
Sourabhh Sethii's Blog
February 6, 2025
Part 5 — Mastering Python Strings: A Beginner’s Guide
Strings are one of the most fundamental data types in Python — and for good reason. They allow you to work with text in a flexible and intuitive way, forming the backbone of everything from user input and data processing to web development and more. In this article, we’ll take a deep dive into Python strings for beginners. We’ll explore what strings are, how to create them, and the powerful operations you can perform with them.
What Are Strings in Python?In Python, a string is a sequence of characters. Whether you’re working with a single letter or a full paragraph, Python treats your text as a string object. One important property of Python strings is that they are immutable — once created, the characters in a string cannot be changed. This design choice offers several advantages, including improved performance and easier debugging.
Creating StringsPython offers multiple ways to define a string:
1. Single and Double QuotesYou can create strings using either single (' ') or double (" ") quotes. The choice is largely stylistic.
single_quote = 'Hello, Python!'double_quote = "Hello, Python!"2. Triple Quotes for Multiline Strings
When your text spans multiple lines, triple quotes (either ''' or """) come in handy.
multiline_string = """This is a stringthat spans multiple
lines."""
print(multiline_string)3. Raw Strings
Raw strings are useful when you want to ignore escape sequences (like in regular expressions or Windows file paths). Precede the string with an r to create a raw string.
raw_string = r"C:\Users\YourName\Documents"print(raw_string) # Outputs: C:\Users\YourName\DocumentsBasic String Operations
Python makes working with strings easy and intuitive. Here are some common operations:
Concatenation and RepetitionYou can join strings using the + operator or repeat them with the * operator.
greeting = "Hello"name = "Alice"
full_greeting = greeting + ", " + name + "!"
print(full_greeting) # Output: Hello, Alice!
echo = "Python! " * 3
print(echo) # Output: Python! Python! Python!Indexing and Slicing
Since strings are sequences, you can access individual characters with indexing and subsets of characters with slicing.
text = "Hello, Python!"print(text[0]) # Output: H
print(text[-1]) # Output: !
print(text[7:13]) # Output: Python
Note: Indexing starts at 0, and negative indexes count from the end of the string.
String FormattingFormatting strings is essential when you need to include dynamic data. Python provides several methods:
1. The format() Methodname = "Alice"age = 30
formatted_string = "My name is {} and I am {} years old.".format(name, age)
print(formatted_string)2. f-Strings (Formatted String Literals)
Introduced in Python 3.6, f-strings offer a concise and readable way to format strings.
formatted_string = f"My name is {name} and I am {age} years old."print(formatted_string)Useful String Methods
Python provides a variety of built-in methods to help you manipulate and analyze strings:
lower() / upper(): Convert the string to lowercase or uppercase.
text = "Hello, Python!"print(text.lower()) # Output: hello, python!
print(text.upper()) # Output: HELLO, PYTHON!
strip(): Remove leading and trailing whitespace.
messy = " hello "print(messy.strip()) # Output: hello
split(): Divide the string into a list of substrings.
sentence = "Python is fun"words = sentence.split()
print(words) # Output: ['Python', 'is', 'fun']
join(): Concatenate an iterable of strings into a single string.
words = ["Python", "is", "fun"]sentence = " ".join(words)
print(sentence) # Output: Python is fun
find() / replace(): Locate a substring or replace parts of the string.
text = "Hello, Python!"print(text.find("Python")) # Output: 7
new_text = text.replace("Python", "World")
print(new_text) # Output: Hello, World!Escape Sequences and Special Characters
Sometimes you’ll need to include special characters in your strings. Escape sequences allow you to insert characters that are otherwise hard to type directly:
\n: Newline\t: Tab\\: Backslash\' and \": Single and double quotesescaped = "First Line\nSecond Line\tIndented"print(escaped)
For most cases where you have many backslashes (like file paths), consider using raw strings to simplify your code.
ConclusionStrings in Python are a powerful and versatile tool. Whether you’re concatenating text, slicing for specific data, or formatting dynamic messages, mastering strings is essential for any budding Python programmer. This guide has covered the basics — from creating strings using various quoting styles to performing operations and formatting them effectively.
As you continue your journey in Python, experiment with these concepts in an interactive environment like the REPL or a Jupyter Notebook. The more you practice, the more natural working with strings will become.
I hope this article provides you with a clear and engaging introduction to one of Python’s most essential data types.
What are your favorite string tricks in Python? Share your thoughts and experiences in the comments below!
[image error]Part 5 — Mastering Python Strings: A Beginner’s Guide was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.


February 5, 2025
Part 4 — Deep Dive into Python Numbers: A Beginner’s Guide
Python is famous for its readability and ease of use — and one of the simplest yet most essential concepts you’ll encounter is how numbers work. From whole numbers to decimals and even complex numbe understanding Python’s number system is key to mastering the language. In this article, we’ll explore Python numbers in depth, explaining their types, behavior, and practical use cases. we’ll break down these concepts for beginners in a clear and approachable way.
 1. Why Numbers Matter in Python
1. Why Numbers Matter in PythonNumbers form the basis of most programming tasks. Whether you’re performing calculations, working with data, or building algorithms, Python’s number system is the foundation upon which many operations are built. In Python, every number is an object, which means numbers have both a value and associated behavior (methods). This object-oriented approach simplifies many tasks and leads to powerful features like dynamic type handling.
2. The Core Number Types in PythonPython has three primary number types, each with its own characteristics:
a. Integers (int)Description: Integers represent whole numbers, without a fractional component. In Python, integers are of arbitrary size — meaning they can grow as large as the available memory allows.Example:x = 42y = -7
print(type(x)) # Key Points:No fixed limits on size.Immutable: once an integer is created, it cannot be changed (operations create new integers).b. Floating-Point Numbers (float)Description: Floating-point numbers represent real numbers with a fractional part. They are stored in a format that conforms to the IEEE 754 standard.Example:pi = 3.14159
negative_float = -0.001
print(type(pi)) # Key Points:Subject to rounding errors and precision limitations.Often used in scientific and engineering calculations.c. Complex Numbers (complex)Description: Complex numbers include both a real part and an imaginary part, expressed as a bj (where j is the imaginary unit).Example:z = 2 3j
print(type(z)) #
print(z.real) # 2.0
print(z.imag) # 3.0Key Points:Useful for advanced mathematical computations, signal processing, and more.Both the real and imaginary parts are floats.3. Basic Arithmetic Operations
Python supports all standard arithmetic operations, and thanks to its intuitive syntax, these operations are easy to use.
Addition, Subtraction, Multiplication, and Divisiona = 10b = 3
# Addition
print(a b) # 13
# Subtraction
print(a - b) # 7
# Multiplication
print(a * b) # 30
# Division (always returns a float)
print(a / b) # 3.3333333333333335
# Floor Division (integer division)
print(a // b) # 3
# Modulus (remainder)
print(a % b) # 1Exponentiation
Python uses the ** operator for exponentiation:
print(2 ** 3) # 8print(9 ** 0.5) # 3.0 (square root of 9)
Tip: Remember that division / always returns a float in Python 3, even when dividing two integers.
