
Maciej Aniserowicz's Blog
September 19, 2023
Siedem grzechów głównych testowania jednostkowego
Poniżej znajdziesz listę naszych subiektywnych 7 największych błędów, które programiści popełniają w temacie testów jednostkowych. Możliwych problemów jest oczywiście o wiele więcej, ale dziś skupimy się na takich najważniejszych – pod względem konsekwencji albo częstotliwości występowania.
1. Brak jakichkolwiek testów
Autorką tekstu jest Olga Maciaszek-Sharma, a listę kompletował również Marcin Grzejszczak. Oboje są Mentorami w bestsellerowym Szkoleniu SmartTesting, do którego serdecznie zapraszamy! Zapisy trwają do środy 20 września, do godziny 21:00.
Zobacz szczegóły na SmartTesting.pl »!
Pierwszym, dość oczywistym może grzechem jest brak jakichkolwiek testów, w tym testów jednostkowych. Niestety wciąż jeszcze zdarzają się zespoły, które uważają, że – z różnych powodów – nie muszą wcale pisać testów. Niektórzy myślą, że są w stanie przetestować wszystko w głowie… i może niektóre są, choć w to wątpię.
Inni uważają, że wystarczy przeklikać nową funkcjonalność na środowisku lokalnym. Prawda jest jednak taka, że nawet jeśli mamy geniusza będącego w stanie „przetestować w głowie” wraz z innymi członkami zespołu bardzo dokładnie i pieczołowicie weryfikującymi działanie aplikacji na środowisku lokalnym, to nie wystarczy. Przecież inne osoby z tego samego zespołu mogą nie zrozumieć, o co chodziło w danej funkcjonalności i wprowadzić niepoprawne zmiany – co spowoduje regresję. Regresję, która nie zostanie wychwycona i prawdopodobnie trafi na produkcję.
Inne zespoły rozumieją potrzebę testowania, ale i tak nie testują, ponieważ biznes nie wie, dlaczego testy są potrzebne. Napięte harmonogramy wywierają presję, by nie poświęcać czasu na testy. Jednak z naszego doświadczenia wynika, że biznes można przekonać rozmawiając o testach od strony finansowej. Prawda jest taka, że brak testów na dłuższą metę powoduje koszty, a nie oszczędności. Koszty spowodowane niewykrytymi odpowiednio wcześnie błędami w systemach IT są niebotyczne, a naprawienie błędów wykrytych w początkowych fazach tworzenia oprogramowania jest 100x tańsze, niż w fazie utrzymania. Wprost wynika z tego, że testy – a szczególnie testy jednostkowe, będące niezwykle istotnym źródłem feedbacku już na bardzo wczesnym etapie tworzenia oprogramowania – przyczyniają się w praktyce do bardzo dużych oszczędności.
Testy bardzo usprawniają też pracę całego zespołu nie tylko przy dodawaniu nowych funkcjonalności, ale też na etapie utrzymania. Zespoły często poświęcają znacznie więcej czasu na zmiany istniejącego kodu niż dodawanie nowego, a dobrze napisane testy pozwalają to robić znacznie łatwiej, szybciej i w sposób mniej zachowawczy. Gdy mamy dobre testy, bardzo szybko wykryjemy ewentualne regresje. Testy jednostkowe umożliwiają też bardzo szybkie debugowanie małych fragmentów kodu, bez konieczności uruchamiania całej aplikacji czy kontekstu.
Testy stanowią również żywą dokumentację projektu. Jeżeli mamy dobre testy, i jeszcze do tego dobrze nazwane, to – w przeciwieństwie do tradycyjnej, pisanej ręcznie dokumentacji – opisują one to, jak system faktycznie działa, a nie tylko jak chcielibyśmy, żeby działał. Co więcej, są narzędzia, przy pomocy których możemy wygenerować dokumentację z istniejących testów.
2. Testowanie absolutnie wszystkiego
Z drugiej strony, gdy zespół podejdzie trochę zbyt entuzjastycznie do kwestii testowania (szczególnie w testach jednostkowych) zdarzają się sytuacje, że próbujemy testować zbyt wiele. Można tu wymienić takie kwestie jak testowanie jednostkowe funkcjonalności / kodu wygenerowanego przez zewnętrzne narzędzia bądź frameworki albo metod dostarczanych przez zewnętrzne biblioteki. W tego typu sytuacjach często wystarczy weryfikacja danej funkcjonalności z poziomu testów integracyjnych.
Podobnie, nie powinniśmy próbować testować metod prywatnych. Często gdy wydaje nam się, że weryfikacja działania jakiejś metody prywatnej zasługuje na oddzielny test, może to świadczyć o tym, że jest problem w strukturze klas naszej aplikacji i metoda ta powinna być na przykład wyekstrahowana do metody pakietowej nowej, bardziej wyspecjalizowanej klasy.
Zdarzają się też przypadki, choć bardzo szczególne i ograniczone, na przykład gdy tworzymy na szybko jakiś prototyp, który nie będzie używany produkcyjnie lub banalnie prostą aplikację, na przykład typu CRUD, bez dodatkowej logiki biznesowej, kiedy można rozważać rezygnację z pisania testów w ogóle.
3. Testy, które nic nie weryfikująWbrew pozorom, testy, które nic nie weryfikują, zdarzają się częściej, niż mogłoby się wydawać. Pierwszy ich rodzaj, najłatwiejszy do wykrycia i poprawienia to testy, które nie kończą się jednoznacznym wynikiem negatywnym lub pozytywnym. Każdy test, który w ogóle jest testem, ma asercję(/e), która jasno wskazuje na to czy test przeszedł. Testy bez asercji nie kończą się jednoznacznym wynikiem (na przykład tylko coś logując). A testy wymagające dodatkowych manualnych kroków po wykonaniu (jak, na przykład, weryfikacja czegoś w bazie danych), nie powinny pojawiać się w naszych projektach.
Trudniejsze do wykrycia są testy, które przechodzą tylko dlatego, że weryfikowany wynik jest zbieżny z wartościami domyślnymi. Albo nawet takie, które w istocie wcale nie powodują (na przykład ze względu na błędną konfigurację) wywołania pod spodem testowanych metod (funkcji). Zdarza się też, że asercje zostały błędnie skonstruowane.
Jest kilka prostych rzeczy, które można zrobić, żeby uchronić się przed takimi sytuacjami. Warto pracując nad testem na chwilę „zepsuć dane”, czyli testując na przykład przypadek pozytywny, zmienić dane wejściowe (np. użytkownik, któremu przysługuje kredyt) na takie, dla których przypadek powinien być negatywny (np. użytkownik ze złą historią kredytową) i zobaczyć czy wtedy nasz test nie przejdzie. Inna weryfikacja czy test faktycznie coś testuje, to sprawdzenie co się stanie jeżeli odwrócimy asercje (np. z `isEqualTo` na `isNotEqualTo`) lub na chwilę zakomentujemy kawałek logiki biznesowej, którą chcielibyśmy przetestować. Jeżeli w tych sytuacjach test nadal będzie przechodził, to prawdopodobnie nic on w praktyce nie testuje.
Warto też weryfikować liczbę wykonanych testów w outpucie naszego narzędzia do budowania. Może się zdarzyć, że pomimo poprawnie działających testów uruchamianych w naszym środowisku uruchomieniowym, to z powodu złej konfiguracji narzędzia do budowania, bądź niezastosowania się do danej konwencji przy nazywaniu naszych klas czy metod (funkcji) testowych, nie zostaną one w ogóle uruchomione w najważniejszym momencie, czyli w procesie budowania naszej aplikacji.

Odwrotnością testów, które nic nie weryfikują, są testy weryfikujące zbyt wiele, prowadząc do tzw. zabetonowania aplikacji testami. Wtedy przy każdej, nawet najmniejszej zmianie w naszej aplikacji, przestają przechodzić dziesiątki testów. Co się wtedy dzieje? Zazwyczaj zespoły przestają w ogóle uruchamiać testy i tracą wszelkie korzyści płynące z ich posiadania.
Najczęściej do „zabetonowania” dochodzi wtedy gdy używamy zbyt szczegółowych asercji. Na przykład w teście sprawdzającym, że dana metoda (funkcja) została uruchomiona, będziemy sprawdzać, że została uruchomiona np. z konkretnym Stringiem jako argumentem. Czy to znaczy, że nigdy nie powinniśmy zweryfikować tego konkretnego Stringa? Nie, jeżeli wartość jest istotna dla naszej logiki biznesowej, to możemy chcieć ją zweryfikować, ale… w jednym teście, a nie w dwudziestu.
Podobnie, problem może się pojawić, gdy zamiast weryfikować efekty danej operacji, staramy się sprawdzać jak dokładnie została ona, krok po kroku, zrealizowana – czyli weryfikujemy szczegóły implementacyjne, zamiast rezultatu.
5. Nieczytelne testyJednym z powodów, dla których testy bywają określane jako “trudne” lub “zbędne”, jest kwestia ich czytelności. Często zdarza się, że zespół nie dokłada takich samych starań w zakresie czytelności kodu testowego jak w przypadku pisania kodu produkcyjnego, przez co testy trudno się czyta i trudno refaktoruje.
Problemem bywa niejasne nazewnictwo pól i zmiennych, weryfikacja zbyt wielu rzeczy w jednym teście, brak jasnego podziału testu na sekcje „Arrange”, „Act”, „Assert”, brak wydzielenia setupu bądź przygotowania danych testowych do oddzielnych metod. Często problematyczne jest też stosowanie asercji na poziomie szczegółów implementacyjnych, zamiast wykorzystania np. wzorca „AssertObject” do utworzenia asercji na poziomie logiki biznesowej.
Negatywny wpływ na czytelność testów często ma brak spójności i stosowania konwencji, np. jeżeli chodzi o nazewnictwo klas i metod (funkcji) czy wykorzystywane narzędzia i biblioteki testowe.
6. Stubowanie i mockowanie wszystkiegoW środowisku od dawna trwają spory dotyczące tego, czy stubowanie i mockowanie (używanie zaślepek i narzędzi do weryfikacji wywołań metod/ funkcji) w testach jednostkowych jest dobrą praktyką. Stanowiska i argumentację obydwu stron sporu przedstawiamy bardziej szczegółowo w szkoleniu SmartTesting ». Naszym zdaniem nierzadko warto je stosować dla lepszej izolacji testowanych obiektów, co może polepszyć czytelność testów i ułatwić życie w sytuacji zbyt skomplikowanego setupu testu. Ze stubowaniem i mockowaniem zdecydowanie można jednak przesadzić, osiągając wręcz przeciwny efekt i negatywnie wpływając na czytelność. Może się też zdarzyć, że test nawet nie będzie odpowiednio weryfikował tego, na czym nam zależało.
Jedną z rzeczy, która praktycznie zawsze jest złym pomysłem, jest stubowanie lub mockowanie metod z bibliotek i narzędzi nieutrzymywanych przez nas. Jest wtedy duża szansa, że nie zorientujemy się, gdy autorzy biblioteki postanowią zmienić implementację i nasze stuby przestaną odzwierciedlać jej zachowanie. To z kolei może prowadzić do sytuacji, w której nasze testy przestaną w rzeczywistości weryfikować jak aplikacja zachowuje się w interakcji z tą zewnętrzną biblioteką.
