
Nicholas C. Zakas's Blog, page 2
December 15, 2020
Creating a JavaScript promise from scratch, Part 6: Promise.all() and Promise.allSettled()
In my last post, I walked you through the creation of the Promice.race() and Promise.any() methods, both of which work on multiple promises and return a single promise that indicates the result of the operation. This post continues on to discuss Promise.all() and Promise.allSettled(), two operations that are similar to one another as well as Promise.any(). Each of these methods use the same basic algorithm so if you’re able to understand one of them then you can understand them all.
This is the sixth post in my series about creating JavaScript promises from scratch. If you haven’t already read the previous posts, I’d suggest you do before continuing on:
Part 1: Constructor
Part 2: Resolving to a promise
Part 3: then(), catch(), and finally()
Part 4: Promise.resolve() and Promise.reject()
Part 5: Promise.race() and Promise.any()
As a reminder, this series is based on my promise library, Pledge. You can view and download all of the source code from GitHub.
The Promise.all() method
The Promise.all() method is the essentially the inverse of the Promise.any() method (discussed in part 5): it returns a rejected promise if any of the promises is rejected and returns a promise that is fulfilled to an array of promise results if all promises are fulfilled. Here are a couple examples:
const promise1 = Promise.all([
Promise.resolve(42),
Promise.reject(43),
Promise.resolve(44)
]);
promise1.catch(reason => {
console.log(reason); // 43
});
const promise2 = Promise.all([
Promise.resolve(42),
Promise.resolve(43),
Promise.resolve(44)
]);
promise2.then(value => {
console.log(value[0]); // 42
console.log(value[1]); // 43
console.log(value[2]); // 44
});
Because Promise.all() is so closely related to Promise.any(), you can actually implement it using essentially the same algorithm.
Creating the Pledge.all() method
The specification1 for Promise.all() describes the same basic algorithm that you’ve already seen for Promise.race() and Promise.any().
class Pledge {
// other methods omitted for space
static all(iterable) {
const C = this;
const pledgeCapability = new PledgeCapability(C);
let iteratorRecord;
try {
const pledgeResolve = getPledgeResolve(C);
iteratorRecord = getIterator(iterable);
const result = performPledgeAll(iteratorRecord, C, pledgeCapability, pledgeResolve);
return result;
} catch (error) {
let result = new ThrowCompletion(error);
if (iteratorRecord && iteratorRecord.done === false) {
result = iteratorClose(iteratorRecord, result);
}
pledgeCapability.reject(result.value);
return pledgeCapability.pledge;
}
}
// other methods omitted for space
}
I’ve explained this algorithm in detail in part 5, so I’m going to skip right to discussing the PerformPromiseAll() 2 operation and how I’ve implemented it as performPledgeAll().
As I’ve already mentioned, this algorithm is so close to PerformPromiseAny()3 that it’s almost copy-and-paste. The first difference is that instead of tracking rejected values, you instead track fulfilled values (so the array is named values instead of errors). Then, instead of attaching a common fulfillment handler and a custom rejection handler, you attach a custom fulfillment handler and a common rejection handler. The last difference is that instead of tracking remaining elements so you can reject an array of errors, you track remaining elements to so you can fulfill an array of values. All of that is wrapped in the wacky iteration algorithm just as in Promise.any(). Here’s the code:
function performPledgeAll(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
// in performPledgeAny, this is the errors array
const values = [];
const remainingElementsCount = { value: 1 };
let index = 0;
while (true) {
let next;
try {
next = iteratorStep(iteratorRecord);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
if (next === false) {
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
// in performPledgeAny, this is where you reject errors
resultCapability.resolve(values);
}
return resultCapability.pledge;
}
let nextValue;
try {
nextValue = iteratorValue(next);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
values.push(undefined);
const nextPledge = pledgeResolve.call(constructor, nextValue);
// in performPledgeAny, you'd create a reject element
const resolveElement = createPledgeAllResolveElement(index, values, resultCapability, remainingElementsCount);
remainingElementsCount.value = remainingElementsCount.value + 1;
// in performPledgeAny, you'd attach resultCapability.resolve
// and a custom reject element
nextPledge.then(resolveElement, resultCapability.reject);
index = index + 1;
}
}
I’ve commented in the code the differences from performPledgeAny() so hopefully you can see that there really isn’t a big difference. You’ll also find that the createPledgeAllResolveElement() function (which implements the Promise.all Resolve Element Functions algorithm4) is very similar to the createPledgeAnyRejectElement() function:
function createPledgeAllResolveElement(index, values, pledgeCapability, remainingElementsCount) {
const alreadyCalled = { value: false };
return x => {
if (alreadyCalled.value) {
return;
}
alreadyCalled.value = true;
values[index] = x;
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
return pledgeCapability.resolve(values);
}
};
}
The createPledgeAllResolveElement() function returns a function that is used as the fulfillment handler for the promise returned from Pledge.all(). The x variable is the fulfilled value and is stored in the values array when available. When there are no further elements remaining, a resolved pledge is returned with the entire values array.
Hopefully you can now see the relationship between Promise.any() and Promise.all(). The Promise.any() method returns a rejected promise with an array of values (wrapped in an AggregateError) when all of the promises are rejected and a fulfilled promise with the value from the first fulfilled promise; the Promise.all() method returns a fulfilled promises with an array of fulfillment values when all of the promises are fulfilled and returns a rejected promise with the reason from the first rejected promise (if one exists). So for Promise.any(), you create a new promise and assign the same fulfillment handler to each promise that was passed in; for Promise.all(), you create a new promise and assign the same rejection handler to each promise that was passed in. Then, in Promise.any() you create a new rejection handler for each promise to track the rejection; for Promise.all() you create a new fulfillment handler for each promise to track fulfillments.
If it seems like Promise.any() and Promise.all() are just two sides of the same coin, then you are correct. The next step is to combine both of these methods into one, and that’s what Promise.allSettled() does.
The Promise.allSettled() method
The Promise.allSettled() method is the last of the four promise methods that work on multiple promises. This method is unique because the promise returned is never rejected unless an error is thrown during the iteration step. Instead, Promise.allSettled() returns a promise that is fulfilled with an array of result objects. Each result object has two properties:
status - either "fulfilled" or "rejected"
value - the value that was fulfilled or rejected
The result objects allow you to collect information about every promise’s result in order to determine the next step to take. As such, Promise.allSettled() will take longer to complete than any of the other multi-promise methods because it has no short-circuiting behavior. Whereas Promise.race() returns as soon as the first promise is settled, Promise.any() returns as soon as the first promise is resolved, and Promise.all() returns as soon as the first promise is rejected, Promise.allSettled() must wait until all promises have settled. Here are some examples showing how Promise.allSettled() is used:
const promise1 = Promise.allSettled([
Promise.resolve(42),
Promise.reject(43),
Promise.resolve(44)
]);
promise1.then(values => {
console.log(values[0]); // { status: "fulfilled", value: 42 }
console.log(values[1]); // { status: "rejected", value: 43 }
console.log(values[2]); // { status: "fulfilled", value: 44 }
});
const promise2 = Promise.allSettled([
new Promise(resolve => {
setTimeout(() => {
resolve(42);
}, 500);
}),
Promise.reject(43),
Promise.resolve(44)
]);
promise2.then(values => {
console.log(values[0]); // { status: "fulfilled", value: 42 }
console.log(values[1]); // { status: "rejected", value: 43 }
console.log(values[2]); // { status: "fulfilled", value: 44 }
});
const promise3 = Promise.allSettled([
Promise.reject(42),
Promise.reject(43),
Promise.reject(44)
]);
promise3.then(values => {
console.log(values[0]); // { status: "rejected", value: 42 }
console.log(values[1]); // { status: "rejected", value: 43 }
console.log(values[2]); // { status: "rejected", value: 44 }
});
Notice that a fulfilled promise is returned even when all of the promises passed to Promise.allSettled() are rejected.
Creating the Pledge.allSettled() method
Once again, the Promise.allSettled() method follows the same basic algorithm5 as the other three multi-promise methods, so the Pledge.allSettled() implementation is the same the others except for naming:
class Pledge {
// other methods omitted for space
static allSettled(iterable) {
const C = this;
const pledgeCapability = new PledgeCapability(C);
let iteratorRecord;
try {
const pledgeResolve = getPledgeResolve(C);
iteratorRecord = getIterator(iterable);
const result = performPledgeAllSettled(iteratorRecord, C, pledgeCapability, pledgeResolve);
return result;
} catch (error) {
let result = new ThrowCompletion(error);
if (iteratorRecord && iteratorRecord.done === false) {
result = iteratorClose(iteratorRecord, result);
}
pledgeCapability.reject(result.value);
return pledgeCapability.pledge;
}
}
// other methods omitted for space
}
The algorithm for the PerformPromiseAllSettled() operation6 should look very familiar at this point. In fact, it is almost exactly the same as the PerformPromiseAll() operation. Just like PerformPromiseAll(), PerformPromiseAllSettled() uses a remainingElementsCount object to track how many promises must still be settled, and index variable to track where each result should go in the values array, and a values array to keep track of promise results. Unlike PerformPromiseAll(), the values stored in the values array in PerformPromiseAllSettled() are the result objects I mentioned in the previous section.
The other significant difference between PerformPromiseAll() and PerformPromiseAllSettled() is that the latter creates a custom rejection handler for each promise in addition to a custom fulfillment handler. Those handlers are also created using the same basic algorithm you’ve already seen in other multi-promise methods.
Without any further delay, here’s the implementation of performPledgeAllSettled():
function performPledgeAllSettled(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
const values = [];
const remainingElementsCount = { value: 1 };
let index = 0;
while (true) {
let next;
try {
next = iteratorStep(iteratorRecord);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
if (next === false) {
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
resultCapability.resolve(values);
}
return resultCapability.pledge;
}
let nextValue;
try {
nextValue = iteratorValue(next);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
values.push(undefined);
const nextPledge = pledgeResolve.call(constructor, nextValue);
const resolveElement = createPledgeAllSettledResolveElement(index, values, resultCapability, remainingElementsCount);
// the only significant difference from performPledgeAll is adding this
// custom rejection handler to each promise instead of resultCapability.reject
const rejectElement = createPledgeAllSettledRejectElement(index, values, resultCapability, remainingElementsCount);
remainingElementsCount.value = remainingElementsCount.value + 1;
nextPledge.then(resolveElement, rejectElement);
index = index + 1;
}
}
As you can see, the only significant change from performPledgeAll() is the addition of the rejectElement that is used instead of resultCapability.reject. Otherwise, the functionality is exactly the same. The heavy lifting is really done by the createPledgeAllSettledResolveElement() and createPledgeAllSettledRejectElement() functions. These functions represent the corresponding steps in the specification for Promise.allSettled Resolve Element Functions7 and Promise.allSettled Reject Element Functions8 and are essentially the same function with the notable exception that one specifies the result as “fulfilled” and the other specifies the result as “rejected”. Here are the implementations:
function createPledgeAllSettledResolveElement(index, values, pledgeCapability, remainingElementsCount) {
const alreadyCalled = { value: false };
return x => {
if (alreadyCalled.value) {
return;
}
alreadyCalled.value = true;
values[index] = {
status: "fulfilled",
value: x
};
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
return pledgeCapability.resolve(values);
}
};
}
function createPledgeAllSettledRejectElement(index, values, pledgeCapability, remainingElementsCount) {
const alreadyCalled = { value: false };
return x => {
if (alreadyCalled.value) {
return;
}
alreadyCalled.value = true;
values[index] = {
status: "rejected",
value: x
};
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
return pledgeCapability.resolve(values);
}
};
}
You’ve already seen several of these functions at this point, so I’ll just point out how these are different. First, even the reject element calls pledgeCapability.resolve() because the returned promise should never be rejected due to a passed-in promise being rejected. Next, the value inserted into the values array is an object instead of just x (as you saw in Promise.any() and Promise.all()). Both the resolve and reject elements are just inserting a result object into the values and array, and when there are no further promises to wait for, returns a resolved promise.
Wrapping Up
This post covered creating Promise.all() and Promise.allSettled() from scratch. These are the last two of the built-in methods that work on multiple promises (the previous two were covered in part 5). The Promise.all() method is essentially the inverse of the Promise.any() method: it returns a rejected promise if any of the promises is rejected and returns a promise that is fulfilled to an array of promise results if all promises are fulfilled. The Promise.allSettled() method combines aspects of Promise.all() and Promise.any() so that it almost always returns a fulfilled promise with an array of result objects containing the results of both fulfilled and rejected promises.
In the next, and final, part of this series, I’ll be covering unhandled promise rejections.
All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
References
PerformPromiseAll ( iteratorRecord, constructor, resultCapability, promiseResolve ) ↩
PerformPromiseAny ( iteratorRecord, constructor, resultCapability, promiseResolve ) ↩
Promise.all Resolve Element Functions ↩
Promise.allSettled ( iterable ) ↩
PerformPromiseAllSettled ( iteratorRecord, constructor, resultCapability, promiseResolve ) ↩
Promise.allSetled Resolve Element Functions ↩
Promise.allSetled Reject Element Functions ↩







November 23, 2020
Creating a JavaScript promise from scratch, Part 5: Promise.race() and Promise.any()
In the previous posts in this series, I discussed implementing a promise from scratch in JavaScript. Now that there’s a full promise implementation, it’s time to look at how you can monitor multiple promises at once using Promise.race() and Promise.any() (Promise.all() and Promise.allSettled() will be covered in the next post). You’ll see that, for the most part, all of the methods that work with multiple promises follow a similar algorithm, which makes it fairly easy to move from implementing one of these methods to the next.
Note: This is the fifth post in my series about creating JavaScript promises from scratch. If you haven’t already read the first post, the second post, the third post, and the fourth post, I would suggest you do so because this post builds on the topics covered in those posts.
As a reminder, this series is based on my promise library, Pledge. You can view and download all of the source code from GitHub.
Prerequisite: Using iterators
Most of the time you see examples using Promise.race() and Promise.any() with an array being passed as the only argument, like this:
Promise.race([p1, p2, p3]).then(value => {
console.log(value);
});
Because of this, it’s easy to assume that the argument to Promise.race() must be an array. In fact, the argument doesn’t need to be an array, but it must be an iterable. An iterable is just an object that has a Symbol.iterator method that returns an iterator. An iterator is an object with a next() method that returns an object containing two properties: value, the next value in the iterator or undefined if none are left, and done, a Boolean value that is set to true when there are no more values in the iterator.
Arrays are iterables by default, meaning they have a default Symbol.iterator method that returns an iterator. As such, you can pass an array anywhere an iterator is required and it just works. What that means for the implementations of Promise.race() and Promise.all() is that they must work with iterables, and unfortunately, ECMA-262 makes working with iterables a little bit opaque.