4. Built-In Functions and Type ConversionPython makes it easy to convert between number types using built-in functions:
int() converts values to integers.float() converts values to floating-point numbers.complex() converts values to complex numbers.Examples:# Converting a string to an integernum_str = "123"
num_int = int(num_str)
print(num_int, type(num_int)) # 123
# Converting an integer to a float
num_float = float(456)
print(num_float, type(num_float)) # 456.0
# Converting numbers to a complex number
num_complex = complex(3, 4)
print(num_complex, type(num_complex)) # (3 4j)
These conversions are particularly useful when handling user input or data from external sources.
5. The Math Module: Extending Python’s Number CapabilitiesFor more advanced mathematical operations, Python offers the built-in math module. It provides functions for trigonometry, logarithms, factorials, and much more.
Example:import math# Calculate the square root of 16
print(math.sqrt(16)) # 4.0
# Calculate the sine of 90 degrees (convert degrees to radians)
angle_degrees = 90
angle_radians = math.radians(angle_degrees)
print(math.sin(angle_radians)) # 1.0
# Calculate factorial of 5
print(math.factorial(5)) # 120
The math module is an indispensable tool when working with numbers in Python, especially for scientific and engineering applications.
6. Immutability and NumbersAll number types in Python (integers, floats, and complex numbers) are immutable. This means that when you perform an operation that appears to modify a number, Python actually creates a new number rather than altering the original. Consider:
x = 100print(id(x))
x = 50
print(id(x))
Even though x seems to be “updated,” its identity changes because a new object is created. This immutability has important implications for memory management and program behavior.
7. Best Practices for BeginnersBe Aware of Precision:When using floats, be mindful of rounding errors. For critical applications, consider using the decimal module for better precision.Explicit Conversions:
Always be explicit about type conversions to avoid unexpected behavior — especially when combining integers and floats.Leverage the Math Module:
Don’t reinvent the wheel. Use Python’s math module to handle complex mathematical operations.Practice with Interactive Tools:
Use the Python REPL or Jupyter Notebooks to experiment with numbers. Interactive experimentation is a great way to understand how Python treats different number types.Conclusion
Numbers in Python are more than just symbols on a screen — they are powerful objects that form the backbone of countless applications. By understanding the different types of numbers, how arithmetic works, and the underlying principles of immutability and type conversion, you gain a solid foundation in Python programming.
Whether you’re a beginner just starting out or looking to deepen your understanding, mastering Python’s number system is an essential step on your programming journey. So fire up your interpreter, experiment with code, and let these concepts empower you to write efficient, accurate, and elegant Python code.
I hope this guide helps you see the big picture — and the finer details — of Python’s numerical capabilities.
What are your favorite tips or tricks when working with numbers in Python? Share your thoughts in the comments below!
[image error]Part 4 — Deep Dive into Python Numbers: A Beginner’s Guide was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
February 4, 2025
Part 3 : Python Data Types: The Big Picture
Python is renowned for its simplicity and readability, but beneath that elegant surface lies a powerful engine built on its core data types. In Python, every value is an object, and these objects are instances of various data types that determine how they behave, interact, and are stored in memory. This article takes a high-level look at Python’s data types and why they matter.
 1. The Role of Data Types in Python
1. The Role of Data Types in PythonData types are the foundation of any programming language. In Python, they define not only the kind of data you’re working with (numbers, text, collections, etc.) but also the operations you can perform on that data. Because Python is dynamically typed, variables don’t have a fixed type — the type is associated with the object itself. This dynamic nature is what makes Python both flexible and expressive.
Everything is an ObjectOne of the key concepts in Python is that everything is an object. Whether it’s a simple integer or a complex user-defined class, every entity in Python carries both data and behavior. This uniformity simplifies the language and allows for powerful operations like introspection and dynamic modification.
2. Built-In Data Types: The Core CategoriesPython’s built-in data types can be broadly classified into several groups. Here’s a big-picture overview:
Numeric TypesIntegers (int): Whole numbers of unlimited precision.Floating-Point Numbers (float): Numbers with a fractional component.Complex Numbers (complex): Numbers with a real and imaginary part.These types enable all standard mathematical operations. Python’s handling of numbers — especially its support for arbitrary-precision integers — is one of the features that sets it apart.
Sequence TypesStrings (str): Immutable sequences of Unicode characters.Lists (list): Ordered, mutable collections that can contain elements of different types.Tuples (tuple): Ordered, immutable collections often used to group related data.Ranges (range): Immutable sequences commonly used for looping a fixed number of times.The immutable nature of strings and tuples versus the mutability of lists has significant implications for performance, memory usage, and how these objects can be used (for example, as keys in dictionaries).
Mapping TypesDictionaries (dict): Unordered collections of key-value pairs. Because keys must be immutable (and hashable), dictionaries are central to how Python manages namespaces and object attributes.Set TypesSets (set): Unordered collections of unique elements.Frozen Sets (frozenset): Immutable versions of sets that can be used as dictionary keys.Sets are especially useful when you need to test membership or perform mathematical operations like unions and intersections.
3. Mutable vs. Immutable: Why It MattersA critical aspect of Python’s data types is whether they are mutable or immutable.
Immutable ObjectsImmutable objects, such as numbers, strings, and tuples, cannot be changed once they are created. When you perform an operation that modifies an immutable object, Python actually creates a new object in memory. For example:
a = 10print(id(a)) # e.g., 140352304745776
a += 5
print(id(a)) # a different id, since 15 is a new object
This behavior leads to benefits in terms of safety and predictability. Immutable objects can be freely shared between parts of a program without fear of accidental modifications.
Mutable ObjectsMutable objects like lists, dictionaries, and sets can be changed in place. This allows for efficient updates but also means you must be cautious — especially when using mutable default arguments or sharing objects across functions. Consider:
my_list = [1, 2, 3]print(id(my_list))
my_list.append(4)
print(id(my_list)) # Same id, since the object is modified in place
Understanding this distinction is crucial because it affects function behavior, memory management, and even the use of objects as keys in dictionaries.
4. Dynamic Typing and Type ConversionPython’s dynamic typing means that the type of a variable is determined at runtime, not in advance. This offers great flexibility but also requires you to be aware of the types of the objects you’re working with. When necessary, Python provides built-in functions like int(), float(), and str() to convert between types. However, implicit conversion happens only in certain situations—being explicit with conversions often leads to clearer code.
5. The Big Picture: Why Data Types Are Central to PythonUnderstanding data types in Python is more than an academic exercise. It directly impacts:
Memory Usage: Immutable objects can be shared and reused, leading to optimized memory usage, while mutable objects allow in-place modifications.Performance: Knowing when objects are mutable or immutable helps in writing more efficient code.Program Behavior: Decisions about data types affect debugging, function design, and how your program interacts with external systems.By grasping the big picture of Python’s data types, you lay a strong foundation for writing robust and efficient code.
ConclusionPython’s data types are the building blocks of the language, and understanding them is key to harnessing Python’s power. From the immutable safety of numbers and strings to the dynamic flexibility of lists and dictionaries, every type has its role. Recognizing whether an object is mutable or immutable helps you write safer functions, optimize performance, and avoid common pitfalls. This exploration offers a high-level perspective that can guide both beginners and seasoned developers in mastering Python’s core concepts.
