
Sourabhh Sethii's Blog, page 4
April 1, 2019
Building a simple chatbot in python
In next few years, chatbot will be handling 90 percent of customer services interactions and Digital technologies are helping us to come up with interactive solutions to solve day to day problems.
I am sure you’ve seen chatbots while using different application on mobile as well as desktop where chatbots are solving your query in interactive mode.
 ChatterBoxWhat is chatbot?
ChatterBoxWhat is chatbot?Chatbot is an artificial Intelligence’s application that tries to understand the customer’s needs and then assist them to perform a particular task like transactions, form submission, bookings etc.
What are the types of chatbot?There are two types of chatbots:
1.) Rule Based : In this approach, bot answers the questions based on some rules on which it trained on but it wouldn’t be able to manage complex queries.
2.) Self Learning : In this approach, we uses Machine Learning-based approaches which are more efficient than rule base approach.
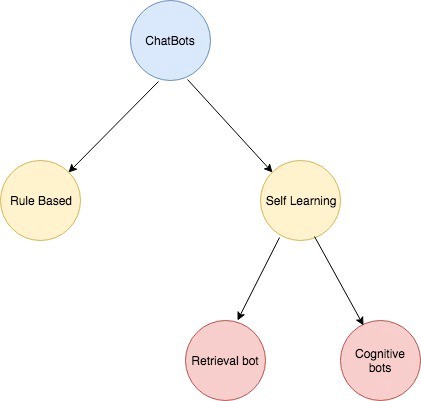 Types of Chatbot
Types of ChatbotSelf Learning Bots are classified further as Retrieval bots and Cognitive bots
Retrieval bots are bots which doesn’t have cognitive ability but on the basic of context and messages of the conversation it would selects the best response from a predefined responses. Response can be generated from rule based if-else condition to machine learning cluster and classifiers.
Cognitive bots are bots which has cognitive ability which can generate the answers and provides different answers. These are more intelligent bots.
Chatbot Architecture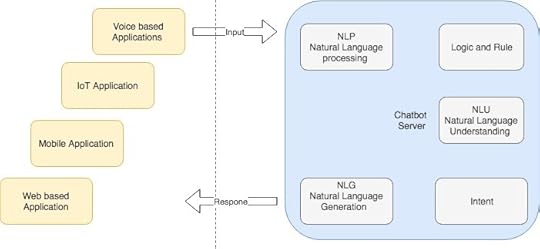
Input can be taken from Mobile,IoT, Web, and Voice applications which would be processed by chatbot server using NLP,NLU,NLG components.
In this article, we would look into simple retrieval chatbot to understand the working of chatbot using python.Installation
1.) Python 3.6
2.) NLTK
3.) Scikit library
We would look into brief about NLP and NLTK library in brief, it would help us to perform language processing tasks.
NLP (Natural Language Processing)NLP help us to perform language processing tasks which helps us to structure knowledge to perform tasks such as Tokenization, Stemming, Lemmatization, Relationship extraction, Topic segmentation etc.
NLTKNLTK(Natural Language Toolkit) is platform for building application to work with human language. It provides easy-to-use interfaces such as WordNet, along with a suite of text processing libraries for classification, tokenisation, stemming, tagging, parsing, and semantic reasoning etc for NLP libraries.
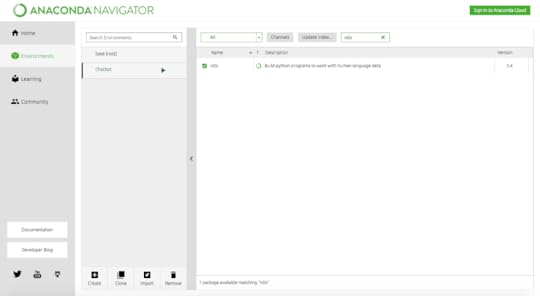
Downloading and installing NLTK1.) Install Anaconda with Python 3.7
2.) Create environment with chatbox
3.) Install NLTK and Sci-Learn Library in chatbox environment as shown in below screen shot.
4.) Download the source code from here
or clone the repository ( git clone https://github.com/Sourabhsethi/Building-a-simple-chatbot-in-python.git )
5.) Open this project in Spyder shown in below screen shot.
