
Maciej Aniserowicz's Blog, page 12
November 3, 2019
DevTalk #105 – O SAP z Pawłem Wiejkutem
 Możliwe, że enigmatyczny akronim SAP mignął Ci gdzieśtam kiedyśtam. Może wiesz, że jest związany z ogarnianiem zasobów w przedsiębiorstwach. A może obiło Ci się o uszy, że SAP jest nudny, ale można na nim zbić kokosy? Dziś zweryfikujesz swoją wiedzę, bo goszczę Eksperta w tej dziedzinie. Poznaj Pawła!
Możliwe, że enigmatyczny akronim SAP mignął Ci gdzieśtam kiedyśtam. Może wiesz, że jest związany z ogarnianiem zasobów w przedsiębiorstwach. A może obiło Ci się o uszy, że SAP jest nudny, ale można na nim zbić kokosy? Dziś zweryfikujesz swoją wiedzę, bo goszczę Eksperta w tej dziedzinie. Poznaj Pawła!
Paweł Wiejkut jest SAP ABAP BW Developerem. Swoją przygodę z SAP rozpoczął w 2016 roku i od tego momentu pracuje też przy module Business Warehouse. Jego pasją jest poszerzanie swojej wiedzy i umiejętności w zakresie ABAPa , HANY i innych rozwiązań z zakresu Big Data w świecie SAP. Po godzinach wykłada na jednej z uczelni wyższych i lata dronem. Jest fanem społeczności skupionej wokół SAP. Kiedy kalendarz pozwala, pojawia się na dedykowanych eventach. Ciekawe SAPowe odkrycia publikuje na swoim blogu.
Odpowiemy na pytania:
Czy SAP to “tylko” kasa i nuda?
Czym jest SAP, a czym ABAP?
ABC SAPa: w czym się programuje, jakich narzędzi się używa?
Ile w tym wszystkim klikania a ile programowania?
Jak wygląda typowy task dla programisty SAP?
Czy są „freelancerzy” SAP?
Ile osób zwykle liczy zespół?
Czy naprawdę tak ogromne zapotrzebowanie? (czytaj: ile można zarobić?)
Czy możesz się nauczyć SAPa w domu?
I najważniejsze: czy SAP jest fajny?
Cóż więcej mogę powiedzieć? Słuchaj, bo masa informacji czeka na Ciebie!
PS. Podobał Ci się ten odcinek? Zostaw gwiazdkę i opinię na iTunes! Będę dozgonnie wdzięczny!
Wiesz, co zrobić… PLAY!!

http://traffic.libsyn.com/devtalk/DevTalk_105_-_O_SAP_z_Pawem_Wiejkutem.mp3
Montaż odcinka: Krzysztof Śmigiel.
Ważne adresy:
zapisz się na newsletter
zasubskrybuj w iTunes, Spotify lub przez RSS
ściągnij odcinek w mp3
Linki:
DevTalk
DevTalk#29 – O wydajności baz danych z Damianem Widerą
DevTalk#03 – O testach z Adamem Kosińskim
DevTalk#66 – O Massive Data Processing z Łukaszem Dziekanem
DevTalk #90 – O Własnym Produkcie SAAS z Boguszem Pękalskim
Paweł Wiejkut
Blog
SAP
UI5 JavaScript Framework
abapGit
developers.sap.com
Muzyka wykorzystana w intro:
“Misuse” Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
The post DevTalk #105 – O SAP z Pawłem Wiejkutem appeared first on devstyle.pl.


October 28, 2019
October 27, 2019
Golang #4 – pakiety oraz dostępność
Zapraszam na kolejny odcinek kursu Go. W tej części zajmiemy się pakietami. Krótko mówiąc, pakiety odpowiadają za katalogowanie i logiczny podział funkcjonalności na oddzielne „worki”. Umieszczanie wszystkich plików w jednym folderze wprowadza niepotrzebny bałagan. Właśnie ten problem rozwiązują pakiety.
Z pierwszym pakietem mieliśmy już do czynienia. Jest to pakiet main, który pełni specjalną funkcję. Odpowiada on za miejsce, w którym może rozpoczynać się wykonywanie naszego kodu. Do pełni szczęścia będziemy potrzebować tylko funkcji main().
package main
func main() {
// execution starts here
}
Jeśli funkcja main() znajdzie się w innym pakiecie main, to będzie się zachowywać jak każda inna funkcja. W folderze może znajdować się maksymalnie jeden pakiet (to nie do końca prawda, lecz o testach opowiem później). Owe pakiety fizycznie są umieszczane w osobnych folderach. To coś na wzór pakietów w Javie. Mogłem trochę namieszać, więc wyjaśnię na przykładzie.
➜ ls -la
drwxr-xr-x 6 bkielbasa staff 192 Aug 30 19:55 .
drwxr-xr-x 3 bkielbasa staff 96 Aug 30 19:51 ..
-rw------- 1 bkielbasa staff 18 Aug 30 19:52 go.mod
-rw-r--r-- 1 bkielbasa staff 60 Aug 30 19:52 main.go
drwxr-xr-x 2 bkielbasa staff 64 Aug 30 19:55 pkg1
drwxr-xr-x 2 bkielbasa staff 64 Aug 30 19:55 pkg2
W powyższym zestawieniu mamy plik main.go, będący miejscem, od którego zaczyna się wykonywanie aplikacji. Są też foldery pkg1 oraz pkg2. Nazwy podfolderów powinny pasować do nazw pakietów, które znajdują się wewnątrz. Jest od tego jeden wyjątek, mianowicie pakiet main. Tak, można mieć wiele pakietów main w obrębie jednego projektu, a każdy będzie uruchamiać inną wersję aplikacji.
Go modules
Od wersji Go 1.11 mamy wbudowany system zarządzania pakietami. W końcu! Aby móc zacząć z niego korzystać, należy wpisać komendę go mod init github.com/some/pkg w katalogu głównym projektu.
Dobrą praktyką jest nazywanie pakietu od adresu repozytorium. Pozwala to zachować spójność oraz umożliwia tworzenie unikatowych nazw pakietów.
Tym sposobem otrzymujemy nowy plik o nazwie go mod, w którym będą znajdować się informacje o naszych zależnościach. Gdy wykonamy polecenia takie jak go test/build/run i tym podobne, Go automatycznie pobierze wszystkie te zależności za nas. W wyżej wymienionym pliku znajdować się mogą też dwie inne informacje.
module github.com/some/pkg
go 1.13
require (
github.com/stretchr/testify v1.4.0
)
Pierwsza to nazwa naszego modułu, a kolejna to wersja języka Go, który jest wymagany przez bibliotekę/aplikację. Jak pobrać zależność? Przede wszystkim należy zacząć jej używać. Golang jest w tej kwestii dość restrykcyjny i nie pozwala na kompilację, gdy w kodzie jest nieużyty import.
Import jest to słowo kluczowe, które daje nam możliwość użycia jakiegoś pakietu w naszym pliku. Nie ma znaczenia, czy ten pakiet znajduje się w projekcie, czy też jest zewnętrzną zależnością.
package yours
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestSomething(t *testing.T) {
assert.True(t, true, "True is true!")
}
Następnie wpisujemy komendę go get github.com/nazwa/pakietu i czekamy kilka chwil. Środowisko takie jak GoLand (od JetBrains) potrafi tę operację wykonać z poziomu edytora. Wystarczy wcisnąć alt+enter. Od tego momentu możemy korzystać z zewnętrznej zależności bez problemów.
To, co warto podkreślić, to fakt, że tę nazwę, którą podamy w pliku go.mod, użytkownicy naszej biblioteki będą musieli podać u siebie. To znaczy, że jeśli nasz moduł nazywa się module github.com/some/pkg, to pobieranie tej zależności będzie wyglądać następująco:
go get github.com/some/pkg
Wróćmy jeszcze do dostępności funkcji oraz struktur. Warto pamiętać, że ta sama zasada będzie się tyczyła również zewnętrznych zależności – nie można użyć funkcji/struktur/stałych, które nie są wyeksportowane (zapisane wielką literą).
Istnieje też specjalny i dość specyficzny rodzaj pakietu – internal.
Jeśli coś jest dla Ciebie niezrozumiałe, to śmiało pytaj w komentarzach. Chętnie zaktualizuję wpis. :) Zachęcam również do dodawania propozycji zagadnień, które mógłbym poruszyć. Powoli kończą się tematy podstawowe, a chcę dostosowywać treści do Twoich potrzeb.
The post Golang #4 – pakiety oraz dostępność appeared first on devstyle.pl.
October 24, 2019
October 22, 2019
Już nic mnie nie zaskoczy, czyli Wrzesień 2019. Podsumowanie i raport finansowy.
Na swoim (nieaktywnym już) profilu na Patronite obiecałem publikować co miesiąc “raport finansowy”. Dodatkowo zamieszczam podsumowanie tego, co działo się w imperium devstyle w ostatnim miesiącu. Pokazuję… wszystko. Bez tajemnic. Enjoy!
Tym razem raport mocno spóźniony. A dlaczego? Bo biję się z myślami, czy w ogóle nadal publikować takie rzeczy. Dzisiaj jeszcze idzie, ale w przyszłości: nie wiem. Jak sądzisz? Daj znać w komentarzu!
Podczas wakacji było dużo odpoczynku i strat finansowych, ale też dużo spokoju. Bo wiedziałem, że na dłuższą metę te straty nie mają znaczenia. I się okazało, że faktycznie! Bo (jeśli ktoś jeszcze nie widział):

