
Daniel Miessler's Blog, page 93
November 21, 2018


Unsupervised Learning: No. 152

This is a member-only even episode. Members get the newsletter every week, as well as access to all previous episodes, while free subscribers only get odd episodes every other week.
—
I spend between 5 and 20 hours creating this content every week. Iif you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
November 11, 2018
Some of My Favorite Shell Aliases From Over the Years

Aliases are one of those things that follow you, from laptop to laptop, and server to server—like snippets of your educational DNA.
Here are some of mine that have followed me for two decades:
Sorry for the immature language. It’s funny; get over it.
Make sure that command executes
$ alias fucking="sudo"
$ alias isaid="sudo"
Type f to find things by name using find
$ alias f="find . -name"
A super quick speed test
You can do this with a utility, but I like using built-in tools as much possible.
$ alias bt="wget http://cachefly.cachefly.net/400mb.test > /dev/null"
Get your current IP address and ISP
$ alias gip="curl ipinfo.io/ip && curl ipinfo.io/org"
Always use ncat when I type nc
ncat is the nc equivalent within the nmap suite.
$ alias nc="ncat"
Find out what’s taking up space on your disk
$ alias s="du -hs * | sort -rh | head -5"
Create a quick password
$ alias np="openssl rand -base64 24"
Add color to grep output
$ alias grep="grep –color=auto -n"
Search your history for something, with colorized output
$ alias hs="history | grep –color=auto -n"
Notes
I also use zsh instead of bash.
—
I spend between 5 and 20 hours creating this content every week. Iif you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
November 6, 2018
The Few Are Winning, The Many Are Losing
I recommend reading this in its native typography at The Few Are Winning, The Many Are Losing
—

I was just watching the mid-term results come in this evening and was struck with an idea: even in our democratic republic, it’s the few elites that seem to be winning.
Trump won by electoral college, and he lost the popular vote. The electoral college is a collection of a few super influential people. The people are—well—the people.
In this year’s mid-terms, the House of Representatives went Democratic, but the Senate went Republican. The House has many many people in it, and the Senate only has two per state.
In both cases you have the more selective group going right, and the larger and more inclusive group going left.
This also reminds me of income inequality, but I think I’m crossing the streams on that one.
It just seems like the system is rigged to fail in certain ways. One of the founders in the Federal papers was worried about powerful special interests taking over, and I think that’s what we have here.
We have a small number of elites who have a disproportionate amount of power, and they keep getting more and more of the pie, and more and more influence. I think it can only go on for so long, though. Before there’s a correction.
Perhaps that’ll be 2020, but I worry even more about the correction to that correction in 2024. I can only assume that the Democrats will mess things up bad enough to make that happen.
Seems like the cycle we can expect for the perceivable future.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
November 4, 2018
Unsupervised Learning: No. 151
Security News
October 27, 2018
Building Your Own Dedicated IPSEC VPN in Less Than 10 Minutes
I recommend reading this in its native typography at Building Your Own Dedicated IPSEC VPN in Less Than 10 Minutes
—

There are tons of VPN options out there, and the field is confusing enough that I did a post on the topic a while back to help people pick one of the better ones and avoid the scams.
But if you look at the considerations for making a good choice, they mostly reduce to the following:
Privacy
Log retention
Bandwidth
Legal issues
Customer service
Etc.
Just build your own
I sidestep most of these issues by just making my own VPN using one of my favorite projects by hwdsl2, called setup-ipsec-vpn. This way you don’t have to worry about your VPN provider messing with your log data, or capturing your packets, or getting served a warrant by law enforcement for something someeone else did, or any of that.
VPN services are nice, but my preference is to just run my own VPN from a system I fully control.
It’s just you, a dedicated Linux box that you control, and a full-featured IPSEC VPN all for your own use! Here’s the entire process in just three (3) steps.
It also works on Windows, but…yuck.
1. Create yourself a clean Linux system

You just need a barebones Ubuntu, Debian, or CentOS server. Don’t forget to update the OS and packages.
2. Install the VPN
wget https://git.io/vpnsetup -O vpnsetup.sh && sudo sh vpnsetup.sh
This runs for a couple of minutes and then shows you the credentials to put into your client.
3. Configure your client

