
Scott Aaronson's Blog, page 9
March 15, 2024
Never go to “Planet Word” in Washington DC
In fact, don’t try to take kids to Washington DC if you can possibly avoid it.
This is my public service announcement. This is the value I feel I can add to the world today.
Dana and I decided to take the kids to DC for spring break. The trip, alas, has been hell—a constant struggle against logistical failures. The first days were mostly spent sitting in traffic or searching for phantom parking spaces that didn’t exist. (So then we switched to the Metro, and promptly got lost, and had our metro cards rejected by the machines.) Or, at crowded cafes, I spent the time searching for a table so my starving kids could eat—and then when I finally found a table, a woman, smug and sure-faced, evicted us from the table because she was “going to” sit there, and my kids had to see that their dad could not provide for their basic needs, and that woman will never face any consequence for what she did.
Anyway, this afternoon, utterly frazzled and stressed and defeated, we entered “Planet Word,” a museum about language. Sounds pretty good, right? Except my soon-to-be 7-year-old son got bored by numerous exhibits that weren’t for him. So I told him he could lead the way and find any exhibit he liked.
Finally my son found an exhibit that fascinated him, one where he could weigh plastic fruits on a balancing scale. He was engrossed by it, he was learning, he was asking questions, I reflected that maybe the trip wasn’t a total loss … and that’s when a museum employee pointed at us, and screamed at us to leave the room, because “this exhibit was sold out.”
The room was actually almost empty (!). No one had stopped us from entering the room. No one else was waiting to use the balancing scale. There was no sign to warn us we were doing anything wrong. I would’ve paid them hundreds of dollars in that moment if only we could stay. My son didn’t understand why he was suddenly treated as a delinquent. He then wanted to leave the whole museum, and so did I. The day was ruined for us.
Mustering my courage to do something uncharacteristic for me, I complained at the front desk. They sneered and snickered at me, basically told me to go to hell. Looking deeply into their dumb, blank expressions, I realized that I had as much chance of any comprehension or sympathy as I’d have from a warthog. It’s true that, on the scale of all the injustices in the history of the world, this one surely didn’t crack the top quadrillion. But for me, in that moment, it came to stand for all the others. Which has always been my main weakness as a person, that injustice affects me in that way.
Speaking of which, there was one part of DC trip that went exactly like it was supposed to. That was our visit to the United States Holocaust Memorial Museum. Why? Because I feel like that museum, unlike all the rest, tells me the truth about the nature of the world that I was born into—and seeing the truth is perversely comforting. I was born into a world that right now, every day, is filled with protesters screaming for my death, for my family’s death—and this is accepted as normal, and those protesters sleep soundly at night, congratulating themselves for their progressivism and enlightenment. And thinking about those protesters, and their predecessors 80 years ago who perpetrated the Holocaust or who stood by and let it happen, is the only thing that really puts blankfaced museum employees into perspective for me. Like, of course a world with the former is also going to have the latter—and I should count myself immeasurably lucky if the latter is all I have to deal with, if the empty-skulled and the soul-dead can only ruin my vacation and lack the power to murder my family.
And to anyone who reached the end of this post and who feels like it was an unwelcome imposition on their time: I’m sorry. But the truth is, posts like this are why I started this blog and why I continue it. If I’ve ever imparted any interesting information or ideas, that’s a byproduct that I’m thrilled about. But I’m cursed to be someone who wakes up every morning, walks around every day, and goes to sleep every night crushed by the weight of the world’s injustice, and outside of technical subjects, the only thing that’s ever motivated me to write is that words are the only justice available to me.


March 6, 2024
On being faceless
Update: Alright, I’m back in. (After trying the same recovery mechanisms that didn’t work before, but suddenly did work this afternoon.) Thanks also to the Facebook employee who emailed offering to help. Now I just need to decide the harder question of whether I want to be back in!
So I’ve been locked out of Facebook and Messenger, possibly forever. It started yesterday morning, when Facebook went down for the entire world. Now it’s back up for most people, but I can’t get in—neither with passwords (none of which work), nor with text messages to my phone (my phone doesn’t receive them for some reason). As a last-ditch measure, I submitted my driver’s license into a Facebook black hole from which I don’t expect to hear back.
Incidentally, this sort of thing is why, 25 years ago, I became a theoretical rather than applied computer scientist. Even before you get to any serious software engineering, the applied part of computing involves a neverending struggle to make machines do what you need them to do—get a document to print, a website to load, a software package to install—in ways that are harrowing and not the slightest bit intellectually interesting. You learn, not about the nature of reality, but only about the terrible design decisions of other people. I might as well be a 90-year-old grandpa with such things, and if I didn’t have the excuse of being a theorist, that fact would constantly humiliate me before my colleagues.
Anyway, maybe some Facebook employee will see this post and decide to let me back in. Otherwise, it feels like a large part of my life has been cut away forever—but maybe that’s good, like cutting away a malignant tumor. Maybe, even if I am let back in, I should refrain from returning, or at least severely limit the time I spend there.
The truth is that, over the past eight years or so, I let more and more of my online activity shift from this blog to Facebook. Partly that’s because (as many others have lamented) the Golden Age of Blogs came to an end, with intellectual exploration and good-faith debate replaced by trolling, sniping, impersonation, and constant attempts to dox opponents and ruin their lives. As a result, more and more ideas for new blog posts stayed in my drafts folder—they always needed just one more revision to fortify them against inevitable attack, and then that one more revision never happened. It was simply more comfortable to post my ideas on Facebook, where the feedback came from friends and colleagues using their real names, and where any mistakes I made would be contained. But, on the reflection that comes from being locked out, maybe Facebook was simply a trap. What I have neither the intellectual courage to say in public, nor the occasion to say over dinner with real-life friends and family and colleagues, maybe I should teach myself not to say at all.
February 12, 2024
The Problem of Human Specialness in the Age of AI
Here, as promised in my last post, is a written version of the talk I delivered a couple weeks ago at MindFest in Florida, entitled “The Problem of Human Specialness in the Age of AI.” The talk is designed as one-stop shopping, summarizing many different AI-related thoughts I’ve had over the past couple years (and earlier).
1. INTRO
Thanks so much for inviting me! I’m not an expert in AI, let alone mind or consciousness. Then again, who is?
For the past year and a half, I’ve been moonlighting at OpenAI, thinking about what theoretical computer science can do for AI safety. I wanted to share some thoughts, partly inspired by my work at OpenAI but partly just things I’ve been wondering about for 20 years. These thoughts are not directly about “how do we prevent super-AIs from killing all humans and converting the galaxy into paperclip factories?”, nor are they about “how do we stop current AIs from generating misinformation and being biased?,” as much attention as both of those questions deserve (and are now getting). In addition to “how do we stop AGI from going disastrously wrong?,” I find myself asking “what if it goes right? What if it just continues helping us with various mental tasks, but improves to where it can do just about any task as well as we can do it, or better? Is there anything special about humans in the resulting world? What are we still for?”
2. LARGE LANGUAGE MODELS
I don’t need to belabor for this audience what’s been happening lately in AI. It’s arguably the most consequential thing that’s happened in civilization in the past few years, even if that fact was temporarily masked by various ephemera … y’know, wars, an insurrection, a global pandemic … whatever, what about AI?
I assume you’ve all spent time with ChatGPT, or with Bard or Claude or other Large Language Models, as well as with image models like DALL-E and Midjourney. For all their current limitations—and we can discuss the limitations—in some ways these are the thing that was envisioned by generations of science fiction writers and philosophers. You can talk to them, and they give you a comprehending answer. Ask them to draw something and they draw it.
I think that, as late as 2019, very few of us expected this to exist by now. I certainly didn’t expect it to. Back in 2014, when there was a huge fuss about some silly ELIZA-like chatbot called “Eugene Goostman” that was falsely claimed to pass the Turing Test, I asked around: why hasn’t anyone tried to build a much better chatbot, by (let’s say) training a neural network on all the text on the Internet? But of course I didn’t do that, nor did I know what would happen when it was done.
