
Stephen Diehl's Blog
March 31, 2021
FPTs: Pure Fungibility on the Blockchain
You may have heard a lot about NFT speculative mania in the news and how people are shelling out millions of dollars of monopoly money for digitally signed URLs. And I too initially thought this was an absurd farce and that the emperor was running around with no clothes, up until I realised a way I could personally profit from it, and then it all made perfect sense. It���s time to lean into the crypto grift but with purity.
The key idea of this functional pearl is based on the simple notion that we shouldn���t be trading URLs to Nyan Cat GIFs for millions of dollars, but instead we should be trading pointers to functions for billions of dollars!
Now say you wanted to do some super complex logic, like printing to stdout. Normally we would perform the arcane dark category theory rites and summon the IO monad from the nameless void with the following incantation:
main :: IO ()main = print "Hello World"Now this works just fine, but it has a serious problem. It doesn���t involve blockchain. Let���s fix that:
import Control.Monad.FpthelloWorld :: FPT '[IO] ()helloWorld = bid $ 100000 (print "Hello World")There we go, now this this function involves a monadic wrapper which encodes what we call an FPT (Functional Programming Token) represented at the type level. It is a higher kinded type that wraps a type-level list of effects of the functions we wish to bid on for evaluation. In this case we���re bidding $100,000 for the exclusive rights to print ���Hello World��� to the screen. This is probably too low an ask, but it���s just an example.
Now instead of just evaluating the IO function directly, we want to evaluate it exclusively using the paradigm-shifting power of the blockchain to write to stdout. We do this by providing our bitcoin private key in the first argument to the runFpt function which evaluates the auction monad to bid on the evaluation of the function we wrote.
main :: IO (Either MoarMoney ())main = runFpt privKey $ embedToFinal @IO helloWorld where privKey = "$PRIVATEKEYHERE"This function will run for about 32 hours while your transaction propagates through the bitcoin mempool, then through a bunch of coal-guzzling server farms in Xinjiang. This ultimately burns through an acre of rainforest in the Amazon, but we can ignore that because it���s an unobservable side effect. If the market is good it will eventually evaluate and yield a response. The result is wrapped in a Either value where the right success value will contain the result of your function or a left failure value in the case where you���ve been outbid. If you���ve been outbid, you���ll simply have to bid higher to evaluate your code because that���s how code under capitalism works.
Many people claim that lazy evaluation is actually a misfeature. Au contraire, consider the real world application of computing the nth Fibonacci number. Since every call to fib will cost us upwards of tens of thousands of dollars (depending on rapidly fluctuating exchange rates) we want to minimize the evaluation of unnecessary calls to the market. With FPTs we���ve finally found the only killer application of laziness: not draining our bank account with useless computation.
fib :: FPT '[IO] ()fib 0 = pure 0fib 1 = pure 1fib n = liftM (+) (fib (n-1)) (fib (n-2))In the brave new frontier of cryptocurrency our business logic will probably involve some combination of money laundering, ransomware, securities fraud, puppy smashing and IO. It���s important to note that effects aren���t necessarily commutative, we don���t necessarily want to smash the puppies before we launder money, but we can do securities fraud and launder money commutatively. And we���ll probably end up adding a logging interface after-the-fact if our budget affords that level of luxury.
To facilitate with money laundering there is a set of wrappers provided by Control.Monad.WireFraud module which provides a high-level streaming interface for cleaning money tied to crime in a space-efficient way. Simply chain together a bunch of sources and sinks using the launder combinator, which will compose the dirty funds through a series of seemingly legit business and the output will be squeaky clean and run in constant memory.
import Control.Monad.WireFraudlaunder :: DodgySource m o -> LegitSink iUsing the effect system of FPT we can magically combine all of this business logic together locally into a single token and then put it up for auction.
cryptoBusinessLogic :: FPT '[IO, Puppy, LaunderMoney] ()cryptoBusinessLogic = bid $ 10000000 $ do profits runRansomware launderMoney profits drugCartels void $ smashPuppiesAs with NFTs this token can itself become a laundering instrument, so an FPT can become a higher-order money laundering token in which we launder money through money laundering, just like we do with higher order functions. This ���Internet Computer��� is vastly more advanced than just shuffling art for organized crime around in a freeport in Switzerland.
Perhaps it���s a valid criticism that functional programmers aren���t concerned with the side effects of their work, and fair enough ��� only time will tell on that. But at the very least we should be able to use the type system to abstractly model the harm we do to the world at a more granular level using advanced type system features. Because at the end of the day purity and fancy types are what really matters.
The FPT token presale starts next week. To the moon. ������������


December 4, 2020
Exotic Programming Ideas: Part 4 (Datalog)
Continuing on in our series on exotic programming ideas, we���re going to explore the topic of logic programming and a particular form known as datalog.
Week 1 - Module SystemsWeek 2 - Term RewritingWeek 3 - Effect SystemsWeek 4 - DatalogDatalog is a very simple formalism, it consists of only two things:
A database of factsA set of rules for deriving new facts from existing factsDatalog is executed by a query processor that given these two inputs, finds all instance of facts implied by both the databased and rules. For our examples we���re going to be coding our examples in the Souffle language. The namesake of the language is an acronym for the Systematic, Ontological, Undiscovered Fact Finding Logic Engine. It can be installed simply on many Linux systems with the command:
$ apt-get install souffleSouffle is a minimalist datalog system designed for complex queries over large data sets, such as those encountered in the context of doing static program analysis over large codebases. Souffle is implemented in C++ and can compile datalog programs into standalone executables via compilation to C. It is one of the simpler and most efficient implementations of these systems to date, and notably it has a simple type system on top of the logic engine.
Datalog encodes a decidable fragment of logic for which satisfaction is directly computable over a finite universe of terms. These terms consist of three classes of expressions. A fact represented syntactically by a expression suffixed by a period.
fact.A rule represented by a head and body term with a turnstile (\(\vdash\)) symbol between.
head :- body.And query terms which query the truth value of fact within the database.
?- body.An example of these terms would be ���classical��� categorical syllogism about the Greek philosopher Socrates. Socrates is a man, all men are mortal, therefore we can deduce that Socrates is mortal.
// All men are mortal / valar morghulismortal(X) :- human(X).// Socrates is a man.human("Socrates").// Is Socrates mortal??- mortal("Socrates").Execution of a Souffle program is in effect a set of transformations from input facts to deduced output facts by a prescription of rules.
[image error]
Souffle can read input facts from a variety of sources including stdin, CSV files, and SQLite databases. he default input source is a tab-separated file for a relation where each row in the file represents a fact in the relation. This is specified with a IO input declaration of the form.
.decl A (n: symbol).input AThis would read from a file A.facts of tab separated values for a symbolic value n. However we can modify our input by passing explicit IO parameters to it instead.
.input A(IO=file, filename="fact_database.csv", delimiter=",").input A(IO=stdin, delimiter=",").input A(IO=sqlite, dbname="fact_database.db")Simple ExampleA simple end to end example would be the program that associates a set of symbolic inputs with a set of numerical ones by a simple one-to-one mapping. We could write the simple A to B transformation as the following rules.
/* Input from A.facts */.decl A (n: symbol).input A/* Output to B.csv */.decl B (n: number)B(0) :- A("Hello").B(1) :- A("World")..output BThis reads from the input facts in A.facts and outputs B.csv which not surprisingly looks like the following when we invoke Souffle with the following command.
$ souffle hello.dlThe output matches A to B according to the rules in hello.dl.
ABHello0World1RelationsLogic inside of datalog is specified by relations, which are ordered tuples of typed variables that relate quantities. For example if we had a set of named entities (represented as symbols) we can assign a relation that maps a property to each of them as facts.
.decl Human(x : symbol).decl Klingon(x : symbol).decl Android(x : symbol)Human("Picard").Human("Riker").Klingon("Worf").Android("Data").Each variable is given a specific type indicated by var : type where type is one of the following builtins.
symbol - Symbolic quantities represented as strings.number - Signed integersunsigned - Unsigned integersfloat - Floating point valuesRelations can take multiple arguments that assign properties to a collection of symbols according to rules over that relation.
.decl Rank(x:symbol, y:symbol).decl Peers(x:symbol, y:symbol)Rank("Captain", "Picard").Rank("Officer", "Riker").Rank("Officer", "Worf").Rank("Officer", "Data").Rules over these relations are defined by clauses. The following can be read as a pair (x,y) is in A relation, if it is in B relation.
A(x,y) :- B(x,y).Clauses in Souffle are known in logic as Horn clauses. They are comprised of subterms joined together with a conjunction (\(\land\)) (logical AND in programming) that implies a statement \(u\). Can read the following statement in math as
if a and b and ��� and z all hold, then also u holds
\[u \leftarrow a \land b \land \ldots \land z\]
The above is known as the implicative form. Logically this is equivalent to the statement written in terms of disjunction (\(\lor\)) (logical OR in programming) and negation (\(\lnot\)) (logical NOT in programming).
\[\lnot a \lor \lnot b \lor \ldots \lor z\]
In Datalog notation we write this Horn clause in the following syntax.
u :- a, c, ..., z.In clauses, free variables that occur inside of the conjoined expressions are implicitly universally quantified, i.e.��they are required to hold forall (denoted \(\forall\)) substitutions of the variable in a domain. The domain in this case is the set of inhabitants of a given type (i.e.��symbol, unsigned, etc).
So the datalog expression above
A(x,y) :- B(x,y).Is equivalent to the Horn clause.
\[\forall x. \forall y. \lnot B(x,y) \lor A(x,y)\]
So for example we know that Klingons and Humans both eat food, but obviously androids do not. We write the following rules over a variable term X of type symbol.
.decl Eats(x:symbol)Eats(X) :- Human(X).Eats(X) :- Klingon(X)..output EatsWhich produces the following output from the given set of input facts about the symbols in scope given the constraint on their species.
EatsRikerPicardWorfTerms can also be negated, for instance if we wanted to enumerate all officers that eat could write the following rule which excludes androids.
InvitedToDinner(X) :- Rank("Officer", X), !Android(X).InvitedToDinnerRikerWorfA more complex rule can consist of multiple terms separated by command, all of which have to evaluate true. For example two officers are peers if they have same rank and are not the same person. We use an intermediate variable Z to test the equality of rank in this relation.
.decl Peers(x:symbol, y:symbol)Peers(X, Y) :- Rank(Z, X), Rank(Z, Y), X != Y.PeersRikerWorfRikerDataWorfRikerWorfDataDataRikerDataWorfRules can also be recursive. For example we we wanted to write a query which found all first degree friend relations of a given set of facts we could write the following recursive definition.
.decl Friend(x:symbol, y:symbol).decl FriendOfFriend(x:symbol, y:symbol)FriendOfFriend(X, Y) :- Friend(X, Z), FriendOfFriend(Z, Y).An important class of relations are that of equivalence relations. These are relations between two terms that satisfy an additional set of constraints: reflexivity, symmetry, and transitivity. Relations of this form behave similar to how the equality symbol is treated in algebra.
\[\begin{align*}a &= a \\a &= b \Rightarrow b = a \\a &= c, b = c \Rightarrow a = c\end{align*}\]
// every element of R1 is equivalent to every element of R2.decl equivalence(x:number, y:number)equivalence(a, b) :- R(a), R(b).// reflexivityequivalence(a, a) :- equivalence(a, _).// symmetryequivalence(a, b) :- equivalence(b, a). // transitivityequivalence(a, c) :- equivalence(a, b), equivalence(b, c).In the implementation of the relation, the data and intermediary deductions are stored in a common B-tree data structure. However this can be modified by passing an explicit argument to force the use of a disjoint-set or trie data structure for specific uses cases.
.decl A(x : number, y : number) eqrel // Disjoint-set.decl B(x : number, y : symbol) btree // B-tree.decl C(x : number, y : symbol) brie // Dense trieWhen working with integral types (number, unsigned and float) arithmetic expressions behave as expected and can be pattern matched on. For example we can write the Fibonacci function as a relation in terms of itself.
fib(0, 0).fib(1, 1).fib(n+1, x+y) :- fib(n, x), fib(n-1, y), n < 15.This generates the following output facts.
fib00112132435568713821934105511891214132331437715610Type SystemSouffle has a limited type system that can be used to track the types of variables quantified in clause expressions. For example one cannot have a variable which simultaneously holds a symbol and unsigned integer. We can however define custom type synonyms on top of the ground types of the languages that will let us semantically distinguish different user-defined types of symbols and numeric quantities. For example:
.type Person symbol.type Food symbol.decl Eats(x : Person, y : Food).decl Dinner(x : Person, y : Food)Dinner(x, y) :- Eats(x, y). // Well-typedDinner(x, y) :- Eats(y, x). // Not well-typed, Person != FoodUnions of type synonyms are also permitted so long as the underlying types of the synonyms are equivalent.