The first operation we need is GetIterator()1, which is the operation that retrieves the iterator for an iterable and returns an IteratorRecord containing the iterator, the next() method for that iterator, and a done flag. The algorithm is a bit difficult to understand, but fundamentally GetIterator() will attempt to retrieve either an async or sync iterator based on a hint that is passed. For the purposes of this post, just know that only sync iterators will be used, so you can effectively ignore the parts that have to do with async iterators. Here’s the operation translated into JavaScript:
export function getIterator(obj, hint="sync", method) {
if (hint !== "sync" && hint !== "async") {
throw new TypeError("Invalid hint.");
}
if (method === undefined) {
if (hint === "async") {
method = obj[Symbol.asyncIterator];
if (method === undefined) {
const syncMethod = obj[Symbol.iterator];
const syncIteratorRecord = getIterator(obj, "sync", syncMethod);
// can't accurately represent CreateAsyncFromSyncIterator()
return syncIteratorRecord;
}
} else {
method = obj[Symbol.iterator];
}
}
const iterator = method.call(obj);
if (!isObject(iterator)) {
throw new TypeError("Iterator must be an object.");
}
const nextMethod = iterator.next;
return {
iterator,
nextMethod,
done: false
};
}
In ECMA-262, you always use IteratorRecord to work with iterators instead of using the iterator directly. Similarly, there are several operations that are used to manually work with an iterator:
IteratorNext()2 - calls the next() method on an iterator and returns the result.
ItereatorComplete()3 - returns a Boolean indicating if the iterator is done (simply reads the done field of the given result from IteratorNext()).
IteratorValue()4 - returns the value field of the given result from IteratorNext().
IteratorStep()5 - returns the result from IteratorNext() if done is false; returns false if done is true (just for fun, I suppose).
Each of these operations is pretty straightforward as they simply wrap built-in iterator operations. Here are the operations implemented in JavaScript:
export function iteratorNext(iteratorRecord, value) {
let result;
if (value === undefined) {
result = iteratorRecord.nextMethod.call(iteratorRecord.iterator);
} else {
result = iteratorRecord.nextMethod.call(iteratorRecord.iterator, value);
}
if (!isObject(result)) {
throw new TypeError("Result must be an object.");
}
return result;
}
export function iteratorComplete(iterResult) {
if (!isObject(iterResult)) {
throw new TypeError("Argument must be an object.");
}
return Boolean(iterResult.done);
}
export function iteratorValue(iterResult) {
if (!isObject(iterResult)) {
throw new TypeError("Argument must be an object.");
}
return iterResult.value;
}
export function iteratorStep(iteratorRecord) {
const result = iteratorNext(iteratorRecord);
const done = iteratorComplete(result);
if (done) {
return false;
}
return result;
}
To get an idea about how these operations are used, consider this simple loop using an array:
const values = [1, 2, 3];
for (const nextValue of values) {
console.log(nextValue);
}
The for-of loop operates on the iterator creates for the values array. Here’s a similar loop using the iterator functions defined previously:
const values = [1, 2, 3];
const iteratorRecord = getIterator(values);
// ECMA-262 always uses infinite loops that break
while (true) {
let next;
/*
* Get the next step in the iterator. If there's an error, don't forget
* to set the `done` property to `true` for posterity.
*/
try {
next = iteratorStep(iteratorRecord);
} catch (error) {
iteratorRecord.done = true;
throw error;
}
// if `next` is false then we are done and can exit
if (next === false) {
iteratorRecord.done = true;
break;
}
let nextValue;
/*
* Try to retrieve the value of the next step. The spec says this might
* actually throw an error, so once again, catch that error, set the
* `done` field to `true`, and then re-throw the error.
*/
try {
nextValue = iteratorValue(next);
} catch (error) {
iteratorRecord.done = true;
throw error;
}
// actually output the value
console.log(nextValue);
}
}
As you can probably tell from this example, there’s a lot of unnecessary complexity involved with looping over an iterator in ECMA-262. Just know that all of these operations can be easily replaced with a for-of loop. I chose to use the iterator operations so that it’s easier to go back and forth between the code and the specification, but there are definitely more concise and less error-prone ways of implementing the same functionality.
The Promise.race() method
The Promise.race() method is the simplest of the methods that work on multiple promises: whichever promise settles first, regardless if it’s fulfilled or rejected, that result is passed through to the returned promise. So if the first promise to settle is fulfilled, then the returned promise is fulfilled with the same value; if the first promise to settle is rejected, then the returned promise is rejected with the same reason. Here are a couple examples:
const promise1 = Promise.race([
Promise.resolve(42),
Promise.reject(43),
Promise.resolve(44)
]);
promise1.then(value => {
console.log(value); // 42
});
const promise2 = Promise.race([
new Promise(resolve => {
setTimeout(() => {
resolve(42);
}, 500);
}),
Promise.reject(43),
Promise.resolve(44)
]);
promise2.catch(reason => {
console.log(reason); // 43
});
The behavior of Promise.race() makes it easier to implement than the other three methods that work on multiple promises, all of which require keeping at least one array to track results.
Creating the Pledge.race() method
The specification6 for Promise.race() describes the algorithm as follows:
Let C be the this value.
Let promiseCapability be ? NewPromiseCapability(C).
Let promiseResolve be GetPromiseResolve(C).
IfAbruptRejectPromise(promiseResolve, promiseCapability).
Let iteratorRecord be GetIterator(iterable).
IfAbruptRejectPromise(iteratorRecord, promiseCapability).
Let result be PerformPromiseRace(iteratorRecord, C, promiseCapability, promiseResolve).
If result is an abrupt completion, then
If iteratorRecord.[[Done]] is false, set result to IteratorClose(iteratorRecord, result).
IfAbruptRejectPromise(result, promiseCapability).
Return Completion(result).
The main algorithm for Promise.race() actually takes place in an operation called PerformPromiseRace. The rest is just setting up all of the appropriate data to pass to the operation and then interpreting the result of the operation. All four of the methods that deal with multiple promises, Promise.race(), Promise.any(), Promise.all(), and Promise.allSettled(), all follow this same basic algorithm for their methods with the only difference being the operations they delegate to. This will become clear later in this post when I discussed Promise.any().
class Pledge {
// other methods omitted for space
static race(iterable) {
const C = this;
const pledgeCapability = new PledgeCapability(C);
let iteratorRecord;
try {
const pledgeResolve = getPledgeResolve(C);
iteratorRecord = getIterator(iterable);
const result = performPledgeRace(iteratorRecord, C, pledgeCapability, pledgeResolve);
return result;
} catch (error) {
let result = new ThrowCompletion(error);
if (iteratorRecord && iteratorRecord.done === false) {
result = iteratorClose(iteratorRecord, result);
}
pledgeCapability.reject(result.value);
return pledgeCapability.pledge;
}
}
// other methods omitted for space
}
Like many of the other methods in the Pledge class, this one starts by retrieving the this value and creating a PledgeCapability object. The next step is to retrieve the resolve method from the constructor, which basically means pledgeResolve is set equal to Pledge.resolve() (discussed in part 4). The getPledgeResolve() method is the equivalent of the GetPromiseResolve7 operation in the spec. Here’s the code:
function getPledgeResolve(pledgeConstructor) {
assertIsConstructor(pledgeConstructor);
const pledgeResolve = pledgeConstructor.resolve;
if (!isCallable(pledgeResolve)) {
throw new TypeError("resolve is not callable.");
}
return pledgeResolve;
}
After that, an iterator is retrieved for the iterable that was passed into the method. All of the important pieces of data are passed into performPledgeRace(), which I’ll cover in a moment.
The catch clause of the try-catch statement handles any errors that are thrown. In order to make the code easier to compare the specification, I’ve chosen to once again use completion records (completion records were introduced in part 3 of this series). This part isn’t very important to the overall algorithm, so I’m going to skip explaining it and the iteratorClose() function in detail. Just know that when an error is thrown, the iterator might not have completed and so iteratorClose() is used to close out the iterator, freeing up any memory associated with it. The iteratorClose() function may return its own error, and if so, that’s the error that should be rejected into the created pledge. If you’d like to learn more about iteratorClose(), please check out the source code on GitHub.
The next step is to implement the PerformPromiseRace()8 operation as performPledgeRace(). The algorithm for this operation seems more complicated than it actually is due to the iterator loop I described at the start of this post. See if you can figure out what is happening in this code:
function performPledgeRace(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
while (true) {
let next;
try {
next = iteratorStep(iteratorRecord);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
if (next === false) {
iteratorRecord.done = true;
return resultCapability.pledge;
}
let nextValue;
try {
nextValue = iteratorValue(next);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
const nextPledge = pledgeResolve.call(constructor, nextValue);
nextPledge.then(resultCapability.resolve, resultCapability.reject);
}
}
The first thing to notice is that, unlike the loops described in the first section of this post, no errors are thrown. Instead, any errors that occur are passed to the resultCapability.reject() method and the created pledge object is returned. All of the error checking really gets in the way of understanding what is a very simple algorithm, so here’s a version that better illustrates how the algorithm works using JavaScript you’d write in real life:
function performPledgeRaceSimple(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
// You could actually just pass the iterator instead of `iteratatorRecord`
const iterator = iteratorRecord.iterator;
try {
// loop over every value in the iterator
for (const nextValue of iterator) {
const nextPledge = pledgeResolve.call(constructor, nextValue);
nextPledge.then(resultCapability.resolve, resultCapability.reject);
}
} catch (error) {
resultCapability.reject(error);
}
iteratorRecord.done = true;
return resultCapability.pledge;
}
With this stripped-down version of performPledgeRace(), you can see that the fundamental algorithm is take each value returned from the iterator and pass it to Pledge.resolve() to ensure you have an instance of Pledge to work with. The iterator can contain both Pledge objects and any other non-Pledge value, so the best way to ensure you have a Pledge object is to pass all values to Pledge.resolve() and use the result (nextPledge). Then, all you need to do is attach resultCapability.resolve() as the fulfillment handler and resultCapability.reject() as the rejection handler. Keep in mind that these methods only work once and otherwise do nothing, so there is no harm in assigning them to all pledges (see part 3 for detail on how this works).
With that, the Pledge.race() method is complete. This is the simplest of the static methods that work on multiple promises. The next method, Pledge.any(), uses some of the same logic but also adds a bit more complexity for handling rejections.
The Promise.any() method
The Promise.any() method is a variation of the Promise.race() method. Like Promise.race(), Promise.any() will return a promise that is fulfilled with the same value as the first promise to be fulfilled. In effect, there’s still a “race” to see which promise will be fulfilled first. The difference is when none of the promises are fulfilled, in which case the returned promise is rejected with an AggregateError object9 that contains an errors array with the rejection reasons of each promise. Here are some examples to better illustrate:
const promise1 = Promise.any([
Promise.resolve(42),
Promise.reject(43),
Promise.resolve(44)
]);
promise1.then(value => {
console.log(value); // 42
});
const promise2 = Promise.any([
new Promise(resolve => {
setTimeout(() => {
resolve(42);
}, 500);
}),
Promise.reject(43),
Promise.resolve(44)
]);
promise2.then(value => {
console.log(value); // 44
});
const promise3 = Promise.any([
Promise.reject(42),
Promise.reject(43),
Promise.reject(44)
]);
promise2.catch(reason => {
console.log(reason.errors[0]); // 42
console.log(reason.errors[1]); // 43
console.log(reason.errors[2]); // 44
});
The first two calls to Promise.any() in this code are resolved to a fulfilled promise because at least one promise was fulfilled; the last call resolves to an AggregateError object where the errors property is an array of all the rejected values.
Creating an AggregateError object
The first step in implementing Pledge.any() is to create a representation of AggregateError. This class is new enough to JavaScript that it’s not present in a lot of runtimes yet, so it’s helpful to have a standalone representation. The specification9 indicates that AggregateError is not really a class, but rather a function that can be called with or without new. Here’s what a translation of the specification looks like:
export function PledgeAggregateError(errors=[], message) {
const O = new.target === undefined ? new PledgeAggregateError() : this;
if (typeof message !== "undefined") {
const msg = String(message);
Object.defineProperty(O, "message", {
value: msg,
writable: true,
enumerable: false,
configurable: true
});
}
// errors can be an iterable
const errorsList = [...errors];
Object.defineProperty(O, "errors", {
configurable: true,
enumerable: false,
writable: true,
value: errorsList
});
return O;
}
An interesting note about this type of error is that the message parameter is optional and may not appear on the object. The errors parameter is also optional, however, the created object will always have an errors property. Due to this, and the fact that the implementation is done with a function, there are a variety of ways to create a new instance:
const error1 = new PledgeAggregateError();
const error2 = new PledgeAggregateError([42, 43, 44]);
const error3 = new PledgeAggregateError([42, 43, 44], "Oops!");
const error4 = PledgeAggregateError();
const error5 = PledgeAggregateError([42, 43, 44]);
const error6 = PledgeAggregateError([42, 43, 44], "Oops!");
This implementation matches how the specification defines AggregateError objects, so now it’s time to move on to implementing Pledge.any() itself.
Creating the Pledge.any() method
As I mentioned in the previous section, all of the algorithms for the static methods that work on multiple promises are similar, with the only real exception being the name of the operation that it delegates to. The Promise.any() method10 follows the same structure as the Promise.race() method, and so the Pledge.any() method in this library should look familiar:
class Pledge {
// other methods omitted for space
static any(iterable) {
const C = this;
const pledgeCapability = new PledgeCapability(C);
let iteratorRecord;
try {
const pledgeResolve = getPledgeResolve(C);
iteratorRecord = getIterator(iterable);
const result = performPledgeAny(iteratorRecord, C, pledgeCapability, pledgeResolve);
return result;
} catch (error) {
let result = new ThrowCompletion(error);
if (iteratorRecord && iteratorRecord.done === false) {
result = iteratorClose(iteratorRecord, result);
}
pledgeCapability.reject(result.value);
return pledgeCapability.pledge;
}
}
// other methods omitted for space
}
Because you’re already familiar with this basic algorithm, I’ll skip directly to what the performPledgeAny() function does.
The algorithm for the PerformPromiseAny() method11 looks more complicated than it actually is. Part of the reason for that is the wacky way iterators are used, but you are already familiar with that. In fact, all this method does is attach resultCapability.resolve to be the fulfillment handler of each promise and attaches a special rejection handler that simply collects all of the rejection reasons in case they are needed.
To keep track of rejection reasons, the operation defines three variables:
errors - the array to keep track of all rejection reasons
remainingElementsCount - a record whose only purpose is to track how many promises still need to be fulfilled
index - the index in the errors array where each rejection reason should be placed
These three variables are the primary difference between performPledgeAny() and performPledgeRace(), and these will also appear in the implementations for Pledge.all() and Pledge.allSettled().
