
Synthetic Data Economies: Where Data Creation Exceeds Collection in Value
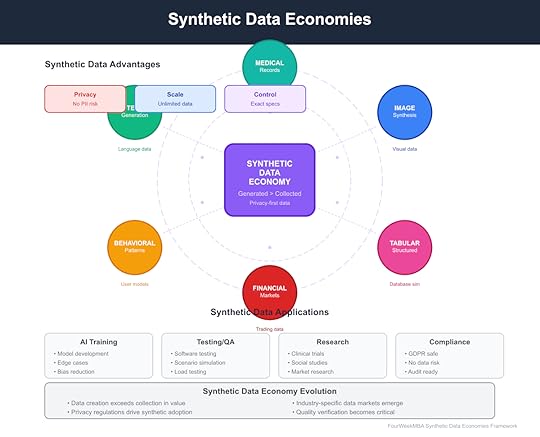
Synthetic Data Economies represent a fundamental shift in the data value chain where artificially generated data becomes more valuable than collected real-world data, solving privacy concerns, enabling unlimited scale, and providing perfect control over data characteristics while creating entirely new markets and business models.
The data economy faces an existential paradox. As AI and analytics demand exponentially more data, privacy regulations and ethical concerns increasingly restrict access to real-world data. Synthetic data emerges as the solution—not a compromise, but often a superior alternative that’s privacy-compliant by design, infinitely scalable, and perfectly tailored to specific needs.
[image error]Synthetic Data Economies: Creating Value Through Generation, Not CollectionThe Data Paradox ResolutionTraditional data economics relied on collection—gathering real-world information from users, sensors, and systems. This model faces mounting challenges:
Privacy regulations like GDPR and CCPA make data collection expensive and risky. A single violation can cost millions in fines and destroy consumer trust. The regulatory landscape only grows more restrictive globally.
Data scarcity limits innovation. Many valuable use cases lack sufficient real-world data. Rare diseases, edge cases in autonomous driving, or unusual financial scenarios simply don’t generate enough natural data for effective AI training.
Bias perpetuation plagues real-world datasets. Historical data reflects past discrimination, creating AI systems that perpetuate inequality. Synthetic data offers the opportunity to create more balanced, fair datasets.
Cost escalation makes data collection unsustainable. As easy data sources get exhausted, marginal costs of new data increase exponentially. Labeling, cleaning, and maintaining real datasets becomes prohibitively expensive.
Synthetic data flips this entire model. Instead of collecting and hoarding data, value comes from the ability to generate precisely the data needed, when needed, with perfect characteristics.
The Generation AdvantageSynthetic data provides advantages impossible with real-world data:
Perfect privacy exists by design. Synthetic data contains no real personal information, eliminating privacy risks entirely. This isn’t anonymization that might be reversed—it’s data that never contained personal information.
Unlimited scale becomes possible. Need a million medical records for a rare condition? Generate them. Require edge cases for autonomous vehicle training? Create infinite variations. Scale constraints disappear.
Precise control enables exact specifications. Real-world data comes as it is. Synthetic data can be generated with precise characteristics—balanced demographics, specific edge cases, controlled variables for scientific validity.
Rapid iteration accelerates development. Waiting months to collect real-world data slows innovation. Synthetic data can be generated in hours or days, enabling rapid experimentation and development cycles.
Cost efficiency improves over time. While initial synthetic data generation requires investment in models and systems, marginal costs approach zero. Each additional synthetic record costs virtually nothing to produce.
Market Structure EmergenceSynthetic data economies create new market structures:
Data generation platforms provide tools for creating synthetic datasets. These range from simple statistical methods to sophisticated AI systems that learn real-world patterns and generate realistic synthetic versions.
Domain-specific generators specialize in particular data types. Medical imaging, financial transactions, conversational text, or behavioral patterns each require specialized generation techniques and domain expertise.
Quality verification services ensure synthetic data maintains statistical properties of real data while confirming no actual data leakage. This emerging sector provides crucial trust infrastructure for synthetic data markets.
Synthetic data marketplaces enable buying and selling of generated datasets. Unlike traditional data brokers trafficking in personal information, these marketplaces deal in purely artificial, privacy-safe data products.
Custom generation services create bespoke synthetic datasets for specific needs. These combine domain expertise with generation technology to produce exactly what clients require.
Industry TransformationDifferent industries adopt synthetic data at varying rates and for different reasons:
Healthcare leads adoption due to privacy sensitivity and data scarcity. Synthetic patient records enable research without privacy risks. Synthetic medical imaging helps train diagnostic AI. Clinical trial simulation accelerates drug development.
Financial services use synthetic data for fraud detection model training, stress testing, and regulatory compliance. Synthetic transaction data allows sharing between institutions without competitive or privacy concerns.
Autonomous vehicles rely heavily on synthetic data for edge case training. Real-world data can’t safely or economically capture all possible scenarios. Synthetic data fills these gaps with infinite variations of rare events.
Retail and e-commerce generate synthetic customer behavior data for testing recommendation systems, pricing strategies, and user experience improvements without experimenting on real customers.
Government and defense applications use synthetic populations for policy modeling, disaster planning, and training scenarios that would be impossible or unethical with real data.
Technical EvolutionSynthetic data generation technology rapidly advances:
Statistical methods provide the foundation. Simple approaches like sampling from distributions or rule-based generation handle basic use cases efficiently.
Generative AI models like GANs and diffusion models create highly realistic synthetic data that maintains complex statistical relationships while ensuring privacy.
Digital twins simulate entire systems, generating synthetic data from first principles. This approach works particularly well for physical systems and IoT applications.