I git. Tylko to jedno liczyło się we wrześniu. Cały letni odpoczynek został “skeszowany” przy wrześniowej sprzedaży DNA, która była jednym z bardziej wyczerpujących okresów w moim życiu. I raczej AŻ TAK to nie będzie już nigdy.
W październiku natomiast dwie konferencje (Future3 w Gdańsku i Founders Mind w Wawie) i decyzja: co dalej? My już wiemy :). Jeśli interesuje Cię temat baz danych to uważaj, bo … ale na razie ććśśś.
W tym miesiącu – oraz wszystkich nadchodzących – BARDZO pomoże fakt, że Ania jest już u nas na full time. Zaczynała jako asystentka na kilka godzin tygodniowo, ale teraz koordynuje całą masę projektów, dzięki czemu całość stabilnie toczy się do przodu.
A teraz jak zwykle: kasa -> podsumowanie -> linki.
Raport finansowy: przychody
Założenia:
pieniądze (brutto) wpływające na konto w bieżącym miesiącu
usługa mogła być zrealizowana w innym terminie
Pozycje:
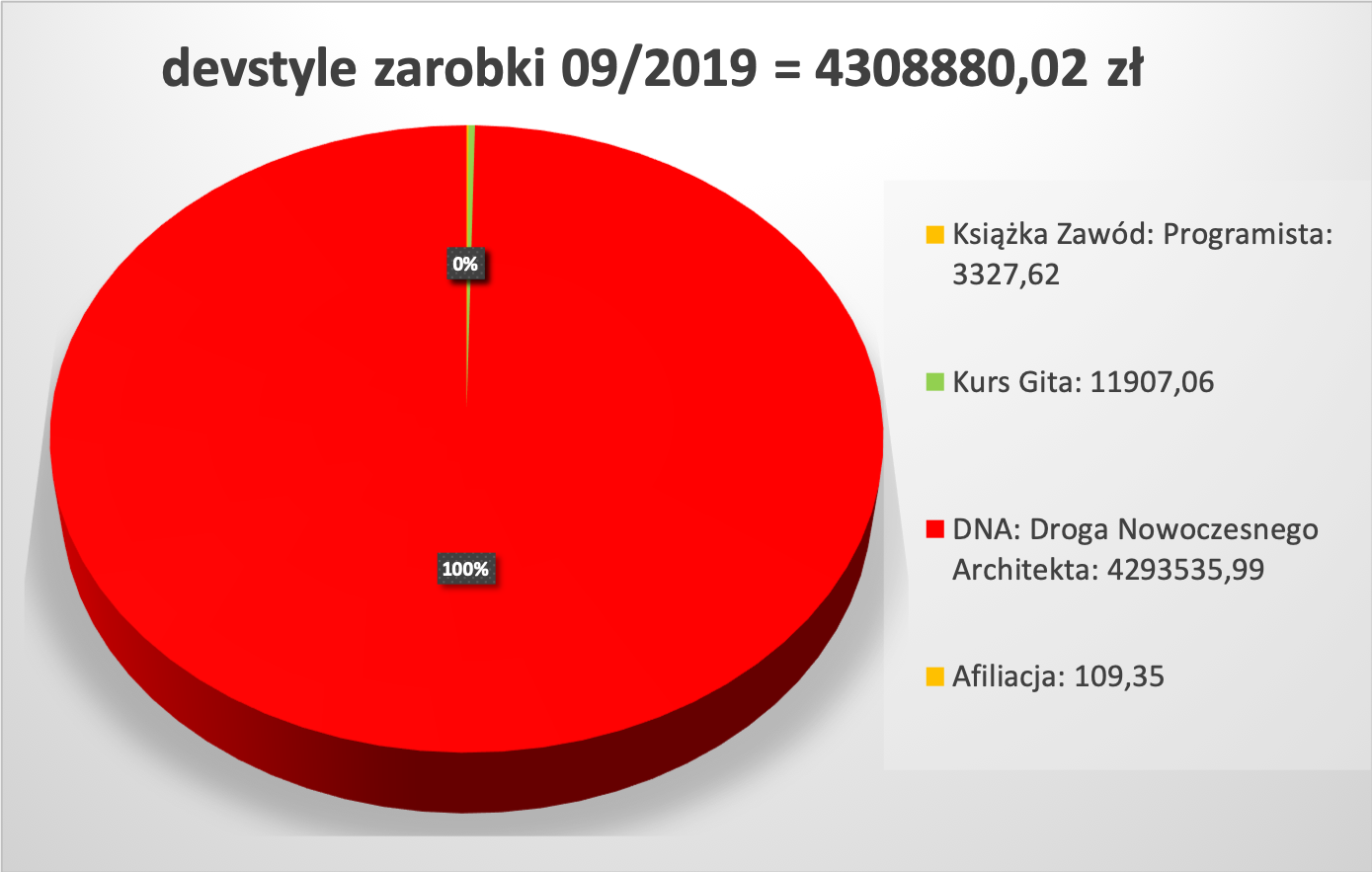
książka “Zawód: Programista”: 3 327,62 zł
Kurs Gita: 11 907,06 zł
Program “DNA: Droga Nowoczesnego Architekta”: 4 293 535,99 zł
Afiliacja: 109,35 zł
W sumie: 4 308 880,02 zł
Raport finansowy: wydatki
Założenia:
kwota brutto, znikająca z konta, bez uwzględnienia odliczeń od podatków
Pozycje (linki afiliacyjne):
ZUS: 1 549,69 zł
stały zespół: 14 913,10 zł
Ania (asystentka / PM / COO)
Magda (slowbiz & gitmastery & marketing)
Julita (księgowa)
Andrzej (montaż video)
Krzysiek (montaż audio)
Agnieszka (korekta tekstów)
PIT-4: 885,00 zł
usługi prawnicze: 307,50 zł
kurier #1: 21,65 zł
kurier #2: 54,98 zł
DNA Droga Nowoczesnego Architekta:
fundusz zwrotów i bonusów: 293 535,99 zł
Mentorzy: 3 000 000,00 zł
PKP Ania: 62,00 zł
programowanie #1: 2 152,50 zł
programowanie #2: 799,50 zł
wynajem studio video: 1 230,00 zł
promo video: 4 858,50 zł
grafiki: 1 623,60 zł
rysunki: 6 849,00 zł
inne usługi programistyczne: 28 236,00 zł
grafiki (devstyle, slowbiz, gitmastery): 2 570,70 zł
sklep / programowanie: 369,00 zł
Pajacyk: 110,00 zł
domeny
devtalk.pl: 68,88 zł
biuro
czynsz: 554,03 zł
narzędzia i usługi
Obsługa Klienta (IMKER): 664,20 zł
LibSyn: 66,06 zł
Shoplo (sklep): 60,27 zł
SalesCRM (sklep): 243,54 zł
obsługa płatności online (BlueMedia): 684,50 zł
obsługa płatności online (Przelewy24 – nie polecam): 28 914,82 zł
telefon Orange: 50,00 zł
internet T-Mobile: 55,00 zł
XMind Zen: 0 zł (opłacone do 09/2019)
MailTrack: 0 zł (opłacone do 05/2020)
Vimeo: 0 zł (opłacone do 10/2019)
ConvertKit: 7 184,74 zł (opłacone do 09/2020)
LeadPages: 0 zł (opłacone do 10/2019)
CoSchedule: 2 366,85 zł (opłacone do 09/2020)
Google Storage: 0 zł (opłacone do 11/2019)
DropBox: 0 zł (opłacone do 02/2020)
DropBox (dla Ani): 0 zł (opłacone do 06/2020)
infakt: 0 zł (opłacone do 01/2020)
wFirma: 147,60 zł (opłacone do 09/2020)
ToDoist: 0 zł (opłacone do 11/2019)
Headspace: 0 zł (anulowane)
Bonjoro: 294,08 zł
SleepCycle: 0 zł (opłacone do 06/2020)
ActiveCampaign: 0 zł (na slowbiz; 3 miesiące, opłacone do 09/2019)
Grammarly (dla Magdy): 0 zł (opłacone do 01/2020)
Bear: 59,99 zł (opłacone do 09/2020)
StreamYard: 97,97 zł
Updraft Plus (WP backup plugin): 238,73 zł (opłacone do 09/2020)
sprzęt
Kamera internetowa Logitech c920: 259,00 zł
iPad Pro 11 512GB LTE: 6 399,00 zł
Smart Keyboard Folio: 849,00 zł
Apple Pencil: 599,00 zł
PaperLike dla iPada: 125,65 zł
Uchwyt do monitora i laptopa 2F80BH3: 242,00 zł
edukacja
kurs Bezproblemowe Studio Domowe: 199,00 zł
zdrowie
psychoterapia: 880,00 zł
marketing
reklama Facebook: 19 209,46 zł
reklama Google: 0 zł
książki
brak
wsparcie 1 autora na Patronite: 16,00 zł
książka “Zawód: Programista” (obsługuje firma IMKER)
wysyłka: 809,34 zł
magazynowanie: 301,35 zł
samochód:
leasing: 1 774,56 zł
benzyna: 894,38 zł
mandat #1: 300,00 zł
mandat #2: 200,00 zł
W sumie: 3 434 887,71 zł
Podsumowanie i plany
Ponad 4 bańki przychodu… SZOK PANIE! W sumie DNA w jednej edycji zarabia prawie 6,5 miliona. Z tego co wiem to jeszcze nikt nigdy tego w Polsce nie dokonał, w żadnej branży. Więc szapoba dla nas.
Wiąże się z tym oczywiście i ta druga strona:
To jest już po podziale kasy :). Ale za to 500+ dostajemy od lipca, więc jesteśmy kwita.
Ja ze swojej strony bardzo dziękuję Mentorom DNA, swojemu zespołowi oraz wszystkim osobom zaangażowanym w DNA. Wszyscy wykonaliśmy wspaniałą robotę!
Dziękujemy również wszystkim Uczestnikom DNA. Dotychczasowy feedback bardzo grzeje nasze serduszka, bo DLA WAS SIĘ PODOBA. I to jest w całym ambarasie najważniejsze.
W powyższym zestawieniu (i w poprzednich miesiącach) można poczytać ile kosztuje wszystko związane z takim biznesem. Abstrahując już nawet od 3 milionów wysłanych chłopakom, to wszystko może pokazać naprawdę dużą skalę działania.
Dostaję czasami pytania: i co teraz z tą kasą? To odpowiadam: nudzą mnie takie tematy, naprawdę. Nie inwestuję w diamenty, samochody, zegarki, wina czy nawet mieszkania. Część leży sobie na koncie, część na lokatach, a część w obligacjach. I nie zamierzam tego póki co zmieniać.
Operacyjnie: podczas wakacji zmieniliśmy sklep na SalesCRM od firmy IMKER i to była świetna decyzja. Zmieniliśmy też operatora płatności i to już skończyło się nieco gorzej.
Dużo wydane na narzędzia, bo odnowiły się abonamenty ConvertKit i CoSchedule.
Wydałem też trochę na iPada i w tym temacie mała ciekawostka, pokazująca potęgę produktów online. Na iPada ostrzyłem ząbki już od długiego czasu, ale tak naprawdę nie wiedziałem czy mi to potrzebne i czy mogę uzasadnić wydatek kilku tys na taką fanaberię. Przed odpaleniem DNA musiałem jednak jakoś sprawdzić, czy wszystko w (nowym) sklepie działa jak trzeba: zamówienie, faktury, płatności itd. Puściłem więc maila do garstki osób, że przez 24 godziny w celach testowych można kupić mój Kurs Gita. Bez marketingu, bez wysiłku, jednym mailem akcja taka wygenerowała prawie 12 tysięcy złotych. Co prawda na wykresie wygląda to blado przy milionach z DNA, ale 12 tysi to masa kasy! Wystarczyło na top iPada z gadżetami i jeszcze na OculusQuesta zostało (ale na to się jeszcze nie skusiłem).
A teraz:
Podsumowanie aktywności devstyle 09/2019
Treści głównie do słuchania, bo aż cztery DevTalki! A od października będzie więcej (już jest)!
I przy okazji zapytanie:
Chcesz pisać na devstyle? Chcesz dotrzeć do setek/tysięcy polskich programistów?
Jeśli masz wiedzę “do podzielenia się” i chęci dołączenia do naszej Redakcji to daj znać!
Teksty:
Sierpień 2019. Cisza przed burzą. Podsumowanie i raport finansowy.
DNA: Droga Nowoczesnego Architekta… wystartowała!.
Podcasty (i inne audio):
DevTalk #99 – O nauce programowania z Mirosławem Zelentem
DevTalk #100 – O devstyle z Maciejem Aniserowiczem
DevTalk #101 – O CQRS z Łukaszem Szydło
DevTalk #102 – O Systemach Rozproszonych z Jakubem Kubryńskim
VLOGi:
Kiedy SZYPKO, kiedy WOLMO? [vlog #307]
Moje Fakapy (ale wstyd!) [vlog #308]
Status Update [vlog #309]
Video:
DNA LIVE: Architektura a Refactoring, bez nudy!
To TY masz swój biznes, czy biznes MA CIEBIE? (slowbiz offline by Maciej Aniserowicz)
[DNA] Poznajmy Mentorów DNA!
PatoDNA: Inkrementacja vs Iteracja by Jakub K. [DNA]
PatoDNA: ZAMIESZKI podczas PROGRAMOWANIA by Jakub P. [DNA]
PatoDNA: Brak komunikacji w zespole, by Łukasz Sz. [DNA]
PatoDNA: Bez CODE REVIEW ??? by Łukasz Sz. [DNA]
PatoDNA: Dlaczego analizował błąd na PRODZIE przez 3 dni ? by Jakub K. [DNA]
Wyjazdy / konferencje:
brak
====
Dzięki za uwagę i pozdro!
P.S. Jak zwykle, jeśli masz jakiekolwiek pytania: nie wahaj się, tylko je zadawaj! Na co mogę, na to odpowiem :).
P.S. 2 Możliwe, że to ostatni taki raport. Nie wiem jeszcze czy tak będzie czy nie – i nie wiem kiedy zdecyduję – ale miło było Cię tu gościć!
The post Już nic mnie nie zaskoczy, czyli Wrzesień 2019. Podsumowanie i raport finansowy. appeared first on devstyle.pl.
October 21, 2019
October 20, 2019
DevTalk #104 – O angielskim w IT z Maciejem Jędrzejewskim
 Możesz go nienawidzić, przeklinać i zgrzytać na niego zębami. Stety/Niestety, pracując w IT nie uciekniesz od języka angielskiego. Jest WSZĘDZIE, od samego kodu na materiałach edukacyjnych kończąc. Nie przesadzę stwierdzając, że programista olewający angielski zamyka sobie wiele drzwi. Dlatego przydałoby się żyć z dobrze z tym językiem. Gość sto czwartego odcinka podcastu DevTalk podpowie, jak się za to zabrać!
Możesz go nienawidzić, przeklinać i zgrzytać na niego zębami. Stety/Niestety, pracując w IT nie uciekniesz od języka angielskiego. Jest WSZĘDZIE, od samego kodu na materiałach edukacyjnych kończąc. Nie przesadzę stwierdzając, że programista olewający angielski zamyka sobie wiele drzwi. Dlatego przydałoby się żyć z dobrze z tym językiem. Gość sto czwartego odcinka podcastu DevTalk podpowie, jak się za to zabrać!
Maciej Jędrzejewski jest programistą u schyłku kariery. Zarządza projektami, jego specjalizacją są tak zwane trudne przypadki. W wolnych chwilach występuje jako prelegent, a także organizuje programistyczne kursy i warsztaty. Prowadzi YouTube’owy kanał English IT Today! o nauce języka angielskiego dla osób z branży IT. Jest wielkimi fanem NBA i polskiej ekstraklasy kopanej.
A w dzisiejszym odcinku DevTalk dowiemy się…
Jakie są najczęstsze błędy programistów?
I’m saying it from the mountain: jak Polacy radzą sobie z angielskim na tle innych narodów?
Mówienie vs. pisanie vs. czytanie – na czym polegają różnice?
Czym jest “angielski piątek”?
Jak skutecznie uczyć się angielskiego?
Brzmi jak dobry plan na spędzenie wieczoru, prawda? Zaopatrz się w gorące lub schłodzone płyny, usiądź wygodnie i chłoń wiedzę!
PS. Podobał Ci się ten odcinek? Zostaw gwiazdkę i opinię na iTunes! Trzy minuty Twojego czasu pomogą mi dotrzeć do większego grona programistów! Dzięki!
Ready… Steady… PLAY!
http://traffic.libsyn.com/devtalk/DevTalk_104_-_O_angielskim_w_IT_z_Maciejem_Jdrzejewskim.mp3
Montaż odcinka: Krzysztof Śmigiel.
Ważne adresy:
zapisz się na newsletter
zasubskrybuj w iTunes, Spotify lub przez RSS
ściągnij odcinek w mp3
Linki:
Maciej Jędrzejewski
blog
kanał YT English IT Today!
fanpage
deepl.com– translator zazwyczaj rewelacyjnie tłumaczący teksty pod względem gramatycznym
Cambridge Dictionary– potężna baza słów z wymową
gazety
tabloidy (prosty angielski)
The Sun
Mirror
The New York Times(angielski na wysokim poziomie)
Harvard Business Review(angielski na wysokim poziomie)
The Washington Post(angielski na wysokim poziomie)
aplikacja do gadania po angielsku
Busuu
książka do nauki gramatyki Arleny Witt (z kanału Po Cudzemu)
Grama to nie drama
Filmy
Avengers(wszystkie części, do sprawdzenia na stronie Marvela)
Shrek(wszystkie części)
Epoka lodowcowa
Seriale
How I Met Your Mother
Silicon Valley
Friends
Różowe lata 70-te<
Wszelkie bajki i kreskówki po angielsku :)
DevTalk
DevTalk #100 – O devstyle z Maciejem Aniserowiczem
DevTalk Trio S02E11 – Praca zdalna
DevTalk Trio S02E10 – Jak się komunikować z biznesem
Muzyka wykorzystana w intro:
“Misuse” Kevin MacLeod (incompetech.com)
Licensed under Creative Commons: By Attribution 3.0
http://creativecommons.org/licenses/by/3.0/
The post DevTalk #104 – O angielskim w IT z Maciejem Jędrzejewskim appeared first on devstyle.pl.
October 17, 2019
Byłem HEJTEREM [vlog #313]
The post Byłem HEJTEREM [vlog #313] appeared first on devstyle.pl.
October 16, 2019
Doświadczenia z BI w Azure w pigułce
Od kilku lat zajmuję się tworzeniem rozwiązań w Azure. Miałem okazję wdrażać rozwiązania, od takich trwających kilka dni, po takie, przy których pracowało wielu dostawców, ekspertów z całego świata oraz angażowane były grupy produktowe z Azure. Projekty realizowane w chmurze Azure są różnorodne, poczynając od aplikacji mobilnych, webowych, poprzez migracje firm z on-premises do chmury, IoT dla inteligentnych fabryk oraz miast, analizy obrazów czy inteligentnych chatbotów, kończąc zaś na rozwiązaniach raportowych BI. Dzisiaj opowiem właśnie o tych ostatnich.
Przedstawię swoje doświadczenia i przemyślenia na temat raportowania BI w Azure z ostatnich kilku lat. Które usługi najlepiej sprawdziły się w projektach, a które nie? Na jakie rzeczy warto zwrócić uwagę, projektując swoje rozwiązania? Na koniec zostawię Was z architekturą referencyjną, która sprawdza się na większości projektów i od której można śmiało zacząć projektowanie swoich rozwiązań.
Czyli w wielkim skrócie: jak to jest z tym BI w Azure?

