
Archiving My Blog Posts in Obsidian
Lately, I have been working on a series of small archiving projects. I have been gathering 35 years of digital data, and organizing it locally, mostly in Obsidian. I’m working toward a single, text-based archive that can serve as the source of a personal LLM that will take over the role of traditional search. I want to be able to converse with an LLM about everything and anything I have ever produced. Archiving is a first step in that process.
My most recent venture was to archive into Obsidian all of the blog posts I’ve written over the last 19+ years. I did this in two discrete steps:
Generate markdown files from the WordPress export of my blog.Replace any markdown links to other blog posts with Obsidian-style linksAfter my cleaning process, which included de-duping posts (some early posts were duplicated as part of a migration that happened 16 years ago), the archive stands, as of this writing, at 6,982 posts, totaling 2,936,072 words. Give me the benefit of the doubt and let’s call it 7,000 posts and 3 million words to keep things simple.
Step 1 in my archiving process converted the posts to markdown and also organized the posts into subfolders by year. It also added YAML front-matter to each post containing a title, URL where it appears, and the date the post was originally published. The URL in particular was important for Step 2 to work.
Step 2 went through all of the posts looking for markdown-style links. It built a library of front-matter, mapping the original URL to the archive markdown filename. It then whittled the links down to those that just referenced other posts (as opposed to “external” links) and converted the links within those posts to Obsidian style links. This allowed me to see the connections between all 7,000 of my posts. The results are interesting.
 Obsidian graph of my blog posts.There are a total 15,366 links in my blog posts.Of those, about a third (just over 5,000) are links to other posts I’ve written.The remaining two-thirds are links to other sites.
Obsidian graph of my blog posts.There are a total 15,366 links in my blog posts.Of those, about a third (just over 5,000) are links to other posts I’ve written.The remaining two-thirds are links to other sites.Above is the graph of just the 7,000 blog posts in my Obsidian vault, and within that graph you can see the posts that link to one other. If we zoom in, you can begin to see clusters within the linked posts, a few of which I have identified below:
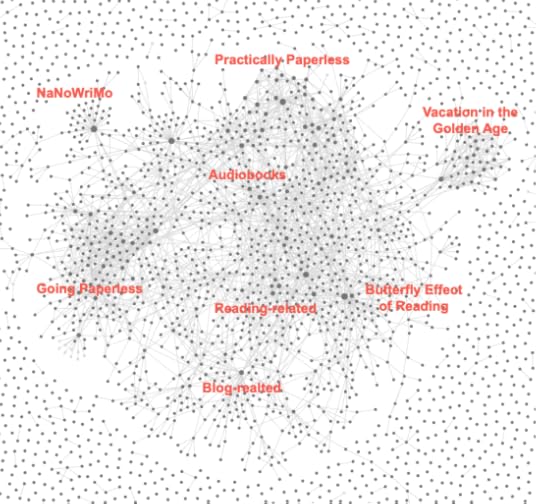
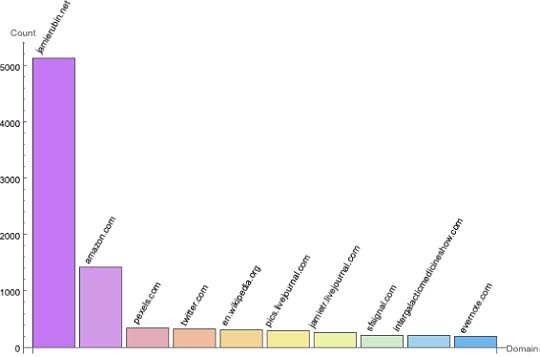
Out of curiosity, I took a look at those 15,000 total links across all 7,000 posts. I was curious about the most-frequent domains I linked to. Here is a chart showing the top 10 domain I’ve linked to over the years by the number of links:
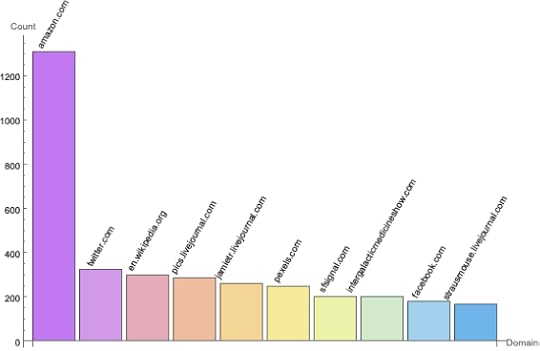
If I take out internal references to my own blog, the chart looks like this:
Searching is much faster in Obsidian than in WordPress, and I can use complex searches like regular expressions.
I imagine a few people will have questions about the technical aspect of how I did this. In early 2023, I mentioned that I was consolidating all of my coding into Wolfram Language, in part because I like the idea of a purely symbolic language, and in part because I wanted to learn something entirely new. As I said at the time:
I’ve been a very casual, hobbyist user of Mathematica for years now. But the more I play with it, and the more I learn about its symbolic and functional structure, the more impressed I am with the language. Moreover, the language now reaches into all aspects of computing so that it seems useful as a general purpose language. Finally, as a developer, I’ve already mastered more common languages like Python, JavaScript, C#, Perl, PHP, Ruby, etc., to my personal satisfaction. Becoming equally proficient in Wolfram Language would something new.
In the nearly 2 years since writing that, I have written countless Wolfram Langauge scripts, and while by no means an expert, I’ve become fairly proficient. One nice thing about Wolfram Language is it makes dealing with AI, machine learning, and LLMs fairly simple and straightforward (as much as such things can be) so it makes for more seamless integration with my ultimately goal of being able to search my archive using an LLM.
What’s next? I’ve got thousands of handwritten diary pages that I am archiving. I originally thought this would be a project for retirement, but after some experimentation, I’ve discovered that GPT-4o is a wiz at taking images of handwritten pages and almost flawlessly transcribing them into markdown format. It works just as flawlessly on pages that I have written in cursive as it does pages that I have printed. The biggest hurdle is the labor involved in taking photos of the thousands of pages. Fortunately, my daughters have agreed to help me with that task. Stay-tuned.
Did you enjoy this post?
If so, consider subscribing to the blog using the form below or clicking on the button below to follow the blog. And consider telling a friend about it. Already a reader or subscriber to the blog? Thanks for reading!




