
Russell Atkinson's Blog, page 80
April 21, 2017
Delphi polygons
I just discovered the Polygons method in Delphi yesterday, so now I have a new toy to play with. I’m working on creating my own USA state-by-state map. You can expect to be inundated with maps showing all sorts of possibly meaningless correlations. There’s probably some freeware out there that does the same thing, but that wouldn’t be as much fun and there’s always a hangup of some kind with that stuff. Here’s my work in progress.
The post Delphi polygons appeared first on OnWords.


April 17, 2017
The Snowden Files by Luke Harding
 The Snowden Files: The Inside Story of the World’s Most Wanted Man by Luke Harding
The Snowden Files: The Inside Story of the World’s Most Wanted Man by Luke Harding
My rating: 3 of 5 stars
I read this book because my book club chose it. I had expected to hate it largely because I expected it to lionize a man I considered a traitor, yet I harbored a secret fear that I might be persuaded to find Snowden to be a true hero, proving my own instincts wrong. In the end I was, surprisingly, rather bored with the whole thing.
The book is written well enough, but for a purported piece of investigative journalism it sure didn’t say much. It gave a bit of Snowden’s background, and at the end a short epilogue about his unintended self-exile in Russia. The big “revelations” in the book consist of a general description of the NSA’s major programs, such as listening to cell phone traffic, buffering internet data, and so forth, and listed their rather fanciful code names. My reaction to that was much the same as one British politician quoted near the end: “Spies spy.” Well, duh! Other than that, the remaining 90% of the book was pretty much a puff piece for The Guardian, the British tabloid that Snowden chose as his outlet for the stolen documents, or some of them at least. The author, a writer for that paper, seems to have an inferiority complex and tried mightily to use this platform to cast his employer as a major player and knight in shining armor for civil liberties everywhere. Ho hum (although I do like their cryptic crosswords).
What the book didn’t do is provide a single instance of anyone who was ever harmed by the NSA’s surveillance actions. Balance this with the fact the NSA did provide a few examples of terrorist plots that had been disrupted thanks to their monitoring efforts. To be fair, it also didn’t provide any examples of how Snowden’s action resulted in any harm to the U.S. or its Anglophone Five. As a former FBI agent I know how public foofaraw can be disruptive to an agency, but soon enough such revelations fade into irrelevance like a mosquito bite on an elephant.
Perhaps the same homily can be applied to both the NSA and Snowden: no harm, no foul. I have no doubt the NSA continues to intercept almost everything. Spies spy. I’m happy to have them record, read, watch, listen to, or parse everything I say or do. I’m not a criminal or terrorist. I will never understand those people who are outraged at the idea their communications are monitored by the government. Whenever I hear someone say that they are, I wonder what crime they’re worried about being caught committing. I’m afraid of criminals (of whom terrorists are merely a subset, and rather a small one at that – drivers with cell phones are much more of a threat), not the government. Criminals actually hurt people. The NSA doesn’t. I’ve seen many innocent people’s lives ruined by criminals but never once by the FBI or NSA. Even Snowden is quoted only as saying that the massive collection of data has the potential to be abused and result in an innocent person being accused. True. Letting a doctor give you general anesthesia and cut into your body has the potential for abuse, and so does giving police guns, but there’s such a thing as necessary risk.
Unlike many former FBI agents, I don’t see Snowden as one of the worst breaches of U.S. national security, and I don’t see getting him back for prosecution as all that important. He’s languishing in his own prison of sorts living with no job in Russia. The irony is delicious. I still think he’s a traitor and should go to prison, but his current situation is close to that.
The post The Snowden Files by Luke Harding appeared first on OnWords.
April 12, 2017
Prices lowered on all Cliff Knowles novels
I’ve lowered the Kindle price on all the Cliff Knowles novels, including all the overseas markets (except where it was already the lowest permitted price). Amazon does not permit a lower price except for very limited promotional days. The U.S. price for all of them is now $2.99 and if you have Amazon Prime, which I’ve read is now subscribed to by more than 50% of American households, you can borrow it for free. You get a one free book download a month. If you have Kindle Unlimited, you also have all the free downloads you want. All the books are available there, too. You don’t need a Kindle device – there are free apps for all the desktop and mobile devices in common use, I believe.
See my Cliff Knowles Mysteries page for descriptions and links.
The post Prices lowered on all Cliff Knowles novels appeared first on OnWords.
