
Neil Clarke's Blog, page 2
August 3, 2024
Rebuilding Clarkesworld Subscriptions
I’ve been posting most of these updates in recent Clarkesworld editorials, but it’s only the 3rd and that’s a long time to wait for the next one. Here’s a recap:
Last year, we were informed by Amazon that they were ending their magazine subscription program. We had been in the program for well over a decade and it had been where the majority of our subscribers received their ebook editions. If you had a Kindle (which is the most popular ebook device), it was extremely convenient and easy-to-use. The ecosystem was designed so anyone could figure it out. As a result, it was quite popular.
There were some downsides for publishers, the biggest being that Amazon treated subscribers as their customers. That was great for things like customer support, but when it came time to help those people move their subscriptions to other services, it became a nightmare. Amazon would not share their contact information with us. We did what we could, but when the program ended, so did thousands of our subscriptions.
At the same time, Amazon opted to launch a Kindle Unlimited program for magazines. (Different terms than the book program.) We were among those invited and the non-negotiable terms included paying us less than half of what we once earned from them. I’ve described this previously as a hostage situation and what I meant by that is we were left with a choice, take the deal or close. Even taking the deal, we weren’t sure we’d make it, but the odds were better, so we held our nose and took it. Now that enough time has passed, I can say that taking the bad deal is the reason we survived that year. It gave us the time we needed to make a dent in rebuilding our subscriptions elsewhere.
A few months ago, they invited us to renew our existing contract for three months, but with an additional 50% cut in revenue. The idea was to move to new terms in July which, when we did the math, included another steep cut. Thanks to combined cuts, the anticipated revenue was not only insulting, but potentially harmful to our ability to sell subscriptions elsewhere. This time, however, they were open to negotiating, but that didn’t work out. As of July 1st, we’re no longer in the program. We won’t rule out returning, but I’d rate the chances as slim.
We were able to walk away from the table for a few reasons.
there was overlap between the old and new program, so we socked away that revenue for such an emergencyour subscription rebuilding efforts were more successful than anticipatedthe amount offered wouldn’t have closed the gap anywaya sliver of hope that the time allowed by #1 would be enough to close the subscription gapIn my July editorial, I laid it all out on the table and explained that we still had some time to recover the remaining 347 subscriptions needed to continue. The response was wonderful. Throughout the month, the number creeped downwards. It was in the 130s by the time I wrote our August editorial. That swift response extended the amount of time our reserves would last and, for the first time in a year, I felt confident that we could pull this off.
Early on August 1st, BaltSHOWPLACE shared my July editorial on Reddit (specifically the printSF reddit, but it would later spread to others) and we experienced a surge in new subscriptions. The first few days of the month are usually a bit chaotic. It’s when a bunch of subscriptions come up for renewals, so there’s loss to churn (people not renewing) and a fresh batch of credit card processing errors. It can take a few days to figure out just where the numbers will settle, but it’s easy to work out the best and worst case scenarios. The surge left us sitting somewhere between the two.
More of the data resolved overnight and now I can confidently declare: We did it!
We are now back to the number of subscribers we had before Amazon pulled the plug! What we did not include in our goal was making up for the lost time (recovering the anticipated growth we would have experienced had the program not ended) and I can happily say that the surge has bitten into some of that as well, giving it a great start.
What we have now will allow the lights to stay on. Our bare minimum line in the sand. Everything that builds on that from here forward will be put towards our continued efforts to pay our staff a living wage. That has been and will continue to be a priority for us. Only a few genre publications have professionally-paid staff and none of those publications were born of the digital age like us. We aim to be the first and believe that it’s not only attainable, but a goal worth prioritizing. We hope you agree and that the ball can keep rolling towards that.
Thank you to everyone that has subscribed and boosted and cheered us on. You have no idea how much this means to all of us here.
Thank you.