You can put these credentials in basically any solid IPSEC VPN client, including the native ones in macOS and iOS.
Summary
That’s it!
Build a box.
Run a single command to install the VPN.
Plug the credentials into your client.
Connect and enjoy!
Notes
In the readme there are additional options for providing your own credentials in various ways, so you don’t have to accept and use the ones spit out by the wizard.
You might wonder if this is secure, since you’re running someone else’s script to build the VPN. One, I took a cursory look and didn’t find anything suspect, so that satisfied me decently well. But second, the project is so large and popular that it’s likely received significant scrutiny at this point. There is still risk there, for sure, but I don’t think it’s anywhere near as much risk as using these massively centralized VPN services that are no-doubt being used by criminal elements—and are thus likely to be under tremendous scrutiny.
Dont’t forget to keep both your host and your VPN updated, and make sure you don’t have any services other than SSH (ideally on a non-standar port) enabled, preferably with either a great passphrase or even better key-based authentication with passwords disabled. When we avoid the risk of third-party services we take on the (small) burden of administration. I’m happy with that exchange in this case.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
What If Corporations Provided For Their Customers?
I recommend reading this in its native typography at What If Corporations Provided For Their Customers?
—

I was talking about books with my friend Jon Robinson the other day, and he said something offhand that I’ve not been able to chase out of my brain.
It sounds like a silly idea until you realize that what we’re doing now is not likely to work for much longer.
Corporations are becoming more powerful. They’re buying and corrupting the governments that used to regulate them. And even worse, the people who used to participate in government by being citizens are now completely checked out.
And soon they won’t have jobs anyway.

So what if you basically enter into an agreement with your Corporation, where you agree to be monitored, you agree to be safe and non-violent, and you agree to learn the right things and say the right things (which could have a pretty broad range potentially), and in return you are provided with a prefab house, prefab meals, a gaming rig, and all the entertainment content you could ever want.
If you get sick you’re taken care of. If you are in danger the police are sent to help.
Why?
Because you’re a customer (kind of like an employee, but better) and you are providing them a service by doing things in the virtual world. You’re evangelizing for your ecosystem, which is the ecosystem made by your employer, and as a result you’re either creating actual value in the virtual world or you are earning the Corporation a stipend from the government.
So basically, the government is a control structure that pays corporations to keep the people happy. And corporations compete to have the most compelling combination of experiences for people.
The best prefab houses, with the best on-demand food, the best romantic partners, and the best gaming rigs, and the best skin access for the games themselves, etc. Plus you have the best chance of being discovered as a value creator, which turns you into various types of celebrity—either in or out of game.
I’m not saying this is a good idea. Sounds like it’d be pretty easy to have it go bad.
But at least it’s a path forward. Right now we don’t have one of those.
As Harari talks about in his books, the current concepts of government and corporations had their time. They were useful and performed a function, but now they are proving inflexible and in need of replacement.
Maybe government-funded and all-inclusive Corporate-life-ecosystems are the way to go.
Would love to hear your thoughts.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
October 26, 2018
Entropy and Security
I recommend reading this in its native typography at Entropy and Security
—

I’ve been obsessed with entropy since I learned about it in high school.
It’s highly depressing, but it’s awesome at the same time given how inevitable it is, and how it’s happening all the time and all around us.
I was just reading The Most Human Human, by Brian Christian, and it reminded me that I’ve wanted to write a short post on the topic for a while now.
Here are a few different definitions and concepts related to entropy, just as a flow of discrete statements.
These statements are not flawless; they’re designed to inspire you regarding the topic, not teach it technically.
Entropy, at its most base level, is disorder.
It’s the opposite of order, pattern, and potential.
As things move forward in time, they become less ordered—unless they’re receiving energy from an outside source (like the sun).
The endgame for the entire universe is heat death, which is a giant, consistent soup of disorder and lost potential.
One way to think about entropy is to imagine the light coming off of a light bulb in your living room. Energy cannot be destroyed, right? Well where did that light go? It went into the objects it hit, and every so slightly aroused them. It was absorbed and integrated into the things around it. But there’s no way to ever get it back. It’s gone. And any effort to retrieve it would take far more energy that it was ever worth.
In computer security entropy also means disorder, which we call randomness.
In security we need sources of randomness as part of cryptography so that we can remove patterns from our secret messages. Patterns allow for attackers to change the inputs and figure out what the inputs are for an unknown output. The less random (lower entropy) the input, the higher the chance that such analysis will be successful.
Entropy in this sense is a measure of uncertainty. The more you can guess the next item in a sequence, the less entropy that sequence has.
Another way to rate or think of entropy is the amount of surprise present in each consecutive data point. Maximum randomness has maximum surprise.
A big problem occurs in computer security when something is considered to be random when it isn’t, like taking the time from a system clock. Time is predictable, so all you have to do is make multiple guesses as to the time when that entropy source was pulled and you’ll have a chance at guessing (and therefore counteracting) that entropy. That turns it from disordered to ordered.
Perfect entropy is perfect randomness. It is a complete lack of patterns, organization, or uniformity. It’s not lumpy, it’s not banded, it’s not sequenced. It’s just completely flat and unpredictable noise.
The best source we’ve found for this level of randomness in nature is the radioactive decay of atoms.
Notes
Information can be seen as the reduction of uncertainty.
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
October 21, 2018
Summary: Algorithms to Live By
I recommend reading this in its native typography at Summary: Algorithms to Live By
—