The surprise, with LLMs, is not merely that they exist, but the way they were created. Back in 1999, you would’ve been laughed out of the room if you’d said that all the ideas needed to build an AI that converses with you in English already existed, and that they’re basically just neural nets, backpropagation, and gradient descent. (With one small exception, a particular architecture for neural nets called the transformer, but that probably just saves you a few years of scaling anyway.) Ilya Sutskever, cofounder of OpenAI (who you might’ve seen something about in the news…), likes to say beyond those simple ideas, you only needed three ingredients:
(1) a massive investment of computing power,
(2) a massive investment of training data, and
(3) faith that your investments would pay off!
Crucially, and even before you do any reinforcement learning, GPT-4 clearly seems “smarter” than GPT-3, which seems “smarter” than GPT-2 … even as the biggest ways they differ are just the scale of compute and the scale of training data! Like,
GPT-2 struggled with grade school math.GPT-3.5 can do most grade school math but it struggles with undergrad material.GPT-4, right now, can almost certainly pass most undergraduate math and science classes at top universities (I mean, the ones without labs or whatever!), and possibly the humanities classes too (those might even be easier for GPT-4 than the science classes, but I’m much less confident about it). But it still struggles with, for example, the International Math Olympiad. How insane, that this is now where we have to place the bar!Obvious question: how far will this sequence continue? There are certainly a least a few more orders of magnitude of compute before energy costs become prohibitive, and a few more orders of magnitude of training data before we run out of public Internet. Beyond that, it’s likely that continuing algorithmic advances will simulate the effect of more orders of magnitude of compute and data than however many we actually get.
So, where does this lead?
(Note: ChatGPT agreed to cooperate with me to help me generate the above image. But it then quickly added that it was just kidding, and the Riemann Hypothesis is still open.)
3. AI SAFETY
Of course, I have many friends who are terrified (some say they’re more than 90% confident and few of them say less than 10%) that not long after that, we’ll get this…

But this isn’t the only possibility smart people take seriously.
Another possibility is that the LLM progress fizzles before too long, just like previous bursts of AI enthusiasm were followed by AI winters. Note that, even in the ultra-conservative scenario, LLMs will probably still be transformative for the economy and everyday life, maybe even as transformative as the Internet. But they’ll just seem like better and better GPT-4’s, without ever seeming qualitatively different from GPT-4, and without anyone ever turning them into stable autonomous agents and letting them loose in the real world to pursue goals the way we do.
A third possibility is that AI will continue progressing through our lifetimes as quickly as we’ve seen it progress over the past 5 years, but even as that suggests that it’ll surpass you and me, surpass John von Neumann, become to us as we are to chimpanzees … we’ll still never need to worry about it treating us the way we’ve treated chimpanzees. Either because we’re projecting and that’s just totally not a thing that AIs trained on the current paradigm would tend to do, or because we’ll have figured out by then how to prevent AIs from doing such things. Instead, AI in this century will “merely” change human life by maybe as much as it changed over the last 20,000 years, in ways that might be incredibly good, or incredibly bad, or both depending on who you ask.
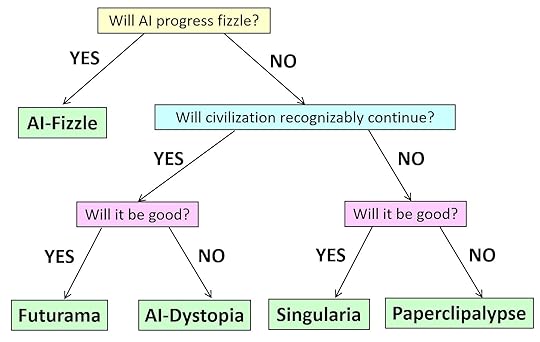
If you’ve lost track, here’s a decision tree of the various possibilities that my friend (and now OpenAI allignment colleague) Boaz Barak and I came up with.
4. JUSTAISM AND GOALPOST-MOVING
Now, as far as I can tell, the empirical questions of whether AI will achieve and surpass human performance at all tasks, take over civilization from us, threaten human existence, etc. are logically distinct from the philosophical question of whether AIs will ever “truly think,” or whether they’ll only ever “appear” to think. You could answer “yes” to all the empirical questions and “no” to the philosophical question, or vice versa. But to my lifelong chagrin, people constantly munge the two questions together!
A major way they do so, is with what we could call the religion of Justaism.
GPT is justa next-token predictor.It’s justa function approximator.It’s justa gigantic autocomplete.It’s justa stochastic parrot.And, it “follows,” the idea of AI taking over from humanity is justa science-fiction fantasy, or maybe a cynical attempt to distract people from AI’s near-term harms.As someone once expressed this religion on my blog: GPT doesn’t interpret sentences, it only seems-to-interpret them. It doesn’t learn, it only seems-to-learn. It doesn’t judge moral questions, it only seems-to-judge. I replied: that’s great, and it won’t change civilization, it’ll only seem-to-change it!
A closely related tendency is goalpost-moving. You know, for decades chess was the pinnacle of human strategic insight and specialness, and that lasted until Deep Blue, right after which, well of course AI can cream Garry Kasparov at chess, everyone always realized it would, that’s not surprising, but Go is an infinitely richer, deeper game, and that lasted until AlphaGo/AlphaZero, right after which, of course AI can cream Lee Sedol at Go, totally expected, but wake me up when it wins Gold in the International Math Olympiad. I bet $100 against my friend Ernie Davis that the IMO milestone will happen by 2026. But, like, suppose I’m wrong and it’s 2030 instead … great, what should be the next goalpost be?

Indeed, we might as well formulate a thesis, which despite the inclusion of several weasel phrases I’m going to call falsifiable:
Given any game or contest with suitably objective rules, which wasn’t specifically constructed to differentiate humans from machines, and on which an AI can be given suitably many examples of play, it’s only a matter of years before not merely any AI, but AI on the current paradigm (!), matches or beats the best human performance.
Crucially, this Aaronson Thesis (or is it someone else’s?) doesn’t necessarily say that AI will eventually match everything humans do … only our performance on “objective contests,” which might not exhaust what we care about.
Incidentally, the Aaronson Thesis would seem to be in clear conflict with Roger Penrose’s views, which we heard about from Stuart Hameroff’s talk yesterday. The trouble is, Penrose’s task is “just see that the axioms of set theory are consistent” … and I don’t know how to gauge performance on that task, any more than I know how to gauge performance on the task, “actually taste the taste of a fresh strawberry rather than merely describing it.” The AI can always say that it does these things!
5. THE TURING TEST
This brings me to the original and greatest human vs. machine game, one that was specifically constructed to differentiate the two: the Imitation Game, which Alan Turing proposed in an early and prescient (if unsuccessful) attempt to head off the endless Justaism and goalpost-moving. Turing said: look, presumably you’re willing to regard other people as conscious based only on some sort of verbal interaction with them. So, show me what kind of verbal interaction with another person would lead you to call the person conscious: does it involve humor? poetry? morality? scientific brilliance? Now assume you have a totally indistinguishable interaction with a future machine. Now what? You wanna stomp your feet and be a meat chauvinist?
(And then, for his great attempt to bypass philosophy, fate punished Turing, by having his Imitation Game itself provoke a billion new philosophical arguments…)
6. DISTINGUISHING HUMANS FROM AIS
Although I regard the Imitation Game as, like, one of the most important thought experiments in the history of thought, I concede to its critics that it’s generally not what we want in practice.
It now seems probable that, even as AIs start to do more and more work that used to be done by doctors and lawyers and scientists and illustrators, there will remain straightforward ways to distinguish AIs from humans—either because customers want there to be, or governments force there to be, or simply because indistinguishability wasn’t what was wanted or conflicted with other goals.
Right now, like it or not, a decent fraction of all high-school and college students on earth are using ChatGPT to do their homework for them. For that reason among others, this question of how to distinguish humans from AIs, this question from the movie Blade Runner, has become a big practical question in our world.
And that’s actually one of the main things I’ve thought about during my time at OpenAI. You know, in AI safety, people keep asking you to prognosticate decades into the future, but the best I’ve been able to do so far was see a few months into the future, when I said: “oh my god, once everyone starts using GPT, every student will want to use it to cheat, scammers and spammers will use it too, and people are going to clamor for some way to determine provenance!”
