
Gordon Rugg's Blog, page 20
March 19, 2014
Visions of course structure
By Gordon Rugg
There’s a long-running debate in education about course structure. The debate tends to be polarised by visions of a stark choice between total control on the one hand, and total chaos on the other hand.
The Brueghel painting below sums those visions up pretty well, with its depiction of embattled educators striving against the forces of darkness and chaos.
However, the reality is more complex, and also more useful.

Image from wikimedia
The “total control” model can be shown diagramatically like this.

In this model, the course consists only of the topics represented as dark blue circles, which have to be covered in the prescribed sequence.
People who argue for this model tend to make the implicit assumption that the only other possibility is complete chaos, like the image below.

In this model, the student can do whichever components they want, in whichever sequence they want, and with no constraints on the number of components they take or on the amount of time that they take.
However, those aren’t the only possible options. There are others, such as the one below.

This image shows a model commonly used in student-centred learning, where there is a prescribed set of content (i.e. only the dark blue modules) but where there are no constraints on the sequence in which those topics are covered.
The student-centred model is often misunderstood. One common misconception is that it does not involve any restrictions on the content of the course. As the diagram above shows, this is not necessarily the case; it’s perfectly possible to use student-centred learning in combination with a completely constrained set of topics.
Another common misconception is that a course needs to be covered in a particular sequence so that the students learn foundational concepts before moving on to higher-level concepts that build on those foundations. This sounds plausible, but it’s a simplification that doesn’t take account of the realities of how students actually learn. That’s a big topic that goes outside the scope of this article; I’ll return to it in later articles.
Returning to models of course structure, another common model is of a core set of topics, plus an option chosen from a limited set of closely related topics, as in the diagram below.

An example would be a student on a maths degree course who chooses to do an optional module on statistics.
A related, but not identical, model involves a core set of content, plus a broader set of options, that include topics quite different from the core content, as in the figure below.

An example of this would be a history student who does one optional module on politics and another optional module on fine art.
So, in summary, structure in a course does not need to mean rigid control of every aspect of the content and sequence, and student choice does not need to mean chaos and anarchy. There are other ways of tackling the issue.
I’ll stop here, on that encouraging note. I’ll return to the issue of student learning in later articles.
Notes
The Brueghel painting is from here: https://commons.wikimedia.org/wiki/File:Pieter_Bruegel_the_Elder_-_The_Fall_of_the_Rebel_Angels_-_Google_Art_Project.jpg
The Hyde & Rugg images above are copyleft; you’re welcome to use them for any non-commercial purpose, including lectures, provided that you retain the Hyde & Rugg copyleft attribution.




March 15, 2014
Data, information, knowledge and wisdom: The knowledge pyramid
By Gordon Rugg
Definitions of terms relating to knowledge have been debated for centuries. Here’s one simple way of categorising some key concepts, in a diagram.

Different disciplines use the terms above in slightly different ways, but the core principle is widely used in various fields.
Here are some examples of how these concepts can be applied to education.
Wisdom: Knowing why different schools of history view the significance of the Battle of Edgehill in different ways.
Knowledge: Knowing that both sides at the Battle of Edgehill were inexperienced and poorly trained.
Information: Knowing the comparative figures for cavalry, infantry etc in the Parliamentarian and Royalist armies at the Battle of Edgehill.
Data: Knowing the number of soldiers in a particular unit at the Battle of Edgehill.
Implications for education
Educational philosophies emphasise different parts of the knowledge pyramid.
Some philosophies emphasise “facts”. Those approaches focus on individual pieces of data, at the expense of understanding how those pieces fit together.
Other philosophies emphasise “understanding”. These approaches focus on how the pieces of data fit together as information and/or knowledge, but can encounter problems if the students don’t have enough individual pieces of data to see how the information and knowledge map on to reality.
These issues overlap with the concept of craft skills, which I’ve blogged about earlier.
http://hydeandrugg.wordpress.com/2014/02/27/what-are-craft-skills-a-brief-overview
They also raise important issues about the meaning of “reality” and “truth”. This is well known to professional academics, especially in disciplines such as history, where simplistic rhetoric about “just teaching the facts” tends to get short shrift. Conversely, empirical sciences tend to take a dim view of models of reality that don’t pay close attention to the low-level data.
In later articles, I’ll unpack some of these concepts in more detail, and show what the practical and theoretical implications are for education.
Notes
Note for curious readers: I’ve deliberately shown the data-level circles as unevenly distributed, to indicate the way that data are usually messy and often incomplete, because of their interactions with reality. The higher levels, being less directly in contact with reality, are often fitted into neat levels and categories by the human beings who try to make sense of the data.
Note for historically knowledgeable readers: I’m aware that the statement above about both armies at Edgehill being inexperienced and poorly trained is a simplification of the reality. That awareness is exactly the sort of meta-knowledge that’s important in education, where your explanation to students will vary depending on the level of detail at which you’re describing something.
The Hyde & Rugg image above is copyleft; you’re welcome to use it for any non-commercial purpose, including lectures, provided that you retain the Hyde & Rugg copyleft attribution.


