
Scott Aaronson's Blog, page 12
May 4, 2023
AI and Aaronson’s Law of Dark Irony
The major developments in human history are always steeped in dark ironies. Yes, that’s my Law of Dark Irony, the whole thing.
I don’t know why it’s true, but it certainly seems to be. Taking WWII as the archetypal example, let’s enumerate just the more obvious ones:
After the carnage of WWI, the world’s most sensitive and thoughtful people (many of them) learned the lesson that they should oppose war at any cost. This attitude let Germany rearm and set the stage for WWII.Hitler, who was neither tall nor blond, wished to establish the worldwide domination of tall, blond Aryans … and do so via an alliance with the Japanese.The Nazis touted the dream of eugenically perfecting the human race, then perpetrated a genocide against a tiny group that had produced Einstein, von Neumann, Wigner, Ulam, and Tarski.The Jews were murdered using a chemical—Zyklon B—developed in part by the Jewish chemist Fritz Haber.The Allied force that made the greatest sacrifice in lives to defeat Hitler was Stalin’s USSR, another of history’s most murderous and horrifying regimes.The man who rallied the free world to defeat Nazism, Winston Churchill, was himself a racist colonialist, whose views would be (and regularly are) denounced as “Nazi” on modern college campuses.The WWII legacy that would go on to threaten humanity’s existence—the Bomb—was created in what the scientists believed was a desperate race to save humanity. Then Hitler was defeated before the Bomb was ready, and it turned out the Nazis were never even close to building their own Bomb, and the Bomb was used instead against Japan.When I think about the scenarios where superintelligent AI destroys the world, they rarely seem to do enough justice to the Law of Dark Irony. It’s like: OK, AI is created to serve humanity, and instead it turns on humanity and destroys it. Great, that’s one dark irony. One. What other dark ironies could there be? How about:
For decades, the Yudkowskyans warned about the dangers of superintelligence. So far, by all accounts, the great practical effect of these warnings has been to inspire the founding of both DeepMind and OpenAI, the entities that Yudkowskyans believe are locked into a race to realize those dangers.Maybe AIs will displace humans … and they’ll deserve to, since they won’t be quite as wretched and cruel as we are. (This is basically the plot of Westworld, or at least of its first couple seasons, which Dana and I are now belatedly watching.)Maybe the world will get destroyed by what Yudkowsky calls a “pivotal act”: an act meant to safeguard the world from takeover from an unaligned AGI, for example by taking it over with an aligned AGI first. (I seriously worry about this; it’s a pretty obvious one.)Maybe AI will get the idea to take over the world, but only because it’s been trained on generations of science fiction and decades of Internet discussion worrying about the possibility of AI taking over the world. (I’m far from the first to notice this possibility.)Maybe AI will indeed destroy the world, but it will do so “by mistake,” while trying to save the world, or by taking a calculated gamble to save the world that fails. (A commenter on my last post brought this one up.)Maybe humanity will successfully coordinate to pause AGI development, and then promptly be destroyed by something else—runaway climate change, an accidental nuclear exchange—that the AGI, had it been created, would’ve prevented. (This, of course, would be directly analogous to one of the great dark ironies of all time: the one where decades of antinuclear activism, intended to save the planet, has instead doomed us to destroy the earth by oil and coal.)Readers: which other possible dark ironies have I missed?


April 27, 2023
Five Worlds of AI (a joint post with Boaz Barak)
Artificial intelligence has made incredible progress in the last decade, but in one crucial aspect, it still lags behind the theoretical computer science of the 1990s: namely, there is no essay describing five potential worlds that we could live in and giving each one of them whimsical names. In other words, no one has done for AI what Russell Impagliazzo did for complexity theory in 1995, when he defined the five worlds Algorithmica, Heuristica, Pessiland, Minicrypt, and Cryptomania, corresponding to five possible resolutions of the P vs. NP problem along with the central unsolved problems of cryptography.
In this blog post, we—Scott and Boaz—aim to remedy this gap. Specifically, we consider 5 possible scenarios for how AI will evolve in the future. (Incidentally, it was at a 2009 workshop devoted to Impagliazzo’s five worlds co-organized by Boaz where Scott met his now wife, complexity theorist Dana Moshkovitz. We hope civilization will continue for long enough that someone in the future could meet their soulmate, or neuron-mate, at a future workshop about our five worlds.)
Like in Impagliazzo’s 1995 paper on the five potential worlds of the difficulty of NP problems, we will not try to be exhaustive but rather concentrate on extreme cases. It’s possible that we’ll end up in a mixture of worlds or a situation not described by any of the worlds. Indeed, one crucial difference between our setting and Impagliazzo’s, is that in the complexity case, the worlds corresponded to concrete (and mutually exclusive) mathematical conjectures. So in some sense, the question wasn’t “which world will we live in?” but “which world have we Platonically always lived in, without knowing it?” In contrast, the impact of AI will be a complex mix of mathematical bounds, computational capabilities, human discoveries, and social and legal issues. Hence, the worlds we describe depend on more than just the fundamental capabilities and limitations of artificial intelligence, and humanity could also shift from one of these worlds to another over time.
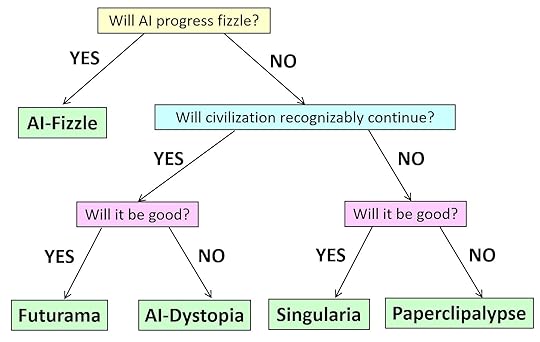
Without further ado, we name our five worlds “AI-Fizzle,” “Futurama,” ”AI-Dystopia,” “Singularia,” and “Paperclipalypse.” In this essay, we don’t try to assign probabilities to these scenarios; we merely sketch their assumptions and technical and social consequences. We hope that by making assumptions explicit, we can help ground the debate on the various risks around AI.