Kolejnym problemem jest stubowanie obiektów, które bardzo łatwo byłoby po prostu utworzyć, np. Stringów, kolekcji czy wyników wywołań metod użytkowych (“utils”) standardowych bibliotek języków. Na przykład zamiast stubować metodę zwracającą informację czy String jest pusty, lepiej po prostu przekazać pustego Stringa. Tego typu nadmierne stubowanie sprawia, że nasze testy robią się niepotrzebnie skomplikowane i mało czytelne.
Podobnie jak przy testowaniu metod (funkcji) prywatnych, nie jest najlepszym pomysłem ich stubowanie czy mockowanie. Gdy widzimy potrzebę mockowania czy stubowania takich metod (funkcji), to zazwyczaj świadczy to o tym, że albo można by poprawić strukturę naszego kodu produkcyjnego (o czym pisałam wyżej) albo że próbujemy zbyt szczegółowo weryfikować implementację – a to prawdopodobnie doprowadzi do „betonowania” aplikacji (o czym też była mowa już wcześniej).
Warto wziąć tu pod uwagę także tak zwane „Prawo Demeter dla mocków i stubów”. Zgodnie z nim nasze stuby nie powinny zwracać innych stubów bądź mocków. Czasami trudno jest uniknąć takiej sytuacji, ale najlepiej byłoby postarać się ograniczyć używanie takiego setupu do minimum.
7. Zbyt wolne testyLast, but not least… żeby testy (szczególnie jednostkowe) były regularnie uruchamiane przez zespół i nie ograniczały jego produktywności, powinny być one szybkie. A dobrze napisane testy faktycznie takie są. Jest jednak kilka często spotykanych błędów w tym aspekcie.
Jednym z nich jest podnoszenie kontekstu frameworka aplikacyjnego bądź kontenerów z bazami danych (lub innymi zewnętrznymi komponentami). O ile jest to normalne przy testach integracyjnych, o tyle nie powinno mieć miejsca w testach jednostkowych. Często bywa to nadużywane szczególnie w sytuacji użycia frameworków bazujących na IoC (odwróceniu kontroli), kiedy to w polach klas pojawiają się obiekty od razu łączące się do zewnętrznych komponentów. Najłatwiejszym rozwiązaniem w takiej sytuacji bywa wykorzystanie interfejsów i przekazywanie do testów jednostkowych implementacji zwracających dane w znacznie szybszy sposób. Na przykład pole z obiektem pobierającym i zwracającym dane z bazy, możemy w teście wypełnić obiektem implementującym ten sam interfejs, ale pobierającym dane ze zwykłej kolekcji.
Często też problemem jest zbyt długie oczekiwanie w testach. Nierzadko zdarza się, że musimy chwilę odczekać, żeby móc coś zweryfikować. Jeżeli w takiej sytuacji ustawimy sztywny czas oczekiwania, to musi on być tak długi, jak długo może maksymalnie zająć realizacja oczekiwanej operacji. Niepotrzebnie wydłuża to testy. Zamiast tego, lepiej jest użyć pomocniczego narzędzia. Np. w Javie mamy Awaitility, które w krótkich interwałach będzie ponawiać próby weryfikacji, czy wynik już jest dostępny.
Więcej?Po duuuużo więcej wiedzy zapraszamy do SmartTesting »! Do zobaczenia!
The post Siedem grzechów głównych testowania jednostkowego appeared first on devstyle.pl.


September 14, 2023
Inteligentny fotel biurowy Ergohuman 2: Przenieś komfort pracy na wyższy poziom!
Zdrowie i komfort podczas długich godzin pracy przy komputerze, to niezwykle istotne aspekty, które nie tylko wpływają na naszą wydajność, ale również mają długotrwały wpływ na nasze dobre samopoczucie. Jeśli jesteś informatykiem, który spędza większość dnia w wirtualnym świecie, wiesz doskonale, jak ważne jest dbanie o swoje ciało i umysł. Wybór właściwego fotela biurowego, który zapewni ci ergonomiczną postawę i wsparcie dla kręgosłupa, może mieć kluczowe znaczenie dla twojego zdrowia. Przygotowaliśmy dla ciebie przewodnik, który omawia kluczowe czynniki wyboru idealnego fotela biurowego, a także prezentuje model, który cieszy się ogromnym uznaniem wśród profesjonalistów.
Ergonomiczne fotele biurowe – jakie przyniosą korzyści dla Twojego zdrowia?Nowoczesne biura coraz częściej wyposażone są w zaawansowane technologicznie urządzenia, które ułatwiają pracę oraz poprawiają jej efektywność. Jedną z najnowszych nowinek w branży biurowej jest druga generacja bestsellerowego ergonomicznego fotela biurowego Ergohuman, który w znacznym stopniu może zmienić sposób, w jaki pracujemy. Inteligentny fotel obrotowy Ergohuman 2 to nowoczesne rozwiązanie, które pozwala na maksymalne dostosowanie siedzenia do indywidualnych potrzeb użytkownika. Dzięki zaawansowanym technologicznie mechanizmom, fotel zapewnia maksymalny komfort i wygodę podczas pracy, a także minimalizuje ból i napięcie mięśniowe. Wprowadzenie inteligentnego fotela biurowego do pracy, może znacznie poprawić efektywność i jakość wykonywanych zadań, a także przyczynić się do poprawy zdrowia i dobrego samopoczucia pracowników.

Dla współczesnego informatyka, który spędza większość dnia przed komputerem, wybór odpowiedniego fotela biurowego może mieć znaczący wpływ na komfort pracy oraz zdrowie kręgosłupa. Optymalna ergonomia stanowi kluczowy element w zapobieganiu dolegliwościom, takim jak bóle pleców, szyi czy ramion, które często występują w wyniku nieodpowiedniej pozycji ciała. Wybór właściwego fotela biurowego powinien uwzględniać kilka istotnych czynników, takich jak regulacje, materiały, design oraz dodatkowe ergonomiczne funkcje.
Czym powinien wyróżniać się fotel ergonomiczny do pracy i do domu?Pierwszym elementem, na który warto zwrócić uwagę, są regulacje fotela biurowego. Informatyk czy programista powinien mieć możliwość dostosowania wysokości siedziska, nachylenia oparcia oraz podłokietników do swoich indywidualnych potrzeb. Ergonomiczny fotel biurowy powinien umożliwiać utrzymanie naturalnej krzywizny kręgosłupa i wspierać odpowiednią postawę ciała.
Kolejnym istotnym aspektem jest wybór odpowiednich materiałów. Fotel biurowy powinien być wytrzymały, a jednocześnie zapewniać odpowiedni komfort użytkowania. Materiały obiciowe powinny być łatwe w czyszczeniu oraz przyjemne w dotyku, zapewniając komfort przez wiele godzin pracy. Polecanym materiałem jest siatka, która idealnie przylega do pleców i zapewnia odpowiednia cyrkulację powietrza, która doceniana jest szczególnie w upalne dni.
Design fotela również odgrywa rolę, zwłaszcza jeśli pomieszczenie biurowe ma być również estetyczne. Wybór między nowoczesnym a klasycznym stylem zależy od preferencji użytkownika oraz ogólnego wystroju wnętrza.
Dodatkowe funkcje fotela biurowego mogą być niezwykle przydatne dla informatyka. Fotele wyposażone w regulowany zagłówek, podparcie lędźwi, mechanizm dostosowujący oparcie i siedzisko do ruchu ciała, czy podnóżek, mogą zapewnić jeszcze większy komfort i wsparcie podczas długich godzin pracy przy biurku.
Wybór odpowiedniego fotela biurowego dla informatyka to istotna decyzja, która może wpłynąć zarówno na komfort pracy, jak i zdrowie. Ergonomia, regulacje, materiały i dodatkowe funkcje, to kluczowe elementy, które warto wziąć pod uwagę podczas poszukiwań, by stworzyć optymalne warunki pracy przy biurku.
Poznaj funkcje fotela Ergohuman 2Ciekawą propozycją dla osób pracujących przy komputerze jest fotel Ergohuman 2 – druga generacja bestsellerowych foteli Ergohuman Plus Elite. Jego zaawansowane regulacje pozwalają na dostosowanie do indywidualnych potrzeb użytkownika, z dbałością o prawidłową postawę ciała. To krzesło biurowe oferuje wyjątkowe wsparcie dla kręgosłupa, dzięki zaawansowanemu profilowi lędźwiowemu, rozbudowanemu mechanizmowi z ujemnym kątem siedziska i oparcia, ergonomicznym podłokietnikom 5D i komfortowemu zagłówkowi 2D.
Wykonany z wysokiej jakości materiałów, gwarantuje trwałość i komfort, dodatkowo zapewniając odpowiednią cyrkulację powietrza. To doskonałe narzędzie dla informatyka, któremu zależy na wygodzie i zdrowiu w pracy.
Ergohuman 2 to seria foteli biurowych dostępnych w trzech wersjach: Ergohuman 2 Basic, Ergohuman 2 Elite i Ergohuman 2 Luxury. Wszystkie modele są wyjątkowo ergonomiczne, ale to wersja Luxury wyróżnia się na tle konkurencji, dzięki swojej innowacyjnej funkcjonalności.

Bezprzewodowe sterowanie w fotelu Ergohuman 2 Luxury to innowacyjne rozwiązanie, które sprawia, że korzystanie z fotela staje się jeszcze bardziej wygodne i efektywne. Sterowanie zostało elegancko ukryte w podłokietniku, co nadaje fotelowi estetyczny wygląd i pozwala na łatwy dostęp do wszystkich funkcji.
Bezprzewodowe sterowanie umożliwia regulację wysokości siedziska oraz blokadę mechanizmu synchronicznego, który odpowiada za ruchy siedziska i oparcia. Za pomocą estetycznych przycisków umieszczonych na podłokietniku, użytkownik może łatwo dostosować wysokość fotela do swoich preferencji, zapewniając optymalną pozycję siedzenia. Możliwość blokady mechanizmu synchronicznego pozwala na zablokowanie pozycji siedziska i oparcia, co jest przydatne podczas wielogodzinnej pracy.

Największą zaletą bezprzewodowego sterowania jest fakt, że użytkownik nie musi przerywać pracy, aby dostosować ustawienia fotela. Wszystkie funkcje są dostępne bezpośrednio z poziomu podłokietnika, co pozwala na płynne i natychmiastowe regulacje. Użytkownik może dostosować fotel do swoich indywidualnych potrzeb w czasie rzeczywistym, bez konieczności szukania regulacji manualnych. To doskonałe rozwiązanie dla osób, które cenią sobie nowoczesność, funkcjonalność i elegancję w swoim biurze.
Dlaczego warto wybrać ergonomiczny fotel biurowy Ergohuman 2?Fotele Ergohuman 2 to nie tylko doskonałe rozwiązanie pod względem ergonomii i wygody, ale także atrakcyjne korzyści zakupowe. Przede wszystkim, fotele Ergohuman 2 objęte są aż 5-letnią gwarancją, co daje pewność co do ich jakości i trwałości na długie lata.