February 11, 2024
On fast rejections
At Clarkesworld, we try to respond to submissions in under 48 hours. Sometimes life gets in the way and that can slide to a week, but we always make an effort to catch up and return to normal. We’ve made this response time a goal and have been committed to it for a very long time.
Every now and then, an author decides to take affront at a quick response. It happens often enough, that I’ve sometimes sat on stories just to get them over the 24 hour mark, which seems to decrease, but not eliminate, the outrage factor. Rather than repeat myself with those authors, I’m just going to start pointing people to this post.
Things you need to know
We actually read every submission. Seriously, why would we waste our time handling this many submissions if we had no intention of reading them? Suggesting otherwise is insulting.A good or great story can still be rejected. Most well-known editors have rejected at least one story that has gone on to win awards and usually, they have no regrets about that. The story simply wasn’t right for their project or they weren’t the right editor for that story. It eventually landed in the right market with the right editor, found it’s audience, and was celebrated for it. We like to see that.Don’t be misled. Magazines that have slower response times don’t necessarily spend more time reading your story than we did. The difference in response times is almost entirely related to the amount of time your story sits in a pile, unread. If a publication averages 30 days, it means they can keep up with the daily volume and could have a 48-hour response time, if it was one of their priorities.To us, getting back to you quickly is a sign of respect. The sooner we reject this one, the sooner you can send it to the next market. It also resets the clock on when you can send us your next one. Every story is a clean-slate, so rejecting one or ten or hundred doesn’t mean we’ve given up on you. While a few authors sell quickly, others have submitted over fifty before landing an acceptance here. Everyone’s journey is different.We did warn you. Our average response time is listed in our guidelines and on the submission confirmation screen.February 2, 2024
2023 Clarkesworld Submissions Snapshot
Now that the year is over and I’ve had some time to sit with the data, I can share a snapshot of the 2023 submissions data and a few observations. For the sake of clarity, the data here represents stories that were submitted from January 1, 2023 through December 31, 2023. It does not include the submissions that we identified as plagiarism or generated by LLMs (also loosely called “AI” submissions).
We received a total of 13,207 submissions in 2023. This includes the 1,124 Spanish language submissions that were part of a one-month Spanish Language Project (SLP). We were closed to submissions from February 20, 2023 through March 12, 2023 due to a surge (hundreds in a month) of “AI”-generated submissions. During that period, we made updates to our software in an attempt to better manage this new form of unwanted works. The changes made helped us avoid the need to close submissions again, despite continued surges. (This is a band aid, not a cure. Higher volumes could necessitate future closures.)
Combined, the number of submissions received was our second-highest year ever. (2020 and its wild pandemic submission patterns holds the record by just a few dozen.) If we consider just the English language submissions, it was down, but only because we were closed for a few weeks. Assuming the weekly submissions volume would have held during that time, we would have had roughly the same volume as we did in 2022 and, with SLP submissions, our best overall year ever.
7,898 (59.8%) of the submissions were from authors that had never submitted to Clarkesworld before. Courtesy of the SLP, that percentage is considerably higher than normal. In case it isn’t clear, I consider this to be a good thing. Opening the door for authors that had been unable to submit in the past was a major point of that project.
We received submissions from 154 different countries, smashing our previous record by 12. US-based authors accounted for 7780 (58.9%) of all works, a new record for lowest levels from there. However, if we remove the SLP, it increases to 64.1%, which is the highest percentage we’ve seen in several years. I’ve tried to dig into the reasons for this change have have identified two likely causes, both of which are tied to the generated submissions crisis:
The press coverage concerning our situation with “AI” submissions was global and effectively spread the word that we had closed submissions, but the news of our reopening did not receive similar attention. American authors were far more likely to hear that we were once again accepting submissions.With the amount of time we had to spend on the “AI” and Amazon subscription problems, we did not put as much effort into promoting our openness to international submissions. As I’ve noted in past years, many foreign authors have difficulty believing that US-based publications are open to submissions from them. (History certainly makes it look that way.) Making public statements about your willingness to do so is an important part of undoing the damage and it must be maintained. The decrease in the time we spent doing that in 2023 almost certainly had an impact.While the percentage is disappointing (please don’t take this as not wanting more US-based authors, we want everyone, but one group needs more encouragement than the other), it is recoverable and was offset by the SLP. If anything, that’s a reason for doing more language-based projects in the future. It was clearly more effective than anything we’ve done in the past.
