
Martin Fowler's Blog, page 40
July 6, 2014



June 30, 2014
Retreaded: StranglerApplication
Retread of post orginally made on 29 Jun 2004
When Cindy and I went to Australia, we spent some time in the
rain forests on the Queensland coast. One of the natural wonders of
this area are the huge strangler vines. They seed in the upper
branches of a fig tree and gradually work their way down the tree
until they root in the soil. Over many years they grow into fantastic
and beautiful shapes, meanwhile strangling and killing the tree that
was their host.
This metaphor struck me as a way of describing a way of doing a
rewrite of an important system. Much of my career has involved
rewrites of critical systems. You would think such a thing as easy -
just make the new one do what the old one did. Yet they are always
much more complex than they seem, and overflowing with risk. The big
cut-over date looms, the pressure is on. While new features (there are
always new features) are liked, old stuff has to remain. Even old bugs
often need to be added to the rewritten system.
An alternative route is to gradually create a new system around
the edges of the old, letting it grow slowly over several years until
the old system is strangled. Doing this sounds hard, but increasingly
I think it's one of those things that isn't tried enough. In
particular I've noticed a couple of basic strategies that work well.
The fundamental strategy is EventInterception, which
can be used to gradually move functionality to the strangler and to
enable AssetCapture.
My colleague Chris Stevenson
was involved in a project that did this recently with a great deal of
success. They published a first
paper on this at XP 2004, and
I'm hoping for more that describe more aspects of this project. They
aren't yet at the point where the old application is strangled - but
they've delivered valuable functionality to the business that gives
the team the credibility to go further. And even if they stop now,
they have a huge return on investment - which is more than many
cut-over rewrites achieve.
The most important reason to consider a strangler application
over a cut-over rewrite is reduced risk. A strangler can give value
steadily and the frequent releases allow you to monitor its progress more carefully. Many people still
don't consider a strangler since they think it will cost more - I'm
not convinced about that. Since you can use shorter release cycles
with a strangler you can avoid a lot of the unnecessary features that
cut over rewrites often generate.
There's another important idea here - when designing a new
application you should design it in such a way as to make it easier
for it to be strangled in the future. Let's face it, all we are doing
is writing tomorrow's legacy software today. By making it easy to be
strangled in the future, you are enabling the graceful fading away of
today's work.
Further Reading
Paul Hammant has a good summary of case studies using this approach.
reposted on 30 Jun 2014
June 26, 2014
Bliki: CanaryRelease
Canary release is a technique to reduce the risk of
introducing a new software version in production by slowly rolling out the
change to a small subset of users before rolling it out to the entire
infrastructure and making it available to everybody.
Similar to a BlueGreenDeployment, you start by deploying the
new version of your software to a subset of your infrastructure, to which no
users are routed.
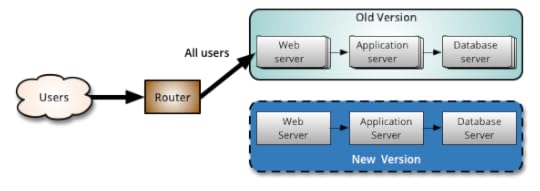
When you are happy with the new version, you can start routing a few
selected users to it. There are different strategies to choose which users
will see the new version: a simple strategy is to use a random sample; some
companies choose to release the new version to their internal users and
employees before releasing to the world; another more sophisticated approach
is to choose users based on their profile and other demographics.
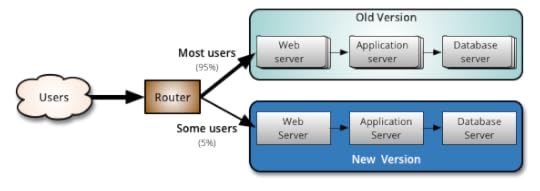
As you gain more confidence in the new version, you can start releasing it
to more servers in your infrastructure and routing more users to it. A good
practice to rollout the new version is to repurpose your existing
infrastructure using PhoenixServers or to provision new
infrastructure and decommission the old one using ImmutableServers.
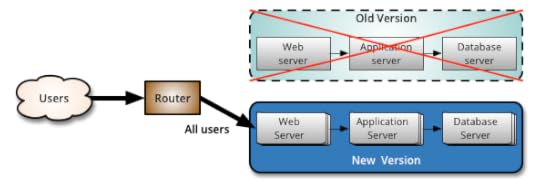
Canary release is an application of ParallelChange, where the
migrate phase lasts until all the users have been routed to the new version.
At that point, you can decomission the old infrastructure. If you find any
problems with the new version, the rollback strategy is simply to reroute
users back to the old version until you have fixed the problem.
A benefit of using canary releases is the ability to do capacity testing of
the new version in a production environment with a safe rollback strategy if
issues are found. By slowly ramping up the load, you can monitor and capture
metrics about how the new version impacts the production environment. This
is an alternative approach to creating an entirely separate capacity testing
environment, because the environment will be as production-like as it can be.
Although the name for this technique might not be familiar [1],
the practice of canary releasing has been adopted for some time. Sometimes
it is referred to as a phased rollout or an incremental
rollout.
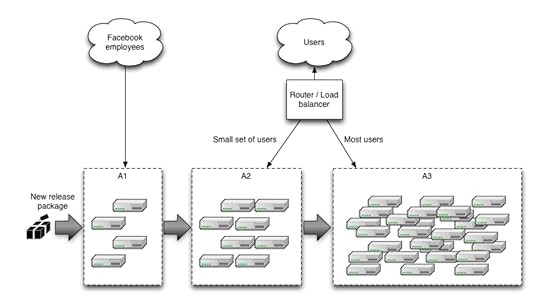
