
DNA Refactor Project
I’m Mark Neves, a technical architect on the DNA Refactor Project.
What is DNA?
Regular readers of the Internet Blog will know that DNA is the platform that supplies User Generated Content (UGC) in the form of comments, messageboard posts and the like to the BBC website. It also powers the moderation tools needed to manage this content. For a brief history of DNA and how it got its name please visit Wikipedia.
The DNA Refactor Project
The DNA Refactor Project is focused on rebuilding the DNA functionality using best-of-breed software engineering techniques. This blog post explains how DNA became what it is today and the plans for ‘refactoring’ the code base into a modern architecture making the platform easier to maintain, faster to extend and portable to other platforms.
Evolution of the DNA Code Base

Coding began with the creation of the h2g2.com website back in 1999. It was initially a Perl application with a SQL Server back end. Shortly after its inception the platform was acquired by the BBC and developed over the years using many technologies by approximately 24 different developers. (While researching this figure I naturally hoped to find that 42 developers had worked on it. Still, 24 is practically the same, digit-wise.)
The first major refactor was the move to C++. As you can see some admin functionality remained in Perl for a very long time. The second major change was the decision to implement all new features in C# in around 2006 and have, as a background task, the job of migrating existing C++ functions to C#.
Again, like the Perl code before it, some features and tools remain in the C++ code base to this day. With tight time scales and limited resources it’s always difficult to justify spending time rewriting or refactoring existing code. It’s an age old issue in software development.
The last major architectural development was to implement RESTful APIs to expose functionality to support moderated comments (among other services), allowing the user-facing elements to be implemented on the central BBC application platform. This drives comments on BBC News and Sports pages as you see them today.
Why Refactor?
So why is the BBC investing in the refactoring of the DNA code base? After all, DNA has stood the test of time providing a rock solid, reliable platform for hosting UGC and Moderation Services even in the most demanding of situations (such as comments on high profile News stories, moderated Twitter feeds during the Olympics and the extremely busy but now decommissioned 606 sports messageboard).
UGC is an important aspect of the BBC website and will remain so for the foreseeable future. The platform that delivers this requirement needs to be built for the future. Let’s examine the current DNA architecture to see where the issues lie:

Current DNA architecture
With 24 developers working at different times over 14 years on the platform it’s not surprising that the code base is suffering from a little technical debt:
Another aspect is that the current code base has a large amount of functionality that is no longer used. The BBC sold h2g2 a couple of years ago and at that point the considerable amount of functionality that h2g2 exclusively used became redundant. Add to that the code behind other decommissioned social network sites like 606, Action Network, Get Writing and Comedy Soup and it’s clear that a lot of inactive code can be laid to rest.
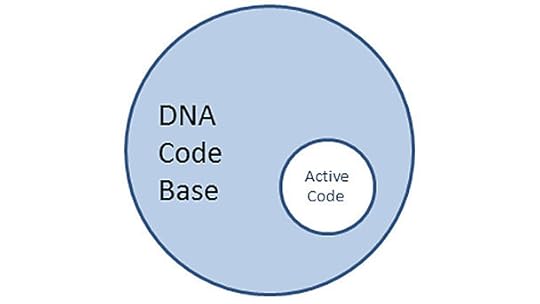
This is by no means a criticism of the way DNA has evolved. DNA has had a number of very talented software engineers working on it over the years. The history of the product is long and interesting and the code base gets a lot of things right. The time has come to take a step back and see how we can do things even better.
The Brave New World
The engineers in the DNA team have always been keen to embrace best practices when developing software. The DNA Refactor project will result in a platform that embraces S.O.L.I.D. software development principles:
S - Single responsibility principle: A class should have only a single responsibility.O - Open/closed principle: “software entities [… ] should be open for extension, but closed for modification”.L - Liskov substitution principle: “objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.”I - Interface segregation principle: “many client-specific interfaces are better than one general-purpose interface.”D - Dependency inversion principle: One should “Depend upon Abstractions. Do not depend upon concretions.” Dependency injection is one method of following this principle.
Here’s what the new architecture will look like:
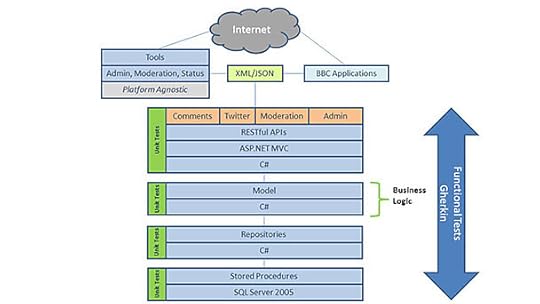
The new DNA architecture model
The main features are:
It’s easy to see how you each layer could be ported to different platforms and technologies. The BDD tests would provide confidence that all the functionality has been ported successfully.
It would be interesting to hear your feedback/comments below.
Mark Neves is a technical architect.


BBC's Blog

- BBC's profile
- 28 followers

