
Jay Fields's Blog, page 8
May 22, 2012
sidenum function
sidenum function
The sidenum function appends a sign to a number based on a side. The name sidenum was chosen due to it's similarities with signum in spelling and behavior (dealing with signs).
Definition
The sidenum function of a side x and a number y is defined as follows:

note: 'bid' can be replaced with 'buy', and 'ask' can be replaced with 'sell' or 'offer'. The string representation or type of side varies by trading system.
Usage
The sidenum function appears in most trading applications, though not always named 'sidenum'. It can be helpful for both position related math and conserving screen real-estate by displaying 2 concepts (side & quantity) as 1 (a signed quantity).
Examples
Java
public static int sidenum(String side, int quantity) {
if (side.equals("ask"))
return -quantity;
return quantity;
}
Clojure
(defn sidenum [side quantity]
(if (= side "ask")
(- quantity)
quantity))
Ruby
def sidenum(side, quantity)
if side == "ask"
-quantity
else
quantity
end
end
© Jay Fields - www.jayfields.com

The sidenum function appends a sign to a number based on a side. The name sidenum was chosen due to it's similarities with signum in spelling and behavior (dealing with signs).
Definition
The sidenum function of a side x and a number y is defined as follows:

note: 'bid' can be replaced with 'buy', and 'ask' can be replaced with 'sell' or 'offer'. The string representation or type of side varies by trading system.
Usage
The sidenum function appears in most trading applications, though not always named 'sidenum'. It can be helpful for both position related math and conserving screen real-estate by displaying 2 concepts (side & quantity) as 1 (a signed quantity).
Examples
Java
public static int sidenum(String side, int quantity) {
if (side.equals("ask"))
return -quantity;
return quantity;
}
Clojure
(defn sidenum [side quantity]
(if (= side "ask")
(- quantity)
quantity))
Ruby
def sidenum(side, quantity)
if side == "ask"
-quantity
else
quantity
end
end
© Jay Fields - www.jayfields.com


May 17, 2012
jQuery find function
I've recently been using Tilava Table on a few different projects. At one point I ran into a situation where I wanted to change all of the visible rows as well as the template, but the row template was no longer found when using a traditional jQuery selection. The solution to my problem was a combination of holding on to the template as well and using jQuery find to select the td elements I was interested in altering.
In Tilava Table you create a template, but that template row isn't displayed within the table. We could use that as an example, but it seems easier to simplify the example to the following code:
<script src="http://code.jquery.com/jquery-1.7.2.m...
</script>
<label><input type="checkbox" id="hideMoreData"/>hide more data</label>
<table id="myTable" style="border:1px solid black">
<tr class="template">
<td>row data</td><td class="additional-field">more data</td>
</tr>
</table>
<button id="addButton">Add</button>
<script>
$(document).ready(function () {
function addRow(template) {
$('#myTable').append(template.clone().removeClass('template'));
}
var template = $(".template");
$('#myTable').html("");
$("#addButton").click(function () {
addRow(template);
});
$("#hideMoreData").click(function () {
$(".additional-field").toggle(!$('#hideMoreData').is(':checked'));
});
addRow(template);
addRow(template);
});
</script>
The executing version of that code can be found below.
hide more data
row datamore data
Add
In the above example we have a table in which we can dynamically add rows by clicking the 'Add' button. We also have a checkbox that determines whether or not the additional data is displayed in our table. Click the add button a few times and show and hide the additional data, just to make sure everything is working as you'd expect.
You may have noticed (either by reading the code, or by playing with the example) that when you hide the additional data it hides what is already in the table; however, if you add additional rows the additional data for the new rows will be shown. This is due to the fact that when you select all td elements with the class 'additional-field' the template is not included in the results. Even though the template is not returned in our 'additional-field' selection, it does still exist and is accessible as the var 'template'. When we clone the template var the cloned row will contain the additional-field td, but it will not be 'correctly' toggled.
One solution would be to append the row and rerun the toggle code, but that wouldn't be as efficient - and, jQuery gives us a better solution anyway: find
template.find(".additional-field").toggle(!$('#hideMoreData').is(':checked'));The finished code is below in it's entirety, and the working version of the code can also be found at the bottom.
<label><input type="checkbox" id="hideMoreData2"/>hide more data</label>
<table id="myTable2" style="border:1px solid black">
<tr class="template2">
<td>row data</td><td class="additional-field2">more data</td>
</tr>
</table>
<button id="addButton2">Add</button>
<script>
$(document).ready(function () {
function addRow(template) {
$('#myTable2').append(template.clone().removeClass('template2'));
}
var template = $(".template2");
$('#myTable2').html("");
$("#addButton2").click(function () {
addRow(template);
});
$("#hideMoreData2").click(function () {
$(".additional-field2").toggle(!$('#hideMoreData2').is(':checked'));
template.find(".additional-field2").toggle(!$('#hideMoreData2').is(':checked'));
});
addRow(template);
addRow(template);
});
</script>
hide more data
row datamore data
Add
© Jay Fields - www.jayfields.com