Solving a 6×6 Tri-Square Cipher
Recently I had occasion to tackle a 6×6 Tri-Square cipher published on a puzzle geocache. I had some misadventures but eventually solved it. I thought the process might be both amusing and instructive to some, so I am writing up my experience. First, here’s the ciphertext in case you want to try it.
JEX PQD YHN 979 L00 ALT Q91 BKZ Q0B 990 SEX 8LW KTD 5RE 2RT PGW OWH 962 SZQ P4V CEI BRA KSN L0C JLD O9A EKS P6G CTO HIA 3T4 ZIP 2CY 0M8 3SQ 1U6 990 IEX O17 CSL T0A 7TO 6NA L1E S9J ALT O6R S0E 2R0 Z7G 9VT LUP 5RE P5Z YH3 8M0 Q11 6LW N9J MYP XVW TEP RBQ JUF 5HO PQD 7L4 G3D 2RJ 8PZ QGT 9VT ZCZ 4K7 1TQ S4H ZIA crib: characters sharing the same common environments
With the crib, it’s not very hard to solve the plaintext. That was accomplished quickly. But to get the coordinates I needed, one must enter the key(s) into an online checker. It is thus the process of recovering the keys that was challenging and is set forth here.
The first obstacle was my lack of computer tools for a 6×6 Tri-Square. I have one for the 5×5, but not the 6×6. This meant I either had to rewrite the one I had, or solve with paper and pencil. I chose the latter option. After solving the plaintext I had many equivalencies established in all three cipher squares, that is, I knew various letters had to be in the same row or column as other letters. For the leftmost square (Sq. 1) I saw an alphabetic series that told me the probable route used. I also saw what I thought was the beginning of the key. Bear in mind that with a 6×6 key, under American Cryptogram Association (ACA) rules the letters A-J are followed by the numbers 1 – 0. Thus BAD would be written B2A1D4 and an entire row or column may be filled with only three letters.
I decided to try finding the key to that square using a tool I had: a 6×6 Polybius square solver. The solver uses word lists. I ran it and was unable to find a one-word key that met all the known letter relationships in any of the ACA routes. That told me the key was not a single word, or, possibly, was not a common word. I reran the program using some very complete word lists still without results. I decided to move on to the other keysquares. I should mention that I have always positioned the squares differently from the way they are shown in the linked ACA page. I always put the square marked 2 (the one on top) underneath the corner square. I always thought of them in a different order for that reason, with the numbering of squares 2 and 3 reversed from the diagram. I will use the standard diagram numbering for reference here, but I still think of the corner square as being in the middle and thus number 2, with the others being 1 and 3.
With square 2 I worked in a similar way and was able to reconstruct a large part of the square. Once again I tried my polybius square solver and confirmed that no one-word key worked completely, but I got some keys that had almost all the right equivalencies. I was confident enough that I knew the first word of the phrase, that I modified my program to run through the word list again tacking the first word of the phrase in front of every word to make a two-word key. I got several good-looking keys this way that were almost perfect, but not quite. There were still some conflicts. I was able to produce a list of keys and select only the letters that were the same in all of them. Then I went back to square 1 and working with paper and pencil again, I was able to fill in more of that keysquare. The numerals actually helped finish off that square since if you know the route and can place a numeral, you know the letter that comes before it, and vice versa. Thus I completed square 1 first. I could tell it was a phrase, and while I recognized all the words in the phrase, the phrase itself made no sense to me. I had never seen those words in that combination. I searched the complete phrase online and got no hits on Google.
Going back to sq. 2 again, I was able to complete the first, third, and fourth rows of the square, but still had gaps in the others. Still, working with the letters I was sure of in squares 1 and 2, I was able to fill in sq. 3 enough that I could tell the route and much of the alphabetic sequence. Eventually I was able to completely fill sq. 3. Again, I recognized the first word, but could not tell what the complete phrase was for sq. 3. After completing that square, I was then able to go back to sq. 2 and complete it. Like the others, I recognized the first word, but could not tell what the full phrase was for sqs. 2 or 3. Bear in mind that polybius square keys use condensed forms. That is, repeated letters are removed, so Banana Rebel will condense to BANREL which could equally be Ban Barbell or various other things. Since I was confident of the three initial words, and they were vaguely related, I tried searching them together online to find a common thread. I did not succeed. As it turned out, this was because I had two of the words wrong.
