsh from the thirteenth and fourteenth centuries, including the following:

The first thirteen lines of the first page of Peniarth MS4. The first sentence is "Pwẏll pendeuic dẏuet a|oed ẏn arglỽẏd ar seith cantref dẏuet" (Pwyll Prince of Dyfed was lord over the seven cantrefs of Dyfed"). Image credit: National Library of Wales.
Word length
My copy of The White Book of Mabinogion contains 112,154 words, with 430,466 letters (excluding punctuation), for an average word length of 3.84 letters. To make a comparison with the Voynich manuscript, I selected my v101④ transliteration. This differs from Glen Claston’s v101 in that I replace all instances of the v101 string {4o} with the Unicode symbol ④. In v101④, the average length of a “word” is 3.78 glyphs.
Glyph and letter frequencies
As I have outlined in other articles on this platform, I have worked on the assumption that there is no single “best” transliteration of the Voynich manuscript. There are several symbols, like the v101 {m}, that might be a single glyph or a ligature of several glyphs. There are several families of glyphs, such as the v101 {6}, {7}, {8} and {&}, that could be distinct glyphs, or could be no more than variations in handwriting. Therefore, I have taken the position that we need multiple transliterations; and selecting one over another is a matter of trial and error.
Accordingly, as of this writing, I have developed thirty-seven alternative transliterations, each derived from Claston’s v101 but differing from v101 in one respect or several respects. When investigating a possible mapping to a target precursor language, I have used two alternative metrics: the statistical correlation between glyph frequencies and letter frequencies, and the average absolute difference between the frequencies of equally-ranked glyphs and letters.
Of these transliterations, two have a good statistical fit with The White Book of Mabinogion, as follows:
The most frequent glyphs in the v121.mF and v171 transliterations, and the most frequent letters in The White Book of Mabinogion, are as follows:
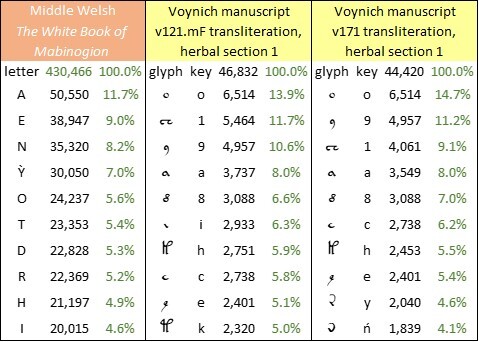
The ten most frequent letters in Middle Welsh, as represented by "The White Book of Mabinogion", and the ten most frequent glyphs in my v121.mF and v171 transliterations of the Voynich manuscript. Author's analysis.
Mapping the Voynich
With that, I again embarked on my standard test of mapping the most frequent Voynich “words” of one to four glyphs to text strings in the target language. I tested the v121.mF and v171 transliterations separately. In each case, for some assurance of mapping from a uniform language, I used the "herbal" section. I searched for each text string in The White Book of Mabinogion to see whether it occurred as a real word, and if so, how often.
The v121.mF transliteration yielded essentially no real words in Middle Welsh, except for some single-letter words which could be the product of chance. The v171 transliteration yielded real Welsh words of one and two letters; the most encouraging was the “word” {oe} yielding the Welsh “ar” (in English, “on”). But, as I had found with several other target languages, at the three-glyph and four-glyph level the mapping broke down.
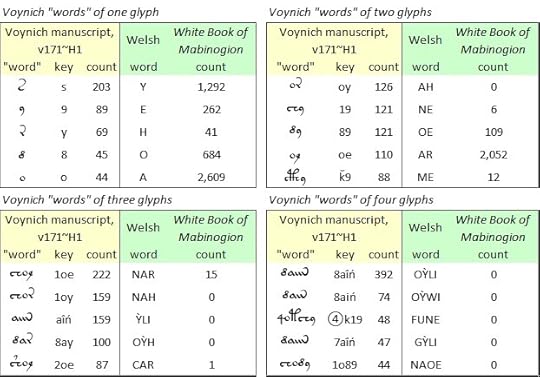
Provisional mappings of the most common "words" of one to four glyphs in the Voynich manuscript, v171 transliteration, to Middle Welsh. Author's analysis.
My provisional conclusion is that Middle Welsh, at least as represented by The White Book of Mabinogion, is probably not a precursor language of the Voynich manuscript.
I am using the term "Middle Welsh" to refer to the Welsh language as spoken and written from the twelfth to the fifteenth centuries.
As with other languages that I have examined, the first step in this process was to identify a suitable corpus of documents of the right time period. For this purpose, I thought of the Peniarth Manuscripts.
At the National Library of Wales, the Peniarth Manuscripts are the single most important collection. These manuscripts were collected by Robert Vaughan (c.1592-1667), whose library was in Hengwrt, Meirioneth county. Among the collection there are several manuscripts in Middle Welsh from the thirteenth and fourteenth centuries, including the following:
• Peniarth MS 4: Llyfr Gwyn Rhydderch (The White Book of Rhydderch), copied in the mid-fourteenth century, which contains the earliest copy of the Middle Welsh tales now collectively known as the MabinogionAccordingly, I downloaded The White Book of Mabinogion: Welsh tales [and] romances produced from the Peniarth manuscripts, which is a compilation by John Gwenogvryn Evans of tales from Peniarth Manuscripts 4 and 6. I believe that this compilation reproduces accurately the text in the original manuscripts.
• Peniarth MS 6: which contains fragments of Branwen, Manawydan and Geraint ap Erbin, from the second half of the thirteenth century.
The first thirteen lines of the first page of Peniarth MS4. The first sentence is "Pwẏll pendeuic dẏuet a|oed ẏn arglỽẏd ar seith cantref dẏuet" (Pwyll Prince of Dyfed was lord over the seven cantrefs of Dyfed"). Image credit: National Library of Wales.
Word length
My copy of The White Book of Mabinogion contains 112,154 words, with 430,466 letters (excluding punctuation), for an average word length of 3.84 letters. To make a comparison with the Voynich manuscript, I selected my v101④ transliteration. This differs from Glen Claston’s v101 in that I replace all instances of the v101 string {4o} with the Unicode symbol ④. In v101④, the average length of a “word” is 3.78 glyphs.
Glyph and letter frequencies
As I have outlined in other articles on this platform, I have worked on the assumption that there is no single “best” transliteration of the Voynich manuscript. There are several symbols, like the v101 {m}, that might be a single glyph or a ligature of several glyphs. There are several families of glyphs, such as the v101 {6}, {7}, {8} and {&}, that could be distinct glyphs, or could be no more than variations in handwriting. Therefore, I have taken the position that we need multiple transliterations; and selecting one over another is a matter of trial and error.
Accordingly, as of this writing, I have developed thirty-seven alternative transliterations, each derived from Claston’s v101 but differing from v101 in one respect or several respects. When investigating a possible mapping to a target precursor language, I have used two alternative metrics: the statistical correlation between glyph frequencies and letter frequencies, and the average absolute difference between the frequencies of equally-ranked glyphs and letters.
Of these transliterations, two have a good statistical fit with The White Book of Mabinogion, as follows:
• v121.mF, which has the following variations from v101④:These statistical fits are comparable with the best results that I have previously found: those of my comparisons between the Voynich manuscript and documents in medieval Latin and Italian.o The v101 glyphs {2}, {3}, {5}, {!}, {%}, {+} and {#} are all equated with v101 {1} plus a catch-all accent {‘};• The glyph frequencies in v121.mF have the highest correlation (97.2 percent) with the letter frequencies in The White Book of Mabinogion.
o The v101 glyph {m} is disaggregated into the three-glyph string {iiń};
o The “bench gallows” glyphs are redefined as gallows + bench, so that {F} becomes {fπ} and so on;
o The v101 glyph {A} is equated with {a}
• v171, which has the following variations from v101④:o The v101 glyphs {m}, {M} and {n} are disaggregated, so that {m} => {îń}, {M} => {iîń}, {n} => {iń}• The glyph frequencies in v171 have the lowest average absolute difference (0.38 percent) from the frequencies of equally-ranked letters in The White Book of Mabinogion.
The most frequent glyphs in the v121.mF and v171 transliterations, and the most frequent letters in The White Book of Mabinogion, are as follows:
The ten most frequent letters in Middle Welsh, as represented by "The White Book of Mabinogion", and the ten most frequent glyphs in my v121.mF and v171 transliterations of the Voynich manuscript. Author's analysis.
Mapping the Voynich
With that, I again embarked on my standard test of mapping the most frequent Voynich “words” of one to four glyphs to text strings in the target language. I tested the v121.mF and v171 transliterations separately. In each case, for some assurance of mapping from a uniform language, I used the "herbal" section. I searched for each text string in The White Book of Mabinogion to see whether it occurred as a real word, and if so, how often.
The v121.mF transliteration yielded essentially no real words in Middle Welsh, except for some single-letter words which could be the product of chance. The v171 transliteration yielded real Welsh words of one and two letters; the most encouraging was the “word” {oe} yielding the Welsh “ar” (in English, “on”). But, as I had found with several other target languages, at the three-glyph and four-glyph level the mapping broke down.
Provisional mappings of the most common "words" of one to four glyphs in the Voynich manuscript, v171 transliteration, to Middle Welsh. Author's analysis.
My provisional conclusion is that Middle Welsh, at least as represented by The White Book of Mabinogion, is probably not a precursor language of the Voynich manuscript.
April 30, 2024
Voynich Reconsidered: "leaf words"
Here is a thought experiment. Let us imagine that we know the Latin alphabet and that, even if not native speakers, we can read the English language. Let us suppose that we come across a manuscript containing the image below.

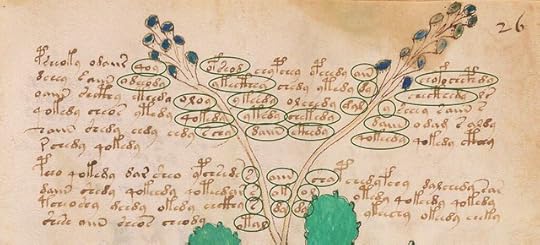
A re-imagination of page f26r of the Voynich manuscript, in which the scribe filled the spaces with Shelley's poem "Ozymandias". Image credit: Andrew Steckley; additional graphics by author.
We know immediately that the scribe started with a page containing only a drawing of a plant. Around and within the drawing, he wrote the text of Percy Bysshe Shelley's poem "Ozymandias", filling the spaces as best he could, without regard for case, punctuation or hyphenation.
Where the text abuts the plant drawing, we see fragments of English words, sometimes single letters, most of them making no sense on their own. Our eyes and minds attach them to the text where they belong. However, if we did not know the English language well, we might suppose these fragments to be meaningless.
Something like this could be happening in the Voynich manuscript.
Particularly in the "herbal" section, there are hundreds of instances where an illustration (usually a drawing of a plant) breaks up the text. In such cases, there is usually a "word" to the left, and another "word" to the right, of the illustration. The "words" seem to fit the intervening spaces rather well. We might wonder whether these are really "words". For example, could they be fragments of words? could they represent abbreviations? or could they be space fillers without meaning?
I wanted to find a simple mnemonic for such "words". Since they are usually adjacent to the stems of plants, until I think of something better I will call them "leaf words".
An extract from page f26r of the Voynich manuscript, identifying the "words" which abut the drawing of a plant. Image credit: Beinecke Rare Book and Manuscript Library; graphics by author.
Andrew Steckley of the Voynich Ninja forum kindly provided me with csv files, extracted from the "herbal" pages written by Scribe 1 (which for brevity I will call the "herbal 1" section). These files identify the "leaf words". In the "herbal 1" section, there are 992 occurrences of "leaf words", or 12.0 percent of the total "word" count.
I assembled all of these occurrences in a text file, and calculated the "word" frequency in the Browserling word counter. The "leaf words" had a substantially different vocabulary from that of the "herbal 1" section as a whole. In particular:
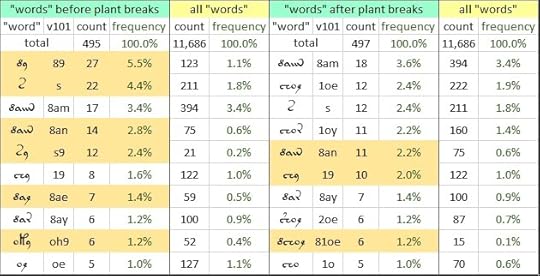
Voynich manuscript, “herbal” section, Scribe 1: the most common “leaf words", and their frequencies in the section as a whole. Data by courtesy of Andrew Steckley; author's analysis.
We would be entitled to suspect that these particular "words", in these particular locations, are meaningless – that the scribe inserted them for visual effect, so that the text would nicely fill the spaces within the drawings, or between the drawings and the margins.
However, the “leaf words” as a whole are not meaningless. We can apply Alexander Boxer's test. In his paper at the Voynich 2022 conference, he observed that a high incidence of hapax legomena (words occurring only once) was a "fingerprint of gibberish". A low incidence of hapax legomena was an indicator of meaningful content.