My book summaries are designed as captures for what I’ve read, and aren’t necessarily great standalone resources for those who have not read the book. Their purpose is to ensure that I capture what I learn from any given text, so as to avoid realizing years later that I have no idea what it was about or how I benefited from it.
Lessons
Optimal stopping
There are many algorithms that come from computer science that can be used to improve human decision making in everyday life.
The Secretary Problem is a form of the Optimum Stopping problem, where you’re not sure when you should stop searching for an optimum form of something. You could keep searching and maybe find something better, but that might be a waste of time you should be spending on something else. There is an actual answer: which is 37%. Optimum Stopping is about avoiding stopping too early or too late. If you follow this optimal strategy you will also have a 37% chance of finding the best thing.
This is also related to the look-then-leap rule, which is where you spend a certain amount of time looking and not choosing anyone, and then after that point you pick the very first person that’s better than everyone you’ve seen so far.
It’s a whole other game if you have a metric you’re going by: like typing speed. If that’s the case just wait for the person who satisfies a high standard and pull the trigger.
That’s called The Threshold Rule.
All quotes here are from the book itself unless otherwise indicated: Christian, Brian. Algorithms to Live By: The Computer Science of Human Decisions (p. 14). Henry Holt and Co.. Kindle Edition
Any yardstick that provides full information on where an applicant stands relative to the population at large will change the solution from the Look-Then-Leap Rule to the Threshold Rule and will dramatically boost your chances of success.
A 63% failure rate, when following the best possible strategy, is a sobering fact.
If you’re a skilled burglar and have a 90% chance of pulling off each robbery (and a 10% chance of losing it all), then retire after 90/10 = 9 robberies.
Most people do something like the look-then-leap rule, but they leap too early.
Exploring vs. enjoying (pattern vs. novelty)
Every day we are constantly forced to make decisions between options that differ in a very specific dimension: do we try new things or stick with our favorite ones?
If you don’t know anything about the situation other than how many times a thing has happened, say (3 out of 5), then the proper estimate for whether it will happen again is attained by adding one to the numerator and two to the denominator. So, 4 out of 7.
When balancing favorite experiences and new ones, nothing matters as much as the interval over which we plan to enjoy them.
And…
A sobering property of trying new things is that the value of exploration, of finding a new favorite, can only go down over time, as the remaining opportunities to savor it dwindle.
So when you’re at the start of your interval, you should be doing more and more exploration, and when you’re at the end of your interval, you should do more exploitation.
He points out that since Hollywood is doing so many sequels, they seem to be at the end f their lifespan.
Robbins specifically considered the case where there are exactly two slot machines, and proposed a solution called the Win-Stay, Lose-Shift algorithm: choose an arm at random, and keep pulling it as long as it keeps paying off. If the arm doesn’t pay off after a particular pull, then switch to the other one.
Exploration in itself has value, since trying new things increases our chances of finding the best. So taking the future into account, rather than focusing just on the present, drives us toward novelty.
To try and fail is at least to learn; to fail to try is to suffer the inestimable loss of what might have been.
Chester Bernard
The framework I found, which made the decision incredibly easy, was what I called—which only a nerd would call—a “regret minimization framework.” So I wanted to project myself forward to age 80 and say, “Okay, now I’m looking back on my life. I want to have minimized the number of regrets I have.” I knew that when I was 80 I was not going to regret having tried this. I was not going to regret trying to participate in this thing called the Internet that I thought was going to be a really big deal. I knew that if I failed I wouldn’t regret that, but I knew the one thing I might regret is not ever having tried. I knew that that would haunt me every day, and so, when I thought about it that way it was an incredibly easy decision.
Jeff Bezos
Upper Confidence Bound algorithms are those that minimize regret. They basically have you select options not based on what’s likely, but by what’s possible. He goes on to say that the best defense against regret is optimism.
Practically, this means selecting possible adventures based on their potential to be good, not factoring in their potential to be bad.
To live in a restless world requires a certain restlessness in oneself. So long as things continue to change, you must never fully cease exploring.
Taking the ten-city vacation problem from above, we could start at a “high temperature” by picking our starting itinerary entirely at random, plucking one out of the whole space of possible solutions regardless of price. Then we can start to slowly “cool down” our search by rolling a die whenever we are considering a tweak to the city sequence. Taking a superior variation always makes sense, but we would only take inferior ones when the die shows, say, a 2 or more. After a while, we’d cool it further by only taking a higher-price change if the die shows a 3 or greater—then 4, then 5. Eventually we’d be mostly hill climbing, making the inferior move just occasionally when the die shows a 6. Finally we’d start going only uphill, and stop when we reached the next local max. This approach, called Simulated Annealing, seemed like an intriguing way to map physics onto problem solving.
Sorting
This is the first and most fundamental insight of sorting theory. Scale hurts.
Big-O notation is an indication of how much scale hurts the solving of your problem.