Adam Marczak
Cloud Architect z ponad 8-letnim doświadczeniem w branży IT, aktualnie pracujący w firmie Lingaro. Entuzjasta technologiczny ze szczególnym ukierunkowaniem na technologie Microsoftu oraz chmurę Azure, z którą jest związany zawodowo od kilku lat. Adam wdraża rozwiązania dla dużych firm międzynarodowych. Specjalizuje się w branży FMCG. Najnowszą pasją Adama jest prowadzenie własnego kanału na YouTubie o nazwie „Azure 4 Everyone”.
Od małych projektów wszystko się zaczyna…
Różnorodność projektów BI jest bardzo duża, ale większość wdrożeń raportowych BI da się podsumować w jednym zdaniu – „z Excela do Power BI”. Można śmiało stwierdzić, że Excel to wciąż najpopularniejsze narzędzie BI na świecie. W związku z tym migracje z Excela jeszcze przez długi czas będą powszechną praktyką.
Oczywiście tutaj pojawia się Power BI, który w bardzo krótkim czasie stał się jednym z liderów rynku raportowania.
Naturalnie nasuwa się też pytanie: gdzie ten Azure i czy w ogóle jest potrzebny? Nie zawsze. Sądzę, że Azure stanowi naturalną ścieżkę podczas rozrostu rozwiązań BI. Uwaga całkiem banalna, chociaż wynika ona z ograniczonych możliwości tych narzędzi. Żeby dobrze wyjaśnić, kiedy i dlaczego odpowiedź powinna brzmieć „tak”, trzeba najpierw zrozumieć, czym jest Power BI i dlaczego to właśnie Azure idealnie nadaje się jako ścieżka rozwoju.
Architektura Referencyjna BI Reporting dla Azure i Power BI
Zacznijmy od architektury referencyjnej, która odzwierciedla około 80% średnich i dużych projektów BI dostarczanych przez naszą firmę. Poniższy schemat przedstawia ogólny zarys architektury takich rozwiązań.
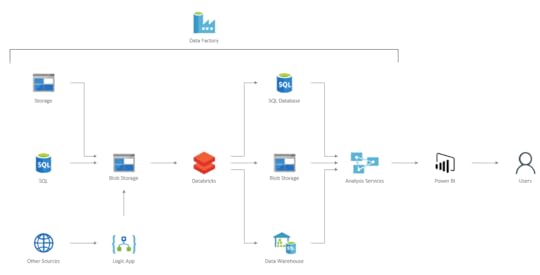
Całość procesu orkiestrujemy za pomocą usługi Azure Data Factory. Data Factory używamy również do kopiowania danych ze wszystkich wspieranych źródeł. Zwykle jest to kopiowanie w postaci 1:1 ze źródła do chmury. Do źródeł, których Data Factory nie wspiera, używamy Logic Apps. Zdarza się, choć bardzo rzadko, że korzystamy z Azure Functions, czyli zwykłego kodu C# w chmurze do zaciągania danych z zewnętrznych interfejsów aplikacyjnych, np. Google Analytics etc. Taki komponent wywołujemy wtedy z Logic Apps lub Data Factory w zależności od procesu.
Gdy dane są już w chmurze na usłudze Blob Storage, mamy zapewnione pewne kontrolki – np. w razie błędów podczas procesowania nie musimy obciążać źródeł danych ponownie. Nie obciążamy łączy, więc mamy dane w Data Center, w którym będziemy je przetwarzać, co też redukuje koszty. Biorąc pod uwagę cennik usługi Blob Storage, mamy również bardzo mały koszt przetrzymywania ogromnych ilości danych. Dużo usług bardzo dobrze współpracuje z Blob Storage.
W większości wypadków wrzucamy dane na Blob Storage, ale SQL lub Data Warehouse też się świetnie do tego nadają. Kwestia, dlaczego Analysis Services ładuje dane z Data Warehouse szybciej niż z Blob Storage, to historia na inny czas. Taka architektura zapewnia dużą optymalność kosztową, a jeśli używamy Analysis Services, to nie zawsze potrzebujemy bazy danych. Sama usługa Analysis Services używana jest do budowania modeli danych, gdzie Power BI jest ich konsumentem oraz narzędziem do wizualizacji danych.
Czym jest ten cały Power BI?
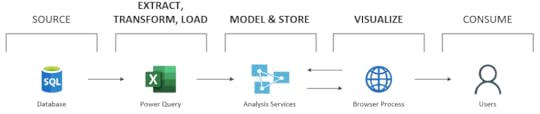
Power BI jest usługą do analizy biznesowej dostarczaną przez firmę Microsoft w ramach oferty chmury Office 365. W skład tej usługi wchodzą narzędzia do transformacji danych, ich analizy oraz wizualizacji, jak również współpracy pomiędzy użytkownikami a zespołami. Ilustruje to poniższy schemat.
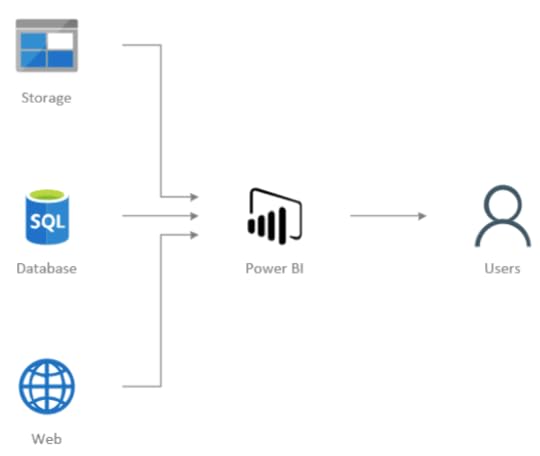
Wszystko to oczywiście można wyczytać na stronie głównej Microsoftu w instrukcji Power BI. Natomiast to, co warto wiedzieć, to fakt, że narzędzie Power BI Desktop, które jest głównym elementem używanym do tworzenia raportów, jest tak naprawdę czymś, co w środowisku BI w technologiach Microsoftu było znane już od dawna, czyli połączeniem Power Query (oryginalnie znanego jako dodatek do Excela 2013), SQL Server Analysis Services oraz emulatora przeglądarki.
Uproszczone użycie można zaprezentować w następujący sposób:
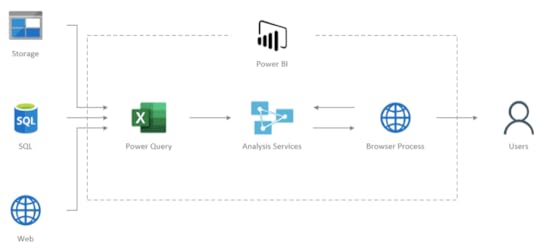
Poniżej krótki opis tych elementów:
Power Query – służy do budowania transformacji i ładowania danych do modeli analitycznych w Analysis Services. Jest to proste narzędzie ETL (Extract Transform Load) dla analityków w ramach self-service. Ma świetny interfejs użytkownika.
SQL Server Analysis Services – umożliwia tworzenie analitycznych modeli relacyjnych (Tabular) oraz analizowanie danych za pomocą języka DAX. Narzędzie to znane jest od dawna jako część rodziny usług Microsoft SQL Server, gdzie służyło jako serwer analityczny dla Reporting Services i PowerPivot dla Excela.
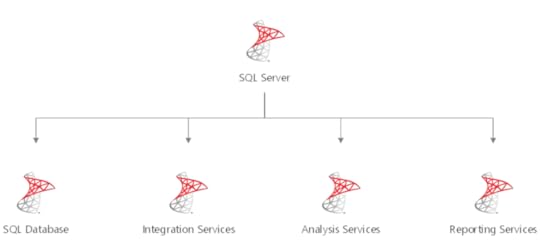
Browser Process – czyli proces przeglądarki, który wizualizuje dane zwrócone z silnika analitycznego Analysis Services.
Dzięki tym informacjom łatwiej jest zrozumieć, jak działa sam Power BI i w jaki sposób będzie się on skalować dla większych rozwiązań. Przykładowo: wiedząc, że Analysis Services jest silnikiem całego rozwiązania, można bez trudu znaleźć ogromne zasoby wiedzy w internecie dotyczące zarówno samego silnika, jak i sposobów jego optymalizacji czy automatyzacji.
Proces wdrażania BI w Azure
Mówiąc o procesie wdrażania BI w Azure, warto określić zakresy odpowiedzialności i wylistować wszystkie możliwe usługi w Azure, które mogą nas wesprzeć.
Na przykładzie migracji z Power BI podzielmy jego komponenty na odpowiednie zakresy odpowiedzialności:
Warto zwrócić od razu uwagę na poszczególne usługi w Azure, które w prawdzie nie są wszystkimi usługami, których można użyć, ale zaspokoją potrzeby ponad 90% aplikacji.
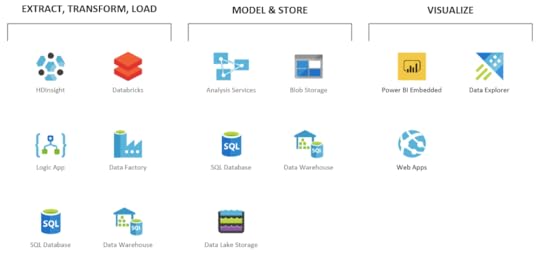
ETL, czyli procesy ekstrakcji, transformacji i ładowania danych
Azure dostarcza ogromną liczbę narzędzi, które pozwalają na sprawne przetwarzanie danych. Zwykle nie używa się jednego, lecz kilku naraz. Często wynika to z faktu, że każda z usług ma określony zbiór zastosowań, do których idealnie się nadaje. Jest to chyba jedna z najczęściej poruszanych kwestii przez naszych klientów czy programistów, którzy dopiero zaczynają swoją przygodę z Azure. Lepiej używać więcej usług, ale do wyłącznie do zadań im dedykowanych.
Usługa HDInsight (HDI)

