
Daniel Miessler's Blog, page 95
September 4, 2018
Unsupervised Learning: No. 141
I recommend reading this in its native typography at Unsupervised Learning: No. 141
—

Subscribe here to get this in your inbox every week.
Security News


September 2, 2018
My Current Top 3 Intellectual & Creative Challenges
I recommend reading this in its native typography at My Current Top 3 Intellectual & Creative Challenges
—

Just on a personal note, I want to capture three of my top projects right now:
Learning and implementing machine learning. This includes getting a decent understanding of the math that goes into it, but not going too deep there. The primary focus is to be able to make real-world predictions for real-world problems.
Making electronic music. Specifically this is learning the basics of Ableton, finding the style that I like, and smashing my face against the wall of true creation.
Writing fiction. My friend Andrew and I have a couple of universes that we can play with, of our own creation, and we’re going to basically do exercises of creating 3-5 pages of content for a specific scene in that universe. Then review, critique, adjust, or start another area.
These are three wildly different endeavors.
The machine learning is what I’m most enthused about. Making music is something I’ve wanted to do for years. And writing fiction just seems impossible to me, i.e., way harder than the other two.
I. Will. Do. Them. All.
Doesn’t mean I’m going to write a fiction book, or have a famous track on iTunes, or go to work for Google doing machine learning.
But I’m going to push myself in all three of these areas until I have some significant measure of competence and confidence.
What are your three?
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
September 1, 2018
Concise Argument and Evidence That Steven Pinker is Wrong About How Good Things Are
I recommend reading this in its native typography at Concise Argument and Evidence That Steven Pinker is Wrong About How Good Things Are
—

As I covered in this earlier piece, despite having massive respect for Steven Pinker, and loving his latest book, Englightenment Now, I think he’s very, very wrong about the current state of America.
My opinion on this is best described as a feeling of increasing unease—which is an emotion—but I only arrived at that emotion after consuming a great number of books on topics related to economics, working-class life, and the future of work and automation. The basic argument, broken into individual claims, is captured below.
This focuses mostly on Americans because that’s what I am most familiar with and have read the most about, but I think the points largely apply globally.
For a number of interconnected reasons, it’s becoming harder for everyday Americans to survive and thrive.
At the same time, the rich are doing better than any time in recent history, and income inequality is quickly moving towards recent historical maximums.
A big part of this is the fact that technology is becoming better at replacing human workers, and AI and robotics are about to remove millions more jobs.
AI is a threat to human work unlike anything we’ve seen before because it has the ability to permanently render humans as inferior to machines for most types of work.
Some of those jobs will be replaced by new types of work that humans will be better at (for now), but they will often require a skill or talent level that most of the displaced and new workers won’t have.
Human meaning is deeply tied to feeling valuable, and having millions of people who are unable to do anything that a machine can’t do better, is going to be a humanity-scale challenge.
With the great depression and the recent recession, it was accepted that there were fewer jobs right now, but that they’d eventually come back. That’s the part that’s different: because of AI and automation, millions of those jobs are going away permanently.

MCKINSEY analysis on coming job losses
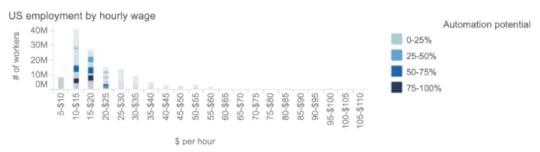
The hourly wage chart shows what I believe to be the core of the problem, i.e., that the people who will be most affected by automation are already the lowest paid, which will lead to even more social tension in coming years.
Many companies—especially large ones—see their human workforce as a major detriment to productivity and profitability, and are actively seeking ways to improve their bottom line by replacing them with technology.
Companies are also transitioning their workforces to temporary workers in various different ways because they impart less of a financial burden on the business and give them more flexibility to expand and contract their workforce—ultimately reducing costs.
These changes from permanent-hire to part-time employee, contractors, or gig economy workers are often associated with highly undesirable working conditions for those workers, including reduced hours per worker, unpredictable work schedules, a lack of benefits, and the constant threat of having work reduced.
Having millions of people who don’t feel useful or appreciated at work is bad. It will make people depressed. It will make people angry. And they will point that anger at others.
This anger will open the door to populist leaders who will use it to foster nationalism, scapegoating, xenophobia, and other negativity observed in turbulent times in the past.
Opportunistic politicians will not solve the problem, however, because the underlying issue is the impending obsolescence of human labor. That is the thing we must address.
For all these reasons, we need to first acknowledge how bad the situation has the potential to become—up to and including a breakdown of society and/or social upheaval and revolution, and second—start taking serious, practical action to find new ways for humans to feel like valuable contributors to their loved ones, and to society.
This is my own working mindmap on the various causes, effects, and correlations at play.