March 14, 2014
The Three Ignoble Truths (with apologies to the Four Noble Truths)
By Gordon Rugg
The Four Noble Truths are profound Buddhist insights into the nature of being. The Three Ignoble Truths aren’t… However, they’re useful to know when you’re making plans.
First Ignoble Truth: Hardware breaks and software crashes.
Second Ignoble Truth: Resources are never there when you need them.
Third Ignoble Truth: People fail to deliver, get sick, and die.
But, as part of the balance of being, there’s always chocolate as a consolation…
From Rugg & Petre, A Gentle Guide to Research Methods (2006). Open University Press/McGraw-Hill, Maidenhead, UK


March 9, 2014
Finding out what people want, in a nutshell
By Gordon Rugg
Here’s a short summary of why it’s difficult to find out what people really want, and of what to do about it. It’s our do/don’t/can’t/won’t model. We’ve blogged about this topic before, and we’ll blog about it again, since it’s important. This diagram gives an overview of the framework we use.



March 1, 2014
Hoaxing the Voynich Manuscript, part 7: Producing the text
By Gordon Rugg
The six previous articles in this series looked at the component parts of a hoax. This article shows how those components can be put together, to produce the text for a large document consisting of meaningless gibberish. This process is much the same regardless of which script you use for that gibberish, and regardless of which illustrations you use. The script and illustration issues are discussed in article 8, which I’ve already published
There are a few key points about this hoaxing process that are absolutely central to understanding why it gives new insights into Voynich Manuscript research. These points are:
This process isn’t random.
This process isn’t deterministic – there isn’t an algorithm that would let a future researcher reproduce the text within a given page using the same table and grille.
This process produces numerous complex statistical regularities in the output text as completely unintended side-effects of a very simple production process.
This method is fast and easy to use. You can generate meaningless gibberish text as fast as you can write it down. I’ve produced quasi-copies of various pages from the Voynich Manuscript, where I’ve copied the original illustration, and generated the appropriate amount of meaningless gibberish text to match the amount of text in the original page. It consistently took about an hour and a half per page. More time spent on text within a page was balanced by less time spent on illustration and vice-versa, so each page took about the same time regardless of whether it was mainly text, mainly picture or a mixture.
At that rate, one person working alone could produce a document as long as the Voynich Manuscript (about 240 pages) in under ten weeks.
Here’s how the method works.
The starting point is a large table of meaningless gibberish. Here’s what a table populated with Voynichese syllables looks like.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
The table has a structure, as follows. The table is divided into sets of three columns. Each of those sets contains one column that contains prefixes, another column that contains roots, and another column that contains suffixes. The image below shows the structure for a small section of a table. I’ve used colour coding to show the sets of columns, and the initials P, R and S to show which of those columns contain prefixes, roots and suffixes respectively.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
The easiest way to fill the table in is one category at a time – for instance, doing all the prefix columns first, then doing all the roots, and then doing the suffixes. I’ve tried other ways, and this way is the least error-prone.
Here’s what the table section above looks like with some of the cells populated with syllables. I’ve used the EVA transcription of some common Voynichese syllables, to make them easier to read. Their relative frequencies are similar to the frequencies in Voynichese, but I haven’t tried to replicate the real frequencies exactly, because I wanted to construct a table fragment that demonstrated how some key points work.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
The next figure shows the same section of table, completed.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
Some of the cells are empty. That’s deliberate. It replicates the way that many Voynichese words don’t have prefixes, or don’t have suffixes, or don’t have roots, or some combination of all three.
That, incidentally, is one of the many odd features of Voynichese; quite a few of its words consist only of a prefix and a suffix, with no root in between. I don’t know of any real language that does this.
Selecting syllables
The next stage involves taking a grille, i.e. a piece of card with three holes cut in it, like this. I’ve shown the same grid pattern on the grille that I used on the table; this makes it easier to keep track of what’s happening.