6.) Run this command in console nltk.download(‘wordnet’) to dowload the resource WordNet.
7.) Run the chatbot.py Python file to run the project.
Before moving to code I would like to go thought text processing concepts and terms which would help us to understand code better.
Text Pre- Processing1.) Converting text into lower case or upper case so that algorithm does not work on same words in different cases.
2.) Tokenisation : It is used to convert the normal text into list of tokens.
3.) NLTK data package includes a pre-trained Punkt tokenizer for English, It will remove noise i.e everything which is not a standard number or letter.
4.) It will also help us to remove Stop words, these are the most common words.
5.) Stemming: it is a process of reducing inflected (or sometimes derived) words to their stem for example ( “Stems”, “Stemming”, “Stemmed”, “and Stemtization”, the result would be a single word “stem”).
6.) Lemmatization: it is the process of find out the same form of the words. For example of Lemmatization are that “run” is a base form for words like “running” or “ran” or that the word “better” and “good” are in the same lemma so they are considered the same.
Bag of Word ModelOne need to transform the text into a meaningful vector of numbers. it is representation of text that describes the occurrence of words within a document. The main idea behind the Bag of Words is that documents are similar if they have similar content.
For example, if our dictionary contains the words {Chatterbot, is, the, great, application}, and we want to vectorise the text “Chatterbot is great”, we would have the following vector: (1, 1, 0, 1, 0).
Document {Chatterbot, is, the, great, application}
Query : “Chatterbot is great”
Vector: (1, 1, 0, 1, 0).TF-IDF Model
The problem with the Bag of Words approach is that highly frequent words start to dominate in the document but may not contain as much “informational content” another approach is to rescale the frequency of words by how often they appear in all documents so that the scores for frequent words like “an” that are also frequent across all documents are penalized. This approach is called Term Frequency-Inverse Document Frequency (TF-IDF)
Term Frequency: is a scoring of the frequency of the word in the current document.
TF = (Number of times term t appears in a document)/(Number of terms in the document)
Inverse Document Frequency: is a scoring of how rare the word is across documents.
IDF = 1+log(N/n), where, N is the number of documents and n is the number of documents a term t has appeared in.
Tf-idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus
Tf-IDF can be implemented in scikit learn as : from sklearn.feature_extraction.text import TfidfVectorizer
you can check the syntax and usage from hereCosine Similarity
TF-IDF is a transformation applied to texts to get two real-valued vectors in vector space. We can then obtain the Cosine similarity of any pair of vectors by taking their dot product and dividing that by the product of their norms.
Using this formula we can find out the similarity between any two documents d1 and d2.
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
For More Details look into below Urls
https://www.kaggle.com/antriksh5235/cosine-similarity-using-tfidf-weighting
https://www.youtube.com/watch?v=_f37gnigkRg
https://medium.com/media/9dcb4bc414e6976fc53e213b7cebfd1c/hrefHurray, now we have some idea about the NLP process, now let’s dig into code.Import Librariesimport nltk
import warnings
warnings.filterwarnings(“ignore”)
# nltk.download() # for downloading packages
import numpy as np
import random
import io
import string # to process standard python stringsCorpus
we will be using the some information about chatbox, which is available in the code in a text file named ‘data.txt’. However, one can use any corpus of your choice.
Read from fileWe will read in the corpus file and convert the entire corpus into a list of sentences and a list of words for further pre-processing.
readFile=io.open(‘data.txt’,’r’,errors = ‘ignore’)
data=readFile.read()
lowerData=data.lower()# converts to lowercase
#nltk.download(‘punkt’) # first-time use only # for downloading packages
#nltk.download(‘wordnet’) # first-time use only # for downloading packages
sentences_tokens = nltk.sent_tokenize(lowerData)# converts to list of sentences
word_tokens = nltk.word_tokenize(lowerData)# converts to list of words
sentences_tokens[:2]
word_tokens[:5]Pre-processing the raw text
We shall now define a function called LemTokens which will take as input the tokens and return normalized tokens.
lemmer = nltk.stem.WordNetLemmatizer()
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))Keyword Matching
lets look into a function for a greeting by the chatterbot i.e if a user’s input is a greeting, the bot shall return a greeting response.