Wszystkie innowacyjne funkcje Ergohuman 2 sprawiają, że jest on niezastąpionym narzędziem dla informatyków i programistów. Nie tylko zapewniają one optymalne wsparcie dla ciała, ale również umożliwiają dostosowanie fotela do indywidualnych preferencji i potrzeb. Dzięki temu, informatycy mogą pracować w wygodnym i ergonomicznym środowisku, co przekłada się na ich zdrowie, wydajność i efektywność w wykonywaniu codziennych zadań.
Jeśli zdecydujesz się na zakup fotela Ergohuman 2 w sklepie CentrumKrzesel.pl, możesz skorzystać z dodatkowych udogodnień. Sklep oferuje darmową dostawę fotela, co oznacza, że nie poniesiesz dodatkowych kosztów za wysyłkę. Dodatkowo, istnieje możliwość bezpłatnego zwrotu w ciągu 14 dni, co daje Ci elastyczność w przypadku zmiany zdania.
Warto również wspomnieć, że sklep CentrumKrzesel.pl umożliwia skorzystanie z opcji płatności ratalnej. Dzięki platformie PayU, możesz wziąć raty 0% z 0% RRSO, co pozwala na rozłożenie kosztu fotela na dogodne dla Ciebie raty bez żadnych dodatkowych opłat.
Specjalnie dla czytelników devstyle.pl przygotowaliśmy wyjątkową promocję – aż 10% rabatu na fotele Ergohuman 2 z kodem DEVSTYLE. Kod ważny do 31.12.2023 r.

The post Inteligentny fotel biurowy Ergohuman 2: Przenieś komfort pracy na wyższy poziom! appeared first on devstyle.pl.
June 5, 2023
Zapraszamy na LIVE o ChatGPT, AI i innych narzędziach dla odpowiedzialnego Legacy Fightera!
Poniedziałek, 5 czerwca, godzina 20:00.
Trzech Ekspertów: Mariusz GIL, Kuba PILIMON i Sławek SOBÓTKA.
Super ciekawy temat:
ChatGPT w służbie Legacy Fightera! 🔥Jak wykorzystać AI (i inne narzędzia),
zanim one wykorzystają Ciebie?
Spotkajmy się o tutaj!
Przy tej okazji
otworzymy nabór
do 3. Edycji Legacy Fighter!
Pozdrawiamy serdecznie i do zobaczenia,
Maciej Aniserowicz, Mariusz Gil, Kuba Pilimon & Sławek Sobótka
LF Team
The post Zapraszamy na LIVE o ChatGPT, AI i innych narzędziach dla odpowiedzialnego Legacy Fightera! appeared first on devstyle.pl.
September 21, 2022
Prowadzisz bloga? Oto Twoje zbawienie: Marketing Calendar by CoSchedule
W moim życiu social media mają dwie strony: prywatną i marketingową. Prywatnie: utrzymuję kontakt ze znajomymi i dzielę się swoimi refleksjami. Marketingowo: promuję “devstyle” i wszystko co z tym terminem związane.
Fair enough.
Manual vs autoDo niedawna wychodziłem z założenia, że wszystko w socialach “powinno” być robione ręcznie, by nie utracić autentyczności i szczerości. A to… generowało wiele problemów. Życie stało się o wiele prostsze, gdy wykrystalizował się wspomniany wyżej podział.
Prywatnym zastosowaniom sociali nie zależy na zasięgach, na “odpowiednim czasie publikacji”, na numerkach i klikach. Tam pierwsze skrzypce grają emocje. U mnie tak działa większość mojego Twittera, prywatne konto na fejsie (od niedawna) i Instagram. W skrócie: na “prywatnych” socialach nie zarabiam. I do nich faktycznie pięknie stosuje się zasada: serducho i własne palce, a nie bezduszny automat.
Ale druga strona medalu to sociale “zawodowe”. Fanpage, “promocyjna” część Twittera czy LinkedIn… one służą do promowania treści i docierania do jak największej rzeszy odpowiednich osób. To część pracy. A im mniej pracy, tym lepiej, c’nie? ;). No właśnie. I tu jest social pogrzebany.
W przypadku devstyle stało się to o tyle istotne, że od kilku miesięcy z “bloga” zrobił się “portal” i nasze teksty są teraz pisane przez wiele par rąk, a nie tylko moje. Jeszcze do niedawna nastawiałem budzik (sic!), żeby o odpowiedniej godzinie puścić na fanpage informację o nowym tekście. Uwiązany do komputera, przyciśnięty do wirtuala, skuty cyber-kajdanami.
Oczywiście wiem, że da się “zaschedulować” treści na przyszłość. Ale – w przypadku facebooka czy LinkedIn – dopiero, gdy post na WordPress jest już opublikowany, co mocno sprawy komplikuje.
I wtedy, na białym rumaku, dumnie wjeżdża…
CoScheduleO CoSchedule dowiedziałem się ze SmartPassiveIncome (a z Patem z SPI miałem niedawno zaszczyt porozmawiać przed mikrofonami :) ). Najpierw temat olałem, ale w końcu coś mnie tknęło i… postanowiłem sprawdzić.
Jest to narzędzie do “ogarniania” sociali. Miałem wcześniej romans z dwoma innymi programami tego typu, ale się nie polubiliśmy. Dlatego też tym razem podchodziłem do sprawy bardzo sceptycznie. Ba, umówiłem się nawet na skype z zaoceanicznym supportem, żeby porozmawiać o tym rozwiązaniu, zanim się w nie zaangażuję!
Porozmawiałem. Poznałem. Zaangażowałem się. Uzależniłem się. Wykupiłem i zostałem klientem. A teraz polecam dalej.
Dlaczego? Poniżej pokażę trzy funkcje, z których korzystam regularnie. CoSchedule oferuje ich więcej, ale mi na razie wystarcza tylko to. Zaoszczędziłem dzięki temu masę czasu. I – co dla mnie ostatnio bardzo ważne – odzyskałem odrobinę wolności.
Zobaczcie:
Po pierwsze: promocja postówNapisanie tekstu to jedno. Potem trzeba go puścić na WordPressa i… wypromować, oczywiście! Tej części nigdy nie lubiłem. Skakania po oknach, pilnowania odpowiednich godzin… Eh.
Teraz? CoSchedule daje plugin do WordPressa, dzięki któremu kilkoma kliknięciami planuję wysyłkę informacji o tekście na wszystkie swoje kanały:
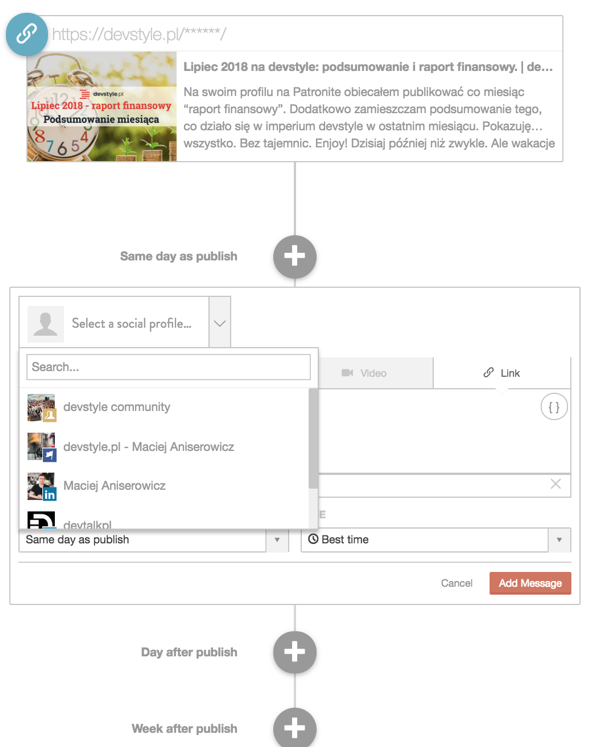
Siup! Bezpośrednio z widoku edycji posta.
Ale to nie wszystko, bo… po co tyle klikać? Można zapisać sobie szablon (social template), który jednym klikiem zaplanuje wiadomości w odpowiednich godzinach na różne kanały:
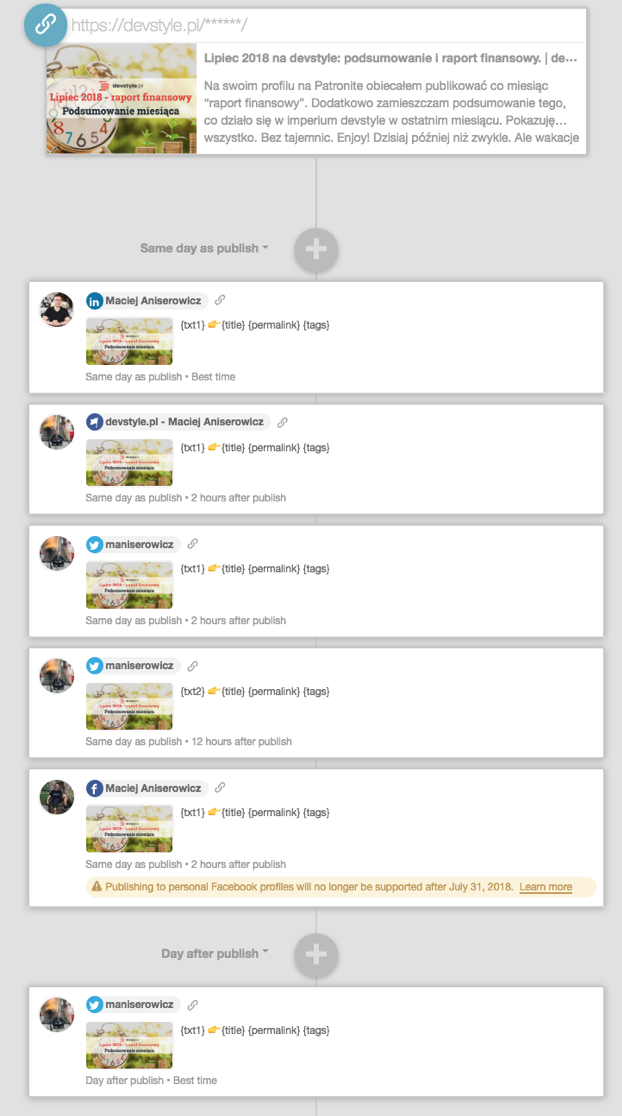
Potem tylko wypełniam teksty (moje własne placeholdery: txt1, txt2 i tags) i… i już! Gotowe!
Oczywiście mógłbym zrobić “scheduling” z każdej platformy bezpośrednio. I tak robiłem przez lata. Jednak z tym wiąże się problem, o którym już nieco wspomniałem: to (na Facebooku i LinkedIn) działa tylko dla już opublikowanych treści! Te portale zaciągają i cache’ują sobie graficzną reprezentację linków. WordPressowy szkic zwróci im 404. Z CoSchedule ten problem znika! Lowe Wielkie za to.
Zresztą w podobny sposób planuję promocję odcinków VLOGa, publikowanych tylko na YT, nie na WordPress. Upload i schedule na YouTube to jedno. Ale od razu, w tym samym momencie, mogę zaplanować informacje wysłane na wszystkie social-kanały. A potem bezpiecznie wyłączam komputer i wszystko magicznie dzieje się samo.
W poszukiwaniu utraconego czasu? To właśnie tutaj!
Bardzo, bardzo wielka oszczędność czasu. A z moich raportów finansowych można łatwo wywnioskować, że z chęcią kupuję czas.