So there I sat with the three key squares filled in completely but did not know two of the phrases, and had no confidence in the one I thought I did have (sq. 1). Here, another factor came into play. The online checker for the geocache page shows how many successful and unsuccessful attempts had been made. It showed 5 successful attempts and no unsuccessful ones. This meant the solvers had known exactly what to enter and didn’t have to guess. This made me nervous, because even if I figured out the complete phrases, it seemed to me that there were six possible ways to enter the keys, at least if one were to enter all three phrases. I began entering the keys in their condensed forms one by one and kept getting rejected. Obviously I need to figure out the complete phrases. I felt somewhat bad spoiling the perfect 5-0 record on the checker, racking up multiple wrong guesses. It began to look like I was guessing randomly. A true solver, I thought, shouldn’t enter a key until he was certain of the answer, so I stopped. I felt very inadequate.
I don’t know how long I sat there staring at the keys before I finally realized that the square 2 key first word could be another word, one not in my word list. Using that as the first word, the remaining letters made a logical phrase. I searched that phrase online and something popped up immediately, something that made sense. I had to do a bit of research since I was unfamiliar with the subject matter, but once I did, I quickly knew what all three phrases were. It turns out that previously I had had only the first word right in sq. 1, but none of the words right in sq. 2, or sq. 3. That is to say, I had the keys right in condensed form, but had not deduced the full form correctly, even a single word. The checker, I thought, required the full phrases spelled out. I zipped back to the checker and entered them in using what I thought was the most logical order. I got rejected once again. Aarghh! It must not be the three keys, after all, I thought. Instead, I became sure it was the common subject matter that connected the three keys. That was a much shorter phrase that was very recognizable. I entered that into the checker and still got rejected. I tried using variations of it and still no luck.
I gave up and began writing an email to the cache owner for a hint. As I was composing it I started to say I had tried entering all the keys in without luck as well as the connecting phrase in all its variations when I realized that I actually had not entered in the three keys in every possible order, only in the most logical order. I went back to the checker and entered the keys in using a different order, then another, and so on until I got to the only remaining possible order. I was sure that wasn’t going to work, either, and was composing my email in my head when I hit enter and saw the checker return with a thumbs up and the coordinates to the cache! It had taken me thirteen wrong guesses before I got the correct key despite having completely solved the cipher and the three keysquares. My total unfamiliarity with the subject matter connecting the keys was part of the problem, but not the only problem. I understand now how others could enter the full correct keys in the correct order without having to guess. If you have read this whole post carefully, you can probably figure out why, too.
The post Solving a 6×6 Tri-Square Cipher appeared first on OnWords.
April 10, 2017
A Puzzle to be Named Later by Parnell Hall
My rating: 2 of 5 stars
I like the concept of this cozy mystery since I am a crossword fan and constructor as well as big mystery fan and writer, but I think it could be done better. Solving the crossword or the Sudoku won’t help solve the mystery, which was a disappointment. I found the main character, the so-called Puzzle Lady, to be irritating and unlikable. The main appeal for fans, I suppose, is the dialogue, but I found it forced and distracting from what I hoped would be an actual mystery plot. It turned out there was no actual plot. The Puzzle Lady’s outrageous personality and (snappy?) dialogue is the whole thing. You either like it or you don’t.
The post appeared first on OnWords.
April 3, 2017
Conspiracy nuts
I recently received an email from Audible.com with a graph showing where various genres of books are most popular. I thought the pattern looked familiar for one of them. The top graph shows the percentage vote for Trump; the bottom shows the relative popularity of conspiracy books. Please share, retweet and all that.
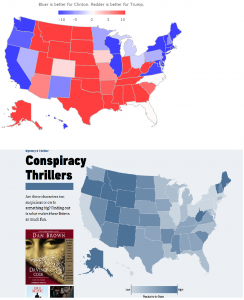
The post Conspiracy nuts appeared first on OnWords.
April 1, 2017
Computer cipher solving – Lesson 5½ : cribs revisited
I thought it might be useful to expand a bit on the use of cribs. In particular, I’d like to go into more detail on what I called Length scoring back in Lesson 5. Hence the captioned 5½ on this post. Here’s the original paragraph on that reposted for convenience:
Length scoring: I’ve found this to be a quite effective improvement to tetragram scoring, although they can be used together. Like tetragram scoring it has the advantage of not requiring any additional programming on individual ciphertexts, but unlike tetragram scoring, it does use up a bit of extra run time. It solves the problem I just mentioned in the previous paragraph. What I do is run the crib down the decryption and in each spot count the number of letters that are in the same place in both crib and decrypt. In the example above hisbeard and hixbeaqd have six letters in common. I then take the highest-scoring instance for the length of a decryption, 6 in this example. I typically take that number, subtract 3 (assuming it is at least 3), and square the result, then add that to my score. In this example it would add 9 points (6-3 squared) to the score, the equivalent of a high-scoring tetragram. I use this method mostly on cipher types that have longer cribs. It has a good ability to hold hillclimbers close when they get close. It works well with a wide variety of cipher types, but not as well on transposition types or combination tramp/sub types like Bazeries or Myszkowskis. Those types may have the crib letters in close proximity to each other, but not in the right order, or with an extra letter or two between. I’ve considered writing something that will give extra points for those situations, but I haven’t been industrious enough to do that yet.