Short stories (works under 7,500 words) represented 85.9% of all submissions, followed by novelettes (works between 7,500 and 17,500 words) at 12.7% and novellas (17,500+, our cap is 22,000) at 1.4%. Acceptances followed a similar trend with 82.9%, 14.8%, and 2.3% respectively.
Science fiction took the lead across all categories. The following is our submission funnel (by genre) for 2023. The outer ring is all submissions. The middle ring includes stories that were passed onto the second round of evaluation. The inner ring is acceptances.

I discourage people from using this data to determine what they should and should not send to us. The data reflects our opinions on the individual works submitted to us at that specific time, and does not represent a general opinion on the length or genre of works submitted to us. If we were no longer interested in considering a specific type of work, it would either be present in our hard-sell list or missing from our list of accepted genres. (This already happened with horror.) We will not waste your (or our) time by leaving a category open if we have no intention of considering it for publication.
Genres have trends and right now, some of those trends are working for or against stories in our submissions review process. Works across all categories are still reaching the second round, indicating (to me) that it is still important that we continue to encourage and consider works in those genres.
January 27, 2024
Clarkesworld Readers’ Poll (round one) now open for 48 hours
The 48-hour nomination phase of our annual Clarkesworld Readers’ Poll is now open. Nominate your favorite 2023 Clarkesworld short stories, novelettes/novellas, and cover art. Finalists will be revealed in our February issue.
https://www.surveymonkey.com/r/cwreaders2023
CLOSES MONDAY AT NOON
December 17, 2023
Clarkesworld Magazine 2023 Stories and Cover Art
Here are the stories and cover art published in Clarkesworld Magazine’s 2023 issues:
Short Stories
“Symbiosis” by D.A. Xiaolin Spires“Sharp Undoing” by Natasha King“Pearl” by Felix Rose Kawitzky“The Portrait of a Survivor, Observed from the Water” by Yukimi Ogawa“Somewhere, Its About to Be Spring” by Samantha Murray“Larva Pupa Imago” by Eric Schwitzgebel“Silo, Sweet Silo” by James Castles“Going Time” by Amal Singh“Love in the Season of New Dance” by Bo Balder“Pinocchio Photography” by Angela Liu“The Spoil Heap” by Fiona Moore“Failure to Convert” by Shih-Li Kow“Zeta-Epsilon” by Isabel J. Kim“AI Aboard the Golden Parrot” by Louise Hughes“Love is a Process of Unbecoming” by Jonathan Kincade“Re/Union” by L Chan“There Are the Art-Makers, Dreamers of Dreams, and There Are Ais” by Andrea Kriz“Rake the Leaves” by R.T. Ester“Keeper of the Code” by Nick Thomas“The Librarian and the Robot” by Shi Heiyao“Voices Singing in the Void” by Rajan Khanna“Better Living Through Algorithms” by Naomi Kritzer“Through the Roof of the World” by Harry Turtledove“LOL, Said the Scorpion” by Rich Larson“Sensation and Sensibility” by Parker Ragland“The Giants Among Us” by Megan Chee“Action at a Distance” by An Hao“The Fall” by Jordan Chase-Young“The Officiant” by Dominica Phetteplace“Vast and Trunkless Legs of Stone” by Carrie Vaughn“Day Ten Thousand” by Isabel J. Kim“The Moon Rabbi” by David Ebenbach“. . . Your Little Light” by Jana Bianchi“To Helen” by Bella Han“Mirror View” by Rajeev Prasad“Cheaper to Replace” by Marie Vibbert“Death