
Maciej Aniserowicz's Blog, page 38
July 24, 2018
Wednewsday #16 – programistyczne nowinki
Witam w kolejnej wydaniu wednewsday. Na początek, krótka instrukcja jak komuś wyjaśnić czym się różni Java od JavaScript:
“Java and Javascript are similar like Car and Carpet are similar.”
Zrozumiałe? No raczej :)
Piaskownica
InterviewMap – mind mapa, która pozwoli lepiej przygotować się do następnej rozmowy o pracę.
What Is React?
Learn at your own pace with Microsoft Quantum Katas – ćwiczenia nauczające języka Q# oraz Quantum Computing
Programowanie
Every method begins with “new” – code smells series – Dino Esposito i jego10 tygodniowa seria postów dotyczącą code smells i code structure.
Mint – A refreshing programming language for the front-end web
Rockstar – język programowania inspirowany muzyką rockową lat 80. Napisany kod może być jednocześnie tekstem piosenki!
Supercharge your debugging experience for Node.js
octobox.io – zarządzasz wieloma projektami na GitHubie? To narzędzie pomoże Ci ogarnąć notyfikacje.
2018 WebDev Resources – skąd w 2018 roku zdobywać wiedzę dotyczącą tworzenia aplikacji webowych. Dyskusja na Reddit.
An automatic interactive pre-commit checklist – wykorzystanie Git hooks do wywołania checklisty przy każdym poleceniu git commit.
Packaging Applications for Docker and Kubernetes: Metaparticle vs Pulumi vs Ballerina
Artykuły, ciekawostki
Microsoft is updating the Windows Notepad app for the first time in years
Postmortem for Malicious Packages Published on July 12th, 2018 – Postmortem problemu z udostępnieniem złośliwej wersji pakietu eslint.
1500 Archers on a 28.8: Network Programming in Age of Empires and Beyond – art. z 2001 roku wyjaśniający architekturę, szczegóły implementacji trybu multiplayer w grze Age of Empires
Virtual AGC — AGS — LVDC — Gemini – kod, dokumentacja oraz symulator komputerów nawigacyjnych użytych podczas misji księżycowych w programie Apollo.
How is JavaScript used within the Spotify desktop application?
Code Prediction with a Neural Network – TLDR; I used Python to create a neural network that implements an F# function to predict C# code.
todo.sh – prosta ToDo lista w shellu.
Hints for Computer System Design – dokument z 1983 roku dotyczący projektowania systemów komputerowych. Co ciekawe każda zaprezentowana idea jest opatrzona cytatem ze znanych dzieł literatury lub znanych osób.
How Fortnite approaches analytics, cloud to analyze petabytes of game data
Zapraszam również do śledzenia audycji podcastowej, w której prezentuję najnowsze wiadomości, ciekawostki, wpadki oraz wydarzenia ze świata IT:
http://devsession.pl/podkast/
The post Wednewsday #16 – programistyczne nowinki appeared first on devstyle.pl.


July 23, 2018
#bstoknet 83: programistyczny sposób na wakacyjny letarg
Uff… Nareszcie wakacje. Nadszedł długo oczekiwany koniec roku akademickiego. W końcu można na spokojnie iść do pracy, nie martwiąc się egzaminami i projektami. Cały rok nie miałam czasu skorzystać z opcji pogłębiania wiedzy na tematy IT, przez co szerokim łukiem omijałam wszystkie programistyczne wydarzenia zarówno w Białymstoku, jak i poza granicami Podlasia. „Dla mnie się to nie podobało”. ;)
Postanowiłam naprawić swój błąd i sprawdzić, czy pomimo wakacji znajdę coś dla siebie w moim pięknym mieście. Nie zawiodłam się! 18 lipca swoje 83. spotkanie miała Białostocka Grupa .NET. Jako zagorzała fanka .NET nie mogłam tym razem odpuścić.
Szybki obiad i kawa po pracy, aby o godzinie 18:00 pojawić się w siedzibie firmy SoftwareHut przy ulicy Sienkiewicza 110. Pomimo wakacji i okresu urlopów na miejscu przywitała mnie spora grupa ludzi, którzy – tak jak i ja – chcieli w to lipcowe popołudnie zaczerpnąć programistycznej wiedzy od ekspertów. Jak zawsze na takich wydarzeniach nie mogło zabraknąć napojów orzeźwiających, zarówno tych bez, jak i tych z procentami, aby ślina nie wyschła przy dywagacjach na wszelakie tematy bardziej lub mniej związane z IT.  Szybkie rozpoznanie nieznanego terenu, ponieważ miejsce to nówka sztuka wyświęcona sala Centrum konferencyjno-coworkingowego. Znalazłam wolne miejsce i mogłam w spokoju oddać się pochłanianiu wiedzy.
Szybkie rozpoznanie nieznanego terenu, ponieważ miejsce to nówka sztuka wyświęcona sala Centrum konferencyjno-coworkingowego. Znalazłam wolne miejsce i mogłam w spokoju oddać się pochłanianiu wiedzy.
Na scenie pojawił się Rafał Hryniewski – jeden z obecnych ojców dyrektorów #bstoknet. Pokrótce opowiedział, co nas dzisiaj czeka, i bez zbędnego przedłużania oddał głos pierwszemu prelegentowi.
Wprowadzenie do Emulacji i Emulatorów
Sebastian Gierłowski, programista .NET w firmie SoftwareHut, poruszył dość niebanalny temat, jakim są emulatory. Jako początkującej programistce takie rzeczy zawsze kojarzyły mi się z nudnymi wykładami na uczelni, gdzie zakurzeni wykładowcy opowiadają o jeszcze bardziej zakurzonych sprzętach, na których „za ich czasów” (czy ktoś w końcu mi odpowie, kiedy to było?) zaczynało się przygodę z programowaniem.
Otóż nic bardziej mylnego!
 Sebastian dysponuje ogromną wiedzą na ten temat, dzięki czemu poprowadził prezentację tak płynnie, że zanim się obejrzałam, już ją skończył. Strzałem w 10 było przyniesienie Game Boya, aby każdy z uczestników mógł zobaczyć na żywo wyniki pracy Sebastiana. Mogę się założyć, że wielu obecnym tam “starszym studentom” łezka się w oku zakręciła na widok dawnego przyjaciela. Autor prezentacji przeszedł od krótkiej historii poprzez obecne zastosowania, aby zakończyć na przedstawieniu projektu własnego emulatora. Uchylił nam rąbka tajemnicy na temat tego, w jaki sposób i gdzie szukał informacji, by móc zakończyć swój projekt sukcesem.
Sebastian dysponuje ogromną wiedzą na ten temat, dzięki czemu poprowadził prezentację tak płynnie, że zanim się obejrzałam, już ją skończył. Strzałem w 10 było przyniesienie Game Boya, aby każdy z uczestników mógł zobaczyć na żywo wyniki pracy Sebastiana. Mogę się założyć, że wielu obecnym tam “starszym studentom” łezka się w oku zakręciła na widok dawnego przyjaciela. Autor prezentacji przeszedł od krótkiej historii poprzez obecne zastosowania, aby zakończyć na przedstawieniu projektu własnego emulatora. Uchylił nam rąbka tajemnicy na temat tego, w jaki sposób i gdzie szukał informacji, by móc zakończyć swój projekt sukcesem.
Kod emulatora Game Boya w C# można poprzeglądać na GitHubie Sebastiana.
 Po tej prezentacji zaczęłam się zastanawiać, czy gdzieś w domu nie mam starego sprzętu, na którym mogłabym się pobawić w MacGyvera i spróbować swoich sił w programowaniu w C# niskopoziomowo.
Po tej prezentacji zaczęłam się zastanawiać, czy gdzieś w domu nie mam starego sprzętu, na którym mogłabym się pobawić w MacGyvera i spróbować swoich sił w programowaniu w C# niskopoziomowo.
Jednak szybko moje myśli rozproszyło szeleszczenie sreberek i delikatny zapach świeżych kanapek prosto od jednego ze sponsorów wydarzenia – Infinity Group.
Dłuższa przerwa między prelekcjami była doskonałym momentem, aby odwiedzić stoisko firmy SoftServe i porozmawiać z rekruterką Michaliną Boguszewską o jej punkcie widzenia odnośnie do tego typu wydarzeń.

Moja rozmówczyni stwierdziła, że taka forma zainteresowania potencjalnego pracownika ich firmą może być najbardziej skuteczna. Zgadzam się z nią w 100%. Na pewno byłoby mi łatwiej pogadać na luzie i z colą w ręku z przedstawicielem firmy niż od rana denerwować się i w stresie, zapominając po drodze wszystkie różnice pomiędzy klasą abstrakcyjną a interfejsem (klasyk), jechać do siedziby firmy na pierwszą oficjalną rozmowę.
Po miłym spotkaniu z Michaliną przyszedł czas na kolejną prezentację.
Internet is made of cats, porn and stuff your neighbors shouldn’t know about you
Skłamałabym, mówiąc, że temat tej prezentacji mnie nie zaniepokoił. Gdzieś w mojej głęboko uśpionej podświadomości zapaliła się malutka czerwona dioda pod nazwą „To nie może być takie proste”. Skąd pomysł, aby na wydarzeniu poświęconym .NET i całej jego otoczce mówić o małych kotkach w piwnicy?
I wtedy wchodzi Rafał Hryniewski – .NET Developer w Elastic Cloud Solutions. Niestety nieubrany cały na biało.
Na początku pokazał nam, w jak prosty sposób sprzedajemy swoją prywatność. I nie, nie chodziło mu o zdjęcia na Facebuczku, Instagramie lub innym Snapczacie. Jego celem nie były też tzw. patostreamy, na których za pieniądze ludzie pokazują, jak piją piwo.
Przekaz Rafała był o wiele prostszy. Otóż zwrócił on uwagę na to, jak mało ludzi przejmuje się hasłami do swoich sprzętów elektronicznych. Ba, jak mało ludzi zmienia fabryczne hasło na własne. I właśnie dzięki tej ludzkiej ignorancji, no i kilku godzinom przeszukiwania Internetu, jesteśmy w stanie dostać się do paneli sterowania monitoringów domowych, kamer przemysłowych lub nawet sygnalizacji świetlnej. Ilu z nas nie marzyło o tym, by podczas stania w korku do pracy mieć moc niczym Bruce Wszechmogący i sprawić, że światła magicznie zmienią się na zielone?
Ale to nie wszystko. Rafał zaczął budować napięcie coraz to poważniejszymi przykładami wyszukanymi w sieci. Znalazły się tam między innymi panele sterowania turbiną, kopalnią czy nawet stacją transformatorową. Jednak wisienką na torcie był system sterowania zaporą wodną. Wyobraźcie sobie, że ktoś ma gorszy dzień, siada do komputera, znajduje panel sterowania takiej tamy i jak Thanos robi „klik” – lekką ręką ludzkości nie ma.
Straszne, ale prawdziwe.
Ta prelekcja naprawdę dała mi do myślenia. Miałam ciarki. Lubię prezentacje, na których napięcie jest budowane niczym w filmach Kubricka.
Rafał po mistrzowsku kontrolował całą salę i pomimo późnej godziny i wcześniejszej mocno technicznej prezentacji wszyscy słuchali go w maksymalnym skupieniu. Najważniejsze wnioski, które wyniosłam z tego wykładu: zabezpiecz swoje kamerki, aby następna część Paranormal Activity nie była o Tobie, drogi Czytelniku.
Tym pozytywnym akcentem zakończyła się ostatnia z oficjalnych prezentacji tego wieczoru. Jednak Grupa .NET nie próżnowała i wyszła z fajną inicjatywą pt. Open Mic.
Open Mic, czyli co mi na wątrobie leży
Open Mic to moim zdaniem świetna metoda, aby spróbować swoich sił jako prelegent. Zasady są proste.
Święcie wierzę, że każdy z nas ma coś ciekawego do powiedzenia – Rafał Hryniewski, organizator spotkań #bstoknet
Bierzesz mikrofon w jedną rękę, w drugą chwytasz swój napój bogów i nawijasz o tym, co cię martwi, co cię smuci. Rafał, autor tej idei, na pytanie o to, skąd wziął się pomysł na taką inicjatywę, odpowiada: Święcie wierzę, że każdy z nas ma coś ciekawego do powiedzenia, tak samo jak każdy ma jakieś doświadczenia, którymi mógłby się podzielić. I to jest chyba najlepsze podsumowanie.