INPUTS = (“hello”, “hi”, “greetings”, “good morning”, “good evening”,”good afternoon”,)
RESPONSES = [“hi”, “hello”,]
# Checking for greetings
def greeting(sentence):
“””If user’s input is a greeting, return a greeting response”””
for word in sentence.split():
if word.lower() in INPUTS:
return random.choice(RESPONSES)Response
Response would be generated using the concept of document similarity. So we begin by importing necessary modules.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
This will be used to find the similarity between words entered by the user and the words in the corpus.
We define a function response which searches the user’s utterance for one or more known keywords and returns one of several possible responses.
# Generating response
def response(user_response):
chatterBox_response=’’
sentences_tokens.append(user_response)
TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words=’english’)
tfidf = TfidfVec.fit_transform(sentences_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
chatterBox_response=chatterBox_response+”I am sorry! I am not able to get you”
return chatterBox_response
else:
chatterBox_response = chatterBox_response+sentences_tokens[idx]
return chatterBox_response
we will feed the lines that we want our bot to say while starting and ending a conversation depending upon user’s input.
flag=True
print(“ChatterBox: My name is ChatterBox. I will answer your queries about ChatterBox. If you want to exit, sat bye or thanks!”)
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!=’bye’):
if(user_response==’thanks’ or user_response==’thank you’ ):
flag=False
print(“ChatterBox: You are welcome..”)
else:
if(greeting(user_response)!=None):
print(“ChatterBox: “+greeting(user_response))
else:
print(“ChatterBox: “,end=””)
print(response(user_response))
sentences_tokens.remove(user_response)
else:
flag=False
print(“ChatterBox: Bye! have a nice day..”)Conclusion
It is simple bot without cognitive ability. It would help you to start with NLP processing and to know about the chatbot and this example would help you to understand the chatbox application and you can extend this to build your own bots.
Happy learning and coding!

Building a simple chatbot in python was originally published in DXSYS on Medium, where people are continuing the conversation by highlighting and responding to this story.


March 28, 2019
Vector
Collections
Vector implements list Interface. It maintains insertion order and it is thread safe as well as it is synchronized hence gives poor performance in searching, adding, deleting and updating of its elements.
It creates empty Vector with the default initial capacity of 10 which means that Vector will be re-sized when the 11th elements needs to be inserted into the Vector.
Vector would be 10th if Vector’s size = 10 till 10th elements and once one try to insert the 11th element It would become 20 (double of default capacity 10).
Vector are used in thread-safe environment

March 27, 2019
TreeSet
Collections
TreeSet is the implementation of SortedSet Interface in Java. It is used for storage. It doesn’t contains duplicate values.
Objects are stored in a sorted and ascending order.
It is implementation of a self-balancing binary search tree such as RED-BLACK tree hence operations like add, remove and search take O(Log n) time.
TreeSet is similar to hashset except that it sorts the elements in the ascending order while HashSet doesn’t maintain any order.
TreeSet is not synchronized, if multiple threads access a tree set concurrently, and one of the threads modifies the set, it must be synchronized hence to synchronize set, set should be “wrapped” using the Collections.synchronizedSortedSet method at the creation time, to prevent accidental unsynchronized access to the set.
TreeSet treeset = new TreeSet();
Set syncSet = Collections.synchronziedSet(treeset);

March 25, 2019
ArrayList Vs LinkedList
Collections
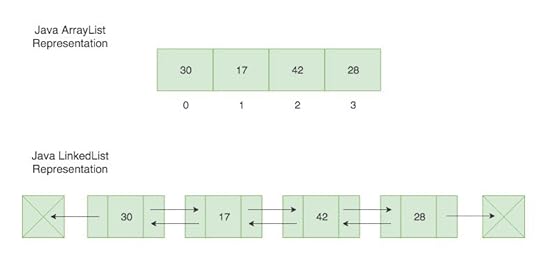 ArrayList V/S LinkedListArrayList and LinkedList both implements List interface.ArrayList’s search operation is faster than Linked List’s search operation.