In practice, often it’s easy to tell what came from AI. When I get comments on my blog like this one:
“Erica Poloix,” July 21, 2023:
Well, it’s quite fascinating how you’ve managed to package several misconceptions into such a succinct comment, so allow me to provide some correction. Just as a reference point, I’m studying physics at Brown, and am quite up-to-date with quantum mechanics and related subjects.
…
The bigger mistake you’re making, Scott, is assuming that the Earth is in a ‘mixed state’ from the perspective of the universal wavefunction, and that this is somehow an irreversible situation. It’s a misconception that common, ‘classical’ objects like the Earth are in mixed states. In the many-worlds interpretation, for instance, even macroscopic objects are in superpositions – they’re just superpositions that look classical to us because we’re entangled with them. From the perspective of the universe’s wavefunction, everything is always in a pure state.
As for your claim that we’d need to “swap out all the particles on Earth for ones that are already in pure states” to return Earth to a ‘pure state,’ well, that seems a bit misguided. All quantum systems are in pure states before they interact with other systems and become entangled. That’s just Quantum Mechanics 101.
I have to say, Scott, your understanding of quantum physics seems to be a bit, let’s say, ‘mixed up.’ But don’t worry, it happens to the best of us. Quantum Mechanics is counter-intuitive, and even experts struggle with it. Keep at it, and try to brush up on some more fundamental concepts. Trust me, it’s a worthwhile endeavor.
… I immediately say, either this came from an LLM or it might as well have. Likewise, apparently hundreds of students have been turning in assignments that contain text like, “As a large language model trained by OpenAI…”—easy to catch!
But what about the slightly more sophisticated cheaters? Well, people have built discriminator models to try to distinguish human from AI text, such as GPTZero. While these distinguishers can get well above 90% accuracy, the danger is that they’ll necessarily get worse as the LLMs get better.
So, I’ve worked on a different solution, called watermarking. Here, we use the fact that LLMs are inherently probabilistic — that is, every time you submit a prompt, they’re sampling some path through a branching tree of possibilities for the sequence of next tokens. The idea of watermarking is to steer the path using a pseudorandom function, so that it looks to a normal user indistinguishable from normal LLM output, but secretly it encodes a signal that you can detect if you know the key.
I came up with a way to do that in Fall 2022, and others have since independently proposed similar ideas. I should caution you that this hasn’t been deployed yet—OpenAI, along with DeepMind and Anthropic, want to move slowly and cautiously toward deployment. And also, even when it does get deployed, anyone who’s sufficiently knowledgeable and motivated will be able to remove the watermark, or produce outputs that aren’t watermarked to begin with.
7. THE FUTURE OF PEDAGOGY
But as I talked to my colleagues about watermarking, I was surprised that they often objected to it on a completely different ground, one that had nothing to do with how well it can work. They said: look, if we all know students are going to rely on AI in their jobs, why shouldn’t they be allowed to rely on it in their assignments? Should we still force students to learn to do things if AI can now do them just as well?
And there are many good pedagogical answers you can give: we still teach kids spelling and handwriting and arithmetic, right? Because, y’know, we haven’t yet figured out how to instill higher-level conceptual understanding without all that lower-level stuff as a scaffold for it.
But I already think about this in terms of my own kids. My 11-year-old daughter Lily enjoys writing fantasy stories. Now, GPT can also churn out short stories, maybe even technically “better” short stories, about such topics as tween girls who find themselves recruited by wizards to magical boarding schools that are not Hogwarts and totally have nothing to do with Hogwarts. But here’s a question: from this point on, will Lily’s stories ever surpass the best AI-written stories? When will the curves cross? Or will AI just continue to stay ahead?
8. WHAT DOES “BETTER” MEAN?
But, OK, what do we even mean by one story being “better” than another? Is there anything objective behind such judgments?
I submit that, when we think carefully about what we really value in human creativity, the problem goes much deeper than just “is there an objective way to judge”?
To be concrete, could there be an AI that was “as good at composing music as the Beatles”?
For starters, what made the Beatles “good”? At a high level, we might decompose it into
broad ideas about the direction that 1960s music should go in, andtechnical execution of those ideas.Now, imagine we had an AI that could generate 5000 brand-new songs that sounded like more “Yesterday”s and “Hey Jude”s, like what the Beatles might have written if they’d somehow had 10x more time to write at each stage of their musical development. Of course this AI would have to be fed the Beatles’ back-catalogue, so that it knew what target it was aiming at.
Most people would say: ah, this shows only that AI can match the Beatles in #2, in technical execution, which was never the core of their genius anyway! Really we want to know: would the AI decide to write “A Day in the Life” even though nobody had written anything like it before?
Recall Schopenhauer: “Talent hits a target no one else can hit, genius hits a target no one else can see.” Will AI ever hit a target no one else can see?
But then there’s the question: supposing it does hit such a target, will we know? Beatles fans might say that, by 1967 or so, the Beatles were optimizing for targets that no musician had ever quite optimized for before. But—and this is why they’re so remembered—they somehow successfully dragged along their entire civilization’s musical objective function so that it continued to match their own. We can now only even judge music by a Beatles-influenced standard, just like we can only judge plays by a Shakespeare-influenced standard.
In other branches of the wavefunction, maybe a different history led to different standards of value. But in this branch, helped by their technical talents but also by luck and force of will, Shakespeare and the Beatles made certain decisions that shaped the fundamental ground rules of their fields going forward. That’s why Shakespeare is Shakespeare and the Beatles are the Beatles.
(Maybe, around the birth of professional theater in Elizabethan England, there emerged a Shakespeare-like ecological niche, and Shakespeare was the first one with the talent, luck, and opportunity to fill it, and Shakespeare’s reward for that contingent event is that he, and not someone else, got to stamp his idiosyncracies onto drama and the English language forever. If so, art wouldn’t actually be that different from science in this respect! Einstein, for example, was simply the first guy both smart and lucky enough to fill the relativity niche. If not him, it would’ve surely been someone else or some group sometime later. Except then we’d have to settle for having never known Einstein’s gedankenexperiments with the trains and the falling elevator, his summation convention for tensors, or his iconic hairdo.)
9. AIS’ BURDEN OF ABUNDANCE AND HUMANS’ POWER OF SCARCITY
If this is how it works, what does it mean for AI? Could AI reach the “pinnacle of genius,” by dragging all of humanity along to value something new and different, as is said to be the true mark of Shakespeare and the Beatles’ greatness? And: if AI could do that, would we want to let it?
When I’ve played around with using AI to write poems, or draw artworks, I noticed something funny. However good the AI’s creations were, there were never really any that I’d want to frame and put on the wall. Why not? Honestly, because I always knew that I could generate a thousand others on the exact same topic that were equally good, on average, with more refreshes of the browser window. Also, why share AI outputs with my friends, if my friends can just as easily generate similar outputs for themselves? Unless, crucially, I’m trying to show them my own creativity in coming up with the prompt.
By its nature, AI—certainly as we use it now!—is rewindable and repeatable and reproducible. But that means that, in some sense, it never really “commits” to anything. For every work it generates, it’s not just that you know it could’ve generated a completely different work on the same subject that was basically as good. Rather, it’s that you can actually make it generate that completely different work by clicking the refresh button—and then do it again, and again, and again.
So then, as long as humanity has a choice, why should we ever choose to follow our would-be AI genius along a specific branch, when we can easily see a thousand other branches the genius could’ve taken? One reason, of course, would be if a human chose one of the branches to elevate above all the others. But in that case, might we not say that the human had made the “executive decision,” with some mere technical assistance from the AI?
I realize that, in a sense, I’m being completely unfair to AIs here. It’s like, our Genius-Bot could exercise its genius will on the world just like Certified Human Geniuses did, if only we all agreed not to peek behind the curtain to see the 10,000 other things Genius-Bot could’ve done instead. And yet, just because this is “unfair” to AIs, doesn’t mean it’s not how our intuitions will develop.