In large, distributed scenarios, instead of using a router to decide which
users will be redirected to the new version, it is also common to use
different partitioning strategies. For example: if you have geographically
distributed users, you can rollout the new version to a region or a specific
location first; if you have multiple brands you can rollout to a single
brand first, etc. Facebook chooses to use a strategy with multiple canaries,
the first one being visible only to their internal employees and having all
the FeatureToggles turned on so they can detect problems with new
features early.
Canary releases can be used as a way to implement A/B testing due to
similarities in the technical implementation. However, it is preferable to
avoid conflating these two concerns: while canary releases are a good way
to detect problems and regressions, A/B testing is a way to test a hypothesis
using variant implementations. If you monitor business metrics to detect
regressions with a canary [2], also using
it for A/B testing could interfere with the results. On a more practical
note, it can take days to gather enough data to demonstrate statistical
significance from an A/B test, while you would want a canary rollout to
complete in minutes or hours.
One drawback of using canary releases is that you have to manage multiple
versions of your software at once. You can even decide to have more than two
versions running in production at the same time, however it is best to keep
the number of concurrent versions to a minimum.
Another scenario where using canary releases is hard is when you distribute
software that is installed in the users' computers or mobile devices. In
this case, you have less control over when the upgrade to the new version
happens. If the distributed software communicates with a backend, you can
use ParallelChange to support both versions and monitor which
client versions are being used. Once the usage numbers fall to a certain
level, you can then contract the backend to only support the new version.
Managing database changes also requires attention when doing canary releases.
Again, using ParallelChange is a technique to mitigate this
problem. It allows the database to support both versions of the application
during the rollout phase.
Further Reading
Canary release is described by Jez Humble and Dave Farley in the book
Continuous Delivery.
In this talk,
Chuck Rossi describes Facebook's release process and their use of canary
releases in more detail.
Acknowledgements
Thanks to many ThoughtWorks colleagues for their feedback: Jez Humble,
Rohith Rajagopal, Charles Haynes, Andrew Maddison, Mark Taylor, Sunit
Parekh, and Sam Newman.
Notes
1:
The name for this technique originates from miners who would carry a
canary in a cage down the coal mines. If toxic gases leaked into the mine,
it would kill the canary before killing the miners. A canary release
provides a similar form of early warning for potential problems before
impacting your entire production infrastructure or user base.
2:
The technique of monitoring business metrics and automatically rolling
back a release on a statistically significant regression is known as
a cluster immune system and was pioneered by IMVU. They
describe this and other practices in their Continuous Deployment approach
in this blog post.
Retreaded: ThrownEstimate
Retread of post orginally made on 22 Jun 2004
If you're using XP style planning, you need to get rapid consensus
estimates from developers. Throwing the estimates lets you quickly
tell when developers have same similar views on an estimate (so you
can note it and move on) or if there is disagreement (when you need
to talk about the UserStory in more detail.
Here's the basic sequence. The customer puts together the list of
stories that need to estimated. With each story:
The customer briefly describes the stories to the developers
Developers ask clarifying questions about the story. They
shouldn't discuss technical issues about how to implement, just
ask about scope from the customer's point of view.
On the count of three, the developers show fingers to indicate
their estimate of how many NUTs there are in the story. I call
this a thrown estimate because you can use the same style of pacing
throws that you use
for Rock Paper
Scissors..
If most estimates are similar the scribe notes down the
estimate. If you get a significant variation in estimate then you
should discuss the story further - bringing in the technical issues of
how to implement it.
You can use different conventions for how many fingers to
use. One project I've seen uses 1 or 2 fingers to indicate 1 or 2
NUTs and three fingers to indicate the story is too big and needs
splitting up. Another group uses fingers for 1-4 NUTs and five
fingers to indicate it's too large. Notice that it's important to
have a convention to say that a story has a problem and can't be
estimated - most often because it's too big, but also if it can't be
tested or there's some other problem.
Teams using this report that they are able to estimate stories at
a very rapid rate, avoiding much discussion on stories that are
straightforward to estimate and concentrating time on those that are
more problematic. This keeps everyone engaged in the estimating
process. It also helps that it's fun.
reposted on 26 Jun 2014
June 12, 2014
Summary for final "Is TDD Dead" hangout