.type A number.type B number.type C = A | B // Either in A or BThe language also has the ability to define both sum and product types which let us both options and records as terms in our clauses.
.type Sum = A { x: number } | B { x: symbol }.type Prod = C { x: number, y : symbol }For example we could build a linked list (or cons list) out of a product type which has both a head element and a tail element.
// Linked list.type List = [ head : number, tail : List ].decl MyList(x : List)MyList( [1, [2, nil]] ).Logic programming is a very natural way of expressing abstract program semantics and with tools like Souffle we have excellent logic engine that can be embedded in other static analysis applications to collect facts about code and deduce implications about code composition and usage. This a powerful technique and future static analysis tools are going to yield whole new ways of reasoning about and synthesising code in the future.
External ReferencesSouffle Language ReferenceSWI-Prolog Online��Z in Z3Tool Talk: SouffleDomain Modeling with DatalogNovember 21, 2020
Exotic Programming Ideas: Part 3 (Effect Systems)
Continuing on in our series on exotic programming ideas, we���re going to explore the topic of effects. Weak forms of effect tagging are found in many mainstream programming languages, however the use of programming with whole effect systems that define syntax for defining and marking regions of effects in the surface syntax is still an open area in language design.
Week 1 - Module SystemsWeek 2 - Term RewritingWeek 3 - Effect SystemsWeek 4 - DatalogFirst, we should define what we mean by an effect. We���ll adopt the definitions commonly used in functional programming discipline, simply because it has a precise definition wheres colloquial usage often does not. First a pure function is a unit of code whose return value is entirely determined by its inputs, and has no observable effect other than simply returning a value. A pure function is a function in programming which behaves a like a function in mathematics. For example in Python code we denote a ���function��� called f:
def f(x): return x**2In the pseudocode traditionally known as mathematics we denote the function \(f\):
\[f(x) = x^2\]
There are a few subtle points to mention in this definition. The first is the matter of perspective in our analysis of effects. This Python function compiles into a sequence of bytecodes which manipulate stack variables, mallocs megabytes of data on the heap, invokes the garbage collector, and swaps hundreds of thousands of values in and out of registers on the CPU all corresponding to doing the exponentiation of an arbitrary size integer inside a PyObject struct. All this is very effectful from the perspective of the underlying implementation, however we can���t observe the functioning of these internals from within the normal language.
The big idea in pure functional programming is that programming will inevitably consist of both pure and effectful (sometimes called impure) logic. Additionally we suppose it is a useful property of the surface language to be able to distinguish between units of logic which have effects, and to be able to classify these type of effects in order to greater reason about program composition.
The alternative to this is the model found in most languages where all logic is mushed upto in a big soup of effects and relies on the programmer���s intuition and internal mental model to distinguish between which code can do perform effects (memory allocations, side channels, etc) and logic which cannot. The research into effect systems is fundamentally about canonising our intuition about correct program effect synthesis into a formal model that compilers can reason about on our behalf and interact with developer tools in an ergonomic way.
Functional Languages like Idris, Haskell, F* and a few other research languages have been exploring the design space for the better part of the last decade. Concepts such as monads saw initial exploration for demarcating pure and impure logic but have fallen off in recent years as that model has hit a wall in terms of usefulness. The most common area of active exploration is one known as algebraic effect handlers which admits a tractable inference algorithm for checking effectful logic while not introducing any runtime overhead.
There are no mainstream languages which use this model, however there is a academic language out of Microsoft Research lab called Koka which presents the most developed implementations of these ideas. As far as I can tell no one uses this language for anything, however it is downloadable and quite usable to explore these ideas. We will write all of our example code in Koka.
In Koka the absence of any effect is denoted by the effect total. The only result of computing the function f is simply returning the square of its input.
fun f( x : int ) : total int{ return pow(x,2)}However we can write a effectful function, such as one that reads from the screen, by tagging it with a console effect. The body of this function can then invoke functions such println and the result of the invocation of thees functions is captured in the signature of the function that invokes them. The return type () denotes the unit type which is called void in C-like languages.
fun main() : console (){ println("I can write to the screen!");}It is worth noting that the println function provided by the standard library has the following type signature which itself includes the effect.
fun println( s : string ) : console ()And as such the compiler is aware of the effect it carries and the following function can be written without an annotation and effect inference will deduce the appropriate signature without the user having to specify it. The return type can also be inferred using the usual type inference techniques.
fun main(){ println("I can write to the screen!");}ExceptionsBesides input/output, the most common type of effect found in most programming is the ability to fail. Usually langauge runtimes will implement this functionality using some exceptions which perform a non-local jump to logic which handles the exception or unwinds the call stack and aborts. This is clearly an effect that we can model and we can create an interface similar to checked exceptions found in other languages.
The throw function will take an error sum type and result in a effect marked by exn. While the try function will consume a function which results in exn type and return an error. The error type is either an Error or a Ok on successful execution.
type error { Error( exception : exception ) Ok( result : a )}The error handling functions can be written as higher order functions that consume and handle functions taged with the exn effect.
fun throw( err : error ) : exn afun try( action : () -> a ) : e errorfun maybe( t : error ) : maybeFor example we can do classic case of handling division of mero and wrapping up the arithmetic error in a maybe sum type which handles the zero case with a nothing.
fun divide(a : int, b : int) : exn int { match(b) { 0 -> throw("Division by zero"); _ -> return (a / b); }}fun safeDiv(a : int, b : int) : maybe<int>{ maybe( try { divide(a,b) } );}Elaboration of pattern matching inside the compiler can deduce incomplete patterns and infer that an exception should be added to the type of the pattern match that can fail at runtime.
fun unjust( m : maybe ) : exn a { match(m) { Just(x) -> x }}Whereas a complete pattern match is deduced as total.
fun unmaybe( m : maybe, default : a ) : total a { match(m) { Just(x) -> x Nothing -> default }}Non-termination is an EffectBy our above definition about effects, the only observable result of invoking a function is return a resulting value. Therefore functions which do not compute a value, and run infintely are not functions and have a side-effect called divergence. Deducing whether a given function is total is non-trivial in the general case, however a function which is the composition of units of logic which are all independently total must itself be total.
There are many simple cases where we can immedietely deduce non-totality from simply analysising call-sites. For example the following function is automatically tagged with the div effect since it recurses on itself.
fun forever(f) { f(); forever(f);}The forever combinator has the inferred type:
forever: forall (() -> a) -> bThe effect checker can deduce totality across mutually recusive definitions, so functions that invoke each other must themselves either be entirely total or possibly diverge on composition.
fun f1() : div int{ return 1 + f2();}fun f2() : div int{ return 2 + f1();}Rows of effectsWhile tagging individual effects independently is useful in its own right, programing in the large requires us to compose logic together and thus we need a way to synthesize the combination of effects. In Koka this is represented as a row of effects. This is denoted with the bracket syntax:
In the language of mathematics, effect rows are commutative monoids with an operation extension denoted by the pipe and a neutral element (total or <>) representing the absence of effects. The commutative and associativity of the extension operation allows for a canonical ordering of effects in signatures.
| e2 = | e3 = | <> = | e1 = =For example we can write down a function which invokes a random number generator with the non-determinism effect ndet as well as raising an exception with the effect exn. The synthesis of the two is now the row .
fun multiEffect() : (){ val n = srandom-int() throw("I raise an exception");}The effect system denotes functions which may diverge or throw exceptions as pure with the following alias.
alias pure =In the Haskell approach to effects there is a single opaque IO monad which inhabits any action which can perform any type of console input, output or system operation. However languages which richer effect systems can model the IO hierarchy in much more granularity. For example Koka defines the following three tiers of IO effects in increasing expressivity.
// Functions that perform arbitrary IO operations// but are terminating without raising exceptionsalias io-total = >// Functions that perform arbitrary IO operations// but raise no exceptionsalias io-noexn = // Functions that perform arbitrary IO operations.alias io = Reference Lifetimes & BoundariesState is an essential part of programing, and it is one which is inherently effectful. Importantly we���d like to be talk about which regions of memory or logic we are able to write to within a given scope. For this we need to be able to refer to effects over a given region of memory as a paramter to the effect. The language allows us to parameterise effects with a heap parameter using bracket notation. There are three core stateful effects provided by the standard library:
alloc - The alloc effect for allocating references over heap parameter h.read - The read effect from a reference from a heap parameter h.write - The write effect for writing to a reference on heap parameter h.To create and manipulate references there are three core functions:
fun ref( value : a ) : (alloc) reffun set( ref : ref, assigned : a ) : (write) ()fun (!)( ref : ref ) : |e> aFunctions which no observable leakage of internal references can be marked as total if the types of references are not referenced in either the argument types or the return type. Thus local state can be embedded inside pure functions. For instance the following function is total even though internally it uses mutable references:
fun localState() : total int{ val z = ref(0); set(z, 10); set(z, 20); return (!z);}The compiler itself also has a level of syntactic sugar for working with references. The val introduces an immutable named variable, however the var syntax can be used to define a mutable reference concisely.
val z = ref(0) var z : int = 0 // Identical to aboveVariables can be updated using := operator.
set(z, 10) z := 10 // Identical to aboveThus we can write pseudo-imperative logic like the following counter function:
fun bottlesOfBeer() { var i := 0; while { i >= 99 } { println(i) i := i + 1 }}References can be passed as arguments to functions and heap parameters can be quantified as type variables, allowing us to write generic functions which operate over references of any type.
fun add-refs( a : refint>, b : refint> ) : st int { a := 10 b := 20 (!a + !b)}The combination of the ability to read, write, and allocate is given the name st in the standard library to denote stateful computations.
alias st = ,write,alloc>Using this kind of effect system for tracking references gives us a powerful abstraction for denoting regions of logic that have read barriers and write barriers and separating mutation from pure logic in a way that is machine checkable. Future languages that had this kind of information at compile-time could use it to inform compilation of regions of local mutation into more efficient efficient code with still maintaining guarantees about the boundaries of pure logic.
Effect polymorphismFinally we���d also like to be able to write higher order functions which can take arguments which are either effectful or pure and incorporate their effects as part of the types of output. The common map function is a higher-order function which takes a list and applies a given function argument over each element of the list. To write this in a language with an effect system we need to be able to refer to the effect of the function argument as a type variable (e in this example) and use it the output type for map.
fun map( xs : list, f : (a) -> e b ) : e listIn the case where we apply a total arithmetic function over the list, we simply get back a list of ints. While in the IO case we can apply a function like println which will individually print each integer out to the console, and resulting type is a list of units. Both use cases are subsumed by the same function using this parametric polymorphism over the abstract effect type variables.
val e1 = map([1,2,3,4], println); // console listval e2 = map([1,2,3,4], dbl); // listfun dbl(x : int) : total int{ return (x+x)}It is still early days for effect system research. The key takeaway that I would like to push for future work is the observation that languages which aim to improve the ergonomics and performance of effect modeling cannot simply push the entire system into a library. There needs to be language-level support for both integrated effect types and annotations in the surface language for labeling subexpressions and giving hints to type inference. A lot of approaches to do this in Haskell, Scala, etc are inevitably doomed to poor ergonomics by this simple fact.
There is a whole new level of static analysis tools that can be built by not just inferring types, but providing a whole new level of static information on top of our code that is otherwise tossed out by the compiler. This is a very exciting technique and I hope it bears more fruit in the coming decade.
External ReferencesF* ReferenceEff Programming LangaugeKoka Language SpecificationAlgebraic Effects for Functional Programming - Daan LeijenNovember 14, 2020
Exotic Programming Ideas: Part 2 (Term Rewriting)
Continuing on from our series last week, this time we���re going to discuss the topic of term rewriting. Term rewriting is a very general model of computation that consists of programmatic systems for describing transformations (called rules) which transform expressions called terms into other sets of terms.
Week 1 - Module SystemsWeek 2 - Term RewritingWeek 3 - Effect SystemsWeek 4 - DatalogThe most widely used rewriting engines often sit at the heart of programs and languages used for logic programming, proof assistants and computer algebra systems. One of the most popular of these is Mathematica and the Wolfram language. This is a proprietary programming language that is offered by the company Wolfram Research as part of a framework for scientific computing. At the core of this system is a rewrite system that can manipulate composite symbolic expressions that represent mathematical expressisons. Other languages such as Maude, Pure, Aldor, and some Lisp variants implement similar systems but for the purpose of our examples we will use code written in Mathematica to demonstrate the more general concept.
Mathematica is normally run in a notebook environment, where the In and Out expressions are vectors indexed by a monotonically increasing index for each line entered at the REPL.
Wolfram Language 12.0.1 Engine for Linux x86 (64-bit)Copyright 1988-2019 Wolfram Research, Inc.In[1]:= 1+2Out[1]= 3In[2]:= 1+2+xOut[2]= 3 + xIn[3]:= List[x,y,z]Out[3]= {x, y, z}The language itself is spiritually a Lisp that operates on expressions, which can include symbolic terms (such as the x term above). These expressions are not variables but irreducible atoms that stand for variables in expressions. Composite expressions are similar to Lisp���s S-expressions and consist of a head term and a set of nested subexpressions which are arguments to the expressions.