That’s the overall flow of the argument, and I feel I’ve arrived at this position through careful consideration of what data exists today. But this is seldom enough—even for me.
Many (and one friend in particular) believes that the AI and automation threat is just like previous threats to human work that we saw in the industrial revolution, the depression, and in the recession of 2008. He thinks we’ll bounce back, as humans, like we always do.

I used to agree with him, but now I think he’s wrong. It’s different this time, and here are some of my favorite books that brought me to this conclusion:
Humans Need Not Apply, Jerry Kaplan
Life 3.0, Max Tegmark
What Do You Think About Machines That Think, John Brockman
The War on Normal People, Andrew Yang
Homo Deus, Yuval Harari
Prediction Machines, Ajay Agrawal
Bullshit Jobs, David Graeber
The Evolution of Everything, Matt Ridley
Algorithms to Live By, Brian Christian
Superforecasting, Phillip Tetlock
Player Piano, Kurt Vonnegut
Sleeping Giant, Tamara Draut
Capital in the 21st Century, Thomas Piketty
The Master Algorithm, Pedro Domingos
The Inevitable, Kevin Kelly
I’m sure I missed a few, but those were the main ones—combined with hundreds of articles of course.
But the reason for this post is not to try to convince you again through crisp or alarmist prose, or by telling you to go read all those books (although I do recommend you do that). The issue is that I need to be able to make data-backed arguments on the fly. As it turns out, it’s pretty hard to recall hundreds of data points from dozens of books you’ve read on a topic over five years.
So I created this post to avoid feeling like I was peddling religion instead of presenting a data-based opinion—to whatever degree possible given our epistemic limitations. As such, this is going to be a running collection of data points, references, sources, links, etc., that support the position above. I hope you find it informative.
Jobs and finances
59% of American workers are paid hourly as opposed to being salaried. Link
66% of jobs in the US pay less than $20 an hour. Link
U.S. renters make an average of $16.38 an hour, but to afford rent in a 2-bedroom home you need to make an average of $21.21. Link
43% of U.S. households can’t afford monthly bills such as rent, food, child care, healthcare, and a mobile phone. Link
40% of Americans couldn’t cover a $400 emergency expense without selling something or borrowing money. Link
Only 15% of Americans have more than $10,000 in savings, and almost 70% have less than $1,000. Link
The mean credit card debt in the U.S. is $5,700 per household, but for households that are carrying debt it’s $9,333. Link
AI and automation