In another article on this platform, I noted that in William Shakespeare's Macbeth, the incidence of hapax legomena is about 60 percent. That is, about 60 percent of the play's vocabulary consists of words that are used only once. There is no doubt that Macbeth is a meaningful text.
In the Voynich "herbal 1" section as a whole, the incidence of hapax legomena is 71.4 percent of the vocabulary. Among the "leaf words", just 34.7 percent are hapax legomena (relative to the "herbal 1" section). In some way, the "leaf words" are more likely to be meaningful than the "herbal 1" section as a whole.
Postscript: mappings
It occurred to me that since the "leaf words" had a different vocabulary from the "herbal" section as a whole, their presence or absence might significantly affect the frequency distribution of the glyphs. That is to say, if the "leaf words" were removed, we would have a new text in which the glyphs had different frequencies; and some glyphs might move up or down a rank or two.
As I have proposed in other articles on this platform, if we are attempting a mapping of Voynich text to any natural language, the frequency rankings are crucial. As I found with mappings to medieval Italian: one ranking made the v101 glyph {m} map to "d"; a slightly different ranking made {m} map to "c". When mapping the v101 "word" {8am}, that made the difference between the fairly common Italian word "don" and the ubiquitous word "con".
Accordingly, starting with my v101④ transliteration, I created a variant, which I numbered v101④-L, with all the "leaf words" removed. The glyph frequencies did change a little; but the rankings of the 28 most frequent glyphs were identical.
Therefore, I think that the presence or absence of the "leaf words" will have little or no impact on frequency-based mapping of Voynich text to natural languages.
A re-imagination of page f26r of the Voynich manuscript, in which the scribe filled the spaces with Shelley's poem "Ozymandias". Image credit: Andrew Steckley; additional graphics by author.
We know immediately that the scribe started with a page containing only a drawing of a plant. Around and within the drawing, he wrote the text of Percy Bysshe Shelley's poem "Ozymandias", filling the spaces as best he could, without regard for case, punctuation or hyphenation.
Where the text abuts the plant drawing, we see fragments of English words, sometimes single letters, most of them making no sense on their own. Our eyes and minds attach them to the text where they belong. However, if we did not know the English language well, we might suppose these fragments to be meaningless.
Something like this could be happening in the Voynich manuscript.
Particularly in the "herbal" section, there are hundreds of instances where an illustration (usually a drawing of a plant) breaks up the text. In such cases, there is usually a "word" to the left, and another "word" to the right, of the illustration. The "words" seem to fit the intervening spaces rather well. We might wonder whether these are really "words". For example, could they be fragments of words? could they represent abbreviations? or could they be space fillers without meaning?
I wanted to find a simple mnemonic for such "words". Since they are usually adjacent to the stems of plants, until I think of something better I will call them "leaf words".
An extract from page f26r of the Voynich manuscript, identifying the "words" which abut the drawing of a plant. Image credit: Beinecke Rare Book and Manuscript Library; graphics by author.
Andrew Steckley of the Voynich Ninja forum kindly provided me with csv files, extracted from the "herbal" pages written by Scribe 1 (which for brevity I will call the "herbal 1" section). These files identify the "leaf words". In the "herbal 1" section, there are 992 occurrences of "leaf words", or 12.0 percent of the total "word" count.
I assembled all of these occurrences in a text file, and calculated the "word" frequency in the Browserling word counter. The "leaf words" had a substantially different vocabulary from that of the "herbal 1" section as a whole. In particular:
* Among the "leaf words" before (to the left of) drawings, the v101 "words" {89}, {s}, {8an}, {s9} and a few others were vastly more frequent than as "words" in unbroken text.Furthermore, in writing “leaf words”, the Voynich scribe used a rather compact vocabulary. For example, among the "leaf words" before drawings, he had a preference, if that is the right term, for ten very common “words”. These ten “words” account for 25 percent of such "words"; whereas in the “herbal 1” pages as a whole, the same “words” account for just 11 percent of the overall word count. A similar phenomenon is present in the "leaf words" that occur after drawings.
* Among the "leaf words" after (to the right of) drawings, the v101 "words" {8an}, {19} and {81oe} were much more frequent than as "words" in unbroken text.
* But the v101 "word" {8am} occurred, both before and after drawings, at close to its normal frequency.
Voynich manuscript, “herbal” section, Scribe 1: the most common “leaf words", and their frequencies in the section as a whole. Data by courtesy of Andrew Steckley; author's analysis.
We would be entitled to suspect that these particular "words", in these particular locations, are meaningless – that the scribe inserted them for visual effect, so that the text would nicely fill the spaces within the drawings, or between the drawings and the margins.
However, the “leaf words” as a whole are not meaningless. We can apply Alexander Boxer's test. In his paper at the Voynich 2022 conference, he observed that a high incidence of hapax legomena (words occurring only once) was a "fingerprint of gibberish". A low incidence of hapax legomena was an indicator of meaningful content.
In another article on this platform, I noted that in William Shakespeare's Macbeth, the incidence of hapax legomena is about 60 percent. That is, about 60 percent of the play's vocabulary consists of words that are used only once. There is no doubt that Macbeth is a meaningful text.
In the Voynich "herbal 1" section as a whole, the incidence of hapax legomena is 71.4 percent of the vocabulary. Among the "leaf words", just 34.7 percent are hapax legomena (relative to the "herbal 1" section). In some way, the "leaf words" are more likely to be meaningful than the "herbal 1" section as a whole.
Postscript: mappings
It occurred to me that since the "leaf words" had a different vocabulary from the "herbal" section as a whole, their presence or absence might significantly affect the frequency distribution of the glyphs. That is to say, if the "leaf words" were removed, we would have a new text in which the glyphs had different frequencies; and some glyphs might move up or down a rank or two.
As I have proposed in other articles on this platform, if we are attempting a mapping of Voynich text to any natural language, the frequency rankings are crucial. As I found with mappings to medieval Italian: one ranking made the v101 glyph {m} map to "d"; a slightly different ranking made {m} map to "c". When mapping the v101 "word" {8am}, that made the difference between the fairly common Italian word "don" and the ubiquitous word "con".
Accordingly, starting with my v101④ transliteration, I created a variant, which I numbered v101④-L, with all the "leaf words" removed. The glyph frequencies did change a little; but the rankings of the 28 most frequent glyphs were identical.
Therefore, I think that the presence or absence of the "leaf words" will have little or no impact on frequency-based mapping of Voynich text to natural languages.
April 27, 2024
Voynich Reconsidered: what is a "word"
The Voynich manuscript contains, in addition to its profuse illustrations, over 150,000 glyphs arranged in strings which have the appearance of text. That is to say, the glyph strings are generally delimited to left and right by line breaks, or by intervening illustrations, or by spaces. In most of my research, I have been inclined to regard strings of glyphs, thus delimited, as “words” – or the equivalent of words in natural languages.
My assumptions (and they are no more than that) have been that word breaks occur in the following places:
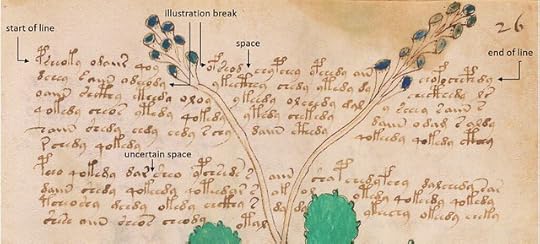
An extract from page f026r of the Voynich manuscript, identifying various types of presumed "word" break. Image credit: Beinecke Rare Book and Manuscript Library; additional graphics and legend by author.
On the basis of these assumptions, a considerable part of my research has been devoted to testing the lengths, frequencies, distributions and placement of Voynich “words” in comparison with the words in natural languages.
However, these assumptions are open to question. Captain Prescott Currier said as much in Mary D’Imperio’s path-breaking seminar on the Voynich manuscript in 1976:
Hapax legomena
A word, by definition, has meaning. If we are searching for words in the Voynich manuscript, we are searching for meaning.
Here I am indebted to Alexander Boxer’s paper “Fingerprinting Gibberish” in the Voynich 2022 Conference, sponsored by the University of Malta. Boxer used the phenomenon known as hapax legomena to distinguish meaningful text from nonsense or gibberish. The Greek expression hapax legomenon (plural: legomena), for which so far I have not found a colloquial English equivalent, simply means a word which occurs only once in a given body of text.
As an example of a meaningful text: my copy of William Shakespeare’s Macbeth contains 18,609 words including stage directions, making it somewhat comparable in length with the Voynich manuscript. Its vocabulary (the set of distinct words) contains 3,273 words. Of these, 1,321 (or 40 percent) occur at least twice. The five most common words, for example, are: "the" (732 occurrences), "and" (564), "to" (383), "I" (371), "of" (343). There are 1,932 words which occur only once (that is, hapax legomena); they include, for example: "clamorous", "unshrinking", "witchcraft". They are equivalent to 60 percent of the vocabulary of Macbeth.
As an example of a text which is universally acknowledged to be meaningless, Boxer cited the purported "angelic speech" as transcribed in "John Dee's Actions With Spirits (1581-1583)", also known as Sloane Manuscript 3188. This text contains passages such as "Asmar gehotha galseph achandas vnascor satquama". Nearly all the "words" occur exactly once. In several passages that I examined, the incidence of hapax legomena was 100 percent.
Boxer argued that the higher the proportion of hapax legomena, the more likely it was that the text, as written, was gibberish; and conversely, the lower the proportion of hapax legomena, the more likely it was that the text was meaningful. From his comparison of the Voynich manuscript with Sloane 3188, and with selected meaningful texts from classical and medieval literature, he concluded that the text of the Voynich manuscript was more likely to be meaningful than to be meaningless.
Them's the breaks
With this tool in hand, we may now turn to various ways of defining the words in the Voynich manuscript. If we start by defining the word breaks, then any string of glyphs delimited by consecutive word breaks, thus defined, is a “word”.
Here I would like to acknowledge my correspondence with Brian Corliss Tawney on the Facebook group “Decoding the Voynich Manuscript” at https://www.facebook.com/groups/62802....
Brian Tawney has developed a programming code which tests whether a given object in a text is or is not a word break. Applying this code to the Voynich text in Currier Language A, he concluded that in these pages, the space was indeed a word break, and that no other object functioned as a word break. With regard to the text in Currier Language B, his test did not confirm the space as a word break; but nor did any other object appear to function as a word break.
My test has a similar objective, but I have used the proportion of hapax legomena as a test for word breaks.
There is a straightforward procedure for doing this test. We copy a machine-readable transliteration of the Voynich text (I prefer Glen Claston’s v101) into Microsoft Word; convert all line breaks, illustration breaks and label breaks into spaces; convert all “uncertain spaces” (for which v101 makes a distinction) into spaces; and import the resulting text into any online word counter. I use the Browserling counter at https://www.browserling.com/tools/wor... no doubt there are others.
I applied this procedure to the text in Language B. This yielded the following results:
Glyphs as word breaks
What if certain glyphs are word breaks: either (a) instead of, or (b) in addition to, the conventional breaks?
We can test that hypothesis. The procedure for (a) would be to:
If any glyph functions as a word break, it must be a common glyph: simply because word breaks are very common in natural languages. In either case, therefore, I think that the prime candidate glyphs would be, in the v101 transliteration, {o}, {9}, {c} and {a}, which are the four most frequent glyphs in Language B and in the manuscript as a whole.
Below is a summary of a series of statistical tests which I conducted on the text in Language B.

The incidence of hapax legomena in the text in Language B, under various definitions of word breaks. The columns "average length of word" and "hapax legomena" are color-coded, with green denoting a greater probability of compatibility with meaningful documents in European languages.
The results for test (a), in which we drop the conventional breaks, include the following:
The latter result raises the possibility that some glyphs have no semantic meaning: for example, they could be some form of punctuation.
In other articles on this platform, I have presented some tests on what I call the “truncation effect”: the hypothesis that certain glyphs, in the initial or final positions, add no semantic meaning to the manuscript.
Separable words
Finally, I am indebted to Massimilano Zattera for his paper “A New Transliteration Alphabet Brings New Evidence of Word Structure and Multiple "Languages" in the Voynich Manuscript”, also presented at the Voynich 2022 Conference. As Zattera pointed out in his paper, the manuscript contains separable "words" (10.4% of the text, and 37.1% of the vocabulary, by his count). By this he means "words" which can be divided into two parts, each of which is a Voynich "word".
For example, the v101 "word" {2coehcc89} (which occurs only once) consists of two parts: {2coe} (50 occurrences) and {hcc89} (18 occurrences). In such cases we might conjecture that there is a word break, but it is not a space and it is not a glyph; it is invisible (as in "Grundwort" or any other compound word in German).
To my mind, the phenomenon of separable words provides further support for the hypothesis that Voynich “words” (or at least, most of them) are really words. With a complete list of separable words (which probably Zattera could provide), we could further refine our estimate of the incidence of hapax legomena in the Voynich manuscript.
My assumptions (and they are no more than that) have been that word breaks occur in the following places:
• the left-hand and right-hand end of an approximately horizontal line, or of any line that has a clear beginning and endWe can call these points "the conventional breaks". That is, we can adopt the convention that if it looks like a word, then it is a word.