In Tilava Table you create a template, but that template row isn't displayed within the table. We could use that as an example, but it seems easier to simplify the example to the following code:
<script src="http://code.jquery.com/jquery-1.7.2.m...
</script>
<label><input type="checkbox" id="hideMoreData"/>hide more data</label>
<table id="myTable" style="border:1px solid black">
<tr class="template">
<td>row data</td><td class="additional-field">more data</td>
</tr>
</table>
<button id="addButton">Add</button>
<script>
$(document).ready(function () {
function addRow(template) {
$('#myTable').append(template.clone().removeClass('template'));
}
var template = $(".template");
$('#myTable').html("");
$("#addButton").click(function () {
addRow(template);
});
$("#hideMoreData").click(function () {
$(".additional-field").toggle(!$('#hideMoreData').is(':checked'));
});
addRow(template);
addRow(template);
});
</script>
The executing version of that code can be found below.
hide more data
row datamore data
Add
In the above example we have a table in which we can dynamically add rows by clicking the 'Add' button. We also have a checkbox that determines whether or not the additional data is displayed in our table. Click the add button a few times and show and hide the additional data, just to make sure everything is working as you'd expect.
You may have noticed (either by reading the code, or by playing with the example) that when you hide the additional data it hides what is already in the table; however, if you add additional rows the additional data for the new rows will be shown. This is due to the fact that when you select all td elements with the class 'additional-field' the template is not included in the results. Even though the template is not returned in our 'additional-field' selection, it does still exist and is accessible as the var 'template'. When we clone the template var the cloned row will contain the additional-field td, but it will not be 'correctly' toggled.
One solution would be to append the row and rerun the toggle code, but that wouldn't be as efficient - and, jQuery gives us a better solution anyway: find
find: Get the descendants of each element in the current set of matched elements, filtered by a selector, jQuery object, or element.The simple solution is to add the following line in the #hideMoreData click handler.
template.find(".additional-field").toggle(!$('#hideMoreData').is(':checked'));The finished code is below in it's entirety, and the working version of the code can also be found at the bottom.
<label><input type="checkbox" id="hideMoreData2"/>hide more data</label>
<table id="myTable2" style="border:1px solid black">
<tr class="template2">
<td>row data</td><td class="additional-field2">more data</td>
</tr>
</table>
<button id="addButton2">Add</button>
<script>
$(document).ready(function () {
function addRow(template) {
$('#myTable2').append(template.clone().removeClass('template2'));
}
var template = $(".template2");
$('#myTable2').html("");
$("#addButton2").click(function () {
addRow(template);
});
$("#hideMoreData2").click(function () {
$(".additional-field2").toggle(!$('#hideMoreData2').is(':checked'));
template.find(".additional-field2").toggle(!$('#hideMoreData2').is(':checked'));
});
addRow(template);
addRow(template);
});
</script>
hide more data
row datamore data
Add
© Jay Fields - www.jayfields.com
May 16, 2012
How I Open Source
It's been recently brought to my attention that I don't view open-source the way that many of my friends do. My attitude has always been:
It finally occurred to me that others don't think this way when they began telling me that they don't open-source due to - the code isn't mature enoughthey don't want to write documentationthey don't want their time monopolized by feature request emailsI can understand each point of view, but events have occurred in my career that have shaped my (differing) opinion.
I still remember my first open-source project: I didn't tell a soul about it until I had used it in production for over a year and was very confident that I'd addressed the majority of common use cases. It was a .net object relational mapper called NORM, and it was released in 2005. No, you haven't ever heard of it. I polished it for months, and no one cared. After that I never waited to release anything. I now believe that it's highly unlikely that whatever I create will ever gain any traction, so I might as well get it out there, fail quickly, and move on.
No one writes documentation for themselves, they write it for people who they hope will use their software - and very few people people ever gain anything from someone else using their open-source software. That simple equation makes documentation scarce; however, scarce documentation doesn't mean you can't open-source your software, it just means adoption rates will very likely be slowed.
Two years ago I open-sourced expectations with zero documentation, and documentation stayed at zero for at least a year. In that year very few people paid any attention to expectations; however, expectations does fit a sweet spot for some people, and some adoption did occur. Eventually, new adopters began to send pull requests with documentation, and their contributions inspired me to write some documentation of my own. It can be hard to get motivated about providing documentation to theoretical adopters; however, I got my code out there and adoption began, and the motivation came along with those (no longer theoretical) adopters.
If you end up lucky enough to create a project that is widely used, there's no doubt that you'll start getting swamped with email. In the beginning I expect everyone will be overjoyed with their success, and the added workload will be no big deal. However, I imagine over time it begins to feel like a second full-time job, and for what? Developer-fame doesn't get you closer to retirement any faster than watching grass-grow. However, I don't believe that should deter you from putting your work out there. Additionally, I think GitHub has changed the game with respect to moving on. If your project is on GitHub and you decide to call it quits tonight, there will probably be plenty of forks that are more than happy to take your place.
I have no qualms with walking away from projects, as I expect that if the idea is valuable, someone else will be happy to step up and take my place; furthermore, it's more likely that several people will step up and the strongest will survive - which is best for everyone. The best example I've ever seen of this behavior was Capistrano. Jamis Buck famously walked away from Cap in 2009, yet I still know plenty of people using it today without any issue. I firmly believe that if an idea is good, it'll live on even if you've decided you're ready to do something else.
It occurs to me that I might be a bad open-source citizen - releasing way too early and walking away too early as well. If that's the case, then I expect well deserved criticism, but that's just not how I see the world at this point...
© Jay Fields - www.jayfields.com

Here's some code that works well for what I want. If it works well for what you want, great! If not, I'm willing to make changes that improve the library; however, I'm also going to reject any code that causes the library to bloat. Lastly, the library will likely be 'done' in the next few years - at which time I expect it will be mature enough that a stable final release will be possible, or someone will (re)write a superior version. I don't expect an open-source project will ever define what I accomplish in our industry.
It finally occurred to me that others don't think this way when they began telling me that they don't open-source due to - the code isn't mature enoughthey don't want to write documentationthey don't want their time monopolized by feature request emailsI can understand each point of view, but events have occurred in my career that have shaped my (differing) opinion.
I still remember my first open-source project: I didn't tell a soul about it until I had used it in production for over a year and was very confident that I'd addressed the majority of common use cases. It was a .net object relational mapper called NORM, and it was released in 2005. No, you haven't ever heard of it. I polished it for months, and no one cared. After that I never waited to release anything. I now believe that it's highly unlikely that whatever I create will ever gain any traction, so I might as well get it out there, fail quickly, and move on.
No one writes documentation for themselves, they write it for people who they hope will use their software - and very few people people ever gain anything from someone else using their open-source software. That simple equation makes documentation scarce; however, scarce documentation doesn't mean you can't open-source your software, it just means adoption rates will very likely be slowed.
Two years ago I open-sourced expectations with zero documentation, and documentation stayed at zero for at least a year. In that year very few people paid any attention to expectations; however, expectations does fit a sweet spot for some people, and some adoption did occur. Eventually, new adopters began to send pull requests with documentation, and their contributions inspired me to write some documentation of my own. It can be hard to get motivated about providing documentation to theoretical adopters; however, I got my code out there and adoption began, and the motivation came along with those (no longer theoretical) adopters.
If you end up lucky enough to create a project that is widely used, there's no doubt that you'll start getting swamped with email. In the beginning I expect everyone will be overjoyed with their success, and the added workload will be no big deal. However, I imagine over time it begins to feel like a second full-time job, and for what? Developer-fame doesn't get you closer to retirement any faster than watching grass-grow. However, I don't believe that should deter you from putting your work out there. Additionally, I think GitHub has changed the game with respect to moving on. If your project is on GitHub and you decide to call it quits tonight, there will probably be plenty of forks that are more than happy to take your place.
I have no qualms with walking away from projects, as I expect that if the idea is valuable, someone else will be happy to step up and take my place; furthermore, it's more likely that several people will step up and the strongest will survive - which is best for everyone. The best example I've ever seen of this behavior was Capistrano. Jamis Buck famously walked away from Cap in 2009, yet I still know plenty of people using it today without any issue. I firmly believe that if an idea is good, it'll live on even if you've decided you're ready to do something else.
It occurs to me that I might be a bad open-source citizen - releasing way too early and walking away too early as well. If that's the case, then I expect well deserved criticism, but that's just not how I see the world at this point...
© Jay Fields - www.jayfields.com
May 15, 2012
Agile Development with Clojure
 If you've ever spent any time learning Rails then you probably read one of the editions of Agile Web Development with Rails, and if you're like me (skeptical & pedantic) then you probably asked yourself: what the hell does Rails have to do with Agile development? At the time, I assumed that Dave and David were merely capitalizing on the buzz around Agile; however, even if that's the case, I think they did manage to highlight one of my favorite aspects to building websites with Rails: The ability to make a change, reload the page and see the results makes you a much more agile programmer - where 'agile' is defined as: Characterized by quickness, lightness, and ease of movement; nimble
If you've ever spent any time learning Rails then you probably read one of the editions of Agile Web Development with Rails, and if you're like me (skeptical & pedantic) then you probably asked yourself: what the hell does Rails have to do with Agile development? At the time, I assumed that Dave and David were merely capitalizing on the buzz around Agile; however, even if that's the case, I think they did manage to highlight one of my favorite aspects to building websites with Rails: The ability to make a change, reload the page and see the results makes you a much more agile programmer - where 'agile' is defined as: Characterized by quickness, lightness, and ease of movement; nimbleIt turns out, it's not very hard to get that same productivity advantage in Clojure as well. I would go so far as to say that the ability to change the server while it's running is assumed if you're using emacs+slime; however, what's not often mentioned is that it's also possible (and trivial) to reload your server code (while it's running) even if you're using IntelliJ, scripts, or anything else.
The majority of the servers I'm working on these days have some type of web UI; therefore, I tie my server side code reloading to a page load. Specifically, each time a websocket is opened the server reloads all of the namespaces that I haven't chosen to ignore. The code below can be found in pretty much every Clojure application that I work on.
(defonce ignored-namespaces (atom #{}))
(defn reload-all []
(doseq [n (remove (comp @ignored-namespaces ns-name) (all-ns))]
(require (ns-name n) :reload )))
Like I said, when I open a new websocket, I call (reload-all); however, the (reload-all) fn can be called on any event. When discussing this idea internally at DRW, Joe Walnes pointed out that you could also watch the file system and auto-reload on any changes. That's true, and the important take-away is that you can easily become more productive simply by finding the appropriate hook for what you're working on, and using the code above.
The ignored-namespaces are important for not reloading namespaces that don't ever need to be reloaded (user); other times you'll have a namespace that doesn't behave properly if it's reloaded (e.g. I've found a record + protocol issue in the past, so I don't dynamically reload defrecords in general).
The change-reload webpage-test loop is nice for making changes and seeing the results very quickly - and I strongly prefer it to having to stop and start servers to see new functionality.
© Jay Fields - www.jayfields.com


