
Maciej Aniserowicz's Blog, page 40
April 22, 2018
DevTalk #76 – O rekrutacji z Agatą Dzierlińską
 Dzisiaj, w 76. odcinku, poruszamy gorący temat. W końcu za oknem robi się coraz goręcej, c’nie?
Dzisiaj, w 76. odcinku, poruszamy gorący temat. W końcu za oknem robi się coraz goręcej, c’nie?
Do rozmowy zaprosiłem Agatę Dzierlińską, kierującą procesami rekrutacji w obszarze IT, w Grupie Pracuj. Agata ma wieloletnie doświadczenie i właśnie dzisiaj podzieli się nim z nami!
Jak można się domyślić, tematem odcinka jest rekrutacja w IT. Temat można ugryźć z różnych stron i różnych perspektyw. Z naszej rozmowy dowiecie się między innymi czy warto się specjalizować, czy stawiać na wiedzę ogólną? Jak stale podnosić swoje kompetencje? Jak często zmieniać pracę, aby nie zostać odebranym negatywnie przez pracodawców? Czy faktycznie mamy teraz do czynienia z rynkiem pracownika i… czy ta sytuacja utrzyma się w kolejnych latach?
Dużo ciekawego materiału! A sponsorem dzisiejszego odcinka DevTalk jest Grupa Pracuj – właściciel
serwisu rekrutacyjnego Pracuj.pl, wszyscy dziękujemy za wsparcie!

Pracuj.pl to wiodący polski serwis rekrutacyjny. Kandydatom dostarcza codziennie ponad 40 tysięcy ofert pracy od atrakcyjnych pracodawców, a także porady specjalistów dotyczące poszukiwania pracy, rozwoju kariery zawodowej oraz zdobywania dodatkowych kwalifikacji. Jest dostępna również aplikacja mobilna Pracuj.pl, której głównym założeniem jest łatwy i wygodny dostęp do funkcji i wyszukiwarki serwisu. Portal powstał w 2000 r. i należy do Grupy Pracuj, będącej właścicielem wiodących marek na rynku rekrutacji on-line w Polsce i na Ukrainie. www.pracuj.pl
PLAY!

http://traffic.libsyn.com/devtalk/DevTalk_E76-Agata_Dzierlinska-Rekrutacja_w_IT.mp3
Montaż odcinka: Krzysztof Śmigiel.
Ważne adresy:
zapisz się na newsletter
zasubskrybuj w iTunes lub przez RSS
ściągnij odcinek w mp3
zostań Patronem! :)
Linki:
Pracuj.pl: http://pracuj.pl
Grupa Pracuj: https://grupapracuj.pl
Muzyka wykorzystana w intro:
“Misuse” Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
The post DevTalk #76 – O rekrutacji z Agatą Dzierlińską appeared first on devstyle.pl.


April 17, 2018
Wednewsday #02 – programistyczne nowinki
Witam w cotygodniowej porcji ciekawostek ze świata programowania.
Wersja audio (podcast Devsession):
W tym tygodniu moją uwagę przykuły następujące tematy:
Machine Learning
Moral Machine – ludzka perspektywa w kontekście sztucznej inteligencji zaszytej w pojazdach autonomicznych. Sprawdź się!
Psy w służbie AI
Oprogramowanie
.NET Core 2.1 Preview 2 – kolejne preview .Net Core i coraz bliżej finalnej wersji.
Mozilla WebAssembly Studio – zapoznaj się z WebAssembly wprost w przeglądarce. IDE ze wsparciem dla C/C++/Rust
Unity.Mathematics – prototyp biblioteki matematycznej C# udostępniającej typy wektorowe i funkcje matematyczne.
Projekt Golem – Jeden z najbardziej ambitnych polskich projektów wykorzystujących Blockchain.
Kayneta – projekt open-source od Google i Netflix redukujący ryzyko nagłego wdrożenia nowej wersji na produkcję.
Programowanie
Front-End Handbook 2018 – miłej lektury i do zobaczenia za czas jakiś ;)
Java na sterydach – 15 frameworków, które zwiększą twoje możliwości.
How to think like programmer – Jak podejść do rozwiązywania problemów.
x = x + 1 – dlaczego ‘=’ oznacza przypisanie
Will Chapel Mark Next Great Awakening for Parallel Programmers? – o HighPerformanceComputing i języku Chapel.
Paczki, paczuszki, zależności. Kilka best practices, które warto mieć na uwadzę dokładając kolejną.
Ciekawostki
Trendy w aplikacjach mobilnych
10-te urodziny GitHub oraz StackOverflow
The Graphing Calculator Story – o przywiązaniu do firmy, pasji i … sami przeczytajcie.
IBM 1401 & Fortran II – Myślę, że starszemu pokoleniu łezka się w oku zakręci a dla młodych będzie to ciekawe dydaktyczne przeżycie. Polecam nie tylko ten film ale i cały kanał.
W nawiązaniu do poprzedniego wpisu korespondencja pomiędzy osobami, które pracowały przy tym maszynach.
Lista ‘awesome’ tym razem ze zbiorem podkastów programistycznych.
Zapraszam również do śledzenia audycji podcastowej, w której co tydzień prezentuję najnowsze wiadomości, ciekawostki, wpadki oraz nadchodzące wydarzenia ze świata IT:
http://devsession.pl/podkast/
The post Wednewsday #02 – programistyczne nowinki appeared first on devstyle.pl.
April 15, 2018
Życie w chmurze, czyli jazda bez transakcji
Jak żyć bez transakcji? To pytanie stawia sobie każdy adept chmury, który postanawia użyć kilku z jej usług.
Czasami, nawet w obrębie jednego serwisu, możemy napotkać na ograniczenia, które nie pozwolą na stary, dobry “transakcyjny zapis”. Co robić jeśli coś się nie uda? Co zrobić aby się udało? Zapraszam do artykułu.
There can be only one
Jeżeli znasz Nieśmiertelnego to pamiętasz, że może być tylko jeden. Niestety, jeżeli kiedykolwiek użyłeś jakiejś usługi kolejkowej, to wiesz, że otrzymanie i utrzymanie gwarancji dostarczenia każdej wiadomości dokładnie raz (ang. exactly-once delivery) jest po prostu niemożliwe.
O co chodzi z tymi gwarancjami? Spójrzmy na następujący scenariusz. Używamy serwisu kolejek, pozwalającego na pobranie wiadomości (odpytanie się o nowe) oraz o potwierdzenie tych już przetworzonych. Zastanówmy się co się stanie, jeżeli nasz kod napisalibyśmy w następujący sposób:
var msg = queue.GetMessage();
ExecuteOperation(msg);
queue.Acknowledge(msg.Data);
Operacje wykonywane kolejno: pobranie wiadomości, przetworzenie wiadomości, potwierdzenie wiadomości. Zastanówmy się, co się stanie, jeżeli z jakiegoś powodu aplikacja przestanie działać po wykonaniu operacji, a przed potwierdzeniem wiadomości? W większości systemów wiadomość wróci do kolejki po jakimś czasie – usługa nie wie, czy ktoś ją przetworzył, czy nie. Oznacza to, że ta sama wiadomość trafi do nas po raz kolejny i przetworzymy ją po raz drugi. Jak widać powyższe ustrukturyzowanie kodu pozwala na pojawienie się tej samej wiadomości więcej niż raz (ang. at-least-once delivery).