• any point at which a string of glyphs abuts an illustration
• the left-hand and right-hand end of any free-floating “label”
• any clearly defined space between strings of glyphs
• any "uncertain space" between strings of glyphs, if it appears larger than the typical spacing of consecutive glyphs.
An extract from page f026r of the Voynich manuscript, identifying various types of presumed "word" break. Image credit: Beinecke Rare Book and Manuscript Library; additional graphics and legend by author.
On the basis of these assumptions, a considerable part of my research has been devoted to testing the lengths, frequencies, distributions and placement of Voynich “words” in comparison with the words in natural languages.
However, these assumptions are open to question. Captain Prescott Currier said as much in Mary D’Imperio’s path-breaking seminar on the Voynich manuscript in 1976:
Question: “How do you account for the full-word repeats?”If the “words” in the Voynich manuscript are not words in the intuitive sense of those in a natural language, then research on the properties of the "words" will lead nowhere. It seems to me worthwhile, therefore, to pose the question: in the Voynich manuscript, what is a “word”?
Currier: “That's just the point - they're not words!”
Hapax legomena
A word, by definition, has meaning. If we are searching for words in the Voynich manuscript, we are searching for meaning.
Here I am indebted to Alexander Boxer’s paper “Fingerprinting Gibberish” in the Voynich 2022 Conference, sponsored by the University of Malta. Boxer used the phenomenon known as hapax legomena to distinguish meaningful text from nonsense or gibberish. The Greek expression hapax legomenon (plural: legomena), for which so far I have not found a colloquial English equivalent, simply means a word which occurs only once in a given body of text.
As an example of a meaningful text: my copy of William Shakespeare’s Macbeth contains 18,609 words including stage directions, making it somewhat comparable in length with the Voynich manuscript. Its vocabulary (the set of distinct words) contains 3,273 words. Of these, 1,321 (or 40 percent) occur at least twice. The five most common words, for example, are: "the" (732 occurrences), "and" (564), "to" (383), "I" (371), "of" (343). There are 1,932 words which occur only once (that is, hapax legomena); they include, for example: "clamorous", "unshrinking", "witchcraft". They are equivalent to 60 percent of the vocabulary of Macbeth.
As an example of a text which is universally acknowledged to be meaningless, Boxer cited the purported "angelic speech" as transcribed in "John Dee's Actions With Spirits (1581-1583)", also known as Sloane Manuscript 3188. This text contains passages such as "Asmar gehotha galseph achandas vnascor satquama". Nearly all the "words" occur exactly once. In several passages that I examined, the incidence of hapax legomena was 100 percent.
Boxer argued that the higher the proportion of hapax legomena, the more likely it was that the text, as written, was gibberish; and conversely, the lower the proportion of hapax legomena, the more likely it was that the text was meaningful. From his comparison of the Voynich manuscript with Sloane 3188, and with selected meaningful texts from classical and medieval literature, he concluded that the text of the Voynich manuscript was more likely to be meaningful than to be meaningless.
Them's the breaks
With this tool in hand, we may now turn to various ways of defining the words in the Voynich manuscript. If we start by defining the word breaks, then any string of glyphs delimited by consecutive word breaks, thus defined, is a “word”.
Here I would like to acknowledge my correspondence with Brian Corliss Tawney on the Facebook group “Decoding the Voynich Manuscript” at https://www.facebook.com/groups/62802....
Brian Tawney has developed a programming code which tests whether a given object in a text is or is not a word break. Applying this code to the Voynich text in Currier Language A, he concluded that in these pages, the space was indeed a word break, and that no other object functioned as a word break. With regard to the text in Currier Language B, his test did not confirm the space as a word break; but nor did any other object appear to function as a word break.
My test has a similar objective, but I have used the proportion of hapax legomena as a test for word breaks.
There is a straightforward procedure for doing this test. We copy a machine-readable transliteration of the Voynich text (I prefer Glen Claston’s v101) into Microsoft Word; convert all line breaks, illustration breaks and label breaks into spaces; convert all “uncertain spaces” (for which v101 makes a distinction) into spaces; and import the resulting text into any online word counter. I use the Browserling counter at https://www.browserling.com/tools/wor... no doubt there are others.
I applied this procedure to the text in Language B. This yielded the following results:
• This text contains 25,122 “words”.If the Voynich “words”, as conventionally defined, are really words, then to my mind the incidence of hapax legomena is not far off from that in Shakespeare’s Macbeth. This encourages us to think that the text of the Voynich manuscript, or most of it, is meaningful.
• The text has a vocabulary of 5,762 distinct "words".
• The five most frequent "words" are {oe} with 555 occurrences, {am} with 543, {1c89} with 367, {ay} with 357, {oy} with 301, and {8am} with 280.
• Of the vocabulary “words”, 1,803 (31 percent) occur at least twice and 3,959 (69 percent) occur only once. Thus the incidence of hapax legomena is 69 percent.
Glyphs as word breaks
What if certain glyphs are word breaks: either (a) instead of, or (b) in addition to, the conventional breaks?
We can test that hypothesis. The procedure for (a) would be to:
1. replace the conventional breaks with an arbitrary character which v101 does not use, for example the hyphen (-)The procedure for (b) would be the same, but skipping step 1.
2. replace a selected glyph with a space
3. run the word counter
4. see whether the incidence of hapax legomena goes up or down.
If any glyph functions as a word break, it must be a common glyph: simply because word breaks are very common in natural languages. In either case, therefore, I think that the prime candidate glyphs would be, in the v101 transliteration, {o}, {9}, {c} and {a}, which are the four most frequent glyphs in Language B and in the manuscript as a whole.
Below is a summary of a series of statistical tests which I conducted on the text in Language B.
The incidence of hapax legomena in the text in Language B, under various definitions of word breaks. The columns "average length of word" and "hapax legomena" are color-coded, with green denoting a greater probability of compatibility with meaningful documents in European languages.
The results for test (a), in which we drop the conventional breaks, include the following:
• If we replace all the conventional breaks with any one of the v101 glyphs {o}, {9}, {c} or {4o}, we greatly increase the incidence of hapax legomena.The results for test (b), in which we retain the conventional breaks, include the following:
• It is evident that if we try successively less frequent glyphs as candidates for word breaks, the percentage of hapax legomena will further increase.
• So, an assumption that the word breaks are glyphs moves the manuscript in the direction of gibberish.
• If we treat any of the glyphs o, 9, c, a, 1, 8, h or 4o as an additional word break, we slightly decrease the incidence of hapax legomena.We could reasonably conclude, firstly that the conventional breaks are word breaks (that is, the Voynich "words" are really words); secondly, that glyphs, on their own, do not function as word breaks; thirdly that certain glyphs might sometimes function as additional word breaks.
• If we treat two or three of the glyphs o, 9, c or 4o as additional word breaks, we can significantly decrease the incidence of hapax legomena, but we make the words much shorter, perhaps implausibly so.
The latter result raises the possibility that some glyphs have no semantic meaning: for example, they could be some form of punctuation.
In other articles on this platform, I have presented some tests on what I call the “truncation effect”: the hypothesis that certain glyphs, in the initial or final positions, add no semantic meaning to the manuscript.
Separable words
Finally, I am indebted to Massimilano Zattera for his paper “A New Transliteration Alphabet Brings New Evidence of Word Structure and Multiple "Languages" in the Voynich Manuscript”, also presented at the Voynich 2022 Conference. As Zattera pointed out in his paper, the manuscript contains separable "words" (10.4% of the text, and 37.1% of the vocabulary, by his count). By this he means "words" which can be divided into two parts, each of which is a Voynich "word".
For example, the v101 "word" {2coehcc89} (which occurs only once) consists of two parts: {2coe} (50 occurrences) and {hcc89} (18 occurrences). In such cases we might conjecture that there is a word break, but it is not a space and it is not a glyph; it is invisible (as in "Grundwort" or any other compound word in German).
To my mind, the phenomenon of separable words provides further support for the hypothesis that Voynich “words” (or at least, most of them) are really words. With a complete list of separable words (which probably Zattera could provide), we could further refine our estimate of the incidence of hapax legomena in the Voynich manuscript.
April 25, 2024
Voynich Reconsidered: mappings of {8am}
In Voynich Reconsidered (Schiffer Publishing, 2024) and in various articles on this platform, I presented the results of some of my experiments in mapping from “words” in the Voynich manuscript to letter strings in natural languages.
In all of these experiments, my working assumptions (and they are no more than that) included the following:
In addition I suspected, on the basis of the work of Mary D'Imperio and Massimiliano Zattera, that the glyphs that we could see on the page were not in their original order. That is, the Voynich producer had specified a process, after the mapping from letters to glyphs, of re-ordering glyphs within “words”.
The assumption of a one-to-one mapping between letters and glyphs permits a corollary: that the Voynich text preserved the frequencies of letters in the precursor documents. That is, the glyph frequencies in the Voynich manuscript should approximately match the typical letter frequencies in the precursor languages.
Permutations
In these experiments, there were at least three permutations to consider.
Firstly, there were multiple languages to test as precursors. A priori, there was no definitive way to include or exclude a language. But the carbon-dating of samples of the vellum to the fourteenth and early fifteenth centuries, and the presumption that Wilfrid Voynich rediscovered the manuscript in Italy, suggested a focus on medieval European languages. As priorities, I was inclined to favor the languages spoken and written in medieval Italy or in neighboring countries.
Secondly, I had developed multiple transliterations of the Voynich manuscript, all based on Glen Claston's v101, each with one or more variations from v101. There were several metrics whereby I could rank these transliterations: for example the statistical correlation between letter and glyph frequencies, and the average absolute difference between letter and glyph frequencies.
The third variable was: which samples of the text should be tested? There were many possibilities, for example the following:
Focus on {8am}
It seemed to me that a more efficient strategy would be to focus on a single very common “word” in the Voynich manuscript. It would be feasible to map such a “word” from multiple transliterations to multiple precursor languages. Each mapping would yield a string of letters; that string could be checked against a suitable corpus of the precursor language; it might yield a real word; and if so, it might be a common word, or a rare word.
For this strategy, one Voynich “word” came to the forefront: the “word” expressed in v101 as {8am}. It is the most common word in the Voynich manuscript; in the v101 transliteration, it occurs 739 times.

The Voynich “word” {8am}, rendered in the Voynich v101 font. Image credit: Rebecca G Bettencourt / KreativeKorp.
Here it was necessary to recognise that the v101 glyph {m} might not be a single glyph. In the EVA transliteration, {m} is rendered as a three-glyph string {iin}; so {8am} becomes the five-glyph string {daiin}. Likewise, in several of my transliterations, I rendered {8am} as the four glyphs {8aîn} or as the five glyphs {8aiiń}. I viewed these renderings as improbable, because to my knowledge, there are no natural languages in which the most common word has four or five letters. But these interpretations could be tested.
Re-ordering the glyphs
I wished to address the possibility to which I referred above (indeed, I thought that it approached a probability) that within the Voynich “words”, the scribes had re-ordered the glyphs. If so, I could conjecture that the producer had defined some rule or rules for re-ordering. These rules needed to be relatively simple, so that the producer could set the project in motion and the scribes could proceed with minimal supervision. Some illustrations may clarify this concept.
Mary D'Imperio, in her classified research for the National Security Agency around 1978, used a computer program called PTAH to categorise the glyphs according to their typical position within the “word”. She defined at least five positions; her research results, as eventually published, suggest that ultimately she recognised seven. She called these positions, for example, “beginners”, “post-beginners”, “middles” and “enders”. If we visualise the Voynich workplace, we can imagine the producer giving instructions to the scribes along the following lines:
This means a search for anagrams; and that is a slippery slope. Anagrams lead us into a world of subjectivity. A four-letter word has twenty-four anagrams; if we are willing to accept any of them, we have twenty-four degrees of freedom.
Fortunately, that freedom is constrained. In natural languages, words have rules regarding sequences of letters. In most languages, words have to include vowels; and they seldom have more than two consecutive consonants. As Boris Sukhotin observed, and made the core of his eponymous algorithm, in a phonetic language a vowel, more often than not, is preceded and followed by a consonant.
For example: in Italian as written before the year 1400, the most common four-letter word was “come” (in English, “as” or “how”). This word has twenty-four anagrams, but among them, the only real word is “come”. If (for the sake of argument) the precursor language were Italian, and if we mapped a Voynich “word” to any anagram of “come”, the precursor word could only be “come”.
The first mappings
In the implementation of this strategy, I started with four potential precursor languages, as follows:
I was able quickly to exclude Finnish, in which {8am} and its variants in most cases mapped only to strings of consonants. The mappings to German yielded many strings of letters which included the vowel “u”, but none of these strings, nor any of their anagrams, was a real word. The mappings to Italian, on the basis of the letter frequencies in La Divina Commedia, yielded only the words “don” (1,241 occurrences in the OVI corpus) and “mond” (106 occurrences in OVI), plus a few rare words.
The most encouraging result came from the mappings to Italian using the letter frequencies in OVI. These frequencies are only slightly different from those in La Divina Commedia, but are based on a much larger corpus of text.
