
Martin Fowler's Blog, page 34
June 13, 2015



June 3, 2015
Bliki: MonolithFirst
As I hear stories about teams using a microservices architecture, I've
noticed a common pattern.
Almost all the successful microservice stories have started with a
monolith that got too big and was broken up
Almost all the cases where I've heard of a system that was built as a
microservice system from scratch, it has ended up in serious trouble.
This pattern has led many of my colleagues to argue that you
shouldn't start a new project with microservices, even if you're
sure your application will be big enough to make it worthwhile.
.

Microservices are a useful architecture, but even their advocates
say that using them incurs a significant
MicroservicePremium, which means they are only useful
with more complex systems. This premium, essentially the cost of
managing a suite of services, will slow down a team, favoring a
monolith for simpler applications. This leads to a powerful argument
for a monolith-first strategy, where you should build a new
application as a monolith initially, even if you think it's likely
that it will benefit from a microservices architecture later on.
The first reason for this is classic Yagni. When you begin a new
application, how sure are you that it will be useful to your users?
It may be hard to scale a poorly designed but successful software
system, but that's still a better place to be than its inverse. As
we're now recognizing, often the best way to find out if a software
idea is useful is to build a simplistic version of it and see how
well it works out. During this first phase you need to prioritize
speed (and thus cycle time for feedback), so the premium of
microservices is a drag you should do without.
The second issue with starting with microservices is that they
only work well if you come up with good, stable boundaries between
the services - which is essentially the task of drawing up the right
set of BoundedContexts. Any refactoring of functionality
between services is much harder than it is in a monolith. But even
experienced architects working in familiar domains have great
difficulty getting boundaries right at the beginning. By building a
monolith first, you can figure out what the right boundaries are,
before a microservices design brushes a layer of treacle over them.
It also gives you time to develop the
MicroservicePrerequisites you need for finer-grained
services.
I've heard different ways to execute a monolith-first strategy.
The logical way is to design a monolith carefully,
paying attention to modularity within the software, both at the API
boundaries and how the data is stored. Do this well, and it's a
relatively simple matter to make the shift to microservices. However
I'd feel much more comfortable with this approach if I'd heard a
decent number of stories where it worked out that way. [1]
A more common approach is to start with a monolith and gradually
peel off microservices at the edges. Such an approach can leave a
substantial monolith at the heart of the microservices
architecture, but with most new development occurring in the
microservices while the monolith is relatively quiescent.
Another common approach is to just replace the monolith entirely.
Few people look at this as an approach to be proud of, yet there are
advantages to building a monolith as a
SacrificialArchitecture. Don't be afraid of building a
monolith that you will discard, particularly if a monolith can get
you to market quickly.
Another route I've run into is to start with just a couple of
coarse-grained services, larger than those you expect to end up
with. Use these coarse-grained services to get used to working with
multiple services, while enjoying the fact that such coarse granularity
reduces the amount of inter-service refactoring you have to do. Then
as boundaries stabilize, break down into finer-grained services. [2]
While the bulk of my contacts lean toward the monolith-first
approach, it is by no means unanimous. The counter argument says
that starting with microservices allows you to get used to the
rhythm of developing in a microservice environment. It takes a lot,
perhaps too much, discipline to build a monolith in a sufficiently
modular way that it can be broken down into microservices easily. By
starting with microservices you get everyone used to developing in
separate small teams from the beginning, and having teams separated
by service boundaries makes it much easier to scale up the
development effort when you need to. This is especially
viable for system replacements where you have a better chance of
coming up with stable-enough boundaries early. Although the evidence
is sparse, I feel that you shouldn't start with microservices unless
you have reasonable experience of building a microservices system in
the team.
I don't feel I have enough anecdotes yet to get a firm handle on
how to decide whether to use a monolith-first strategy. These are
early days in microservices, and there are relatively few anecdotes
to learn from. So anybody's advice on these topics must be seen as
tentative, however confidently they argue.
Further Reading
Sam Newman describes a case study of a team considering using
microservices on a greenfield project.
Notes
1:
You cannot assume that you can take an arbitrary system and
break it into microservices. Most systems acquire too many
dependencies between their modules, and thus can't be sensibly
broken apart. I've heard of plenty of cases where an attempt to
decompose a monolith has quickly ended up in a mess. I've
also heard of a few cases where a gradual route to microservices has
been successful - but these cases required a relatively good
modular design to start with.
