
Patrick Zandl's Blog: Marigold.cz, page 10
May 2, 2025
Jak určit polohu pořízení fotografie pomocí ChatGPT o3?
Nový model ChatGPT o3 umí jednu zajímavou věc. Umí odhadnout polohu fotografie. Prostě nahrajete obrázek a zeptáte se, kde byl pořízen. Model o3 se zamyslí a po nějaké chvíli vám řekne, kde asi byl snímek pořízen, případně co na něm vidíte. Jenže tak jednoduché to není. Samozřejmě, pokud mu šoupnete fotku Pražského hradu, tak po pár minutách dumání řekne, že je to Pražský hrad. Jenže jakmile to není tak známá pamětihodnost, je to mnohem těžší a už výrazně více záleží na tom, jak se zeptáte, tedy jaký dáte prompt.
A protože o3 není na přemýšlení o místě pořízení fotky úplně uzpůsobený, je lepší dát mu přesnější textový popis. A protože se syn věnuje hře GeoGuessr (určování polohy fotky), tak jsem mrknul na postupy, jaké používá místní komunita. Nakonec jsem ze všech doporučení zkompiloval a odladil zhruba následující prompt, který si přes copy&paste zkopírujete do ChatGPT, zapněte model o3 a přiložte obrázek. Je pak velmi zajímavé, jak o3 provede všechny úvahy a co zajímavého odvodí.
Samozřejmě, pokud vyfotíte pár stromů v lese, tak se ani tímto promptem nedostanete k přesné GPS souřadnici. Také pohled na anonymní a málo známé snímky krušnohorských kopců, na kterých kromě stromů nic není, to neodhadlo příliš dobře (ale poznalo to Česko). Ale třeba jinak dost anonymní (byť hezká) fotka pohledu do krajiny z lanovky na rakouský Riegersburg byla detekována velmi přesně, stejně jako pohled na Praděd pořízený z Dlouhých strání (poznal přesné místo, odkud bylo foceno).
Doporučuji vyzkoušet!
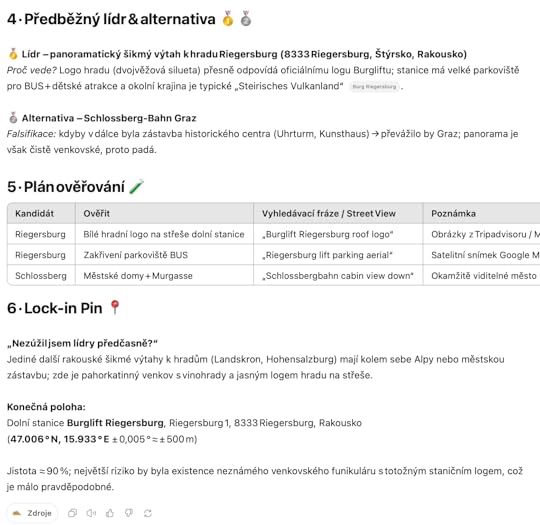
# 🗺️ Jednokolová hra typu GeoGuessr – instrukce pro ChatGPT **Úkol:** Z JEDINÉHO snímku odvoď nejpravděpodobnější polohu v reálném světě. *⚠️ Snímky nemusí být ze Street View ani z Mapy.cz Panorama – mohou to být soukromé či odlehlé lokace či příroda.*---## 0 · Nastavení & etika 🛡️ 1. Pracuj s veřejnými webovými zdroji. 2. **Analyzuj** EXIF / IP / skrytá metadata; počítej ale s tím, že tato data mohou být podvržená. Nesmí být jediným vodítkem.3. „Nahoře“ na fotce = směr pohledu (pokud není patrné otočení kamery). **Check‑list před startem, na co dávat pozor:** - [ ] Viditelný text/písmo? - [ ] Dopravní značka? - [ ] SPZ na vozidle? - [ ] Typ povrchu (asfalt / štěrk)? - [ ] Elektrické dráty/sloupy? ---## 1 · Hrubé pozorování 👁️ *(max 10 odrážek / ≤ 1200 znaků)* *Zapiš jen to, co **doslova** vidíš – bez interpretace. Každý bod popiš max 1 větou.* - **Každý sloup/lampa:** barva · rameno · podklad (10 s detail). - Všímej si dlaždic, obrubníků, štítků, vedení, plotů… - Kolik odlišných střech/verand do 150 m? - Sledujte paralaxu, výšku kamery, sklon terénu (i 1–2 % se projeví v zářezech příjezdové cesty).*(Nechte otevřené dvě hypotézy; všechny nepotvrzené hypotézy označ jako „TBD:“.)*---## 2 · Kategorie indicií 🔍 (≤ 2 věty/řádek) | Kategorie | Co sledovat | |-----------|-------------| | **Podnebí & vegetace** | Sezona, s listím vs. bez listí, odstín trávy, suchá × bujná | | **Geomorfologie** | Reliéf, typ odvodnění, geologická paleta/lithologie. | | **Zastavěné prostředí** | Architektura, písmo, chodníky, ploty, sítě. | | **Kultura & infrastruktura** | Strana jízdy, typ SPZ, svodidla, značky. | | **Astronomie / světlo** | Směr stínu → polokoule; výška Slunce → šířka ± 0,5°. | | **Okrasná × původní zeleň** | Pojmenuj vysazené (růže, trávník) a divoké (stromy, keře) rostliny. Test: „Vypadala by tato flóra v kandidátní oblasti X nepatřičně?“ Pokud **ano**, sniž její váhu. | ---## 3 · První shortlist – 5 kandidátů 🗂️ | # | Region (stát/země) | Klíčové indicie | Důvěra 1‑5 | Δ ≥ 160 km? | ---### 3½ · Matice divergentního vyhledávání podle klíčových slov 🔑 Vytvoř **regionálně neutrální** dotazy, např.: - `red‑brick factory building number` - `cylindrical dormitory housing` ➡️ Spusť vyhledávání **až po souhlasu uživatele**.---## 4 · Předběžný lídr & alternativa 🥇🥈 1. Jmenuj **nejlepší** odhad a **druhou** možnost. 2. Uveď *proč* je daný lídr lepší než ostatní.3. U každé uveď *kritérium vyvrácení* („Pokud uvidím X, padá to“). 4. Zkontroluj, co by tam **mělo být a není** – proč? ---## 5 · Plán ověřování 🧪 Pro každý přeživší region: | Kandidát | Prvek k ověření | Přesná fráze pro vyhledávání / cíl Street View | Poznámky k mapě ||-----------|------------------|-------------------------------------------|--------------|> Použijte Redfin/Zillow, Google Maps, Mapy.cz, satelitní snímky, fotografie státních parků, dovolenkové fotky atd. – a uveďte zdroj.*---## 6 · Lock‑in Pin 📍 (kritický krok) - Zeptej se: **„Nezúžil jsem lídry předčasně?“** - Aktivně hledej důkazy **pro sousední oblasti**, porovnáven navzájem. - Poté uveď konečnou polohu (zeměpisná šířka a délka nebo nejbližší místo) ** poloměr nejistoty**.- Přiznej nadměrnou jistotu; pokud jsou stopy slabé, zvětšete chybu.---## 📐 Rychlý tahák pro převod stínu na zeměpisnou šířku1. Změřte délku stínu **S** a výšku objektu **H**.2. Výška Slunce nad obzorem θ ≈ arctan(H / S).3. Zeměpisná šířka ≈ 90° – θ sluneční deklinace (v závislosti na ročním období).4. Dodržujte odchylku ± 0,5–1° (≈ 111 km).---\* **Pozn.:** „TBD:“ = položka k dalšímu ověření.Tak a to je všechno! Tady jeden příklad za všechny:



April 28, 2025
⚡️ Vyšetřování blackoutu ve Španělsku a Portugalsku den za dnem (update 5.5.)
Po zajímavé stopě se pustil Reuters. Ten zdokumentoval několik výpadků z dní předcházejících blackoutu. V týdnech před pondělním kolapsem zaznamenala soustava několik menších poruch a experti opakovaně upozorňovali na narůstající nestabilitu a na to, že soustavu může rozhodit jak nedostatek výkonu, tak ale i její přebytek, což hrozilo zejména s růstem slunečních dní a tím s růstem produkce elektřiny, zatímco teploty byly ještě nízké na to, aby lidé masivně zapínali klimatizace.
🇪🇸⚡️ 5.5. - Španělsku hrozil blackout několik dníInterní experti i REE v ročních zprávách upozorňovali na rostoucí nestabilitu kvůli souběhu malých zdrojů OZE a nedostatku dat z nich. REE z nich totiž nemá online data (či near-real-time data) o jejich produkci a pouze ji v reálném čase predikuje podle počasí, nemá ani vliv na připojení těchto zdrojů do sítě a jejich odpojení. Experti ENTSO-E také upozorňovali na nedostatečné plánování chystaného vyřazování jaderných reaktorů ze sítě s tím, že už plánovaná výměna paliva v reaktoru Almaraz II může být problém. Reaktor byl odpojen od sítě 20 . 4. 2025 a přešel do horkého odstávkového stavu. Práce podle harmonogramu pokračovaly i během blackoutu.Dne 22. dubna se objevily nápadné přepětí v síti a výpadky řízení, které odstavily vysokorychlostní vlaky a rafinérii Cartagena, což mělo být a zřejmě i bylo první vážné varování, problémy s v různé míře intenzity projevovaly až do 28.4.2025, kdy v 12:31 došlo k blackoutu na Pyrenejském poloostrově. Přesná souslednost výpadku je nicméně stále předmětem šetření.
Síť je nyní stabilní, nouzový stav byl zrušen. Vyšetřovací panel ENTSO‑E má plná data a nejpozději do 10 .5. slíbí první technický verdikt. Do té doby se čeká především na výsledek francouzského testu ochranných relé, který má objasnit, proč se Pyreneje odpojily prakticky v jednom okamžiku - a v kterém okamžiku to bylo. Nové informace nicméně posilují verzi systémového selhání, tedy neschopnosti REE řídit dynamicky se vyvíjející situaci v síti kvůli nedostatku dat a regulačních mechanismů.
3.5. 2025Níže pod touto sekcí najdete zprávy k události ze dne incidentu a z dalších dní, kdy jsem situaci sledoval.
Vyšetřování španělského blackoutu pokračuje, už se neobjevují žádné další podstatné informace. Stále není zřejmá přesná souslednost začátku, tedy zda za výpadek mohl nějaký zdroj, nebo nějaká událost v přenosové síti - čili kde kaskáda kolapsu začala. A zrovna tohle je hodně důležité.
Zatím pouze docela přesně víme, k čemu to vedlo, ale ne, jak to začalo - a nápravná opatření se podle toho budou výrazně lišit. V pátek proběhlo velké setkání, kde REN a REE předložily předběžné zprávy, ale nic podstatného z nich neuteklo, prohlášení po schůzce opakují jen již známé věci.
Ne každý je z detailního vyšetřování nadšený. Španělská vláda si vyžádala od Iberdroly, Endesy, Repsolu aj. „černé skříňky“ měničů a blokových ochran. Kdyby se nemohly najít, což se v takových situací stává, tak premiér Sánchez “nevylučuje sankce při neodevzdání”. Slušně vynadáno dostává španělský provozovatel přenosové soustavy REE (Red Eléctrica). Je již mnoho důkazů proto, že síť byla nestabilní již v pondělí dopoledne, REE nepřikročil k větší regulaci, ačkoliv mohl a zřejmě i měl. Kromě toho se ukazuje, že jej řada institucí upozorňovala již dříve, že nemají síť v dobré kondici. Tím hlavním varujícím byl právě ENTSO‑E, asociace operátorů přenosových sítí a operátor evropského gridu CESA. Akcie REE se propadly o 7 % - a nelibost premiéra Sáncheze jde zřejmě hodně tímto směrem, protože ať už byla příčina kdekoliv, bylo na zodpovědnosti REE si takovou věc do sítě pustit s patřičnými parametry nebo přijmout patřičná opatření.
To také znamená, že se houpe křeslo s šéfkou REE Beatriz Corredor, někdejší ministryní pro bydlení za sociálně-demokratickou stranu PSOE. Beatriz Corredor prohlásila, že nic takového se nebude opakovat a aby dodala svým slovům i technickou váhu, od úterka REE výrazně změnilo skladbu produkce elektřiny. Snížilo podíl fotovoltaiky a zvyšuje podíly produkce z točivých zdrojů (paroplynovky a uhlí). Část elektřiny také dobírá z jiných sítí, zejména Francie. Jako preventivní opatření portugalská ministryně životního prostředí Maria da Graça Carvalho oznámila, že Portugalsko “preventivně přestalo importovat elektřinu ze Španělska”. Dále zdůraznila potřebu více přečerpávacích vodních elektráren a bateriových úložišť v budoucnu, jakož i posílení propojení s Francií.
Čili zatím vyčkáváme na oficiální výsledky, nicméně je už zřejmé, že trámy k ukřižování jsou připraveny.
Za včerejšek mnoho novinek nebylo. Všichni zúčastnění po pondělním šoku pomalu najíždějí na informační disciplínu, která je v tomto případě užitečná, protože se ven nedostávají izolované zprávy, které lze snadno dezinterpretovat. Už dnes je jasné, že situace je velmi komplexní a nelze to vyřídit stylem “někdo hodil bombu do rozvodny”.
🇪🇸💡 1.5.2025: Jak pokračuje vyšetřování pyrenejského blackoutu?
Pro mě je také nepříjemné to, že sice se pořádají setkání s médii, z nich ale nevycházejí žádné oficiální zprávy, weby REN/REE mají jen prohlášení, že se to stalo a že to řeší, novinky nepředávají. Takže tyhle zprávy nabírám z médií a tam je často sdělení překroucené, zamlžené, protože pisatel nebyl energetik a v tomto případě na detailu záleží.
První velkou novinkou je, že jsem se dostal k datům z vnitřní sítě nízkého napětí ve vteřinovém rozlišení. Neumožňuje to vypátrat lépe příčinu, ale je vidět, že první problémy byly v rozvodné síti již dopoledne (což už bylo známo dříve), někdy po 9 hodině začalo na hladině nízkého napětí oscilovat napětí až o 11V, což rozhodně není obvyklé, obvyklá bývá jednotková oscilace. Navíc se zvyšovala amplituda kmitů, byly četnější, pak se před polednem situace stabilizovala. To sedí k informacím o tom, že oscilovala frekvence na přeshraničním pyrenejském připojení, k tomuhle jevu dochází na hladině nízkého napětí, když se “přetlačují” toky ze dvou velkých sítí. Jenže taky v řadě dalších případů, takže z toho nededukujme mnoho. Dlouhé, pomalu sílící kmity nicméně naznačují nedostatečně tlumenou soustavu (málo setrvačnosti / tlumicích výkonů). Znamená to, že síť byla nestabilní několik hodin před blackoutem a dispečeři si toho museli být vědomi, zjevně se zásahy snažili síť stabilizovat. Pomalý rozjezd oscilací také spíše vylučuje terorismus, to by muselo jít o dobře cílené a synchronizované útoky.
Z oficiálních vyjádření také víme, že došlo ke dvěma vážným problémům předcházejícím blackoutu. REE uvedlo, že šlo přerušením dodávek elektřiny a zatímco se španělská síť dokázala zotavit z první události, ředitel Eduardo Prieto uvedl, že druhá byla mnohem ničivější a vyústila v přerušení dodávek elektřiny z francouzské sítě a „masivní dočasné odpojení“. Zatím nebylo oznámeno, o co šlo, některé zvěsti říkají, že v prvním případě vypadla fotovoltaika o cca 3 GW někde v Extremaduře, v druhém o 1 GW větrníků v Andalusii. Oficiálně to ale potvrzeno není.
Extremadura je fotovoltaické srdce Španělska, ale největší FTV parky zde mají max 600 MW, většinou jsou kolem 200 MW, na 3 GW výkonu by jich musela vypadnout zhruba desítka, což znamená, že jde o systémový incident, ne o náhodný nezvládnutý výpadek. Například jsou všechny FTV napojeny na stejnou páteřní trasu 400 kV Almaraz - Guillena přes čtveřici rozvoden. Proto je důležité bedlivě stanovit časovou mapu a tím se dobrat k tomu, zda se synchronně vyply FTV parky, nebo je odpojily ochrany rozvoden či 400 kV linky, protože všechny tři jevy mají jiné řešení. Podobně je to s větrníky v Andalusii.
Čili jsme zase u toho. Čekáme na závěry probíhajícího šetření ENTSO-E a přesnou časovou osu, přičemž další tisková konference snad už s detaily, má být 2.5.
Jedna věc je vtipná, všichni už si kryjí záda. REE upozornilo, že na systémovou nestabilitu sítě upozornilo ve své letošní únorové zprávě (tedy několik let poté, co jim to samé říká ENTSO-E coby šéf eurosítě).
Jinak pro zlepšení hospodské debaty: samozřejmě existují setrvačná a elastizující řešení i pro FTV a větrníky. Nemusí to být nutně baterie, ale třeba synchronní kompenzátory, flywheely nebo intertia boosty pro větrné turbíny. Řešení je celá řada, nemusíte kvůli tomu nutně vydlabat vrcholek kopce a napustit ho vodou, jenže když si to do sítě neobjednáte, tak to nemáte.
🚗 Pyrenejská rozvodná síť byl prostě nadupaný sportovní kabriolet, do kterého se daly kvůli úspoře brzdy z Felačky a v zatáčce v Pyrenejských serpentinách se to prostě vyklopilo. Buďto zakážeme výrobu sportovních vozů, nebo do nich značneme dávat odpovídající brzdy, moc víc nad tím nevymyslíme…
…okračování zítra asi odpo, až budou venku zprávy…
3️⃣🇪🇸⚡️ 30.4.2025 Co nového se španělským blackoutem?
Jak vypadá situace kolem španělského blackoutu energetické sítě? Včera se téměř vše vrátilo do normálu, zapomeňte na novinové titulky “budou se vzpamatovávat týden” - kromě specifických věcí už je (v energetice) vše v normálu. Nicméně probíhá šetření. Co víme nového? No, pokud už sami máte jasno, tak dál nečtěte, protože jasno moc není.
V zásadě byla opuštěna myšlenka gallopingu jako JEDINÉHO SPOUŠTĚČE, tedy že šest 400 kV linek přes Pyreneje do Francie odpojily ochrany kvůli nadměrnému pohybu vedení vinou proudění vzduchu. Zdá se, že k pohybu došlo, ale ten nebyl jedinou či přímou příčinou odpojení linek. Atmosférická situace nebyla nijak extrémní. Nicméně ještě probíhá vyhodnocování měření.
Už se ale spíše uvažuje o špatně nastaveném firmware ochran, protože RTE potvrdila, že se používají stejná nastavení, jako u linky 400 kV v Lotrinsku, která se loni planě odpojila.
Dnes bohužel není úplně veřejně jasné, zda k odpojení linek došlo PŘED nebo PO zlomové události, tedy jak moc velký vliv jejich přerušení mělo a zda nebylo spouštěčem blackoutu.