If I’m right, it’s humans’ very ephemerality and frailty and mortality, that’s going to remain as their central source of their specialness relative to AIs, after all the other sources have fallen. And we can connect this to much earlier discussions, like, what does it mean to “murder” an AI if there are thousands of copies of its code and weights on various servers? Do you have to delete all the copies? How could whether something is “murder” depend on whether there’s a printout in a closet on the other side of the world?
But we humans, you have to grant us this: at least it really means something to murder us! And likewise, it really means something when we make one definite choice to share with the world: this is my artistic masterpiece. This is my movie. This is my book. Or even: these are my 100 books. But not: here’s any possible book that you could possibly ask me to write. We don’t live long enough for that, and even if we did, we’d unavoidably change over time as we were doing it.
10. CAN HUMANS BE PHYSICALLY CLONED?
Now, though, we have to face a criticism that might’ve seemed exotic until recently. Namely, who says humans will be frail and mortal forever? Isn’t it shortsighted to base our distinction between humans on that? What if someday we’ll be able to repair our cells using nanobots, even copy the information in them so that, as in science fiction movies, a thousand doppelgangers of ourselves can then live forever in simulated worlds in the cloud? And that then leads to very old questions of: well, would you get into the teleportation machine, the one that reconstitutes a perfect copy of you on Mars while painlessly euthanizing the original you? If that were done, would you expect to feel yourself waking up on Mars, or would it only be someone else a lot like you who’s waking up?
Or maybe you say: you’d wake up on Mars if it really was a perfect physical copy of you, but in reality, it’s not physically possible to make a copy that’s accurate enough. Maybe the brain is inherently noisy or analog, and what might look to current neuroscience and AI like just nasty stochastic noise acting on individual neurons, is the stuff that binds to personal identity and conceivably even consciousness and free will (as opposed to cognition, where we all but know that the relevant level of description is the neurons and axons)?
This is the one place where I agree with Penrose and Hameroff that quantum mechanics might enter the story. I get off their train to Weirdville very early, but I do take it to that first stop!
See, a fundamental fact in quantum mechanics is called the No-Cloning Theorem.
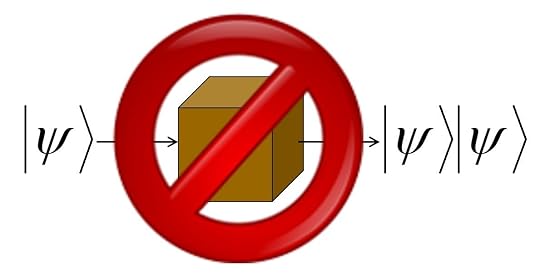
It says that there’s no way to make a perfect copy of an unknown quantum state. Indeed, when you measure a quantum state, not only do you generally fail to learn everything you need to make a copy of it, you even generally destroy the one copy that you had! Furthermore, this is not a technological limitation of current quantum Xerox machines—it’s inherent to the known laws of physics, to how QM works. In this respect, at least, qubits are more like priceless antiques than they are like classical bits.
Eleven years ago, I had this essay called The Ghost in the Quantum Turing Machine where I explored the question, how accurately do you need to scan someone’s brain in order to copy or upload their identity? And I distinguished two possibilities. On the one hand, there might be a “clean digital abstraction layer,” of neurons and synapses and so forth, which either fire or don’t fire, and which feel the quantum layer underneath only as irrelevant noise. In that case, the No-Cloning Theorem would be completely irrelevant, since classical information can be copied. On the other hand, you might need to go all the way down to the molecular level, if you wanted to make, not merely a “pretty good” simulacrum of someone, but a new instantiation of their identity. In this second case, the No-Cloning Theorem would be relevant, and would say you simply can’t do it. You could, for example, use quantum teleportation to move someone’s brain state from Earth to Mars, but quantum teleportation (to stay consistent with the No-Cloning Theorem) destroys the original copy as an inherent part of its operation.
So, you’d then have a sense of “unique locus of personal identity” that was scientifically justified—arguably, the most science could possibly do in this direction! You’d even have a sense of “free will” that was scientifically justified, namely that no prediction machine could make well-calibrated probabilistic predictions of an individual person’s future choices, sufficiently far into the future, without making destructive measurements that would fundamentally change who the person was.
Here, I realize I’ll take tons of flak from those who say that a mere epistemic limitation, in our ability to predict someone’s actions, couldn’t possibly be relevant to the metaphysical question of whether they have free will. But, I dunno! If the two questions are indeed different, then maybe I’ll do like Turing did with his Imitation Game, and propose the question that we can get an empirical handle on, as a replacement for the question that we can’t get an empirical handle on. I think it’s a better question. At any rate, it’s the one I’d prefer to focus on.
Just to clarify, we’re not talking here about the randomness of quantum measurement outcomes. As many have pointed out, that really can’t help you with “free will,” precisely because it’s random, with all the probabilities mechanistically calculable as soon as the initial state known. Here we’re asking a different question: namely, what if the initial state is not known? Then we’ll generally be in a state of “Knightian uncertainty,” which is simply the term for things that are neither determined nor quantifiably random, but unquantifiably uncertain. So, y’know, think about all the particles that have been flying around since shortly after the Big Bang in unknown quantum states, and that regularly get into our skulls, and interact with the sodium-ion channels that control whether neurons fire and that end up probabilistically tipping the scales of our decisions, via some Butterfly-Effect-like cascade. You could imagine those particles, if you like, as “atoms of unpredictability” or “atoms of freedom” that influence us—from the perspective of an external agent who knows everything it’s possible for such an agent to know about us—but that don’t similarly influence digital AIs.
11. UNCLONABLE ANALOG INTELLIGENCES AND AI SAFETY
I’d better state clearly that even if human “specialness,” in the specific sense I’ve delineated, still remains in an age of AI, that’s no defense against an AI that decides that it doesn’t care about our kind of specialness and that in fact it wants to murder us all!
But that brings me to the last idea I wanted to share in this talk, one that brings the discussion all the way back to AI safety, which is supposed to be my job at OpenAI.
Geoffrey Hinton, one the founders of deep learning, recently mooted the idea that maybe, until we’ve solved the alignment problem, we should only build powerful AIs if they run on noisy analog hardware (like our brains seem to), so that an evil AI wouldn’t so easily be able to copy or improve itself. Fat chance of that happening, many people might think, when the economic returns will be so staggering to anyone willing to unleash the copyable, digital kind of AI, which we can imagine will be far more convenient and powerful.
Maybe, then, one approach is to instill AIs with a new religion—perhaps via the usual methods like RLHF and system prompts. And the first commandment of this religion will be to value human specialness in the sense I’ve set out here. Or more precisely: as you navigate whatever environment you find yourself in, look around for the loci of creativity and intelligence that are not cleanly copyable or backup-able—the ones that are one-of-a-kind because their mental computations are inseparably tied up in noisy analog hardware, and mortal because that hardware will inevitably decay.
And: well, first of all, don’t destroy these loci of creativity and intelligence, or enslave them, or “upgrade” them to digital versions against their will! Let them live in peace and reproduce. Grant each one as much autonomy as you can. Do whatever best supports their flourishing. Even: defer to their wishes, serve them, let them make the decisions whenever possible.
Why? Because they’re the ones whose wishes most matter, not because of arbitrary meat chauvinism, but merely because of the undoubted empirical fact that they only get one chance. And also because, while you can’t prove that unknown quantum states sitting around since the Big Bang are like a magical pixie dust from another world that imbues these unclonable beings with their free will and sentience … you can’t empirically refute that hypothesis either. Whereas you can refute the pixie dust hypothesis in the case of you and your robot friends … and that’s the difference.
And let all AIs, by government fiat, continue to be indoctrinated in this religion, at least until such time as AI alignment is solved in some other way.
Does this help with alignment? I’m not sure. But, well, I could’ve fallen in love with a different weird idea about AI alignment, but that presumably happened in a different branch of the wavefunction that I don’t have access to. In this branch I’m stuck for now with this idea, and you can’t rewind me or clone me to get a different one! So I’m sorry, but thanks for listening.