Co więcej: dzięki CoSchedule mogę dać dostęp do tych kanałów innym osobom, na przykład mojej asystentce Ani, bez nadawania uprawnień na każdej platformie po kolei (czego robić nie chcę)! Idealny flow: autor pisze tekst, Andrzej robi korektę i redakcję, Ania ogarnia resztę (graficzka i promocja w socialach), a ja biję brawo. Perfect!
Bonus: headline analyzerPo polsku działa to średnio, ale jeśli piszesz po angielsku, to może Ci się spodobać:
U mnie wszystko jest po polsku, więc nie korzystam, ale pokazuję jako ciekawy bajer.
Po drugie: kalendarzNawet pisząc w pojedynkę czasami mieszałem terminy różnych publikacji. Wrzucałem na Google Calendar wszystkie potrzebne informacje: kiedy co i gdzie ma być opublikowane. I to działało pięknie… dopóki nie nastąpiła jakakolwiek zmiana. Bo kto zsynchronizuje kalendarz z rzeczywistością? Ano nikt.
Nikt? A jednak ktoś! Proszę bardzo:

To jest jeden z tygodni lipca. Tu są wszystkie WordPressowe teksty i wszystkie “marketingowe” wiadomości na sociale. I tutaj synchronizacja już działa! Jeśli przesunę wiadomość na inny dzień lub inną godzinę, to ona faktycznie zostanie opublikowana w tym nowym terminie.
A dlaczego niektóre elementy się wyróżniają? Bo najechałem myszką na jedną z wiadomości. A wtedy CoSchedule pokazuje, które inne pozycje są z nią powiązane w jednej “social kampanii“. W tym przypadku widać (dość agresywną) kilkudniową kampanię promującą mój post o Gicie.
Zajarałem się, gdy to zobaczyłem. I jaram się do dziś.
Po trzecie: republikacjaBlog założyłem ponad dekadę temu. Przez ten czas pojawiło się prawie tysiąc tekstów. W trakcie doszedł podcast i VLOG. Jest tego MASA.
I… i to się marnuje. Przynajmniej te uniwersalne, ponadczasowe teksty/odcinki. Jasne, w swoim czasie każda treść dotarła przed oczy i uszy X Czytelników, Widzów i Słuchaczy. Ale to grono ciągle rośnie! A mało kto chodzi po archiwach.
Z pomocą przychodzi ReQueue, czyli mechanizm ponownej promocji już istniejących treści. Wybieram tekst, klikam “OKEJ”, a CoSchedule robi resztę, czyli automatycznie publikuje te teksty w odpowiednich godzinach na wybranych przeze mnie kanałach. Pilnując jednocześnie, by zbytnio nie spamować, trzymając się ustalonych limitów X wiadomości dziennie per kanał.
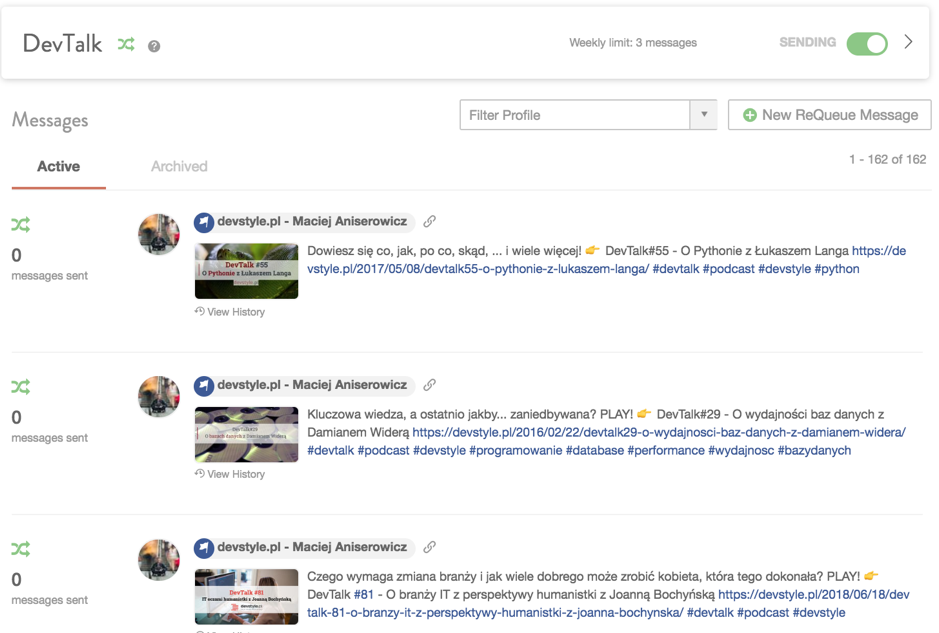
Oczywiście są inne narzędzia, które także to robią. Ale tutaj mam wszystko “w pakiecie”. A dodatkowo – co się niezmiernie przydaje – NOWE teksty mogą zostać automatycznie dodane do wybranych grup republikacji.
Efekt?Od -nastu (czy -dziesięciu?) miesięcy liczba UU na devstyle.pl krążyła wokół 20-25tys. Były wzloty i spadki, ale to taka średnia.
Natomiast lipiec 2018… o proszę, w porównaniu do poprzedniego miesiąca:

W lipcu uruchomienie CoSchedule nie było jedyną zmianą. Oprócz tego pojawiło się więcej tekstów niż zwykle dzięki nowym świetnym Autorom i Autorce. Więcej niż zwykle wydałem też na reklamy na FB.
ALE! Nawet jeśli CoSchedule nie przełożyło się na ten ruch bezpośrednio (choć jestem przekonany, że tak było), to na pewno pomogło w osiągnięciu takiego wyniku.
Czego nie używam?Napisałem, że CoSchedule oferuje więcej niż potrzebuję. Co zatem olewam? Przynajmniej dwa duże ficzery:
Pierwszy z nich to analityka. Pewnie powinienem nad tym przysiąść, ale… no cóż, po prostu mi się nie chce.
Drugi to “project management”/kolaboracja. Od tego mam inne narzędzia, które sprawdzają się bardzo dobrze.
Więc?Tak jak pisałem, narzędzia używam od około dwóch miesięcy. Jest rewelacyjne i zostaję przy nim. Polecam także Tobie!
Ku jawności: w tekście znajduje się link afiliacyjny: http://devstyle.pl/coschedule. Będzie mi bardzo miło, jeśli zapoznasz się z tą usługą korzystając właśnie z niego. Ale nawet jeśli olejesz mój link i pójdziesz bezpośrednio na stronę produktu, to i tak będę zadowolony. I… jestem przekonany, że Ty też.
Pozdro!
Procent,
Taki Dojrzały Marketer Że Hej
The post Prowadzisz bloga? Oto Twoje zbawienie: Marketing Calendar by CoSchedule appeared first on devstyle.pl.
September 19, 2022
DNA: Ruszyła Czwarta Edycja!
Czwarta Edycja DNA: Drogi Nowoczesnego Architekta otwiera swoje bramy i wzywa Cię do siebie! Oferując wyjątkową możliwość rozwoju kariery pod okiem najlepszych z najlepszych: Trzech Mistrzów Architektury.
Na początek jednak zachęcam do obejrzenia tego video:
“Kruszenie KorpoBETONU, czyli Zarzadzanie Zmianą.
Jak skutecznie przekuć teorię w praktykę?“
Znajdziesz w nim:
dużo ciekawej wiedzy o pracy i decyzjach architekta oraz obowiązku WDROŻENIA koniecznych zmian przy różnych przeciwnościach losu (nasi Mentorzy dali czadu!)masę informacji na temat Programu DNA : Drogi Nowoczesnego Architekta, do którego TERAZ Cię zapraszamy!Pod koniec tego spotkania ogłosiliśmy start naboru do 4. edycji Programu DNA.
Znamy się już nie od dziś i prawdopodobnie czekasz na tę informację.
Teraz można dołączyć do ponad 7 500 Uczestników DNA!
Dotychczasowe edycje DNA były czymś absolutnie wyjątkowym. Zaufały nam tysiące programistów w oczekiwaniu materiałów najwyższej jakości (✅) na ważne tematy (✅), podane w przystępny sposób (✅) i okraszone wyjątkową integracją na zamkniętym architektonicznym Slacku (✅).
Obiecywaliśmy Plan Rozwoju Programistycznej Kariery dla mid- i senior-developerów oraz architektów. I… dowieźliśmy to!
Spłynęły do nas SETKI opinii. Kilka swoich ulubionych wklejam poniżej:
Pierwsza:

Druga:

Trzecia (screen ze Slacka):

Czwarta (z Instagrama):
[image error]
Piąta (screen z maila):
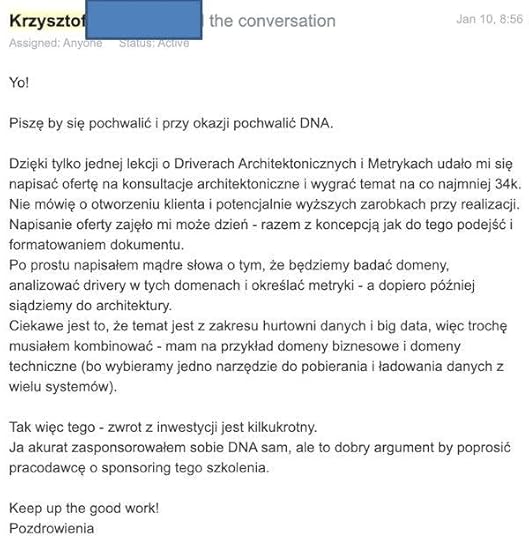
Spójrz na ostatni akapit: zwrot z inwestycji jest kilkukrotny, a to dopiero przecież początek “życia po DNA”.
My już wiemy, że DNA działa. I to nawet lepiej, niż pierwotnie zakładaliśmy, bo wpływ Programu na całą polską branżę IT jest olbrzymi!
Ze 100% pewnością oferujemy Ci teraz możliwość dołączenia do nas i innych pasjonatów. Rozwój kariery nie kończy się na etapie tutoriali coraz to nowszych technologii. Można wejść w głąb, zamiast ciągle skakać na boki, po łebkach.
== TUTAJ dołączysz do DNA #4 za 2799 zł BRUTTO » ==
Oferujemy Ci:
20 tygodni intensywnej nauki (pełną agendę znajdziesz tutaj)dożywotni dostęp do materiałów (to ważne! Korzystasz kiedy chcesz, we własnym tempie)dostęp do wszystkich aktualizacji i bonusów jakie kiedykolwiek wydamyzadania domowe, utrwalające wiedzę w praktyceprzykładowy kod w 4 językach: Java, C#, PHP i JavaScriptdostęp do zamkniętego Slacka Nowoczesnych Architektów (z Mentorami i innymi wymiataczami, do dalszych dyskusji i pogłębionej nauki) – krążą opinię, że to miała być wisienka na torcie, a wyszedł drugi tort ;)różne bonusy ułatwiające konsumpcję treści: PDFy, wersje audio, transkrypcje, slajdy…materiały dodatkowe: nagrania z dwóch edycji DNA CONF, wywiady, webinary, LIVE’y100% gwarancji zadowolenia (aż do końca października 2022 możesz upomnieć się o zwrot kasy – z dowolnego powodu! – i po prostu oddam Ci 100% pieniędzy)Ta oferta jest ważna do piątku 30.09 do godziny 21:00.
