
Maciej Aniserowicz's Blog, page 3
October 21, 2020
Raport finansowy – lipiec 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!


October 13, 2020
5 dni Darmowej Konferencji o Testach: SmartTesting Conf!
5 Ekspertów. 5 dni. 5 tematów. Jeden motyw przewodni: TESTY ✅
October 11, 2020
NAJobszerniejsze wprowadzenie do Event Stormingu. Z przykładem!
W dwóch poprzednich postach opowiedziałem o tym, jak poniosłem porażkę przy swoim projekcie. Opisałem też model biznesowy i jego założenia. Teraz nadszedł czas, by na zgliszczach tamtego nieudanego przedsięwzięcia zbudować coś sensownego. A przy okazji podszkolić techniczne umiejętności.
Zarówno w tym, jak i w dwóch kolejnych postach zajmiemy się Event Stormingiem. Weźmiemy przedstawioną wcześniej domenę, bo nadal wydaje mi się ona bardzo fajna do ćwiczeń, i zaczniemy ją modelować.
Event Storming – co to i na co to komu?
Możliwe, że mignęło Ci kiedyś przed oczami zdjęcie, na którym ludzie zgromadzeni w jednym pokoju przyklejali kolorowe karteczki do ściany. Może to brzmieć jak kolejny fancy warsztat z umiejętności miękkich, których przecież prawdziwy programista czy programistka się brzydzą, bo „twardym trzeba być, a nie miętkim, Stefan”. Niech Cię to jednak nie zwiedzie! Event Storming jest potężnym narzędziem służącym do modelowania procesów biznesowych. W zasadzie nie tylko biznesowych. Krążą legendy o osobach planujących tą techniką swój ślub. ;)
A dlaczego karteczki na ścianie? Bo tak jest najprościej. Na początek Twoim jedynym zadaniem jako uczestnika jest zapisywanie na karteczkach zdań w czasie przeszłym (zdarzeń biznesowych) i przyklejanie ich na ścianie. Dzięki temu uwidaczniamy braki w procesie biznesowym i uzupełniamy wiedzę uczestników. Dlatego ważne jest też, żeby w warsztacie brali udział eksperci domenowi, osoby techniczne, biznesowe oraz wszystkie inne, które mogą przedstawić jakąś interesującą perspektywę.
Nieocenioną pomocą jest obecność facylitatora. Taka osoba ma w swoim narzędziowniku zestawy heurystyk (zaraz poznasz kilka z nich) pozwalających sprawnie przeprowadzić taki warsztat i pomagających wyjść uczestnikom ze schematów myślowych. Poza tym często ma ona doświadczenie w tworzeniu różnego rodzaju systemów informatycznych, przez co dostrzega wzorce, które można zastosować, aby rozwiązać konkretne problemy.

Samą technikę Event Stormingu zapoczątkował w 2013 roku Alberto Brandolini i cały czas bardzo aktywnie ją promuje. Jest on także w trakcie pisania książki, którą można zakupić na Leanpub. Na ten moment jest ukończona w 70%, ale już na tym etapie stanowi doskonałe źródło wiedzy o tej technice. Znajdziesz tam wiele wskazówek, jak taki warsztat przeprowadzić.
Na polskim poletku też mamy się czym pochwalić: na przykład Mariusz Gil jest rozchwytywany na arenie międzynarodowej i bardzo mocno popularyzuje te warsztaty. Był też gościem 110 odcinka DevTalk, w którym opowiadał właśnie o Event Stormingu. Mariusz odegra jeszcze istotną rolę w tym cyklu postów, ale o tym trochę później.

Event Storming dzięki synchronizacji wiedzy uczestników pozwala na ujednolicenie wizji i zrozumienie całego procesu oraz na zidentyfikowanie problemów, które w nim występują. Wiedza na temat podejmowanych decyzji nie powinna być skupiona w rękach tylko jednej osoby lub małej grupy. To bardzo ważne, ponieważ często w ramach firmy proces biznesowy jest rozbity na wiele komponentów. Konkretne zespoły zazwyczaj interesują się decyzjami dotyczącymi wyłącznie „ich kawałka”. Takie lokalne modelowanie bez wiedzy o pozostałych częściach domeny może mieć negatywny wpływ na całość procesu biznesowego. Event Storming wychodzi temu naprzeciw i pozwala zrozumieć, jak proces wygląda z dalszej perspektywy. Dzięki temu możemy znaleźć globalne rozwiązania problemów.
Istnieje tu jeszcze jeden bardzo ważny aspekt – jako osoby piszące kod mamy mnóstwo bibliotek, usług, dobrych praktyk czy wzorców projektowych, z których na co dzień korzystamy. Innymi słowy, koncentrujemy się głównie na rozwiązaniach, pomijając szukanie wzorców na poziomie samego problemu. Dlatego też kluczowe dla programistów jest zrozumienie domeny, w której pracują. Zwracano na to uwagę już w latach 70. ubiegłego stulecia przy badaniach nad kohezją. Jeśli chcemy pisać dobry kod, musimy rozumieć proces i model biznesowy, a tego nie dowiemy się lepiej od nikogo innego jak od biznesu i ekspertów domenowych. My za to ze swoją wiedzą techniczną możemy pomóc w odpowiedziach na pytania, jak konkretne problematyczne kawałki procesu zautomatyzować lub usprawnić dzięki dostępnym technologiom. Podsumowując: warto rozmawiać.
Jak przebiega warsztat? Najpierw mamy Big Picture Event Storming, podczas którego chcemy zobaczyć proces biznesowy z lotu ptaka. Sam Big Picture jest podzielony na pewne fazy i w oryginalnym przepisie na pizzę – Brandolini używa takiej metafory – znajduje się 6 składników:
Rozpoczęcie – przedstawienie celów warsztatu, szybka prezentacja uczestników. Informacje o tym, jak będzie wyglądał warsztat. Opcjonalna rozgrzewka.
Chaotyczna eksploracja – zapisywanie i przyklejanie na ścianie pomarańczowych karteczek ze zdarzeniami biznesowymi. Zdania na karteczkach powinny być sformułowane w czasie przeszłym.
Wprowadzenie osi czasu – prawdopodobnie karteczki znalazły się w różnych miejscach, dlatego w tej fazie istotne jest, aby poukładać je tak, jak występują w czasie. Możliwe, że zobaczymy, gdzie są duplikaty albo gdzie takie same koncepty opisywane są innym językiem. Nieraz stosuje się tu również technikę zwaną reverse narrative. Polega ona na tym, że wybiera się zdarzenie z końca całego procesu i sprawdza, czy mamy wszystkie wcześniejsze zdarzenia, które są dla niego istotne. Takie przejście procesu od końca pozwala znaleźć ogniwa, które pominęliśmy.
Ludzie i systemy – zdarzenia zazwyczaj nie występują w izolacji i ich źródłem mogą być konkretna osoba, dział, wewnętrzny albo zewnętrzny system.