ArrayList V/S LinkedListArrayList and LinkedList both implements List interface.ArrayList’s search operation is faster than Linked List’s search operation.ArrayList gives the performance of o(1) while LinkedList performance is o(n) beacuse ArrayList maintains index based system for its elements as it uses array data structure which makes it faster for searching an element in the list.
LinkedList implements DLL (Doubly Linked Link-list)which requires the traversal through all the elements for searching an element.
Linked List’s insertion and deletion is faster than ArrayList’s insertion and deletion.Insertion and deletion operation gives o(1) performance while ArrayList gives variable performance: o(n) in worst case (while removing first element) and o(1) in best case (While removing last element).
UsageIf there is a requirement of frequent addition and deletion in application then LinkedList is a best choice.
If there are less add and remove operations and more search operations requirement, ArrayList would be one’s best fit.

Hashset V/s HashMap
Collections
HashsetIn hashset, one can store values or objects such as { obj1, obj2, obj3, obj4 }It doesn't allow duplicate elements. Hashset is the implementation of set interface whereas HashMap implements the Map interface.HashMap
In HashMap, one can store key, value pair such as {1>”Apple”, 2>”Mango”,3>”Banana” }HashMap does not allow duplicate keys whereas it allows to have duplicate values and HashMap implements the Map interface.
Both HashMap and HashSet are not synchronized. HashSet is slower that HashMap because HashMap internally uses hashing to store or add objects and HashSet internally uses HashMap object to store or add the objects.

February 23, 2019
DevOps and the need of Continuous Integration(CI) — Continuous Delivery(CD) and its impact on the…
Continuous Integration, Continuous Delivery, Continuous Deployments is collaborated goal that is to make software development and release process faster and more robust.Its main focus is on integrating and deploying the software with zero turn around time.
As soon as code is checked-in by developer in the remote repository the reviewer would review the code, if code is accepted by reviewer, build would be triggered and moved to the servers automatically which reduce the manual intervention with zero turn(least time to release the code to production) around time to production hence it would impact the people by reducing the manual intervention in processes such as code integration, merging, review, running build scripts, test scripts and deployment of different severs to production.
Continuous DeliveryContinuous Delivery is process which automates the Continuous Integration and Continuous Deployment process.The main idea is to automatically prepare and track the release to production, it would be of multiple stages, and deployment to production.
In case of continuous delivery there can be chances of the manual intervention is required to deploy to production after application acceptance testing where as Continuous deployment is the next step of continuous delivery, where changes are passed through the automated tests and then it is deployed to production automatically.
Continuous Integration(Continuous Integration) CI would lead developers to integrate their code into the shared repository. Before CI, developer used to develop features in isolation and integrate at the end of the development but with CI approach code is getting integrated with the shared repository by each developer. One can use CI tools to integrated the latest code checked-in by the each developer a team. once can used CI tools such as Jenkins, TeamCity, Bamboo, GitLab CI, Circle CI, Code Ship, Code Fresh etc.
Code is developed and checked-in by developers using code repository such as SVN, GIT, BIT Bucket, GitHub, GitLab, Sourceforge etc. Team is merging their individual code in master branch multiple times per day.
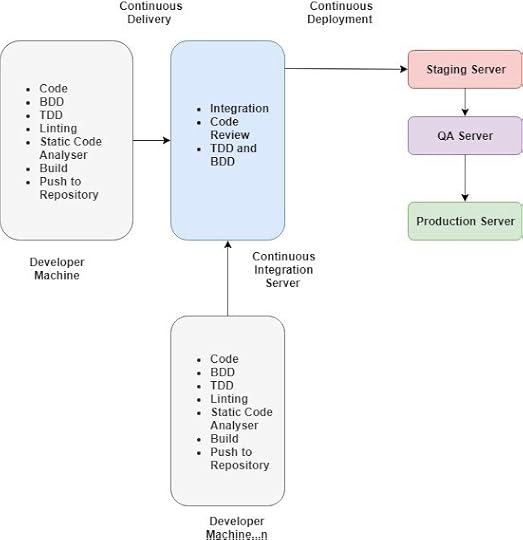 Figure 1 : Continuous Delivery — Continuous Integration — Continuous Deployment.
