
Voynich Reconsidered: Persian as precursor
In the sourse of my ongoing search for meaning in the text of the Voynich manuscript, I have investigated the hypothesis that the underlying or precursor language was Persian.
Persian, like Arabic, Hebrew and Ottoman Turkish, uses an abjad script in which the long vowels are written but the short vowels usually are not. The pronunciation of a written Persian word therefore has to be inferred from the context, or from diacritics which the writer may have placed above or below the consonants.
Pareidolia
In any exercise of mapping from the Voynich manuscript to a language in an abjad script, there is a risk of pareidolia: of seeing words that are not necessarily there. This is because of what I am inclined to call the abjad effect: in the absence of short vowels, any short string of letters is quite likely to be a real word.
A classic example of pareidolia: the “Face on Mars”. Image credit: NASA.
Here is an example.
The modern Persian alphabet has thirty-three letters, as follows, with acknowledgement to Dr Mehrzad Mansouri, “Examining the frequency of Persian characters and their suitability on the computer keyboard” (Journal of Linguistics and Khorasan Dialects, No. 7, fall and winter 2013).

We can use the =RAND() function in Microsoft Excel to generate three random numbers between 1 and 33. My first run of this function yielded the following numbers:
To my mind it follows that, if we wish to map the Voynich manuscript to Persian (or to any other language which uses an abjad script), we cannot be satisfied with finding individual words. We must seek to map at least a whole line, or a paragraph, or a whole page, and the result must make sense.
Upsides of abjad
The upside of any abjad script proposed as a precursor to the Voynich text is that the words are typically short.
For example, I have a corpus of Persian, drawn from the works of forty-eight Persian poets. It contains 8,102,157 words with 26,572,744 letters. The average length of words is 3.27 letters.
In Arabic, Dr Jiří Milička of Charles University has studied a large diachronic corpus (Corpus Linguae Arabicae Universalis Diachronicus, or CLAUDia), with about 420 million words. He found that in the fifteenth century, the average length of Arabic words was 4.12 letters.
The Voynich manuscript, in the v101 transliteration, has an average of 3.90 glyphs per "word". Thus in terms of length, Persian and Arabic words match Voynich "words" much better than those in most European languages.
A Voynich-Persian mapping
The researcher on the Voynich Ninja forum proposed a mapping from Voynich glyphs to Persian letters based (in my understanding) on visual similarities. For example, the v101 glyphs {m} and {N} were proposed to map (as I understand, interchangeably) to the Persian letters ﻡ (m) and ﻥ (n).
A consequence of this proposed mapping is that in the resulting Persian text, the letters have a frequency distribution which is greatly different from that of the Persian language as a whole.
With thanks to bi3mw of the Voynich ninja forum, I was able to calculate that in my Persian corpus, the letters ﻡ (m) and ﻥ (n) together accounted for 13.7 percent of the total. In the Voynich manuscript, if we use the v101 transliteration, the glyphs {m} and {N}, and their variants {M} and {n}, together account for 4.5 percent of all the glyphs.
The proposed mapping would therefore create a Persian text in which the letters ﻡ (m) and ﻥ (n) were unusually rare: a text quite unlike the corpus of written Persian.
In any language, individual documents can have letter frequency distributions that diverge from that the language as a whole. In my experience, these divergences are not large, and are typically evident from around the tenth most common letter onwards. For example, in the OVI corpus of medieval Italian, and in Dante’s La Divina Commedia, the nine most common letters are the same, and in the same order. The tenth and eleventh most common letters in OVI are respectively D and C; in La Divina Commedia, they are C and D.
Likewise, we can make a comparison of my corpus of Persian poets with the Ruba’iyat of Omar Khayyam, which in my copy has 19,876 letters. The top ten letters are the same in the Ruba’iyat as in the larger corpus, although in a slightly different order. For the whole Persian alphabet, the correlation of letter frequencies between the Ruba’iyat and the corpus is 98.6 percent. In short, we do not expect an individual document to have a greatly different letter frequency from that of the language as a whole.
There can of course be exceptions, such as lipograms: texts which intentionally omit a selected letter or letters. For example, in the English language we have the novel Gadsby by Ernest Vincent Wright, and in French La Disparition by Georges Perec, neither of which contains the letter e, the most common letter in both English and French. We have to hope that the Voynich manuscript is not a lipogram.