It gets worse from there. There’s “exponential time,” O(2n), where each additional guest doubles your work. Even worse is “factorial time,” O(n!), a class of problems so truly hellish that computer scientists only talk about it when they’re joking—as we were in imagining shuffling a deck until it’s sorted—or when they really, really wish they were.
Sorting something that you will never search is a complete waste; searching something you never sorted is merely inefficient. Err on the side of messiness.
The verdict is clear: ordering your bookshelf will take more time and energy than scanning through it ever will.
Caching
He makes an argument that a slower mind in old age could simply be a search problem, because the database is exponentially larger than when you’re 20.
There’s a general concept of clumps of caches, with smaller faster ones close by, a medium fast one nearby, and then a slow but large one with everything.
This is very much like L2 cache, CPU, main memory, hard disc, and cloud storage
Scheduling
Reducing maximum lateness is one option.
Another is shortest processing time, which is part of GTD
The optimal strategy for that goal is a simple modification of Shortest Processing Time: divide the weight of each task by how long it will take to finish, and then work in order from the highest resulting importance-per-unit-time (call it “density” if you like, to continue the weight metaphor) to the lowest. And while it might be hard to assign a degree of importance to each one of your daily tasks, this strategy nonetheless offers a nice rule of thumb: only prioritize a task that takes twice as long if it’s twice as important.
The best time to plant a tree is twenty years ago. The second best time is now. ~ Proverb
It turns out, though, that even if you don’t know when tasks will begin, Earliest Due Date and Shortest Processing Time are still optimal strategies, able to guarantee you (on average) the best possible performance in the face of uncertainty. If assignments get tossed on your desk at unpredictable moments, the optimal strategy for minimizing maximum lateness is still the preemptive version of Earliest Due Date—switching to the job that just came up if it’s due sooner than the one you’re currently doing, and otherwise ignoring it. Similarly, the preemptive version of Shortest Processing Time—compare the time left to finish the current task to the time it would take to complete the new one—is still optimal for minimizing the sum of completion times.
Bayes’s Rule
Laplace’s Law, and it is easy to apply in any situation where you need to assess the chances of an event based on its history. If you make ten attempts at something and five of them succeed, Laplace’s Law estimates your overall chances to be 6/12 or 50%, consistent with our intuitions. If you try only once and it works out, Laplace’s estimate of 2/3 is both more reasonable than assuming you’ll win every time, and more actionable than Price’s guidance (which would tell us that there is a 75% metaprobability of a 50% or greater chance of success).
The mathematical formula that describes this relationship, tying together our previously held ideas and the evidence before our eyes, has come to be known—ironically, as the real heavy lifting was done by Laplace—as Bayes’s Rule.
You still need some previous knowledge (priors) for it to work
The Copernican Principle says that if you want to estimate how long something will go on, look at how long it’s been alive, and add that amount of time
This doesn’t work for things that have a known limit though, like a human age
In the broadest sense, there are two types of things in the world: things that tend toward (or cluster around) some kind of “natural” value, and things that don’t.
Power law distributions or scale-free distributions are ranges that can have many scales, so we can’t say that “normal” is any one thing.
And for any power-law distribution, Bayes’s Rule indicates that the appropriate prediction strategy is a Multiplicative Rule: multiply the quantity observed so far by some constant factor. For an uninformative prior, that constant factor happens to be 2, hence the Copernican prediction; in other power-law cases, the multiplier will depend on the exact distribution you’re working with. For the grosses of movies, for instance, it happens to be about 1.4. So if you hear a movie has made $6 million so far, you can guess it will make about $8.4 million overall; if it’s made $90 million, guess it will top out at $126 million.
When we apply Bayes’s Rule with a normal distribution as a prior, on the other hand, we obtain a very different kind of guidance. Instead of a multiplicative rule, we get an Average Rule: use the distribution’s “natural” average—its single, specific scale—as your guide. For instance, if somebody is younger than the average life span, then simply predict the average; as their age gets close to and then exceeds the average, predict that they’ll live a few years more. Following this rule gives reasonable predictions for the 90-year-old and the 6-year-old: 94 and 77, respectively.
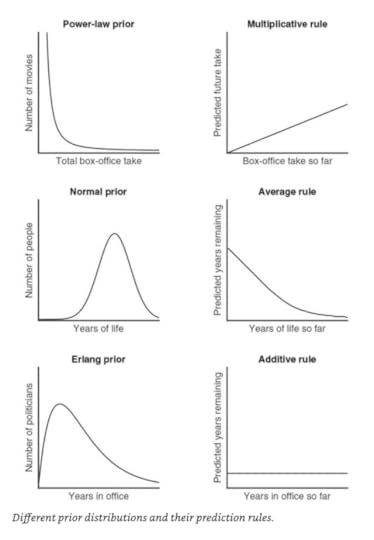
A third type is Additive, where you just add a constant to the end. Like “five more minutes!”, or “20 more hands”.
If you want to be a good intuitive Bayesian—if you want to naturally make good predictions, without having to think about what kind of prediction rule is appropriate—you need to protect your priors. Counterintuitively, that might mean turning off the news.