I think it’s worthwhile to follow a more typical example than what I used above. Let’s take AC-1159 in the MA2017 issue, a 6×6 Seriated Playfair. The crib is SELSEWHERETOESTAB. Clearly we can safely extend that to SELSEWHERETOESTABLISH, a crib of length 21. This method works better with longer cribs. Seriated Playfairs are not ideal types to use. As long as you have the correct seriation period, a trial decrypt that is getting close to the correct solution will usually have some crib crib letters in their correct relative positions, however, this cipher type inserts extra X’s to avoid doubles so the crib and correct decryption may not match. Since I happen to know the crib does fit exactly in this case, I will use it. Now the point of this crib method is to identify a trial solution that has a section that “looks like” the crib, i.e. is more like the crib than random chance would dictate, and then boost the score of that trial decrypt in an amount relative to the degree it departs from random chance (and is thus likely to be generated by the crib) .
First we need to establish what random chance would dictate, since we don’t want to boost the score of a trial decrypt that shows some similarity to the crib here and there by chance. Since the index of coincidence in English is around 7%, random chance would dictate that if you compare the crib to any trial decrypt that is close to English in its index of coincidence and letter frequencies, 7% of the crib letters are going to match the decrypt letters. For this 21-letter crib, that’s about two letters. Of course this is only an average. Some will hit three, four or even more letters by random chance while in other cases there will be no matches. Bear in mind that, assuming we haven’t placed the crib by other means, we are not testing the crib in just one spot. We are running the crib through the entire trial decrypt and using the highest scoring spot. We don’t care how well the crib fits lots of different spots, but whether there is one spot where it really strongly seems to fit. Since the length of this con ct is 190 characters, that’s 190-21 or 169 comparisons. The question thus arises, given random variation, what can we expect the maximum number of letter matches to be by random chance in 163 trials? We need that to establish a baseline number.
There’s no doubt a way to do this using the index of coincidence, lengths, and known probability formulas, but for me it’s easier just to write a program that tests this. My somewhat limited testing indicates that for a ct and crib of this length, random chance will produce a best fit for the crib of 5 or 6 letters even if the crib is totally unrelated to the correct plaintext. So a positive result is really only indicated if your test shows seven or more letters that match the crib in the best spot, and even seven is within the range of normal. The shorter the crib and shorter the trial decrypt being tested, the smaller that number will be. Since most cribs and ACA cons are shorter than this example, I use normally 3 as my baseline since I don’t have a chart or formula that applies to all crib and ct lengths. Even though testing shows 6 is probably a better number to use for this con, let’s examine it using my normal 3.
The way I use this to score a trial decrypt is with a routine called CribFit that runs the crib along the trial decrypt and in each possible spot measures the number of letters that match crib with decrypt. I find the maximum number for that decrypt, let’s assume this placement: “qelmnuharptorrtingise”, which produces 9 letter matches with the crib.
selsewheretoestablish
qelmnuharptorrtingise
-xx---x-x-xx--x---xx-
Subtract the baseline number of 3, and square the difference. Here 9-3=6 so that would add 6×6 or 36 points to my score, a significant enough number to influence the hill-climbing function. So even though “qelmnuharptorrtingise” does not look to the eye like a good crib fit, the computer recognizes it as one. If 10 letters matched the score would increase by 49 points, and 11 would produce 64. As you can see, the change in decrypt score really starts changing a lot as a long crib appears in the decrypt.
The post Computer cipher solving – Lesson 5½ : cribs revisited appeared first on OnWords.
March 30, 2017
E- book borrowing is increasing
As an author I have noticed a trend in book sales. Not only are readers moving toward more digital content and less paper, which is unsurprising, but they are also moving toward more e-book borrowing and less purchasing. I decided to graph the royalties I receive on my best selling book, Cached Out, comparing on a percentage basis the royalties I receive from those who borrow the book (either through Amazon Prime or Kindle Unlimited) and those from sales of Kindle ebooks. This chart excludes the paperback and audiobook royalties.