Problemy i okazje – do tego momentu na Event Stormingu pojawiły się pewnie również karteczki, które oznaczają miejsca, co do których uczestnicy nie mogli dojść do konsensusu. Miejsca takie nazywamy hotspotami. W aktualnej fazie zastanawiamy się, czy nie występuje tu jakiś problem albo wręcz przeciwnie – okazja.
Wybór problemu – z racji tego, że najczęściej nie możemy zająć się wszystkimi problemami i okazjami, jakie odkryliśmy, przeprowadzamy głosowanie.
Poszczególne fazy można by rozbić na mniejsze fragmenty, ale tutaj nie będziemy się tym zajmować. Sam Brandolini zachęca do eksperymentowania i wypracowywania własnych podejść. Zwraca też uwagę na to, że w zależności od tego, czy będziemy modelować istniejący proces, nową funkcjonalność czy proces dla start-upu, liczba faz i ich forma mogą się różnić. Jeśli chcesz wejść głębiej w temat, zachęcam do przeczytania książki Brandoliniego. My też zaprezentujemy tu własną wersję warsztatu. Zobaczymy, jaka pizza z tego wyjdzie. (Oby nie z ananasem).
Po Big Picture następuje Process Level Event Storming, w którym przechodzimy już na poziom rozwiązania. Skupiamy się na mniejszych kawałkach i je modelujemy. Pojawia się tu koncept komend, modeli odczytu i reguł biznesowych.
Na koniec zostaje Design Level Event Storming – tworzymy docelowy model, który będziemy przenosić 1:1 do kodu. Jest to część, w którą angażują się głównie osoby techniczne. Wprowadzamy też pojęcie agregatu. Można zauważyć tutaj kolejną wielką zaletę Event Stormingu: jak doskonale wiesz, najtrudniejszą rzeczą w programowaniu jest nazywanie rzeczy, a z racji tego, że mamy tu wszystko na karteczkach, to łatwiej nam zmieniać nazwy na papierze niż w kodzie.

Jeszcze raz podkreślam, że przed warsztatem należy określić jego cel. Ściana pokryta karteczkami to pomocna wizualizacja procesu, a nie cel sam w sobie. Celem może być na przykład przyspieszenie procesu, jego automatyzacja lub po prostu lista problemów, jakie w procesie występują.
Przemilczana ciekawostka
Od dość wczesnej fazy kciuki za mój projekt trzymał sam Andrzej Krzywda – idealne połączenie programisty, przedsiębiorcy i marketera. Między innymi dzięki niemu zobaczyłem, jak istotne jest myślenie marketingowo-sprzedażowe i dlaczego warto rozmawiać z biznesem. Ze swoim ówczesnym podejściem pewnie wyklepałbym tego SaaSa, wrzuciłbym info na Hacker News, Product Hunt, może na Twittera, zrobiłbym – tak na chybił trafił – kampanię reklamową na Facebooku, w którą pewnie wtopiłbym trochę kasy, a następnie bym usiadł i zapłakał, bo „nie ma żadnego ruchu”.
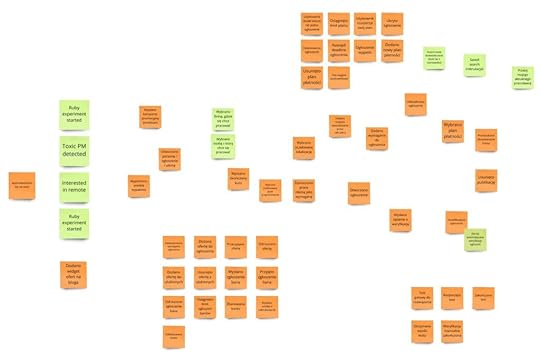
Pewnego dnia spotkaliśmy się z Andrzejem w jego domu pod lasem i podczas rozmowy padł pomysł, żeby zrobić na szybko coś na kształt Event Stormingu. Nie trzymaliśmy się wtedy żadnej agendy, faz ani konwencji dotyczącej kolorów karteczek. Wzięliśmy, co było pod ręką, i zaczęliśmy zapisywać zdarzenia. Rezultat dosłownie kilku minut pracy widzisz poniżej:

Skupiłem się na tym, co dzieje się w samym systemie, czyli że ogłoszenie zostało stworzone albo że została złożona oferta. Andrzej przyjął zupełnie inną taktykę: szukał, co musiałoby się wydarzyć w życiu programisty, żeby zechciał skorzystać z naszego narzędzia. Tym sposobem na drzwiach pojawiły się takie zdarzenia jak „Toxic PM detected”, „Ruby/Elixir experiment started” czy „Interested in remote”.
Przy okazji wpadliśmy na pomysł filtrowania zdarzeń i informowania o nich ludzi z HR. Przykładowo: CTO szukający dobrych leadów może być zainteresowany, gdy do systemu wpadnie ogłoszenie zawierające informację o ukończeniu przez programistę programu Droga Nowoczesnego Architekta. ;) Takie funkcjonalności mogłyby być dodatkowo płatne. Kolejnym pomysłem było to, że skoro blog Arkency czytają też ludzie, którzy szukają kogoś do swojego zespołu, to DevMountJob mógłby udostępniać widget użyty na tym blogu. Pokazywałby programistów szukających pracy, których profil byłby zgodny z tym, o czym jest czytany post.
Pamiętam, że po tamtym spotkaniu miałem lekki mind blown. Jako osoba wyłącznie techniczna tak naprawdę nie myślałem, jak później swój produkt sprzedać i przyciągać potencjalnych odbiorców.
Nasza forma warsztatu
Sam autor metody mówi o tym, że jest to dość luźna forma i dużo zależy od facylitatora, który operuje zestawem narzędzi i dobiera odpowiednie z nich w zależności od grupy i celu warsztatu. Częstym błędem jest traktowanie Event Stormingu jako zamkniętej koncepcji. Przykładowo: jeśli w swojej domenie masz coś, co jest ważne i na pewno powinno się znaleźć na ścianie, to zwizualizuj to według własnego klucza. Bardzo fajnym i niestandardowym rozwiązaniem jest mapowanie konkretnych operacji bazodanowych (INSERT/UPDATE/DELETE/SELECT) na karteczkach w różnych kolorach.
Fazami, które zawsze występują w Big Picture, są chaotyczna eksploracja i wprowadzenie osi czasu. Zdecydowaliśmy się je wykorzystać przy modelowaniu domeny na potrzeby tej serii postów. Piszę tutaj „my”, ponieważ zaprosiłem do tego przedsięwzięcia trzy osoby. Każda z nich ma ogromne doświadczenie zarówno w programowaniu, jak i w ustalaniu wymagań biznesowych w różnych projektach. Oto one:
Mariusz Gil – mówiłem, że odegra tu jeszcze pewną rolę. ;) Jest związany z branżą IT od ponad dwudziestu lat. Pasjonuje się projektowaniem i implementacją systemów o złożonych wymaganiach biznesowych, machine learningiem i rozwiązaniami, które można przełożyć na realną wartość biznesową dla klienta. Mariusz to zwierzę konferencyjne, a przy tym niesamowicie sympatyczna osoba, więc jeśli zagadasz do niego na konferencji, nie zdziw się, że za chwilę będziecie rozmawiać o czymś zupełnie niezwiązanym z IT, a Ty będziesz mieć wrażenie, że znacie się nie od dziś. Mariusz opowiadał o Event Stormingu w 110 odcinku DevTalka, a w 51 o PHP.