Na opisywanym spotkaniu z tej opcji skorzystała jedna osoba, a był nią nie kto inny jak jeden z ojców założycieli Białostockiej Grupy .NET – Marcin Iwanowski, Team Leader i Senior SharePoint Developer w firmie Roche.
Open Mic – pierwsze koty za płoty z… NUCLEONem?
A tutaj – niespodzianka. Wbrew temu, co wcześniej napisałam, to wystąpienie na pewno nie było niezaplanowane. Marcin zaskoczył nas wszystkich profesjonalną prezentacją na temat wydajności zespołu developerskiego.
Podczas wystąpienia dał nam odpowiedzi na pytania: jak ją mierzyć, czy warto ją mierzyć, a ponadto jak możemy skorzystać z uzyskanych informacji. Spodziewałam się nudnego rozwlekania na tematy tabelek i nikomu niepotrzebnych cyferek mierzących liczbę wykonanych tasków w sprincie, a dostałam konkretny fundament na temat tego, jak można poprawić wydajność mojego zespołu. Na pewno gdybym nie była zwykłym klepaczem kodu, taka wiedza przydałaby mi się, aby jeszcze bardziej podkręcić pracę moich teamów, i to nie tylko tych programistycznych.
To już jest koniec… Nie ma już… nic?
I tak oto zakończyła się ostatnia prelekcja.
Na koniec jak zwykle każdy z występujących z prezentacją mógł założyć legendarny już sweter Białostockiej Grupy .NET i zapozować do profesjonalnej sesji zdjęciowej. Legenda głosi, że ów sweter może założyć tylko osoba, która wystąpiła jako prelegent, aby nasiąkł jej mądrością i nabrał magicznych właściwości. Może kiedyś uda mi się to sprawdzić…?
Uczestnicy mieli szansę zgarnąć licencję do ReSharpera. Wystarczyło wypełnić ankietę dotyczącą wydarzenia. I myk, licencja jest nasza – pod warunkiem, że maszyna losująca wybierze nas. Tym razem mi się nie udało, ale to w sumie dobrze – będzie motywacja, żeby wpaść na kolejne spotkanie i jeszcze raz spróbować szczęścia.
Podsumowując: jeżeli nudzicie się w domu, a jesteście głodni wiedzy, to Białostocka Grupa .NET przyjmie was z otwartymi ramionami. Możecie tam spotkać nie tylko .NET-owców, ale też wyznawców innych religii, jak np. JS czy Python. Jeżeli grupa będzie nadal trzymała tak wysoki poziom, to na pewno pojawię się na kolejnych spotkaniach, a kto wie, czy sama nie spróbuję swoich sił jako prelegent.
I na koniec niespodzianka: jeżeli chcesz zobaczyć wystąpienia tych zdolnych ludzi, to klikaj w poniższy zapis streamu z tego spotkania!
Kilka dodatkowych fotek wykonanych przez Lucjana Rudziaka znajdziesz na grupie FB #bstoknet: https://www.facebook.com/groups/bstoknet/.
The post #bstoknet 83: programistyczny sposób na wakacyjny letarg appeared first on devstyle.pl.
July 19, 2018
Wasze Historie #18: Uciekłem z życia
Decyzje… nic nadzwyczajnego, mamy z nimi do czynienia codziennie. Te najprostsze podejmujemy mechaniczne. Te wymagające długich przemyśleń i rodzące wątpliwości – odkładamy na później, a często wręcz próbujemy o nich zapomnieć.
Mimo to decyzje trzeba podejmować. Raz na zawsze… Ale czy na pewno?
Niniejszy post jest częścią cyklu „Wasze Historie”.
Autor: Wojciech Burczyk.
Odwiedź też blog Wojtka
Wiele znanych mi osób przyjmuje życie takim, jakie jest. „Jest, jak jest”, „po co coś zmieniać?”. Przez wiele lat po mojej głowie krążyły podobne myśli. Zawsze uważałem, że istnieją ludzie, którzy już od momentu urodzenia są skazani na sukces. Mieli szczęście i w momencie pojawienia się na tym świecie dostali w pakiecie startowym szczęśliwą kartę. Inni nie mieli tak dobrze – jak ja.
A może też Ty?
Niezliczoną ilość razy mówiłem sobie „zrobię to! Zmienię *coś*!”. Ale tak naprawdę stałem w miejscu. Dosłownie: nie kiwnąłem palcem, żeby zmienić bieg swojego życia. Z każdą porażką, jaką odnosiłem w swoich próbach, czułem się coraz gorzej. Kompletnie bez ambicji. Ogarniały mnie beznadzieja i zwątpienie we własne umiejętności, nie miałem w sobie ani krzty motywacji. Oczywiście słyszałem od różnych osób, zarówno tych bliskich, jak i tych dalszych, że „wystarczy, że w siebie uwierzysz, i na pewno ci się uda”.
Niestety sytuacja, w której się znalazłem, nie dała się rozwiązać wyświechtanym i nadużywanym frazesem. To tak nie działa. Wydaje mi się, że tekst ten jest równie skuteczny co pocieszanie osoby z depresją słowami: „wystarczy, że będziesz się uśmiechał, i wszystko będzie w porządku”.
Skoro czytasz ten tekst, to zapewne znasz ten stan
Skąd to wszystko się bierze? Dlaczego ludzie – w tym ja – boją się prostych rzeczy, jak rozmowa z obcą osobą, podjęcie próby nauki nowej umiejętności, odwiedzenie nieznanego im miejsca czy zwolnienie się z pracy?
Pokusiłem się o postawienie hipotezy, którą postanowiłem się z Wami podzielić. Otóż uważam, że social media i Internet są – lub mogą być – w dużym stopniu odpowiedzialne za ten nietypowy lęk przed porażką. W zasadzie mam na myśli ludzi kreujących bezrefleksyjny content, w którym wszystko im się zawsze udaje. Nie wydaje mi się, by ten pogląd w jakimkolwiek przypadku odbiegał daleko od prawdy. To, co widzimy na profilach naszych znajomych w social mediach, już dawno minęło granicę prawdy i stało się wykreowaną fikcją. Nikt nie chce być postrzegany przez pryzmat porażek. Ale to temat na kompletnie inny wpis.
Od fizjoterapeuty do programisty
Moją historię o tym, jak z fizjoterapeuty stałem się programistą, opowiedziałem już tyle razy, że podjąłem decyzję o udokumentowaniu jej w formie pisemnej. Początek 2016 roku, ja mający niespełna 27 lat. Przeprowadziłem się do kolejnego miasta. Znów ten sam schemat i najzwyczajniejsza w świecie walką o pracę. Miałem tego dosyć. Fizjoterapeuci nie mają łatwej sytuacji w naszym kraju – stosunek wiedzy i obowiązków do wypłacanej pensji jest komiczny. Tragikomiczny. A wszyscy oni pracują bardzo ciężko, porównywalnie do pielęgniarek. Pod warunkiem, że w ogóle mają pracę, ponieważ wakatów w tym zawodzie jest naprawdę niewiele.
By uniknąć zarzutów, że przekłamuję dane: gdy pracowałem w Kołobrzegu w jednym z sanatoriów, na 15 zatrudnionych osób tylko 2 były miejscowe. Reszta przyjechała do pracy z Poznania, Katowic, Opola, Łodzi, Chełma czy Przemyśla. Jeszcze więcej atrakcji temu zawodowi dodaje to, że nie jest regulowany. To znaczy, że ktokolwiek może zostać fizjoterapeutą, kończąc byle jaki kurs czy szkołę. Z pewnością każdy słyszał o znajomym kręgarzu, który co prawda wykształcenia nie ma, ale dobrze mu idzie.
Miałem już tego wszystkiego serdecznie dosyć. Zacząłem szukać nowego zajęcia. Znajomy znajomego opowiedział mi, że jest web developerem. Na początku byłem zafascynowany jego opowieściami o pasji do pracy i zaangażowaniu. Wiedziałem, że jest taki zawód, ale zawsze uważałem, że taka praca jest niezwykle prosta i nudna (o, naiwności!).
Czy web development miałem już we krwi i nie wiedziałem o tym?
Być może tak jak ja, gdy byliście o wiele młodsi, bawiliście się w „robienie stron internetowych” w prostych generatorach języka HTML, jakie były popularne w początkach Internetu. Ja takich stron stworzyłem dziesiątki. Na początku przerabiałem gotowe szablony, później tworzyłem swoje. Ale to nie było nic specjalnego. Przez lata, kiedy skupiałem się na zdrowiu swoich pacjentów, technologie ruszyły mocno do przodu. Gdy w końcu się zdecydowałem i zacząłem czytać na ich temat, było tego tyle, że nie wiedziałem, od czego zacząć.
Pierwszym językiem programowania, z jakim miałem styczność, był C++. Zająłem się nim bez konkretnego powodu, ze zwykłej ciekawości. Znalazłem w Internecie darmowe kursy popełnione przez rodaków na stronach A.D. 2010 (lub jeszcze starszych). Napisałem kilka bardzo prostych programów, nauczyłem się warunków, pętli, tablic itp. Było to bardzo przyjemne. Wreszcie sam coś stworzyłem. Niestety po kilku tygodniach natrafiłem na ścianę, której nie byłem w stanie pokonać, i znikąd nie widać było pomocy. Nie wiedziałem, jak zadać pytanie, by nie wyjść na głupka (#lęk). Na szczęście to były tylko początki.
Zacząłem interesować się tworzeniem stron, dowiedziałem się, czym są Front-End, Back-End itp. W końcu trafiłem na bootcampy. Byłem totalnie zaskoczony, ponieważ był to dla mnie kompletnie nowy rodzaj nauki. Zostać programistą w tak krótkim czasie? Jasne, że wchodzę w to!
Niestety, nie można płynąć z prądem, mając dziury w łodzi. Po pierwsze: to kosztuje i to sporo. Po drugie: ukończenie kursu nie czyni od razu programistą. W końcu trzeba znaleźć pierwszą pracę. Zadanie tak proste i tak trudne zarazem. No i trzeba było sobie zadać przed tym całym cyrkiem pytania: czy mam czas i czy podołam?
Trudne początki
Mój kurs trwał siedem miesięcy. Zajęcia odbywały się co drugi weekend, a pomiędzy nimi trzeba było mocno przysiąść nad materiałem i się uczyć. Mój typowy dzień wyglądał mniej więcej tak: pies–praca–nauka–trening–nauka–spać. SIEDEM miesięcy. Nie powiem, że nie wygospodarowałem żadnego czasu na odpoczynek, bobym skłamał. Jakoś w połowie kursu zacząłem chodzić na meetupy związane z IT. Czasem były one niezwiązane z moją przyszłością, ale można było poznać kogoś nowego. Takie znajomości mają bardzo duże znaczenie, bo nawet jeśli ktoś cię nie zapamięta, to być może w przyszłości skojarzy. A i zawsze można było nauczyć się czegoś przydatnego od takiej osoby. W ten oto sposób nadrabiałem brak studiów IT.
Pierwszą rozmowę miałem około dwa tygodnie przed zakończeniem kursu. Byłem tak podekscytowany, że prawie chodziłem po suficie. To była praca marzeń dla kompletnego świeżaka: obiecujące szanse rozwoju, wyjazdy służbowe do Miami i Londynu, praca częściowo zdalna i komunikacja w języku angielskim (dla mnie plus). Rekrutujący dał mi mocno do zrozumienia, że praca jest już moja. Musi jedynie potwierdzić ze swoim kolegą z pracy, czy wszystko jest w porządku. Miała to być czysta formalność.
Zmiany, zmiany i jeszcze raz zmiany…
Oczywiście – nie była. Za to była to moja pierwsza odmowa. Mogę powiedzieć, że trochę przeczuwałem, że tak to się skończy. Końcówka procesu mnie bardzo zmyliła. Nos do góry, nie poddałem się. I dalej do przodu!