Image copyleft Hyde & Rugg, 2014
To generate some text, you start by putting the grille over the table, so that the holes in the grille show you the contents of three cells – a prefix cell, a root cell, and a suffix cell. For the illustration below, I’ve started with the grille at the top left of the table. I’ve shown the grille as grey and faintly transparent, so you can see the underlying table. The left hand side of the grille sticks off the end of the table, and isn’t shown in the figure.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
This reveals the word ochedy, which is a perfectly respectable Voynichese word. You can now write this word down as the first word on your hoaxed page.
Moving the grille for the next word
This is the step that has most often been misunderstood. You now need to move the grille across the table to produce the next word. However, you can’t simply move it three cells to the right horizontally.
If you simply move the grille horizontally across each time, then you’ll end up with a regular sequence of syllables in successive words.
Suppose, for example that you use Grille 1 to produce a line of words from the row that starts with the rare syllable oqo (the third row down from the top). The first four words will start with the prefixes oqo olo y or respectively. I’ve indicated that with highlight on the figure below.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
Now suppose that you use Grille 2, which has a different pattern of holes, to produce a line of words from the same row. You’ll get different roots and suffixes, but your first four words will still begin with the prefixes oqo olo y or respectively.
That’s a glaringly obvious give-away to anyone with any knowledge of code breaking. They’ll spot that sequence very quickly, and swiftly use it to unravel the structure of your hoax.
Simply using a regular sequence of moves up or down whenever you move across doesn’t help. Because that sequence of moves is regular, you’d still end up with a regular sequence of syllables. It would simply be a different regular sequence of syllables from the one you’d get if you moved the grille straight across horizontally.
What you have to do instead is introduce an element of unpredictability into the horizontal move. So, for example, you might move three cells across and one row up to produce the next word, and then move three more cells across and two rows down to produce the word after it. The key thing is not to have any regular pattern in those vertical moves that would produce an identifiable regular sequence of syllables.
This is one place where the very repetitive nature of Voynichese works on the side of the hoaxer. It’s easy to spot sequences of syllables that involve rare syllables, but it’s much more difficult for a code breaker to spot sequences that involve very common syllables.
The next figure shows this principle in action. The grille has been moved across three columns, and down one row, to break up the pattern. It shows the word qo, with no root or suffix. That’s your second word.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
You now repeat the process, with another move three cells across, and an arbitrary number of cells up or down.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
Handling repetition
This third move shows you another word consisting of only a prefix. It’s the word qo again.
So what do you do? You now have the same word occurring twice in a row. One option is simply to write it down and keep going. Another option is to move the grille further up or down so that you get a different word, and write that word instead of the second qo.
The “move the grille till you get a different word” option has obvious attractions. However, if you’re tired and bored after a couple of hours of generating material that you know to be meaningless gibberish, then there’s a fairly reasonable argument for the “just write it down and keep going” option.
Anyone familiar with Latin (which would include any educated western European in the fifteenth or sixteenth century) would know that Latin contains a fair number of reduplications and near-reduplications, where the same syllable is repeated for grammatical reasons. An example is Latin quisquis, meaning whoever, which is a reduplication of the more common quis, meaning who.
The amount of repetition in the Voynich Manuscript is well beyond what occurs in any known real language, but scholars at the time had no way of knowing what was plausible for an unknown language, and what was implausible. So, even if someone picked up on the amount of repetition, they would have no way of knowing whether it was implausibly high or not.
Scholars in the fifteenth and sixteenth centuries might speak a fair number of languages, but that’s a very, very different proposition from knowing the core findings of comparative linguistics and historical linguistics. Linguistics as an academic discipline isn’t about learning to speak lots of languages; it’s about the underlying principles of language in general. Linguistics students learn about the general principles of how languages operate, and learn about the rare features that only crop up in a few languages, as well as the features that occur in all known languages. A handful of languages, for instance, use whispered vowels; a lot of languages use tone to differentiate two or more words that consist of the same consonants and vowels; all languages have rules about word order.