What are your experiences with Python’s data types? Share your insights and questions in the comments below!
[image error]Part 3 : Python Data Types: The Big Picture was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
Understanding Mutability in Python: A Deep Dive into Immutable and Mutable Objects
Python’s simplicity is one of its greatest strengths — but behind that simplicity lies a powerful yet sometimes subtle concept: the difference between mutable and immutable objects. This article explores what makes an object mutable or immutable, why this distinction matters, and how it affects your everyday coding in Python.
 Introduction
IntroductionIn Python, data types are classified broadly into two categories:
Immutable objects: These are objects whose state cannot be modified once created. Think of them as “read-only” entities.Mutable objects: In contrast, these objects allow their content to be changed after creation.Understanding the difference is essential. It influences everything from function parameter passing and performance to debugging subtle bugs. Let’s break down these concepts and see how they play out in practice.
What Are Immutable Objects?Immutable objects are those that cannot be changed after they are created. When you modify an immutable object, you aren’t altering the original object — instead, a new object is created. Common examples include:
Numbers: Integers, floats, and complex numbers.Strings: All string objects are immutable.Tuples: Unlike lists, tuples cannot be changed after creation.Frozen sets: Immutable versions of sets.How It WorksConsider a simple example with integers:
a = 10print(id(a)) # Let's say it prints 140352304745776
a = a + 5
print(id(a)) # Now it prints a different value, e.g., 140352304745808l string remains unchanged — a key property that contributes to the stability and predictability of immutable objects.
Here, instead of modifying the integer 10, Python creates a new integer (15) and assigns it to the variable a. The old value (10) remains unchanged in memory (until garbage-collected).
Likewise, for strings:
s = "Hello"print(id(s))
s += " World"
print(id(s))
Each concatenation results in a new string object. This behavior ensures that the original string remains unchanged — a key property that contributes to the stability and predictability of immutable objects.
What Are Mutable Objects?Mutable objects, on the other hand, allow modification of their contents without creating a new object. This flexibility comes with great power — but also great responsibility.
Common mutable objects include:
Lists: The quintessential mutable sequence.Dictionaries: Key-value pairs that can be updated dynamically.Sets: Collections that allow modification (unlike their immutable counterpart, frozenset).Custom objects: When you define a class, instances are mutable by default unless you explicitly prevent changes.How It WorksConsider the behavior of lists:
my_list = [1, 2, 3]print(id(my_list))
my_list.append(4)
print(id(my_list))
Notice that the list’s identity (its id) remains the same before and after appending. Python directly modifies the existing list in memory, rather than creating a new one.
This direct modification is very efficient for operations where you need to update data in place. However, it can lead to unexpected behavior if you’re not careful — for example, when passing mutable objects as default arguments or across function boundaries.
Key Differences and Their ImplicationsMemory and PerformanceImmutable Objects: Because they cannot change, Python can optimize memory usage by reusing objects (for example, small integers and interned strings). However, creating a new object on each modification might lead to additional memory allocations.Mutable Objects: They allow in-place changes, which can be more memory- and time-efficient when many updates are required. But if not handled carefully, modifications can lead to bugs that are hard to track.Function Arguments and Side EffectsImmutable objects guarantee that a function’s parameter won’t be changed by accident. In contrast, mutable objects can be altered within a function, leading to side effects.
Consider this example:
def add_item(lst):lst.append("new item")
my_list = [1, 2, 3]
add_item(my_list)
print(my_list) # Output: [1, 2, 3, "new item"]
Since lists are mutable, the function modifies the original object. If you need to avoid this, you might create a copy of the list inside the function.
Hashability and Use in CollectionsImmutable objects are hashable (if they contain only immutable elements) and can be used as keys in dictionaries or elements in sets. Mutable objects, which can change over time, are not hashable by default because their hash value would change with their content.
Best Practices and Common PitfallsUse Immutable Types for SafetyWhenever possible, prefer immutable objects if you don’t need to change the data. This helps avoid accidental modifications and can lead to safer and more predictable code.
Be Cautious with Mutable Default ArgumentsA classic pitfall in Python involves mutable default arguments. Consider this example:
def append_value(val, lst=[]):lst.append(val)
return lst
print(append_value(1)) # Output: [1]
print(append_value(2)) # Output: [1, 2] – Unexpected if you thought lst resets every
The default list persists across function calls. Instead, use None and create a new list inside the function:
def append_value(val, lst=None):if lst is None:
lst = []
lst.append(val)
return lstKnow When to Copy
If you’re working with mutable objects and you need a “snapshot” of the current state, use methods like slicing (my_list[:]), the copy module, or specific methods provided by the data type to create a copy.
ConclusionUnderstanding the distinction between mutable and immutable objects in Python is key to writing robust, efficient, and bug-free code. Immutable objects offer safety and predictability, making them ideal for constants and dictionary keys, while mutable objects provide flexibility and efficiency when data changes frequently.
This deep dive into Python’s mutability concepts not only clarifies how Python manages its data but also empowers you to choose the right data types for the right tasks. Whether you’re optimizing performance or debugging tricky issues, a clear grasp of mutability is an essential tool in your Python toolkit.
I hope this article provides you with clarity and actionable knowledge for your journey with Python.
What are your experiences with mutable and immutable objects? Share your tips and stories in the comments below!
[image error]Understanding Mutability in Python: A Deep Dive into Immutable and Mutable Objects was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
Part 1 : Unveiling the Inner Workings of Python: A Deep Dive into Its Internal Machinery
Python’s simplicity and readability have made it one of the most popular programming languages in the world. Yet, beneath its elegant syntax lies a complex engine that transforms your human‐readable code into machine instructions. In this article, we’ll explore the journey of Python code — from the moment you hit “run” to the internal processes that execute your program.
 1. From Source Code to Bytecode
1. From Source Code to BytecodeWhen you write a Python script, you’re crafting source code in a high-level, human-friendly language. However, computers don’t execute this code directly. Instead, the Python compiler converts your .py file into an intermediate representation known as bytecode. This process involves several stages:
Tokenization and Parsing: The source code is first broken down into tokens and then organized into a parse tree.Abstract Syntax Tree (AST): The parse tree is transformed into an AST, which represents the syntactic structure of your code.Bytecode Generation: Finally, the AST is compiled into bytecode — a compact, platform-independent set of instructions that the Python Virtual Machine (PVM) can execute.This multi-step process not only checks your code for syntax errors but also performs basic optimizations (like constant folding) to streamline execution. As explained in Faizaan Khan’s exploration of Python internals faizaankhan.hashnode.dev , this transformation is what bridges the gap between your code and the low-level operations performed by the computer.
