
Martin Fowler's Blog, page 42
May 13, 2014
Audio version of first "Is TDD Dead" Hangout
Here is an audio version of our first hangout, for those of you who, like me, can’t stand watching video. It’s a raw translation of the video’s audio. We may try to do something more refined later, such as sorting out a podcast feed, but it’s not something we’ve done before so it may take a while for us to get around to it.


Bliki: ParallelChange
Making a change to an interface that impacts all its consumers requires two thinking modes:
implementing the change itself, and then updating all its usages. This can be hard when you
try to do both at the same time, especially if the change is on a PublishedInterface
with multiple or external clients.
Parallel change, also known as expand and contract, is a pattern to
implement backward-incompatible changes to an interface in a safe manner, by breaking the
change into three distinct phases: expand, migrate, and contract.
To understand the pattern, let's use an example of a simple Grid class that stores
and provides information about its cells using a pair of x and y
integer coordinates. Cells are stored internally in a two-dimentional array and clients can use
the addCell(), fetchCell() and isEmpty() methods to
interact with the grid.
class Grid {
private Cell[][] cells;
…
public void addCell(int x, int y, Cell cell) {
cells[x][y] = cell;
}
public Cell fetchCell(int x, int y) {
return cells[x][y];
}
public boolean isEmpty(int x, int y) {
return cells[x][y] == null;
}
}
As part of refactoring, we detect that x and y are a DataClump
and decide to introduce a new Coordinate class. However, this will be a
backwards-incompatible change to clients of the Grid class. Instead
of changing all the methods and the internal data structure at once, we decide to apply the
parallel change pattern.
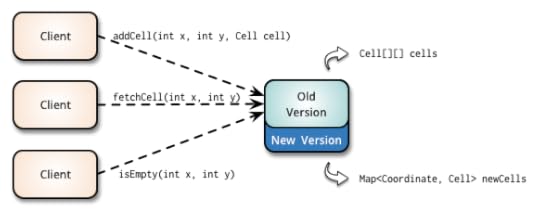
In the expand phase you augment the interface to support both the old and the new
versions. In our example, we introduce a new Map<Coordinate, Cell> data
structure and the new methods that can receive Coordinate instances without
changing the existing code.
class Grid {
private Cell[][] cells;
private Map<Coordinate, Cell> newCells;
…
public void addCell(int x, int y, Cell cell) {
cells[x][y] = cell;
}
public void addCell(Coordinate coordinate, Cell cell) {
newCells.put(coordinate, cell);
}
public Cell fetchCell(int x, int y) {
return cells[x][y];
}
public Cell fetchCell(Coordinate coordinate) {
return newCells.get(coordinate);
}
public boolean isEmpty(int x, int y) {
return cells[x][y] == null;
}
public boolean isEmpty(Coordinate coordinate) {
return !newCells.containsKey(coordinate);
}
}
Existing clients will continue to consume the old version, and the new changes can be introduced
incrementally without affecting them.
During the migrate phase you update all clients using the old version to the new
version. This can be done incrementally and, in the case of external clients, this will be the
longest phase.

Once all usages have been migrated to the new version, you perform the contract phase to
remove the old version and change the interface so that it only supports the new version.