With that basic explanation out of the way, here’s the code:
function performPledgeAny(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
const errors = [];
const remainingElementsCount = { value: 1 };
let index = 0;
while (true) {
let next;
try {
next = iteratorStep(iteratorRecord);
} catch (error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
if (next === false) {
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
const error = new PledgeAggregateError();
Object.defineProperty(error, "errors", {
configurable: true,
enumerable: false,
writable: true,
value: errors
});
resultCapability.reject(error);
}
return resultCapability.pledge;
}
let nextValue;
try {
nextValue = iteratorValue(next);
} catch(error) {
iteratorRecord.done = true;
resultCapability.reject(error);
return resultCapability.pledge;
}
errors.push(undefined);
const nextPledge = pledgeResolve.call(constructor, nextValue);
const rejectElement = createPledgeAnyRejectElement(index, errors, resultCapability, remainingElementsCount);
remainingElementsCount.value = remainingElementsCount.value + 1;
nextPledge.then(resultCapability.resolve, rejectElement);
index = index + 1;
}
}
The first important part of this function is when remainingElementsCount.value is 0, then a new PledgeAggregateError object is created and passed to resultCapability.reject(). This is the condition where there are no more promises in the iterator and all of the promises have been rejected.
The next important part of the code is the createPledgeAnyRejectElement() function. This function doesn’t have a corresponding operation in the specification, but rather, is defined as a series of steps12 to take; I split it out into a function to make the code easier to understand. The “reject element” is the rejection handler that should be attached to each promise, and it’s job is to aggregate the rejection reason. Here’s the code:
function createPledgeAnyRejectElement(index, errors, pledgeCapability, remainingElementsCount) {
const alreadyCalled = { value: false };
return x => {
if (alreadyCalled.value) {
return;
}
alreadyCalled.value = true;
errors[index] = x;
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
const error = new PledgeAggregateError();
Object.defineProperty(error, "errors", {
configurable: true,
enumerable: false,
writable: true,
value: errors
});
return pledgeCapability.reject(error);
}
};
}
As with other fulfillment and rejection handlers, this function returns a function that first checks to make sure it’s not being called twice. The x parameter is the reason for the rejection and so is placed into the errors array at index. Then, remainingElementsCount.value is checked to see if it’s 0, and if so, a new PledgeAggregateError is created. This is necessary because the promises might be rejected long after the initial called to Pledge.any() has completed. So the check in performPledgeAny() handles the situation where all of the promises are rejected synchronously while the reject element functions handle the situation where all of the promises are rejected asynchronously.
And for clarify, here is what the performPledgeAny() method would look like without the iterator craziness:
function performPledgeAnySimple(iteratorRecord, constructor, resultCapability, pledgeResolve) {
assertIsConstructor(constructor);
assertIsCallable(pledgeResolve);
// You could actually just pass the iterator instead of `iteratatorRecord`
const iterator = iteratorRecord.iterator;
const errors = [];
const remainingElementsCount = { value: 1 };
let index = 0;
try {
// loop over every value in the iterator
for (const nextValue of iterator) {
errors.push(undefined);
const nextPledge = pledgeResolve.call(constructor, nextValue);
const rejectElement = createPledgeAnyRejectElement(index, errors, resultCapability, remainingElementsCount);
nextPledge.then(resultCapability.resolve, rejectElement);
remainingElementsCount.value = remainingElementsCount.value + 1;
index = index + 1;
}
remainingElementsCount.value = remainingElementsCount.value - 1;
if (remainingElementsCount.value === 0) {
const error = new PledgeAggregateError();
Object.defineProperty(error, "errors", {
configurable: true,
enumerable: false,
writable: true,
value: errors
});
resultCapability.reject(error);
}
} catch (error) {
resultCapability.reject(error);
}
iteratorRecord.done = true;
return resultCapability.pledge;
}
This version is not as straightforward as the performPledgeRace() equivalent, but hopefully you can see that the overall approach is still just looping over the promises and attaching appropriate fulfillment and rejection handlers.
Wrapping Up
This post covered creating Promise.race() and Promise.any() from scratch. These are just two of the built-in methods that work on multiple promises. The Promise.race() method is the simplest of these four methods because you don’t have to do any tracking; each promise is assigned the same fulfillment and rejection handlers, and that is all you need to worry about. The Promise.any() method is a bit more complex because you need to keep track of all the rejections in case none of the promises are fulfilled.
All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
Want more posts in this series?
If you are enjoying this series and would like to see it continue, please sponsor me on GitHub. For every five new sponsors I receive, I’ll release a new post. Here’s what I plan on covering:
Part 6: Promise.all() and Promise.allSettled() (when I have 40 sponsors)
Part 7: Unhandled promise rejection tracking (when I have 45 sponsors)
It takes a significant amount of time to put together posts like these, and I appreciate your consideration in helping me continue to create quality content like this.
References
GetIterator ( obj [ , hint [ , method ] ] ) ↩
IteratorNext (IteratorNext ( iteratorRecord [ , value ] )) ↩
IteratorComplete ( iterResult ) ↩
IteratorValue ( iterResult ) ↩
IteratorStep ( iteratorRecord ) ↩
GetPromiseResolve ( promiseConstructor ) ↩
PerformPromiseRace ( iteratorRecord, constructor, resultCapability, promiseResolve ) ↩
PerformPromiseAny ( iteratorRecord, constructor, resultCapability, promiseResolve ) ↩
Promise.any Reject Element Functions ↩



October 12, 2020
Creating a JavaScript promise from scratch, Part 4: Promise.resolve() and Promise.reject()
When you create a promise with the Promise constructor, you’re creating an unsettled promise, meaning the promise state is pending until either the resolve or reject function is called inside the constructor. You can also created promises by using the Promise.resolve() and Promise.reject() methods, in which case, the promises might already be fulfilled or rejected as soon as they are created. These methods are helpful for wrapping known values in promises without going through the trouble of defining an executor function. However, Promise.resolve() doesn’t directly map to resolve inside an executor, and Promise.reject() doesn’t directly map to reject inside an executor.
Note: This is the fourth post in my series about creating JavaScript promises from scratch. If you haven’t already read the first post, the second post, and the third post, I would suggest you do so because this post builds on the topics covered in those posts.
As a reminder, this series is based on my promise library, Pledge. You can view and download all of the source code from GitHub.
The Promise.resolve() method
The purpose of the Promise.resolve() method is to return a promise that resolves to a given argument. However, there is some nuanced behavior around what it ends up returning:
If the argument isn’t a promise, a new fulfilled promise is returned where the fulfillment value is the argument.
If the argument is a promise and the promise’s constructor is different than the this value inside of Promise.resolve(), then a new promise is created using the this value and that promise is set to resolve when the argument promise resolves.
If the argument is a promise and the promise’s constructor is the same as the this value inside of Promise.resolve(), then the argument promise is returned and no new promise is created.
Here are some examples to illustrate these cases:
// non-promise value
const promise1 = Promise.resolve(42);
console.log(promise1.constructor === Promise); // true
// promise with the same constructor
const promise2 = Promise.resolve(promise1);
console.log(promise2.constructor === Promise); // true
console.log(promise2 === promise1); // true
// promise with a different constructor
class MyPromise extends Promise {}
const promise3 = MyPromise.resolve(42);
const promise4 = Promise.resolve(promise3);
console.log(promise3.constructor === MyPromise); // true
console.log(promise4.constructor === Promise); // true
console.log(promise3 === promise4); // false
In this code, passing 42 to Promise.resolve() results in a new fulfilled promise, promise1 that was created using the Promise constructor. In the second part, promise1 is passed to Promise.resolve() and the returned promise, promise2, is actually just promise1. This is a shortcut operation because there is no reason to create a new instance of the same class of promise to represent the same fulfillment value. In the third part, MyPromise extends Promise to create a new class. The MyPromise.resolve() method creates an instance of MyPromise because the this value inside of MyPromise.resolve() determines the constructor to use when creating a new promise. Because promise3 was created with the Promise constructor, Promise.resolve() needs to create a new instance of Promise that resolves when promise3 is resolved.
The important thing to keep in mind that the Promise.resolve() method always returns a promise created with the this value inside. This ensures that for any given X.resolve() method, where X is a subclass of Promise, returns an instance of X.
Creating the Pledge.resolve() method
The specification1 defines a simple, three-step process for the Promise.resolve() method:
Let C be the this value.
If Type(C) is not Object, throw a TypeError exception.
Return ? PromiseResolve(C, x).
As with many of the methods discussed in this blog post series, Promise.resolve() delegates much of the work to another operation called PromiseResolve()2, which I’ve implemented as pledgeResolve(). The actual code for Pledge.resolve() is therefore quite succinct:
export class Pledge {
// other methods omitted for space
static resolve(x) {
const C = this;
if (!isObject(C)) {
throw new TypeError("Cannot call resolve() without `this` value.");
}
return pledgeResolve(C, x);
}
// other methods omitted for space
}
You were introduced to the the pledgeResolve() function in the third post in the series, and I’ll show it here again for context:
function pledgeResolve(C, x) {
assertIsObject(C);
if (isPledge(x)) {
const xConstructor = x.constructor;
if (Object.is(xConstructor, C)) {
return x;
}
}
const pledgeCapability = new PledgeCapability(C);
pledgeCapability.resolve(x);
return pledgeCapability.pledge;
}
When used in the finally() method, the C argument didn’t make a lot of sense, but here you can see that it’s important to ensure the correct constructor is used from Pledge.resolve(). So if x is an instance of Pledge, then you need to check to see if its constructor is also C, and if so, just return x. Otherwise, the PledgeCapability class is once again used to create an instance of the correct class, resolve it to x, and then return that instance.
With Promise.resolve() fully implemented as Pledge.resolve() in the Pledge library, it’s now time to move on to Pledge.reject().
The Promise.reject() method
The Promise.reject() method behaves similarly to Promise.resolve() in that you pass in a value and the method returns a promise that wraps that value. In the case of Promise.reject(), though, the promise is in a rejected state and the reason is the argument that was passed in. The biggest difference from Promise.resolve() is that there is no additional check to see if the reason is a promise that has the same constructor; Promise.reject() always creates and returns a new promise, so there is no reason to do such a check. Otherwise, Promise.reject() mimics the behavior of Promise.resolve(), including using the this value to determine the class to use when returning a new promise. Here are some examples:
// non-promise value
const promise1 = Promise.reject(43);
console.log(promise1.constructor === Promise); // true
// promise with the same constructor
const promise2 = Promise.reject(promise1);
console.log(promise2.constructor === Promise); // true
console.log(promise2 === promise1); // false
// promise with a different constructor
class MyPromise extends Promise {}
const promise3 = MyPromise.reject(43);
const promise4 = Promise.reject(promise3);
console.log(promise3.constructor === MyPromise); // true
console.log(promise4.constructor === Promise); // true
console.log(promise3 === promise4); // false
Once again, Promise.reject() doesn’t do any inspection of the reason passed in and always returns a new promise, promise2 is not the same as promise1. And the promise returned from MyPromise.reject() is an instance of MyPromise rather than Promise, fulfilling the requirement that X.reject() always returns an instance of X.
Creating the Pledge.reject() method
According to the specification3, the following steps must be taken when Promise.reject() is called with an argument r:
Let C be the this value.
Let promiseCapability be ? NewPromiseCapability(C).
Perform ? Call(promiseCapability.[[Reject]], undefined, « r »).
Return promiseCapability.[[Promise]].
Fortunately, converting this algorithm into JavaScript is straightforward:
export class Pledge {
// other methods omitted for space
static reject(r) {
const C = this;
const capability = new PledgeCapability(C);
capability.reject(r);
return capability.pledge;
}
// other methods omitted for space
}
This method is similar to pledgeResolve() with the two notable exceptions: there is no check to see what type of value r and the capability.reject() method is called instead of capability.resolve(). All of the work is done inside of PledgeCapability, once again highlighting how important this part of the specification is to promises as a whole.
Wrapping Up
This post covered creating Promise.resolve() and Promise.reject() from scratch. These methods are important for converting from non-promise values into promises, which is used in a variety of ways in JavaScript. For example, the await operator calls PromiseResolve() to ensure its operand is a promise. So while these two methods are a lot simpler than the ones covered in my previous posts, they are equally as important to how promises work as a whole.
All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
Want more posts in this series?
So far, I’ve covered the basic ways that promises work, but there’s still more to cover. If you are enjoying this series and would like to see it continue, please sponsor me on GitHub. For every five new sponsors I receive, I’ll release a new post. Here’s what I plan on covering:
Part 5: Promise.race() and Promise.any() (when I have 35 sponsors)
Part 6: Promise.all() and Promise.allSettled() (when I have 40 sponsors)
Part 7: Unhandled promise rejection tracking (when I have 45 sponsors)
It takes a significant amount of time to put together posts like these, and I appreciate your consideration in helping me continue to create quality content like this.
References



October 5, 2020
Creating a JavaScript promise from scratch, Part 3: then(), catch(), and finally()
In my first post of this series, I explained how the Promise constructor works by recreating it as the Pledge constructor. In the second post in this series, I explained how asynchronous operations work in promises through jobs. If you haven’t already read those two posts, I’d suggest doing so before continuing on with this one.
This post focuses on implementing then(), catch(), and finally() according to ECMA-262. This functionality is surprisingly involved and relies on a lot of helper classes and utilities to get things working correctly. However, once you master a few basic concepts, the implementations are relatively straightforward.
As a reminder, this series is based on my promise library, Pledge. You can view and download all of the source code from GitHub.
The then() method
The then() method on promises accepts two arguments: a fulfillment handler and a rejection handler. The term handler is used to describe a function that is called in reaction to a change in the internal state of a promise, so a fulfillment handler is called when a promise is fulfilled and a rejection handler is called when a promise is rejected. Each of the two arguments may be set as undefined to allow you to set one or the other without requiring both.
The steps taken when then() is called depends on the state of the promise:
If the promise’s state is pending (the promise is unsettled), then() simply stores the handlers to be called later.
If the promise’s state is fulfilled, then() immediately queues a job to execute the fulfillment handler.
If the promise’s state is rejected, then() immediately queues a job to execute the rejection handler.
Additionally, regardless of the promise state, then() always returns another promise, which is why you can chain promises together like this:
const promise = new Promise((resolve, reject) => {
resolve(42);
});
promise.then(value1 => {
console.log(value1);
return value1 1;
}).then(value2 => {
console.log(value2);
});
In this example, promise.then() adds a fulfillment handler that outputs the resolution value and then returns another number based on that value. The second then() call is actually on a second promise that is resolved using the return value from the preceding fulfillment handler. It’s this behavior that makes implementing then() one of the more complicated aspects of promises, and that’s why there are a small group of helper classes necessary to implement the functionality properly.
