
Daniel Miessler's Blog, page 101
April 2, 2018
Unsupervised Learning: No. 119
I spent lots of time on typography, so you should read this article in its original form at Unsupervised Learning: No. 119
—
This week’s episode of Unsupervised Learning is now available. Subscribe below and get this episode’s podcast and newsletter.



This week’s topics: Atlanta disabled, MyFitnessPal hacked, Cambridge Analytica election tampering, Drupal, Saks, DARPA drones, Cloudflare 1.1.1.1, Slack bosses, Democratic Chinese AIs, Georgia facepalm, tech, humans, ideas, and more…
—
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel


March 31, 2018
Why I Switched from Patreon to Memberful
I spent lots of time on typography, so you should read this article in its original form at Why I Switched from Patreon to Memberful
—

Like many people I’ve been soured on ads and sponsors for my podcast and newsletter: Unsupervised Learning.
If you hav a decent following it’s actually possible to make a significant living off of both sponsors and ads—and especially sponsors. At one point I was getting a couple thousand a month from just a couple of sponsors, and I was just experimenting. Implementing a basic ad network with a tiny, rotating text-only add was getting me around $500 a month when I was doing that.
But it just started to feel gross.
I didn’t like what it did to my site’s appearance, and I didn’t like the feeling of selling something (I never have). Ironically, it also kept me from being able to mention products that I liked because, since I was ACTUALLY selling other products, it would seem as if I must have some relationship with those brands as well. I never did.
I stopped supporting NPR when they started having tons of commercials from all the usual corporate suspects.
It was Sam Harris that finally convinced me to migrate to the subscriber-based model. At the beginning of all his podcasts, he’d stress that the show is ad-free and that the only support from the show comes from listeners. It reminded me a lot of NPR, which I have also subscribed to in the past.
I am also a serious believer in the role of individual influencers in the future of entertainment, media, and business, and am even involved in a gaming startup that supports this vision called Opera Event.

My first move when switching from ads/sponsors to member-supported, was to go with Patreon. Their service deserves credit for being very early in the “direct” support model (more on this later), and it does work fairly well.
My problem with Patreon is that it’s not really a direct connection between the supporter and the content creator.
Patreon simply isn’t direct enough. It has too much going on in the middle. It has it’s own business model, it’s own values, it’s own culture, and it’s own rules. And these rules have caused them to start shutting down content creators that they don’t agree with.
So it’s not really a connection between you as a content creator and your followers—it’s more like their own thing that happens to live on the connection between you two.
It feels parasitic.
So that’s about when I came across Ben Thompson’s Stratechery, which is another fantastic offering by the way, and noticed that he was using Memberful.