F[x,y]In this case F is the head and x and y are arguments. This form of notation is known as an M-expression. The key notation is that all language constructs are themelves symbolic expressions and can be introspected and transformed by rules. For example the Head function extracts the head symbol from a given expression.
In[4]:= Head[f[a,b,c]]Out[4]= fIn[5]:= Symbol["x"]Out[5]= xIn[6]:= Head[x]Out[6]= SymbolThe arguments for a given M-expression can be extracted using the Level function which extracts the arguments of the given depth as a vector (denoted by braces). In this case the first level is the arguments a, b and c.
In[7]:= Level[f[a,b,c],1]Out[7]= {a, b, c}Expressions can be written in multiple forms which reduce down to this base M-expression form. For example the addition operation is simply syntactic sugar for an expression with a Plus head. We can reduce this expression to its internal canonical form using the FullForm function. Multiplication is also denoted in infix by separating individual terms by spaces similar to convention used common algebra.
In[8]:= FullForm[x+y]Out[8]//FullForm= Plus[x, y]In[9]:= FullForm[x y]Out[9]//FullForm= Times[x, y]In addition to infix syntactic sugar the two operators @ and // can be used to apply functions to arguments in either prefix or postfix form respectively.
In[10]:= Sin[x] (* Full form *)Out[10]= Sin[x]In[11]:= Sin @ x (* Prefix sugar *)Out[11]= Sin[x]In[12]:= x // Sin (* Postfix sugar *)Out[12]= Sin[x]Complex mathematical expressions are simply nested combinations of terms. For example a simple monomial expression \(x^3 + (1+x)^2\) would be given by:
In[13]:= FullForm[x^3 + (1 + x)^2]Out[13]//FullForm= Plus[Power[x, 3], Power[Plus[1, x], 2]]In[14]:= TeXForm[x^3 + (1 + x)^2]Out[14]//TeXForm= x^3+(x+1)^2This expression itself is a graph structure, and it���s implementation consists of a set of nodes with pointers to its subexpressions. The index notation using brackets can be used to directly manipulate a given subexpression which are enumerated left to right, starting at the head term.
In[15]:= f[a,b,c][[0]]Out[15]= fIn[16]:= f[a,b,c][[1]]Out[16]= aIn[17]:= f[a,b,c][[2]]Out[17]= bIndividual arguments to expressions can be reordered and substituted into other expressions be referencing their slots by index.
In[18]:= F[#3, #1, #2] & [x, y, z]Out[18]= F[z, x, y]Complex mathematical expressions can be expressed in terms of graphs of expressions and can be rendered in a graphical tree form. Effectively all rules and functions in this system are transformations of directed graphs to other directed graph structures. For example a simple trigonometric series can be expressed symbolically as:
In[19]:= Series[Cos[x]/x, {x, 0, 10}]This has the internal representation as this graph structure of M-expressions.

This symbolic expression can be expanded into individual terms by evaluating the Series term into individual terms.
\[\sum_{x=0}^{10} \frac{\cos{x}}{x}=\frac{1}{x}-\frac{x}{2}+\frac{x^3}{24}-\frac{x^5}{720}+\frac{x^7}{40320}-\frac{x^9}{3628800}+O\left(x^{11}\right)\]
Evaluation OrderEvaluation in the language proceeds by reduction of terms until there are no more rules that apply to the reduced expression. Such an expression is said to be in normal form. This mode of evaluation differs from sequential, statement-based languages where sequential updates to memory and the sequencing of effectful statements is the mode of execution.
For example the Range function produces a series of values as a list. This list can itself be passed to another function which applies a function over each element, such as the querying the primality of a given integer.
In[20]:= Range[1,10]Out[20]= {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}In[21]:= Map[PrimeQ, Range[1,10]]Out[21]= {False, True, True, False, True, False, True, False, False, False}This sequence of booleans is the final form, no subsequent rules in scope can be applied and the final expression is returned.
RulesThe primary mechanism of introducing new user-defined logic to the environment is the introduction of rewrite rules. These are defined by either a Rule definition or it���s infix sugar ->. The left-hand side is given in pattern syntax and may bind variable definitions over the right-hand side.
For example the rule that writes all occurrences of the integer 1 to 2.
In[22]:= Rule[1,2]Out[22]= 1 -> 2Or the rule that transforms each explicit occurance of the symbol x into the symbol y.
In[23]:= Rule[x,y]Out[23]= x -> yPattern variables can also be introduced which match on subexpression and name them in the scope of the rule. The resulting match on this ���hole��� is bbound as a variable name over the right-hand side of the rule. For example the rule that matches any quantity x_ and binds this to the definition x.
In[24]:= Rule[x_,x]Out[24]= x_ -> xMore usefully these pattern variables can occur within expressions. So for instance if we wanted to rewrite any argument given to the sine function as a cosine function, we could write the following rule:
In[25]:= Sin[x_] -> Cos[x]Out[25]= Sin[x_] -> Cos[x]Rules can be applied to a given expression using either ReplaceAll function and it���s infix form /. applies a given rule to the expression on the left.
In[26]:= ReplaceAll[x, Rule[x,y]]Out[26]= yIn[27]:= x /. Rule[x,y]Out[27]= yIn our trigonometric example from above, we can rewrite nested trigonometric functions from within their expression body.
In[28]:= Sin[a+b] /. Sin[x_] -> Cos[x]Out[28]= Cos[a + b]Rules can be combined by passing a list of rules as an argument to ReplaceAll. For example the following does a single pass over the given list and rewrites all x to y and all y to z.
In[29]:= {x,y,z} /. {x->y, y->z}Out[29]= {y, z, z}Since the rules are applied in order, to the given intermediate expression of the last rule, this does not transform the entire list into the same element. However the function ReplaceRepeated will apply a given set of rules repeatedly until a fix point is reached and the term is identical the last set reduction.
In[30]:= ReplaceRepeated[x, Rule[x,y]]Out[30]= yIn[31]:= ReplaceRepeated[x, {Rule[x,y], Rule[y,z]}]Out[31]= zIn[32]:= {x,y,z} /. {x->y, y->z} (* Non-repeated *)Out[32]= {y, z, z}In[33]:= {x,y,z} //. {x->y, y->z} (* Repeated *)Out[33]= {z, z, z}It is quite possible to define a set of rules for which this process simply repeats ad infinitum and does not converge. This has no normal form either blows up in time (or space) or until the runtime decides to give up.
In[34]:= {1,2} //. {1 -> 2, 2 -> 1}ReplaceRepeated::rrlim: Exiting after {1, 2} scanned 65536 times.Algebraic TransformationsMany sets of rules admit multiple rewriting paths that do not necessarily result in the same final term. A system of rules in which the ordering of the rewrites are chosen does not make a difference to the eventual result is called confluent. The prescription on evaluation order used inside the rewrite rules inside of the runtime. This is arbitrary choice, however Mathematica evaluates the head of an expression and then evaluates each element of the expression. These elements are in themselves expressions and the same evaluation procedure is recursively applied.
Within the standard library there are many sets of these transformations for working with algebraic simplifications and term reordering. The function FullSimplify is the most general and will collect and simplify real-valued algebraic expressions according to a enormous corpus of idenities and relations it has defined internally.
In[35]:= FullSimplify[x^2 x + y x + z + x y]Out[35]= Plus[Power[x, 3], Times[2, x, y], z]However we can introduce and extend these rule sets ourselves. For example if we wanted to encode a new simple set of rules for simplifying trigonometric functions according to given identity we could write a rule for the following math identity.
\[\sin(\alpha + \beta )=\sin \alpha \cos \beta + \cos \alpha \sin \beta \\\cos(\alpha + \beta )=\cos \alpha \cos \beta - \sin \alpha \sin \beta\]
This would be encoded as the following two pattern and rewrites:
In[36]:= ElemTrigExpand = { Sin[a_ + b_] -> Sin[a] Cos[b] + Cos[a] Sin[b], Cos[a_ + b_] -> Cos[a] Cos[b] - Sin[a] Sin[b] }This could then we applied to trigonometric functions of linear arguments repeatedly to reduce the nested terms to a single variable.
In[37]:= Sin[a+b+c] //. ElemTrigExpandOut[37]= Cos[a] (Cos[c] Sin[b] + Cos[b] Sin[c]) Sin[a] (Cos[b] Cos[c] + Sin[b] Sin[c])Attributes & PropertiesTerms that occur within rules can also have additional structure which rules can dispatch on. Symbols can have defined Attributes which can inform reductions and reorderings of symbols into canonical forms according. Often those common algebraic properties like associativity, commutativity, identities and annihilation.
In[38]:= Attributes[f] = {Flat, OneIdentity}Out[38]= {Flat, OneIdentity}In[39]:= f[1, f[2, f[3, 4]]] (* Associative *)Out[39]= f[1, 2, 3, 4]In[40]:= f[f[1]] (* Idempotent *)Out[40]= f[1]In addition to structural properties of functions, symbols can be enriched with assumptions about their origin and the domain or set from which they are defined. For exmaple whether a given number is nonzero, integral, prime, or a member of a given set. These properties are themselves symbolic expressions, so for example if we to encode the assumption that a given variable z is in the complex plane:
\[z \in \mathbb{C}\]
We could write the following expression, where Complexes is a given builtin standing for \(\mathbb{C}\).
Out[41]= Element[p, Complexes]These can be added to either the global assumption set which is defined by the variable `\(Assumptions\).
In[42]:= $Assumptions = {a > 0, b > 1}Out[42]= a > 0Rewrite such algebraic simplifications will dispatch on the assumptions of terms encountered in redexes and take different reduction paths based on chains of deductions about the properties of symbols. For example the identity that the square root of a square reduces to identity dependencies on the sign of the given symbol. Using the Refine function we can incorporate the global assumptions to tell the simplifier which branch to choose.
In[43]:= Refine[Sqrt[a^2 b^2]]Out[43]= a bThe truth value of a predicate over a symbol can be queried using this function as well. This either results in a True, False or indeterminate answer when the symbol has no local assumptions over it.
In[44]:= Refine[Positive[b]]Out[44]= TrueIn[45]:= Refine[Positive[x]]Out[45]= Positive[x] (* Has no truth value *)Many functions also take a named Assumptions parameter which can be used to introduce local assumptions over the arguments given a to a function.
In[46]:= Refine[Sqrt[x^2], Assumptions -> {x < 0}]Out[46]= -xThe assumption is capable of doing limited first order resolution in order to deduce properties of symbols within certain domains. For example the assumption x > 1 will imply the fact that x is non-zero and not negative. Or the assumption than an integer is y > 2 and prime implies that y is not even.
Patterns on the left hand side of rules can also dispatch both on the type of an expression and on assumptions and attributes of pattern variables. For example the LHS x_Symbol matches any symbolic quantity (but not numbers) can rewrites it to a given constant. Note that this matches on the head of the List itself and rewrite the head to a constant.
In[47]:= {1, x, Pi} /. x_Symbol -> 0 (* Matches List, x, Pi *)Out[47]= 0[1, 0, 0]Predicate functions can be wrapped around pattern variables by passing a _?s suffix followed by the function. For example to check whether a given term is a numerical quantity we can use the NumericQ function. This will match on the Pi and 1 terms but not the List or 1 terms.
In[48]:= {1, x, Pi} /. x_?NumericQ -> 0 (* Matches 1, Pi *)Out[48]= {0, x, 0}Special FunctionsWithin the standard library there is a vast corpus of mathematical knowledge encoded in a library of assumptions and rules over symbolic quantities. For example the Riemann zeta function has hundreds of known idenities and representations in terms of other functions. For even integer quantities is a simple closed form expressed in terms of \(\pi\) and Bernoulli numbers.
\[\zeta(2) = \frac{\pi^2}{6}\]
Mathematica is aware of these identities and will chose to transform the Zeta function to this reduced form automatically. For non-even values there is no simple closed form (in general) but there is a series approximation that can be computed to an arbitrary number of digits using the N function.
In[49]:= Zeta[2]Out[49]= Times[Rational[1, 6], Power[Pi, 2]]In[50]:= Zeta[3]Out[50]= Zeta[3]In[51]:= N[Zeta[3], 30]Out[51]= 1.20205690315959428539973816151CalculusThe famous XKCD cartoon illustrates the asymmetry of certain calculus problems. This cartoon finds direct representation when trying to encode simplifications over derivatives and integrals within these rewrite systems.

Indeed, differentiation is almost trivial to encode using the techniques from above. The linearity of the differential operator, product rule, power rule and constant rule can be written in four lines of rules. The standard library has a larger corpus of these definitions but they are usually about this succinct.
