
Martin Fowler's Blog, page 24
March 16, 2017
What the Product is (and isn't)

Paulo continues his Lean Inception
discussion by moving onto an activity that explores the key
characteristics of the product. Participants explicitly list both what the
product does and what it does not do.


March 15, 2017
The Lean Inception
Agile projects don't start with a detailed plan, but let the
direction of a project emerge as we learn more. But there is value in doing some
upfront work to determine the vision of a new development. At ThoughtWorks, we
carry out inception workshops to help do this.
Paulo Caroli has developed a style of
one week inceptions, that are particularly suited for sketching out the
characteristics of a Minimum Viable Product (MVP). In this evolving article, he'll outline this one week
workshop and what goes into it. He starts with Monday morning's activity "Write the
Product Vision". We'll be publishing further activities over the next few
weeks.
March 9, 2017
Bliki: SelfEncapsulation
Data encapsulation is a central tenet in object-oriented style. This says that the
fields of an object should not be exposed publicly, instead all access from outside the
object should be via accessor methods (getters and setters). There are languages that
allow publicly accessible fields, but we usually caution programmers not to do this.
Self-encapsulation goes a step further, indicating that all internal
access to a data field should also go through accessor methods as well. Only the
accessor methods should touch the data value itself. If the data field isn't exposed to
the outside, this will mean adding additional private accessors.
Here's an example of a reasonably encapsulated java class
class Charge...
private int units;
private double rate;
public Charge(int units, double rate) {
this.units = units;
this.rate = rate;
}
public int getUnits() { return units; }
public Money getAmount() { return Money.usd(units * rate); }
Both fields are immutable. The units field is exposed to clients of the class via a
getter, but the rate field is only used internally, so doesn't need a getter.
Here is a version using self-encapsulation.
class ChargeSE...
private int units;
private double rate;
public ChargeSE(int units, double rate) {
this.units = units;
this.rate = rate;
}
public int getUnits() { return units; }
private double getRate() { return rate; }
public Money getAmount() { return Money.usd(getUnits() * getRate()); }
Self encapsulaton means that getAmount needs to access both fields
through getters. This also means I have to add a getter for rate, which I
should make private.
Encapsulating mutable data is generally a good idea. Update functions can contain
code to execute validations and consequential logic. By restricting access through
functions, we can support the UniformAccessPrinciple, allowing us to hide
which data is computed and which is stored. These accessors allow us to modify the data
structures while retaining the same public interface. Different languages differ in
details of what is "outside" for an object by various kinds of
AccessModifier, but most environments support data encapsulation to some
degree.
I've come across a few organizations that mandated self-encapsulation, and whether to
use it or not was a regular topic of debate since the 90's. Its advocates said that
encapsulation was such a benefit, that you wanted to incorporate it to internal access
too. Critics argued that it was unnecessary ceremony leading to unnecessary code that
obscured what was going on.
My view on this is that most of the time there's little value in self-encapsulation.
The value of encapsulation is proportional to the scope of the data access. Classes are
usually small (at least mine are) so direct access isn't going to be an issue within
that scope. Most accessors are simple assignments for the setter and retrieval for the
getter, so there's little value in using them internally.
But there are common circumstances where self-encapsulation is worth the effort. If there is
logic in the setter, then it's wise to consider it for any internal updates too. Another
circumstance is when the class is part of an inheritance structure, in which case the
accessors provide valuable hook points for subclasses to override behavior.
So my usual first move is to use direct access to fields, but refactor using Self Encapsulate
Field should circumstances demand it. Often the forces that lead me to
consider self-encapsulation I can resolve by extracting a new class.
Further Reading
Kent Beck discusses these trade-offs under the names Direct Access and
Indirect Access in both Implementation Patterns and
and
Smalltalk Best Practice Patterns
Acknowledgements
Ian Cartwright, Matteo Vaccari, and Philip Duldig
commented on drafts of this post
Share:



if you found this article useful, please share it. I appreciate the feedback and encouragement
February 14, 2017

February 13, 2017
Bliki: FunctionAsObject
In programming, the fundamental notion of an object is the bundling of data and
behavior. This provides a common data context when writing a set of related functions.