Łukasz Szydło – jeden z mentorów w programie DNA. Doświadczony programista, sprawdzony w bojach architekt, a także konsultant, trener i ekspert Bottega IT Minds. Spotkacie go na wielu konferencjach, gdzie chętnie dzieli się swoją nieocenioną wiedzą. Z Łukaszem znam się od początku swojej programistycznej kariery. Miałem i nadal mam ogromne szczęście z nim współpracować przy okazji różnych projektów. Łukasz był też gościem 101 i 45 odcinka DevTalk.
Andrzej Krzywda – założyciel rozpoznawanej w kręgach Ruby na całym świecie firmy Arkency, organizator konferencji wroclove.rb, prelegent, autor książek, bloger, leśniczy polskiego IT. ;) Jako gorliwi zwolennicy OOP lubimy ponarzekać na jego aktualny stan, choć nasze spojrzenia i preferencje mogą się lekko różnić. Robimy to podczas górskich wycieczek, a czasami specjalnie tylko po to się zdzwaniamy. Andrzeja możesz posłuchać w 35 i 7 odcinku DevTalka albo w całej serii DevTalk Trio.
Z racji tego, że wszyscy się znamy, nasze spotkania miały bardzo luźną formę. Dzięki nim mogliśmy wymienić się myślami i doświadczeniami w tych naznaczonych piętnem izolacji czasach. A teraz Ty na tym skorzystasz, bo dostaniesz crème de la crème z naszych pogadanek.
Przystępując do warsztatu, miałem pewne założenia i wymagania biznesowe, o których pisałem w poprzednich postach. Chciałem, żeby projekt miał jak największą wartość edukacyjną, dlatego byłem gotowy na rozkminy różnych pomysłów. Mieliśmy wspólną bazę, ale biorąc pod uwagę odrębne doświadczenia każdego z nas, byłem świadomy, że oryginalne założenia samego projektu mogą się całkowicie zmienić. To jest jedna z zalet Event Stormingu – w zależności od tego, jak bardzo jesteśmy otwarci na zmiany, warsztat może prowadzić do odkrywania zmian, usprawnień czy optymalizacji nawet na poziomie całej organizacji.
Przy aktualnym klimacie, chcąc nie chcąc, wszystkie warsztaty musiały się przenieść online. O ile jeszcze niedawno padały pytania, czy praca zdalna w ogóle ma sens, o tyle teraz w wielu przypadkach jest ona normą. Okazuje się, że dzięki dostępnym narzędziom wychodzi to bardzo dobrze. Wykorzystaliśmy Miro, które ostatnimi czasy stało się pewnego rodzaju standardem. Jeśli chcesz bardziej zgłębić temat „zdalności” takich warsztatów, to Mariusz rozmawiał o tym z Alberto Brandolinim w swoim podcaście Better Software Design.
Teraz już zabieramy się do samego warsztatu.
No to lecim!
Przed spotkaniem wysłałem chłopakom opis domeny i wrzuciłem na naszą wirtualną ścianę design interfejsu użytkownika. Dzięki temu mieliśmy referencję pod ręką, jeśli chciałem coś wytłumaczyć na przykładzie.
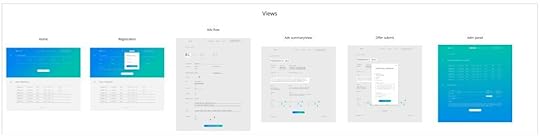
Następnie zaczęliśmy zapisywać zdarzenia, które mieliśmy w głowach. Pojawiły się też pytania, co sprowokowało kilka dłuższych dyskusji. Wszystkie pomysły w tej fazie postanowiliśmy dorzucić jako dodatkowe zielone karteczki. Jest to dobra praktyka, bo pozwala uwolnić w ludziach kreatywność. Po pewnym czasie nasza tablica wyglądała tak:
Można tu zauważyć grupy eventów, które są dodane w „kupie”. Jest to efekt funkcjonalności „bulk mode” w Miro. To bardzo przydatna rzecz w początkowej fazie, bo pozwala każdemu w szybki sposób dodać kilka zdarzeń. Wpisujesz je jako kolejne wiersze w nowym okienku, a następnie dodajesz wszystkie na tablicę. Podczas stacjonarnego warsztatu odpowiadałoby temu zapisanie wszystkich zdarzeń najpierw na bloczku z karteczkami.
Potem poukładaliśmy zdarzenia w czasie, bo były rozrzucone losowo. Tę fazę zacząłem próbą opowiedzenia, co się po kolei dzieje. Przy okazji mogłem dorzucić trochę informacji o wymaganiach, co wywołało nową dyskusję. Wyszedł nam dzięki temu fajny koncept. Mariusz zaprezentował heurystykę, którą nazywa „fantastyczną czwórką” lub „0, 50, 100, 150”. O co chodzi? Gdy mamy zdarzenie opisujące coś zero-jedynkowego (0% – coś się nie wydarzyło; 100% – coś się wydarzyło), to warto pomyśleć, czy nie ma tam innych możliwości – na przykład że coś się wydarzyło „nie w pełni” (50%) albo nawet „za bardzo” (150%). W naszym przypadku takim zdarzeniem było „Zaakceptowano wymagania ogłoszenia”. Ja podchodziłem do tego dość radykalnie: albo rekruter zaakceptował wymagania programisty, albo nie. Mariusz jednak zastanawiał się, czy nie ma tutaj jednak miejsca na negocjację warunków, czyli coś w stylu „niestety nie możemy zaproponować owocowych czwartków, ale za to mamy słodyczowe środy”. Zapisaliśmy to wstępnie jako pomysł do rozważenia w późniejszym etapie, bo wydawało się to ciekawym podejściem.
Dobrym przykładem na użycie tej heurystyki są procesy, w których mamy do czynienia z opłatami. Intuicyjnie rozpatrujemy to w kategorii zapłacono lub nie, ale tak naprawdę często mogą tu wystąpić cztery scenariusze (np. w przypadku zwykłego przelewu, gdy ręcznie uzupełniamy kwoty):
0% – nie opłacono,
50% – opłacono część (możliwe, że przez pomyłkę, i musimy poprosić klienta o zapłacenie reszty),
100% – opłacono całość,
150% – opłacono więcej, niż trzeba (wtedy musimy rozpocząć proces zwrotu nadpłaty).
W końcu udało nam się ułożyć wszystkie zdarzenia w odpowiedniej kolejności. Na razie nie usuwaliśmy duplikatów ani niepotrzebnych zdarzeń. Zaznaczyliśmy jednak pewne mniejsze, w miarę autonomiczne procesy, które mogą sugerować istnienie potencjalnych subdomen. Pomoże nam to podczas Process Level Event Stormingu koncentrować się na konkretnych kawałkach.