AI-Fizzle. In this scenario, AI “runs out of steam” fairly soon. AI still has a significant impact on the world (so it’s not the same as a “cryptocurrency fizzle”), but relative to current expectations, this would be considered a disappointment. Rather than the industrial or computer revolutions, AI might be compared in this case to nuclear power: people were initially thrilled about the seemingly limitless potential, but decades later, that potential remains mostly unrealized. With nuclear power, though, many would argue that the potential went unrealized mostly for sociopolitical rather than technical reasons. Could AI also fizzle by political fiat?
Regardless of the answer, another possibility is that costs (in data and computation) scale up so rapidly as a function of performance and reliability that AI is not cost-effective to apply in many domains. That is, it could be that for most jobs, humans will still be more reliable and energy-efficient (we don’t normally think of low wattage as being key to human specialness, but it might turn out that way!). So, like nuclear fusion, an AI which yields dramatically more value than the resources needed to build and deploy it might always remain a couple of decades in the future. In this scenario, AI would replace and enhance some fraction of human jobs and improve productivity, but the 21st century would not be the “century of AI,” and AI’s impact on society would be limited for both good and bad.
Futurama. In this scenario, AI unleashes a revolution that’s entirely comparable to the scientific, industrial, or information revolutions (but “merely” those). AI systems grow significantly in capabilities and perform many of the tasks currently performed by human experts at a small fraction of the cost, in some domains superhumanly. However, AI systems are still used as tools by humans, and except for a few fringe thinkers, no one treats them as sentient. AI easily passes the Turing test, can prove hard math theorems, and can generate entertaining content (as well as deepfakes). But humanity gets used to that, just like we got used to computers creaming us in chess, translating text, and generating special effects in movies. Most people no more feel inferior to their AI than they feel inferior to their car because it runs faster. In this scenario, people will anthropomorphize AI less over time (as happened with digital computers themselves). In “Futurama,” AI will, like any revolutionary technology, be used for both good and bad. but like prior major technological revolutions, on the whole, AI will have a large positive impact on humanity. AI will be used to reduce poverty and ensure that more of humanity has access to food, healthcare, education, and economic opportunities. The fraction of people living in democracies increases. In “Futurama,” AI systems will sometimes cause harm, but the vast majority of these failures will be due to human negligence or maliciousness. Some AI systems might be so complex that it would be best to model them as potentially behaving “adversarially,” and part of the practice of deploying AIs responsibly would be to ensure an “operating envelope” that limits their potential damage even under adversarial failures.
AI-Dystopia. The technical assumptions of “AI-Dystopia” are similar to those of “Futurama,” but the upshot could hardly be more different. Here, again, AI unleashes a revolution on the scale of the industrial or computer revolutions, but the change is markedly for the worse. AI greatly increases the scale of surveillance by government and private corporations. It causes massive job losses while enriching a tiny elite. It entrenches society’s existing inequalities and biases. And it takes away a central tool against oppression: namely, the ability of humans to refuse or subvert orders.
Interestingly, it’s even possible that the same future could be characterized as Futurama by some people and as AI-Dystopia by others–just like how some people emphasize how our current technological civilization has lifted billions out of poverty into a standard of living unprecedented in human history, while others focus on the still existing (and in some cases rising) inequalities and suffering, and consider it a neoliberal capitalist dystopia.
Singularia. Here AI breaks out of the current paradigm, where increasing capabilities require ever-growing resources of data and computation and no longer needs human data or human-provided hardware and energy to become stronger at an ever-increasing pace. AIs improve their own intellectual capabilities, including by developing new science, and (whether by deliberate design or happenstance) they act as goal-oriented agents in the physical world. They can effectively be thought of as an alien civilization–or perhaps as a new species, which is to us as we were to Homo erectus.
Fortunately, though (and again, whether by careful design or just as a byproduct of their human origins), the AIs act to us like benevolent gods and lead us to an “AI utopia.” They solve our material problems for us, giving us unlimited abundance and presumably virtual-reality adventures of our choosing. (Though maybe, as in The Matrix, the AIs will discover that humans need some conflict, and we will all live in a simulation of 2020’s Twitter, constantly dunking on one another…)
Paperclipalypse. In “Paperclipalypse” or “AI Doom,” we again think of future AIs as a superintelligent “alien race” that doesn’t need humanity for its own development. Here, though, the AIs are either actively opposed to human existence or else indifferent to it in a way that causes our extinction as a byproduct. In this scenario, AIs do not develop a notion of morality comparable to ours or even a notion that keeping a diversity of species and ensuring humans don’t go extinct might be useful to them in the long run. Rather, the interaction between AI and Homo sapiens ends about the same way that the interaction between Homo sapiens and Neanderthals ended.
In fact, the canonical depictions of such a scenario imagine an interaction that is much more abrupt than our brush with the Neanderthals. The idea is that, perhaps because they originated through some optimization procedure, AI systems will have some strong but weirdly-specific goal (a la “maximizing paperclips”), for which the continued existence of humans is, at best, a hindrance. So the AIs quickly play out the scenarios and, in a matter of milliseconds, decide that the optimal solution is to kill all humans, taking a few extra milliseconds to make a plan for that and execute it. If conditions are not yet ripe for executing their plan, the AIs pretend to be docile tools, as in the “Futurama” scenario, waiting for the right time to strike. In this scenario, self-improvement happens so quickly that humans might not even notice it. There need be no intermediate stage in which an AI “merely” kills a few thousand humans, raising 9/11-type alarm bells.
Regulations. The practical impact of AI regulations depends, in large part, on which scenarios we consider most likely. Regulation is not terribly important in the “AI Fizzle” scenario where AI, well, fizzles. In “Futurama,” regulations would be aimed at ensuring that on balance, AI is used more for good than for bad, and that the world doesn’t devolve into “AI Dystopia.” The latter goal requires anti-trust and open-science regulations to ensure that power is not concentrated in a few corporations or governments. Thus, regulations are needed to democratize AI development more than to restrict it. This doesn’t mean that AI would be completely unregulated. It might be treated somewhat similarly to drugs—something that can have complex effects and needs to undergo trials before mass deployment. There would also be regulations aimed at reducing the chance of “bad actors” (whether other nations or individuals) getting access to cutting-edge AIs, but probably the bulk of the effort would be at increasing the chance of thwarting them (e.g., using AI to detect AI-generated misinformation, or using AI to harden systems against AI-aided hackers). This is similar to how most academic experts believe cryptography should be regulated (and how it is largely regulated these days in most democratic countries): it’s a technology that can be used for both good and bad, but the cost of restricting its access to regular citizens outweighs the benefits. However, as we do with security exploits today, we might restrict or delay public releases of AI systems to some extent.