and Redemption, Somewhere Near Tuba City” by Lou J Berger“Estivation Troubles” by Bo Balder“Tigers for Sale” by Risa Wolf“Timelock” by Davian Aw“What Remains, the Echoes of a Flute Song” by Alexandra Seidel“The Orchard of Tomorrow” by Kelsea Yu“Every Seed is a Prayer (And Your World is a Seed)” by Stephen Case“Window Boy” by Thomas Ha“Empathetic Ear” by M. J. Pettit“Gel Pen Notes from Generation Ship Y” by Marisca Pichette“Resistant” by Koji A. Dae“Stones” by Nnedi Okorafor“The Queen of Calligraphic Susurrations” by D.A. Xiaolin Spires“A Guide to Matchmaking on Station 9” by Nika Murphy“The People from the Dead Whale” by Djuna“The Five Remembrances, According to STE-319” by R. L. Meza“Upgrade Day” by RJ Taylor“Possibly Just About A Couch” by Suzanne Palmer“The Blaumilch” by Lavie Tidhar“Post Hacking for the Uninitiated” by Grace Chan“Rafi” by Amal Singh“Timothy: An Oral History” by Michael Swanwick“Eddies are the Worst” by Bo Balder“Bird-Girl Builds a Machine” by Hannah Yang“The Long Mural” by James Van Pelt“The Parts That Make Me” by Louise Hughes“The Mub” by Thomas Ha“Thin Ice” by Kemi Ashing-Giwa“To Carry You Inside You” by Tia Tashiro“Morag’s Boy” by Fiona Moore“Thirteen Ways of Looking at a Cyborg” by Samara Auman“In Memories We Drown” by Kelsea Yu“Waffles Are Only Goodbye for Now” by Ryan Cole“The Worlds Wife” by Ng Yi-Sheng“The Last Gamemaster in the World” by Angela Liu“Kill That Groundhog” by Fu Qiang
Novelettes
Novellas
Cover Art
 “Harvest II” by Arthur Haas
“Harvest II” by Arthur Haas “Home” by Alex Rommel
“Home” by Alex Rommel “Android” by Lyss Menold
“Android” by Lyss Menold “Taking a Sample” by Arthur Haas
“Taking a Sample” by Arthur Haas “Raid” by Pascal Blanché
“Raid” by Pascal Blanché “Autumn Pond” by Sergio Rebolledo
“Autumn Pond” by Sergio Rebolledo “Old Ways” by J.R. Slattum
“Old Ways” by J.R. Slattum “Escape” by Ignacio Bazan-Lazcano
“Escape” by Ignacio Bazan-Lazcano “Utopia #2” by Dofresh
“Utopia #2” by Dofresh “The pirates on the beach” by Dofresh
“The pirates on the beach” by Dofresh “The Gift” by Matt Dixon
“The Gift” by Matt Dixon
October 27, 2023
Thank you!
I spent a portion of this month in Chengdu, China attending the 2023 Worldcon. I have lots to nice things to say about my time there, but I contracted Covid somewhere along the line and I’m a bit fatigued right now. (So far, it’s an extremely mild case. Boosters are demonstrating their value right now.)
I did want to offer my thanks for a very enjoyable convention and express my joy at winning the Hugo Award for Best Editor (Short Form) for the second year in a row. I’ve had a long relationship with Chinese SF, so this was a very personally rewarding win among friends. It’s also been a particularly rough year, so well-timed on that front too. Thanks to everyone that voted for me!
I opted not to travel through three airports and multiple security checkpoints with my Hugo this time. It’s slowly making it’s way to the US, but for now, I have a few photos:



August 23, 2023
Block the Bots that Feed “AI” Models by Scraping Your Website
“AI” companies think that we should have to opt-out of data-scraping bots that take our work to train their products. There isn’t even a required no-scraping period between the announcement and when they start. Too late? Tough. Once they have your data, they don’t provide you with a way to have it deleted, even before they’ve processed it for training.