Zacząłem rozsyłać więcej CV. Kilka dziennie. Dostawałem odpowiedzi w stylu „dziękujemy, ale nie szukamy nikogo” lub „[…] z większym doświadczeniem”, jednak najczęściej nie otrzymywałem nic. Trudno. Gorsze były te momenty, kiedy po wykonaniu zadania rekrutacyjnego i odbyciu rozmowy wszystko wskazywało na to, że wreszcie znalazłem swoją przystań, ale koniec końców pozostawałem bez odpowiedzi ze strony firmy. Po miesiącu, kiedy o wszystkim zapominałem, dostawałem znaną mi już odpowiedź: „Potrzebujemy kogoś z większym doświadczeniem”. Kompletnie nie mogłem zrozumieć, czemu większość firm zachowuje się wobec mnie w ten sam sposób. Wiele razy podczas prób wyegzekwowania jakiegokolwiek feedbacku (po niezwykle przyjemnej rozmowie) byłem zbywany spychologią.
Odbyłem kilkanaście rozmów. Spędziłem kilkadziesiąt godzin na zadaniach i wysłałem setki CV. Były momenty, w których chciałem się po prostu poddać. Zacząłem wierzyć, że to kompletnie nie moja bajka. W dodatku moja ówczesna praca wpędzała mnie w depresję. Nie zmieniałem jej wyłącznie dlatego, że nie byłem pewien, kiedy i czy w ogóle dostanę ofertę pracy w IT. Nie chciałem też być nie w porządku wobec nowego pracodawcy i szybko się zwolnić. Wydawało mi się, że moja pozycja była beznadziejna – ktoś musiałby zaufać byłemu fizjoterapeucie bez żadnego doświadczenia i dać mu poważną pracę w IT. No i dochodziła do tego kwestia okresu wypowiedzenia – potencjalny pracodawca musiałby czekać na mnie około 1,5 miesiąca. Musiałem podjąć męską decyzję.
Zwolniłem się
Poświęciłem 100% swojego czasu na naukę, mogłem skupić się na rozwijaniu własnych umiejętności informatycznych. Nie chciałem wchodzić w rolę osoby bezrobotnej. Miałem trochę oszczędności – spokojnie starczyłoby mi na kilka miesięcy życia bez obniżania swoich standardów, ale nie chciałem spalić wszystkiego do ostatniej złotówki. Starałem się mądrze wydawać swoje pieniądze, dlatego w pierwszej kolejności zainwestowałem w kurs Androida.
Wydaje mi się, że moja decyzja opłaciła mi się, ponieważ po tak intensywnym okresie inwestowania wszystkich zasobów w samego siebie wreszcie usłyszałem to piękne pytanie:
Rekruter: Kiedy może pan zacząć?
Ja: Jutro.
To było świetne uczucie – zobaczyć zupełną zmianę nastawienia rozmówcy. Co prawda tej konkretnej pracy nie dostałem, ale wszystkie kolejne rozmowy toczyły się już zupełnie inaczej. W momencie kiedy rekruter słyszał o moim miesięcznym okresie wypowiedzenia, automatycznie traciłem na atrakcyjności. Możliwość zatrudnienia od zaraz zmieniała wszystko. Wciąż jednak czułem, że to, co robię, to nadal zbyt mało, żeby zwrócić na siebie uwagę. Wiedziałem, że gdzieś w Polsce jest firma, która mnie zatrudni. Musiałem tylko przebić się przez skrzynkę mailową, na której codziennie pojawiały się setki, jak nie tysiące wiadomości.
Podszedłem do tematu zupełnie inaczej
Nakręciłem o sobie film. Jestem introwertykiem, więc muszę przyznać, że nie było mi łatwo. Byłem zmęczony odpowiadaniem w kółko na te same pytania, dlatego wypowiedziałem się na każdy z tych tematów raz – na nagraniu – i dzięki temu mogłem uniknąć fazy rekrutacyjnej, która powodowała moje złe samopoczucie. Zmieniłem również CV na prostsze i nowocześniejsze.
Następnym krokiem były telefony od potencjalnych pracodawców. Po zazwyczaj przyjemnej rozmowie wysyłałem e-mail, w którym załączałem moje standardowe CV oraz nagranie. I to był strzał w dziesiątkę, bo po większości takich wiadomości rekruterzy oddzwaniali. Żeby nadać większego tempa moim poszukiwaniom, udostępniłem post o tym, że szukam pracy, na LinkedInie. W zasadzie nie oczekiwałem wiele i uwierzcie mi – było dla mnie szokiem, kiedy uświadomiłem sobie, że znalazłem się w 14 procesach rekrutacyjnych w tym samym czasie! To było świetne i jednocześnie przerażające przeżycie. Znalazły się firmy, które rozmawiały ze mną w zasadzie z czystej ciekawości. Nie przeszkadzało mi to ani trochę. Ostatecznie z 14 firm zostały 2.
Wybór
Jedna była niedużym przedsiębiorstwem zajmującym się tworzeniem portali intranetowych. Druga znowuż okazała się olbrzymią korporacją, jedną z najstarszych i najbardziej znanych w świecie IT. Byłem bardzo podekscytowany, kiedy łamiącym się głosem tym razem to ja odmawiałem współpracy gigantowi. Bo widzicie, w głębi ducha czułem, że wybór pracy w małym zespole będzie o wiele lepszy. Skąd taka decyzja? Duża firma zaoferowała od razu bardzo wysokie wynagrodzenie jak na standardy osoby początkującej. Dodatkowo doskonały sprzęt do pracy i jeszcze jeden na własny użytek. Na dodatek stanowisko, jakie miałbym objąć, byłoby perfidnym szpanem w moim CV. Ja jednak potrzebowałem kogoś, kto mnie poprowadzi, nauczy wielu rzeczy i w miarę szybko. Czy to w ogóle możliwe w firmie zatrudniającej tak wiele osób? Do dzisiaj uważam, że nie.
Nowa praca
Dostałem propozycję pracy jako specjalista, ale wybrałem staż, co przekładało się m.in. na niższą pensję. W zamian za to mogłem się nieskrępowanie uczyć, biorąc udział w dużych projektach, bez większych konsekwencji i strat finansowych dla firmy. Poznałem wielu wartościowych, przyjaznych i chętnych do pomocy ludzi, dostałem pracę, do której chcę przychodzić. Możliwości podniesienia kwalifikacji? Bezcenne. Jestem właśnie po pierwszym awansie i czuję, że decyzja, którą podjąłem trzy miesiące temu, była jedną z najlepszych w moim życiu.
Porady dla początkujących:
Nie patrzcie na pieniądze. Jeść trzeba, ale wysokość pensji musi być czymś poparta. Na początku najważniejsze są nauka i nowe umiejętności. Wynagrodzenie to drugi plan, a ciężka praca i pokora bardzo się opłacą.
Firmy światowej sławy nie zawsze zaoferują Wam to, czego tak naprawdę potrzebujecie. Dla mnie najważniejsze są rozwój, projekty, w których biorę udział, i świetna atmosfera w pracy. Wy musicie sami ustalić swoje priorytety – to, z czym czujecie się najlepiej.
W ten sposób od ukończenia przeze mnie kursu minął rok ciężkiej pracy i rozczarowań, ale też rozwoju umiejętności programistycznych i społecznych. Najważniejsza lekcja: nauczyć się wierzyć w siebie. Nie łudźcie się, że wszystko łatwo i bezproblemowo przyjdzie samo. Czasem – jak w moim przypadku – trzeba postawić wszystko na jedną kartę i zacząć życie od nowa.
The post Wasze Historie #18: Uciekłem z życia appeared first on devstyle.pl.
July 17, 2018
Wednewsday #15 – programistyczne nowinki
Cześć. W tygodniu natrafiłem na tweeta @gkoberger wyjaśniającego jak wystartować z inteligentnym startupem:
How to start an AI startup
1. Hire a bunch of minimum wage humans to pretend to be AI pretending to be human
2. Wait for AI to be invented
¯\_(ツ)_/¯ I tą wskazówką, której rozwinięcie znajdziecie w jednym z dzisiejszych artykułów The rise of ‘pseudo-AI’ zapraszam na kolejny wednewsday.
W między czasie możecie delektować się moimi ostatnimi przemyśleniami nt. przydatnych narzędzi w pracy programisty.
Machine Learning
13 Common Mistakes Amateur Data Scientists Make and How to Avoid Them?
Text Mining on the Command Line
The rise of ‘pseudo-AI’: how tech firms quietly use humans to do bots’ work
Netflix and Chill: Building a Recommendation System in Excel
WHY DID THE HUMAN CROSS THE ROAD? TO CONFUSE THE SELF-DRIVING CAR
Piaskownica
cheat.sh
Building your first interactive Node JS CLI
Reading and Writing CSV Files in Python
The Complete CSS Flex Box Tutorial
Architektura
Web Architecture 101
The System Design Primer
VIDEO SERIES: MODERNIZING .NET APPS FOR DEVELOPERS
Programowanie
Cancellable async functions in JavaScript
Lay Out Your Code Like You’d Lay Out Your House
Optimizing a Python application with C++ code
Which hashing algorithm is best for uniqueness and speed?
Artykuły, ciekawostki
How to be a responsible and badass developer
Teleconsole – Share Your Linux Terminal with Your Friends
Sort Any List Alphabetically Using These Online Tools
WebAssembly is more than the web
SpreadIT 2017 – playlista z nagraniami prelekcji z zeszłorocznej edycji SpreadIT
Zapraszam również do śledzenia audycji podcastowej, w której prezentuję najnowsze wiadomości, ciekawostki, wpadki oraz wydarzenia ze świata IT:
http://devsession.pl/podkast/
The post Wednewsday #15 – programistyczne nowinki appeared first on devstyle.pl.
July 15, 2018
Niecodzienne zastosowania LINQ, czyli monady w C#
Witaj w trzeciej odsłonie cyklu poświęconego programowaniu funkcyjnemu! W części pierwszej omówiłem najważniejsze podstawy. Część druga skupiała się na kluczowym aspekcie tego paradygmatu programowania – tworzeniu programu poprzez komponowanie funkcji. Dzięki temu artykułowi dowiesz się, czym są monady oraz jakie są ich praktyczne zastosowania.
Monady cieszą się złą sławą w świecie programowania funkcyjnego. To pojęcie dość abstrakcyjne, które często tłumaczy się, korzystając z formalnych, matematycznych definicji. Ja chciałbym pokazać Ci monady od strony praktycznej!
LINQ oraz query expressions
Raczej nie pomylę się, zakładając, że wiesz, czym jest LINQ. Aby nie było żadnych wątpliwości, poniżej kilka słów przypomnienia.
LINQ jest rozszerzeniem języka C# wprowadzonym w wersji 3.5. Jednym z jego głównych zastosowań jest umożliwienie przeprowadzania operacji na kolekcjach w sposób deklaratywny. Poniżej przykład zastosowania LINQ w celu zamiany tablicy liczb na tablicę kwadratów tych liczb.
var numbers = new[] { 1, 2, 3, 4, 5 };
var squares = numbers.Select(x => x * x);
Jak widzisz, LINQ sam w sobie jest dość mocno funkcyjny – wykorzystuje funkcje wyższego rzędu oraz funkcje czyste.
Powyższe wyrażenie można zapisać również jako query expression. Jest to element składni języka przypominający język zapytań SQL.
var squares = from x in numbers select x * x;
Kolekcja jednoelementowa – klasa Maybe
Dość łatwo zrozumieć, jak działa wyrażenie select w powyższym przykładzie. Przyjmuje ono funkcję, która jest aplikowana na każdym z elementów kolekcji. Rezultatem wywołania jest nowa kolekcja (a w zasadzie IEnumerable) zawierająca wyniki przekształceń.
Wyobraźmy sobie teraz, że pracujemy ze specjalnym typem kolekcji. Nazwijmy go Maybe. Kolekcja Maybe może zawierać maksymalnie jeden element. Innymi słowy albo zawiera ona element (wtedy jest pełna), albo nie zawiera żadnego (wtedy jest pusta).
W jaki sposób powinno zachować się wyrażenie select zaaplikowane na takiej kolekcji? Dokładnie tak samo jak na każdej innej. Jeśli kolekcja jest pełna, powinna zostać zwrócona nowa kolekcja zawierająca wynik przekształcenia elementu przechowywanego w pierwotnej kolekcji. W przeciwnym razie powinna zostać zwrócona pusta kolekcja.