In eighteen of the thirty-seven transliterations, the “word” {8am} mapped to the letter string “noc” or “onc”; and in four transliterations, to the letter string “roc”. None of these strings is a word in Italian, at least not in OVI. But “roc” can be re-ordered as “cor”, a real word which occurs 4,436 times in OVI, and is the old form of “cuore” (in English, “heart”). Better still, “noc” and “ocn” can be re-ordered in only one way as a real Italian word. That word is “con”, which occurs 135,186 times in OVI and translates to English as “with”.
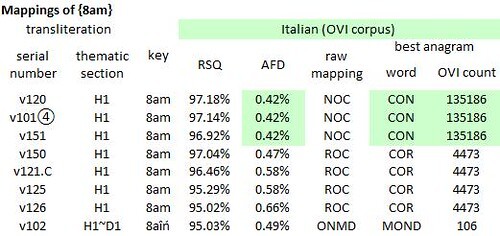
A series of mappings of [8am} from various transliterations of the Voynich manuscript to medieval Italian, as represented by the OVI corpus. Author's analysis. H1 = “herbal” section, parts A and B. D1 = Scribe 1 (per Dr Lisa Fagin Davis). RSQ = correlation coefficient between glyph and letter frequencies. AFD = average absolute difference between glyph and letter frequencies.
Next steps
None of this means that Italian is necessarily or even probably a precursor language of the Voynich manuscript. To my mind, however, it suggests that a systematic process exists whereby, with a minimum of subjectivity, we can rank and prioritise transliterations and precursor languages. If one transliteration and one language emerge from the pack, yielding more real words than others, we can focus on that transliteration and that language.
At present I am working on mappings of {8am} to Albanian, Bohemian, English, French, Galician-Portuguese and Latin, each language represented by an appropriate medieval corpus or document. These tests may, or may not, generate more common words than the Italian "con".
The next step would be to map some other ubiquitous “words” in the Voynich manuscript, such as {oe} and {am}; and to see whether we can make some more real words in the target language. If several common Voynich “words” can be mapped to real words in some language, we might venture onwards, to mappings of whole lines. Those mappings would have to make sense.
In all of these experiments, my working assumptions (and they are no more than that) included the following:
* that the Voynich text, or some substantial part of it, possessed meaning;All of this, I imagined as the vision of a producer: a wealthy person who had conceived and paid for the project, and had given these instructions to the scribes.
* that the Voynich scribes had worked from precursor documents in natural languages;
* that they had mapped words in the precursor documents to “words” in the Voynich manuscript; that is to say, they had preserved the word breaks;
* and that they had mapped letters to glyphs on a one-to-one basis.
In addition I suspected, on the basis of the work of Mary D'Imperio and Massimiliano Zattera, that the glyphs that we could see on the page were not in their original order. That is, the Voynich producer had specified a process, after the mapping from letters to glyphs, of re-ordering glyphs within “words”.
The assumption of a one-to-one mapping between letters and glyphs permits a corollary: that the Voynich text preserved the frequencies of letters in the precursor documents. That is, the glyph frequencies in the Voynich manuscript should approximately match the typical letter frequencies in the precursor languages.
Permutations
In these experiments, there were at least three permutations to consider.
Firstly, there were multiple languages to test as precursors. A priori, there was no definitive way to include or exclude a language. But the carbon-dating of samples of the vellum to the fourteenth and early fifteenth centuries, and the presumption that Wilfrid Voynich rediscovered the manuscript in Italy, suggested a focus on medieval European languages. As priorities, I was inclined to favor the languages spoken and written in medieval Italy or in neighboring countries.
Secondly, I had developed multiple transliterations of the Voynich manuscript, all based on Glen Claston's v101, each with one or more variations from v101. There were several metrics whereby I could rank these transliterations: for example the statistical correlation between letter and glyph frequencies, and the average absolute difference between letter and glyph frequencies.
The third variable was: which samples of the text should be tested? There were many possibilities, for example the following:
* a line from page f1r, the first page of the manuscript, which Prescott Currier assigned to his “Language A”My tests incorporated multiple combinations of languages, transliterations and text samples. In the early experiments, the text samples were generally whole horizontal lines. Each mapping yielded text strings in the selected precursor language. Usually, the text strings did not make sense; in many cases, the text strings did not contain any recognisable words in the target precursor language.
* a line from page f26r, the first page in Currier's “Language B”
* a random line from each of the thematic “sections” of the manuscript: for example “herbal”, “pharmaceutical”, “zodiac”
* a random line from a random page of the manuscript
* and so on …
Focus on {8am}
It seemed to me that a more efficient strategy would be to focus on a single very common “word” in the Voynich manuscript. It would be feasible to map such a “word” from multiple transliterations to multiple precursor languages. Each mapping would yield a string of letters; that string could be checked against a suitable corpus of the precursor language; it might yield a real word; and if so, it might be a common word, or a rare word.
For this strategy, one Voynich “word” came to the forefront: the “word” expressed in v101 as {8am}. It is the most common word in the Voynich manuscript; in the v101 transliteration, it occurs 739 times.
The Voynich “word” {8am}, rendered in the Voynich v101 font. Image credit: Rebecca G Bettencourt / KreativeKorp.
Here it was necessary to recognise that the v101 glyph {m} might not be a single glyph. In the EVA transliteration, {m} is rendered as a three-glyph string {iin}; so {8am} becomes the five-glyph string {daiin}. Likewise, in several of my transliterations, I rendered {8am} as the four glyphs {8aîn} or as the five glyphs {8aiiń}. I viewed these renderings as improbable, because to my knowledge, there are no natural languages in which the most common word has four or five letters. But these interpretations could be tested.
Re-ordering the glyphs
I wished to address the possibility to which I referred above (indeed, I thought that it approached a probability) that within the Voynich “words”, the scribes had re-ordered the glyphs. If so, I could conjecture that the producer had defined some rule or rules for re-ordering. These rules needed to be relatively simple, so that the producer could set the project in motion and the scribes could proceed with minimal supervision. Some illustrations may clarify this concept.
Mary D'Imperio, in her classified research for the National Security Agency around 1978, used a computer program called PTAH to categorise the glyphs according to their typical position within the “word”. She defined at least five positions; her research results, as eventually published, suggest that ultimately she recognised seven. She called these positions, for example, “beginners”, “post-beginners”, “middles” and “enders”. If we visualise the Voynich workplace, we can imagine the producer giving instructions to the scribes along the following lines:
* You have mapped a word in (say) Italian into a “word” in glyphs. But these glyphs must be written in a specific order.Massimiliano Zattera, in his presentation at the Voynich 2022 conference, took this concept further. Where D'Imperio had identified seven positions, he saw twelve. He numbered them from zero to eleven; he called them “the slot alphabet”. Zattera's version of the Voynich producer would have given instructions somewhat like the following:
* If your “word” contains a “beginner” glyph, you must write that glyph first.
* If it contains a “middle” and a “beginner” glyph, you must write the “beginner” before the “middle”.
* If it contains a “ender” and an “middle” glyph, you must write the “middle” before the “ender”.
* and so on …
* If your “word” contains a “slot 0” glyph, you must write that glyph first.If D'Imperio and Zattera identified a real Voynich process, it follows that the glyphs are not necessarily in their original order. When we attempt to reverse-engineer a Voynich “word” to its precursor word, in the first instance we create a letter string which is not necessarily in the right order. Therefore, we may have have to re-order the letters.
* If it contains a “slot 4” and a “slot 3” glyph, you must write the “slot 3” before the “slot 4”.
* If it contains a “slot 11” and a “slot 7” glyph, you must write the “slot 7” before the “slot 11”.
* and so on …
This means a search for anagrams; and that is a slippery slope. Anagrams lead us into a world of subjectivity. A four-letter word has twenty-four anagrams; if we are willing to accept any of them, we have twenty-four degrees of freedom.
Fortunately, that freedom is constrained. In natural languages, words have rules regarding sequences of letters. In most languages, words have to include vowels; and they seldom have more than two consecutive consonants. As Boris Sukhotin observed, and made the core of his eponymous algorithm, in a phonetic language a vowel, more often than not, is preceded and followed by a consonant.
For example: in Italian as written before the year 1400, the most common four-letter word was “come” (in English, “as” or “how”). This word has twenty-four anagrams, but among them, the only real word is “come”. If (for the sake of argument) the precursor language were Italian, and if we mapped a Voynich “word” to any anagram of “come”, the precursor word could only be “come”.
The first mappings
In the implementation of this strategy, I started with four potential precursor languages, as follows:
* Finnish as written around 1548 (as represented by Uusi Testamentti (The New Testament)and with thirty-seven alternative transliterations of the Voynich manuscript, which I numbered from v101④ to v202.
* Early New High German as written around 1401 (as represented by von Tepl's Der Ackerman aus Böhmen)
* Italian as written around 1308-21 (as represented by Dante's La Divina Commedia)
* Italian as written prior to 1400 (as represented by the OVI corpus, or Opera del Vocabolario Italiano),
I was able quickly to exclude Finnish, in which {8am} and its variants in most cases mapped only to strings of consonants. The mappings to German yielded many strings of letters which included the vowel “u”, but none of these strings, nor any of their anagrams, was a real word. The mappings to Italian, on the basis of the letter frequencies in La Divina Commedia, yielded only the words “don” (1,241 occurrences in the OVI corpus) and “mond” (106 occurrences in OVI), plus a few rare words.
The most encouraging result came from the mappings to Italian using the letter frequencies in OVI. These frequencies are only slightly different from those in La Divina Commedia, but are based on a much larger corpus of text.
In eighteen of the thirty-seven transliterations, the “word” {8am} mapped to the letter string “noc” or “onc”; and in four transliterations, to the letter string “roc”. None of these strings is a word in Italian, at least not in OVI. But “roc” can be re-ordered as “cor”, a real word which occurs 4,436 times in OVI, and is the old form of “cuore” (in English, “heart”). Better still, “noc” and “ocn” can be re-ordered in only one way as a real Italian word. That word is “con”, which occurs 135,186 times in OVI and translates to English as “with”.
A series of mappings of [8am} from various transliterations of the Voynich manuscript to medieval Italian, as represented by the OVI corpus. Author's analysis. H1 = “herbal” section, parts A and B. D1 = Scribe 1 (per Dr Lisa Fagin Davis). RSQ = correlation coefficient between glyph and letter frequencies. AFD = average absolute difference between glyph and letter frequencies.
Next steps
None of this means that Italian is necessarily or even probably a precursor language of the Voynich manuscript. To my mind, however, it suggests that a systematic process exists whereby, with a minimum of subjectivity, we can rank and prioritise transliterations and precursor languages. If one transliteration and one language emerge from the pack, yielding more real words than others, we can focus on that transliteration and that language.
At present I am working on mappings of {8am} to Albanian, Bohemian, English, French, Galician-Portuguese and Latin, each language represented by an appropriate medieval corpus or document. These tests may, or may not, generate more common words than the Italian "con".
The next step would be to map some other ubiquitous “words” in the Voynich manuscript, such as {oe} and {am}; and to see whether we can make some more real words in the target language. If several common Voynich “words” can be mapped to real words in some language, we might venture onwards, to mappings of whole lines. Those mappings would have to make sense.
April 10, 2024
Voynich Reconsidered: the Ashmole 61 manuscript
As I mentioned in a previous article, in my investigations for Voynich Reconsidered I examined the possibility that English was a precursor language of the Voynich manuscript.
To this end, I examined the correlations between the glyph frequencies in the Voynich manuscript and the letter frequencies in various documents in Middle English. Among these documents were the Auchinleck Manuscript, and the Codex Ashmole 61.
Here, I am reporting on my analysis of Ashmole 61, also known as the Rate manuscript after the presumed scribe, who signed his name nineteen times therein. This document currently resides at the Bodleian Library in Oxford, England. It is a compilation of popular verse in Middle English, specifically the dialect of northeast Leicestershire, dating from the period approximately between 1488 and 1510. Ashmole 61 uses all twenty-six letters of the modern English alphabet, plus é. The letter y serves both as a vowel, as in “lystyns” (modern “listens”), and as a consonant, as in “dey” (modern “day”).
The text of Ashmole 61 is abbreviated in some places, as the image below illustrates. In the first line, the word "cover" is written as "co" followed by a symbol that resembles the Voynich glyph {n}. Indeed the word could easily be written in Voynich glyphs as {con}: except that no such "word" exists in the Voynich manuscript.

An extract from folio 107r of the Ashmole 61 manuscript. The rubric reads "The governans of man"; the first line is "ffor helth of body couer fro cold þi hede". Image credit: Bodleian Library.
For the purposes of the analysis, I assembled the first twenty-seven parts of Ashmole 61, from Part 1, "Saint Eustace" to Part 27 "Ypotis"; converted all the letters to lower case; and removed all punctuation. The result was a text file containing 53,731 words and 219,311 characters excluding spaces; this again was comparable with the v101 transliteration of the Voynich manuscript.
Word length
In my extract from Ashmole 61, the average word length is 4.08 letters. In the Voynich manuscript, if we use my v101④ transliteration (which is my preferred point of departure), the average length of “words” is 3.78 glyphs.