In our example, since the internal two-dimentional array is not used anymore after the old
methods have been deleted, we can safely remove that data structure and rename newCells
back to cells.
class Grid {
private Map<Coordinate, Cell> cells;
…
public void addCell(Coordinate coordinate, Cell cell) {
cells.put(coordinate, cell);
}
public Cell fetchCell(Coordinate coordinate) {
return cells.get(coordinate);
}
public boolean isEmpty(Coordinate coordinate) {
return !cells.containsKey(coordinate);
}
}
This pattern is particularly useful when practicing ContinuousDelivery because it
allows your code to be released in any of these three phases. It also lowers the risk of change
by allowing you to migrate clients and to test the new version incrementally.
Even when you have control over all usages of the interface, following this pattern is still
useful because it prevents you from spreading breakage across the entire codebase all at once.
The migrate phase can be short, but it is an alternative to leaning on the compiler to find all
the usages that need to be fixed.
Some example applications of this pattern are:
Refactoring: when changing a method or function signature, especially when doing a
Long Term
Refactoring or when changing a PublishedInterface. A variant implementation of
this pattern during a refactoring is to implement the old method in terms of the new API and
use Inline Method to update
all usages at once. Delegating the old method to the new method is also a way to break the
migrate phase into smaller and safer steps, allowing you to change the internal implementation
first before changing the exposed API to clients. This is useful when the migrate phase is longer
so you don't have to maintain two separate implementations.
Database refactoring: this is a key component to
evolutionary database design. Most
database refactorings follow the parallel change pattern, where the migrate phase is the
transition period between the original and the new schema, until all database access code has
been updated to work with the new schema.
Deployments: deployment techniques such as canary
releases and
BlueGreenDeployment are applications of the parallel change pattern where you
have both old and new versions of the code deployed side by side, and you incrementally
migrate users from one version to another, therefore lowering the risk of change. In a
microservices architecture,
it can also remove the need for complex deployment orchestration of different services due to
version dependencies between them.
Remote API evolution: parallel change can be used to evolve a remote API (e.g.
a REST web service) when you can't make the change in a backwards compatible manner. This
is an alternative to using an explicit version in the exposed API. You can apply the
pattern when making a change to the payload accepted or returned by the API on a given
endpoint, or you can introduce a new endpoint to distinguish between the old and new
versions. In the case of using parallel change in the same endpoint, following
Postel's Law is a good
technique to avoid consumers breaking when the payload is expanded.
During the migrate phase, a FeatureToggle can be used to control which version of
the interface is used. A feature toggle on the client side allows it to be forward-compatible
with the new version of the supplier, which decouples the release of the supplier from the
client.
When implementing BranchByAbstraction, parallel change is a good way to introduce
the abstraction layer between the clients and the supplier. It is also an alternative way to
perform a large-scale change without introducing the abstraction layer as a seam for
replacement on the supplier side. However, when you have a large number of clients, using branch
by abstraction is a better strategy to narrow the surface of change and reduce confusion during
the migrate phase.
The downside of using parallel change is that during the migrate phase the supplier has to
support two different versions, and clients could get confused about which version is new
versus old. If the contract phase is not executed you might end up in a worse state than you
started, therefore you need discipline to finish the transition successfully. Adding deprecation
notes, documentation or TODO notes might help inform clients and other developers working on
the same codebase about which version is in the process of being replaced.
Further Reading
Industrial Logic's
refactoring album documents and demonstrates an example of performing a parallel change.
Acknowledgements
This technique was first documented as a refactoring strategy by Joshua Kerievsky in 2006
and presented in his talk The
Limited Red Society presented at the Lean Software and Systems Conference in 2010.
Thanks to Joshua Kerievsky for giving feedback on the first draft of this post. Also thanks to
many ThoughtWorks colleagues for their feedback: Greg Dutcher, Badrinath Janakiraman, Praful Todkar,
Rick Carragher, Filipe Esperandio, Jason Yip, Tushar Madhukar, Pete Hodgson, and Kief Morris.
May 12, 2014
Goto Fail, Heartbleed, and Unit Testing Culture

The “goto fail” and heartbleed bugs have shaken our confidence in the security and privacy of the internet. Mike Bland believes that a culture of unit testing would greatly reduce the chances that such bugs would escape into production. As part of a group that spread such a culture inside Google, he believes that it’s important for software teams to take on such a culture. He is writing an article that will look at how unit testing could catch the “goto fail” and heartbleed bugs, the costs and benefits of a testing culture, and the experience of instilling this culture at Google. This first installment looks in detail at the “goto fail” bug and how a testing culture would examine that code.
May 11, 2014
Open-Sourcing ThoughtWorks Go