Na tym etapie nasza tablica prezentowała się następująco:
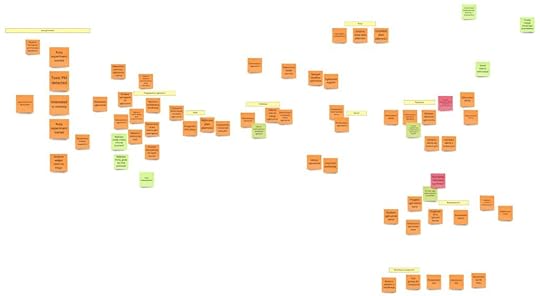
Pierwsza sesja w telegraficznym skrócie:
W kolejnym kroku oddzieliliśmy kreską wyniki pierwszej sesji. Pod nią umieściliśmy tylko te zdarzenia, które faktycznie zmieniają coś w systemie, czyli zdarzenia domenowe. Przy okazji pozbyliśmy się duplikatów. Postanowiliśmy też nie przenosić niżej zdarzeń z funkcjonalności, których nie chcemy od razu implementować w nowym systemie. Jako wynik otrzymaliśmy uporządkowany przyszły proces biznesowy, z uwzględnieniem pierwotnego modelu biznesowego.
Przy usuwaniu „niepotrzebnych” zdarzeń pomocna okazała się kolejna heurystyka, która też ma związek z liczbą 4, ale tym razem chodzi o typy zdarzeń. Mariusz podpowiedział nam, że na swoich sesjach wyróżnia 4 poziomy zdarzeń:
zdarzenia środowiskowe – występują poza systemem, w świecie rzeczywistym. Przykładowo: zdarzenie wejścia do sklepu przez klienta. Często są mało istotne z perspektywy warsztatu, ale pomagają złapać kontekst,
zdarzenia interfejsowe – poziom UI. Klikamy, ale jeszcze nie zatwierdzamy, czyli nie nastąpiła żadna zmiana w systemie. Przykładowo: gdy wybieramy plan płatności na interfejsie użytkownika, ale możemy jeszcze to zmienić dowolną liczbę razy, dopóki ostatecznie nie potwierdzimy wyboru,
zdarzenia infrastrukturalne – odnoszą się do rzeczy technicznych i nie mają wpływu na system: „Podbito metrykę”, „Wrzucono event na Kafkę”,
zdarzenia domenowe – serce Event Stormingu i to nimi właśnie powinniśmy się zajmować.
Temat bardzo fajnie rozwija Mariusz w swoim krótkim video na ten temat.
Uzbrojeni w powyższe założenia i wiedzę, wzięliśmy się do roboty, a wynik naszej pracy możesz podziwiać poniżej:
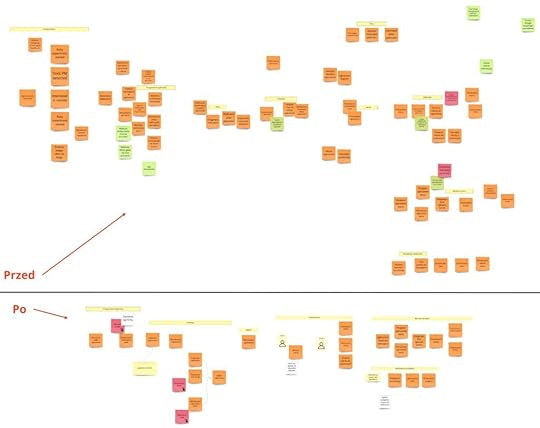
Jak widzisz, część pod kreską różni się znacząco od tej nad nią, dlatego też w szczegółach opowiem, co i dlaczego się zmieniło. Będziemy szli od lewej do prawej.
Na początek pozbyliśmy się zdarzeń związanych z tzw. lead generation:

W wersji pod kreską ich nie ma, ponieważ jeśli chodzi o sam system (przynajmniej ten do zamieszczania ogłoszeń), to nie zmieniają one jego stanu. Są one natomiast punktem wejścia, czymś, co się wydarzy przed korzystaniem z niego, czyli lejkiem. Będę to niesamowicie istotne dla działu marketingu. Możemy teraz pomyśleć o innej małej apce, która będzie mierzyła poziom Twojego wypalenia albo zadowolenia z aktualnej pracy. Jeśli wykryłaby, że przydałaby Ci się zmiana pracy, mogłaby kierować prosto do DevMountJob. ;)
Zwróć uwagę na ciekawą redukcję zdarzeń:
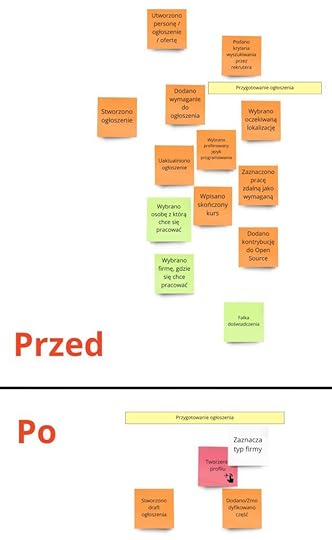
Tutaj widzisz w akcji heurystykę, o której wcześniej wspomniałem. Pozbyliśmy się zdarzeń interfejsowych. Zauważ, że „Wpisano ukończony kurs” czy „Zaznaczono pracę zdalną jako wymaganą” tak naprawdę nie zmieniają w żaden sposób naszego systemu. Wykonujemy wtedy wyłącznie operacje na interfejsie użytkownika. Innymi słowy, pracujemy na drafcie – dopiero przygotowujemy ogłoszenie. Wszystkie te zdarzenia możemy zgromadzić po prostu pod jednym „Dodano/zmodyfikowano część ogłoszenia”. Właściwie moglibyśmy się pozbyć całkowicie tych dwóch zdarzeń związanych z draftem, jeśli nie zdecydowalibyśmy się trzymać go w systemie. Jednak chcemy to robić, żeby dać użytkownikowi możliwość powrócenia do przerwanego procesu tworzenia ogłoszenia. W przeciwnym razie cały proces mógłby się rozpoczynać dopiero w momencie opłacenia (zatwierdzenia) ogłoszenia. Wszystko to, co byłoby wcześniej, moglibyśmy wykonywać tylko w ramach UI.