Potem lecimy z materiałem z czwartą grupą i DNA znika z rynku.
Zauważ, że Trzecia Edycja DNA wystartowała w maju 2021! Na Trzecią Edycję trzeba było czekać aż 16 miesięcy!
Czy będzie piąta? Tego nie wiemy, nie możemy obiecać. Możliwe, że to jest ostatnia edycja DNA w takim kształcie.
A cena teraz jest najniższa – nigdy nie będzie taniej!
A jak dokładnie, w praktyce, prezentuje się DNA?
Na stronie Programu znajdziesz m.in. przykładowe lekcje DEMO, więc możesz przekonać się, jak to wygląda od środka.
Tamże przygotowaliśmy obszerną sekcję FAQ, gdzie znajdziesz odpowiedzi na większość dręczących Cię pytań.
Dołączając TERAZ otrzymujesz OD RAZU dostęp do naszej Społeczności oraz całej masy materiałów bonusowych.
A już w poniedziałek 26 września ruszają pierwsze lekcje (i tak przez kolejnych 20 poniedziałków :) ).
Do zobaczenia w DNA!
DNA Team: Maciej Aniserowicz, Jakub Pilimon, Jakub Kubryński, Łukasz Szydło
droga.dev | devstyle.pl
P.S. Pamiętaj: niczym nie ryzykujesz! Masz czas aż do końca października na decyzję o ewentualnym zwrocie Programu i odzyskanie 100% pieniędzy. Zależy nam przede wszystkim na Twoim zadowoleniu.
The post DNA: Ruszyła Czwarta Edycja! appeared first on devstyle.pl.
September 4, 2022
Zapraszamy na KONGRES Architektury Oprogramowania!
Dziś Wyjątkowo Excytująca Informacja…
We wrześniu odbędzie się KONGRES Architektury Oprogramowania! Składający się z 7 Mega Fajnych Atrakcji.
Organizujemy tę świetną inicjatywę z Mentorami DNA: Drogi Nowoczesnego Architekta. Kuba Pilimon, Łukasz Szydło i Kuba Kubryński dadzą z siebie wszystko podczas tych wyjątkowych 2 tygodni.
Poniżej znajdziesz wszystkie niezbędne informacje:
Startujemy 19 września 2022! Tego dnia o 20:00 rozpoczniemy Kongres specjalnym LIVEm o Kruszeniu Korpobetonu – czyli jak skutecznie “zarządzać zmianą” w praktyce? Nie tylko architekt powinien to potrafić, a to niezmiernie trudna umiejętność.
Później czekają nas 4 spotkania z cyklu GORĄCE KRZESŁA 🔥! Case study… na żywo! 21, 23, 26 i 28 września.
Na wizji nasi Mentorzy przeanalizują problem, pokażą swoją perspektywę i postarają się wskazać możliwe rozwiązania, trzymając się określonych ograniczeń. To jak konsultacje z Najlepszymi Komandosami Architektury!
Czegoś takiego jeszcze nie było. Spodziewamy się MEGA atrakcyjnych wieczorów!
A co dalej?
Podczas całego Kongresu będzie można dołączyć do odpalanej wtedy przez nas 4. Edycji kultowego Szkolenia DNA: Droga Nowoczesnego Architekta. 27 września zaproszę kilka osób, które ukończyły DNA, by podzieliły się swoimi wrażeniami.
Z kolei 30 września zrobimy Q&A o architekturze oraz o DNA. Wtedy zakończymy też nabór do 4. Edycji DNA i podzielimy się swoimi wrażeniami z Kongresu.
Co TY musisz zrobić, aby w tym wszystkim uczestniczyć?
ZAREJESTROWAĆ się, za darmo.
I tylko tyle.
Żal nie skorzystać, co nie?
No to SIUP!
== REJESTRUJĘ się na KONGRES Architektury Oprogramowania! » ==

Klikaj, podaj swój adres i….
Do zobaczenia!
LINKI do wszystkich tych spotkań znajdziesz w niedługiej przyszłości na mailu po rejestracji.
To będą Bardzo Gorące dwa tygodnie!
Pozdrawiamy serdecznie,
Maciej Aniserowicz, Kuba Kubryński, Łukasz Szydło, Kuba Pilimon
DNA Team
The post Zapraszamy na KONGRES Architektury Oprogramowania! appeared first on devstyle.pl.
April 20, 2022
I LOVE DEV: Ogłaszamy Wielki Powrót ❤️ DEV konferencji!
Mieliśmy w tym roku kilka ogłoszeń. I właśnie wjeżdża kolejne! Tym razem będę się streszczał: odpalamy swoją świetną programistyczną konfę! I robimy co w naszej mocy, żeby to wydarzenie na długo zostało w Twojej pamięci ;).
Jako devstyle mamy doświadczenie w organizowaniu fajnych wydarzeń programistycznych. Gale Finałowe konkursów Daj Się Poznać, dwie edycje devstyle speakers, współorganizacja kilku wydań Programistoku, wieloletnia współpraca z 4Developers to tylko kilka wybranych aktywności na tym polu.
I… stęskniliśmy się bardzo za eventami! Za mięsistymi prezentacjami, za dyskusjami i za networkingiem. Zdecydowaliśmy, że chyba już wszyscy jesteśmy gotowi na Wielki Powrót DEV-konferencji. Tym razem jednak chcieliśmy podnieść poprzeczkę i weszliśmy w partnerstwo. Partnerstwo nie byle jakie, bo to o czym dzisiaj piszę tworzymy z prawdziwymi EKSPERTAMI w temacie eventów. Połączyliśmy bowiem siły z firmą sprawny.marketing – organizatorami świetnych wydarzeń marketingowych I LOVE MARKETING, znanych ze świetnej oprawy, logistyki i merytoryki.
Podział obowiązków był właściwie naturalny: oni odpowiadają za organizację, a my za to na czym znamy się najlepiej – czyli agendę / merytorykę! I zapowiada się to wszystko bardzo smakowicie…
Zapraszamy Cię serdecznie na konferencję I ❤️ DEV!
Która odbędzie się 17 maja 2022 w Multikinie Złote Tarasy (Warszawa)
To wydarzenie pełne wiedzy, doświadczenia, pasji i networkingu! Skupiamy się na tym, by każdy element naszego eventu był TOP. Idziemy w JAKOŚĆ, a nie ILOŚĆ.
Nie znajdziesz u nas kilkunastu ścieżek i setki prelegentów.
Oferujemy Ci szóstkę najlepszych.
Na jednej, starannie przemyślanej ścieżce.
W klimatycznej sali kinowej.
Takiego line-upu nie znajdziesz nigdzie indziej! Zagłębimy się w różne aspekty programistycznego rzemiosła tak, by każdy kwadrans spędzony na I ❤️ Dev był świetnie wykorzystany.
Nie zabraknie też możliwości zadania pytań, prowadzenia ciekawych dyskusji i spotkania innych pasjonatek i pasjonatów.
Nie może Cię zabraknąć! Jak GDZIEŚ pojechać to… właśnie tu!
Sprawdź agendę i szczegóły wydarzenia na stronie:
TUTAJ OBADAJ STRONĘ
I ❤️ LOVE . DEV
I KUP WEJŚCIÓWKĘ! »
Kogo zobaczymy? Wystąpią przed nami:
Sylwana Kaźmierska – specjalistka od sztucznej inteligencji.Tomasz Ducin – mistrz zaawansowanego frontendu (i Mentor w ANF).Andrzej Krzywda – ojciec polskiego IT ;) szczycący się tym, że pracuje tylko z legacy.Sławek Sobótka – polski kapłan Domain Driven Design.Jakub Mrugalski – topowy ekspert security.Jakub Pilimon – programista, architekt, komandos do zadań specjalnych; Mentor w kultowym DNA i Legacy Fighter.SZTOS 🔥, co nie?
I na koniec jeszcze…
TUTAJ Odklikaj się na naszym FEJBUKOWYM WYDARZENIU! »
Do zobaczenia w maju w Warszawie! :)
Pozdrawiamy serdecznie,
Maciej Aniserowicz z ekipą devstyle & I Love Dev
The post I LOVE DEV: Ogłaszamy Wielki Powrót ❤️ DEV konferencji! appeared first on devstyle.pl.
January 2, 2022
Legacy CONF 2022 – darmowa konferencja!
Hej hej w nowym roku! Przybywam z dobrymi wiadomościami :).
Tadamtadam, już wkrótce (od 10 do 28 stycznia) odbędzie się konferencja online, poświęcona w całości pracy z kodem legacy. Zgromadzimy tam świetną ekipę, bezpośrednio związaną z projektem LegacyFighter.
Co zrobić, by wziąć udział? To proste! Wpadaj na stronę, zarejestruj się i… obserwuj maila :). Będę tam przysyłał zaproszenia na wystąpienia.
== Zarejestruj się bezpłatnie TUTAJ na Legacy CONF » ==
A będzie co oglądać, zobacz!
Sławek Sobótka “Logiczne podejście do logiki w kodzie”Mariusz Gil “5 mitów dookoła EventStormingu”Kuba Pilimon “Czego uczy nas system Legacy?”Panel dyskusyjny wszystkich Mentorów Legacy FighterPlanujemy też 1 lub 2 praktyczne case studies z omówieniem konkretnych dużych systemów!Legacy Fighter Q&ATa świetna ekipa to albo Mentorzy LegacyFighter + goście!
Ważna uwaga: warto być na żywo, bo nagrania z tych wystapień będą dostępne tylko dla Uczestników LegacyFighter, którzy wykupią dostęp do szkolenia.
Do zobaczenia!
The post Legacy CONF 2022 – darmowa konferencja! appeared first on devstyle.pl.
September 21, 2021
Prowadzisz bloga? Oto Twoje zbawienie: Marketing Calendar by CoSchedule
W moim życiu social media mają dwie strony: prywatną i marketingową. Prywatnie: utrzymuję kontakt ze znajomymi i dzielę się swoimi refleksjami. Marketingowo: promuję “devstyle” i wszystko co z tym terminem związane.
Fair enough.
Manual vs autoDo niedawna wychodziłem z założenia, że wszystko w socialach “powinno” być robione ręcznie, by nie utracić autentyczności i szczerości. A to… generowało wiele problemów. Życie stało się o wiele prostsze, gdy wykrystalizował się wspomniany wyżej podział.
Prywatnym zastosowaniom sociali nie zależy na zasięgach, na “odpowiednim czasie publikacji”, na numerkach i klikach. Tam pierwsze skrzypce grają emocje. U mnie tak działa większość mojego Twittera, prywatne konto na fejsie (od niedawna) i Instagram. W skrócie: na “prywatnych” socialach nie zarabiam. I do nich faktycznie pięknie stosuje się zasada: serducho i własne palce, a nie bezduszny automat.
Ale druga strona medalu to sociale “zawodowe”. Fanpage, “promocyjna” część Twittera czy LinkedIn… one służą do promowania treści i docierania do jak największej rzeszy odpowiednich osób. To część pracy. A im mniej pracy, tym lepiej, c’nie? ;). No właśnie. I tu jest social pogrzebany.