Przejdźmy zatem do implementacji. Poniższa klasa Maybe realizuje kolekcję, która może mieć od zera do jednego elementów. Gdy kolekcja jest pusta, pole hasValue ustawione jest na false, a pole value przechowuje nulla lub wartość domyślną (w przypadku value type). W przeciwnym razie hasValue ustawione jest na true, a value zawiera przechowywany element.
public class Maybe
{
private readonly TValue value;
private readonly bool hasValue;
internal Maybe(TValue value, bool hasValue)
{
this.value = value;
this.hasValue = hasValue;
}
}
Dodajmy teraz dwie statyczne metody służące do tworzenia instancji Maybe.
public static class MaybeFactory
{
public static Maybe Some(T value) => new Maybe(value, true);
public static Maybe None() => new Maybe(default(T), false);
}
Mamy zatem dwa sposoby tworzenia instancji Maybe – możemy utworzyć kolekcję pustą lub pełną. Dzięki statycznym importom możemy używać tych metod w całkiem wygodny sposób.
var some = Some(10); // pełne Maybe
var none = None(); // puste Maybe
Dodajemy wsparcie dla LINQ
Na początku artykułu zastanawialiśmy się, jak działałaby metoda Select na Maybe. Przekonajmy się zatem i zaimplementujmy ją!
Aby nasza metoda działała z query expressions, musi ona spełniać specjalną sygnaturę (nie istnieje żaden interfejs definiujący tę sygnaturę).
Maybe Select(Func mapperExpression) { /*...*/ }
Jak widać, Select przyjmuje funkcję przekształcającą przechowywany typ TValue na nowy typ TResult. Wynikiem wywołania jest nowe Maybe przechowujące TResult.
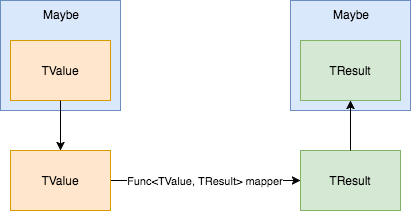
Jak będzie wyglądać implementacja? Tak, jak już opisaliśmy. Jeśli hasValue jest prawdziwe, to zwracamy nowe Maybe zawierające wynik zaaplikowania mapperExpression na value.
if (this.hasValue)
{
return MaybeFactory.Some(mapperExpression(this.value));
}
return MaybeFactory.None();
Pozostaje przetestować naszą nową metodę.
Maybe age = Some(27);
Maybe result = from x in age select string.Format("I'am {0} years old", x);
Działa!
Maybe w akcji
OK, ale po co to wszystko? Spójrzmy na przykład, w którym Maybe pozwoli nam znacznie uprościć fragment kodu.
Załóżmy, że mamy zadaną klasę PersonRepository z poniższą metodą GetPersonById:
public Person GetPersonById(Guid id) { ... }
Klasa Person wygląda następująco:
class Person
{
public string Name { get; set; }
public Person ReportsTo { get; set; }
}
Naszym zadaniem jest napisanie metody wyświetlającej imię szefa osoby o zadanym identyfikatorze. Implementując taką metodę, musimy pamiętać, że osoba o podanym identyfikatorze może nie istnieć. Co więcej, pole ReportsTo może być nullem, co oznacza, że dana osoba nie ma szefa.
public static string GetSupervisorName(PersonRepository repo, Guid id)
{
var employee = repo.GetPersonById(id);
if (employee != null)
{
if (employee.ReportsTo != null)
{
return employee.ReportsTo.Name;
}
}
return null;
}
Jak widać, stworzony kod zawiera zagnieżdżone instrukcje warunkowe i nie jest specjalnie czytelny. Czy możemy w jakiś sposób go poprawić?
Metoda GetPersonById zwraca instancję klasy Person lub null, jeśli osoba o podanym identyfikatorze nie istnieje. Zmieńmy ją w taki sposób, aby wykorzystać klasę Maybe. Jeśli osoba o zadanym identyfikatorze istnieje, to zwrócimy pełne Maybe. W przeciwnym razie zwrócimy Maybe puste.
public static Maybe GetPersonById(Guid id) { /*...*/ }
Następnie dostosujmy klasę Person. Ponieważ osoba może – ale nie musi – mieć szefa, jest to ponownie dobre miejsce na zastosowanie Maybe.
class Person
{
public string Name { get; set; }
public Maybe ReportsTo { get; set; }
}
Możemy teraz skorzystać z możliwości klasy Maybe i przepisać metodę GetSupervisorName w następujący sposób:
public static Maybe GetSupervisorName(PersonRepository repo, Guid id)
{
return from employee in repo.GetPersonById(id)
from supervisor in employee.ReportsTo
select supervisor.Name;
}
Czy ten kod jest lepszy od poprzedniej wersji? Moim zdaniem zdecydowanie tak. Nie ma tutaj „szumu” wprowadzonego przez instrukcje warunkowe. Intencja programisty jest wyrażona dużo lepiej.
Co więcej, doprowadziliśmy do sytuacji, w której typy lepiej odzwierciedlają rzeczywistość. W poprzedniej wersji metoda GetPersonById mogła zwrócić null, ale nie było żadnego mechanizmu, który zmuszałby nas do obsłużenia takiego przypadku. Przy zastosowaniu Maybe nie możemy tego uniknąć!
Brakujące ogniwo
Przeklejając kod z tego posta do Visual Studio z pewnością zauważysz, że w tej chwili program się nie kompiluje. Dzieje się tak dlatego, że brakuje nam jeszcze jednego elementu.
Spójrzmy na poniższe wyrażenie:
var maybeSupervisor = maybeEmployee.Select(e => e.ReportsTo);
Jeśli spojrzysz na maybeSupervisor, to okaże się, że jest to Maybe>. Wartość takiego typu nie jest zbyt użyteczna. Jako że chcemy uniknąć takich zagnieżdżeń, musimy zaimplementować jeszcze jedną funkcję pozwalającą na spłaszczanie zagnieżdżonych Maybe.
public Maybe SelectMany(
Func> mapper,
Func getResult
)
{
if (this.hasValue)
{
var intermediate = mapper(this.value);
if (intermediate.hasValue)
{
return MaybeFactory.Some(getResult(this.value, intermediate.value));
}
}
return MaybeFactory.None();
}
Pierwszym parametrem SelectMany jest funkcja, która przyjmuje wartość zagnieżdżoną w Maybe i zwraca nowe Maybe z wartością innego typu.
Drugi parametr to funkcja przekształcająca wartość pierwotną oraz wartość z nowego Maybe w ostateczny wynik.
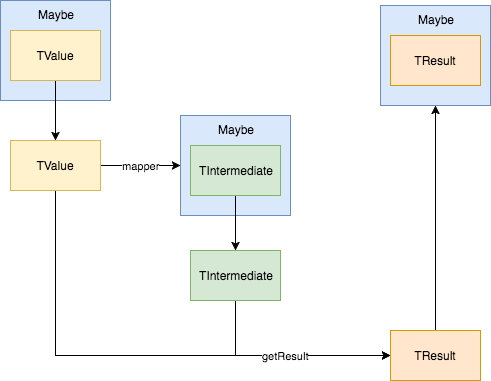
Sama implementacja jest podobna do implementacji Select. Tak długo, jak Maybe jest niepuste, przekształcamy przechowywaną wartość. W przeciwnym razie zwracamy puste Maybe.
Po zaimplementowaniu tej metody wyrażenie z poprzedniego akapitu powinno się kompilować.
To co to są te monady?
W prostych słowach monada to dowolny typ implementujący SelectMany oraz Select (oczywiście formalna definicja jest bardziej złożona). W programowaniu funkcyjnym zamiast SelectMany często używana jest nazwa bind lub flatMap.
Dlaczego ta operacja jest taka ważna? SelectMany pozwala zaimplementować dodatkowe operacje (w naszym przypadku było to sprawdzanie, czy mamy do czynienia z pustą wartością) w sposób transparentny dla użytkownika.
Maybe to tylko jeden z wielu przykładów zastosowania monad. Zupełnie innym może być Task (tak, zwykły Task z biblioteki standardowej!). Co prawda nie posiada on SelectMany, ale taką funkcję pełni ContinueWith. „Dodatkowe operacje”, które są ukryte w tym przypadku, to obsługa asynchroniczności. Kolejnym przykładem jest IEnumerable, które również jest jak najbardziej monadą.
Podsumowanie
Widać zatem, że monady to bardzo szeroka abstrakcja. Posiada ona wiele zastosowań i między innymi dlatego jest kluczowa dla programowania funkcyjnego. W językach czysto funkcyjnych – takich jak Haskel – monady umożliwiają ukrycie efektów ubocznych np. komunikacji ze światem zewnętrznym poprzez I/O.
Jeśli temat Cię zainteresował i chciałbyś zobaczyć więcej przykładów monad, to polecam bibliotekę language-ext. Monada Maybe występuje w niej pod nazwą Option.
To już wszystko na ten temat. Koniecznie daj znać, co myślisz o monadach. Czy wszystko jest dla Ciebie jasne? Kontynuujmy dyskusję w komentarzach!
The post Niecodzienne zastosowania LINQ, czyli monady w C# appeared first on devstyle.pl.
July 11, 2018
Co zabija programistów? Czyli: co warto zmienić w swojej pracy już dzisiaj
Siedzenie zabija.
Większość z nas intuicyjnie zaprzeczy tej tezie. Przecież w tej pozycji odpoczywamy, czujemy się komfortowo i wygodnie.
Skąd zatem pomysł, że siedząca postawa ciała może być dla nas szkodliwa? Przecież media nieustannie informują nas o zgubnych skutkach palenia, o smogu unoszącym się nad polskimi miastami, o coraz częstszej zapadalności na choroby cywilizacyjne. Przy tych jakże groźnych zjawiskach siedzenie wydaje się czynnością zupełnie nieszkodliwą i bardzo przyjemną.
Czy aby na pewno?
Ewolucja nie przystosowała nas do siedzenia, tylko do ruchu
Zastanówmy się, jak wyglądało życie człowieka jeszcze 100 lat temu. Powoli kończyła się druga rewolucja przemysłowa, seryjnie produkowane samochody pojawiały się na drogach, a elektryczność zawitała pod strzechy. Nasi prapradziadkowie pracowali przy prasach drukarskich, w zakładach produkcyjnych, docierali do pracy na piechotę i tak samo z niej wracali. Siedzenie było zasłużonym odpoczynkiem, a nie pozycją, w której spędza się długie godziny. Stulecia wcześniej człowiek pracował na roli, polował, eksplorował.
Dopiero rewolucja cyfrowa posadziła człowieka w biurze, przy biurku i komputerze!
Dopiero rewolucja cyfrowa w XX wieku na stałe posadziła człowieka w biurze, przy biurku i komputerze. Szacuje się, że jeszcze w latach 60. ubiegłego wieku 50% Amerykanów podczas pracy zażywało choćby umiarkowanej dawki ruchu. Na początku obecnego stulecia już aż 80% mieszkańców USA pracowało wyłącznie na siedząco. Te statystyki wyglądają podobnie w całej zachodniej cywilizacji, a trend ten będzie się tylko pogłębiał.
Dziś naszym problemem jest nie tylko to, że nasza aktywność zawodowa sprowadza się do wielogodzinnego siedzenia, ale także sam tryb życia, jaki prowadzimy. W tej jakże wygodnej pozycji docieramy do swoich firm tramwajami, autobusami czy samochodami. Siedzimy, spożywając posiłki, oglądając telewizję, czekając w kolejce w banku czy u lekarza. Po podsumowaniu wszystkich tych aktywności okazuje się, że średnio w ciągu doby około 13 godzin spędzamy na siedząco, 8 godzin poświęcamy na sen i tylko 3 godziny na ruch.
Możemy zapytać siebie – i co w tym złego? Otóż okazuje się, że już od ponad trzydziestu lat naukowcy i lekarze donoszą, że taki model codziennej egzystencji skutkuje zapadalnością na choroby, również te śmiertelne.
W jaki sposób siedzenie nas zabija
W 2014 roku ukazała się książka Get Up!. Jej autor, dr James Levine, od ponad trzech dekad prowadzi badania w obszarach takich jak otyłość, siedzący tryb życia czy negatywne skutki długotrwałego siedzenia. Zdobyta wiedza pozwoliła doktorowi Levine’owi na przygotowanie swoistego alfabetu chorób zagrażających tym z nas, którzy siedzą praktycznie przez cały dzień, poczynając od problemów z kręgosłupem, większego prawdopodobieństwa zachorowania na nowotwór jelita grubego, nadciśnienie, poprzez otyłość i cukrzycę typu drugiego, kończąc na różnorakich dysfunkcjach układu mięśniowo-szkieletowego… lista zdaje się nie mieć końca.