Letter frequencies
My own predilection is to ignore any visual similarities that may exist between Voynich glyphs and letters in natural languages, and to focus on glyph and letter frequencies. This was a device used by Edgar Allen Poe in his short story The Gold Bug, and by Sir Arthur Conan Doyle in his Sherlock Holmes tale The Adventure of the Dancing Men. In both cases the protagonist used frequency comparisons to solve enciphered messages.
In the case of the Voynich manuscript, following Occam’s Razor, we could adopt the simplest assumptions: that the scribes worked from a precursor document or documents in a natural language or languages; and that they chose to use, or the producer instructed them to use, a one-to-one mapping between letters and glyphs. If so, the frequencies of the precursor letters should have been preserved. If the precursor language was Persian, then the frequencies of the Persian letters should match, in some respect, the frequencies of the glyphs that the scribes committed to vellum.
As a start, we could look at the ten most common symbols in Persian and in Voynich.
For Persian, I used the above-mentioned corpus of the works of forty-eight poets: for which my colleague bi3mw kindly calculated the letter frequencies. For the Voynich manuscript, I used a range of alternative transliterations to Glen Claston’s classic v101 transliteration. To select the best-fitting transliteration, I used the average frequency difference (which I defined in another post on this platform). The best fit was the transliteration which I numbered v170. This had the following differences from v101:
The results are as follows.
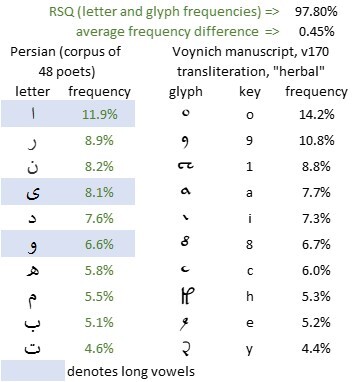
The Voynich manuscript, v170 transliteration, “herbal” section, the ten most frequent glyphs; and the ten most frequent letters in a corpus of the works of forty-eight Persian poets (frequencies by courtesy of bi3mw)
Here it is tempting to see not merely a visual resemblance but a correspondence between the v101 glyph {9} and the Persian letter و. But to minimise the element of subjectivity, I felt that it would be better to stay with the frequencies, and to see where that led.
The correlation between the v170 glyph frequencies and the Persian letter frequencies is 97.8 percent. This correlation is comparable with my results for many modern and medieval European languages. They do not, in themselves, imply that Persian is more or less likely than a European language to be a precursor of the Voynich manuscript.
The common “words”
If the above juxtapositions of frequencies have any merit as correspondences (we might say: mappings), then we should be able to map some of the common “words” in the Voynich manuscript to letter strings in Persian, and see whether this process yields any real Persian words.
In the v170 transliteration, "herbal" section, I identified the top five "words" of one, two, three and four glyphs, and mapped each of them to Persian, one glyph at a time, according to the rankings in the frequency tables.
The results were as follows:
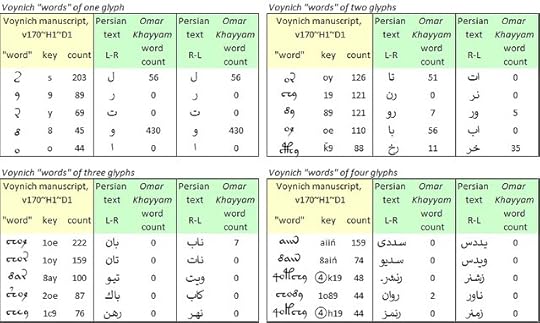
Voynich manuscript, v170 transliteration, “herbal” section: the five most frequent “words” of one, two, three and four glyphs; and test mappings to Persian. Author's analysis.
In short, the results are weak. Notwithstanding the abjad effect, few of the Voynich “words” map to real words in Persian, whether we read the glyphs from left to right or from right to left.
Postscript: the scribes
Persian is, and always has been, written from right to left; and by (I think) universal agreement, the Voynich manuscript is written from left to right. Therefore, if the manuscript is in Persian, we are compelled to conjecture that the Voynich scribes did not work directly from written documents. I imagine them, rather, taking dictation.
If so (and this would apply to dictation in any language), I could imagine that they would not always be sure where words began and ended. That might help us understand why the "word" breaks are so irregular, and why there are so many instances of what Zattera calls "separable words".
Finally: the quality and consistency of the Voynich script leads us to believe that the scribes were professionals. They made a living by writing what other people wanted written. If they wrote from dictation, is it possible they wrote phonetically from a language that they did not themselves understand?