May 9, 2012
Follow-up Thoughts on Aligning Business & Programmer Goals
My recent entry on Aligning Business & Programmer Goals led to an email conversation that I thought might be worth sharing.
From A. Nonymous:
A. Nonymous followed up with:
© Jay Fields - www.jayfields.com

From A. Nonymous:
My response:
I have an issue with tying bonuses to performance due to, basically, performance being out of the
programmer's hands. Where I'm working right now developers are treated
as code monkeys: We're there to implement features the business people
dream up, and nothing more. How could I provide more value
when I work in an environment whereThe visual
design phase has already happened (no pushback on any design elements
taken seriously) The business development phase has already happened (i.e. the business
decides to create a new service tells it's code monkeys: "we need feature x, y, and z")
The individual
projects we're working on is out of our control.
I can't figure out how to tie what I do to business value in the short
term (or even in the year-long-term), because I don't have the
autonomy to work on things that I think would benefit the business.
I'm forced to do the work that someone else assigns me.
Are the new features/bug fixes creating value? Definitely.
How much value? Not a clue. How can the value I bring be measured? The only metric I'm
seeing is "ease of implementing the next new feature", but the next
feature that touches the code I wrote probably won't be developed for
months, if not years.
So, it doesn't seem justified to assign me a bonus based on the value that
features create, when I have no control over the features.
Given your context, I wouldn't want a bonus either. I imagine
that many people are in the same situation... probably most people.
2 notes-
The blog entry isn't solely about bonuses, the ending is all about a
visible P&L and nothing about a bonus. I hope people don't completely
miss that point.
While your position is status quo, I think we should strive to do
better as an industry. I don't think it's healthy that we (programmers
in general, not necessarily you or me) work for organizations where we
know little about the business, don't trust our business counterparts,
and are not trusted by our business counterparts. Programmers are
often ruthless about measurement and improvement, and wasting that
effort on resume driven development or process tweaks is bad for our
businesses and our reputations.
It's easy for me to say that the good programmers should quit
companies that don't expose a P&L and don't empower their programmers,
but I know that personal situations can limit people's choices. At the
same time, I feel good about continuing to write about the path that I
take, which includes quitting companies that I don't feel are aligned.
Even if my ideas can't help you at this point; hopefully, something
will come of them in the future.
A. Nonymous followed up with:
I totally get the visible P&L part and agree with you on it. HavingAnd, my final response:
more visibility into the inner workings of the business can only help
focus effort where it's important. Not every business leader feels
that way, unfortunately. I'm currently fighting with my boss about a similar issue.
I alluded to it before, but he wants to
follow what many consultancies are now calling "Agile":analyst meets with business team
analyst comes up with featuresqa writes acceptance test for features
developer receives/estimates/completes featuresAt no point
in this process does the developer have any contact with the business
team.
Do you have any idea how I'd go about convincing
upper management that sharing the P&L would be a good idea?
While A. Nonymous may never get to see the P&L, and may never be in a situation where we would want a bonus - there are steps that can be taken to align the business & the programmers.
I've never seen studies on the impact of sharing the P&L. Most of the
discussion around this stuff is still in it's infancy as far as I can
tell. Brian Goetz has been talking about 'language & framework
introduction' for awhile, but I've never heard it combined with P&L.
I would attack your situation in one of the two following ways-
Fully support your boss' plan, but request to be put on a 'research'
or 'experimental' team where you interact directly with the business
on a new product (assuming that's possible). I've done this
successfully. The rest of IT followed the traditional approach that
your boss is proposing, but I broke off with 1 PM and we worked
directly with the business on technology for new business lines. I
never got to see P&L (though, I never asked), but I would get
requirements and deliver features on demand and we ended up constantly
impressing the business. e.g. "business: How quickly can you deliver
this? (I start thinking of my estimate) business: August? me:
(shocked, it was March) I was thinking in the next 2 weeks. -- that
conversation actually happened, I'll never forget it. If you get this
approved, your boss still gets to do what he wants, and you get to try
to do better. If you succeed, he can take the credit for approving the
experiment - win/win.
Assuming you cannot find a way to interact with the business,
focus all your efforts on reducing the delivery cycle. If he's going
to force the team to be basically skilled labor, you need to deliver
at a rapid enough pace that you fail quickly and pivot toward
profitable business goals. You build, they point you in a better
direction, you build, they point you in a better direction, on and on.
Your 'interaction' with the business is delivering them software, and
you will benefit from doing that as often as possible. So, focus on
things like choosing the best tools for the job, getting the build
time down, reducing the test running time, etc, etc. Anything that's
slowing you down from delivering faster, it's in your best interest to
remove that, so you can get the business feedback as fast as possible.
Even if your boss forced you to only do a roll-out monthly (or worse),
the more you have to roll-out, the more feedback you'll get - so
removing any thing that takes your time and isn't contributing to
feature delivery. Dan Bodart is doing interesting stuff with build
times and you should be able to find plenty of advice on speeding up tests -
attack that stuff so you deliver as much to the business as possible.
© Jay Fields - www.jayfields.com
May 7, 2012
Clojure: Conditionally Importing
I recently ran into a test that needed (org.joda.time.DateTime.) to always return the same time - so it could easily be asserted against. This situation is fairly common, so it makes sense to add support to expectations. However, I didn't want to force a joda-time dependency on everyone who wanted to use expectations. Luckily, Clojure gives me the ability to conditionally import dependencies.
The test looked something like the following code snippet.
(scenario
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 1335758400000} (in (first @fills))))
note: build is a fn that creates domain objects (I do a lot of Java Interop).
The test builds a PartialFill domain object, and passes it to handle-fill. The handle-fill fn converts the domain object to a map and conj's the new map onto the fills vector (which is an atom).
The build fn creates a PartialFill who's time is (DateTime.), which means you can either not test the time or you need to freeze the time. Joda time makes it easy to freeze time by calling DateTimeUtils/setCurrentMillisFixed, so you could write the test as:
(scenario
(DateTimeUtils/setCurrentMillisFixed 100)
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 100} (in (first @fills)))
(DateTimeUtils/setCurrentMillisSystem))
Of course, that would cause issues if expect ever failed, as failure throws an exception and the time reset would never occur. Even if that wasn't the case, the time related code takes away from what I'm really testing - so I set out to create a declarative approach from within expectations.
The syntax for the freezing time is fairly straightforward, and the original test can be written as what follows (with expectations 1.4.3 & up)
(scenario
:freeze-time "2012-4-30"
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 1335758400000} (in (first @fills))))
Writing the code to freeze time with expectations is trivial enough, but it's only relevant if you actually use joda-time. Since not everyone uses joda-time, it seemed like the best option was to make expectations import joda only if you actually use :freeze-time within your code.
The code linked here shows the conditional imports: https://github.com/jaycfields/expectations/blob/f2a8687/src/clojure/expectations/scenarios.clj#L81-L86
Even if you're not familiar with macros it should be obvious that I'm importing and using the joda-time classes conditionally. At macro expansion time I'm checking for the presence of freeze-time, and if it does exist the necessary classes are imported. If freeze-time is never found, the joda-time classes will never be imported, and no joda-time dependency will need to live within your project.
I always assumed this would be possible, but I'd never actually attempted to put this type of code together. I'm definitely happy with how the code turned out - I can freeze time in expectations if I want, but I don't force anyone to use joda.
© Jay Fields - www.jayfields.com

