
Kevin Rutherford's Blog, page 3
June 29, 2022
Suitable for work
I’ve renamed this newsletter.
Until today the name of this newsletter was “Explicit Coupling”. Of course, I intended that to refer to my take on how to decide what “good” code looks like: all of this module’s coupling with the rest of the world is explicitly documented locally, here, in the source code of this module itself. All of the coupling is Explicit.
But there’s a NSFW interpretation of the phrase Explicit Coupling too. Some people found that offensive, and some found it sufficiently risqué...


June 23, 2022
Runtime and compile time
I’ve received a few questions about Implicit and Explicit Coupling via channels other than the comments here. So in this and the next couple of articles I’m going to have a go at answering them…
Recently on a Slack channel somewhere in Manchester, someone asked:
I've always known the terms loose and tight coupling, is there any difference to implicit/explicit?
I was in the car somewhere and didn’t see the message for a few hours, but in the meantime Ross had replied:
Implicit coupling tends to revea...
June 10, 2022
If this were a book...
Hello again. Sorry it’s taken me a while to write this edition of the newsletter — I’ve been busy getting to the MVP stage with my new website kevinrutherford.info, which will have an emphasis on mob programming training, my software development coaching work, and of course this newsletter.
Anyway, back to the newsletter. Thus far I’ve been writing articles to get them out of my system and off my ancient to-do list — or occasionally somewhat at random, as the topics occurred to me. So part of the...
May 27, 2022
Thinking about APIs, part 2
In Thinking about APIs I talked about the common problem of coupling between a client application and a server, via their shared knowledge of resource URLs:
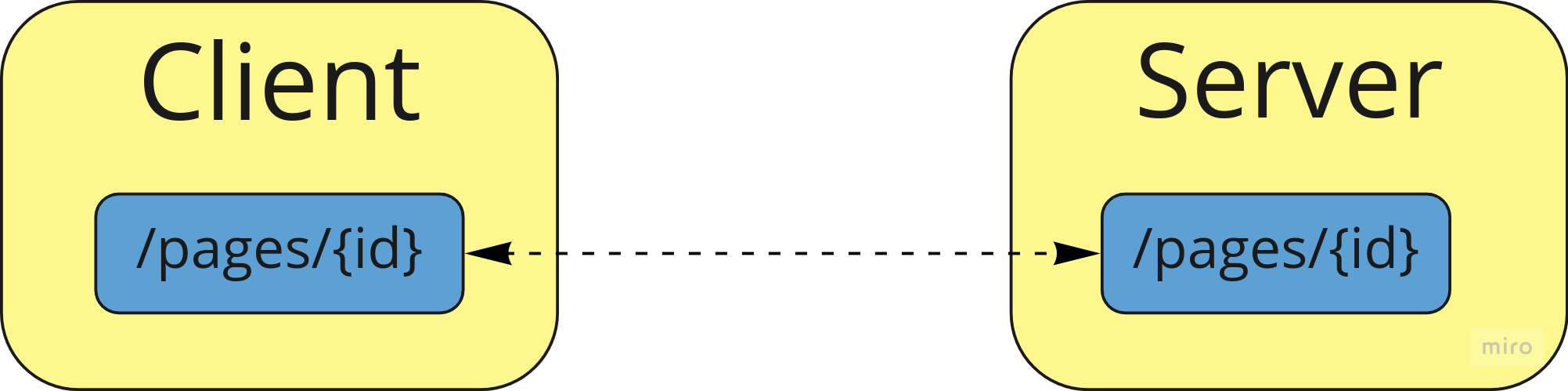
As I noted in that previous article, and as @Ivan pointed out in the comments, this is exactly analogous to a local function call, in that both the client and the server need to agree on the resource path (Connascence of Name) and the structure of the call and its response (Connascence of Type?).
But what makes this problem a real challenge — ...
June 27, 2015
An event-sourcing conundrum
I have a side project that I use as a sounding board to help me learn about “modern stuff”. The front end is built with React + Flux, and the back end persists information via event sourcing instead of a SQL or document database. I’m enjoying the experience of working with these tools, and so far everything has gone smoothly. But now I have a puzzle, which I will share here in the hope that one of you can point me in a good direction.
One of the components in my React app shows a list of recent activities: those performed by a specific user, or a group of users, or on a specific document. I would like a typical element in the list to look like this:

The words in blue will be hyperlinks to other views in the client app, and these will be built using the IDs of the document and the user. This means that the client needs the following information about each activity:
The type of activity (create, delete, update, etc)
The user’s name
The user’s ID
The document’s title
The document’s ID
Currently the client gets the list of relevant activities by hitting an endpoint on the server’s API. The API gets this data from a read model which in turn is built up in memory as the events occur. But those events don’t carry all of the information that the client will now need. Specifically, the server events only carry the user’s ID, not their name.
So I need to provide information to the client, but no part of the server currently has all of that information available to it. What should I do?
I thought of several alternatives, none of which seemed entirely satisfactory:
Have the client make extra API calls to get the information it needs. This would slow the client down, increase server traffic, and seems like an awful lot of work: extra API endpoints, with extra read models supporting them.
Allow the activities read model to get usernames from the users read model. However, other read models may not be up to date, so this approach seems inherently unreliable.
Augment the activities read model so that it keeps track of usernames and username changes. This would duplicate information kept in other read models, and seems like a lot of effort.
Add the username to the payload of all document change events. Does it really make sense to add information to events just because one particular read model might need it? And besides, the username isn’t available to the code that raises document change events: it would have to be fetched from a read model, which (as above) may not be up to date.
What would you do?
Of course, the act of writing this post has helped me clarify my thinking on this problem, and I have now decided which approach to take. So in a few days I’ll document that here, eventually also with a short report describing how it turned out. In the meantime, I’m really interested in how you event-sourcing experts would proceed. Have I missed a fifth option? Have I mis-analysed one of the options above? Should I just stop thinking and get on with coding?