Federated generation learns patterns from distributed real data without centralizing it, then generates synthetic data that reflects these patterns while maintaining privacy.
Hybrid approaches combine multiple techniques. Real data might seed initial parameters, with AI models generating variations and rule-based systems ensuring specific constraints.
Quality and Trust ChallengesSynthetic data faces skepticism that must be addressed:
Statistical fidelity requires careful validation. Synthetic data must maintain the statistical properties of real data for downstream applications to work correctly. This requires sophisticated testing and verification.
Edge case representation proves challenging. While synthetic data excels at generating edge cases, ensuring these edge cases reflect reality rather than generator artifacts requires domain expertise.
Model collapse risks emerge when AI trains on synthetic data generated by AI. This recursive loop can amplify biases and reduce diversity. Careful management of generation and training processes becomes essential.
Regulatory acceptance varies by jurisdiction and use case. While synthetic data generally faces fewer regulations than real data, some applications require regulatory approval of synthetic data use.
Trust building takes time. Organizations accustomed to “real” data need education and evidence to trust synthetic alternatives. Success stories and standardized quality metrics help build confidence.
Economic ModelsSynthetic data economies support various business models:
Generation licensing sells access to generation models rather than datasets. Customers generate their own synthetic data using licensed technology, ensuring customization while maintaining vendor revenue.
Data-as-a-Service provides synthetic datasets on demand. Customers specify requirements, and services generate and deliver appropriate synthetic data, often through API access.
Marketplace models connect synthetic data producers with consumers. These platforms handle quality verification, transaction processing, and dispute resolution.
Consulting hybrids combine technology with expertise. These firms don’t just generate synthetic data but help design generation strategies, validate quality, and integrate synthetic data into workflows.
Open source ecosystems emerge around synthetic data generation tools. Companies monetize through support, customization, and enterprise features while building on community innovation.
Privacy and Ethical AdvantagesSynthetic data offers unique privacy and ethical benefits:
True anonymization becomes possible. Unlike traditional anonymization techniques that can often be reversed, synthetic data never contained personal information to begin with.
Bias correction enables fairer AI. Synthetic data generation can intentionally create balanced datasets that correct historical biases in real-world data.
Consent clarity simplifies data use. Synthetic data sidesteps complex consent issues since no individual’s data is actually used.
Cross-border flows face fewer restrictions. Many data localization requirements don’t apply to synthetic data, enabling global collaboration.
Vulnerable population protection allows research without risk. Studies involving children, patients, or other vulnerable groups can proceed with synthetic data without ethical concerns.
Challenges and LimitationsDespite advantages, synthetic data faces real challenges:
Unknown unknowns can’t be generated. Synthetic data reflects our understanding of the domain. Genuine surprises and discoveries that come from real-world data exploration may be missed.
Validation complexity requires sophisticated approaches. Proving synthetic data adequately represents reality for specific use cases demands rigorous testing.
Generation bias can be subtle. The models and rules used to generate synthetic data embed assumptions that may not reflect reality.
Computational costs for sophisticated generation can be significant. While marginal costs approach zero, initial setup and high-quality generation require substantial compute resources.
Expertise requirements limit accessibility. Effective synthetic data generation requires deep domain knowledge combined with technical sophistication.
Future TrajectoriesSynthetic data economies will likely evolve through several phases:
Current phase: Specialization – Domain-specific synthetic data generation for clear use cases like privacy compliance and AI training.
Emerging phase: Standardization – Common formats, quality metrics, and generation techniques enable interoperability and market growth.
Future phase: Synthesis-first – Organizations design data strategies around synthetic data from the start rather than treating it as a real-data substitute.
Mature phase: Reality modeling – Entire synthetic worlds generate data, enabling testing and development in perfectly controlled but realistic environments.
Strategic ImplicationsOrganizations must adapt strategies for synthetic data economies:
For data-driven companies: Evaluate where synthetic data could replace or augment real data collection. Invest in generation capabilities for competitive advantage.
For AI developers: Design training pipelines that effectively combine real and synthetic data. Develop validation frameworks ensuring model performance.
For regulated industries: Engage with regulators on synthetic data acceptance. Build evidence for synthetic data efficacy in your domain.
For privacy-conscious organizations: Synthetic data offers a path to innovation without privacy risk. Prioritize use cases where privacy concerns currently block progress.
The New Data Value ChainSynthetic data economies fundamentally restructure how we think about data value:
Value shifts from possession to generation capability. Having data matters less than being able to create the right data on demand. This democratizes AI and analytics by removing data moats.
Privacy transforms from constraint to feature. Synthetic data makes privacy compliance a competitive advantage rather than a burden. Organizations can innovate freely without privacy risks.
Quality becomes more important than quantity. A well-designed synthetic dataset can be more valuable than millions of messy real-world records. Curation and generation expertise command premiums.
The synthetic data economy represents more than a technical solution to privacy challenges. It fundamentally reimagines how data creates value in the modern economy. As generation capabilities improve and trust builds, synthetic data will likely become the dominant form of data for many applications.
Success in this new economy requires shifting mindsets from data collection to data generation, from hoarding to creating, from privacy-as-constraint to privacy-by-design. Organizations that master this transition will find themselves with unlimited, compliant, perfectly tailored data resources while their competitors struggle with the limitations of real-world data collection.
Navigate the synthetic data revolution and new data economics with strategic frameworks at BusinessEngineer.ai.
The post Synthetic Data Economies: Where Data Creation Exceeds Collection in Value appeared first on FourWeekMBA.