The Technical Potential for Automation in the US
Some of the study authors think there will be easy transitions to other jobs for many of these workers, but I think that’s less grounded than the loss predictions themselves.
McKinsey says automation could remove up to 73 million US jobs by 2030. Link
83% of jobs where people make less than $20 per hour will be subject to automation or replacement according to at 2016 White House report. Link
High-wage workers are expected to be less affected by the sweeping changes because they have skills that machines can’t replace. Low-wage jobs also could grow rapidly, partly because they cost employers less and so are often not worth supplanting with technology, while many are in health care, such as home health aides. That means middle-wage jobs will continue to decline, widening the divide between wealthy and low-income households, the report says.
USA Today on the McKinsey study
Between 64 and 69 percent of data collecting and processing tasks common in administrative settings are automatable: McKinsey Global Institute, A Future That Works: Automation, Employment, and Productivity, January 2017 Link
McKinsey says around 50% of current work activities are automatable by currently demonstrable technologies, with 6 out of 10 current occupations having more than 30% of activities that are automatable. Link
Goldman Sachs useded to have 600 taders, and now they have 2. They hired 200 software engineers to replace them, which—of course—isn’t a permanent position. Link
Summary
I’ll continue updating this post’s data section as new studies and estimates come in, but hopefully this short collection of analysis will give pause to anyone who thinks we’ve been through this before.
Notes
There is a must-read / watch book and video called Humans Need Not Apply Link
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
August 31, 2018
5 Things You Didn’t Know You Could do with Nmap
I recommend reading this in its native typography at 5 Things You Didn’t Know You Could do with Nmap
—

For those who have been in information security for a while, nmap is like a warm and familiar blanket. Except this blanket kicks ass. It is—without question—the most versatile portscanner ever.
A lot of people know that.
Read my masscan tutorial.
What fewer people know, however, is that with NSE scripting functionality nmap can do things you wouldn’t expect from a portscanner. There are faster scanners, but there’s nothing as versatile and indespensable.
Let’s look at 10 things you can do with Nmap that might surprise you.
Nmap NSE
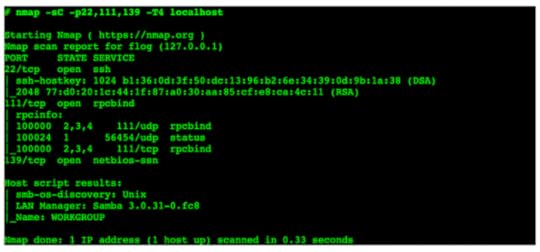
Typical NSE Output
First, what are NSE scripts?
NSE stands for Nmap Scripting Engine, and they basically allow you (yes, you) to write and share additional functionality that can be bolted onto the scanner we all love.
NSE somewhat blurs the line between portscanner and vulnerability scanner.
So in addition to checking for open ports, learning more about the service running on it, etc.—you can also further interact with it, e.g., see if it’s configured correctly, see what information is available, see if it’s using weak credentials, etc.
It basically turns Nmap into a platform for interacting with network services.
Nmap NSE Examples
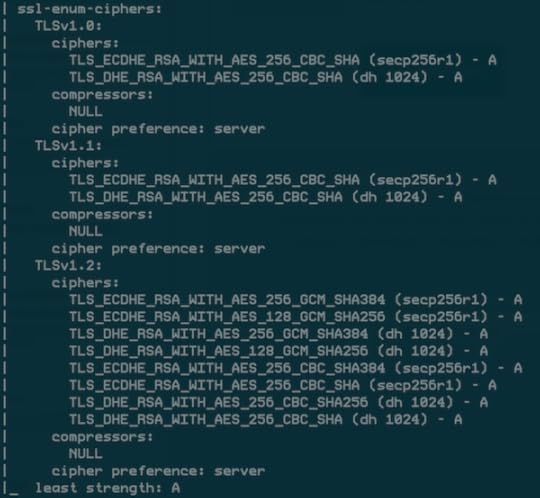
There are currently 598 NSE scripts, which you can find under the scripts directory in your nmap path.
ssl-enum-ciphers-
web
Get the TLS ciphers used by the target site.
http-wordpress-enum
web
Looks at a WordPress site and tells you what plugins and themes it’s running.
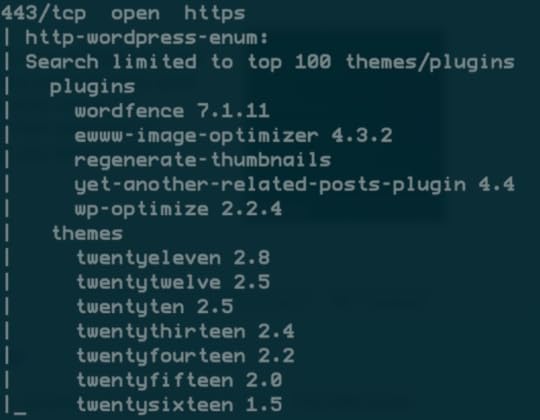
Each of these has better standalone alternatives, but sometimes it’s better to get good enough data from a common tool like Nmap.
asn-query
network
Finds GEO, ASN, and organization information for the target you specify.