2:
I suppose that strictly you should call this a "duolith", but I
think the approach follows the essence of monolith-first
strategy: start with coarse-granularity to gain knowledge and split later.
Acknowledgements
I stole much of this thinking from my coleagues: James Lewis, Sam
Newman, Thiyagu Palanisamy, and Evan Bottcher. Stefan Tilkov's
comments on an earlier draft played a pivotal role in clarifying
my thoughts. Chad Currie created the lovely glyphy
dragons. Steven Lowe, Patrick Kua, Jean Robert D'amore, Chelsea
Komlo, Ashok Subramanian, Dan Siwiec, Prasanna Pendse, Kief
Morris, Chris Ford, and Florian Sellmayr discussed drafts on our
internal mailing list.
Share: 


May 29, 2015
Bliki: Yagni
Yagni originally is an acronym that stands for "You Aren't Gonna
Need It". It is a mantra from ExtremeProgramming
that's often used generally in agile software teams. It's a
statement that some capability we presume our software needs in the future
should not be built now because "you aren't gonna need it".
Yagni is a way to refer to the XP practice of Simple Design (from
the first edition of The White Book , the second edition refers to
, the second edition refers to
the related notion of "incremental design"). [1] Like many elements of XP, it's a sharp contrast to
elements of the widely held principles of software engineering in
the late 90s. At that time there was a big push for careful up-front
planning of software development.
Let's imagine I'm working with a startup in Minas Tirith selling
insurance for the shipping business. Their software system is broken
into two main components: one for pricing, and one for sales. The
dependencies are such that they can't usefully build
sales software until the relevant pricing software is completed.
At the moment, the team is working on updating the pricing
component to add support for risks from storms. They know that in six
months time, they will need to also support pricing for piracy
risks. Since they are currently working on the pricing engine they consider
building the presumptive feature [2] for piracy pricing now, since that way the pricing
service will be complete before they start working on the sales
software.
Yagni argues against this, it says that since you won't need
piracy pricing for six months you shouldn't build it until it's
necessary. So if you think it will take two months to build this
software, then you shouldn't start for another four months
(neglecting any buffer time for schedule risk and updating the sales
component).
The first argument for yagni is that while we may now think we
need this presumptive feature, it's likely that we will be wrong.
After all the context of agile methods is an acceptance that we
welcome changing requirements. A plan-driven requirements guru might
counter argue that this is because we didn't do a good-enough job of
our requirements analysis, we should have put more time and effort
into it. I counter that by pointing out how difficult and costly it is to
figure out your needs in advance, but even if you can, you can still
be blind-sided when the Gondor Navy wipes out the pirates, thus
undermining the entire business model.
In this case, there's an obvious cost of the presumptive feature
- the cost of build: all the effort spent on analyzing, programming,
and testing this now useless feature.
But let's consider that we were completely correct with our
understanding of our needs, and the Gondor Navy didn't wipe out the
pirates. Even in this happy case, building the
presumptive feature incurs two
serious costs. The first cost is the cost of delayed value. By
expending our effort on the piracy pricing software we didn't build
some other feature. If we'd instead put our energy into building
the sales software for weather risks, we could have put a full
storm risks feature into production and be generating revenue two
months earlier. This cost of delay due to the presumptive feature is
two months revenue from storm insurance.
The common reason why people build presumptive features is
because they think it will be cheaper to build it now rather than
build it later. But that cost comparison has to be made at least
against the cost of delay, preferably factoring in the
probability that you're building an unnecessary feature, for which
your odds are at least ⅔. [3]
Often people don't think through the comparative cost of building
now to building later. One approach I use when mentoring developers
in this situation is to ask them to imagine any refactoring they
would have to do later to introduce the capability when it's needed.
Often that thought experiment is enough to convince them that it
won't be significantly more expensive to add it later. Another
result from such an imagining is to add something that's easy to do
now, adds minimal complexity, yet significantly reduces the later
cost. Using lookup tables for error messages rather than inline
literals are an example that are simple yet
make later translations easier to support.