Glyph and letter frequencies
As with other medieval documents that I have investigated, I compared the letter frequencies in Ashmole 61 with the glyph frequencies in a range of alternative transliterations of the Voynich manuscript. As measured by the average frequency difference, the best-fitting transliteration was the one which I numbered v121mF. This transliteration diverges from v101④ in the following respects:
The most frequent glyphs in the v101④, v121mF and v170 transliterations, and the most frequent letters in Ashmole 61, lined up as follows:

The five most frequent characters in selected transliterations of the Voynich manuscript, and in Ashmole 61, Parts 1-27. Author’s analysis.
In comparison with the Auchinleck manuscript, Ashmole 61 had much higher frequencies of the letters “t” and “h”. Probably the main reason was that Ashmole 61 no longer used the Middle English letters ȝ (yogh), which had become “gh”, and þ (thorn), which had become “th”.
Mapping the Voynich
As in my tests of other potential precursor languages, I identified the most common “words” of one to four glyphs, mapped them to text strings in Middle English using the frequencies in the selected transliterations, and searched the source document (in this case, Ashmole 61) for occurrences of these text strings as words.
Long story short: with minor exceptions, these mappings produced text strings, but no recognisable words, in the English of Ashmole 61. Nor did D’Imperio’s and Zattera’s glyph sequences come to the rescue: again with few exceptions, there were no text strings that could be re-ordered to yield real words.
It seems to me a reasonable conclusion that Middle English, as written for popular consumption around 1500, was not a precursor language of the Voynich manuscript. As written in the early fourteenth century, possibly it could be. In any case, there are other medieval languages worth testing. On this, more later.
To this end, I examined the correlations between the glyph frequencies in the Voynich manuscript and the letter frequencies in various documents in Middle English. Among these documents were the Auchinleck Manuscript, and the Codex Ashmole 61.
Here, I am reporting on my analysis of Ashmole 61, also known as the Rate manuscript after the presumed scribe, who signed his name nineteen times therein. This document currently resides at the Bodleian Library in Oxford, England. It is a compilation of popular verse in Middle English, specifically the dialect of northeast Leicestershire, dating from the period approximately between 1488 and 1510. Ashmole 61 uses all twenty-six letters of the modern English alphabet, plus é. The letter y serves both as a vowel, as in “lystyns” (modern “listens”), and as a consonant, as in “dey” (modern “day”).
The text of Ashmole 61 is abbreviated in some places, as the image below illustrates. In the first line, the word "cover" is written as "co" followed by a symbol that resembles the Voynich glyph {n}. Indeed the word could easily be written in Voynich glyphs as {con}: except that no such "word" exists in the Voynich manuscript.
An extract from folio 107r of the Ashmole 61 manuscript. The rubric reads "The governans of man"; the first line is "ffor helth of body couer fro cold þi hede". Image credit: Bodleian Library.
For the purposes of the analysis, I assembled the first twenty-seven parts of Ashmole 61, from Part 1, "Saint Eustace" to Part 27 "Ypotis"; converted all the letters to lower case; and removed all punctuation. The result was a text file containing 53,731 words and 219,311 characters excluding spaces; this again was comparable with the v101 transliteration of the Voynich manuscript.
Word length
In my extract from Ashmole 61, the average word length is 4.08 letters. In the Voynich manuscript, if we use my v101④ transliteration (which is my preferred point of departure), the average length of “words” is 3.78 glyphs.
Glyph and letter frequencies
As with other medieval documents that I have investigated, I compared the letter frequencies in Ashmole 61 with the glyph frequencies in a range of alternative transliterations of the Voynich manuscript. As measured by the average frequency difference, the best-fitting transliteration was the one which I numbered v121mF. This transliteration diverges from v101④ in the following respects:
• the v101 glyphs {2}, {3}, {5}, {!}, {%}, {+} and {#} are equated with the visually similar glyph {1}, with a superscript which I assigned the symbol {‘}, assuming for the moment that all the superscripts were the same;As measured by the correlation coefficient, the best-fitting transliteration was the one which I numbered v170. This transliteration differs from v101④ in the following respects:
• the glyph {A} is equated with the glyph {a};
• the glyph {m} is disaggregated into {îń}, using ń in place of the v101 {N};
• the “bench gallows” glyphs are disaggregated as follows: F => fπ, G => gπ, H => hπ, K => kπ, where π denotes the “bench” which resembles an elongation of the glyph {1}.
• the glyph {m}, {M} and {n} are disaggregated as follows: m = iiń, M = iiiń, n = iń, using ń in place of the v101 {N}.With the v121mF transliteration, the average frequency difference was 0.45 percent. With the v170 transliteration, the correlation between letter frequencies and glyph frequencies was 98.1 per cent. These statistical results were slightly better than I had obtained with the Auchinleck manuscript, which predated Ashmole 61 by at least 150 years.
The most frequent glyphs in the v101④, v121mF and v170 transliterations, and the most frequent letters in Ashmole 61, lined up as follows:
The five most frequent characters in selected transliterations of the Voynich manuscript, and in Ashmole 61, Parts 1-27. Author’s analysis.
In comparison with the Auchinleck manuscript, Ashmole 61 had much higher frequencies of the letters “t” and “h”. Probably the main reason was that Ashmole 61 no longer used the Middle English letters ȝ (yogh), which had become “gh”, and þ (thorn), which had become “th”.
Mapping the Voynich
As in my tests of other potential precursor languages, I identified the most common “words” of one to four glyphs, mapped them to text strings in Middle English using the frequencies in the selected transliterations, and searched the source document (in this case, Ashmole 61) for occurrences of these text strings as words.
Long story short: with minor exceptions, these mappings produced text strings, but no recognisable words, in the English of Ashmole 61. Nor did D’Imperio’s and Zattera’s glyph sequences come to the rescue: again with few exceptions, there were no text strings that could be re-ordered to yield real words.
It seems to me a reasonable conclusion that Middle English, as written for popular consumption around 1500, was not a precursor language of the Voynich manuscript. As written in the early fourteenth century, possibly it could be. In any case, there are other medieval languages worth testing. On this, more later.
April 8, 2024
Voynich Reconsidered: the Auchinleck manuscript
In my research for Voynich Reconsidered (Schiffer Books, 2024), I investigated the correlations between the glyph frequencies in the Voynich manuscript and the letter frequencies in various natural languages. I focussed on the languages written and spoken in medieval Europe. One of the languages that I considered was Middle English. Since Wilfrid Voynich was said to have purchased the manuscript in Italy, the English language seemed geographically a little remote, but nevertheless worth testing.
My first hope was to find a manuscript or corpus of medieval English, dating from between 1400 and 1450, which would be approximately contemporary with the vellum of the Voynich manuscript, if not necessarily with the text. Such a document would serve as a database for calculating the letter frequencies. However, it seemed quite difficult to find such data, or even meta-data. The first relevant analysis that I found was Marsha Lynn Moreno’s paper on letter frequencies in the biblical Psalms and Gospels, as written in eleventh century English.
Recently, I was fortunate to correspond with professors at Oxford University who directed me to two documents which are more contemporary with the Voynich manuscript, and are both available in electronic full text. One is the Auchinleck Manuscript, a large collection of poetry, probably produced in the 1330s; the other is Ashmole 61, a compilation of popular verse dating from probably between 1488 and 1510. The Middle English language changed significantly between these two periods. The Auchinleck Manuscript retained the Middle English letters ȝ (yogh) and þ (thorn), and the abbreviation & for “and”, all of which would disappear by the time of Ashmole 61.
This article will report on my analysis of the Auchinleck Manuscript, in comparison with the Voynich manuscript.

An extract from folio 326r of the Auchinleck Manuscript. The first line reads: "Lord Ihesu, kyng of glorie". Image credit: National Library of Scotland.
For the purposes of the analysis, I assembled the first 2,330 lines of the Auchinleck Manuscript, converted all letters to lower case and removed all punctuation. This yielded a flat text file containing 59,323 words and 217,052 characters excluding spaces, which is comparable in size with the v101 transliteration of the Voynich manuscript.
Word length
In my extract from the Auchinleck Manuscript, the average word length is 3.66 letters. To make the equivalent calculation for the Voynich manuscript, I used my v101④ transliteration. This is based on Glen Claston’s v101 transliteration, but replaces all occurrences of the v101 string {4o} with the Unicode symbol ④. This yielded an average of 3.78 glyphs per “word”.
Glyph and letter frequencies
As I have mentioned in other articles on this platform, I have developed several alternative transliterations of the Voynich manuscript. Each was based on v101, but differed from v101 in one or more respects, combining certain groups of glyphs and/or disaggregating certain glyphs. For any given source document, in order to test which transliteration had the best statistical fit with the document, I used two alternative metrics, as follows:
In order to have some assurance of referring to a single Voynich “language”, I calculated the glyph frequencies on the basis of the “herbal” section alone. In 1976, at Mary D’Imperio’s Voynich seminar, Captain Prescott Currier took the view that most of this section was written in what he called “Language A”. In the case of the v102 transliteration (of which, more below), for greater assurance I used only those pages of the “herbal” section written by Scribe 1 (as recently identified by Dr Lisa Fagin Davis). It seemed to me probable that each scribe would work from precursor documents in a single language. By my calculations, Scribe 1 wrote about 71 percent of the “herbal” section.
In the case of the Auchinleck manuscript, the best-fitting transliteration on both metrics was v102 (which I discussed briefly in Voynich Reconsidered). The correlation coefficient was 97.0 percent, and the average frequency difference was 0.54 percent. The v102 transliteration differs from v101④ in the following respects:
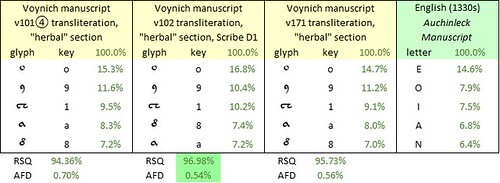
The five most frequent characters in the v101④, v102 and v171 transliterations, “herbal” section, and in the Auchinleck Manuscript, lines 1 to 2330. Scribe D1 is Scribe 1 as identified by Dr Lisa Fagin Davis. Author's analysis.
Mapping from the Voynich
The next step was to select suitable extracts from the Voynich manuscript, map them to text strings in Middle English, and see whether any of those strings were real English words. For this purpose, I selected the top five “words” of one to four glyphs in the v102 and v171 transliterations, “herbal” section. The v102 transliteration did not produce anything resembling English words, beyond a few words of a single letter or two letters, which could easily be by chance. The v171 transliteration yielded some glimmerings of possible meaning, but only with “words” of up to three glyphs, as shown below.
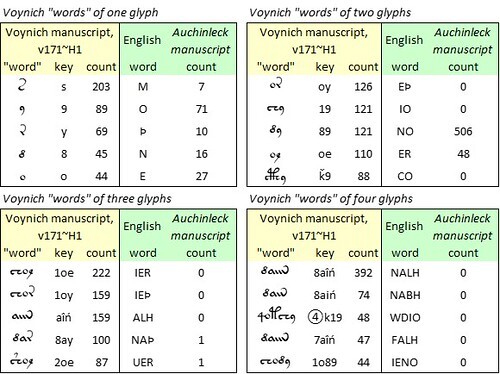
Provisional mappings of the top five "words" of one to four glyphs in the Voynich manuscript, v171 transliteration, "herbal" section, to Middle English as written in the 1330s. Author's analysis.
In summary, on these tests, we could reasonably draw the following conclusions (approximately in order of probability):
In another article on this platform, I gave the hypothetical example of a scribe mapping from the Italian word "con" to the glyph string {ma8}; but because this was not a permitted sequence, he reversed the order and wrote the familiar {8am}.
In the case of the Auchinleck manuscript and the v171 transliteration, we see a mapping of the “word” {oy} to the text string eþ, which is not an English word. However, one of the most common words in Middle English was þe (modern “the”), which occurs 2,101 times in the Auchinleck manuscript. If a scribe had mapped þe to glyphs using something like our v171, he would have come up with {yo}. This would not be a permitted sequence; and he would have written {oy}.
Another example: in v171, {8ay} maps to naþ, which is a Middle English word but a rare one. However, the word þan (modern “than”) occurs 303 times in the Auchinleck manuscript. If a scribe had mapped it to {ya8}, he would again be obliged to reverse the order and write {8ay}.
I am inclined to think that some more work on Middle English is justifiable. Next stop: Ashmole 61.
My first hope was to find a manuscript or corpus of medieval English, dating from between 1400 and 1450, which would be approximately contemporary with the vellum of the Voynich manuscript, if not necessarily with the text. Such a document would serve as a database for calculating the letter frequencies. However, it seemed quite difficult to find such data, or even meta-data. The first relevant analysis that I found was Marsha Lynn Moreno’s paper on letter frequencies in the biblical Psalms and Gospels, as written in eleventh century English.