Co stanie się, jeśli potwierdzenie przesuniemy linijkę wyżej, zmieniając kod na następujący?
var msg = queue.GetMessage();
queue.Acknowledge(msg);
ExecuteOperation(msg.Data);
Stosując dokładnie takie samo podejście, możemy zapytać o przypadek, w którym to zaraz po potwierdzeniu operacji, następuje jakiś krytyczny błąd i aplikacja zostaje zatrzymana. Co wówczas się dzieje z operacją biznesową, która miała być wykonana? Nie zostaje wykonana. Wiadomość, potwierdzona wcześniej, została usunięta z kolejki. Oznacza to, że istnieją sytuacje, w których wiadomość może być przetworzona najwyżej raz (ang. at-most-once).
To tylko kolejki
Biorąc powyższe przykłady, można by powiedzieć, że dotyczą one tylko serwisów kolejkowych, wiadomości. Jest to nieprawda. Ponieważ żadne dwie linijki naszego kodu nie są spięte transakcją, efektywnie pomiędzy każdym wywołaniem serwisów może nastąpić wyjątek, przerywając operację biznesową w połowie. To nie wina kolejek. Po prostu: przy braku wsparcia dla transakcji, należy świadomie projektować systemy tak, aby odporne były na (potencjalnie) kilkukrotne wykonanie tej samej operacji. Jak to zrobić?
Czy jesteś idempotentny?
Idempotencja to nie choroba, a cecha, która pozwala zaaplikować tę samą operację kilka razy, bez zmiany jej wyniku. Jeżeli chcielibyśmy opisać to w sposób matematyczny, to wyglądałoby to następująco:
f(f(x)) = f(x)
W jaki sposób zastosować to podejście w naszym kodzie? Zacznijmy od przykładu jak mogłoby to wyglądać, który będzie zmodyfikowanym przykładem at-least-once
var msg = queue.GetMessage();
ExecuteOperation(msg.Data, msg.Id);
queue.Acknowledge(msg);
Dodatkowym argumentem przekazywanym do funkcji ExecuteOperation jest identyfikator wiadomości (większość systemów kolejkowych dostarcza taki identyfikator; jeżeli konkretna usługa by go nie podawała, wówczas nadawca może to zrobić, dodając takie pole). Identyfikator przekazany zostaje do wywołania operacji biznesowej. Na jej poziomie może zostać użyty do sprawdzenia, czy dane związane z tą konkretną operacją nie zostały już zapisane/przetworzone.
Ostatecznie, aby umożliwić takie sprawdzenie, razem z danymi biznesowymi należy zapisać identyfikator operacji. W ten sposób, kolejne wykonania, o ile nastąpią, będą mogły w prosty sposób sprawdzić, czy coś się udało.
REST i inne serwisy
Nic nie stoi na przeszkodzie, aby podczas aplikowania tego wzorca w Waszych rozwiązaniach nie pozwolić mu wyciec do warstwy API jako, np. nagłówek. Wówczas wołający Wasze serwisy, mogliby zapewnić idempotentność wywołań podając swoje identifkatory.
Jak widać, wchodząc raz do świata idempotencji warto opublikować go na zewnątrz, tak, aby i inni mogli zapewnić wykonanie operacji biznesowych dokładnie raz.
Azure Functions i Durable Task
Zbliżone podejście do idempotentnego odbiorcy zostało zaimplementowane w Durable Task: frameworku pozwalającym opisywać procesy wykonywane jako Azure Functions. Pod kodem bazującym na składni async/await umieszczono mechanizm nagrywania zmian wykonanych przez proces. W ten sposób nawet w przypadku wystąpienia wyjątku w połowie, Durable Task automatycznie będzie w stanie wznowić działanie od ostatnio zapisanej operacji, nie wykonując już tych wcześniejszych.
Kawałek po kawałku
Stwierdzenie, że “po prostu przeniosę się do chmury”, o ile jest popularne, to uznałbym je za nie zawsze prawdziwe.
Jeżeli Twój system działał dotychczas z jedną bazą zapewniającą transakcje, a teraz chcesz przenieść go do chmury, zwiększając zestaw jego fundamentów, to musisz rozważyć brak transakcji. Jak zaadresujesz potencjalne błędy pojawiające się w trakcie wykonania?
Jak najbardziej można i należy robić to kawałek po kawałku. Ważne elementy systemu przepisane w sposób zapewniający 100% gwarancji poprawnego wykonania będą mogły być wołane nawet kilka razy, ostatecznie pozwalając na wytworzenie rozwiązania prawdziwie gotowego na jazdę bez transakcji.
Witamy w świecie chmury!
The post Życie w chmurze, czyli jazda bez transakcji appeared first on devstyle.pl.
April 11, 2018
Wednewsday #01 – programistyczne nowinki
Witam Was w pierwszym po dłuższej przerwie wydaniu środowych newsów.
Co tydzień będę się starał obdarowywać Was starannie przygotowaną garścią linków do wiadomości oraz artykułów ze świata programowania.
Grzegorz Kotfis: Zapraszam także do audycji Devsession News, w której co tydzień prezentuję najnowsze wiadomości, ciekawostki, wpadki oraz nadchodzące wydarzenia ze świata IT: http://devsession.pl/podcast-5.
Machine Learning
Google Brain Team wydał nową wersję biblioteki Tensorflow 1.7 oraz przedstawił całkowicie nowy projekt Tensorflow.js
Fundacja Linuksa zainicjowała “Linux Foundation Deep Learning” – organizację wspierającą innowacyjne projekty open source w takich dziedzinach jak AI, Machine Learnig czy Deep Learning.
25 otwartych źródeł danych pomagających przy pracy z Deep Learning.
Cloud
Google Text-To-Speech API
Stackdriver – Narzędzie do monitoringu, logowania i diagnostyki rozwiązań hostowanych w GCP oraz AWS
Oprogramowanie
Educational Products by JetBrains – darmowe narzędzie dla nauczycieli i uczniów wspomagające przygotowywanie materiałów i nauczanie programowania.
Netflix FlameScope – diagnozowanie problemów typu time-based w oparciu o tzw. FlameGraphs
NGINX Unit 1.0 – serwer aplikacyjny przeznaczony dla mikroserwisów.
GIT 2.17.0
Programowanie
The 10 Most Prestigious Programming Contests and Challenges – najbardziej prestiżowe konkursy programistyczne dla studentów oraz profesjonalistów.
5 Best Websites By Google for Programmers and Developers
Google JavaScript Style Guide i skrócona do 13 najważniejszych punktów wersja
W Microsoft Professional Program pojawiły się dwie nowe ścieżki: Artifical Inteligence oraz Entry Level Software Development.
Ciekawostki
ZeroVer: 0-based Versioning
Wyniku plebiscytu StackShare.io na m.in najlepsze narzędzia/usługi dla developerów.
RedHat zmienia wizerunek. Podziel się swoimi pomysłami pod hastagiem #openbrandproject
Lubisz oglądać seriale na Netflix i przy okazji wykrywać dziury? Ruszył Bug Bounty Program od Netflixa. Prócz wiecznej chwały do zgarnięcia $100 – $15,000
The post Wednewsday #01 – programistyczne nowinki appeared first on devstyle.pl.
April 8, 2018
DevTalk #75 – O zdrowiu z Kamilem Lelonkiem (część 2)
 Odcinek #75 to bardzo wyczekiwana kontynuacja mojej pierwszej rozmowy z Kamilem Lelonkiem (DevTalk #71). Więc… cóż, do dzieła!