The test looked something like the following code snippet.
(scenario
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 1335758400000} (in (first @fills))))
note: build is a fn that creates domain objects (I do a lot of Java Interop).
The test builds a PartialFill domain object, and passes it to handle-fill. The handle-fill fn converts the domain object to a map and conj's the new map onto the fills vector (which is an atom).
The build fn creates a PartialFill who's time is (DateTime.), which means you can either not test the time or you need to freeze the time. Joda time makes it easy to freeze time by calling DateTimeUtils/setCurrentMillisFixed, so you could write the test as:
(scenario
(DateTimeUtils/setCurrentMillisFixed 100)
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 100} (in (first @fills)))
(DateTimeUtils/setCurrentMillisSystem))
Of course, that would cause issues if expect ever failed, as failure throws an exception and the time reset would never occur. Even if that wasn't the case, the time related code takes away from what I'm really testing - so I set out to create a declarative approach from within expectations.
The syntax for the freezing time is fairly straightforward, and the original test can be written as what follows (with expectations 1.4.3 & up)
(scenario
:freeze-time "2012-4-30"
(handle-fill (build PartialFill))
(expect {:px 10 :size 33 :time 1335758400000} (in (first @fills))))
Writing the code to freeze time with expectations is trivial enough, but it's only relevant if you actually use joda-time. Since not everyone uses joda-time, it seemed like the best option was to make expectations import joda only if you actually use :freeze-time within your code.
The code linked here shows the conditional imports: https://github.com/jaycfields/expectations/blob/f2a8687/src/clojure/expectations/scenarios.clj#L81-L86
Even if you're not familiar with macros it should be obvious that I'm importing and using the joda-time classes conditionally. At macro expansion time I'm checking for the presence of freeze-time, and if it does exist the necessary classes are imported. If freeze-time is never found, the joda-time classes will never be imported, and no joda-time dependency will need to live within your project.
I always assumed this would be possible, but I'd never actually attempted to put this type of code together. I'm definitely happy with how the code turned out - I can freeze time in expectations if I want, but I don't force anyone to use joda.
© Jay Fields - www.jayfields.com
April 9, 2012
Eval a Clojure Snippet in Java
The vast majority of the existing code for my current project is in Java, but the majority of the new code that we write is in Clojure; as a result, I spend quite a bit of time bouncing between Clojure & Java. Recently I was working with some Clojure code that was easily testable (in isolation) within Clojure, but was also executed as part of some higher-level Java integration tests. Within the Clojure tests I used with-redefs to temporarily set the state of a few atoms I cared about; however, setting the same state within the higher-level Java tests turned out to be a bit more of an interesting task.
Our Java integration tests, like all integration tests I've ever run into, look simple enough when looking at the code of the test; however, if you want to understand how the simple test exercises several collaborations you'll need to dig deep into the bowels of the integration test helpers. Integration test helpers are usually a very fragile combination of classes that stub behavior, classes with preloaded fake datasets, and classes that provide event triggering hooks. In my experience you also generally need the High-Level Test Whisperer on hand to answer any questions, and you generally don't want to make any changes without asking for the HLTW's assistance.
Today's experience went exactly as I expect all of my experiences with the functional tests to go:
I added a bit of behavior, and tested everything that I thought was worth testing. With all the new tests passing, I ran the entire suite - 85 errors. The nice thing about errors in functional tests: they generally cause all of the functional tests to break in an area of code that you know you weren't working in. I wasn't that surprised that so many tests had broken, I was adding a bit of code into a core area of our application. However, I wasn't really interested in testing my new behavior via the functional tests, so I quickly looked for the easiest thing I could do to make the functional tests unaware of my change. The solution was simple enough, conceptually, the new code only ran if specific values were set within the atom in my new namespace; therefore, all I needed to do was clear that atom before the functional tests were executed.
Calling Clojure from Java is easy, so I set out to grab the atom from the Clojure and swap! + dissoc the values I cared about. Getting the atom in Java was simple enough, and clojure.lang.Atom has a swap() method, but it takes an IFn. I spent a few minutes looking at passing in a IFn that dissoc'd correctly for me; however, when nothing was painfully obvious I took a step back and considered an easier solution: eval.
As I previously mentioned, this is not only test code, but it's test code that I already expect to take a bit longer to run**. Given that context, eval seemed like an easy choice for solving my issue. The following code isn't pretty, but it got done exactly what I was looking for.RT.var("clojure.core", "eval").invoke(
RT.var("clojure.core","read-string").invoke("(swap! my-ns/my-atom dissoc :a-key)"));I wasn't done yet, as I still needed the HLTW's help on getting everything to play nice together; however, that little Clojure snippet got me 90% of what I needed to get my behavior out of the way of the existing functional tests. I wouldn't recommend doing something like that in prod, but for what I needed it worked perfectly.
** let's not get carried away, the entire suite still runs in 20 secs. That's not crazy fast, but I'm satisfied for now.
© Jay Fields - www.jayfields.com