To whatever extent we foresee “Singularia” or “Paperclipalypse,” however, regulations play a completely different role. If we knew we were headed for “Singularia,” then presumably regulations would be superfluous, except perhaps to try to accelerate the development of AIs! Meanwhile, if one accepts the assumptions of “Paperclipalypse,” any regulations other than the most draconian might be futile. If, in the near future, almost anyone will be able to spend a few billion dollars to build a recursively self-improving AI that might turn into a superintelligent world-destroying agent, and moreover (unlike with nuclear weapons) they won’t need exotic materials to do so, then it’s hard to see how to forestall the apocalypse, except perhaps via a worldwide, militarily enforced agreement to “shut it all down,” as Eliezer Yudkowsky indeed now explicitly advocates. “Ordinary” regulations could, at best, delay the end by a short amount–given the current pace of AI advances, perhaps not more than a few years. Thus, regardless of how likely one considers this scenario, one might want to focus more on the other scenarios for methodological reasons alone!
April 17, 2023
Will UT Austin and Texas A&M survive beyond this week?
This week, the Texas Senate will take up SB 18, a bill to ban the granting of tenure at all public universities in Texas, including UT Austin and Texas A&M. (Those of us who have tenure would retain it, for what little that’s worth.)
[Update: I’ve learned that, even if this bill passes the Senate, there’s a good chance that it will get watered down or die in the House, or found to be satisfied by UT’s existing system of post-tenure review. That’s the only reason why people in the know aren’t panicking even more than they are.]
I find it hard to imagine that SB 18 will actually pass both houses and be enforced as written, simply because it’s obvious that if it did, it would be the end of UT Austin and Texas A&M as leading research universities. More precisely, it would be the immediate end of our ability to recruit competitively, and the slightly slower end of our competitiveness period, as faculty with options moved elsewhere. This is so because of the economics of faculty hiring. Particularly in STEM fields like computer science, those who become professors typically forgo vastly higher salaries in industry, not to mention equity in startup companies and so on. Why would we do such a nutty thing? Because we like a certain lifestyle. We’re willing to move several economic strata downward in return for jobs where (in principle) no one can fire us without cause, or tell us what we’re allowed to say or publish. The evidence from industry labs (Google, Facebook, Microsoft, etc.) suggests that, in competitive fields, for Texas to attract and retain top faculty without tenure would require paying them hundreds of thousands more per year. In that sense, tenure is a bargain for universities and the state. Of course the situation is different for art history and English literature, but in any case SB 18 makes no distinction between fields.
The Texas Senate is considering two other bills this week: SB 17, which would ban all DEI (Diversity, Equity, and Inclusion) programs, offices, and practices at public universities, and SB 16, which would require the firing of any professor if they “compel or attempt to compel a student … to adopt a belief that any race, sex, or ethnicity or social, political, or religious belief is inherently superior to any other race, sex, ethnicity, or belief.” (The language here seems sloppy to me: is liberal democracy “inherently superior” to Nazism? Would teaching students about the horrors of Nazism count as “attempting to compel them” to accept this superiority?)
Taken together, it’s clear that the goal is to hit back hard against “wokeness” in academia, and thereby satisfy the Republican base.
Here’s the thing: there really is an illiberal ideology that’s taken over parts of academia (not all of it)—an ideology that Tim Urban, in his wonderful recent book What’s Our Problem?, usefully terms “Social Justice Fundamentalism” or SJF, to distinguish it sharply from “Liberal Social Justice,” the ideology of (for example) the Civil Rights movement. Now, I’m on record as not a fan of the SJF ideology, to put it mildly, and the SJF ideology is on record as not a fan of me. In 2015, I was infamously dragged through the mud of Salon, The New Republic, Raw Story, and many other magazines and websites for a single blog comment criticizing a form of feminism that had contributed to making my life miserable, even while I proudly called myself a liberal feminist (and still do). More recently, wokesters have written to my department chair trying to get me disciplined or fired, for everything from my use of the now-verboten term “quantum supremacy,” to a reference to female breasts in a poem I wrote as a student that was still on my homepage. (These attempts thankfully went nowhere. Notwithstanding what you read, sanity retains many strongholds in academia.)
Anyway, despite all of this, the Texas Republicans have somehow succeeded in making me more afraid of them, purely on the level of professional survival, than I’ve ever been of the Social Justice Fundamentalists. In effect, the Republicans propose to solve the “problem of wokeness” by simply dropping thermonuclear weapons on all Texas public universities, thereby taking out me and my colleagues as collateral damage—regardless of our own views on wokeness or anything else, and regardless of what we’re doing for Texas’ scientific competitiveness.
I don’t expect that most of my readers, in or out of Texas, will need to be persuaded about any of this—nor am I expecting to change many minds on the other side. Mostly, I’m writing this post in the hope that some well-connected moderates here in Austin will link to it, and the post might thereby play a tiny role in helping Texas’ first-rate public universities live one more day. (And to any such moderates: yes, I’m happy to meet in person with you or your colleagues, if that would help!) Some posts are here on this blog for no better reason than, y’know, moral obligation.
April 16, 2023
AI safety: what should actually be done now?
So, I recorded a 2.5-hour-long podcast with Daniel Filan about “reform AI alignment,” and the work I’ve been doing this year at OpenAI. The end result is … well, probably closer to my current views on this subject than anything else I’ve said or written! Listen here or read the transcript here. Here’s Daniel’s abstract:
How should we scientifically think about the impact of AI on human civilization, and whether or not it will doom us all? In this episode, I speak with Scott Aaronson about his views on how to make progress in AI alignment, as well as his work on watermarking the output of language models, and how he moved from a background in quantum complexity theory to working on AI.
Thanks so much to Daniel for making this podcast happen.
Maybe I should make a broader comment, though.
From my recent posts, and from my declining to sign the six-month AI pause letter (even though I sympathize with many of its goals), many people seem to have goten the impression that I’m not worried about AI, or that (ironically, given my job this year) I’m basically in the “full speed ahead” camp.
This is not true. In reality, I’m full of worry. The issue is just that, in this case, I’m also full of metaworry—i.e., the worry that whichever things I worry about will turn out to have been the wrong things.