It also provides an interface to manipulating the data that allows the object to control
access to that data, making it easy to support derived data and prevent invalid
modifications of data. Many languages provide explicit syntax to define classes, which
act as definitions for objects. But if you have a language with first-class functions
and closures, you can use these constructs to create objects using the Function As
Object pattern (originally described by Eugene Wallingford).
Here is an example of a simplistic person object, done using the function-as-object
style in JavaScript. [1]
function createPerson(name) {
let birthday;
return {
name: () => name,
setName: (aString) => name = aString,
birthday: () => birthday,
setBirthday: (aLocalDate) => birthday = aLocalDate,
age: age,
canTrust: canTrust,
};
function age() {
return birthday.until(clock.today(), ChronoUnit.YEARS);
}
function canTrust() {
return age() <= 30;
}
}
The outer form of a function-as-object is a function, which is called as a
constructor function. The result of the call is, in essence, a hashmap of functions
[2] which acts as a method selector. This map captures the state
of any variables in the function in a closure, allowing the data to persist beyond a
single function invocation. This result hashmap can be treated like a classical object.
const kent = createPerson("kent");
kent.setBirthday(LocalDate.parse("1961-03-31"));
const youngEnoughToTrust = kent.canTrust();
Looking at the function-as-object from a classical OO point of view:
the fields of the object are represented by the parameters to the constructor
function (name)together with the local variables (birthday).
the methods of the object are the functions nested within the constructor
function. Like object methods they can freely call each other and manipulate the data
in these locally scoped variables (fields)
Nothing outside the constructor function can access the variables, preserving data
encapsulation.
The public methods of the object are those functions that are present in the
result hashmap.
Any functions nested inside the constructor function but not present in the result
hashmap are private methods
The names of the public methods are the keys of the result hashmap, not the names
of the functions within the constructor function. I prefer to keep the keys and
function names the same to avoid confusion (although it can be handy to alias
functions if needed). [3]
A common alternative implementation of this pattern is to return a function as the
method selector rather than the hashmap which is the natural method selector in
JavaScript. To use a function as the method selector, I'd return a function whose first
argument is the name of the method to invoke. The function body then switches on that
value (see Wallingford for more on this).
The function-as-object approach has been around for a long time, I've seen it
described in lisp many times, and it's been widely used in JavaScript (until ES6,
JavaScript had a very limited notion of classes). It's often used as an argument that a
specific syntax for classes isn't necessary, which is the equivalent of
object-aficionados arguing that you don't need first class functions when you can write
a class with a single "call" method. As a consequence many people in the JavaScript
world argue against using the ES6 class syntax. Personally, I like having both first
class functions and first class classes, and prefer ES6's class syntax.
Further Reading
Eugene Wallingford coined the name "Function as Object" in his 1999 pattern language "Envoy". His paper is worth reading for more
details on this, including using a function as the method selector and delegation to
support some notion of inheritance. The examples in the paper use Scheme.
Acknowledgements
Chris Ford, Fred George, James Shore, Kevin Yeung, Lucas Lego, Matteo Vaccari,
Rob Miles, and Eugene Wallingford
commented on drafts of this post
Notes
1:
For date handling I'm using joda-js, a port of the
Joda-Time library that cleaned up the appalling mess that was Java's date and time
handling. I'm glad joda-js is repeating the service of bringing sanity to date and
time handling.
2:
In JavaScript terminology it's called an object, although it is a JavaScript object,
not the classical object that we're trying to create. I'll thus refer to it as a
hashmap, to try and reduce the confusion.
3:
In ES6 I can use shorthand property names to remove the duplication by replacing
"age: age," with "age,".
Share:
if you found this article useful, please share it. I appreciate the feedback and encouragement
Interview about the Agile Manifesto
The agile uprising podcast has been doing a series of interviews with the
authors of the agile manifesto. Here is my interview, where I reveal that I
remember little of the event, but can describe a bit about the context of the time
that led to it. We also talk a bit about how the agile world has developed
since.
February 7, 2017
What do you mean by “Event-Driven”
Towards the end of last year I attended a workshop with my colleagues in
ThoughtWorks to discuss the nature of “event-driven” applications. Over the last
few years we've been building lots of systems that make a lot of use of events, and
they've been often praised, and often damned. Our North American office organized a
summit, and ThoughtWorks senior developers from all over the world showed up to
share ideas.