{ Diff[f_ g_, x_] -> f Diff[g, x] + g Diff[f, x], Diff[f_ + g_, x_] -> Diff[f, x] + Diff[g, x], Diff[Pow[x_,n_Integer], x_] -> n * Pow[x,n-1], Diff[x_, x_] -> 1 Diff[n_?NumericQ, x_] -> 0}However many computer algebra systems are capable of doing calculations of indefinite integrals through almost magical means. For example:
In[52]:= Integrate[Log[1/x], x]Out[52]= Plus[x, Times[x, Log[Power[x, -1]]]]While Mathematica���s symbolic integration capacities may seem like magic, they are indeed just the canonical example of rewriting machinery combined a corpus of transformations and some analysis from the 1930s. While there are certain integrals that are computable directly by pattern matching, there is a non-trivial result in the study of the Meijer G-function which admits a transformation of many types of transcendental functions into a convenient closed form to compute integrals.
The Meijer G-function is an indexed function of 4 vector parameters expressed the following complex integral where \(L\) runs from \(-i{\infty}\) to \(i \infty\).
\[G_{p,q}^{m,n}\left(z\left| \begin{array}{c} a_1,\ldots ,a_n,a_{n+1},\ldots ,a_p \\ b_1,\ldots ,b_m,b_{m+1},\ldots ,b_q \\ \end{array} \right.\right)={\frac {1}{2\pi i}}\int _{L}{\frac {\prod _{j=1}^{m}\Gamma (b_{j}-s)\prod _{j=1}^{n}\Gamma (1-a_{j}+s)}{\prod _{j=m+1}^{q}\Gamma (1-b_{j}+s)\prod _{j=n+1}^{p}\Gamma (a_{j}-s)}}\,z^{s}\,ds\]
This is well-studied function, and supririsngly a great many classes of special functions (trigonometric functions, Bessel functions, hypergeoemtric, etc) can be expresed in terms in terms of the G functions and thus we can reduce complex nestings of these functions down in terms of simply manipulating G-functino terms. Apply integration theorems over this reduced expression produces one or more other G-function terms. We can then expand that result back into the special functions to get the integration result. This practice does not work universally, but practically in enough cases to be incredibly useful.
One of the very general indefinte integration theorems rexpressses the integrand in terms of permutations of the G-function indexes. On the left hand side we have an integral expression and on the right hande side we have the computed integral both in terms of G-functions.
\[\int G_{p,q}^{m,n}\left(z\left| \begin{array}{c} a_1,\ldots ,a_n,a_{n+1},\ldots ,a_p \\ b_1,\ldots ,b_m,b_{m+1},\ldots ,b_q \\ \end{array} \right.\right) \, dz=G_{p+1,q+1}^{m,n}\left(z\left| \begin{array}{c} 1,a_1+1,\ldots ,a_n+1,a_{n+1}+1,\ldots ,a_p+1 \\ b_1+1,\ldots ,b_m+1,0,b_{m+1}+1,\ldots ,b_q+1 \\ \end{array} \right.\right)\]
A entire book of integrals can be reduced down to a simple set of multiplication and transform rules of G-functions in a few lines of term rewrite logic.
At the core of Mathematica���s integration engine is transformations involving this approach along with a variety of other heuristics that work quite well. For example the MeijerGReduce function can be used to transform many clases of special functions into the G-function equiveleants and then FullSimplify and other identities can reduce these expressions further.
In[53]:= MeijerGReduce[Sqrt[x] Sqrt[1+x],x]\[\sqrt{x} \sqrt{1+x} \quad \Rightarrow \quad\frac{- \sqrt{x} \quad { G_{0,0}^{1,1}\left(x\left| \begin{array}{c} \frac{3}{2}, 0 \\ - \\ \end{array} \right.\right) }}{2 \sqrt{\pi }}\]
The confluence of all of these features gives rise to a programming environment that is tailored for working with and abstract expressions in a way that differs drastically from the semantics of most mainstream languages.
It is true that this system can be used to program arbitrary logic, it can however become a bit clunky when trying to code imperative logic that works with inplace references and mutable data structures. Nevertheless it is a very powerful domain tool for working in scientific computing and the number of functions related to technical domains that are surfaced in the language represents decades of meticulous expert domain expertise.
Many universities have site licenses for this software so it is worth playing around with the ideas found in this system if you are keen on programming langauges with heterodox evaluation models and semantics.
External ReferencesTerm Rewriting and All ThatThe Essense of Strategic RewritingMaudePureWolfram EngineMathematica ExpressionsNovember 3, 2020
Exotic Programming Ideas: Part 1 (Module Systems)
All successful programming languages are alike; every unsuccessful programming language is unsuccessful in its own way.
The history of software is one that runs parallel to a simultaneous but separate conversation, and that is the story of how we think about computation and how we communicate those ideas with other humans. And the story of computation has been about the evolution of this very novel and peculiar form of human expression we call code. I suspect being a programmer in the 21st century must be like what being a royal scribe was like in Ancient Egypt in 3200 BCE. There���s this new modality of communication that most of the population is unaware of, yet it���s existence simultaneously enables commerce, culture and civilization to flourish.
And just like with natural languages we���ve seen a convergence of semantics and syntax into what is becoming like Latin was for European languages. These languages fall into the paradigm of C-inspired imperative paradigm with some object oriented features. This describes languages like C++, Go, Python, Ruby, Rust, Java, and Javascript that together make up the bulk of all new code that is written today. While most of programming activity has converged onto this local maxima of productivity, there are ideas at the fringes of our programming that contain more esoteric ideas with wildly different semantics and grammar than those found in the mainstream.
Throughout my life as professional programmer, I���ve realized there are two different groups of programmers. Those that see programming languages primarily as an instrument of human reason and those that see as a means of production for specific tasks. Just like there are few limited speakers of Pirah��, Navajo, Klingon or Berik; there are programming languages with similarly limited adoption. Nonetheless these languages encode some very interesting semantic structures that are often lost in translation when we try to encode in them in the mainstream.
For my Advent Blogging (because I���m bored and in lockdown), going to write about seven language semantics features at the fringes of software culture. The ones with the wacky wild ideas that will take you on a trip through what might had been if the Romans (i.e C) hadn���t conquered.
Week 1 - Module SystemsWeek 2 - Term RewritingWeek 3 - Effect SystemsWeek 4 - DatalogModule SystemsLet���s start with module systems and modular programming. The big idea of modules is to break code up into reusable components called modules. Modules as a language feature were first developed in Modula-2 and Pascal, which were developed as a way to demarcate units of compilation. The notion found maturity in the Standard ML language in 1984 which developed the notion further and allowed abstraction and parameterisation of modules. notion. These days full module systems are found in languages within the ML family such as F#, OCaml, Standard ML although a few others such as Agda have them as well. We���ll look at OCaml which is a statically typed ML dialect with type inference.
module MyModule = struct (* Set of Definitions *)endThe information contained in a module can be both values and types. For example the type t and the function of a single argument square.
module MyModule = struct type t = int let square x = x * xendThe components of a module can be bound to a description known as signature which constrains both the visibility of symbols within the module and enforces a consistent interface across the module.
module MyModule : sig val square : int -> intend = struct let square x = x * xendAlternatively module signatures can be bound to specific name at the typelevel and defined independently across multiple modules using the module type syntax. This separates from the specification from the implementation. Here we define an abstract type t that can be referenced inside the signature abstractly to refer to its eventual instantiation with a concrete type. The term s is defined to be a ���value of type t��� in the specification.
(* Specification of MySig *)module type MySig = sig (* Set of Type Signatures *) type t val s : t end(* Implementation of MySig *)module MyModule : MySig = struct (* Set of Definitions *) type t = int let s = 0 endModules can be opened using the open syntax. This will scope all exposed symbols within the module inside the given scope or globally if used at the toplevel.
open MyModule;; (* Toplevel *)let open MyModule in expr;; (* In let binding *)Modules can also be projected into using dot syntax to retrieve specific symbol within a module���s scope. For example:`
module Foo = struct let a = 5 let b = 6end;;print_int(Foo.a);;print_int(Foo.(a*b));;The signature of a module need not neccessarily constrain all symbols defined in the module. A signature may seal the implementation of specific parameters or types that implementation details internal the module and not exposed publically. For example in the following module the Hello signature hides the message used by the hello function and does not allow the downstream user to modify the internals of the message itself, only to the call the function.
module type Hello = sig val hello : unit -> unitendmodule Impl : Hello = struct (* Private variable message *) let message = "Messaage is sealed Inside Impl" let hello () = print_endline messageend;;Impl.hello();;Modules themselves can also be nested within other modules, to an arbitrary depth. Projection into the Outer module can retrieve the Inner module and its contents in this example:
module Outer = struct let a = 1 module Inner = struct let b = 2 endendlet c = Outer.Inner.b;;In addition to nested, modules can include the contents of other modules either by temporarily scoping their values in scope within the module���s definition or by using the include syntax which copy���s the contents of given module���s scope into the new definition.
module A = struct let a = 10endmodule B = struct let b = 20endmodule Arith1 = struct include A include B let c = a+bendmodule Arith2 = struct open A open B let c = a+bend;;Arith1.a;;Arith2.a;; (* Not in scope *)A module itself can be parameterised by types, including other modules. These are known as functors and allow us to instantiate modules by specifying the interface that given module parameters must conform. In this example the parameter M is an abstract module that conforms to the signature S. There is an implementation of this signature by the given module A which can be passed as the parameter M in the instantiation of FA. Within the definition of F we project into M to retrieve the s and t parameters abstractly. Functors are effectively functions from modules to modules.
module type S = sig type t val s : t endmodule A : S = struct type t = int let s = 0end(* Functor *)module F (M : S) = struct type a = M.t let b = M.send(* F applied to module A *)module FA = F(A);;Normally two invocations of the same functor will produce modules containing equal abstract types. However we can define a different class of functor known as a generative functor which is denoted by an extra parameter () which will produce an output module containing non-equal abstract types. In this example the output types of F and G are distinct. This is particularly important when dealing with references which require mutation and uniqueness.
module G (M : S) () = struct type a = M.t let b = M.sendmodule GA = G(A)();;This is the essence of module systems. While many languages have simple ways of namespacing and encapsulating units of code, the ML family enriches this by making the modules themselves both first order objects and parametrisable. This is a very powerful technique that is rarely seen elsewhere and the notion of programming with functors is one that gives rise to a rich set of abstractions for code reuse. Module systems are essential part of functional programming and future languages should learn from and explore new branches in this rich design space.
External ReferencesCornell CS3110Practical Foundations for Programming: Chapter 42July 29, 2020
The Haskell Elephant in the Room
Many blog posts about Haskell often discuss the latest advances in our compiler, research in type systems and clever new ideas that make the Haskell language such a fun and inspiring tool. However, if you peel back the curtain on a lot of what we do as functional programmers you see the economic machinery that shapes everything we do and informs the problems we chose to spend our cycles on. While the last few years have seen enormous progress and excitement, there is an enormous elephant in the room that we���ve collectively chosen not to discuss.
For a while it has been a public secret the Haskell ecosystem has become increasingly entangled with an unsavoury ICO schemes in the cryptocurrency sector as one of primary mechanisms for funding development. This has been a double edged sword in that it has created jobs and allowed a lot of questionable ICO money and funds of dubious origin into the language ecosystem without a lot of questions being asked. It is time to ask that question. Does the deal with the devil come at too high a price?
What is happening?Cryptocurrency is not a traditional business in any sense. The basic economic structure of a business is a group of people who exchange their goods or services for money. For example, your traditional software consulting business sells your time and expertise to clients to write software for them. Your ecommerce website provides a marketplace to sell physical goods. Your local coffee shops sells you wifi under the guise of coffee. However cryptocurrency companies do not produce anything, instead they offer synthetic financial products which are marketed to the generic public as investments. These ���investments��� are not tied directly to economic activity, these are what economists call non-productive assets. The value of these assets is only determined by what other people are willing to pay for them. This has created a giant ecosystem in which products aren���t traded on any investment fundamentals but on the hope to sell them off to a ���greater fool���.
This is not a new phenomenon. We���ve seen markets with this kind of structure early in the early history of the development of modern market economies. We saw this with Wildcat banking in the 1800s in which frontier banks would issue massive amounts of new worthless currencies supposedly backed by other securities. Another variation occurred in the 20s with widespread Ponzi schemes where new investor money was used to pay out earlier investors. And again in the 80s with the rise of boiler rooms that would massive volumes of penny stocks and municipal bonds to the public with inflated promises of returns. The history of finance is full of scams and cryptocurrency is simply the latest iteration in a long line of frauds.
Normally these frauds are recognized for what they are quite quickly and the courts and regulatory bodies can clean up the mess and rectify the damages to those who have been misled. However this new type of scam is particularly nefarious in that it has found a way to decentralise operations and move the trading operations to offshore entities. Following the money on these companies leads to these deeply layered networks of shell entities across Lichtenstein, Isle of Man, and the Cayman Islands which are set up to be immune to prosecution while still being able to funnel money across less reputable actors in these jurisdictions.
