
How Big Data Will not Help our Understanding of Complexity
It is not possible anymore nowadays to open a serious newspaper or a financial investment document without reading about the great prospects of “Big Data”: analyzing the troves of data progressively acquired by organizations when we surf, shop, spend money, etc., to create Value. And companies have been setup which raise money on the markets to exploit data like other exploit mines and oil wells.
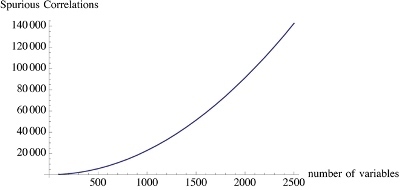
The number of spurious correlations increase with the size of the data. Be careful when you read about discoveries from “Big Data”!
Be careful, says Taleb in his book Antifragile, lots of data also means lots of spurious correlations. The argument is detailed in the book and in this Wired Article “Beware the Big Errors of ‘Big Data’“, from which we reproduce the curve on the right (it is also in the book).
To translate the point in conventional language, the bigger the size of the data and the number of potential variables considered, the higher the probability that bullshit is produced when it comes to the identification of possible trends. From there to consider that all this “Big Data” trend is just a vast hoax, there is a step we won’t take (I don’t invest in this “Big Data” thing unless it is very focused application). However, this potentially shows that a high proportion of the ‘discoveries’ that people do analyzing “Big Data” will be spurious. Be careful next time you read about one of these new ‘discoveries’.
A further challenge: is it really possible to understand complexity through more advanced data analysis? Following Taleb, we can have high doubts about that. In particular because all data analysis tools will never consider anything than conventional statistical approaches, and will never consider those discontinuities and benefits from volatility which makes real life what it is: interesting!