The biggest outcome of the summit was recognizing that when people talk about
“events”, they actually mean some quite different things. So we spent a lot of time
trying to tease out what some useful patterns might be. This note is a brief
summary of the main ones we identified.
January 25, 2017
Bliki: SyntheticMonitoring
Synthetic monitoring (also called semantic monitoring [1])
runs a subset of an application's
automated tests against the live production system on a regular basis. The results are
pushed into the monitoring service, which triggers alerts in case of failures. This
technique combines automated testing with monitoring in order to detect failing business
requirements in production.
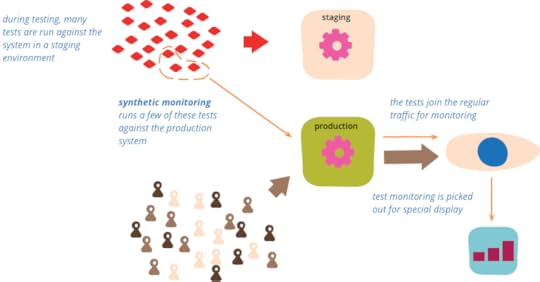
In the age of small independent services and frequent deployments it's very difficult
to test pre-production with the exact same combination of versions as they
will later exist in production. One way to mitigate this problem is to extend
testability from pre-production into production environments - the idea behind
QA in production. Doing this shifts the mindset from a focus on
Mean-Time-Between-Failures (MTBF) towards a focus on Mean-Time-To-Recovery (MTTR).
MTTR > MTBF, for most types of F
-- John Allspaw
A technique for this is synthetic monitoring, which we used at a client who is a digital marketplace for cars with
millions of classifieds across a dozen countries. They have close to a hundred services
in production, each deployed multiple times a day. Tests are run in a ContinuousDelivery pipeline before the service is deployed to production. The dependencies for the
integration tests do not use TestDoubles, instead the tests run against components in
production.
Here is an example of these tests that's well suited for synthetic monitoring. It impersonates a user
adding a classified to her list of favourites. The steps she takes are as follows:
Go to the homepage, log in and remove all favourites, if any. At this point
the favourites counter is zero.
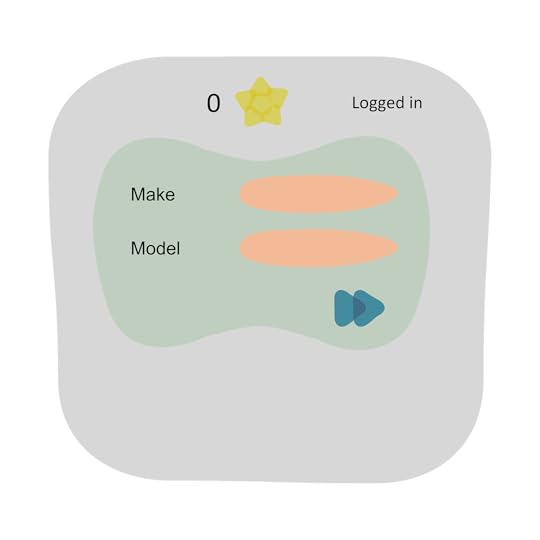
Select some filtering criteria and execute search.
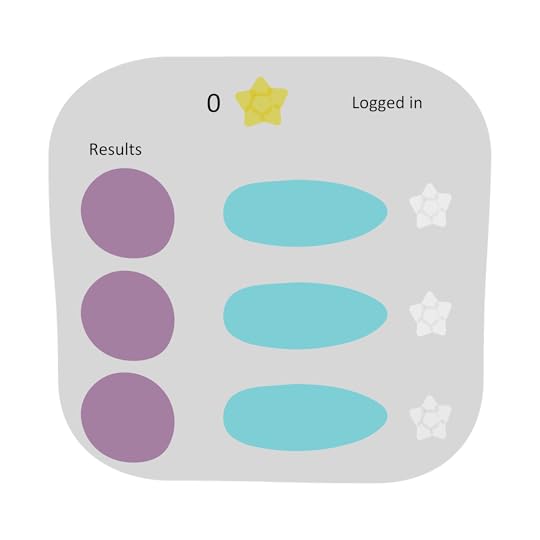
Add two entries from the results to the favourites by clicking the star. The stars
change from grey to yellow.