W przypadku devstyle stało się to o tyle istotne, że od kilku miesięcy z “bloga” zrobił się “portal” i nasze teksty są teraz pisane przez wiele par rąk, a nie tylko moje. Jeszcze do niedawna nastawiałem budzik (sic!), żeby o odpowiedniej godzinie puścić na fanpage informację o nowym tekście. Uwiązany do komputera, przyciśnięty do wirtuala, skuty cyber-kajdanami.
Oczywiście wiem, że da się “zaschedulować” treści na przyszłość. Ale – w przypadku facebooka czy LinkedIn – dopiero, gdy post na WordPress jest już opublikowany, co mocno sprawy komplikuje.
I wtedy, na białym rumaku, dumnie wjeżdża…
CoScheduleO CoSchedule dowiedziałem się ze SmartPassiveIncome (a z Patem z SPI miałem niedawno zaszczyt porozmawiać przed mikrofonami :) ). Najpierw temat olałem, ale w końcu coś mnie tknęło i… postanowiłem sprawdzić.
Jest to narzędzie do “ogarniania” sociali. Miałem wcześniej romans z dwoma innymi programami tego typu, ale się nie polubiliśmy. Dlatego też tym razem podchodziłem do sprawy bardzo sceptycznie. Ba, umówiłem się nawet na skype z zaoceanicznym supportem, żeby porozmawiać o tym rozwiązaniu, zanim się w nie zaangażuję!
Porozmawiałem. Poznałem. Zaangażowałem się. Uzależniłem się. Wykupiłem i zostałem klientem. A teraz polecam dalej.
Dlaczego? Poniżej pokażę trzy funkcje, z których korzystam regularnie. CoSchedule oferuje ich więcej, ale mi na razie wystarcza tylko to. Zaoszczędziłem dzięki temu masę czasu. I – co dla mnie ostatnio bardzo ważne – odzyskałem odrobinę wolności.
Zobaczcie:
Po pierwsze: promocja postówNapisanie tekstu to jedno. Potem trzeba go puścić na WordPressa i… wypromować, oczywiście! Tej części nigdy nie lubiłem. Skakania po oknach, pilnowania odpowiednich godzin… Eh.
Teraz? CoSchedule daje plugin do WordPressa, dzięki któremu kilkoma kliknięciami planuję wysyłkę informacji o tekście na wszystkie swoje kanały:
Siup! Bezpośrednio z widoku edycji posta.
Ale to nie wszystko, bo… po co tyle klikać? Można zapisać sobie szablon (social template), który jednym klikiem zaplanuje wiadomości w odpowiednich godzinach na różne kanały:
Potem tylko wypełniam teksty (moje własne placeholdery: txt1, txt2 i tags) i… i już! Gotowe!
Oczywiście mógłbym zrobić “scheduling” z każdej platformy bezpośrednio. I tak robiłem przez lata. Jednak z tym wiąże się problem, o którym już nieco wspomniałem: to (na Facebooku i LinkedIn) działa tylko dla już opublikowanych treści! Te portale zaciągają i cache’ują sobie graficzną reprezentację linków. WordPressowy szkic zwróci im 404. Z CoSchedule ten problem znika! Lowe Wielkie za to.
Zresztą w podobny sposób planuję promocję odcinków VLOGa, publikowanych tylko na YT, nie na WordPress. Upload i schedule na YouTube to jedno. Ale od razu, w tym samym momencie, mogę zaplanować informacje wysłane na wszystkie social-kanały. A potem bezpiecznie wyłączam komputer i wszystko magicznie dzieje się samo.
W poszukiwaniu utraconego czasu? To właśnie tutaj!
Bardzo, bardzo wielka oszczędność czasu. A z moich raportów finansowych można łatwo wywnioskować, że z chęcią kupuję czas.
Co więcej: dzięki CoSchedule mogę dać dostęp do tych kanałów innym osobom, na przykład mojej asystentce Ani, bez nadawania uprawnień na każdej platformie po kolei (czego robić nie chcę)! Idealny flow: autor pisze tekst, Andrzej robi korektę i redakcję, Ania ogarnia resztę (graficzka i promocja w socialach), a ja biję brawo. Perfect!
Bonus: headline analyzerPo polsku działa to średnio, ale jeśli piszesz po angielsku, to może Ci się spodobać:
U mnie wszystko jest po polsku, więc nie korzystam, ale pokazuję jako ciekawy bajer.
Po drugie: kalendarzNawet pisząc w pojedynkę czasami mieszałem terminy różnych publikacji. Wrzucałem na Google Calendar wszystkie potrzebne informacje: kiedy co i gdzie ma być opublikowane. I to działało pięknie… dopóki nie nastąpiła jakakolwiek zmiana. Bo kto zsynchronizuje kalendarz z rzeczywistością? Ano nikt.
Nikt? A jednak ktoś! Proszę bardzo:
To jest jeden z tygodni lipca. Tu są wszystkie WordPressowe teksty i wszystkie “marketingowe” wiadomości na sociale. I tutaj synchronizacja już działa! Jeśli przesunę wiadomość na inny dzień lub inną godzinę, to ona faktycznie zostanie opublikowana w tym nowym terminie.
A dlaczego niektóre elementy się wyróżniają? Bo najechałem myszką na jedną z wiadomości. A wtedy CoSchedule pokazuje, które inne pozycje są z nią powiązane w jednej “social kampanii“. W tym przypadku widać (dość agresywną) kilkudniową kampanię promującą mój post o Gicie.
Zajarałem się, gdy to zobaczyłem. I jaram się do dziś.
Po trzecie: republikacjaBlog założyłem ponad dekadę temu. Przez ten czas pojawiło się prawie tysiąc tekstów. W trakcie doszedł podcast i VLOG. Jest tego MASA.
I… i to się marnuje. Przynajmniej te uniwersalne, ponadczasowe teksty/odcinki. Jasne, w swoim czasie każda treść dotarła przed oczy i uszy X Czytelników, Widzów i Słuchaczy. Ale to grono ciągle rośnie! A mało kto chodzi po archiwach.
Z pomocą przychodzi ReQueue, czyli mechanizm ponownej promocji już istniejących treści. Wybieram tekst, klikam “OKEJ”, a CoSchedule robi resztę, czyli automatycznie publikuje te teksty w odpowiednich godzinach na wybranych przeze mnie kanałach. Pilnując jednocześnie, by zbytnio nie spamować, trzymając się ustalonych limitów X wiadomości dziennie per kanał.
Oczywiście są inne narzędzia, które także to robią. Ale tutaj mam wszystko “w pakiecie”. A dodatkowo – co się niezmiernie przydaje – NOWE teksty mogą zostać automatycznie dodane do wybranych grup republikacji.
Efekt?Od -nastu (czy -dziesięciu?) miesięcy liczba UU na devstyle.pl krążyła wokół 20-25tys. Były wzloty i spadki, ale to taka średnia.
Natomiast lipiec 2018… o proszę, w porównaniu do poprzedniego miesiąca:
W lipcu uruchomienie CoSchedule nie było jedyną zmianą. Oprócz tego pojawiło się więcej tekstów niż zwykle dzięki nowym świetnym Autorom i Autorce. Więcej niż zwykle wydałem też na reklamy na FB.
ALE! Nawet jeśli CoSchedule nie przełożyło się na ten ruch bezpośrednio (choć jestem przekonany, że tak było), to na pewno pomogło w osiągnięciu takiego wyniku.
Czego nie używam?Napisałem, że CoSchedule oferuje więcej niż potrzebuję. Co zatem olewam? Przynajmniej dwa duże ficzery:
Pierwszy z nich to analityka. Pewnie powinienem nad tym przysiąść, ale… no cóż, po prostu mi się nie chce.
Drugi to “project management”/kolaboracja. Od tego mam inne narzędzia, które sprawdzają się bardzo dobrze.
Więc?Tak jak pisałem, narzędzia używam od około dwóch miesięcy. Jest rewelacyjne i zostaję przy nim. Polecam także Tobie!
Ku jawności: w tekście znajduje się link afiliacyjny: http://devstyle.pl/coschedule. Będzie mi bardzo miło, jeśli zapoznasz się z tą usługą korzystając właśnie z niego. Ale nawet jeśli olejesz mój link i pójdziesz bezpośrednio na stronę produktu, to i tak będę zadowolony. I… jestem przekonany, że Ty też.
Pozdro!
Procent,
Taki Dojrzały Marketer Że Hej
The post Prowadzisz bloga? Oto Twoje zbawienie: Marketing Calendar by CoSchedule appeared first on devstyle.pl.
June 24, 2021
Modelowanie domeny przy użyciu TypeScripta
W sieci krąży mnóstwo postów i prezentacji opisujących różne typy wbudowane TypeScripta, a także, jak na ich podstawie zbudować dziesiątki innych typów. To zaś, jakie problemy chcemy dzięki nim rozwiązać, to zupełnie inny temat. Ważniejszy, bo determinuje, PO CO mielibyśmy w ogóle dane rozwiązanie zastosować. I na tym się w poniższym tekście skupimy. Zapraszam do lektury :)
TypeScript jest jedną z tych technologii, o których sporo się mówi od dobrych kilku lat, a w ostatnim czasie w szczególności. Używamy go głównie po to, aby błędy, które mogłyby wystąpić w trakcie działania aplikacji (runtime), wyłapać wcześniej, w kompilacji (compile-time). Dzięki temu na produkcji ląduje mniej błędów. Ale dodatkowo, jeśli odpowiednio wcześnie weźmiemy to pod uwagę, będzie nam łatwiej refaktorować kod oraz poruszać się po projekcie, którego nie znamy. W efekcie łatwiej nam będzie go utrzymywać – i na tym się skupmy.
Wyobraźmy sobie, że pracujemy nad systemem, w którym wykonywanych jest wiele transakcji płatniczych. Może system do fakturowania, może bank, może pożyczki – w każdym razie hasła takie jak „pieniądz”, „kwota”, „opłata” i im podobne pojawiają się bardzo często. Zarówno na poziomie API, jak i w warstwie wizualnej.
Dość wcześnie trzeba przyjąć jakąś reprezentację dla typu określającego pieniądze. Potrzebujemy go jakoś zamodelować. Pierwszy pomysł, jaki może nam przyjść do głowy – to siup! – number. Rozwiązania proste są o tyle wartościowe, że mają niski próg wejścia i ludziom powszechnie łatwo je zrozumieć, dodatkowo zmniejszamy ryzyko tak zwanego overengineeringu, czyli przekomplikowania rozwiązania. Rozwiązania proste warto brać pod uwagę od samego początku, bo często są zwyczajnie good enough.
Budujemy więc nasz system w oparciu o pieniądze, które zamodelowaliśmy jakonumber. Tu amount: number, tam debt: number, discount: number. Po paru latach wystąpień number jest kilkaset, jeżeli nie więcej. Przychodzi do nas Product Owner i mówi, że nasz produkt doskonale sobie radzi na rodzimym rynku, więc czas na podbój rynków zagranicznych. W związku z czym przyjęta implicite waluta (PLN) musi zostać określona explicite w każdej funkcjonalności. Jeżeli na przykład sprzedajemy towary w Polsce, ale wysyłamy je do Czech – i Czesi chcą płacić w koronach czeskich – to siłą rzeczy musimy uwzględnić dwie waluty. To taka dość oczywista sprawa. „No to ile to będzie kosztować story pointów?” – pyta PO. Cisza trwa niepokojąco długo. „Przecież to jest dodanie jednego pola”. Cisza się przedłuża. „Na pewno w jednym sprincie nie zdążymy”. „Ok, a potraficie w przybliżeniu oszacować, jak duże jest to zadanie?”
