
Greg L. Turnquist's Blog, page 4
June 13, 2017
Why do we need experts?
In this day and age, the DIY (Do It Yourself) movement is strong. The internet has made it super simple to start reading about somthing, but a few things from Amazon, and reach and get going! On one hand, that’s really good. I’ve seen countless businesses launched in this fashion. Many show up on Shark Tank. But sometimes, we need experts. Sometimes we need people with a very focused sense of knowledge, and if we don’t hire them, we’ll end up either paying too much, or losing out on opportunity.
Real Estate Experts
 I have a handful of rental properties. In fact, it’s the principal part of my retirement portfolio, given 401K funds don’t work. Every month, my tenants send in a check to my property manager. Property manager collections 10% fee, sends the rest to me. And I then send in a payment to my lender, with extra rent used to pay down the debt faster.
I have a handful of rental properties. In fact, it’s the principal part of my retirement portfolio, given 401K funds don’t work. Every month, my tenants send in a check to my property manager. Property manager collections 10% fee, sends the rest to me. And I then send in a payment to my lender, with extra rent used to pay down the debt faster.
See how that works? It’s not hard. But it’s something in which you need the right experts in the right places.
My property management company are experts at writing leases, enforcing leases, changing locks with tenants, maintaining the property, doing background checks, and maintaining quality of that process.
But their motivation is to keep the property rented, so they resist raising rents. I recently got notice of a tenant wanting to vacate, and my property manager showed me the proposed rent rate. Within five minutes, I ALSO got an email from my other agent.
Other agent? Who’s that? I have a real estate agent on retainer whose job is to find me new tenants when my properties are available. She gets paid a month of rent for this service, meaning she is motivated to keep the rates up.
Her email tipped me of that the market rent rate of these properties had risen about 12% from what my property manager was doing. This is called “opportunity cost”, something only the right experts in the right places can alert you to.
Other Experts
But this isn’t confined to real estate. There are many areas in life where we should listen to experts. I have seen people slap together “RESTful” interfaces in many places that had nothing to do with REST. For example, I tinkered with the API for my house thermostat, only to discover it was NOTHING like REST.
curl -s -H 'Content-Type: text/json' -H 'Authorization: Bearer ACCESS_TOKEN' 'https://api.ecobee.com/1/thermostat?f...'
This thing barely scratches the surface of an API. There is no hypermedia. The URIs aren’t very “pretty” (which isn’t REALLY a REST thing). It’s more of a query language than anything, which as I’ve said before, isn’t really REST.
My impression after struggling with their API, is that they are experts at building thermostats, not APIs.
Spring Experts
 So if you’re seeking to work with a certain technology, a certain business, or other, it pays to go and learn what the most experienced people are doing. It’s part of why I love going to SpringOne Platform every year. I meet people that are ALSO using Spring in incredible detail against some of the largest systems.
So if you’re seeking to work with a certain technology, a certain business, or other, it pays to go and learn what the most experienced people are doing. It’s part of why I love going to SpringOne Platform every year. I meet people that are ALSO using Spring in incredible detail against some of the largest systems.
It’s an opportunity to see how they have conquered many problems, and an opportunity to share things they may not know, making us all better Spring experts.
The post Why do we need experts? appeared first on Greetings Programs.


June 9, 2017
I signed a contract!
 Something I’ve been working on for seven years now has taken a big turn. I signed a contract with Clean Reads to publish my novel, DARKLIGHT!
Something I’ve been working on for seven years now has taken a big turn. I signed a contract with Clean Reads to publish my novel, DARKLIGHT!
I’m pretty stoked about this. Of course it will be lots of work. Not even sure if it’s coming out this year or next. Either way, it’s going to be fun.
In the meantime, I invite you to go grab my short story prequel FOR FREE.
The post I signed a contract! appeared first on Greetings Programs.
June 5, 2017
The Power of REST – Part 3
 Last week in The Power of REST – Part 2, I talked about how investing effort in backward compatibility and having flexible settings, it’s possible to avoid a lot of “API versioning”, something Roy Fielding has decried. In this article, we’ll look more closely at the depth and power of hypermedia.
Last week in The Power of REST – Part 2, I talked about how investing effort in backward compatibility and having flexible settings, it’s possible to avoid a lot of “API versioning”, something Roy Fielding has decried. In this article, we’ll look more closely at the depth and power of hypermedia.