Ryzyko zgonu osób większość dnia spędzających na siedząco jest o 50% wyższe
W 2009 roku opublikowany został artykuł naukowy zatytułowany „Długość siedzenia a umieralność z przyczyn ogólnych, z powodu chorób układu krążenia i raka”. Opisano w nim wyniki trwającego 12 lat badania prospektywnego kohorty siedemnastu tysięcy Kanadyjczyków w wieku od 18 do 90 lat. Badacze odkryli statystycznie istotną korelację pomiędzy tym, jak długo w ciągu dnia ludzie siedzą, oraz ich śmiertelnością – zarówno ogólną, jak i związaną z chorobami układu krążenia, które, tak się składa, są na pierwszym miejscu na liście przyczyn zgonów publikowanej przez Światową Organizację Zdrowia.
Podsumowując ten 12-letni okres badań, naukowcy wykazali, że ryzyko zgonu tych osób, które większość dnia spędzały na siedząco, było o 50% wyższe w porównaniu z osobami siedzącymi bardzo mało.
Rozwiązanie problemu? Rusz się z miejsca!
Ludowa mądrość głosi, iż w zdrowym ciele zdrowy duch, i trudno się z tą opinią nie zgodzić. Gdy choruje nasze ciało, trudno o dobre samopoczucie psychiczne czy pogodny nastrój. Właśnie dlatego siedząc godzinami, cierpimy zarówno fizycznie, jak i mentalnie. Ciało ludzkie jest niesamowitą maszyną, która często podpowiada nam, co zrobić, by poczuć się lepiej. Przypomnij sobie wszystkie sytuacje, gdy spacer, krótka przejażdżka rowerem czy poranny kilometr przepłynięty na basenie przełożył się na Twoją kreatywność i zawodową efektywność.
Perypatetycy – uczniowie Arystotelesa, „ci, którzy lubią się ciągle przechadzać”
Nie bez powodu wybitni filozofowie spacerowali, aby pobudzić swoje umysły. Arystoteles nauczał, chodząc, a jego zwolennicy nazywani byli „tymi, którzy lubią się ciągle przechadzać” (perypatetykami). Jean Jacques Rousseau był w ciągłym ruchu, ponieważ wyznawał zasadę, że gdy staje jego ciało, zatrzymuje się także jego umysł. Również Kant regularnie spacerował, dbając w ten sposób o klarowność swoich przemyśleń.
Po godzinach spędzonych przed komputerem czujemy atawistyczną potrzebę zaczerpnięcia świeżego powietrza czy wykonania paru ćwiczeń rozciągających. Brak ruchu sprawia, że jesteśmy smutni, podirytowani, częściej chorujemy na depresję. Siedzenie zwiększa także poziom kortyzolu – hormonu stresu – w naszej krwi. To dlatego w dzisiejszych czasach tak często mówimy o wypaleniu zawodowym, presji w miejscu pracy, nierealnych terminach, które prowadzą do tego, że jesteśmy zestresowani praktycznie cały czas.
Z przedstawionego opisu wyłania się dość ponury obraz naszej codzienności. Postęp naukowy i rozwój technologiczny zamknęły nas w przestrzeni biurowej, a nasze dwunożne ciało – stworzone przecież do przemieszczania się – osiadło na laurach.
Czy zatem musimy pogodzić się z tym, że siedzenie będzie tak samo szkodliwym nałogiem, jakim dla naszych ojców było palenie papierosów? Nie cofniemy świata, wracając do wykonywania prac fizycznych. Dzisiejsze gospodarki potrzebują od większości z nas wysiłku intelektualnego, a nie fizycznego, wiele prostych prac zostało zautomatyzowanych, niedługo przy wielu wyzwaniach wyręczą nas roboty. Dlatego jedyną szansą na ocalenie naszego zdrowia i przeciwstawienie się siedzącemu światu jest większa aktywność fizyczna w ciągu całej doby, w tym także w trakcie pracy przy komputerze.
Sekret długowieczności
Skąd taki wniosek? Na potwierdzenie tej tezy można przytoczyć wiele badań i odkryć naukowych, ale warto skupić się na tych, które wskażą nam stosunkowo prostą drogę do zmiany naszych codziennych nawyków.
Wyjdźmy od tematu długowieczności. W każdej kolejnej dekadzie średnia długość życia rośnie. Główny Urząd Statystyczny wskazuje, że w 2016 roku mężczyźni w Polsce żyli przeciętnie 73,9 lat, zaś kobiety 81,9 lat. W porównaniu z rokiem 1990 żyjemy dłużej odpowiednio o 7,7 i 6,7 lat. Ale są miejsca na Ziemi, gdzie mieszkańcy mocno przebijają pod tym względem polskich emerytów, a posiadanie sąsiada stulatka nie jest dla nikogo zaskakujące. Na naszej planecie jest pięć takich regionów, na przykład Sardynia we Włoszech czy Archipelag Okinawa w Japonii. Podobnych miejsc przez wiele lat poszukiwał Dan Buettner – amerykański odkrywca, autor książek i mówca – wraz z National Geographic oraz amerykańskim Narodowym Instytutem ds. Starzenia się (NIA). Fenomen długowieczności w tych kilku regionach został dokładnie zbadany i opisany w projekcie Blue Zones.
We wszystkich społecznościach, w których ludzie żyją przeciętnie o 10 lat dłużej niż reszta populacji, powtarzają się te same schematy zachowań
Okazuje się, że we wszystkich społecznościach, w których ludzie żyją przeciętnie o 10 lat dłużej niż reszta populacji, powtarzają się te same schematy zachowań, codzienne nawyki. Mimo że zidentyfikowane w ramach projektu miejsca znajdują się w różnych częściach globu, ludzie w nich żyjący są stosunkowo podobni do siebie.
Nadrzędnymi, wspólnymi dla nich elementami są ponadprzeciętna ruchliwość w ciągu dnia i brak tradycyjnie pojmowanej aktywności fizycznej. Stulatkowie z Blue Zones nie uprawiają fitnessu czy CrossFitu, nie chodzą na siłownię i nie biegają maratonów. Zamiast tego ruch jest naturalnie wpisany w ich codzienność. Ich domy znajdują się na wzniesieniach, więc każdego dnia muszą pokonywać wiele kilometrów, aby zrobić zakupy, odwiedzić znajomych czy udać się do lekarza. Okazuje się, że wiele lat po przejściu na emeryturę nadal spędzają czas, wypasając owce, pracując w zakładach stolarskich czy łowiąc ryby, czyli na wszystkich tych czynnościach, które składały się wcześniej na ich codzienne życie. Nie zasiadają w ciepłych kapciach przed telewizorem, po prostu ciągle prowadzą taką egzystencję, do jakiej byli przyzwyczajeni. Podsumowując – korzystają z dobrodziejstw N.E.A.T, czyli Non–Exercise–Activity–Thermogenesis.
Termogeneza to zespół procesów wytwarzających ciepło, które zachodzą w organizmach wszystkich zwierząt stałocieplnych. Pierwszy typ termogenezy jest indukowany dietą. Zaraz po posiłku organizm zaczyna zużywać, przetwarzać i magazynować energię. Drugi typ wiąże się z ćwiczeniami fizycznymi. Z punktu widzenia naszych rozważań najciekawsza jest jednak N.E.A.T, czyli termogeneza niezwiązana z wykonywaniem ćwiczeń fizycznych. To energia, którą wydatkujemy na wszystkie pozostałe czynności takie jak gotowanie, sprzątanie, uprawianie ogródka, a nawet stanie czy wiercenie się. Te zwykłe, prozaiczne czynności to swoisty długi ogon na wykresie naszej przemiany materii – na koniec dnia sumują się one do całkiem nietrywialnej liczby spalonych kalorii.
Praca na stojąco – pierwszy krok we właściwym kierunku
W godzinach pracy nie uda nam się poświęcać czasu na dodatkowy N.E.A.T. w postaci choćby prania czy prasowania, ale już samo powstanie z krzesła i praca w pozycji stojącej będzie miała zbawienny wpływ na nasze zdrowie. Samo to, że stoimy, sprawia, że nasz metabolizm przyśpiesza o około 30%. Poprawia się krążenie krwi, a nasze mięśnie posturalne aktywują się, bo teraz mają co robić – stabilizują nasz kręgosłup i pomagają utrzymać stojącą pozycję.
Pojawia się jednak pytanie – jak w praktyce nakłonić szefa, by wyposażył Twoje miejsce pracy w biurko z regulowaną wysokością? Dla firmy oznacza to dodatkowy wydatek, a niewiele osób ma świadomość, jakie spustoszenie w naszym organizmie czyni praca siedząca. Ponadto już od miesięcy nie możesz doprosić się o podwyżkę. Jest jednak grupa zawodowa (może akurat do niej należysz), której będzie zdecydowanie łatwiej zażądać dla pracowników biurowych zdrowszych warunków do wykonywania pracy.
Na całym świecie brakuje dziś specjalistów branży IT, również w Polsce ten problem jest mocno odczuwalny. Firmy prześcigają się w liczbie i jakości oferowanych benefitów tylko po to, by ściągnąć do siebie kolejnego programistę czy testera. Wydaje się, że pracodawcy są w stanie zaspokoić praktycznie każdą zachciankę komputerowego geeka, byle ten nie rozważał ofert pracy z konkurencyjnych organizacji. Z drugiej strony jest to grupa zawodowa szczególnie mocno narażona na wszystkie zgubne efekty długotrwałego siedzenia. Stereotyp zahukanego gościa w okularach i kraciastej koszuli spędzającego kilkanaście godzin na dobę przy komputerze z kubkiem kawy i wczorajszą pizzą już dawno odszedł do lamusa.
Nie zmieniło się jedno: eksperci IT nadal siedzą bardzo dużo, programując w pracy, ale również w czasie prywatnym. I to szczególnie im powinno zależeć na rozpoczęciu anty-krzesłowej rewolucji.
Apel do branży IT. Przyłączysz się?
Z takiego właśnie założenia wyszedłem, inicjując projekt standitup.org. Sam, będąc programistą, na własnej skórze odczułem skutki długotrwałego siedzenia. Dlatego dziś szerzę wiedzę na temat szkodliwości siedzenia oraz ideę pracy na stojąco, ale także staram się inspirować do większej aktywności fizycznej oraz lepszego dbania o swoje ciało i umysł.
Jako członkowie branży IT możemy zawalczyć u pracodawców o aktywne wsparcie lepszego samopoczucia i zdrowia
Uważam, że jako członkowie branży IT jesteśmy w dzisiejszych czasach w doskonałej sytuacji, żeby zawalczyć u naszych pracodawców o aktywne wsparcie naszych starań o lepsze samopoczucie i zdrowie, zwłaszcza w dłuższej perspektywie. Tego typu batalie oczywiście łatwiej toczy się w dużej i silnej grupie, dlatego jednym z głównych celów inicjatywy standitup.org jest właśnie zjednoczenie środowiska IT.

standitup.org jednoczy środowisko IT
Jeśli chcesz pomóc, najlepiej zacznij od polubienia naszej strony na Facebooku albo śledzenia naszego profilu na Twitterze. Dzięki temu nie tylko dostaniesz porady, filmiki i treści pomagające poprawić postawę, pozbyć się złych nawyków ruchowych itp., ale również pomożesz nam dotrzeć do szerszej grupy ludzi. Możesz w ten sposób przyczynić się do zwiększenia świadomości i poprawy jakości życia wśród swoich bliskich. Jesteśmy także otwarci na osoby, które bardziej aktywnie chciałyby wesprzeć rozwój projektu – wystarczy skontaktować się z nami poprzez któryś z wymienionych wyżej kanałów.
Miejmy nadzieję, że między innymi dzięki inicjatywom takim jak standitup.org uda się przekonać nie tylko Kowalskiego, ale także jego szefa, że pierwszym krokiem do zdrowszej, wydajniejszej i efektywniejszej pracy jest powstanie z krzesła.
Wtrącenie od Aniserowicza: hardware!