2. The Role of the Python Virtual MachineOnce the bytecode is generated, it is handed over to the Python Virtual Machine (PVM). The PVM is essentially the runtime engine of Python, responsible for reading and executing the bytecode instructions one by one. Here’s how it works:
Execution Loop: The PVM operates in a continuous loop — often implemented as a large switch-case statement in CPython — that fetches each bytecode instruction and dispatches it to the corresponding handler. For example, operations like LOAD_CONST or CALL_FUNCTION trigger specific low-level routines that manipulate Python objects and execute functions.Interpreting Bytecode: Unlike compiled languages where machine code runs directly on the CPU, Python’s bytecode is interpreted at runtime. This extra layer adds flexibility (and dynamic features) but can also influence performance.The mechanics of this execution loop are a core component of Python’s internals, as detailed in various explorations of the CPython evaluation loop blog.sourcerer.io.
3. Memory Management and the Global Interpreter LockPython’s approach to memory management is another fascinating aspect of its internal design:
Reference Counting: Every Python object maintains a count of references pointing to it. When this count drops to zero, the memory occupied by the object is deallocated automatically.Garbage Collection: To handle cyclic references (objects referencing each other, which can prevent reference counts from dropping to zero), Python uses a cycle-detecting garbage collector.The Global Interpreter Lock (GIL): CPython, the standard implementation of Python, uses the GIL to simplify memory management. This lock ensures that only one thread executes Python bytecode at a time, preventing race conditions. While this design simplifies many aspects of interpreter implementation, it can also limit multi-threaded performance for CPU-bound tasks.These memory management strategies, along with the GIL, are fundamental to Python’s runtime behavior and help maintain its dynamic and flexible nature discuss.python.org.
4. Error Handling and TracebacksEven the most well-crafted code can encounter errors. Python’s error handling mechanism is built around the concept of tracebacks, which provide a detailed snapshot of the call stack at the time an exception is raised. Here’s what happens:
Exception Raising: When an error occurs, Python creates an exception object and begins unwinding the call stack.Traceback Generation: A traceback is assembled, showing the sequence of function calls that led to the error. This information is invaluable for debugging.User-Friendly Messages: Python’s interpreter formats these tracebacks into clear, readable error messages, guiding developers to the source of the problem.Understanding how tracebacks are generated can help you diagnose and fix issues more efficiently — a crucial skill for any serious Python developer.
5. Optimizations and Alternative ImplementationsWhile CPython remains the most widely used implementation, it isn’t the only one:
Performance Considerations: Python’s internal design prioritizes simplicity and readability over raw execution speed. However, insights into the interpreter’s internals can help you write more optimized code.Alternative Runtimes: Projects like PyPy offer just-in-time (JIT) compilation, which can significantly boost performance for certain workloads. Other implementations (such as Jython or IronPython) cater to different ecosystems and use cases.Each of these alternatives handles the core processes — compilation, execution, memory management, and error handling — in slightly different ways, reflecting the diverse needs of Python’s global community.
ConclusionThe journey from a simple .py file to the execution of machine-level instructions is a marvel of modern computing. Python’s internal processes—from compiling source code into bytecode and executing it via the Python Virtual Machine, to managing memory and handling errors—are intricate yet elegantly designed. By understanding these mechanisms, developers can not only demystify how their code runs but also write more efficient and robust programs.
Whether you’re a beginner curious about what happens “under the hood” or an experienced developer looking to optimize your applications, delving into Python’s internals offers a rewarding glimpse into the heart of one of the world’s most beloved programming languages.
What are your thoughts on Python’s inner workings? Share your experiences and tips in the comments below!
[image error]Part 1 : Unveiling the Inner Workings of Python: A Deep Dive into Its Internal Machinery was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
February 2, 2025
System Design for Building Agentic AI Applications — Part 1
With the rise of AI-driven applications, the concept of Agentic Applications is gaining momentum. These applications operate autonomously, make decisions, and optimize workflows by leveraging Large Language Models (LLMs), Reinforcement Learning (RL), and Multi-Agent Systems (MAS).
Designing such applications requires a robust system architecture that supports real-time processing, scalability, security, and adaptability. This article explores the key design principles, architecture, and best practices for building agentic applications.
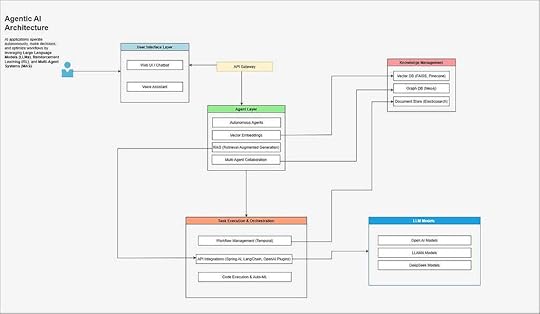 Agentic AI ArchitectureKey Characteristics of Agentic Applications
Agentic AI ArchitectureKey Characteristics of Agentic ApplicationsAgentic applications are distinguished by the following attributes:
Autonomy: These applications leverage Autonomous Agents that can perform tasks with minimal human intervention. By integrating Multi-Agent Collaboration, different agents can communicate, delegate tasks, and achieve a common goal efficiently.Adaptability: Using LLMs and Embeddings, agentic applications can dynamically adjust responses based on user inputs, changing environments, and new information. Reinforcement Learning (RLHF) ensures continuous learning from feedback.Multi-Agent Collaboration: These applications implement a Decentralized AI system, where agents work together through message-passing and shared memory. Technologies like Graph Databases (Neo4j) help model relationships between agents and entities.Goal-Oriented Behavior: Tasks are executed efficiently using Workflow Management (Temporal, Airflow) and Task Orchestration mechanisms. Agents prioritize tasks based on importance, dependency, and available computational resources.Context Awareness: Agentic applications leverage Vector Databases (FAISS, Pinecone) to store and retrieve relevant information efficiently. Retrieval-Augmented Generation (RAG) enhances responses by incorporating external knowledge from document stores like Elasticsearch.Observability & Feedback Loop: These applications implement Logging & Tracing (OpenTelemetry, Datadog) to ensure transparency and auditability. Monitoring & Metrics (Prometheus, Grafana) track system performance, and user feedback helps in optimizing the response generation process.
Autonomy: Agents operate with minimal human intervention.
Adaptability: They learn and evolve over time.
Multi-Agent Collaboration: Various agents communicate to accomplish tasks.
Goal-Oriented Behavior: Agents optimize for efficiency and accuracy.
Context Awareness: Understanding user intent and adapting responses accordingly.
Examples of agentic applications include AI-powered research assistants, automated financial advisors, and intelligent chatbots.
System Architecture for Agentic ApplicationsA well-designed agentic application consists of multiple interconnected layers, each responsible for specific functionalities. These layers work together to ensure efficient execution, communication, and learning.
A. Architectural OverviewA well-designed agentic application consists of multiple layers:
1. User Interface LayerWeb UI / Mobile Applications: Provides user-friendly interaction interfaces, such as dashboards, conversational interfaces, or AI-driven search engines.Voice/Chat Interfaces: Enables natural language interactions using speech-to-text and text-based chatbots, ensuring smooth user engagement.API Gateway: Acts as a secure interface for third-party services and applications to interact with the agentic system.
Web UI / Mobile Applications: For user interaction.
Voice/Chat Interfaces: Conversational AI-driven experiences.
2. Agent Layer (Core AI Processing)
API Gateway: External programmatic access.