Tak oto przechodzimy w naszym procesie do płatności i publikacji ogłoszenia:

Tutaj też nastąpiła pewna zmiana. Już w opisie domeny i wymagań dało się zauważyć, że nie miałem tego dobrze przemyślanego. Dlatego przy porządkowaniu zdarzeń wywiązała się dłuższa rozmowa dotycząca opcji. Łukasz zauważył, że skoro ogłoszenia są zamieszczane na pewien czas, to może zamiast wymyślać teraz plany płatności, moglibyśmy sprzedawać okresy, na jakie ogłoszenie jest dostępne na portalu. Spodobało nam się to. W pierwotnym zamyśle płatne plany różniłyby się głównie liczbą ogłoszeń, jaką użytkownik mógłby zamieszczać. Doszliśmy jednak do wniosku, że w praktyce użytkownicy nie umieszczaliby więcej niż jedno ogłoszenie w tym samym czasie. Za to dokupienie kilku dodatkowych dni poza podstawowym darmowym okresem może wydawać się kuszące. Tak narodził się pierwszy model biznesowy. Pozbyliśmy się całej część związanej z planami abonamentowymi. Tym samym wszystkie związane z nimi zdarzenia mogły zostać pominięte. Przy okazji zaznaczyliśmy tutaj hotspot, żeby mieć na względzie to, że były wokół tego dyskusje.
Początkowo miałem też pomysł, że po wystawieniu ogłoszenia nie będzie można go zmieniać. Powód? Mogłoby to prowadzić do pewnej niespójności: programista po dostaniu kilku ofert mógłby zmienić swoje wymagania i chociaż stare oferty nie spełniałyby nowych wymagań to w systemie widniałyby jako takie, które je spełniają. Jednak przechodzenie ogłoszenia w tryb „tylko do odczytu” zaraz po jego publikacji byłoby zupełnie niepraktyczne. Ludzie popełniają błędy i głupotą byłoby kazać im zakładać nowe ogłoszenie, kiedy zdarzyłaby się jakaś literówka. Dlatego też pierwszym pomysłem było dodanie możliwości zmiany ogłoszenia przez X minut po publikacji, dlatego na karteczce znalazło się zdarzenie „Upłynął czas edycji ogłoszenia”. Ostatecznie jednak doszliśmy do tego, że przecież rekruter akceptuje warunki programisty na dany moment, dlatego też w głowach pojawił się zarys „snapshotu”, czyli oferty złożonej do konkretnych wymagań. Tym samym wspomniane zdarzenie przestało istnieć na nowej tablicy.
Tak oto płynnie przeszliśmy do procesu negocjacji czy też ofertowania:
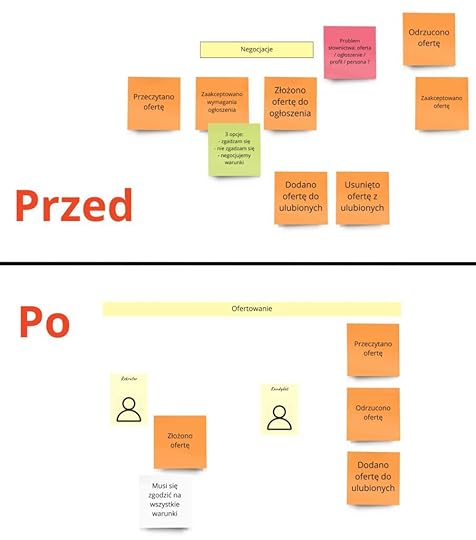
Tutaj wystarczy wspomnieć, że ostatecznie biznes nie zdecydował się wspierać konceptu negocjacji warunków, co zaznaczyliśmy notatką.
Zostały nam jeszcze tylko dwa mniejsze procesy do omówienia: banowanie rekruterów i weryfikacja umiejętności kandydata. Warto zauważyć, że umieściliśmy je najpóźniej na osi czasu, ale tak naprawdę każdy z nich może wystąpić w dowolnym momencie całego procesu biznesowego. Nieraz warto to zaznaczyć jakąś notacją. My tego nie zrobiliśmy.
Przejdźmy do banowania:
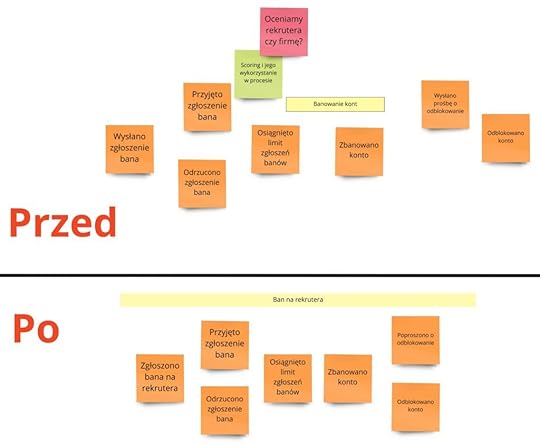
Możesz zauważyć, że zmieniło się wyłącznie słownictwo – nazwy dwóch zdarzeń:
„Wysłano zgłoszenie bana” zmieniliśmy na „Zgłoszono bana na rekrutera”.
„Wysłano prośbę o odblokowanie” przeszło w „Poproszono o odblokowanie”.
Słowo „wysłano” sugeruje formę czynności. Tutaj chodziło nam o wysłanie żądania HTTP z jakiegoś formularza. W praktyce jednak nie powinniśmy się zamykać na inne opcje. Dlaczego nie rozważyć przykładowo zgłaszania banów przez maila, telefonicznie, na Slacku czy faksem? Jest to szczegół warty rozpatrzenia, bo otwiera na inne możliwości, o których wcześniej byśmy nie pomyśleli.
Teraz czas na porządki w ostatnim procesie, czyli weryfikacji kandydata:
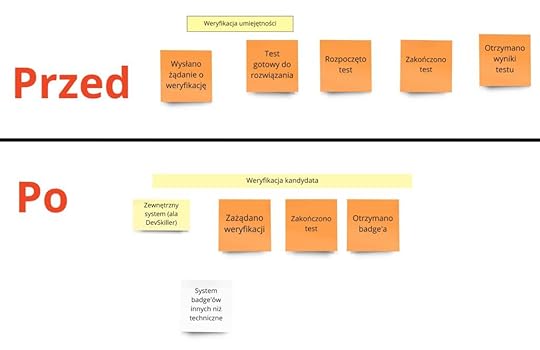
Na potrzeby serii naszych postów zdecydowaliśmy się zawrzeć go w pierwszej wersji produktu, ponieważ wydaje się ciekawym miejscem na pokazanie integracji z zewnętrznym systemem. Może to być też proces mocno rozciągnięty w czasie. Skoro ogłoszenia są zamieszczane anonimowo, chcielibyśmy dać programistkom i programistom szansę wyróżnienia się przez pewnego rodzaju wstępne potwierdzenie umiejętności. Innymi słowy, istniałaby możliwość zdobywania odznak (badge) dzięki integracji z takimi systemami jak DevSkiller. W tym przypadku zdarzenia mówiące o gotowości do testu i samym rozpoczęciu testu zostały usunięte. Stało się tak dlatego, że są to zdarzenia spoza naszej domeny i należą do zewnętrznego systemu, z którym się integrujemy. Z naszej strony chcielibyśmy wyłącznie zainicjować weryfikację, a następnie dostać wynik, gdy dostawca usługi zakończy proces.
To by było na tyle, jeśli chodzi o nasz Big Picture Event Storming. W przyszłym poście zejdziemy już na poziom modelowania konkretnych procesów. Czas na krótkie podsumowanie i małe zadanie domowe.