Hello! Ja sam od dawna planowałem poeksperymentować z pracą na stojąco. Miałem jednak pewien problem: gdzie ja wstawię kolejne biurko? Odpowiedź była prosta: NIGDZIE, bo nie mam na nie miejsca w domu!
I wtedy (dokładnie w styczniu 2018) napisał do mnie ziom Robert, u którego zresztą radośnie kodowałem przez… chyba prawie trzy lata…? Nevermind. W każdym razie Robert nie pracuje z domu, ale urzęduje w coworkingu. A w coworkingu często nie można wstawić własnego biurka. Zmułka!
No i właśnie – w tej przykrej sytuacji się znajdując, Robert polecił mi pewne cudko:


(Uwaga: specjalnie nie retuszowałem zdjęć, nie sprzątałem pokoju; pokazuję, jak jest na co dzień: czyli sajgon ;) ).
A co to jest? To specjalna nakładka z regulowaną wysokością. Z każdego normalnego biurka/stołu robi biurko do pracy na stojąco! Dokładnie tego było mi trzeba. Zastrzegam, że nie wykorzystuję w pełni jej funkcji: do tego, co widać na zdjęciach, można doczepić jeszcze podkładkę na klawiaturę. Jednak jeszcze nie dorobiłem się bezprzewodowego Apple’owego zestawu myszowo-klawiaturowego, więc jest, jak jest.
I… od około kwartału testuję taki setup. Okazało się, że to po prostu rewelacja. Stabilne (uwaga, waży 20 kg!), wygodne, z czystym sumieniem mogę polecić. Dosłownie spadło mi to z nieba i sprawdza się rewelacyjnie! A co istotne – u Ciebie też może!
Sprzęt nazywa się „Elevo Convert” i możesz go obejrzeć pod tym linkiem. Co ważne:
W sklepie Elevo użyj kodu devstyle, który da Ci 5% rabatu na wszystkie biurka (także te „pełne”)!
Wspomnę jeszcze, że w chwili pisania tego tekstu jestem w trakcie przeprowadzki z domu do biura. I w biurze… też będę tego używał! Planuję napisanie czy nagranie normalnej recenzji tego sprzętu, pewnie już z podkładką pod myszkę/klawiaturę i z przypiętym zewnętrznym monitorem. Póki co: jestem do dyspozycji, jeśli pojawią się jakiekolwiek pytania.
The post Co zabija programistów? Czyli: co warto zmienić w swojej pracy już dzisiaj appeared first on devstyle.pl.
July 10, 2018
Wednewsday #14 – programistyczne nowinki
Jeśli słuchawki mam na głowie i nie jest to sytuacja awaryjna – może poczekać!
I tym akcentem witam was w kolejnej środzie z programistycznymi nowinkami. Słuchawki na głowę i zapraszam do czytania.
Wersja audio (linki z podcastu znajdziecie na devsession.pl/podcast-12):
Chmura
Architecting Distributed Cloud Applications – darmowy kurs video nt. rozproszonych aplikacji w chmurze. Prezentuje Jeffrey Richter – Azure Software Architect.
I was billed for 14k USD on Amazon Web Services – thriller ze szczęśliwym zakończeniem
Machine Learning
Can Markov Logic Take Machine Learning to the Next Level? – o idei logiki i sieci Markova i jakie problemy rozwiązuje w świecie ML.
Piaskownica
Learn Ruby on Rails for Free With These 6 Websites – 6 stron, kursów, które nauczą cię Ruby on Rails!
Top 30 Eclipse Keyboard Shortcuts for Java Programmers
5 Best C Programming Books For Beginners- 2018 – ksiązki przydatne w nauce języka C
Programowanie
Mutation Testing in .NET, part 2 – testy mutacyjne w dotnecie. Eksperymetalna biblioteka, w ciągłym rozwoju. Zobaczymy czy z tej mąki będzie chleb ;)
C# functional language extensions – Zestaw klas bazowych dla C# dodający funkcyjnego boosta!
JavaScript essentials: why you should know how the engine works – zaglądamy pod maskę aby dowiedzieć się jak działą silnik JS-a.
The Node.js Ecosystem Is Chaotic and Insecure – temat wałkowany nie raz ale uświadamiać trzeba.
.NET Core Microservices – DShop – implementacja opartego o .Net Core, mikroserwisy, Dockera, Redisa sklepu internetowego. Implementacja pokazująca jak ugryźć takie rozwiązania.
Build Your Own Lisp – jak w tytule. Wymagana znajomość C.
Vue.js: the good, the meh, and the ugly – dobre i złe strony Vue.js
Concurrency ideologies of Java, C#, C, C+, Go, and Rust – idea współbieżności w różnych językach programowania.
System.IO.Pipelines: High performance IO in .NET – obszerny opis nowej wysoko wydajnej biblioteki do przetwarzania strumieni w .NET
Rozwój osobisty
Porady dla Team Leadera – kompletny cykl postów autorstwa Radosława Maziarka o byciu team liderem.
Artykułu, ciekawostki
The Computer Language Benchmarks Game – bitwa na języki :) A tak naprawdę ciekawe porównanie czasu wykonania różnych algorytmów dla danego języka.
The 20 most influential programmers of all time – TOP20 najbardziej wpływowych programistów wszechczasów.
Slack client for Commodore 64 – to jest po prostu piękne. Całkowicie nieprzydatne ale piękne. A i jest ‘malinka’ na pokładzie.
hacker-job-trends – analiza występowania słów kluczowych w popularnym wątku “Ask HN: Who is Hiring?”.
The Bulk of Software Engineering in 2018 is Just Plumbing
GitHub Windows Edition – w tym miejscu powinna być wszystkomówiąca grafika.
Vim Ported to WebAssembly – próba stworzenia edytora Vim z użyciem Wasm.
Supercharging the Git Commit Graph III: Generations and Graph Algorithms – jak działa commit-graph dostępny w najnowszym Git 2.18
Robot Odyssey online – popularna w latach 80 gra, która zainspirował tysiące młodych do programowania dostępna w przeglądarce. Miłej zabawy :)
Uff trochę się tego uzbierało. Ale na koniec zapraszam jeszcze do zostawienia w komentarzu przydatnego, ciekawego linka. A może daj znać, którzy programiści są dla Ciebie “influential” :)
Zapraszam również do śledzenia audycji podcastowej, w której prezentuję najnowsze wiadomości, ciekawostki, wpadki oraz wydarzenia ze świata IT:
http://devsession.pl/podkast/
The post Wednewsday #14 – programistyczne nowinki appeared first on devstyle.pl.
July 8, 2018
200% asynchronicznej mocy w C# z .NET Core 2.1
Programowanie asynchroniczne na dobre zagościło na platformie .NET. Proces transformacji wszystkich bibliotek nie był najszybszy, ale większość liczących się graczy na rynku komponentów przygotowało już wersje asynchroniczne. Z przyrostkiem Async czy bez, metody zwracające Task albo Task stały się naszą codziennością, zwiększając przepustowość aplikacji i zmniejszając jałowy czas czekania na zwrócenie danych przez bazę (albo dowolne inne IO).
Zatem skoro cała asynchroniczność miała przynieść takie zyski, to czy da się wycisnąć coś więcej? Czym może pochwalić się .NETCore 2.1 i w jakich przypadkach może nam pomóc w pisaniu bardziej wydajnych aplikacji? Na te pytania odpowiem w poniższym artykule.
Na początku był async
Zacznijmy od przypomnienia najprostszej składni związanej z programowaniem asynchronicznym. Załóżmy, że chcesz napisać metodę wywołującą inną metodę asynchroniczną Task GetData () i dodającą do jej wyniku jeden. Następnie wynik dodawania ma zostać zwrócony jako rezultat.
Pierwszym krokiem będzie zadeklarowanie sygnatury metody:
public Task GetDataAndAdd1(int id)
{
// TODO
}
Aby użyć słowa kluczowego await, musimy oznaczyć metodę jako async.
public async Task GetDataAndAdd1(int id)
{
var result = await GetData(id);
}
Pozostaje dodanie jedynki i zwrócenie rezultatu. Całe opakowanie wyniku w Task wykona za nas kompilator, podobnie jak transformację do tzw. kontynuacji, czyli metody wykonywanej po tym, jak GetData zakończy swoje wywołanie.
public async Task GetDataAndAdd1(int id)
{
var result = await GetData(id);
return result + 1;
}
Dodatkowo, jeżeli nasz kod nie dba o kontekst synchronizacji (to temat na osobny artykuł), możemy dodać wywołanie funkcji ConfigureAwait(false), otrzymując nasze ostateczne wywołanie:
public async Task GetDataAndAdd1(int id)
{
var result = await GetData(id).ConfigureAwait(false);
return result + 1;
}
Nie taki Task lekki, jak go malują
Istnieją przypadki, w których metoda asynchroniczna może być za ciężka. Weźmy pod lupę następującą modyfikację, która używa jakiegoś mechanizmu cache’owania.
public async Task GetDataAndAdd1(int id)
{
if (cache.TryGet(id, out var v))
{
return v;
}
var result = await GetData(id).ConfigureAwait(false);
cache.Put(id, result + 1);
return result + 1;
}
Jeżeli nasz cache został użyty w dobrym miejscu (i poprawnie), metoda zazwyczaj powinna pobierać swoje dane z cache’a. Zauważ, że we fragmencie z cache’em nie ma żadnej asynchroniczności – brak tam awaita. Mimo to rezultat będzie jednak opakowywany w nowo wygenerowany obiekt Task. Tworzenie obiektu to alokacje, a usuwanie alokacji to jedna z pewniejszych ścieżek do przyśpieszenia aplikacji. Co zatem można zrobić?
Pierwszym krokiem może być podzielenie metody na ścieżkę faktycznie asynchroniczną oraz tę synchroniczną, bez awaita.
public Task GetDataAndAdd1(int id)
{
if (cache.TryGet(id, out var v))
{
return Task.FromResult(v);
}
return RealGetDataAndAdd1AndPutInCache(id);
}
async Task RealGetDataAndAdd1AndPutInCache(int id)
{
var result = await GetData(id).ConfigureAwait(false);
cache.Put(id, result + 1);
return result + 1;
}
Alokacja pozostała: nowy Task jest tworzony przy każdym odnalezieniu danych w cache’u. Oczywiście można cache’ować obiekty Tasków, ale nadal wymaga to alokacji. Czy więc możemy cokolwiek zrobić? Okazuje się, że tak. W przypadkach, gdy metoda posiada ścieżkę wywołania synchronicznego, możemy użyć nowego typu ValueTask, który jest strukturą, a zatem nie alokuje pamięci na stercie. Oczywiście przekazywanie wartości zamiast referencji może kosztować więcej, dlatego warto to zmierzyć. Spójrzmy na zmienioną metodę.
public ValueTask GetDataAndAdd1(int id)
{
if (cache.TryGet(id, out var v))
{
return new ValueTask(v);
}
return new ValueTask(RealGetDataAndAdd1AndPutInCache(id));
}
async Task RealGetDataAndAdd1AndPutInCache(int id)
{
var result = await GetData(id).ConfigureAwait(false);
cache.Put(id, result + 1);
return result + 1;
}
Zauważ, że ścieżka asynchroniczna się nie zmieniła, podczas gdy ścieżka synchroniczna – bez awaitów – będzie alokować mniej. Mamy więc szansę na zysk wydajności.
Asynchroniczny ValueTask
Skoro ValueTask może spowodować szybsze wykonanie kodu synchronicznego, na pewno zastanawiasz się, czy nie dałoby się obsłużyć tą strukturą także ścieżki asynchronicznej. Aż do .NET Core 2.1 nie było takiej możliwości – ValueTask można było skonstruować tylko na podstawie wartości, co robiliśmy powyżej, używając danych z cache’a, albo na podstawie obiektu Task, który jest alokowany na stercie. Na szczęście wraz z .NET Core 2.1 nadszedł nowy konstruktor ValueTask umożliwiający podanie czegoś, co wygląda jak Task i może być używane jak Task, ale Taskiem nie jest. To nic innego jak IValueTaskSource, przy którym dodano nowy konstruktor dla ValueTask:
public ValueTask(IValueTaskSource source, short token)
Patrząc na powyższy kod, można się zastanowić: „OK, ale ktoś będzie musiał stworzyć IValueTaskSource i to za każdym razem. Gdzie jest więc zysk?”. To bardzo dobre pytanie. Odpowiada na nie drugi parametr nazwany tokenem.