So, returning to the production process, you choose your option and you write down whichever word that gives you, and you continue the process across the table till you reach the end of the table or the end of the line.
Handling shortfalls
If you reach the end of the line before you reach the end of the table, then the next step is easy; you just move your grille back to the first three columns of the table, a bit further down, and repeat the process. If your table is about forty rows deep, that’s usually more than enough to generate a page of text without having to change grilles.
Sometimes, though, you reach the end of the table before you reach the end of the line that you’re writing on the page. The grille quite often shows short words, and sometimes it shows empty cells for all three syllables. That can easily produce a batch of output text that isn’t long enough to fill a line on the page.
Again, you have various options. One is to use the grille in some way to generate more words. Another is just to make some words up out of your head, and write them down. If you’re just dealing with a few words, then this is easy to do, because Voynichese is so repetitive. It’s nowhere near so easy to do this for more than a few lines, because inventing text in your head is tiring.
That’s one big advantage of using table and grille; if you’re aiming to produce over two hundred pages of output, then the table and grille is much less mental effort.
The figure below shows what happens when you reach the bottom of the table. You take a different grille, with a different pattern of holes in it, and you start again at the top of the table, generating a new set of text from the same table. This time, we get the word okedy as the first word of the next batch of text.
 Image copyleft Hyde & Rugg, 2014
Image copyleft Hyde & Rugg, 2014
Further tables
There’s a limit to the number of different patterns of holes that you can use; if the holes are too many rows apart, then the grilles become tiring to use. The precise limit will depend on the size of the cells in your table, and the size of the table, but whatever the precise number, it won’t be enough to produce over two hundred pages from one single table. You’ll eventually need to produce a different table, which involves lots of scope for human error; I’ve blogged about the implications of that in various articles on this site.
Another major advantage of using table and grille is that you can have one or more assistants producing text for you at the same time using different tables and grilles, to speed up the production process and to save you from having to do the work. If the different tables use roughly the same set of syllables in the same proportions as each other, then you’d expect the output text from the different tables to look pretty similar. However, you’d be wrong. The output is significantly affected by things like how regularly you populate the cells with the syllables. Also, when you’re working down your list of syllables that need to go into your new table, it’s horribly easy to overlook one syllable completely, so that the output from your new table doesn’t contain any examples of that syllable.
That would make sense of why the Voynich Manuscript contains at least two “dialects” – these could reflect the use of two master tables, and probably of other tables derived from those masters.
Conclusion and some further thoughts
So, that’s an overview of how to produce the text for a hoax. The basic principle is simple; you just move a grille across a table, writing down the words that it shows, and remembering to move the grille up or down in some non-systematic way each time you move it across three columns to show the next word.
It’s a simple process, but it produces a lot of accidental complexities.
For instance, in the table section above, the rare syllable oqo will usually only appear at the start of a line. However, if you reach the end of the table before you reach the end of the page of output text, and you generate the remaining text by moving your grille back to the start of the table, then you’ll produce a few cases where the syllable oqo also occurs near the end of a line, probably without even noticing that you’ve done it. From the viewpoint of a modern analyst, that would be a puzzling pattern – why does oqo usually occur at the start of a line, and sometimes occur near the end of a line, but never occur in the middle of a line?
Which is exactly the sort of pattern that occurs for some syllables in Voynichese. It’s a pattern that would be hard to produce via a schizophrenic rant or automatic writing in a trance or by making up text in your head, which is one of the reasons that the hoax theory was not seriously considered until the table and grille theory came along, providing an explanation for how such complex regularities could emerge as an accidental side-effect of a simple process. That, however, is another story, and one about which I’ve already blogged at length…
Notes
All images above are copyleft Hyde & Rugg, unless otherwise stated. You’re welcome to use the copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
Other articles in this series:
http://hydeandrugg.wordpress.com/2013/08/20/hoaxing-the-voynich-manuscript-part-4-the-materials/
http://hydeandrugg.wordpress.com/2013/07/23/hoaxing-the-voynich-manuscript-part-1/