HDInsight jest pierwszą z usług opartą na rozwiązaniach z obszaru Big Data. Bazuje na Apache Hadoop, dzięki czemu wspiera wiele frameworków, takich jak Hadoop, Spark, Hive, Kafka, Storm czy też R. Pozwala to na przeniesienie praktycznie każdego procesu ETL bez potrzeby zadawania sobie pytania, czy technologia będzie wystarczająco wydajna. Z doświadczenia wiem, że nie zawsze jest to takie oczywiste podczas używania usług oferowanych w chmurach publicznych.
Krótko mówiąc, HDInsight jest usługą pozwalającą na transformację danych. Narzędziem służącym do tworzenia transformacji są skrypty napisane w znanych językach programistycznych, takich jak Scala, Python czy R. Usługa sama zajmuje się podziałem zadań oraz rozłożeniem ich w odpowiedni sposób na serwerach (nodach). Za skalowanie liczby serwerów odpowiada również sama usługa, dzięki czemu programista musi jedynie stworzyć transformację.
Głównym minusem usługi jest to, że obecnie nie można jej wyłączyć. Nieważne, czy proces działa, czy nie, płacimy za usługę. Najlepsze, co możemy zrobić, to ustawić skalowanie, ale koszty za minimalny rozmiar klastra i tak pozostaną. I tutaj z pomocą przychodzi kolejna usługa, znana jako Azure Databricks.
Dokumentacja HDInsight
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-overview
Usługa Databricks