May 20, 2015
Red, green … what now?!
This month James Jeffries and I ran a session at Agile Manchester in which we (ie. Jim) live-coded Dave Thomas‘s Back to the Checkout kata. The twist was that during TDD’s “refactor” step we used only connascence to decide what to change.
(I know I’ve done that before, on this blog. But this time Jim and I started with different tests. And we practiced a bit first. So the resulting refactoring steps are quite different than those I wrote about earlier.)
@ruby_gem kindly pointed her laptop at the screen and recorded the session. (The beauty of this setup is that you get to see what Jim types and hear how we explain it, but you don’t have to suffer from seeing either of us.)
The slides we used are on slideshare, and I’ve uploaded the resulting video to youtube for you to view at your leisure. Comments welcome, as always.


March 26, 2015
Where is the constraint in software development?
I just had a thought about the relationship between software development and the Theory of Constraints. It probably isn’t a new thought, although it seems to differ from some of the analyses I’ve seen elsewhere. Also, I probably won’t be able to express it in any coherent way; but here goes…
I’ve read articles suggesting that the constraint in software development is the writing of the code; indeed I’ve written some of them myself. If it were true, then our first concern should be to EXPLOIT the bottleneck, by making sure we only write code for things that matter. This includes not working on buggy starting code, but it also includes only spending our precious time on developing those features that the customer actually needs.
So how can we ensure that we only work on features that represent real value? One way would be to analyse the requirements deeply and thoroughly before we begin coding. But if that worked, there would never have been any need to seek an alternative to the waterfall approach. Up-front analysis doesn’t work (most of the time); I suggest that this implies that the writing of code cannot be the constraint.
XP says we should value feedback. One reason is that without it we would work on the wrong stuff. We write code partly in order to deliver value, and also partly in order to find out what the customer really wants. We run a small batch through the whole system in order to find out whether we guessed the requirements correctly, and to discover what to do next.
The constraint is our limited understanding of what is valuable. We EXPLOIT it by creating feedback loops based on small increments; smaller increments create more opportunities to understand where the value lies, which in turn limits wasted programming effort. Then we SUBORDINATE to it by not planning or designing too much in advance; that would build up WIP — not of plans or design per se, but of guesses.
I feel I ought to be able to express the above analysis using TOC thinking tools. Can anyone help out with that?


February 25, 2015
Connascence of Value: a different approach
Recently I wrote a series of posts in which I attempted to drive a TDD episode purely from the point of view of connascence. But as I now read over the articles again, it strikes me that I made some automatic choices. I explicitly called out my design choices in some places, while elsewhere I silently used experience to choose the next step. So here, I want to take another look at the very first step I took.
You will recall that in making the first test pass I introduced some CoV (Connascence of Value), because the test and the Checkout class both know the magic number 50:

I fixed that CoV by passing the magic value as a parameter, following the Dependency Inversion Principle. But there are plenty of alternatives. Instead of using the DIP, I could directly convert the CoV into CoN (Connascence of Name) by introducing a constant in the Checkout class:
public class CheckoutTests {
@Test
public void basicPrices() {
Checkout checkout = new Checkout();
checkout.scan("A");
assertEquals(Checkout.ITEM_PRICE, checkout.currentBalance());
}
}
public class Checkout {
public static final int ITEM_PRICE = 50;
public void scan(String sku) { }
public int currentBalance() {
return ITEM_PRICE;
}
}
(This isn’t something I would do in real life, but let’s just see where it leads, for curiosity’s sake.)
That was a really simple step, and it completely fixes the CoV: CoN is level 1 on the connascence scale, and is thus the weakest kind of coupling I could have. Note that I can no longer use random values in the test; I wonder where that fact will lead…
As before, I am now left with CoM (Connascence of Meaning), because both the test and the Checkout know that monetary values are represented using an int. I fix that in the same way as I did last time, by introducing a Money class:
public class Checkout {
public static final Money ITEM_PRICE = Money.fromPence(50);
//...
}
Next, I recycle the test to make it a little more complex, just as before:
@Test
public void basicPrices() {
Checkout checkout = new Checkout();
checkout.scan("A").scan("B");
assertEquals(Checkout.ITEM_PRICE.add(Money.fromPence(30)), checkout.currentBalance());
}
As before, I have to add a few useful things to Money to get this to compile; all good. But this time around, it seems I have more choices when it comes to getting the test to pass. That’s because I fixed the CoV with a constant, thus imposing less structure on the Checkout.
For the sake of similarity I will do the same as last time (even though I know it causes problems later). So I calculate the running balance inside scan():
public class Checkout {
static final Money ITEM_PRICE = Money.fromPence(50);
private Money balance;
public Checkout scan(String sku) {
if (sku == "A")
balance = ITEM_PRICE;
else
balance = balance.add(Money.fromPence(30));
return this;
}
public Money currentBalance() {
return balance;
}
}
Yikes! I now have CoV due to the 30, and also CoV due to the “A”. Which should I fix first? And does it matter? Let’s find out…
First, I will add another constant to hold the price of a “B”:
@Test
public void basicPrices() {
Checkout checkout = new Checkout();
checkout.scan("A").scan("B");
assertEquals(Checkout.PRICE_OF_A.add(Checkout.PRICE_OF_B), checkout.currentBalance());
}
That doesn’t change much, but those constant names are interesting. I feel they are tied to the SKU strings somehow, and that makes me uncomfortable. Then I see it: I have now introduced some new CoV, because the name PRICE_OF_A depends on the value of the string “A”. If either changes, the code will not break, but my head will. All of which means that the introduction of the constant for the price of B didn’t really fix the CoV; it just moved it around a bit!
I guess that means I have to fix the CoV of the SKU names in order to make any progress. Let’s just take a moment to look at the extent of this coupling:

The SKU name is known in three places, each of which is coupled to both of the other two. So in order to fix this CoV, I have to move that value into exactly one place.
As always, I have choices. What would you do?


February 12, 2015
Peculiar algorithms
Am I over-thinking things with this Checkout TDD example? Or is there a real problem here?
Based on insightful input from Pawel and Ross, it is clear to me (now) that there is CoA between the currentBalance() method and the special offer object(s), because the method doesn’t give those objects any opportunity to make final adjustments to the amount of discount they are prepared to offer.
However, as things stand there is no requirement demanding that. Does that still mean the connascence exists? Or is it a tree falling in the forest, with no tests around to hear it?
I could add peculiar discount rules, as Pawel suggests. Or I could add asymmetric discount rules such as those used in Kata Potter. Indeed, I could require that the Checkout provide an itemised receipt — in which case it would have to remember each scan event, thus making the refactoring to stateless discounts easier.
I knew at the time that exotic special offers would cause the code to change. That is to be expected. I had done the exercise to a reasonable point, and I chose to stop where I did because I had covered the ideas I thought were most useful. I could have gone further, but I felt that would mainly repeat ideas that I had already covered.
My real problem with all of this is the following: I have arrived at a destination that feels uncomfortable; I know which tests to write next, should I wish to steer the code to a better place; and I know that doing so will be a fairly hefty (ie. risky) rewrite of the code thus far. But I also know that the source of the discomfort stems from a decision I made very early in the kata. At that stage, I didn’t see the problems coming over the horizon. Because nothing I can see in the rules of connascence told me they were lurking there.
Only 2 effective lines of code, in two methods, are involved. And yet — or maybe, and therefore — the pending CoA was not visible (to me). I would like to understand whether there is something I should be looking for next time in order to avoid that, or whether occasional risky rewrites are an inevitable consequence of (this style of) TDD?


February 11, 2015
Connascence: a mis-step
I had a very interesting discussion today with Ross about my recent connascence/TDD posts. Neither of us was happy about either of the solutions to the corruption problem with the special offer object. Even with the cloning approach, it still seems that both the Checkout and the MultiBuyDiscount have to collude in avoiding the issue; if either gets it wrong, the tests will probably fail.
After a few minutes, we realised that the root of the problem arises from the MultiBuyDiscount having state, and we began to cast around for alternatives. At some point it dawned on me that the origins of the problem go right back to the first article and the first couple of refactorings I did.
Let’s revisit that early code. After I had fixed the CoV arising from making the first test pass, the Checkout looked like this:
public class Checkout {
private int balance = 0;
public void scan(String sku, int price) {
balance = price;
}
public int currentBalance() {
return balance;
}
}
Then in the second article, after I had recycled the test to add multiple scanned items, the Checkout had become:
public class Checkout {
private Money balance = Money.ZERO;
public Checkout scan(String sku, Money price) {
balance = balance.add(price);
return this;
}
public Money currentBalance() {
return balance;
}
}
I had blindly made the Checkout keep a running balance, without pausing to realise that there was an alternative: I could have made it remember the scanned items, and only total them up in the currentBalance() method. Had I done so, it would then have been natural to calculate the discounts there too. And that could have been done by a special offer object that had no state. Thus avoiding all that faffing about with factories!
The problem I have with that, though, is that the code I wrote for the first (recycled) test was simpler than the alternative. I had no test, and no connascence, pushing me to remember the scanned items and total them later. At least, right now I can’t see that test or that connascence.
I feel that either my blind approach has led me to a poor design that will cost a lot to correct, or that I failed to spot something that could have prevented this. Food for thought…


Kevin Rutherford's Blog

- Kevin Rutherford's profile
- 20 followers