These companies should be prevented from using data that they haven’t been given explicit consent for. Opt-out is problematic as it counts on concerned parties hearing about new or modified bots BEFORE their sites are targeted by them. That is simply not practical.
It should be strictly opt-in. No one should be required to provide their work for free to any person or organization. The online community is under no responsibility to help them create their products. Some will declare that I am “Anti-AI” for saying such things, but that would be a misrepresentation. I am not declaring that these systems should be torn down, simply that their developers aren’t entitled to our work. They can still build those systems with purchased or donated data.
There are ongoing court cases and debates in political circles around the world. Decisions and policies will move more slowly than either side on this issue would like, but in the meantime, SOME of the bots involved in scraping data for training have been identified and can be blocked. (Others may still be secret or operate without respect for the wishes of a website’s owner.) Here’s how:
(If you are not technically inclined, please talk to your webmaster, whatever support options are at your disposal, or a tech-savvy friend.)
robots.txt
This is a file placed in the home directory of your website that is used to tell web crawlers and bots which portions of your website they are allowed to visit. Well-behaved bots honor these directives. (Not all scraping bots are well-behaved and there are no consequences, short of negative public opinion, for ignoring them. At this point, there have been no claims that bots being named in this post have ignored these directives.)
This what our robots.txt looks like:
User-agent: CCBotDisallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: GPTBot
Disallow: /
The first line identifies CCBot, the bot used by the Common Crawl. This data has been used by ChatGPT, Bard, and others for training a number of models. The second line states that this user-agent is not allowed to access data from our entire website. Some image scraping bots also use Common Crawl data to find images.
The next two user-agents identify ChatGPT-specific bots.
ChatGPT-User is the bot used when a ChatGPT user instructs it to reference your website. It’s not automatically going to your site on its own, but it is still accessing and using data from your site.
GPTBot is a bot that OpenAI specifically uses to collect bulk training data from your website for ChatGPT.
ChatGPT has been previously reported to use another unnamed bot that had been referencing Reddit posts to find “quality data.” That bot’s user agent has never been officially identified and its current status is unknown.
Updating or Installing robots.txt
You can check if your website has a robots.txt by going to yourwebsite.com/robots.txt. If it doesn’t find that page, then you don’t have one.
If your site is hosted by Squarespace, Wix, or another simple website-building site, you have a problem. At present, those companies don’t allow you to update or add your own robots.txt. They may not even have the ability to do it for you. I recommend contacting support so you can get specific information regarding their current abilities and plans to offer such functionality. Remind them that once slurped up, you have no ability to remove your work from their hold, so this is an urgent priority. (It also demonstrates once again why “opt-out” is a bad model.)
If you are using WordPress, there are a few plugins that allow you to modify your robots.txt. Many of these include SEO (Search Engine Optimization) plugins have robots.txt editing features. (Use those instead of making your own.) Here’s a few we’ve run into:
Yoast: directionsAIOSEO: directionsSEOPress: directionsIf your WordPress site doesn’t have a robots.txt or something else that modifies robots.txt, these two plugins can block GPTBot and CCBot for you. (Disclaimer: I don’t use these plugins, but know people who do.)
For more experienced users: If you don’t have a robots.txt, you can create a text file by that name and upload it via FTP to your website’s home directory. If you have one, it can be downloaded, altered and reuploaded. If your hosting company provides you with cPanel or some other control panel, you can use its file manager to view, modify, or create the file as well.
If your site already has a robots.txt, it’s important to know where it came from as something else may be updating it. You don’t want to accidentally break something, so talk to whoever set up your website or your hosting provider’s support team.
Firewalls and CDNs (less common, but better option)
Your website may have a firewall or CDN in front of your actual server. Many of these products have the ability to block bots and specific user agents. Blocking the three user agents (CCBot, GPTBot, and ChatGPT-User) there is even more effective than using a robots.txt directive. (As I mentioned, directives can be ignored. Blocks at the firewall level prevent them from accessing your site at all.) Some of these products include Sucuri, Cloudflare, QUIC.cloud, and Wordfence. (Happy to add more if people let me know about them. Please include a link to their user agent blocking documentation as well.) Contact their support if you need further assistance.