Our Java integration tests, like all integration tests I've ever run into, look simple enough when looking at the code of the test; however, if you want to understand how the simple test exercises several collaborations you'll need to dig deep into the bowels of the integration test helpers. Integration test helpers are usually a very fragile combination of classes that stub behavior, classes with preloaded fake datasets, and classes that provide event triggering hooks. In my experience you also generally need the High-Level Test Whisperer on hand to answer any questions, and you generally don't want to make any changes without asking for the HLTW's assistance.
Today's experience went exactly as I expect all of my experiences with the functional tests to go:
I added a bit of behavior, and tested everything that I thought was worth testing. With all the new tests passing, I ran the entire suite - 85 errors. The nice thing about errors in functional tests: they generally cause all of the functional tests to break in an area of code that you know you weren't working in. I wasn't that surprised that so many tests had broken, I was adding a bit of code into a core area of our application. However, I wasn't really interested in testing my new behavior via the functional tests, so I quickly looked for the easiest thing I could do to make the functional tests unaware of my change. The solution was simple enough, conceptually, the new code only ran if specific values were set within the atom in my new namespace; therefore, all I needed to do was clear that atom before the functional tests were executed.
Calling Clojure from Java is easy, so I set out to grab the atom from the Clojure and swap! + dissoc the values I cared about. Getting the atom in Java was simple enough, and clojure.lang.Atom has a swap() method, but it takes an IFn. I spent a few minutes looking at passing in a IFn that dissoc'd correctly for me; however, when nothing was painfully obvious I took a step back and considered an easier solution: eval.
As I previously mentioned, this is not only test code, but it's test code that I already expect to take a bit longer to run**. Given that context, eval seemed like an easy choice for solving my issue. The following code isn't pretty, but it got done exactly what I was looking for.RT.var("clojure.core", "eval").invoke(
RT.var("clojure.core","read-string").invoke("(swap! my-ns/my-atom dissoc :a-key)"));I wasn't done yet, as I still needed the HLTW's help on getting everything to play nice together; however, that little Clojure snippet got me 90% of what I needed to get my behavior out of the way of the existing functional tests. I wouldn't recommend doing something like that in prod, but for what I needed it worked perfectly.
** let's not get carried away, the entire suite still runs in 20 secs. That's not crazy fast, but I'm satisfied for now.
© Jay Fields - www.jayfields.com
March 4, 2012
When to Break Apart your Application
At speakerconf Aruba 2012, Stefan Tilkov presented on the topic of building Systems. One aspect of his presentation that really struck a chord with me was around the competing desires while designing and delivering an application. This blog entry is about summarizing that aspect and what I took away from it.**

Stefan noted that early in an application's life, a monolithic application is far easier to deliver; however, as the application grows, what is important begins to change. The slide to the right shows how priorities can change over time.
While starting with a monolithic application is easier to deliver, that application often grows to an unmaintainable size - i.e. the vast majority of the time we boil the frog. Stefan argued that the benefits are so obviously there that for an application of any moderate size it's more efficient to bite the bullet and break things up (where logical) in the beginning.
I'm guessing the vast majority of the applications that Stefan and innoQ encounter probably began knowing that they would grow to significant size and would have benefited from any type of modularization, but my working environment is a bit different. When I start something new for a trader at DRW -
the project may never grow to the unmaintainable size
if it does, it's likely that I'll want things broken up in a way that I couldn't have anticipated when the project began.
Given my context, I couldn't conclude that things should be broken up immediately, but I didn't want to ignore the point that Stefan was making about goals changing over time.

Stefan also had a slide about Modularization (also on the right) that gave numbers and recommendations on how to break things up. This slide reminded me of Matt Deiters' presentation at speakerconf Rome 2011. Matt told us about his experience teaching kids in Africa to program. While teaching programming, Matt observed that giving the children the single rule that they shouldn't have methods longer than 10 lines resulted in the children writing code with SRP, encapsulation, and other positive attributes. Matt argued that beginning with a simple rule that could get you 80% of what you want is likely better than 10 rules that, if followed correctly, could get you 100% of what you want.
I applied Matt's idea to Stefan's talk and suggested that perhaps the easiest thing was to take Stefan's modularization table and strictly adhere to changing things when LOC thresholds are broken. This would allow you to quickly deliver a monolithic application early in the development process, while avoiding boiling the frog in the future - once you cross the agreed upon magic number (LoC) then you aggressively address breaking the application into smaller and independent modules/processes/components/projects/whatever.
This strategy gives a nod to the fact that priorities do change as an application evolves and it's best to evolve the application along with those priorities, but not when it's too late. I plan to try this on my next greenfield application.
** I'm going from memory, so I could be slightly off. Don't hold Stefan accountable for my interpretation of his ideas.
© Jay Fields - www.jayfields.com