How is it happening?These companies could not be set up in countries with financial regulators because what they are offering would be blatantly illegal to offer to the general public. Instead we���ve seen this metastasize across the world to form what are effectively digital gambling sites, in which unsophisticated investors trade unregulated products on markets that are directly manipulated by exchanges with no oversight. Most of the traded volume on these sites is directly manipulated by the exchange itself with no transparency or guarantees of market conditions. If these dodgy exchanges steal your funds, you have absolutely no legal recourse. Not surprisingly this has attracted an enormous amount of interest from global criminals and market manipulation is allowed to run wild allowing massive extraction of wealth from unsuspecting users.
The duplicitous story of these financial product offerings appeals to a lot of software engineers on a pure technical level. There are indeed massive inefficiencies in the financial system that could be addressed by the use of better technologies. And even in the most progressive countries it is undeniable that there exists an ambient level of corruption and fraud, which has especially hurt a younger generation who come of age in the financial crisis. However cryptocurrency does not provide any technical answers to the inefficiencies since its entire existence is purely predicated on the appeal as a speculative investment first and not on its efficacy to transmit value. The insidious mechanism embedded inside of crypto is that as investment it has a negative expected return. In this negative sum game each early investor mathematically needs to onboard more investors or inflate the price of the asset. The mechanism that has risen to achcieve this is creation of what is effectively a new religious movement deeply entangled with fringe economic theories and right wing conspiracies, whose purpose is to onboard new followers.
New religious movements like the cryptocult provide a psychological and philosophical framework that provides sense-making for a world that seems hostile and out of their control. The crypto movement fits all the textbook criteria, it provides a mechanism for determining an in-crowd and an out-crowd (no-coiners vs bitcoiners). It gives a framework for assessing the virtue of other followers based on their faith (HODLing) in the cause. It offers simple answers to complex issues in economics and monetary policy. It gives a linguistic framework of ���thought-terminating clich��s��� and acronyms to quell dissent. It gives a mechanism of social control in which one can acquire influence and status in exchange proselytizing and onboarding more followers to buy tokens. It makes miraculous promises of wealth, not derived from effort but from faith. It presents an eschatological narrative of retributive justice about the end-times of the global financial system, in which the true believers will be reborn with a new life in an anarcho-capitalist utopia. And most importantly, it gives people a sense of a community, hope and belonging which is a powerful force that can be exploited by charismatic leaders. David Golumbia���s excellent book The Politics of Bitcoin: Software as Right-Wing Extremism outlines the rabbit-hole effect that this ecosystem is having on software engineers onboarding them into deeper forms of right-wing extremism.
May 29, 2020
On Marketing Haskell
In the last year, the Haskell language and associated technology have been seen developing into the most mature ecosystem we���ve seen to date, with innovation happening left and right across a variety of fronts. Editor tooling, for instance, is reaching levels of maturity we only dreamed about years ago. Simultaneously, there has been a fair bit of discussion about the economics of the Haskell ecosystem and the confounding factors that have led to its potential stagnation. Most recently, for instance, there have been discussions about ���Simple Haskell��� as a set of best practices to spur more successful industry projects.
At this point, the Haskell ecosystem sits on a knife-edge: it could easily fall apart and leave behind the remains of an advanced ecosystem with no practitioners left to maintain the bit-rotted pieces. Alternatively, it could thrive and evolve into a widely used and continuously researched technology that continues to refresh and reinvent itself in every new generation of programmers who join. I probably won���t be involved long enough myself to see what happens but I have a strong inclination to see it on the latter path.
However, the singular truth remains that unless Haskell sees more industrial use then there can never be any serious progress. Many people have written root-cause analyses on why this is the case, but most of them are very engineering-centric arguments about the technical minutiae of language extensions and advanced type systems. While there is some truth to the technical deficiencies, I would argue that these are not correlated with industrial success in any meaningful way.
The hard economic truth for engineers is that technical excellence is overwhelmingly irrelevant, and the history of our profession is full of cases that demonstrate this. Javascript as a language, for instance, largely came to dominate the browser ecosystem only due to the Netscape marketing department, who decided on a clever marketing ploy to circumvent Sun Microsystems and give their own new language cachet by hijacking existing name of Java. While we can���t attribute all of Javascript���s success to this naming, it is quite likely this trick was sufficient to convince enough non-technical stakeholders to make a significant difference in early adoption. These kinds of marketing tricks and positioning are likely the most fruitful path to reaching a large technical audience.
Persuasion and Decision MakersYears ago a friend gave me a wonderful book called ���Christ Was an Ad Man��� by Robert Pritikin (ISBN: 9780965906906). Offering a real-politik description of the world of advertising, the book is a funny read written from the perspective of a 1980s ad executive who gives an inside view behind consumer advertisements and persuasion, as well as the psychology of targeting. The thesis of the book is that the dichotomy between honest advertising and deceptive marketing is an illusion. Instead the world is divided into four quadrants of people across two axes. The first axis is people who are informed enough to make a decision versus those too uninformed to decide. The second axis is people who are looking to make a decision versus those who have already made a decision.
People who have already made a decision and are economically invested in that decision rarely change their minds about anything; this is readily apparent in high-investment ���purchases��� such as software. People who are uninformed and who haven���t made a decision will either choose randomly or require more information. However, conveying correct information to this group is time-consuming, so for marketers it doesn���t actually provide a good return on investment for their time. As a result, the only group that���s actually worth advertising to are people who are informed enough to make a decision but who haven���t made up their minds yet. Through hype and subterfuge, marketers should specifically target this group all while emphasizing four factors about their product:
It is memorableIt includes a key benefitIt differentiatesIt imparts positivityHaskell���s MarketingIf you look at comparative discussion about programming languages, you���ll realise that very little critical thinking is typically involved. Universities simply don���t give students the cognitive frameworks to perform comparative discussions of tools. Thus, instead of our discourse being about semantics, engineering quality, and implementation, we instead discuss our tools in terms of social factors and emotions (i.e.��it ���feels readable���, ���feels usable���, ���feels fast���).
Going back to marketing, we have to ask ourselves how exactly is Haskell perceived in the larger programming world? The official haskell.org site comes with this slogan:
An advanced, purely functional programming language
Unfortunately, this slogan is not optimal inside the above matrix because it���s addressing people who are already informed who have already decided. It isn���t memorable, it doesn���t include the key benefits of the tooling, and it doesn���t differentiate the language in any way. This isn���t great marketing.
Outside of the official site, one narrative overwhelmingly dominates all others: Haskell offers ���correctness��� and code written in Haskell is more correct than code written in other languages. Indeed, this viewpoint in and of itself would normally be a meaningful and succinct statement of value if it didn���t go completely against the grain of where software has been heading over the last 15 years.
Economics of CorrectnessThis will be a bitter pill to swallow for many Haskellers but outside of very few domains, software correctness doesn���t matter. Software deals worth hundreds of millions of dollars are done based on little to no code and are sold as successes even if they���re failures. Around 66% of enterprise software projects fail or are vastly over budget1. Increasing labour costs means that the only thing that overwhelmingly matters is time-to-market. In other words, managing a software project isn���t about correctness or engineering anymore: it���s about running a risk portfolio of distressed assets. It���s true that if you���re managing a software project the choice of tools does matter, but this choice pales in comparison to the following simpler ways to mitigate risk:
Offset the risk using as many legal and insurance instruments possible.Having a highly liquid talent pool.Factoring software failures into the expectations and economics of projects.Ability to restart the project with different assumptions and team if it all goes awry.The above factors overwhelmingly dominate decision-making for software projects and these feed back into the choice of tooling. If the talent pool is illiquid or geographically locked, that���s a non-starter. If there isn���t a large corporate vendor to go to to sign up for a support contract, then that���s a non-starter. If there isn���t a party to sue as an insurance policy against failure, then that���s a non-starter. These are existential problems for small, organic ecosystems that don���t have large corporate backing.
The bottom line is that rather than using more correct tools and engineering practices, it is simply far easier and more economical to hedge software risk with non-technical approaches. Moreover, if you throw enough bodies writing Java at a project for a long-enough period of time, it will produce a result or fail with a fairly predictable set of cashflows, which is itself a low quantifiable risk that���s very easy for a business to plan for. Thus, the economics of corporate software and a management culture that has fully embraced neo-Taylorism are in contradiction with the Haskell narrative that correctness through engineering excellence are the most important goals.
Simple HaskellThe ���Simple Haskell��� doctrine offers a new take on Haskell���s industrial stagnation, proscribing various fixes for the technical problems that prevent the language from seeing wide adoption. While I���ve read these arguments and there are some genuinely thoughtful critiques involved, I can���t help but feel it���s a bit backwards. What I see are manifestos from engineers writing about problems for other engineers, under the assumption that changing engineering practices will somehow change the situation that gave rise to these problems in the first place. Changing our engineering practices isn���t going to save us.
The fundamental question is: how will the community present the language in a way that gives it any industrial relevance in the 2020-2030 era? How will the next generation of engineers shape the Haskell narrative so that we don���t have to restrict ourselves from these advanced tools we have? We do have an advanced compiler and we have tools to build correct software, but these are not enough to foster adoption. We will also need some equally clever marketing beyond just ���correctness���.
In Pritikin���s book there���s one advertising slogan that comes off as most applicable to Haskell:
There is a steak in every hot dog.
This statement is intrinsically deceptive but hints at a deeper truth. We could sell Simple Hot Dogs to the masses, but what is the ���steak��� for Haskell that will make you want to buy that brand over others? What is Haskell���s marketing slogan and key differentiation for the new decade?
December 31, 2019
Haskell For a New Decade
It has been a decade since I started writing Haskell, and I look back on all the projects that I cut my teeth on back in the early part of this decade and realise how far the language and tooling have come. Back then Haskell was really barely usable outside of the few people who would ���go dark��� for months to learn it or those lucky enough to study under researchers working on it. These days it still remains quite alien and different to most mainstream languages. However, it���s now much more accessible and exciting to work with.
We programming communities always like to believe our best days are ahead of us and our worst days behind us. But it���s the right now that���s the issue and always has been. The problems we work on in the present are those that shape the future, and often the choice of problems is what matters more than anything else.
At the turn of the century, the mathematician David Hilbert laid out 23 problems for mathematicians to solve in the 19th century. These were the Big Hairy Audacious Goals (BHAG) for the program of mathematics at the time, problems that drove forward progress and were exciting, adventurous areas to work in. Haskell has always been at the frontier of what is possible in computer science, and it also sustains a devoted community that regularly drags the future into the present. This can���t be done without the people who dare to dream big and build toward ambitious projects.
Here I am proposing a set of ambitious problems for the next decade:
Algebraic Effect SystemsThe last few years have seen a lot of emerging work with new and practical effect systems. These are alternative approaches to the mtl style of modeling effects that has dominated Haskell development for the last decade. These effect-system libraries may help to achieve a boilerplate-free nirvana of tracking algebraic effects at much more granular levels.
In the usual Haskell tradition, there are several models exploring different points in the design space. In their current state, these projects introduce quite a bit of overhead, and some of them even require a plethora of GHC plugins to optimise away certain abstractions or to fix type inference problems. Still, it���s likely that one of these projects will see critical adoption in this decade:
fused-effectspolysemyeffI predict that by 2030 one of these models will emerge as the next successor to mtl and that we will have a standard Control.Effect module inside of the Prelude with language-integrated support in GHC. There will likely be a few more years of experimentation before this occurs, but this will become the standard way of modeling effects in Haskell programs in the next decade.
Practical Dependent TypesToday you can achieve a measure of dependent types in Haskell by enabling enough language extensions and using frameworks like singletons. This experience is not a pleasant one, and there have long been discussions about whether there exists a sensible migration path to full dependent types that won���t kill the golden goose of GHC in the process.
Personally, I think GHC, with its increasingly rich System-F, represents a local maxima (not a global maxima) in the functional language design space but it is one that produces a massive amount of economic value. Tens of millions of dollars depend on GHC maintaining compatibility with its existing ecosystem, and I���m a bit frightened that massive changes to the core language would become a bridge too far to cross for industrial users.
On the opposite side, companies like Galois and Github have pushed the language to the limits of what is possible. However, this is still not the predominant paradigm of writing Haskell and it comes with some rather serious tradeoffs for the level of power it provides.
Achieving full dependent types is probably the biggest and hairiest problem in Haskell and one that would require a massive amount of time, funding, and interdisciplinary collaboration to achieve. There is perhaps a seamless path to full dependent types, so this may be the decade in which Haskell puts the problem to rest in favour of a new decade of dependent type supremacy.
Lower barriers to GHC DevelopmentGHC Haskell is a miracle. It is an amazing compiler that has moved our discipline forward decades. That said, GHC is itself not the most accessible codebase in the world due to the inherent complexity of the engineering involved.