Generalnie numbernie jest w stanie przechować informacji o walucie – i wszystkie miejsca, gdzie występuje, trzeba zaktualizować tak, aby była nie tylko kwota, ale i explicite waluta. Jest może kilkadziesiąt miejsc do zmiany, może kilkaset, a do tego jeszcze gros testów, w sumie ciężko to oszacować… Przeszukiwanie codebase po frazie number daje kiepskie wyniki, bo number, czyli liczba reprezentuje liczbę sztuk, jakie klient zamówił, albo ilość powtórzeń transakcji, albo kolejny numer na liście (na przykład pozycja na fakturze). I informacja, że number występuje 1591 razy, niewiele nam mówi.
Dodatkowo, gdybyśmy hipotetycznie namierzyli te wszystkie miejsca, gdzie występuje number, i dodali obok drugie pole currency to zaczęłaby się jazda, bo obok amount: number trzeba by dodatkowo obsługiwać currency. Wygodniej byłoby zareprezentować hajs jako jeden spójny byt, tzw. Value Object. Problem w tym, że jest o te dwa lata za późno, wszędzie mamy number, bo za wczasu nie pomyślelismy o odpowiedniej abstrakcji. Nie zamodelowaliśmy naszej domeny.
Primitive ObsessionSytuacja, w której się znaleźliśmy, powszechnie nazywana jest primitive obsession, czyli „znam typy prymitywne, nie bawię się w abstrakcje, bo po co, więc tłukę stringi i numbery”. Nie opakowuję tych danych w dodatkowe (nadmiarowe?) typy, bo przecież liczba to liczba. Prawda?
Takie podejście jest kłopotliwe z co najmniej dwóch powodów. Po pierwsze, jeśli reprezentujemy hajsiwo jako number, to na hajsiwie możemy wykonywać te same operacje co na każdej liczbie. Hajs można oczywiście dodawać i odejmować. A czy można go mnożyć? 10 zł można pomnożyć przez 10. Ale czy 10 zł można pomnożyć przez 10 zł i mieć 100 zł^2? Mnożenie przez liczbę a mnożenie przez pieniądz to inne operacje. Jest to potencjalny błąd, który – odpowiednio skonfigurowany – system typów może nam łatwo wychwycić. Część z Was pomyśli: „no przecież ja takich błędów nie popełniam”. Widząc mnożenie pieniądza przez pieniądz pewnie szybko wychwycimy, że coś jest nie halo w kodziku. Natomiast jeśli pracujemy na istniejącym, działającym produkcyjnie kodzie… i potrzebujemy zaaplikować zmianę, która dotknie wielu miejsc, przejrzenie dokładnie wszystkich miejsc, których zmiana dotyka, mogłoby zająć za dużo czasu. Ostatecznie zmieniamy więc kodzik i patrzymy, czy się kompiluje; i patrzymy, czy testy przechodzą. Mamy mieszane uczucia, nie ufamy tej zmianie – mimo że po to są testy i kompilacja, aby im ufać. No bo ta zmiana taka krzywa, może być różnie. Chyba na czas rilisa wezmę wolne…
Drugi kłopot z primitive obsession to pozbawianie kodu znaczenia. Jeśli widzę funkcję process(value: number), to wiem tyle, że to liczba. A w przypadku process(value: Money)wiem już trochę więcej. Odpowiednio długo czytając okoliczny kod, dojdziemy pewnie do tego, że chodzi o pieniądze. Tylko czy nie lepiej sobie od razu ułatwić, skoro jakiś typ trzeba i tak wpisać?
Jakie zatem jest rozwiązanie? Pamiętajmy, żeby nie przeinżynierować. Spróbujmy od stworzenia zwykłego aliasu typu:
type Money = numberI w miejscach, gdzie definiujemy pieniądze, stosujemy od tej pory Money. To wszystko. Narzut na kod jest niemalże zerowy. Definiujemy jedno źródło prawdy (znane wszem wobec Single Source of Truth) i – chyba najważniejsze – nadajemy temu typowi nowe, osobne znaczenie. Osobne niż prymityw number.
Patrząc zaś od strony technicznej – co się zmieniło?
jeśli będziemy chcieli zmienić typ reprezentujący pieniądz, zmieniamy jego 1 deklarację (bo teraz istnieje!) i patrzymy, w ilu miejscach kod wybucha. Liczba błędów kompilacji jest mierzalna, dodatkowo kompilator pokazuje czarno na białym linijki, którymi się trzeba zaopiekować. Możemy chociażby wyrywkowo oszacować, czy docelowe zmiany będą raczej powierzchowne, czy inwazyjne. Low hanging fruit.niestety, nadal możemy mnożyć pieniądze, potęgować, całkować i kto wie co jeszcze.co gorsza, liczba nóg krowy jest kompatybilna z naszym typem Money. Jedno number i drugie number. Alias typu w TypeScripcie to jedynie „alias”, czyli nowa nazwa, a pod spodem istnieje ten sam typ co wcześniej.Być może ta niewielka zmiana – mały krok dla człowieka, ale wielki skok dla projektu ;) – jest póki co wystarczający. I nie chcemy iść dalej. Sztuka w architekturze polega między innymi na tym, aby rozwiązywać faktyczne problemy, a nie domniemane. I żeby wskutek naszych zmian rachunek zysków i strat był na plusie. Zmiana, w której narobimy się jak dzikie osły – a korzyść jest niewielka – niestety powinna zostać wycofana. Człowiek jest emocjonalnie związany z potem i znojem, wysiłkiem, jaki władował w kod… tylko że ten kod dopiero wyląduje na produkcji i inni będą go musieli utrzymywać. Miejmy z tyłu głowy, że to, co piszemy, inni będą musieli rozkminiać. I to wielokrotnie. Czasami coś musi być skomplikowane, bo tak działa biznes (essential complexity), a czasami jest to przeinżynierowane – i można to, i tamto zwyczajnie usunąć (accidental complexity). Tak więc, zanim poszarżujemy dalej, zanim zainwestujemy w kolejne rozwiązanie, przeanalizujmy, jakie są jego koszty i zyski, zanim się w nie władujemy.
Fajnie, fajnie. Tylko ta myśl, że mogę przypisać liczbę nóg krowy do typu type Money = number, jakoś nie daje spokoju…
Structural TypingA gdyby tak stworzyć nowy typ (lub interfejs)? To jeden z pierwszych pomysłów, jakie przychodzą do głowy, zwłaszcza jeśli mamy doświadczenie z technologiami takimi jak Java czy .NET. Tworzę nowy interfejs/klasę i – dopóki go nie rozszerzam – jest on niekompatybilny z całą resztą typów. Taka cecha systemów typów nazywa się „typowanie nominalne”: jeśli dwa interfejsy (lub dwie klasy) są niekompatybilne, jeśli nie są w żaden sposób „spokrewnione”, to znaczy ani nie implementują wspólnego interfejsu, ani jedna po drugiej nie dziedziczy. Programiści backendowi początkujący w TS-ie często zakładają, że skoro TS bazuje na typowaniu statycznym, tak jak Java – to może kompatybilność interfejsów (i cała mechanika polimorfizmu) również będzie podobna do tej Javowej. A skoro o tym mówimy, to najpewniej tak nie jest :)
Bardzo istotną i szczególną cechą TypeScripta jest jego cel. W wielkim skrócie sprowadza się do: „weźmy JavaScript taki, jaki jest – ładny czy brzydki, nowy czy stary, nieważne – i opakujmy go typami, aby wychwytywać błędy”. Wśród kilku punktów wyszczególnionych w TypeScript Design Goals możemy przeczytać między innymi: „utrzymanie runtime’owego zachowania JavaScriptu”. To bardzo ważny punkt – strategicznym założeniem TS-a jest to, że ma NIE zmieniać sposobu, w jaki działa JavaScript. To znaczy ma nie zmieniać semantyki, ma nie dodawać nowych JS-owych konstruktów (wyjątków jest bardzo mało, na przykład dekoratory), nie tworzyć własnego środowiska uruchomieniowego, i tym podobne. Ogólnie – ma być bezpieczną, type-safe wersją JavaScriptu, która w dodatku kompiluje się do niemalże takiego samego JavaScriptu, jaki sami byśmy napisali – tyle że bez typów. I jeśli programiści używali JS-a w konkretny sposób, to TS powinien co najwyżej wyłapać błędy związane z typami, ale nie wymuszać innego podejścia, paradygmatu. A na koniec ma zniknąć :) (fully erasable).
Weźmy pod uwagę to, że w JS-ie nie ma interfejsów – i nic nie zapowiada, aby się miały pojawić. W zamian powszechnie stosowany jest duck-typing, który najczęściej sprowadza się do „macania” obiektu, czy przypadkiem może akurat ma zdefiniowaną jakąś metodę – jeśli tak, to wywołaj, a nie – to olej. Albo zdefiniowane jakieś property – jeśli tak, to bierzemy – a jeśli nie, to – „proszę, tu masz wartość domyślną”. Sprawdzanie, czy property istnieje, jest w JavaScripcie czymś powszechnym i oczywistym. W JavaScripcie, czyli w runtime. A skoro typy znikają (fully erasable), to w runtime nie ma już informacji o typach, dopóki nie stosujemy czarnej magii refleksji, która ma sens jedynie dla bibliotek/frameworków. Więc skoro informacji o typach, dostępnej w czasie kompilacji, w runtime już nie ma – i w JavaScripcie powszechne jest bezpieczeństwo typów oparte o duck typing – i TypeScript ma zachować semantykę JS-a – to o co należałoby się oprzeć? :)
TypeScript wśród swoich celów ma również typowanie „strukturalnie”, co stoi w opozycji do typowania „nominalnego”. W typowaniu strukturalnym kompilatora nie interesuje, skąd się interfejs wziął… czy to interfejs, czy typ… czy może klasa… czy coś po sobie dziedziczy, rozszerza, przecina, i tak dalej. Ważne są jedynie struktury i ich zawartość – bez względu na „pochodzenie” i „nazwy” tych struktur (łac. nominal – nazwa). Jeśli oczekuję, że dostanę obiekt, który ma metodę then() -> Promise, to przyjmę nawet papieża – o ile ten implementuje tę metodę.
Czy to oznacza, że OOP, jakie znamy, nie ma w TS-ie zastosowania? Oczywiście, że MA zastosowanie, jak najbardziej. Tylko nie na podstawie pochodzenia interfejsów, a na podstawie struktur. Polimorfizm nie jest oparty o implementowanie interfejsu, a o to, czy wymagana zawartość struktury jest spełniona, czy nie. Na przykład w poniższym kodzie:
interface Runnable {run(): void
}
const queue: Runnable[] = []
function schedule(runnable: Runnable){
queue.push(runnable)
}
funkcja schedule oczekuje typu Runnable jako parametru. Ale możemy przekazać jej każdy obiekt, który będzie implementował funkcję run(). Na przykład:
const john = {name: "John",
run(){
console.log("biegam sobie")
}
}
schedule(john);
też się nada. „Na dobre i na złe”. Jak widać, obiekt nie musi być instancją klasy ani nawet zawierać anotacji typu (jeśli jej nie ma, to uruchomi się wnioskowanie – i tak czy siak wyrażenie otrzyma jakiś typ). Wreszcie, co jest istotne, typowanie strukturalne ma zastosowanie zarówno do typów obiektowych, jak i typów prymitywnych.
