
Edin Kapić's Blog
September 27, 2023
New Blog, Hello Gatsby!


February 7, 2020
HTTP Redirect with non-ASCII characters in the URL
Another day, another small learning.
SITUATION
I have been extending ASP.NET Core REST API service that returns redirect (HTTP 301) results for a query. I would submit something like /redirect/A10293 and it would look up the associated SharePoint library URL for that entity.
/redirect/A10293 would then be redirected to https://sharepoint/site/library.
The customer wanted to add another piece of input, to be passed as a parameter of type string: the description of the entity. In SharePoint I had made a SPFx application customizer extension that showed this information in the header.
The new flow would be:
/redirect/A10293?name=Hello%20World should return a redirect to https://sharepoint/site/library?name=....
SYMPTOMS
In testing, we found out that for some entity names the service would return a Server error (HTTP 500). In particular, for the names with strange characters in the name, such as German umlauts like Müller.
/redirect/A10293?name=Hello%20Herr%20M%C3%BCller would fail with a 500.
CAUSE
Thanks to my colleague Christoph König (yes, with umlaut in the surname).
The cause of the error is that HTTP redirects are restricted to ASCII characters in the redirect result, as per the RFC.
 I do, really. Especially my surname last character: ć. Thanks Unicode!
I do, really. Especially my surname last character: ć. Thanks Unicode!In the code I was constructing a string and adding the name parameter as a string. It was being automatically URL-decoded by ASP.NET, and the redirection URL was then something like https://sharepoint/site/library?name=... Herr Müller. This tripped the redirect ActionResult parser to raise an exception.
SOLUTION
Use the System.Uri class to parse the string and return its AbsoluteUri property. A string, with the canonical, encoded version safe to be used in redirect result.
string redirectUrl = " https://sharepoint/site/library?name=... Herr Müller ";
Uri redirectURI = new Uri(redirectUrl);
return RedirectPermanent(redirectURI.AbsoluteUri);
February 6, 2020
HTTP Redirect with non-ASCII characters in the URL
January 3, 2020
Static Initializers in C#: A Cautionary Tale
I have been chasing a weird bug in a solution I’ve been working on. The insight on how certain C# feature work by design, which I got after catching of the culprit, made me write this post in the hope that somebody can save hours or days of debugging.
My solution uses SPMeta2 library to define a structure of a SharePoint site to be provisioned. You specify a collection of “nodes” that represent your lists, content types, site columns and so on. It can be then “provisioned” on the target side using CSOM or SSOM.
 Static Function (yes, it’s PHP but it gets the point, right?)
Static Function (yes, it’s PHP but it gets the point, right?)The structure was defined using static properties on static classes such as FieldDefinitions.cs or ContentTypeDefinitions.cs. A new content type, for instance, would be defined as a ContentTypeDefinition property initialized inline with a static initializer.
public static ContentTypeDefinition BaseContentType = new ContentTypeDefinition()
{
Name = "BaseContentType",
Id = new Guid("EC0463EA-2AA1-4461-8407-2A4D0FD58B8B"),
ParentContentTypeId = BuiltInContentTypeId.Document,
Group = GroupNames.MyContentTypeGroupName
};
However, when I retrieved a template (a sum of all ModelNodes in the definition) I would get a weird System.TypeInitializationException in the nodes collection.
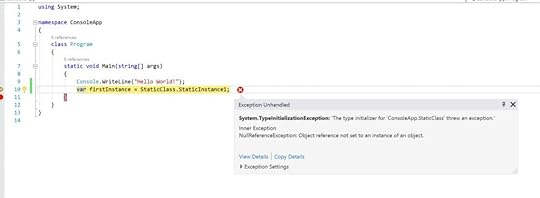 The source of my headache for a couple of days (simplified)
The source of my headache for a couple of days (simplified)I spent a couple of days trying to find the root of the issue. As I couldn’t debug static initializers, I had to rely on removing and adding nodes to see what triggers the error. Finally I got it.
The offending code was like this:
public static class ContentTypeDefinitions
{
public static ContentTypeDefinition ContentType1 = new ContentTypeDefinition()
{
Name = "ContentType1",
...