Here are the things that brought me over to Memberful:
It’s truly lightweight and creator-focused in the sense that it’s YOU connecting with your fans, not Memberful. It stays out of the way, just facilitating rather than marketing its own thing.
It’s backed by Stripe, which is an industry leader in secure payment infrastructure.
It’s super slick in how it handles subscription links (via Stripe popups).
It’s easy to make multiple different subscription types and levels, and to have unique URLs for each of them.
Member management is quite elegant, both for the creator and for the subscriber.
The whole system integrates into WordPress cleanly, meaning that you can have member-only content for subscribers and you don’t have to do much more than tick the box for who should be able to see the content.
Every creator should do this in my opinion. My support page, for example, lives at, danielmiessler.com/support, not with Memberful.
Another important thing for me is having the payment structure live at your actual domain instead of at the domain of the provider. This stays in the spirit of the creator’s domain being the single source of truth for their entire online presence.
Basically, if supporters start the process of supporting you by going to a domain other than yours, there is an incentive misalignment problem.
So I switched, and I’ve been very happy with the decision.
Patreon isn’t horrible, and they deserve respect for being early to this movement. But if you’re not happy with them for any of the reasons I mentioned—or other reasons—you should give Memberful a look.
If I had to summarize as a piece of advice, it would be this:
Ensure that your support infrastructure lives on your own domain—ideally at domain.tld/support—and that the solution you use for taking payment and managing memberships stays mostly invisible.
I hope this helps someone dodge a few of the early landmines involved in moving to a subscriber support model.
—
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 29, 2018
DevOps as the Art and Science of Deliberate Practice
I spent lots of time on typography, so you should read this article in its original form at DevOps as the Art and Science of Deliberate Practice
—
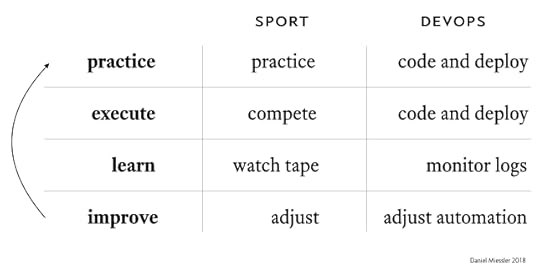
The best definition I’ve ever heard for DevOps is the ability to practice often.
I prefer DevOps to DevSecOps because I feel security should be part of both development and operations, but I also see the merit in calling it out where this isn’t regular practice.
I think there is a powerful analog here to professional team sports, and I want to capture a few of the ways they’re similar.
Can you imagine being successful in a professional team sport if you only practiced together twice a year?
Professional teams get and stay at peak performance through constant practice. And it’s not just repeating the same drills over and over—it’s based on continuous iterative improvement, which has multiple components.
Practicing a particular activity
Playing mock games against each other
Playing scrimmage games against other local teams
All practice is recorded
Coaches watch all recordings and notice what worked and didn’t work
Coaches watch the competition play other teams
Based on those observations, they change how the team practices
Then the go and execute in the next real game
In DevOps the practicing and execution are basically condensed into a single step, but otherwise we still have the same activities taking place: we automate our tasks, we monitor everything, we execute in terms of building and deploying software, we review the logs, we make adjustments, and then we do the process again.
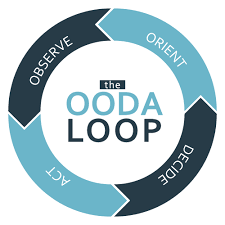
This methodology also closely resembles OODA Loops, where you observe, orient, decide, and then act. These are all forms of extremely fast improvement cycles, and they all require that you execute often in order to capture mistakes so you can make adjustments.
In the military I heard a great example of this where patrols encountering IEDs on the ground in Iraq would report their findings to West Point each day, and the classes would change daily based on the new tactics being seen in the real world.
There are lots of definitions for DevOps, but perhaps the best one is “The Art and Science of Deliberate Practice” when building and deploying software.
I hope this definition gives someone clarity on the topic the way it has for me.
Notes
Many thanks to the customer team down in Brazil who invited me to speak at their DevOps conference. It was at one of their presentations that I first heard this concept of constant practice as the central concept of DevOps.
—
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 26, 2018
Analysis of the 2018 F5 Threat Intel Report
I spent lots of time on typography, so you should read this article in its original form at Analysis of the 2018 F5 Threat Intel Report

F5 just released a threat intel report that covered 433 breach cases spanning 12 years, 37 industries, and 27 countries.
When companies release reports like these I go through them and extract nuggets for those who don’t have time to look at the full report. You will find the extraction for this report below.
Applications were the initial target in 53% of the breaches.
Identities were the initial target of 33% of them.
The apps are evidently the target, but you have to be cautious about this message because F5 is selling WAFs. So much of this kind of research is done in DIRECT coordination with the marketing and product teams, so I am always weary when someone discovers a trend that happens to help their exact product.
86% of the U.S. population has had their SSN compromised. Interesting stat.

Root cause analysis
38% breaches by web app vulnerability, 19% by phishing, 12% stolen assets, 8% unauthorized access (not sure what that means exactly), and 6% credential stuffing. When I read lists like this I think about what fundamentals would solve these issues. For web app vulns it’s an appsec program, clearly, phishing is hard because you need a multi-layered defense and the attacks are constantly evolving, and the stolen assets piece is mostly just good asset management and organizational discipline.
They break down the web vulnerabilities in a strange way. They don’t use OWASP or any other main classification, but rather mix the software type (forums) with vendors, e.g., vBulletin. Using that system they come up with forum software being #1, with SQL injection being second. This is strange because one is a target and the other is a vulnerability. In other words, if you have broken forum software, that means it’s vulnerable to XSS, or SQL Injection, or some other thing. So I think they’re mixing apples with hatchets here. Not super useful.
Also wondering where XSS, CSRF, XSRF and other web vulns are in the list.
The industries that were attacked the most were Healthcare, Technology, Online Gaming, Financial, Online Forums, Government, and Social Networks (the list continues).
But in terms of impact, those hit hardest were Retail, Government, Technology, Financial, and Online Gaming. The thing I see in common here is a strong requirement for availability.
Then if you look at the number of records breached, it’s a different order again: Technology, Cybercrime, Social Network, Adult, Retail, Financial, Online Forum, Government, and the list continues.
Out of the 433 cases, 42 of the companies had no idea they were breached for years.
Credentials are rising in popularity as targets relative to credit cards because credentials are often used elsewhere and therefore add additional value, whereas there’s so much credit card data out there that the prices are lower.
Most companies are still using weak hashing mechanisms to protect passwords.
Lots of fake people are being made and used to do various things.
Third party breaches are hurting companies as well.
Great work to the F5 team on this research! If you liked the summary, consider going over to read the entire report.
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 21, 2018
Practical Security Principles
I spent lots of time on typography, so you should read this article in its original form at Practical Security Principles