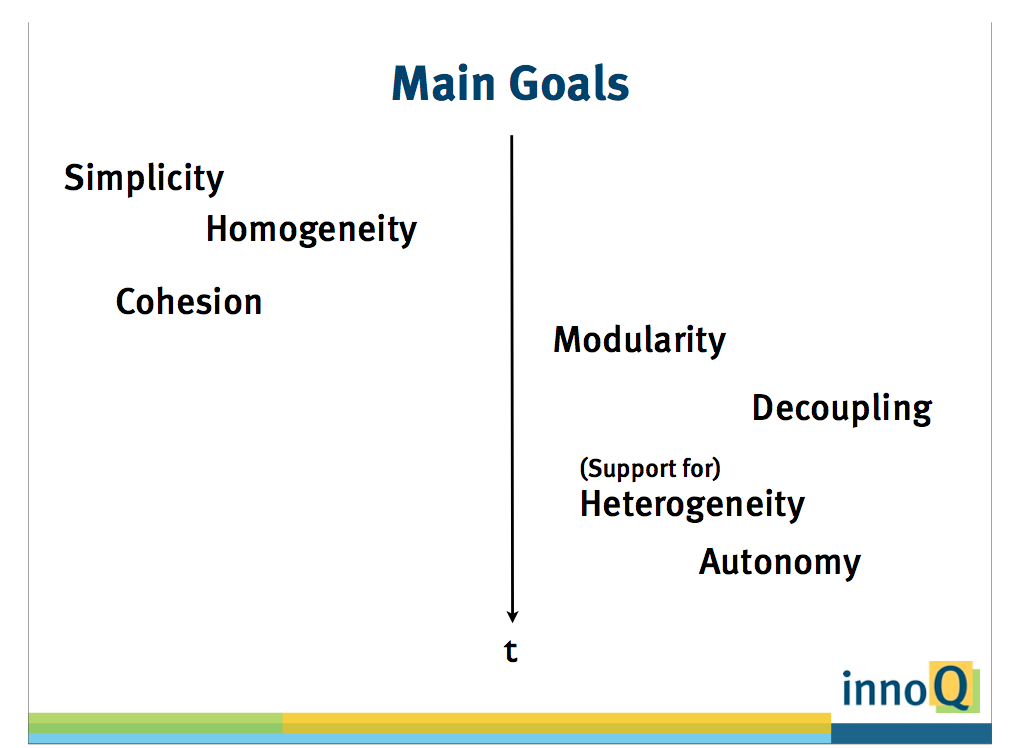
Stefan noted that early in an application's life, a monolithic application is far easier to deliver; however, as the application grows, what is important begins to change. The slide to the right shows how priorities can change over time.
While starting with a monolithic application is easier to deliver, that application often grows to an unmaintainable size - i.e. the vast majority of the time we boil the frog. Stefan argued that the benefits are so obviously there that for an application of any moderate size it's more efficient to bite the bullet and break things up (where logical) in the beginning.
I'm guessing the vast majority of the applications that Stefan and innoQ encounter probably began knowing that they would grow to significant size and would have benefited from any type of modularization, but my working environment is a bit different. When I start something new for a trader at DRW -
the project may never grow to the unmaintainable size
if it does, it's likely that I'll want things broken up in a way that I couldn't have anticipated when the project began.
Given my context, I couldn't conclude that things should be broken up immediately, but I didn't want to ignore the point that Stefan was making about goals changing over time.
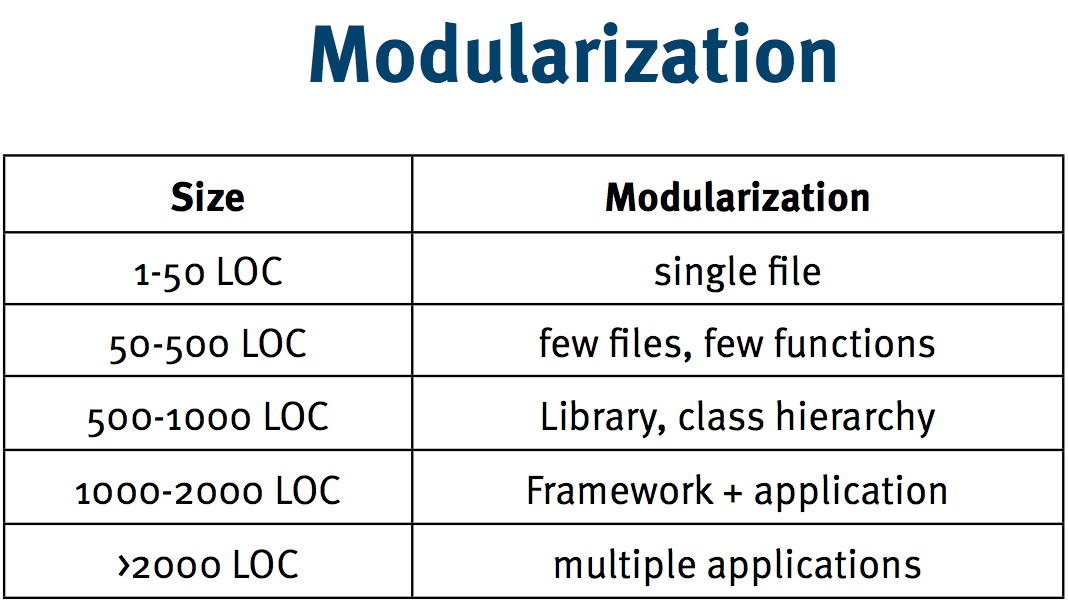
Stefan also had a slide about Modularization (also on the right) that gave numbers and recommendations on how to break things up. This slide reminded me of Matt Deiters' presentation at speakerconf Rome 2011. Matt told us about his experience teaching kids in Africa to program. While teaching programming, Matt observed that giving the children the single rule that they shouldn't have methods longer than 10 lines resulted in the children writing code with SRP, encapsulation, and other positive attributes. Matt argued that beginning with a simple rule that could get you 80% of what you want is likely better than 10 rules that, if followed correctly, could get you 100% of what you want.
I applied Matt's idea to Stefan's talk and suggested that perhaps the easiest thing was to take Stefan's modularization table and strictly adhere to changing things when LOC thresholds are broken. This would allow you to quickly deliver a monolithic application early in the development process, while avoiding boiling the frog in the future - once you cross the agreed upon magic number (LoC) then you aggressively address breaking the application into smaller and independent modules/processes/components/projects/whatever.
This strategy gives a nod to the fact that priorities do change as an application evolves and it's best to evolve the application along with those priorities, but not when it's too late. I plan to try this on my next greenfield application.
** I'm going from memory, so I could be slightly off. Don't hold Stefan accountable for my interpretation of his ideas.
© Jay Fields - www.jayfields.com
February 28, 2012
Aligning Business & Programmer Goals
A theme emerged, last week at speakerconf, around the idea that programmers and businesses still don't seem to be on the same page. I'm not sure if it came up even earlier, but for me it began after I gave a presentation on Lessons Learned Adopting Clojure. The talk is similar to Lessons Learned while Introducing a New Programming Language, but focuses more on the technical aspects of selecting Clojure. Upon talk completion the first question I got was from Brian Goetz, something along the lines of:
I answered somewhat noncommittally, along the lines of: While selecting a language, I chose one that I felt anyone in DRW could easily learn and use. Additionally, I selected a language that aligned with our business goals of developing software quickly and delivering applications that performed at the speeds required by the traders. And, if not the man on the ground, who is better suited for selecting languages to introduce into production?
Brian followed up with:
These are truly great questions, and no one had a great response. The discussion basically died off as we pondered the tough answers to these questions.
At lunch the next day I asked Brian how he thought companies should go about selecting languages, and I think his response was spot-on (again, going from memory, so likely misquoting): I'm not sure, but I sure do see a lot of developers introducing whatever language or framework they want, leaving within a year, and sticking their employer with a big maintenance problem. The same can be said for consultants. They often show up advocating a sexy new language, mostly deliver a new application and then leave the company with an application that can't be maintained by the existing full-time staff.
Someone quickly spoke up, stating that Resume Driven Development has been going on for years. I can't argue with that, but I did have a different perspective.
A few years ago I joined DRW, and a substantial portion of my salary became bonus money. I had previously worked in places where getting bonus money was about as likely as meeting your future wife at a JavaOne, so I was obviously skeptical. Luckily, I had a friend who already worked for DRW; he reassured me that, in finance, having a bonus as part of your compensation was common, and so was it actually getting paid. I took the job, and instantly my performance at work was more directly tied to my income. I'm sure this reality influenced my decision making, and I witnessed the difference in the decisions my colleagues were making. When people spoke about using/upgrading frameworks/libraries, we didn't talk about what was cool, we discussed the risks of breaking things, the outstanding bugs with the framework/lib, and the immediate value that the inclusion would provide.
Given this experience, I advocated to the other speakerconf presenters that bonuses are a potential solution to combatting Resume Driven Development. The other speakerconf presenters gave me the same response I generally get when advocating bonuses for programmers: That works for you and your trading firm, but most people can't directly tie what they do to how the business makes money. I'm always skeptical of this response for 2 reasons: The business must be able to track whether or not their new idea is making them money, or, if the new software isn't targeted to an external customer, then it should be able to be rated by internal customers. Also, shouldn't the CTO or the Director of Software be able to make an informed bonus decision by either directly interacting with the teams, or trusting the feedback of the managers of those teams?
I guess, if you can't tie what you are doing to the value it's providing the company, and you don't trust your managers to give an accurate assessment, building your resume is probably the best use of your time... and the results aren't very surprising... but, I digress.
I gave the same response I've given a few dozen times: I just don't buy it. You should be able to see how many new customers your new website generated, or less cancellations, new reservations, policy efficiency, auction traffic, add-on sales purchased, etc. Each of the projects I've worked on for the past 8 years could generate metrics that I would have been happy to tie to a bonus. In our back-office, it's harder to tie the value of a back office system to an individual trade; however, we can capture metrics on uptime, latency, and any other attribute that we deem important to the internal systems that are customers of the back office systems.
If you want to measure your value and you trust your management, receiving part of your salary as a bonus is completely viable.
Aligning the goals of the business and the programmers came up again when the afternoon presentations began. Joshua Kerievsky is looking to tackle this same issue at Industrial Logic. Joshua's presentation discussed bridging the gap between managers and programmers, which is a more general version of the same conversation we'd been having about language adoption. Bridging this gap is something he's begun focusing on at Industrial Logic. The benefits are obvious for customers, they should receive higher quality and more relevant software. However, it's not just about customers, the programmers will be more effective and should also have higher job satisfaction rates. No one likes being stuck on yet another, doomed to fail, misguided project using outdated technology. Both parties should benefit by unifying the goals of the programmer and the business.
Josh knew my opinion on using bonuses to help align both parties; however, he and I both incorrectly assumed that the developers at Forward also received business performance based bonuses. I believe that they have some things in the works and situations can vary, but Fred George made it clear that in general a bonus is not tied to business focus. That's fairly standard, but what makes Forward unique is that the business works very, very closely with the programmers. I think Fred nicely summed up the situation: Our programmers are gamers, and we show them the P&L. They want to see that number grow, even if it doesn't directly deposit in their account.
Fred's statement rang very true to me. I've had jobs in the past where I didn't even have a bonus, but the ones that I felt most dedicated to were the ones where I was given visibility into the business. If I can't see the outcome of my programming choices to the business, I'll have a much harder time iterating towards success - worse, I won't even know at what level we are failing and I'll lack the motivation that the failure would provide me.
At the end of the day, programmers like to measure and improve. If you give them a P&L and let them know that it's the most important thing, they'll do whatever they can to help. If you don't give them a P&L they'll focus on making other metrics more efficient. This may include using new technologies to inspire more blog entires, spending hours unnecessarily tweaking the development process, or any other way of measuring their "success." The answer is obvious, let the programmers measure success the same way the business does, using the bottom line. What's not always obvious is how to properly share that information; however, all the discussion at speakerconf definitely convinced me that it's worth solving this issue even if it requires a bit of extra effort.
© Jay Fields - www.jayfields.com