ParentContentTypeId = ContentTypeDefinitions.ContentType2.Id
};
public static ContentTypeDefinition ContentType2 = new ContentTypeDefinition()
{
Name = "ContentType2",
...
ParentContentTypeId = BuiltInContentTypeId.Document
};
...
}
Do you see the error?
ContentType1 (a static field) relies on the ContentType2 definition (another static field) to be initialized. However, ContentType2 is defined AFTER the ContentType1 in the source code. But, since when the order of definitions in C# is important? Shouldn’t the strongly-typed nature of C# make it irrelevant?
As per C# specifications, section 10.11 Static Constructors says:
If a class contains any static fields with initializers, those initializers are executed in textual order immediately prior to executing the static constructor.
C# 1.2 Language Specification, section 10.11 paragraph 7.
I fixed the code just by reordering the static fields:
public static class ContentTypeDefinitions
{
public static ContentTypeDefinition ContentType2 = new ContentTypeDefinition()
{
Name = "ContentType2",
...
ParentContentTypeId = BuiltInContentTypeId.Document
};
public static ContentTypeDefinition ContentType1 = new ContentTypeDefinition()
{
Name = "ContentType1",
...
ParentContentTypeId = ContentTypeDefinitions.ContentType2.Id
};
...
}
And it just works.
If you want to see it by yourself, this is a minimal demo that makes the error. You can run it inside DotNetFiddle.
As soon as the order of static fields is reversed, it works.
January 2, 2020
Static Initializers in C#: A Cautionary Tale
February 1, 2019
Materials from my Azure AD Session at NetCoreConf Barcelona 2019
Last Saturday I attended the NetCoreConf Barcelona, a free conference dedicated to .NET Core and related technologies.
I spoke about the key concepts and authentication flows in Azure Active Directory from the perspective of an average developer. I had a great time and I heard some good feedback about the session, so it might just have helped someone. There is no better reward.

I used demos from the following sources on GitHub:
Integrating Azure AD v2 in a NET Core web appOpenID Connect with NET Core web appDaemon app with NET Core Framework and Azure AD v2
The slides are available on my OneDrive:
The post Materials from my Azure AD Session at NetCoreConf Barcelona 2019 appeared first on EdinKapic.com.
January 31, 2019
Materials from my Azure AD Session at NetCoreConf Barcelona 2019
July 24, 2018
La triste realidad de los eventos técnicos: el no-show
Desde hace unos años observo una tendencia en los eventos técnicos a los que asisto o los que colaboro a organizar. Esta tendencia es la creciente ausencia no notificada, o el temido no-show.
Se considera no-show cuando una persona registrada para un evento no asiste, sin cancelar su entrada. También es no-show cuando la persona avisa el mismo día o el día anterior, ya que deja muy poco márgen para poder reutilizar la entrada a reajustar la logística.
Un no-show individual no es un problema. Todo el mundo tiene alguna cosa que le surge en el último momento. El problema es cuando el no-show es masivo, como lo que le pasó a Luís Fraile no hace mucho.
Te voy a poner un ejemplo: si esperas 100 personas en un evento, siempre cuentas con un porcentaje de no-show de digamos 20%. Entonces, dejas que se apunten 120 contando que al final irán 100. Compras comida para 100, pides merchanidising para los 100, buscas un sitio para los 100…ya me entiendes. Al final vienen 20. De 120. Te sobran tres cuartos de todo. Los patrocinadores con cara de circunstancias. Y tú, con cara de tonto…
Evidencia empírica (y subjetiva) de los últimos eventos en los que estuve colaborando
SharePoint Saturday Barcelona 2017: creo recordar que se apuntaron 180 y vinieron 130. No-show:
SharePoint Saturday Madrid 2018: apuntados 300. asistieron 270. No-show de 10%. ¡Para tirar cohetes!
Azure Bootcamp 2018 Barcelona: apuntados 150, asistieron 70. No-show de >50%
Insider Dev Tour 2018 Barcelona: apuntados 220, asistieron 70. No show de >65%. Suerte que pudimos llevar la comida sobrante a un comedor social.