http-enum
web
Looks at the web server software, robots.txt, and does some basic “interesting content” crawling—kind of like nikto.

http-headers
web
Shows you all the headers being sent by a given web server.

More scripts
There are tons of scripts for tons of common protocols.
SMB

HTTP
DNS

MYSQL

Summary
Nmap may not be the fastest portscanner, but it’s the most versatile.
With its NSE functionality, the lines are blurred between portscanner and vuln scanner.
The next time you have something common you want to do with a service, check to see if there’s an NSE script available. Let Nmap do the work for you.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
The Most Important Questions
I recommend reading this in its native typography at The Most Important Questions
—

I think it’d be a useful exercise to try to capture the most important questions in the world.
Here’s an initial attempt:
If we don’t have free will, how should we build a society in such a way that both accepts this truth yet doesn’t descend into nihilism or other negative philosophies?If we were designed by evolution, and all our goals and sense of meaning come from what it taught us, then how do we transcend that molding to become something independent yet still fulfilled? What are we without our desires that evolution gave us?How does one perfectly balance the tradeoff between the primal and rational parts of being human? Being a man or a woman is inherently primitive. Genders are the appendixes of our psyche. Yet just as with the illusion of free will, we ignore their cries for attention at our peril. What is the proper level of indulgence vs. ignoring of these less evolved versions of ourselves?How are we 1) getting out of this next 100 years without killing ourselves, 2) getting off of Earth before the sun destroys us, 3) finding a new home in the galaxy, 4) finding other life forms to collaborate with, and 5), surviving the heat death of the universe?
I would love to hear more questions of this type that I can add to the list.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
August 30, 2018
The Future of Work is Everyone Running the “Work” App
I recommend reading this in its native typography at The Future of Work is Everyone Running the “Work” App
—

Let me propose one potential future to you—a future where most everything is done through the gig economy. Here is roughly how that might take place.
Companies get rid of many or most of their employees, and decide to go with short-term contracts instead. There is extraordinary data showing that 94% of job growth (jobs created vs. jobs lost) from 2005 to 2015 was in alternative (non-9-to-5) work.
People will have their respective skillsets, and all these skills will be part of their online profile—similar to what we have now with LinkedIn. Some people will be dog-sitters, paralegals, nurses, tech writers, EMTs, garbage collectors, accountants, security researchers, and hundreds of others. Your profile will also include your experience, your ratings, your credentials, and all of this will be validated through various third-party services.

From a Harvard / Princeton study in 2016
Rather than use traditional contracting agencies, many companies will switch to using a dynamic, technology-based solution to find the right workers. They will simply put out a request for X number of Y type of workers, along with plenty of data about what an ideal candidate would look like, and that request will be sent to services like LinkedIn and UpWork where people have peoples’ profiles.
The service will then send a notification to eligible people who fit those requirements, e.g., someone who can edit a chapter for a book, who’s been highly rated as an editor on a successful book within the last year, and who also did so for fantasy-based fiction.
Everyone will be running the Work application on their phone, which is a universal application for finding either jobs or workers. Just like an Uber driver does today, people will receive an incoming request that says something like this, which they will either accept or decline.