Additional Protection for Images
There are some image-scraping tools that honor the following directive:
when placed in the header section of your webpages. Unfortunately, many image-scraping tools allow their users to ignore this directives.
Tools like Glaze and Mist that can make it more difficult for models to perform style mimicry based on altered images. (Assuming they don’t get or already have an unaltered copy from another source.)
There are other techniques that you can apply for further protection (blocking direct access to images, watermarking, etc.) but I’m probably not the best person to talk to for this one. If you know a good source, recommend them in the comments.
ai.txt
I just came across this one recently and I don’t know which “AI” companies are respecting Spawning’s ai.txt settings, but if anyone is, it’s worth having. They provide a tool to generate the file and an assortment of installation directions for different websites.
https://site.spawning.ai/spawning-ai-txt
Closing
None of these options are guarantees. They are based on an honor system and there’s no shortage of dishonorable people who want to acquire your data for the “AI” gold rush or other purposes. Sadly, the most effective means of protecting your work from scraping is to not put it online at all. Even paywall models can be compromised by someone determined to do so.
Writers and artists should also start advocating for “AI”-specific clauses in their contracts to restrict publishers using, selling, donating, or licensing your work for the purposes of training these systems. Online works might be the most vulnerable to being fed to training algorithms, but print, audio, and ebook editions developed by publishers can be used too. It is not safe to assume that anyone will take the necessary efforts to protect your work from these uses, so get it in writing.
[This post will be updated with additional information as it becomes available.]
August 2, 2023
Busting a Myth
“Only writers subscribe to genre magazines.” or “Most subscribers are writers”
I don’t know why this myth keeps surfacing. It could be writers trying to blame non-writers for the woes of magazines. It could be people who don’t like short fiction trying to suggest that real readers don’t bother with it.
With the current nonsense surrounding Amazon and subscriptions (if you are one of our subscribers on Amazon, see this), it’s cropping up again.
I’ve addressed this issue in the past, but can’t remember where. It was a while ago, so let’s re-run the numbers and see if it still holds up.
I have to start by acknowledging some assumptions for the purpose of this exercise:
We’re defining an author as someone who has submitted at least one story to Clarkesworld. At present, that data set includes over 69,000 writers (bans removed) since 2009. I know there are writers that don’t submit work to us, but the underlying current of the argument is that it is really just the people who want to be published at a magazine.Some of our vendors (Amazon, B&N, Weightless) do not supply subscriber data, so we are working with data from other subscriptions (Patreon, Clarkesworld Citizens, PayPal, Ko-Fi, and the small percentage of Amazon subscribers that opted-in to data sharing). This provided us with nearly 5,300 different people who subscribed or supported the magazine sometime in the last decade.The overlap between the two groups is only 708 or roughly 13% of our known subscribers. That’s only 1% of the authors that have sent us stories. The percentages show very little variation (1-2%) when broken down by subscription source. It even holds for subscriptions from the Amazon readers that have switched over since March (when Amazon announced their plans to end subscriptions).
With the size of the data sets involved, I feel very comfortable stating that this myth is busted.
[EDIT: Some people want exact numbers, but the only one I provided above was 708. Everything else was rounded to keep it simple. Moving the rounding out a few decimal places, authors as known subscribers is 13.37% and known subscribers submitting to the magazine is 1.022% percent.]
May 28, 2023
AI statement
I’ve complained that various publishing industry groups have been slow to respond to recent developments in AI, like LLMs. Over the last week, I’ve been tinkering with a series of “belief” statements that other industry folks could sign onto. I’m finally ready to start sharing a draft. Feedback welcome, but if you are here to discourage, move along. Not interested in a fight.