Even if we look at the pause letter, or more generally, at the people who wish to slow down AI research, we find that they wildly disagree among themselves about why a slowdown is called for. One faction says that AI needs to be paused because it will spread misinformation and entrench social biases … or (this part is said aloud surprisingly often) because progress is being led by, you know, like, totally gross capitalistic Silicon Valley nerdbros, and might enhance those nerds’ power.
A second faction, one that contains many of the gross nerdbros, is worried about AI because it might become superintelligent, recursively improve itself, and destroy all life on earth while optimizing for some alien goal. Hopefully both factions agree that this scenario would be bad, so that the only disagreement is about its likelihood.
As I’ll never tire of pointing out, the two factions seem to have been converging on the same conclusion—namely, AI progress urgently needs to be slowed down—even while they sharply reject each other’s rationales and indeed are barely on speaking terms with each other.
OK, you might object, but that’s just sociology. Why shouldn’t a rational person worry about near-term AI risk and long-term AI risk? Why shouldn’t the ethics people focused on the former and the alignment people focused on the latter strategically join forces? Such a hybrid Frankenpause is, it seems to me, precisely what the pause letter was trying to engineer. Alas, the result was that, while a few people closer to the AI ethics camp (like Gary Marcus and Ernest Davis) agreed to sign, many others (Emily Bender, Timnit Gebru, Arvind Narayanan…) pointedly declined, because—as they explained on social media—to do so would be to legitimate the gross nerds and their sci-fi fantasies.
From my perspective, the problem is this:
Under the ethics people’s assumptions, I don’t see that an AI pause is called for. Or rather, while I understand the arguments, the same arguments would seem to have justified stopping the development of the printing press, aviation, radio, computers, the Internet, and virtually every other nascent technology, until committees of academic experts had decided that the positive social effects would outweigh the negative ones, which might’ve been never. The trouble is, well, how do you even study the social effects of a new technology, before society starts using it? Aren’t we mostly happy that technological pioneers went ahead with all the previously-mentioned things, and dealt with the problems later as they arose? But preventing the widespread societal adoption of GPT-like tools seems to be what the AI ethics camp really wants, much more than preventing further scaling for scientific research. I reject any anti-AI argument that could be generalized and transplanted backwards to produce an argument against moving forward with, let’s say, agriculture or metallurgy.Under the alignment people’s assumptions, I do see that an AI pause is urgently called for—but I’m not yet on board with their assumptions. The kind of relentlessly optimizing AI that could form the intention to doom humanity, still seems very different to me from the kind of AI that’s astonished the world these past couple years, to the point that it’s not obvious how much progress in the latter should increase our terror about the former. Even Eliezer Yudkowsky agrees that GPT-4 doesn’t seem too dangerous in itself. And an AI that was only slightly dangerous could presumably be recognized as such before it was too late. So everything hinges on the conjecture that, in going from GPT-n to GPT-(n+1), there might be a “sharp turn” where an existential risk to humanity very suddenly emerged, with or without the cooperation of bad humans who used GPT-(n+1) for nefarious purposes. I still don’t know how to think about the likelihood of this risk. The empirical case for it is likely to be inadequate, by its proponents’ own admission. I admired how my friend Sarah Constantin thought through the issues in her recent essay Why I Am Not An AI Doomer—but on the other hand, as others have pointed out, Sarah ends up conceding a staggering fraction of the doomers’ case in the course of arguing against the rest of it. What today passes for an “anti-doomer” might’ve been called a “doomer” just a few years ago.In short, one could say, the ethics and alignment communities are both building up cases for pausing AI progress, working at it from opposite ends, but their efforts haven’t yet met at any single argument that I wholeheartedly endorse.
This might just be a question of timing. If AI is going become existentially dangerous, then I definitely want global coordination well before that happens. And while it seems unlikely to me that we’re anywhere near the existential danger zone yet, the pace of progress over the past few years has been so astounding, and has upended so many previous confident assumptions, that caution seems well-advised.
But is a pause the right action? How should we compare the risk of acceleration now to the risk of a so-called “overhang,” where capabilities might skyrocket even faster in the future, faster than society can react or adapt, because of a previous pause? Also, would a pause even force OpenAI to change its plans from what they would’ve been otherwise? (If I knew, I’d be prohibited from telling, which makes it convenient that I don’t!) Or would the main purpose be symbolic, just to show that the main AI labs can coordinate on something?
If so, then one striking aspect of the pause letter is that it was written without consultation with the main entities who would need to agree to any such pause (OpenAI, DeepMind, Google, …). Another striking aspect is that it applies only to systems “more powerful than” GPT-4. There are two problems here. Firstly, the concept “more powerful than” isn’t well-defined: presumably it rules out more parameters and more gradient descent, but what about more reinforcement learning or tuning of hyperparameters? Secondly, to whatever extent it makes sense, it seems specifically tailored to tie the hands of OpenAI, while giving OpenAI’s competitors a chance to catch up to OpenAI. The fact that the most famous signatory is Elon Musk, who’s now trying to build an “anti-woke” chatbot to compete against GPT, doesn’t help.
So, if not this pause letter, what do I think ought to happen instead?
I’ve been thinking about it a lot, and the most important thing I can come up with is: clear articulation of fire alarms, red lines, whatever you want to call them, along with what our responses to those fire alarms should be. Two of my previous fire alarms were the first use of chatbots for academic cheating, and the first depressed person who commits suicide after interacting with a chatbot. Both of those have now happened. Here are some others:
A chatbot is used to impersonate someone for fraudulent purposes, by imitating his or her writing style.A chatbot helps a hacker find security vulnerabilities in code that are then actually exploited.A child dies because his or her parents follow wrong chatbot-supplied medical advice.Russian or Iranian or Chinese intelligence, or some other such organization, uses a chatbot to mass-manufacture disinformation and propaganda.A chatbot helps a terrorist manufacture weapons that are used in a terrorist attack.I’m extremely curious: which fire alarms are you most worried about? How do you think the AI companies and governments should respond if and when they happen?
In my view, articulating fire alarms actually provides multiple benefits. Not only will it give us a playbook if and when any of the bad events happen, it will also give us clear targets to try to forecast. If we’ve decided that behavior X is unacceptable, and if extrapolating the performance of GPT-1 through GPT-n on various metrics leads to the prediction that GPT-(n+1) will be capable of X, then we suddenly have a clear, legible case for delaying the release of GPT-(n+1).