The PromiseCapability record
The specification defines a PromiseCapability record1 as having the following internal-only properties:
Field Name
Value
Meaning
[[Promise]]
An object
An object that is usable as a promise.
[[Resolve]]
A function object
The function that is used to resolve the given promise object.
[[Reject]]
A function object
The function that is used to reject the given promise object.
Effectively, a PromiseCapability record consists of a promise object and the resolve and reject functions that change its internal state. You can think of this as a helper object that allows easier access to changing a promise’s state.
Along with the definition of the PromiseCapability record, there is also the definition of a NewPromiseCapability() function2 that outlines the steps you must take in order to create a new PromiseCapability record. The NewPromiseCapability() function is passed a single argument, C, that is a function assumed to be a constructor that accepts an executor function. Here’s a simplified list of steps:
If C isn’t a constructor, throw an error.
Create a new PromiseCapability record with all internal properties set to undefined.
Create an executor function to pass to C.
Store a reference to the PromiseCapability on the executor.
Create a new promise using the executor and extract it resolve and reject functions.
Store the resolve and reject functions on the PromiseCapability.
If resolve isn’t a function, throw an error.
If reject isn’t a function, throw an error.
Store the promise on the PromiseCapability.
Return the PromiseCapability
I decided to use a PledgeCapability class to implement both PromiseCapability and NewPromiseCapability(), making it more idiomatic to JavaScript. Here’s the code:
export class PledgeCapability {
constructor(C) {
const executor = (resolve, reject) => {
this.resolve = resolve;
this.reject = reject;
};
// not used but included for completeness with spec
executor.capability = this;
this.pledge = new C(executor);
if (!isCallable(this.resolve)) {
throw new TypeError("resolve is not callable.");
}
if (!isCallable(this.reject)) {
throw new TypeError("reject is not callable.");
}
}
}
The most interesting part of the constructor, and the part that took me the longest to understand, is that the executor function is used simply to grab references to the resolve and reject functions that are passed in. This is necessary because you don’t know what C is. If C was always Promise, then you could use createResolvingFunctions() to create resolve and reject. However, C could be a subclass of Promise that changes how resolve and reject are created, so you need to grab the actual functions that are passed in.
A note about the design of this class: I opted to use string property names instead of going through the trouble of creating symbol property names to represent that these properties are meant to be internal-only. However, because this class isn’t exposed as part of the API, there is no risk of anyone accidentally referencing those properties from outside of the library. Given that, I decided to favor the readability of string property names over the more technically correct symbol property names.
The PledgeCapability class is used like this:
const capability = new PledgeCapability(Pledge);
capability.resolve(42);
capability.pledge.then(value => {
console.log(value);
});
In this example, the Pledge constructor is passed to PledgeCapability to create a new instance of Pledge and extract its resolve and reject functions. This turns out to be important because you don’t know the class to use when creating the return value for then() until runtime.
Using Symbol.species
The well-known symbol Symbol.species isn’t well understood by JavaScript developers but is important to understand in the context of promises. Whenever a method on an object must return an instance of the same class, the specification defines a static Symbol.species getter on the class. This is true for many JavaScript classes including arrays, where methods like slice() and concat() return arrays, and it’s also true for promises, where methods like then() and catch() return another promise. This is important because if you subclass Promise, you probably want then() to return an instance of your subclass and not an instance of Promise.
The specification defines the default value for Symbol.species to be this for all built-in classes, so the Pledge class implements this property as follows:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
// other methods omitted for space
}
Keep in mind that because the Symbol.species getter is static, this is actually a reference to Pledge (you can try it for yourself accessing Pledge[Symbol.species]). However, because this is evaluated at runtime, it would have a different value for a subclass, such as this:
class SuperPledge extends Pledge {
// empty
}
Using this code, SuperPledge[Symbol.species] evaluates to SuperPledge. Because this is evaluated at runtime, it automatically references the class constructor that is in use. That’s exactly why the specification defines Symbol.species this way: it’s a convenience for developers as using the same constructor for method return values is the common case.
Now that you have a good understanding of Symbol.species, it’s time to move on implementing then().
Implementing the then() method
The then() method itself is fairly short because it delegates most of the work to a function called PerformPromiseThen(). Here’s how the specification defines then()3:
Let promise be the this value.
If IsPromise(promise) is false, throw a TypeError exception.
Let C be ? SpeciesConstructor(promise, %Promise%).
Let resultCapability be ? NewPromiseCapability(C).
Return PerformPromiseThen(promise, onFulfilled, onRejected, resultCapability).
And here’s how I coded up that algorithm:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
then(onFulfilled, onRejected) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
const resultCapability = new PledgeCapability(C);
return performPledgeThen(this, onFulfilled, onRejected, resultCapability);
}
// other methods omitted for space
}
The first thing to note is that I didn’t define a variable to store this as the algorithm specifies. That’s because it’s redundant in JavaScript when you can access this directly. After that, the rest of the method is a direct translation into JavaScript. The species constructor is stored in C and a new PledgeCapability is created from that. Then, all of the information is passed to performPledgeThen() to do the real work.
The performPledgeThen() function is one of the longer functions in the Pledge library and implements the algorithm for PerformPromiseThen() in the specification. The algorithm is a little difficult to understand, but it begins with these steps:
Assert that the first argument is a promise.
If either onFulfilled or onRejected aren’t functions, set them to undefined.
Create PromiseReaction records for each of onFulfilled and onRejected.
Here’s what that code looks like in the Pledge library:
function performPledgeThen(pledge, onFulfilled, onRejected, resultCapability) {
assertIsPledge(pledge);
if (!isCallable(onFulfilled)) {
onFulfilled = undefined;
}
if (!isCallable(onRejected)) {
onRejected = undefined;
}
const fulfillReaction = new PledgeReaction(resultCapability, "fulfill", onFulfilled);
const rejectReaction = new PledgeReaction(resultCapability, "reject", onRejected);
// more code to come
}
The fulfillReaction and rejectReaction objects are always created event when onFulfilled and onRejected are undefined. These objects store all of the information necessary to execute a handler. (Keep in mind that only one of these reactions will ever be used. Either the pledge is fulfilled so fulfillReaction is used or the pledge is rejected so rejectReaction is used. That’s why it’s safe to pass the same resultCapability to both even though it contains only one instance of Pledge.)
The PledgeReaction class is the JavaScript equivalent of the PromiseReaction record in the specification and is declared like this:
class PledgeReaction {
constructor(capability, type, handler) {
this.capability = capability;
this.type = type;
this.handler = handler;
}
}
The next steps in PerformPromiseThen() are all based on the state of the promise:
If the state is pending, then store the reactions for later.
If the state is fulfilled, then queue a job to execute fulfillReaction.
If the state is rejected, then queue a job to execute rejectReaction.
And after that, there are two more steps:
Mark the promise as being handled (for unhandled rejection tracking, discussed in an upcoming post).
Return the promise from the resultCapability, or return undefined if resultCapability is undefined.
Here’s the finished performPledgeThen() that implements these steps:
function performPledgeThen(pledge, onFulfilled, onRejected, resultCapability) {
assertIsPledge(pledge);
if (!isCallable(onFulfilled)) {
onFulfilled = undefined;
}
if (!isCallable(onRejected)) {
onRejected = undefined;
}
const fulfillReaction = new PledgeFulfillReaction(resultCapability, onFulfilled);
const rejectReaction = new PledgeRejectReaction(resultCapability, onRejected);
switch (pledge[PledgeSymbol.state]) {
case "pending":
pledge[PledgeSymbol.fulfillReactions].push(fulfillReaction);
pledge[PledgeSymbol.rejectReactions].push(rejectReaction);
break;
case "fulfilled":
{
const value = pledge[PledgeSymbol.result];
const fulfillJob = new PledgeReactionJob(fulfillReaction, value);
hostEnqueuePledgeJob(fulfillJob);
}
break;
case "rejected":
{
const reason = pledge[PledgeSymbol.result];
const rejectJob = new PledgeReactionJob(rejectReaction, reason);
// TODO: if [[isHandled]] if false
hostEnqueuePledgeJob(rejectJob);
}
break;
default:
throw new TypeError(`Invalid pledge state: ${pledge[PledgeSymbol.state]}.`);
}
pledge[PledgeSymbol.isHandled] = true;
return resultCapability ? resultCapability.pledge : undefined;
}
In this code, the PledgeSymbol.fulfillReactions and PledgeSymbol.rejectReactions are finally used for something. If the state is pending, the reactions are stored for later so they can be triggered when the state changes (this is discussed later in this post). If the state is either fulfilled or rejected then a PledgeReactionJob is created to run the reaction. The PledgeReactionJob maps to NewPromiseReactionJob()4 in the specification and is declared like this:
export class PledgeReactionJob {
constructor(reaction, argument) {
return () => {
const { capability: pledgeCapability, type, handler } = reaction;
let handlerResult;
if (typeof handler === "undefined") {
if (type === "fulfill") {
handlerResult = new NormalCompletion(argument);
} else {
handlerResult = new ThrowCompletion(argument);
}
} else {
try {
handlerResult = new NormalCompletion(handler(argument));
} catch (error) {
handlerResult = new ThrowCompletion(error);
}
}
if (typeof pledgeCapability === "undefined") {
if (handlerResult instanceof ThrowCompletion) {
throw handlerResult.value;
}
// Return NormalCompletion(empty)
return;
}
if (handlerResult instanceof ThrowCompletion) {
pledgeCapability.reject(handlerResult.value);
} else {
pledgeCapability.resolve(handlerResult.value);
}
// Return NormalCompletion(status)
};
}
}
This code begins by extracting all of the information from the reaction that was passed in. The function is a little bit long because both capability and handler can be undefined, so there are fallback behaviors in each of those cases.
The PledgeReactionJob class also uses the concept of a completion record5. In most of the code, I was able to avoid needing to reference completion records directly, but in this code it was necessary to better match the algorithm in the specification. A completion record is nothing more than a record of how an operation’s control flow concluded. There are four completion types:
normal - when an operation succeeds without any change in control flow (the return statement or exiting at the end of a function)
break - when an operation exits completely (the break statement)
continue - when an operation exits and then restarts (the continue statement)
throw - when an operation results in an error (the throw statement)
These completion records tell the JavaScript engine how (or whether) to continue running code. For creating PledgeReactionJob, I only needed normal and throw completions, so I declared them as follows:
export class Completion {
constructor(type, value, target) {
this.type = type;
this.value = value;
this.target = target;
}
}
export class NormalCompletion extends Completion {
constructor(argument) {
super("normal", argument);
}
}
export class ThrowCompletion extends Completion {
constructor(argument) {
super("throw", argument);
}
}
Essentially, NormalCompletion tells the function to exit as normal (if there is no pledgeCapability) or resolve a pledge (if pledgeCapability is defined) and ThrowCompletion tells the function to either throw an error (if there is no pledgeCapability) or reject a pledge (if pledgeCapability is defined). Within the Pledge library, pledgeCapability will always be defined, but I wanted to match the original algorithm from the specification for completeness.
Having covered PledgeReactionJob means that the pledgePerformThen() function is complete and all handlers will be properly stored (if the pledge state is pending) or executed immediately (if the pledge state is fulfilled or rejected). The last step is to execute any save reactions when the pledge state changes from pending to either fulfilled or rejected.
Triggering stored reactions
When a promise transitions from unsettled to settled, it triggers the stored reactions to execute (fulfill reactions if the promise is fulfilled and reject reactions when the promise is rejected). The specification defines this operation as TriggerPromiseReaction()6, and it’s one of the easier algorithms to implement. The entire algorithm is basically iterating over a list (array in JavaScript) of reactions and then creating and queueing a new PromiseReactionJob for each one. Here’s how I implemented it as triggerPledgeReactions():
export function triggerPledgeReactions(reactions, argument) {
for (const reaction of reactions) {
const job = new PledgeReactionJob(reaction, argument);
hostEnqueuePledgeJob(job);
}
}
The most important part is to pass in the correct reactions argument, which is why this is function is called in two places: fulfillPledge() and rejectPledge() (discussed in part 1 of this series). For both functions, triggering reactions is the last step. Here’s the code for that:
export function fulfillPledge(pledge, value) {
if (pledge[PledgeSymbol.state] !== "pending") {
throw new Error("Pledge is already settled.");
}
const reactions = pledge[PledgeSymbol.fulfillReactions];
pledge[PledgeSymbol.result] = value;
pledge[PledgeSymbol.fulfillReactions] = undefined;
pledge[PledgeSymbol.rejectReactions] = undefined;
pledge[PledgeSymbol.state] = "fulfilled";
return triggerPledgeReactions(reactions, value);
}
export function rejectPledge(pledge, reason) {
if (pledge[PledgeSymbol.state] !== "pending") {
throw new Error("Pledge is already settled.");
}
const reactions = pledge[PledgeSymbol.rejectReactions];
pledge[PledgeSymbol.result] = reason;
pledge[PledgeSymbol.fulfillReactions] = undefined;
pledge[PledgeSymbol.rejectReactions] = undefined;
pledge[PledgeSymbol.state] = "rejected";
// global rejection tracking
if (!pledge[PledgeSymbol.isHandled]) {
// TODO: perform HostPromiseRejectionTracker(promise, "reject").
}
return triggerPledgeReactions(reactions, reason);
}
After this addition, Pledge objects will properly trigger stored fulfillment and rejection handlers whenever the handlers are added prior to the pledge resolving. Note that both fulfillPledge() and rejectPledge() remove all reactions from the Pledge object in the process of changing the object’s state and triggering the reactions.
The catch() method
If you always wondered if the catch() method was just a shorthand for then(), then you are correct. All catch() does is call then() with an undefined first argument and the onRejected handler as the second argument:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
then(onFulfilled, onRejected) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
const resultCapability = new PledgeCapability(C);
return performPledgeThen(this, onFulfilled, onRejected, resultCapability);
}
catch(onRejected) {
return this.then(undefined, onRejected);
}
// other methods omitted for space
}
So yes, catch() is really just a convenience method. The finally() method, however, is more involved.
The finally() method
The finally() method was a late addition to the promises specification and works a bit differently than then() and catch(). Whereas both then() and catch() allow you to add handlers that will receive a value when the promise is settled, a handler added with finally() does not receive a value. Instead, the promise returned from the call to finally() is settled in the same as the first promise. For example, if a given promise is fulfilled, then the promise returned from finally() is fulfilled with the same value:
const promise = Promise.resolve(42);
promise.finally(() => {
console.log("Original promise is settled.");
}).then(value => {
console.log(value); // 42
});
This example shows that calling finally() on a promise that is resolved to 42 will result in a promise that is also resolved to 42. These are two different promises but they are resolved to the same value.