Odcinek #75 to bardzo wyczekiwana kontynuacja mojej pierwszej rozmowy z Kamilem Lelonkiem (DevTalk #71). Więc… cóż, do dzieła!
Naszym Gościem po raz drugi jest Kamil Lelonek. Niezwykłe połączenie: programista (blogger, prelegent, “inspirator”), przedsiębiorca, i… dietetyk! A wszystko poparte odpowiednią edukacją. Na Twitterze: @kamillelonek.
Rozmawiamy o… zdrowiu, w drugiej odsłonie. Za pierwszym razem (przesłuchaj to najpierw!) poruszyliśmy dwie odsłony zdrowia: sen i dietę. Dzisiaj natomiast pojawiają się aż cztery (!) kolejne konteksty: ćwiczenia, medytacja, “smart drugs” oraz suplementacja.
Uwaga po raz drugi: nie ma tutaj żadnych plotek, żadnego bro-science! Wiedza i doświadczenia Kamila poparte są edukacją i odpowiednimi najnowszymi badaniami.
Daj znać jak Ci się podoba!
Czekam na Twoje gwiazdki i opinie na iTunes! To bardzo motywuje :). Dzięki!
I… PLAY!!
http://traffic.libsyn.com/devtalk/DevTalk_E75-Kamil_Lelonek-Zdrowie_2.mp3
Montaż odcinka: Krzysztof Śmigiel.
Ważne adresy:
zapisz się na newsletter
zasubskrybuj w iTunes lub przez RSS
ściągnij odcinek w mp3
zostań Patronem! :)
Linki:
programistyczny blog Kamila: https://blog.lelonek.me
dietetyczny blog siostry Kamila – Sylwii – i jego samego: http://livethenature.com, a szczególnie posty:
http://livethenature.com/jakie-badania-wykonac/
http://livethenature.com/regeneracja-od-a-do-z/
http://livethenature.com/zaburzenia-snu/
StandITUp – inicjatywa by Marek Stój: http://www.standitup.org/en/
tabata: https://www.active.com/fitness/articles/what-is-tabata-training
ćwiczenia HIIT: https://www.fitnessblender.com/videos
książka “Skazany na biurko. Postaw się siedzącemu światu”: http://lubimyczytac.pl/ksiazka/4142898/skazany-na-biurko-postaw-sie-siedzacemu-swiatu
badania:
https://www.ncbi.nlm.nih.gov/books/NBK279077
https://www.ncbi.nlm.nih.gov/pubmed/12468415
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2923555
DevTalk:
#71 – O zdrowiu z Kamilem Lelonkiem (część 1): https://devstyle.pl/2018/02/05/devtalk71-o-zdrowiu-z-kamilem-lelonkiem-czesc-1/
#26 – O ergonomii z Ewą Paszkowską-Demidowską: https://devstyle.pl/2015/11/30/devtalk26-o-ergonomii-z-ewa-paszkowska-demidowska/
prezentacja “Medytacja dla programistów”: http://2016.4developers.org.pl/en/program/lectures/medytacja-dla-programistow/
aplikacje do medytacji:
Calm: https://www.calm.com/
Headspace: https://www.headspace.com/
Medytacja Vipassana w prostych słowach: http://sasana.wikidot.com/medytacja-vipassana-w-prostych-slowach
Podcast BHP: https://player.fm/series/cyberkursonline/ep-5-bhp-z-komputerem
suplementy:
Multivitamin (D3, K2, cytrynian magnezu, pikolinian cynku, A retinol, B12 metylokobaamina)
Omega 3 z oleju z kryla
Sanprobi Barrier
Kreatyna monohydrat
Muzyka wykorzystana w intro:
“Misuse” Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
The post DevTalk #75 – O zdrowiu z Kamilem Lelonkiem (część 2) appeared first on devstyle.pl.
April 3, 2018
Raport Finansowy: marzec 2018
Na swoim profilu na Patronite obiecałem publikować co miesiąc “raport finansowy”. Kolejny raz pokazuję… wszystko. Bez tajemnic. Enjoy!
Marzec na spokojnie, pełen luz. Refleksyjnie nawet. Cztery wyjazdy (Warszawa, Wrocław, Wyszków, Radzymin, Żywiec, Bielsko-Biała) i dwa cele.
Pierwszy i najważniejszy to: postanowić “co dalej”. Przejechałem w tym celu 1200 km, myślałem, dumałem.. no i postanowiłem. Co też pokazałem w dwóch odcinkach VLOGa:
Niektórym takie postępowanie wydaje się głupie: tyle myśleć, zamiast robić? Ale… tak! W tym roku to jest świadome działanie: duuużo przestrzeni, dużo wolnego czasu, dużo refleksji. Mniej lecenia do przodu jak chomik w karuzelce. Bo zaczynałem zaganiać się już za bardzo.
Drugi cel: zanurzyć stópkę w kodzie sprawdzając, czy jeszcze syczy i paruje, czy już nie. Zanurzyłem i się okazało, że już mogę, znowu! Cieszę się niezmiernie. Od razu podzieliłem się swoimi wrażeniami tu i tu.
Dodatkowo powitaliśmy na devstyle dwóch nowych autorów: Szymona i Piotra. Ci dwaj przesympatyczni dżentelmeni zostaną z nami na dłużej. A wkrótce ekipa rozrośnie się jeszcze bardziej. Fajnie fajnie, interesujące czasy przed nami!
Ale gdzie tu miejsce na kasę? Na szczęście w tym roku kasa – w ograniczonym zakresie, ale jednak – płynie trochę “sama”.