The first response to the question was the obvious and appropriate one:
(Brian) So, you wanted to use another language and simply introduced it into production?
(me) More or less.
(Brian) Do you think that's the most effective way for organizations to select languages or frameworks?
That sounds better than a CTO making a decision while drunk and on a golf-course with a vendor. -- Josh GrahamOf course, I agree with that response, but that doesn't mean that my choice was the best answer either. The question is actually something I've been struggling with for awhile. At speakerconf Aruba 2011, Lyle (DRW CTO) gave a presentation on how we do things at DRW. One of Lyle's slides listed each language that we use in production at DRW. There were a lot of languages, probably around 25, and Dave Thomas questioned whether it was a positive or a maintenance nightmare. The answer today is the same as it was then, so far the ROI is positive - but, I couldn't help feeling uneasy about the situation.
I answered somewhat noncommittally, along the lines of: While selecting a language, I chose one that I felt anyone in DRW could easily learn and use. Additionally, I selected a language that aligned with our business goals of developing software quickly and delivering applications that performed at the speeds required by the traders. And, if not the man on the ground, who is better suited for selecting languages to introduce into production?
Brian followed up with:
The point I was trying to get at was: how does this scale? If every developer chooses what is best for them, is that necessarily best for the organization? How do we balance between the business value of increasing individual productivity and the business value of reducing maintenance costs or development risk? If we have to make compromises to achieve better scale, who should make these decisions, and how?
The usual developer argument -- "this is more productive for me, and increasing my productivity is good for the company" is good as far as it goes, but most developers incorrectly assume these interests are 100% aligned when they are in reality probably only merely overlapping.
These are truly great questions, and no one had a great response. The discussion basically died off as we pondered the tough answers to these questions.
At lunch the next day I asked Brian how he thought companies should go about selecting languages, and I think his response was spot-on (again, going from memory, so likely misquoting): I'm not sure, but I sure do see a lot of developers introducing whatever language or framework they want, leaving within a year, and sticking their employer with a big maintenance problem. The same can be said for consultants. They often show up advocating a sexy new language, mostly deliver a new application and then leave the company with an application that can't be maintained by the existing full-time staff.
Someone quickly spoke up, stating that Resume Driven Development has been going on for years. I can't argue with that, but I did have a different perspective.
A few years ago I joined DRW, and a substantial portion of my salary became bonus money. I had previously worked in places where getting bonus money was about as likely as meeting your future wife at a JavaOne, so I was obviously skeptical. Luckily, I had a friend who already worked for DRW; he reassured me that, in finance, having a bonus as part of your compensation was common, and so was it actually getting paid. I took the job, and instantly my performance at work was more directly tied to my income. I'm sure this reality influenced my decision making, and I witnessed the difference in the decisions my colleagues were making. When people spoke about using/upgrading frameworks/libraries, we didn't talk about what was cool, we discussed the risks of breaking things, the outstanding bugs with the framework/lib, and the immediate value that the inclusion would provide.
Given this experience, I advocated to the other speakerconf presenters that bonuses are a potential solution to combatting Resume Driven Development. The other speakerconf presenters gave me the same response I generally get when advocating bonuses for programmers: That works for you and your trading firm, but most people can't directly tie what they do to how the business makes money. I'm always skeptical of this response for 2 reasons: The business must be able to track whether or not their new idea is making them money, or, if the new software isn't targeted to an external customer, then it should be able to be rated by internal customers. Also, shouldn't the CTO or the Director of Software be able to make an informed bonus decision by either directly interacting with the teams, or trusting the feedback of the managers of those teams?
I guess, if you can't tie what you are doing to the value it's providing the company, and you don't trust your managers to give an accurate assessment, building your resume is probably the best use of your time... and the results aren't very surprising... but, I digress.
I gave the same response I've given a few dozen times: I just don't buy it. You should be able to see how many new customers your new website generated, or less cancellations, new reservations, policy efficiency, auction traffic, add-on sales purchased, etc. Each of the projects I've worked on for the past 8 years could generate metrics that I would have been happy to tie to a bonus. In our back-office, it's harder to tie the value of a back office system to an individual trade; however, we can capture metrics on uptime, latency, and any other attribute that we deem important to the internal systems that are customers of the back office systems.
If you want to measure your value and you trust your management, receiving part of your salary as a bonus is completely viable.
Aligning the goals of the business and the programmers came up again when the afternoon presentations began. Joshua Kerievsky is looking to tackle this same issue at Industrial Logic. Joshua's presentation discussed bridging the gap between managers and programmers, which is a more general version of the same conversation we'd been having about language adoption. Bridging this gap is something he's begun focusing on at Industrial Logic. The benefits are obvious for customers, they should receive higher quality and more relevant software. However, it's not just about customers, the programmers will be more effective and should also have higher job satisfaction rates. No one likes being stuck on yet another, doomed to fail, misguided project using outdated technology. Both parties should benefit by unifying the goals of the programmer and the business.
Josh knew my opinion on using bonuses to help align both parties; however, he and I both incorrectly assumed that the developers at Forward also received business performance based bonuses. I believe that they have some things in the works and situations can vary, but Fred George made it clear that in general a bonus is not tied to business focus. That's fairly standard, but what makes Forward unique is that the business works very, very closely with the programmers. I think Fred nicely summed up the situation: Our programmers are gamers, and we show them the P&L. They want to see that number grow, even if it doesn't directly deposit in their account.
Fred's statement rang very true to me. I've had jobs in the past where I didn't even have a bonus, but the ones that I felt most dedicated to were the ones where I was given visibility into the business. If I can't see the outcome of my programming choices to the business, I'll have a much harder time iterating towards success - worse, I won't even know at what level we are failing and I'll lack the motivation that the failure would provide me.
At the end of the day, programmers like to measure and improve. If you give them a P&L and let them know that it's the most important thing, they'll do whatever they can to help. If you don't give them a P&L they'll focus on making other metrics more efficient. This may include using new technologies to inspire more blog entires, spending hours unnecessarily tweaking the development process, or any other way of measuring their "success." The answer is obvious, let the programmers measure success the same way the business does, using the bottom line. What's not always obvious is how to properly share that information; however, all the discussion at speakerconf definitely convinced me that it's worth solving this issue even if it requires a bit of extra effort.
© Jay Fields - www.jayfields.com
February 15, 2012
How To Get Invited To speakerconf
Every year it seems that someone is disappointed (or even insulted) that they didn't receive an invite to speakerconf. If you haven't gotten an invite at this point, contrary to popular belief, it's not because Josh and I hate you. There's actually very little magic that goes into receiving a speakerconf invite, so it probably makes sense to put the formula out there.
I'm not a big fan of receiving spam, and while I consider speakerconf to be a great event, I'm sure some people will consider speakerconf related email to be spam. With that in mind, I generally don't like to email people I don't know out of the blue. Along the same lines, some people are going to politely decline every invite I send their way. The less I know you, the less likely I am to continue inviting you, simply because I don't want to bother you. If you say to me "please keep me in mind in the future," I will. If you don't, I'll likely default on the safe side of not bothering you until you show some interest.
So, if you haven't gotten an invite lately (or ever) it's likely only because I don't want to bother you.
With that out of the way, here's roughly how we select who to invite to speakerconf:
speakerconf needs sponsors to run in the way that Josh and I want to run it. If you've previously attended a speakerconf you can guarantee yourself an invite if your company is willing to become a sponsor. If you've never attended a speakerconf you can also guarantee yourself an invite by getting your company to become a sponsor and getting an endorsement from any one of the speakerconf alumni (list available at http://speakerconf.com/speakers). If you are interested in discussing specifics, drop me an email (jay@jayfields.com).
If you're not interested in sponsoring, your invite depends on space or endorsements. If you've previously attended a speakerconf and you'd like to return, all you need to do is let me know. If we have space at the next event, I'll gladly extend you an invite. If we don't have space, I'll extend you an invite to the following event.
Future speakerconf events will likely have a maximum number of 20 attendees. Approximately 15 spots will be reserved for alumni, and the remaining ~5 spots will be available to anyone who has never attended a speakerconf. If you would like to grab one of those spots, all you need to do is get as many alumni as you can to email me and endorse you. They don't need to send a long email, something as simple as "you should invite Josh Graham to the next speakerconf" will do. Then, approximately 6 months before an upcoming speakerconf I will invite the 5 most alumni endorsed new comers.
That's it. If you want to join us all you need to do is to utilize your network or become a sponsor. Hopefully this view into the invitation process will help avoid any disappointment in the future.
© Jay Fields - www.jayfields.com