Autonomous Agents: Independent decision-making entities.
LLM & Embeddings: Understanding and processing natural language queries.
Retrieval-Augmented Generation (RAG): Combining knowledge retrieval and generation.
Autonomous Agents: Specialized agents responsible for performing specific tasks such as query resolution, decision-making, and workflow automation.LLM & Embeddings: Uses Large Language Models (GPT-4, Claude, LLaMA, DeepSeek etc.) and semantic embeddings to process user queries and generate contextually relevant responses.Retrieval-Augmented Generation (RAG): Enhances AI-generated responses by retrieving relevant information from vector databases and document repositories.Multi-Agent Collaboration: Coordinates multiple specialized agents that work together in a decentralized manner to execute complex workflows effectively.3. Knowledge Management
Multi-Agent Collaboration: Coordinating multiple specialized agents.
Vector Databases: (FAISS, Pinecone) for efficient semantic search.
Graph Databases: (Neo4j) for relationship mapping and entity linking.
Vector Databases (FAISS, Pinecone): Store and retrieve high-dimensional embeddings for efficient semantic search and similarity comparisons.Graph Databases (Neo4j, ArangoDB): Maintain knowledge graphs that define relationships between entities, enabling context-aware AI reasoning.Document Stores (Elasticsearch, PostgreSQL): Store and index structured and unstructured text data for retrieval during query processing.4. Task Execution & Orchestration Layer
Document Stores: (Elasticsearch) for structured/unstructured data retrieval.
Workflow Management: (Temporal, Airflow) for long-running tasks.
API Integrations: (LangChain, OpenAI Plugins) for real-time data retrieval.
Workflow Management (Temporal, Airflow): Ensures seamless execution of long-running tasks, managing dependencies and state transitions efficiently.API Integrations (LangChain, OpenAI Plugins): Connects with external services, enabling AI models to access additional knowledge sources and execute API-driven tasks.Code Execution & Auto-ML: Enables agents to execute code dynamically and improve AI models using AutoML frameworks and reinforcement learning.5. Observability & Feedback Loop
Code Execution & Auto-ML: For self-improving AI agents.
Logging & Tracing: (Splunk, OpenTelemetry, Datadog) for debugging.
Monitoring & Metrics: (Prometheus, Grafana) for performance tracking.
Logging & Tracing (OpenTelemetry, Datadog): Tracks system events, errors, and AI decision-making processes to ensure transparency and debugging capabilities.Monitoring & Metrics (Prometheus, Grafana): Provides real-time performance insights and health monitoring for AI models and workflows.Model Feedback Loop: Implements user feedback mechanisms and reinforcement learning strategies to improve model performance continuously.System Design ConsiderationsA. Scalability
Model Feedback Loop: Reinforcement learning for continuous improvement.
Microservices Architecture: Independent, scalable services for different agents.
Serverless Execution: AWS Lambda, Google Cloud Functions for efficiency.
Microservices Architecture: Uses containerized microservices that allow independent scaling of different components like the UI, agent layer, and knowledge retrieval systems.Serverless Execution: Implements serverless computing with AWS Lambda, Google Cloud Functions, and Azure Functions to reduce costs and improve efficiency.Event-Driven Design: Uses Kafka, RabbitMQ, or AWS SQS for asynchronous communication between agents, ensuring high throughput in multi-agent environments.B. Performance Optimization
Event-Driven Design: Kafka, RabbitMQ for real-time communication.
Low-Latency Caching: Redis/Memcached for quick retrieval.
Model Compression & Quantization: ONNX, TensorRT for faster inference.
Low-Latency Caching: Uses Redis/Memcached to cache frequently accessed responses, improving response times for real-time applications.Model Compression & Quantization: Deploys optimized AI models using ONNX, TensorRT, or TensorFlow Lite to reduce inference time and computational load.Edge Processing: Enables real-time AI by offloading inference workloads to edge devices, reducing dependence on centralized cloud resources.C. Security & Privacy
Edge Processing: Running models on-device for real-time AI.
Zero-Trust Architecture: API security and access control.
Data Anonymization: Masking sensitive user data.
Zero-Trust Architecture: Implements strict authentication and authorization controls for all API interactions, ensuring secure data access.Data Anonymization: Uses differential privacy techniques and encryption to protect sensitive user information in logs and training data.Encrypted Model Serving: Serves AI models securely using TLS-encrypted API endpoints and private inference environments.D. Explainability & Auditing
Encrypted Model Serving: Secure API-based LLM inference.
AI Decision Logs: Storing agent reasoning for debugging and compliance.
User Feedback Mechanism: Capturing corrections to refine models.
AI Decision Logs: Stores all AI-generated outputs and decision pathways to enable transparency and debugging.User Feedback Mechanism: Allows real-time user input to fine-tune AI model responses and adapt agent behaviors.Regulatory Compliance: Ensures adherence to GDPR, HIPAA, SOC 2, and industry-specific AI governance standards.Technology StackAgent Frameworks
Regulatory Compliance: GDPR, HIPAA, SOC 2 adherence.
LangChain: LLM-based applications.
AutoGPT / BabyAGI: Autonomous agent workflows.
LangChain: Provides tools for integrating LLMs with knowledge retrieval, workflow automation, and decision-making pipelines.AutoGPT / BabyAGI: Enables autonomous agent workflows that iteratively refine tasks without human intervention.ReAct (Reasoning + Acting): Implements a framework for AI agents to reason and act dynamically based on real-world inputs.Vector & Graph Databases
ReAct (Reasoning + Acting): Decision-making agents.
FAISS, Pinecone, Weaviate: Vector stores.
FAISS, Pinecone, Weaviate: Used for efficient semantic search and retrieval of high-dimensional data embeddings.Neo4j, ArangoDB: Powers graph-based knowledge representations, aiding multi-agent collaboration and relationship mapping.LLM Providers
Neo4j, ArangoDB: Graph-based reasoning.
OpenAI (GPT-4), Claude, Mistral, LLaMA.
OpenAI (GPT-4), Claude, Mistral, LLaMA: Offers pre-trained large language models for agent-based reasoning and decision-making.Self-Hosted Models: Hugging Face models deployed on Triton Inference Server, providing flexibility and cost-effective AI inference.Orchestration & Integration
Self-Hosted: Hugging Face models on Triton Inference Server.
Ray, Temporal, Airflow: Distributed task execution.
FastAPI, gRPC: API development for agents.
Ray, Temporal, Airflow: Enables distributed task execution, agent coordination, and automated workflows.FastAPI, gRPC: Facilitates API development for inter-agent communication and external service interactions.Kafka, RabbitMQ: Supports event-driven communication between AI components, improving system responsiveness.Observability & SecurityOpenTelemetry, Datadog: Provides logging, tracing, and monitoring capabilities to ensure real-time debugging and analytics.Prometheus, Grafana: Enables system-wide monitoring, performance tracking, and real-time alerts for proactive issue resolution.Zero-Trust Security & Encryption: Implements end-to-end encryption for API interactions and model inference security compliance.Example Use Case: Autonomous Research Assistant
Kafka, RabbitMQ: Event-driven communication.