Similarly, if a promise is rejected, the the promise returned from finally() will also be rejected, as in this example:
const promise = Promise.reject("Oops!");
promise.finally(() => {
console.log("Original promise is settled.");
}).catch(reason => {
console.log(reason); // "Oops!"
});
Here, promise is rejected with a reason of "Oops!". The handler assigned with finally() will execute first, outputting a message to the console, and the promise returned from finally() is rejected to the same reason as promise. This ability to pass on promise rejections through finally() means that adding a finally() handler does not count as handling a promise rejection. (If a rejected promise only has a finally() handler then the JavaScript runtime will still output a message about an unhandled promise rejection. You still need to add a rejection handler with then() or catch() to avoid that message.)
With a good understanding of finally() works, it’s time to implement it.
Implementing the finally() method
The first few steps of finally()7 are the same as with then(), which is to assert that this is a promise and to retrieve the species constructor:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
finally(onFinally) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
// TODO
}
// other methods omitted for space
}
After that, the specification defines two variables, thenFinally and catchFinally, which are the fulfillment and rejection handlers that will be passed to then(). Just like catch(), finally() eventually calls the then() method directly. The only question is what values will be passed. For instance, if the onFinally argument isn’t callable, then thenFinally and catchFinally are set equal to onFinally and no other work needs to be done:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
finally(onFinally) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
let thenFinally, catchFinally;
if (!isCallable(onFinally)) {
thenFinally = onFinally;
catchFinally = onFinally;
} else {
// TODO
}
return this.then(thenFinally, catchFinally);
}
// other methods omitted for space
}
You might be confused as to why an uncallable onFinally will be passed into then(), as was I when I first read the specification. Remember that then() ultimately delegates to performPledgeThen(), which in turn sets any uncallable handlers to undefined. So finally() is relying on that validation step in performPledgeThen() to ensure that uncallable handlers are never formally added.
The next step is to define the values for thenFinally and catchFinally if onFinally is callable. Each of these functions is defined in the specification as a sequence of steps to perform in order to pass on the settlement state and value from the first promise to the returned promise. The steps for thenFinally are a bit difficult to decipher in the specification8 but are really straight forward when you see the code:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
finally(onFinally) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
let thenFinally, catchFinally;
if (!isCallable(onFinally)) {
thenFinally = onFinally;
catchFinally = onFinally;
} else {
thenFinally = value => {
const result = onFinally.apply(undefined);
const pledge = pledgeResolve(C, result);
const valueThunk = () => value;
return pledge.then(valueThunk);
};
// not used by included for completeness with spec
thenFinally.C = C;
thenFinally.onFinally = onFinally;
// TODO
}
return this.then(thenFinally, catchFinally);
}
// other methods omitted for space
}
Essentially, the thenFinally value is a function that accepts the fulfilled value of the promise and then:
Calls onFinally().
Creates a resolved pledge with the result of step 1. (This result is ultimately discarded.)
Creates a function called valueThunk that does nothing but return the fulfilled value.
Assigns valueThunk as the fulfillment handler for the newly-created pledge and then returns the value.
After that, references to C and onFinally are stored on the function, but as noted in the code, these aren’t necessary for the JavaScript implementation. In the specification, this is the way that the thenFinally functions gets access to both C and onFinally. In JavaScript, I’m using a closure to get access to those values.
The pledgeResolve() function is straightforward and follows the algorithm described in the specification9 almost exactly:
function pledgeResolve(C, x) {
assertIsObject(C);
if (isPledge(x)) {
const xConstructor = x.constructor;
if (Object.is(xConstructor, C)) {
return x;
}
}
const pledgeCapability = new PledgeCapability(C);
pledgeCapability.resolve(x);
return pledgeCapability.pledge;
}
For the purposes of this post, it’s not important to get into the specifics of checking to see if x is an instance of Pledge because that value is never used within onFinally. (This will be discussed, however, in my next post as it’s an important feature used in Promise.resolve().) Ultimately, the function creates a new PledgeCapability so it can return a Pledge instance.
The steps to create catchFinally10 are similar, but the end result is a function that throws a reason:
export class Pledge {
// constructor omitted for space
static get [Symbol.species]() {
return this;
}
finally(onFinally) {
assertIsPledge(this);
const C = this.constructor[Symbol.species];
let thenFinally, catchFinally;
if (!isCallable(onFinally)) {
thenFinally = onFinally;
catchFinally = onFinally;
} else {
thenFinally = value => {
const result = onFinally.apply(undefined);
const pledge = pledgeResolve(C, result);
const valueThunk = () => value;
return pledge.then(valueThunk);
};
// not used by included for completeness with spec
thenFinally.C = C;
thenFinally.onFinally = onFinally;
catchFinally = reason => {
const result = onFinally.apply(undefined);
const pledge = pledgeResolve(C, result);
const thrower = () => {
throw reason;
};
return pledge.then(thrower);
};
// not used by included for completeness with spec
catchFinally.C = C;
catchFinally.onFinally = onFinally;
}
return this.then(thenFinally, catchFinally);
}
// other methods omitted for space
}
You might be wondering why the catchFinally function is calling pledge.then(thrower) instead of pledge.catch(thrower). This is the way the specification defines this step to take place, and it really doesn’t matter whether you use then() or catch() because a handler that throws a value will always trigger a rejected promise.
With this completed finally() method, you can now see that when onFinally is callable, the method creates a thenFinally function that resolves to the same value as the original function and a catchFinally function that throws any reason it receives. These two functions are then passed to then() so that both fulfillment and rejection are handled in a way that mirrors the settled state of the original promise.
Wrapping Up
This post covered the internals of then(), catch(), and finally(), with then() containing most of the functionality of interest while catch() and finally() each delegate to then(). Handling promise reactions is, without a doubt, the most complicated part of the promises specification. You should now have a good understanding that all reactions are executed asynchronously as jobs (microtasks) regardless of promise state. This understanding really is key to a good overall understanding of how promises work and when you should expect various handlers to be executed.
In the next post in this series, I’ll cover creating settled promises with Promise.resolve() and Promise.reject().
All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
References
Promise.prototype.then( onFulfilled, onRejected ) ↩
NewPromiseReactionJob( reaction, argument ) ↩
The Completion Record Specification Type ↩
TriggerPromiseReactions( reactions, argument ) ↩
Promise.prototype.finally( onFinally ) ↩



September 28, 2020
Creating a JavaScript promise from scratch, Part 2: Resolving to a promise
In my first post of this series, I explained how the Promise constructor works by recreating it as the Pledge constructor. I noted in that post that there is nothing asynchronous about the constructor, and that all of the asynchronous operations happen later. In this post, I’ll cover how to resolve one promise to another promise, which will trigger asynchronous operations.
As a reminder, this series is based on my promise library, Pledge. You can view and download all of the source code from GitHub.
Jobs and microtasks
Before getting into the implementation, it’s helpful to talk about the mechanics of asynchronous operations in promises. Asynchronous promise operations are defined in ECMA-262 as jobs1:
A Job is an abstract closure with no parameters that initiates an ECMAScript computation when no other ECMAScript computation is currently in progress.
Put in simpler language, the specification says that a job is a function that executes when no other function is executing. But it’s the specifics of this process that are interesting. Here’s what the specification says1:
At some future point in time, when there is no running execution context and the execution context stack is empty, the implementation must:
Push an execution context onto the execution context stack.
Perform any implementation-defined preparation steps.
Call the abstract closure.
Perform any implementation-defined cleanup steps.
Pop the previously-pushed execution context from the execution context stack.> > * Only one Job may be actively undergoing evaluation at any point in time.
Once evaluation of a Job starts, it must run to completion before evaluation of any other Job starts.
The abstract closure must return a normal completion, implementing its own handling of errors.
It’s easiest to think through this process by using an example. Suppose you have set up an onclick event handler on a button in a web page. When you click the button, a new execution context is pushed onto the execution context stack in order to run the event handler. Once the event handler has finished executing, the execution context is popped off the stack and the stack is now empty. This is the time when jobs are executed, before yielding back to the event loop that is waiting for more JavaScript to run.
In JavaScript engines, the button’s event handler is considered a task while a job is a considered a microtask. Any microtasks that are queued during a task are executed in the order in which they were queued immediately after the task completes. Fortunately for you and I, browsers, Node.js, and Deno have the queueMicrotask() function that implements the queueing of microtasks.
The queueMicrotask() function is defined in the HTML specification2 and accepts a single argument, which is the function to call as a microtask. For example:
queueMicrotask(() => {
console.log("Hi");
});
This example will output "Hi" to the console once the current task has completed. Keep in mind that microtasks will always execute before timers, which are created using either setTimeout() or setInterval(). Timers are implemented using tasks, not microtasks, and so will yield back to the event loop before they execute their tasks.
To make the code in Pledge look for like the specification, I’ve defined a hostEnqueuePledgeJob() function that simple calls queueMicrotask():
export function hostEnqueuePledgeJob(job) {
queueMicrotask(job);
}
The NewPromiseResolveThenJob job
In my previous post, I stopped short of showing how to resolve a promise when another promise was passed to resolve. As opposed to non-thenable values, calling resolve with another promise means the first promise cannot be resolved until the second promise has been resolved, and to do that, you need NewPromiseResolveThenableJob().
The NewPromiseResolveThenableJob() accepts three arguments: the promise to resolve, the thenable that was passed to resolve, and the then() function to call. The job then attaches the resolve and reject functions for promise to resolve to the thenable’s then() method while catching any potential errors that might occur.
To implement NewPromiseResolveThenableJob(), I decided to use a class with a constructor that returns a function. This looks a little strange but will allow the code to look like you are creating a new job using the new operator instead of creating a function whose name begins with new (which I find strange). Here’s my implementation:
export class PledgeResolveThenableJob {
constructor(pledgeToResolve, thenable, then) {
return () => {
const { resolve, reject } = createResolvingFunctions(pledgeToResolve);
try {
// same as thenable.then(resolve, reject)
then.apply(thenable, [resolve, reject]);
} catch (thenError) {
// same as reject(thenError)
reject.apply(undefined, [thenError]);
}
};
}
}
You’ll note the use of createResolvingFunctions(), which was also used in the Pledge constructor. The call here creates a new set of resolve and reject functions that are separate from the original ones used inside of the constructor. Then, an attempt is made to attach those functions as fulfillment and rejection handlers on the thenable. The code looks a bit weird because I tried to make it look as close to the spec as possible, but really all it’s doing is thenable.then(resolve, reject). That code is wrapped in a try-catch just in case there’s an error that needs to be caught and passed to the reject function. Once again, the code looks a bit more complicated as I tried to capture the spirit of the specification, but ultimately all it’s doing is reject(thenError).
Now you can go back and complete the definition of the resolve function inside of createResolvingFunctions() to trigger a PledgeResolveThenableJob as the last step:
export function createResolvingFunctions(pledge) {
const alreadyResolved = { value: false };
const resolve = resolution => {
if (alreadyResolved.value) {
return;
}
alreadyResolved.value = true;
// can't resolve to the same pledge
if (Object.is(resolution, pledge)) {
const selfResolutionError = new TypeError("Cannot resolve to self.");
return rejectPledge(pledge, selfResolutionError);
}
// non-objects fulfill immediately
if (!isObject(resolution)) {
return fulfillPledge(pledge, resolution);
}
let thenAction;
try {
thenAction = resolution.then;
} catch (thenError) {
return rejectPledge(pledge, thenError);
}
// if the thenAction isn't callable then fulfill the pledge
if (!isCallable(thenAction)) {
return fulfillPledge(pledge, resolution);
}
/*
* If `thenAction` is callable, then we need to wait for the thenable
* to resolve before we can resolve this pledge.
*/
const job = new PledgeResolveThenableJob(pledge, resolution, thenAction);
hostEnqueuePledgeJob(job);
};
// attach the record of resolution and the original pledge
resolve.alreadyResolved = alreadyResolved;
resolve.pledge = pledge;
// reject function omitted for ease of reading
return {
resolve,
reject
};
}
If resolution is a thenable, then the PledgeResolveThenableJob is created and queued. That’s important, because anything a thenable is passed to resolve, it means that the promise isn’t resolved synchronously and you must wait for at least one microtask to complete.
Wrapping Up
The most important concept to grasp in this post is how jobs work and how they relate to microtasks in JavaScript runtimes. Jobs are a central part of promise functionality and in this post you learned how to use a job to resolve a promise to another promise. With that background, you’re ready to move into implementing then(), catch(), and finally(), all of which rely on the same type of job to trigger their handlers. That’s coming up in the next post in this series.
Remember: All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
References
Jobs and Host Operations to Enqueue Jobs ↩ ↩2



September 21, 2020
Creating a JavaScript promise from scratch, Part 1: Constructor
Early on in my career, I learned a lot by trying to recreate functionality I saw on websites. I found it helpful to investigate why something worked the way that it worked, and that lesson has stuck with me for decades. The best way to know if you really understand something is to take it apart and put it back together again. That’s why, when I decided to deepen my understanding of promises, I started thinking about creating promises from scratch.
Yes, I wrote a book on ECMAScript 6 in which I covered promises, but at that time, promises were still very new and not yet implemented everywhere. I made my best guess as to how certain things worked but I never felt truly comfortable with my understanding. So, I decided to turn ECMA-262’s description of promises1 and implement that functionality from scratch.
In this series of posts, I’ll be digging into the internals of my promise library, Pledge. My hope is that exploring this code will help everyone understand how JavaScript promises work.
An Introduction to Pledge
Pledge is a standalone JavaScript library that implements the ECMA-262 promises specification. I chose the name “Pledge” instead of using “Promise” so that I could make it clear whether something was part of native promise functionality or if it was something in the library. As such, wherever the spec using the term “promise,”, I’ve replaced that with the word “pledge” in the library.
If I’ve implemented it correctly, the Pledge class should work the same as the native Promise class. Here’s an example:
import { Pledge } from "https://unpkg.com/@humanwhocodes/pled...
const pledge = new Pledge((resolve, reject) => {
resolve(42);
// or
reject(42);
});
pledge.then(value => {
console.log(then);
}).catch(reason => {
console.error(reason);
}).finally(() => {
console.log("done");
});
// create resolved pledges
const fulfilled = Pledge.resolve(42);
const rejected = Pledge.reject(new Error("Uh oh!"));
Being able to see behind each code example has helped me understand promises a lot better, and I hope it will do the same for you.
Note: This library is not intended for use in production. It’s intended only as an educational tool. There’s no reason not to use the native Promise functionality.
Internal properties of a promise
ECMA-2622 specifies the following internal properties (called slots in the spec) for instances of Promise:
Internal Slot
Description
[[PromiseState]]
One of pending, fulfilled, or rejected. Governs how a promise will react to incoming calls to its then method.