Azure Databricks jest drugą usługą z obszaru Big Data. Wprowadzona dość niedawno do Azure, szybko zyskała sobie w naszej firmie miano najlepszej usługi do przetwarzania danych. Podobnie jak HDInsight oparta jest na technologii Apache Spark. Twórcami usługi jest ten sam zespół, który był odpowiedzialny za stworzenie samego Apache Spark.
Warto tutaj zwrócić uwagę, że samo Databricks jest tak naprawdę platformą, a nie usługą Azure. Platforma ta jest produktem komercyjnym, ale nie została stworzona przez Microsoft. Microsoft w partnerstwie z twórcami Databricks zintegrował ją w ramach usług dostarczanych przez chmurę Azure.
Jak to zwykle bywa, takie rozwiązanie ma dobre i złe strony. Zdecydowanie na plus jest uporanie się z widmem Vendor Lockingu. Vendor Locking to sytuacja, kiedy firma używa rozwiązań tylko jednego dostawcy, co stwarza ryzyko związane z monopolizacją i dużym kosztem przeniesienia do innego dostawcy. Jako że usługa Databricks jest zewnętrzną platformą, w bardzo prosty sposób można wszystkie swoje procesy przenieść do innego dostawcy chmurowego lub własnej infrastruktury. Jedynym minusem platformy jest dodatkowa opłata kalkulowana w ramach metryki znanej jako DBU (Databricks Units). To koszt licencji liczonej na każdy rdzeń procesora. Oznacza to, że na papierze usługa jest sporo droższa niż HDInsight.
Usługa ta działa praktycznie w taki sam sposób jak HDIsnight. Nie jest to tematem tego artykułu, ale warto wiedzieć, że dobra współpraca oraz gwarancja najlepiej zoptymalizowanej wersji Apache Spark na rynku, to główne czynniki sprzedażowe tej technologii.
Dokumentacja Databricks
https://docs.microsoft.com/en-us/azure/azure
https://docs.azuredatabricks.net/
Databricks czy HDInsight