Podsumowanie
Event Storming mimo prostej formy warsztatu, nie jest sam w sobie prosty. Pobudza do tego, żeby zacząć myśleć trochę inaczej niż kodem czy widokami. Pozwala zacząć myśleć zdarzeniami biznesowymi, które mają realny wpływ na naszą domenę i które coś w niej zmieniają. Dobrym pomysłem jest wzięcie udziału w warsztacie pod okiem kogoś tak doświadczonego jak moi goście. Zachęcam!
A teraz TWOJA kolej!
Mam nadzieję, że dzięki temu postowi wzbudziliśmy Twoje zainteresowanie samą techniką i zachęciliśmy Cię do eksperymentowania. Na koniec oczywiście nie może zabraknąć „zawołania do działania”. ;)
Przeprowadź sam lub – jeszcze lepiej – w grupie Big Picture Event Storming. Skorzystaj z procesu biznesowego, który wspierasz w swojej codziennej pracy. Jeśli nie chcesz albo nie możesz tego zrobić, to napisałem już wystarczająco dużo o moim procesie, żebyś mógł z niego skorzystać!
Na koniec zrób fotę i wrzuć na swoje social media. Otaguj materiał jako #OperationEventStorm i oznacz mnie, abym go nie przeoczył! Znajdziesz mnie na Instagramie i na Twitterze.
Do następnego razu!
The post NAJobszerniejsze wprowadzenie do Event Stormingu. Z przykładem! appeared first on devstyle.pl.
October 8, 2020
Raport finansowy – czerwiec 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!
October 7, 2020
Raport finansowy – maj 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!
September 25, 2020
Raport finansowy – kwiecień 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!
September 24, 2020
Raport finansowy – marzec 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!
September 23, 2020
Raport finansowy – luty 2020
Poniżej znajdziesz raport (finansowy i nie tylko) z mojej działalności. 100% transparentności. Bez tajemnic. Enjoy!
Takie raporty publikuję od maja 2017! Wszystkie znajdziesz TUTAJ!
September 20, 2020
Prowadzisz bloga? Oto Twoje zbawienie: CoSchedule / Blog Calendar
W moim życiu social media mają dwie strony: prywatną i marketingową. Prywatnie: utrzymuję kontakt ze znajomymi i dzielę się swoimi refleksjami. Marketingowo: promuję “devstyle” i wszystko co z tym terminem związane.
Fair enough.
Manual vs auto
Do niedawna wychodziłem z założenia, że wszystko w socialach “powinno” być robione ręcznie, by nie utracić autentyczności i szczerości. A to… generowało wiele problemów. Życie stało się o wiele prostsze, gdy wykrystalizował się wspomniany wyżej podział.
Prywatnym zastosowaniom sociali nie zależy na zasięgach, na “odpowiednim czasie publikacji”, na numerkach i klikach. Tam pierwsze skrzypce grają emocje. U mnie tak działa większość mojego Twittera, prywatne konto na fejsie (od niedawna) i Instagram. W skrócie: na “prywatnych” socialach nie zarabiam. I do nich faktycznie pięknie stosuje się zasada: serducho i własne palce, a nie bezduszny automat.
Ale druga strona medalu to sociale “zawodowe”. Fanpage, “promocyjna” część Twittera czy LinkedIn… one służą do promowania treści i docierania do jak największej rzeszy odpowiednich osób. To część pracy. A im mniej pracy, tym lepiej, c’nie? ;). No właśnie. I tu jest social pogrzebany.
W przypadku devstyle stało się to o tyle istotne, że od kilku miesięcy z “bloga” zrobił się “portal” i nasze teksty są teraz pisane przez wiele par rąk, a nie tylko moje. Jeszcze do niedawna nastawiałem budzik (sic!), żeby o odpowiedniej godzinie puścić na fanpage informację o nowym tekście. Uwiązany do komputera, przyciśnięty do wirtuala, skuty cyber-kajdanami.
Oczywiście wiem, że da się “zaschedulować” treści na przyszłość. Ale – w przypadku facebooka czy LinkedIn – dopiero, gdy post na WordPress jest już opublikowany, co mocno sprawy komplikuje.
I wtedy, na białym rumaku, dumnie wjeżdża…
CoSchedule
O CoSchedule dowiedziałem się ze SmartPassiveIncome (a z Patem z SPI miałem niedawno zaszczyt porozmawiać przed mikrofonami :) ). Najpierw temat olałem, ale w końcu coś mnie tknęło i… postanowiłem sprawdzić.
Jest to narzędzie do “ogarniania” sociali. Miałem wcześniej romans z dwoma innymi programami tego typu, ale się nie polubiliśmy. Dlatego też tym razem podchodziłem do sprawy bardzo sceptycznie. Ba, umówiłem się nawet na skype z zaoceanicznym supportem, żeby porozmawiać o tym rozwiązaniu, zanim się w nie zaangażuję!
Porozmawiałem. Poznałem. Zaangażowałem się. Uzależniłem się. Wykupiłem i zostałem klientem. A teraz polecam dalej.
Dlaczego? Poniżej pokażę trzy funkcje, z których korzystam regularnie. CoSchedule oferuje ich więcej, ale mi na razie wystarcza tylko to. Zaoszczędziłem dzięki temu masę czasu. I – co dla mnie ostatnio bardzo ważne – odzyskałem odrobinę wolności.
Zobaczcie:
Po pierwsze: promocja postów
Napisanie tekstu to jedno. Potem trzeba go puścić na WordPressa i… wypromować, oczywiście! Tej części nigdy nie lubiłem. Skakania po oknach, pilnowania odpowiednich godzin… Eh.
Teraz? CoSchedule daje plugin do WordPressa, dzięki któremu kilkoma kliknięciami planuję wysyłkę informacji o tekście na wszystkie swoje kanały:
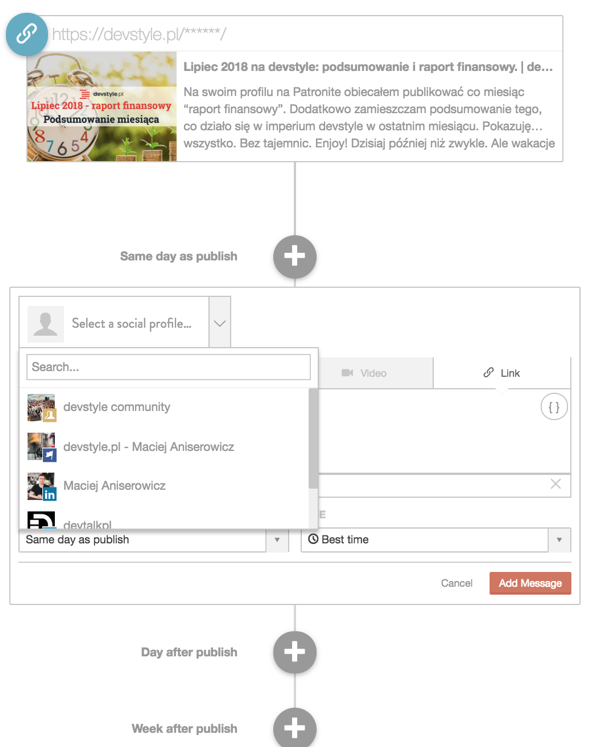
Siup! Bezpośrednio z widoku edycji posta.