Overfitting
Once you know about overfitting, you see it everywhere. Overfitting, for instance, explains the irony of our palates. How can it be that the foods that taste best to us are broadly considered to be bad for our health, when the entire function of taste buds, evolutionarily speaking, is to prevent us from eating things that are bad? The answer is that taste is our body’s proxy metric for health. Fat, sugar, and salt are important nutrients, and for a couple hundred thousand years, being drawn to foods containing them was a reasonable measure for a sustaining diet.
You can also combat overfitting by penalizing complexity.
One way ML does that is by reducing the weights incrementally until only the strongest signals are considered, also know as Regularization
The Lasso is an algorithm that penalizes algorithms for their total weight, so it pulls the weights so low that most factors end up at zero, and only the strongest remain (at low numbers)
Early stopping is an algorithm based on finding the strongest signal, then the next, then the next, instead of just taking all of them at face value to start with
When to Think Less As with all issues involving overfitting, how early to stop depends on the gap between what you can measure and what really matters. If you have all the facts, they’re free of all error and uncertainty, and you can directly assess whatever is important to you, then don’t stop early. Think long and hard: the complexity and effort are appropriate. But that’s almost never the case. If you have high uncertainty and limited data, then do stop early by all means. If you don’t have a clear read on how your work will be evaluated, and by whom, then it’s not worth the extra time to make it perfect with respect to your own (or anyone else’s) idiosyncratic guess at what perfection might be. The greater the uncertainty, the bigger the gap between what you can measure and what matters, the more you should watch out for overfitting—that is, the more you should prefer simplicity, and the earlier you should stop.
When we start designing something, we sketch out ideas with a big, thick Sharpie marker, instead of a ball-point pen. Why? Pen points are too fine. They’re too high-resolution. They encourage you to worry about things that you shouldn’t worry about yet, like perfecting the shading or whether to use a dotted or dashed line. You end up focusing on things that should still be out of focus. A Sharpie makes it impossible to drill down that deep. You can only draw shapes, lines, and boxes. That’s good. The big picture is all you should be worrying about in the beginning.
The power of relaxation
When optimum solutions are elusive, you can often get most of the benefit by relaxing the requirement for precision.
Constrained optimization is where you are working within a particular set of rules and a scorekeeping measure
The prarie lawyer problem is the same as the traveling salesman problem
Constraint Relaxation is where you solve the problem you wish you had instead of the one you actually have, and then you see how much this helped you.
For instance, you can relax the traveling salesman problem by letting the salesman visit the same town more than once, and letting him retrace his steps for free. Finding the shortest route under these looser rules produces what’s called the “minimum spanning tree.” (If you prefer, you can also think of the minimum spanning tree as the fewest miles of road needed to connect every town to at least one other town.
The final step, as with any relaxation, is to ask how good this solution is compared to the actual best solution we might have come up with by exhaustively checking every single possible answer to the original problem. It turns out that for the invitations problem, Continuous Relaxation with rounding will give us an easily computed solution that’s not half bad: it’s mathematically guaranteed to get everyone you want to the party while sending out at most twice as many invitations as the best solution obtainable by brute force. Similarly, in the fire truck problem, Continuous Relaxation with probabilities can quickly get us within a comfortable bound of the optimal answer.
There are many ways to relax a problem, and we’ve seen three of the most important. The first, Constraint Relaxation, simply removes some constraints altogether and makes progress on a looser form of the problem before coming back to reality. The second, Continuous Relaxation, turns discrete or binary choices into continua: when deciding between iced tea and lemonade, first imagine a 50–50 “Arnold Palmer” blend and then round it up or down. The third, Lagrangian Relaxation, turns impossibilities into mere penalties, teaching the art of bending the rules (or breaking them and accepting the consequences). A rock band deciding which songs to cram into a limited set, for instance, is up against what computer scientists call the “knapsack problem”—a puzzle that asks one to decide which of a set of items of different bulk and importance to pack into a confined volume. In its strict formulation the knapsack problem is famously intractable, but that needn’t discourage our relaxed rock stars. As demonstrated in several celebrated examples, sometimes it’s better to simply play a bit past the city curfew and incur the related fines than to limit the show to the available slot.