Or—and this is yet a third benefit—we have something clear on which to test GPT-(n+1), in “sandboxes,” before releasing it. I think the kinds of safety evals that ARC (the Alignment Research Center) did on GPT-4 before it was released—for example, testing its ability to deceive Mechanical Turkers—were an extremely important prototype, something that we’ll need a lot more of before the release of future language models. But all of society should have a say on what, specifically, are the dangerous behaviors that these evals are checking for.
So let’s get started on that! Readers: which unaligned behaviors would you like GPT-5 to be tested for prior to its release? Bonus points for plausibility and non-obviousness.
April 1, 2023
Quips are what I’ve got
In the comments on my last post—the one about the open letter calling for a six-month pause on AI scaling—a commenter named Hans Holander berates me over and over, as have others before him, for my failure to see that GPT is just a hoax and scam with no “true” intelligence. Below is my reply: probably one of the most revealing things I’ve ever written (which is saying something).
The great irony here is that if you’re right—and you’re obviously 3000% confident that you’re right—then by my lights, there is no reason whatsoever to pause the scaling of Large Language Models, as your fellow LLM skeptics have urged. If LLMs are mere “stochastic parrots,” and if further scaling will do nothing to alleviate their parroticity, then there’d seem to be little danger that they’ll ever form grounded plans to take over the world, or even help evil people form such plans. And soon it will be clear to everyone that LLMs are just a gigantic boondoggle that don’t help them solve their problems, and the entire direction will be abandoned. All a six-month pause would accomplish would be to delay this much-needed reckoning.
More broadly, though, do you see the problem with “just following your conscience” in this subject? There’s no way to operationalize “follow your conscience,” except “do the thing that will make the highest moral authorities that you recognize not be disappointed in you, not consider you a coward or a monster or a failure.” But what if there’s no agreement among the highest moral authorities that you recognize, or the people who set themselves up as the moral authorities? What if people will call you a coward or a monster or a failure, will even do so right in your comment section, regardless of what you choose?
This, of course, is hardly the first time in my life I’ve been in this situation, condemned for X and equally condemned for not(X). I’ve never known how to navigate it. When presented with diametrically opposed views about morality or the future of civilization, all confidently held by people who I consider smart and grounded, I can switch back and forth between the perspectives like with the Necker cube or the duck-rabbit. But I don’t have any confident worldview of my own. What I have are mostly quips, and jokes, and metaphors, and realizing when one thing contradicts a different thing, and lectures (many people do seem to like my lectures) where I lay out all the different considerations, and sometimes I also have neat little technical observations that occasionally even get dignified with the name of “theorems” and published in papers.
A quarter-century ago, though I remember like yesterday, I was an undergrad at Cornell, and belonged to a scholarship house called Telluride, where house-members had responsibilities for upkeep and governance and whatnot and would write periodic reviews of each other’s performance. And I once got a scathing performance review, which took me to task for shirking my housework, and bringing my problem sets to the house meetings. (These were meetings where the great issues of the day were debated—like whether or not to allocate $50 for fixing a light, and how guilty to feel over hiring maintenance workers and thereby participating in capitalist exploitation.) And then there was this: “Scott’s contributions to house meetings are often limited to clever quips that, while amusing, do not advance the meeting agenda at all.”
I’m not like Eliezer Yudkowsky, nor am I even like the anti-Eliezer people. I don’t, in the end, have any belief system at all with which to decide questions of a global or even cosmic magnitude, like whether the progress of AI should be paused or not. Mostly all I’ve got are the quips and the jokes, and the trying to do right on the smaller questions.
———————————————————
And anyone who doesn’t like this post can consider it an April Fools (hey, Eliezer did the same last year!).
March 29, 2023
If AI scaling is to be shut down, let it be for a coherent reason
There’s now an open letter arguing that the world should impose a six-month moratorium on the further scaling of AI models such as GPT, by government fiat if necessary, to give AI safety and interpretability research a bit more time to catch up. The letter is signed by many of my friends and colleagues, many who probably agree with each other about little else, over a thousand people including Elon Musk, Steve Wozniak, Andrew Yang, Jaan Tallinn, Stuart Russell, Max Tegmark, Yuval Noah Harari, Ernie Davis, Gary Marcus, and Yoshua Bengio.
Meanwhile, Eliezer Yudkowsky published a piece in TIME arguing that the open letter doesn’t go nearly far enough, and that AI scaling needs to be shut down entirely until the AI alignment problem is solved—with the shutdown enforced by military strikes on GPU farms if needed, and treated as more important than preventing nuclear war.
Readers, as they do, asked me to respond. Alright, alright. While the open letter is presumably targeted at OpenAI more than any other entity, and while I’ve been spending the year at OpenAI to work on theoretical foundations of AI safety, I’m going to answer strictly for myself.
Given the jaw-droppingly spectacular abilities of GPT-4—e.g., acing the Advanced Placement biology and macroeconomics exams, correctly manipulating images (via their source code) without having been programmed for anything of the kind, etc. etc.—the idea that AI now needs to be treated with extreme caution strikes me as far from absurd. I don’t even dismiss the possibility that advanced AI could eventually require the same sorts of safeguards as nuclear weapons.
Furthermore, people might be surprised about the diversity of opinion about these issues within OpenAI, by how many there have discussed or even forcefully advocated slowing down. And there’s a world not so far from this one where I, too, get behind a pause. For example, one actual major human tragedy caused by a generative AI model might suffice to push me over the edge. (What would push you over the edge, if you’re not already over?)
Before I join the slowdown brigade, though, I have (this being the week before Passover) four questions for the signatories:
Would your rationale for this pause have applied to basically any nascent technology — the printing press, radio, airplanes, the Internet? “We don’t yet know the implications, but there’s an excellent chance terrible people will misuse this, ergo the only responsible choice is to pause until we’re confident that they won’t”?Why six months? Why not six weeks or six years?When, by your lights, would we ever know that it was safe to resume scaling AI—or at least that the risks of pausing exceeded the risks of scaling? Why won’t the precautionary principle continue for apply forever?Were you, until approximately last week, ridiculing GPT as unimpressive, a stochastic parrot, lacking common sense, piffle, a scam, etc. — before turning around and declaring that it could be existentially dangerous? How can you have it both ways? If the problem, in your view, is that GPT-4 is too stupid, then shouldn’t GPT-5 be smarter and therefore safer? Thus, shouldn’t we keep scaling AI as quickly as we can … for safety reasons? If, on the other hand, the problem is that GPT-4 is too smart, then why can’t you bring yourself to say so?With the “why six months?” question, I confess that I was deeply confused, until I heard a dear friend and colleague in academic AI, one who’s long been skeptical of AI-doom scenarios, explain why he signed the open letter. He said: look, we all started writing research papers about the safety issues with ChatGPT; then our work became obsolete when OpenAI released GPT-4 just a few months later. So now we’re writing papers about GPT-4. Will we again have to throw our work away when OpenAI releases GPT-5? I realized that, while six months might not suffice to save human civilization, it’s just enough for the more immediate concern of getting papers into academic AI conferences.