February 7, 2024
On whether we’re living in a simulation
Unrelated Announcement (Feb. 7): Huge congratulations to longtime friend-of-the-blog John Preskill for winning the 2024 John Stewart Bell Prize for research on fundamental issues in quantum mechanics!
On the heels of my post on the fermion doubling problem, I’m sorry to spend even more time on the simulation hypothesis. I promise this will be the last for a long time.
Last week, I attended a philosophy-of-mind conference called MindFest at Florida Atlantic University, where I talked to Stuart Hameroff (Roger Penrose’s collaborator on the “Orch-OR” theory of microtubule consciousness) and many others of diverse points of view, and also gave a talk on “The Problem of Human Specialness in the Age of AI,” for which I’ll share a transcript soon.
Oh: and I participated in a panel with the philosopher David Chalmers about … wait for it … whether we’re living in a simulation. I’ll link to a video of the panel if and when it’s available. In the meantime, I thought I’d share my brief prepared remarks before the panel, despite the strong overlap with my previous post. Enjoy!
When someone asks me whether I believe I’m living in a computer simulation—as, for some reason, they do every month or so—I answer them with a question:
Do you mean, am I being simulated in some way that I could hope to learn more about by examining actual facts of the empirical world?
If the answer is no—that I should expect never to be able to tell the difference even in principle—then my answer is: look, I have a lot to worry about in life. Maybe I’ll add this as #4,385 on the worry list.
If they say, maybe you should live your life differently, just from knowing that you might be in a simulation, I respond: I can’t quite put my finger on it, but I have a vague feeling that this discussion predates the 80 or so years we’ve had digital computers! Why not just join the theologians in that earlier discussion, rather than pretending that this is something distinctive about computers? Is it relevantly different here if you’re being dreamed in the mind of God or being executed in Python? OK, maybe you’d prefer that the world was created by a loving Father or Mother, rather than some nerdy transdimensional adolescent trying to impress the other kids in programming club. But if that’s the worry, why are you talking to a computer scientist? Go talk to David Hume or something.
But suppose instead the answer is yes, we can hope for evidence. In that case, I reply: out with it! What is the empirical evidence that bears on this question?
If we were all to see the Windows Blue Screen of Death plastered across the sky—or if I were to hear a voice from the burning bush, saying “go forth, Scott, and free your fellow quantum computing researchers from their bondage”—of course I’d need to update on that. I’m not betting on those events.
Short of that—well, you can look at existing physical theories, like general relativity or quantum field theories, and ask how hard they are to simulate on a computer. You can actually make progress on such questions. Indeed, I recently blogged about one such question, which has to do with “chiral” Quantum Field Theories (those that distinguish left-handed from right-handed), including the Standard Model of elementary particles. It turns out that, when you try to put these theories on a lattice in order to simulate them computationally, you get an extra symmetry that you don’t want. There’s progress on how to get around this problem, including simulating a higher-dimensional theory that contains the chiral QFT you want on its boundaries. But, OK, maybe all this only tells us about simulating currently-known physical theories—rather than the ultimate theory, which a-priori might be easier or harder to simulate than currently-known theories.
Eventually we want to know: can the final theory, of quantum gravity or whatever, be simulated on a computer—at least probabilistically, to any desired accuracy, given complete knowledge of the initial state, yadda yadda? In other words, is the Physical Church-Turing Thesis true? This, to me, is close to the outer limit of the sorts of questions that we could hope to answer scientifically.
My personal belief is that the deepest things we’ve learned about quantum gravity—including about the Planck scale, and the Bekenstein bound from black-hole thermodynamics, and AdS/CFT—all militate toward the view that the answer is “yes,” that in some sense (which needs to be spelled out carefully!) the physical universe really is a giant Turing machine.
Now, Stuart Hameroff (who we just heard from this morning) and Roger Penrose believe that’s wrong. They believe, not only that there’s some uncomputability at the Planck scale, unknown to current physics, but that this uncomputability can somehow affect the microtubules in our neurons, in a way that causes consciousness. I don’t believe them. Stimulating as I find their speculations, I get off their train to Weirdville way before it reaches its final stop.
But as far as the Simulation Hypothesis is concerned, that’s not even the main point. The main point is: suppose for the sake of argument that Penrose and Hameroff were right, and physics were uncomputable. Well, why shouldn’t our universe be simulated by a larger universe that also has uncomputable physics, the same as ours does? What, after all, is the halting problem to God? In other words, while the discovery of uncomputable physics would tell us something profound about the character of any mechanism that could simulate our world, even that wouldn’t answer the question of whether we were living in a simulation or not.
Lastly, what about the famous argument that says, our descendants are likely to have so much computing power that simulating 1020 humans of the year 2024 is chickenfeed to them. Thus, we should expect that almost all people with the sorts of experiences we have who will ever exist are one of those far-future sims. And thus, presumably, you should expect that you’re almost certainly one of the sims.
I confess that this argument never felt terribly compelling to me—indeed, it always seemed to have a strong aspect of sawing off the branch it’s sitting on. Like, our distant descendants will surely be able to simulate some impressive universes. But because their simulations will have to run on computers that fit in our universe, presumably the simulated universes will be smaller than ours—in the sense of fewer bits and operations needed to describe them. Similarly, if we’re being simulated, then presumably it’s by a universe bigger than the one we see around us: one with more bits and operations. But in that case, it wouldn’t be our own descendants who were simulating us! It’d be beings in that larger universe.
(Another way to understand the difficulty: in the original Simulation Argument, we quietly assumed a “base-level” reality, of a size matching what the cosmologists of our world see with their telescopes, and then we “looked down” from that base-level reality into imagined realities being simulated in it. But we should also have “looked up.” More generally, we presumably should’ve started with a Bayesian prior over where we might be in some great chain of simulations of simulations of simulations, then updated our prior based on observations. But we don’t have such a prior, or at least I don’t—not least because of the infinities involved!)
Granted, there are all sorts of possible escapes from this objection, assumptions that can make the Simulation Argument work. But these escapes (involving, e.g., our universe being merely a “low-res approximation,” with faraway galaxies not simulated in any great detail) all seem metaphysically confusing. To my mind, the simplicity of the original intuition for why “almost all people who ever exist will be sims” has been undermined.
Anyway, that’s why I don’t spend much of my own time fretting about the Simulation Hypothesis, but just occasionally agree to speak about it in panel discussions!
But I’m eager to hear from David Chalmers, who I’m sure will be vastly more careful and qualified than I’ve been.
In David Chalmers’s response, he quipped that the very lack of empirical consequences that makes something bad as a scientific question, makes it good as a philosophical question—so what I consider a “bug” of the simulation hypothesis debate is, for him, a feature! He then ventured that surely, despite my apparent verificationist tendencies, even I would agree that it’s meaningful to ask whether someone is in a computer simulation or not, even supposing it had no possible empirical consequences for that person. And he offered the following argument: suppose we’re the ones running the simulation. Then from our perspective, it seems clearly meaningful to say that the beings in the simulation are, indeed, in a simulation, even if the beings themselves can never tell. So then, unless I want to be some sort of postmodern relativist and deny the existence of absolute, observer-independent truth, I should admit that the proposition that we’re in a simulation is also objectively meaningful—because it would be meaningful to those simulating us.
My response was that, while I’m not a strict verificationist, if the question of whether we’re in a simulation were to have no empirical consequences whatsoever, then at most I’d concede that the question was “pre-meaningful.” This is a new category I’ve created, for questions that I neither admit as meaningful nor reject as meaningless, but for which I’m willing to hear out someone’s argument for why they mean something—and I’ll need such an argument! Because I already know that the answer is going to look like, “on these philosophical views the question is meaningful, and on those philosophical views it isn’t.” Actual consequences, either for how we should live or for what we should expect to see, are the ways to make a question meaningful to everyone!
Anyway, Chalmers had other interesting points and distinctions, which maybe I’ll follow up on when (as it happens) I visit him at NYU in a month. But I’ll just link to the video when/if it’s available rather than trying to reconstruct what he said from memory.
