
Markus Gärtner's Blog, page 14
January 16, 2014
Setting the right focus when getting started with ATDD
When it comes to ATDD, people, teams, and companies usually put the wrong emphasize on the elements. This blog entry is going to explore the relevant areas for successful ATDD, and how to overcome some of the misconceptions about it.
Tools
Most companies start with picking a tool. While there is value in picking a tool to automate your tests, that choice usually is not the one that delivers the highest value to you, your team, and your customer. Here is why.
Think about it. The tool you pick comes with a lot of decisions. It constrains how you think about the examples in your stories, it constrains how you can hook up the automation code to your examples. It drives decisions in your glue code. It constraints you about the amount of programming languages that your teams needs to learn. Especially when you get started with automated acceptance tests, you will not be able to deliver a good and flexible automation architecture and design. When learning a new tool, that should not be focus. The focus at this point lies on learning the new tool, and the constraints it comes with. If you intertwine that learning too deeply with too many constraints, you will not learn anything at all.
While teams new to ATDD spend about 90% of their time on learning the new tool, this shouldn’t be the case. Since the focus should resist on getting familiar with the new approach rather than the tool you should spend more time on other things. The tool is a means to an end. Focussing only on the implementation degree of your automated tool is focusing on outputs rather than outcomes.
Picking a tool for your automated acceptance tests should came last when you start with an approach like ATDD. It should be your least concern, since you can refactor your code to any tool necessary. If you don’t know how you can do this, maybe you should dive into design and architecture patterns to learn how to do this – or hire someone who can do the job without shooting you in the foot.
Templates
Depending on the approach that influenced you most, where should we start? There are some templates that help you with the first steps. For example the given/when/then templates of Gherkin constrain how you think about your examples.
Don’t let these templates distract you. I have worked in many tools using different templates. (Don’t make me name anyone.) I always found that the tool does not matter that much, so does not the particular template that underlies the tool. In fact it’s easy to re-write your examples to another template if you switch paradigms. That’s also a side-effect of the large spread of tools. Nowadays most tools and most languages support a variety of templates which makes switching between them more than easy.
For example, if you have worked with tabular data a lot so far, you can use scenario outlines and example tables in gherkin to achieve the same expressiveness. In keyword-driven tools you can use a templated test method to achieve the same. When using Gherkin’s given/when/then style, you can achieve the same using keywords in other approaches.
Most of the time, how you express your tests becomes a hook for your business stakeholders and customers. Ideally you should make tests easy enough for them to understand. The currently available tools you support you in that. Your test templates really shouldn’t be much of a concern to you, either.
Talk
The most undervalued piece of successful ATDD lies in how much knowledge exchange happens while talking about business features. To me this became clear when I realized why I wanted to introduce all of this stuff in first place. Most teams that start with ATDD realize problems after they delivered the software to the customer, and receive the feedback that the customer wanted something totally different. The primary goal of ATDD lies in understanding the business better. That should drive all your efforts.
Most teams start with ATDD without even talking to the customer or someone that understands the needs of the business better than they do. They will have a hard time when they automate 200 of the tests they thought were relevant, and the business asks for something completely different. Tooling and templating will never be a substitute for knowledge exchange. Knowledge exchange does not happen in written communication alone. Deep knowledge exchange comes with communication and removal of shallow agreements. Before even considering a tool or a template, talk to your customers, and really try to understand them, before confronting them with another tool or template.
Specification workshops should come naturally. Try to grasp the ideas of your business stakeholders there. You will have lots of time to rephrase those later in the iteration. The crucial part of the workshops lies in the understanding. Avoid talking about tools and various templates that you can use during that meeting. It will shrug your customers, and they might never return. Tools and templates will still be available, but if your customer is gone, you will have lost access to a large knowledge base.
We got it all wrong
When starting with ATDD, most teams think they should invest 90% on the tooling, 5% on the templates, and probably 5% on the talking to business stakeholders. Even though this approach matches our hunches, I think we got this all wrong. We should spend 90% of our time investigating how we can improve talking to our business stakeholders and ourselves, and spend the remaining 10% on the right expressiveness and tools that support the goals of our customers. The biggest problem with acceptance tests comes from the demand that we don’t understand the business goals well enough. So, whenever we start with ATDD, we should investigate how to improve that, rather than improve the things that business stakeholder will never be interested in in first place. I think this starts with the conversation and understanding of the business goals.
Oh, and a final misconception about ATDD: it’s not about the regression. That is a side-effect, and you should spend fewer than 1% of your time on it. If you find yourself in the position to always hunt after failing tests, then throw away all you got. The cost of test ownership is higher than the degree of benefits you get out of it. Better throws them all away now, and overthink your approach than to keep on letting it slow you down. It means less than 1% of your benefits anyways. Get rid of these if they come with a too high maintenance cost.











January 15, 2014
Maintainable automated tests – the architecture view
When it comes to functional test automation, most legacy application have to deal with the problem, that retro-fitting automated tests to an application that was not built with it from scratch, can be painful. In the long-run, teams may face one problem. The automated tests constrain further development on the production software. The tests are highly coupled to the software that they test. Let’s see how we can solve these problems with a clear architecture in the beginning of our automation journey.
The problem with test automation code on a functional level lies in the coupling. On one hand, we try to express in the examples the business requirements, and business rules. On the other hand, we need to connect to the system under test by any technical means possible.
In my experience the biggest problems occur when we couple both too deeply to each other. This is where programming concepts come into play that help us with low coupling towards the business rules we expressed in our examples, as well as towards the underlying system that we test.
This is a graphic from ATDD by example. It shows a solution to the problems that occur usually when retro-fitting acceptance test to your application. It’s based on agile friendly test automation tools.
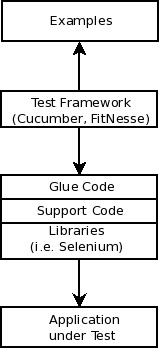
On the top we find the examples. These express our business rules. Ideally these have been discussed in a specification workshop together with SMEs, or business experts. Right below that, we find the test framework that connects the examples with the something that will connect to our application. On the bottom we find the application under test. This is the stuff that we are hooking up our tests against.
The interesting piece is the thing in the middle. I usually find myself separating between a thin layer of glue code, that is written for the framework in use. If you are using cucumber, this will be your step definitions, if you use FitNesse, this will be your fixture classes, if you use robot framework, this will be your test library, and keywords. Ideally the layer of glue code should be thin. In Domain Driven Design terms, the glue code layer provides an anti-corruption layer for the underlying support code. It translates the conventions that come from the examples and the test framework to code that you can re-use in general for testing your application.