ThoughtWorks recently announced the open-sourcing of our product Go - which supports Continuous Delivery. This kind of event tends to raise questions, so I organized an interview with Chad Wathington, who is a Managing Director of ThoughtWorks Studios (our product division). He answers questions on why we did the open-sourcing, why we announced it before making the source available, about the name-clash with the go language, and our future plans for Go.
Bliki: ReportingDatabase
Most EnterpriseApplications store persistent data with a
database. This database supports operational updates of the
application's state, and also various reports used for decision
support and analysis. The operational needs and the reporting needs
are, however, often quite different - with different requirements
from a schema and different data access patterns. When this happens
it's often a wise idea to separate the reporting needs into a
reporting database, which takes a copy of the essential operational data but
represents it in a different schema.
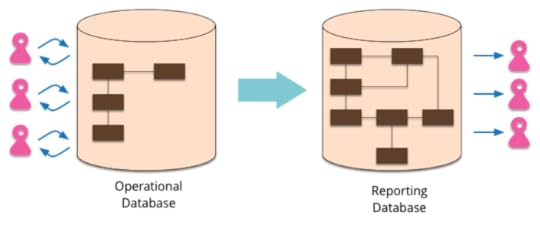
Such a reporting database is a completely different database to
the operational database. It may be a completely different database
product, using PolyglotPersistence. It should be
designed around the reporting needs.
A reporting database has a number of advantages:
The structure of the reporting database can be specifically
designed to make it easier to write reports.
You don't need to normalize a reporting database, because it's
read-only. Feel free to duplicate data as much as needed to make
queries and reporting easier.
The development team can refactor the operational database
without needing to change the reporting database.
Queries run against the reporting database don't add to the load on
the operational database.
You can store derived data in the database, making it easier
to write reports that use the derived data without having to
introduce a separate set of derivation logic.
You may have multiple reporting databases for different
reporting needs.
The downside to a reporting database is that its data has to be
kept up to date. The easiest case is when you do something like use
an overnight run to populate the reporting database. This often
works quite well since many reporting needs work perfectly well with
yesterday's data. If you need more timely data you can use a
messaging system so that any changes to the operational database are
forwarded to the reporting database. This is more complicated, but
the data can be kept fresher. Often most reports can use slightly
stale data and you can produce special case reports for things that
really need to have this second's data [1].
A variation on this is to use views. This encapsulates the
operational data and allows you to denormalize. It doesn't allow you
to separate the operational load from the reporting load. More
seriously you are limited to what views can derive and you can't
take advantage of derivations that are written in an in-memory
programming environment.
A reporting database fits well when you have a lot of domain
logic in a domain model or other in-memory code. The domain logic
can be used to process updates to the operational data, but also to
calculate derived data which to enrich the reporting database.
I originally wrote this entry on April 2nd 2004. I took
advantage of its ten-year anniversary to update the text.
Notes
1:
These days the desire seems to be for near-real time analytics.
I'm skeptical of the value of this. Often when analyzing data
trends you don't need to react right away, and your thinking
improves when you give it time for a proper mulling. Reacting
too quickly leads to a form of information hysteresis, where you
react badly to data that's changing too rapidly to get a proper
picture of what's going on.
photostream 63

Heronswood, Mornington Peninsula, Victoria, Australia
Keynote Talks from OOP

Earlier this year I gave a keynote at the OOP conference in Munich. I gave two short talks (about 25 minutes each), both of which are now available on YouTube. The first talk looks at the topic of Workflows of Refactoring, where I explore various ways in which people can (but often don’t) use refactoring in their work. In the second talk I begin with my concern about the biggest aspect missing from the spread of agile and go on to explore the relationship between programmers, analysts, users and the wider society. (I have a list of all videos of my talks and a YouTube playlist for those on YouTube.)
Bliki: SelfTestingCode
Self-Testing Code is the name I used in Refactoring to refer to the practice
of writing comprehensive automated tests in conjunction with the
functional software. When done well this allows you to invoke a
single command that executes the tests - and you are confident that
these tests will illuminate any bugs hiding in your code.