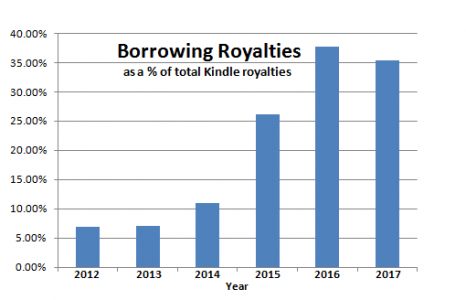
As you can see, I now get more than a third of my Kindle royalties from borrowing. Not all of the increase is due to readers’ changing preferences. Amazon changed its formula for compensating authors for borrowed books in mid-2015. Before that time the authors’ “pot” was split up on a per book basis, i.e. someone whose 15-page children’s book was borrowed once would get the same amount as someone whose 800-page tome was borrowed once. Yielding to complaints, Amazon changed the formula to make the compensation proportional to pages read. (Yes, Amazon can tell how many pages of a book you’ve read with your Kindle/Kindle app, at least if you borrow it). It may be leveling off now, but the 2017 number only shows the average for the first two months. The March numbers aren’t out yet. By the end of the year it may be more.
This trend is consistent with what I read about other digital media. I hear that movie providers are going to earlier streaming because viewers don’t want to buy or borrow the DVDs/Blu-rays when they can stream. Even Snapchat reflects this. Younger people just don’t want to own or even handle digital media; they just want to view it and have it disappear when done. Why fill up your phone or reader with a bunch of books you’ve already read? They aren’t like music that you’re going to listen to again and again.
The post E- book borrowing is increasing appeared first on OnWords.
March 24, 2017
Aurora by Kim Stanley Robinson
 Aurora by Kim Stanley Robinson
Aurora by Kim Stanley Robinson
My rating: 3 of 5 stars
Robinson gets good reviews from Scientific American, Science, and other hard science sources. His educational background, however, is in writing, not science. Perhaps this is why I was surprised that this novel seemed too heavy on the science jargon and too light on the storytelling. It is the story of the first interstellar flight of settlers, destined for a multi-generational trip to the Tau Ceti star system where they are to terraform and settle Aurora, an Earth-like planet there.
The author has conjured up some interesting and mostly credible characters that we follow throughout the book, despite the hurdles of time passage. The narrative is created by the AI that controls the ship and even calls itself ship. The setting is hundreds of years in the future. The central character is Theya, a child at the beginning of the book, much older at the end. For reasons unknown, the author chose to make her taller than anyone else on the ship, over two meters (at least six foot six) but her height became irrelevant and wasn’t mentioned in the second half of the book. She was also a slow learner, not very bright, scientifically ignorant, and somehow became the leader of the mission. (Remind you of anyone?)
The plot was interesting enough, but slow to develop. The author must have been paid by the word, like Dickens or Trollope. He was rather pedantic, too, choosing never to use a simple word like rut or gulch if there was a technical or scientific term for it. Use of robotic arms was waldo work. Every disease had to have the precise medical term for it, somebody’s syndrome, etc., rather than the common one. It made the reading rather tedious. There was an excess of every kind of babble – psycho-, techno-, medico-, and socio-.
It’s clear the author is promoting a certain pro-environmentalist world view, and part of the message is the harm we may do if we don’t straighten up our act here on earth. The book will appeal to hard SF fans with patience.
The post Aurora by Kim Stanley Robinson appeared first on OnWords.
March 22, 2017
Mother’s Cookies – no more Macaroons
I used to love Mother’s Macaroons, but I noticed my wife hadn’t bought them in ages. I put them on the grocery list but she came back saying she couldn’t find them. I looked online, and sure enough, they are no longer made. Mother’s Cookies, which was primarily a west coast brand, is now owned by Kellogg. Mother’s went bankrupt in 2008 during the financial crisis and amid an accounting scandal and sold its recipes and brand to Kellogg’s. Many of the varieties have been brought back, at least to the west coast, including English Tea Cookies and Oatmeal, but I haven’t seen macaroons in a long time. There are some indications online that they were available in 2015, but I can’t find any references newer than that. This wouldn’t be so bad if Kellogg’s replaced them with some other brand of macaroons, but my wife has not been able to find any in the four or five markets she frequents.

Kellogg’s, I’m mad at you! Bring back macaroons!
The post Mother’s Cookies – no more Macaroons appeared first on OnWords.