For example, a couple of years ago, I worked with a test automation system on top of FitNesse. We had grown a large set of helper classes in our support code. The glue code layer then simply needed to provide framework-specific methods (in our case, this was Fixture code from the old FIT system), and call our little tiny helpers in the right way. A few months later, when we discovered SLiM, we were able to replace the glue code with the new conventions, and continue our test automation efforts. It would have been similar for us to replace the test framework completely with another framework. In fact, I remember a group of colleagues that integrated our support code into an android simulator to build a useful tool for the user acceptance tests directly in the plant of our customers.
The glue code provides protected variations when it comes to hooking up the framework with your application. It helps you to protect variations in how your application looks like today, to make it easy to change that without changing the examples at all. Also, the glue code layer provides protected variations when it comes to replacing your examples or your test framework. There is still a bunch of code that you can re-use.
In order to drive the application under test, you need to have driver classes. These are reflected in the Libraries box in the graphic. If you deal with a web front-end, then chances are, that Selenium is your driver. If you hook up your application behind the GUI, then you will probably grow own drivers. For examples, a few years back we used classes from the model in a model-view-presenter (MVP) GUI architecture. The model spoke to the underlying classes that would store data in a central database. By going behind the GUI we were able to make the tests more reliable. Last year, I was involved in a project involving hardware. We grew our own test libraries and test interfaces in that 20 MB Linux box, and were able to influence many of the indirect inputs to the system under test directly. On another product I worked with, we used helper classes that sent xml commands over a proprietary network connection to one of our C/C++-backends in order to trigger stuff there, execute something, or simply collect data to verify from those systems. We used it in combination with that EJB2 connections that were already in place in order to talk to the JBoss backend.
This layer of libraries provides also protected variations. Whenever something in the protocol towards your test application changes, you should just change one thing in your test code base. Otherwise you would be welcome to maintenance hell. (I have been there, don’t try.) This is virtually an anti-corruption layer for your application that lets you translate stuff from your application into terms suitable for the business rules expressed in the examples. When hooking up automated tests for an application that you don’t influence, you are very likely to need something like this. In other applications there might not need to translate your (application) business objects into a language the business – your customer – understands.
The support code in the middle, finally, should be modular enough so that you can re-use it as much as possible. That comes with a certain benefit: you should also unit test your test code when you think about larger functional test automation – especially if you are likely to re-use it. When I worked with a team of testers a few years back, we used that approach. We were able to reach 90%-95% code coverage in that code. It was really better tested than the application under test. We were way more flexible with the stuff that we had grown than our developers, since we refactored rigorously as well. I was never able to validate it, but I claim that such a modular structure with a high degree of automated tests also is better suited to introduce new colleagues.
Here’s an anecdote that I remember. There was a bug in our application that we shipped. The customer had raised it. I took a look, and talked to the programmer. We decided that we would work in parallel on the functional tests, and the implementation. I automated two to three cases that were derived from the bug report. They all failed in the old system. I needed to come up with some examples, and adapt some of our automation code. When I finished, I submitted my code to the code base. Then I went over to the programmer to check back. He was lost in the business code. At the end, we had walked over to my machine, implemented the correct behavior with the bug exposing tests running, and refactored a complicated three-times nested if-statement to something that even a programmer new to it could read and understand. At the end of the day, we submitted the code from my machine.
So, next time, you want to start with automated tests on a functional level, try to keep this graphic in mind. In the beginning you might not start with such an architecture. I don’t. What I do, is start from the examples, implement everything in glue code, and when I see structure evolving, I extract the support code that I need from it. Most of the times, I use TDD for that. Over time, you will realize stuff that changes often in your application. Try to apply the same pattern to the libraries that you grow, and keep your support code independent from it. Oh, and remember the Dependency Inversion Principle there. Over time, you will have a maintainable test automation suite, grown by use, and you are able to start delivering results from day one.
Good luck.

January 14, 2014
How to write good scenarios
During the last week, there was a Behavior Driven Development (BDD) related question on one of my mailing lists. For me it expressed a large misconception about BDD that is so widespread, and so common. Let’s see what it is, and what to do about it.
Here is the relevant part of the original mail:
Basically, the requirements is to ensure a user is redirected back to the product (eBook) page after they register a new account. Login/registration page is the same page.
GIVEN I am a non-logged in user
AND I am not remembered
WHEN I try to add an item to my “Must read list”
THEN I am directed to the eBook store login/registration page
AND I complete the registration
AND I am redirected back to the eBook page I started from
AND the product will be added to my “Must read list”
Can you spot the problem? Here’s a challenge, before reading further, try to come up with a better solution. Everything’s there that you may need to know to improve it.
Done? Good. Let’s see which smells I can identify.
Impersonalized
“Given I am a non-logged in user” is an impersonalization. It describes the setting of who the “I” is. In most cases, I found that such statements can be reframed to ‘When a non-logged in user tries to add an item to his “Must read” list’ for example. Basically there is no need for the “I” in the scenario, and often it leads sentences like the one above. Replace “I” with the user you are talking about.
Passive voice
I was taught that passive voice should not be used. Like the previous sentence, by using more active statements, you get way better scenarios. “Then the website redirects the user to the registration/login page”, “And the “Must read” list contains the product”, … Active voice improves the readability of the scenario to a big deal.
Details
The scenario is very detailed. It contains a lot of unnecessary details. For example the fact that the user is not logged in, includes that he is not remembered to me. The fact that I am redirected to the login/registration page, and login, and am redirected back to the original page, seems to be a single action that happens from the user goal perspective. Overall this leads to a long scenario. Over the years I have seen scenarios that consist of 100 lines of step definitions and more. Usually there is a pretty good reason why people come up with scenarios like this. I am happy with this, as long as they don’t claim to do ATDD or BDD just because they use a tool developed for BDD.
This leads me to the real problem, the process problem.
“Our testers can’t write code”
Now, here’s the problem, whether you like it or not: your testers are writing code in those BDD tools. They are programming. This is widespread knowledge. For example, lesson 118 in Lessons Learned in Software Testing says it clearly.
What’s even worse with the illusion that your testers can’t write code, and asking them to automate tests in such a way is this: The tools are not as powerful as a developer’s IDE. Even if they were, our industry would still be ending up with unskilled people writing code. I have worked with unskilled programmers over the years. Usually they produced what is known as Legacy Code. Code that starts to slow you down. Did you ever experience something like that in test automation? Test automation that slowed you down?
That leads us to the next problem: When your business relies on the production code, and that code slows you down dramatically, what do you do about it? Exactly, you get someone in helping you with that problem since it has a large business impact. Whether you believe that a single day training helps you, or someone should coach you on how to do it, doesn’t matter. You do something about it to improve it.
What happens when you face a problem with your test automation code that slows your business intake down? Very few do the same, and get someone in to help them. More often, you curse test automation as the culprit, give up your test automation efforts, and stick with manual testing. If that slows you down, you skip tests. Reframed: you skip addressing some of your risks. I can’t evaluate whether you really can allow yourself to do that.