How does the web do it?
 Let’s remember that REST is about bringing the scaleable power of the web to APIs. One of those classic features is “Hey, go to XYZ.com, click on ‘Books’, then click on ‘Fiction’, then click on ‘The Job’ and you can get a free copy.”
Let’s remember that REST is about bringing the scaleable power of the web to APIs. One of those classic features is “Hey, go to XYZ.com, click on ‘Books’, then click on ‘Fiction’, then click on ‘The Job’ and you can get a free copy.”
Recognize this pattern? No one can remember long URLs, but we all know about following a chain of menu items based on the shorthand text.
Hypermedia is providing links all along the way. We sometimes refer to this as a “discoverable” API. I once likened it to the classic ZORK text adventure, where you have a confined set of moves, yet can explore a very complex world.
When clients hard code URLs, updates become brittle. Everyone knows this, otherwise there wouldn’t be things like a CORBA Naming Service subspec. So when I see tools that not only support but advocate full focus on URIs, I cringe. This isn’t what REST is about.
It really is aimed at following a chain of links. Because that grants us an incredible power to migrate services.
Migrating a service
Imagine we had started things out with a service used to manage supervisors. It was basic, perhaps a tad crude. Maybe we were wet behind the ears and didn’t totally grok REST. Not a lot of hypermedia. But eventually, we migrated to a newer “manager” service.
The good news with hypermedia is that we can continue to serve data at the old URI:
.gist table { margin-bottom: 0; }
If this fragment was served under the old URI, /supervisors/1, old clients could access the data found there. But with a push toward hypermedia consumption, they could navigate onto the newer version of things.
This legacy representation can be put together by the newer “manager” service to support the old clients.
.gist table { margin-bottom: 0; }
This route, served to the old URI by the “manager” service, can actually retrieve information in the newer format, and repackage it as a legacy “Supervisor” record. But by supplying up-to-date links, we provide an on-ramp for clients to migrate.
Assuming we had shutdown the old “supervisor” service, the following DTO could nicely sustain the old clients until they were ready to move on up.
.gist table { margin-bottom: 0; }
This immutable value type can take the new-and-improved “manager” object and extract the older representation smoothly.
Don’t argue the wrong end of things
 I’ve seen a particular argument pop up in favor of REST many times. It brags about how links can change without impacting clients. Frankly, that argument comes across as lame and weak. That’s because it’s NEVER presented under the guise of backward compatibility. It’s kind of posed in a vacuum.
I’ve seen a particular argument pop up in favor of REST many times. It brags about how links can change without impacting clients. Frankly, that argument comes across as lame and weak. That’s because it’s NEVER presented under the guise of backward compatibility. It’s kind of posed in a vacuum.
Building REST resources with full focus on backward compatibility, supporting old URIs and old formats, is a much stronger message in my book.
SOAP and CORBA weren’t designed to let you slip in an extra field here and there. At least, not without massive effort. It’s why no one ever did. Can you imagine going into an IDL/WSDL file and attempting to “slip in” an extra field to ease migration? It’s almost incomprehensible.
But with Jackson and robust principles applied, it’s easy to update a given route with additional data that can easily support two different clients. One REST resource supporting two clients: THAT is a strong argument. Not “links can change”.
Don’t preach it, use it
It’s why I’m giving you a sneak peek at something I’ve been wanting to write for about three months. I find myself attempting to explain the same concepts about REST on Twitter, at meetups. In Berlin, I ran into a dear friend that pinned me down and asked me hard questions on REST for over an hour. Bring it on! That affirmed my gut decision to create this:
This repository contains several REST-based scenarios and how to implement them with Spring HATEOAS. It’s not complete. It hasn’t even been “publicly” announced, but it gives me a concentrated place to show how REST works compared to RPC-over-HTTP.
The numerous times I’ve watched Oliver defend REST, I too and picking up the banner and striving to help spread the word that if we can adopt HATEOAS and link-driven flows, we can build more sustainable systems.
For a little something to chew on, I’ll close this article with the following tweet.
@tfnico #Swagger is a no-go if you’re into hypermedia, so it’s the HAL browser… If you don’t care (which is fine) go with Swagger…
— Oliver Gierke
June 2, 2017
Python Testing Cookbook 2nd Edition is coming!