Ale to nie wszystko, bo… po co tyle klikać? Można zapisać sobie szablon (social template), który jednym klikiem zaplanuje wiadomości w odpowiednich godzinach na różne kanały:
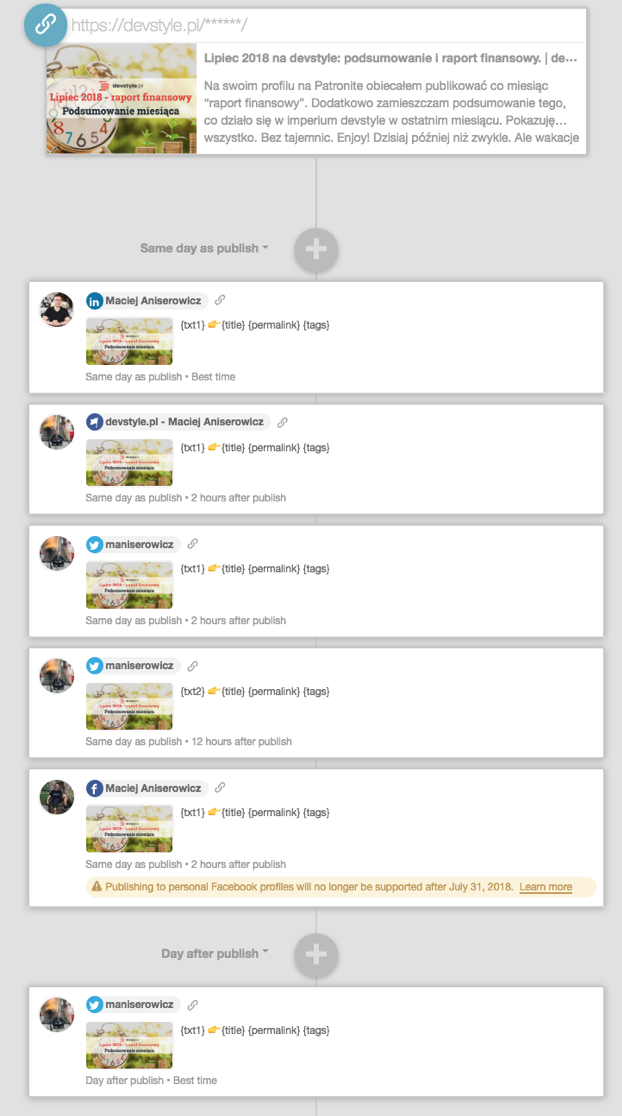
Potem tylko wypełniam teksty (moje własne placeholdery: txt1, txt2 i tags) i… i już! Gotowe!
Oczywiście mógłbym zrobić “scheduling” z każdej platformy bezpośrednio. I tak robiłem przez lata. Jednak z tym wiąże się problem, o którym już nieco wspomniałem: to (na Facebooku i LinkedIn) działa tylko dla już opublikowanych treści! Te portale zaciągają i cache’ują sobie graficzną reprezentację linków. WordPressowy szkic zwróci im 404. Z CoSchedule ten problem znika! Lowe Wielkie za to.
Zresztą w podobny sposób planuję promocję odcinków VLOGa, publikowanych tylko na YT, nie na WordPress. Upload i schedule na YouTube to jedno. Ale od razu, w tym samym momencie, mogę zaplanować informacje wysłane na wszystkie social-kanały. A potem bezpiecznie wyłączam komputer i wszystko magicznie dzieje się samo.
W poszukiwaniu utraconego czasu? To właśnie tutaj!
Bardzo, bardzo wielka oszczędność czasu. A z moich raportów finansowych można łatwo wywnioskować, że z chęcią kupuję czas.
Co więcej: dzięki CoSchedule mogę dać dostęp do tych kanałów innym osobom, na przykład mojej asystentce Ani, bez nadawania uprawnień na każdej platformie po kolei (czego robić nie chcę)! Idealny flow: autor pisze tekst, Andrzej robi korektę i redakcję, Ania ogarnia resztę (graficzka i promocja w socialach), a ja biję brawo. Perfect!
Bonus: headline analyzer
Po polsku działa to średnio, ale jeśli piszesz po angielsku, to może Ci się spodobać:
U mnie wszystko jest po polsku, więc nie korzystam, ale pokazuję jako ciekawy bajer.
Po drugie: kalendarz
Nawet pisząc w pojedynkę czasami mieszałem terminy różnych publikacji. Wrzucałem na Google Calendar wszystkie potrzebne informacje: kiedy co i gdzie ma być opublikowane. I to działało pięknie… dopóki nie nastąpiła jakakolwiek zmiana. Bo kto zsynchronizuje kalendarz z rzeczywistością? Ano nikt.
Nikt? A jednak ktoś! Proszę bardzo:

To jest jeden z tygodni lipca. Tu są wszystkie WordPressowe teksty i wszystkie “marketingowe” wiadomości na sociale. I tutaj synchronizacja już działa! Jeśli przesunę wiadomość na inny dzień lub inną godzinę, to ona faktycznie zostanie opublikowana w tym nowym terminie.
A dlaczego niektóre elementy się wyróżniają? Bo najechałem myszką na jedną z wiadomości. A wtedy CoSchedule pokazuje, które inne pozycje są z nią powiązane w jednej “social kampanii“. W tym przypadku widać (dość agresywną) kilkudniową kampanię promującą mój post o Gicie.
Zajarałem się, gdy to zobaczyłem. I jaram się do dziś.
Po trzecie: republikacja
Blog założyłem ponad dekadę temu. Przez ten czas pojawiło się prawie tysiąc tekstów. W trakcie doszedł podcast i VLOG. Jest tego MASA.
I… i to się marnuje. Przynajmniej te uniwersalne, ponadczasowe teksty/odcinki. Jasne, w swoim czasie każda treść dotarła przed oczy i uszy X Czytelników, Widzów i Słuchaczy. Ale to grono ciągle rośnie! A mało kto chodzi po archiwach.
Z pomocą przychodzi ReQueue, czyli mechanizm ponownej promocji już istniejących treści. Wybieram tekst, klikam “OKEJ”, a CoSchedule robi resztę, czyli automatycznie publikuje te teksty w odpowiednich godzinach na wybranych przeze mnie kanałach. Pilnując jednocześnie, by zbytnio nie spamować, trzymając się ustalonych limitów X wiadomości dziennie per kanał.