There really is only one way out of this: train your test automators in enough coding so that they can write down reasonable scenarios, are aware of the shortcomings, and have enough design background to refactor the code smells they are creating, and can transfer that knowledge to their scenarios.
Forgotten business goal
The biggest problem with the initial description lies in the mismatch between the scenario, the stuff with the given/when/then in it, and the description in front of that. Let’s take another look:
Basically, the requirements is to ensure a user is redirected back to the product (eBook) page after they register a new account. Login/registration page is the same page.
GIVEN I am a non-logged in user
AND I am not remembered
WHEN I try to add an item to my “Must read list”
THEN I am directed to the eBook store login/registration page
AND I complete the registration
AND I am redirected back to the eBook page I started from
AND the product will be added to my “Must read list”
The business goal of being redirected back to the product page is not obvious in the scenario. If you face that scenario later, then you will have a hard time understandings the business goal. Why couldn’t we just express that? It turns out we can:
When I register a new account from a product page
Then I am redirected back to the product page
There are still a bunch of the smells I mentioned. But the original business goal is now clear. Of course, there are now things you need to hide in step definitions, and of course your testers need to be able to write enough code so that they can deal with the situation.
Events
What most people do not know is that BDD consists of a combination of TDD, ATDD, DDD, Specification Workshops, and outside-in development. That said, it helps to take a closer look on the events that are happening, and try to express the outcomes as messages that should be forwards from your different bounded contexts in your application. Let’s see how that situation could turn out for the example:
Given a non-logged in user adds a product to his “Must read” list
When the user registers a new account
Then the user is redirected back to the product page
And the product is added to his “Must read” list
In the given and when parts we now have events that happen inside your domain, and could be fired in your solution. DDD calls these domain events, since they are something relevant that happens in your domain. The then part also consists of events, but these are raised by your solution.
Stop claiming BDD if you are not
That last example serves the point that you shouldn’t claim to be doings BDD if you are not. Just because you found some shiny tool that helps you write fluent text that is executed, and can be used as regression test tool does not mean that you are doing BDD. BDD foremost starts with a conversation with your customer, users, and clients. If you sit down on your own computer and try to build a prototype with a BDD tool, then you are not doing BDD. From my perspective you are not even yet doing ATDD, either. But this is probably a loaded discussion for another day.

January 13, 2014
Software Tester – from new to good to great
Software testing has come a long way. We have more than thirty years of experience with software testing. The world turned around in that time period. Depending on who you listen to, there are various opinions on what to learn about testing. Thinking about testing and learning, I am aware that there are different learning methodologies, and preferences. Nonetheless, I think the topic of testing can be split up on three general skill-levels that have brought me value: beginners, practitioners, and journeymen. Let’s see what’s in for you on each of these.
Beginners
In my book, testers new to software testing have the beginner’s mind. They are fresh, energized, and passionate about learning about this new shiny topic in their life. At this point beginners learn everything, and they need to since they are not yet skilled in their new position.
That said, they should work together with experienced testers, sitting on the same desk, working and reflecting together. The more experienced tester should debrief the beginner early and often. In this early state I learn best by watching others doing it, and taking on tacit knowledge. Additionally they be coached by the more experienced testers in their new profession.
The beginner’s mind is best at getting familiar with the different aspects of testing. Test design, test execution, and test related learning about the product in this stage are very open, and testers will receive a lot of impressions about testing. It’s crucial for the beginner’s mind to get familiar with the new work.
Practitioners
As practitioner you already have a large amount of knowledge about testing. In your beginners days you learned all you needed to get familiar with the job, and to know the “ways of work” at your new workplace.
At this point, the practitioner is well-prepared to share her knowledge with others, and learn from others, and exercise new things. At this point, you should go out, and reach out to the greater community. Visit public Testing Dojos, testing challenges, expose yourself in local user groups, and tester conferences. You might also want to start a blog on your own, and expose your experience in a more written way to the outside world.
But be aware that you should seek to expose your story about testing, and try to gain new inspirations about additional things that might be worthwhile to try out back at your desk. Don’t try to take those new things too seriously. Try them out for some time, and adapt what works, and stop doing what doesn’t, or is no longer needed. Over time you will build your own testing knowledge, be able to train and coach beginning testers, and reflect with other colleagues.
Also, you should dive deeper into topics that don’t seem related to testing at all. That probably starts with programming knowledge that can help you simplify things during your daily work, and goes beyond. Dive into management topics, into systems thinking, and other areas that will help you notice and evaluate your current situation, and make more-informed decisions about adaptations that mitigate some of the liabilities that you experience.
Journeymen
As journeymen you have learned a lot about what worked in the past, and what could be adapted to improve your situation from the outside world. You are now ready to dive deeper. Now is the time when you should read about the standard methodologies about testing out there. Now is the time when you have enough experience, and an adaptable mindset about additional things. You are ready now.
Ready for what? Ready to face the literature that is out there, and question it in a constructive way. With that background knowledge of testing experience, you are able to evaluate better what sounds like theoretical crap, and what could actually work. You are now able to question the bodies of knowledge and standards that you are exposed to. You are now in the situation to have a professional network of other great testers that can help you challenge the teachings out there.
The journeymen among you, though, might find out that they need to step up, and change their organization or change their organization. At some time, they might leave their first job, onwards to greener pastures, and gain more experience there. That holds especially if you find out that in your workplace you are not delivering any value to your colleagues and your company with the practices that you learned as a beginner.
Adaptation and improvisation
Most of traditional testing lessons focus on practices from a theoretical background. I remember one guy telling me that he went to a traditional testing class. He found out that the methodology he learned there was too bloated for his particular environment. So, even though he got the cert, it was a waste of his time.
I can resonate with that (and probably wasted a lot of people’s time by giving training classes on my own). Anyway, I think we should stop teaching testers practices that they might or might not need. Instead we should focus more on teaching testers how to evaluate their situation, and make useful improvements to their work where it’s appropriate.
Then the hardest part will be to create an environment where testers can make necessary adaptations. They should have the empowerment to change their ways of work, and adapt new practices as suitable to their situation. To me that involves moving from test management where managers pick the practices for the ones who do the work towards test leadership where the leader provides the environment where testers can contribute, and improve, and shine. As a group of testers with well-intentions we can leverage the full power of our combined brains to improve how we do business. As a profession that will make us more powerful and influential.

January 12, 2014
Tale of a company Temenos workshop
Back in June 2013, I met Olaf Lewitz in Vienna at the XP conference. In a coffee break discussion, he was speaking very passionately about something called Temenos. That’s Greek, and translates roughly to “your room”. I grasped the concept, and immediately had a couple of clients in mind where I thought this would help a big deal for the team members to understand each other on a deeper level – mostly because personal stakes and misunderstandings over a long period of time had piled up. I never thought about applying it to the situation with my colleagues at it-agile. Some of my colleagues influenced enough from us to try this out. We did a company-wide Temenos so to speak as kick-off for 2014 just last week facilitated by Olaf Lewitz and Christine Neidhardt. Beforehand I was suspicious about the two days. Here is what I learned.