Token to nic innego jak identyfikator danego użycia IValueTaskSource. Oznacza to, że implementując metodę z użyciem tego konstruktora dla ValueTask, przy każdej nowej operacji i zwróceniu nowej wartości powinniśmy odpowiednio modyfikować token tak, aby powtórzenie się jego wartości było mało prawdopodobne. Operacja używana przez nową implementację gniazd sieciowych Socket polega na dodawaniu +1 do ostatnio użytej i zapewnianiu, że „short” nie zostanie przepełniony.
Kiedy będzie można użyć ponownie tego samego obiektu IValueTaskSource? Gdy ktoś wykona na nim await.
Jak zapewnić, że nie zostanie użyty kilka razy? Przechowując w source ostatnio użyty token. Jeżeli obiekt zostanie użyty ponownie, jego aktualny token będzie się różnił od zwróconego wcześniej w ValueTask. Proste, efektywne i wydajne.
To właśnie mechanizm wielokrotnego używania tych samych IValueTaskSource pomógł w niezwykle efektywnej implementacji gniazd sieciowych w .NET Core 2.1. Ze względu na to, że na jednym gnieździe może odbywać się naraz operacja odczytu i zapisu, do obsługi tych operacji potrzeba tylko dwóch instancji obiektu, którego klasa implementuje IValueTaskSource – m.in. dzięki temu implementacja gniazd jest tak efektywna.
Pokaż mi swoje liczby
Możemy gdybać na temat wzrostu wydajności, ale warto przyjrzeć się liczbom. Do tego celu użyję wyników, które zaprezentował Microsoft w swoim poście. W kategorii Networking możemy znaleźć przykład wysyłania i odbierania danych na pojedynczym gnieździe sieciowym. Poniżej załączam wyniki:
SocketReceiveThenSend – .NET Core 2.0 – 102.82 ms,
SocketReceiveThenSend – .NET Core 2.1 – 48.95 ms.
Jak widać, na tak podstawowej operacji, jaką jest wysyłanie i odbieranie danych z sieci, oszczędzamy 50% czasu. To bardzo dużo, biorąc pod uwagę niezauważalne zmiany z punktu widzenia użytkownika frameworka.
Asynchroniczność jest wszędzie
Droga przebyta przez programowanie asynchroniczne nie była łatwa. W dodatku – jak zobaczyliśmy powyżej – kolejne etapy jego ewolucji często były wręcz rewolucyjne. Kierunek rozwoju zarówno języka C#, jak i całego frameworka, a także wprowadzanie coraz większej liczby elementów programowania systemowego wskazują jednak, że jeszcze wydajniejsze przetwarzanie jest nieuniknione. Najwyższy czas wycisnąć 200% asynchronicznej normy, używając .NET Core 2.1.
The post 200% asynchronicznej mocy w C# z .NET Core 2.1 appeared first on devstyle.pl.
July 4, 2018
5 Obowiązkowych Sposobów Na Rewelacyjną Pracę Z Gitem (I Nie Tylko)
Git jest git – to oklepany suchar. Fakty są jednak takie, że to narzędzie zmieniło branżę IT. Z jego pomocą programistyczna praca może przebiegać sprawniej, bardziej zorganizowanie i… po prostu przyjemniej.
Niestety podczas wielu lat swojej działalności niejednokrotnie obserwowałem marnowanie potencjału tego narzędzia. Daleko zresztą szukać nie trzeba – gdy ogłosiłem, że tworzę mój autorski Kurs Gita, pojawiły się komentarze w stylu:
Przecież Git to pull, commit i push – o czym tu robić kurs?
Albo:
Może zrobisz coś bardziej ambitnego niż kurs Gita? Git to na początek 6 komend, które wystarczą do używania przez juniora.
Albo:
Git, serio? Nauka podstaw zajęła mi jako kompletnemu żółtodziobowi godzinę z YouTube.
I z jednej strony: to (prawie) wszystko prawda, ale z drugiej: dużo osób zostaje na wspomnianym poziomie „godzina z YT”. Ignorance is bliss, ale tylko czasami. Przez to marnujemy Massive opportunities.
Czubek góry
Ostatnio robiłem porządki na swoim Dropboksie i znalazłem pewien katalog. Przywołał on wiele wspomnień i… szeroki uśmiech na mym licu:

To jeden z projektów realizowanych przeze mnie kilkanaście lat temu. Wtedy nie dość, że niewiele wiedziałem, to jeszcze nie wiedziałem, jak niewiele wiem, a jak wiele nie wiem (BUM, chrząszcz brzmi w trzcinie)!
To właśnie ten katalog przyszedł mi do głowy, gdy czytałem przytoczone komentarze. Niestety – cały geniusz, inżynierski kunszt i ogromny potencjał stojące za Gitem (w szczególności, a za koncepcją kontroli wersji w ogóle) są sprowadzane często właśnie do tego: Prostej Metody Na Robienie ZIP-ów (albo – jak na screenie – RAR-ów).
A to tylko czubek góry lodowej! Wielkiej, pięknej góry kryjącej się w zero-jedynkowym oceanie zajebistości. Czytaj dalej, jeśli chcesz choć trochę się zanurzyć.
BTW, zanim będziemy kontynuowali – przygotowałem dla Ciebie jeszcze jeden smakołyk na deser. Kliknij poniższy obrazek, jeśli chcesz otrzymać specjalny PDF!

A teraz zapraszam Cię do poznania pięciu sposobów na to, by Twoja przygoda z Gitem (a właściwie z dowolnym systemem kontroli wersji) nabrała rumieńców.
LET’S GO!
1. Decentralizacja – opcjonalne wymaganie
(czyli oksymoronik na dobry początek)
Pierwszym niezbędnym krokiem w stronę światła ;) jest decentralizacja. Ta porada nie dotyczy Gita per se: niestety scentralizowane systemy kontroli wersji – chociażby SVN – są nadal dość popularne i wykorzystywane na co dzień w wielu firmach.
Oprócz oczywistych wad (powolne działanie, brak efektywnej pracy offline itd.) niosą one również ukryte niebezpieczeństwo: zachęcają do korzystania z repozytorium kodu jak z głupiego serwera FTP, do którego byle jak i byle kiedy dokleja się kolejne archiwa z datą utworzenia. Zupełnie jak na pokazanym wyżej obrazku. FUJ!
A przecież starannie budowana historia projektu to zdecydowanie coś więcej!
(No dobra, można się spierać, czy one faktycznie do tego zachęcają, ale umówmy się: przynajmniej nie zachęcają do innych praktyk).
Programistę Haskella poznasz po tym, że przed powiedzeniem „cześć” poinformuje: „programuję w Haskellu”. A po czym poznasz programistę skazanego na SVN-a czy TFS-a? Tacy powiedzą:
Ja to wysyłam jeden commit dziennie: przed wyjściem z pracy do domu.
Albo:
Commituję kod po zaimplementowaniu całego ficzera, nawet jeśli zajęło mi to kilka dni.
W efekcie powstaje „śmietnik historii”, podczas gdy niewielkim nakładem pracy możemy znaleźć się w o wiele przyjemniejszym miejscu.
Decentralizuj choćby we własnym zakresie.
W kontekście tego tekstu zajmujemy się głównie Gitem. A co, jeśli Twój zespół nie używa Gita? Na szczęście nie oznacza to wcale, że Ty nie możesz! Zrzuć ohydne jarzmo scentralizowanego systemu kontroli wersji: rączki skalane SVN-em wspaniale odkazi git-svn. W razie potrzeby zerknij na git-tfs. One naprawdę dają radę!
A co dalej?
2. Single Responsibility Principle – does that ring a bell?
Sztuka tworzenia oprogramowania otoczona jest baaardzo wieloma złotymi zasadami. Ich przestrzeganie nie gwarantuje co prawda sukcesu, lecz może znacznie poprawić jakość efektów naszej pracy. Chociażby: SOLID!
Odpowiednio pracując nad codziennymi praktykami – nie tylko na poziomie kodu – możemy pozytywnie wpłynąć na kształt projektu. Tak pozornie banalna sprawa jak przemyślany sposób commitowania kodu drastycznie zwiększy komfort pracy nad systemem!
Pierwsza zasada SOLID to Single Responsibility Principle. SRP radzi, by każda klasa w systemie miała tylko jeden powód do zmiany. Albo inaczej: by każda klasa w systemie miała tylko jedną, ściśle określoną odpowiedzialność.
No i co z tego? Po co o tym piszę?
Otóż warto postępować wedle tych zaleceń nie tylko przy programowaniu! Równie dobrze sprawdzą się one w przypadku konstruowania commitów. Niech każdy z nich będzie skoncentrowany na rozwiązaniu jednego, określonego, malutkiego problemu. Tym samym niech nie zawiera niepowiązanych ze sobą bezpośrednio zmian dotykających wielu plików. Tak jak klasa w kodzie nie powinna być odpowiedzialna za wiele czynności, tak samo każdy wpis do systemu kontroli wersji powinien tworzyć logiczną całość.
NIECH commity (sic!) będą zgodne z Single Responsibility Principle!
Jeśli zmiany zgrupowane w jeden commit będą odnosić się tylko do jednego niewielkiego kroku wykonywanego na drodze do zakończenia implementacji danego zadania, historia projektu stanie się o wiele łatwiejsza do przeglądania. Nie chodzi jednak wyłącznie o przeglądanie historii. W końcu co nas obchodzi, że ktoś gdzieś będzie kiedyś się drapał w głowę, oglądając nasz ubercommit dotykający 500 plików? „Bylebym to nie był ja!” i do przodu!
Przybliżmy jednak tę przyszłość: code review. O, to co innego, bo to się może dziać już, teraz i tutaj. Drobne i spójne commity ogromnie usprawniają proces przeglądania i komentowania kodu w zespole. O wiele łatwiej przetrawić i omówić ściśle powiązane ze sobą zmiany w trzech pliczkach niż czytać wielką masę kodu, zastanawiając się: „jak jedno ma się do drugiego?”.
Ale zaraz, zaraz – padło słowo „spójność”! Buzzword detected! Warto w tym miejscu wrzucić kolejny termin z inżynierii oprogramowania:
Cohesion (za WIKI) – degree to which the elements inside a module belong together.
To również – podobnie jak SRP – możemy przenieść do świata kontroli wersji. A potem poklepać się po pleckach i pogratulować samym sobie tak mądrej decyzji.
Warto pamiętać, że w Gicie nie budujemy historii plików. W Gicie tworzymy historię STANÓW. Jak to rozumieć? Otóż nawet jeśli jeden plik zawiera wiele zmian, to możemy je rozbić na kilka małych – sensownych – commitów, zamiast pakować wszystkie modyfikacje do jednego! To nic, że zmiany występują w jednym pliku – do niczego nas to nie zobowiązuje. Takie rozwiązanie – do wykorzystania za pomocą komendy git add --patch – daje ogromne możliwości tworzenia SPÓJNYCH commitów, zgodnych z SRP pławiącej się w kohezji. ;)
Git add --patch przyda Ci się, gdy podczas normalnej pracy:
poprawisz literówkę (osobny, dedykowany commit),
poprawisz znaki końca linii CR / LF (osobny, dedykowany commit),
zrobisz mały refactoring, na przykład zmianę nazwy metody (osobny, dedykowany commit),
zmienisz taby na spacje… albo na odwrót, w zależności od wyznania (osobny, dedykowany commit).
Tak naprawdę rekomenduję „git add --patch” jako domyślny (albo nawet jedyny!) sposób świadomego dodawania zmian do repozytorium.
„U mnie działa ”.
”.
3. Commit-Driven Development
A co, jeśli pójdziemy jeszcze o krok dalej? Nawet siedmiomilowy?
Było o SOLID, było o COHESION… Ewidentnie brakuje odniesienia do Test-Driven Development, by móc z czystym sumieniem nałożyć sobie michę jarmużu!
W TDD najpierw piszemy testy, a potem kod. A w CDD (Commit Driven Development – nazwa wymyślona, pantent pending)? Najpierw określamy, CO chcemy zrobić, poprzez przygotowanie commit message, a dopiero potem doklejamy do takiej pustej (sic!) wrzutki kolejne kawałki kodu. Aż do momentu, gdy złożona obietnica zostanie spełniona.