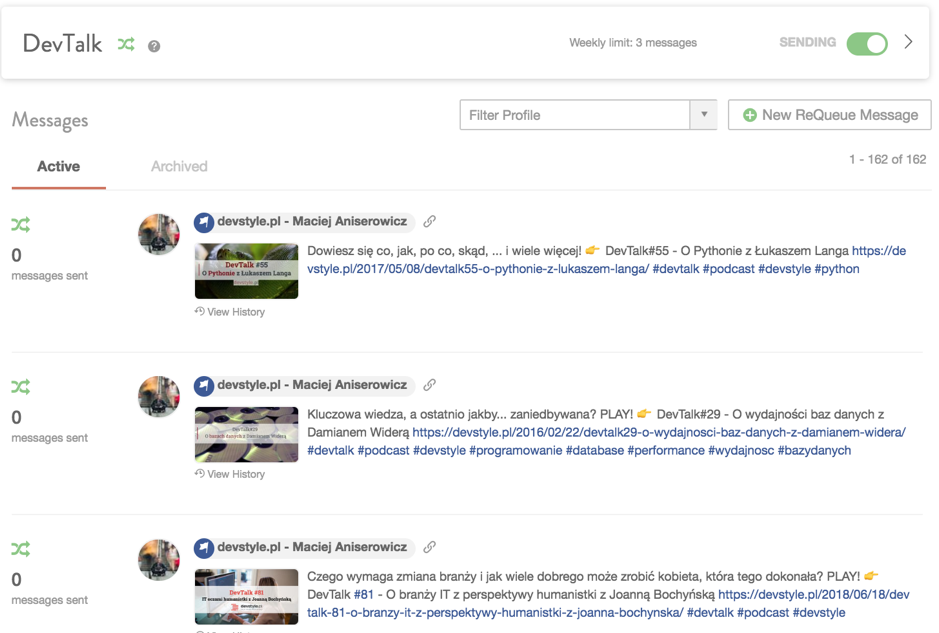
Oczywiście są inne narzędzia, które także to robią. Ale tutaj mam wszystko “w pakiecie”. A dodatkowo – co się niezmiernie przydaje – NOWE teksty mogą zostać automatycznie dodane do wybranych grup republikacji.
Efekt?
Od -nastu (czy -dziesięciu?) miesięcy liczba UU na devstyle.pl krążyła wokół 20-25tys. Były wzloty i spadki, ale to taka średnia.
Natomiast lipiec 2018… o proszę, w porównaniu do poprzedniego miesiąca:

W lipcu uruchomienie CoSchedule nie było jedyną zmianą. Oprócz tego pojawiło się więcej tekstów niż zwykle dzięki nowym świetnym Autorom i Autorce. Więcej niż zwykle wydałem też na reklamy na FB.
ALE! Nawet jeśli CoSchedule nie przełożyło się na ten ruch bezpośrednio (choć jestem przekonany, że tak było), to na pewno pomogło w osiągnięciu takiego wyniku.
Czego nie używam?
Napisałem, że CoSchedule oferuje więcej niż potrzebuję. Co zatem olewam? Przynajmniej dwa duże ficzery:
Pierwszy z nich to analityka. Pewnie powinienem nad tym przysiąść, ale… no cóż, po prostu mi się nie chce.
Drugi to “project management”/kolaboracja. Od tego mam inne narzędzia, które sprawdzają się bardzo dobrze.
Więc?
Tak jak pisałem, narzędzia używam od około dwóch miesięcy. Jest rewelacyjne i zostaję przy nim. Polecam także Tobie!
Ku jawności: w tekście znajduje się link afiliacyjny: http://devstyle.pl/coschedule. Będzie mi bardzo miło, jeśli zapoznasz się z tą usługą korzystając właśnie z niego. Ale nawet jeśli olejesz mój link i pójdziesz bezpośrednio na stronę produktu, to i tak będę zadowolony. I… jestem przekonany, że Ty też.
Pozdro!
Procent,
Taki Dojrzały Marketer Że Hej
The post Prowadzisz bloga? Oto Twoje zbawienie: CoSchedule / Blog Calendar appeared first on devstyle.pl.
August 9, 2020
DevTalk #120 – O testach część 3 z Olgą Maciaszek-Sharmą
 Co testy mają wspólnego ze Starożytnym Egiptem? Temat piramid testów podejmuje dzisiaj Olga Maciaszek-Sharma, mentorka SmartTesting. Z tego odcinka wyniesiesz cenna wiedzę o komunikacji i różnicach między programistą a testerem, nazewnictwie testów oraz wcześniej wspomnianej piramidzie.
Co testy mają wspólnego ze Starożytnym Egiptem? Temat piramid testów podejmuje dzisiaj Olga Maciaszek-Sharma, mentorka SmartTesting. Z tego odcinka wyniesiesz cenna wiedzę o komunikacji i różnicach między programistą a testerem, nazewnictwie testów oraz wcześniej wspomnianej piramidzie.
Olga Maciaszek-Sharma jest programistką Java oraz Groovy, wcześniej pracowała jako Inżynier Jakości Oprogramowania. Interesuje się mikroserwisami, resilient architecture i rozwiązaniami chmurowymi. Obecnie pracuje w Spring Cloud Team dla VMWare, gdzie rozwija projekty Spring Cloud LoadBalancer, Spring Cloud Contract, Spring Cloud Netflix i Spring Cloud OpenFeign.
Z tego odcinka dowiesz się:
Dla kogo są w ogóle testy?
Czym się różni rola testera a programisty?
Co to jest piramida testów i jak wygląda?
W jakim środowisku testy będą bardziej stabilne i szybsze?
Do jakich testów przykładać się szczególnie?
Jak nazywać testy?
I uwaga! Wraz z Marcinem oraz Olgą Maciaszek-Sharma pracujemy na czymś bardzo fajnym! Nad inicjatywą SmartTesting, dzięki której nauczysz się pisać testy tak, jak trzeba. Odkryjemy piękno testów, poznamy niebezpieczeństwa z nimi związane i przede wszystkim: zobaczymy, dlaczego są tak cholernie ważne!
DZIŚ startuje PRZEDsprzedaż Programu SmartTesting! Materiały będą gotowe jesienią, ale już teraz zapewnij sobie do nich dostęp w wyjątkowej, jednorazowej cenie! Ofertę otrzymasz na stronie Projektu.

A teraz… PLAY!

http://traffic.libsyn.com/devtalk/DevTalk_120_-_O_testach_cz_3_z_Olg_Maciaszek-Sharm.mp3
Montaż odcinka: Krzysztof Śmigiel.
Ważne adresy:
zapisz się na newsletter
zasubskrybuj w iTunes, Spotify lub przez RSS
ściągnij odcinek w mp3
Olga:
Consumer-Driven Contract Testing with Spring Cloud Contract
How to Live in a Post–Spring Cloud Netflix World
Testing REST and Messaging with Spring Cloud Contract at DevSkiller – DevSkiller Tech Blog
Muzyka wykorzystana w intro:
“Misuse” Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
The post DevTalk #120 – O testach część 3 z Olgą Maciaszek-Sharmą appeared first on devstyle.pl.
Maciej Aniserowicz's Blog

- Maciej Aniserowicz's profile
- 22 followers