Separable “words”
In any phonetic language, as George Zipf observed when he formulated Zipf’s Law, the most frequent words are short: like "the" and "and" in English. In an abjad language, with short vowels omitted, the most frequent words will be even shorter. The top ten words in medieval Persian have two letters, or one: for example و ("and").
Some of the top ten Voynich "words" are too long to match the top ten Persian words. Examples, in the v170 transliteration, are the "words" {1oe}, {1oy} and {8ay}.
It seems to me possible that Voynich “words” do not map very well to Persian words because the “words” are not words. As Preston Currier remarked at Mary D’Imperio’s Voynich seminar in 1976:
Zattera, in his paper at Voynich 2022, did not specify the "separable words" that he had identified. I have not yet formulated a systematic approach to the identification of "separable words". For any given transliteration, my provisional process has the following steps: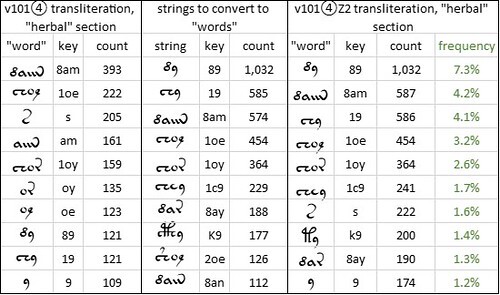
A sequence of steps to identify the “separable words” in the Voynich manuscript, v101 transliteration. Author’s analysis.
If the Voynich manuscript has a Persian precursor, we may need to apply Zattera's concept of "separable words", and break up some of the common Voynich “words”. That is a line of research that seems worth some effort.
Other languages
The approach that I outlined above would apply equally to a mapping from Voynich to any phonetic natural language.
I have already tested mappings from corpora and selected documents in several medieval languages including Albanian, Arabic, Bohemian, English, French, Galician-Portuguese, German, Italian, Latin and Ottoman Turkish. Some of my results are reported in Voynich Reconsidered: others have appeared elsewhere on this platform, or may appear in due course. Readers who would like me to test other languages are invited to send me examples of the respective corpora, preferably as .txt files.
Persian, like Arabic, Hebrew and Ottoman Turkish, uses an abjad script in which the long vowels are written but the short vowels usually are not. The pronunciation of a written Persian word therefore has to be inferred from the context, or from diacritics which the writer may have placed above or below the consonants.
Pareidolia
In any exercise of mapping from the Voynich manuscript to a language in an abjad script, there is a risk of pareidolia: of seeing words that are not necessarily there. This is because of what I am inclined to call the abjad effect: in the absence of short vowels, any short string of letters is quite likely to be a real word.
A classic example of pareidolia: the “Face on Mars”. Image credit: NASA.
Here is an example.
The modern Persian alphabet has thirty-three letters, as follows, with acknowledgement to Dr Mehrzad Mansouri, “Examining the frequency of Persian characters and their suitability on the computer keyboard” (Journal of Linguistics and Khorasan Dialects, No. 7, fall and winter 2013).
We can use the =RAND() function in Microsoft Excel to generate three random numbers between 1 and 33. My first run of this function yielded the following numbers:
5, 12, 23.The fifth, twelfth and twenty-third letters in the Persian alphabet are ف, ر, ث. These three letters, read from right to left, form the string
فرثwhich is a real word in Persian, according to the Dehkhoda dictionary, maintained by the Dehkhoda Lexicon Institute and International Centre for Persian Studies at the University of Tehran. Thus we are able by a random process to create a real word.
To my mind it follows that, if we wish to map the Voynich manuscript to Persian (or to any other language which uses an abjad script), we cannot be satisfied with finding individual words. We must seek to map at least a whole line, or a paragraph, or a whole page, and the result must make sense.
Upsides of abjad
The upside of any abjad script proposed as a precursor to the Voynich text is that the words are typically short.
For example, I have a corpus of Persian, drawn from the works of forty-eight Persian poets. It contains 8,102,157 words with 26,572,744 letters. The average length of words is 3.27 letters.
In Arabic, Dr Jiří Milička of Charles University has studied a large diachronic corpus (Corpus Linguae Arabicae Universalis Diachronicus, or CLAUDia), with about 420 million words. He found that in the fifteenth century, the average length of Arabic words was 4.12 letters.
The Voynich manuscript, in the v101 transliteration, has an average of 3.90 glyphs per "word". Thus in terms of length, Persian and Arabic words match Voynich "words" much better than those in most European languages.