Reminder, any extensibility point that’s never used isn’t just
wasted effort, it’s likely to also get in your way as well
-- Jeremy Miller
The cost of delay is one cost that a successful presumptive
feature imposes, but another is the cost of carry. The code for the
presumptive feature adds some complexity to the software, this
complexity makes it harder to modify and debug that software, thus
increasing the cost of other features. The extra complexity from
having the piracy-pricing feature in the software might add a couple
of weeks to how long it takes to build the storm insurance sales
component. That two weeks hits two ways: the additional cost to
build the feature, plus the additional cost of delay since it look
longer to put it into production. We'll incur a cost of carry on every
feature built between now and the time the piracy insurance software
starts being useful. Should we never need the piracy-pricing
software, we'll incur a cost of carry on every feature built until
we remove the piracy-pricing feature (assuming we do), together with
the cost of removing it.
So far I've divided presumptive features in two categories:
successful and unsuccessful. Naturally there's really a spectrum
there, and with one point on that spectrum that's worth highlighting: the right
feature built wrong. Development teams are always learning, both
about their users and about their code base. They learn about the
tools they're using and these tools go through regular upgrades. They
also learn about how their code works together. All this means that
you often realize that a feature coded six months ago wasn't done
the way you now realize it should be done. In that case you have
accumulated TechnicalDebt and have to
consider the cost of repair for that feature or the on-going
costs of working around its difficulties.
So we end up with three classes of presumptive features, and four
kinds of costs that occur when you neglect yagni for them.
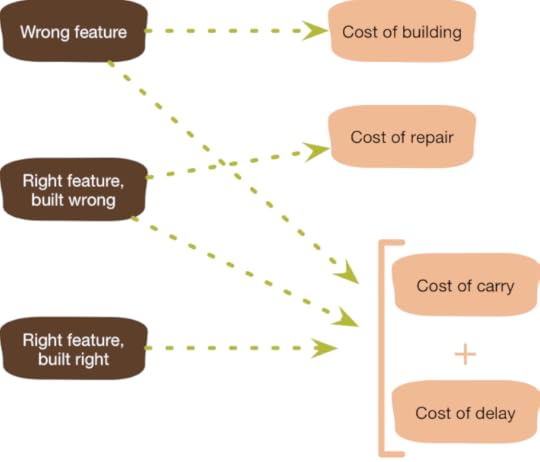
My insurance example talks about relatively user-visible
functionality, but the same argument applies for abstractions to
support future flexibility. When building the storm risk calculator,
you may consider putting in abstractions and parameterizations now
to support piracy and other risks later. Yagni says not to do this,
because you may not need the other pricing functions, or if you do your
current ideas of what abstractions you'll need will not match what
you learn when you do actually need them. This doesn't mean to
forego all abstractions, but it does mean any abstraction that makes
it harder to understand the code for current requirements is
presumed guilty.
Yagni is at its most visible with larger features, but you see it
more frequently with small things. Recently I wrote some code that
allows me to highlight part of a line of code. For this, I allow the
highlighted code to be specified using a regular expression. One
problem I see with this is that since the whole regular expression
is highlighted, I'm unable to deal with the case where I need the
regex to match a larger section than what I'd like to highlight. I
expect I can solve that by using a group within the regex and
letting my code only highlight the group if a group is present. But I
haven't needed to use a regex that matches more than what I'm
highlighting yet, so I haven't extended my highlighting code to
handle this case - and won't until I actually need it. For similar
reasons I don't add fields or methods until I'm actually ready to
use them.
Small yagni decisions like this fly under the radar of project
planning. As a developer it's easy to spend an hour adding an abstraction
that we're sure will soon be needed. Yet all the arguments above
still apply, and a lot of small yagni decisions add up to
significant reductions in complexity to a code base, while speeding
up delivery of features that are needed more urgently.
Now we understand why yagni is important we can dig into a common
confusion about yagni. Yagni only applies to capabilities built
into the software to support a presumptive feature, it does not
apply to effort to make the software easier to modify. Yagni is
only a viable strategy if the code is easy to change, so expending
effort on refactoring isn't a violation of yagni because refactoring
makes the code more malleable. Similar reasoning applies for
practices like SelfTestingCode and
ContinuousDelivery. These are enabling practices for evolutionary
design, without them yagni turns from a beneficial practice into
a curse. But if you do have a malleable code base, then yagni
reinforces that flexibility. Yagni has the curious property that it
is both enabled by and enables evolutionary design.
Yagni is not a justification for neglecting the health of your
code base. Yagni requires (and enables) malleable code.