TUGA IT 2018 en Lisboa: apuntados 120, asistieron 40. No-show de >60%.
Salvo los eventos de SharePoint, y creo que es porque la comunidad de SharePoint es especialmente cohesionada, los eventos técnicos acusan una tendencia a la alza de no-shows.
¿Por qué pasa esto? Causas del no-show
¡Ojalá lo supiera! Según he podido hablar con otros compañeros y compañeras en la comunidad, hay varios posibles factores en juego:
La fecha o el día de la semana el evento va mal a la gente
Pero entonces, ¿por qué se apuntan si les va mal?
El formato del evento ya no atrae
Hay un debate sobre si los eventos presenciales siguen teniendo validez hoy en día o si se tiene que reinventar el evento en un formato más virtual
Pero entoces, ¿por qué se apuntan?
La gente no valora lo que es gratis
Pero hay eventos gratuitos en los que esto no pasa
Cuesta poco apuntarse y no hay consecuencias por no asistir
Aquí estoy de acuerdo, pero no sé que proponer como alternativa
¿Se os ocurren más ideas sobre las posibles causas?
¿Qué podemos hacer para prevenir el no-show?
Si lo supiera…montaría una startup vendiendo la solución. De lo que he escuchado en la comunidad, hay dos posibles alternativas:
Poner un precio simbólico al evento (tipo 5-10 euros) para que no sea gratis
A Microsoft le funcionó bastante bien para la DotNetSpain hace unos años
Pero
Ya es una barrera para asistir, aunque sea más psicológica que real
Hay eventos que por la licencia de marca (como los “____ Saturdays”) que obligan a que el evento sea gratuito
Obliga a los organizadores a tener registro fiscal (que es un dolor de cabeza y sumidero de tiempo) y obligaciones con Hacienda
Llevar un registro de los no-shows pasados y poner un “baneo” a la persona reincidente
No me parece mal y sé que hay grupos de usuarios en Europa y EEUU que lo usan con éxito
Pero no sería una solución a corto plazo. Además, con el tema de GDPR esto de guardar los datos de los asistentes pasados es más peliagudo.
Hasta aquí mi granito de arena. Estoy esperando ver el debate sobre estas y otras propuestas.
The post La triste realidad de los eventos técnicos: el no-show appeared first on EdinKapic.com.
July 23, 2018
La triste realidad de los eventos t��cnicos: el no-show
July 4, 2018
How to Create a Graph Schema Extension using Graph Explorer
I’ve been doing a lot of SPFx, NET Core and Office 365 related development and I have several stories to share.
During the implementation of one of the features in a custom API application, I had to create a schema extension in Microsoft Graph for a Group object, for the purposes of classification. As I stumbled upon a non-intuitive behaviour of the API in Graph Explorer, I hope to save you a couple of hours if you have to do the same.
I went to the extensive Graph documentation to see how to perform such a call to MS Graph. It didn’t seem particularly difficult, just a POST with JSON data on the schemaExtensions endpoint.
In Graph Explorer application that I was using, I kept getting “Request denied due to insufficient permissions”. I double and triple-checked that my Graph Explorer indeed had the needed permissions (Directory.AccessAsUser.All). No matter what I did, I kept getting the same error.
In the end, it seemed to be a limitation on Graph Explorer client. To overcome it, Microsoft added a workaround:
Register another Web / API application in Azure Active Directory
Add the required permissions to create schema extension to that application
In Graph Explorer, prepare a POST request to schemaExtensions endpoint
Add “owner” property in the JSON payload, with the value of the authorized application App ID
Voilà! The schema extension is created.
My schema creation request JSON payload was like this:
{"id": "classificationGroup",
"owner": "937451d2-b057-4d16-8ea0-fd50b9531fef",
"description": "Custom group classification",
"targetTypes": [
"Group"
],
"properties": [
{
"name": "classificationValue",
"type": "String"
}
]
}
The post How to Create a Graph Schema Extension using Graph Explorer appeared first on EdinKapic.com.