Figure 1 : Continuous Delivery — Continuous Integration — Continuous Deployment.As Shown in Figure 1 : Continuous Delivery — Continuous Integration — Continuous Deployment.
TDD — Test driven development.
BDD — Behaviour driven development
Linting — Statics code analyser to detect the issues with code such as cyclomatic complexity.
Build- Build the Source code as single application.
Push— Check-in code to repository.Continuous Deployment
(Continuous Deployment) CD would help people to deploy the code with no time lag between code checked-in repository and passed thought the build process along with testing(TDD and DBB)as Shown in Figure 1 : Continuous Delivery — Continuous Integration — Continuous Deployment. Continuous Integration Server would be responsible for pushing the tested and deployable code to production servers.
DevOps are set of tools and practices to automate the processes to achieve Continuous Integration, Continuous Delivery, Continuous Deployments methodology.
ConclusionContinuous Integration, Continuous Delivery, Continuous Deployments would help people to automate the build to deployment processes which will help in smooth delivery, much happier teams, no overhead of manual testings and deployments. It would enhance the productivity of the developer, developer can focus on the functionality and features of the application.

DevOps and the need of Continuous Integration(CI) — Continuous Delivery(CD) and its impact on the… was originally published in Virtue on Medium, where people are continuing the conversation by highlighting and responding to this story.
December 25, 2018
Introduction to Machine learning Algorithms
Linear Regression
It is based on linear problems which is used to predict the values on continuous steams of data.
Python and Scikit-learn: https://scikit-learn.org/stable/modules/model_evaluation.html
Logistic Regression
It is used to solve the problem using classification problem, model build using this algorithm would be used for solving and estimating discrete values. you can classify the problem using Precision, Recall, F1-score, Support.
Precision: the amount of true positives over the amount of true and false positives. What is the probability of a sample actually being positive if it is labeled as positive?
Recall: the amount of true positives of the amount of true positives plus the false negatives. What is the probability that the model will accurately pick up on a true positive?
F1-score: a combination of precision and recall.
Support: the number of samples of each class in the data-set.
Python and Scikit-learn: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_recall_fscore_support.html
Support Vector Machines
It would be used to find more complex boundaries for classification or regression problems.
Python and Scikit-learn: https://scikit-learn.org/stable/modules/svm.html
K-nearest
It predicts about data based on similarity to other data instances. It can be used for both classification and regression problems.
Naive Bayes
It is used to classify the objects into groups such as can be use to classify text into different type of groups.
Python and Scikit-learn: https://scikit-learn.org/stable/modules/naive_bayes.html
Tree
It is also known as CART (classification and regression trees), and it is used to explore a dataset and visualize a decision tree using graphviz. Decision trees are often used in ensembles called random forests.
K-mean
K-means Clustering is used to find the Clusters of Data.It is an unsupervised learning algorithm.
Python and scikit-learn : https://scikit-learn.org/stable/modules/clustering.html#k-means
Hence I conclude this article would help you to get familiar with Machine leaning algorithms used for Prediction, Classification and Clustering problems.

Introduction to Machine learning Algorithms was originally published in Virtue on Medium, where people are continuing the conversation by highlighting and responding to this story.
December 23, 2018
CMT Cycle ! Creation — Management — Transformation
Introduction to Development, Management and Transformation (DMT or CMT )Cycle.
Creation or Development — Problems are analysed and solutions are developed using Platform, frameworks and technologies as shown in figure CMT Cycle.
Management — Solutions build are organized using management frameworks such as Lean, SiX Sigma, PMP, PRINCE 2, ITIL, Agile and scaled agile as shown in figure CMT Cycle.
Transformation — As New technology evolves and on the bases of experience, domain knowledge and feedbacks, solutions are transformed using emerging technology as innovative solutions and innovative processes.Hence this is endless cycle till human existence.