Haskell is also not immune to the open source sustainability problems that widely-used projects suffer from. As such, GHC development is extremely resource starved and this fact poses an existential threat to the continued existence of the language. Indeed, a certain percentage of the users of GHC will have to become to maintainers of GHC if the ecosystem is going to continue.
As a funny historical quirk, back in 2011 there was an interview with Ryan Dahl, the creator of NodeJS, who mentioned that the perceived difficulty in writing a new IO manager for GHC was a factor in the development of a new language called NodeJS. When asked why he chose Javascript, for the project, he replied:
Originally I didn���t. I had several failed private projects doing the same on C, Lua, and Haskell. Haskell is pretty ideal but I���m not smart enough to hack the GHC.
Simon always says to think of GHC as ���your compiler��� and while it might be a scary codebase, if you are reading this you probably already are smart enough to hack on GHC (although there is a kind of weird twist of fate that Haskell may itself have spawned NodeJS).
All things considered, since 2011 the barriers to entry have gone monotonically down as more people have become familiar with the codebase. There are now lovely new Nix environments for doing rapid GHC development, beautiful documentation, adaptors for working with the GHC API across versions, and the new Hadrian build system.
If you look at the commit logs to GHC itself you���ll see a lot of recent development dominated by about 10 or so supercommiters and a variety of smaller contributors. As a conservative goal, if there were 2 more regular contributors to GHC every year, by 2030 there would be 20 more contributors, and the ecosystem would have a significantly lower bus-factor as a result.
Faster Compile TimesThe singularly biggest issue most industrial users of Haskell face are the long build times with the enormously large memory footprints. GHC itself is not a lightweight compiler and it performs an enormous amount of program transformation that comes at a cost. One might argue that the compile-time costs are simply a tradeoff that one makes in exchange for all the bugs that will never be introduced, but most of us find this an unsatisfying compromise.
GHC spends the majority of its time in the simplifier. Thus, all the big wins in GHC compile-times are to be had in optimising the simplifier. This is not necessarily low-hanging fruit but a lot of this is just a matter of engineering time devoted toward profiling and bringing the costs down. The only reason this isn���t moving forward is almost certainly due to a lack of volunteers to do the work.
Imagine in 2030 compiling your average modern Haskell module 5x faster and using half the memory as GHC 8.10! Now that���s a big hairy goal worth pursuing.
Editor ToolingThe Haskell IDE Engine (HIE) project has been developing slowly for the better part of the last five years. The project has gotten quite stable and is a fully-featured implementation of the Language Server Protocol which can integrate with Vim, VSCode, Emacs etc.
GHC itself has developed a new approach to generating editor tagging called HIE Files which promise to give much better support for symbol lookup in IDEs. There is also rough tooling supporting the new Language Server Index Format which will give GHC much better integration with Github and Language Server ecosystem. The new hie-bios library really helps in setting up GHC sessions and configuring GHC���s use as a library for syntactic analysis tools.
The project itself is still a bit heavy to install, taking about 50 minutes to compile and it uses quite a bit of memory running in the background. Tab completion and refactoring tools are ���best effort��� in many cases but often become quite sluggish on large codebases. That aside, these are largely optimisation and engineering problems that are generally tractable given enough time and engineering effort.
By 2030, Haskell could have world-class editor integration with extremely optimised tab completion, in-editor type search, hole-filling integration, and automatic refactoring tools. Of course, there are also truly magical, type-based editor tools that have yet to be invented. ����
Compiler ModularityAlmost every successful language ultimately ends up spinning off a few research dialects that explore different points in the design space. Python for instance has mainline CPython, but also Jython, PyPy, Unladen Swallow, etc. In the last decade there was the Haskell Suite project which was a particularly brilliant idea around building a full end-to-end Haskell compiler as a set of independent libraries. The pace of GHC development ultimately makes this a very labor intensive project, but the idea is sound and the benefits to even having a minimal ���unfolded compiler��� would likely be enormous. Instead of requiring multiple grad students to prototype a compiler, academic researchers could simply use an existing compiler component for the parts that aren���t relevant to their research.
Similarly, the Grin project has invested a heroic amount of effort in attempting to build a new retargetable backend for a variety of functional languages such as Idris, GHC, and Agda. This kind of model should inspire others for different segments of the compiler. The devil is in the details for this project, of course, but if we had this kind of modular framework, the entire functional language space would benefit from an increase in the pace of research.
GraalVM TargetAnyone who has tried to get Haskell deployed inside an enterprise environment will quickly come up against a common roadblock: ���If it doesn���t run on the JVM, it doesn���t run here. Period.��� It���s a bitter pill to swallow for some of us but it is a fundamental reality of industry.
Java-only environments are largely the norm in enormous swathes of the industry. These aren���t the startups or hot tech companies, but the bulk of the large, boring companies that run everything in the world. They are generally risk averse and anything that doesn���t run on the JVM is banned. Eventually, there may be a sea change in IT attitudes, but I doubt it will happen this decade.
The good news is that the JVM ecosystem isn���t nearly as bad as it used to be: there are several emerging compiler targets in GraalVM, the Truffle Framework, and Sulong that have drastically reduced the barriers to targeting the JVM. A heroic-level task for a very ambitious Haskeller would be to create a JVM-based runtime for GHC Haskell to compile to. There have been a few attempts to do this over the years with Eta Lang but 2030 could be the decade when this finally becomes possible.
Build ToolsCabal has gone through several developments over the last decade. In its latest iteration with its new-style commands, cabal has reached a reasonable level of stability and it now works quite nicely out of the box.
Unfortunately, Cabal gets a lot of undue grief. Since Haskell happens to link all packages during build time, when two packages conflict with each other the last command entered at the terminal was undoubtedly a cabal command. As a result, rather than blaming the libraries themselves, people tend to direct their anger at Cabal since it appears to be the nexus of all failures. This has lead to a sort of ���packaging nihilism��� as of late. The sensible answer isn���t to burn everything to the ground; instead, it���s slow, incremental progress toward smoothing away the rough edges.
These days both Stack and Cabal can adequately build small projects and manage dependencies in both of their respective models. However, both tend to break down when trying to manage a very large, multi-project monorepo as it doesn���t use any sandboxing for reproducible builds or incremental caching.
Moreover, the barrier to entry to using both of these systems is strictly higher than in other languages, which begs the question: is there some higher level project setup and management tool which can abstract away the complexity? The precise details of this are unclear to me but it is certainly a big hairy problem, and probably the most thankless one to work on.
WebAssemblyHaskell needs to become a first class citizen in the WebAssembly ecosystem. The WebAsembly ecosytem is still lacking a key motivating use case in the browser, but in spite of that it is emerging as a standardised target for a variety of platforms outside of the web. I can���t quite predict whether WebAssembly will become embroiled in web committee hell and wither on the vine or continue to accelerate in uptake, but I think we will have more clarity on this in the coming years. There are some early efforts at bolting WebAssembly onto GHC which show promise. There are also nice toolchains for building and manipulating Assembly AST and exchanging between textual and bitcode formats.
Deep Learning FrameworksThe last decade also saw the advancement of deep learning frameworks which allow users to construct dataflow graphs that describe the different topologies of matrix operations involved in building neural networks. These kind of embedded graph constructions are quite natural to build in Haskell, and the only reason there isn���t a standard equivalent in Haskell is likely simply a) time and b) the lack of a standard around unboxed matrix datatypes. For one example, there are some quite advanced bindings to the Torch C++ librires in the HaskTorch project.
I used to work quite heavily on data science in Python, and I���m convinced the entire PyData ecosystem is actually a miracle made of magic fairy dust that has been extracted out of the crushed remains of academic careers. That said, the Python ecosystem lacks a robust framework for building embedded domains for non-Python semantics. Many of the large tech companies are investing in alternative languages such as Swift and Julia in order to build the next iterations of these libraries because of the hard limitations of CPython.
Here, there exists a massive opportunity for someone to start working on this family of differentiable computing libraries in Haskell. It is a huge investment in time, but also has an outsize economic upside if done well.
Fix RecordsHaskell is really the only popular language where record syntax diverges from syntactic norms of dot-notation. The RecordDotSyntax or some revised version of that proposal ideally should be folded into GHC this decade. Admittedly, the GHC syntax zoo is getting trickier to herd as it grows in complexity, but this is one of those changes where the reward vastly outweighs the potential breakage. We���ve navigated worse breaking changes in the past and this one change would really set the language on a different course.
Records are probably the last legacy issue to overcome, and I have faith this will be the decade we���ll finally crack this one.
Refinements and InvariantsAwhile back GHC added support for adding arbitrary annotations to source code. This quickly gave rise to an ecosystem of tools like LiquidHaskell which can use GHC source code enriched with invariants and preconditions that can be fed to external solvers. This drastically expands the proving power of the type system and lets us make even more invalid states inaccessible, including ones that require complex proof obligations beyond the scope of the type system.
This said, programming with SMT solvers is still not widely practiced in the ecosystem, nor is writing additional invariants and specifications. There is definitely a wide opportunity to use this powerful tooling and start integrating it into industrial codebases to provide even more type-safe APIs and high-assurance code.
On top of this, new ideas like Ghosts of Departed Proofs present new ways of encoding invariants at the type-level and in building reusable frameworks for building new libraries. The ecosystem has largely not incorporated such ideas and the big hairy goal of the next decade will be standardisation of these practises of enriched type annotations and proof systems.
Small Reference CompilerMost undergraduates take a compiler course in which they implement C, Java or Scheme. I have yet to see a course at any university, however, in which Haskell is used as the project language. It is within possibility that an undergraduate course could build up a small Haskell compiler during the course of a semester. If the compiler had a reasonable set of features such as algebraic data types, ad-hoc polymorphism, and rank-n types this would prove to be quite an interesting project. The leap from teaching undergraduates to code Scheme to Modern Haskell is a bit of a leap but it���s 2020 now; we���re living in the future and we need to teach the future to our next generation of compiler engineers. The closest project I���ve seen to this is a minimal Haskell dialect called duet.
This is a big hairy project that involves creating a small compiler and a syllabus and then trying it out on some students.
Type-driven Web DevelopmentThe Servant ecosystem has come quite far in recent years. What started as an experimental project in building well-typed REST APIs has become a widely used framework for building industrial codebases. Granted, the limited breadth of Haskell���s ecosystem means that it will never be on parity with other widely used web languages. Nevertheless, a framework like Servant offers a unique set of upsides that is particularly appealing for codebases that are already written in Haskell and need web API exposure.
While the ecosystem is maturing there are definitely some large holes to fill to achieve parity with other languages and frameworks. Indeed, Servant sits at the foundation of many Haskell web applications, but it requires a variety of additional layers and custom code to build a traditional business application with. Those using Servant in their business applications should consider that contributing these additional layers back in the form of resuable components would have a massive impact on the viability of web projects outside of their own companies. These contributions could move the needle on Haskell uptake in web applications.
Project-Driven BooksThe corpus of advanced Haskell knowledge is often mostly gathered through discussions and vast amounts of time reading through code. In the last few years we saw a few authors step up and write Haskell books. In particular Thinking With Types stands out as a rare example of a text which tackles more advanced topics instead of introductory material. Compared with other language ecosystems, there has always been a wide gap in both material covering intermediate Haskell and project-driven texts. Even so, a vast hunger remains present in the community for such material, and filling this gap would advance efforts to onboard new employees as well as help novices move to more advanced levels of Haskell coding.
The economics of writing a book through a technical publisher like O���Reilly, however, are a bit rubbish and tend to favour the publisher over the author. If you set out with an advance from a publisher, rest assured it is not going to be a path to many financial returns for your investment in time. Writing always takes longer than you think! With that said, the investment from a few coauthors could really move the language forward on a staggering level: the broadly-expressed desire for such materials means a large audience is waiting.
Computational Integrity ProofsIn the last few years one of the silent advances in computer science has been in a niche area of cryptography known as verifiable computing. I gave an overview of this topic at ZuriHac back in 2017 and have been working steadily on this research for several years now. Long story short, there is a brilliant new set of ideas that allow the creation and execution of arbitrary computations in a data-oblivious way (so called zero knowledge proofs or zkSNARKs) that, combined with a bit of abstract algebra, give a way for pairs of counterparties (called provers and verifiers) to produce sound proofs of correct execution with minimal assumptions of trust. For a long time the constructions involved were too computationally expensive to be practical but if you draw a line through the state of the art proof systems for the last 10 years the line has been monotonically decreasing in the time cost for proof construction and verification. If trends continue, by the middle of this decade this should give rise to a very powerful new framework for sharing computation across the internet.
This is still early work but I have made available most of the work involved in this research for others to build on. The many recent developments in Haskell cryptography libraries have positioned the ecosystem optimally for building these kind of frameworks over the next decade.