Where We Stand on AI in Publishing
We believe that AI technologies will likely create significant breakthroughs in a wide range of fields, but that those gains should be earned through the ethical use and acquisition of data.
We believe that “fair use” exceptions with regards to authors’, artists’, translators’, and narrators’ creative output should not apply to the training of AI technologies, such as LLMs, and that explicit consent to use those works should be required.
We believe that the increased speed of progress achieved by acquiring AI training data without consent is not an adequate or legitimate excuse to continue employing those practices.
We believe that AI technologies also have the potential to create significant harm and that to help mitigate some of that damage, the companies producing these tools should be required to provide easily-available, inexpensive (or subsidized), and reliable detection tools.
We believe that detection and detection-avoidance will be locked in a never-ending struggle similar to that seen in computer virus and anti-virus development, but that it is critically important that detection not continue to be downplayed or treated as a lesser priority than the development of new or improved LLMs.
We believe that publishers do not have the right to use contracted works in the training of AI technologies without contracts that have clauses explicitly granting those rights.
We believe that submitting a work for consideration does not entitle a publisher, agent, or the submission software developers to use it in the training of AI technologies.
We believe that publishers or agents that utilize AI in the evaluation of submitted works should indicate that in their submission guidelines.
We believe that publishers or agents should clearly state their position on AI or AI-assisted works in their submission guidelines.
We believe that publishers should make reasonable efforts to prevent third-party use of contracted works as training data for AI technologies.
We believe that authors should acknowledge that there are limits to what a publisher can do to prevent the use of their work as training data by a third party that does not respect their right to say “no.”
We believe that the companies and individuals sourcing data for the training of AI technologies should be transparent about their methods of data acquisition, clearly identify the user-agents of all data scraping tools, and honor robots.txt and other standard bot-blocking technologies.
We believe that copyright holders should be able to request the removal of their works from databases that have been created from digital or analog sources without their consent.
We believe that the community should not be disrespectful of people who choose to use AI tools for their own entertainment or productive purposes.
We believe that individuals using AI tools should be transparent about its involvement in their process when those works are shared, distributed, or made otherwise available to a third party.
We believe that publishing contracts should include statements regarding all parties’ use, intended use, or decision not to use AI in the development of the work.
We believe that authors should have the right to decline the use of AI-generated or -assisted cover art or audiobooks on previously contracted works.
We believe that individuals using AI tools should be respectful of publishers, booksellers, editors, and readers that do not wish to engage with AI-generated or -assisted works.
We believe that publishers and booksellers should clearly label works generated by or with the assistance of AI tools as a form of transparency to their customers.
We believe that copyright should not be extended to generated works.
We believe that governments should craft meaningful legislation that both protects the rights of individuals, promotes the promise of this technology, and specifies consequences for those who seek to abuse it.
We believe that governments should be seeking advice on this legislation from a considerably wider range of people than just those who profit from this technology.
ADDITIONS:
We believe that publishers and agents need to recognize that the present state of detection tools for generated art and text is capable of false positives and false negatives and should not be relied upon as the sole source of determination.
Some notes in response to comments:
AI-generated and -assisted are not specifically defined due to the fact that the technology is evolving and any definition would likely create loopholes. Broad terms are meant to encourage transparency and allow individual parties to determine whether or not such uses cross their individual lines. For example, one’s attitude towards AI-assisted research may be different for non-fiction vs. fiction.
In suggesting that AI developers should be required to provide reliable detection tools and that by emphasizing that detection should be a priority, we are stating that the people best equipped to understand and tackle the problem of detection–which can be tackled in several different ways–are the ones developing the AI tools that generate the output. (Some have even suggested that all output should be saved for detection purposes, but we’re not qualified to tell them how to solve the problem.) It’s a problem of the same scale (or even more complex) as generation. Instead, industry professionals have been quoted saying things like “get used to it” and have placed insufficient effort into addressing the problems they are creating. The pricing concern is to make sure that anyone can access it. It’s going to impact more than just the publishing world.