Recently, I was fortunate to correspond with professors at Oxford University who directed me to two documents which are more contemporary with the Voynich manuscript, and are both available in electronic full text. One is the Auchinleck Manuscript, a large collection of poetry, probably produced in the 1330s; the other is Ashmole 61, a compilation of popular verse dating from probably between 1488 and 1510. The Middle English language changed significantly between these two periods. The Auchinleck Manuscript retained the Middle English letters ȝ (yogh) and þ (thorn), and the abbreviation & for “and”, all of which would disappear by the time of Ashmole 61.
This article will report on my analysis of the Auchinleck Manuscript, in comparison with the Voynich manuscript.
An extract from folio 326r of the Auchinleck Manuscript. The first line reads: "Lord Ihesu, kyng of glorie". Image credit: National Library of Scotland.
For the purposes of the analysis, I assembled the first 2,330 lines of the Auchinleck Manuscript, converted all letters to lower case and removed all punctuation. This yielded a flat text file containing 59,323 words and 217,052 characters excluding spaces, which is comparable in size with the v101 transliteration of the Voynich manuscript.
Word length
In my extract from the Auchinleck Manuscript, the average word length is 3.66 letters. To make the equivalent calculation for the Voynich manuscript, I used my v101④ transliteration. This is based on Glen Claston’s v101 transliteration, but replaces all occurrences of the v101 string {4o} with the Unicode symbol ④. This yielded an average of 3.78 glyphs per “word”.
Glyph and letter frequencies
As I have mentioned in other articles on this platform, I have developed several alternative transliterations of the Voynich manuscript. Each was based on v101, but differed from v101 in one or more respects, combining certain groups of glyphs and/or disaggregating certain glyphs. For any given source document, in order to test which transliteration had the best statistical fit with the document, I used two alternative metrics, as follows:
• the correlation coefficient between the glyph frequencies (in descending order) and the letter frequencies (in descending order), as measured by R-squared (the RSQ function in Excel)The R-squared metric typically yields correlations of well over 90 percent for most of my transliterations and for most of the potential precursor languages. It is not difficult to find correlations of over 90 percent between two data sets each with twenty-five to thirty points of data, and both in descending order. However, the average frequency difference has a wider spread, typically in the range 0.3 percent to 1.0 percent, and thus appears a more sensitive metric.
• the average absolute difference between glyph frequencies and equally-ranked letter frequencies.
In order to have some assurance of referring to a single Voynich “language”, I calculated the glyph frequencies on the basis of the “herbal” section alone. In 1976, at Mary D’Imperio’s Voynich seminar, Captain Prescott Currier took the view that most of this section was written in what he called “Language A”. In the case of the v102 transliteration (of which, more below), for greater assurance I used only those pages of the “herbal” section written by Scribe 1 (as recently identified by Dr Lisa Fagin Davis). It seemed to me probable that each scribe would work from precursor documents in a single language. By my calculations, Scribe 1 wrote about 71 percent of the “herbal” section.
In the case of the Auchinleck manuscript, the best-fitting transliteration on both metrics was v102 (which I discussed briefly in Voynich Reconsidered). The correlation coefficient was 97.0 percent, and the average frequency difference was 0.54 percent. The v102 transliteration differs from v101④ in the following respects:
• the v101 glyphs {3}, {5}, {!}, {%}, {+} and {#} are equated with the visually similar glyph {2};One other transliteration seemed worthy of testing: the one that I numbered v171, which had a slightly lower correlation coefficient, at 95.7 percent, and a slightly higher average frequency difference, at 0.56 percent. The v171 transliteration differed from v101④ in only the following respect:
• the glyphs {6}, {7} and {&} are equated with the glyph {8};
• the glyph {(} is equated with the glyph {9};
• the glyph {A} is equated with the glyph {o};
• the glyphs {t} and {T} are equated with the glyph {s};
• the glyphs {x} and {X} are equated with the glyph {y};
• the glyphs m, M and N are disaggregated as follows: m = îń, M = iîń, n = iń (here I used î in place of the v101 {I}, and ń in place of the v101 {N}, to avoid issues of case-sensitivity in Excel or Word).
• the glyphs m, M and N are disaggregated as follows: m = îń, M = iîń, n = iń.The most frequent glyphs in the v101④, v102 and v171 transliterations, and the most frequent letters in the Auchinleck Manuscript, matched up as follows:
The five most frequent characters in the v101④, v102 and v171 transliterations, “herbal” section, and in the Auchinleck Manuscript, lines 1 to 2330. Scribe D1 is Scribe 1 as identified by Dr Lisa Fagin Davis. Author's analysis.
Mapping from the Voynich
The next step was to select suitable extracts from the Voynich manuscript, map them to text strings in Middle English, and see whether any of those strings were real English words. For this purpose, I selected the top five “words” of one to four glyphs in the v102 and v171 transliterations, “herbal” section. The v102 transliteration did not produce anything resembling English words, beyond a few words of a single letter or two letters, which could easily be by chance. The v171 transliteration yielded some glimmerings of possible meaning, but only with “words” of up to three glyphs, as shown below.
Provisional mappings of the top five "words" of one to four glyphs in the Voynich manuscript, v171 transliteration, "herbal" section, to Middle English as written in the 1330s. Author's analysis.
In summary, on these tests, we could reasonably draw the following conclusions (approximately in order of probability):
• that Middle English, as written in the 1330s, was not a precursor language of the Voynich manuscript (at least, not of the ”herbal” section);However, before abandoning Middle English as a potential precursor language, I again recall Mary D’Imperio’s “five states” and Massimiliano Zattera’s “slot alphabet”. Within the Voynich “words”, the glyphs are constrained to follow a narrowly defined sequence. Such a constraint is unknown in natural languages. Therefore, if the glyphs were mapped from natural languages, they are not in their original order.
• or that if it was, the precursor documents had a substantially different distribution of letter frequencies from that of the Auchinleck manuscript;
• or that if it was, our v171 transliteration, notwithstanding its good statistical fit, is not an accurate reflection of the way that the Voynich scribes mapped from letters to glyphs.
In another article on this platform, I gave the hypothetical example of a scribe mapping from the Italian word "con" to the glyph string {ma8}; but because this was not a permitted sequence, he reversed the order and wrote the familiar {8am}.
In the case of the Auchinleck manuscript and the v171 transliteration, we see a mapping of the “word” {oy} to the text string eþ, which is not an English word. However, one of the most common words in Middle English was þe (modern “the”), which occurs 2,101 times in the Auchinleck manuscript. If a scribe had mapped þe to glyphs using something like our v171, he would have come up with {yo}. This would not be a permitted sequence; and he would have written {oy}.
Another example: in v171, {8ay} maps to naþ, which is a Middle English word but a rare one. However, the word þan (modern “than”) occurs 303 times in the Auchinleck manuscript. If a scribe had mapped it to {ya8}, he would again be obliged to reverse the order and write {8ay}.
I am inclined to think that some more work on Middle English is justifiable. Next stop: Ashmole 61.
April 3, 2024
Voynich Reconsidered: 2 for 1
In the course of my research for Voynich Reconsidered (Schiffer Books, 2024), I developed several variants of Glen Claston’s v101 transliteration of the Voynich manuscript. The purpose of these alternative transliterations was to test the hypothesis that the glyphs in v101 might be interpreted in different ways.
For example, the v101 glyphs {2}, {3}, {5} and several others look as if they might be the same glyph; likewise, the glyphs {6}, {7}, {8} and {&} seem to have only minor differences. Conversely, v101 glyphs such as {m}, {n} and {z} look like they should be disaggregated into strings of smaller glyphs. And the glyph string {4o}, which is conventionally treated as two glyphs, is surely a single glyph, since {4} rarely appears on its own.
Using each of these alternative transliterations as a source document, and applying frequency analysis, I mapped the Voynich glyphs to letters in selected medieval European languages. In some cases, these mappings yielded text strings that were real words in the selected languages.
Corpora of reference
The selection of those languages was a matter of trial and error, as well as of availability of corpora of reference. I was guided by the distance-decay hypothesis, which favored languages spoken and written in medieval Italy (such as Tuscan-Italian and Latin), and in nearby countries. Also, the correlations of glyph frequencies and letter frequencies gave some guidance as to which transliterations, and which precursor languages, were more encouraging than others.
I suspected that the precursor documents (especially in Italian or Latin) might have been in abbreviated scripts, but machine-readable corpora of abbreviated medieval texts appeared to be non-existent. I created an abbreviated Latin version of Dante's De Monarchia, drawing upon Cappelli's Lexicon Abbreviaturarum; and an abbreviated Italian version of La Divina Commedia, based on the observable abbreviations on the first page of the first printed edition, published in Foligno in 1472. In that edition, all modern accents disappear; the modern "v" becomes "u"; and there are relatively few doubled letters.
Examples of abbreviations and spelling conventions in the 1472 Foligno edition of La Divina Commedia. Author's analysis.
Each of my alternative transliterations has a different set of glyph frequencies from that of the original v101. For the most common Voynich glyphs, there are relatively good matches (in terms of frequencies) for the most common letters in European languages. However, when we get down to the less common glyphs, there is much more uncertainty in the matching of frequencies. Considerations such as this prompted me to wonder whether certain glyphs should be redefined.
{2} and its variants
The v101 glyph {1} is the fifth most common in the Voynich manuscript, with a frequency of 7.0 percent. What I find intriguing about {1} is that it is the leader of a family of eight glyphs, in which each of the other seven glyphs consists of a {1} with what looks like a superscript or diacritic. These superscripts might be some form of abbreviation – perhaps they represent omitted vowels or consonants – or else some form of punctuation. If so, we could redefine {2} and each of its variants as {1} plus superscript (for the moment, treating all the superscripts as the same).
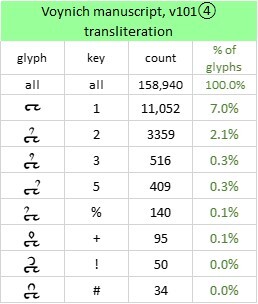
The {1} family of glyphs in the Voynich manuscript, v101 transliteration. Author’s analysis.
(In passing we may note that the v101 glyph {#} bears a resemblance to the Foligno ligature "ct", which the English printer William Caslon (1692-1766) later copied in his famous Caslon font. It is of course tempting to equate {#} with the "ct" ligature, but the frequencies do not come close to matching; the Foligno “ct” is quite common, but the glyph {#} is rare.)

The Foligno "ct" ligature, Caslon's "ct", and the v101 glyph {#}. Images: public domain.
To this end, I developed what I called the v121 transliteration, in which {2} and its variants were thus redefined. This increased the frequency of the glyph {1} from 7.0 percent to 9.8 percent, making it the third most common glyph. (Therefore, if the Voynich glyphs had been mapped one-to-one from letters in natural languages, {1} would probably represent a vowel.) Among the most common glyphs, the frequencies changed as follows:
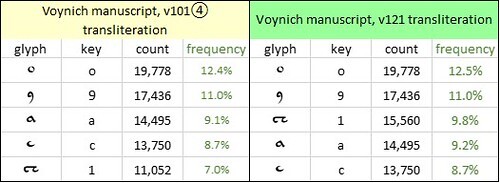
The five most frequent glyphs in the v101④ and v121 transliterations. Author's analysis.
Testing v121
In order to test the v121 transliteration, my first step was to examine which natural languages had the best statistical fit with this transliteration. I compared glyph frequencies with letter frequencies, using two alternative metrics (as outlined in other posts on this platform): the correlation coefficient, and the average frequency difference. The results are summarised below.
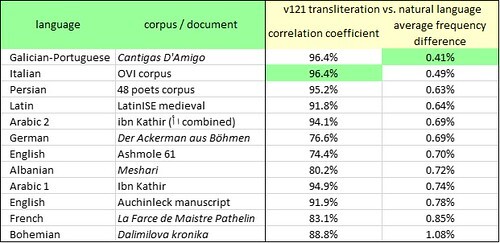
A comparison of the glyph frequencies in the Voynich manuscript, v121 transliteration, and the letter frequencies in selected medieval languages. Author’s analysis.
Here we see that medieval Galician-Portuguese and Italian are the best-fitting languages (depending on which metric we use).
The next step was to line up the glyph frequencies in v121 with the letter frequencies in Galician-Portuguese and Italian, creating a provisional glyph-to-letter mapping. For this purpose, for some assurance of mapping from a single Voynich “language”, I used the glyph frequencies in the “herbal” section. A frequency comparison for the top ten glyphs and letters is shown below.
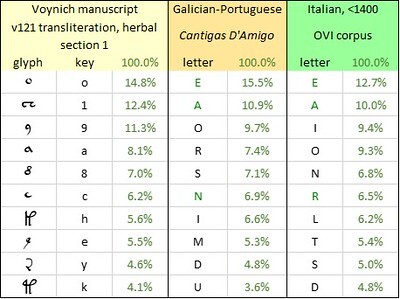
The top ten glyphs in the Voynich manuscript, v121 transliteration, “herbal” section (as defined by Zandbergen); and the top ten letters in medieval Galician-Portuguese and Italian. Author’s analysis.
The next step was to map the most frequent Voynich “words” into Galician-Portuguese and Italian, and see whether the results made any sense. Here, as in other mappings that I have tested, I selected the five most frequent “words” of one, two, three and four glyphs. A summary of the results for Italian is below.