 I had totally forgotten about this, but back in February, Packt Publishing approach me about writing a 2nd Edition to Python Testing Cookbook. This is a title I wrote back in 2011, and from which I still get royalty checks! It’s not huge. In fact, it’s more symbolic than anything. I get real a warm fuzzy knowing people are still using this book today to test their Python apps.
I had totally forgotten about this, but back in February, Packt Publishing approach me about writing a 2nd Edition to Python Testing Cookbook. This is a title I wrote back in 2011, and from which I still get royalty checks! It’s not huge. In fact, it’s more symbolic than anything. I get real a warm fuzzy knowing people are still using this book today to test their Python apps.
I declined the offer back in February, because I felt neither qualified to write it, nor motivated since I’ve shifted to writing Spring-based books. An email showed up two days ago that had been stuck in an acquisition editor’s drafts for months. They have found another author (congrats, Packt!), but since he or she can potentially use my material, they are dealing me in a slice of the royalty pie for this new work.
Yippee!
I wish this author the best of luck. And I appreciate that I’m being rewarded for past effort by being a part of this new one as well. It just goes to show that writing a book can open doors you never see happening.
Happy writing!
The post Python Testing Cookbook 2nd Edition is coming! appeared first on Greetings Programs.
May 29, 2017
The Power of REST – Part 2
Last week, in The Power of REST – Part 1, I challenged someone’s proposal that their client-side query language could supplant the power of REST. It seemed to attack strawman arguments about REST. In this article, I wanted to delve a little more into what REST does and why it does it.
Basis of REST
REST was created to take the concepts that made the web successful, into API development. The success of the web, which some people don’t realize, can be summarized like this: “if the web page is updated, does the browser need an update?”
No.
When we use RCP-oriented toolkits with high specificity, one change can trigger a forced update to all parties. The clinical term for this is “brittle“. And people hate brittleness. When updates are being made, resources are no longer available.
Let’s take a quick peek at the banking industry. Despite what you think, the banking industry isn’t built up on transactions and ACID (Atomicity/Consistency/Isolation/Durability). Nope. It’s built on BASE (Basic Availability/Soft-state/Eventual consistency). An ATM machine can be disconnected from the home office, yet it will dispense cash. You can go over your limit, and still get money. But when things are made consistent, it’s you that will be paying the cost of overdrawing, not the bank.
When it comes to e-commerce, downtimes of hours/minutes/seconds can translate into millions or billions of lost dollars. (Hello, Amazon!)
Updating ALL the clients because you want to split your API’s “name” field into “firstName” and “lastName” will be nixed by management until you A) show that it doesn’t impact business or B) prove the downtime to upgrade won’t cause any loss of revenue.
Evolving an API
Repeat after me: a breaking #API change is a breaking API change. It’s not API evolution. It’s the opposite.
— Oliver Gierke
May 26, 2017
Hidden Figures – A Really Cool Movie
Last night, I watched Hidden Figures with my wife and a friend. The story had me pinned to my seat the entire time.
This is set back in the days of the Mercury space program. Back then, before the days of digital computers, there were human computers to tally up columns of figures. And in those days, such brutal work was menial and deemed secretarial. To put it in a sentence, engineers and scientists decided what formulas to use and this pool of women would be tasked to carry it out.
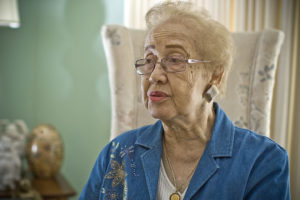 In the movie, one of these human computers, Katherine Goble, an African-American woman that graduated college (at the age of 14 in mathematics!), gets picked to crunch the numbers for the team calculating launch and landing windows for astronauts.
In the movie, one of these human computers, Katherine Goble, an African-American woman that graduated college (at the age of 14 in mathematics!), gets picked to crunch the numbers for the team calculating launch and landing windows for astronauts.
What quickly escalates is the fact that she not only can she do the math, she can spot what formulas to use, and find the solution. She can do the job of both a human computer AND the engineer that would be giving out the task assignments.
That’s not all that escalates. Back in the 1960s, circumstances for minorities was horrendous. And this movie doesn’t gloss over the challenges she and her friends face during the height of the Civil Rights Movement while engaged in the great Space Race.
Bottom line: it’s a great movie that weaves an entertaining story that really happened. The dram is top notch. And it’s not preachy. Instead, it makes you appreciate all that was accomplished while rooting for the home team.