Randomness
Sampling is super powerful, and so is simply starting with a random value and moving from there.
The answer may well come from computer science. MIT’s Scott Aaronson says he’s surprised that computer scientists haven’t yet had more influence on philosophy. Part of the reason, he suspects, is just their “failure to communicate what they can add to philosophy’s conceptual arsenal.” He elaborates: One might think that, once we know something is computable, whether it takes 10 seconds or 20 seconds to compute is obviously the concern of engineers rather than philosophers. But that conclusion would not be so obvious, if the question were one of 10 seconds versus 101010 seconds! And indeed, in complexity theory, the quantitative gaps we care about are usually so vast that one has to consider them qualitative gaps as well. Think, for example, of the difference between reading a 400-page book and reading every possible such book, or between writing down a thousand-digit number and counting to that number.
There’s a concept where you try an equation with a piece of data to see if it works, if it does that’s good. Try it with a few more random pieces of data. If they all work then the odds of this not being a good solution continue to fall. It doesn’t mean you’ve found THE solution, but it does mean that the more you do this the more likely that becomes.
Once you’ve assembled a baseline itinerary, you might test some alternatives by making slight perturbations to the city sequence and seeing if that makes an improvement. For instance, if we are going first to Seattle, then to Los Angeles, we can try doing those cities in reverse order: L.A. first, then Seattle. For any given itinerary, we can make eleven such two-city flip-flops; let’s say we try them all and then go with the one that gives us the best savings. From here we’ve got a new itinerary to work with, and we can start permuting that one, again looking for the best local improvement. This is an algorithm known as Hill Climbing—since the search through a space of solutions, some better and some worse, is commonly thought of in terms of a landscape with hills and valleys, where your goal is to reach the highest peak.
Another approach is to completely scramble our solution when we reach a local maximum, and start Hill Climbing anew from this random new starting point. This algorithm is known, appropriately enough, as “Random-Restart Hill Climbing”—or, more colorfully, as “Shotgun Hill Climbing.” It’s a strategy that proves very effective when there are lots of local maxima in a problem. For example, computer scientists use this approach when trying to decipher codes, since there are lots of ways to begin decrypting a message that look promising at first but end up being dead ends. In decryption, having a text that looks somewhat close to sensible English doesn’t necessarily mean that you’re even on the right track. So sometimes it’s best not to get too attached to an initial direction that shows promise, and simply start over from scratch. But there’s also a third approach: instead of turning to full-bore randomness when you’re stuck, use a little bit of randomness every time you make a decision. This technique, developed by the same Los Alamos team that came up with the Monte Carlo Method, is called the Metropolis Algorithm. The Metropolis Algorithm is like Hill Climbing, trying out different small-scale tweaks on a solution, but with one important difference: at any given point, it will potentially accept bad tweaks as well as good ones.
James thus viewed randomness as the heart of creativity. And he believed it was magnified in the most creative people. In their presence, he wrote, “we seem suddenly introduced into a seething caldron of ideas, where everything is fizzling and bobbing about in a state of bewildering activity, where partnerships can be joined or loosened in an instant, treadmill routine is unknown, and the unexpected seems the only law.” (Note here the same “annealing” intuition, rooted in metaphors of temperature, where wild permutation equals heat.)
When it comes to stimulating creativity, a common technique is introducing a random element, such as a word that people have to form associations with. For example, musician Brian Eno and artist Peter Schmidt created a deck of cards known as Oblique Strategies for solving creative problems. Pick a card, any card, and you will get a random new perspective on your project. (And if that sounds like too much work, you can now download an app that will pick a card for you.) Eno’s account of why they developed the cards has clear parallels with the idea of escaping local maxima: When you’re very in the middle of something, you forget the most obvious things. You come out of the studio and you think “why didn’t we remember to do this or that?” These [cards] really are just ways of throwing you out of the frame, of breaking the context a little bit, so that you’re not a band in a studio focused on one song, but you’re people who are alive and in the world and aware of a lot of other things as well.
Networking
Protocol is how we get on the same page; in fact, the word is rooted in the Greek protokollon, “first glue,” which referred to the outer page attached to a book or manuscript.