I first ran into the thought at an OOPSLA conference listening to
"Beddara" Dave Thomas say
that every object should be able to test itself. I suddenly had the
vision of typing a command and having my whole software system do a
self-test, much in the way that you used to see hardware memory tests when
booting. Soon I was exploring this approach in my own projects and being
very happy with the benefits. A couple of years later I did some
work with Kent Beck and discovered he did the same thing, but in a
much more sophisticated way than I did. This was shortly before Kent
(and Erich Gamma) produced JUnit - a tool that became the
underpinning of much of thinking and practice of self-testing code
(and its sister: TestDrivenDevelopment).
You have self-testing code when you can run a series of automated
tests against the code base and be confident that, should the tests
pass, your code is free of any substantial defects. One way I think
of it is that as well as building your software system, you
simultaneously build a bug detector that's able to detect any faults
inside the system. Should anyone in the team accidentally introduce
a bug, the detector goes off. By running the test suite frequently,
at least several times a day, you're able to detect such bugs soon
after they are introduced, so you can just look in the recent
changes, which makes it much easier to find them. No
programming episode is complete without working code and the tests
to keep it working. Our attitude is to assume that any non-trivial
code without tests is broken.
Self-testing code is a key part of Continuous Integration,
indeed I say that you aren't really doing continuous integration
unless you have self-testing code. As a pillar of Continuous
Integration, it is also a necessary part of Continuous Delivery.
One obvious benefit of self-testing code is that it can
drastically reduce the number of bugs that get into production
software. At the heart of this is building up a testing culture that
where developers are naturally thinking about writing code and tests
together.
But the biggest benefit isn't about merely avoiding production
bugs, it's about the confidence that you get to make changes to the
system. Old codebases are often terrifying places, where developers
fear to change working code. Even fixing a bug can be dangerous,
because you can create more bugs than you fix. In such circumstances
not just is it horribly slow to add more features, you also end up
afraid to refactor the system, thus increasing TechnicalDebt, and
getting into a steadily worsening spiral where every change makes
people more fearful of more change.
With self-testing code, it's a different picture. Here people are
confident that fixing small problems to clean the code can be done
safely, because should you make a mistake (or rather "when I make a
mistake") the bug detector will go off and you can quickly recover
and continue. With that safety net, you can spend time keeping the
code in good shape, and end up in a virtuous spiral where you get
steadily faster at adding new features.
These kinds of benefits are often talked about with respect to
TestDrivenDevelopment (TDD), but it's useful to separate
the concepts of TDD and self-testing code. I think of TDD as a
particular practice whose benefits include producing self-testing
code. It's a great way to do it, and TDD is a technique I'm a big
fan of. But you can also produce self-testing code by writing tests
after writing code - although you can't consider your work to be
done until you have the tests (and they pass). The important point
of self-testing code is that you have the tests, not how you got to
them.
Increasingly these days we're seeing another dimension to
self-testing, with more emphasis put on monitoring in production. Continuous Delivery allows you to
quickly deploy new versions of software into production. In this
situation teams put more effort into spotting bugs once
in production and rapidly fixing them by either deploying a new
fixed version or rolling back to the last-known-good version.
This entry was originally published (in a much smaller form) on
May 5th 2005.
photostream 64