V každém případě již nyní je zřejmé, že došlo k celé souhře událostí, mezi něž bych neváhal přidat španělský čurbes.
Především je třeba říct, že nemáme všechna podkladová data, sice scanuju všechna patřičná média, ale v nich se objevují zprávy útržkovitě a často manipulativně. Například ten galloping, ukázalo se, nebylo oficiální vyjádření portugalského REN, ale rychlý osobní názor jednoho z dispečerů, které bylo v médiích oseknuto tak, že to vypadalo jako oficiální postoj. Stejně tak v deníku el Pais se objevila data z jednoho slide určeného pro krizové jednání vlády, které ukazovaly na konkrétní problém, jenže se později ukázalo, že v prezentaci šlo o dva slajdy a na tom prvním byl zachycený začátek události, který všemu dával jiný kontext. Za třetí se ukázalo, že jeden z důležitých logů měl posunuté časové razítko o skoro dvě minuty, protože neměl přesný čas, což na interpretaci dat vrhalo jiné světlo. Proto nutně s daty opatrně a nedělat unáhlené závěry.
Pojďme si zrekapitulovat, co víme.
Kolaps španělské přenosové soustavy byl extrémně rychlý a rozsáhlý. Během pouhých pěti sekund došlo ke ztrátě přibližně 15 gigawattů (GW) elektrického výkonu. Tato ztráta představovala zhruba 60 % okamžité celostátní poptávky po elektřině v daném okamžiku. Okamžitá poptávka ve Španělsku dramaticky poklesla z úrovně přibližně 26 000 - 27 500 megawattů (MW) na hodnoty blížící se 15 000 MW , přičemž v nejnižším bodě dosáhla pouhých 10 480 MW. Tato bezprecedentní rychlost a rozsah ztráty výkonu byly klíčovými faktory, které vedly k následnému kaskádovému selhání a rozpadu sítě.
Tohle víme vcelku jistě. Nyní je otázkou, co tu ztrátu 15 GW v síti způsobilo.
Podle první teorie to byl výpadek linek přes Pyreneje, zatím z neznámých příčin, kterých mohlo být více (kyberútok se tady zatím stále spíše neuvažuje). Při přerušeném exportu do Francie by frekvence sítě ve španělsku vyletěla nahoru (a v EU dolů) a fotovoltaické a větrné elektrárny v rozmezí 8 sekund odpojily od sítě něco jako 15-30% výkonu. Tento pokles je okamžitý, nemá prakticky žádnou elasticitu, čímž dostane frekveci pod 50 Hz a při poklesu pod 49,5 Hz se odpojily tři plynové bloky a všechny jaderné elektrárny. Ochrana zátěže následně odpojuje část odběratelů, cca 3 GW. Takhle se mohl nasbírat propad o těch 15 GW. Situaci nepomohlo to, že v dlouhodobé odstávce byl jaderný blok Vandellos 2 a v údržbě JE Trillo (čili běží dvě JE) a také to, že náhradní zdroje, které měly okamžitě nastartovat, nastartovaly mírně později, než měly. PVE Alcántara se přifázovala 110 s po oddělení a CCGT Cartagena dodal prvních 250 MW dokonce až 7 min, přičemž první dodávky měla dát už za dvě minuty. Na vině byl možná tlak plynu, ale to už je nepotvrzené.
Podle druhé teorie (zveřejněné REE) došlo k propadu výroby na dvou španělských elektrárnách zatím z neznámého důvodu, což (a to už je interpretace) spolu s dalšími faktory jako špatný firmware a galloping nebo rozhodnutí ochrany evropské sítě vedlo k rozpojení linky a kaskádě tak, jak bylo popsáno výše.
Proč se odpojily dva velké zdroje ze sítě, není zatím jasné - tady není ani náznak a počkal bych na data. V Česku se to nicméně hodilo na tuto verzi a prý to měla způsobit výroba z OZE, což není příliš pravděpodobné.
Jak se nezávisle prokáže, co bylo první, zda výpadek linky nebo zdrojů? Vcelku jednoduše: pokud frekvence stoupla na 50 Hz, znamená to převis výroby v síti, což napovídá na odpojení linky (která exportovala 5 GW do Francie). Pokud naopak frekvence klesla, tak nejprve vypadly zdroje. Bohužel přesnější grafy a časy nebyly publikovány a z veřejně dostupných dat je rozlišení malé (bavíme se o 4 sekundách rozdílu!). Zatím jediná data z údajné interní zprávy RTE cituje článek Euronews, podle nějž frekvence na kontinentální (francouzské) straně vyskočila asi na 50,20 Hz a během několika sekund se vrátila k nominálu. Grafy z kontinentální sítě ukazují, že k výpadku 5 GW (což odpovídá pyrenejské lince) vypadlo ve 12:31 a začínají nabíhat regulace ve zbytku Evropy, které situaci v Evropě dostanou během tří minut zcela pod kontrolu. Bohužel veřejné zdroje o španělské produkci elektřiny jsou agregované na pět minut, takže lze jen potvrdit, že mezi 12:30 a 12:35 došlo ke ztrátě minimálně 11 GW produkce a to nám nepomůže…
Zavržené jsou zaručené zprávy o výbuchu španělské rozvodny Sentmenat - nenese žádné takové známky.
Vysvětlení s primárním výpadkem linky by lépe vysvětlovalo, proč vypadly točivé zdroje, ale zase zůstává nejasné, proč vypadla linka, zatímco primární výpadek zdrojů lépe vysvětlí odpojení linky a zase není jasné, proč by vypadlo tolik zdrojů. Budeme si tedy muset počkat, až se objeví více dat.
Hlavní poznatky, kterými si můžeme být jisti, jsou zatím dva (a na oba byli REE/REN upozorňovány dříve):
chybí lepší propojení do Evropy, mělo by být spíše dvojnásobné až trojnásobné, teď je Pyrenejský poloostrov energeticky spíše ostrov a Evropa mu nemůže moc pomoci. Jsou potřeba další rychlostartující úložiště typu baterie.Pokračování z 29.4.2025Záhy po publikování informací o rozpadu energetické sítě na pyrenejském poloostrově se začaly šířit teorie, kdo za to může. Rusko či jiní teroristé nebo snad Green Deal? Pojďme se s tím vyrovnat.
Za prvé je potřeba říct, že vyšetřování probíhá, incident dostal nejvyšší klasifikaci ICS-3, což znamená mezinárodní odborné vyšetřování, které je na začátku. Nyní jsou více-méně jisté technické příčiny, které si zrekapitulujeme. A zároveň se nenašla kybernetická stopa, i k tomu se dostanu.
ENTSO-E (to je evropské sdružení všech provozovatelů přenosových soustav) potvrdila ztrátu více jak 10 GW během 5 s (v tiskové zprávě REE se psalo 15 GW), což je obrovsky mnoho, na to žádná síť není dimenzována. V energetické síti se spotřeba musí rovnat výrobě a jsou zálohy, ale ne 15 GW. REE a REN (provozovatelé a dispečeři přenosových soustav ve Španělsku a Portugalsku) stále pracují s hypotézou „induced atmospheric vibration“ (galloping) na svazkových vedeních přes Pyreneje; ochrany prý vedení preventivně odpojily, čímž se poloostrov izoloval v okamžiku poruchy tvořily točivé zdroje jen ≈44 % výroby; vysoký podíl FVE a VtE urychlil pád frekvence. Točivé zdroje mohou do určité míry zbrzdit “pád soustavy”, protože “absorbují” pád frekvence, oproti tomu fotovoltaika se v případě problémů okamžitě odpojuje a to síť naopak může destabilizovat. Internetem putují “zvěsti” o podivnostech v britské síti nebo o odpojení kabelu Viking Link mezi Dánskem a Británií, jenže data ničemu takovému nenasvědčují a ani patřičné instituce k tomu nic nevydaly, čili to vypadá na kachnu.Problém může být v tom “ochrany odpojily vedení”. Podle analýzy SCADA logů se nezdá, že by do dálkově servisovatelných prvků někdo přistupoval, přesto je čistě hypoteticky možné, že někdo našel nějakou kombinaci postupů, jimž vyvolal kaskádovité odpojování. Někde jsem četl názor, že přeci stačí vzít klacek a vedení přes Pyreneje rozhoupat, aby hrozilo jeho zkratování. To jistě stačí, když vezmete asi stometrový klacek a nevadí vám ta trocha popálenin, kdy vás do nemocnice odvezou v krabičce od bot. A jelikož k mechanickému poškození (typu exploze) nedošlo, zatím se pracuje s tezí, že ochrany reagovaly příliš agresivně, než že by je k tomu někdo či něco donutilo. Ale uvidíme, tady je na závěry brzy a z pražské kanceláře rozhodně.
Co se děje teď?
Španělsko oznámilo, že od půl sedmé našeho času pokrývá 99 % celostátní poptávky a všechny hlavní uzly vysokého napětí jsou pod napětím . Portugalsko již včera informovalo o napájení 85 z 89 stanic; poslední venkovské okruhy se budou připojovat v průběhu dneška . Nouzové linky Francie - Katalánsko a Maroko - Andalusie zůstávají otevřené, aby pomohly s vyrovnáním výkonu během startu tepelných elektráren Doprava: Z kolejí bylo evakuováno více jak 35 000 cestujících, metro v Madridu a Lisabonu zprovoznilo první linky až dnes ráno . Letiště: Madrid-Barajas i Barcelona-El Prat fungovaly na záložních okruzích; terminály zůstaly osvětlené, ale došlo ke zrušení více jak 400 letů . Telekomunikace: mobilní sítě jely v nouzovém režimu na baterie — operátoři vyzvali uživatele ke střídmému volání, což prý úplně neklapalo, ranní interview na ČRo s reportérkou ze Španělska rušily výpadky. Veřejný pořádek: Španělsko rozmístilo 30 000 policistů; král Filip dnes vede zasedání Národní bezpečnostní rady . Francie a Německo slíbily pomoc s mobilními bateriovými kontejnery a rychlými plynovými turbínami, pokud by přišly další vlny horka . Velkoobchodní cena elektřiny v Iberian Market (OMIE) krátkodobě zhouply, ale už se stabilizují na day ahead průměru 6 €/MWh - problém byl spíš v dopravě elektřiny, než v její výrobní ceně a cenové výkyvy jsou malé.Takže závěr?
Na závěry je brzy. Terorismu nenasvědčuje zatím nic. Ani tomu neruskému (to už by se někdo hlásil s požadavky), ani tomu ruskému (to už by Rusko nabízelo pomoc). Jenže to je také první rychlý pohled a mohlo to jistě být jinak. Logy nelžou, ale mohl je někdo uklidit. Ostatně, konspirátoři předpokládají, že teroristé po sobě poprvé pořádně uklidili stopy (což Rusové nedělají, proč někoho terorizovat, když není jasné, kdo vám dal přes pusu).
Přesto vám sem jeden ilustrační obrázek dám 😎
[image error]
A ten Green Deal? Jistě, kdyby měla pyrenejská síť více točivých zdrojů, mohla dopadnout nějak lépe - jak moc, to se teprve nasimuluje. Ale kdyby měla balanční zdroje, jako jsou baterie, také by to ustála jinak. Na slunném jihu dávají FTV a větrníky velký smysl z hlediska produkčních cen a místní operátoři byli dlouhodobě upozorňováni na to, že tomu musí svoji síť přizpůsobit. Green Deal s nedodržením zásad diverzifikace nemá mnoho společného.
Elektřina už prakticky všude svítí, ale skutečná „detektivka“ právě teď začíná. Podrobné záznamy z ochran a phasor PMU teprve ukážou, zda vedla řetěz selhání opravdu kombinace „rozkmitaných“ pyrenejských linek a nízké setrvačnosti, nebo se v poslední chvíli přidalo ještě něco dalšího.
Zpráva z 28.4.2025:Podle provozovatelů REE a REN došlo v 11:33 WES-T k „el cero“ – úplnému výpadku energetické soustavy na Pyrenejském poloostrově. Extrémní teploty v centrálním Španělsku způsobily neobvyklé kmitání 400 kV vedení. Ochrany postupně odpojily více linek a generátorů, až se Pyrenejský poloostrov oddělil (“islandoval”, přešel do ostrovního provozu) od zbytku kontinentální sítě.
V izolované oblasti pak frekvence klesla ještě hlouběji, část elektráren se odpojila a následovalo masivní zatmění (blackout) Španělska, Portugalska a části jihozápadní Francie. 
⚡️ Blackout: co se 28. 4. 2025 stalo ve Španělsku a Portugalsku?Podívejme se na událost v grafu. Z něj je vidět, že pokles byl v nejostřejším místě jen 0,15 Hz. Pojďme si to vysvětlit pro zájemce o energetiku…
Proč na kontinentu „spadlo“ jen 0,15 Hz?
Po odpojení Iberského poloostrova ztratila zbytek Evropy čistý export ~4–5 GW ze Španělska (obě země měly v poledne vysokou výrobu ze solárních a větrných zdrojů). Tato ztráta se okamžitě promítla do grafu jako −150 mHz. Primární regulace ve zbytku Evropy (turbíny, baterie, HVDC linky) během sekund začala výkon zvyšovat, čímž frekvenci zastavila u ≈ 49,85 Hz a během tří minut ji vytáhla zpět nad 49,9 Hz. Díky rychlé reakci a dostatečné setrvačnosti se kontinentální síť neodstavila – v grafu vidíte jen krátký, ale prudký zářez.[image error]
Co vidíme v grafu
Osa y (Frekvence): nominál evropské synchronní sítě je 50,00 Hz. Tři křivky (žlutá = průměr, černá = maximum, šedá = minimum) ukazují, jak se frekvence mezi ≈ 11:55 a 13:00 CEST pohybovala v různých měřicích bodech propojené soustavy. Až do ≈ 12:30 se frekvence vlnila v běžném koridoru ±20 mHz (49,98–50,02 Hz). V 12:31–12:34 nastal prudký pád až na ≈ 49,85 Hz – to je odchylka −150 mHz. Vzápětí se frekvence díky primární regulaci a automatickým zálohám vrátila k 50 Hz; kolem 12:45 už je systém opět stabilní.Co takový pokles znamená
Frekvence se sníží, když odběr náhle převýší výrobu (nebo když se naopak od sítě odpojí část výrobních kapacit). V evropské soustavě stačí nerovnováha ~30 GW / Hz; −0,15 Hz tedy odpovídá zhruba 4–5 GW náhle chybějícího výkonu.
Důsledky na Pyrenejském poloostrově
Izolovaná Iberská soustava přišla o možnost importů z Francie, které by krátkodobě pomohly stabilizaci. Protože odběr převýšil dostupnou vlastní výrobu, frekvence spadla výrazněji (pravděpodobně < 49 Hz). Ochrany odpojily další zdroje i zátěže, aby chránily zařízení, což se navenek projevilo rozsáhlým blackoutem (vlaky, metro, letiště, domácnosti). Obnova musela probíhat postupně, aby se zamezilo dalšímu kolapsu napětí a frekvence. Takže ve stručnosti:
Z pohledu zbytku Evropy šlo o „pouhou“ ztrátu ~5 GW → pokles frekvence o 0,15 Hz, rychle vyrovnaný zálohami. Z pohledu Španělska a Portugalska to znamenalo ztrátu propojení, hluboký propad frekvence a následný blackout.Taková událost názorně ukazuje, jak citlivá je moderní síť: i malá odchylka frekvence na kontinentu může signalizovat dramatické dění v jedné jeho části, a proč je klíčové mít dostatek rychlých regulačních zdrojů a chytré ochrany.
PS: je to samozřejmě můj neodborný názor založený na tom co k tomu vyšlo
⚡️ Vyšetřování blackoutu ve Španělsku a Portugalsku den za dnem (update 3.5.)
Vyšetřování španělského blackoutu pokračuje, už se neobjevují žádné další podstatné informace. Stále není zřejmá přesná souslednost začátku, tedy zda za výpadek mohl nějaký zdroj, nebo nějaká událost v přenosové síti - čili kde kaskáda kolapsu začala. A zrovna tohle je hodně důležité.
Zatím pouze docela přesně víme, k čemu to vedlo, ale ne, jak to začalo - a nápravná opatření se podle toho budou výrazně lišit. V pátek proběhlo velké setkání, kde REN a REE předložily předběžné zprávy, ale nic podstatného z nich neuteklo, prohlášení po schůzce opakují jen již známé věci.
Ne každý je z detailního vyšetřování nadšený. Španělská vláda si vyžádala od Iberdroly, Endesy, Repsolu aj. „černé skříňky“ měničů a blokových ochran. Kdyby se nemohly najít, což se v takových situací stává, tak premiér Sánchez “nevylučuje sankce při neodevzdání”. Slušně vynadáno dostává španělský provozovatel přenosové soustavy REE (Red Eléctrica). Je již mnoho důkazů proto, že síť byla nestabilní již v pondělí dopoledne, REE nepřikročil k větší regulaci, ačkoliv mohl a zřejmě i měl. Kromě toho se ukazuje, že jej řada institucí upozorňovala již dříve, že nemají síť v dobré kondici. Tím hlavním varujícím byl právě ENTSO‑E, asociace operátorů přenosových sítí a operátor evropského gridu CESA. Akcie REE se propadly o 7 % - a nelibost premiéra Sáncheze jde zřejmě hodně tímto směrem, protože ať už byla příčina kdekoliv, bylo na zodpovědnosti REE si takovou věc do sítě pustit s patřičnými parametry nebo přijmout patřičná opatření.
To také znamená, že se houpe křeslo s šéfkou REE Beatriz Corredor, někdejší ministryní pro bydlení za sociálně-demokratickou stranu PSOE. Beatriz Corredor prohlásila, že nic takového se nebude opakovat a aby dodala svým slovům i technickou váhu, od úterka REE výrazně změnilo skladbu produkce elektřiny. Snížilo podíl fotovoltaiky a zvyšuje podíly produkce z točivých zdrojů (paroplynovky a uhlí). Část elektřiny také dobírá z jiných sítí, zejména Francie. Jako preventivní opatření portugalská ministryně životního prostředí Maria da Graça Carvalho oznámila, že Portugalsko “preventivně přestalo importovat elektřinu ze Španělska”. Dále zdůraznila potřebu více přečerpávacích vodních elektráren a bateriových úložišť v budoucnu, jakož i posílení propojení s Francií.
Čili zatím vyčkáváme na oficiální výsledky, nicméně je už zřejmé, že trámy k ukřižování jsou připraveny.
Níže pod touto sekcí najdete zprávy k události ze dne incidentu a z dalších dní, kdy jsem situaci sledoval.
Za včerejšek mnoho novinek nebylo. Všichni zúčastnění po pondělním šoku pomalu najíždějí na informační disciplínu, která je v tomto případě užitečná, protože se ven nedostávají izolované zprávy, které lze snadno dezinterpretovat. Už dnes je jasné, že situace je velmi komplexní a nelze to vyřídit stylem “někdo hodil bombu do rozvodny”.