[[PromiseResult]]
The value with which the promise has been fulfilled or rejected, if any. Only meaningful if [[PromiseState]] is not pending.
[[PromiseFulfillReactions]]
A List of PromiseReaction records to be processed when/if the promise transitions from the pending state to the fulfilled state.
[[PromiseRejectReactions]]
A List of PromiseReaction records to be processed when/if the promise transitions from the pending state to the rejected state.
[[PromiseIsHandled]]
A boolean indicating whether the promise has ever had a fulfillment or rejection handler; used in unhandled rejection tracking.
Because these properties are not supposed to be visible to developers but need to exist on the instances themselves for easy tracking and manipulation, I chose to use symbols for their identifiers and created the PledgeSymbol object as an easy way to reference them in various files:
export const PledgeSymbol = Object.freeze({
state: Symbol("PledgeState"),
result: Symbol("PledgeResult"),
isHandled: Symbol("PledgeIsHandled"),
fulfillReactions: Symbol("PledgeFulfillReactions"),
rejectReactions: Symbol("PledgeRejectReactions")
});
With PledgeSymbol now defined, it’s time to move on to creating the Pledge constructor.
How does the Promise constructor work?
The Promise constructor is used to create a new promise in JavaScript. You pass in a function (called the executor) that receives two arguments, resolve and reject which are functions that bring the promise’s lifecycle to completion. The resolve() function resolves the promise to some value (or no value) and the reject() function rejects the promise with a given reason (or no reason). For example:
const promise = new Promise((resolve, reject) => {
resolve(42);
});
promise.then(value => {
console.log(value); // 42
})
The executor is run immediately so the variable promise in this example is already fulfilled with the value 42 (the internal [[PromiseState]] property is Fulfilled). (If you used reject() instead of resolve(), then promise would be in a rejected state.)
Additionally, if the executor throws an error, then that error is caught and the promise is rejected, as in this example:
const promise = new Promise((resolve, reject) => {
throw new Error("Oops!");
});
promise.catch(reason => {
console.log(reason.message); // "Oops!"
})
A couple of other notes about how the constructor works:
If the executor is missing then an error is thrown
If the executor is not a function then an error is thrown
In both cases, the error is thrown as usual and does not result in a rejected promise.
With all of this background information, here’s what the code to implement these behaviors looks like:
export class Pledge {
constructor(executor) {
if (typeof executor === "undefined") {
throw new TypeError("Executor missing.");
}
if (!isCallable(executor)) {
throw new TypeError("Executor must be a function.");
}
// initialize properties
this[PledgeSymbol.state] = "pending";
this[PledgeSymbol.result] = undefined;
this[PledgeSymbol.isHandled] = false;
this[PledgeSymbol.fulfillReactions] = [];
this[PledgeSymbol.rejectReactions] = [];
const { resolve, reject } = createResolvingFunctions(this);
/*
* The executor is executed immediately. If it throws an error, then
* that is a rejection. The error should not be allowed to bubble
* out of this function.
*/
try {
executor(resolve, reject);
} catch(error) {
reject(error);
}
}
}
After checking the validity of the executor argument, the constructor next initializes all of the internal properties by using PledgeSymbol. These properties are close approximations of what the specification describes, where a string is used for the state instead of an enum and the fulfill and reject reactions are instances of Array because there is no List class in JavaScript.
Next, the resolve and reject functions used in the executor are created using the createResolvingFunctions() function. (I’ll go into detail about this function later in this post.) Last, the executor is run, passing in resolve and reject. It’s important to run the executor inside of a try-catch statement to ensure that any error results in a promise rejection rather than a thrown error.
The isCallable() function is just a helper function I created to make the code read more like the specification. Here’s the implementation:
export function isCallable(argument) {
return typeof argument === "function";
}
I think you’ll agree that the Pledge constructor itself is not very complicated and follows a fairly standard process of validating the input, initializing instance properties, and then performing some operations. The real work is done inside of createResolvingFunctions().
Creating the resolving functions
The specification defines a CreateResolvingFunctions abstract operation3, which is a fancy way of saying that it’s a series of steps to perform as part of some other function or method. To make it easy to go back and forth between the specification and the Pledge library, I’ve opted to use the same name for an actual function. The details in the specification aren’t all relevant to implementing the code in JavaScript, so I’ve omitted or changed some parts. I’ve also kept some parts that may seem nonsensical within the context of JavaScript – I’ve done that intentionally, once again, for ease of going back and forth with the specification.
The createResolvingFunctions() function is responsible for creating the resolve and reject functions that are passed into the executor. However, this function is actually used elsewhere, as well, allowing any parts of the library to retrieve these functions in order to manipulate existing Pledge instances.
To start, the basic structure of the function is as follows:
export function createResolvingFunctions(pledge) {
// this "record" is used to track whether a Pledge is already resolved
const alreadyResolved = { value: false };
const resolve = resolution => {
// TODO
};
// attach the record of resolution and the original pledge
resolve.alreadyResolved = alreadyResolved;
resolve.pledge = pledge;
const reject = reason => {
// TODO
};
// attach the record of resolution and the original pledge
reject.alreadyResolved = alreadyResolved;
reject.pledge = pledge;
return {
resolve,
reject
};
}
The first oddity of this function is the alreadyResolved object. The specification states that it’s a record, so I’ve chosen to implement it using an object. Doing so ensures the same value is being read and modified regardless of location (using a simple boolean value would not have allowed for this sharing if the value was being written to or read from the resolve and reject properties).
The specification also indicates that the resolve and reject functions should have properties containing alreadyResolved and the original promise (pledge). This is done so that the resolve and reject functions can access those values while executing. However, that’s not necessary in JavaScript because both functions are closures and can access those same values directly. I’ve opted to keep this detail in the code for completeness with the specification but they won’t actually be used.
As mentioned previously, the contents of each function is where most of the work is done. However, the functions vary in how complex they are. I’ll start by describing the reject function, as that is a great deal simpler than resolve.
Creating the reject function
The reject function accepts a single argument, the reason for the rejection, and places the promise in a rejected state. That means any rejection handlers added using then() or catch() will be executed. The first step in that process is to ensure that the promise hasn’t already been resolved, so you check the value of alreadyResolved.value, and if true, just return without doing anything. If alreadyResolved.value is false then you can continue on and the value to true. This ensures that this set of resolve and reject handlers can only be called once. After that, you can continue on change the internal state of the promise. Here’s what that function looks like in the Pledge library:
export function createResolvingFunctions(pledge) {
const alreadyResolved = { value: false };
// resolve function omitted for ease of reading
const reject = reason => {
if (alreadyResolved.value) {
return;
}
alreadyResolved.value = true;
return rejectPledge(pledge, reason);
};
reject.pledge = pledge;
reject.alreadyResolved = alreadyResolved;
return {
resolve,
reject
};
}
The rejectPledge() function is another abstract operation from the specification4 that is used in multiple places and is responsible for changing the internal state of a promise. Here’s the steps directly from the specification:
Assert: The value of promise.[[PromiseState]] is pending.
Let reactions be promise.[[PromiseRejectReactions]].
Set promise.[[PromiseResult]] to reason.
Set promise.[[PromiseFulfillReactions]] to undefined.
Set promise.[[PromiseRejectReactions]] to undefined.
Set promise.[[PromiseState]] to rejected.
If promise.[[PromiseIsHandled]] is false, perform HostPromiseRejectionTracker(promise, "reject").
Return TriggerPromiseReactions(reactions, reason).
For the time being, I’m going to skip steps 7 and 8, as those are concepts I’ll cover later in this series of blog posts. The rest can be almost directly translated into JavaScript code like this:
export function rejectPledge(pledge, reason) {
if (pledge[PledgeSymbol.state] !== "pending") {
throw new Error("Pledge is already settled.");
}
const reactions = pledge[PledgeSymbol.rejectReactions];
pledge[PledgeSymbol.result] = reason;
pledge[PledgeSymbol.fulfillReactions] = undefined;
pledge[PledgeSymbol.rejectReactions] = undefined;
pledge[PledgeSymbol.state] = "rejected";
if (!pledge[PledgeSymbol.isHandled]) {
// TODO: perform HostPromiseRejectionTracker(promise, "reject").
}
// TODO: Return `TriggerPromiseReactions(reactions, reason)`.
}
All rejectPledge() is really doing is setting the various internal properties to the appropriate values for a rejection and then triggering the reject reactions. Once you understand that promises are being ruled by their internal properties, they become a lot less mysterious.
The next step is to implement the resolve function, which is quite a bit more involved than reject but fundamentally is still modifying internal state.
Creating the resolve function
I’ve saved the resolve function for last due to the number of steps involved. If you’re unfamiliar with promises, you may wonder why it’s more complicated than reject, as they should be doing most of the same steps but with different values. The complexity comes due to the different ways resolve handles different types of values:
If the resolution value is the promise itself, then throw an error.
If the resolution value is a non-object, then fulfill the promise with the resolution value.
If the resolution value is an object with a then property:
If the then property is not a method, then fulfill the promise with the resolution value.
If the then property is a method (that makes the object a thenable), then call then with both a fulfillment and a rejection handler that will resolve or reject the promise.
So the resolve function only fulfills a promise immediately in the case of a non-object resolution value or a resolution value that is an object but doesn’t have a callable then property. If a second promise is passed to resolve then the original promise can’t be settled (either fulfilled or rejected) until the second promise is settled. Here’s what the code looks like:
export function createResolvingFunctions(pledge) {
const alreadyResolved = { value: false };
const resolve = resolution => {
if (alreadyResolved.value) {
return;
}
alreadyResolved.value = true;
// can't resolve to the same pledge
if (Object.is(resolution, pledge)) {
const selfResolutionError = new TypeError("Cannot resolve to self.");
return rejectPledge(pledge, selfResolutionError);
}
// non-objects fulfill immediately
if (!isObject(resolution)) {
return fulfillPledge(pledge, resolution);
}
let thenAction;
/*
* At this point, we know `resolution` is an object. If the object
* is a thenable, then we need to wait until the thenable is resolved
* before resolving the original pledge.
*
* The `try-catch` is because retrieving the `then` property may cause
* an error if it has a getter and any errors must be caught and used
* to reject the pledge.
*/
try {
thenAction = resolution.then;
} catch (thenError) {
return rejectPledge(pledge, thenError);
}
// if the thenAction isn't callable then fulfill the pledge
if (!isCallable(thenAction)) {
return fulfillPledge(pledge, resolution);
}
/*
* If `thenAction` is callable, then we need to wait for the thenable
* to resolve before we can resolve this pledge.
*/
// TODO: Let job be NewPromiseResolveThenableJob(promise, resolution, thenAction).
// TODO: Perform HostEnqueuePromiseJob(job.[[Job]], job.[[Realm]]).
};
// attach the record of resolution and the original pledge
resolve.alreadyResolved = alreadyResolved;
resolve.pledge = pledge;
// reject function omitted for ease of reading
return {
resolve,
reject
};
}
As with the reject function, the first step in the resolve function is to check the value of alreadyResolved.value and either return immediately if true or set to true. After that, the resolution value needs to be checked to see what action to take. The last step in the resolve function (marked with TODO comments) is for the case of a thenable that needs handlers attached. This will be discussed in my next post.
The fulfillPledge() function referenced in the resolve function looks a lot like the rejectPledge() function referenced in the reject function and simply sets the internal state:
export function fulfillPledge(pledge, value) {
if (pledge[PledgeSymbol.state] !== "pending") {
throw new Error("Pledge is already settled.");
}
const reactions = pledge[PledgeSymbol.fulfillReactions];
pledge[PledgeSymbol.result] = value;
pledge[PledgeSymbol.fulfillReactions] = undefined;
pledge[PledgeSymbol.rejectReactions] = undefined;
pledge[PledgeSymbol.state] = "fulfilled";
// TODO: Return `TriggerPromiseReactions(reactions, reason)`.
}
As with rejectPledge(), I’m leaving off the TriggerPromiseReactions operations for discussion in the next post.
Wrapping Up
At this point, you should have a good understanding of how a Promise constructor works. The most important thing to remember is that every operation so far is synchronous; there is no asynchronous operation until we start dealing with then(), catch(), and finally(), which will be covered in the next post. When you create a new instance of Promise and pass in an executor, that executor is run immediately, and if either resolve or reject is called synchronously, then the newly created promise is already fulfilled or rejected, respectively. It’s only what happens after that point where you get into asynchronous operations.
All of this code is available in the Pledge on GitHub. I hope you’ll download it and try it out to get a better understanding of promises.
References
Properties of Promise instances ↩
CreateResolvingFunctions(promise) ↩
RejectPromise(promise, reason) ↩



July 20, 2020
How to safely use GitHub Actions in organizations
GitHub Actions1 are programs designed to run inside of workflows2, triggered by specific events inside a GitHub repository. To date, people use GitHub Actions to do things like run continuous integration (CI) tests, publish releases, respond to issues, and more. Because the workflows are executed inside a fresh virtual machine that is deleted after the workflow completes, there isn’t much risk of abuse inside of the system. There is a risk, however, to your data.
This post is aimed at those who are using GitHub organizations to manage their projects, which is to say, there is more than one maintainer. In that situation, you may not always be aware of who is accessing your repository, whether that be another coworker or a collaborator you’ve never met. If you are the only maintainer of a project then your risk is limited to people who steal your credentials and the other recommendations in this post aren’t as necessary.
Credential stealing risk
The primary risk for your workflows is credential stealing, where you provided some sensitive information inside of the workflow and somehow that information is stolen. This credential stealing generally takes two forms:
Opportunistic - sensitive information is accidentally output to the log and an attacker finds it and uses it
Intentional - an attacker is able to insert a program into your workflow that steals credentials and sends them to the attacker
GitHub, to its credit, is aware of this possibility and allows you to store sensitive information in secrets3. You can store secrets either on a single repository or on an organization, where they can be shared across multiple repositories. You can store things like API tokens or deploy keys securely and then reference them directly inside of a workflow.
By default, there are some important security features built in to GitHub secrets:
Once a secret is created, you can never view the value inside of the GitHub interface or retrieve it using the API; you can only rename the secret, change the value, or delete the secret.
Secrets are automatically masked from log output when GitHub Actions execute. You’ll never accidentally configure a secret to show in the log.
Only administrators can create, modify, or delete secrets. For individuals that means you must be the owner of the repository; for organizations that means you must be an administrator.
These measures are a good default starting place for securing sensitive information, but that doesn’t mean this data is completely safe by default.