The post Hidden Figures – A Really Cool Movie appeared first on Greetings Programs.
May 23, 2017
The Power of REST – Part 1
I was kind of shocked when I saw Yet Another Posted Solution to REST. I sighed and commented, and drew the ire of many. So I figured this might be a good time to gather some thoughts on REST.
Love how GraphQL “fixes” the REST by introducing tight coupling and brittleness. And then they duck the impact. https://t.co/JUJrvlpgQU
— Greg L. Turnquist (@gregturn) May 22, 2017
The article starts by criticizing REST and offering their toolkit as the solution. What’s really funny, is that the problems they ding are not RESTful issues.
REST requires lots of hops
Let’s start with this one:
As you might notice, this is less than ideal. When all is said and done we have made 1 + M + M + sum(Am) round trip calls to our API where M is the number of movies and sum(Am) is the sum of the number of acting credits in each of the M movies. For applications with small data requirements, this might be okay but it would never fly in a large, production system.
Conclusion? Our simple RESTful approach is not adequate. To improve our API, we might go ask someone on the backend team to build us a special /moviesAndActors endpoint to power this page. Once that endpoint is ready, we can replace our 1 + M + M + sum(Am) network calls with a single request.
This is the classic problem when you run into when fetching a 3NF (3rd normal form) data structure served up as REST.
Tip #1: REST doesn’t prevent you from merging data or offering previews of combined data. Formats like HAL include ability to serve up _embedded data, letting you give clients what they need. Spring Data REST does this through projections, but you can use anything.
In fact, server-side providers will probably have a better insight into exactly the volume of traffic fetching such data before clients. And through the power of hypermedia, can evolve to add links to the hypermedia without breaking existing clients. Old clients can do multiple hops; new clients can proceed to consume the new links, with full backwards compatibility.
REST serves too much data
If you look closely, you’ll notice that our page is using a movie’s title and image, and an actor’s name and image (i.e. we are only using 2 of 8 fields in a movie object and 2 of 7 fields in an actor object). That means we are wasting roughly three-quarters of the information that we are requesting over the network! This excess bandwidth usage can have very real impacts on performance as well as your infrastructure costs!
Just a second ago, we complained that the REST API was serving up too little data, forcing us to take multiple hops. Now we are complaining that it serves too much data and is wasting bandwidth.
The example in the article is a bit forced, given we are probably talking a couple tweets worth of data. It’s not like they are shipping 50MB too much. In fact, big volume data (images, PDFs) would best be served as links in the hypermedia. This would let the browser efficiently fetch a linked item once, and lean on the browser’s cache.
But I sense the real derision in the article is because the endpoint isn’t tailored to the client’s precise demands. No, the real example here is to illustrate a query technique on the client.
Just put SQL in the client already!
Wouldn’t it be nice if we could build a generic API that explicitly represents the entities in our data model as well as the relationships between those entities but that does not suffer from the 1 + M + M + sum(Am) performance problem? Good news! We can!
With GraphQL, we can skip directly to the optimal query and fetch all the info we need and nothing more with a simple, intuitive query.
So now we get to the real intent of the article: introduce a query language. Presumably solving REST’s straw man “problems” (which it doesn’t).
2/ if you want to query the database, why go there? Instead, just open a SQL connection straight to the DB.
— Greg L. Turnquist (@gregturn) May 22, 2017
If you want to write a highly detailed query, just open a connection the data store and query directly. That’s what query languages are for. Why invent something that’s weblike, but really just Another Query Language?
What problem are you solving?
GraphQL takes a fundamentally different approach to APIs than REST. Instead of relying on HTTP constructs like verbs and URIs, it layers an intuitive query language and powerful type system on top of our data. The type system provides a strongly-typed contract between the client and server, and the query language provides a mechanism that the client developer can use to performantly fetch any data he or she might need for any given page.
This query technology may be quite handy if you must write intense, focused queries. If cutting a couple text-based columns makes that much difference, then REST may not be solution you seek. (Of course, at that point why not just have your JavaScript frontend open a SQL/MongoDB/Neo4j connection?)
What does REST solve? REST solves the brittle problem that arose with CORBA and SOAP.
REST makes it possible to evolve APIs without forcing you to update every client at once.
 Think about that. When web sites make updates, does the web browser require an update? And why?
Think about that. When web sites make updates, does the web browser require an update? And why?