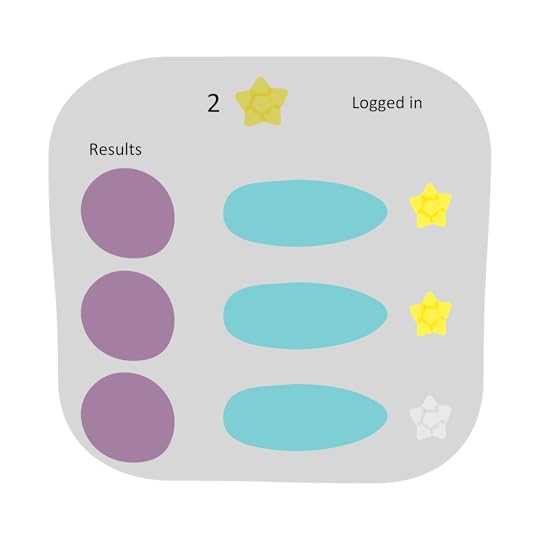
Go to the homepage. At this point the favourites counter should be two.
In order to exclude test requests from analytics we add a parameter
(such as excluderequests=true)
to the URL. The parameter is handed over transitively to all downstream services, each
of which suppresses analytics and third party scripts when it is set to true.
We could use the excluderequests
parameter to mark the data as synthetic in the backend
datastores. In our case this isn't relevant since we re-use the same user account and
clean out its state at the beginning of the test. The downside is that we cannot run
this test concurrently. Alternatively, we could create a new user account for each test run.
To make the test users easily identifiable these accounts would have a specific pre or postfix in the email address.
Another option would be to have a custom HTTP header that would be sent in every request to identify it as a test, though
this is more common for APIs.
Our tests run with the Selenium webdriver and are executed with PhantomJS every 5 minutes against
the service in production. The test results are fed into the monitoring
system and displayed on the team's dashboard. Depending on the
importance of the tested feature, failures can also trigger alerts for
on-call duties.
A selection of Broad Stack Tests at the top of the Test Pyramid are well suited to use for
synthetic monitoring. These would be UI tests, User Journey Tests, User Acceptance tests
or End-to-End tests for web applications; or Consumer-Driven Contract tests (CDCs) for
APIs. An alternative to running a suite of UI tests — for example in the context of
batch processing jobs — would be to feed a synthetic transaction into the system and
assert on its desired final state such as a database entry, a message on a queue or a
file in a directory.
Further Reading
Building Microservices: Designing Fine-Grained Systems -- by Sam Newman
Testing Strategies in a Microservice Architecture -- by Toby Clemson
Acknowledgements
Thanks to Henry Lawson for his feedback.
And a special thanks to Martin Fowler for his support, suggestions and time spent helping us improve this Bliki.
Notes
1: Ryan Murray coined the term "semantic monitoring"
and it appeared on the
ThoughtWorks Technology Radar in late 2012. However
"synthetic monitoring" seems to be the more widely used term, and usefully builds on
the notion of synthetic transactions.
Share:
if you found this article useful, please share it. I appreciate the feedback and encouragement
January 17, 2017
Bliki: ContinuousIntegrationCertification
Continuous Integration is a popular technique in software development. At conferences
many developers talk about how they use it, and Continuous Integration tools are common
in most development organizations. But we all know that any decent technique needs a certification
program — and fortunately one does exist. Developed by one of the foremost experts in
continuous delivery and devops, it’s known for being remarkably rapid to administer, yet
very insightful for its results. Although it’s quite mature, it isn’t as well known as
it should be, so as a fan of the technique I think it’s important for me to share this
certification program with my readers. Are you ready to be certified for Continuous
Integration? And how
will you deal with the shocking truth that taking the test will reveal?