Caution: Some of this may and will sounds esoteric. I found it was helping to set the right stage for the overall two days. Some of my colleagues probably disagree with it. Over the course of the two days, everything was optional. That helped a lot.
Overall, our Temenos was a simple structure with four main phases:
Influence Maps
Clean slate
Personal Vision
Shared Vision
During the Influence Maps we created maps of our past, including stuff that happened in our lives, and shaped the persons we are today. We drew them on an A3 piece of paper, and then had two opportunities to share them. First, in a speed-dating way spending 2,5 minutes each with another one, then hearing her version. We managed to hear four to five different influence maps in this part. The next step was to share the maps more intensely in a working group of up to seven persons. Each of us had more time to describe his picture.
In order to clean our slates, we noted down how we are disappointed by others, and how we disappoint others. Then we walked back in our working groups, and shared our disappointments with each other again. Since we had gained a very deep understanding of the person’s pasts, I was able to connect to the disappointments on a totally different level than before.
This was roughly the first day. And it was very intense, and deep. I learned a lot about my colleagues – more than I ever imagined. I was able to connect with the experiences that I shared with my colleagues, or gains, our losses, what formed the person in front of me. It was deep, intense, and – helpful because it made me reduce some of the projection space that I had before down to the level of “oh, I see where you reaction is coming from”, and I could deal better with the discussions.
On the second day, we checked back in first, and then created our own personal visions. We shared these very personal visions for us in the company in the larger group together with each other.
Then we created a shared vision from all of our individual visions. We used different media and formats to create a vision. One group was doing a painting, another one wrote a text. One group created a movie, I worked with colleagues on a poem. After that we shared the products we created with each other, and laughed a lot, and reflected about the different aspects.
Overall, we managed to incorporate all the various personal visions into our different pictures. At times they were contradicting each other. That didn’t matter. All that matters more is the shared creation, and the level of connectedness that created among us.
The shared vision should not be thought of as a “company mission” in the classical sense, though. It’s more a combined vision into a positive future. On these two days, I could feel that I had become a more connected part of it-agile.
After all, I think the biggest value was in the outcome, not so much in the output of the shared visions. The path towards the results really brought the bigger value to me. Now I feel much more connected to basically all of my colleagues. When I work with colleagues now there is a lot of relief that I feel. Relief that I no longer need to be afraid about the situation in the room, and can dive into the discussions about the contents.
On another level, I noticed that I am now also sharing much deeper insights about me with people that I don’t know – in the bar, on the streets, etc. Before those two days of Temenos, I mostly was afraid to expose too much of myself. The experience – especially of the first day – lets me share personal stories much more easily, and thereby makes me full more whole as a human being.
Temenos and beyond
We are currently experimenting with a concept that one of our CEOs Henning Wolf once called “Scrumpany”. Directly after the two days of Temenos, we held a Sprint Review, and Sprint Planning for the upcoming monthly Sprint. Only there (and in the discussions I had with colleagues during dinner and beers after the days) did I realize how much more we were able to achieve after we had cleaned our slate. We were able to understand backgrounds of various colleagues on a much deeper level. That left out a whole lot of conflicts, and we were able to move forward much more quickly.
The last week has showed me a lot of things. While I was reserved in the beginning, I decided to give in for the two days – and I became overwhelmed positively. I have the impression that I can understand my colleagues on a much deeper level. With this understanding, I need to worry less than before, and I can focus myself and my energy on the content rather than the conflict. It helped me realize that I was pushing forward too soon at times, and it helped me notice when I was triggering emotional reactions in others when that clearly was not the purpose of my actions. The whole sum made me more aware of my situation, my wants, and my influence.
I think the last time I experiences insights this deep was during PSL in 2011. The whole two days never felt painful, and I am re-energized for the new frontiers up to come. Even though we didn’t manage to exchange all thoughts with everyone (I think I even was not up to do that – yet), I support the thought that we should have more of this in the future. I am also convinced that a personal session with my wife will be helpful for our relationship, and plan to convince my wife to attend such a session.
Thanks Olaf Lewitz and Christine Neidhardt for this opportunity. I think this workshop made us more human, more whole, and moved us a giant leap forward as a company.

January 9, 2014
Urban legends on the ProductOwner role
The role of the product owner in Scrum is probably the one that is cursed with the most misunderstandings. Personally, I curse the updates of the Scrum guide – the official guide to Scrum – and people’s lack of following-up with these changes for the variety of opinions about different pieces of Scrum around. This blog entry will deal with the role of the product owner.
Chicken or pig?
In the Scrum history, early on, there was a metaphor around a classical joke around that tried to explain different roles. The joke goes something like this (I’m a terrible joke teller):
A chicken meets a pig, and says: “Hey, we should open a restaurant together.” The pig answers: “Hmmm, interesting idea. What would we serve?” “Eggs and bacon.” “Hmmm, I don’t think this is a good idea. I would be committed while you would be involved.”
The bottom line was that some roles in Scrum were committed up to working overtime to deliver the sprint results, while others were only involved. Personally, I think it’s a good thing that Ken Schwaber and Jeff Sutherland banned this metaphor in 2011.
With the understanding of history behind it, early on, people were wondering whether the product owner is committed, or only involved – a pig or rather a chicken? I even think there are different ways to fill the product owner role that would be more chicken-like or more pig-like. My colleague Stefan Roock blogged about three different ways to fill the product owner role, and one that does not justify the name.
But consider the chicken and pig metaphor again. Personally, I think one of the reasons it was dropped, is because it leads to a dysfunction. Most of us won’t like to work overtime. Most of us won’t like to work overtime when that overtime has been put on us from the outside. Historically, the discussions about whether the product owner is a pig or a chicken probably has more to do with “do I have to work overtime when the team works overtime?” The chicken and pig metaphor provided an excuse for that answer, and I can only imagine the amount of discussions around this topic rather than getting the work done.
In the end, the product owner cannot deliver business value to the customer without the development team. The development team cannot deliver business value to the customer without the product owner. These two roles form a a symbiotic relationship, and in most implementations you are better off by working closely with the product owner rather than leaving her out. The product owner on the other hand should not leave the development team alone for the duration of a sprint. The product owner should provide feedback to the development even during the sprint. The product owner does not order product increments at the development team. It’s in the best of her interest, too, to support the development team to deliver the highest business value at the end of the sprint. I have not seen an implementation where this did not involve collaborating with the development team. Today’s literature has incorporated the term of the Scrum team. The Scrum team includes the product owner, the ScrumMaster, and the development team, and ties them together; it makes clear that we are sitting in the same boat (and it’s not a galley).
The Product Owner accepts stories during Sprint Review
I think this also is a side-effect of the chicken-pig metaphor. Some teams interpreted the role of the product owner as someone who is ordering a product increment during Sprint Planning at the development team. The motivation behind that probably has to do with busy product owners who don’t have enough time to pay attention to what the development team is building.