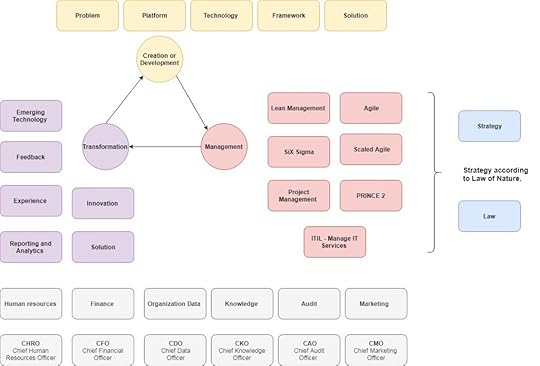 CMT or DMT Cycle.
CMT or DMT Cycle.Reporting and Analytics would enhance the decision making power of the Organization so that they would be able to provide their services and products efficiently to their clients.
Human Resources would ensure that right people are joining the organization to fulfill the organization’s need to run smoothly and would take the concerns of Employee and provide collaborative as well as individual concerns to higher management and employer.
Finance would take care and ensure the money flow within and out the organization such as payment to vendor and employee of the organization. it handles in and out of the finances.
Audit ensure the smooth working of organization by executing general audit within the organization.
Marketing would ensure that the right people at right time would get awareness about the services and products provided by Organization.
Branding would help organization to build their name and provides mission vision and values in the market.
Knowledge and Skillset of employee should be revised and revived time to time within organization which includes top management as well.
Organization Data should be handled correctly, it would help organization while transforming organizational structure and taking effective decisions.
In the end hence I conclude to transform and build innovative solutions, Strategy (Neeti)should be made according to law of nature (Niyam).

CMT Cycle ! Creation — Management — Transformation was originally published in Virtue on Medium, where people are continuing the conversation by highlighting and responding to this story.
December 16, 2018
IoT (Internet of Things) works on giant network of sense of perception.
IoT (Internet of Things) works on sense of perception that is smell, touch, shape, taste and sound which help one’s software or application to take necessary actions from the inputs perceived from senors such as chemical, mechanical etc . These senors are able to measure a physical phenomenon (like temperature, humidity, pressure etc.) and transform it into digital signals.
These five sense of action and the sense of perception are the product of five element of nature that is earth, water, fire, air and ether (prithvi, pani, tejas, vayu and akasa). One can classify these as follows and you can relate it with your existence as human body.
Smell and the earth element.
Taste and the water element.
Touch and the air element.
Sound and the ether element.
Shape which relates to form of the fire element.
[1] IoT sensors as sense organs. Click here for brief introduction to IoT sensors .
[2] IoT boards as Unit of microcontroller and microprocessors to convert and analyze the analog inputs taken from senors and convert it in into digital signal. Click here for brief introduction to IoT Boards .
[3] IoT data are stored in database to do further analysis using algorithms such as Classification, Cluster etc. to get the insight from data received by IoT senors.
[4] These devices are synced through the giant network of IoT devices through IoT platforms.

IoT (Internet of Things) works on giant network of sense of perception. was originally published in Virtue on Medium, where people are continuing the conversation by highlighting and responding to this story.
August 16, 2018
Innovation in service Industry.
Service Industry has there own life cycle for providing innovation in IT Industry. One ought to consider various factors while innovating process and delivering services, for example, Value creation and work flow optimization.
Five stages to deliver and maintain the efficient service delivery are as follows.
[1] Service Strategy, [2] Service Design, [3] Service Transition,[4] Service Operations, [5] Continuous Service Improvement.
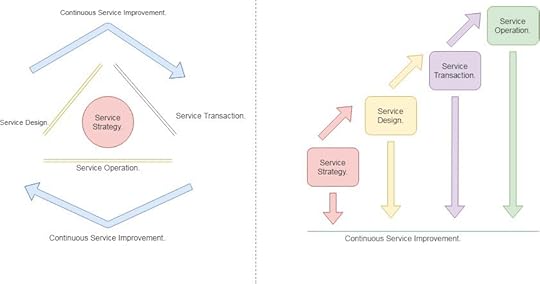 Service Life-cycle.Service Strategy
Service Life-cycle.Service StrategyService strategy is based on business requirements and potential customer. One should design or define services and link them to the business process then assign resources and consider cost and risk.
beginning with objective of Service Strategy.