I’ve written up the summary for the final Is TDD Dead hangout. In this episode we answered questions that viewers submitted via the Google Q&A system. We discussed the dearth of real open-source examples of applications and how this made it harder to examine these questions. We looked at our experiences with TDD and the different kinds of value we’ve drawn from it. We also examined the value of TDD to less experienced developers. We finished by looking at TDD’s place in software development.
Rails: a platform or a suite of components?

Badri Janakiraman and I continue our video conversation about hexagonal Rails by looking into how we should work with the Rails framework. We posit that when you work with a framework like Rails you should decide to either treat it as a platform, meaning you embrace it into your application, or as suite of components, treating each aspect as an independently replaceable unit.

June 5, 2014
Badri Janakiraman on Hexagonal Rails and Databases
The recent series of videos on Is TDD Dead has led to many interesting discussions. One of these was an email exchange I had with my colleague Badri Janakiraman, who is a long-time ThoughtWorker with a lot of experience in Rails and other development stacks. We decided to video this conversation, as I thought some other people would enjoy it too. Our conversation looks at the Hexagonal Rails approach, what it is, and when it’s appropriate. This first video introduces the notion of Hexagonal Architecture, and talks about how it effects the relationship with the database - which ends up being a choice between the Active Record and Data Mapper patterns.
June 3, 2014
How to Change a Culture

Mike Bland concludes his article on testing culture with some general advice on how to change a culture to introduce testing, generalized from his experience at Google and elsewhere. This finishes what’s been a long and fascinating article that really gets into the nitty-gritty of unit testing at a scale of a large software development organization. He finishes with a call to action arguing that it is our professional duty to use techniques like unit testing to prevent catastrophic bugs like goto fail and heartbleed.
June 1, 2014
photostream 67

Coastal Maine Botanical Gardens, ME
Martin Fowler's Blog

- Martin Fowler's profile
- 1104 followers