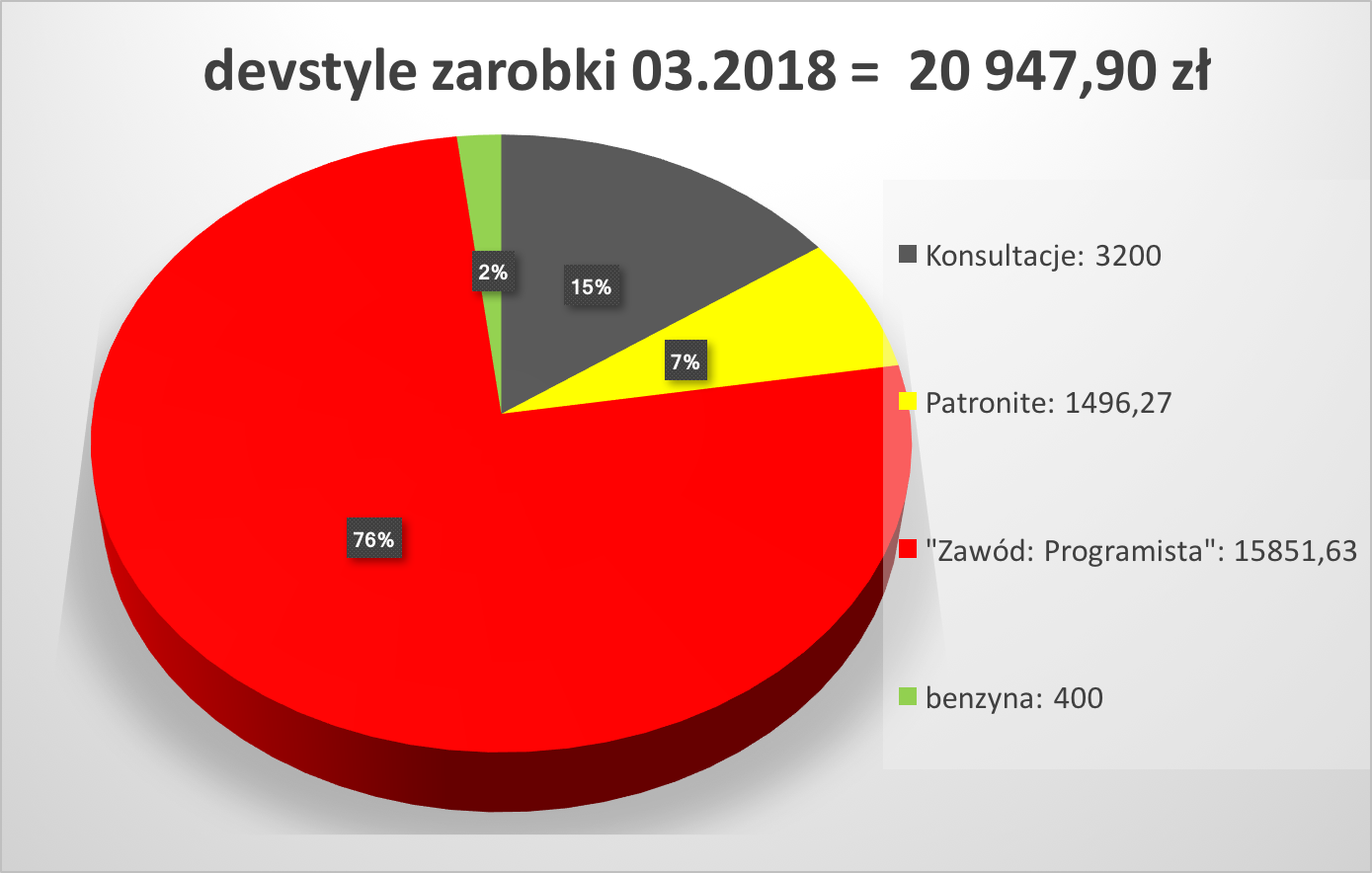
Raport: przychody
Założenia:
pieniądze wpływające na konto w bieżącym miesiącu; usługa mogła być zrealizowana w innym terminie
kwoty to faktury netto (chyba, że zaznaczono inaczej)
Pozycje:
konsultacje: 3 200,00 zł
Patronite: 1 496,27 zł
Convertiser (afiliacja Finansowego Ninja): 0,00 zł
książka “Zawód: Programista”: 15 851,63 zł
zwrot kosztów dojazdu na konferencję: 400,00 zł
W sumie: 20 947,90 zł.
Raport: wydatki
Założenia:
kwota brutto, znikająca z konta, bez uwzględnienia odliczeń od podatków
Pozycje (linki afiliacyjne):
Księgowa: 290,00 zł
ZUS: 1 257,78 zł
PIT-4: 33,00 zł
ConvertKit: 513,95 zł
zoom.us: 51,49 zł
LeadPages: 0 zł (wykupione na 2 lata)
LibSyn: 51,53 zł
Google Storage: 0 zł (wykupione na rok)
DropBox: 0 zł (wykupione na rok)
infakt: 0 zł (wykupione na rok)
wFirma: 0 zł (wykupione na rok)
ToDoist: 0 zł (wykupione na rok)
MacBook Pro + słuchawki Sony: 405,13 zł (20 rat 0%)
Shoplo: 60,27 zł
współpracownicy: 300,00 zł
Pajacyk (z afiliacji Finansowego Ninja): 0,00 zł
Patronite (wsparcie 4 autorów): 42,00 zł
Patronite (koszty): 181,49 zł
książka “Zawód: Programista”
obsługa płatności: 341,48 zł
wysyłka: 2 126,67 zł
magazynowanie: 241,08 zł
skład “Programista… I Co Dalej?”: 500,00 zł
reklama Facebook: 1 023,41 zł
reklama Google: 27,29 zł
reklama mailing: 369,00 zł
samochód:
leasing: 1 774,56 zł
opony i felgi: 4 260,00 zł
benzyna: 1 710,36 zł
wymiana kół, oleju, filtrów: 400,00 zł
parking SkyCash: 50,95 zł
myjnia: 20,00 zł
semi-pro studio video w garażu
dyktafon ZoomH1N: 485,00 zł
przejściówka RodeSC3: 53,60 zł
oświetlenie: 414,00 zł
gadżety devstyle
koperty: 15,84 zł
znaczki: 257,40 zł
poczta: 22,10 zł
WROC#:
hotel: 492,00 zł
parking: 58,00 zł
hotel Żywiec: 103,45 zł
książki:
Seth Godin “All Marketers Are Liars”: 14,10 zł
Seth Godin “Purple Cow”: 19,21 zł
Extreme Ownership: 28,60 zł
W sumie: 17 994,62 zł.
Raport: podsumowanie
Co miesiąc dostaję kilka pytań o koszty utrzymania samochodu. Od dzisiaj, zamiast odpowiadać 1:1, te także upubliczniam jako wydatki firmowe… bo w sumie gdyby nie moja dość wyjazdowa działalność, to ta ślicznotka nie byłaby mi tak bardzo potrzebna:

March 28, 2018
“Swift okiem programisty C#” okiem programisty Swift
Nazywam się Piotr Tobolski, pracuję w intive i mam doświadczenie w pisaniu aplikacji na platformę iOS i pochodne. Zarówno w Swift, jak i Objective-C.
Od dłuższego czasu czytam bloga Macieja i po przeczytaniu Swift okiem programisty C# stwierdziłem, że chciałbym mu się trochę odwdzięczyć i wspomóc swoim doświadczeniem. Odrzucił jednak moją propozycję (ponieważ chce pokazać proces uczenia się samodzielnie) ale wyszedł z inną propozycją – opublikowania mojej odpowiedzi na jego wpis. Jak widać doszło to do skutku.
Autorem tekstu jest Piotr Tobolski, który użycza swojego doświadczenia, komentując moje pierwsze wrażenia z pracy z Swift i Xcode. Dzięki!
Na wstępie chciałbym zaznaczyć, że bardzo cieszę się z nowego członka iOSowej społeczności! Im więcej wśród nas fajnych i kompetentnych ludzi tym lepiej. Uważam wybór technologii za bardzo dobry ;-) Z względu na dość zamkniętą platformę odpada wiele nieprzyjemnych zajęć (jak support dla egzotycznych urządzeń) i można skupić się na tworzeniu wysokiej jakości aplikacji co pozytywnie wpływa na warunki pracy. Estetyka narzędzi dostarczanych przez Apple również, choć z ich działaniem nie jest już aż tak dobrze, co dało się już zauważyć…
Trochę kontekstu
Trzeba pamiętać, że Swift jest bardzo młodym językiem. Został udostępniony w połowie roku 2014 ale trzeba mieć na uwadze kilka rzeczy:
Przechodził bardzo duże zmiany, np. składnia drastycznie zmieniła się wraz z wersją 3.0 czyli w zaledwie 1,5 roku temu.
Dopiero od wersji 3.2 ma stabilne źródła (czyli nowa wersja kompilatora będzie potrafiła skompilować kod starszej wersji języka), a wersja ta wyszła zaledwie pół roku temu (wraz z 4.0)!