🇪🇸💡 1.5.2025: Jak pokračuje vyšetřování pyrenejského blackoutu?
Pro mě je také nepříjemné to, že sice se pořádají setkání s médii, z nich ale nevycházejí žádné oficiální zprávy, weby REN/REE mají jen prohlášení, že se to stalo a že to řeší, novinky nepředávají. Takže tyhle zprávy nabírám z médií a tam je často sdělení překroucené, zamlžené, protože pisatel nebyl energetik a v tomto případě na detailu záleží.
První velkou novinkou je, že jsem se dostal k datům z vnitřní sítě nízkého napětí ve vteřinovém rozlišení. Neumožňuje to vypátrat lépe příčinu, ale je vidět, že první problémy byly v rozvodné síti již dopoledne (což už bylo známo dříve), někdy po 9 hodině začalo na hladině nízkého napětí oscilovat napětí až o 11V, což rozhodně není obvyklé, obvyklá bývá jednotková oscilace. Navíc se zvyšovala amplituda kmitů, byly četnější, pak se před polednem situace stabilizovala. To sedí k informacím o tom, že oscilovala frekvence na přeshraničním pyrenejském připojení, k tomuhle jevu dochází na hladině nízkého napětí, když se “přetlačují” toky ze dvou velkých sítí. Jenže taky v řadě dalších případů, takže z toho nededukujme mnoho. Dlouhé, pomalu sílící kmity nicméně naznačují nedostatečně tlumenou soustavu (málo setrvačnosti / tlumicích výkonů). Znamená to, že síť byla nestabilní několik hodin před blackoutem a dispečeři si toho museli být vědomi, zjevně se zásahy snažili síť stabilizovat. Pomalý rozjezd oscilací také spíše vylučuje terorismus, to by muselo jít o dobře cílené a synchronizované útoky.
Z oficiálních vyjádření také víme, že došlo ke dvěma vážným problémům předcházejícím blackoutu. REE uvedlo, že šlo přerušením dodávek elektřiny a zatímco se španělská síť dokázala zotavit z první události, ředitel Eduardo Prieto uvedl, že druhá byla mnohem ničivější a vyústila v přerušení dodávek elektřiny z francouzské sítě a „masivní dočasné odpojení“. Zatím nebylo oznámeno, o co šlo, některé zvěsti říkají, že v prvním případě vypadla fotovoltaika o cca 3 GW někde v Extremaduře, v druhém o 1 GW větrníků v Andalusii. Oficiálně to ale potvrzeno není.
Extremadura je fotovoltaické srdce Španělska, ale největší FTV parky zde mají max 600 MW, většinou jsou kolem 200 MW, na 3 GW výkonu by jich musela vypadnout zhruba desítka, což znamená, že jde o systémový incident, ne o náhodný nezvládnutý výpadek. Například jsou všechny FTV napojeny na stejnou páteřní trasu 400 kV Almaraz - Guillena přes čtveřici rozvoden. Proto je důležité bedlivě stanovit časovou mapu a tím se dobrat k tomu, zda se synchronně vyply FTV parky, nebo je odpojily ochrany rozvoden či 400 kV linky, protože všechny tři jevy mají jiné řešení. Podobně je to s větrníky v Andalusii.
Čili jsme zase u toho. Čekáme na závěry probíhajícího šetření ENTSO-E a přesnou časovou osu, přičemž další tisková konference snad už s detaily, má být 2.5.
Jedna věc je vtipná, všichni už si kryjí záda. REE upozornilo, že na systémovou nestabilitu sítě upozornilo ve své letošní únorové zprávě (tedy několik let poté, co jim to samé říká ENTSO-E coby šéf eurosítě).
Jinak pro zlepšení hospodské debaty: samozřejmě existují setrvačná a elastizující řešení i pro FTV a větrníky. Nemusí to být nutně baterie, ale třeba synchronní kompenzátory, flywheely nebo intertia boosty pro větrné turbíny. Řešení je celá řada, nemusíte kvůli tomu nutně vydlabat vrcholek kopce a napustit ho vodou, jenže když si to do sítě neobjednáte, tak to nemáte.
🚗 Pyrenejská rozvodná síť byl prostě nadupaný sportovní kabriolet, do kterého se daly kvůli úspoře brzdy z Felačky a v zatáčce v Pyrenejských serpentinách se to prostě vyklopilo. Buďto zakážeme výrobu sportovních vozů, nebo do nich značneme dávat odpovídající brzdy, moc víc nad tím nevymyslíme…
…okračování zítra asi odpo, až budou venku zprávy…
3️⃣🇪🇸⚡️ 30.4.2025 Co nového se španělským blackoutem?
Jak vypadá situace kolem španělského blackoutu energetické sítě? Včera se téměř vše vrátilo do normálu, zapomeňte na novinové titulky “budou se vzpamatovávat týden” - kromě specifických věcí už je (v energetice) vše v normálu. Nicméně probíhá šetření. Co víme nového? No, pokud už sami máte jasno, tak dál nečtěte, protože jasno moc není.
V zásadě byla opuštěna myšlenka gallopingu jako JEDINÉHO SPOUŠTĚČE, tedy že šest 400 kV linek přes Pyreneje do Francie odpojily ochrany kvůli nadměrnému pohybu vedení vinou proudění vzduchu. Zdá se, že k pohybu došlo, ale ten nebyl jedinou či přímou příčinou odpojení linek. Atmosférická situace nebyla nijak extrémní. Nicméně ještě probíhá vyhodnocování měření.
Už se ale spíše uvažuje o špatně nastaveném firmware ochran, protože RTE potvrdila, že se používají stejná nastavení, jako u linky 400 kV v Lotrinsku, která se loni planě odpojila.
Dnes bohužel není úplně veřejně jasné, zda k odpojení linek došlo PŘED nebo PO zlomové události, tedy jak moc velký vliv jejich přerušení mělo a zda nebylo spouštěčem blackoutu.
V každém případě již nyní je zřejmé, že došlo k celé souhře událostí, mezi něž bych neváhal přidat španělský čurbes.
Především je třeba říct, že nemáme všechna podkladová data, sice scanuju všechna patřičná média, ale v nich se objevují zprávy útržkovitě a často manipulativně. Například ten galloping, ukázalo se, nebylo oficiální vyjádření portugalského REN, ale rychlý osobní názor jednoho z dispečerů, které bylo v médiích oseknuto tak, že to vypadalo jako oficiální postoj. Stejně tak v deníku el Pais se objevila data z jednoho slide určeného pro krizové jednání vlády, které ukazovaly na konkrétní problém, jenže se později ukázalo, že v prezentaci šlo o dva slajdy a na tom prvním byl zachycený začátek události, který všemu dával jiný kontext. Za třetí se ukázalo, že jeden z důležitých logů měl posunuté časové razítko o skoro dvě minuty, protože neměl přesný čas, což na interpretaci dat vrhalo jiné světlo. Proto nutně s daty opatrně a nedělat unáhlené závěry.
Pojďme si zrekapitulovat, co víme.
Kolaps španělské přenosové soustavy byl extrémně rychlý a rozsáhlý. Během pouhých pěti sekund došlo ke ztrátě přibližně 15 gigawattů (GW) elektrického výkonu. Tato ztráta představovala zhruba 60 % okamžité celostátní poptávky po elektřině v daném okamžiku. Okamžitá poptávka ve Španělsku dramaticky poklesla z úrovně přibližně 26 000 - 27 500 megawattů (MW) na hodnoty blížící se 15 000 MW , přičemž v nejnižším bodě dosáhla pouhých 10 480 MW. Tato bezprecedentní rychlost a rozsah ztráty výkonu byly klíčovými faktory, které vedly k následnému kaskádovému selhání a rozpadu sítě.
Tohle víme vcelku jistě. Nyní je otázkou, co tu ztrátu 15 GW v síti způsobilo.
Podle první teorie to byl výpadek linek přes Pyreneje, zatím z neznámých příčin, kterých mohlo být více (kyberútok se tady zatím stále spíše neuvažuje). Při přerušeném exportu do Francie by frekvence sítě ve španělsku vyletěla nahoru (a v EU dolů) a fotovoltaické a větrné elektrárny v rozmezí 8 sekund odpojily od sítě něco jako 15-30% výkonu. Tento pokles je okamžitý, nemá prakticky žádnou elasticitu, čímž dostane frekveci pod 50 Hz a při poklesu pod 49,5 Hz se odpojily tři plynové bloky a všechny jaderné elektrárny. Ochrana zátěže následně odpojuje část odběratelů, cca 3 GW. Takhle se mohl nasbírat propad o těch 15 GW. Situaci nepomohlo to, že v dlouhodobé odstávce byl jaderný blok Vandellos 2 a v údržbě JE Trillo (čili běží dvě JE) a také to, že náhradní zdroje, které měly okamžitě nastartovat, nastartovaly mírně později, než měly. PVE Alcántara se přifázovala 110 s po oddělení a CCGT Cartagena dodal prvních 250 MW dokonce až 7 min, přičemž první dodávky měla dát už za dvě minuty. Na vině byl možná tlak plynu, ale to už je nepotvrzené.
Podle druhé teorie (zveřejněné REE) došlo k propadu výroby na dvou španělských elektrárnách zatím z neznámého důvodu, což (a to už je interpretace) spolu s dalšími faktory jako špatný firmware a galloping nebo rozhodnutí ochrany evropské sítě vedlo k rozpojení linky a kaskádě tak, jak bylo popsáno výše.
Proč se odpojily dva velké zdroje ze sítě, není zatím jasné - tady není ani náznak a počkal bych na data. V Česku se to nicméně hodilo na tuto verzi a prý to měla způsobit výroba z OZE, což není příliš pravděpodobné.
Jak se nezávisle prokáže, co bylo první, zda výpadek linky nebo zdrojů? Vcelku jednoduše: pokud frekvence stoupla na 50 Hz, znamená to převis výroby v síti, což napovídá na odpojení linky (která exportovala 5 GW do Francie). Pokud naopak frekvence klesla, tak nejprve vypadly zdroje. Bohužel přesnější grafy a časy nebyly publikovány a z veřejně dostupných dat je rozlišení malé (bavíme se o 4 sekundách rozdílu!). Zatím jediná data z údajné interní zprávy RTE cituje článek Euronews, podle nějž frekvence na kontinentální (francouzské) straně vyskočila asi na 50,20 Hz a během několika sekund se vrátila k nominálu. Grafy z kontinentální sítě ukazují, že k výpadku 5 GW (což odpovídá pyrenejské lince) vypadlo ve 12:31 a začínají nabíhat regulace ve zbytku Evropy, které situaci v Evropě dostanou během tří minut zcela pod kontrolu. Bohužel veřejné zdroje o španělské produkci elektřiny jsou agregované na pět minut, takže lze jen potvrdit, že mezi 12:30 a 12:35 došlo ke ztrátě minimálně 11 GW produkce a to nám nepomůže…
Zavržené jsou zaručené zprávy o výbuchu španělské rozvodny Sentmenat - nenese žádné takové známky.
Vysvětlení s primárním výpadkem linky by lépe vysvětlovalo, proč vypadly točivé zdroje, ale zase zůstává nejasné, proč vypadla linka, zatímco primární výpadek zdrojů lépe vysvětlí odpojení linky a zase není jasné, proč by vypadlo tolik zdrojů. Budeme si tedy muset počkat, až se objeví více dat.
Hlavní poznatky, kterými si můžeme být jisti, jsou zatím dva (a na oba byli REE/REN upozorňovány dříve):
chybí lepší propojení do Evropy, mělo by být spíše dvojnásobné až trojnásobné, teď je Pyrenejský poloostrov energeticky spíše ostrov a Evropa mu nemůže moc pomoci. Jsou potřeba další rychlostartující úložiště typu baterie.Pokračování z 29.4.2025Záhy po publikování informací o rozpadu energetické sítě na pyrenejském poloostrově se začaly šířit teorie, kdo za to může. Rusko či jiní teroristé nebo snad Green Deal? Pojďme se s tím vyrovnat.
Za prvé je potřeba říct, že vyšetřování probíhá, incident dostal nejvyšší klasifikaci ICS-3, což znamená mezinárodní odborné vyšetřování, které je na začátku. Nyní jsou více-méně jisté technické příčiny, které si zrekapitulujeme. A zároveň se nenašla kybernetická stopa, i k tomu se dostanu.
ENTSO-E (to je evropské sdružení všech provozovatelů přenosových soustav) potvrdila ztrátu více jak 10 GW během 5 s (v tiskové zprávě REE se psalo 15 GW), což je obrovsky mnoho, na to žádná síť není dimenzována. V energetické síti se spotřeba musí rovnat výrobě a jsou zálohy, ale ne 15 GW. REE a REN (provozovatelé a dispečeři přenosových soustav ve Španělsku a Portugalsku) stále pracují s hypotézou „induced atmospheric vibration“ (galloping) na svazkových vedeních přes Pyreneje; ochrany prý vedení preventivně odpojily, čímž se poloostrov izoloval v okamžiku poruchy tvořily točivé zdroje jen ≈44 % výroby; vysoký podíl FVE a VtE urychlil pád frekvence. Točivé zdroje mohou do určité míry zbrzdit “pád soustavy”, protože “absorbují” pád frekvence, oproti tomu fotovoltaika se v případě problémů okamžitě odpojuje a to síť naopak může destabilizovat. Internetem putují “zvěsti” o podivnostech v britské síti nebo o odpojení kabelu Viking Link mezi Dánskem a Británií, jenže data ničemu takovému nenasvědčují a ani patřičné instituce k tomu nic nevydaly, čili to vypadá na kachnu.Problém může být v tom “ochrany odpojily vedení”. Podle analýzy SCADA logů se nezdá, že by do dálkově servisovatelných prvků někdo přistupoval, přesto je čistě hypoteticky možné, že někdo našel nějakou kombinaci postupů, jimž vyvolal kaskádovité odpojování. Někde jsem četl názor, že přeci stačí vzít klacek a vedení přes Pyreneje rozhoupat, aby hrozilo jeho zkratování. To jistě stačí, když vezmete asi stometrový klacek a nevadí vám ta trocha popálenin, kdy vás do nemocnice vás v krabičce od bot. A jelikož k mechanickému poškození (typu exploze) nedošlo, zatím se pracuje s tezí, že ochrany reagovaly příliš agresivně, než že by je k tomu někdo či něco donutilo. Ale uvidíme, tady je na závěry brzy a z pražské kanceláře rozhodně.
Co se děje teď?
Španělsko oznámilo, že od půl sedmé našeho času pokrývá 99 % celostátní poptávky a všechny hlavní uzly vysokého napětí jsou pod napětím . Portugalsko již včera informovalo o napájení 85 z 89 stanic; poslední venkovské okruhy se budou připojovat v průběhu dneška . Nouzové linky Francie - Katalánsko a Maroko - Andalusie zůstávají otevřené, aby pomohly s vyrovnáním výkonu během startu tepelných elektráren Doprava: Z kolejí bylo evakuováno více jak 35 000 cestujících, metro v Madridu a Lisabonu zprovoznilo první linky až dnes ráno . Letiště: Madrid-Barajas i Barcelona-El Prat fungovaly na záložních okruzích; terminály zůstaly osvětlené, ale došlo ke zrušení více jak 400 letů . Telekomunikace: mobilní sítě jely v nouzovém režimu na baterie — operátoři vyzvali uživatele ke střídmému volání, což prý úplně neklapalo, ranní interview na ČRo s reportérkou ze Španělska rušily výpadky. Veřejný pořádek: Španělsko rozmístilo 30 000 policistů; král Filip dnes vede zasedání Národní bezpečnostní rady . Francie a Německo slíbily pomoc s mobilními bateriovými kontejnery a rychlými plynovými turbínami, pokud by přišly další vlny horka . Velkoobchodní cena elektřiny v Iberian Market (OMIE) krátkodobě zhouply, ale už se stabilizují na day ahead průměru 6 €/MWh - problém byl spíš v dopravě elektřiny, než v její výrobní ceně a cenové výkyvy jsou malé.Takže závěr?
Na závěry je brzy. Terorismu nenasvědčuje zatím nic. Ani tomu neruskému (to už by se někdo hlásil s požadavky), ani tomu ruskému (to už by Rusko nabízelo pomoc). Jenže to je také první rychlý pohled a mohlo to jistě být jinak. Logy nelžou, ale mohl je někdo uklidit. Ostatně, konspirátoři předpokládají, že teroristé po sobě poprvé pořádně uklidili stopy (což Rusové nedělají, proč někoho terorizovat, když není jasné, kdo vám dal přes pusu).
Přesto vám sem jeden ilustrační obrázek dám 😎
[image error]
A ten Green Deal? Jistě, kdyby měla pyrenejská síť více točivých zdrojů, mohla dopadnout nějak lépe - jak moc, to se teprve nasimuluje. Ale kdyby měla balanční zdroje, jako jsou baterie, také by to ustála jinak. Na slunném jihu dávají FTV a větrníky velký smysl z hlediska produkčních cen a místní operátoři byli dlouhodobě upozorňováni na to, že tomu musí svoji síť přizpůsobit. Green Deal s nedodržením zásad diverzifikace nemá mnoho společného.
Elektřina už prakticky všude svítí, ale skutečná „detektivka“ právě teď začíná. Podrobné záznamy z ochran a phasor PMU teprve ukážou, zda vedla řetěz selhání opravdu kombinace „rozkmitaných“ pyrenejských linek a nízké setrvačnosti, nebo se v poslední chvíli přidalo ještě něco dalšího.
Zpráva z 28.4.2025:Podle provozovatelů REE a REN došlo v 11:33 WES-T k „el cero“ – úplnému výpadku energetické soustavy na Pyrenejském poloostrově. Extrémní teploty v centrálním Španělsku způsobily neobvyklé kmitání 400 kV vedení. Ochrany postupně odpojily více linek a generátorů, až se Pyrenejský poloostrov oddělil (“islandoval”, přešel do ostrovního provozu) od zbytku kontinentální sítě.
V izolované oblasti pak frekvence klesla ještě hlouběji, část elektráren se odpojila a následovalo masivní zatmění (blackout) Španělska, Portugalska a části jihozápadní Francie. 
⚡️ Blackout: co se 28. 4. 2025 stalo ve Španělsku a Portugalsku?Podívejme se na událost v grafu. Z něj je vidět, že pokles byl v nejostřejším místě jen 0,15 Hz. Pojďme si to vysvětlit pro zájemce o energetiku…
Proč na kontinentu „spadlo“ jen 0,15 Hz?