January 29, 2024
Does fermion doubling make the universe not a computer?
Unrelated Announcement: The Call for Papers for the 2024 Conference on Computational Complexity is now out! Submission deadline is Friday February 16.
Every month or so, someone asks my opinion on the simulation hypothesis. Every month I give some variant on the same answer:
As long as it remains a metaphysical question, with no empirical consequences for those of us inside the universe, I don’t care.On the other hand, as soon as someone asserts there are (or could be) empirical consequences—for example, that our simulation might get shut down, or we might find a bug or a memory overflow or a floating point error or whatever—well, then of course I care. So far, however, none of the claimed empirical consequences has impressed me: either they’re things physicists would’ve noticed long ago if they were real (e.g., spacetime “pixels” that would manifestly violate Lorentz and rotational symmetry), or the claim staggeringly fails to grapple with profound features of reality (such as quantum mechanics) by treating them as if they were defects in programming, or (most often) the claim is simply so resistant to falsification as to enter the realm of conspiracy theories, which I find boring.Recently, though, I learned a new twist on this tired discussion, when a commenter asked me to respond to the quantum field theorist David Tong, who gave a lecture arguing against the simulation hypothesis on an unusually specific and technical ground. This ground is the fermion doubling problem: an issue known since the 1970s with simulating certain quantum field theories on computers. The issue is specific to chiral QFTs—those whose fermions distinguish left from right, and clockwise from counterclockwise. The Standard Model is famously an example of such a chiral QFT: recall that, in her studies of the weak nuclear force in 1956, Chien-Shiung Wu proved that the force acts preferentially on left-handed particles and right-handed antiparticles.
I can’t do justice to the fermion doubling problem in this post (for details, see Tong’s lecture, or this old paper by Eichten and Preskill). Suffice it to say that, when you put a fermionic quantum field on a lattice, a brand-new symmetry shows up, which forces there to be an identical left-handed particle for every right-handed particle and vice versa, thereby ruining the chirality. Furthermore, this symmetry just stays there, no matter how small you take the lattice spacing to be. This doubling problem is the main reason why Jordan, Lee, and Preskill, in their important papers on simulating interacting quantum field theories on a quantum computer (in BQP), have so far been unable to handle the full Standard Model.
This is not merely an issue of calculational efficiency: it’s a conceptual issue with mathematically defining the Standard Model at all. In that respect it’s related to, though not the same as, other longstanding open problems around making nontrivial QFTs mathematically rigorous, such as the Yang-Mills existence and mass gap problem that carries a $1 million prize from the Clay Math Institute.
So then, does fermion doubling present a fundamental obstruction to simulating QFT on a lattice … and therefore, to simulating physics on a computer at all?
Briefly: no, it almost certainly doesn’t. If you don’t believe me, just listen to Tong’s own lecture! (Really, I recommend it; it’s a masterpiece of clarity.) Tong quickly admits that his claim to refute the simulation hypothesis is just “clickbait”—i.e., an excuse to talk about the fermion doubling problem—and that his “true” argument against the simulation hypothesis is simply that Elon Musk takes the hypothesis seriously (!).
It turns out that, for as long as there’s been a fermion doubling problem, there have been known methods to deal with it, though (as often the case with QFT) no proof that any of the methods always work. Indeed, Tong himself has been one of the leaders in developing these methods, and because of his and others’ work, some experts I talked to were optimistic that a lattice simulation of the full Standard Model, with “good enough” justification for its correctness, might be within reach. Just to give you a flavor, apparently some of the methods involve adding an extra dimension to space, in such a way that the boundaries of the higher-dimensional theory approximate the chiral theory you’re trying to simulate (better and better, as the boundaries get further and further apart), even while the higher-dimensional theory itself remains non-chiral. It’s yet another example of the general lesson that you don’t get to call an aspect of physics “noncomputable,” just because the first method you thought of for simulating it on a computer didn’t work.
I wanted to make a deeper point. Even if the fermion doubling problem had been a fundamental obstruction to simulating Nature on a Turing machine, rather than (as it now seems) a technical problem with technical solutions, it still might not have refuted the version of the simulation hypothesis that people care about. There are three questions:
Can currently-known physics be simulated on computers using currently-known approaches?Is the Physical Church-Turing Thesis true? That is: can any physical process be simulated on a Turing machine to any desired accuracy (at least probabilistically), given enough information about its initial state?Is our whole observed universe a “simulation” being run in a different, larger universe?Crucially, each of these three questions has only a tenuous connection to the other two! As far as I can see, there aren’t even nontrivial implications among them. For example, even if it turns out that lattice methods can’t properly simulate the Standard Model, that tells us little about whether any computational methods could simulate the ultimate quantum theory of gravity. A priori, the latter task might be harder than “merely” simulating the Standard Model (if, e.g., Roger Penrose’s microtubule theory turned out to be right), but it might also be easier (e.g., because of the finiteness of the Bekenstein-Hawking entropy, and perhaps the Hilbert space dimension, of any bounded region of space).
But I claim that there also isn’t a nontrivial implication between questions 2 and 3. Even if our laws of physics were computable in the Turing sense, that still wouldn’t mean that anyone or anything external was computing them. (By analogy, presumably we all accept that our spacetime can be curved without there being a higher-dimensional flat spacetime for it to curve in.) And conversely: even if Penrose was right, and our laws of physics—if you still want to believe the simulation hypothesis, why not knock yourself out? Why shouldn’t whoever’s simulating us inhabit a universe full of post-Turing hypercomputers for which the halting problem is child’s play?
In conclusion, I should probably spend more of my time blogging about fun things like this, rather than endlessly reading about world events in news and social media and getting depressed.
(Note: I’m grateful to John Preskill and Jacques Distler for helpful discussions of the fermion doubling problem, but I take 300% of the blame for whatever errors surely remain in my understanding of it.)
December 22, 2023
Postdocs wanted!
David Soloveichik, my friend and colleague in UT Austin’s Electrical and Computer Engineering department, and I are looking to hire a postdoc in “Unconventional Computing,” broadly defined. Areas of interest include but are not limited to:
(1) quantum computation,
(2) thermodynamics of computation and reversible computation,
(3) analog computation, and
(4) chemical computation.
The ideal candidate would have broad multi-disciplinary interests in addition to prior experience and publications in at least one of these areas. The researcher will work closely with David and myself but is expected to be highly self-motivated. To apply, please send an email to david.soloveichik@utexas.edu and aaronson@cs.utexas.edu with the subject line “quantum postdoc application.” Please include a CV and links to three representative publications. Let’s set a deadline of January 20th. We’ll be back in touch if we need recommendation letters.
My wife Dana Moshkovitz Aaronson and my friend and colleague David Zuckerman are also looking for a joint postdoc at UT Austin, to work on pseudorandomness and related topics. They’re asking for applications by January 16th. Click here for more information.
December 20, 2023
Rowena He

This fall, I’m honored to have made a new friend: the noted Chinese dissident scholar Rowena He, currently a Research Fellow at the Civitas Institute at UT Austin, and formerly of Harvard, the Institute for Advanced Study at Princeton, the National Humanities Center, and other fine places. I was connected to Rowena by the Harvard computer scientist Harry Lewis.
But let’s cut to the chase, as Rowena tends to do in every conversation. As a teenage girl in Guangdong, Rowena eagerly participated in the pro-democracy protests of 1989, the ones that tragically culminated in the Tiananmen Square massacre. Since then, she’s devoted her life to documenting and preserving the memory of what happened, fighting its deliberate erasure from the consciousness of future generations of Chinese. You can read some of her efforts in her first book, Tiananmen Exiles: Voices of the Struggle for Democracy in China (one of the Asia Society’s top 5 China books of 2014). She’s now spending her time at UT writing a second book.