Nadal nie ma stabilnego ABI choć ma się to zmienić na jesień, niestety nadal bez stabilności modułu co nadal nie pozwoli na dystrybuowanie skompilowanych bibliotek Swifta.
Musi on doskonale współpracować z Objective-C, ponieważ każde API udostępniane przez Apple nadal ma interfejs w tym języku. Co ciekawe – na pierwszy rzut oka tego nie widać – właśnie dzięki pracy włożonej w świetną kooperację tych języków. Do API Objective-C można dodawać odpowiednie adnotacje, które pozwalają na konwersję enumów, nazw metod, a nawet np. zamianę zwykłych funkcji C na metody w strukturach Swifta. Z uwagi na to, że Objective-C jest nadzbiorem C, kooperacja z C jest równie prosta.
Pomimo wymagań dotyczących Objective-C, język ten został stworzony praktycznie OD ZERA. W przeciwieństwie np. do Kotlina czy Scali, które opierają się na Javie. Prace nad nim wymagają więc dużo więcej pracy i czasu.
Nadal warto czasem pisać nowe aplikacje w Objective-C, a pisząc SDK jest to wręcz konieczność. Podchodząc poważnie do programowania na iOS trzeba się tego języka nauczyć.
Warto mieć na uwadze, że programowanie na iOS to nie tylko Swift, a wiele pojawiających się problemów to właśnie jego choroby wieku dziecięcego.
Pamiętajmy też, że używając Swifta w kontekście iOS lub macOS mamy dostępną również całą moc Objective-C ale np. na Linux już nie.
Inferencja typów
Bardzo ciekawa funkcjonalność Swifta ale w praktyce nie jest tak różowo. Niestety zabija złożonością obliczeniową. Nie jestem pewien czy zostało to już poprawione ale jeszcze niedawno sprawdzałem, że stworzenie tak prostej konstrukcji jak przypisanie do zmiennej (bez deklarowania typu) tablicy kilkudziesięciu Stringów może się kompilować godzinami!
Dlaczego? String implementuje wiele protokołów i kompilator musi jakoś wykombinować, że chcemy aby wynikowa referencja była typu [String], a nie np. [Equatable]albo [StringLiteralConvertible]. Z inferencją typów jest właśnie największy problem i najlepszym jego rozwiązaniem jest tworzenie krótkich funkcji lub dodawanie typów tam gdzie inferencja może sprawiać problemy.
Może w tym pomóc opcja kompilacji (Other Swift Flags) -Xfrontend -warn-long-function-bodies=, która spowoduje wygenerowanie ostrzeżenia gdy czas kompilacji metody będzie zbyt wysoki.
Implicitly unwrapped optional variable
Krótkie wyjaśnienie dla osoby z małym doświadczeniem w programowaniu: zwykła referencja, jak w Javie. Jeśli jest nullem i wywołasz na niej metodę to będzie crash.
Krótkie wyjaśnienie dla osoby nie znającej innego języka: taki Optional, który automatycznie i niejawnie (implicitly) wstawia po sobie wykrzyknik (unwrapping) podczas użycia. Co się stanie jeśli spróbujemy na siłę rozpakować Optionala, a on okaże się być nilem? Crash.
Z tego typu nie zaleca się korzystać, choć czasem jest to dużo wygodniejsze i może być akceptowalne, np. w przypadku outletów Interface Buildera (ale o tym może innym razem).
Funkcje
Argument labels – to nie do końca to i nie jest to lukier składniowy. Tutaj warto znać Objective-C żeby wiedzieć skąd takie, a nie inne sygnatury metod. Tak, etykiety przed parametrami są po prostu częścią sygnatury metody, które w Objective-C wyglądały na przykład tak:
(BOOL)insertString:(NSString *)someString atIndex:(int)index {}
// sygnatura to `insertString:atIndex:`
// wywołanie: [myContainer insertString:myString atIndex:myIndex];
A w Swift odpowiednik napisalibyśmy tak:
func insert(string: String, at index: Int) -> Bool {}
// sygnatura to `insert(string:at:)`
// wywołanie: myContainer.insert(string: myString, at: myIndex)
Swift jest pod tym względem bardziej elastyczny ale nadal dzięki wplataniu sygnatury metody pomiędzy parametry kod lepiej się czyta – jak powieść. Jest to chyba moja ulubiona cecha Swifta (a także Objective-C). W powyższym przykładzie można też dyskutować o zasadności użycia słowa “string” w metodzie Swiftowej ale założyłem, że jest to mój własny kontener posiadający również metodę insert(number:at:), która jest już zupełnie inną metodą.
Jeżeli chodzi o method dispatch w Swifcie to jest to dość skomplikowany temat. Napiszę tylko, że występuje wiele wariantów (message, table, static) i w rzadkich przypadkach może się wywołać nie to czego moglibyśmy się spodziewać (referencja typu interfejsu, który ma zaimplementowaną metodę w rozszerzeniu ale sam interfejs nie deklaruje, że obiekt taką metodę może posiadać…). Zainteresowanych szczegółami zapraszam tutaj.
Enumy
Moim zdaniem akurat bardziej dziwne jest to, że właśnie enumy mogą “dziedziczyć” po jakimś typie :-) Enumy w Swifcie są typem samym w sobie, a wręcz kolekcją typów… ciężko to określić. Powiedzmy, że są to takie wyjątkowe pogrupowane struktury, a do referencji można przypisać jedną ze struktur w ramach swojej grupy. Dlaczego akurat struktury, a nie wartości? Bo enumy mogą mieć powiązane wartości!
enum StringDataOperation {
case update(String)
case delete
}
switch(incomingOperation) {
case .update(let newValue): // update record with newValue
case .delete: // delete record
}
Interfejsy
W Swifcie zamiast tworzenia jednego protokołu implementującego kilka innych tworzy się po prostu alias. Przykład z biblioteki standardowej:
public typealias Codable = Decodable & Encodable
Metody opcjonalne to oczywiście korzenie Objective-C. Objective-C jest na tyle dynamicznym językiem, że można w nim zadeklarować metodę lub implementację protokołu… a następnie tego nie zaimplementować. Już od dawna kompilator wyrzuca błędy w takiej sytuacji ale konwencje nadal żyją. Na przykład: protokół źródła danych tabeli wymaga opcjonalnie metody zwracającej wysokość nagłówka jako double. Tabela zanim odpyta źródło danych sprawdzi czy została ona zaimplementowana poprzez użycie respondsToSelector:, a jeśli nie to przyjmie domyślną wartość.
Chciałbym zwrócić jeszcze jedną uwagę – czyste Swiftowe protokoły na to nie pozwalają. Tylko w protokołach z atrybutem @objc czyli są to w sumie protokoły Objective-C ale używane z poziomu Swifta.
Wyjątki
Tutaj powinniśmy sobie wyjaśnić jedną ważną rzecz. Obsługa błędów w Swifcie to NIE SĄ wyjątki!
“Ale jak to? Przecież rzuca się je przy użyciu throw! W jaki sposób nie są więc wyjątkami?!”
Składniowo tak, wyglądają dokładnie jak wyjątki ale pod spodem dzieje się coś zupełnie innego niż np. w C++. Nie jest to jednak prosty temat. Wyjątki wiążą się z rozwikłaniem stosu, które może wyraźnie wpłynąć na wydajność w momencie rzucenia wyjątku. W Swift tego nie ma, jest za to niewielkie pogorszenie wydajności w momencie wywoływania funkcji mogącej zaraportować błąd (czego nie ma w C++).