February 28, 2014
Voynich articles overview
By Gordon Rugg
There are quite a few articles on this site about the Voynich Manuscript. Here’s a list of those articles, by category.
Proposed solutions:
http://hydeandrugg.wordpress.com/2014/02/15/this-weeks-voynich-manuscript-decipherment/
http://hydeandrugg.wordpress.com/2014/02/23/applying-the-bax-proposed-solution/
http://hydeandrugg.wordpress.com/2014/02/04/tucker-and-talbert-and-the-voynich-manuscript/
Hoaxing a manuscript like the Voynich Manuscript:
(Part 7 will appear some time soon)
http://hydeandrugg.wordpress.com/2013/08/20/hoaxing-the-voynich-manuscript-part-4-the-materials/
http://hydeandrugg.wordpress.com/2013/07/23/hoaxing-the-voynich-manuscript-part-1/
Background information:
http://hydeandrugg.wordpress.com/2013/05/17/the-voynich-manuscript-why-should-anyone-care/
My Voynich Manuscript research:
http://hydeandrugg.wordpress.com/2013/06/22/verifier-voynich-and-accidental-complexity/
Other:
http://hydeandrugg.wordpress.com/2013/09/09/the-voynich-manuscript-and-the-unexplained-files/


February 27, 2014
What are craft skills? A brief overview.
By Gordon Rugg
Craft skills are not the same as crafts, although the two concepts are related.
The term “craft” usually relates to a set of practical knowledge about a manual skill, such as basket making or carpentry.
The term “craft skills” originally related to specific pieces of practical knowledge within a craft, but is now often used in a broader sense, to describe any specific pieces of knowledge that are viewed as too low level to be worth including in an academic body of knowledge.
For instance, an academic course on research methods probably wouldn’t include specific information about the best way of typing in data from a paper questionnaire into a spreadsheet. That information would usually be viewed as a craft skill, easily (and often better) learnt via practical experience, or via informal guidance from a mentor while using the craft skill.
That’s the usual view of craft skills. However, there has been a recent growth of interest in craft skills, and particularly in academic craft skills, which has discovered that craft skills are more important for academic learning than was previously assumed. This is particularly relevant to the concept of transferable skills, where the reality turns out to be more complex and problematic than is generally assumed.
Craft skills involving practical knowledge have a very long history. Here’s an example.

When you’re making a flint handaxe like the replica above, you need to check whether the flint you’re starting with is flawed or not. If it’s flawed, it’s likely to shatter in your hand while you’re working on it, which is painful.
You check for flaws via the craft skill of tapping the flint, and listening to the sound. If you hear a dull sound, then the flint is probably flawed. If you hear a clear ringing sound, then the flint is probably good quality.
Because checking for flaws is such a central part of flint working, it’s likely that this craft skill was in use when hand axes were first made, over a million years ago. This particular craft skill almost certainly has an unbroken lineage of transmission from that time.
What’s particularly interesting about this craft skill is that it also turns up in a surprising range of other fields. Tapping a material to test it for hidden flaws is also used in pottery making, in glass making, in stone carving, in metal casting, and in dentistry, when checking whether a filling has cracked. One of the research questions I’m investigating involves the patterns of distributions of craft skills of this type, to see what light they throw on the development of technology and innovation.
Craft skills can also involve abstract skills, such as the use of referencing when writing academic text. The books I’ve co-authored with Marian Petre about research methods deal at some length with academic craft skills, since in our experience there’s a lot of variation between institutions and disciplines as regards how much attention is paid to these craft skills in education.
With the growth of taught courses on research methods as part of PhDs, the issue of academic craft skills has been receiving an increasing amount of intention. It’s become clear that academic craft skills often have a complex structure and involve a significant amount of knowledge. The craft skill of choosing which references to use in a piece of academic writing, for instance, involves a considerable amount of specific knowledge about the choice of most suitable journals for the topic under discussion, as well as specific knowledge about when and how to use other sources of information.
It has also become clear that different disciplines can have very different positions with regard to that craft skill knowledge. This is often for perfectly sensible reasons, but those reasons are often not explained explicitly to students, leading to considerable needless confusion.
A classic example is the use of direct quotes in a piece of writing.
In some disciplines, particularly in the humanities, direct quotes are viewed as invaluable because the analysis is often driven off the precise wording that was used within the quotation.
In other disciplines, however, direct quotes are viewed as an indication that the writer was unable to synthesise the key findings from a body of literature using their own words.
The consequence is that in some disciplines use of direct quotes is viewed as a key skill, whereas in other disciplines the ability to avoid direct quotes is seen as a key skill.
This has obvious implications for the concept of “transferable skills” which is currently in vogue. Many skills, such as academic writing, involve a large body of sub-skills that may take very different forms in different disciplines. The potential for transferability therefore needs to be assessed sub-skill by sub-skill, rather than treating concepts such as “academic writing” as single homogeneous units.
We’ll write in more depth about transferable skills in a later article.
My books with Marian Petre:
A Gentle Guide to Research Methods, by Gordon Rugg & Marian Petre