Of course, this kind of implementation – especially for teams and organizations new to Scrum – is more likely to end in unpleasant surprises like half of the stories being not accepted during the Sprint Review meeting. Consider the following scenario: The development team demonstrates the stuff that it has been working on during the Sprint in front of stakeholders, and the product owner. For half of the things shown, the product owner says that she does not accept it. If I were a team member on that development team, I would feel ashamed, and probably would refuse to attend any other Sprint Review meeting in the future. That does not appear a helpful situation to me.
The foremost objective of the Sprint Review meeting lies in receiving feedback about the product increment. That means that we should invite people from outside the Scrum team to provide us such an outside perspective. We usually call them stakeholders. Since they were not involved with our product for some time – in most cases at the least the current Sprint – we need to show them the product, and especially the stuff that we added in the past two weeks. Then we should collect feedback regarding the product from these stakeholders. Oh, and please, stop justifying your decisions when you collect feedback, otherwise you might find out that your stakeholders will not come back. (Development team members, and product owners should remember this.)
The Product Owner should not be invited to the retrospective
I think this was the most widespread rumor at a recent client. It probably has something to do with product owners having too many meetings already to attend yet-another-one. Especially the retrospective appears to be loaded with meta-discussions about how we work, how we feel. I can understand that dropping such a meeting for the product owner is trying to solve the overloaded-by-meetings situation of the product owner.
Now, consider this scenario: we just finished the eighth Sprint. The development team is disappointed because the product owner does not provide timely feedback during the Sprint on the stuff that the team built. They planned 8 product backlog items, and delivered only 2. Everyone is depressed. Now, the development team sits together in a meeting in order to discuss what to improve – oh, and by the way, the product owner will attend that important client meeting while they are doing that. A good retrospective facilitator will manage to reach an experiment like “arrange an all-hands meeting with the product owner to talk about this.” In most cases, though, the retrospective will end with a catalogue of things the development team wants the product owner to change – without talking to her. I think this is unhelpful.
As I mentioned earlier, neither the development team, nor the product owner can deliver high business value on their own solely. They need each other, and they especially need the feedback from each other. That includes the meetings in which we inspect and adapt our work products, and the meetings in which we inspect and adapt our working process. So, the product owner should be included in the Sprint Retrospective by default. Oh, and trust your ScrumMaster to manage to facilitate the meeting in a way so that we can talk about everything, including addressing trust issues that keep us from there.
That does not mean that there won’t be any retrospective meetings that are pointless for the product owner to attend. For example, when the technical infrastructure of the product has so worn out the team in the last Sprint that they need to talk about technical experiments for the upcoming Sprint. That might be boring for most product owners, and I consider it to be ok if she left then. But this should be an exception rather than a rule.
The bottom line is this: As a product owner you rely much more on your development team, and they surely depend on you. Try to collaborate with them more for the better your product might improve beyond what was possible in the past.

January 8, 2014
Scaling Agile – Why does it matter?
There is a lot of fuzz currently going on the Agile communities around the topic of “scaling”. Why does scaling matter? Let me try to express my view on the matter.
The ongoing increasing complexity
Our whole work runs on software. Software exists in our cars, our telephones, our traffic systems, and our voting systems during elections. Nowadays our whole society is built upon software. I remember about ten years back when I raised the point of the Y10k problem that humanity will hit in eight-thousand years. At that point no one will any longer understand how the underlying date system works anymore, and there will be probably just 5 people in humanity that can change anything about the lower-level programming going on. Software will be so complicated, if we continue to apply the same mode of thinking that brought us into today’s problems with slow delivery rates in our enterprises.
If we can’t think of ways to simplify our current thinking, how are future generations going to deal with the complexity that we create today? 50 years from today, programmers were working with zeroes and ones to program. Forty years from today programmers were working in assembly language. Thirty years from now, programmers discovered structured programming. Twenty years from now, object-oriented software was a hype. Ten years from now, agile software development started. Ten years in the future, we will realize that Lean and Craft were the hypes of today. Twenty years from now, the post-Craftsmanship movement that overcame the year 2036 bug will be hyped. Two hundred years from now, Back to the Future programming will be popular.
Do you know how to program in assembly language? Do you know which bugs are more likely to be created using assembly language? Do you know how to best test a program written in assembly language? All of the existing levels of generalization exist because there was a demand to handle the existing complexity. A hundred lines of code method in C is more usual than a hundred lines of code function in – say – Ruby nowadays. But do you really understand the side-effects of today’s compilers when it comes back to bytecode? How many times have you been surprised by the simplifications that a good compiler could make out of your crappy code to tune the performance? Did you notice any bugs that your coding introduced because you didn’t understand the compiler well enough?
The same holds for the systems that we work in. Once we stop to understand the underlying complexity of the organizations that we work in, we are very likely to misunderstand the communication paths in our organizations, and program something out of value for our customers. We probably create more code that is not earning us any money, but slowing us down because we can’t never understood the other programmer downstream of our activity that has to live with our short-comings and lack of knowledge about his role and problems that he faces.
So, when we think about agile software development, should we think about how to handle the complexity in today’s society? Or should we rather think about how to challenge and reduce the existing complexity in our organizations, and therefore our thinking in order to reduce the amount of unnecessary waste that slows us down?
As Einstein famously said once, we can’t solve our problems by the same thinking that created them. So, is the question around scaling agile really the right question to ask? Maybe it should be something different. Maybe it should be along the line of “how can we enable a team of five persons to deliver something valuable in four weeks of time?”; “how can we get rid of the things that slow us down?”; “how can we reduce the amount of people we need to create something we can earn money from?”; “how can we deliver software faster with fewer people, and thereby serve more client requests in parallel?” We achieve this not b< re-thinking our practices, but by re-thinking our underlying assumptions about the principles that guide our practices.
There is always “hope”
There is one thing that every company has in common with all the other companies around: it’s unique. There is no other company that consists of the same people, the same attitudes, the same types, the same hierarchies – formal and informal – and the same routines – formal and informal. What does make us believe that the same solutions that fit somewhere else will work for us? The short answer – like it or not: hope.
There is always hope that some things will be similar in our workplace, and the same methods can be applied to our situation. There is always hope that we can transfer the wisdom behind that other experience into our situation. There is always hope that this methodology will be different, and will work for others as well as for us.
So, our minds play an awful trick on us. Rather than asking why did it work elsewhere, we put the hope into the question that takes less effort to answer: which of the practices can we easily start using (and hope to receive the same benefits as the others claim to have)? There are two terrible problems with that level of thinking.