It’s no light feat of accomplishment. People were being beaten up left right as APIs would evolve. Updates were tough. Some clients would get broken. And availability is key for web scale business. So adopting the tactics that made the web resilient into API design sounds like a keen idea to try.
Too bad not enough people actually KNOW what these concepts are, and press on to criticize REST while offering “fixes” that don’t even address its fundamentals. The solution served in the article would put strong domain knowledge into the client, resulting in tight coupling. REST doesn’t shoot for this.
Am I making this assessment up?
This “virtual graph” is more explicitly expressed as a schema. A schema is a collection of types, interfaces, enums, and unions that make up your API’s data model. GraphQL even includes a convenient schema language that we can use to define our API.
@gregturn SOAP 2.0 seems more apt a comparison to me.
— Peter Frank (@pefrank13) May 22, 2017
Agreed. Continuing with more tight coupling instead of letting server side logic remain server side would align with SOAP 2.0, in my opinion. And it’s something I don’t much care for.
To dig in a little more about how REST makes it possible to evolve APIs with minimal impact, wait for my next article, The Power of REST – Part 2.
The post The Power of REST – Part 1 appeared first on Greetings Programs.
May 20, 2017
Something Java should never do
I’ve been working on a pull request on Spring HATEOAS for six weeks. That’s right, six weeks. It was a community contribution, and there’s a lot to sift through. Yesterday morning, I was slated to conduct the first review with the project lead. But that wasn’t going to happen, because Java decided to do something Java should never do.
Maven wouldn’t build my project while IntelliJ IDEA would.
 I was alerted to this issue Thursday morning when I created a “run all profiles” script and it wouldn’t work. Huh? Every time I’ve pushed an updated commit to Travis CI, it builds perfectly. That’s right, a CI server, running Maven, built my branch with ease. But my Mac would not.
I was alerted to this issue Thursday morning when I created a “run all profiles” script and it wouldn’t work. Huh? Every time I’ve pushed an updated commit to Travis CI, it builds perfectly. That’s right, a CI server, running Maven, built my branch with ease. But my Mac would not.
This made no sense. This is something Java should never do! Java doesn’t work on Linux but fail on a Mac. It must be my machine, right? So I log onto my wife’s MacBook Air, update Java to the latest version, grab the source, and fire off Maven. BOOM! It breaks just the same.
So…here comes the online review with Ollie. I pronounce my inability to build the system. The man with twenty years professional experience, who has written four tech books and one tech video, who has been fighting this for twenty four hours, pleads with his manager for clues. Ollie grabs the branch, tries to build, and SPLAT. It doesn’t work. He goes through the same questions I do, and finds no answers.
We jump to our OTHER CI server, Bamboo, and he commands it to build my branch. It works. Perfectly.
Score so far: Three Macs – 0 Two Linux CI servers – 2
 “Ollie, this is something Java should never do!” I scream into my Google Hangout. (Okay, maybe I didn’t scream.)
“Ollie, this is something Java should never do!” I scream into my Google Hangout. (Okay, maybe I didn’t scream.)
He nods along. The review is busted. We both flip to our daily standup Hangout, and Ollie’s first words are, “Greg, I know what you did.” Heh.
We wrap that meeting up, and I proceed to dig through every Stackoverflow article I can find on Lombok, maven-compiler-plugin, and Java 6. Talk about a nebulous combination. WIth enough evidence that this is Lombok’s fault, I open a ticket.
Fun day, given it’s my son’s last day of school for the year. I’m irritated at having to stop work to fetch him. My brain keeps churning the whole time. The second I get home, I have him go play. Anything to get back to my keyboard and keep trying options. I flip through a myriad of options for maven-compiler-plugin: memory, forked JDK, use Java 8, hand configure annotation processors. Nothing works.
 My three-year-old is trying to climb up on me, and I push him to the side. “I must find the answer!” Time to pick up our 7-year-old arrives, and I dash off. After getting home, she is asking me to write LOGO code. “No sweetheart, I need to try something first.” I usually stop ANYTHING to help her, but I was too obsessed with this issue.
My three-year-old is trying to climb up on me, and I push him to the side. “I must find the answer!” Time to pick up our 7-year-old arrives, and I dash off. After getting home, she is asking me to write LOGO code. “No sweetheart, I need to try something first.” I usually stop ANYTHING to help her, but I was too obsessed with this issue.