By now my regular readers are wondering if they’ve come across a parody post [1], and yes
I am having a little fun with my opening teaser. But like any good joke there’s an
important kernel of truth buried in it. There is a remarkably good test for proper
Continuous Integration that was created by Jez Humble - and he certainly is a leading
expert in ContinuousDelivery. It’s also a rapid test, he often administers it to his
audience during his talks. The only problem is that I’ve never heard him refer to it as a
certification test - which just shows his lack of vision for money-making schemes.
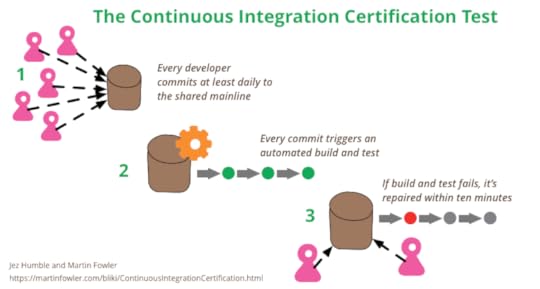
He usually begins the certification process by asking his audience to raise their
hands if they do Continuous Integration. Usually most of the audience raise their hands.
He then asks them to keep their hands up if everyone on their team commits and pushes
to a shared mainline (usually shared master in git) at least daily.
Over half the hands go down.
He then asks them to keep their hands up if each such commit causes an automated
build and test. Half the remaining hands are lowered.
Finally he asks if, when the build fails, it’s usually back to green within ten
minutes. [2]
With that last question only a few hands remain. Those are the people who pass his
certification test.
It’s a simple set of questions, but it gets to the core of what Continuous
Integration is about. The whole idea is that nobody is working on a code base that
deviates significantly from anyone else’s. Continuous Integration means the team knows
what the current state of the code truly is, we avoid big risky merges, and people can
refactor as much as they need to.
The reason so many people raise their hands at the beginning is the common view that
Continuous Integration means running some “Continuous Integration Server” against their
feature branches. But Continuous Integration — as it was originally described and named
by Kent Beck as part of ExtremeProgramming — has nothing to do with tools. At the
beginning it was a human workflow and Jim Shore made an excellent argument that it
should be that. The idea of running a daemon process against a source code
repository came later, and while it is helpful, it’s only Continuous Integration if it’s
run on a shared mainline that people commit to every day. Running such a daemon
otherwise, such as on every FeatureBranch, is Daemonic Continuous Integration that debases the name [3], yielding a workflow that doesn't give you the benefits that make the whole
thing worth the effort.
Further Reading
For more details on Continuous Integration, see my main
article, while written in 2006 it's still a solid summary and definition of the
technique. Jez explains why Continuous Integration is a foundation
for Continuous Delivery. He states the three questions in the FAQ on that page.
Paul Duvall wrote the definitive book on Continuous
Integration. Watch Jez administer the certification test
at GOTO Chicago in 2014 (sadly there was no camera on the audience).
Acknowledgements
All credit for the three questions go to Jez, whose talks I've always enjoyed. A
conversation with Paul Hammant triggered me to come up with the term Daemonic
Continuous Integration, which I hope will catch on for this particularly annoying
piece of cargo culting.
Notes
1:
In general, I'm not a fan of software certification schemes, as they usually fail
the CertificationCompetenceCorrelation
2:
For this step, "green" counts as passing the commit
build, typically compilation and unit tests. While we usually expect a full
DeploymentPipeline to be run for release to production, a repository
should be fine for developers to work on after the commit build is green. You should
have a commit build that takes no more than ten minutes, so quickly fixing it and
re-running the commit build works if the fix is easy. If you can't fix and get a
green commit build within ten minutes, then you should revert to the last green build.
3:
The problem of Daemonic Continuous
Integration leads some people to use the name Trunk-Based Development, arguing that
SemanticDiffusion has rendered the term “Continuous Integration” useless.
While I understand their view, I believe that we shouldn’t give in to semantic
diffusion, instead we need to keep working at re-explaining the proper meaning of
Continuous Integration, just as we should with other terms under this kind of semantic
assault (such as “agile” and “refactoring”).
Share:
if you found this article useful, please share it. I appreciate the feedback and encouragement
January 6, 2017
Martin Fowler's Blog

- Martin Fowler's profile
- 1103 followers