There are many great lists of security principles out there, including those from NIST, IEEE, and perhaps the originals from Saltzer and Schroeder.
I was helping some new security professionals recently and was looking for the best of these lists to provide, and I found them lacking. The Saltzer and Schroeder list is excellent, but it’s a bit abstract and quite dated. And the NIST and IEEE lists have their own issues.
Eric Cole was invaluable for me in conveying these types of concepts when studying for GSEC early in my career.
So I quickly made a list of my own that incorporates the best ideas from all of them and then added several others that I’ve heard from various sources over my 20 years in the industry.
Security means “without worry”
Our goal is functional resilience
Pursue acceptable risk, not the elimination of risk
Make security either invisible or usable
Maintain an evergreen inventory of what you’re protecting
Minimize attack surface
Reduce components and complexity as much as possible
Assume compromise and focus on detection, response, and recovery
Parsers are evil, and more so if they’re listening on a network
Design for zero trust in all environments
Don’t trust unfiltered input
Implement defense in depth
Don’t write your own cryptographic algorithms
Protect access and secrets with least privilege
Filter at each layer
Use secure defaults
Secure sensitive data at rest and in transit
Monitor and enforce secure configuration
Fail securely
Do not rely obscurity/OPSEC as the single layer
Ensure attribution / non-repudiation
Protect the integrity of transaction evidence
This is a rough pass, and I’m not sure what (if any) form it’ll eventually take, but if you have any ideas on how to improve it, let me know!
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 18, 2018
Learn the Difference Between Real and Fake Machine Learning
I spent lots of time on typography, so you should read this article in its original form at Learn the Difference Between Real and Fake Machine Learning

There are few technologies as misunderstood right now as Machine Learning. Some think it’s 100% hype, sales, and marketing, and others think it’s humanity’s Messiah in the form of math and code. Unfortunately, there’s currently not a lot of space between those two extremes.
Here’s how I think about it.
Machine Learning is much like Love and Sex. If you take the time to learn about them, in their true forms, they truly are MAGICAL. But if you see someone lead with them— when they’re trying to sell you something—you can almost guarantee they’re lying to you.
I think machine learning should be thought about a lot more like statistics in the sense that they:
Can be both simple and complex
Are both interesting and boring
Are often executed well and poorly
Can deliver magic, truth, lies, or all three simultaneously
Machine Learning isn’t much different in these regards. It’s an approach to looking at, and modeling, the world. If it’s done well it can yield tremendous insight and even prediction. And if it’s done poorly—or unethically—it can take us down an unlit and dangerous path.
So it’s like any powerful tool really.
Even if it’s implemented correctly, you might also need to ask if it’s implemented ethically.
But for any powerful tool that’s in its infancy, you need to learn the difference between those who are talking alchemy and those who are talking chemistry. Alchemists always come first, and you must be cautious of them not because they’ll always be wrong, but because they’ll be right sometimes—and sometimes not—which is often worse.
Do not discard machine learning as foolish, or hype, or a fad. It truly is one of the most powerful technologies every invented, and ignoring it will put you at a major disadvantage against competitors who do implement it.
But also avoid getting involved in products or solutions just because ML is part of the pitch. At this stage there’s a significant chance that they’re doing it just to say they have, and there’s little guarantee that it’s even needed, or that it’s being implemented correctly.
In short, machine learning really is messianic in its capabilities and potential, but because it’s also a buzzword being used by every marketing department on the planet the industry is permeated with garbage bearing the name.
Learning the difference will benefit you greatly.
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 13, 2018
Unsupervised Learning: No. 116
I spent lots of time on typography, so you should read this article in its original form at Unsupervised Learning: No. 116
This week’s episode of Unsupervised Learning is now available. Subscribe below and get this episode’s podcast and newsletter.
This week’s topics: Chinese at CanSecWest, Applebees POS, Palantir, Poisoning, TensorFlow DoD, Amazon laughing, Google 72-qbits, Amazon FinTech, Android P, and more…
Become a Member to Get This Week’s Newsletter
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
The Two Kinds of Privacy Loss
I spent lots of time on typography, so you should read this article in its original form at The Two Kinds of Privacy Loss