Showing secrets in the log
Workflow logs are displayed on each repository under the “Actions” tab and are visible to the public. GitHub Actions tend to hide a lot of their own output for security purposes but not every command inside of a workflow is implemented with a GitHub Action. Luckily, workflows are designed to hide secrets by default, so it’s unlikely that you’ll end up accidentally outputting the secrets in plain text. When you access a secret as in the following workflow, the output will be masked in the log. For example, suppose this is part of your workflow:
steps:
- name: Try to output a secret
run: echo 'SECRET:${{ secrets.GITHUB_TOKEN }}'
Accessing data off of the secrets object automatically masks the value in the log, so you’ll end up seeing something like this in the log:
SECRET:***
You’re safe so long as your secrets stay within the confines of a workflow where GitHub will mask the values for you. The more dangerous situation is what happens with the command executed as part of your workflow. If they make use of a secret, they could potentially reveal it in the log.
For example, suppose you have a Node.js file named echo.js containing the following:
console.log(process.argv[2]);
This file will output the first argument passed to the Node.js process. If you configure it in a workflow, you could very easily display a secret accidentally, such as:
steps:
- name: Try to output a secret
run: node ./echo.js ${{ secrets.GITHUB_TOKEN }}
While the command line itself will be masked in the log, there is no accounting for the output of the command, which will output whatever is passed in.
Key points about this scenario:
This is most likely an accident rather than an attack. An attacker would most likely want to hide the fact that they were able to get access to your secret. By outputting it into the log, it’s there for anyone to see and trace back to the source.
An accident like this can open the door for opportunistic credential stealing4 by someone who notices the secrets were exposed.
Although accidentally outputting secrets to the log is a bad situation, remote credential stealing is worse.
Remote credential stealing
This scenario is more likely an attack than an accident. The way this happens is that a rogue command has made it into your workflow file and is able to read your secrets and then transmit them to a different server. There isn’t any overt indication that this has happened in the log so it may go unnoticed for a long time (or forever).
There are a number of ways for these rogue utilities to be introduced because GitHub workflows rely on installing external dependencies to execute. Whether you need to execute a third-party GitHub action or install something using a package manager, you are assuming that you’re not using malicious software.
The most important question to ask is how might a malicious utility make it into your workflow files? There are two answers: accidentally or intentionally. However, there are several ways each can play out:
As with outputting secrets to the log, a well-intentioned developer might have copy-pasted something from another workflow file and introduced it into your codebase. Maybe it was committed directly to the development branch without review because it’s a small project. This scenario plays out every day as attackers try to trick developers into installing malicious software that otherwise looks harmless.
An attacker might have gained control of a package that already has a reputation as reliable and update it to contain malicious code. (I’m painfully aware of how this can happen.5) Your workflow may blindly pull in the package and use it expecting it to be safe.
An attacker might submit a pull request to your repository containing a workflow change, hoping no one will look at it too closely before merging.
An attacker might have stolen someone’s credentials and used them to modify a workflow to contain a malicious command.
In any case, there are enough ways for attackers to introduce malicious software into your workflow. Fortunately, there are a number of ways to protect yourself.
Protection strategies
Generally speaking, the strategies to further protect your GitHub workflows fall into the following categories:
Protect yourself
Protect your development branch
Limit scopes
Workflow best practices
Protect yourself
The easiest way to steal credentials is for an attacker to pretend that they’re you. Once they have control of your GitHub or package manager account, they have all the access they need to not only harm you but also harm others. The advice here is timeless, but worth repeating:
Use a password manager and generate a strong, unique password for each site you use. Your GitHub password should not be the same as your npm password, for example.
Enable two-factor authentication (2FA) on GitHub6 and any other sites you use. Prefer to use an authentication app or a security key instead of text messages whenever possible.
If you are a GitHub organization administrator, require all organization members to enable 2FA.7
By protecting your own login information, you make it a lot harder for attackers to use your projects to attack you or others.
Protect your branches
At a minimum, you should protect your development branch with rules about what is allowed to be merged. Your development branch is the branch where pull requests are sent and where your releases are cut from. In many cases that will be the master branch, but some teams also use dev, trunk, or any number of other names. Once code makes it into your development branch, it is effectively “live” (for workflows) and highly likely to make it into a release (where it could negatively affect others). That’s why protecting your development branch is important.
GitHub allows you to protect any branch in a number of ways.8 To set up a protected branch, go to your repository settings, click on “Branches” on the menu, then under “Branch Protection Rules” click the “Add Rule” button. Then, you can specify the branches to protect and exactly how to protect them.
There are a lot of options, but here are the ones I recommend as a starting point for your development branch:
Require pull requests before merging - this prevents you from pushing directly to the development branch. All changes must go through a pull request, even from admins (though you can override this to allow specific people to override the protection – but that’s not advisable). This is important to ensure that there’s some notification of any changes made to the development branch and someone has the opportunity to review them before merging.
Required approval reviews - by default this is set to one. Ideally, you should require approvals from at least two people to avoid the case where a malicious actor has secured the login of one team member and can therefore self-approve a pull request.
Dismiss stale pull request approvals when new commits are pushed - by default this is off, and you should turn it on. This prevents an attack where a malicious actor submits an appropriate pull request, waits for approval, and then adds new commits to the pull request before merging. With this option enabled, new commits pushed to the pull request will invalidate previous approvals.
Require review from Code Owners - it’s a good idea to set up code owners8 for workflow files and other sensitive files. Once you do, you can enable this option to require the code owners approve any pull requests related to the code they own. This ensures that those who are most knowledgeable about GitHub Actions are required to approve any pull requests.
Require status checks to pass before merging - assuming you have status checks running on pull requests (such as automated testing or linting), enable this option to ensure pull requests can’t be merged that have failing status checks. This is another layer of security to prevent malicious code from making it into your repository.
Include administrators - this option ensures that even administrators must adhere to the rules you’ve set up for the branch. While a compromised administrator account can turn this setting off, turning it on ensures administrators don’t accidentally merge or push changes.
Allow force pushes - this is off by default and should remain off. Force pushes allow someone to completely overwrite the remote branch, which opens you up to all kinds of bad situations. Force pushes to the development branch should never be allowed in an organization.
Allow deletions - this is also off by default and should remain off. You don’t want to accidentally delete your development branch.
While these settings won’t prevent all attacks, they certainly make a number of common attacks a lot more difficult. You can, of course, create rules that are more strict if you have other needs.
Because GitHub Actions and workflows are executed in every branch of your repository, it’s important to consider whether or not you need to protect all of your remote branches. If your team doesn’t use remote branches for feature development then I would recommend protecting all of your branches.
Limit scopes
One of the classic pieces of computer security advice is to always limit the scope of changes allowed at one time. For protecting your secrets, here are a number of ways you can limit scope:
Favor repository-only secrets - if you only have one repository that needs access to a secret, then create the secret only on the repository instead of on the organization. This further limits the attack surface.
Limit organization secret scope - organization secrets can be scoped to only public, only private, or just specific repositories. Limiting the number of repositories with access to the secrets also decreases the attack surface. Your credentials are only as secure as your least secure repository with access to your secrets.
Limit the number of admins - keep the number of repository or organization administrators small. Only admins can manage GitHub secrets, so keeping this group small will also minimize the risk.
Minimize credentials - ensure that any credentials generated to use in secrets have the minimal required permissions to be useful. If an app needs write permission and not read permission, then generate a credential that only allows writes. This way you minimize the damage if a credential is stolen.
Even if you don’t follow any of the other advice in this article, limiting the scope of your secrets is really the minimum you should do to protect them.
Never store a GitHub token with administrator privileges as a secret. This would allow any workflow in any branch (even unprotected branches) to modify your repository in any way it wants, including pushing to protected branches.9
Workflow best practices
The last step is to ensure your workflows are as safe as possible. The concern here is that you pass secrets into a utility that will either log that data unmasked or steal the credentials silently. Naturally, the first step is to verify the actions and utilities you are using are safe to use.
Disabling Actions
If you don’t intend to use GitHub Actions in your organization, you can disable them for the entire organization. On the organization Settings page, go to “Actions” and then select “Disable actions for this organization.”10 This ensures that no repositories can use GitHub Actions and is the safest setting if you don’t intend to use them.
Use only local Actions
Another options is to allow the organization to use workflows but only with actions that are contained inside the same repository. This effectively forces repositories to install their own copies of actions to control which actions may be executed.
To enable this setting, go to the organization Settings page, go to “Actions”, and then select “Enable local Actions only for this organization.”10
Identifying safe Actions
There are a couple ways you can know that a published GitHub Action is safe:
It begins with action/, such as actions/checkout. These are published by GitHub itself and are therefore safe to use.
The action is published in the GitHub Action Marketplace11 and has a “verified creator” badge next to the author. This indicates that the creator is a verified partner of GitHub and therefore the action is safe.
If an action doesn’t fall into one of these two categories, that doesn’t mean it’s not safe, just that you need to do more research into the action.
All actions in the GitHub Action Marketplace link back to the source code repository they are published from. You should always look at the source code to ensure that it is performing the operations it claims to be performing (and doing nothing else). Of course, you happen to know and trust the publisher of the Action, you may want to trust that the action does what it says.
Provide secrets one command at a time
When configuring a workflow, ensure that you are limiting the number of commands with access. For example, you might configure a secret as an environment variable to run a command, such as this:
steps:
- name: Run a command
run: some-command
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
Here, the GITHUB_TOKEN environment variable is set with the secrets.GITHUB_TOKEN secret value. The some-command utility has access to that environment variable. Assuming that some-command is a trusted utility, there is no problem. The problem occurs when you run multiple commands inside of a run statement, such as:
steps:
- name: Run a command
- run: |
some-command
some-other-command
yet-another-command
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
In this case, the run statement is running multiple commands at once. The env statement now applies to all of those commands and will be available whether they need access to GITHUB_TOKEN or not. If the only utility that needs GITHUB_TOKEN is some-command, then limit the use of env to just that command, such as:
steps:
- name: Run a command
run: some-command
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- run: |
some-other-command
yet-another-command
With this rewritten example, only some-command has access to GITHUB_TOKEN while the other commands are run separately without GITHUB_TOKEN. Limiting which commands have access to your secrets is another important step in preventing credential stealing.
Conclusion
While GitHub Actions are a great addition to the GitHub development ecosystem, it’s still important to take security into account when using them. The security considerations are quite a bit different when you’re dealing with a GitHub organization maintaining projects rather than a single maintainer. The more people who can commit directly to your development branch, the more chances there are for security breaches.
The most important takeaway from this post is that you need to have protections, both automated and manual, in order to safely using GitHub Actions in organizations. Whether you decide to only allow local actions or to assign someone as a code owner who must approve all workflows, it’s better to have some protections in place than to have none. That is especially true when you have credentials stored as GitHub secrets that would allow people to interact with outside systems on your behalf.
Remember, you are only as secure as your least secure user, branch, or repository.
GitHub: Configuring and managing workflow files and runs ↩
GitHub: Creating and storing encrypted secrets ↩
Credential Stealing as an Attack Vector ↩
ESLint postmortem for malicious package publishes ↩
GitHub: Securing your account with two-factor authentication (2FA) ↩
GitHub: Requiring two-factor authentication in your organization ↩
GitHub: Configuring protected branches ↩ ↩2
Allowing github-actions(bot) to push to protected branch ↩
GitHub: Disabling or limiting GitHub Actions for your organization ↩ ↩2



February 17, 2020
How I think about solving problems
Early on in my career as a software developer I thought my primary contribution was writing code. After all, software engineers are paid to ship software and writing code is a key component of that. It took several years for me to realize that there are numerous other contributions that go into shipping software (if not, why are there managers, designers, product managers, salespeople, etc.?). I slowly came to see myself less as a coder and more as a problem solver. Sometimes the problem could be solved by writing code while other times the solution didn’t involve code at all.
Once I realized my value as a problem solver, I set out to determine the most efficient way to address problems as they occurred. Moving into a tech lead position immediately thrust me into the middle of numerous ongoing daily problems. I had to figure out some way to act decisively, prioritize effectively, and solve as many problems as possible.
Eventually, I settled on a list of questions I would ask myself for each problem as it arose. I found that asking these questions, in order, helped me make the best decision possible:
Is this really a problem?
Does the problem need to be solved?
Does the problem need to be solved now?
Does the problem need to be solved by me?
Is there a simpler problem I can solve instead?
Each question is designed to reveal something about the problem that allows you to go to the next step, or if you’re lucky, just avoid the problem altogether. There is some nuance to each question, so it’s helpful to describe each in more detail.
Is this really a problem?
The first step to addressing any problem is to determine if it actually is a problem, and that requires a definition. For the purposes of this article, I’ll define a problem as anything that leads to an objectively undesirable outcome if not addressed. That means leaving your window open over night when it’s raining is a problem because the inside will get wet and that could potentially ruin your floor, furniture, or other possessions. A solution to the problem prevents the undesirable outcome, so closing the window before you go to bed will prevent your belongings from being ruined.
When in a leadership role, it’s common to receive complaints that sound like problems but are just opinions. For example, I’ve spoken with many software engineers who immediately upon starting a new job or joining a new team feel like the team is doing many things wrong: the framework they are using is wrong; the code style is wrong; the way files are organized is wrong. How will they ever get around to fixing all of these problems? It’s a monumental task.
I ask these software engineers this question: is it a problem or is it just different?
In many cases “wrong” just means “not what I’m used to or prefer.” If you can identify that a reported problem is not, in fact, a problem, then you no longer need to spend resources on a solution. A team member being unhappy with the way things are done is not an objectively undesirable outcome. There is nothing inherently problematic with disagreements on a team.
If you’re able to determine that a problem is not a problem, then you can move on to other tasks.
Does the problem need to be solved?
After you’ve determined that there is a problem, then next step is to determine if the problem needs to be solved. A problem doesn’t need to be solved if the undesirable outcome is tolerable and either constant or slow growing. For example, if a section of a web application is used by only admins (typically five or fewer people) and is slower to load than the rest of the application, you could determine that’s something you’re okay with. The problem is narrowly contained and affects a small number of people on the rare occasion that they use it. While it would be nice to solve the problem, it’s not required and the downside is small enough that not addressing it is unlikely to lead to bigger problems down the road.
Another way to ask this question is, “what happens if the problem is never solved?” If the answer is, “not much,” then it might be okay to not solve the problem.
Does the problem need to be solved now?
If you have a problem that needs to be solved, then the next question is to determine whether it needs to be solved now or if it can wait until later. Some problems are obviously urgent and need to be addressed immediately: the site is down, the application crashes whenever someone uses it, and so on. These problems need to be addressed because the undesirable outcome is immediate, ongoing, and likely to grow: the longer the site is down, the more money the company loses; the more times the application crashes, the more likely a customer will use a competitor.
Equally important is to determine if solving the problem can be deferred. There are a surprising number of non-urgent problems that bubble up to leadership. These are problems that need to be solved eventually but not immediately. The most common problem in software that fits this description is technical debt. Technical debt is any part of your application (or related infrastructure) that is not performing as well as it should. It’s something that will not cause a significant problem today or tomorrow, but it will eventually. In my experience, tech debt is rarely addressed until it becomes an emergency (which is too late). However, tech debt isn’t something that everything else should be dropped to address. It falls into that middle area where it shouldn’t be done today but definitely needs to get done.