Relocatable CodeThere have been many conversations about the dream of being able to serialise the Haskell AST over a network and then to evaluate code dynamically on remote servers. There have also been many stalwart attempts to build the primitives required but standing in the way are some legitimately hard engineering problems that require environment-handling and potential changes to the language itself.
Languages which can serialise to bytecode often times have a distinct advantage in this domain where the problem becomes much simpler. The nature of how GHC Haskell is compiled limits this approach and much more clever work will need to be done. In 2030, if we had a reliable way to package up a Haskell function along with all its transitive dependencies and ship this executable closure over the wire this would allow all sorts of amazing applications.
EmploymentHaskell is never really going to be a mainstream programming language. The larger programming ecosystem is entirely dominated by strong network forces that make it impossible for small community-driven languages to thrive, except in a few niche areas. This isn���t cause for despair; instead, we should really just focus on expanding the ���carrying capacity��� of the ecosystem we have and focus on making Haskell excel in the areas it is well-suited for.
Progress in the open source Haskell ecosystem has always been dominated by engineers working in small startups to mid-size enterprises more so than large organisations. I strongly encourage other Haskellers to start companies and teams where you have the autonomy to use the tools you want to serve the market opportunities you want. The experience is enormously stressful and will shave years off your life but it is a rewarding one.
The big hairy goal here is for some ambitious folks to start new ventures. Modern dev teams are always going to be polyglot. The rub is always to ensure that Haskell is used industrially in places where it is well-suited, and not used in places where it is not. When used poorly it can cause massive technical debt, but when tactically applied, Haskell can give your architecture a huge market advantage.
DocumentationHaskell documentation has gotten much better over the last few years. This is not to say that it���s in a great situation but there���s now enough to muddle through. If you look at the top 100 packages on Hackage, around a third of them have proper documentation showing the simple use cases for the library. This is markedly improved from years ago when any semblance of documentation was extraordinarily rare. The hyperlinked source code on Hackage has also made traversing through the ecosystem quite friendly.
By 2030 we can hope that about half of the top 100 packages will have some measure of documentation. Additionally, the continued proliferation of static types in other ecosystems will acclimate new users to the type-driven model of documentation. The Github ecosystem will likely have Haskell language information built and ���go to definition��� across packages will decrease the barriers to entry to exploring new libraries. All of this will further aid adoption and newcomers to the language.
In ConclusionSome of the ideas outlined above, such as the need for more contributors to GHC, are vital for the viability of Haskell in the long-term. Overall, we should start addressing these big hairy goals in order to achieve not only a healthy Haskell ecosystem by 2030, but one that continues the tradition of innovation and technical leadership that the Haskell community has shown in its history.
November 22, 2017
Reflecting on Haskell in 2017
Alas, another year has come and gone. It feels like just yesterday I was writing the last reflection blog post on my flight back to Boston for Christmas. I���ve spent most of the last year traveling and working in Europe, meeting a lot of new Haskellers and putting a lot of faces to names.
Haskell has had a great year and 2017 was defined by vast quantities of new code, including 14,000 new Haskell projects on Github . The amount of writing this year was voluminous and my list of interesting work is eight times as large as last year. At least seven new companies came into existence and many existing firms unexpectedly dropped large open source Haskell projects into the public sphere. Driven by a lot of software catastrophes, the intersection of security, software correctness and formal methods have been become quite an active area of investment and research across both industry and academia. It���s really never been an easier and more exciting time to be programming professionally in the world���s most advanced (yet usable) statically typed language.
Per what I guess is now a tradition, I will write my end of year retrospective on my highlights of what happened in the Haskell scene in retrospect.
WritingThe amount of Haskell writing this year was vast and it���s impossible to enumerate all of the excellent writing that occurred. Some of the truly exceptional bits that were drafted in 2017 included:
Old Graphs From New Types by Andrey MokhovType Tac Toe by Chris PennerTyping the Technical Interview by Kyle KingsburyCompiling to Categories by Conal ElliottInlining and Specialisation by Matthew PickeringCounterexamples of Typeclasses by Phil FreemanAn Informal Guide to Better Compiler Errors by Jasper Van der JeugtA Tutorial on Higher Order Unification by Danny GratzerOn Competing with C Using Haskell by Chris (kqr)Making Movie Monad by David LettierAvoid Overlapping Instances With Closed Type Families by Kwang Yul SeoWriting a Formally Verified Browser in Haskell by Michael BurgeGHC Generics Explained by Mark KarpovREST API in Haskell by Maciej Spycha��aI Haskell a Git by Vaibhav SagarWhy prove programs equivalent when your compiler can do that for you? by Joachim BreitnerFree Monads Considered Harmful by Mark KarpovBeautiful Aggregations with Haskell by Evan BordenSubmitting Haskell Functions to Z3 by John WiegleyBooks & Courses
Vladislav Zavialov and Artyom Kazak set out to write a book on the netherlands of Intermediate Haskell development, a mythical place that we all seemingly pass through but never speak of again. The project is intuitively called Intermediate Haskell and is slated to be released in 2018
Bartosz Milewski finished writing Category Theory for Programmers which is freely available and also generated as PDF.
Brent Yorgey drafted a new course for teaching introduction to Computer Science using Haskell at Hendrix University. Dmitry Kovanikov and Arseniy Seroka also drafted a course for a wide variety of intermediate to advanced Haskell topics at ITMO university. Some of which are in Russian but nevertheless �������������� ������������!
GHCThe Glorious Glasgow Haskell Compiler had it���s 8.2 release, and landed to much rejoicing. Major features such as unboxed sum types landed as planned in GHC 8.2. There were many longstanding issues that were closed and many miscellaneous fixes contributed in 2017. For instance GHC now uses alternative linkers such as ld.gold or ld.lld instead of the system default ld.
Semigroup is now a superclass of Monoid.
There was quite a bit of work on GHC cross compilation to ARM. The new build system Hadrian has been in work for the past three years, has was finally been merged into the GHC tree.
The DevOps Group has officially started and is being funded to help maintain the infrastructure used to host Haskell packages and build GHC. The general push of the group has been toward using hosted CI services, Appveyor and CircleCI and a greater use of more transparent platforms such as Github for GHC development.
There is work on a major refactor of the AST types to use the new Trees that Grow research to allow GHC API user to extend the AST for their own purposes. Eventually this may allow the split of the AST types out of the ghc package, allowing tooling authors, Template Haskell users, and the compiler itself to use the same AST representation.
GHC is partially accepting pull requests on Github although most of the development still occurs on the mailing list and Phabricator.
There was significant engineering effort to allow GHC to produce deterministic build artifacts to play nicely with caching reproducible build systems such as Buck and Bazel. Previously the emitted .hi files would contain non-deterministic data such as hashes, timestamps and unique name supply counts.
Errors
GHC 8.2 added wonderful new colorful error messages with caret diagnostics for syntax and type errors:
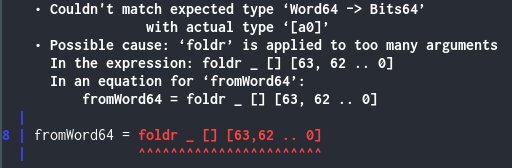
Compact Regions
Support for ���Compact Regions��� landed in GHC 8.2. Compact regions are manually allocated regions where the data allocated inside it are compacted and not traversed by the GC. This is amenable for long-lived data structures that are resident in memory without mutation frequently occurring.
The interface can be accessed through the ghc-compact modules and used to create compact malloc���d memory.
import Control.DeepSeqimport Control.Exceptionimport qualified Data.ByteString.Char8 as Bimport Data.Compactmain = compact (B.pack ['a'..'c'])The test suite inside GHC maintains the best illustrations of its use for complex non-traditional data structures.
Type.Reflection
GHC added a new more expressive Typeable mechanism using the Type.Reflection module. typeRep can be applied with explicit type applications to arrows and functions can checked for type-level equality after application.
��> typeRep @(->)(->) 'LiftedRep 'LiftedRep��> typeRep @(Maybe Int) == App (typeRep @Maybe) (typeRep @Int)TrueCoercible
Not new to GHC 8.2 although the base library now exposes the Coercible constraints allowing polymorphism over types which have the same runtime representations to be safely coerced at runtime. This can also be extended to polymorphic functions which take a compile-time proof of the equivalence of two runtime data layouts.
import Data.Coercenewtype Meters = Meters Integer deriving (Num)newtype Feet = Feet Integer deriving (Num)f :: (Coercible a b, Num b) => a -> b -> bf x y = coerce x + y��> f (Meters 3) 47��> f (Feet 3) 47��> f 4 (Feet 3)Feet 7GHC tracks the usage (i.e.��role) of type variables used as parameters as either nominal representational or phantom allowing types that differ only in a phantom type of nominal parameters to be safely coerced.
Join Points
Luke Maurer and Simon Peyton Jones merged new work on join points which modifies GHC Core to optimize for join points in code. In Core, a join point is a specially tagged function whose only occurrences are saturated tail calls. In the actual GHC Core AST, a join point is simple bit of metadata indicated by IdDetails of the binder.
Simon Peyton Jones presented the keynote at Haskell Exchange on his collaboration on Compiling without Continuation which present the ideas and core optimizations that are allowed by the new join points.
Deriving Strategies
In GHC 8.0 there were two alternative methods for automatic deriving of typeclass instances, using GeneralizedNewtypeDeriving and DeriveAnyClass. In addition there was also the wired-in deriving mechanisms for Show, Read, etc that were hardcoded into the compiler. These all used the same syntax and would conflict if multiple pragmas were enabled in a module.
The addition of DerivingStrategies allows us to disambiguate which deriving mechanism to use for a specific instance generation.
newtype Meters = Meters Int deriving stock (Read, Show) deriving newtype (Num) deriving anyclass (ToJSON, FromJSON)BackpackEdward Yang finished his PhD thesis on Backpack which was integrated in the GHC tree. The new branch adds support .bkp files, which specify abstract interfaces which can be instantiated in modules and used to construct Haskell modules which work polymorphically across multiple module instantiations.
For example an abstract string type can be written which operates over a module parameter `Str``:
unit abstract-str where signature Str where data Str len :: Str -> Int module AStr (alen) where import Str alen :: Str -> Int alen = lenWe can create (contrived) instantiations of this module for lists of ints and chars which expose a polymorphic length function over both.
unit str-string where module Str where type Str = String len :: Str -> Int len = lengthunit str-list where module Str where type Str = [Int] len :: Str -> Int len = lengthThe modules can then be opened as specific namespaces with the exported functions able to be called over both module types.
unit main where dependency abstract-str[Str=str-string:Str] (AStr as AStr.Int) dependency abstract-str[Str=str-list:Str] (AStr as AStr.String) module Main (main) where import qualified AStr.Int import qualified AStr.String main :: IO () main = do print $ AbstractStr.String.alen "Hello world" print $ AbstractStr.Int.alen [1, 2, 3]With the latest GHC this can be compiled with the --backpack which generates the sum of all the hi files specified in the .bkp file and resolves values at link-time.
$ stack exec -- ghc --backpack example.bkpWhile the functionality exists today, I���m not aware of any large projects using Backpack. Bolting this functionality onto an ecosystem that has spent a decade routing around many of the problems this system aims to solve, poses a huge engineering cost and may take a while to crystallize.
Summer of HaskellGoogle lacked vision this year and did not sponsor the Haskell Organization for Summer of Code. But the program proceeded regardless with private sponsorship from industrial users. Fifteen students were paired with mentors and many successful projects and collaborations resulted.
LLVMThe LLVM bindings for Haskell saw quite a bit of work this year and were forked into a new organization llvm-hs and added support for LLVM 4.0 - 5.1:
llvm-hsllvm-hs-purellvm-hs-prettyIn a collaboration with Joachim Breitner and myself at Zurihac a type-safe LLVM library which embeds the semantics of LLVM instructions into the Haskell type-system was written.
Siddharth Bhat started work on an STG to LLVM backend simplehxc before doing a rewrite in C++.
Moritz Angermann has been continuing to develop a Haskell library for emitting and reading LLVM Bitcode format as well as work on the llvm-ng backend which is a major rewrite of the GHC LLVM code generator.
Linear TypesArnaud Spiwack prototyped a extension of GHC which augments the type system with linear types. Edsko de Vries wrote a detailed blog post about the nature of linearity and its uses.
The proposal extends the typing of functions to include linearity constraints on arrows, enforcing that variables or references are created and consumed with constrained reference counts. This allows us to statically enforce reference borrowing and allocations in the typechecker potentially allowing us to enforce lifetime constraints on closures and eliminating long-lived memory from being used with constructed unbounded lifetimes, thereby eliminating garbage collection for some Haskell functions.
