
Rasmus Lerdorf's Blog, page 2
January 10, 2010
SQLi Detection - Duh Moment
Not sure why it took me so long to figure out what I am sure is obvious to most other people who have thought about this, but it never clicked for me how to get anywhere near useful SQL Injection detection. The injection itself is trivial, of course, but determining whether it actually worked and weeding out false positives in an automated manner was something that seemed too hard.
During my run on Friday I had a Duh! moment on it. Annoyingly simple. Do it in 3 requests. Request #1 is a normal request. For example, "?id=1" in the URL. If the id is being passed to an SQL request it will return a single record or perhaps no record, it doesn't really matter. Now on request #2 do "?id=1 or 3=4", that is, inject a false 'OR' condition. If the output changes, we are done. Nothing to see here. However, if the output does not change we send request #3 with "?id=1 or 3=3" and if that output differs from request #2 then we have a potential SQLi situation. There are of course still chances of false positives (and negatives) with page stamps and such, but filtering out the response headers and html comments cuts down on that a bit. Add different combinations of single and double-quotes, like "?id=1'or'3'='3" (without the double-quotes, of course) and it might be able to catch something.
The best thing about it is that it can slide into an existing scanner framework quite easily. If you have a base reference request, then it just adds a single request to the common case where the false 'OR' condition output does not match the base reference. You only need to do the true 'OR' condition request in case it does match.
Anybody have any other approaches?
During my run on Friday I had a Duh! moment on it. Annoyingly simple. Do it in 3 requests. Request #1 is a normal request. For example, "?id=1" in the URL. If the id is being passed to an SQL request it will return a single record or perhaps no record, it doesn't really matter. Now on request #2 do "?id=1 or 3=4", that is, inject a false 'OR' condition. If the output changes, we are done. Nothing to see here. However, if the output does not change we send request #3 with "?id=1 or 3=3" and if that output differs from request #2 then we have a potential SQLi situation. There are of course still chances of false positives (and negatives) with page stamps and such, but filtering out the response headers and html comments cuts down on that a bit. Add different combinations of single and double-quotes, like "?id=1'or'3'='3" (without the double-quotes, of course) and it might be able to catch something.
The best thing about it is that it can slide into an existing scanner framework quite easily. If you have a base reference request, then it just adds a single request to the common case where the false 'OR' condition output does not match the base reference. You only need to do the true 'OR' condition request in case it does match.
Anybody have any other approaches?


September 24, 2009
Playing with Gearman
This was written in September 2009 when the current version of Gearman was 0.9.
Thanks to Eric Day for answering my dumb questions along the way.
To get started, install Gearman. I am on Debian, so this is what I installed:
% apt-get install gearman gearman-job-server gearman-tools libgearman1 libgearman-dev libdrizzle-dev
Enable Gearman in /etc/default/gearman-server
Set up Gearman to use MySQL for its persistent queue store in /etc/default/gearman-job-server
PARAMS="-q libdrizzle --libdrizzle-host=127.0.0.1 --libdrizzle-user=gearman \
--libdrizzle-password=your_pw --libdrizzle-db=gearman \
--libdrizzle-table=gearman_queue --libdrizzle-mysql"
% mysqladmin create gearman
% mysql
mysql> create USER gearman@localhost identified by 'your_pw';
mysql> GRANT ALL on gearman.* to gearman@localhost;
** Careful, if you are running MySQL using --old-passwords this won't work with libdrizzle.
You will need to get the 41-char password hash with a little snippet of PHP that does
the double sha1 encoding:
% php -r "echo '*'.strtoupper(sha1(sha1('your_pw',true)));"
% mysql
mysql> UPDATE mysql.user set Password='above_output' where User='gearman';
% mysqladmin flush-privileges
Continue reading "Playing with Gearman"
Thanks to Eric Day for answering my dumb questions along the way.