I also argue that yagni only applies when you introduce extra
complexity now that you won't take advantage of until later. If you
do something for a future need that doesn't actually increase the
complexity of the software, then there's no reason to invoke
yagni.
Having said all this, there are times when applying yagni does cause
a problem, and you are faced with an expensive change when an
earlier change would have been much cheaper. The tricky thing here
is that these cases are hard to spot in advance, and much easier to
remember than the cases where yagni saved effort [4]. My sense is that yagni-failures are relatively
rare and their costs are easily outweighed by when yagni
succeeds.
Further Reading
My essay Is Design
Dead talks in more detail about the role of design and
architecture in agile projects, and thus role yagni plays as an
enabling practice.
This principle was first discussed and fleshed out on Ward's Wiki.
Notes
1:
The origin of the phrase is an early conversation between Kent
Beck and Chet Hendrickson on the C3 project. Chet
came up to Kent with a series of capabilities that the system
would soon need, to each one Kent replied "you aren't
going to need it". Chet's a fast learner, and quickly became
renowned for his ability to spot opportunities to apply yagni.
Although "yagni" began life as an acronym, I feel it's now
entered our lexicon as a regular word, and thus forego the
capital letters.
2:
In this post I use "presumptive feature" to refer to any code
that supports a feature that isn't yet being made available for
use.
3:
The ⅔ number is suggested by Kohavi
et al, who analyzed the value of features built and deployed
on products at microsoft and found that, even with careful
up-front analysis, only ⅓ of them improved the metrics they were
designed to improve.
4:
This is a consequence of availability bias
Acknowledgements
Rachel Laycock talked through this post with me and played a
critical role in its final organization. Chet Hendrickson and
Steven Lowe reminded
me to discuss small-scale yagni decisions.
Rebecca Parsons, Alvaro Cavalcanti, Mark Taylor, Aman King, Rouan
Wilsenach, Peter Gillard-Moss, Kief Morris, Ian Cartwright, James
Lewis, Kornelis Sietsma, and Brian Mason participated in an insightful
discussion about drafts of this article on our internal mailing list.
Share:
May 22, 2015
Bliki: MicroservicePremium
The microservices
architectural style has been the hot topic over the last year.
At the recent O'Reilly software
architecture conference, it seemed like every session talked
about microservices. Enough to get everyone's over-hyped-bullshit
detector up and flashing. One of the consequences of this is that
we've seen teams be too eager to embrace microservices, [1] not
realizing that microservices introduce complexity on their own
account. This adds a premium to a project's cost and risk - one that
often gets projects into serious trouble.
While this hype around microservices is annoying, I do think it's a
useful bit of terminology for a style of architecture which has been
around for a while, but needed a name to make it easier to talk
about. The important thing here is not how annoyed you feel about the
hype, but the architectural question it raises: is a microservice
architecture a good choice for the system
you're working on?
any decent answer to an interesting question begins, "it depends..."
-- Kent Beck
"It depends" must start my answer, but then I must shift the
focus to what factors it depends on. The fulcrum of whether
or not to use microservices is the complexity of the system you're
contemplating. The microservices approach is all about handling a
complex system, but in order to do so the approach introduces its
own set of complexities. When you use microservices you have to work
on automated deployment, monitoring, dealing with failure, eventual
consistency, and other factors that a distributed system introduces.
There are well-known ways to cope with all this, but it's extra
effort, and nobody I know in software development seems to have
acres of free time.

So my primary guideline would be don't even consider
microservices unless you have a system that's too complex to manage
as a monolith. The majority of software systems should be built
as a single monolithic application. Do pay attention to good
modularity within that monolith, but don't try to separate it into
separate services.
The complexity that drives us to microservices can come from many
sources including
dealing with large teams [2], multi-tenancy,
supporting many
user interaction models, allowing different business functions to
evolve independently, and scaling. But the biggest factor
is that of sheer size - people finding they have a monolith that's too big
to modify and deploy.
At this point I feel a certain frustration. Many of the problems
ascribed to monoliths aren't essential to that style. I've heard people say that
you need to use microservices because it's impossible to do
ContinuousDelivery with monoliths - yet there are plenty of
organizations that succeed with a cookie-cutter
deployment approach: Facebook and Etsy are two well-known
examples.
