
Outage Post Mortem

Metaposts: This site (and all other sites hosted on the same server park) have been offline for 72 hours. That’s completely unacceptable, of course, and the underlying fault still isn’t fixed. Here’s what happened.
At 08:45 UTC on January 14, I noticed that my server farm (including falkvinge.net and multiple other websites, as many as you can run on some thirty-odd servers), my main workstation, and the wi-fi in my place was offline. Scrambling to troubleshoot and checking piece by piece, it took me twelve minutes to arrive at the conclusion that my uplink provider was broken – the worst possible scenario, since it means I can’t fix it myself.
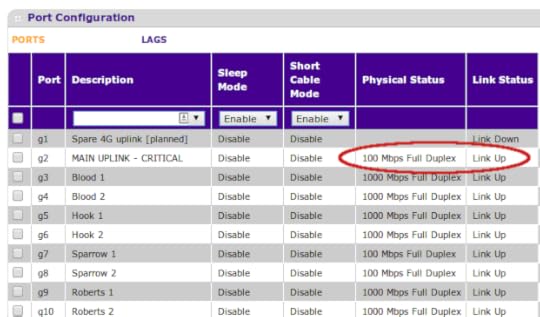
The last recorded activity on the server farm had taken place at 08:15 UTC. The event at 08:30 UTC had failed to connect upstream.
It’s dangerous to go alone. Take this!
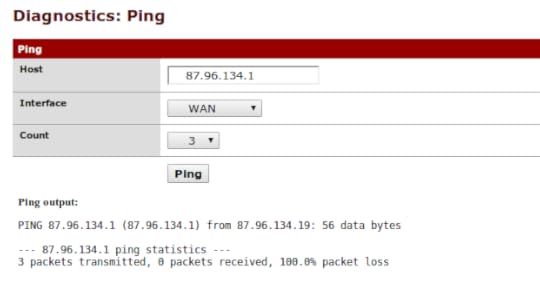
There was a good link to the upstream ISP, but nothing above the link level. I had a good 100Mbit full-duplex connection upstream, but my assigned gateway IP did not respond to pings from the perimeter firewall. Double-checking the physical uplink cable with a laptop (to make sure the switch or firewall weren’t broken) gave the same result.
No joy, no joy.
At this point, I fired up my mobile 4G broadband as a spare way out, so that I could at least communicate with the outside world via laptop and tablet, even if I had lost the ability to publish articles, thoughts, and ideas. (More on that insight in a later article.) I used that 4G connection to file an outage report with my ISP, and I was being quite specific in my troubleshooting (“this is how I know there’s an error, and these are the steps I’ve taken to make sure it’s not in my equipment. By the way, here’s my IP config.”). They wanted my mail address in that outage report. Good thinking, there.

Here’s my mail server, right outside the kitchen window.
Here’s my mail server. It’s on my balcony. Go right ahead and send me mail to here. By the way, please fix its upstream connectivity first. That will assist the mail in, you know, actually arriving at the server.
After nothing had happened for two hours, I decided to give the techs a voicecall as well. The first tech I spoke to was everything I had hoped for – I was prepared for “have you tried turning it off and on again”-level support, but they apparently saw from my outage report that I was past that level, and the first question was for the MAC address of my perimeter switch or firewall, so they could debug the link to a known endpoint. I was totally not prepared for that level of technical respect, but appreciated it.
However, the tech told me that this can take a while, that they’re submitting a fault ticket to the municipal broadband station and that they will take at least two days. This obviously wasn’t what I wanted to hear. Then, nothing happened for the rest of that day.
The second call to support – on Wednesday – was much less of a joy, where they started by telling me “but you’ve only been offline for a day?”. After I had detonated, explaining not very patiently that downtime is measured in seconds or minutes and not in days, essentially told me that it would take two to five days per round trip to the technical staff, and that he couldn’t care less if I was offline.
These are the times when I’m happy I have my rather large offline music collection, so I’m not totally dependent on Pandora.
I have a blog with a million visits a month, I need that bloody uplink, and this is what I get for fifteen years of continuous custom (yes, I’ve had that fiber uplink since 1999)?
What did they think I was going to do with four static, public IPv4 addresses – that I pay a monthly rent for, nota bene – for a consumer-grade connection? I was outraged, but I was just being stonewalled. I realized no amount of anger would change this person’s mind, and decided to settle for the day.
On Thursday January 16, I woke up with the uplink still down, and figured it would be up by lunch. No joy. Nothing happened at all. I realized that the “two to five business days” was actually intended as serious, and as Thursday’s business day came to a close, I realized that Friday may come and go as well, and if so, this already-unacceptable outage is going to last past the weekend.
The situation just isn’t okay by any measure. So I created a makeshift uplink from spare parts, one that isn’t intended for any kind of long-time use or stability, but one that will work until the primary uplink is restored. On Friday morning, I think I got most of it working, breaking pretty much every best practice in existence, but honoring “if it’s stupid but works, it ain’t stupid”.
If you can read this, then that makeshift uplink – using sort-of mobile 4G broadband, spare homemade antennas and firewall multi-uplink failover configurations – has worked.
Now, for another angry phonecall to my ISP who still haven’t fixed my fiber connection as of 09:00 UTC on Friday Jan 17…



Rick Falkvinge's Blog

- Rick Falkvinge's profile
- 17 followers