Once the job is accepted, work will begin, the task will be performed, money will be transparently exchanged, ratings will be given on both sides, third-parties will validate those ratings, and both parties will move on.
We can be fairly sure this will happen because we’re already seeing it today in the form of multiple applications. There could be multiple players though, just as we currently have Uber and Lyft.
What will make this so powerful is that it will enable so much work to take place with very little friction. It’ll essentially enable peer-to-peer interaction without middleware companies taking a cut. There will still be fees associated with having your data on the platform, and perhaps with using the Work app, but they will be negligible compared to the time and effort of coordinating manually through a third party.

Need some stuff moved? Need someone to take a look at your son’s knee? Need a bodyguard for a concert? Need a website tested for vulnerabilities? These will all be done through an application like Work.
Even if you have a full-time job, most people will still run the Work app to supplement their income.
Background checks, insurance, reference checks, testimonials—all these things will be managed by the Work backend, which will be one or more companies like LinkedIn, UpWork, etc.
To be sure, there will still be jobs that companies will keep internal, and that still make sense to have as permanent positions rather than on contract. But given the current trending, most jobs will be temporary as opposed to permanent, and something like the Work app will be the result.
We’ll all be in the gig economy soon—but it’ll be for every skill we have.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
The Future Belongs to Those With Grit
I recommend reading this in its native typography at The Future Belongs to Those With Grit
—
If you’re not imbuing your children and friends with grit—as a core part of their identity—they will soon be driving rich people around and bringing them food. Rich people who probably have grit themselves.
Grit
/’grit’/
noun
A positive, non-cognitive trait based on an individual’s perseverance of effort combined with the passion for a particular long-term goal or end state.
The way I describe grit to my friends is that it’s the quality that allows you to aggressively and consistently pursue long-term goals. It’s basically a superpower.
I mean the hard-working, education/career-based elite, not the super-rich class.
It’s what many immigrants have that later generations don’t. It’s what the new Chinese elite have in the US, where parents from China instill the concepts of elitism and pedigree and competition into their children from an extremely early age.

One of the learning chains popular in the Bay Area
There are learning centers like this all over the Bay Area, and most big cities, and they’re full of Asians. They’re full of kids who have parents who have grit, and who will soon have grit themselves.
They’re full of kids who will soon be running the country.
Why?
Because people with grit are better at saving money. They are better at school. They’re better at postponing gratification (almost the definition), and because of these things they’re going to be the ones with the good jobs, the high salaries, and the vast proportion of the wealth and power.
This is especially true now, in a world where Humans Need Not Apply. In a marketplace where only the smartest and most knowledgeable will have good jobs, it’ll be the people who are most educated and financially disciplined that will succeed.

They will be the ones who can pay to stay continuously educated, can ensure their kids have the best schooling, the best connections, and have access to the most resources.
The other 75-90% will either be out of the job market altogether or will be working jobs that basically support the top 10%’s comfortable lifestyles. These jobs will be largely in the services industries: transportation, healthcare, food service, personal assistants, etc.
And these jobs will not be pleasant. Hours will be unpredictable, grueling, sporadic, and the employers will have all the leverage because there will be many people out of work trying to get the same positions.
Anyway, some of that is a diversion into a separate topic, where I’m seriously concerned about the health of the American system due to the force of automation and AI.
Read my related piece titled The Bifurcation of America: The Forced Class Separation into Alphas and Betas
But even taking that off the table, I see the world splitting into two main classes–Alphas and Betas.
There’s a lot of support for this in the data.
And I believe grit will be one of the top attributes that differentiate who goes into which class.
Intelligence obviously plays a factor, as does luck, but I believe the biggest advantage will be the ability to grind. Grinding through school. Grinding through saving money. Grinding through acquiring credentials and wealth. And then grinding through doing all of this again for their kids.
If you don’t have grit, or you know friends (and especially parents) who don’t have it, do your best to improve it in yourself and in them.
Notes
Luck is often indiscernible from talent, but as someone once said: “Luck favors the well-prepared”.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
August 29, 2018
Rewards Programs Are Another Way We Pay for Things With Our Data
I recommend reading this in its native typography at Rewards Programs Are Another Way We Pay for Things With Our Data
—