The breakthrough turned out to be increasing the average delay after every successive failure—specifically, doubling the potential delay before trying to transmit again. So after an initial failure, a sender would randomly retransmit either one or two turns later; after a second failure, it would try again anywhere from one to four turns later; a third failure in a row would mean waiting somewhere between one and eight turns, and so on. This elegant approach allows the network to accommodate potentially any number of competing signals. Since the maximum delay length (2, 4, 8, 16…) forms an exponential progression, it’s become known as Exponential Backoff.
TCP works with a sawtooth, which says more, more, more, SLOW WAY DOWN. More, more, more, SLOW WAY DOWN
ACKS are super important in speed of communication. If you can’t ACK, you don’t know if you’re being heard and thus can’t speak quickly
This is also why you don’t want to completely eliminate background noise from phones, because it’ll make the speaker think there’s nobody on the other end
UDP says better never than late
Game Theory
A Nash Equilibrium is where both sides should keep doing what they’re doing, assuming both sides keep doing what they’re doing.
Every two player game has at least one Nash equilibrium.

“In poker, you never play your hand,” James Bond says in Casino Royale; “you play the man across from you.” In fact, what you really play is a theoretically infinite recursion. There’s your own hand and the hand you believe your opponent to have; then the hand you believe your opponent believes you have, and the hand you believe your opponent believes you to believe he has … and on it goes. “I don’t know if this is an actual game-theory term,” says the world’s top-rated poker player, Dan Smith, “but poker players call it ‘leveling.’ Level one is ‘I know.’ Two is ‘you know that I know.’ Three, ‘I know that you know that I know.’ There are situations where it just comes up where you are like, ‘Wow, this is a really silly spot to bluff but if he knows that it is a silly spot to bluff then he won’t call me and that’s where it’s the clever spot to bluff.’ Those things happen.”
A dominant strategy is the best one no matter what your opponent does.
Redwoods are getting taller and taller, but for no reason other than stupid competition, since their canopy takes the same amount of light if it were lower. There’s just no agreement that would save them from having to make such a tall trunk.
The Dutch auction keeps lowering the price until someone pays.
The English auction does the opposite and keeps raising until someone won’t pay.
Named for Nobel Prize–winning economist William Vickrey, the Vickrey auction, just like the first-price auction, is a “sealed bid” auction process. That is, every participant simply writes down a single number in secret, and the highest bidder wins. However, in a Vickrey auction, the winner ends up paying not the amount of their own bid, but that of the second-place bidder. That is to say, if you bid $25 and I bid $10, you win the item at my price: you only have to pay $10.
This incentivizes honesty.
One of the implicit principles of computer science, as odd as it may sound, is that computation is bad: the underlying directive of any good algorithm is to minimize the labor of thought. When we interact with other people, we present them with computational problems—not just explicit requests and demands, but implicit challenges such as interpreting our intentions, our beliefs, and our preferences. It stands to reason, therefore, that a computational understanding of such problems casts light on the nature of human interaction. We can be “computationally kind” to others by framing issues in terms that make the underlying computational problem easier.
I’ve always been about this. This is what curation is. It’s why you should be concise in most things.
Asking someone what they want to do, or giving them lots of options, sounds nice, but it usually isn’t. It usually transfers a burden, from you to them. Don’t transfer burdens. Give them simple options where most of the work is already done.
He calls this Computational Kindness. Beautiful.
Designs should be computationally kind.
Takeaways
When you’re finding yourself stuck making decisions, consult this book, and other similar resources and see if there’s a better way to approach the problem. It could be that a heuristic or algorithm exists that will calm your mind and get you to a better decision at the same time.
In almost every domain we’ve considered, we have seen how the more real-world factors we include—whether it’s having incomplete information when interviewing job applicants, dealing with a changing world when trying to resolve the explore/exploit dilemma, or having certain tasks depend on others when we’re trying to get things done—the more likely we are to end up in a situation where finding the perfect solution takes unreasonably long. And indeed, people are almost always confronting what computer science regards as the hard cases. Up against such hard cases, effective algorithms make assumptions, show a bias toward simpler solutions, trade off the costs of error against the costs of delay, and take chances. These aren’t the concessions we make when we can’t be rational. They’re what being rational means.
You can find my other book summaries here.
Notes
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
October 20, 2018
Falling Testosterone, Poverty, and Violence, and How That Will Combine With Rising Inequality
I recommend reading this in its native typography at Falling Testosterone, Poverty, and Violence, and How That Will Combine With Rising Inequality
—