To get started, install Gearman. I am on Debian, so this is what I installed:
% apt-get install gearman gearman-job-server gearman-tools libgearman1 libgearman-dev libdrizzle-dev
Enable Gearman in /etc/default/gearman-server
Set up Gearman to use MySQL for its persistent queue store in /etc/default/gearman-job-server
PARAMS="-q libdrizzle --libdrizzle-host=127.0.0.1 --libdrizzle-user=gearman \
--libdrizzle-password=your_pw --libdrizzle-db=gearman \
--libdrizzle-table=gearman_queue --libdrizzle-mysql"
% mysqladmin create gearman
% mysql
mysql> create USER gearman@localhost identified by 'your_pw';
mysql> GRANT ALL on gearman.* to gearman@localhost;
** Careful, if you are running MySQL using --old-passwords this won't work with libdrizzle.
You will need to get the 41-char password hash with a little snippet of PHP that does
the double sha1 encoding:
% php -r "echo '*'.strtoupper(sha1(sha1('your_pw',true)));"
% mysql
mysql> UPDATE mysql.user set Password='above_output' where User='gearman';
% mysqladmin flush-privileges
Continue reading "Playing with Gearman"
April 27, 2009
Using pecl/oauth to post to Twitter
I have seen a lot of questions about OAuth and specifically how to do OAuth from PHP. We have a new pecl oauth extension written by which does a really good job simplifying OAuth.
I added Twitter support to Slowgeek.com the other day and it was extremely painless. The goal was to let users have a way to have Slowgeek send a tweet on their behalf when they have completed a Nike+ run. Here is a simplified description of what I did.
First, I needed to get the user to authorize Slowgeek to tweet on their behalf. This is done by asking Twitter for an access token and secret which will be stored on Slowgeek. This access token and secret will allow us to act on behalf of the user. This is made a bit easier by the fact that Twitter does not expire access tokens at this point, so I didn't need to worry about an access token refresh workflow.
Continue reading "Using pecl/oauth to post to Twitter"
I added Twitter support to Slowgeek.com the other day and it was extremely painless. The goal was to let users have a way to have Slowgeek send a tweet on their behalf when they have completed a Nike+ run. Here is a simplified description of what I did.
First, I needed to get the user to authorize Slowgeek to tweet on their behalf. This is done by asking Twitter for an access token and secret which will be stored on Slowgeek. This access token and secret will allow us to act on behalf of the user. This is made a bit easier by the fact that Twitter does not expire access tokens at this point, so I didn't need to worry about an access token refresh workflow.
Continue reading "Using pecl/oauth to post to Twitter"
March 19, 2009
Select * from World
I have been having a lot of fun with two Yahoo! technologies that have been evolving quickly. YQL and GeoPlanet. The first, YQL, puts an SQL-like interface on top of all the data on the Internet. And the second, GeoPlanet, introduces the concept of a WOEID (Where-On-Earth ID) that you can think of as a foreign key for your geo-related SQL expressions.
First some example YQL queries to get you used to this concept of treating the Internet like a database. Go to the YQL Console and paste these queries into the console to follow along.
select * from geo.places where text="SJC"
This looks up "SJC" in GeoPlanet and returns an XML result containing this information:
<woeid>12521722</woeid>
<placeTypeName code="14">Airport</placeTypeName>
<name>Norman Y Mineta San Jose International Airport</name>
<country code="US" type="Country">United States</country>
<admin1 code="US-CA" type="State">California</admin1>
<admin2 code="" type="County">Santa Clara</admin2>
<admin3/>
<locality1 type="Town">Downtown San Jose</locality1>
<locality2/>
<postal type="Zip Code">95110</postal>
<centroid>
<latitude>37.364079</latitude>
<longitude>-121.920662</longitude>
</centroid>
<boundingBox>
<southWest>
<latitude>37.35495</latitude>
<longitude>-121.932152</longitude>
</southWest>
<northEast>
<latitude>37.373211</latitude>
<longitude>-121.909172</longitude>
</northEast>
</boundingBox>
The first thing to note is the woeid. It is just an integer, but it uniquely identifies San Jose Airport. If you were to search for "San Jose Airport" instead of "SJC" you would find that one of the places returned has the exact same woeid. So, the woeid is a way to normalize placenames. The other thing to note here is that you get an approximate bounding box. This is what makes the woeid special. A place is more than just a lat/lon. If I told you that I would meet you in Paris next week, that doesn't tell you as much as if I told you that I would meet you at the Eiffel Tower next week. If we pretend that the Eiffel tower is in the center of Paris, those two locations might actually have the same lat/lon, but the concept of the Eiffel Tower is much more precise than the concept of Paris. The difference is the bounding box. And yes, landmarks like the Eiffel Tower or Central Park also have unique woeids. Try it:
select * from geo.places where text="Eiffel Tower"
Note that the YQL console also gives you a direct URL for the results. This last one is at http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20geo.places%20where%20text%3D%22Eiffel%20Tower%22&format=xml. Not the prettiest URL in the world, but you can feed that to a simple little PHP program to integrate these YQL queries in your PHP code. Something like this:
<?php
$url = "http://query.yahooapis.com/v1/public/...