There’s a famous, often-misattributed quote in the tech scene that says something like:
If you’re not paying for a given service, then you’re not the customer—you’re the product.
Many people, going back to the 70’s
This is fairly well understood for services like Google and Facebook, where the service is basically free but the companies make most of their money selling your data. Many don’t realize this is happening, but for most people who are aware the tradeoff is still worth it.
But there’s another way this happens as well that people think less about: rewards programs. When you enroll in an awards program, a few things happen:
You provide information about yourself to sign up.
You are then given a member identifier that entitles you to discounts.
You use that identifier whenever you make purchases.
That means the company gets to continue gathering all sorts of information about you. What you buy, where you buy, etc.—plus they find ways to make sure your other data is current as well.
Just as with free services like Google and Facebook, rewards programs involve trading your personal data for something you would have paid for otherwise.
So what you’ve basically done—as a member of these loyalty programs—is literally trade data about yourself for money.
You get a discount on that latte, or that new jacket, or whatever it is, and in exchange the company gets to learn more about you.
The issue is that once they have your data they can not only use it to improve their products and services, but perhaps they could also sell it in various ways to further help their bottom line. I’m sure you read all the loyalty program fine print to make sure they couldn’t?
Again, most people will be ok with this. My concern is when people blindly participate in products, services, and programs without realizing the nature of the relationship. Don’t let yourself, or anyone you care about, be one of those people.
If you’re getting a discount on something—or getting it for free—always ask yourself what the other side is getting out of the interaction.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
The Difference Between Deductive and Inductive Reasoning
I recommend reading this in its native typography at The Difference Between Deductive and Inductive Reasoning
—

Pretty much anyone who thinks about how to solve problems in a formal way has probably run across the concepts of deductive and inductive reasoning.
As with all my tutorials, the purpose of this article is to explain the differences between these two approaches as clearly as possible.
Both deduction and induction are often referred to as a type of inference, which basically just means reaching a conclusion based on evidence and reasoning.
First, both deduction and induction are ways to learn more about the world and to convince others about the truth of those learnings. None of these terms would mean anything or are useful to anyone if they weren’t used to do something useful, like determining who committed a crime, or how many planets might harbor life in the Milky Way galaxy. Induction and Deduction help us deal with real-world problems.
The biggest difference between deductive and inductive reasoning is that deductive reasoning starts with a statement or hypothesis and then tests to see if it’s true through observation, where inductive reasoning starts with observations and moves backward towards generalizations and theories.
Key points

Deduction moves from idea to observation, while induction moves from observation to idea.
Deduction moves from more general to more specific, while induction moves from more specific to more general.
Deductive arguments have unassailable conclusions assuming all the premises are true, but inductive arguments simply have some measure of probability that the argument is true—based on the strength of the argument and the evidence to support it.
All men are mortal. Harold is a man. Therefore, Harold is mortal.
Deduction
This third sentence is absolutely true because (if) the first two sentences are true.
I have a bag of many coins, and I’ve pulled 10 at random and they’ve all been pennies, therefore this is probably a bag full of pennies.
Induction
This gives some measure of support for the argument that the bag only has pennies in it, but it’s not complete support like we see with deduction.

Deduction has theories that predict an outcome, which are tested by experiments. Induction makes observations that lead to generalizations for how that thing works.
If the premises are true in deduction, the conclusion is definitely true. If the premises are true in induction, the conclusion is probably true.
There’s another type of reasoning called Abductive Reasoning, where you take a set of observations and simply take the most likely explanation given the evidence you have.
Deduction is hard to use in everyday life because it requires a sequential set of facts that are known to be true. Induction is used all the time in everyday life because most of the world is based on partial knowledge, probabilities, and the usefulness of a theory as opposed to its absolute validity.