Skoro te usługi są tak do siebie podobne, to którą wybrać? Często słysze to pytanie u nas w firmie. Moja odpowiedź w większości wypadków brzmi: używaj Databricks, ponieważ klastry są powoływane szybciej, co często jest krytycznym wymogiem, aby przetworzyć dane w określonym czasie. Dzięki lepszej wydajności przetwarzanie trwa krócej. Zaobserwowaliśmy, że samo przeniesienie skryptów bez zmian dało nam zysk w czasie przetwarzania na poziomie 10–20%. Dodatkowo Databricks w przeciwieństwie do HDIsnight ma opcję Auto Terminate, czyli po określonym czasie serwery same się wyłączają (czyt. usuwają, przy czym ich konfiguracja jest zapamiętana), przez co sama usługa wychodzi sporo taniej i nie wymaga to pisania dodatkowych skryptów automatyzujących platformę.
Dla mnie to wystarczające argumenty przemawiające za wyborem Databricks.
Data Factory (ADF)

Data Factory jest jedną z moich ulubionych usług w Azure. Jest to idealny przykład, jak powinny wyglądać usługi tworzone w modelu Platform as a Service. Estetyczny i prosty w obsłudze interfejs pozwala na tworzenie rozwiązań w oknie przeglądarki bez dogłębnej wiedzy technicznej.

Głównym założeniem usługi jest orkiestracja procesów oraz przenoszenie danych, chociaż sama usługa potrafi jedynie orkiestrować procesy, a do samych transformacji musi używać innych usług. Możliwości jest tutaj sporo, bo można wykonywać kwerendy zarówno na źródłach danych, jaki i miejscach ich docelowego przeniesienia, ale również HDInsight, Databricks, Batch Service, Data Lake Analytics i Machine Learning.
W chwili pisania artykułu w Preview jest dostępny dodatek do Data Factory, znany jako Data Flows. Element ten adresuje brak możliwości transformacji w samej usłudze dzięki nowemu edytorowi graficznemu, który pozwala na tworzenie w prosty sposób procesów transformacji danych. Tak zbudowany proces Data Factory skompiluje jako paczkę i wyśle do Databricks do przetworzenia. A my zapłacimy jedynie za czas wykonania zadania.
Dokumentacja Data Factory
https://docs.microsoft.com/en-us/azure/data-factory/
Logic Apps
Logic Apps jest zdecydowanie moją ulubioną usługą w Azure. Nosi ona znamiona tzw. Enterprise Integration Service. Oznacza to, że jej głównym założeniem jest tworzenie integracji pomiędzy wieloma serwisami, nie tylko tymi z chmury Azure. Sama usługa podobnie jak Data Factory ma bardzo przyjemny interfejs użytkownika.
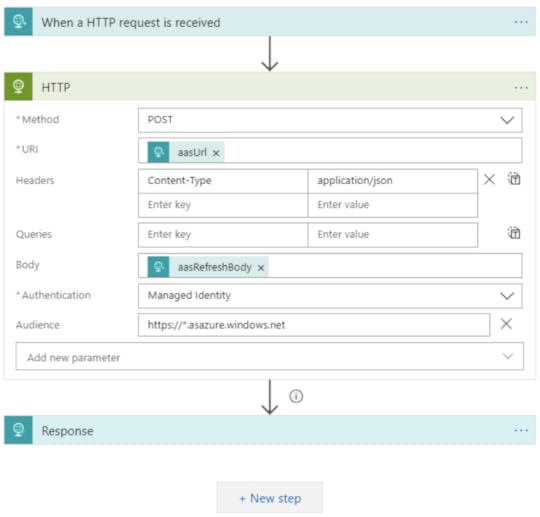
To, w czym Logic Apps jest o wiele lepsze od Data Factory, to liczba serwisów, z jakimi się integruje. Ponad 200 obecnie dostępnych konektorów do różnych serwisów oraz dziesiątki różnych akcji, dzięki którym tworzenie nawet bardzo kompleksowych procesów nigdy wcześniej nie było proste. Jeśli potrzebujemy wyciągnąć dane z serwisów takich jak Box, OneDrive, SharePoint czy też wysłać e-mail przez Exchange, napisać na kanale Microsoft Teams, to powinna nam to umożliwić właśnie usługa Logic Apps. To idealne dopełnienie procesów orkiestracji w Data Factory.
Dokumentacja Logic Apps
https://docs.microsoft.com/en-us/azure/logic-apps/
SQL Database (SQL DB) oraz Data Warehouse (SQL DW)