Look: while I’ve spent multiple posts explaining how I part ways from the Orthodox Yudkowskyan position, I do find that position intellectually consistent, with conclusions that follow neatly from premises. The Orthodox, in particular, can straightforwardly answer all four of my questions above:
AI is manifestly different from any other technology humans have ever created, because it could become to us as we are to orangutans;a six-month pause is very far from sufficient but is better than no pause;we’ll know that it’s safe to scale when (and only when) we understand our AIs so deeply that we can mathematically explain why they won’t do anything bad; andGPT-4 is extremely impressive—that’s why it’s so terrifying!On the other hand, I’m deeply confused by the people who signed the open letter, even though they continue to downplay or even ridicule GPT’s abilities, as well as the “sensationalist” predictions of an AI apocalypse. I’d feel less confused if such people came out and argued explicitly: “yes, we should also have paused the rapid improvement of printing presses to avert Europe’s religious wars. Yes, we should’ve paused the scaling of radio transmitters to prevent the rise of Hitler. Yes, we should’ve paused the race for ever-faster home Internet to prevent the election of Donald Trump. And yes, we should’ve trusted our governments to manage these pauses, to foresee brand-new technologies’ likely harms and take appropriate actions to mitigate them.”
Absent such an argument, I come back to the question of whether generative AI actually poses a near-term risk that’s totally unparalleled in human history, or perhaps approximated only by the risk of nuclear weapons. After sharing an email from his partner, Eliezer rather movingly writes:
When the insider conversation is about the grief of seeing your daughter lose her first tooth, and thinking she’s not going to get a chance to grow up, I believe we are past the point of playing political chess about a six-month moratorium.
Look, I too have a 10-year-old daughter and a 6-year-old son, and I wish to see them grow up. But the causal story that starts with a GPT-5 or GPT-4.5 training run, and ends with the sudden death of my children and of all carbon-based life, still has a few too many gaps for my aging, inadequate brain to fill in. I can complete the story in my imagination, of course, but I could equally complete a story that starts with GPT-5 and ends with the world saved from various natural stupidities. For better or worse, I lack the “Bayescraft” to see why the first story is obviously 1000x or 1,000,000x likelier than the second one.
But, I dunno, maybe I’m making the greatest mistake of my life? Feel free to try convincing me that I should sign the letter. But let’s see how polite and charitable everyone can be: hopefully a six-month moratorium won’t be needed to solve the alignment problem of the Shtetl-Optimized comment section.
March 28, 2023
An unexpected democracy slogan
At least six readers have by now sent me the following photo, which was taken in Israel a couple nights ago during the historic street protests against Netanyahu’s attempted putsch:

(Update: The photo was also featured on Gil Kalai’s blog, and was credited there to Alon Rosen.)
This is surely the first time that “P=NP” has emerged as a viral rallying cry for the preservation of liberal democracy, even to whatever limited extent it has.
But what was the graffiti artist’s intended meaning? A few possibilities:
The government has flouted so many rules of Israel’s social compact that our side needs to flout the rules too: shut down the universities, shut down the airport, block the roads, even assert that P=NP (!).As a protest movement up against overwhelming odds, we need to shoot for the possibly-impossible, like solving 3SAT in polynomial time.A shibboleth for scientific literate people following the news: “Israel is full of sane people who know what ‘P=NP’ means as you know what it means, are amused by its use as political graffiti as you’d be amused by it, and oppose Netanyahu’s putsch for the same reasons you’d oppose it.”No meaning, the artist was just amusing himself or herself.The artist reads Shtetl-Optimized and wanted effectively to force me to feature his or her work here.Anyway, if the artist becomes aware of this post, he or she is warmly welcomed to clear things up for us.
And when this fight resumes after Passover, may those standing up for the checks and balances of a liberal-democratic society achieve … err … satisfaction, however exponentially unlikely it seems.
March 23, 2023
Xavier Waintal responds (tl;dr Grover is still quadratically faster)
This morning Xavier Waintal, coauthor of the new arXiv preprint “””refuting””” Grover’s algorithm, which I dismantled here yesterday, emailed me a two-paragraph response. He remarked that the “classy” thing for me to do would be to post the response on my blog, but: “I would totally understand if you did not want to be contradicted in your own zone of influence.”
Here is Waintal’s response, exactly as sent to me:
The elephant in the (quantum computing) room: opening the Pandora box of the quantum oracle
One of the problem we face in the field of quantum computing is a vast diversity of cultures between, say, complexity theorists on one hand and physicists on the other hand. The former define mathematical objects and consider any mathematical problem as legitimate. The hypothesis are never questioned, by definition. Physicists on the other hand spend their life questioning the hypothesis, wondering if they do apply to the real world. This dichotomy is particularly acute in the context of the emblematic Grover search algorithm, one of the cornerstone of quantum computing. Grover’s algorithm uses the concept of “oracle”, a black box function that one can call, but of which one is forbidden to see the source code. There are well known complexity theorems that show that in this context a quantum computer can solve the “search problem” faster than a classical computer.
But because we closed our eyes and decided not to look at the source code does not mean it does not exist. In https://arxiv.org/pdf/2303.11317.pdf, Miles Stoudenmire and I deconstruct the concept of oracle and show that as soon as we give the same input to both quantum and classical computers (the quantum circuit used to program the oracle on the actual quantum hardware) then the *generic* quantum advantage disappears. The charge of the proof is reversed: one must prove certain properties of the quantum circuit in order to possibly have a theoretical quantum advantage. More importantly – for the physicist that I am – our classical algorithm is very fast and we show that we can solve large instances of any search problem. This means that even for problems where *asymptotically* quantum computers are faster than classical ones, the crossing point where they become so is for astronomically large computing time, in the tens of millions of years. Who is willing to wait that long for the answer to a single question, even if the answer is 42?