Workflow:
User Query: A researcher enters a query via text or voice.Query Understanding: The system classifies the intent (e.g., literature review, summarization).Knowledge Retrieval: Searches vector databases, graphs, and external APIs.Response Generation: Uses RAG to generate a structured answer.User Feedback: The researcher provides feedback for continuous improvement.This approach ensures real-time response generation, context awareness, and scalability.
Future EnhancementsSelf-Improving Agents: Meta-learning techniques for continuous improvement.Multi-Agent Collaboration: Decentralized AI with collective decision-making.Personalized AI Experiences: Federated learning for user-specific adaptations.ConclusionAgentic applications represent the next generation of AI-driven automation. Designing these systems requires careful consideration of architecture, scalability, security, and adaptability. By leveraging multi-agent coordination, RAG, and efficient retrieval mechanisms, developers can build highly autonomous, intelligent applications that revolutionize industries.
[image error]System Design for Building Agentic AI Applications — Part 1 was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
January 30, 2025
Setting Up Ollama and Running DeepSeek R1 Locally for a Powerful Retrieval-Augmented Generation…
The advancement of Large Language Models (LLMs) has necessitated the need for efficient Retrieval-Augmented Generation (RAG) systems to enhance factual accuracy and context awareness. This article explores the setup of Ollama and DeepSeek R1 locally to develop a powerful RAG system. By leveraging local computation, the approach ensures privacy, customization, and optimized performance. The article provides a step-by-step guide on installing Ollama, configuring DeepSeek R1, and integrating them with a RAG pipeline.
 Introduction
IntroductionLarge Language Models (LLMs) such as GPT-4 have demonstrated remarkable capabilities in natural language understanding and generation. However, their reliance on pre-trained knowledge can lead to outdated or hallucinated responses. Retrieval-Augmented Generation (RAG) addresses this limitation by incorporating an external knowledge retrieval mechanism. Ollama, an efficient model runner, enables local execution of such models, ensuring privacy and performance optimization. This article details the setup of Ollama and DeepSeek R1 for a fully functional RAG system.
RAGRAG is an AI technique that retrieves external data (e.g., PDFs, databases) and augments the LLM’s response. Why use it? Improves accuracy and reduces hallucinations by referencing actual documents. Example: AI-powered PDF Q&A system that fetches relevant document content before generating answers.
Understanding Ollama and DeepSeek R1Ollama: A tool that facilitates running LLMs on local machines, providing an easy-to-use interface for deploying open-source models.
DeepSeek R1: A powerful open-source language model optimized for retrieval-augmented workflows. It supports efficient tokenization and fast inference speeds, making it suitable for RAG-based applications.
Installation and SetupTo set up Ollama, follow these steps:Download and Install: Ollama can be installed from Ollama’s official website.
Verify Installation:
ollama --versionRun a Test Model:
ollama run llama2Setting Up DeepSeek R1Download DeepSeek R1 model:
ollama pull deepseek-ai/deepseek-r1Run DeepSeek R1 locally:
ollama run deepseek-ai/deepseek-r1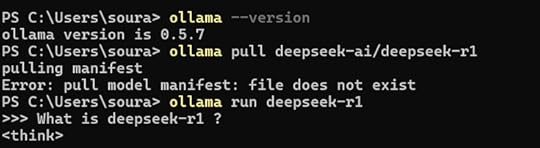
 Ollama is a framework for running large language models (LLMs) locally on your machine. It lets you download, run, and interact with AI models without needing cloud-based APIs.LangChain is a Python/JS framework for building AI-powered applications by integrating LLMs with data sources, APIs, and memory. Why use it? It helps connect LLMs to real-world applications like chatbots, document processing, and RAG.DeepSeek R1
Ollama is a framework for running large language models (LLMs) locally on your machine. It lets you download, run, and interact with AI models without needing cloud-based APIs.LangChain is a Python/JS framework for building AI-powered applications by integrating LLMs with data sources, APIs, and memory. Why use it? It helps connect LLMs to real-world applications like chatbots, document processing, and RAG.DeepSeek R1DeepSeek R1 is an open-source AI model optimized for reasoning, problem-solving, and factual retrieval. Why use it? Strong logical capabilities, great for RAG applications, and can be run locally with Ollama.
How They Work Together?
Ollama runs DeepSeek R1 locally.
LangChain connects the AI model to external data.
RAG enhances responses by retrieving relevant information.
DeepSeek R1 generates high-quality answers.
Example Use Case: A Q&A system that allows users to upload a PDF and ask questions about it, powered by DeepSeek R1 + RAG + LangChain on Ollama.
Setting Up a RAG System Using StreamlitNow that you have DeepSeek R1 running, let’s integrate it into a retrieval-augmented generation (RAG) system using Streamlit.
PrerequisitesBefore running the RAG system, make sure you have:
Python installed
Conda environment (Recommended for package management)
Required Python packagesInstall Below Packagespip install -U langchain langchain-community
pip install streamlit
pip install pdfplumber
pip install semantic-chunkers
pip install open-text-embeddings
pip install faiss
pip install ollama
pip install prompt-template
pip install langchain
pip install langchain_experimental
pip install sentence-transformers
pip install faiss-cpuRunning the RAG System
Create a new project directory
mkdir rag-system && cd rag-systemCreate a Python script ( app.py)
import streamlit as stfrom langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
# Streamlit UI
st.title("📄 RAG System with DeepSeek R1 & Ollama")
uploaded_file = st.file_uploader("Upload your PDF file here", type="pdf")
if uploaded_file:
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
embedder = HuggingFaceEmbeddings()
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
llm = Ollama(model="deepseek-r1:1.5b")
prompt = """
Use the following context to answer the question.
Context: {context}
Question: {question}
Answer:"""
QA_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(llm=llm, prompt=QA_PROMPT)
combine_documents_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="context")
qa = RetrievalQA(combine_documents_chain=combine_documents_chain, retriever=retriever)
user_input = st.text_input("Ask a question about your document:")
if user_input:
response = qa(user_input)["result"]
st.write("**Response:**")
st.write(response)Running the Appstreamlit run app.py
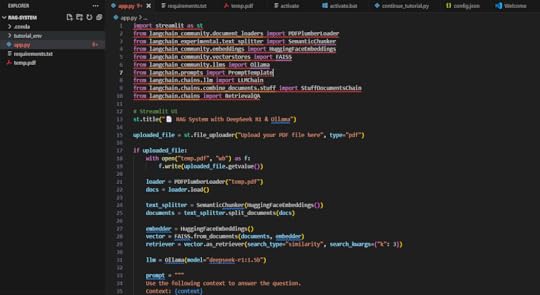 Project ViewOnce the script is ready, start your Streamlit app:
Project ViewOnce the script is ready, start your Streamlit app:

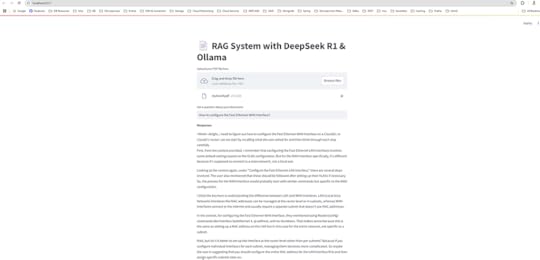
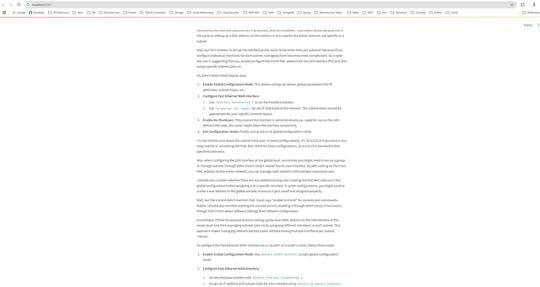
Upload A PDF so that retrieves external data (e.g., PDFs) and augments the LLM’s response. I have upload the pdf which has network dataset, and asked the question to configure the Fast Ethernet WAN Interface.