I've also heard arguments that say that as a system increases in
size, you have to use microservices in order to have parts that are
easy to modify and replace. Yet there's no reason why you can't make
a single monolith with well defined module boundaries. At least
there's no reason in theory, in practice it seems too easy for
module boundaries to be breached and monoliths to get tangled as
well as large.
We should also remember that there's a substantial variation in
service-size between different microservice systems. I've seen
microservice systems vary from a team of 60 with 20 services to a
team of 4 with 200 services. It's not clear to what degree service
size affects the premium.
As size and other complexity boosters kick into a project I've
seen many teams find that microservices are a better place to be.
But unless you're faced with that complexity, remember that the
microservices approach brings a high premium, one that can slow down
your development considerably. So if you can keep your system simple
enough to avoid the need for microservices: do.
Notes
1:
It's a common enough problem
that our recent radar called it out as Microservice
Envy.
2: Conway's
Law says that the structure of a system follows the
organization of the people that built it. Some examples of
microservice usage had organizations deliberately split
themselves into small, loosely coupled groups in order to push
the software into a similar modular structure - a notion that's
called the Inverse
Conway Maneuver.
Acknowledgements
I stole much of this thinking from my colleagues: James Lewis, Sam
Newman, Thiyagu Palanisamy, and Evan Bottcher. Stefan Tilkov's
comments on an earlier draft were instrumental in sharpening this post. Rob
Miles, David Nelson, Brian Mason, and Scott Robinson discussed
drafts of this article on our internal mailing list.
Share:

March 28, 2015
Retreaded: CodeAsDocumentation
Retread of post orginally made on 22 Mar 2005
One of the common elements of agile methods is that they raise
programming to a central role in software
development - one much greater than the software engineering
community usually does. Part of this is classifying the code as a
major, if not the primary documentation of a software system.
Almost immediately I feel the need to rebut a common
misunderstanding. Such a principle is not saying that code is the
only documentation. Although I've often heard this said of Extreme
Programming - I've never heard the leaders of the Extreme
Programming movement say this. Usually there is a need for
further documentation to act as a supplement to the code.
The rationale for the code being the primary source of
documentation is that it is the only one that is sufficiently
detailed and precise to act in that role - a point made so
eloquently by Jack Reeves's famous essay "What
is Software Design?"
This principle comes with a important consequence - that it's
important that programmers put in the effort to make sure that this
code is clear and readable. Saying that code is documentation isn't
saying that a particular code base is good documentation. Like any
documentation, code can be clear or it can be gibberish. Code is no
more inherently clear than any other form of documentation. (And
other forms of documentation can be hopelessly unclear too - I've
seen plenty of gibberish UML diagrams, to flog a popular horse.)
Certainly it seems that most code bases aren't very good
documentation. But just as it's a fallacy to conclude that declaring
code to be documentation excludes other forms, it's a fallacy to say
that because code is often poor documentation means that it's
necessarily poor. It is possible to write clear code, indeed I'm
convinced that most code bases can be made much more clear.
I think part of the reason that code is often so hard to read is
because people aren't taking it seriously as documentation. If
there's no will to make code clear, then there's little chance it
will spring into clarity all by itself. So the first step to clear
code is to accept that code is documentation, and then put the
effort in to make it be clear. I think this comes down to what was
taught to most programmers when they began to program. My teachers didn't put much emphasis on
making code clear, they didn't seem to value it and certainly didn't
talk about how to do it. We as a whole industry need to put much
more emphasis on valuing the clarity of code.
The next step is to learn how, and here let me offer you the
advice of a best selling technical author - there's nothing like
review. I would never think of publishing a book without having many
people read it and give me feedback. Similarly there's nothing more
important to clear code than getting feedback from others about
what is or isn't easy to understand. So take every opportunity to
find ways to get other people to read your code. Find out what they
find easy to understand, and what things confuse them. (Yes, pair
programming is a great way to do this.)
For more concrete advice - well I suggest reading good books on
programming style. Code Complete is the first place to look. I'll
naturally suggest Refactoring - after all much of refactoring is
about making code clearer. After Refactoring, Refactoring to
Patterns is an obvious suggestion.