Działa to trochę tak jakby pod spodem metoda zwracała wartość LUB błąd, a przy każdym wywołaniu był warunek – jeśli wartość to działaj dalej, a jeśli błąd to przejdź do bloku catch lub zwróć go dalej gdy bloku nie ma.
Generyki
Temat rzeka. Chyba najtrudniejszy w całym Swifcie. Są bardzo elastyczne, pozwalają np. na stworzenie generycznego rozszerzenia innego obiektu z dodanymi warunkami (np. generyczny typ musi implementować protokół) i jeszcze sprawić, że rozszerzany obiekt będzie implementował jakiś protokół. Co do generycznych enumów to dobrym przykładem ze standardowej biblioteki może być… Optional. Tak, te znaki zapytania to tak naprawdę tylko lukier składniowy :-)
// Tak to z grubsza wygląda w bibliotece standardowej
enum Optional {
case some(T)
case none
}
// Kolejny przykład z biblioteki standardowej
extension Array : Encodable where Element : Encodable {
public func encode(to encoder: Encoder) throws { // ... }
}
Xcode
Wiem dobrze co ludzie mówią o Xcode. Nie jestem jednak jednym z narzekaczy. Może to przez to, że do niego jestem najbardziej przyzwyczajony i to inne IDE są dla mnie nieintuicyjne, problematyczne i źle działają? W rzeczywistości zapewne po prostu Xcode umiem używać, umiem rozwiązać jego problemy, a inne IDE do niego porównuję i uważam za gorsze tylko przez to, że są inne… Nie znam wyników żadnych badań w tej kwestii więc powstrzymam się od silnych opinii ale z pewnością można stwierdzić, że Xcode wyraźnie różni się od innych IDE.
Osobiście najbardziej lubię w nim jego interfejs. Jest ładny, czysty i nie zaśmiecony. Dlaczego tak mało twórców programów narzędziowych przykłada się do estetyki? Czy wszystkie profesjonalne aplikacje muszą wyglądać jak MS Office 97?
Crashe
Po drugiej stronie barykady jest stabilność. Ciężko zaprzeczyć temu czego doświadczył Maciej. Xcode się wywala i to często. Zdecydowanej większości tych błędów winny jest Swift. Jako, że jest to język pisany od podstaw – narzędzia z nim związane są równie młode, ulegają równie dynamicznym zmianom i są jeszcze niedopracowane.
Gorsze jednak jest to, że nawet sample potrafią być nieaktualne! Gdy coś było pokazywane na konferencji Apple w Swift 2.0 to aktualna wersja IDE nie tylko nie skompiluje tego kodu ale nawet nie udostępnia migracji kodu do nowej wersji Swift bo wspiera w tej kwestii tylko jedną wersję wstecz.
Osobiście nie doświadczam crashy tak często ale może być to związane z większym doświadczeniem w Swifcie. Crashe pojawiają się szczególnie wtedy gdy napiszemy niepoprawny składniowo kod w wariancie, na który kompilator nie był przygotowany. Wiadomo, że ludzka kreatywność nie zna granic. Nie uważam jednak żeby to była odpowiednia wymówka dla programistów Apple. Dałoby się to rozwiązać lepiej, tak aby nie przerywać pracy programisty.
Warto wspomnieć, że przy używaniu Objective-C crashe nie pojawiają się tak często, a wręcz bardzo rzadko. Choć nadal Xcode ma tak dużo funkcji, że ciężko ich całkiem uniknąć. Np. podczas korzystania z bardzo rozbudowanego Interface Buildera.
Pobieranie
Mac App Store nie cieszy się dobrą sławą wśród użytkowników macOS, a szczególnie w przypadku gdy trzeba pobrać duży program lub co gorsza – zaktualizować go. Wielokrotnie zdarzało się, że aktualizacja, która miała mieć np. 300MB nie powiodła się, a Mac App Store zdecydował aby pobrać program ponownie. Cały. Kilka GB. I tak kilka razy…
Problem pojawia się też gdy potrzebujemy mieć kilka wersji Xcode. Xcode jest ściśle powiązany z SDK jakie jest z nim dostarczane. Pobierając Xcode 9.2 możemy używać tylko SDK iOS 11.2 (deploy oczywiście też na starsze systemy). Ale jeśli chcemy użyć np. SDK iOS 10.3 to musimy pobrać np. Xcode 8.3.3.
Do tego celu polecam użyć narzędzia xcode-install. Pozwala na łatwe zarządzanie wersjami Xcode z linii komend. Szczególnie przydaje się na CI ale lokalnie też warto z niego skorzystać. Dodatkowo upewnia się, że każda instalacja ma dostęp do odpowiednich pozycji w Pęku Kluczy i zaakceptowaną licencję aby uniknąć późniejszych żądań o wpisanie hasła.
Przy okazji wspomnę też o innych konsolowych narzędziach będących aktualnie praktycznie obowiązkowymi dla każdego programisty iOS:
CocoaPods
Fastlane
Homebrew
Polecam też użyć jakiegoś menedżera wersji ruby (3/4 ze wspomnianych narzędzi jest w ruby). Osobiście korzystam z rbenv.
Playground
Zgadzam się, że jest to świetna koncepcja. Niestety wykonanie jest trochę gorsze, a ich domyślny tryb pracy (automatyczna kompilacja co chwilę, po wpisaniu kodu) potęguje tylko ilość crashy.
Warto wspomnieć, że są również na iPada choć w nieco innej formie.
AppCode
AppCode to chyba jedyne inne IDE, które może służyć do pisania aplikacji na iOS z użyciem Swifta. Niestety nie jestem w stanie go polecić. Szczególnie nie polecam go początkującym. Do wielu rzeczy i tak potrzebne jest Xcode (choćby Interface Builder!).
Często jest też w tyle za nowymi funkcjonalnościami iOSa lub Swifta. W świecie iOS nie można być w tyle. Gdy wychodzi nowe SDK to używa się go niemal natychmiast, a często nawet jak jeszcze jest w becie. Apple narzuca duże tempo ale ułatwia też radzenie sobie z nim. Po paru miesiącach od wyjścia nowego SDK aplikacje wysyłane do App Store muszą z niego korzystać ale użycie nowego SDK zwykle nie generuje problemów lub są one stosunkowo małe.
Dla osób mających doświadczenie z innymi IDE od JetBrains może się ono wydawać bardziej przyjazne i łatwiejsze do obsługi. Nie zamierzam się sprzeciwiać. Sam osobiście uważam takie Android Studio za bardzo dobre IDE. Ba! AppCode niektóre rzeczy robi lepiej od Xcode (np. refactoring). Niestety ze względu na opisane braki docelowo można z niego korzystać jak z uzupełnienia Xcode, a nie zastępstwa.
Usability
Jeśli chodzi o code completion to ctrl+spacja u mnie działa i nigdy nie miałem z tym problemów. Może inny program przechwycił ten skrót? Nie wiem. Musiałem u siebie specjalnie sprawdzić bo naprawdę rzadko z tego korzystam. Zwykle po prostu wpisuję fragment metody. Od niedawna wspierane jest też fuzzy search. Wystarczy wpisać kilka liter wchodzących w skład nazwy metody aby aby ją znaleźć. Czyli pisując “myViewController.vwiapp” podpowie nam metody viewWillAppear(animated:) oraz viewWillDisappear(animated:).
