
Voynich Reconsidered: Exon Domesday (part 3)
In a previous article on this platform, I reported on my reconstruction of the Latin abbreviations in the English manuscript Exon Domesday, probably written in 1087. I worked from the expanded transcription by Dr Frank Thorn, Visiting Fellow at King's College London. My sample so far has 5,498 characters including letters and abbreviation symbols.
Although the sample is small, the frequency distributions of the abbreviated Exon Domesday are already shaping up to be very different from those of the Voynich manuscript.
In the frequencies of the characters, we see an egregious presence of the lower-case “i”, largely as a result of its occurrence as a vowel within words, and also as the Roman numeral for 1 (which, as far as I can tell from the manuscript, is written identically). If the Voynich producer had given the scribes a set of Latin documents containing “i” as both letter and number, I imagine that he or she would have instructed them to treat both forms the same way. Any other instruction, I think, would have increased the requirement for quality control; I imagine the producer as desiring the scribes to work with minimal supervision.
So far, among my alternative transliterations of the Voynich manuscript, the best statistical fit with Exon Domesday is v102, for which the correlation between glyph frequencies and character frequencies is 85.0 percent. This is relatively low by comparison with the results that I have obtained for texts in unabbreviated natural languages.
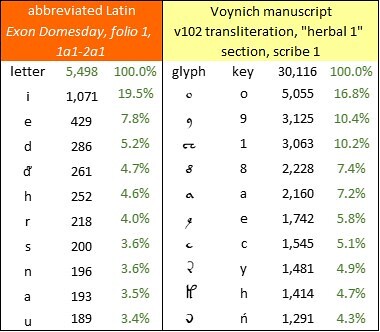
The ten most frequent characters in the abbreviated Exon Domesday, sections 1a1-2a1; and the ten most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As for the frequencies of the "words": in Exon Domesday the single-letter “word” “&” is by far the most frequent. This seems to me partly the consequence of the natural frequency of the precursor word “et” in medieval Latin, as illustrated by the LatinISE subcorpus. The second most frequent “word” is “hiᵭ”, the abbreviation for “hidas” or “hidis” (from “hida”, a measure of land area). In both cases, the frequencies are partly a reflection of the highly repetitive nature of Exon Domesday.
The ”words” in Exon Domesday conform closely to Zipf’s Law, with a correlation of 94.1 percent between the actual word counts and those predicted by the Zipf sequence. The incidence of hapax legomena (“words” occurring only once) is 65.1 percent of the vocabulary, which in my understanding is normal for a medieval document in a natural language.
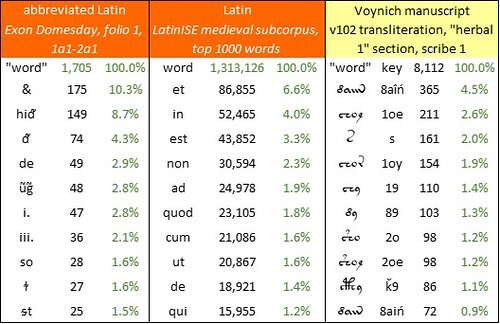
The ten most frequent "words" in the abbreviated Exon Domesday, sections 1a1-2a1 (written in 1087?); in the LatinISE corpus, medieval subcorpus (seventh to fourteenth centuries); and in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As to whether any plausible mapping exists between common “words” in Exon Domesday and in the Voynich manuscript: this hypothesis will have to await a larger sample of text.
Although the sample is small, the frequency distributions of the abbreviated Exon Domesday are already shaping up to be very different from those of the Voynich manuscript.
In the frequencies of the characters, we see an egregious presence of the lower-case “i”, largely as a result of its occurrence as a vowel within words, and also as the Roman numeral for 1 (which, as far as I can tell from the manuscript, is written identically). If the Voynich producer had given the scribes a set of Latin documents containing “i” as both letter and number, I imagine that he or she would have instructed them to treat both forms the same way. Any other instruction, I think, would have increased the requirement for quality control; I imagine the producer as desiring the scribes to work with minimal supervision.
So far, among my alternative transliterations of the Voynich manuscript, the best statistical fit with Exon Domesday is v102, for which the correlation between glyph frequencies and character frequencies is 85.0 percent. This is relatively low by comparison with the results that I have obtained for texts in unabbreviated natural languages.
The ten most frequent characters in the abbreviated Exon Domesday, sections 1a1-2a1; and the ten most frequent glyphs in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As for the frequencies of the "words": in Exon Domesday the single-letter “word” “&” is by far the most frequent. This seems to me partly the consequence of the natural frequency of the precursor word “et” in medieval Latin, as illustrated by the LatinISE subcorpus. The second most frequent “word” is “hiᵭ”, the abbreviation for “hidas” or “hidis” (from “hida”, a measure of land area). In both cases, the frequencies are partly a reflection of the highly repetitive nature of Exon Domesday.
The ”words” in Exon Domesday conform closely to Zipf’s Law, with a correlation of 94.1 percent between the actual word counts and those predicted by the Zipf sequence. The incidence of hapax legomena (“words” occurring only once) is 65.1 percent of the vocabulary, which in my understanding is normal for a medieval document in a natural language.
The ten most frequent "words" in the abbreviated Exon Domesday, sections 1a1-2a1 (written in 1087?); in the LatinISE corpus, medieval subcorpus (seventh to fourteenth centuries); and in the Voynich manuscript, v102 transliteration, “herbal 1” section, pages written by Scribe 1. Author’s analysis.
As to whether any plausible mapping exists between common “words” in Exon Domesday and in the Voynich manuscript: this hypothesis will have to await a larger sample of text.


No comments have been added yet.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