You'll always find people will disagree on various
points. Remember that a code base is owned primarily by a team (even
if you practice individual code ownership over bits of it). A
professional programmer is prepared to bend her personal style to
reflect the needs of the team. So even if you like ternary operators
don't use them if your team doesn't find them easy to
understand. You can program in your own style on your personal
projects, but anything you do in a team should follow the needs of
that team.
reposted on 25 Mar 2015
Share:
March 4, 2015

March 2, 2015
Bliki: BeckDesignRules
Kent Beck came up with his four rules of simple design while he
was developing ExtremeProgramming in the late 1990's. I express
them like this. [1]
Passes the tests
Reveals intention
No duplication
Fewest elements
The rules are in priority order, so "passes the tests" takes
priority over "reveals intention"

Kent Beck developed Extreme Programming, Test Driven Development,
and can always be relied on for good Victorian facial hair for his
local ballet.
The most important of the rules is "passes the tests". XP was
revolutionary in how it raised testing to a first-class activity in
software development, so it's natural that testing should play a
prominent role in these rules. The point is that whatever else you
do with the software, the primary aim is that it works as
intended and tests are there to ensure that happens.
"Reveals intention" is Kent's way of saying the code
should be easy to understand. Communication is a core value of
Extreme Programing, and many programmers like to stress that
programs are there to be read by people. Kent's form of expressing
this rule implies that the key to enabling understanding is to express your
intention in the code, so that your readers can understand what your
purpose was when writing it.
The "no duplication" is perhaps the most powerfully subtle of
these rules. It's a notion expressed elsewhere as DRY or SPOT [2], Kent
expressed it as saying everything should be said "Once and only Once."
Many programmers have observed that the exercise of eliminating
duplication is a powerful way to drive out good designs. [3]
The last rule tells us that anything that doesn't serve the three
prior rules should be removed. At the time these rules were
formulated there was a lot of design advice around adding elements to
an architecture in order to increase flexibility for future requirements.
Ironically the extra complexity of all of these elements usually
made the system harder to modify and thus less flexible in practice.
People often find there is some tension between "no duplication"
and "reveals intention", leading to arguments about which order
those rules should appear. I've always seen their order as
unimportant, since they feed off each other in refining the code. Such things
as adding duplication to increase clarity is often papering over a problem,
when it would be better to solve it. [4]
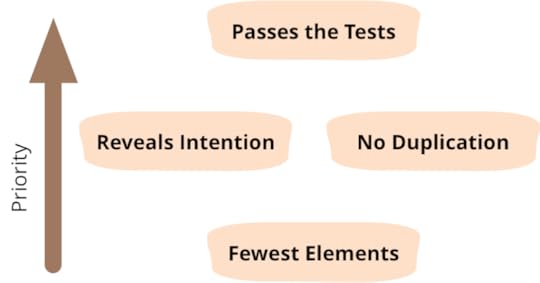
What I like about these rules is that they are very simple to
remember, yet following them improves code in any language or
programming paradigm that I've worked with. They are an example of
Kent's skill in finding principles that are generally applicable and
yet concrete enough to shape my actions.
At the time there was a lot of “design is subjective”, “design is
a matter of taste” bullshit going around. I disagreed. There are
better and worse designs. These criteria aren’t perfect, but they
serve to sort out some of the obvious crap and (importantly) you can
evaluate them right now. The real criteria for quality of design,
“minimizes cost (including the cost of delay) and maximizes benefit
over the lifetime of the software,” can only be evaluated post hoc,
and even then any evaluation will be subject to a large bag full of
cognitive biases. The four rules are generally predictive.
-- Kent Beck
Further Reading
There are many expressions of these rules out there, here are a
few that I think are worth exploring:
J.B.
Rainsberger's summary. He also has a good discussion of the
interplay between the rules 2&3.
Ron Jeffries
These rules, like much else of Extreme Programming, were
originally discussed and refined on Ward's Wiki.
Acknowledgements
Kent reviewed this post and sent me some very helpful feedback,
much of which I appropriated into the text.
Notes
1: Authoritative Formulation
There are many expressions of the four rules out there,
Kent stated them in lots of media, and plenty of other people
have liked them and phrased them their own way. So you'll see
plenty of descriptions of the rules, but each author has their
own twist - as do I.
If you want an authoritative formulation from the man
himself, probably your best bet is from the first edition of
The
White Book (p 57) in the section that outlines the XP practice
of Simple Design.