Warto też zapamiętać skrót Command+Shift+O gdyż służy on do przeszukiwania projektu i zależności (w tym też np. UIKit czy biblioteka standardowa Swift). Można znaleźć w ten sposób zarówno pliki jak i symbole (metody, klasy).
Możliwości refactoringu rzeczywiście są ograniczone. Szczególnie w przypadku Swifta – refactoring pojawił się ok. pół roku temu. Wraz z Xcode 9 i pierwszą wersją Swifta, która miała stabilne źródła. Co ciekawe te możliwości są trochę większe niż może się wydawać na pierwszy rzut oka, ponieważ w Xcode prawie wszystkie funkcje pojawiają się kontekstowo.
Kontekstowość funkcji Xcode może odpowiadać za wrażenie małych możliwości Xcode. W istocie tak jednak nie jest. Dla początkującego programisty to nawet dobrze bo nie przeraża go ogrom funkcjonalności i przeróżnych paneli. Ale w sumie to po co nam przyciski zatrzymywania i debugowania aplikacji gdy nie jest ona uruchomiona? Pojawią się dopiero jak się ją odpali. Wystarczy kliknąć na plik storyboard aby pojawił się bardzo zaawansowany Interface Builder służący do graficznej edycji widoków. W podobny sposób możemy odkryć, że Xcode posiada wbudowane np. View Debugger, edytor modeli baz danych Core Data, kompilator i generator kodu modeli CoreML, a nawet edytor scen 2D i 3D! Do tego bardzo rozbudowane Instruments służące do profilowania (dostarczane z Xcode jednak jako osobna aplikacja, podobnie jak symulator iOS).
Symulator iOS
Warto zwrócić uwagę na nazewnictwo. Symulator, nie emulator.
Na czym polega różnica? macOS oraz iOS są bardzo podobnymi systemami. Na tyle podobnymi, że podczas uruchamiania aplikacji iOS na symulatorze są one kompilowane na architekturę x86_64 i uruchamiane natywnie. Nie ma tam wirtualizacji. Symulowane jest środowisko uruchomieniowe, np. menedżer okien czy niektóre usługi systemowe.
Sprawia to, że aplikacje na symulatorze działają bardzo szybko i na fizycznym urządzeniu uruchamia się je względnie rzadko (choć oczywiście zależy tu dużo od specyfiki aplikacji). Dla mnie osobiście w większości przypadków wygodniejszy jest symulator, ponieważ nie muszę co chwilę odrywać rąk od klawiatury i myszy. Niestety symulacja OpenGL ES jest dość obciążająca, więc aplikacje, które z tego korzystają (gry, mapy) nie działają równie szybko (choć i tak radzą sobie całkiem sprawnie).
Deploy
To też jest jedna z rzeczy, która ostatnimi laty mocno się poprawiła. Łatwo jest podłączyć urządzenie, wybrać konto deweloperskie, kliknąć (raz lub kilka razy) “Fix issue” i będzie działać. Niestety na dłuższą metę może to bardziej zaszkodzić niż pomóc bo nie wiemy co namiesza w profilach. Albo wiemy – ale wtedy nie jest nam ta funkcja potrzebna.
Apple bardzo mocno stawia na bezpieczeństwo. Na tyle bardzo, że staje się to uciążliwe. Niestety na to nie ma mocnych. Aby sobie z tym szybko i sprawnie radzić trzeba dobrze zrozumieć te mechanizmy bezpieczeństwa. Ale z drugiej strony może to i dobrze? Myślę, że nadal wielu programistów za mało przykłada się do kwestii bezpieczeństwa.
Długi okres oczekiwania na “Preparing debugger support” jest związany z koniecznością skopiowania symboli debugowania z konkretnej wersji systemu urządzenia na komputer. Symbole te potrafią zająć ~2 GB dla jednej wersji, więc warto co jakiś czas stare pliki kasować z ~/Library/Developer/Xcode/iOS DeviceSupport.
Płacić za konto deweloperskie trzeba gdy nasze wymagania rosną lub gdy chcemy wrzucić aplikację do sklepu. To również jest w miarę świeża zmiana, a informacja o konieczności płacenia nadal bywa błędnie rozpowszechniana. Poza tym co możemy znaleźć tutaj, limity narzucone na darmowe konta to:
7 dniowy czas wygasania Provisioning Profile – czyli aplikacja na urządzeniu działa przez 7 dni od instalacji przez Xcode
10 zmian w App ID w ciągu 7 dni – czyli w ciągu 7 dniach można zarejestrować do App ID 10 nowych aplikacji lub wykonać 10 aktualizacji App ID jednej aplikacji. Nic nie zabrania używania tego samego App ID w kilku projektach podczas pisania aplikacji. Aplikację można też bez problemu budować i instalować wielokrotnie
Podsumowanie
Bardzo ciekawe było dla mnie czytanie doświadczeń osoby wchodzącej teraz do środowiska Apple. Moje doświadczenia kilka lat temu trochę się różniły. Teraz wszystko działa zauważalnie sprawniej i wiele obiegowych opinii zamieniło się w mity. Jako programistę iOS bardzo mnie cieszy obecna sytuacja i dobrze wróży na przyszłość.
To kto jeszcze chce zostać programistą iOS? :-)
Powodzenia!
The post “Swift okiem programisty C#” okiem programisty Swift appeared first on devstyle.pl.
Będzie… GIT! [devstyle vlog #151]
The post Będzie… GIT! [devstyle vlog #151] appeared first on devstyle.pl.
March 25, 2018
Niebezpieczne programowanie w .NET
Jest takie słowo kluczowe, przed którym truchleje część programistów C#. Sama jego nazwa zaznacza, że opuszczamy bezpieczny świat zarządzany i wkraczamy w królestwo gwiazdek i operacji na byte’ach.
UWAGA: autorem tekstu jest Szymon Kulec. Dajcie znać jak się podoba, Szymon prawdopodobnie zagości na devstyle na dłużej ;).
Czy słowo to faktycznie przysparza samych problemów? A może istnieją przypadki w których warto je użyć? W tym artykule spojrzymy na unsafe z punktu widzenia tego, co możemy zrobić w niebezpiecznym kontekście i co nam on daje.
O mój Stosie!
Każdy kto pracuje w środowisku .NET świadomy jest zapewne dwóch obszarów pamięci z którymi pracujemy.
Pierwszym jest sterta (ang. heap), na której alokowane są instancje typów referencyjnych, czyli wszystkie, które zadeklarowano jako klasy. Trafiają tam też tablice.
Zależnie od rozmiaru, obiekt może być umieszczony na stercie małych obiektów (ang. Small Object Heap, SOH) lub stercie dużych obiektów (ang. Large Object Heap, LOH).
Drugim obszarem jest stos, czyli obszar roboczy wątku, który wykonuje nasz kod. To tam znajdą się wszystkie zmienne lokalne.
Wspomniana wcześniej tablica jest wyjątkowo niefortunnym przypadkiem. Tworzenie tablic możemy znaleźć w wielu miejscach. Szczególnie bolesne jest tworzenie tablic małych, których używamy do różnego rodzaju prostych obliczeń, transformacji i potem się ich pozbywamy.