Po odpojení Iberského poloostrova ztratila zbytek Evropy čistý export ~4–5 GW ze Španělska (obě země měly v poledne vysokou výrobu ze solárních a větrných zdrojů). Tato ztráta se okamžitě promítla do grafu jako −150 mHz. Primární regulace ve zbytku Evropy (turbíny, baterie, HVDC linky) během sekund začala výkon zvyšovat, čímž frekvenci zastavila u ≈ 49,85 Hz a během tří minut ji vytáhla zpět nad 49,9 Hz. Díky rychlé reakci a dostatečné setrvačnosti se kontinentální síť neodstavila – v grafu vidíte jen krátký, ale prudký zářez.[image error]
Co vidíme v grafu
Osa y (Frekvence): nominál evropské synchronní sítě je 50,00 Hz. Tři křivky (žlutá = průměr, černá = maximum, šedá = minimum) ukazují, jak se frekvence mezi ≈ 11:55 a 13:00 CEST pohybovala v různých měřicích bodech propojené soustavy. Až do ≈ 12:30 se frekvence vlnila v běžném koridoru ±20 mHz (49,98–50,02 Hz). V 12:31–12:34 nastal prudký pád až na ≈ 49,85 Hz – to je odchylka −150 mHz. Vzápětí se frekvence díky primární regulaci a automatickým zálohám vrátila k 50 Hz; kolem 12:45 už je systém opět stabilní.Co takový pokles znamená
Frekvence se sníží, když odběr náhle převýší výrobu (nebo když se naopak od sítě odpojí část výrobních kapacit). V evropské soustavě stačí nerovnováha ~30 GW / Hz; −0,15 Hz tedy odpovídá zhruba 4–5 GW náhle chybějícího výkonu.
Důsledky na Pyrenejském poloostrově
Izolovaná Iberská soustava přišla o možnost importů z Francie, které by krátkodobě pomohly stabilizaci. Protože odběr převýšil dostupnou vlastní výrobu, frekvence spadla výrazněji (pravděpodobně < 49 Hz). Ochrany odpojily další zdroje i zátěže, aby chránily zařízení, což se navenek projevilo rozsáhlým blackoutem (vlaky, metro, letiště, domácnosti). Obnova musela probíhat postupně, aby se zamezilo dalšímu kolapsu napětí a frekvence. Takže ve stručnosti:
Z pohledu zbytku Evropy šlo o „pouhou“ ztrátu ~5 GW → pokles frekvence o 0,15 Hz, rychle vyrovnaný zálohami. Z pohledu Španělska a Portugalska to znamenalo ztrátu propojení, hluboký propad frekvence a následný blackout.Taková událost názorně ukazuje, jak citlivá je moderní síť: i malá odchylka frekvence na kontinentu může signalizovat dramatické dění v jedné jeho části, a proč je klíčové mít dostatek rychlých regulačních zdrojů a chytré ochrany.
PS: je to samozřejmě můj neodborný názor založený na tom co k tomu vyšlo
⚡️ Vyšetřování blackoutu ve Španělsku a Portugalsku den za dnem (update 1.5.)
Za včerejšek mnoho novinek nebylo. Všichni zúčastnění po pondělním šoku pomalu najíždějí na informační disciplínu, která je v tomto případě užitečná, protože se ven nedostávají izolované zprávy, které lze snadno dezinterpretovat. Už dnes je jasné, že situace je velmi komplexní a nelze to vyřídit stylem “někdo hodil bombu do rozvodny”.
🇪🇸💡 1.5.2025: Jak pokračuje vyšetřování pyrenejského blackoutu?
Pro mě je také nepříjemné to, že sice se pořádají setkání s médii, z nich ale nevycházejí žádné oficiální zprávy, weby REN/REE mají jen prohlášení, že se to stalo a že to řeší, novinky nepředávají. Takže tyhle zprávy nabírám z médií a tam je často sdělení překroucené, zamlžené, protože pisatel nebyl energetik a v tomto případě na detailu záleží.
Níže pod touto sekcí najdete zprávy k události ze dne incidentu a z dalších dní, kdy jsem situaci sledoval.
První velkou novinkou je, že jsem se dostal k datům z vnitřní sítě nízkého napětí ve vteřinovém rozlišení. Neumožňuje to vypátrat lépe příčinu, ale je vidět, že první problémy byly v rozvodné síti již dopoledne (což už bylo známo dříve), někdy po 9 hodině začalo na hladině nízkého napětí oscilovat napětí až o 11V, což rozhodně není obvyklé, obvyklá bývá jednotková oscilace. Navíc se zvyšovala amplituda kmitů, byly četnější, pak se před polednem situace stabilizovala. To sedí k informacím o tom, že oscilovala frekvence na přeshraničním pyrenejském připojení, k tomuhle jevu dochází na hladině nízkého napětí, když se “přetlačují” toky ze dvou velkých sítí. Jenže taky v řadě dalších případů, takže z toho nededukujme mnoho. Dlouhé, pomalu sílící kmity nicméně naznačují nedostatečně tlumenou soustavu (málo setrvačnosti / tlumicích výkonů). Znamená to, že síť byla nestabilní několik hodin před blackoutem a dispečeři si toho museli být vědomi, zjevně se zásahy snažili síť stabilizovat. Pomalý rozjezd oscilací také spíše vylučuje terorismus, to by muselo jít o dobře cílené a synchronizované útoky.
Z oficiálních vyjádření také víme, že došlo ke dvěma vážným problémům předcházejícím blackoutu. REE uvedlo, že šlo přerušením dodávek elektřiny a zatímco se španělská síť dokázala zotavit z první události, ředitel Eduardo Prieto uvedl, že druhá byla mnohem ničivější a vyústila v přerušení dodávek elektřiny z francouzské sítě a „masivní dočasné odpojení“. Zatím nebylo oznámeno, o co šlo, některé zvěsti říkají, že v prvním případě vypadla fotovoltaika o cca 3 GW někde v Extremaduře, v druhém o 1 GW větrníků v Andalusii. Oficiálně to ale potvrzeno není.
Extremadura je fotovoltaické srdce Španělska, ale největší FTV parky zde mají max 600 MW, většinou jsou kolem 200 MW, na 3 GW výkonu by jich musela vypadnout zhruba desítka, což znamená, že jde o systémový incident, ne o náhodný nezvládnutý výpadek. Například jsou všechny FTV napojeny na stejnou páteřní trasu 400 kV Almaraz - Guillena přes čtveřici rozvoden. Proto je důležité bedlivě stanovit časovou mapu a tím se dobrat k tomu, zda se synchronně vyply FTV parky, nebo je odpojily ochrany rozvoden či 400 kV linky, protože všechny tři jevy mají jiné řešení. Podobně je to s větrníky v Andalusii.
Čili jsme zase u toho. Čekáme na závěry probíhajícího šetření ENTSO-E a přesnou časovou osu, přičemž další tisková konference snad už s detaily, má být 2.5.
Jedna věc je vtipná, všichni už si kryjí záda. REE upozornilo, že na systémovou nestabilitu sítě upozornilo ve své letošní únorové zprávě (tedy několik let poté, co jim to samé říká ENTSO-E coby šéf eurosítě).
Jinak pro zlepšení hospodské debaty: samozřejmě existují setrvačná a elastizující řešení i pro FTV a větrníky. Nemusí to být nutně baterie, ale třeba synchronní kompenzátory, flywheely nebo intertia boosty pro větrné turbíny. Řešení je celá řada, nemusíte kvůli tomu nutně vydlabat vrcholek kopce a napustit ho vodou, jenže když si to do sítě neobjednáte, tak to nemáte.
🚗 Pyrenejská rozvodná síť byl prostě nadupaný sportovní kabriolet, do kterého se daly kvůli úspoře brzdy z Felačky a v zatáčce v Pyrenejských serpentinách se to prostě vyklopilo. Buďto zakážeme výrobu sportovních vozů, nebo do nich značneme dávat odpovídající brzdy, moc víc nad tím nevymyslíme…
…okračování zítra asi odpo, až budou venku zprávy…
3️⃣🇪🇸⚡️ 30.4.2025 Co nového se španělským blackoutem?
Jak vypadá situace kolem španělského blackoutu energetické sítě? Včera se téměř vše vrátilo do normálu, zapomeňte na novinové titulky “budou se vzpamatovávat týden” - kromě specifických věcí už je (v energetice) vše v normálu. Nicméně probíhá šetření. Co víme nového? No, pokud už sami máte jasno, tak dál nečtěte, protože jasno moc není.
V zásadě byla opuštěna myšlenka gallopingu jako JEDINÉHO SPOUŠTĚČE, tedy že šest 400 kV linek přes Pyreneje do Francie odpojily ochrany kvůli nadměrnému pohybu vedení vinou proudění vzduchu. Zdá se, že k pohybu došlo, ale ten nebyl jedinou či přímou příčinou odpojení linek. Atmosférická situace nebyla nijak extrémní. Nicméně ještě probíhá vyhodnocování měření.
Už se ale spíše uvažuje o špatně nastaveném firmware ochran, protože RTE potvrdila, že se používají stejná nastavení, jako u linky 400 kV v Lotrinsku, která se loni planě odpojila.
Dnes bohužel není úplně veřejně jasné, zda k odpojení linek došlo PŘED nebo PO zlomové události, tedy jak moc velký vliv jejich přerušení mělo a zda nebylo spouštěčem blackoutu.
V každém případě již nyní je zřejmé, že došlo k celé souhře událostí, mezi něž bych neváhal přidat španělský čurbes.
Především je třeba říct, že nemáme všechna podkladová data, sice scanuju všechna patřičná média, ale v nich se objevují zprávy útržkovitě a často manipulativně. Například ten galloping, ukázalo se, nebylo oficiální vyjádření portugalského REN, ale rychlý osobní názor jednoho z dispečerů, které bylo v médiích oseknuto tak, že to vypadalo jako oficiální postoj. Stejně tak v deníku el Pais se objevila data z jednoho slide určeného pro krizové jednání vlády, které ukazovaly na konkrétní problém, jenže se později ukázalo, že v prezentaci šlo o dva slajdy a na tom prvním byl zachycený začátek události, který všemu dával jiný kontext. Za třetí se ukázalo, že jeden z důležitých logů měl posunuté časové razítko o skoro dvě minuty, protože neměl přesný čas, což na interpretaci dat vrhalo jiné světlo. Proto nutně s daty opatrně a nedělat unáhlené závěry.
Pojďme si zrekapitulovat, co víme.
Kolaps španělské přenosové soustavy byl extrémně rychlý a rozsáhlý. Během pouhých pěti sekund došlo ke ztrátě přibližně 15 gigawattů (GW) elektrického výkonu. Tato ztráta představovala zhruba 60 % okamžité celostátní poptávky po elektřině v daném okamžiku. Okamžitá poptávka ve Španělsku dramaticky poklesla z úrovně přibližně 26 000 - 27 500 megawattů (MW) na hodnoty blížící se 15 000 MW , přičemž v nejnižším bodě dosáhla pouhých 10 480 MW. Tato bezprecedentní rychlost a rozsah ztráty výkonu byly klíčovými faktory, které vedly k následnému kaskádovému selhání a rozpadu sítě.
Tohle víme vcelku jistě. Nyní je otázkou, co tu ztrátu 15 GW v síti způsobilo.
Podle první teorie to byl výpadek linek přes Pyreneje, zatím z neznámých příčin, kterých mohlo být více (kyberútok se tady zatím stále spíše neuvažuje). Při přerušeném exportu do Francie by frekvence sítě ve španělsku vyletěla nahoru (a v EU dolů) a fotovoltaické a větrné elektrárny v rozmezí 8 sekund odpojily od sítě něco jako 15-30% výkonu. Tento pokles je okamžitý, nemá prakticky žádnou elasticitu, čímž dostane frekveci pod 50 Hz a při poklesu pod 49,5 Hz se odpojily tři plynové bloky a všechny jaderné elektrárny. Ochrana zátěže následně odpojuje část odběratelů, cca 3 GW. Takhle se mohl nasbírat propad o těch 15 GW. Situaci nepomohlo to, že v dlouhodobé odstávce byl jaderný blok Vandellos 2 a v údržbě JE Trillo (čili běží dvě JE) a také to, že náhradní zdroje, které měly okamžitě nastartovat, nastartovaly mírně později, než měly. PVE Alcántara se přifázovala 110 s po oddělení a CCGT Cartagena dodal prvních 250 MW dokonce až 7 min, přičemž první dodávky měla dát už za dvě minuty. Na vině byl možná tlak plynu, ale to už je nepotvrzené.
Podle druhé teorie (zveřejněné REE) došlo k propadu výroby na dvou španělských elektrárnách zatím z neznámého důvodu, což (a to už je interpretace) spolu s dalšími faktory jako špatný firmware a galloping nebo rozhodnutí ochrany evropské sítě vedlo k rozpojení linky a kaskádě tak, jak bylo popsáno výše.
Proč se odpojily dva velké zdroje ze sítě, není zatím jasné - tady není ani náznak a počkal bych na data. V Česku se to nicméně hodilo na tuto verzi a prý to měla způsobit výroba z OZE, což není příliš pravděpodobné.
Jak se nezávisle prokáže, co bylo první, zda výpadek linky nebo zdrojů? Vcelku jednoduše: pokud frekvence stoupla na 50 Hz, znamená to převis výroby v síti, což napovídá na odpojení linky (která exportovala 5 GW do Francie). Pokud naopak frekvence klesla, tak nejprve vypadly zdroje. Bohužel přesnější grafy a časy nebyly publikovány a z veřejně dostupných dat je rozlišení malé (bavíme se o 4 sekundách rozdílu!). Zatím jediná data z údajné interní zprávy RTE cituje článek Euronews, podle nějž frekvence na kontinentální (francouzské) straně vyskočila asi na 50,20 Hz a během několika sekund se vrátila k nominálu. Grafy z kontinentální sítě ukazují, že k výpadku 5 GW (což odpovídá pyrenejské lince) vypadlo ve 12:31 a začínají nabíhat regulace ve zbytku Evropy, které situaci v Evropě dostanou během tří minut zcela pod kontrolu. Bohužel veřejné zdroje o španělské produkci elektřiny jsou agregované na pět minut, takže lze jen potvrdit, že mezi 12:30 a 12:35 došlo ke ztrátě minimálně 11 GW produkce a to nám nepomůže…
Zavržené jsou zaručené zprávy o výbuchu španělské rozvodny Sentmenat - nenese žádné takové známky.
Vysvětlení s primárním výpadkem linky by lépe vysvětlovalo, proč vypadly točivé zdroje, ale zase zůstává nejasné, proč vypadla linka, zatímco primární výpadek zdrojů lépe vysvětlí odpojení linky a zase není jasné, proč by vypadlo tolik zdrojů. Budeme si tedy muset počkat, až se objeví více dat.
Hlavní poznatky, kterými si můžeme být jisti, jsou zatím dva (a na oba byli REE/REN upozorňovány dříve):
chybí lepší propojení do Evropy, mělo by být spíše dvojnásobné až trojnásobné, teď je Pyrenejský poloostrov energeticky spíše ostrov a Evropa mu nemůže moc pomoci. Jsou potřeba další rychlostartující úložiště typu baterie.Pokračování z 29.4.2025Záhy po publikování informací o rozpadu energetické sítě na pyrenejském poloostrově se začaly šířit teorie, kdo za to může. Rusko či jiní teroristé nebo snad Green Deal? Pojďme se s tím vyrovnat.
Za prvé je potřeba říct, že vyšetřování probíhá, incident dostal nejvyšší klasifikaci ICS-3, což znamená mezinárodní odborné vyšetřování, které je na začátku. Nyní jsou více-méně jisté technické příčiny, které si zrekapitulujeme. A zároveň se nenašla kybernetická stopa, i k tomu se dostanu.
ENTSO-E (to je evropské sdružení všech provozovatelů přenosových soustav) potvrdila ztrátu více jak 10 GW během 5 s (v tiskové zprávě REE se psalo 15 GW), což je obrovsky mnoho, na to žádná síť není dimenzována. V energetické síti se spotřeba musí rovnat výrobě a jsou zálohy, ale ne 15 GW. REE a REN (provozovatelé a dispečeři přenosových soustav ve Španělsku a Portugalsku) stále pracují s hypotézou „induced atmospheric vibration“ (galloping) na svazkových vedeních přes Pyreneje; ochrany prý vedení preventivně odpojily, čímž se poloostrov izoloval v okamžiku poruchy tvořily točivé zdroje jen ≈44 % výroby; vysoký podíl FVE a VtE urychlil pád frekvence. Točivé zdroje mohou do určité míry zbrzdit “pád soustavy”, protože “absorbují” pád frekvence, oproti tomu fotovoltaika se v případě problémů okamžitě odpojuje a to síť naopak může destabilizovat. Internetem putují “zvěsti” o podivnostech v britské síti nebo o odpojení kabelu Viking Link mezi Dánskem a Británií, jenže data ničemu takovému nenasvědčují a ani patřičné instituce k tomu nic nevydaly, čili to vypadá na kachnu.Problém může být v tom “ochrany odpojily vedení”. Podle analýzy SCADA logů se nezdá, že by do dálkově servisovatelných prvků někdo přistupoval, přesto je čistě hypoteticky možné, že někdo našel nějakou kombinaci postupů, jimž vyvolal kaskádovité odpojování. Někde jsem četl názor, že přeci stačí vzít klacek a vedení přes Pyreneje rozhoupat, aby hrozilo jeho zkratování. To jistě stačí, když vezmete asi stometrový klacek a nevadí vám ta trocha popálenin, kdy vás do nemocnice vás v krabičce od bot. A jelikož k mechanickému poškození (typu exploze) nedošlo, zatím se pracuje s tezí, že ochrany reagovaly příliš agresivně, než že by je k tomu někdo či něco donutilo. Ale uvidíme, tady je na závěry brzy a z pražské kanceláře rozhodně.
Co se děje teď?
Španělsko oznámilo, že od půl sedmé našeho času pokrývá 99 % celostátní poptávky a všechny hlavní uzly vysokého napětí jsou pod napětím . Portugalsko již včera informovalo o napájení 85 z 89 stanic; poslední venkovské okruhy se budou připojovat v průběhu dneška . Nouzové linky Francie - Katalánsko a Maroko - Andalusie zůstávají otevřené, aby pomohly s vyrovnáním výkonu během startu tepelných elektráren Doprava: Z kolejí bylo evakuováno více jak 35 000 cestujících, metro v Madridu a Lisabonu zprovoznilo první linky až dnes ráno . Letiště: Madrid-Barajas i Barcelona-El Prat fungovaly na záložních okruzích; terminály zůstaly osvětlené, ale došlo ke zrušení více jak 400 letů . Telekomunikace: mobilní sítě jely v nouzovém režimu na baterie — operátoři vyzvali uživatele ke střídmému volání, což prý úplně neklapalo, ranní interview na ČRo s reportérkou ze Španělska rušily výpadky. Veřejný pořádek: Španělsko rozmístilo 30 000 policistů; král Filip dnes vede zasedání Národní bezpečnostní rady . Francie a Německo slíbily pomoc s mobilními bateriovými kontejnery a rychlými plynovými turbínami, pokud by přišly další vlny horka . Velkoobchodní cena elektřiny v Iberian Market (OMIE) krátkodobě zhouply, ale už se stabilizují na day ahead průměru 6 €/MWh - problém byl spíš v dopravě elektřiny, než v její výrobní ceně a cenové výkyvy jsou malé.Takže závěr?