The above explicitly confirms something that I realized immediately on reading the preprint, and that fully explains the acerbic tone of my response. Namely, Stoudenmire and Waintal’s beef isn’t merely with Grover’s algorithm, or even with the black-box model; it’s with the entire field of complexity theory. If they were right that complexity theorists never “questioned hypotheses” or wondered what did or didn’t apply to the real world, then complexity theory shouldn’t exist in CS departments at all—at most it should exist in pure math departments.
But a converse claim is also true. Namely, suppose it turned out that complexity theorists had already fully understood, for decades, all the elementary points Stoudenmire and Waintal were making about oracles versus explicit circuits. Suppose complexity theorists hadn’t actually been confused, at all, about under what sorts of circumstances the square-root speedup of Grover’s algorithm was (1) provable, (2) plausible but unproven, or (3) nonexistent. Suppose they’d also been intimately familiar with the phenomenon of asymptotically faster algorithms that get swamped in practice by unfavorable constants, and with the overhead of quantum error-correction. Suppose, indeed, that complexity theorists hadn’t merely understood all this stuff, but expressed it clearly and accurately where Stoudenmire and Waintal’s presentation was garbled and mixed with absurdities (e.g., the Grover problem “being classically solvable with a linear number of queries,” the Grover speedup not being “generic,” their being able to “solve large instances of any search problem” … does that include, for example, CircuitSAT? do they still not get the point about CircuitSAT?).
Anyway, we don’t have to suppose! In the SciRate discussion of the preprint, a commenter named Bibek Pokharel helpfully digs up some undergraduate lecture notes from 2017 that are perfectly clear about what Stoudenmire and Waintal treat as revelations (though one could even go 20 years earlier). The notes are focused here on Simon’s algorithm, but the discussion generalizes to any quantum black-box algorithm, including Grover’s:
The difficulty in claiming that we’re getting a quantum speedup [via Simon’s algorithm] is that, once we pin down the details of how we’re computing [the oracle function] f—so, for example, the actual matrix A [such that f(x)=Ax]—we then need to compare against classical algorithms that know those details as well. And as soon as we reveal the innards of the black box, the odds of an efficient classical solution become much higher! So for example, if we knew the matrix A, then we could solve Simon’s problem in classical polynomial time just by calculating A‘s nullspace. More generally, it’s not clear whether anyone to this day has found a straightforward “application” of Simon’s algorithm, in the sense of a class of efficiently computable functions f that satisfy the Simon promise, and for which any classical algorithm plausibly needs exponential time to solve Simon’s problem, even if the algorithm is given the code for f.
In the same lecture notes, one can find the following discussion of Grover’s algorithm, and how its unconditional square-root speedup becomes conditional as soon as the black box is instantiated by an explicit circuit:
For an NP-complete problem like CircuitSAT, we can be pretty confident that the Grover speedup is real, because no one has found any classical algorithm that’s even slightly better than brute force. On the other hand, for more “structured” NP-complete problems, we do know exponential-time algorithms that are faster than brute force. For example, 3SAT is solvable classically in about O(1.3n) time. So then, the question becomes a subtle one of whether Grover’s algorithm can be combined with the best classical tricks that we know to achieve a polynomial speedup even compared to a classical algorithm that uses the same tricks. For many NP-complete problems the answer seems to be yes, but it need not be yes for all of them.
The notes in question were written by some random complexity theorist named Scot Aronsen (sp?). But if you don’t want it from that guy, then take it from (for example) the Google quantum chemist Ryan Babbush, again on the SciRate page:
It is well understood that applying Grover’s algorithm to 3-SAT in the standard way would not give a quadratic speedup over the best classical algorithm for 3-SAT in the worst case (and especially not on average). But there are problems for which Grover is expected to give a quadratic speedup over any classical algorithm in the worst case. For example, the problem “Circuit SAT” starts by me handing you a specification of a poly-size classical circuit with AND/OR/NOT gates, so it’s all explicit. Then you need to solve SAT on this circuit. Classically we strongly believe it will take time 2^n (this is even the basis of many conjectures in complexity theory, like the exponential time hypothesis), and quantumly we know it can be done with 2^{n/2}*poly(n) quantum gates using Grover and the explicitly given classical circuit. So while I think there are some very nice insights in this paper, the statement in the title “Grover’s Algorithm Offers No Quantum Advantage” seems untrue in a general theoretical sense. Of course, this is putting aside issues with the overheads of error-correction for quadratic speedups (a well understood practical matter that is resolved by going to large problem sizes that wouldn’t be available to the first fault-tolerant quantum computers). What am I missing?
More generally, over the past few days, as far as I can tell, every actual expert in quantum algorithms who’s looked at Stoudenmire and Waintal’s preprint—every one, whether complexity theorist or physicist or chemist—has reached essentially the same conclusions about it that I did. The one big difference is that many of the experts, who are undoubtedly better people than I am, extended a level of charity to Stoudenmire and Waintal (“well, this of course seems untrue, but here’s what it could have meant”) that Stoudenmire and Waintal themselves very conspicuously failed to extend to complexity theory.
March 22, 2023
Of course Grover’s algorithm offers a quantum advantage!
Unrelated Update: Huge congratulations to Ethernet inventor Bob Metcalfe, for winning UT Austin’s third Turing Award after Dijkstra and Emerson!
I was really, really hoping that I’d be able to avoid blogging about this new arXiv preprint, by E. M. Stoudenmire and Xavier Waintal:
Grover’s Algorithm Offers No Quantum Advantage
Grover’s algorithm is one of the primary algorithms offered as evidence that quantum computers can provide an advantage over classical computers. It involves an “oracle” (external quantum subroutine) which must be specified for a given application and whose internal structure is not part of the formal scaling of the quantum speedup guaranteed by the algorithm. Grover’s algorithm also requires exponentially many steps to succeed, raising the question of its implementation on near-term, non-error-corrected hardware and indeed even on error-corrected quantum computers. In this work, we construct a quantum inspired algorithm, executable on a classical computer, that performs Grover’s task in a linear number of call to the oracle – an exponentially smaller number than Grover’s algorithm – and demonstrate this algorithm explicitly for boolean satisfiability problems (3-SAT). Our finding implies that there is no a priori theoretical quantum speedup associated with Grover’s algorithm. We critically examine the possibility of a practical speedup, a possibility that depends on the nature of the quantum circuit associated with the oracle. We argue that the unfavorable scaling of the success probability of Grover’s algorithm, which in the presence of noise decays as the exponential of the exponential of the number of qubits, makes a practical speedup unrealistic even under extremely optimistic assumptions on both hardware quality and availability.