I like to think about our impending loss of privacy as two separate issues.
The first type is against the will of the victim and is caused by malice and/or negligence on the part of the entity with your data. This is where you trust your data to a company, and they sell that data to a number of unscrupulous third-parties just so they can make money. Alternatively, they’re so bad at data security that they leak it through sloppy transactions or allow it to be stolen through poor security hygiene.
The second kind is where the data is given willfully—by the user—to a number of trustworthy vendors, who then share it with other trustworthy vendors, who then share it some more, and the whole process continues for many years until your data ends up saturated throughout the internet.
Let’s call the first Involuntary, and the second Voluntary.
Importantly, both end up yielding the same result—your data spread across the internet like ashes in an ocean. Once the decision is made, either knowingly or unknowingly, to provide rich data to a series of data-centric companies, it’s a one-way function. It goes in, but can never come back.
But although the results are the same in both cases, I see these two situations very differently.
I believe that the loss of privacy is inevitable because the internet of things will be powered by personal data, and we know from experience that people—especially young people—will gladly sacrifice privacy for functionality.

The internet of things, machine learning, and big data are all extreme cases of this tradeoff. The more data you give, the better peoples’ experiences with technology will get. Their assistants will anticipate their desires. Restaurants will bring your favorite dishes without asking. The world will basically be customized for each of us.
I believe the loss of privacy is inevitable, and I’m actually quite optimistic and forward-leaning on the issue. But I still want to avoid giving my data to companies with incentives misaligned to my own.
Companies with free services, for example, are not really free. Instead, the service itself is the hook, and the data that you provide the service is the actual product. This is true for Facebook and largely for Google as well.
So even though I know my data will inevitably be leaked due to the porous nature of the internet of things and machine learning powered services, I still want it to happen the slow way, through companies I trust to care for my data and only share it with other companies that have the same values or with my permission.
It’s not that I think this will stop the inevitable, but at least the inevitable will happen more on my own terms.
If you want to learn more about what I believe the Internet of Things will look like, you can read my book on the topic.
I guess the point here is that there’s a bit of cognitive dissonance here on my part, or at least it seems like there is sometimes. I am for digital assistants. I am for machine-learning-powered services. I am for an adaptive and personalized internet of things. And I believe that if you’re in cybersecurity you should accept the inevitability of the death of privacy, and work to make people comfortable in a post-privacy world.
But at the same time, I want to control that transition—using vendors that I trust—as much as possible.
Perhaps I’ll change my mind in one way or another, but that’s my current position.
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
March 12, 2018
How to Download the Data Facebook Has on You
I spent lots of time on typography, so you should read this article in its original form at How to Download the Data Facebook Has on You
People are becoming increasingly worried about the data that Facebook and other social media sites have on them.
Luckily, the platforms make it fairly easy to download that data to see for yourself.
For Facebook, here’s the process.
1. Go to any Facebook page and hit the down arrow in the corner.
3. Click “Download a Copy of Your Facebook Data”
 Start Membership
Start Membership
Thank you,
Daniel
The Reason Software Remains Insecure
I spent lots of time on typography, so you should read this article in its original form at The Reason Software Remains Insecure

There are myriad theories as to why software remains insecure after we’ve spend decades trying to solve the problem.
Some say it’s the lack of will to secure things, the lack of vendor liability, the insecure languages we use, insufficient developer training, not enough security products—and the list continues…
But there’s a far simpler and more powerful explanation, which is best demonstrated in a visualization like the one above: the existence of insecure software has so far helped society far more than it has harmed it.
Basically, software remains vulnerable because the benefits created by insecure products far outweigh the downsides. Once that changes, software security will improve—but not a moment before.
Consider the mystery solved.
These failures are likely to start, by the way, largely due to the explosion of the Internet of Things.
When we start having complete and long-lasting internet outages, companies being knocked offline for days or weeks and going out of business, and—most importantly—large numbers of people dying, then we’ll see a serious push for secure software.
In the meantime, quickly developed, quickly deployed, and insecure code will continue to perform miracles for human civilization, and will therefore continue to be welcomed into businesses and society.
In short, don’t expect change until we see the downsides of insecure software start to rival the benefits. And it’s currently not even close.
I spend between 5 and 20 hours on this content every week, and if you're a generous type who can afford fancy coffee, please consider becoming a member for just $5/month…
Thank you,
Daniel
Daniel Miessler's Blog

- Daniel Miessler's profile
- 18 followers