Na závěry je brzy. Terorismu nenasvědčuje zatím nic. Ani tomu neruskému (to už by se někdo hlásil s požadavky), ani tomu ruskému (to už by Rusko nabízelo pomoc). Jenže to je také první rychlý pohled a mohlo to jistě být jinak. Logy nelžou, ale mohl je někdo uklidit. Ostatně, konspirátoři předpokládají, že teroristé po sobě poprvé pořádně uklidili stopy (což Rusové nedělají, proč někoho terorizovat, když není jasné, kdo vám dal přes pusu).
Přesto vám sem jeden ilustrační obrázek dám 😎
[image error]
A ten Green Deal? Jistě, kdyby měla pyrenejská síť více točivých zdrojů, mohla dopadnout nějak lépe - jak moc, to se teprve nasimuluje. Ale kdyby měla balanční zdroje, jako jsou baterie, také by to ustála jinak. Na slunném jihu dávají FTV a větrníky velký smysl z hlediska produkčních cen a místní operátoři byli dlouhodobě upozorňováni na to, že tomu musí svoji síť přizpůsobit. Green Deal s nedodržením zásad diverzifikace nemá mnoho společného.
Elektřina už prakticky všude svítí, ale skutečná „detektivka“ právě teď začíná. Podrobné záznamy z ochran a phasor PMU teprve ukážou, zda vedla řetěz selhání opravdu kombinace „rozkmitaných“ pyrenejských linek a nízké setrvačnosti, nebo se v poslední chvíli přidalo ještě něco dalšího.
Zpráva z 28.4.2025:Podle provozovatelů REE a REN došlo v 11:33 WES-T k „el cero“ – úplnému výpadku energetické soustavy na Pyrenejském poloostrově. Extrémní teploty v centrálním Španělsku způsobily neobvyklé kmitání 400 kV vedení. Ochrany postupně odpojily více linek a generátorů, až se Pyrenejský poloostrov oddělil (“islandoval”, přešel do ostrovního provozu) od zbytku kontinentální sítě.
V izolované oblasti pak frekvence klesla ještě hlouběji, část elektráren se odpojila a následovalo masivní zatmění (blackout) Španělska, Portugalska a části jihozápadní Francie. 
⚡️ Blackout: co se 28. 4. 2025 stalo ve Španělsku a Portugalsku?Podívejme se na událost v grafu. Z něj je vidět, že pokles byl v nejostřejším místě jen 0,15 Hz. Pojďme si to vysvětlit pro zájemce o energetiku…
Proč na kontinentu „spadlo“ jen 0,15 Hz?
Po odpojení Iberského poloostrova ztratila zbytek Evropy čistý export ~4–5 GW ze Španělska (obě země měly v poledne vysokou výrobu ze solárních a větrných zdrojů). Tato ztráta se okamžitě promítla do grafu jako −150 mHz. Primární regulace ve zbytku Evropy (turbíny, baterie, HVDC linky) během sekund začala výkon zvyšovat, čímž frekvenci zastavila u ≈ 49,85 Hz a během tří minut ji vytáhla zpět nad 49,9 Hz. Díky rychlé reakci a dostatečné setrvačnosti se kontinentální síť neodstavila – v grafu vidíte jen krátký, ale prudký zářez.[image error]
Co vidíme v grafu
Osa y (Frekvence): nominál evropské synchronní sítě je 50,00 Hz. Tři křivky (žlutá = průměr, černá = maximum, šedá = minimum) ukazují, jak se frekvence mezi ≈ 11:55 a 13:00 CEST pohybovala v různých měřicích bodech propojené soustavy. Až do ≈ 12:30 se frekvence vlnila v běžném koridoru ±20 mHz (49,98–50,02 Hz). V 12:31–12:34 nastal prudký pád až na ≈ 49,85 Hz – to je odchylka −150 mHz. Vzápětí se frekvence díky primární regulaci a automatickým zálohám vrátila k 50 Hz; kolem 12:45 už je systém opět stabilní.Co takový pokles znamená
Frekvence se sníží, když odběr náhle převýší výrobu (nebo když se naopak od sítě odpojí část výrobních kapacit). V evropské soustavě stačí nerovnováha ~30 GW / Hz; −0,15 Hz tedy odpovídá zhruba 4–5 GW náhle chybějícího výkonu.
Důsledky na Pyrenejském poloostrově
Izolovaná Iberská soustava přišla o možnost importů z Francie, které by krátkodobě pomohly stabilizaci. Protože odběr převýšil dostupnou vlastní výrobu, frekvence spadla výrazněji (pravděpodobně < 49 Hz). Ochrany odpojily další zdroje i zátěže, aby chránily zařízení, což se navenek projevilo rozsáhlým blackoutem (vlaky, metro, letiště, domácnosti). Obnova musela probíhat postupně, aby se zamezilo dalšímu kolapsu napětí a frekvence. Takže ve stručnosti:
Z pohledu zbytku Evropy šlo o „pouhou“ ztrátu ~5 GW → pokles frekvence o 0,15 Hz, rychle vyrovnaný zálohami. Z pohledu Španělska a Portugalska to znamenalo ztrátu propojení, hluboký propad frekvence a následný blackout.Taková událost názorně ukazuje, jak citlivá je moderní síť: i malá odchylka frekvence na kontinentu může signalizovat dramatické dění v jedné jeho části, a proč je klíčové mít dostatek rychlých regulačních zdrojů a chytré ochrany.
PS: je to samozřejmě můj neodborný názor založený na tom co k tomu vyšlo
Byl španělský blackout dílo teroristů či Green Dealu? (update 30.4.)
3️⃣🇪🇸⚡️ 30.4.2025 Co nového se španělským blackoutem?
Jak vypadá situace kolem španělského blackoutu energetické sítě? Včera se téměř vše vrátilo do normálu, zapomeňte na novinové titulky “budou se vzpamatovávat týden” - kromě specifických věcí už je (v energetice) vše v normálu. Nicméně probíhá šetření. Co víme nového? No, pokud už sami máte jasno, tak dál nečtěte, protože jasno moc není.
Níže pod touto sekcí najdete zprávy k události ze dne incidentu a z dalších dní, kdy jsem situaci sledoval.
V zásadě byla opuštěna myšlenka gallopingu jako JEDINÉHO SPOUŠTĚČE, tedy že šest 400 kV linek přes Pyreneje do Francie odpojily ochrany kvůli nadměrnému pohybu vedení vinou proudění vzduchu. Zdá se, že k pohybu došlo, ale ten nebyl jedinou či přímou příčinou odpojení linek. Atmosférická situace nebyla nijak extrémní. Nicméně ještě probíhá vyhodnocování měření.
Už se ale spíše uvažuje o špatně nastaveném firmware ochran, protože RTE potvrdila, že se používají stejná nastavení, jako u linky 400 kV v Lotrinsku, která se loni planě odpojila.
Dnes bohužel není úplně veřejně jasné, zda k odpojení linek došlo PŘED nebo PO zlomové události, tedy jak moc velký vliv jejich přerušení mělo a zda nebylo spouštěčem blackoutu.
V každém případě již nyní je zřejmé, že došlo k celé souhře událostí, mezi něž bych neváhal přidat španělský čurbes.
Především je třeba říct, že nemáme všechna podkladová data, sice scanuju všechna patřičná média, ale v nich se objevují zprávy útržkovitě a často manipulativně. Například ten galloping, ukázalo se, nebylo oficiální vyjádření portugalského REN, ale rychlý osobní názor jednoho z dispečerů, které bylo v médiích oseknuto tak, že to vypadalo jako oficiální postoj. Stejně tak v deníku el Pais se objevila data z jednoho slide určeného pro krizové jednání vlády, které ukazovaly na konkrétní problém, jenže se později ukázalo, že v prezentaci šlo o dva lidé a na tom prvním byl zachycený začátek události, který všemu dával jiný kontext. Za třetí se ukázalo, že jeden z důležitých logů měl posunuté časové razítko o skoro dvě minuty, protože neměl přesný čas, což na interpretaci dat vrhalo jiné světlo. Proto nutně s daty opatrně a nedělat unáhlené závěry.
Pojďme si zrekapitulovat, co víme.
Kolaps španělské přenosové soustavy byl extrémně rychlý a rozsáhlý. Během pouhých pěti sekund došlo ke ztrátě přibližně 15 gigawattů (GW) elektrického výkonu. Tato ztráta představovala zhruba 60 % okamžité celostátní poptávky po elektřině v daném okamžiku. Okamžitá poptávka ve Španělsku dramaticky poklesla z úrovně přibližně 26 000 - 27 500 megawattů (MW) na hodnoty blížící se 15 000 MW , přičemž v nejnižším bodě dosáhla pouhých 10 480 MW. Tato bezprecedentní rychlost a rozsah ztráty výkonu byly klíčovými faktory, které vedly k následnému kaskádovému selhání a rozpadu sítě.
Tohle víme vcelku jistě. Nyní je otázkou, co tu ztrátu 15 GW v síti způsobilo.
Podle první teorie to byl výpadek linek přes Pyreneje, zatím z neznámých příčin, kterých mohlo být více (kyberútok se tady zatím stále spíše neuvažuje). Při přerušeném exportu do Francie by frekvence sítě ve španělsku vyletěla nahoru (a v EU dolů) a fotovoltaické a větrné elektrárny v rozmezí 8 sekund odpojily od sítě něco jako 15-30% výkonu. Tento pokles je okamžitý, nemá prakticky žádnou elasticitu, čímž dostane frekveci pod 50 Hz a při poklesu pod 49,5 Hz se odpojily tři plynové bloky a všechny jaderné elektrárny. Ochrana zátěže následně odpojuje část odběratelů, cca 3 GW. Takhle se mohl nasbírat propad o těch 15 GW. Situaci nepomohlo to, že v dlouhodobé odstávce byl jaderný blok Vandellos 2 a v údržbě JE Trillo (čili běží dvě JE) a také to, že náhradní zdroje, které měly okamžitě nastartovat, nastartovaly mírně později, než měly. PVE Alcántara se přifázovala 110 s po oddělení a CCGT Cartagena dodal prvních 250 MW dokonce až 7 min, přičemž první dodávky měla dát už za dvě minuty. Na vině byl možná tlak plynu, ale to už je nepotvrzené.
Podle druhé teorie (zveřejněné REE) došlo k propadu výroby na dvou španělských elektrárnách zatím z neznámého důvodu, což (a to už je interpretace) spolu s dalšími faktory jako špatný firmware a galloping nebo rozhodnutí ochrany evropské sítě vedlo k rozpojení linky a kaskádě tak, jak bylo popsáno výše.
Proč se odpojily dva velké zdroje ze sítě, není zatím jasné - tady není ani náznak a počkal bych na data. V Česku se to nicméně hodilo na tuto verzi a prý to měla způsobit výroba z OZE, což není příliš pravděpodobné.
Jak se nezávisle prokáže, co bylo první, zda výpadek linky nebo zdrojů? Vcelku jednoduše: pokud frekvence stoupla na 50 Hz, znamená to převis výroby v síti, což napovídá na odpojení linky (která exportovala 5 GW do Francie). Pokud naopak frekvence klesla, tak nejprve vypadly zdroje. Bohužel přesnější grafy a časy nebyly publikovány a z veřejně dostupných dat je rozlišení malé (bavíme se o 4 sekundách rozdílu!). Zatím jediná data z údajné interní zprávy RTE cituje článek Euronews, podle nějž frekvence na kontinentální (francouzské) straně vyskočila asi na 50,20 Hz a během několika sekund se vrátila k nominálu. Grafy z kontinentální sítě ukazují, že k výpadku 5 GW (což odpovídá pyrenejské lince) vypadlo ve 12:31 a začínají nabíhat regulace ve zbytku Evropy, které situaci v Evropě dostanou během tří minut zcela pod kontrolu. Bohužel veřejné zdroje o španělské produkci elektřiny jsou agregované na pět minut, takže lze jen potvrdit, že mezi 12:30 a 12:35 došlo ke ztrátě minimálně 11 GW produkce a to nám nepomůže…
Zavržené jsou zaručené zprávy o výbuchu španělské rozvodny Sentmenat - nenese žádné takové známky.
Vysvětlení s primárním výpadkem linky by lépe vysvětlovalo, proč vypadly točivé zdroje, ale zase zůstává nejasné, proč vypadla linka, zatímco primární výpadek zdrojů lépe vysvětlí odpojení linky a zase není jasné, proč by vypadlo tolik zdrojů. Budeme si tedy muset počkat, až se objeví více dat.
Hlavní poznatky, kterými si můžeme být jisti, jsou zatím dva (a na oba byli REE/REN upozorňovány dříve):
chybí lepší propojení do Evropy, mělo by být spíše dvojnásobné až trojnásobné, teď je Pyrenejský poloostrov energeticky spíše ostrov a Evropa mu nemůže moc pomoci. Jsou potřeba další rychlostartující úložiště typu baterie.Pokračování z 29.4.2025Záhy po publikování informací o rozpadu energetické sítě na pyrenejském poloostrově se začaly šířit teorie, kdo za to může. Rusko či jiní teroristé nebo snad Green Deal? Pojďme se s tím vyrovnat.
Za prvé je potřeba říct, že vyšetřování probíhá, incident dostal nejvyšší klasifikaci ICS-3, což znamená mezinárodní odborné vyšetřování, které je na začátku. Nyní jsou více-méně jisté technické příčiny, které si zrekapitulujeme. A zároveň se nenašla kybernetická stopa, i k tomu se dostanu.
ENTSO-E (to je evropské sdružení všech provozovatelů přenosových soustav) potvrdila ztrátu více jak 10 GW během 5 s (v tiskové zprávě REE se psalo 15 GW), což je obrovsky mnoho, na to žádná síť není dimenzována. V energetické síti se spotřeba musí rovnat výrobě a jsou zálohy, ale ne 15 GW. REE a REN (provozovatelé a dispečeři přenosových soustav ve Španělsku a Portugalsku) stále pracují s hypotézou „induced atmospheric vibration“ (galloping) na svazkových vedeních přes Pyreneje; ochrany prý vedení preventivně odpojily, čímž se poloostrov izoloval v okamžiku poruchy tvořily točivé zdroje jen ≈44 % výroby; vysoký podíl FVE a VtE urychlil pád frekvence. Točivé zdroje mohou do určité míry zbrzdit “pád soustavy”, protože “absorbují” pád frekvence, oproti tomu fotovoltaika se v případě problémů okamžitě odpojuje a to síť naopak může destabilizovat. Internetem putují “zvěsti” o podivnostech v britské síti nebo o odpojení kabelu Viking Link mezi Dánskem a Británií, jenže data ničemu takovému nenasvědčují a ani patřičné instituce k tomu nic nevydaly, čili to vypadá na kachnu.Problém může být v tom “ochrany odpojily vedení”. Podle analýzy SCADA logů se nezdá, že by do dálkově servisovatelných prvků někdo přistupoval, přesto je čistě hypoteticky možné, že někdo našel nějakou kombinaci postupů, jimž vyvolal kaskádovité odpojování. Někde jsem četl názor, že přeci stačí vzít klacek a vedení přes Pyreneje rozhoupat, aby hrozilo jeho zkratování. To jistě stačí, když vezmete asi stometrový klacek a nevadí vám ta trocha popálenin, kdy vás do nemocnice vás v krabičce od bot. A jelikož k mechanickému poškození (typu exploze) nedošlo, zatím se pracuje s tezí, že ochrany reagovaly příliš agresivně, než že by je k tomu někdo či něco donutilo. Ale uvidíme, tady je na závěry brzy a z pražské kanceláře rozhodně.
Co se děje teď?
Španělsko oznámilo, že od půl sedmé našeho času pokrývá 99 % celostátní poptávky a všechny hlavní uzly vysokého napětí jsou pod napětím . Portugalsko již včera informovalo o napájení 85 z 89 stanic; poslední venkovské okruhy se budou připojovat v průběhu dneška . Nouzové linky Francie - Katalánsko a Maroko - Andalusie zůstávají otevřené, aby pomohly s vyrovnáním výkonu během startu tepelných elektráren Doprava: Z kolejí bylo evakuováno více jak 35 000 cestujících, metro v Madridu a Lisabonu zprovoznilo první linky až dnes ráno . Letiště: Madrid-Barajas i Barcelona-El Prat fungovaly na záložních okruzích; terminály zůstaly osvětlené, ale došlo ke zrušení více jak 400 letů . Telekomunikace: mobilní sítě jely v nouzovém režimu na baterie — operátoři vyzvali uživatele ke střídmému volání, což prý úplně neklapalo, ranní interview na ČRo s reportérkou ze Španělska rušily výpadky. Veřejný pořádek: Španělsko rozmístilo 30 000 policistů; král Filip dnes vede zasedání Národní bezpečnostní rady . Francie a Německo slíbily pomoc s mobilními bateriovými kontejnery a rychlými plynovými turbínami, pokud by přišly další vlny horka . Velkoobchodní cena elektřiny v Iberian Market (OMIE) krátkodobě zhouply, ale už se stabilizují na day ahead průměru 6 €/MWh - problém byl spíš v dopravě elektřiny, než v její výrobní ceně a cenové výkyvy jsou malé.Takže závěr?
Na závěry je brzy. Terorismu nenasvědčuje zatím nic. Ani tomu neruskému (to už by se někdo hlásil s požadavky), ani tomu ruskému (to už by Rusko nabízelo pomoc). Jenže to je také první rychlý pohled a mohlo to jistě být jinak. Logy nelžou, ale mohl je někdo uklidit. Ostatně, konspirátoři předpokládají, že teroristé po sobě poprvé pořádně uklidili stopy (což Rusové nedělají, proč někoho terorizovat, když není jasné, kdo vám dal přes pusu).
Přesto vám sem jeden ilustrační obrázek dám 😎
[image error]
A ten Green Deal? Jistě, kdyby měla pyrenejská síť více točivých zdrojů, mohla dopadnout nějak lépe - jak moc, to se teprve nasimuluje. Ale kdyby měla balanční zdroje, jako jsou baterie, také by to ustála jinak. Na slunném jihu dávají FTV a větrníky velký smysl z hlediska produkčních cen a místní operátoři byli dlouhodobě upozorňováni na to, že tomu musí svoji síť přizpůsobit. Green Deal s nedodržením zásad diverzifikace nemá mnoho společného.
Elektřina už prakticky všude svítí, ale skutečná „detektivka“ právě teď začíná. Podrobné záznamy z ochran a phasor PMU teprve ukážou, zda vedla řetěz selhání opravdu kombinace „rozkmitaných“ pyrenejských linek a nízké setrvačnosti, nebo se v poslední chvíli přidalo ještě něco dalšího.
Zpráva z 28.4.2025:Podle provozovatelů REE a REN došlo v 11:33 WES-T k „el cero“ – úplnému výpadku energetické soustavy na Pyrenejském poloostrově. Extrémní teploty v centrálním Španělsku způsobily neobvyklé kmitání 400 kV vedení. Ochrany postupně odpojily více linek a generátorů, až se Pyrenejský poloostrov oddělil (“islandoval”, přešel do ostrovního provozu) od zbytku kontinentální sítě.