May 18, 2023
It continues…
Since last November, we’ve seen a steadily-increasing influx of submissions written with these ChatGPT and other LLMs. In February, it increased so sharply that we were left with no alternative but to close submissions, regroup, and start investing in changes to our submission system to help deter or identify these works.
All of this nonsense has cost us time, money, and mental health. (Far more than the $1000 threshold that Microsoft Chief Economist and Corporate Vice President Michael Schwarz sees as a harm threshold before any regulation of generative AI should be implemented. But let’s not go down that path. It’s not like I’d trust regulation advice from the guy with his hand in the cookie jar.)
When we reopened submissions in March, I acknowledged that any solution would need to evolve to meet the countermeasures it encounters. Much like dealing with spam, credit card fraud, or malware, there are people constantly looking for ways to get around whatever blocks you can throw in their path. That pattern held.
Here’s a look at how things have been since November:
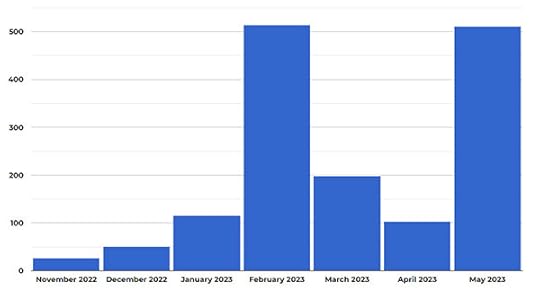
This graph represents the number of “authors” we’ve had to ban. With very rare exceptions, those are people sending us machine-generated works in violation of our guidelines. All of them are aware of our policy and the consequences should they be caught. It’s right there on the submission form and they check a box acknowledging it.
Our normal workload is about 1100 legitimate submissions each month. The above numbers are in addition to that. Before anyone does the “but the quality” song and dance number, none of those works had any chance at publication, even if they weren’t in violation of our guidelines.
As you can see, our prevention efforts bore some fruit in March and April before being thwarted in May. So then, why aren’t we closed this time?
Honestly, I’m not ruling out the possibility. We were honestly surprised by just how effective some basic elimination efforts were at reducing volume in March and April. That was a shot in the dark, is still blocking some, but is not a viable option for the latest wave. We’re only keeping our head above water this time because we have some new tools at our disposal. From the start, our primary focus has been to find a way to identify “suspicious” submissions and deprioritize them in our evaluation process. (Much like how your spam filter deals with potentially unwanted emails.) That’s working well enough to help.
I’m not going to explain what makes a submission suspicious, but I will say that it includes many indicators that go beyond the story itself. This month alone, I’ve added three more to the equation. The one thing that is presently missing from the equation is integration with any of the existing AI detection tools. Despite their grand claims, we’ve found them to be stunningly unreliable, primitive, significantly overpriced, and easily outwitted by even the most basic of approaches. There are three or four that we use for manual spot-checks, but they often contradict one another in extreme ways.
If your submission is flagged as suspicious, it isn’t the end of the world. We still manually check each of those submissions to be certain it’s been properly classified. If you’re innocent, the worst that happens is that it takes us longer to get to your story. Here are the possible outcomes:
Yep, you deserved it. Banned.Hmm… not entirely sure. Reject as we would have normally, but future submissions are more likely to receive this level of scrutiny.Nope, innocent mistake. Reset suspicion indicator and process as a regular submission.If spam doesn’t get caught by the filter, the process changes to:
Make note of any potentially identifying features that can be worked into future detection measures.Banned.As I’ve said from the beginning, this is very much a volume problem. Since reopening, we’ve experienced an increasing number of double-workload days. Based on those trends and what we’ve learned from source-tracing submissions, it’s likely that we will experience triple or quadruple volume days within a year. That’s not sustainable, but each enhancement to the present model (or even applying temporary submission closures) buys us some more time to come up with something else and we’re not out of ideas yet.