I'm not a big fan of receiving spam, and while I consider speakerconf to be a great event, I'm sure some people will consider speakerconf related email to be spam. With that in mind, I generally don't like to email people I don't know out of the blue. Along the same lines, some people are going to politely decline every invite I send their way. The less I know you, the less likely I am to continue inviting you, simply because I don't want to bother you. If you say to me "please keep me in mind in the future," I will. If you don't, I'll likely default on the safe side of not bothering you until you show some interest.
So, if you haven't gotten an invite lately (or ever) it's likely only because I don't want to bother you.
With that out of the way, here's roughly how we select who to invite to speakerconf:
speakerconf needs sponsors to run in the way that Josh and I want to run it. If you've previously attended a speakerconf you can guarantee yourself an invite if your company is willing to become a sponsor. If you've never attended a speakerconf you can also guarantee yourself an invite by getting your company to become a sponsor and getting an endorsement from any one of the speakerconf alumni (list available at http://speakerconf.com/speakers). If you are interested in discussing specifics, drop me an email (jay@jayfields.com).
If you're not interested in sponsoring, your invite depends on space or endorsements. If you've previously attended a speakerconf and you'd like to return, all you need to do is let me know. If we have space at the next event, I'll gladly extend you an invite. If we don't have space, I'll extend you an invite to the following event.
Future speakerconf events will likely have a maximum number of 20 attendees. Approximately 15 spots will be reserved for alumni, and the remaining ~5 spots will be available to anyone who has never attended a speakerconf. If you would like to grab one of those spots, all you need to do is get as many alumni as you can to email me and endorse you. They don't need to send a long email, something as simple as "you should invite Josh Graham to the next speakerconf" will do. Then, approximately 6 months before an upcoming speakerconf I will invite the 5 most alumni endorsed new comers.
That's it. If you want to join us all you need to do is to utilize your network or become a sponsor. Hopefully this view into the invitation process will help avoid any disappointment in the future.
© Jay Fields - www.jayfields.com