$q = "select * from geo.places where text='Eiffel Tower'";
$fmt = "xml";
$x = simplexml_load_file($url.urlencode($q)."&format=$fmt");
?>
For a higher daily limit on your YQL queries you can grab an OAuth consumer key and use the OAuth-authenticated YQL entry point. There is an example of how to use pecl/oauth with YQL at http://paul.slowgeek.com/hacku/examples/yql-oath.php. Take a close look at the YQL query in that example. It is:
select * from html where xpath= '//tr//a[@href="http://toys.lerdorf.com/wiki/Capital_...'
and url in (select url from search.web where url like '%wikipedia%' and query='Denmark' limit 1)
Sub-selects! So, we do a web search for urls containing the string 'wikipedia' whose contents contains 'Denmark'. That is going to get us the Wikipedia page for Denmark. We then perform an xpath query on that page to extract the text of the link containing the name of the capital of Denmark. Change 'Denmark' in that query to any country and the query will magically return the capital of that country. So, YQL is also a general-purpose page scraper.
But back to the woeid. Places belong to other places, and they are next to other places and they contain even more places. That is, a place has a parent, siblings and children. You can query all of these. Here is a woeid explorer application written entirely in Javascript:
http://paul.slowgeek.com/hacku/examples/geoBoundingBoxTabs.html
Try entering some places or points of interest around the world and click on the various radio buttons and then the "Geo It" button to see the relationship between the places and the bounding boxes for all these various places. If you look at the source for this application you can see that it uses YQL's callback-json output, so there is no server-side component required to get this to work. Try doing a search for "Eiffel Tower" and turn on the "Sat" version of the map. You can see that the bounding box is pretty damn good. Try it for other landmarks. Then walk up the parent tree, or across the siblings. Or check out the Belongs-To data.
Once you have a woeid for a place, you can start using it on other services such as Upcoming:
select * from upcoming.events where woeid=2487956
and Flickr:
select * from flickr.photos.search where woe_id=2487956
(yes, I know, it would have been nice if the column names were consistent there)
And finally you can also add YQL support for any open API out there. There is a long list of them here:
http://github.com/spullara/yql-tables/tree/master
To use one of these, try something like this:
use 'http://github.com/spullara/yql-tables...' as yelp;
select * from yelp where term='pizza' and location='sunnyvale, ca' and ywsid='6L0Lc-yn1OKMkCKeXLD4lg'
As a bit of Geo and API nerd, this is super cool to me. I hope you can find some interesting things to do with this as well. If you build something cool with it, please let me know.
First some example YQL queries to get you used to this concept of treating the Internet like a database. Go to the YQL Console and paste these queries into the console to follow along.
select * from geo.places where text="SJC"
This looks up "SJC" in GeoPlanet and returns an XML result containing this information:
<woeid>12521722</woeid>
<placeTypeName code="14">Airport</placeTypeName>
<name>Norman Y Mineta San Jose International Airport</name>
<country code="US" type="Country">United States</country>
<admin1 code="US-CA" type="State">California</admin1>
<admin2 code="" type="County">Santa Clara</admin2>
<admin3/>
<locality1 type="Town">Downtown San Jose</locality1>
<locality2/>
<postal type="Zip Code">95110</postal>
<centroid>
<latitude>37.364079</latitude>
<longitude>-121.920662</longitude>
</centroid>
<boundingBox>
<southWest>
<latitude>37.35495</latitude>
<longitude>-121.932152</longitude>
</southWest>
<northEast>
<latitude>37.373211</latitude>
<longitude>-121.909172</longitude>
</northEast>
</boundingBox>
The first thing to note is the woeid. It is just an integer, but it uniquely identifies San Jose Airport. If you were to search for "San Jose Airport" instead of "SJC" you would find that one of the places returned has the exact same woeid. So, the woeid is a way to normalize placenames. The other thing to note here is that you get an approximate bounding box. This is what makes the woeid special. A place is more than just a lat/lon. If I told you that I would meet you in Paris next week, that doesn't tell you as much as if I told you that I would meet you at the Eiffel Tower next week. If we pretend that the Eiffel tower is in the center of Paris, those two locations might actually have the same lat/lon, but the concept of the Eiffel Tower is much more precise than the concept of Paris. The difference is the bounding box. And yes, landmarks like the Eiffel Tower or Central Park also have unique woeids. Try it:
select * from geo.places where text="Eiffel Tower"
Note that the YQL console also gives you a direct URL for the results. This last one is at http://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20geo.places%20where%20text%3D%22Eiffel%20Tower%22&format=xml. Not the prettiest URL in the world, but you can feed that to a simple little PHP program to integrate these YQL queries in your PHP code. Something like this:
<?php
$url = "http://query.yahooapis.com/v1/public/...