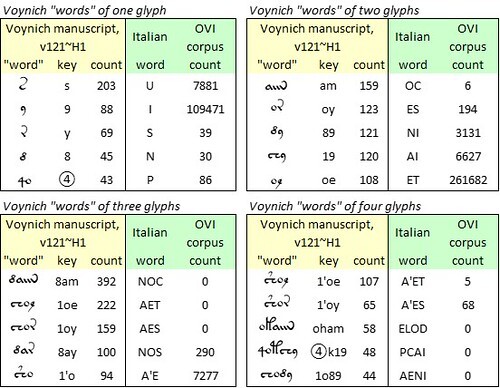
Voynich manuscript, v121 transliteration, “herbal” section: the most common “words” of one to four glyphs; and raw mappings to medieval Italian. Author’s analysis.
Here, I detected a phenomenon that was evident in other mappings that I tried, from Voynich transliterations to selected medieval languages. For very short Voynich “words”, of one of two glyphs, the mapping yielded real words in Italian. But this could be pure chance or coincidence. For “words” of three or four glyphs, the mapping tended to break down.
At this point, it seemed that D’Imperio’s “five states” and Zattera’s “slot alphabet” might come to the rescue. As I have observed in several other articles on this platform, D’Imperio’s and Zattera’s findings are persuasive evidence that the Voynich scribes re-ordered the glyphs in some way. Specifically, the order of the glyphs within “words” is so inflexible that we are compelled to conjecture that the glyphs are not in their original order.
If this was the case, then we have to imagine what sequences of letters in the precursor languages could have yielded the “words” that we see in the Voynich manuscript. That is: we have to look for anagrams. This is a process to be attempted with great caution, since anagrams can lead us into a world of subjectivity. A word of just four letters has twenty-four anagrams; a word of five letters has 120. If we accept any anagram of a five-letter word, we permit ourselves 120 degrees of freedom.
However, an anagram has to make sense. It has to be a real word, and a common one. We have to find it in a corpus of the precursor language, and it has to occur with a reasonable frequency. Ultimately, if we generate a string of anagrams, the sequence has to make sense.
Here, I turned to the OVI corpus of medieval Italian. OVI stands for Opera del Vocabolario Italiano. It is the largest database of the Italian language as used before 1400. Currently, the corpus contains 3,443 texts with 30,245,108 words. In cases where my raw mappings of Voynich “words” did not yield real Italian words, I looked for plausible and pronounceable anagrams and searched for occurrences of these anagrams in the OVI corpus. A summary of the results is below.
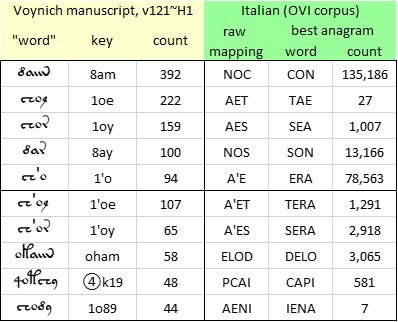
Voynich manuscript, v121 transliteration, “herbal” section: trial mappings of selected “words” to medieval Italian. Author’s analysis.
To my mind, what was encouraging about this process is that it lent support to the hypothesis that the Voynich scribes re-ordered the glyphs in some or all of the Voynich “words”. To take just one example: if a scribe came across the ubiquitous Italian word “con” (in English: “with”); and if the mapping that he used was something like my v121 transliteration; then he would map the Italian word to the Voynich “word” {ma8}. But on the wall or desk of the workplace, the producer had affixed a rule that this was not a permitted order of glyphs within a “word”; the order had to be {8am}. Accordingly, this is what the scribe wrote down.
In these mappings, I can see some evidence that the re-ordering rule might have been even more basic. The rule might have been simply to reverse the order of the glyphs in every “word”. This looks like what the scribe did to arrive at {8am}; also {8ay}; possibly also {2oe} and {2oy}.
This is by no means the end of the story. My v121 transliteration is a simple variant of v101; it is not necessarily the right one. But it lends weight to the hypothesis that {2} and its sister glyphs are variants of {1}. To take this hypothesis further, I will need to map more “words”, and in due course, lines of Voynich text; and the mappings will have to make sense. On this, more later.
For example, the v101 glyphs {2}, {3}, {5} and several others look as if they might be the same glyph; likewise, the glyphs {6}, {7}, {8} and {&} seem to have only minor differences. Conversely, v101 glyphs such as {m}, {n} and {z} look like they should be disaggregated into strings of smaller glyphs. And the glyph string {4o}, which is conventionally treated as two glyphs, is surely a single glyph, since {4} rarely appears on its own.
Using each of these alternative transliterations as a source document, and applying frequency analysis, I mapped the Voynich glyphs to letters in selected medieval European languages. In some cases, these mappings yielded text strings that were real words in the selected languages.
Corpora of reference
The selection of those languages was a matter of trial and error, as well as of availability of corpora of reference. I was guided by the distance-decay hypothesis, which favored languages spoken and written in medieval Italy (such as Tuscan-Italian and Latin), and in nearby countries. Also, the correlations of glyph frequencies and letter frequencies gave some guidance as to which transliterations, and which precursor languages, were more encouraging than others.
I suspected that the precursor documents (especially in Italian or Latin) might have been in abbreviated scripts, but machine-readable corpora of abbreviated medieval texts appeared to be non-existent. I created an abbreviated Latin version of Dante's De Monarchia, drawing upon Cappelli's Lexicon Abbreviaturarum; and an abbreviated Italian version of La Divina Commedia, based on the observable abbreviations on the first page of the first printed edition, published in Foligno in 1472. In that edition, all modern accents disappear; the modern "v" becomes "u"; and there are relatively few doubled letters.
Examples of abbreviations and spelling conventions in the 1472 Foligno edition of La Divina Commedia. Author's analysis.
Each of my alternative transliterations has a different set of glyph frequencies from that of the original v101. For the most common Voynich glyphs, there are relatively good matches (in terms of frequencies) for the most common letters in European languages. However, when we get down to the less common glyphs, there is much more uncertainty in the matching of frequencies. Considerations such as this prompted me to wonder whether certain glyphs should be redefined.
{2} and its variants
The v101 glyph {1} is the fifth most common in the Voynich manuscript, with a frequency of 7.0 percent. What I find intriguing about {1} is that it is the leader of a family of eight glyphs, in which each of the other seven glyphs consists of a {1} with what looks like a superscript or diacritic. These superscripts might be some form of abbreviation – perhaps they represent omitted vowels or consonants – or else some form of punctuation. If so, we could redefine {2} and each of its variants as {1} plus superscript (for the moment, treating all the superscripts as the same).
The {1} family of glyphs in the Voynich manuscript, v101 transliteration. Author’s analysis.
(In passing we may note that the v101 glyph {#} bears a resemblance to the Foligno ligature "ct", which the English printer William Caslon (1692-1766) later copied in his famous Caslon font. It is of course tempting to equate {#} with the "ct" ligature, but the frequencies do not come close to matching; the Foligno “ct” is quite common, but the glyph {#} is rare.)
The Foligno "ct" ligature, Caslon's "ct", and the v101 glyph {#}. Images: public domain.
To this end, I developed what I called the v121 transliteration, in which {2} and its variants were thus redefined. This increased the frequency of the glyph {1} from 7.0 percent to 9.8 percent, making it the third most common glyph. (Therefore, if the Voynich glyphs had been mapped one-to-one from letters in natural languages, {1} would probably represent a vowel.) Among the most common glyphs, the frequencies changed as follows:
The five most frequent glyphs in the v101④ and v121 transliterations. Author's analysis.
Testing v121
In order to test the v121 transliteration, my first step was to examine which natural languages had the best statistical fit with this transliteration. I compared glyph frequencies with letter frequencies, using two alternative metrics (as outlined in other posts on this platform): the correlation coefficient, and the average frequency difference. The results are summarised below.
A comparison of the glyph frequencies in the Voynich manuscript, v121 transliteration, and the letter frequencies in selected medieval languages. Author’s analysis.
Here we see that medieval Galician-Portuguese and Italian are the best-fitting languages (depending on which metric we use).
The next step was to line up the glyph frequencies in v121 with the letter frequencies in Galician-Portuguese and Italian, creating a provisional glyph-to-letter mapping. For this purpose, for some assurance of mapping from a single Voynich “language”, I used the glyph frequencies in the “herbal” section. A frequency comparison for the top ten glyphs and letters is shown below.
The top ten glyphs in the Voynich manuscript, v121 transliteration, “herbal” section (as defined by Zandbergen); and the top ten letters in medieval Galician-Portuguese and Italian. Author’s analysis.
The next step was to map the most frequent Voynich “words” into Galician-Portuguese and Italian, and see whether the results made any sense. Here, as in other mappings that I have tested, I selected the five most frequent “words” of one, two, three and four glyphs. A summary of the results for Italian is below.
Voynich manuscript, v121 transliteration, “herbal” section: the most common “words” of one to four glyphs; and raw mappings to medieval Italian. Author’s analysis.
Here, I detected a phenomenon that was evident in other mappings that I tried, from Voynich transliterations to selected medieval languages. For very short Voynich “words”, of one of two glyphs, the mapping yielded real words in Italian. But this could be pure chance or coincidence. For “words” of three or four glyphs, the mapping tended to break down.
At this point, it seemed that D’Imperio’s “five states” and Zattera’s “slot alphabet” might come to the rescue. As I have observed in several other articles on this platform, D’Imperio’s and Zattera’s findings are persuasive evidence that the Voynich scribes re-ordered the glyphs in some way. Specifically, the order of the glyphs within “words” is so inflexible that we are compelled to conjecture that the glyphs are not in their original order.
If this was the case, then we have to imagine what sequences of letters in the precursor languages could have yielded the “words” that we see in the Voynich manuscript. That is: we have to look for anagrams. This is a process to be attempted with great caution, since anagrams can lead us into a world of subjectivity. A word of just four letters has twenty-four anagrams; a word of five letters has 120. If we accept any anagram of a five-letter word, we permit ourselves 120 degrees of freedom.
However, an anagram has to make sense. It has to be a real word, and a common one. We have to find it in a corpus of the precursor language, and it has to occur with a reasonable frequency. Ultimately, if we generate a string of anagrams, the sequence has to make sense.
Here, I turned to the OVI corpus of medieval Italian. OVI stands for Opera del Vocabolario Italiano. It is the largest database of the Italian language as used before 1400. Currently, the corpus contains 3,443 texts with 30,245,108 words. In cases where my raw mappings of Voynich “words” did not yield real Italian words, I looked for plausible and pronounceable anagrams and searched for occurrences of these anagrams in the OVI corpus. A summary of the results is below.
Voynich manuscript, v121 transliteration, “herbal” section: trial mappings of selected “words” to medieval Italian. Author’s analysis.
To my mind, what was encouraging about this process is that it lent support to the hypothesis that the Voynich scribes re-ordered the glyphs in some or all of the Voynich “words”. To take just one example: if a scribe came across the ubiquitous Italian word “con” (in English: “with”); and if the mapping that he used was something like my v121 transliteration; then he would map the Italian word to the Voynich “word” {ma8}. But on the wall or desk of the workplace, the producer had affixed a rule that this was not a permitted order of glyphs within a “word”; the order had to be {8am}. Accordingly, this is what the scribe wrote down.
In these mappings, I can see some evidence that the re-ordering rule might have been even more basic. The rule might have been simply to reverse the order of the glyphs in every “word”. This looks like what the scribe did to arrive at {8am}; also {8ay}; possibly also {2oe} and {2oy}.
This is by no means the end of the story. My v121 transliteration is a simple variant of v101; it is not necessarily the right one. But it lends weight to the hypothesis that {2} and its sister glyphs are variants of {1}. To take this hypothesis further, I will need to map more “words”, and in due course, lines of Voynich text; and the mappings will have to make sense. On this, more later.
March 29, 2024
Voynich Reconsidered: punctuation or junk
In recent articles on this platform, and in my bookVoynich Reconsidered (Schiffer Publishing, 2024), I alluded to two phenomena that I had detected in the text of the Voynich manuscript. They are as follows:
Glyphs as punctuation
If some of the glyphs represent punctuation in the precursor documents, we need to find some means of distinguishing them from glyphs that represent letters.
Here, frequency analysis might be a useful tool.
I am inclined again to turn to some of my favorite medieval documents: Dante’s La Divina Commedia (Italian) and Monarchia (Latin); Meshari (Albanian), Dalimilova kronika (Bohemian), the Auchinleck manuscript (English), La Farce de Maistre Pathelin (French), Cantigas d'Amigo (Galician-Portuguese), and Der Ackermann aus Böhmen (German). In these documents, punctuation accounts for between 3.2 percent and 6.9 percent of the characters.
In the v101 transliteration of the Voynich manuscript, there are 158,940 glyphs and 40,706 “words”, of which 1,948 are single-glyph “words” and 38,758 have “initial” glyphs and “final” glyphs. Thus “initial” glyphs alone account for 24.3 percent of all the glyphs: which seems far too many to represent punctuation.