V izolované oblasti pak frekvence klesla ještě hlouběji, část elektráren se odpojila a následovalo masivní zatmění (blackout) Španělska, Portugalska a části jihozápadní Francie. 
⚡️ Blackout: co se 28. 4. 2025 stalo ve Španělsku a Portugalsku?Podívejme se na událost v grafu. Z něj je vidět, že pokles byl v nejostřejším místě jen 0,15 Hz. Pojďme si to vysvětlit pro zájemce o energetiku…
Proč na kontinentu „spadlo“ jen 0,15 Hz?
Po odpojení Iberského poloostrova ztratila zbytek Evropy čistý export ~4–5 GW ze Španělska (obě země měly v poledne vysokou výrobu ze solárních a větrných zdrojů). Tato ztráta se okamžitě promítla do grafu jako −150 mHz. Primární regulace ve zbytku Evropy (turbíny, baterie, HVDC linky) během sekund začala výkon zvyšovat, čímž frekvenci zastavila u ≈ 49,85 Hz a během tří minut ji vytáhla zpět nad 49,9 Hz. Díky rychlé reakci a dostatečné setrvačnosti se kontinentální síť neodstavila – v grafu vidíte jen krátký, ale prudký zářez.[image error]
Co vidíme v grafu
Osa y (Frekvence): nominál evropské synchronní sítě je 50,00 Hz. Tři křivky (žlutá = průměr, černá = maximum, šedá = minimum) ukazují, jak se frekvence mezi ≈ 11:55 a 13:00 CEST pohybovala v různých měřicích bodech propojené soustavy. Až do ≈ 12:30 se frekvence vlnila v běžném koridoru ±20 mHz (49,98–50,02 Hz). V 12:31–12:34 nastal prudký pád až na ≈ 49,85 Hz – to je odchylka −150 mHz. Vzápětí se frekvence díky primární regulaci a automatickým zálohám vrátila k 50 Hz; kolem 12:45 už je systém opět stabilní.Co takový pokles znamená
Frekvence se sníží, když odběr náhle převýší výrobu (nebo když se naopak od sítě odpojí část výrobních kapacit). V evropské soustavě stačí nerovnováha ~30 GW / Hz; −0,15 Hz tedy odpovídá zhruba 4–5 GW náhle chybějícího výkonu.
Důsledky na Pyrenejském poloostrově
Izolovaná Iberská soustava přišla o možnost importů z Francie, které by krátkodobě pomohly stabilizaci. Protože odběr převýšil dostupnou vlastní výrobu, frekvence spadla výrazněji (pravděpodobně < 49 Hz). Ochrany odpojily další zdroje i zátěže, aby chránily zařízení, což se navenek projevilo rozsáhlým blackoutem (vlaky, metro, letiště, domácnosti). Obnova musela probíhat postupně, aby se zamezilo dalšímu kolapsu napětí a frekvence. Takže ve stručnosti:
Z pohledu zbytku Evropy šlo o „pouhou“ ztrátu ~5 GW → pokles frekvence o 0,15 Hz, rychle vyrovnaný zálohami. Z pohledu Španělska a Portugalska to znamenalo ztrátu propojení, hluboký propad frekvence a následný blackout.Taková událost názorně ukazuje, jak citlivá je moderní síť: i malá odchylka frekvence na kontinentu může signalizovat dramatické dění v jedné jeho části, a proč je klíčové mít dostatek rychlých regulačních zdrojů a chytré ochrany.
PS: je to samozřejmě můj neodborný názor založený na tom co k tomu vyšlo
Byl španělský blackout dílo teroristů či Green Dealu?
Podle provozovatelů REE a REN došlo v 11:33 WES-T k „el cero“ – úplnému výpadku energetické soustavy na Pyrenejském poloostrově. Extrémní teploty v centrálním Španělsku způsobily neobvyklé kmitání 400 kV vedení. Ochrany postupně odpojily více linek a generátorů, až se Pyrenejský poloostrov oddělil (“islandoval”, přešel do ostrovního provozu) od zbytku kontinentální sítě.
V izolované oblasti pak frekvence klesla ještě hlouběji, část elektráren se odpojila a následovalo masivní zatmění (blackout) Španělska, Portugalska a části jihozápadní Francie. 
⚡️ Blackout: co se 28. 4. 2025 stalo ve Španělsku a Portugalsku?Podívejme se na událost v grafu. Z něj je vidět, že pokles byl v nejostřejším místě jen 0,15 Hz. Pojďme si to vysvětlit pro zájemce o energetiku…
Proč na kontinentu „spadlo“ jen 0,15 Hz?
Po odpojení Iberského poloostrova ztratila zbytek Evropy čistý export ~4–5 GW ze Španělska (obě země měly v poledne vysokou výrobu ze solárních a větrných zdrojů). Tato ztráta se okamžitě promítla do grafu jako −150 mHz. Primární regulace ve zbytku Evropy (turbíny, baterie, HVDC linky) během sekund začala výkon zvyšovat, čímž frekvenci zastavila u ≈ 49,85 Hz a během tří minut ji vytáhla zpět nad 49,9 Hz. Díky rychlé reakci a dostatečné setrvačnosti se kontinentální síť neodstavila – v grafu vidíte jen krátký, ale prudký zářez.[image error]
Co vidíme v grafu
Osa y (Frekvence): nominál evropské synchronní sítě je 50,00 Hz. Tři křivky (žlutá = průměr, černá = maximum, šedá = minimum) ukazují, jak se frekvence mezi ≈ 11:55 a 13:00 CEST pohybovala v různých měřicích bodech propojené soustavy. Až do ≈ 12:30 se frekvence vlnila v běžném koridoru ±20 mHz (49,98–50,02 Hz). V 12:31–12:34 nastal prudký pád až na ≈ 49,85 Hz – to je odchylka −150 mHz. Vzápětí se frekvence díky primární regulaci a automatickým zálohám vrátila k 50 Hz; kolem 12:45 už je systém opět stabilní.Co takový pokles znamená
Frekvence se sníží, když odběr náhle převýší výrobu (nebo když se naopak od sítě odpojí část výrobních kapacit). V evropské soustavě stačí nerovnováha ~30 GW / Hz; −0,15 Hz tedy odpovídá zhruba 4–5 GW náhle chybějícího výkonu.
Důsledky na Pyrenejském poloostrově
Izolovaná Iberská soustava přišla o možnost importů z Francie, které by krátkodobě pomohly stabilizaci. Protože odběr převýšil dostupnou vlastní výrobu, frekvence spadla výrazněji (pravděpodobně < 49 Hz). Ochrany odpojily další zdroje i zátěže, aby chránily zařízení, což se navenek projevilo rozsáhlým blackoutem (vlaky, metro, letiště, domácnosti). Obnova musela probíhat postupně, aby se zamezilo dalšímu kolapsu napětí a frekvence. Takže ve stručnosti:
Z pohledu zbytku Evropy šlo o „pouhou“ ztrátu ~5 GW → pokles frekvence o 0,15 Hz, rychle vyrovnaný zálohami. Z pohledu Španělska a Portugalska to znamenalo ztrátu propojení, hluboký propad frekvence a následný blackout.Taková událost názorně ukazuje, jak citlivá je moderní síť: i malá odchylka frekvence na kontinentu může signalizovat dramatické dění v jedné jeho části, a proč je klíčové mít dostatek rychlých regulačních zdrojů a chytré ochrany.
PS: je to samozřejmě můj neodborný názor založený na tom co k tomu vyšlo
Pokračování z 29.4.2025Záhy po publikování informací o rozpadu energetické sítě na pyrenejském poloostrově se začaly šířit teorie, kdo za to může. Rusko či jiní teroristé nebo snad Green Deal? Pojďme se s tím vyrovnat.
Za prvé je potřeba říct, že vyšetřování probíhá, incident dostal nejvyšší klasifikaci ICS-3, což znamená mezinárodní odborné vyšetřování, které je na začátku. Nyní jsou více-méně jisté technické příčiny, které si zrekapitulujeme. A zároveň se nenašla kybernetická stopa, i k tomu se dostanu.
ENTSO-E (to je evropské sdružení všech provozovatelů přenosových soustav) potvrdila ztrátu více jak 10 GW během 5 s (v tiskové zprávě REE se psalo 15 GW), což je obrovsky mnoho, na to žádná síť není dimenzována. V energetické síti se spotřeba musí rovnat výrobě a jsou zálohy, ale ne 15 GW. REE a REN (provozovatelé a dispečeři přenosových soustav ve Španělsku a Portugalsku) stále pracují s hypotézou „induced atmospheric vibration“ (galloping) na svazkových vedeních přes Pyreneje; ochrany prý vedení preventivně odpojily, čímž se poloostrov izoloval v okamžiku poruchy tvořily točivé zdroje jen ≈44 % výroby; vysoký podíl FVE a VtE urychlil pád frekvence. Točivé zdroje mohou do určité míry zbrzdit “pád soustavy”, protože “absorbují” pád frekvence, oproti tomu fotovoltaika se v případě problémů okamžitě odpojuje a to síť naopak může destabilizovat. Internetem putují “zvěsti” o podivnostech v britské síti nebo o odpojení kabelu Viking Link mezi Dánskem a Británií, jenže data ničemu takovému nenasvědčují a ani patřičné instituce k tomu nic nevydaly, čili to vypadá na kachnu.Problém může být v tom “ochrany odpojily vedení”. Podle analýzy SCADA logů se nezdá, že by do dálkově servisovatelných prvků někdo přistupoval, přesto je čistě hypoteticky možné, že někdo našel nějakou kombinaci postupů, jimž vyvolal kaskádovité odpojování. Někde jsem četl názor, že přeci stačí vzít klacek a vedení přes Pyreneje rozhoupat, aby hrozilo jeho zkratování. To jistě stačí, když vezmete asi stometrový klacek a nevadí vám ta trocha popálenin, kdy vás do nemocnice vás v krabičce od bot. A jelikož k mechanickému poškození (typu exploze) nedošlo, zatím se pracuje s tezí, že ochrany reagovaly příliš agresivně, než že by je k tomu někdo či něco donutilo. Ale uvidíme, tady je na závěry brzy a z pražské kanceláře rozhodně.
Co se děje teď?
Španělsko oznámilo, že od půl sedmé našeho času pokrývá 99 % celostátní poptávky a všechny hlavní uzly vysokého napětí jsou pod napětím . Portugalsko již včera informovalo o napájení 85 z 89 stanic; poslední venkovské okruhy se budou připojovat v průběhu dneška . Nouzové linky Francie - Katalánsko a Maroko - Andalusie zůstávají otevřené, aby pomohly s vyrovnáním výkonu během startu tepelných elektráren Doprava: Z kolejí bylo evakuováno více jak 35 000 cestujících, metro v Madridu a Lisabonu zprovoznilo první linky až dnes ráno . Letiště: Madrid-Barajas i Barcelona-El Prat fungovaly na záložních okruzích; terminály zůstaly osvětlené, ale došlo ke zrušení více jak 400 letů . Telekomunikace: mobilní sítě jely v nouzovém režimu na baterie — operátoři vyzvali uživatele ke střídmému volání, což prý úplně neklapalo, ranní interview na ČRo s reportérkou ze Španělska rušily výpadky. Veřejný pořádek: Španělsko rozmístilo 30 000 policistů; král Filip dnes vede zasedání Národní bezpečnostní rady . Francie a Německo slíbily pomoc s mobilními bateriovými kontejnery a rychlými plynovými turbínami, pokud by přišly další vlny horka . Velkoobchodní cena elektřiny v Iberian Market (OMIE) krátkodobě zhouply, ale už se stabilizují na day ahead průměru 6 €/MWh - problém byl spíš v dopravě elektřiny, než v její výrobní ceně a cenové výkyvy jsou malé.Takže závěr?
Na závěry je brzy. Terorismu nenasvědčuje zatím nic. Ani tomu neruskému (to už by se někdo hlásil s požadavky), ani tomu ruskému (to už by Rusko nabízelo pomoc). Jenže to je také první rychlý pohled a mohlo to jistě být jinak. Logy nelžou, ale mohl je někdo uklidit. Ostatně, konspirátoři předpokládají, že teroristé po sobě poprvé pořádně uklidili stopy (což Rusové nedělají, proč někoho terorizovat, když není jasné, kdo vám dal přes pusu).
Přesto vám sem jeden ilustrační obrázek dám 😎
[image error]
A ten Green Deal? Jistě, kdyby měla pyrenejská síť více točivých zdrojů, mohla dopadnout nějak lépe - jak moc, to se teprve nasimuluje. Ale kdyby měla balanční zdroje, jako jsou baterie, také by to ustála jinak. Na slunném jihu dávají FTV a větrníky velký smysl z hlediska produkčních cen a místní operátoři byli dlouhodobě upozorňováni na to, že tomu musí svoji síť přizpůsobit. Green Deal s nedodržením zásad diverzifikace nemá mnoho společného.
Elektřina už prakticky všude svítí, ale skutečná „detektivka“ právě teď začíná. Podrobné záznamy z ochran a phasor PMU teprve ukážou, zda vedla řetěz selhání opravdu kombinace „rozkmitaných“ pyrenejských linek a nízké setrvačnosti, nebo se v poslední chvíli přidalo ještě něco dalšího.
April 27, 2025
Čínské AI posiluje, vlastní GPU nadohled. A další dubnové novinky v AI aplikacích
Pojďme se podívat na průlet novinkami v AI na druhou půlku dubna. A ano, máte pravdu, novinky se hromadí! Čínské společnosti představily nové konkurenty pro západní modely, OpenAI pokračuje v rozšiřování svého ekosystému, a i menší hráči přicházejí s inovativními technologiemi. Pojďme se podívat na nejdůležitější oznámení, která formují budoucnost umělé inteligence.
Baidu: Cenově dostupné “Turbo” modelyČínský technologický gigant Baidu vstupuje do přímé konkurence s OpenAI a DeepSeek prostřednictvím svých nových cenově výhodných modelů ERNIE 4.5 Turbo a ERNIE X1 Turbo.
ERNIE 4.5 Turbo nabízí pokročilé multimodální schopnosti za pouhých 11 centů a 44 centů za milion vstupních/výstupních tokenů, což představuje pouhých 0,2 % ceny GPT-4.5. Model vyniká rychlostí, logickým uvažováním, redukcí halucinací a programovacími schopnostmi. Podle benchmarků obstojí ve srovnání s GPT-4.1 a v některých měřeních dokonce překonává GPT-4o.
ERNIE X1 Turbo, navržený pro hloubkové přemýšlení s vylepšenými schopnostmi řetězení myšlenek (chain-of-thought), se prodává za 14 centů a 55 centů za milion vstupních/výstupních tokenů, čímž překonává modely DeepSeek R1 a V3 nejen výkonem, ale i cenou, která je jen zlomkem ceny jeho předchůdce.
Baidu současně oznámilo několik nových AI aplikací. Nejpozoruhodnější je Xinxiang, aplikace pro multi-agentní spolupráci, která transformuje jednotlivé pokyny do kompletních pracovních postupů napříč 200 typy úloh, s plány na rozšíření až na 100 000. Společnost také představila nový operační systém Cangzhou OS, který usnadňuje multimodální vytváření poznámek.
Svou AI Open Initiative a standard MCP společnost Baidu cílí na usnadnění vývoje aplikací na těchto modelech. Jak uvedl Robin Li na konferenci Baidu Create 2025: “Modely jsou důležité, ale skutečnými vítězi budou aplikace, které je oživí.”
OpenAI: Rozšíření funkcí a přístupnostiOpenAI nezůstává pozadu a nadále rozšiřuje svůj ekosystém produktů a služeb:
Deep Research MiniOpenAI představil odlehčenou verzi své funkce Deep Research, která zpřístupňuje pokročilé výzkumné nástroje širšímu okruhu uživatelů. Tato “odlehčená” verze, poháněná modelem o4-mini, je “téměř stejně inteligentní” jako plnohodnotná verze, ale poskytuje kratší odpovědi a spotřebovává méně zdrojů. Společnost rozšířila limity používání pro uživatele úrovní Plus, Team a Pro a zpřístupnila tuto funkci i bezplatným uživatelům. Jakmile jsou vyčerpány limity pro plnou verzi, dotazy uživatelů se automaticky přepnou na odlehčenou verzi.
Nové limity:
Free – 5 odlehčených úloh/měsíc Plus & Team – 10 plných 15 odlehčených úloh/měsíc Pro – 125 plných 125 odlehčených úloh/měsíc Enterprise – 10 plných úloh/měsícGPT-Image-1OpenAI zveřejnilo svůj nový model pro generování obrázků v API. Model, který dokáže pracovat jak s textem, tak s obrázky, pohání funkci vytváření obrázků, která byla spuštěna v ChatGPT na konci března a uživatelé s ní během prvního týdne vytvořili přes 700 milionů obrázků. Pro vývojáře je model dostupný za cenu 5 USD za milion textových tokenů, 10 USD za vstupní obrazové tokeny a 40 USD za výstupní obrazové tokeny.
Aktualizace GPT-4oOpenAI také aktualizovalo svůj model GPT-4o, čímž vylepšilo jeho schopnosti řešení problémů, inteligenci a osobnost. Nicméně CEO Sam Altman později sdílel, že aktualizace učinila asistenta “servílním a otravným” (i když s některými pozitivními aspekty) a společnost nyní pracuje na nápravě.
Finanční cíle a partnerstvíOpenAI sdělila investorům, že očekává dosažení příjmů ve výši 125 miliard dolarů v roce 2029 a 174 miliard dolarů v roce 2030, díky AI agentům, předplatným, monetizaci bezplatných uživatelů a affiliate poplatkům. Společnost také oznámila partnerství s deníkem The Washington Post na vyhledávací obsah a s aerolinkami Singapore Airlines pro vylepšení jejich virtuálního asistenta.
Liquid AI: Hybridní architekturaLiquid Sciences představila Hyena Edge, hybridní AI model s “konvoluční” architekturou. Tato technologie poskytuje rychlejší zpracování a vylepšené benchmarkové výsledky, překonávající základní modely založené na transformerech jak v oblasti výpočetní efektivity, tak v kvalitě modelu na edge hardwaru.
xAI: Grok s novými funkcemixAI představilo Grok Studio s dlouhodobou pamětí, čili si můžete přát, aby si Grok o vás něco zapamatoval, třeba že vám má tykat. Platforma nabízí rozdělené rozhraní, kde mohou uživatelé vytvářet dokumenty, aplikace nebo hry. Důležitou funkcí je schopnost pamatovat si minulé konverzace, což činí systém chytřejším v průběhu času.
Grok Vision byl spuštěn s výkonnými multimodálními funkcemi, které uživatelům umožňují namířit fotoaparát telefonu na objekty nebo prostředí a získat okamžitou analýzu v reálném čase. Spolu s tím byla přidána podpora zvuku v několika jazycích a funkce vyhledávání v reálném čase, což činí celý zážitek interaktivnějším a užitečnějším.