[1]. Define the strategy.One ought to define Strategy management, this would ensure that service strategy is defined, maintained and managed. One would always do SWOT analysis that is Identify strengths, weaknesses, opportunities and threat.
[2]. Define services and their customer.One would defining it’s market space, then looks for developing and maintaining the market prospective.
[3]. Value creation and delivery.Creating value which means the balance between utility of the service (functionality of the services) delivered and warranty that is whether it is fit for use. Perfect balance between functionality and its use would create maximum value to customer.
e.g. Let’s consider a scenario where one has created web application having beautiful and adaptive design but what if that is not able to handle appropriate traffic.
or
Let’s consider another scenario where one has created web application able to handle million of users but what if that is not able to serve the need of people.
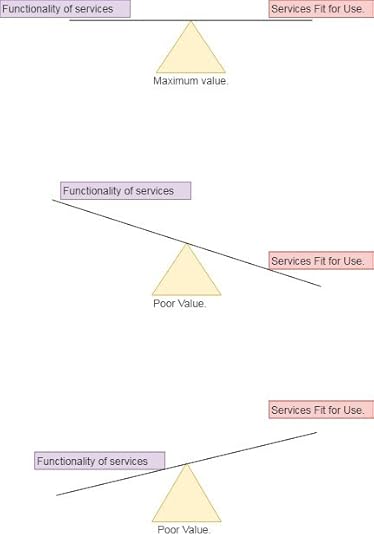 Maximum Value V/s Poor Value.
Maximum Value V/s Poor Value.Maximum Value depends upon Utility( i.e. functionality of services )and Warranty (i.e. Services Fit for use after developing it).
[4]. Assets — Define required capability and resources.Types of Assets are as follows
Resources — Can be purchase e.g. Financial capital, Infrastructure, Application and Information.
One need Financial capital(money) ready for the investment. One need to check capital invest or ability to borrow. Infrastructure (e.g Buildings, Server rooms, Hardware, UPS) and Application. Applications are of two types that is Off the shelf ,for example, web portals etc. and Custom Software ,for example, In house or outsource software developed. At last people, One have to check and hire right people with right skill set. Labor can be considered as commodity even skilled Labor can be acquired as quickly.
Capabilities — Must be developed e.g. Management, Organization, Processes, Knowledge, and people.
it is difficult but not impossible to find good management that understand business process and management. We ought to build the capability in the person. there are many organizational methods are available but you ought to build your own method.one need to develop processes in the organization. There are so many management tools available to manage process but one need to develop their own process before purchasing it. Knowledge management is the key factor to build the organization.it synthesis the data and able to provide correct information out of it. Apart from Management, Organization, Processes, Knowledge. One need motivated, trained and experienced workforce.Consultant can bridge temporary skill gaps between process and workforce so that People should perform long-term process and functions.Resources are tangible in nature and Capability are abstract in nature.
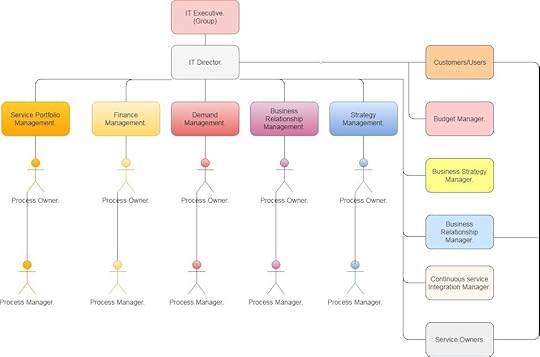 Service Roles Strategy.One has gone through brief introduction of Service Life-cycle, We would go through brief introduction about Service Design, Service Transition, Service Operation and Continuous Service Improvement in next article.
Service Roles Strategy.One has gone through brief introduction of Service Life-cycle, We would go through brief introduction about Service Design, Service Transition, Service Operation and Continuous Service Improvement in next article.
Innovation in service Industry. was originally published in Virtue on Medium, where people are continuing the conversation by highlighting and responding to this story.