Runs all the tests
Has no duplicated logic. Be wary of hidden duplication like
parallel class hierarchies
States every intention important to the programmer
Has the fewest possible classes and methods
(Just to be confusing, there's another formulation on page
109 that omits "runs all the tests" and splits "fewest classes"
and "fewest methods" over the last two rules. I recall this was
an earlier formulation that Kent improved on while writing the
White Book.)
2:
DRY stands for Don't Repeat Yourself, and comes from The Pragmatic Programmer. SPOT stands
for Single
Point Of Truth.
3:
This principle was the basis of my first design column for IEEE Software.
4:
When reviewing this post, Kent said "In the rare case they are
in conflict (in tests are the only examples I can recall),
empathy wins over some strictly technical metric." I like his
point about empathy - it reminds us that when writing code we
should always be thinking of the reader.
Share:
February 19, 2015
Retreaded: ConversationalStories
Retread of post orginally made on 04 Feb 2010
Here's a common misconception about agile methods. It centers on
the way user stories are created and flow through the development
activity. The misconception is that the product owner (or business
analysts) creates user stories and then put them in front of
developers to implement. The notion is that this is a flow from
product owner to development, with the product owner responsible for
determining what needs to be done and the developers
how to do it.
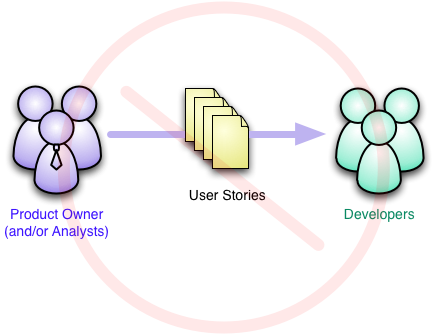
A justification for this approach is that this separates the
responsibilities along the lines of competence. The product owner
knows the business, what the software is for, and thus what needs to
be done. The developers know technology and know how to do things,
so they can figure out how to realize the demands of the product
owner.
This notion of product owners coming up with
DecreedStories is a profound misunderstanding of the way
agile development should work. When we were brainstorming names at
Snowbird, I
remember Kent suggesting "conversational". This emphasized the fact
that the heart of our thinking was of an on-going conversation
between customers and developers about how a development project
should proceed.
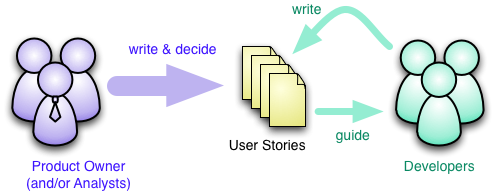
In terms of coming up with stories, what this means is that they
are always something to be refined through conversation - and that
developers should play an active role in helping that
definition.
spotting inconsistencies and gaps between the stories
using technical knowledge to come up with new stories that
seem to fit the product owner's vision
seeing alternative stories that would be cheaper to build
given the technological landscape
split stories to make them easier to plan or implement
This is the Negotiable principle in Bill Wake's INVEST test for
stories. Any member of an agile team can create stories and suggest
modifications. It may be that just a few members of a team gravitate
to writing most of the stories. That's up to the team's
self-organization as to how they want that to happen. But everyone
should be engaged in coming up and refining stories. (This
involvement is in addition to the develpers' responsibility to
estimate stories.)
The product owner does have a special responsibility. In the end
the product owner is the final decider on stories, particularly
their prioritization. This reflects the fact that the product owner
should be the best person to judge that slippery attribute of
business value. But having a final decision maker should never stop
others from participating, and should not lead people astray into a
decreed model of stories.
reposted on 19 Feb 2015
Share:
February 18, 2015
Refactoring code that accesses external services
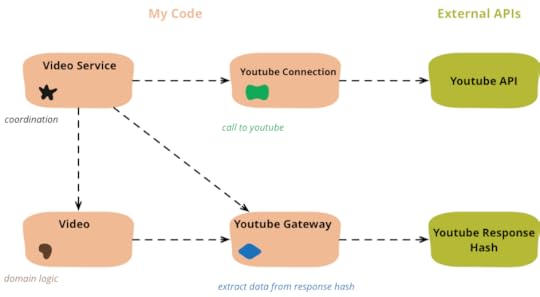
When I write code that deals with external services, I find
it valuable to separate that access code into separate objects.
Here I show how I would refactor some congealed code into a
common pattern of this separation.
Martin Fowler's Blog

- Martin Fowler's profile
- 1103 followers