Częste alokacje to jedna z częstych przyczyn powolnego działania aplikacji .NET. Czy istnieje zatem jakiś bardziej wydajny sposób, być może “niebezpieczny”, który pozwala efektywniej używać pamięci, niekoniecznie zmuszając mechanizm Garbage Collectora (GC) do zbierania pozostawionych obiektów?
Odpowiedzią jest słowo kluczowe stackalloc, które pozwala na tworzenie odpowiednika tablic na stosie. Spójrzmy na następujący przykład funkcji, która dla danego klucza pobiera dane i wylicza na nich jakiś hash. Widać, że dzięki posiadaniu informacji o maksymalnym rozmiarze danych, możemy utworzyć bufor na stosie i podać go jako parametr do wypełnienia. Potem, przekazać do funkcji hashującej i zwrócić wartość bez kosztownej alokacji tablicy.
public unsafe int HashValue (Guid key)
{
const int size = 40;
byte* data = stackalloc byte[size];
var length = FillWithData (key, data);
return Hash(data, length);
}
O ile taka operacja niekoniecznie będzie potrzebna w Twoim kontrolerze API, o tyle, przy częstym wykonywaniu jakiejś funkcji z logiki biznesowej (szczególnie algorytmu), może w znacznym stopniu zmniejszyć obciążenie związane z alokacjami na stercie, zmniejszając czas działania GC, a tym samym zwiększając przepustowość Twojej aplikacji.
Przypnij sobie uchwyt
W poprzednim przykładzie pojawiła się już magiczna gwiazdka, czyli nic innego jak stary dobry wskaźnik, którego na co dzień nie uświadczysz w kodzie pisanym w C#. Wskaźniki, w przeciwieństwie do referencji, nie są zarządzane przez CLR i to właśnie Ty musisz odpowiednio je obsłużyć.
Co natomiast, jeżeli w jakimś przypadku chcielibyśmy uzyskać wskaźnik, np. do tablicy, po to, aby wykonać na niej pewne operacje? Czy istnieje coś, co łączy świat obiektów alokowanych na stercie i świat wskaźników?
Rzeczą, która pomoże nam połączyć te dwa odległe światy, jest słowo kluczowe fixed. Pozwala ono na przypięcie (ang. pinning) obiektu tablicy w tym samym miejscu pamięci i otrzymanie wskaźnika do tak przypiętego (ang. pinned) obiektu. Poniższy przykład, z implementacji funkcji hashującej Murmur3 pokazuje, jak uzyskać dostęp do wskaźnika do danych. Zauważmy, że ze względu na to, iż wskaźnik nie posiada długości, dodatkowo do kolejnej metody podajemy liczbę byte’ów.
public static unsafe uint Hash32(byte[] buffer, uint seed)
{
fixed (byte* bufPtr = buffer)
{
return Hash32(bufPtr, buffer.Length, seed);
}
}
public static unsafe uint Hash32(byte* data, int length, uint seed)
{
// very fast and very unsafe implementation here ;-)
}
Przypięcie obiektu przy użyciu słowa fixed trwa do momentu wyjścia z bloku tego słowa. Po wyjściu, obiekt może być przenoszony przez Garbage Collector, jeżeli ten wykonywał będzie zbieranie śmieci. W czasie gdy obiekt jest przypięty, nie może zostać poruszony przez mechanizm Garbage Collectora.
Przypinam was, dopóki koniec aplikacji nas nie rozłączy
Istnieją przypadki, w których przypięcie obiektów nie powinno być limitowane do jednego bloku. Typowym przykładem są tablice byte’ów, które chcemy używać podczas całego działania aplikacji i które chcemy używać zarówno ze świata zarządzalnego (operowanie na byte[]) jak i niezarządzanego (byte*). Szczególnie przydatne jest to w pisaniu niskopoziomowych bibliotek, takich jak Kestrel, czy innych, łączących się ściśle z systemem operacyjnym, siecią czy platformą.
Jak zatem uzyskać obiekt, który nie będzie się poruszał (będzie przypięty) przez dłuższy czas i w jaki sposób uzyskać do niego wskaźnik?
Okazuje się, że .NET dostarcza strukturę do tego potrzebną. Nazywa się GCHandle i pozwala na przypięcie obiektu w pamięci, dopóki nie zostanie wywołana odpowiednia metoda kończąca to przypięcie. Spójrzmy na przykład, który pozwala na używanie tablicy utworzonej na zarządzanej stercie, która może być także używana w kodzie używającym wskaźników:
var bigTableForProcessing = new byte [1024 * 1024];
var gc = GCHandle.Alloc(bigTableForProcessing, GCHandleType.Pinned);
byte* unsafeBigTableForProcessing = (byte*) gc.AddrOfPinnedObject();
// when this buffer is no longer needed
gc.Free(); // to unpin object
Nadpisywania, wycieki i inne problemy 1-ego świata
Z wszystkimi technikami opisanymi powyżej wiąże się kilka niebezpieczeństw.
Użycie wskaźników pozwala odczytać dane z innych obszarów aplikacji, nawet jeśli danych tego typu tam nie było. Podobnie z obszarem pamięci dostarczonym przez stackalloc – to po naszej stronie leży odpowiedzialność za sprawdzenie czy nie wychodzimy poza długość bloku pamięci tam dostarczonego.
Czy zatem warto używać tych mechanizmów? Tak, ale ostrożnie!
Jeżeli fragment Twojego kodu przelicza tony danych, jeżeli alokacje to faktyczny problem, jeżeli musisz porozumiewać się ze światem niezarządzanym, to powyższe konstrukcje jak najbardziej mogą przyczynić się do dużych wydajnościowych zysków.
Not so unsafe
Ponieważ alokacja na stosie, przy użyciu stackalloc, jest bardzo częstym mechanizmem do pozyskania małego obszaru roboczego pamięci, w najnowszej wersji języka C# i platformy .NET przesunięto go do bezpiecznej części języka. Możliwe to było dzięki nowej struktury danych, Span. Struktura ta zachowuje się bardzo podobnie do tablicy, czy też wskaźnika, ale pozwala na konstrukcję jej w bezpiecznym kontekście.
Span bytes = stackalloc byte [32];
Przypuszczam, że Span i związany z nim stackalloc będzie coraz częściej spotykanym tworem w naszym kodzie, pozwalając na wytwarzanie oprogramowania, które od samego począku, będzie niezwykle wydajne.
Podsumowanie
Słowa unsafe nie znajdziesz w kontrolerach API ani w mapowaniu encji EntityFramework. Obszary, gdzie jest to przydatne to funkcje, które są często wykonywane i alokują niepotrzebnie duże ilości obiektów albo elemety współpracujące z niskimi API systemu operacyjnego lub bibliotek napisanych w kodzie niezarządzalnym.
Będąc uzbrojonym w unsafe, stackalloc i GCHandle możesz śmiało wejść do Królestwa Niezarządzanego Performance’u.
Materiały dodatkowe:
Span – świetny artykuł Adama Sitnika opisujący jak działa Span
Implementacja Span w CoreCLR
Allocation is cheap… until it is not – dogłębny opis alokacji w .NET by Konrad Kokosa
The post Niebezpieczne programowanie w .NET appeared first on devstyle.pl.
March 24, 2018
… I Co Dalej? [devstyle vlog #150]
The post … I Co Dalej? [devstyle vlog #150] appeared first on devstyle.pl.
Maciej Aniserowicz's Blog

- Maciej Aniserowicz's profile
- 22 followers