If a problem doesn’t have to be addressed now, it’s usually a good idea to defer it. By defer it, I mean plan to address it in the future, not avoid doing anything about it. If now is not the right time to solve the problem then decide when is: in a week, a month, six months? Put it on your calendar or task management system so you won’t lose track of it.
Another way to ask this question is, “is the problem urgent?”
Does the problem need to be solved by me?
This question is most applicable to anyone in a leadership position but could also apply to anyone who already has too many tasks to complete. Is this problem something that requires special skills only you possess, or is it possible someone else could complete the task?
This is a question I adapted from advice one mentor gave me. I was complaining about how I just seemed to be collecting tasks and couldn’t keep up. He said I should ask myself, “is this a Nicholas problem?” There were certain things only I knew how to do and those were the things I should be focusing. Anything else should be delegated to someone else. Another important tip he gave me: just because you can do something faster than someone else doesn’t mean you should do it yourself. For most non-urgent tasks, it doesn’t matter if it is completed in one day or two.
So if the problem can be solved by someone else, and you’re either a leader or already have too much work, then delegate.
Is there an easier problem I can solve instead?
The final step in the process once you’ve determined that there’s an urgent problem that you need to solve personally is to determine if there’s an easier problem to solve. The key is that the easier problem must give you the same or a similar outcome to the original problem while saving time (or other resources).
When I was working on the new My Yahoo! page, one of our product managers proclaimed that beta customers had requested we add resizable columns to the page. This was something that would be fairly complicated because it was 2006 and web browsers were not anywhere as capable as they are today. The task wasn’t impossible, but on a page that was already overflowing with JavaScript, adding more to manage complex mouse movements and needing to save that information back to the server was a lot of painstaking error-prone work.
I asked for the raw data from the customer feedback sessions to see if I could figure out what the problem was that resizable columns would solve. In turned out no customers had asked for resizable columns (the product manager had inferred this request from the complaints). Instead, they were complaining that they couldn’t get the new My Yahoo! page to look like their old My Yahoo! page. We had created completely new layouts that didn’t match the old layouts, but it turned out people really liked the old layouts. This allowed us to focus on an easier problem: recreating the old layouts.
So, we spent a little time recreating the old layouts in the new page and re-ran the customer sessions. People were delighted that the new page now looked very similar to the old page. By solving the easier problem, we saved a lot of development time and the customers ended up just as happy.
There isn’t always an easier problem to solve, but it’s worth taking a moment to check whenever a problem seems particularly large or difficult.
Conclusion
These five questions have become the basis for my problem-solving approach not just in my work, but in my life in general. Going through these questions whenever presented with a problem has made me a more efficient problem solver and, in general, happier with the outcomes. Can’t calculate a 15% tip for my waiter? I calculate 20% instead (or 10% if I’m displeased with the service). My high school alumni office keeps sending me notices that I’m not a verified alumnus? That’s not a problem I need to solve. I need to get a new driver’s license if I want to travel within the United States? That’s a problem I need to address this year, but not right now.
There are many ways to approach problem solving, and I’m not sure my approach will work for everyone. What I do know is that having an approach to solving problems is better than not having any approach. Life is filled with problems, small and large, that you’ll face every day. Having a clearly defined, repeatable strategy is the easiest way to make problem solving more tolerable.



September 30, 2019
Scheduling Jekyll posts with Netlify and GitHub Actions
Last year, I wrote about how to schedule Jekyll posts using Netlify and AWS Lambda[^1]. I used that approach from the moment I wrote that blog post up until today. What changed? In the past year, GitHub has introduced GitHub Actions[^2], a way to run container jobs triggered by different GitHub events. One of those events is a schedule defined in start cron format. So now instead of using AWS to schedule a cron job to deploy my static site, I use a GitHub Action.
For the sake of completeness, I’m duplicating some of the relevant content from my original post.
Configuring Jekyll
By default, Jekyll generates all blog posts in the _posts directory regardless of the publish date associated with each. That obviously doesn’t work well when you want to schedule posts to be published in the future, so the first step is to configure Jekyll to ignore future posts. To do so, add this key to Jekyll’s _config.yml:
future: false
Setting future to false tells Jekyll to skip any posts with a publish date in the future. You can then set the date field in the front matter of a post to a future date and know that the post will not be generated until then, like this:
---
layout: post
title: "My future post"
date: 2075-01-01 00:00:00
---
This post will be published on January 1, 2075, so it will not be built by Jekyll until that point in time. I find it easier to schedule all posts for midnight so that whenever the site gets published, so long as the date matches, the post will always be generated.
Generating a Netlify build hook
One of the things I like about Netlify is that you can trigger a new site build whenever you want, either manually or programmatically. Netlify has a useful feature called a build hook[^3], which is a URL that triggers a new build. To generate a new build hook, go to the Netlify dashboard for your domain and go Site Settings and then to the Build & Deploy page. When you scroll down, you’ll see a section for Build Hooks. Click “Add build hook”, give your new hook a name (something like “Daily Cron Job” would be appropriate here), and choose the branch to build from.
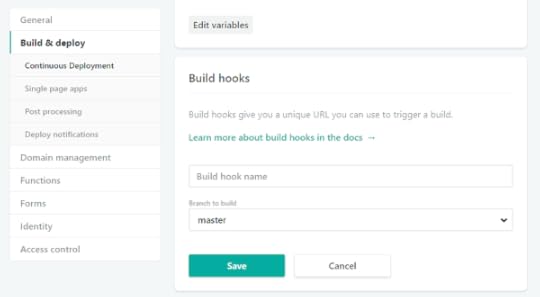
You’ll be presented with a new URL that looks something like this:
https://api.netlify.com/build_hooks/{... long unique identifier}
Whenever you send a POST request to the build hook, Netlify will pull the latest files from the GitHub repository, build the site, and deploy it. This is quite useful because you don’t need to worry about authenticating against the Netlify API; you can use this URL without credentials. Just make sure to keep this URL a secret. You can see the URL in your list of build hooks on the same page.
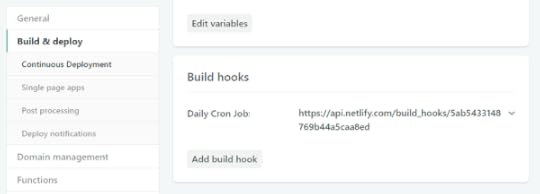
(Don’t worry, the build hook URL in the screenshot has already been deleted.)
Storing the build hook as a GitHub secret
Along with GitHub Actions, GitHub introduced a new feature that allows you to store secrets[^4] for each repository. Each repository has its own secret store that allows anyone with write access to store key-value pairs of sensitive information. Each key is written once and is never shown in the UI again but you can read that information from within a GitHub workflow file.
To find the secret store for your repository, click on the Settings tab at the top of the repository page, then select Secrets from the left menu. Type a name for your secret (for the purposes of this post, I used netlify_build_url) and paste in the value. Click the Add Secret button to store the secret.
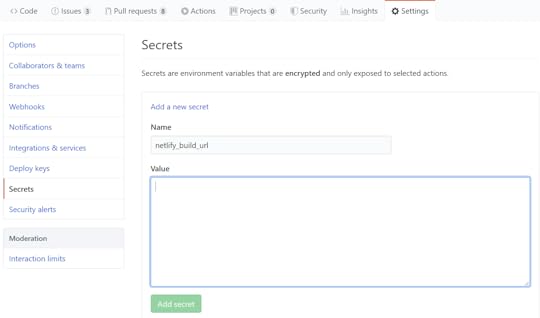
With the Netlify build hook stored safely in the secret store, it’s time to create the GitHub workflow file.
Setting up the GitHub Workflow
GitHub Actions are triggered by workflows[^5] defined within your GitHub repository. Workflow files are defined in YAML format and must be stored in the .github/workflows folder of your project for GitHub to automatically detect them. An action starts up a container or virtual machine and runs any number of commands on it. You can choose to use MacOS, Windows, or Ubuntu environments to run the commands. You only need a way to make HTTP requests in order to trigger the Netlify build hook, so the Ubuntu environment (with curl available) is an easy choice.
Each workflow is triggered by one or more events specified by the on key. To create a cron job, define the schedule array and include at least one object containing a cron key. For example:
name: Netlify Deploy
on:
schedule:
- cron: "0 15 * * *"
This workflow is triggered at 3pm UTC every day of the week. All of the POSIX cron syntax is supported in workflows, making it easy to translate existing cron jobs.
Keep in mind that the cron job schedule is always relative to UTC time. Make sure to take into account your time zone when determining your schedule.
The next step is to set up a job to be run on Ubuntu. To do that, create a jobs object. Here’s an example:
name: Netlify Deploy
on:
schedule:
- cron: "0 15 * * *"
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Trigger Netlify Hook
run: curl -X POST ${{ secrets.netlify_build_url }}
Each property of the jobs object is a separate job to be run (in order). The name of the job doesn’t really matter as long as it’s unique (build is a common job name). The runs-on property specifies the environment to run the command and steps is an array of commands to execute in the environment. There’s only one step in this example, which is triggering the Netlify hook. The name property should be set to something meaningful because it is displayed in the GitHub interface. The run property is the actual command to run. In this case, the command is a curl POST request to a specified URL, which is represented by a secret value. When the job executes, the Netlify deploy is triggered.
Conclusion
I switched this website over to use this GitHub Action approach as soon as I got access to the GitHub Actions beta. So far, I haven’t seen any difference in the end result (publishing my blog daily) and being able to modify the cron job within the website repository streamlines my work. I currently have this website being autogenerated every morning, and that includes pulling in new data via various APIs and publishing future-dated posts.
While I enjoyed experimenting with AWS Cloudwatch and Lambdas for scheduling future posts, I now feel that GitHub Actions is a better solution.
References
Scheduling Jekyll posts with Netlify and AWS
About GitHub Actions
Netlify Webhooks - Incoming Hooks
GitHub Actions - Creating and using secrets
GitHub Actions - Configuring a Workflow



September 2, 2019
Securing persistent environment variables using Vercel (formerly Vercel)
I’m a big fan of Vercel1 as an application hosting provider. The way the service abstracts all of the cloud computing details and allows teams to focus on building and deploying web applications is fantastic. That said, I had a lot of trouble setting up secure environment variables for my first application to use. I was used to other services like Netlify2 and AwS Lambda3 exposing environment variables in the web interface to allow secure transmission of important information. When Vercel didn’t provide the same option in its web interface, I had to spend some time researching how to securely set persistent environment variables on my application.
For the purposes of this post, assume that you need to set two environment variables, CLIENT_ID and CLIENT_SECRET. These values won’t change between deployments (presumably because they are used to authenticate the application with OAuth). As such, you don’t want to manually set these environment variables during every deployment but would rather have them stored and used each time the application is deployed.
Setting environment variables in Vercel
According to the documentation4, there are two ways to set environment variables for your Vercel project. The first is to use the vercel command line tool with the -e option, such as:
vercel -e CLIENT_ID="abcdefg" -e CLIENT_SECRET="123456789abcdefg"
This approach not only sets the environment variables but also triggers a new deploy. The environment variables set here are valid only for the triggered deploy and will not automatically be available for any future deploys. You need to include the environment variables any time you deploy, which isn’t ideal when the information doesn’t need to change between deploys.
The second way to set environment variables is to include them in the vercel.json file. There are actually two keys that can contain environment variables in vercel.json:
env is used for environment variables needed only during application runtime.
build.env is used for environment variables needed only during the build process.
Whether you need the environment variables in one or both modes is up to how your application is built.
Be particularly careful if your build process uses the same JavaScript configuration file as your runtime, as you may find both the build and runtime will require the same environment variables even if it’s not immediately obvious (this happened to me). This is common with universal frameworks such as Next.js and Nuxt.js.
Both the env and build.env keys are objects where the property names are the environment variables to set and the property values are the environment variable values. For example, the following sets CLIENT_ID and CLIENT_SECRET in both the build and runtime environments:
{
"env": {
"CLIENT_ID": "abcdefg",
"CLIENT_SECRET": "123456789abcdefg"
},
"build": {
"env": {
"CLIENT_ID": "abcdefg",
"CLIENT_SECRET": "123456789abcdefg"
}
}
}
The environment variables in vercel.json are set for each deploy automatically, so this is the easiest way to persist important information for your application. Of course, if your environment variables contain sensitive information then you wouldn’t want to check vercel.json into your source code repository. That’s not a great solution because vercel.json contains more than just environment variables. The solution is to use vercel.json with project secrets.
Using Vercel secrets
Vercel has the ability to store secrets associated with each project. You can set a secret using the vercel CLI. You can name these secrets whatever you want, but the documentation4 suggests using lower dash case, Here’s an example:
vercel secrets add client-id abcdefg
vercel secrets add client-secret 123456890abcdefg
These commands create two secrets: client-id and client-secret. These are automatically synced to my Vercel project and only available within that one project.
By default, secrets will be added to your personal account. To assign to a team account, be sure to use --scope team-name as part of the command.
The next step is to reference these secrets inside of the vercel.json file. To specify that the value is a secret, prefix it with the @ symbol. For example, the following sets CLIENT_ID and CLIENT_SECRET in both the build and runtime environments:
{
"env": {
"CLIENT_ID": "@client-id",
"CLIENT_SECRET": "@client-secret"
},
"build": {
"env": {
"CLIENT_ID": "@client-id",
"CLIENT_SECRET": "@client-secret"
}
}
}
This vercel.json configuration specifies that the environment variables should be filled with secret values. Each time your application is deployed, Vercel will read the client-id and client-secret secrets and expose them as the environment variables CLIENT_ID and CLIENT_SECRET. It’s now safe to check vercel.json into your source code repository because it’s not exposing any secure information. You can just use the vercel command to deploy your application knowing that all of the important environment variables will be added automatically.
Summary
The way Vercel handles environment variables takes a little getting used to. Whereas other services allow you to specify secret environment variables directly in their web interface, Vercel requires using the vercel command line tool to do so.
The easiest way to securely persist environment variables in your Vercel project is to store the information in secrets and then specify the environment variables in your vercel.json file. Doing so allows you to check vercel.json into your source code repository without exposing sensitive information. Given the many configuration options available in vercel.json, it’s helpful to have that file in source control so you can make changes when necessary.
Updates
2020-August-04 - Updated to rename from ZEIT Now to Vercel.
References
Vercel - Build Step - Environment Variables ↩ ↩2



Nicholas C. Zakas's Blog

- Nicholas C. Zakas's profile
- 106 followers