A Gentle Guide to Research Methods



February 23, 2014
General update
By Gordon Rugg
After the last few articles about the Voynich Manuscript, we’re now returning to our previous theme of knowledge modeling in relation to client requirements and the design of products and buildings.
We’re also starting a set of articles about another core theme of our work, namely knowledge modeling in relation to education, learning, teaching and training.
We hope you’ll find these articles useful and interesting.


Education versus training, academic knowledge versus craft skills: Some useful concepts
By Gordon Rugg
At the heart of education theory is a widely used distinction between education and training. This overlaps with a closely related distinction between academic knowledge and craft skills.
Although these concepts are extremely important, there is widespread debate about just what they mean, and what they imply for education theory and practice.
In knowledge modelling terms, these two distinctions can be neatly represented using the concepts of closed sets versus open sets, and of connected graphs versus unconnected graph fragments.
The illustrations below show how this works, and what some of the implications are for education theory and practice.
There’s a useful distinction in set theory between a closed set and an open set, as shown below.
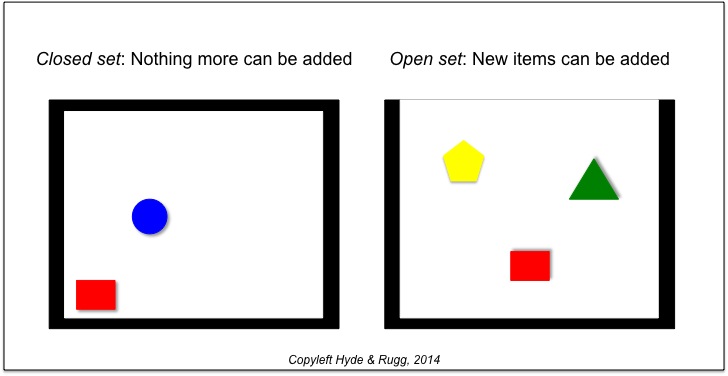
A closed set is by definition closed; nothing new can be added to it. An open set is by definition open, and new items can be added.
An example would be the distinction between the set of education papers published in 2013 and the set of education papers ever published. The first of these is closed, since 2013 has ended, and no more papers can be added to that set. The second set is open, and will remain open for as long as education papers are being published.
This distinction maps neatly on to the traditional concepts of training and education. We can treat training as a closed set of knowledge, and education as an open set.
So, for example, a particular module on a training course will be a closed set, where the student learns only what is in that module, and the student’s learning of that set of knowledge stops once the module ends.
In contrast, a particular module on an education course should be an open set, where the student learns how to learn more about the topic, so that the student goes on learning about that set of knowledge even after the module is officially over.
A related issue is the widely-used distinction between academic knowledge and craft skills. This can be modelled as shown in the figure below.
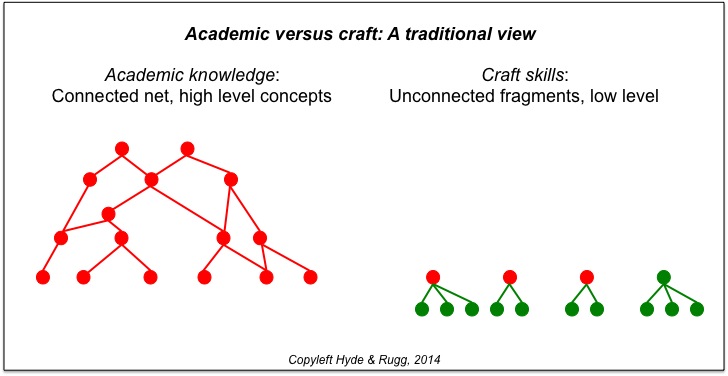
According to the traditional view, academic knowledge is a formalised body of interconnected knowledge. Much of this knowledge is high level in the sense that it brings together more specific, lower-level concepts. For example, the laws of thermodynamics are unifying principles that join together a wide range of narrow lower-level specific facts, in the same way that the two red circles at the top of the “academic knowledge” diagram are the highest-level points that join together all the points below them.
According to this same traditional view, craft skills are an unsystematised body of fragments of low-level very specific knowledge, that take over where academic knowledge ends, and that handle the process of translating the academic knowledge into practical, real-world application. In the illustration, the three craft skill fragments on the left (green circles) all join up to academic concepts (red circles), while the fourth craft skill fragment on the far right isn’t connected to any academic concept, and is just about practical issues at the craft skill level. (For visual clarity, I haven’t shown the network of academic concepts that fit above the craft skills fragments shown. )
We’ve found these concepts very useful as tools for thought when examining the underpinnings of knowledge and learning.
When they’re applied to actual cases, they produce some unexpected and powerful insights, which we will discuss in future articles.