Path of the Gods, Italy
Bliki: UnitTest
Unit testing is often talked about in software development, and
is a term that I've been familiar with during my whole time writing
programs. Like most software development terminology, however, it's
very ill-defined, and I see confusion can often occur when people
think that it's more tightly defined than it actually is.
Although I'd done plenty of unit testing before, my definitive
exposure was when I started working with Kent Beck and used the Xunit
family of unit testing tools. (Indeed I sometimes think a good term
for this style of testing might be "xunit testing.") Unit testing
also became a signature activity of ExtremeProgramming (XP), and led
quickly to TestDrivenDevelopment.
There were definitional concerns about XP's use
of unit testing right from the early days. I have a distinct memory
of a discussion on a usenet discussion group where us XPers were
berated by a testing expert for misusing the term "unit test." We
asked him for his definition and he replied with something like "in
the morning of my training course I cover 24 different definitions of
unit test."
Despite the variations, there are some common elements. Firstly
there is a notion that unit tests are low-level, focusing on a small
part of the software system. Secondly unit tests are usually written
these days by the programmers themselves using their regular tools -
the only difference being the use of some sort of unit testing
framework [1]. Thirdly unit tests are
expected to be significantly faster than other kinds of tests.
So there's some common elements, but there are also differences.
One difference is what people consider to be a unit.
Object-oriented design tends to treat a class as the unit,
procedural or functional approaches might consider a single function
as a unit. But really it's a situational thing - the team decides
what makes sense to be a unit for the purposes of their
understanding of the system and its testing. Although I start with
the notion of the unit being a class, I often take a bunch of
closely related classes and treat them as a single unit. Rarely I
might take a subset of methods in a class as a unit. However you
define it doesn't really matter.
Isolation
A more important distinction is whether the unit you're testing
should be isolated from its collaborators. Imagine you're testing an
order class's price method. The price method needs to invoke some
functions on the product and customer classes. If you follow the
principle of collaborator isolation you don't want to use the real
product or customer classes here, because a fault in the customer
class would cause the order class's tests to fail. Instead you use
TestDoubles for the collaborators.
But not all unit testers use this isolation. Indeed when xunit
testing began in the 90's we made no attempt to isolate unless
communicating with the collaborators was awkward (such as a remote
credit card verification system). We didn't find it difficult to
track down the actual fault, even if it caused neighboring tests
to fail. So we felt isolation wasn't an issue in practice.
Indeed this lack of isolation was one of
the reasons we were criticized for our use of the term "unit
testing". I think that the term "unit testing" is appropriate because
these tests are tests of the behavior of a single unit. We write
the tests assuming everything other than that unit is working
correctly.
As xunit testing became more popular in the 2000's the notion of
isolation came back, at least for some people. We saw the rise of
Mock Objects and frameworks to support mocking. Two schools of
xunit testing developed, which I call the classic and mockist
styles. Classic xunit testers don't worry about isolation but
mockists do. Today I know and respect xunit testers of both styles
(personally I've stayed with classic style).
Even a classic tester like myself uses test doubles when there's an
awkward collaboration. They are invaluable to remove
non-determinism
when talking to remote services. Indeed some classicist xunit testers
also argue that any collaboration with external resources, such as
a database or filesystem, should use doubles. Partly this is due to
non-determinism risk, partly due to speed. While I think this is a
useful guideline, I don't treat using doubles for external resources
as an absolute rule. If talking to the resource is stable and fast
enough for you then there's no reason not to do it in your unit
tests.
Speed
The common properties of unit tests — small scope, done by the
programmer herself, and fast — mean that they can be run very
frequently when programming. Indeed this is one of the key
characteristics of SelfTestingCode. In this situation
programmers run unit tests after any change to the code. I may run unit
tests several times a minute, any time I have code that's worth
compiling. I do this because should I accidentally break something,
I want to know right away. If I've introduced the defect with my
last change it's much easier for me to spot the bug because I don't
have far to look.
When you run unit tests so frequently, you may not run all
the unit tests. Usually you only need to run those tests that are
operating over the part of the code you're currently working on. As
usual, you trade off the depth of testing with how long it takes to
run the test suite. I'll call this suite the compile
suite, since it what I run it whenever I think of compiling -
even in an interpreted language like Ruby.
If you are using Continuous Integration you should run a test
suite as part of it. It's common for this suite, which I call the
commit suite, to include all the unit tests. It may
also include a few BroadStackTests. As a programmer you
should run this commit suite several times a day, certainly before
any shared commit to version control, but also at any other time you
have the opportunity - when you take a break, or have to go to a
meeting. The faster the commit suite is, the more often you can run
it. [2]
Different people have different standards for the speed of unit tests
and of their test suites. David
Heinemeier Hansson is happy with a compile suite that takes a few
seconds and a commit suite that takes a few minutes. Gary
Bernhardt finds that unbearably slow, insisting on a compile suite
of around 300ms and Dan Bodart doesn't want his commit suite to be
more than ten seconds
I don't think there's an absolute answer here. Personally I don't
notice a difference between a compile suite that's sub-second or a
few seconds. I like Kent Beck's rule of thumb that the commit suite
should run in no more than ten minutes. But the real point is that
your test suites should run fast enough that you're not discouraged
from running them frequently enough. And frequently enough is so
that when they detect a bug there's a sufficiently small amount of
work to look through that you can find it quickly.
Notes
1:
I say "these days" because this is certainly something
that has changed due to XP. In the turn-of-the-century debates,
XPers were strongly criticized for this as the common view was that
programmers should never test their own code. Some shops had
specialized unit testers whose entire job would be to write unit
tests for code written earlier by developers. The reasons for this
included: people having a conceptual blindness to testing their own
code, programmers not being good testers, and it was good to have a
adversarial relationship between developers and testers. The XPer
view was that programmers could learn to be effective testers, at
least at the unit level, and that if you involved a separate group
the feedback loop that tests gave you would be hopelessly slow.
Xunit played an essential role here, it was designed specifically to
minimize the friction for programmers writing tests.
2:
If you have tests that are useful, but take longer than you want
the commit suite to run, then you should build a DeploymentPipeline
and put the slower tests in a later stage of the pipeline.
Martin Fowler's Blog

- Martin Fowler's profile
- 1104 followers