At this point, I start to De-lombok the code. Maybe if I can flip Lombok off. I get 90% of the code converted, and IT STILL WON’T BUILD! What could this possibly be? Every debug/verbose flag I activate still shows me nothing about what is actually breaking. Just some missing symbols followed a completely corrupted class.
Then I get a strange idea. A curious insight. What if the first class that Maven claims about, a nested static class, was made top level? I command IntelliJ to perform this refactoring. Poof, the error message changes. So I make the next nested static class in the list of errors top level as well.
BANG! Reading “[INFO] BUILD SUCCESS” makes my jaw drop.
I cancel all my changes, and build again. Same failure. I then strategically pick one nest static class, and move it. Everything suddenly works. What the…? This is something Java should never do.
Looking at the Jackson2HalModule (the predecessor to my work on Jackson2HalFormsModule), I count the number of nested static classes and compare to this one. The HAL parser has eight or nine, the new work has over twelve. Somehow, this enclosing class has TOO MANY NESTED STATIC CLASSES!
 Not wanting to move everything into public classes, I rig up HalFormsSerializers and HalFormsDeserializers, and split up the nested static classes into these two “namespaces”. Everything is humming. This change is mind boggling. Because this is something Java should never do.
Not wanting to move everything into public classes, I rig up HalFormsSerializers and HalFormsDeserializers, and split up the nested static classes into these two “namespaces”. Everything is humming. This change is mind boggling. Because this is something Java should never do.
So what is happening? Still not sure, but it implies that Lombok’s annotation processor must scan every class looking for its annotations. If the class is too deep, the scanner breaks and doesn’t recover, hence causing any nested classes further on to fail. And somehow, this state is contingent on the platform, because it works jim dandy on Linux while failing on the Mac.
I copy all these details into the Lombok ticket I opened. I hope I shined a light on an issue perhaps the committers can pinpoint and fix. But for now, my PR is buffed up and reviewable again. And as I go to bed, I can finally sleep in peace, having slain another dragon in the realm of open source hacking.

The post Something Java should never do appeared first on Greetings Programs.
May 16, 2017
Marketing your book with a launch group
 I’ve recently been working on building up a new aspect of marketing – forming a launch group. A launch group is a close knit circle of people that help you get the word out when your book, as they say, hits the stands.
I’ve recently been working on building up a new aspect of marketing – forming a launch group. A launch group is a close knit circle of people that help you get the word out when your book, as they say, hits the stands.
I have two fronts in progress: Darklight and Learning Spring Boot 2nd Edition.
One is my speculative fiction title that I’ve sent off to a tentative publisher. The other is my latest tech book slated to go out this September.
Getting the word out
When it comes to marketing, it’s key to get the word out. In fact, it’s so important, that I learned of an author that used Russian pirate book sites to actually distribute his novel. What had been maybe 1000 downloads per year, turned into one million downloads a year, resulting in him carrying #1 ranking on Amazon.

(I’m not ready to pull the lever on THAT strategy yet. But if you can write a fleet of books, it’s a path to consider.)
When it comes to writing, people have a rather dated concept of marketing. Perhaps some of us can remember an author visiting our hometown. We’d load everyone up in the car and drive to the bookstore to get in line, buy a copy, and have the author sign it. Sorry, but those days are long gone. Book signings draw such little attendance these days, that authors tend to lose money carrying them out.
If you’re writing a book, tech or not, you may assume your publisher will advertise and publicize it. Nein! The only marketing dollars that are getting spent are on authors that don’t need it. In other words, unless your name is Stephen King or Lee Child, publishers aren’t spending two nickels on you. You (an unestablished author) are flat out not worth the risk of that investment.
Marketing is up to the author. Each of us has to get the word out on our works. And one of those avenues can be putting together a collection of people to help share it in various circles.
Launch group, assemble!
As I said, I’m putting together two core teams of people. For each team, I have a super secret Facebook group where I share in progress work, advanced copies ahead of public release, and will host contests from time-to-time when I need help with things like character names, plot tips, and more. On the day of release, I turn to my inner circle to help blog/tweet/facebook about the title.
 If you’re interested in being a part of The Undergrounders and fighting the forces that oppose Darklight‘s release, you can sign up right here.
If you’re interested in being a part of The Undergrounders and fighting the forces that oppose Darklight‘s release, you can sign up right here.