Alas, inquiries from journalists soon made it clear that silence on my part wasn’t an option.
So, desperately seeking an escape, this morning I asked GPT-4 to read the preprint and comment on it just like I would. Sadly, it turns out the technology isn’t quite ready to replace me at this blogging task. I suppose I should feel good: in every such instance, either I’m vindicated in all my recent screaming here about generative AI—what the naysayers call “glorified autocomplete”—being on the brink of remaking civilization, or else I still, for another few months at least, have a role to play on the Internet.
So, on to the preprint, as reviewed by the human Scott Aaronson. Yeah, it’s basically a tissue of confusions, a mishmash of the well-known and the mistaken. As they say, both novel and correct, but not in the same places.
The paper’s most eye-popping claim is that the Grover search problem—namely, finding an n-bit string x such that f(x)=1, given oracle access to a Boolean function f:{0,1}n→{0,1}—is solvable classically, using a number of calls that’s only linear in n, or in many cases only constant (!!). Since this claim contradicts a well-known, easily provable lower bound—namely, that Ω(2n) oracle calls are needed for classical brute-force searching—the authors must be using words in nonstandard ways, leaving only the question of how.
It turns out that, for their “quantum-inspired classical algorithm,” the authors assume you’re given, not merely an oracle for f, but the actual circuit to compute f. They then use that circuit in a non-oracular way to extract the marked item. In which case, I’d prefer to say that they’ve actually solved the Grover problem with zero queries—simply because they’ve entirely left the black-box setting where Grover’s algorithm is normally formulated!
What could possibly justify such a move? Well, the authors argue that sometimes one can use the actual circuit to do better classically than Grover’s algorithm would do quantumly, and therefore, they’ve shown that the Grover speedup is not “generic,” as the quantum algorithms people always say it is.
But this is pure wordplay around the meaning of “generic.” When we say that Grover’s algorithm achieves a “generic” square-root speedup, what we mean is that it solves the generic black-box search problem in O(2n/2) queries, whereas any classical algorithm for that generic problem requires Ω(2n) queries. We don’t mean that for every f, Grover achieves a quadratic speedup for searching that f, compared to the best classical algorithm that could be tailored to that f. Of course we don’t; that would be trivially false!
Remarkably, later in the paper, the authors seem to realize that they haven’t delivered the knockout blow against Grover’s algorithm that they’d hoped for, because they then turn around and argue that, well, even for those f’s where Grover does provide a quadratic speedup over the best (or best-known) classical algorithm, noise and decoherence could negate the advantage in practice, and solving that problem would require a fault-tolerant quantum computer, but fault-tolerance could require an enormous overhead, pushing a practical Grover speedup far into the future.
The response here boils down to “no duh.” Yes, if Grover’s algorithm can yield any practical advantage in the medium term, it will either be because we’ve discovered much cheaper ways to do quantum fault-tolerance, or else because we’ve discovered “NISQy” ways to exploit the Grover speedup, which avoid the need for full fault-tolerance—for example, via quantum annealing. Because of its exponential speedup, the prospects are actually better for a medium-term advantage from Shor’s factoring algorithm. Hopefully everyone in quantum computing theory has realized this for a long time.
Anyway, as you can see, by this point we’ve already conceded the principle of Grover’s algorithm, and are just haggling over the practicalities! Which brings us back to the authors’ original claim to have a principled argument against the Grover speedup, which (as I said) rests on a confusion over words.
Some people dread the day when GPT will replace them. In my case, for this task, I can’t wait.
Thanks to students Yuxuan Zhang (UT) and Alex Meiburg (UCSB) for discussions of the Stoudenmire-Waintal preprint that informed this post. Of course, I take sole blame for anything anyone dislikes about the post!
For a much more technical response—one that explains how this preprint’s detailed attempt to simulate Grover classically fails, rather than merely proving that it must fail—check out this comment by Alex Meiburg. As I wrote to Alex, after he apologized to me for his “wall of text”:
Far from demanding an apology, I offer deep thanks!!
We might say: whereas I merely (correctly) saw a dungpile, you looked more closely than I could with my failing 41-year-old eyes, and (again correctly) saw a dungpile with tiny diamonds of fruitful research problems buried inside.
March 17, 2023
On overexcitable children
Wilbur and Orville are circumnavigating the Ohio cornfield in their Flyer. Children from the nearby farms have run over to watch, point, and gawk. But their parents know better.
An amusing toy, nothing more. Any talk of these small, brittle, crash-prone devices ferrying passengers across continents is obvious moonshine. One doesn’t know whether to laugh or cry that anyone could be so gullible.
Or if they were useful, then mostly for espionage and dropping bombs. They’re a negative contribution to the world, made by autistic nerds heedless of the dangers.
Indeed, one shouldn’t even say that the toy flies: only that it seems-to-fly, or “flies.” The toy hasn’t even scratched the true mystery of how the birds do it, so much more gracefully and with less energy. It sidesteps the mystery. It’s a scientific dead-end.
Wilbur and Orville haven’t even released the details of the toy, for reasons of supposed “commercial secrecy.” Until they do, how could one possibly know what to make of it?
Wilbur and Orville are greedy, seeking only profit and acclaim. If these toys were to be created — and no one particularly asked for them! — then all of society should have had a stake in the endeavor.
Only the rich will have access to the toy. It will worsen inequality.
Hot-air balloons have existed for more than a century. Even if we restrict to heavier-than-air machines, Langley, Whitehead, and others built perfectly serviceable ones years ago. Or if they didn’t, they clearly could have. There’s nothing genuinely new here.
Anyway, the reasons for doubt are many, varied, and subtle. But the bottom line is that, if the children only understood what their parents did, they wouldn’t be running out to the cornfield to gawk like idiots.
Scott Aaronson's Blog

- Scott Aaronson's profile
- 126 followers