W konsekwencji wszystkie poniższe typy są ze sobą w pełni kompatybilne:
type Money = numbertype Debt = number
type Balance = number
Możemy nie tylko tworzyć wiele aliasów typów, wielorakie interfejsy, klasy, możemy je implementować, dziedziczyć po nich…, cuda wianki. TypeScripta obchodzi jedynie zawartość danego typu, danej struktury – i tylko na tej podstawie określi kompatybilność. Tak więc javowo-dotnetowe tworzenie osobnych interfejsów po to, aby zablokować kompatybilność, ma się do TS-a trochę nijak, bo to inna bajka.
Określiliśmy fundamentalne reguły, którymi rządzi się kompatybilność typów.
Mając tę bazę możemy już budować…
…konkretne rozwiązania!Czas wcielić w życie wiedzę o kompatybilności typów: skupimy się na budowaniu konkretnych rozwiązań z wykorzystaniem TypeScripta.
UWAGA! Właśnie trwa nabór do 1. Edycji Programu ANF: Architektura Na Froncie!
Zapraszamy serdecznie, tam nauczysz się frontendu na Poziomie PRO!
Zapisy zamykamy 30 czerwca o 21:00!
Wpadaj do nas TUTAJ »
 Opaque Types
Opaque TypesJeśli chcemy zablokować przypisanie zwykłego number do naszego specyficznego (to znaczy bardziej doprecyzowanego) typu Money, to możemy w ten sposób skorzystać z typowania strukturalnego:
type Money = number & { readonly type: unique symbol }Nasz alias składa się teraz z dwóch elementów: number jako taki oraz sztuczny dodatek na potrzeby kompilatora, czyli { readonly type: unique symbol }. Z chęcią poruszyłbym temat semantyki przecięć typów oraz ich reguł kompatybilności, natomiast to zasługuje na osobny wpis (i będzie omawiane podczas Architektury na Froncie). Najistotniejsze dla nas jest teraz to, że chcąc przypisać jakiekolwiek wyrażenie do typu Money, to wyrażenie musi „spełniać wymagania” nie tylko typu number, ale i { readonly type: unique symbol }. I tego drugiego nie spełni nic poza innymi wyrażeniami Money – a o to nam dokładnie chodzi! Ta druga składowa to sztuczny obiekt z polem readonly type, którego wartością jest unikalny symbol… Brzmi grubo – nie ma co ukrywać, zwiększa próg wejścia zrozumienia kodu. W rozwiązaniu ważne jest to, że ten drugi człon jest tylko do wglądu dla kompilatora – w runtime wcale go nie będzie. Takie troszkę oszustwo, ale działa:
type Money = number & { readonly type: unique symbol }declare let m: Money
declare let n: number
m = n // ❌ Type 'number' is not assignable to type 'Money'.
n = m // ✅
Ufff… już nie można przypisać liczby nóg krowy do Money. Dlaczego? Bo liczba (nóg krowy) nie zawiera tego dodatkowego elementu { readonly type: unique symbol }. W runtime żadne z wyrażeń go nie zawierają, ale w czasie kompilacji liczy się to, co widzi kompilator. Szczegóły tego zjawiska omówimy w Architekturze na Froncie. Kompilator widzi, że typ Money to number plus coś jeszcze. Teraz, aby stworzyć zmienną Money, potrzebujemy trochę oszukać kompilator. Jeśli podstawimy zwykłą liczbę, kompilator przecież tego nie przepuści:
const money: Money = 99.99 // ❌ Type 'number' is not assignable to type 'Money'.Musimy zatem wymusić na kompilatorze, że w niektórych miejscach my „wiemy lepiej” niż on:
const asMoney = (value: number) => value as Moneyconst money = asMoney(99.99) // ✅ Money
Z byciem mądrzejszym od kompilatora (czyli poprawianiem wyników jego analiz) trzeba uważać, bo często możemy nie mieć racji i w konsekwencji błędy nie będą wychwytywane przez kompilator. To jest temat rzeka i również będzie omawiany w Architekturze na Froncie. Tutaj jednak zakres zmian jest bardzo mały i kontrolujemy go. Osiągnęliśmy to, że nie możemy typu number przypisać do Money. Pozostaje jednak otwarta kwestia dozwolonych operacji, bo nie tylko potęgowanie pieniędzy jest dozwolone: money ** money, ale i operacje na styku Money i number: money + 10. A to dlatego, że zablokowaliśmy jedynie przypisanie, a nie operatory.
Value ObjectsMożemy pójść o krok dalej i zastosować pochodzący z DDD pattern Value Object. Jest to rozwiązanie nieco bardziej inwazyjne, bo wymaga więcej kodu i w deklaracji, i w miejscach użycia. Opiera się on na stworzeniu obiektu reprezentującego wartość. I jedynie wartość. Będzie z założenia niemutowalny – bo „10 złotych” jako wartość nie zmienia się w czasie (nominalnie inflację pomijamy :P). Nie będzie też miał swojej tożsamości (ID), czyli na przykład pieniądz.
class Money {private constructor(
private value: number
){}
static from(value: number){
return new Money(value)
}
add(another: Money){
return new Money(this.value + another.value)
}
multiply(factor: number){
return new Money(this.value * factor)
}
valueOf(){
return this.value
}
}
Dla uproszczenia nie uzupełniliśmy go o walutę. W razie potrzeby należy dodać nowe pole plus obsłużyć je potencjalnie we wszystkich metodach. I to jest cała idea Value Object – obsługa struktury danych zostaje zamknięta (zaenkapsulowana) w strukturze danych – i nie wycieka do komponentu, kontrolera czy gdziekolwiek indziej. Traktujemy wartość razem z jej regułami jako spójną całość.
Zerknijmy, jak nasz VO radzi sobie w akcji:
const m = _Money.from(99.99) // deklaracjam + 4 // ❌ Operator '+' cannot be applied to types 'Money' and 'number'.
const n: number = _m // ❌ is not assignable to type 'number'
const sum = _m.add( _Money.from(1.23) ) // ✅ Money
const product = _m.multiply( 2 ) // ✅ Money
Całkiem nieźle. Zabezpieczyliśmy niechciane podstawienia oraz niechciane operacje. Jednocześnie umożliwiliśmy mu tylko te operacje, które w naszym biznesie są dozwolone.
Nie sposób nie zauważyć, że to rozwiązanie w porównaniu z aliasami typów jest znacznie bardziej inwazyjne. Kiedy warto je stosować? O tym zaraz.
Aplikacja, domena i typyWracając do tematu rozszerzenia pieniędzy w całej aplikacji tak, aby obejmowała również różne waluty, prędzej czy później pojawia się pytanie: kiedy należy stosować aliasy, opaque types, VO, a kiedy jechać na prymitywach? Jednoznacznej odpowiedzi nie ma, natomiast można wyróżnić kilka wskazówek-pytań, które pomogą nam określić, czy pozostajemy z typem prymitywnym, czy lepiej zamodelować to jako osobny typ, explicite:
czy to, co otypowaliśmy jako string , to faktycznie dowolny string? Na przykład imię firstName: string – wprawdzie istnieje skończona liczba imion (przynajmniej w Polsce), ale bez przesady – imię to po prostu tekst, który nie ma swojego dodatkowego znaczenia. Albo komentarz comment: string – to po prostu tekst. Ale na przykład stanowisko pracownika – position? Być może pierwotnie będzie to po prostu string z wartościami JavaScript Developer. Ale jeśli pracujemy nad systemem kadrowym, w którym chcemy domenowo rozróżniać Senior od Junior,to z czasem stanowisko może przestać być stringiem i stać się obiektem z kilkoma polami – { title: string, level: ENUM }. I alias będzie jak znalazł. czy element, który chcemy otypować, funkcjonuje samodzielnie w naszym biznesie ? Przykładowo w aplikacji operującej na finansach pieniądz pojawia się wielokrotnie i nie jest po prostu liczbą taką, jak każda inna. Bo ma swoje dodatkowe znaczenie W aplikacji HR-owej umiejętność JavaScript to nie musi być po prostustring. JavaScript, który ktoś zna od roku – i JavaScript, który ktoś trzaska od 10 lat w wielu projektach – to nie to samo. I prędzej czy później biznes będzie chciał to rozróżnić. Choćby dlatego, że kontraktornia, podsyłając CV kandydatów „grubemu globalnemu graczowi”, chce posortować malejąco kandydatów według skomplikowanych kryteriów. A kandydatów jest sporo.Generalnie, nie jesteśmy w stanie z góry przewidzieć, które typy w przyszłości się zmienią. Rozsądne zatem wydaje się zacząć z aliasem typu tam, gdzie ma on samodzielne biznesowe znaczenie (na przykład pieniądz) – i rozszerzać go w przyszłości, kiedy pojawi się wymaganie biznesowe. Lub jeśli programiści zauważą, że często zdarzają się bugi, które na poziomie TypeScripta dałoby się rozwiązać. Ta mała inwestycja – ale zaaplikowana odpowiednio wcześnie – kosztuje bardzo mało, a zapewnia elastyczność. Nie mówiąc o łatwiejszym rozumieniu kodu – jeśli w kodzie jest Money, a nie number, to nie tylko więcej wiem o tych danych, czytając kod – ale także łatwiej mi wyszukać wystąpienia tego typu.
Miejmy zawsze z tyłu głowy, że wypuszczenie kodu na produkcję to dopiero początek potencjalnie długiego życia tego kodu. Jeśli pracujemy w agencji interaktywnej i tworzymy apkę reklamową z czerwoną ciężarówką słodkiego napoju, pędzącego na tle zimowej scenerii – to po świętach nasza apka zostanie zaorana i świat o niej zapomni. Długoterminowe inwestowanie w jakość… nie ma sensu. Ale jeśli tworzymy systemy biznesowe, to ktoś będzie je z większym lub mniejszym bólem utrzymywał. Perspektywa łatwego tworzenia kodu – i perspektywa łatwego jego późniejszego utrzymania – to często dwie różne perspektywy. Implementowanie aliasu zamiast prymitywa może nam nie zrobić wielkiej różnicy w momencie kodowania. Ale jeśli będziemy chcieli zmienić go kilka lat później, to dopiero wtedy się okaże, czy task kosztuje jeden tydzień czy dwa miesiące.
PodsumowanieOmówiliśmy, po co, kiedy, kiedy nie i w jaki sposób można stworzyć alias typów reprezentujących dane domenowe. Poruszony tu temat to zaledwie wierzchołek góry lodowej możliwości TypeScripta :).
Aby wejść głębiej w zagadnienia type-safety, projektowania aplikacji i wielu innych wątków frontendowych, zapraszam na Architekturę na Froncie.

The post Modelowanie domeny przy użyciu TypeScripta appeared first on devstyle.pl.
Maciej Aniserowicz's Blog

- Maciej Aniserowicz's profile
- 22 followers