 Conclusion
ConclusionSetting up Ollama and running DeepSeek R1 locally offers a robust foundation for RAG systems. The approach ensures enhanced privacy, lower latency, and high customization potential. By leveraging optimized retrieval and response generation, enterprises and researchers can deploy powerful AI solutions on local infrastructure.
[image error]Setting Up Ollama and Running DeepSeek R1 Locally for a Powerful Retrieval-Augmented Generation… was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
January 22, 2025
Building Intelligent AI Agents with Spring AI: Agentic Patterns Explained — Part 0
In the evolving landscape of artificial intelligence, integrating Large Language Models (LLMs) into applications has become increasingly accessible. Spring AI, a project within the Spring ecosystem, offers developers a robust framework to incorporate AI functionalities seamlessly into their applications.
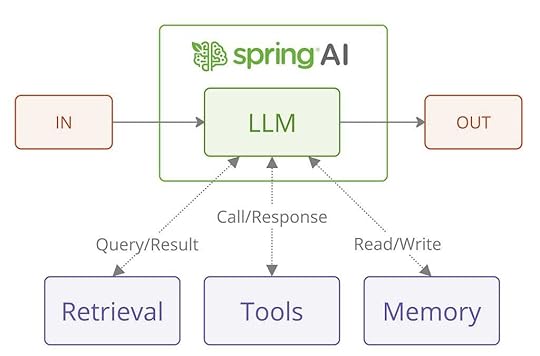
This article delves into the agentic patterns introduced by Spring AI, inspired by Anthropic’s research on building effective LLM agents, and demonstrates how these patterns can be implemented to create efficient AI-driven workflows.
Agentic Systems in Spring AIAnthropic’s research distinguishes between two primary types of agentic systems:
Workflows: Systems where LLMs and tools are orchestrated through predefined code paths, ensuring predictability and consistency.Agents: Systems where LLMs dynamically direct their own processes and tool usage, offering flexibility but potentially less predictability.Spring AI aligns with these concepts by providing structured patterns that facilitate the development of both workflows and agents, catering to various application needs.
Chain WorkflowThe Chain Workflow pattern involves breaking down complex tasks into a sequence of simpler, manageable steps, where the output of one step serves as the input for the next.
Implementation in Spring AIpublic class ChainWorkflow {
private final ChatClient chatClient;
private final String[] systemPrompts;
// Processes input through a series of prompts, where each step's output
// becomes input for the next step in the chain.
public String chain(String userInput) {
String response = userInput;
for (String prompt : systemPrompts) {
// Combine the system prompt with previous response
String input = String.format("%s\n%s", prompt, response);
// Process through the LLM and capture output
response = chatClient.prompt(input).call().content();
}
return response;
}
}
This approach ensures that each step is focused on a specific subtask, enhancing clarity and maintainability.
Parallelization WorkflowThe Parallelization Workflow pattern enables simultaneous processing of multiple tasks, either by dividing a task into independent subtasks (sectioning) or by running multiple instances of the same task to achieve consensus (voting).
Implementation in Spring AI:public class ParallelizationWorkflow {
private final ChatClient chatClient;
// Processes multiple inputs in parallel and aggregates the results
public List parallelProcess(List inputs) {
return inputs.parallelStream()
.map(input -> chatClient.prompt(input).call().content())
.collect(Collectors.toList());
}
}
This pattern is particularly useful for tasks that can be executed concurrently, thereby reducing processing time and increasing efficiency.
ReAct AgentThe ReAct (Reasoning and Acting) Agent pattern combines reasoning and action by allowing the LLM to interact with external tools or data sources iteratively, refining its responses based on the information retrieved.
Implementation in Spring AI:public class ReActAgent {
private final ChatClient chatClient;
private final ToolExecutor toolExecutor;
// Iteratively refines responses by interacting with external tools
public String interact(String userInput) {
String response = chatClient.prompt(userInput).call().content();
while (needsFurtherAction(response)) {
String action = extractAction(response);
String toolResult = toolExecutor.execute(action);
response = chatClient.prompt(toolResult).call().content();
}
return response;
}
}
This pattern is ideal for scenarios where the LLM needs to perform actions based on user input and refine its responses accordingly.
Plan-and-Execute AgentThe Plan-and-Execute Agent pattern involves the LLM creating a comprehensive plan to achieve a goal and then executing each step, adjusting as necessary based on the outcomes.
Implementation in Spring AI:public class PlanAndExecuteAgent {
private final ChatClient chatClient;
// Creates a plan and executes each step, adjusting as necessary
public String planAndExecute(String goal) {
String plan = chatClient.prompt("Create a plan to: " + goal).call().content();
for (String step : extractSteps(plan)) {
String result = chatClient.prompt(step).call().content();
if (needsAdjustment(result)) {
plan = adjustPlan(plan, result);
}
}
return plan;
}
}
This pattern is suitable for complex tasks requiring a structured approach with the flexibility to adapt as the execution progresses
AutoGPT AgentThe AutoGPT Agent pattern empowers the LLM to autonomously set goals and execute tasks without explicit user prompts, making decisions based on predefined objectives.
Implementation in Spring AI:public class AutoGPTAgent {
private final ChatClient chatClient;
// Autonomously sets goals and executes tasks
public void run() {
String goal = determineInitialGoal();
while (!goal.isEmpty()) {
String plan = chatClient.prompt("Plan to achieve: " + goal).call().content();
for (String step : extractSteps(plan)) {
chatClient.prompt(step).call().content();
}
goal = determineNextGoal();
}
}
}
This pattern is effective for applications requiring continuous operation with minimal human intervention, such as monitoring systems or automated content generation.
ConclusionSpring AI provides a versatile framework for implementing various agentic patterns, enabling developers to build AI-driven applications tailored to specific needs. By adopting these patterns, developers can create systems that balance autonomy and control, ensuring both flexibility and reliability in AI integrations.
For a comprehensive understanding and practical examples of these patterns, refer to the official Spring AI documentation and the agentic-patterns project on GitHub.