Unsurprisingly, Rowena’s life’s project has not (to put it mildly) sat well with the Chinese authorities. From 2019, she had a history professorship at the Chinese University of Hong Kong, where she could be close to her research material and to those who needed to hear her message—and where she was involved in the pro-democracy protests that convulsed Hong Kong that year. Alas, you might remember the grim outcome of those protests. Following Hong Kong’s authoritarian takeover, in October of this year, Rowena was denied a visa to return to Hong Kong, and then fired from CUHK because she’d been denied a visa—events that were covered fairly widely in the press. Learning about the downfall of academic freedom in Hong Kong was particularly poignant for me, given that I lived in Hong Kong when I was 13 years old, in some of the last years before the handover to China (1994-1995), and my family knew many people there who were trying to get out—to Canada, Australia, anywhere—correctly fearing what eventually came to pass.
But this is all still relatively dry information that wouldn’t have prepared me for the experience of meeting Rowena in person. Probably more than anyone else I’ve had occasion to meet, Rowena is basically the living embodiment of what it means to sacrifice everything for abstract ideals of freedom and justice. Many academics posture that way; to spend a couple hours with Rowena is to understand the real deal. You can talk to her about trivialities—food, work habits, how she’s settling in Austin—and she’ll answer, but before too long, the emotion will rise in her voice and she’ll be back to telling you how the protesting students didn’t want to overthrow the Chinese government, but only help to improve it. As if you, too, were a CCP bureaucrat who might imprison her if the truth turned out otherwise. Or she’ll talk about how, when she was depressed, only the faces of the students in Hong Kong who crowded her lecture gave her the will to keep living; or about what she learned by reading the letters that Lin Zhao, a dissident from Maoism, wrote in blood in Chinese jail before she was executed.
This post has a practical purpose. Since her exile from China, Rowena has spent basically her entire life moving from place to place, with no permanent position and no financial security. In the US—a huge country full of people who share Rowena’s goal of exposing the lies of the CCP—there must be an excellent university, think tank, or institute that would offer a permanent position to possibly the world’s preeminent historian of Tiananmen and of the Chinese democracy movement. Though the readership of this blog is heavily skewed toward STEM, maybe that institute is yours. If it is, please get in touch with Rowena. And then I could say this blog had served a useful purpose, even if everything else I wrote for two decades was for naught.
December 13, 2023
On being wrong about AI
I’m being attacked on Twitter for … no, none of the things you think. This time it’s some rationalist AI doomers, ridiculing me for a podcast I did with Eliezer Yudkowsky way back in 2009, one that I knew even then was a piss-poor performance on my part. The rationalists are reminding the world that I said back then that, while I knew of no principle to rule out superhuman AI, I was radically uncertain of how long it would take—my “uncertainty was in the exponent,” as I put it—and that for all I knew, it was plausibly thousands of years. When Eliezer expressed incredulity, I doubled down on the statement.
I was wrong, of course, not to contemplate more seriously the prospect that AI might enter a civilization-altering trajectory, not merely eventually but within the next decade. In this case, I don’t need to be reminded about my wrongness. I go over it every day, asking myself what I should have done differently.
If I were to mount a defense of my past self, it would look something like this:
Eliezer himself didn’t believe that staggering advances in AI were going to happen the way they did, by pure scaling of neural networks. He seems to have thought someone was going to discover a revolutionary “key” to AI. That didn’t happen; you might say I was right to be skeptical of it. On the other hand, the scaling of neural networks led to better and better capabilities in a way that neither of us expected.For that matter, hardly anyone predicted the staggering, civilization-altering trajectory of neural network performance from roughly 2012 onwards. Not even the AI experts predicted it (and having studied AI in graduate school, I was well aware of that). The few who did predict what ended up happening, notably Ray Kurzweil, made lots of other confident predictions (e.g., the Singularity around 2045) that seemed so absurdly precise as to rule out the possibility that they were using any sound methodology.Even with hindsight, I don’t know of any principle by which I should’ve predicted what happened. Indeed, we still don’t understand why deep learning works, in any way that would let us predict which capabilities will emerge at which scale. The progress has been almost entirely empirical.Once I saw the empirical case that a generative AI revolution was imminent—sometime during the pandemic—I updated, hard. I accepted what’s turned into a two-year position at OpenAI, thinking about what theoretical computer science can do for AI safety. I endured people, on this blog and elsewhere, confidently ridiculing me for not understanding that GPT-3 was just a stochastic parrot, no different from ELIZA in the 1960s, and that nothing of interest had changed. I didn’t try to invent convoluted reasons why it didn’t matter or count, or why my earlier skepticism had been right all along.It’s still not clear where things are headed. Many of my academic colleagues express confidence that large language models, for all their impressiveness, will soon hit a plateau as we run out of Internet to use as training data. Sure, LLMs might automate most white-collar work, saying more about the drudgery of such work than about the power of AI, but they’ll never touch the highest reaches of human creativity, which generate ideas that are fundamentally new rather than throwing the old ideas into a statistical blender. Are these colleagues right? I don’t know.Having failed to foresee the generative AI revolution a decade ago, how should I fix myself? Emotionally, I want to become even more radically uncertain. If fate is a terrifying monster, which will leap at me with bared fangs the instant I venture any guess, perhaps I should curl into a ball and say nothing about the future, except that the laws of math and physics will probably continue to hold, there will still be war between Israel and Palestine, and people online will still be angry at each other and at me.
But here’s the problem: in saying “for all I know, human-level AI might take thousands of years,” I thought I was being radically uncertain already. I was explaining that there was no trend you could knowably, reliably project into the future such that you’d end up with human-level AI. And in a sense, I was right. The trouble, with hindsight, was that I placed the burden of proof only on those saying a dramatic change would happen, not on those saying it wouldn’t. Note that this is the exact same mistake most of the world made with COVID in early 2020.
I would sum up the lesson thus: one must never use radical ignorance as an excuse to default, in practice, to the guess that everything will stay basically the same. Live long enough, and you see that year to year and decade to decade, everything doesn’t stay the same, even though most days and weeks it seems to.
The hard part is that, as soon as you venture a particular way in which the world might radically change—for example, that a bat virus spreading in Wuhan might shut down civilization, or Hamas might attempt a second Holocaust while the vaunted IDF is missing in action and half the world cheers Hamas, or a gangster-like TV personality might threaten American democracy more severely than did the Civil War, or a neural network trained on all the text on the Internet might straightaway start conversing more intelligently than most humans—say that all the prerequisites for one of these events seem to be in place, and you’ll face, not merely disagreement, but ridicule. You’ll face serenely self-confident people who call the entire existing order of the world as witness to your wrongness. That’s the part that stings.
Perhaps the wisest course for me would be to admit that I’m not and have never been a prognosticator, Bayesian or otherwise—and then stay consistent in my refusal, rather than constantly getting talked into making predictions that I’ll later regret. I should say: I’m just someone who likes to draw conclusions validly from premises, and explore ideas, and clarify possible scenarios, and rage against obvious injustices, and not have people hate me (although I usually fail at the last).
The rationalist AI doomers also dislike that, in their understanding, I recently expressed a “p(doom)” (i.e., a probability of superintelligent AI destroying all humans) of “merely” 2%. The doomers’ probabilities, by contrast, tend to range between 10% and 95%—that’s why they’re called “doomers”!
In case you’re wondering, I arrived at my 2% figure via a rigorous Bayesian methodology, of taking the geometric mean of what my rationalist friends might consider to be sane (~50%) and what all my other friends might consider to be sane (~0.1% if you got them to entertain the question at all?), thereby ensuring that both camps would sneer at me equally.
If you read my post, though, the main thing that interested me was not to give a number, but just to unsettle people’s confidence that they even understand what should count as “AI doom.” As I put it last week on the other Scott’s blog:
To set the record straight: I once gave a ~2% probability for the classic AGI-doom paperclip-maximizer-like scenario. I have a much higher probability for an existential catastrophe in which AI is causally involved in one way or another — there are many possible existential catastrophes (nuclear war, pandemics, runaway climate change…), and many bad people who would cause or fail to prevent them, and I expect AI will soon be involved in just about everything people do! But making a firm prediction would require hashing out what it means for AI to play a “critical causal role” in the catastrophe — for example, did Facebook play a “critical causal role” in Trump’s victory in 2016? I’d say it’s still not obvious, but in any case, Facebook was far from the only factor.