First, the stories of other companies are polished to protect the guilty. When it comes to conference talks, articles, and marketing material, almost no company would tell the blunt truth. There are almost always polished stories out there. Some people polish their stories on purpose, others on not knowing (or not seeing) better. Since there is always hope that this time will be better, there is always some filter applied – like a splinter in your mind – that this time it really works. Until we realize there has been something hidden from us. That foreign element can, and will drive us down. That’s when we start to notice a crisis – that really is just the end of some illusion.
Second, since our company, our system is totally different from any other company, from any other system, why do we think we will receive the same benefits by applying the same practices? Companies, especially large ones, are complex enough for us not to understand side-effects, and root-cause relationships. So, when we change one thing, how do we know that the changed behavior we observe really is an outcome of our change? How do we know that the changed behavior is the one desired? How do we know there is no cost attached to the benefit we hope to see?
Hope can blind us from the truth. Hope can turn on all of our filters. Hope can make us unaware of the grizzly that is waiting for us in the tar pit that we are heading to. Hope can make us unaware about the fact that we are heading for that tar pit. Hope can influence the metrics that we measure to justify our decisions.
What does “scaling” mean?
I think we have to re-think what “scaling” means in the context of agility. Traditionally scaling meant that we put 5000 people instead of 50 on a problem that is 100 times larger than the 50 people problem, and have it solved. Unfortunately this is a trap. The trap lies in thinking that scaling simply means any ratio of “problem size” to “body count”. Most of the times I have seen a linear fallacy attached to that: thinking that there is a 1:1 ratio involved.
So, when it comes to agility, how should we define “scaling”? Agility is meant from the viewpoint of business value, from the customer point of view. For a customer, what counts is “how fast can you ship this thing to me so that I will have less problems sooner for less money?” From a company’s perspective – in the traditional sense – “scaling” means something else: “how can we solve this more complex problem with the more complex hierarchy that we have in place?”; “we estimated this problem in the range of 50 times that problem. How can we solve this problem with 50 times the people cost in there?”
And I think there lies the real underlying problem, the problem with yesterday’s thinking. We try to scale agile by “scaling” by the amount of estimation that we made, and assume we need similarly scaled people to do the job. From the customer perspective we should ask how to change our organization so that we can deliver the solution to the customer problem sooner by spending less money? When it comes to scaling agile in the enterprise, unfortunately, I don’t see many answers to these kind of questions.
Scaling the majority
What does that mean for scaling agile in the enterprise? I think we have reached a point where more and more “enterprises” became attracted to the successes of agile software development form smaller companies. They now realize they need to change something.
But keep in mind that this is most likely the conservative early or even late majority that adopts agile right now. That means that there are less conservative moves that company is taking. That means that the enterprise is more likely stuck with their thinking, and the underlying culture in the enterprises that adopt agile need a more dramatic shift towards leaner, more agiler methodologies – not more blown answers to problems they thing they have. And this is the real drag of current large-scale agile introductions.
There are more rules, because more people need to be governed without questioning the motivation behind governance to start with. There is more structure, and more hierarchy introduced together with the agile frameworks than should be necessary. Unfortunately the short-term changes introduced now will only reveal their outcomes in years to come in such enterprises. So it will take years before the last enterprise starts to stop cursing their agile adoption a failure. Unfortunately that warning will come as late as the next wave of new methodologies starts to raise.
I think we should not bother with “scaling agile” or large scale enterprise agility which should be disciplined because all that we lack surely is discipline. Instead we should wonder why we think we need such large enterprises to start with. Only then might we be able as a craft, as an engineering culture, as artists, and scientists to see behind the curtain that has been pulled over our eyes with terms like “scaling”, “enterprise”, and “agility”, and start to wonder how deep the rabbit hole really goes.

January 7, 2014
Software lessons from a supermarket
Back when I studied, I worked part time in a local store. I was responsible for juice, soda, beer, wine, and other bottles of alcoholic drinks. I was responsible to order them, and to manage and refill remains over the week. Being a small shop, I also needed to be a jack of all traits. At times I had to have an eye on refilling vegetables, and fruits. At other times, I needed to refill milk, or answer inquiries from our cashiers. That said, there are some lessons I learned in that shop that helped me find my way once I joined my first job. Here are some nuggets from that time.
Customer-driven
In a local shop, over time, you know everyone. You know the customers that come regularly, of course you know all your colleagues, and over time, you find out who is still coming back to get their weekly shopping done, and who doesn’t. Over the course of the ten years that I worked in that shop, I learned a crucial lesson: your customer matters.
For example the customer matters when you work in the shop, are currently busy with refilling what was left from the last order, have five minutes until the end of your shift, and he approaches you with the question where he may find coal for his barbecue. If you tell him that you can’t answer that question because your shift will be over in five minutes, he is likely to walk out of the shop – and never come back.
For a long time, I thought that “the customer matters” means to do everything for your customer. That is not the case. It’s more that you should be honest, and seek to help him. If I didn’t have a clue about that other department that was in charge for the bbq coals, I still could find a colleague from that department, and refer the customer to her. If I was unable to find anyone with a clue, I could still say sorry to the customer – and make sure the problem in our shop gets addressed to the right person, so that it won’t reoccur again. If we were out of milk on a Saturday by noon, I could still inform our department lead about that problem, so he can have a chat with the responsible person.
So, the customer matters, but don’t lie to her or him.
When I started consulting a few years back, I had another terrible lesson to learn. In a local shop there is a sort of natural equilibrium between customer demand, and the persons working there. No one would put 100 employees in a shop that only had 20 customers during a day. That would be too much staff overhead – or the wrong location to run that shop to start with. In consulting the demand from your customers may rise higher than the amount of time you can actually throw in. That comes with particular stress, if you combine it with a total freedom of stuff that you can do. In short time you overburden yourself. I have felt into that trap, and from time to time I try to make experiments to stress the point whether this is really all I can do, or whether there is more. For example that kept me from writing more blog entries recently.
But I digress.
In a shop there is a limit to the amount of questions you will get on average over the course of the day. In consulting that is not necessarily the case. At that point you need to find a way to limit what you put on your shoulder, and learn to say “no” to some things that look shiny. The same holds for some larger product development companies as well. They start things all over the place, and keep on wondering why it’s so hard and expensive to get work done. The short answer is you have overburdened yourself. Start to really prioritize, and staff the projects that you really need to do. If you find yourself with a list of ten projects that don’t get staffed afterwards, then this is your inventory of projects that slows you down. You should think hard, how you could realize them. Maybe taking on more staff is a good thing for you, maybe saying “no” is the right thing. The only thing that will happen for sure, is that the other projects that you staffed will get stuff done – and usually a whole lot faster than before.
Inventory can overload you
I remember a time when I ordered vast amounts of stuff to fill the shelfs, for example there were breaks between Christmas and New Year’s where we didn’t receive any additional orders for some foods. At that point, I had to pre-plan, and order more. Or for father’s day in Germany, there is a habit to buy lots of beer, and wander with your friends through nature. One year, I had ordered four times the usual amount. Of course, all of that did not fit into the shelf. So, I put it back to inventory, and had to re-fill over the course of the week once customers bought out all of our beer.