BTW, warto zauważyć, jak fajnie dwuznacznie wpasowuje się tutaj słowo „commit”, c’nie?
Jest to całkowite odwrócenie „normalnego” sposobu commitowania pracy. Zwykle najpierw modyfikujemy kod, a dopiero potem opisujemy (albo i nie…?) wprowadzone zmiany i gdzieś je wysyłamy.
Eksperymentalne odwrócenie procesu: najpierw commit, potem praca.
Co może dać takie eksperymentalne, świeże spojrzenie na ten proces?
Po pierwsze: definiujemy dla samych siebie, co dokładnie mamy osiągnąć w ciągu najbliższych minut/kwadransów. Pewnie Tobie, tak jak i mi, zdarza się na chwilę zawiesić przy pracy, wypaść z flow (o czym więcej za chwilę), zgubić kontekst. Jeśli będziemy mieć gotowe commit message, wystarczy, że zerkniemy na jedną linijkę tekstu (git log -n1) i… I’M BACK IN THE GAME, BABY!
Po drugie: skupiamy się na implementacji tej jednej rzeczy, realizacji jednego celu. Nie ma miejsca na nagłe rozproszenie typu „o, literówka w nazwie metody – fixnę od razu”. A potem się okazuje, że ta literówka była z jakiegoś powodu konieczna (bo ktoś w jakimś XML-u też jej użył i po tej zmianie system się wywali). Albo: „o, nieaktualny komentarz”, „o, dwa entery zamiast jednego”. I po godzinie – peszek! – zrobiliśmy masę nie-tego-co-planowaliśmy. W tym trybie dążymy do konkretnego, najlepiej niewielkiego, rezultatu. I tylko do niego.
Efektem ubocznym opisywanej praktyki jest piękna historia projektu. Nie znajdziemy modyfikacji kodu procedury składowanej (tfu!) w commicie zmieniającym kolor przycisku na stronie (bo „akurat fajnie byłoby przy okazji w końcu tę procedurę tknąć”). Czyli… wracamy do SRP!
Przy tej okazji można zaobserwować ciekawe zjawisko – zupełnie inny typ treści komentarzy do commitów. Całkiem nowa jakość.
Nie znajdziemy tam opisu implementacji, ponieważ na etapie pisania tekstu nie będziemy w stanie dokładnie określić, jak ta implementacja przebiegnie. Opisy będą zawierać treści zrozumiałe nawet dla nowego programisty, dołączającego do zespołu za pół roku!
„Co się zmieniło w zachowaniu systemu” vs „co narobiliśmy w kodzie”.
W Gicie bardzo łatwo można wypróbować taki sposób pracy. Umożliwia to komenda git commit --allow-empty. A jak taki twór uzupełnić? Zmiany dorzucimy za pomocą git commit --amend.
Nie twierdzę, że to praktyka rekomendowana zawsze i wszędzie, ale warto dać szansę, szczególnie przy (na początku) prostszych zadaniach.
Przy okazji CDD wspomnieliśmy o jednej ważnej praktyce. Nie możemy jej zostawić takiej niedopieszczonej! Zatem…
4. Test-Driven Development…
…i co to ma do kontroli wersji?
Akurat bardzo dużo!
Na szczęście z tym tematem możemy się uporać niezwykle sprawnie:
Ulepszone TDD: red -> green -> refactor -> commit
Byłem w szoku, jak bardzo mi tego brakowało, gdy w jednym projekcie musiałem z Gita przestawić się na dosłownie na „czystego” TFS-a. Tam podobna praktyka jest po prostu niemożliwa (bo commity od razu lecą na serwer).
Można nawet pójść o krok dalej i zrobić pewne założenie: nie każdy commit musi zawierać poprawny kod (dla dowolnej definicji „poprawności”)!
Kod nie musi się kompilować,
testy nie muszą przechodzić,
projekt nie musi się otwierać w IDE!
Commity dokumentują naszą programistyczną drogę. Każdy z nich pokazuje jeden krok: „zakończono pewną czynność”. A nasze kroki, jak wiadomo, nie zawsze lądują na miękkim puchu. Niejednokrotnie nastąpimy na krowi placek. I ten ślad także warto rozsmarować po historii w Gicie.
Kolejny krok – dla odważnych:
red -> commit -> green -> commit -> refactor -> commit
Eksperyment nie boli!
„Czy ktoś widział kiedyś za dużo commitów?”
Można się zastanawiać, czy to nie przesada. Oczadział? Kto to potem będzie czytał?
Moim zdaniem to zdecydowanie NIE JEST przesada. Commituj kod CZĘSTO. Nawet: bardzo często! Przyzwyczaj się do sytuacji, w której jeszcze przed lunchem masz zrobionych 30 commitów. 50 commitów dziennie? To norma!
Oczywiście dużo zależy od projektu, ale generalnie:
Nie ma czegoś takiego jak „za dużo commitów”
(albo – jak mówi Abelard Giza – „widział ktoś kiedyś za dużo zajęcy?”. BTW, bardzo polecam).
Co to daje? Dzięki temu gdy patrzę w historię projektu, dokładnie widzę:
co,
kiedy,
(najważniejsze) DLACZEGO
zrobiłem.
A jeśli komuś wyżej nie spodoba się taki styl pracy? Żaden problem – możesz mieć sytego wilka (czyli nieświadomego przełożonego) oraz całą owcę (czyli swoją niezakłóconą niczyim widzimisię produktywność).
Należy pamiętać, że 20 commitów lokalnych wcale nie musi przekładać się na 20 commitów wysłanych na serwer! Przed wykonaniem PUSH warto przejrzeć zmiany (git log origin/..) i w razie potrzeby scalić niektóre commity. Szczegółowość przydatna przy pracy bieżącej wcale nie musi być konieczna w perspektywie globalnej historii projektu. Wtedy niezastąpiona jest komenda git rebase -i, czyli tzw. interactive rebase.
20 commitów lokalnych != 20 commitów wysłanych na serwer.
Ale jak stosować powyższe zasady, skoro „robię jeden commit dziennie – przed wyjściem z pracy”? Wyjaśnijmy sobie jedną rzecz: praktyka jednego commita dziennie jest – ujmę to najdelikatniej, jak potrafię – nie najlepsza. Nie stosujmy jej, pliz.
Przepiękny Side-Effect
Poboczną korzyścią z takiego postępowania jest fakt, że przez większość czasu pracujemy na „czystym” kodzie zawierającym bardzo niewiele zmian w stosunku do zapisanego w Gicie stanu. Nawet jeśli coś Cię rozproszy i wybije z tego magicznego programistycznego flow, w ciągu kilku sekund (przeczytanie króciutkiego efektu komendy „git diff”) możesz znaleźć się z powrotem w wirze produktywnego klepania (no dobra, niech będzie: kombinowania).
Najlepsze w tym wszystkim: NICZEGO NIE ZEPSUJESZ!
Chcesz zawsze, w każdej chwili spędzonej nad projektem, czuć: „nieważne, co zrobię, na pewno niczego nie zepsuję”? To jest – jak to mawiają za oceanem – LIBERATING. Wyzwalające. Uzależniające. To niesamowite uczucie.
Niczego nie zepsujesz! Bo w razie fuckupu w każdej chwili możesz cofnąć się do poprawnego kodu sprzed kilku MINUT (a nie GODZIN czy DNI).
I na koniec to, o czym już wcześniej napomknęliśmy:
5. Treść commit message
Sama paczka kodu podpisana nazwiskiem autora oraz datą nie jest wystarczająca. Tyle to mamy i w ZIP-ie. Bez pisania sensownych opisów zmian daleko nie zajedziemy.
Trzeba tu znaleźć złoty środek. Z jednej strony: należy zawrzeć „odpowiednio wiele” informacji. A z drugiej: nie duplikować treści przechowywanych w narzędziu (i samym kodzie) do zarządzania projektem.
Ja zwykle w commit message staram się zawierać takie dane jak typ zadania, jego ID oraz krótki opis zmian (jakie i dlaczego). Jeśli to nie wystarcza, po dwóch enterach rozwodzę się nieco bardziej.
Dla Gita istnieją bardziej szczegółowe praktyki (tutaj można zacząć o tym czytać).
Zamiast standardowego „dupa” warto rozważyć:
dlaczego taka zmiana (niskopoziomowe wyjaśnienia rozumowania, żeby nie zniknęły w otchłani czasu),
to, co wpisalibyśmy jako komentarz w kodzie (bo te się bardzo szybko rozsynchronizują z rzeczywistością),
co się faktycznie zmieniło w systemie (niekoniecznie JAK zostało zrealizowane – od tego jest kod).
Dodatkowo niektóre (prawie wszystkie?) systemy do zarządzania projektem potrafią czytać repozytorium Gita i wyłuskiwać instrukcje z commit messages. Na przykład Redmine zrozumie takie coś i podejmie odpowiednie działania, zmieniając status taska:
refs #1234,
fixes #1234,
closes:#1234.
Więcej o Redmine w tym kontekście poczytasz tutaj.
Ale to nadal nie wszystko!
Sam się zdziwiłem, jak niesamowicie prostsze staje się wypuszczanie kolejnych wersji oprogramowania wraz z release notes. Wiesz dlaczego?
Wiesz???
…
…
A lubisz je pisać?
„Lubię pisać release notes” said no one ever.
Ale przecież przy odpowiednio prowadzonej historii projektu wystarczy wyeksportować log zmian do pliku, usunąć mało znaczące wpisy i… już!
Przykład? [bug #2876]clicking on OK button works in IE 6
Log z kontroli wersji to Release Notes!
Oczywiście nie umieścimy w tym dokumencie – szczególnie publicznym, dostarczanym klientowi lub użytkownikom – wszystkich commitów, całej drogi prowadzącej do udanej implementacji danego ficzera czy poprawienia buga. Ludziska by się zanudzili, a wartość w tym dla nich zerowa.
Możemy natomiast podjąć decyzję o spójnym, egzekwowanym przez cały zespół sposobie pracy z Gitem. Takim, w którym treść opisującą kwestie istotne jedynie z punktu widzenia „biznesu” wygeneruje na przykład komenda git log --merges v1..v2.
Brzmi ciekawie? O, na pewno! Ale… to już nie na dziś.
Podejmiesz rękawicę?
Wiesz co – to naprawdę robi różnicę. Ogromną.
Nie sprowadzajmy Gita do roli durnego generatora paczek. To wspaniałe narzędzie i warto je poznać o wiele głębiej. Ta inwestycja zwróci się szybko, pozytywnie wpływając na pracę nie tylko Twoją, ale także Twojego zespołu!
W tym tekście pojawiło się kilka komend Gita i ich ciekawych przełączników. Chcesz więcej? Proszę bardzo, tutaj przypominam o kolejnym kroku:
POBIERZ: 10 Sekretnych Komend Gita, O Których Nie Masz Pojęcia
Masz jakieś przemyślenia odnośnie do kontroli wersji? Chcesz dowiedzieć się więcej na jakiś konkretny temat? Zmagasz się z czymś? Daj znać w komentarzach!
A tymczasem… borem gitem.
Twój Procent,
Committed to no-conflict @ 100%.
P.S. Brace yourselves, Kurs Gita is coming.
The post 5 Obowiązkowych Sposobów Na Rewelacyjną Pracę Z Gitem (I Nie Tylko) appeared first on devstyle.pl.
May 9, 2018
Nagranie webinara “RODO dla programistów: devstyle LIVE z Beatą Marek z cyberlaw.pl”
Pod koniec kwietnia miałem przyjemność poprowadzić rozmowę online z Beatą Marek z cyberlaw.pl na temat RODO: Rozporządzenia o Ochronie Danych Osobowych. Wszystko w kontekście pracy (i innych działalności) programisty.
Startowałem z poziomu “wiem, że nic nie wiem”. Przez te półtorej godziny dowiedziałem się baaardzo dużo. Nasi widzowie również!
Zapraszam do obejrzenia nagrania… szczególnie, że do “magicznej daty” RODO pozostało już tylko pół miesiąca!
The post Nagranie webinara “RODO dla programistów: devstyle LIVE z Beatą Marek z cyberlaw.pl” appeared first on devstyle.pl.
Maciej Aniserowicz's Blog

- Maciej Aniserowicz's profile
- 22 followers