It’s interesting to think about all the different trends happening at the same time right now:
This is obviously not a complete list.
Testosterone has been falling in men for decades Link
Global violence is at an all-time low Link
Global poverty is at an all-time low Link
Income inequality is the worst it’s been in over a centurty, and the trend seems to be accelerating Link
Those are the big ones for me, but if you add the spike in young people’s depression, the tendency for young people to stay home and not go out, not go to parties, and instead to live much of their life via social media and their smartphones—well, it’s going to get interesting.
There are obviously too many variables to make any hard analysis here, and you shouldn’t trust anyone who says they can. But I can’t help but think about these things and wonder how the factors will interact with each other.
We have more and more people leaving abject poverty worldwide. One way to see that is to say that they’ll obviously be doing better than before, but another way to see it is that they’ll now become aware of how screwed they are. It’s like going from the pain of true poverty into the pain of knowing how much better other people have it. Politically that will cause more tension, not less.
Then in the Western countries (or let’s stick with the US) you have people having less children, fewer people even looking for work, and more people content to just live at home and play video games. All the while the distance between the top 10% and 1% in terms of income and wealth continues to grow.
As I’ve written about before, you’re basically going to have a superclass at the top that has the good tech and other jobs, while the bottom 90% will get automated out of their positions and relegated to service and administrative work that algorithms and machines cannot do. Yet.
Testosterone is dropping. Crime is lower than ever. But how long does that last when the jobs go away and the top 10% of the country are bussed around to work at amazing jobs, while everyone else takes care of their kids, serves them food, and get treated like absolute garbage at work. Unpredictable schedules, screwed out of benefits at every turn, and basically treated as expendable bodies.
How long can that last before the bottom 90% just say:
Um, no. Enough.
And that’s where the other factor comes in. Gaming.
As more and more people are taken out of the job market, and the real world gets less and less enjoyable, I think massive numbers of people are going to retreat into the better worlds inside of games.
Their relationships will be in the games. Their main skills will be in the games. And their value to others will be within the games.
That last part is key. If you can’t do anything better than an algorithm or a robot on the outside, you can still offer something inside. And that’s where most people will find their worth.
But meanwhile, on the outside, you’ll have the top 10% still thriving. Of course many of them will also be spending a lot of their time in games as well. And it’ll be crucial that games don’t allow people to pay-to-win to such a degree that it ruins the meaning structure of various games.
What does that look like, though?
The bottom 90% spend 8 hours a day doing a menial job in the real world, taking care of a top 10% person’s food or laundry or childcare, and then uses that meager money to pay for their game subscription?
It seems obvious that universal basic income has to be part of this equation. The bottom 90% simply aren’t going to have jobs. As Yuval Harari calls it, many of them will simply be in the Useless Class. Basically people who cannot offer value at anything in the real world that an algorithm or robot can’t do better.
The percentage of the world that belong to that class will rise quickly starting in the next few years I think. How fast? Nobody knows.
Automation will destroy jobs, but it will also create new ones. It seems obvious that it will ultimately destroy far more than it will create. But at what pace? The adding and subtracting will clearly be lumpy, not linear.
There’s no way to know exactly how it’ll proceed, but we can think about the variables and at least consider some possibilities.
Let’s do that, at the longer timescale:
The top 10% continues to pull away from the bottom 90% (and maybe that becomes 5/95 over time), and they basically see gaming as the way to keep the masses happy and quiet. They invest massively, in some sort of semi-organized campaign, to keep them enthralled in the virtual world, so that nobody notices how little they have in the real one.
Another option is the same as #1, except it just happens naturally, without any conspiratorial planning. I’m inclined towards this option, and that’s what seems to be currently happening.
The bottom 90%, through a combination of economic hardship and horrible left and right political leaders, stay focused on the real world and finally figure out how little they have compared to the top 10%, and they simply decide to table flip. This will likely come with the help of information warfare from Russia (if they’re still a player at the time), but there could be another political actor doing the same thing either way. In this scenario we have lots of riots, some serious mayhem, for a period of weeks or months (hopefully not years), and the result is either a very hard shift left towards redistribution and UBI and labor unions (which will be highly artificial and silly at that point), or some sort of fascist totalitarian control by the military and an oligarchy that sets up red and green zones and only allows “productive” people (the top 10%) to move freely and enjoy society. Everyone else is stuck finding their meaning in games and/or being persecuted by the gestapo.
We figure out how bad inequality is for long-term stability, and we find a way to implement universal basic income. We start manufacturing millions of pre-made homes with solar, which we give to people to keep their small, non-violent families safe, secure, and happy. People transition from being workers to being creators and consumers and seekers. Universities move away from being tech schools alone, and add liberal arts back in (say 2040 or so). We have universal health care. We have safe streets. We have safe places for people to become entrepreneurs and influencers and in-game celebreties. The worlds of in-game and out-of-game celebrity mixes, and it’s no longer considered lower to be an in-game hero or famous person.
I’m hoping deeply for #4, obviously.
The problem is that income redistribution and socialism and basic income and universal healthcare can easily fail if not implemented correctly. It cannot be a handout to able people who don’t want to be anything, or do anything. That will produce a growing underclass that exacerbates the problem rather than making it better. See the last few decades of welfare policy.
What it has to be instead is enablement for personal growth in a world where the people receiving it cannot hope to compete with algorithms or robots for “regular” work. It needs to be starting capital for people becoming scientists, in-game influencers, teachers, mentors, and other useful occupations that have value in the human world but not necessarily in the legacy, external business world.
So the value moves virtual.
But we have to encourage and incentivize education, and self-discipline, and a knowledgeable population. We have to grow that along with the universal lifting of the bottom, otherwise we just grow a source of our overall suffering over time.
What variables am I missing?
What would you add to this analysis?
—
I spend between 5 and 20 hours on this content every week, and if you're someone who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
Daniel Miessler's Blog

- Daniel Miessler's profile
- 18 followers