For most of the time, I had four to five ‘rollies’ with stuff that didn’t fit on the shelf. In that week I had eight of them. That hurt me a lot later, because refilling also took a whole lot longer. I had to move double the amount of ‘rollies’ over the week, I had to re-arrange what was still remaining, and for the pieces where I had too positively ordered too much, I had to suffer for even longer than the one to two weeks around father’s day.
But I remember a particular time when our inventory in the lager kept on going up. That was really painful. It almost seemed we had dramatically slowed down with refilling from our inventory. It also felt crowded, and I felt work as pretty busy. It seemed everyone was busy ordering new stuff since they did not get to refill the inventory. So inventory went up even further, and slowed us even more down. Still, the customer was happy, but was the price for that happiness worth paying for? I never thought so.
Now, while inventory in a supermarket is pretty painful, because you can see it all day, how does this relate to software? In software, as Alistair Cockburn taught me, inventory can be thought of as unvalidated decisions laying around and waiting for the next person in sequence to take it, and build it further. For example, the classical requirements document that carries unvalidated decisions about requirements. Architecture and design decisions will be built as another layer of unvalidated decisions upon that. Finally, the first time these decisions will be validated is when the finished software faces the customer.
The problem with unvalidated decisions in software compared to a supermarket is that in a supermarket the inventory will really hurt you, because there is limited storage area, and you will have a lot of work moving all those inventory ‘rollies’. In software, I never managed to fill my hard-drive with unvalidated decisions. Even if I did, I would probably start spreading some of the decisions in the virtual cloud, online, or on DVDs, long before I ran out of disk space. That is why visual management with paper on wall has a dramatic effect in most companies: it hurts. And remember, all that is telling you, is that you have too much inventory going on. In the supermarket situation, we were only able to change the amount of our inventory with a large change in how we organized our work. And it took a lot of time to do so. That’s the case with most legacy code as well. The first few tests will not help you. It will take a lot of time to pay off for all the pain that you created earlier. Sorry, there is no free lunch.
Why do I remember these lessons?
While reading Larman and Vodde on Scaling Lean & Agile Development, I remembered these lessons, and could resonate well with queueing theory, systems thinking, and Lean management. I think it is time to take these lessons more seriously into practice. So, back at work, think about all the inventory that you have currently at work, and try to think about at least three ways to reduce it. Also keep in mind that there is always a deeper reason behind the problems you realize. Wonder what caused you to introduce that inventory in first place, and how to solve that. Oh, and really think more about your customer. I know, he’s probably far-far away in a land of fairy dust and unicorns, but a customer that disappointedly runs out of your workplace because you couldn’t help him, could infect other potential customers. Think about it.

January 6, 2014
Surprised and shocked by traditional testing literature
Over the course of the last year, I decided to dive deeper towards the source of traditional testing wisdom. That said, I read a book on the foundation knowledge behind one of the testing methodology (I won’t name anyone to protect the guilty). In the end, I was both surprised, and shocked. Here are some of the things that stood out to me. I will not name the book or the authors, as I was able to receive them as sort of a gift. If you want to know more details, feel free to contact me privately, and I might share more on the book.
What surprised me
There were a lot of things that surprised. Here are some of those pieces that I will paraphrase.
Even if you execute all tests, and those did not reveal any error, that does not mean that there are no additional test cases that would trigger errors. Yeah, I can agree to that.
Testing cannot proof absence of errors. Complete testing in this sense is impossible since there are too many possible combinations. I certainly can agree to that.
Testing effort at times is expressed as ratio of testers to developers. The authors claim they have seen ratios between one tester for 10 developers up to three testers per developer. The authors also conclude that testing effort practically varies a lot.
Testing consists of various short sections of of work activities, including test planning, test analysis, test design, test execution, evaluation of results, and conclusions of testing related work. The book claims that some of these activities may be carried out in parallel. The authors fail to mention exploratory testing at this point, but that’s what I was thinking, surely.
“Is it possible for a developer to test his own code?” The authors cannot give a commonly valid answer to this question. Yeah, I would also say, that depends.
Developers and testers can collaborate better with each other if they know each others’ work. Developers should know some basics about testing, as well as testers should know some basics about programming. I certainly agree to that.
Overall, I was wondering where some of the rumors like “developers cannot test their own code”, or “tester do not need to program” came up. It seems not from this particular testing methodology.
What shocked me
Most of me reading a traditional testing methodology book was triggered by James Bach. He claimed in April that he read some of the traditional testing literature, and was wondering what people were actually doing, and where the mention of people in that literature was. Since January 2013, I already was aware about Roberts’ Elements of Organizational Design, in short, PArchitecture, Routines, and Culture. So, if you address only the hierarchy in the organization, and change the routines, your are likely to miss out on an important factor, the humans that actually do the work, their culture. I found the same holds for that particular book that I read. The language that was used in the book was quite passive. If humans, testers, appeared, they were supposed to do something. The writing style bored me. How can a book about such a widespread testing methodology miss out on such an important audience as the reader? I was shocked.
What shocked me as well is the bogusness of test coverage metrics. It really hit me in the face. Here is an example. The technique used is boundary analysis. Test coverage can be derived by
boundary value coverage = amount of tested boundary values divided by the total amount of boundary values times 100%
The math is pretty straight forward, so what is my problem with something like that? Here is a another example from equivalence class partitioning:
equivalence class coverage = (amount of tested equivalence classes divided by total amount of equivalence classes) times 100%
Can you spot it now? Here are three problems I have with such a statement. First, it includes an ambiguous term. “total amount” in the equations above should be translated to “total amount of stuff we identified”. That would make it clearer that the applied technique needs a skilled tester. Take for example the total amount of equivalence classes. How were these derived? Did the analysis include analysis of solely input variables? Input and output variables? What about secondary dimensions? Proficient testers might realize that the world is a bit more complicated than the picture I read about coverage metrics in the book. To say the least, I have never found a single technique alone is applicable to derive good tests in my work. I also needed some combination of different techniques – and that is probably why it’s hard up to impossible to say anything about the coverage of the tests that I have ran.
My second problem with such statements is, that the unfamiliar test or project manager will be faced with some number, say “we have reached 75% test coverage yesterday”, and will not understand what that really means. Does that mean that we finished 75% of the tests we thought of when we knew little to nothing about the implemented product? Did we execute the most critical 75% tests? Will all areas be covered, even those areas of the product that existed before we began further development? Or does that number just reflect the percentage of test cases we came up with for the areas that we thought were changed during this development cycle? As you can see, there might be a lot of hidden assumptions in a statement like that. Most times in the past I have found a surprised project manager that later found out we had a different understanding about the underlying assumptions – in other words we finished with a shallow agreement about the statement.