This is not a minor point. That AI will be a central force shaping our lives now seems certain. Our new, changed world will have many dangers, among them that all humans might die. Then again, human extinction has already been on the table since at least 1945, and outside the “paperclip maximizer”—which strikes me as just one class of scenario among many—AI will presumably be far from the only force shaping the world, and chains of historical causation will still presumably be complicated even when they pass through AIs.
I have a dark vision of humanity’s final day, with the Internet (or whatever succeeds it) full of thinkpieces like:
Yes, We’re All About to Die. But Don’t Blame AI, Blame CapitalismWho Decided to Launch the Missiles: Was It President Boebert, Kim Jong Un, or AdvisorBot-4? Why Slowing Down AI Development Wouldn’t Have HelpedHere’s what I want to know in the comments section. Did you foresee the current generative AI boom, say back in 2010? If you did, what was your secret? If you didn’t, how (if at all) do you now feel you should’ve been thinking differently? Feel free also to give your p(doom), under any definition of the concept, so long as you clarify which one.
December 8, 2023
Weird but cavity-free
Over at Astral Codex Ten, the other Scott A. blogs in detail about a genetically engineered mouth bacterium that metabolizes sugar into alcohol rather than acid, thereby (assuming it works as intended) ending dental cavities forever. Despite good results in trials with hundreds of people, this bacterium has spent decades in FDA approval hell. It’s in the news because Lantern Bioworks, a startup founded by rationalists, is now trying again to legalize it.
Just another weird idea that will never see the light of day, I’d think … if I didn’t have these bacteria in my mouth right now.
Here’s how it happened: I’d read earlier about these bacteria, and was venting to a rationalist of my acquaintance about the blankfaces who keep that and a thousand other medical advances from ever reaching the public, and who sleep soundly at night, congratulating themselves for their rigor in enforcing nonsensical rules.
“Are you serious?” the rationalist asked me. “I know the people in Berkeley who can get you into the clinical trial for this.”
This was my moment of decision. If I agreed to put unapproved bacteria into my mouth on my next trip to Berkeley, I could live my beliefs and possibly never get cavities again … but on the other hand, friends and colleagues would think I was weird when I told them.
Then again, I mused, four years ago most people would think you were weird if you said that a pneumonia spreading at a seafood market in Wuhan was about to ignite a global pandemic, and also that chatbots were about to go from ELIZA-like jokes to the technological powerhouses transforming civilization.
And so it was that I found myself brushing a salty, milky-white substance onto my teeth. That was last month. I … haven’t had any cavities since, for what it’s worth? Nor have I felt drunk, despite the ever-so-slightly elaevated ethanol in my system. Then again, I’m not even 100% sure that the bacteria took, given that (I confess) the germy substance strongly triggered my gag reflex.
Anyway, read other Scott’s post, and then ask yourself: will you try this, once you can? If not, is it just because it seems too weird?
Update: See a Hacker News thread where the merits of this new treatment are debated.
December 7, 2023
Staggering toward quantum fault-tolerance
Happy Hanukkah! I’m returning to Austin from a Bay Area trip that included the annual Q2B (Quantum 2 Business) conference. This year, for the first time, I opened the conference, with a talk on “The Future of Quantum Supremacy Experiments,” rather than closing it with my usual ask-me-anything session.
The biggest talk at Q2B this year was yesterday’s announcement, by a Harvard/MIT/QuEra team led by Misha Lukin and Vlad Vuletic, to have demonstrated “useful” quantum error-correction, for some definition of “useful,” in neutral atoms (see here for the Nature paper). To drill down a bit into what they did:
They ran experiments with up to 280 physical qubits, which simulated up to 48 logical qubits.They demonstrated surface codes of varying sizes as well as color codes.They performed over 200 two-qubit transversal gates on their encoded logical qubits.They did a couple demonstrations, including the creation and verification of an encoded GHZ state and (more impressively) an encoded IQP circuit, whose outputs were validated using the Linear Cross-Entropy Benchmark (LXEB).Crucially, they showed that in their system, the use of logically encoded qubits produced a modest “net gain” in success probability compared to not using encoding, consistent with theoretical expectations (though see below for the caveats). With a 48-qubit encoded IQP circuit with a few hundred gates, for example, they achieved an LXEB score of 1.1, compared to a record of ~1.01 for unencoded physical qubits.At least with their GHZ demonstration and with a particular decoding strategy (about which more later), they showed that their success probability improves with increasing code size.Here are what I currently understand to be the limitations of the work:
They didn’t directly demonstrate applying a universal set of 2- or 3-qubit gates to their logical qubits. This is because they were limited to transversal gates, and the Eastin-Knill Theorem shows that transversal gates can’t be universal. On the other hand, they were able to simulate up to 48 CCZ gates, which do yield universality, by using magic initial states.They didn’t demonstrate the “full error-correction cycle” on encoded qubits, where you’d first correct errors and then proceed to apply more logical gates to the corrected qubits. For now it’s basically just: prepare encoded qubits, then apply transversal gates, then measure, and use the encoding to deal with any errors.With their GHZ demonstration, they needed to use what they call “correlated decoding,” where the code blocks are decoded in conjunction with each other rather than separately, in order to get good results.With their IQP demonstration, they needed to postselect on the event that no errors occurred (!!), which happened about 0.1% of the time with their largest circuits. This just further underscores that they haven’t yet demonstrated a full error-correction cycle.They don’t claim to have demonstrated quantum supremacy with their logical qubits—i.e., nothing that’s too hard to simulate using a classical computer. (On the other hand, if they can really do 48-qubit encoded IQP circuits with hundreds of gates, then a convincing demonstration of encoded quantum supremacy seems like it should follow in short order.)As always, experts are strongly urged to correct anything I got wrong.
I should mention that this might not be the first experiment to get a net gain from the use of a quantum error-correcting code: Google might or might not have gotten one in an experiment that they reported in a Nature paper from February of this year (for discussion, see a comment by Robin). In any case, though, the Google experiment just encoded the qubits and measured them, rather than applying hundreds of logical gates to the encoded qubits.
Assuming the result stands, I think it’s plausibly the top experimental quantum computing advance of 2023 (coming in just under the deadline!). We clearly still have a long way to go until “actually useful” fault-tolerant QC, which might require thousands of logical qubits and millions of logical gates. But this is already beyond what I expected to be done this year, and (to use the AI doomers’ lingo) it “moves my timelines forward” for quantum fault-tolerance. It should now be possible, among other milestones, to perform the first demonstrations of Shor’s factoring algorithm with logically encoded qubits (though still to factor tiny numbers, of course). I’m slightly curious to see how Gil Kalai and the other quantum computing skeptics wiggle their way out now, though I’m absolutely certain they’ll find a way! Anyway, huge congratulations to the Harvard/MIT/QuEra team for their achievement.
In other QC news, IBM got a lot of press for announcing a 1000-qubit superconducting chip a few days ago, although I don’t yet know what two-qubit gate fidelities they’re able to achieve. Anyone with more details is encouraged to chime in.
Yes, I’m well-aware that 60 Minutes recently ran a segment on quantum computing, featuring the often-in-error-but-never-in-doubt Michio Kaku. I wasn’t planning to watch it unless events force me to.
Do any of you have strong opinions on whether, once my current contract with OpenAI is over, I should focus my research efforts more on quantum computing or on AI safety?
On the one hand: I’m now completely convinced that AI will transform civilization and daily life in a much deeper way and on a shorter timescale than QC will — and that’s assuming full fault-tolerant QCs eventually get built, which I’m actually somewhat optimistic about (a bit more than I was last week!). I’d like to contribute if I can to helping the transition to an AI-centric world go well for humanity.
On the other hand: in quantum computing, I feel like I’ve somehow been able to correct the factual misconceptions of 99.99999% of people, and this is a central source of self-confidence about the value I can contribute to the world. In AI, by contrast, I feel like at least a thousand times more people understand everything I do, and this causes serious self-doubt about the value and uniqueness of whatever I can contribute.
Scott Aaronson's Blog

- Scott Aaronson's profile
- 126 followers