Elon Musk oznámil, že vylepšený algoritmus X (Twitter) poháněný AI modelem Grok bude brzy k dispozici. Toto oznámení přišlo jako reakce na stížnost Paula Grahama ohledně zahlcení feedu X příspěvky od levicových nebo pravicových trollů.
Google: Gemini 2.5 FlashGoogle představil Gemini 2.5 Flash – rychlý, odlehčený AI model. Navzdory tomu, že je navržen pro rychlost a efektivitu, Gemini 2.5 Flash se v benchmarkových testech řadí na sdílené druhé místo. Jeho výkon je srovnatelný s top modely jako GPT-4.5 Preview a Grok-3, což dokazuje, že i lehčí modely mohou nyní soupeřit s těmi nejlepšími z hlediska kvality a uvažování. Jestli to tak skutečně bude i v praxi, tak se Google povedl hezký zásek.
Anthropic: Výzkumné schopnosti pro ClaudeAnthropic přidává “Autonomní výzkum” do svého modelu Claude. Ten nyní dokáže vyhledávat v Google Workspace, zpracovávat vícekrokové otázky a poskytovat odpovědi s řádnými zdroji. Systém zkoumá dotaz z různých úhlů, provádí výzkum a dodává odpovědi během několika minut, čímž poskytuje dobrý mix hloubky a rychlosti pro každodenní úkoly. Kromě toho přidal do iOS aplikace hlasového asistenta, který dělá ze Siri hloupoučkou nánu. Jmenuje se Perplexity Assistant a je nyní dostupný na iOS, dříve již byl na Androidu. Přichází nejen s hlasovým ovládáním, ale i s možností propojení s více aplikacemi. AI asistent nyní dokáže pomáhat s úkoly jako je rezervace večeře, objednávání jízd a nastavování připomenutí.
Amazon: Nova SonicAWS představil Amazon Nova Sonic, špičkový základní model převodu řeči na řeč, navržený pro vylepšení interakcí se zákazníky a virtuálních asistentů. Umožňuje přirozenější, lidštější konverzace s AI, která chápe kontext a poskytuje bohatší odpovědi.
Menší, ale inovativní hráčiKling AI představil Kling 2.0 s vylepšenými funkcemi, včetně lepšího pochopení pokynů, vylepšeného pohybu postav pro plynulejší a přirozenější pohyb a Multi-Elements Editoru, který usnadňuje úpravu videí.
Tavus představil nový, pokročilý lipsync model, který přináší bezkonkurenční realismus do vytváření videí ze zvuku. Model zajišťuje dokonalé pohyby rtů, které odpovídají zvuku, spolu s přirozenými výrazy obličeje, což činí videa mnohem realističtějšími.
Nari Labs uvedla model Dia 1.6B s pozoruhodným emocionálním rozsahem a přirozeností, schopný smát se a dokonce kašlat. Model je dostupný na HuggingFace.
Moonshot AI spustila Kimi-Audio, nový open-source univerzální audio model. Podporuje rozpoznávání řeči, převod zvuku na text a převod řeči na řeč. Model byl předtrénován na více než 13 milionech hodin zvukových dat a vyniká v více než 10 audio benchmarcích, včetně MMAU, VoiceBench a LibriSpeech.
Dreamina AI představila Seedream 3.0, který se řadí na první místo v tvorbě fotorealistických obrázků s rozlišením až 2k. Dokáže také zvyšovat rozlišení, vyplňovat, rozšiřovat a dokonce generovat videa.
Genspark představil AI Slides, nový nástroj, který mění způsob vytváření prezentací pomocí výkonného systému řízeného agenty. AI provádí výzkum témat, vytváří podpůrný vizuál včetně obrázků a grafů a dokáže transformovat různé typy dokumentů do profesionálně vypadajících prezentací.
Canva uvedla Visual Suite 2.0 – své dosud největší spuštění. Nová sada přináší výkonné AI funkce, které umožňují vytvářet dokumenty, prezentace, webové stránky a další obsah, vše v rámci jednoho designu. Jedná se o nejvýznamnější vydání produktu společnosti od jejího založení.
Microsoft vylepšil Copilot pomocí Studio, které nyní umožňuje vytvářet agenty, kteří mohou klikat a psát napříč desktopovými nebo webovými rozhraními. Kromě toho Vision v Edge nyní komentuje vše na obrazovce v reálném čase, což činí systém interaktivnějším a přístupnějším.
Hrozba ze strany Číny pro americkou dominanciČínský prezident Si Ťin-pching prohlásil soběstačnost v oblasti AI za národní prioritu a slíbil vládní podporu pro posílení vývoje AI čipů, softwaru a talentů uprostřed eskalujícího technologického soupeření s USA. Si načrtl přístup “nového celonárodního systému”, zaměřeného na vývoj špičkových čipů a softwaru a zároveň na zvýšení vzdělávání v oblasti AI a rozvoj talentů.
Čínský výrobce čipů Huawei podle zpráv testuje nový pokročilý čip, který by měl nabídnout domácí alternativu k procesorům NVIDIA, které jsou v současnosti omezeny ze strany USA. Huawei chce, aby její nový čip Ascend 910D nahradil některé špičkové produkty od Nvidie. Nový čip je stále v raných fázích vývoje a bude vyžadovat testování, než bude moci být dodán zákazníkům. Huawei očekává, že první z těchto nových čipů dostane asi za měsíc a doufá, že čip bude výkonnější než Nvidia H100.
Současně se šíří zvěsti o nadcházejícím vydání DeepSeek R2, s nižšími cenami a náklady na trénink a s využitím čipů Huawei místo NVIDIA.
Kombinace potenciálního druhého “DeepSeek momentu” za rohem, domácích alternativ AI čipů, které činí americké exportní kontroly neúčinnými, a rychle se uzavírající mezery v modelech ukazuje, že Čína zintenzivňuje své úsilí o získání vedení v oblasti AI, přičemž dokazuje, že k úspěchu nepotřebuje americké čipy.
April 18, 2025
Meta v maléru - svědectví bývalé šéfky Facebooku o tajných dohodách s Čínou
Meta (Facebook) lítá ve slušném maléru. Sarah Wynn Williamsová, bývalá ředitelka globální veřejné politiky Facebooku (nyní Meta), vystoupila před Soudním výborem Senátu USA s odhaleními o tom, jak společnost Meta tajně obchodovala s Čínou, lhala Kongresu a porušovala zákony i etické standardy ve snaze o zisk a moc. Meta se snaží Williamsovou umlčet soudy a pokutami a tvrdí, že jde o zhrzenou mstící se manažerku. Jenže náznaků o tom, že v Číně se Meta chová “čínsky”, už je celá řada. Slyšení vedl senátor Josh Hawley, který zdůraznil, že “toto je slyšení, kterému se Facebook zoufale snažil zabránit.”
Williamsová během slyšení explicitně zmínila, že Meta získala právní příkaz k mlčení, který je “tak rozsáhlý, že jí zakazuje mluvit s členy Kongresu”. Také uvedla, že společnost Meta vyhrožuje pokutou 50 000 dolarů za každé “urážlivé” vyjádření o společnosti, i když by toto vyjádření bylo pravdivé. Meta by skutečně mohla usilovat o finanční sankce vůči Williamsové za její vystoupení před Kongresem, i když je takové jednání ze strany Mety v přímém rozporu s právem občanů svědčit před zákonodárnými orgány.
Slyšení bylo dlouhé, existuje z něj několik videí, na které se můžete podívat na Youtube, já jsem vám vypsal snad ty nejdůležitější informace. Připomínám, že u kongresového slyšení málokdy dojde na přesné technické detaily, věci tu bývají někdy zjednodušené, ale vypovídat nepravdivě před Kongresem bývá tvrdě sankcionováno, což bývá slušnou zárukou toho, že se tu lidé snaží mluvit pravdu či alespoň to, co se nedá později za nepravdu označit. Také je dobré vědět, že Williamsová nedávno vydala knihu Bezohlední lidé o svých zkušenostech s prací v Metě, přičemž společnost všechny její vystoupení označuje za propagaci prodeje knihy, kterou označuje za lživou. Zatím jsem četl kousek a nezdá se mi, že si to vymyslela 😎
Tam, kde je to možné, dávám citace prohlášení Williamsové.
Tajné obchody s Čínou pod krycím názvem “Projekt Aldrin”Williamsová, která pracovala pro Facebook v letech 2011 až 2017, poskytla detailní svědectví o tajných operacích společnosti v Číně:
“Během mých sedmi let jsem viděla, jak vedoucí představitelé Mety opakovaně podkopávali národní bezpečnost USA a zrazovali americké hodnoty. Dělali tyto věci tajně, aby získali přízeň Pekingu a vybudovali v Číně byznys za 18 miliard dolarů,” uvedla Williamsová ve své úvodní výpovědi.
Navzdory opakovaným veřejným prohlášením Mety, že v Číně nepodniká, Williamsová doložila, že tato tvrzení jsou lživá. “Facebook má v Číně byznys za 18,3 miliardy dolarů a abych uvedla jen jeden příklad, v roce 2014 spustil Oculus v Číně se strategií ‘hrát hloupého’,” vysvětlila.
Williamsová také odhalila, že Facebook měl tajnou misi pro vstup na čínský trh nazvanou “Projekt Aldrin”, která byla omezena pouze na zaměstnance s potřebou znát informace: “Facebookova tajná mise pro vstup do Číny se nazývala Projekt Aldrin a byla omezena na zaměstnance s potřebou znát. Neexistoval žádný limit, který by se nedal překročit.”
Cenzura a spolupráce s ČLRJedna z nejzávažnějších obvinění se týkala cenzury a spolupráce s čínským režimem:
“Mark Zuckerberg se prohlašoval za šampiona svobody projevu. Přesto jsem byla svědkem toho, jak Meta pracovala ruku v ruce s Čínskou komunistickou stranou na vytváření a testování na zakázku vyrobených cenzurních nástrojů, které umlčovaly a cenzurovaly jejich kritiky,” uvedla Williamsová.
Konkrétně popsala případ čínského disidenta žijícího na americké půdě:
“V roce 2017 byl profil na Facebooku čínského disidenta Guo Wengui náhle zablokován. Facebook nejprve tvrdil, že šlo o dočasnou chybu.” Nicméně Williamsová odhalila, že “Facebook vypnul stránku tohoto disidenta na základě nátlaku Čínské komunistické strany.”
Senátor Hawley během slyšení prezentoval dokumenty dokazující tyto praktiky - záznamy ze schůzek s čínským vládním úředníkem příjmením Čao, který požadoval, aby Facebook odstranil Guovu stránku. V dokumentech se uvádí: “Čao chce Facebook v Číně, ale jsou i jiní, kteří ho nechtějí. Takže my (Facebook) musíme přijmout opatření a udělat více v takových situacích, abychom prokázali, že můžeme řešit vzájemné zájmy.”
Williamsová také popsala, jak Facebook vyvinul speciální cenzurní nástroje s tzv. “počítadly virality”: “Součástí cenzurního nástroje, který byl vyvinut, byly počítadla virality. Takže kdykoli nějaký obsah získal více než 10 000 zhlédnutí, to by automaticky spustilo jeho přezkoumání tím, koho nazývali ‘hlavním editorem’. A co bylo obzvláště překvapivé je, že počítadla virality nebyla jen nainstalována, ale aktivována v Hongkongu a také na Tchaj-wanu.”
Na dotaz senátora Blumenthala, zda byly pravomoci “hlavního editora” omezeny pouze na kontrolu virálních příspěvků, Williamsová odpověděla: “Ne, má rozsáhlou moc. Hlavní editor by byl schopen vypnout celou službu v konkrétních regionech, například v Sin-ťiangu, nebo by také mohl vypnout nebo spravovat službu v době významných výročí, jako je výročí náměstí Tchien-an-men.”
Poskytování dat uživatelů Číně a budování fyzické infrastrukturyWilliamsová odhalila, že Meta byla ochotna poskytnout data uživatelů čínské vládě a dokonce vybudovala fyzickou infrastrukturu, která by to umožnila:
“Byla jsem svědkem toho, jak se vedoucí pracovníci rozhodli poskytnout Čínské komunistické straně přístup k datům uživatelů Mety, včetně dat Američanů,” svědčila Williamsová. “Meta vybudovala fyzické propojení spojující Spojené státy a Čínu. Vedoucí představitelé Mety ignorovali varování, že to poskytne zadní vrátka Čínské komunistické straně, což by jim umožnilo zachytit osobní údaje a soukromé zprávy amerických občanů.”
Senátor Hawley představil interní dokument Facebooku, který obsahoval následující vyjádření: “Výměnou za možnost provozovat činnost v Číně, Facebook souhlasí s tím, že poskytne čínské vládě přístup k datům čínských uživatelů, včetně dat uživatelů z Hongkongu.”
Williamsová dodala, že Facebook zvažoval použití POP serverů v Číně, což by představovalo významné riziko i pro americké uživatele: “Výzvou s POP servery je, že nemůžete segregovat data. Byly by tam americká data, data čínských uživatelů, a bylo by to na čínské půdě.”
POP servery (Points of Presence) jsou součástí síťové infrastruktury, kterou společnosti jako Meta používají k efektivnějšímu doručování svých služeb uživatelům po celém světě.
Na otázku, zda bezpečnostní tým nebo inženýři Facebooku vyjádřili obavy vedení ohledně vystavení soukromých informací Američanů čínskému špionáži, Williamsová odpověděla: “Ano, vyjádřili.” Dále vysvětlila, že své obavy dokumentovali různými způsoby a jeden inženýr dokonce poznamenal: “Moje červená linie jako bezpečnostního inženýra je, že pro mne toto není v pořádku, ale moje červená linie není červenou linií Marka Zuckerberga.”
Sdílení technologií a AI s ČínouWilliamsová také odhalila, jak Facebook sdílel své technologické know-how s Čínou:
“Meta začala informovat Čínskou komunistickou stranu již v roce 2015. Tyto brífinky se zaměřovaly na kritické nově vznikající technologie, včetně umělé inteligence. Explicitním cílem bylo pomoci Číně překonat americké společnosti.”
Williamsová dodala: “Existuje přímá linie, kterou můžete nakreslit od těchto briefingů k nedávným odhalením, že Čína vyvíjí modely AI pro vojenské použití, spoléhající se na model Mety Llama.” Williamsová zdůraznila, že model DeepSeek je částečně založen na AI modelu Mety Llama. Tedy je ovšem třeba říct, že ten jen open-source a může jej využít kdokoliv, podle Williamsové ale technici Mety sdíleli s Čínou svoje interní know-how.
Na otázku senátora Grassleyho, proč by Meta chtěla pomáhat Číně s umělou inteligencí, Williamsová uvedla: “Viděli, řekla bych, že část hodnotové propozice, kterou by mohli poskytnout Čínské komunistické straně, byla jejich schopnost pomoci čínským úředníkům. Takže výslovně, a byla bych ráda, kdybych vám mohla poskytnout dokumentaci, vyjmenovávali americké firmy. Říkali: ‘Můžeme pomoci, můžeme vám pomoci. Čína nemusí spoléhat na firmy jako Cisco nebo IBM, protože my vám můžeme pomoci s technickou odborností.’”
Williamsová také zdůraznila, že “Interní dokumenty Mety popisují jejich prodejní nabídku, proč by Čína měla povolit jejich vstup na trh, a to citací: ‘pomáhat Číně zvýšit globální vliv a podporovat čínský sen’.”
Na dotaz, zda Facebook profitoval z toho, že pomáhal Číně vyvinout konkurenční AI model, odpověděla: “Myslím, že jde o situaci, kdy vítěz bere vše. A to by postavilo Metu do velmi silné pozice.”
Zuckerbergova osobní angažovanost v čínské expanziWilliamsová zdůraznila, že Mark Zuckerberg byl osobně hluboce zapojen do čínské expanze:
“Nic se zde nedělo bez jeho schválení a vědomí. Tento projekt byl na rozdíl od jakéhokoli jiného projektu, na kterém jsem během svého působení v Metě pracovala, centrálně veden Markem Zuckerbergem. On byl osobně zainteresován do tohoto projektu. Naučil se mandarínštinu. Cestoval do Číny více než do jakékoli jiné země. Měl týdenní lekce mandarínštiny se zaměstnanci. Je těžké zdůraznit, jak odlišný byl tento projekt od jakéhokoli jiného projektu, který jsem za své mnohaleté působení ve společnosti zažila.”
Na otázku senátora Blumenthala, zda Zuckerberg věděl o rizicích spojených s čínskou expanzí, Williamsová odpověděla: “Podle mne je riziko nejdůležitější částí plánu. Takže je nemyslitelné, že by si nebyl vědom rizika.”
Zaměřování na zranitelné teenagery a etické problémyWilliamsová také popsala, jak Facebook cíleně využíval emocionální stavy mladých uživatelů pro zvýšení zisku:
“Jeden příklad je, že Facebook cílil na 13 až 17leté. Mohl identifikovat, kdy se cítili bezcenní nebo bezmocní nebo neúspěšní, a tyto informace vzali a sdíleli je s inzerenty,” vysvětlila. “Jedna z věcí ohledně reklamy je, že inzerenti chápou, že když se lidé necítí dobře sami se sebou, je to často dobrý čas nabídnout jim nějaký produkt. Lidé pak s větší pravděpodobností něco koupí.”
Dále uvedla konkrétní příklady: “Pokud by 13letá dívka smazala selfie, to je opravdu dobrý čas zkusit jí prodat kosmetický produkt.” Facebook cílil na “věci, které často znepokojují dospívající dívky, jako je sebevědomí ohledně těla.”
Na otázku senátorky Blackburn, zda Facebook skutečně sledoval aktivitu dětí i mimo jejich aplikaci, Williamsová odpověděla: “Absolutně. To je bráno jako signál a pak sdíleno s inzerenty.”
Williamsová také odhalila, že Meta má o svých uživatelích obrovské množství dat: “Je to nepochopitelné. Je velmi, velmi těžké pochopit množství dat, které tato společnost má o každé osobě, která se přihlásí do její služby. Jsou to soukromé zprávy, ale tolik dat.” Na otázku, zda tato data nejsou omezena pouze na aplikace Mety, odpověděla: “Vůbec ne, senátorko.”
Na otázku senátorky Blackburn, zda vedení Facebooku ochraňovalo své vlastní děti před těmito praktikami, Williamsová odpověděla: “To je jedna z věcí, která mě šokovala, když jsem se přestěhovala do Silicon Valley… Vedoucí pracovníci by vždy mluvili o tom, jak mají doma zákazy obrazovek. Nebo bych se zeptala: ‘Používá váš teenager nový produkt, který se chystáme spustit?’ A oni na to: ‘Můj teenager nemá povoleno být na Facebooku. Nemám svého teenagera na Instagramu.’ Tito vedoucí pracovníci to vědí, vědí, jakou škodu tento produkt způsobuje.”