 If you’re interesting in being a part of The Turnquist Techies and helping spread the word of Spring Boot, you can sign up for that group right here.
If you’re interesting in being a part of The Turnquist Techies and helping spread the word of Spring Boot, you can sign up for that group right here.
The post Marketing your book with a launch group appeared first on Greetings Programs.
May 1, 2017
The myth of polymorphism
I remember reading about polymorphism for the first time. I was in high school, and boy it sure looked cool! Too bad I didn’t realize that the myth of polymorphism was a bunch of poppy cock.
You see, polymorphism never seems to be presented in its real state. Instead, we get this goofy, toy-app type presentation. Does Shape -> Rectangle -> Square ring a bell?
The fallacy of geometrical shapes being polymorphic
 One of the simplest ways people seem to introduce polymorphism is using geometric shapes. We all know that a Square is a Rectangle. We covered that nicely in geometry, right? Problem is, geometry doesn’t equal software.
One of the simplest ways people seem to introduce polymorphism is using geometric shapes. We all know that a Square is a Rectangle. We covered that nicely in geometry, right? Problem is, geometry doesn’t equal software.
When discussing things in light of geometry, the reason we value this relationship is because we are looking at things like angles, parallelism, vertices, and intersections. Hence, squares carry all the attributes of rectangles. They simply have the same width and height.
But software isn’t geometry. The things we construct we must also interact with. The shapes must afford us operations to grab them, interrogate them, draw them, and manipulate them. A rectangle has two attributes: width and height. A square has one: width.
If we grabbed a square, set its width, then set its height, the assumptions of what would happen is unclear. Should a square morph into a rectangle? Or should setting the height induce the side effect of also updating the width? Either way is bad form. Hence, its best to break apart this faulty geometric relationship and realize that squares are NOT rectangles.
The fallacy of inheriting behavior
So shaking off the trivial example of geometric shapes, another common example is to talk about the glorious ability to reuse code. With polymorphism, it will be SO easy to code something once, and then reuse it across dozens if not hundreds of classes! And with late binding options, gobs of 3rd party libraries can go forth and reuse your code.
The problem is, no programming language has adequately been invented to gather ALL the semantic nuances of code. As more and more classes extend a given class, they all either realize EXACTLY what the abstract parent class does and agree with it, or they discover some new wrinkle not quite handled. The API may be supported, but some underlying assumption is buried that requires an update.
As the tail of inheritance grows, maintainers are less likely to accept new changes to the shared code. The risk of breaking someone else grows, because everyone knows not the ENTIRE nature of the code can be captured.
Some of the avenues to remedy this involves opening up the API a bit more. Perhaps a private utility method is needed by a new extender. But opening it up introduces more maintenance down the road. Or more opportunities for others to abuse things that used to be kept tightly controlled.
History has proven that composition beats inheritance for sustainability. Raise your hand if maintenance, not new development, doesn’t encompass much of your work.
The alternative are more sophisticated languages where you can capture more of the concepts. Yet these languages come across as too complex to many, arguably because CAPTURING all semantics is inherently challenging. And more often than not, we don’t KNOW all these semantics on the first round.
The myth of polymorphism vs. the reality
 One thing that has emerged is programming to interfaces. Interfaces provide a nice contract to work against. Naturally, we can’t capture everything. But at least every “Shape” can institute the defined methods. In Java, interfaces can be combined, allowing multiple behaviors to be pulled together.
One thing that has emerged is programming to interfaces. Interfaces provide a nice contract to work against. Naturally, we can’t capture everything. But at least every “Shape” can institute the defined methods. In Java, interfaces can be combined, allowing multiple behaviors to be pulled together.
So when it comes to abstract and refactor, think about extracting interfaces when possible and delegating solutions.
Strangely enough, despite my consternation with static variables, I’ve come to appreciate static methods in the right scenario. Factories that support interfaces can be quite handy dandy. But a well modeled, inheritance hierarchy is to hard to accomplish. If possible, try to avoid multiple layers, and see if it’s not possible to extract share code into various utility classes.
And when the entire hierarchy is nicely contained INSIDE your framework, and not as an extension point to consumers, the fallacies of polymorphism can be contained. But watch out! It takes much effort to put this together. Never think it will be easy.
Of course, I could be entirely wrong. If you have some keen examples, please feel free to share!
Happy coding.
The post The myth of polymorphism appeared first on Greetings Programs.