For instance, use of the linear arrow (a ->. b) can enrich the existing raw memory access functions enforcing the matching of allocation and free commands statically. The multiplicity of usage is either 0, 1 or �� and the linear arrow is syntatic sugar for unit multiplicity are aliases for (:'1 ->).
malloc :: Storable a => a ->. (Ptr a ->. Unrestricted b) ->. Unrestricted bread :: Storable a => Ptr a ->. (Ptr a, a)free :: Ptr a ->. ()New abstractions such as movable, consumable and dupable references can be constructed out of existing class hierarchies and enriched with static linearity checks:
class Consumable a where consume :: a ->. ()class Consumable a => Dupable a where dup :: a ->. (a, a)class Dupable a => Movable a where move :: a ->. Unrestricted ainstance Dupable a => Dupable [a] where dup [] = ([], []) dup (a:l) = shuffle (dup a) (dup l) where shuffle :: (a, a) ->. ([a], [a]) ->. ([a], [a]) shuffle (a, a') (l, l') = (a:l, a':l')instance Consumable a => Consumable [a] where consume [] = () consume (a:l) = consume a `lseq` consume lAs part of the Summer of Haskell Edvard H��binette used linear types to construct a safer stream processing library which can enforce resource consumption statically using linearity.
There is considerable debate about the proposal and the nature of integration of linear types into GHC. With some community involvement these patches could be integrated quite quickly in GHC.
LiquidHaskellLiquidHaskell the large suite of tools for adding refinement types to GHC Haskell continued development and became considerably more polished. At HaskellExchange several companies were using it in anger in production. For example, we can enforce statically the lists given at compile-time statically cannot contain certain values by constructing a proposition function in a (subset) of Haskell which can refine other definitions:
measure hasZero :: [Int] -> ProphasZero [] = falsehasZero (x:xs) = x == 0 || (hasZero xs)type HasZero = {v : [Int] | (hasZero v)}-- Rejectedxs :: HasZeroxs = [1,2,3,4]-- Acceptedys :: HasZeroys = [0,1,2,3]This can be used to statically enforce that logic that consumes only a Just value can provably only be called with a Just with a isJust measure:
measure isJust :: forall a. Data.Maybe.Maybe a -> BoolisJust (Data.Maybe.Just x) = true isJust (Data.Maybe.Nothing) = falseThis year saw the addition of inductive predicates, allowing more complex properties about non-arithmetic refinements to be checked. Including properties about lists:
measure len :: [a] -> Intlen [] = 0len (x:xs) = 1 + (len xs)-- Spec for Data.List exports refined types which can be statically refined with-- length constraints.[] :: {v:[a]| len v = 0}(:) :: _ -> xs:_ -> {v:[a]| len v = 1 + len xs}append :: xs:[a] -> ys:[a] -> {v:[a]| len v = len xs + len ys}The full library of specifications is now quite extensive and adding LiquidHaskell to an existing codebase is pretty seamless.
FoundationFoundation is an alternative Prelude informed by modern design practices and data structures. It ships a much more sensible and efficient packed array of UTF8 points as its default String type. Rethinks the Num numerical tower , and statically distinguishes partial functions. Also has fledgling documentation beyond just
Last year Foundation was a bit early, but this year at Zurihac several companies in London reported using it fully in production as a full industrial focused Prelude.
Editor ToolingEditor integration improved, adding best in modern tooling to most of the common editors:
EditorHaskell IntegrationAtom
https://atom.io/packages/ide-haskell
Emacs
https://commercialhaskell.github.io/i...
IntelliJ
https://plugins.jetbrains.com/plugin/...
VSCode
https://marketplace.visualstudio.com/...
Sublime
https://packagecontrol.io/packages/Su...
Monica Lent wrote a lovely post on the state of art in Vim and Haskell integration.
Rik van der Kleij has done an impressive amount of work adapting the IntellJ IDE to work with Haskell. Including a custom parser handling all of the syntax extensions, name lookup, Intero integration and integration with haskell-tools refactoring framework.
Development on the haskell-ide-engine has picked up again in the last few months.
Formal MethodsThe DeepSpec, a collaboration between MIT, UPenn, Princeton and Yale, is working on a network of specification that span many compilers, languages and intermediate representations with the goal of achieving full functional correctness of software and hardware. Both Haskell and LLVM are part of this network of specifications. The group has successfully written a new formal calculus describing the GHC core language and proved it type sound in Coq. The project is called corespec and is described in the paper ���A Specification for Dependent Types in Haskell���.
In addition the group also published a paper ���Total Haskell is Reasonable Coq��� and provided a utlity hs-to-coq which converts haskell code to equivalent Coq code.
The Galois group started formalizing the semantics of Cryptol, a compiler for high-assurance cryptographic protocols which is itself written in Haskell.
Michael Burge wrote a cheeky article about extracting a specification for a ���domain specific��� browser from Coq into Haskell.
Pragma Proliferation & PreludeWriting Haskell is almost trivial in practice. You just start with the magic fifty line {-# LANGUAGE ... #-} incantation to fast-forward to 2017, then add 150 libraries that you���ve blessed by trial and error to your cabal file, and then just write down a single type signature whose inhabitant is Refl to your program. In fact if your program is longer than your import list you���re clearly doing Haskell all wrong.
In all seriousness, Haskell is not the small language it once was in 1998, it���s reach spans many industries, hobbyists, academia and many classes of people with different incentives and whose ideas about the future of the language are mutually incompatible. Realistically the reason why the Prelude and extension situation aren���t going to change anytime soon is that no one person or company has the economic means to champion such a change. It would be enormously expensive and any solution will never satisfy everyone���s concerns and desires. Consensus is expensive, while making everything opt-in is relatively cheap. This is ultimately the equilibrium we���ve converged on and barring some large sea change the language is going to remain in this equilibrium.
Haskell SurveyTaylor Fausak conducted an unofficial survey of Haskell users with some surprising results about widespread use of Haskell. Surprisingly there are reportedly 100 or more people who maintain 100,000 or more lines of Haskell code. Not so surprisingly most people have migrated to Stack while vim and emacs are the editors of choice.
While the majority of respondents are satisfied with Haskell the language the response are somewhat mixed the quality of libraries and the bulk of respondents reported Haskell libraries being undocumented , hard to use hard to find, and don���t integrate well.
ProjectsIdris, the experimental dependently typed language, reached 1.0 release and became one of the larger languages which is itself written in Haskell.
The most prolific Haskell library Pandoc released its version 2.0.
Several other groups published new compilers in the Haskell-family of languages. Intel finally open sourced the Intell Haskell compiler which was a research project in more optimal compilation techniques. Morgan Stanley also released Hobbes a Haskell-like language used internally at the bank featuring several novel extensions to row-types and C++ FFI integration. A prototype Haskell compiler was also written in Rust.
The SMT solver integration library SBV saw a major rewrite of its internal and its old tactics system. The library is heavily used in various projects as an interface to Z3 and CVC4 solvers.
Uber released a library for parsing and analysis of Vertica, Hive, and Presto SQL queries.
Wire released the backend service to their commercial offering.
The Advanced Telematic Systems group in Berlin released a Quickcheck family library for doing for property testing of models about state machines. Bose also released Smudge a tool for doing development and analysis of large state machines for hardware testing.
Florian Knupfer released a new high-performance HTML combinator library for templating.
Galois continued with HalVM unikernel development this year, and several HalVM Docker Imagaes were published allowing a very convenient way to write and test code against HalVM.
Facebook released a Haskell string parsing library duckling which parses human input into a restricted set of semantically tagged data. Facebook also prototyped a technique for hot-swapping Haskell code at runtime using clever GHC API trickery.
Chris Done released vado a browser engine written in Haskell.
Jonas Carpay released apecs an entity component system for game development in Haskell.
Csaba Hruska continued work on a GRIN compiler and code generator, an alternative core language for compiling lazy functional languages based on the work by Urban Boquist.
Dima Szamozvancev released mezzo a library and embedded domain-specific language for music description that can enforce rules of compositionality of music statically and prevent bad music from being unleashed on the world.
Conal Elliot and John Wiegley advanced a novel set of ideas on Compiling with Categories which allows the bidirectional representation of Haskell functions as categorical structures. Although currently implemented as a GHC typechecker extension it is a promising research area.
Harry Clarke published a paper on Generics Layout-Preserving Refactoring using a reprinter. i.e.��a tool which takes a syntax tree, the original source file, and produces an updated source file which preserves secondary notation. This can be used to build tools like haskell-tools for arbitrary languages and write complicated refactoring suites.
Joachim Breitner contributed a prolific amount of open source projects including a new technique (ghc-proofs) for proving the equivalence of Haskell programs using a GHC plugin, (veggies) a verified simple LLVM code generator for GHC, and (inspection-testing) new technique for verifying properties of Core.
veggiesghc-proofsinspecction-testingThe ghc-proofs plugin allows us to embed equation and relations into our Haskell module and potentially allow GHC to prove them correct by doing symbolic evaluation and evaluating them as far as possible and checking the equational relations of the equations sides. Right now it works for contrived and simple examples, but is quite a interesting approach that may yield further fruit.
{-# OPTIONS_GHC -O -fplugin GHC.Proof.Plugin #-}module Simple whereimport GHC.Proofimport Data.Maybemy_proof1 = (\f x -> isNothing (fmap f x)) === (\f x -> isNothing x)$ ghc Simple.hs[1 of 1] Compiling Simple ( Simple.hs, Simple.o )GHC.Proof: Proving my_proof1 ���GHC.Proof proved 1 equalitiesHaddockHaddock is creaking at the seams. Most large Haskell projects (GHC, Stack, Agda, Cabal, Idris, etc) no longer use it for documentation. The codebase is dated and long standing issues like dealing with reexported modules are still open.
There is a large vacuum for a better solution to emerge and compatibility with RestructuredText would allow easy migration of existing documentation.
DatabasesThis year saw two new approaches to Haskell database integration:
Selda - A library interacting with relational databases inspired by LINQ and Opaleye.Squeal - A deep embedding of PostgreSQL in Haskell using generics-sop.This still remains an area in the ecosystem where many solutions end up needlessly falling back to TemplateHaskell to generate data structures and typically tend to be a pain point. Both these libraries use generics and advanced type system features to statically enforce well-formed SQL query construction.
Data Science & Numerical ComputingChris Doran presented a concise interpretation of Geometric Algebra, a generalization of linear algebra in terms of graded algebra written in Haskell. A talk on this project was presented at the Haskell Exchange.
At ZuriHac several people expressed interest in forming a Data Haskell organization to work on advancing the state of Haskell libraries for data science and macing learning. There is considerable interest of the constructing the right abstractions for a well-typed dataframe library.
Tom Nielson is furiously working on a suite of of projects, mostly related to data science, machine learning and statistics in Haskell.
The Accelerate project has been seeing a lot of development work recently and now has support for latest versions of LLVM and CUDA through llvm-hs project.
A group at the University of Gothenburg released TypedFlow a statically typed higher-order frontend to TensorFlow.
EtaTypelead continued working on a Java Virtual Machine backend to GHC called Eta. The project has seen considerable amount of person-hours invested in compatibility and the firm has raised capital to pursue the project as a commercial venture.
The project does seem to be diverging from the Haskell mainline language in both syntax and semantics which raises some interesting questions about viability. Although the Haskell language standard seems to be stuck and not moving forward, so there���s an interesting conundrum faced by those trying to build on top of GHC in the long run.
WebAssemblyWebAssembly has been released and is supported by all major browsers as of December 2017. This is been piquing the interest of quite a few Haskellers (including myself) who have been looking for a saner way to interact with browsers than the ugly hack of ejecting hundreds of thousands of lines of generated Javascript source. WebAssembly in either standalone projects or as a target from GHC���s intermediate form STG to the browser offers an interesting path forward.
Haskell WASMWebGHCministgwasmforest-langIndustryAn incomplete list of non-consulting companies who are actively using Haskell or have published Haskell open sources libraries follows:
Product CompaniesStandard CharteredGaloisIntelTargetUberVente PriveeFrontRowNStackMorgan StanleyTaktFugueHabitoAsahi NetSentenaiIOHKAwake NetworksFacebookAdjointDigitalAssetAlphaSheetsChannableSlamDataWireJP MorganBoseThere are four consulting companies also supporting Haskell in industry.
ConsultanciesWell-TypedTweagFP CompleteObsidian SystemsConferencesBoth the Haskell Exchange and ZuriHac conference had record attendance this year. Haskell was well-represented in many interdisciplinary conferences include StrangeLoop, CurryOn, LambdaDays, LambdaConf, and YOW.
Most of the videos are freely available online.
Haskell Exchange VideosComposeConf VideosZuriHac VideosICFP Videos[image error]
In 2018 I have plans to visit Zurich, Sydney, Budapest, Amsterdam, San Francisco, Paris, Copenhagen and Tokyo this year. Hopefully I get to meet more Haskellers and share some ideas about the future of our beautiful language. Until then, Merry Christmas and Happy New Haskell Year.
Stephen Diehl's Blog

- Stephen Diehl's profile
- 6 followers