Applying the Bax proposed solution
By Gordon Rugg
Stephen Bax’s article provides provisional “real” transliterations for over half the commonly used letters in the Voynich Manuscript’s alphabet. If his transliteration is even approximately correct, that should be enough to give some useful insights when applied to a page from the manuscript.
I’ve tried that, and the results are unconvincing. For instance, according to his transliteration, about half the words in one of the pages he analysed end in the letter “r”.
A language where half the words end in “r”? Even in a Latin page crammed with third person passives, that would take a lot of doing. There’s a lot more that’s strange about what emerges.
If this is a decipherment, as claimed by the press release, or even a partial decipherment, as claimed by the actual article, then it’s an interesting use of the word “decipherment”.
The story begins with the idea that possible interpretations of ten words in a document more than two hundred pages long counts as enough of a decipherment to merit a press release. (Italics are in the original.)

The original article doesn’t claim to identify a language, or even a language family.

That’s actually a more reasonable claim than it might appear. Bax begins by trying to find out possible transliterations for Voynichese words that he believes to be the names of plants and a constellation. Names need to be treated with care in linguistics, since they’re disproportionately likely to come from another language. English, for instance, has a lot of names for stars that come from Arabic, which belongs to a completely different language family. However, foreign-language names might give you transliterations for the script that will then let you get further into the language that you’re really interested in.
So far, so good.
When Bax applied this method to a number of illustrations, he came up with possible readings for ten words, which gave him possible values for more than half the commonly used letters in the Voynich alphabet (fourteen out of about twenty – the precise number depends on the definition you choose).
The next step is to plug those letter values into some chunks of text from the Manuscript, and see what you get. Bax viewed this as future work, and only plugged the letter values into other possible plant names, producing his reading of “kaur” and his reading for “cotton”. The latter raised problems that he acknowledges in his article, since the plant image on the page with a name apparently meaning “cotton” didn’t look like a cotton plant.
That’s scarcely a surprise to anyone who’s familiar with the history of Voynich Manuscript research. Bax’s approach is just another variation on a theme that has been tried repeatedly over the years, and has failed repeatedly over the years, because it simply doesn’t fit the facts in any sort of sensible way.
When you plug some of his proposed transliterations into the Voynich Manuscript text, you soon (i.e. within the first half hour) start to see the problems with it.
Some problems with the obvious approach.
It sounds sensible that the first word on each page with a picture of a plant (the “plant pages” for brevity) will be the name of the plant in the picture. However, if you look at the plant pages, then you spot something odd. A high proportion of them start with one or other of the same two letters. We’re dealing with about a hundred plant pages, so it doesn’t take long to do the sums. That’s either an awful lot of plants which have names starting with one of just two letters, or those first words aren’t as straightforward as Bax has assumed.
The obvious counter-claim that this might just be the equivalent of pages starting with the Voynichese equivalent of the word “The” doesn’t hold up well either. You just don’t get the same word occurring at the start of various different plant pages.
So there are already problems with the idea that the first word is a name, and that the image gives you some insight into what that name might be.
This has been known for years in the Voynich research community, and is one reason that nobody in the community uses this approach in its simple form any more.
The body text
If you look closely at the body text of a plant page, you soon see more problems.
I’ve tried plugging Bax’s letter values into one of the pages he analysed, folio 3v, shown below. If his transliteration is correct, then about half the words in the body text end with the letter “r” and most of the rest end in the letter “n”. Just two letters accounting for the endings of most of the words in a real language? If that’s correct, then just about every known language could be excluded as a candidate for the language of the manuscript, which would be extremely useful to researchers.
Or, perhaps, Bax is simply wrong.
Here’s are some close-ups showing the text of the page in question. It’s f3v, which he identifies as a hellebore, and transliterates as “kauur” (with a schwa for the first “u”) or “kaur” when he searched for it with Google.