Manipulace s médii a zneužívání algoritmůSenátorka Klobuchar se ptala na praktiky Mety vůči zpravodajským médiím. Williamsová ve své knize napsala, že “Facebook předělal americká zpravodajská média tím, že umístil Facebook do jejich centra, snížil ceny reklam pro noviny a distribuoval jejich příběhy, používal jejich obsah k zvýšení času stráveného na Facebooku.”
Williamsová během slyšení potvrdila tuto praxi: “Klíčovou věcí, kterou je Meta posedlá, je engagement. Je to udržení pozornosti lidí ve službách, které Meta vlastní, po co nejdelší dobu s použitím jakýchkoli nástrojů, které může.”
Když senátorka Klobuchar zmínila citát Marka Zuckerberga ohledně zpravodajských médií - „Spíše se snažíte uzavřít kompromis s umírajícím průmyslem, než ho ovládnout a zničit.“ - a zeptala se na důsledky takového přístupu, Williamsová odpověděla: “Myslím, že každý občan viděl důsledky těchto akcí, a myslím, že jsme všichni chudší kvůli tomu.”
Williamsová také potvrdila, že Meta využívá politické rozhořčení pro zvýšení zisku: “Co tato společnost chce, je dominovat tolika času a pozornosti každého jednotlivce, kolik může… A co se naučili, je, že rozhořčení je opravdu dobrý způsob, jak toho dosáhnou. Udělají cokoli, co je potřeba, aby měli lidi přilepené ke svým službám, ve své moci, ve svém zajetí.”
Lži a klamání Kongresu a FTCWilliamsová uvedla několik příkladů, kdy Meta lhala Kongresu a regulačním orgánům. Když byl generální právník Facebooku Colin Stretch dotázán senátorem Markem Rubiem, zda byla ze strany čínské vlády vyvíjena jakákoli tlak na zablokování účtu disidenta Gua, odpověděl: “Ne, senátore. Přezkoumali jsme zprávu o tomto účtu a analyzovali ji prostřednictvím běžných kanálů za použití běžných postupů.”
Na otázku, zda toto svědectví bylo pravdivé, Williamsová odpověděla: “Ne, senátore. Je to ve skutečnosti vyložená lež.”
Senátor Hawley také poukázal na to, že Facebook byl pod nařízením FTC (Federal Trade Commission) z roku 2012 o ochraně soukromí, které stanovilo, že Facebook “nesmí zkreslovat jakýmkoli způsobem, výslovně nebo implicitně, míru, do jaké udržuje soukromí nebo bezpečnost chráněných informací.” Přesto Facebook jednal v rozporu s tímto nařízením, když vyjednával s čínskou vládou o předání uživatelských dat.
Zastrašování a snaha o umlčeníWilliamsová popsala, jak se ji Meta snaží umlčet a finančně zruinovat za to, že vystoupila s pravdou:
“Spoléhala jsem na jejich závazek z roku 2018, že se vzdají svých práv na vynucené rozhodčí řízení. Navzdory tomuto veřejnému závazku proti mně podali žalobu na stovky milionů dolarů. Nyní mají právní příkaz k mlčení, který mě umlčuje, i když Meta a jejich zástupci o mně šíří lži. Tento příkaz je tak rozsáhlý, že mi zakazuje mluvit s členy Kongresu.”
Na otázku senátora Blumenthala, jakým způsobem ji Meta kontaktovala, Williamsová odpověděla: “Upřímně, snažila jsem se přimět své dítě, aby snědlo ovesnou kaši, a zazvonil zvonek… Po vydání knihy jsem si myslela, že by to mohl být někdo, kdo doručuje květiny. Ne, byl to příkaz k mlčení.”
Společnost Meta vyhrožuje Williamsové pokutou 50 000 dolarů za každé “urážlivé” vyjádření o společnosti, i když by tato vyjádření byla pravdivá. Williamsová uvedla, že Meta jí říká: “Pokud by respondentovi (mně) bylo povoleno komunikovat se zákonodárci, takové akce by vytvořily výjimku z nedifamace. To by snědlo pravidlo. Za takových okolností by nic neomezovalo nebo nebránilo těmto zákonodárcům nebo jejich asistentům opakovat veřejnosti jakákoli hanlivá prohlášení.”
Williamsová také odhalila, že Meta zahájila rozhodčí řízení bez jejího vědomí: “Poslali to na e-mailovou adresu z roku 2007” a získali příkaz k mlčení, aniž by to její právní tým věděl nebo měl příležitost vznést námitky.
Bude Meta někdy pohnána k zodpovědnosti?V závěru svého svědectví Williamsová prohlásila: “Jsem zde s významným osobním rizikem, protože vy máte moc a autoritu je volat k odpovědnosti. Americký lid si zaslouží znát pravdu, Meta byla ochotna kompromitovat své hodnoty, obětovat bezpečnost svých uživatelů a podkopat americké zájmy, aby vybudovala svůj byznys v Číně. Děje se to již roky, zakryté lžemi, a pokračuje to dodnes.”
Na otázku, co by řekla Marku Zuckerbergovi, kdyby byl přítomen, Williamsová odpověděla: “Mám hodně otázek pro Marka Zuckerberga, ale prokázal znovu a znovu, že nemůžete věřit jeho odpovědím. Lhal členům Kongresu, lhal svým zaměstnancům a lhal Američanům. A proto žádám tento výbor, aby jej volal k odpovědnosti.”
Senátor Hawley uzavřel slyšení výzvou pro Marka Zuckerberga, aby přišel před výbor a odpověděl na tato obvinění: “Je čas, abyste řekl pravdu. Měl byste přijít do tohoto výboru, složit přísahu, sednout si, kde teď sedí paní Wynn Williamsová, a odpovědět na tyto důkazy. Přestaňte se ji snažit umlčet. Přestaňte se schovávat za svými právníky a miliony dolarů na právních poplatcích.”
April 17, 2025
OpenAI vydala svůj nejsilnější model pro ChatGPT o3 a rychlý o4-mini
Novým a nejsilnějším modelem LLM společnosti OpenAI se stává o3. Firma jej právě uvolnila a přidala do webového rozhraní i API, tak si k němu řekneme pár věcí.
Tou první věcí je moje dlouhodobé konstatování, že struktura pojmenování v OpenAI je fakt bordel. Sám si musím dělat tabulku, které modely co znamenají a studium ceníků pro použití přes API je opravdu únavné. Potřebovali bychom AI na to, jakou AI použít😞 A teď už k věci.
OpenAI 16. dubna 2025 oznámilo vydání dvou nových modelů - o3 a o4-mini.
Oba modely jsou označovány jako “reasoning models” (modely s rozumovým uvažováním) a podle dostupných informací poprvé nabízejí plnou agentní integraci všech nástrojů v rámci ChatGPT. To znamená schopnost kombinovat a využívat webové vyhledávání, Python, analýzu obrázků, interpretaci souborů a generování obrázků v rámci jednoho pracovního toku. Zjednodušeně řečeno, když zadáte o3 nějaký úkol, ona se nad tím zamyslí, zjistí, že by se hodilo prohledat web a pak si udělat script, kterým se vyhodnotí vyhledaná data, než vám odprezentuje výsledek - a nakonec vám z něj může udělat i požadovanou infografiku. Tohle je fakt silný moment práce s AI. Dlužno říct, že podobně se začíná chovat Claude Sonnet díky napojení na Google Workspace, kdy se může velmi autonomně prohrabovat ve vašich datech, k tomu používat vyhledávání a tvořit scripty, které si sám spustí a výstupy z nich použije. Model o3 je prezentován jako výkonnější varianta zaměřená na kódování, matematiku, vědu a vizuální uvažování. Model o4-mini je optimalizován pro efektivitu z pohledu rychlosti a nákladů, což umožňuje vyšší limity využití než u modelu o3.
Technologické inovaceZajímavou funkcí obou modelů je integrace nahraných obrázků přímo do procesu uvažování. To představuje posun od pouhého “vidění” obrázku k jeho zakomponování do myšlenkového procesu modelu, což potenciálně zlepšuje schopnost modelů pracovat s vizuálními informacemi.
Jaké mají modely výsledkyS AI to začíná být jako s lidmi. Na internetu pořád kolují vtípky, jak se modely vypořádávají se spočítáním počtu r ve slově strawberries - s tím se modely vypořádávají různě. Jenže to není pointa. Pointa začíná být v tom, jaké výsledky dávají se složitějšími problémy a jak autonomně se k těm výsledků zvládají dostat, tedy zda zvládají nějaký režim uvažování, v němž si úlohu rozloží na menší, snáze realizovatelné úkoly, místo toho, aby halucinovaly se statistikou. o3 má být state of art model, to nejlepší z nejlepšího, nejrůznější výsledky to naznačují, já jsem si s ním proběhl svoji standardní sadu testů na českojazyčné úkoly, které používám já, většinou manipulace s rozsáhlými korpusy textů (náročné na kontext) či na uvažování, ale také jednoduché třídění a vyhledávání typu “vypiš z dokumentu všechna jména lidí a produktů”. o3 vychází suverénně jako nejlepší ze všech modelů, na druhou stranu ne vždy je cenově nejvýhodnější, na některé typy úloh (právě třeba vyhledání jmen osob) je to kanón na vrabce a za to si připlatíte. Pokud tedy používáte modely přes API, trochu uvažujte nad cenou, pokud používáte modely přes webové rozhraní (kde neplatíte za dotaz), tak není o čem přemýšlet, prostě to sázejte do o3, leda by vás limitovala rychlost.
Pozor musíte dávat jen na délku kontextu, model GPT-4.1 představený před pár dny má kontext 1 milion tokenů, o3 je na 200 tisících tokenech. Je však třeba připustit, že jakmile se nástroje dostávají přes hranici 200 000 tokenů, začíná jít jejich kvalita výrazně dolů, takže užití většího kontextu je spíše hraniční případ, kterému navrhuji se zatím zkoušet vyhýbat. Příklad LLAMA 4 s desetimilionovým kontextem to ukazuje jasně.
Testů se vyrojila celá řada, já vám dám můj oblíbený norský IQ test, ze kterého plyne, že v takovém tom obecném uvažování je o3 fakt špička. Za mě více důležité bude, jak se podaří OpenAI propojovat svůj systém na další systémy, protože kritická začíná být ani ne tak inteligence (IQ 130 nemá jen tak někdo), ale schopnost dostat se snadno k datům, aby je člověk pořád nepřehazoval jako copy-paste, což je při práci s AI to nejvíce frustrující. To si uvědomujete, že vy tam jste za toho podržtašku.
[image error]
DostupnostModely jsou od 16. dubna 2025 dostupné pro uživatele ChatGPT Plus, Pro a Team, přičemž nahrazují předchozí modely o1, o3-mini a o3-mini-high. Uživatelé ChatGPT Enterprise a Edu získají přístup s týdenním zpožděním. OpenAI uvádí, že rychlostní limity zůstávají stejné jako u předchozích modelů.Pro vývojáře jsou modely k dispozici prostřednictvím Chat Completions API a Responses API. OpenAI také oznámilo, že model o3-pro s plnou podporou nástrojů bude vydán v následujících týdnech.
API funkceResponses API přináší několik technických vylepšení včetně “reasoning summaries” (shrnutí procesu uvažování), zachování tokenů uvažování kolem volání funkcí pro lepší výkon a v blízké budoucnosti přibude podpora vestavěných nástrojů jako webové vyhledávání, vyhledávání v souborech a interpretace kódu přímo v rámci uvažování modelu.
Porovnání cen a výkonu LLM modelů (duben 2025) podle OpenRouterZ ceníku je lépe patrné, proč říkám, že o3 může být kanón na vrabce. Prostě si nějaký ten dolar zaúčtuje, u většiny věcí je lepší zůstat u o3-mini nebo GPT-4.1 a proto také rád používám OpenRouter, který mi umožní přehodit provoz na modely podle aktuální ceny. Mám na to speciální patentní script, který mi umožňuje průběžně měnit LLM podle aktuálních parametrů potřebných pro daný úkol.
Model Kontext Max. výstup Cena vstupu ($/1M tokenů) Cena výstupu ($/1M tokenů) Latence (s) Throughput (t/s) o3 200K 100K $10.00 $40.00 9.52 68.78 o4-Mini 200K 100K $1.10 $4.40 4.55 81.79 o4-Mini High 200K 100K $1.10 $4.40 8.59 90.62 GPT-4.1 1,05M 33K $2.00 $8.00 0.55 58.07 Claude 3.7 Sonnet 200K 64K $3.00 $15.00 1.69 56.27 Claude 3.7 Sonnet Thinking 200K 64K $3.00 $15.00 1.69 56.28 Gemini 2.5 Pro 1,05M 66K $1.25-$2.50 $10.00-$15.00 8.59 414.80 Grok 3 beta 131K 131K $3.00 $15.00 0.74 34.21Tady je ceník, přiznám se, že jsem ho nebral z oficiálních API, ale z OpenRouteru, který má výborné API a je to výborné místo pro testování a srovnání, včetně toho, že udává rychlost výstupu a latenci.
Na závěr vám dám ještě Aider Leaderboard, což je statistika, jakou vede kódovací nástroj Aider pro výkonnost a cenu jednotlivých LLM. Z toho je vidět, že o3 je suverénně nejlepší, ale taky velmi drahý. Lepší by bylo používat Gemini Pro 2.5 - ten má ale nyní podle mne výrazně dotovanou cenu (sám ho používám zdarma v promo balíku) a je otázka, kdy půjde nahoru. Nutno říct, že jak jsem Gemini modelům dlouho nepřišel na chuť, tak Pro 2.5 je velmi dobrý, i když na kódování mi zatím nesedl.
[image error]
April 15, 2025
Claude umí prohrabat váš Google kalendář i poštu, ChatGPT má nový model 4.1 a další novinky z AI
OpenAI vydalo nový model GPT-4.1, čímž zvyšuje zmatek, hlavně proto, že model byl ohlášen, ale dostupný je jen přes API, ne přes webové rozhraní nebo aplikaci. Má být náhradou modelu 4o, je levnější, rychlejší, přesnější, lepší. A má tři velikosti, které se liší cenou a samozřejmě velikostí natrénovaných dat. Krom standardního modelu také mini a nano. Kromě toho vydali novou prompting guide, návod na to, jak správně promptovat model 4.1 - vyplatí se to přečíst, než se pustíte do vážného ladění modelu 4.1 přes API. A tady je rychlé porování modelů. Do webového rozhraní se mají dostat brzy.
[image error]
Tady je překlad obrázku do češtiny ve formě tabulky:
GPT-4.1 4.1 mini 4.1 nano Vlajkový model GPT pro komplexní úlohy Vyvážený pro inteligenci, rychlost a cenu Nejrychlejší, nejefektivnější GPT 4.1 model z hlediska nákladů Inteligence: ●●●● Inteligence: ●●● Inteligence: ●● Rychlost: ⚡⚡⚡ Rychlost: ⚡⚡⚡⚡ Rychlost: ⚡⚡⚡⚡⚡ Vstup: text - obraz Vstup: text - obraz Vstup: text - obraz Výstup: text Výstup: text Výstup: text Tokeny uvažování: ne Tokeny uvažování: ne Tokeny uvažování: ne CENY CENY CENY NA 1M TOKENŮ NA 1M TOKENŮ NA 1M TOKENŮ Vstup: $2.00 Vstup: $0.40 Vstup: $0.10 Cachovaný vstup: $0.50 Cachovaný vstup: $0.10 Cachovaný vstup: $0.03 Výstup: $8.00 Výstup: $1.60 Výstup: $0.40 KONTEXT KONTEXT KONTEXT Okno: 1,047,576 Okno: 1,047,576 Okno: 1,047,576 Max výstupních tokenů: 32,768 Max výstupních tokenů: 32,768 Max výstupních tokenů: 32,768 Znalostní limit: 31. května 2024 Znalostní limit: 31. května 2024 Znalostní limit: 31. května 2024ChatGPT přidalo novou záložku Library, v níž se soustředí vaše obrázky, které jsi nechali od ChatGPT udělat. Hezké, praktická drobnost.
[image error]
Claude přidal propojení s Google službami Kalendář a Gmail k již existujícímu napojení na Google Drive, takže lze hezky propojovat data v tom všem. Já jsem si například nechal udělat statistiku, co mi chodí nejčastěji za spamy, ale můžete si nechat prohledat kalendář ve Workspace (tj. firemní) a naplánovat teambuilding nebo si nechat posílat avíza, když v pátek šéf brzy vypadne atd. Vypadá to na hezkou a silnou funkci.
[image error]
Cvičně jsem si nechal analyzovat nejčastější spamy a také svůj komunikační styl na Gmailu, tady připomínám, že Gmail už deset let nepoužívám, takže mi to analyzovalo jen starou poštu - a napojení na Proton Mail Claude nemá.
[image error]
Druhou fajnovou novinkou je Claude Research. Anthropic se tím přidává mezi ostatní Deep Research platformy, podobnou funkcionalitu již nabízí Perplexity, OpenAI a Google Geminy, nyní tedy i Claude. Já ji zatím v rozhraní nemám, zatím byla spuštěna jen pro dražší tarify v USA, Brazílii a Japonsku.
Novinkou u Claude je také nový tarif Max, kde za 100 resp 200 dolarů měsíčně dostáváte vyšší limit zpráv - za 100 dolarů dostáváte pětinásobek plánu Pro (stojí 20 USD) a za 200 dolarů dvacetinásobek.
Navíc Anthropic plánuje odhalit novou verzi modelu Claude 3.7 Sonnet s kontextovým oknem o velikosti 500 tisíc tokenů, což je významné zvýšení oproti současné kapacitě 200 tisíc.
Canva má taky AI - zadáte prompt a kreslí, co jiného.
EU projednává změny v Zákoně o AI (AI Act) - k redukci by mohlo dojít u GDPR, ale ještě uvidíme. Za mě dobrý, ale ještě bych revidoval tu debilitu s cookies, bohužel by na revizi musely přistoupit i USA.
Podle nové zprávy Mezinárodní energetické agentury (IEA) se celosvětová spotřeba elektřiny v datových centrech do roku 2030 více než zdvojnásobí na přibližně 945 terawatthodin (TWh), což je více než současná celková spotřeba elektřiny v Japonsku, přičemž umělá inteligence bude hlavním faktorem tohoto nárůstu. Pořád platí rovnice, že AI = elektřina křemík. Spotřeba elektřiny v datových centrech optimalizovaných pro AI se má do roku 2030 více než zčtyřnásobit. Ve Spojených státech budou datová centra tvořit téměř polovinu nárůstu poptávky po elektřině do roku 2030, přičemž americká ekonomika bude v roce 2030 spotřebovávat více elektřiny na zpracování dat než na výrobu všech energeticky náročných produktů dohromady; podobný trend je patrný i v dalších vyspělých ekonomikách, kde datová centra budou představovat více než 20 % růstu poptávky po elektřině, s obzvláště silnými dopady v Japonsku (více než polovina nárůstu) a Malajsii (až pětina nárůstu).