Deduction is more precise and quantitative, while induction is more general and qualitative.
Examples
If A = B and B = C, then A = C.
Deduction
…
Since all squares are rectangles, and all rectangles have four sides, so all squares have four sides.
Deduction
…
All cats have a keen sense of smell. Fluffy is a cat, so Fluffy has a keen sense of smell.
Deduction
…
Every time you eat peanuts, your throat swells up and you can’t breathe. This is a symptom of people who are allergic to peanuts. So, you are allergic to peanuts.
Induction
…
Ray is a football player. All football players weigh more than 170 pounds. Ray weighs more than 170 pounds.
Induction
…
All cars in this town drive on the right side of the street. Therefore, all cars in all towns drive on the right side of the street.
Induction
We can see here that deduction is a nice-to-have. It’s clean. But life is seldom clean enough to be able to apply it perfectly.
Most real problems and questions deal more in the realm of induction, where you might have some observations—and those observations might be able to take you to some sort of generalization or theory—but you can’t necessarily say for sure that you’re right. It’s about working as best you can within a world where knowledge is usually incomplete.
Summary

Deduction gets you to a perfect conclusion—but only if all your premises are 100% correct.
Deduction moves from theory to experiment to validation, where induction moves from observation to generalization to theory.
Deduction is harder to use outside of lab/science settings because it’s often hard to find a set of fully agreed-upon facts to structure the argument.
Induction is used constantly because it’s a great tool for everyday problems that deal with partial information about our world, and coming up with usable conclusions that may not be right in all cases.
Be willing to use both types of reasoning to solve problems, and know that they can often be used together cyclically as a pair, e.g., use induction to come up with a theory, and then use deduction to determine if it’s actually true.
The main thing to avoid with these two is arguing with the force of deduction (guaranteed to be true) while actually using induction (probability based on strength of evidence).
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
August 28, 2018
A Chromium-based Command-line Alternative to Curl
I recommend reading this in its native typography at A Chromium-based Command-line Alternative to Curl
—

If you’ve spent any time coding in InfoSec, you’ve probably used a ton of curl to pull websites, check them for various issues or attributes, etc.
This will follow redirects and provide a non-curl User Agent.
curl -LA 'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5' reddit.com
This used to work quite well, but now—not so much.
For one, curl doesn’t parse and render JavaScript, and that’s what the internet is made out of. But perhaps even worse, many companies are employing technologies to outright detect and block curl because it’s often used for scraping.
Either way, if you use curl to pull a lot of sites en masse, you’re likely to have a massive failure rate in getting the HTML you’re looking for.
What we’ve needed for quite some time is something like curl, i.e., command-line and relatively simple, but that renders sites fully.
I’ve been using chromium (part of the Chrome project) to solve this problem for years, and I wanted to pass along the syntax for others.
I am usually doing things from Ubuntu, but you can get this to work on most UNIXy systems.
cat domains.txt | xargs -I {} -P 4 sh -c timeout 25s chromium-browser –headless –no-sandbox –user-agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' –dump-dom https://{} 2> /dev/null > {}.html
That’s a lot to uravel, so:
sending domains.txt to xargs with -P 4 means spin up 4 processes to run xargs on incoming domains from your list, which makes things go quite fast.
a timeout of 25 seconds keeps things from timing out while you’re waiting for xargs to do its thing, and/or for the site to respond.
headless means don’t display a GUI, and no-sandbox is a security issue if you’re running as root, so be careful with that.
dump-dom means pull everything that comes back from the render.
the {} bits are placeholders for the content of the current cycle of xargs
the 2> /dev/null is because Chromium can be noisy
the {}.html writes the file based on the name of the domain coming from domains.txt.
What you basically end up with—assuming you have a decent machine to run this on—is hundreds of nicely rendered HTML files being created very quickly. Chromium is Chrome, so you’re getting the full rendering of the JavaScript and all the goodness that comes with that.
Anyway, I hope this helps someone who’s smashing their face on the desk because of curl.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
Daniel Miessler's Blog

- Daniel Miessler's profile
- 18 followers