First paragraph detail:

Second paragraph detail:

(Original image courtesy of the Beinecke Library)
If you look at the page closely, then you start noticing that the same few letters occur over and over again at the ends of words. There’s the one that looks like the number “9” and the one that looks like a number “2” on a slant and the one that looks like a looped “x” – those are usual suspects for word endings. In this particular page, there are also a fair few instances of the character that looks like a curly “n”.
Whatever transliteration system you use for the text, you’re going to end up with only a very few letters at the ends of the words, because there are only a very few letters at the ends of words in the original text. However, since the Bax transliteration treats no fewer than three Voynichese characters as being an “r” the result is that the number of word endings in the transliterations is even further reduced.
You also notice that a lot of the words are very short, and that the letter that looks like a backward “S” occurs several times in isolation, as if it’s a word in its own right. That’s odd, because usually consonants don’t occur on their own in real languages; it’s usually vowels that occur on their own, like “I” and “a” in English, or “y” and “à” in French. The examples on this page of Voynichese might be a case of a single symbol standing for the combination of “s plus vowel” but that doesn’t fit well with the comparatively small number of commonly used letters in the Voynich alphabet.
You get other oddities as well. There are words that begin with “nk” and words that end with “tn”. That’s unusual among the written versions of Indo-European languages. As with the isolated “S” words, this might be a case of one symbol standing for a combination of consonant plus vowel, but that hits the same problem of the comparatively small number of commonly used letters in the Voynich Manuscript.
There’s also a huge amount of repetition. This is particularly striking with another of Bax’s claimed readings, for the plant centaury. The four middle characters of the Voynichese word come out as “tuir” (with a schwa for the “u”) in his transliteration. These characters happen to be one of the most common words in Voynichese. It has some odd characteristics in its distribution, including the fact that it sometimes occurs twice or even three times in a row. You can get repetition in normal languages, but on nothing like this scale. If you start claiming that the Manuscript contains some form of incantation or poetry or both, then that’s hard to reconcile with Bax’s starting assumption that the Manuscript is what it appears at first sight to be, namely a straightforward document in prose whose main function is to transmit factual information. It’s also hard to reconcile with the sheer length of the Manuscript – over two hundred pages – and with the lack of end rhyme, alliteration or metre that would be expected with known types of poetry.
When you dig into the Voynich literature, you find that these and numerous other issues were spotted decades ago, and have been analysed in considerable depth by some of the best brains in relevant fields. There are some features of letter distributions in the Voynich Manuscript that are very odd indeed, and that have been thoroughly analysed by code breakers who analyse letter distributions for a living.
The conclusion that those features force you into is that the “straightorward unidentified language” theory just doesn’t explain most of the puzzling anomalies within the text in the Manuscript.
In brief, the idea that the Manuscript is simply written in a language that nobody has identified yet is an idea that looks plausible at first sight, and that looks like an obvious starting place. However, the fact that it’s obvious should ring alarm bells to anyone wanting to try their luck with the Voynich Manuscript. The Manuscript has been studied in detail for over a century. Does anyone really think that nobody will have tried this approach before? In fact, it’s been tried repeatedly, and it’s failed repeatedly, because it simply ignores the facts about the Manuscript that make it a difficult challenge.
In summary, Bax’s proposed solution doesn’t hold up for long when you apply it to the text in the Manuscript. The problems with the simple “unidentified language” theory were exposed by Currier and others decades ago, and they’re show-stopping problems. Bax may be an award-winning expert on eye tracking, but when it comes to the Voynich Manuscript, his theory appears to be just another example of the tragedy at the heart of science: The slaying of beautiful theories by ugly facts.


Gordon Rugg's Blog

- Gordon Rugg's profile
- 12 followers


{kind=link}