Trudno jest mówić o procesach transformacji danych i nie wspomnieć o Azure SQL Database oraz Data Warehouse. Bazy te są bardzo często nierozłącznym elementem architektury w aplikacjach. Azure SQL jest tradycyjną bazą relacyjna, która została zmigrowana do chmury na bazie produktu Microsoft SQL Server. Natomiast SQL Data Warehouse jest wariancją bazy SQL Server skierowaną na MPP (Multi Parallel Processing).
Bazy te świetnie sprawdzają się jako miejsce do składowania oraz modelowania danych, lecz choć świetnie sobie radzą z przetwarzaniem danych, to w Azure usługi takie jak Databricks niestety w moim mniemaniu mają sporą przewagę pod względem wygody, skalowalności czy też elastycznego modelu kosztowego.
Najłatwiej zobrazować to na przykładzie przetwarzania danych. Poniżej mamy uproszczony schemat czasu przetwarzania na bazie, która ma 100 DTU i 50 DTU (DTU to Data Transaction Unit – czyli jednostka wydajności w ramach usługi Azure SQL).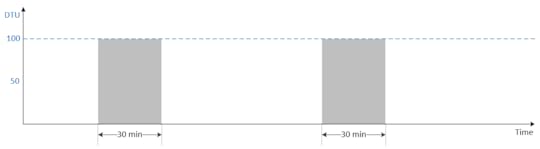
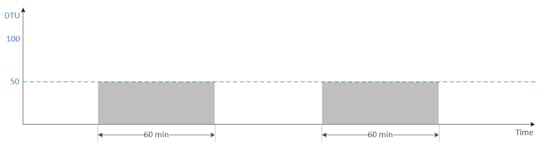
To, co się dzieje, jest raczej oczywiste: przy dwa razy mniejszej mocy obliczeniowej czas przetwarzania wydłuży się dwukrotnie. Oznacza to, że jeśli mamy wymóg przetworzenia danych w 30 minut, to nie ma innej możliwości niż posiadanie bazy, która ma 100 DTU. Problem, jaki się tutaj pojawia z Azure SQL i SQL DW, jest taki, że obecnie te usługi nie oferują autoskalowania, więc cały czas płacimy za wydajność, której potrzebujemy jedynie w momencie przetwarzania. Oczywiście niektóre projekty tworzą własną logikę autoskalowania za pomocą skryptów, ale nie jest to bez wad, bo bazy SQL zrywają podłączania podczas skalowania. No i chyba najważniejsze: po co? Są usługi, które się skalują, to nie są już czasy, kiedy programiści powinni się zajmować takimi problemami. Po to właśnie jest chmura.
Zostawiłem je na liście głównie dlatego, że są konkretne przypadki, w których sprawdzają się lepiej niż konkurencyjne produkty. Podkreślam jednak, że nie są moim pierwszym wyborem, kiedy tworzę rozwiązania BI w Azure. Ale pamiętajmy, że mówimy tutaj o samym przetwarzaniu (bardzo często używamy ich do składowania danych).
Dokumentacja SQL Database oraz Data Warehouse
https://docs.microsoft.com/en-us/azure/sql-database/
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/
Modelowanie i składowanie danych
Gdy już wybierzemy usługi, dzięki którym przetwarzamy dane, to warto się zastanowić, gdzie te dane następnie składować oraz modelować.
Jeśli chodzi o raportowanie oparte na Power BI, trzeba rozważyć dwie opcje:
1. W Azure jedynie składujemy dane, a w Power BI tworzymy modele analityczne.

2. W Azure składujemy dane i tworzymy modele analityczne, a Power BI jedynie je konsumuje.

Trudno podjąć taką decyzję w początkowych fazach projektu. Dla uproszczenia można przyjąć, że dla małych projektów idziemy w opcję 1, dla średnich w 1 lub 2 a dla dużych od razu w 2. Jeśli chodzi o średnie projekty, to nie ma co się martwić decyzją, bo gdy zajdzie potrzeba, zawsze można wprowadzić zmiany. Oczywiście trzeba takie rzeczy wyjaśnić odpowiednio klientom, aby nie było zaskoczenia. Jak już wspomniałem, Power BI ma Analysis Services wewnątrz, co oznacza, że ścieżka migracyjna do Azure Analysis Services jest bardzo prosta.
Analysis Services (AAS)

Analysis Services jest sercem analityki dla rozwiązań opartych na Power BI i Azure. Mówiąc prostymi słowami, jest to relacyjna baza danych skierowana na wysoką wydajność oraz analizowanie modeli danych. Analysis Services posiada potężny język analitycznych zapytań DAX (Data Analysis Expression), który pozwala na analizowanie danych oraz definiowanie dynamicznych miar. Właśnie ten język używany jest w Power BI, w związku z czym zrozumienie limitacji tej technologii pomoże wydłużyć etap, w którym nie trzeba jeszcze migrować z naszym rozwiązaniem do chmury.
Jest to potężna, aczkolwiek dość droga usługa. Warto dobrze poznać jej plusy i minusy. Główną zaletą tej usługi jest jej szybkość. Dzięki modelom trzymanym w pamięci serwera można uzyskać odpowiedzi na zapytania w milisekundach, nawet jeśli tabele mają kilkanaście miliardów wierszy. Jest to krytyczne dla raportów, które będą się łączyć w modelu na żywo do tej usługi.
Najlepiej można to zobrazować na przykładzie pojedynczego raportu Power BI.
Jeśli w zakładce raportu mamy 10 wizualizacji, to Power BI wyśle 10 zapytań do Analysis Services. Oznacza to, że musi na wszystkie 10 zapytań odpowiedzieć maksymalnie w przeciągu kilku sekund, inaczej użytkownicy zaczną odczuwać dyskomfort. Niestety nie jest to na razie do osiągnięcia przy użyciu innych usług w Azure w połączeniu na żywo z Power BI.
Kolejną zaletą usługi jest dobra kompresja. Według dokumentacji mówimy tutaj o wartości pomiędzy 5- a 100-krotnością względem źródła danych. Oczywiście 100 to przypadek specjalnie przygotowanych danych. W naszych projektach zaobserwowaliśmy kompresję na poziomie około 10–20 razy. Wiadomość ta jest krytyczna podczas planowania architektury oraz kosztów, ponieważ wiedząc, ile nasz model będzie zajmować, można łatwo zaplanować, jaki rozmiar tej usługi będziemy potrzebować.
Jeśli już chodzi o sam wybór, to zwykle mówię, że magii tutaj nie ma. Jeśli wasz model po kompresji zajmuje 10 GB pamięci, to niestety nie można tego zrobić bez Analysis Services, które posiada minimum 20 GB dostępnej pamięci (lub Power BI Premium; odpowiednikiem Analysis Services w Power BI service). W Power BI są limitacje na ilość zużytej pamięci przez model i w momencie przekroczenia tego limitu zaczynają się pojawiać błędy na wizualizacjach.
Dokumentacja Azure Analysis Services
https://docs.microsoft.com/en-us/azure/analysis-services/
Blob Storage oraz Data Lake Storage Gen2 (ADLSv2)