A Voynich-Persian mapping
The researcher on the Voynich Ninja forum proposed a mapping from Voynich glyphs to Persian letters based (in my understanding) on visual similarities. For example, the v101 glyphs {m} and {N} were proposed to map (as I understand, interchangeably) to the Persian letters ﻡ (m) and ﻥ (n).
A consequence of this proposed mapping is that in the resulting Persian text, the letters have a frequency distribution which is greatly different from that of the Persian language as a whole.
With thanks to bi3mw of the Voynich ninja forum, I was able to calculate that in my Persian corpus, the letters ﻡ (m) and ﻥ (n) together accounted for 13.7 percent of the total. In the Voynich manuscript, if we use the v101 transliteration, the glyphs {m} and {N}, and their variants {M} and {n}, together account for 4.5 percent of all the glyphs.
The proposed mapping would therefore create a Persian text in which the letters ﻡ (m) and ﻥ (n) were unusually rare: a text quite unlike the corpus of written Persian.
In any language, individual documents can have letter frequency distributions that diverge from that the language as a whole. In my experience, these divergences are not large, and are typically evident from around the tenth most common letter onwards. For example, in the OVI corpus of medieval Italian, and in Dante’s La Divina Commedia, the nine most common letters are the same, and in the same order. The tenth and eleventh most common letters in OVI are respectively D and C; in La Divina Commedia, they are C and D.
Likewise, we can make a comparison of my corpus of Persian poets with the Ruba’iyat of Omar Khayyam, which in my copy has 19,876 letters. The top ten letters are the same in the Ruba’iyat as in the larger corpus, although in a slightly different order. For the whole Persian alphabet, the correlation of letter frequencies between the Ruba’iyat and the corpus is 98.6 percent. In short, we do not expect an individual document to have a greatly different letter frequency from that of the language as a whole.
There can of course be exceptions, such as lipograms: texts which intentionally omit a selected letter or letters. For example, in the English language we have the novel Gadsby by Ernest Vincent Wright, and in French La Disparition by Georges Perec, neither of which contains the letter e, the most common letter in both English and French. We have to hope that the Voynich manuscript is not a lipogram.
Letter frequencies
My own predilection is to ignore any visual similarities that may exist between Voynich glyphs and letters in natural languages, and to focus on glyph and letter frequencies. This was a device used by Edgar Allen Poe in his short story The Gold Bug, and by Sir Arthur Conan Doyle in his Sherlock Holmes tale The Adventure of the Dancing Men. In both cases the protagonist used frequency comparisons to solve enciphered messages.
In the case of the Voynich manuscript, following Occam’s Razor, we could adopt the simplest assumptions: that the scribes worked from a precursor document or documents in a natural language or languages; and that they chose to use, or the producer instructed them to use, a one-to-one mapping between letters and glyphs. If so, the frequencies of the precursor letters should have been preserved. If the precursor language was Persian, then the frequencies of the Persian letters should match, in some respect, the frequencies of the glyphs that the scribes committed to vellum.
As a start, we could look at the ten most common symbols in Persian and in Voynich.
For Persian, I used the above-mentioned corpus of the works of forty-eight poets: for which my colleague bi3mw kindly calculated the letter frequencies. For the Voynich manuscript, I used a range of alternative transliterations to Glen Claston’s classic v101 transliteration. To select the best-fitting transliteration, I used the average frequency difference (which I defined in another post on this platform). The best fit was the transliteration which I numbered v170. This had the following differences from v101:
• I replaced the v101 glyph pair {4o} by the single Unicode symbol ④Furthermore, since the Voynich manuscript has evidence of multiple languages, I thought it advisable to work with only the “herbal” section, which appeared to use a single homogenous language. I followed Rene Zandbergen’s definition of the “herbal” section: that is, the folios which contain full-page drawings of objects that resemble plants. We do not need to assume that the text of this section has anything to do with plants or herbs.
• I disaggregated three related v101 glyphs as follows: m => iiN, M= iiiN, n => iN.
The results are as follows.
The Voynich manuscript, v170 transliteration, “herbal” section, the ten most frequent glyphs; and the ten most frequent letters in a corpus of the works of forty-eight Persian poets (frequencies by courtesy of bi3mw)
Here it is tempting to see not merely a visual resemblance but a correspondence between the v101 glyph {9} and the Persian letter و. But to minimise the element of subjectivity, I felt that it would be better to stay with the frequencies, and to see where that led.