To my mind, if there is punctuation in the Voynich manuscript, it resides in some smaller set of glyphs. Conceivably, certain glyphs with frequencies of between 0.1 and 2.0 percent are punctuation marks, for example the following:

The most common punctuation marks in selected medieval documents; and some Voynich glyphs with comparable frequencies. In both cases, frequencies are expressed relative to the character total, excluding spaces. Author’s analysis.
The glyph {2} and its variants are particularly interesting, since each of them looks like the glyph {1} with a diacritic or superscript. Perhaps the diacritic itself is the punctuation mark.
Glyphs as junk
In a previous post, I assembled my calculations of the incidence of hapax legomena (words which occur only once) in the Voynich manuscript and other medieval documents. The idea is that hapax legomena is an indicator of the presence of gibberish (or junk). For a given length of document, the higher the incidence of hapax legomena, the more likely that the document is junk, or contains junk.
In that post, I reported that the v101 transliteration of the Voynich manuscript, with 40,706 “words”, had a 16.5 percent incidence of hapax legomena. I took extracts of about 40,000 words from seven medieval literary documents, in Albanian, English, Galician-Portuguese and Italian. These extracts had incidences of hapax legomena ranging from 2.7 percent to 11.8 percent.
Since by this metric the Voynich manuscript was an outlier, I saw here some evidence that the manuscript might contain text without meaningful content: that is, junk.
The question is then: how do we identify junk in the Voynich manuscript?
Random or systematic junk?
It seems to me that if there is junk in the Voynich manuscript, we need to know whether it is random. An example in the English language might illustrate. Let us take the first six words of the Gettysburg Address, and insert random letters at random locations: in both cases, using the RAND() function in Excel to generate randomness. Here is one possible result:
However, there is a possibility that if there is junk in the Voynich manuscript, we can detect it before we know the precursor language or the mapping system. This possibility would arise if the junk had been inserted systematically.
Let us transport ourselves in time and space to the moment of conception of the Voynich manuscript. It could be fifteenth-century Italy, or it could be another date and place; it does not matter. There was a producer who commissioned the manuscript. This person was wealthy: sufficiently so to engage a team of scribes for a period of months or years, and to pay for the vellum from at least fifteen calfskins, and for all the other materials and supplies that the scribes would need.
The scribes would be professionals; their job was to write, for payment, whatever their clients wished to be written. They would not be authors or creators of content. Therefore, the producer had to provide, either precursor documents in languages or scripts which the scribes could read; or a person who could read such documents and could dictate their content to the scribes, and would remain at the workplace with the scribes until the job was done.
If the producer wanted junk to be inserted in the manuscript, he or she would give instructions to the scribes as to how this should be done. Those instructions had to be systematic. Having given them, the producer would go away, to attend to business, or to matters of court, or whatever was his or her source of wealth or power. The scribes would go to work, and the producer would return in due course to collect the finished manuscript.
Herein, to my mind, lies our hope of simplifying or cleaning the Voynich manuscript, if such a process is required. Our task is to recreate the producer’s instructions to the scribes.
I can imagine at least three ways of instructing the scribes to incorporate systematic junk:
I can think of at least one test for identifying systematic junk in the Voynich manuscript. If such junk exists, removing it should preserve the meaningful content. The incidence of hapax legomena is one indicator of the presence of meaning. Therefore, we can take any suitable transliteration of the manuscript, and execute processes such as the following:
I am working on some tests of this nature. More later.
• the well-documented “marching order” of the glyphs within Voynich “words”: first identified by Mary D’Imperio around 1978 in a classified paper for the National Security Agency, and restated in quantitative terms by Massimiliano Zattera at the Voynich 2022 conference;These two phenomena are not necessarily related. But they might be. I have conjectured that they could be interpreted in at least the following ways:
• what I call the “truncation effect”: the phenomenon whereby we can remove the initial and final glyphs from every Voynich “word”, and apparently (at least as measured by the incidence of hapax legomena), retain any meaning that exists within the text.
• as evidence that the Voynich scribes mapped from letters in precursor languages to glyphs; and then, in each Voynich “word”, sorted the glyphs in a prescribed order (which, centuries later, D’Imperio would call the “five states”, and Zattera would characterise as the “slot alphabet”)These interpretations are not mutually exclusive. It could be that the glyphs are ordered within “words”, in some kind of sequence that, in a natural language, we would call alphabetical; and also, that some of the “initial” and “final” glyphs are meaningless fillers, or junk.
• as evidence that in each Voynich “word” (or in some of the “words”) the initial and final glyphs have no semantic meaning: that is, they are either some form of punctuation, or possibly junk.
Glyphs as punctuation
If some of the glyphs represent punctuation in the precursor documents, we need to find some means of distinguishing them from glyphs that represent letters.
Here, frequency analysis might be a useful tool.
I am inclined again to turn to some of my favorite medieval documents: Dante’s La Divina Commedia (Italian) and Monarchia (Latin); Meshari (Albanian), Dalimilova kronika (Bohemian), the Auchinleck manuscript (English), La Farce de Maistre Pathelin (French), Cantigas d'Amigo (Galician-Portuguese), and Der Ackermann aus Böhmen (German). In these documents, punctuation accounts for between 3.2 percent and 6.9 percent of the characters.
In the v101 transliteration of the Voynich manuscript, there are 158,940 glyphs and 40,706 “words”, of which 1,948 are single-glyph “words” and 38,758 have “initial” glyphs and “final” glyphs. Thus “initial” glyphs alone account for 24.3 percent of all the glyphs: which seems far too many to represent punctuation.
To my mind, if there is punctuation in the Voynich manuscript, it resides in some smaller set of glyphs. Conceivably, certain glyphs with frequencies of between 0.1 and 2.0 percent are punctuation marks, for example the following:
The most common punctuation marks in selected medieval documents; and some Voynich glyphs with comparable frequencies. In both cases, frequencies are expressed relative to the character total, excluding spaces. Author’s analysis.
The glyph {2} and its variants are particularly interesting, since each of them looks like the glyph {1} with a diacritic or superscript. Perhaps the diacritic itself is the punctuation mark.
Glyphs as junk
In a previous post, I assembled my calculations of the incidence of hapax legomena (words which occur only once) in the Voynich manuscript and other medieval documents. The idea is that hapax legomena is an indicator of the presence of gibberish (or junk). For a given length of document, the higher the incidence of hapax legomena, the more likely that the document is junk, or contains junk.
In that post, I reported that the v101 transliteration of the Voynich manuscript, with 40,706 “words”, had a 16.5 percent incidence of hapax legomena. I took extracts of about 40,000 words from seven medieval literary documents, in Albanian, English, Galician-Portuguese and Italian. These extracts had incidences of hapax legomena ranging from 2.7 percent to 11.8 percent.
Since by this metric the Voynich manuscript was an outlier, I saw here some evidence that the manuscript might contain text without meaningful content: that is, junk.
The question is then: how do we identify junk in the Voynich manuscript?
Random or systematic junk?
It seems to me that if there is junk in the Voynich manuscript, we need to know whether it is random. An example in the English language might illustrate. Let us take the first six words of the Gettysburg Address, and insert random letters at random locations: in both cases, using the RAND() function in Excel to generate randomness. Here is one possible result:
fohurqo scgarkorltesd apnddl sdecvujenho yealrss akgjok.Although this sequence looks like gibberish, a careful reading will extricate the words:
four score and seven years ago.A reader of English can do this. But there is no-one who reads the Voynich script. Therefore, I think, if the Voynich text contains random sequences of junk, of random length, the only way to detect such junk is first to map the Voynich text successfully to a natural language. Thereafter, a speaker or reader of that language will have a chance of distinguishing the content from the junk.
However, there is a possibility that if there is junk in the Voynich manuscript, we can detect it before we know the precursor language or the mapping system. This possibility would arise if the junk had been inserted systematically.
Let us transport ourselves in time and space to the moment of conception of the Voynich manuscript. It could be fifteenth-century Italy, or it could be another date and place; it does not matter. There was a producer who commissioned the manuscript. This person was wealthy: sufficiently so to engage a team of scribes for a period of months or years, and to pay for the vellum from at least fifteen calfskins, and for all the other materials and supplies that the scribes would need.
The scribes would be professionals; their job was to write, for payment, whatever their clients wished to be written. They would not be authors or creators of content. Therefore, the producer had to provide, either precursor documents in languages or scripts which the scribes could read; or a person who could read such documents and could dictate their content to the scribes, and would remain at the workplace with the scribes until the job was done.
If the producer wanted junk to be inserted in the manuscript, he or she would give instructions to the scribes as to how this should be done. Those instructions had to be systematic. Having given them, the producer would go away, to attend to business, or to matters of court, or whatever was his or her source of wealth or power. The scribes would go to work, and the producer would return in due course to collect the finished manuscript.
Herein, to my mind, lies our hope of simplifying or cleaning the Voynich manuscript, if such a process is required. Our task is to recreate the producer’s instructions to the scribes.
I can imagine at least three ways of instructing the scribes to incorporate systematic junk:
• to add one random glyph (or more than one, but some prescribed number) at some defined position or positions (for example, the beginning or end of every “word”, or line, or paragraph)In all cases, the producer would have to instruct the scribes as to how much flexibility they were permitted; whether or not to preserve word breaks in the precursor documents; and above all, how to order the glyphs within the “words”, so as to create the “marching order” that D’Imperio would discover and Zattera would quantify.
• to define certain glyphs as meaningless, and to insert them at prescribed positions
• to define certain glyphs as meaningless, but only when used in certain positions within the “word”, line or paragraph.
I can think of at least one test for identifying systematic junk in the Voynich manuscript. If such junk exists, removing it should preserve the meaningful content. The incidence of hapax legomena is one indicator of the presence of meaning. Therefore, we can take any suitable transliteration of the manuscript, and execute processes such as the following:
• remove all “initial” glyphs, or all “final” glyphs, or bothand in each case, calculate the incidence of hapax legomena in the truncated document. The process which yields the lowest incidence of hapax legomena might be the cleaning process that removes the junk and leaves the content.
• remove specific glyphs: for example, all occurrences of {4o} or {9}, wherever they may occur
• remove specific glyphs, but only in specific positions in the “word”: for example, all occurrences of {9} as a “final” glyph;
I am working on some tests of this nature. More later.
March 28, 2024
Voynich Reconsidered: the “truncation effect” (Part 2)
For a quick test of the “truncation effect”, I selected a concise and manageable document: Abraham Lincoln’s “Gettysburg Address”. This is of course a very short text, indeed famous for its brevity; and for that reason, not directly comparable with the Voynich manuscript.
My copy of Lincoln’s celebrated speech contains 268 words. There are ninety-three words, or 34.7 percent of the word count, which are used only once: they are hapax legomena. Examples are: battlefield, consecrated, government.

Image credit: Library of Congress / Getty Images.
If we now apply an alphabetic sorting of letters within words, the first line (for example) changes from:
The test for hapax legomena tells us that this document is, in some sense, meaningful, even if the meaning is not apparent in the words as they now appear.
Removal of initial letters
If we now remove the initial letter of every word, the first line becomes:
Examples of hapax legomena in the truncated document include: “cceenorst” (derived from “consecrate”), “ghortu” (derived from “brought”), and efhrst (derived from “fathers”). In words such as these, we see echoes of the rigid order of glyphs, as well as the occasional doubled glyphs, in the Voynich manuscript.
It seems to me a significant result, that following the alphabetic sorting of letters within words, removing initial letters does not increase the incidence of hapax legomena. The test is telling us that there is still meaning in the remaining text.
My copy of Lincoln’s celebrated speech contains 268 words. There are ninety-three words, or 34.7 percent of the word count, which are used only once: they are hapax legomena. Examples are: battlefield, consecrated, government.
Image credit: Library of Congress / Getty Images.
If we now apply an alphabetic sorting of letters within words, the first line (for example) changes from:
“Four score and seven years ago, our fathers brought forth on this continent …”to:
“foru ceors adn eensv ago oru aefhrst bghortu fhort no hist ceinnnott …”The modified document has the same set of words that occur only once; only the interior order of the words has changed. Thus the incidence of hapax legomena remains the same, at ninety-three words or 34.7 percent of the text.
The test for hapax legomena tells us that this document is, in some sense, meaningful, even if the meaning is not apparent in the words as they now appear.
Removal of initial letters
If we now remove the initial letter of every word, the first line becomes:
“oru eors dn ensv go ru efhrst ghortu hort o ist einnnott …”Here the alphabetic order of the letters is preserved, but the vocabulary is reduced. For example, the words “as” and “is” in the original, which remained distinct in the sorted version, now both become “s”. The truncated document has eighty-six words which are hapax legomena; they constitute 32.1 percent of the text.
Examples of hapax legomena in the truncated document include: “cceenorst” (derived from “consecrate”), “ghortu” (derived from “brought”), and efhrst (derived from “fathers”). In words such as these, we see echoes of the rigid order of glyphs, as well as the occasional doubled glyphs, in the Voynich manuscript.
It seems to me a significant result, that following the alphabetic sorting of letters within words, removing initial letters does not increase the incidence of hapax legomena. The test is telling us that there is still meaning in the remaining text.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