Blob Storage to chyba najbardziej popularna usługa w Azure. Jest to usługa składowania BLOB-ów (Binary Large Object), czyli zwykłych plików, niezależnie od ich formatu. Główną zaletą tej usługi jest niski koszt przetrzymywania danych. Mówimy tutaj o 20$ za 1 TB (terabajt) za miesiąc dla danych, które często modyfikujemy. Jeśli dane modyfikujemy rzadko, to koszt wynosi jedynie 10$, natomiast jeśli archiwizujemy nasz backup i go nie modyfikujemy to kosztuje nas to jedynie 1$ za TB.
Oznacza to, że w większości przypadków najlepiej po prostu wszystko wrzucać na nasz Blob Storage, tam wszystko przetwarzać i docelowo jedynie dane biznesowo poprawne załadować do baz danych, gdzie jednak każdy gigabajt kosztuje sporo więcej. Dla przykładu 1TB w Azure SQL to około 113$ miesięcznie.
Istnieje też usługa okrzyknięta przez naszych klientów mianem Glorified Blob Storage, czyli Data Lake Storage Generation 2. To rozszerzenie Blob Storage, przez co cenowo wypada praktycznie tak samo, aczkolwiek z naszych doświadczeń wynika, że w praktyce wychodzi nawet taniej.
ADLSv2 jest również usługą przetrzymywania plików (BLOB), jednak jej głównym wyróżnikiem jest to, że posiada protokół kompatybilny z systemem plików Hadoop. Jako że używamy Databricks i HDInsight do przewarzania danych, śmiało można stwierdzić, że jest ona ich dobrym dopełnieniem. Usługa również posiada system plików kompatybilny ze standardem POSIX oraz integrację z Azure Active Directory, co w połączeniu pozwala użytkownikom i aplikacjom nadawać dostępy do poszczególnych plików oraz katalogów. ADLSv2 jest dość niedawno na rynku, bo wszedł w GA (General Availability) w lutym tego roku. Jedynym jego minusem jest to, że niewiele systemów go jeszcze wspiera, np. wspomniany wcześniej Analysis Services.
Dokumentacja Blob Storage oraz Data Lake v2
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
SQL Database oraz Data Warehouse
O bazach relacyjnych wspomniałem już wcześniej. Są super rozwiązaniem, jeśli chodzi o przetrzymywanie danych. Jeżeli w projekcie potrzebujemy relacyjnych modeli, przetwarzamy duże agregaty, nie chcemy mieć Analysis Services, a chcemy dostarczyć model biznesowy, to te bazy pozwolą nam zaspokoić te potrzeby. Dodatkowo jednym z rekomendowanych zastosowań według Microsoftu dla SQL Data Warehouse jest „self service” dla analityków, którzy potrzebują pracować na bardzo dużych wolumenach danych.
Obie bazy pozwalają również na połączenia na żywo z Power BI, dzięki czemu raporty, które nie wymagają odpowiedzi w sekundy, są dobrym zamiennikiem dla AAS.
Wizualizacje w Azure? Ale o co chodzi?
Długo się zastanawiałem czy w ogóle stworzyć dział o wizualizacjach w Azure. Tak naprawdę w Azure nie ma narzędzi do wizualizacji danych. Oczywiście wynika to z faktu, że do wizualizacji jest Power BI w chmurze Office 365. W tej sekcji opiszę jedynie usługi, które zdarzyło nam się użyć w ramach Azure, a które są dopełnieniem całości, aczkolwiek mówimy tutaj o około 5% aplikacji.
Power BI Embedded

Power BI Embedded jest to usługa, dzięki której można zagnieżdżać raporty Power BI w aplikacjach webowych. Podobnie jak Power BI Premium w Office 365 kupujemy ukryte przed nami Analysis Services z dodatkami do zarządzania oraz licencjonowaniem. Główną zaletą tej usługi jest właśnie licencjonowanie raportów Power BI, które pozwala na ich zagnieżdżanie w aplikacjach webowych bez potrzeby kupowania licencji użytkownikom. Jest to obecnie jedna z dwóch możliwości, gdzie użytkownicy nie muszą mieć licencji Power BI Pro, aby oglądać czyjeś raporty Power BI. Drugą jest Power BI Premium z Office 365. Czyli jedyna taka możliwość w samym Azure.
Plusem zagnieżdżania raportów Power BI w aplikacjach webowych jest SDK w języku JavaScript, dzięki któremu możemy zintegrować raporty z interfejsem użytkownika w naszym portalu webowym. Chociaż biorąc pod uwagę, jak dużo można robić w samym Power BI, ten argument powoli traci na sile.
Dokumentacja Power BI Embedded
https://docs.microsoft.com/en-us/azure/power-bi-embedded/
Data Explorer (ADX)

Data Explorer to usługa chmurowa do analizy dużych wolumenów danych. Usługa jest w pełni obsługiwana z przeglądarki, gdzie użytkownicy mogą tworzyć proste modele danych i odpytywać je za pomocą języka KQL (Kusto Query Language). Posiada parę fajnych funkcjonalności, takich jak tabele przestawne, eksport do Excela czy połączenie na żywo z Power BI.
Uważam jednak, że dostępne są lepsze usługi, w których można osiągnąć więcej i często taniej. Zobaczymy, jak w przyszłości usługa się rozwinie, na razie my w tym kierunku nie inwestujemy.
Dokumentacja Data Explorer (ADX)
https://docs.microsoft.com/en-us/azure/data-explorer/
Dlaczego tak jest i co z tym dalej?
Czy można się tutaj dziwić takiemu kierunkowi? Oczywiście, że nie. Istnieje ogrom argumentów, które przemawiają za Power BI. Jednym z nich jest jego koszt, bo narzędzie jest darmowe w wersji podstawowej. Przy opłacie 9.99 $ miesięcznie można kupić licencję Professional, która posiada zbiór funkcjonalności sprawdzających się idealnie w firmach. Power BI ma również comiesięczny cykl aktualizacyjny, który wdraża naprawdę dużo nowych rozwiązań, dzięki feedbackowi od użytkowników prezentowanemu na forach. Na sam koniec warto podkreślić, że jest to produkt Microsoftu. Oznacza to, że firmy mogą być spokojne o to, że ich narzędzie będzie należycie wspierane, rozwijane i nie zniknie z dnia na dzień. Wisienką na torcie jest to, że Microsoft, który posiada własną chmurę Azure, dostarcza bardzo wiele rozwiązań integracyjnych pomiędzy platformą Power BI a Azure, które zdecydowanie ułatwiają wdrożenia.
Jeśli chodzi o samą architekturę referencyjną, od której zaczęliśmy, to warto wyrzucać nieprzydatne usługi. Jeśli nie potrzebujesz Analysis Services, to polecam dane składować w Azure SQL. Dzięki temu można stworzyć odpowiednie widoki i tabele, aby Power BI sprawnie mógł załadować dane. Natomiast jeśli mamy Analysis Services na pokładzie, to pytanie, po co nam wtedy Azure SQL.
Jeśli ktoś zapyta mnie, czemu nie Data Lake Generation 2, to odpowiem: dlatego że Analysis Services nie potrafi obecnie ciągnąć danych z ADLSv2, chociaż już w preview (na dzień pisania artykułu) pojawia się multi-protocol access dla Blob Storage, dzięki czemu Analysis Services będzie również łączyć się do Data Lake w generacji drugiej.
Architektura referencyjna nie jest odpowiedzią na wszystko. Opisałem moje doświadczenia z ostatnich lat spędzonych na tworzeniu rozwiązań BI i trendy zaobserwowane w naszej firmie. Ostatnio pojawiają się na rynku alternatywy takie jak Snowflake, ale to osobna historia. Czas i wdrożenia pokażą, co dalej.
Chcesz więcej? Posłuchaj DevTalk #93 – O PowerBI z Katarzyną Kulikovich!
Dziękuję za Twój czas i do następnego razu!
Lingaro jest dynamiczną firmą działającą w obszarze Danych i Analityki. Misją firmy jest pomoc Klientom w zdobyciu przewagi konkurencyjnej poprzez szybsze, lepsze i mądrzejsze decyzje w oparciu o Dane i Analitykę. Posiada imponujące doświadczenie zdobyte podczas pracy nad zaawansowanymi rozwiązaniami dla polskich i międzynarodowych klientów z listy Fortune 500.
The post Doświadczenia z BI w Azure w pigułce appeared first on devstyle.pl.
Maciej Aniserowicz's Blog

- Maciej Aniserowicz's profile
- 22 followers