The correlation between the v170 glyph frequencies and the Persian letter frequencies is 97.8 percent. This correlation is comparable with my results for many modern and medieval European languages. They do not, in themselves, imply that Persian is more or less likely than a European language to be a precursor of the Voynich manuscript.
The common “words”
If the above juxtapositions of frequencies have any merit as correspondences (we might say: mappings), then we should be able to map some of the common “words” in the Voynich manuscript to letter strings in Persian, and see whether this process yields any real Persian words.
In the v170 transliteration, "herbal" section, I identified the top five "words" of one, two, three and four glyphs, and mapped each of them to Persian, one glyph at a time, according to the rankings in the frequency tables.
The results were as follows:
Voynich manuscript, v170 transliteration, “herbal” section: the five most frequent “words” of one, two, three and four glyphs; and test mappings to Persian. Author's analysis.
In short, the results are weak. Notwithstanding the abjad effect, few of the Voynich “words” map to real words in Persian, whether we read the glyphs from left to right or from right to left.
Postscript: the scribes
Persian is, and always has been, written from right to left; and by (I think) universal agreement, the Voynich manuscript is written from left to right. Therefore, if the manuscript is in Persian, we are compelled to conjecture that the Voynich scribes did not work directly from written documents. I imagine them, rather, taking dictation.
If so (and this would apply to dictation in any language), I could imagine that they would not always be sure where words began and ended. That might help us understand why the "word" breaks are so irregular, and why there are so many instances of what Zattera calls "separable words".
Finally: the quality and consistency of the Voynich script leads us to believe that the scribes were professionals. They made a living by writing what other people wanted written. If they wrote from dictation, is it possible they wrote phonetically from a language that they did not themselves understand?
Separable “words”
In any phonetic language, as George Zipf observed when he formulated Zipf’s Law, the most frequent words are short: like "the" and "and" in English. In an abjad language, with short vowels omitted, the most frequent words will be even shorter. The top ten words in medieval Persian have two letters, or one: for example و ("and").
Some of the top ten Voynich "words" are too long to match the top ten Persian words. Examples, in the v170 transliteration, are the "words" {1oe}, {1oy} and {8ay}.
It seems to me possible that Voynich “words” do not map very well to Persian words because the “words” are not words. As Preston Currier remarked at Mary D’Imperio’s Voynich seminar in 1976:
“That’s just the point – they’re not words!”I am mindful that, as Massimiliano Zattera demonstrated at the Voynich 2022 conference, the Voynich manuscript contains thousands of “words” that look like compound “words”. To take just one example: the v101 “word” {2coehcc89} can be disaggregated into {2coe} {hcc89} or {2co} {ehcc89} or {2co} {e} {hcc89}, and in each case the components are Voynich “words”. As I observed in a previous post, Zattera estimated that such “separable words” accounted for 10.4 percent of the text and for 37.1 percent of the vocabulary of the manuscript.
Zattera, in his paper at Voynich 2022, did not specify the "separable words" that he had identified. I have not yet formulated a systematic approach to the identification of "separable words". For any given transliteration, my provisional process has the following steps:
* to identify the twenty most common “words” (delimited by spaces or line breaks), by means of an online word frequency counter such as https://www.browserling.com/tools/wor...
* to exclude single-glyph "words" such as {s}: by analogy with single-letter words such as "e" in Italian, which do not carry the implication that other occurrences of such letters are words
* to exclude "words" which are parts of other frequent "words": for example, to exclude {am} which is part of {8am}
* for each of the remaining "words", to search for other occurrences of those “words” as strings within “words”;
* to select the ten most frequent such strings;
* to convert such strings to “words” by adding a preceding and following space.
A sequence of steps to identify the “separable words” in the Voynich manuscript, v101 transliteration. Author’s analysis.
If the Voynich manuscript has a Persian precursor, we may need to apply Zattera's concept of "separable words", and break up some of the common Voynich “words”. That is a line of research that seems worth some effort.
Other languages
The approach that I outlined above would apply equally to a mapping from Voynich to any phonetic natural language.
I have already tested mappings from corpora and selected documents in several medieval languages including Albanian, Arabic, Bohemian, English, French, Galician-Portuguese, German, Italian, Latin and Ottoman Turkish. Some of my results are reported in Voynich Reconsidered: others have appeared elsewhere on this platform, or may appear in due course. Readers who would like me to test other languages are invited to send me examples of the respective corpora, preferably as .txt files.


No comments have been added yet.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