Third problem, consider a workplace where a certain amount of test coverage is demanded by KPIs, and employees will receive a higher or lower pay due to that. Say, a manager asks the testers to deliver always 90% test coverage before the quality gate is passed. Test coverage will go up, for certain. The question is how. You can either deliver a higher amount of ran test cases, putting more effort in there. You can also identify fewer test cases, and still hit the asked for test coverage metric while delivering the basic same amount of work that you always delivered. Clearly, you can look good in face of your manager by coming up with fewer and poorer test cases, and still make a whole bunch of money out of it. I think at times that I am too honest to move away from such kind of positions. I don’t think it serves the manager, the product, and the customer well to do such a lousy and lazy job. I am sorry, my dear tester colleagues. Sure, you can still do a great job of reducing the amount of total test cases to a small amount, and still do very skillful job at test design. And I hope you work in one of the latter environments.
A last thing that shocked me was the amount of test techniques delivered in the book without stating when each technique is best applied. I think this is most crucial piece of a software testing training. Knowing your tools, but more important than knowing how to apply them is knowing when to apply them, and under which circumstances. The examples provided, being textbook examples, were of course simplified so that you understand the techniques in use without reading 300 pages of context first. Given the potential audience of the book, the authors didn’t happen to describe situations in which this particular technique would be worthwhile to follow. So, in the end, the reader wonders when to apply equivalence class partitioning over boundary value analysis, and which of the techniques is applicable for the requirements in that 300 pages document he has back at work. I can only hope that this particular skill is delivered during the training classes that go with the certification – but I doubt it.
What my journey has taught me
Overall, this journey has taught me that there is a lot of misguidance going one with some of the traditional text books. I am not surprised about that, but I really needed to find out what I would be objecting against. I mentioned the two outstanding arguments that I kept up to half a year later.
I recommend you to go to the source as well, and see what it teaches you. The authors usually are well-taught persons with good intentions, I am sure about that. So, there will be something that you can still learn from them. And I urge you to keep your critical mindset while reading on.

January 5, 2014
Exploratory testing as empirical process control
Over the course of the past year, I had the opportunity to work with some great trainers. I learned a lot from them, and by delivering co-trainings together. Today, I decided it was time to reflect on some of that stuff. Blog entries work great for me to do so. Here is a first blog entry in a series of entries to come.
Stick long enough into testing, and you will face an argument pro or contra traditional test cases. Most of us have been there. Most of us know what worked for them in the past. Most of us won’t agree with each other. During a particular co-training, I became aware and reminded again about process control, and realized why I think exploratory testing is better suited in most software development shops around. Let’s see what process control consists of, and check in which of the models testing falls, and where exploratory testing can help you.
What is process control?
Process control comes in two approaches: defined, or empirical. What’s the difference? A process can be thought of as three variables that are relevant for controlling it:
Input
Process (as a black-box)
Output
This should sound familiar to you if you have been involved in software testing. This probably also rings a bell if you have been developing software for some time.
The defined approach to process control is suitable if we can control the input to our process, and the process is reliable, i.e. producing the same outputs if you happen to feed in the same inputs. In that approach we are able to determine which inputs to deliver to our process, and which outputs we can expect from it.
The empirical approach to process control is suitable if the outputs we observe are unreliable, and seem to be rather random. I would also claim that we don’t know enough the process and how it produces outputs so that we can come up with a reliable model about the process. In that case, we need (very short) feedback loops, and either vary the input to our black-box, or change the process a tiny bit, and see what happens with the outputs then. This principle is also spread as “Inspect & Adapt”. We adapt something, one thing, we inspect the results, and learn from it.
Test cases vs. exploratory testing
In order to compare the two process control approaches with testing, let’s take a look into what traditional test cases are, and what exploratory testing is.
To paraphrase Wikipedia, a formal test cases should consist of pre-conditions, and post-conditions after triggering a particular thing in the system under test. For example, if I enter 2, plus, and 2 into a calculator, and hit the equal sign, the post-condition should be to display 4. The pre-conditions in the formal definition relate to the inputs in process control, the post-conditions to the outputs, and the operation that we trigger relates to the black-box, the process in process control terms.
On to exploratory testing:
Exploratory is an approach to software testing that is concisely described as simultaneous learning, test design and test execution.
Let’s inspect the elements. During test execution, we feed the inputs to our system under test, and execute whatever operation necessary. We then observe the outputs of the system, and match them with the expected outputs. During test design we come up with questions to ask the system that will guide our learning about the system, and derive inputs to the system based upon our current understanding, and come up with expected outcomes. Finally, after observing the system, and its outputs we learn more about the system, our internal model of the system, and other questions we might want to ask the system. In short, we vary either the inputs to the system, or our internal understanding of the system, observe the outputs after feeding the system with the input, and then adapt accordingly.
Now what?
At this point, I realized that scripted test cases relate to the defined approach of process control, while exploratory testing relates to the empirical approach. But what does that mean in my daily work? When should I go with either of these?
What I learned from process control is the following: the defined approach is suitable for stable, reliable processes; the empirical approach is suitable for “out of control” processes. Where does software testing fall into? Oh, well, that depends on a lot of factors.
To make a long story short, if your programmers are producing reliable results, and you know where to look, and you have the influence about the project’s constraints, like time, budget, scope, and the competition, then software testing becomes a pretty reliable process, and a defined approach is probably more efficient than an empirical approach with all its overhead of non-necessary feedback loops. On the other hand, if your programmers produce unreliable, or “out of control” results, you work towards arbitrary deadlines, overtime, with unskilled testers, then an empirical process with feedback loops probably is better suited for you. (I am exaggerating a bit.)
Consider this scenario: You receive a new version to test of the software. You fire up your testing machine, run the first 20 tests, and find 100 bugs. In a defined approach you would continue with the remaining 480 test cases, and might find another 2400 bugs by doing so. When reporting that to whoever you are testing for, I can understand that stakeholder of your testing to be disappointed that it took you three days to deliver the message that the software is quite unusable. In an empirical approach you would look for a feedback loop after a reasonable time, i.e. 2 hours, that tells the disappointing news to the stakeholder of your testing, so that both of you can adapt to that.
In another scenario, if you fire up that new software version, and don’t find any problems while running 500 test cases, and that’s how you have worked for years, the burden of the extra feedback loops to the stakeholder of your testing every two hours will become a drag for you.
In other news, I think the empirical approach to process control is the reason why session-based test management works so well in many contexts. It helps you ensure the necessary feedback loops to adapt the process of that seems to be “out of control”. The debriefing activity together with short timeframes of uninterrupted testing, and test-related learning going on helps you to inspect and adapt the progress early, and often, and notice when things go awry. Using a defined approach in such circumstances does not ensure that you receive the necessary feedback, i.e. a junior tester that does not (and can not) realize that he has become stuck at whatever he is doing will be asking for help too late.
So, think about the context in which you are working, and look for opportunities where the defined or the empirical approach to controlling your software with tests will help you.