[image error]Building Intelligent AI Agents with Spring AI: Agentic Patterns Explained — Part 0 was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
November 7, 2024
My Journey to an EB-1A Visa: Insights, Challenges, and Tips

I’m incredibly fortunate to share that I recently received approval for my EB-1A visa, paving the way to permanent residency (Green Card) in the United States. This journey has been one of growth, persistence, and learning. Working exclusively with Chen Immigration Law Associates (Wegreened) over the past two years, I found great support and guidance for this intricate process.
In this article, I’ll share my experiences, challenges, and tips to help others on the same path.
Professional BackgroundI am a technical author, researcher, and software engineer. Since 2014, my career has spanned many roles and projects, with a focus on emerging technology in finance, microservices and distributed systems. I authored Building Digital Experience Platforms and published over ten research papers on topics like fintech applications, microservice patterns, distributed systems, and databases. My research and contributions have been recognized within the industry, leading to citations and validation across the tech community.
I hope my story provides valuable insights for anyone pursuing the EB-1A visa process.
What is the EB-1A Visa?The EB-1A visa is designed for individuals with extraordinary abilities in fields like science, education, business, and arts. It requires applicants to meet at least three of ten USCIS criteria. Once approved, it provides eligibility for a Green Card, offering a path to permanent residency. For me, it represented not just an opportunity for residency but validation of years of professional and academic dedication.
Starting with EB2-NIWI first learned about the self-sponsored EB2-NIW and EB-1A visa categories in April 2023. Referred by a friend, I reached out to Chen Associates. After evaluating my profile, they recommended starting with an EB2-NIW petition while I built a stronger case for EB-1A.
Timeline Highlights for EB2-NIW:
Initial Approach: May 20, 2023
Retainer Signed: May 25, 2023
Petition Filed: September 5, 2023
Approval Received: October 5, 2023 (with Premium Processing)
My EB2-NIW petition was submitted in September 2023, and thanks to Premium Processing, I received approval in just 20 days. The process went smoothly — Chen Associates managed all communications through their online case management system, providing timely responses and making document management easy.
Moving Forward with EB1AAfter my EB2-NIW approval, I was eager to start my EB1A application. However, the attorneys advised me to strengthen my profile with more publications and citations. This honesty was one of the standout aspects of Chen Associates; they were transparent about my chances and what I needed to improve.
By March 2024, I had built a more solid case, including over 300 citations across my papers and books. We worked carefully on my EB1A petition, focusing on meeting three USCIS criteria to demonstrate “extraordinary ability.” By June 2024, my petition was ready, and I requested Premium Processing. Shortly after, I received an RFE (Request for Evidence), which was disheartening but ultimately a turning point.
EB1A Approvals Timelines
Overcoming the RFE
Approached Chen Associates : 20th March 2024
Signed Retainer Agreement : 19th May 2024
Submitted Summary Of Contribution : 1st June 2024
Finalized Recommenders : 3rd June 2024
Recommenders Signed Letters : 13th June 2024
Attorney Finalized EB1-A Petition: 20th June 2024
Petition Submitted to USCIS : 24th June 2024
Premium Processing Requested : 15th July 2024
RFE Received : 24th July 2024
The RFE was challenging, but Chen Associates quickly assigned a new attorney who handled it exceptionally well. She collaborated with me to build a strong response, incorporating additional achievements like awards, news articles, and comparative analysis of my citations.
RFE Timeline:
RFE Strategy Finalized: July 30, 2024
Additional Evidence Gathered: August 2024
Response Submitted: October 5, 2024
EB1A Approval Received: October 24, 2024
The RFE response required significant effort, but we succeeded, and my EB1A was finally approved. The experience taught me the value of persistence, precise documentation, and having a proactive attorney by your side.
Tips from My Journey1. Follow Attorney Guidance — but Trust Your Instincts
My attorneys advised against filing with Premium Processing, noting that it often leads to more RFEs (Requests for Evidence) since USCIS has less time to evaluate each case thoroughly. Despite their advice, I opted for Premium Processing, understanding the potential risks but preferring a faster response.
2. Strongly Showcase Independent Achievements
In retrospect, I learned that independent recognitions, such as news articles or awards, carry significant weight. They were pivotal in my RFE response and bolstered the overall strength of my petition.
3. Create a Detailed Summary of Contributions
A clear, compelling summary of contributions is key for your attorney to write a compelling petition letter with objective evidence. Include why your work stands out and demonstrate its broader impact.
4. Choose Recommenders Thoughtfully
Independent recommenders, who can objectively verify the impact of your work, are highly valuable. They add authenticity and credibility to your case. In retrospect, I learned that independent recommenders and recognitions are crucial. Additionally, researching your citation sources carefully before finalizing and approaching individuals for recommendation letters can strengthen your case.
5. Sometimes, Trust Your Own Judgment
Initially, I suggested including news articles and awards related to my book in my petition, but my attorney recommended excluding them. This meant that some of my key achievements weren’t part of the original submission.
Final ThoughtsMy EB-1A journey was challenging but ultimately rewarding. Working closely with Chen Associates and taking a proactive role in my application made a huge difference. I hope this article serves as a useful roadmap for anyone pursuing an EB-1A visa — success is achievable with the right strategy, right attorney, perseverance, and a bit of patience.
[image error]My Journey to an EB-1A Visa: Insights, Challenges, and Tips was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.
May 5, 2021
Why Java ?
Why Java is better than other traditional programing languages?
Java have significant features which makes it unique such as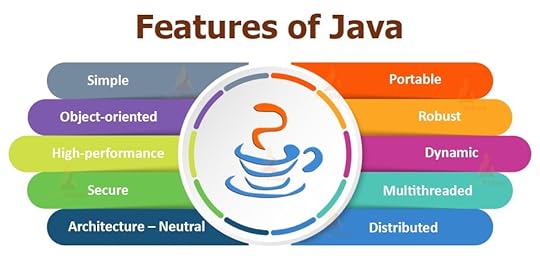
It is build on top of OOPS (Object Oriented programing)
It is simple to learn.
It is portable & Platform independent — Once Code is written & compiled — It coverts into byte code, these byte codes are platform independent ( Windows, Unix, Linux, OSX).
It is secured & Robust — Java can manage the huge loads of data generated by the industries like telecom, finance, banking etc.
Interpreted & High Performance — It provides lots many feature's such as memory management, garbage collection , multithreading, distributed hence these features makes it High Performance language.
Exception Handling — Java help us with handling exception efferently. It provides the check and uncheck exceptions where we can control the behavior of the code.
What is JIT & What is JVM
Garbage Collection — Memory allocations and removing unused object is completely taken care by GC(Garbage Collections).
JIT is the part of JVM and It provides the capabilities to improve the performance of JVM. It converts the compiling code into native instructions.
JVM — Java Virtual Machine, used in Java programing platform to run or execute the code. JVM makes java platform independent. Java code can be run on any platform such as Unix, Linux, Windows by executing byte codes. Java code is complied to class files which contains byte codes. These byte codes are executed by JVM.
JIT — Just In Time Compilation. execution of byte code is slower than execution of machine language code, JIT help JVM by compiling byte code into machine language.
I feel everyone has their own story to tell about the doing code, programing in Java. Feel free to provide more features, story and advantages of using Java over other languages in the comments box below.
Why Java ? was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.