$q = "select * from geo.places where text='Eiffel Tower'";
$fmt = "xml";
$x = simplexml_load_file($url.urlencode($q)."&format=$fmt");
?>
For a higher daily limit on your YQL queries you can grab an OAuth consumer key and use the OAuth-authenticated YQL entry point. There is an example of how to use pecl/oauth with YQL at http://paul.slowgeek.com/hacku/examples/yql-oath.php. Take a close look at the YQL query in that example. It is:
select * from html where xpath= '//tr//a[@href="http://toys.lerdorf.com/wiki/Capital_...'
and url in (select url from search.web where url like '%wikipedia%' and query='Denmark' limit 1)
Sub-selects! So, we do a web search for urls containing the string 'wikipedia' whose contents contains 'Denmark'. That is going to get us the Wikipedia page for Denmark. We then perform an xpath query on that page to extract the text of the link containing the name of the capital of Denmark. Change 'Denmark' in that query to any country and the query will magically return the capital of that country. So, YQL is also a general-purpose page scraper.
But back to the woeid. Places belong to other places, and they are next to other places and they contain even more places. That is, a place has a parent, siblings and children. You can query all of these. Here is a woeid explorer application written entirely in Javascript:
http://paul.slowgeek.com/hacku/examples/geoBoundingBoxTabs.html
Try entering some places or points of interest around the world and click on the various radio buttons and then the "Geo It" button to see the relationship between the places and the bounding boxes for all these various places. If you look at the source for this application you can see that it uses YQL's callback-json output, so there is no server-side component required to get this to work. Try doing a search for "Eiffel Tower" and turn on the "Sat" version of the map. You can see that the bounding box is pretty damn good. Try it for other landmarks. Then walk up the parent tree, or across the siblings. Or check out the Belongs-To data.
Once you have a woeid for a place, you can start using it on other services such as Upcoming:
select * from upcoming.events where woeid=2487956
and Flickr:
select * from flickr.photos.search where woe_id=2487956
(yes, I know, it would have been nice if the column names were consistent there)
And finally you can also add YQL support for any open API out there. There is a long list of them here:
http://github.com/spullara/yql-tables/tree/master
To use one of these, try something like this:
use 'http://github.com/spullara/yql-tables...' as yelp;
select * from yelp where term='pizza' and location='sunnyvale, ca' and ywsid='6L0Lc-yn1OKMkCKeXLD4lg'
As a bit of Geo and API nerd, this is super cool to me. I hope you can find some interesting things to do with this as well. If you build something cool with it, please let me know.
May 8, 2008
SearchMonkey

One of the things I have been playing with lately is Yahoo!'s SearchMonkey project. It appeals to me on many different levels. The geeky name is a play on GreaseMonkey. But instead of writing plugins that run locally in the browser, SearchMonkey is a way to write plugins for the Yahoo! Search results page that change the appearance of the results themselves. Best explained with an example. Assume I am looking for a Japanese restaurant, and on my search results page I see:

That's ok, I guess. It tells me it is somewhere in Redwood City and that it is a neighborhood restaurant, whatever that means. Compare that to:

This gets me a real address and phone number plus a number of other useful bits of information. That is the first level SearchMonkey appeals to me on. The usefulness is obvious. My usefulness test is to see if I can explain it to my mother. Having her search for recipes and get pictures of dishes, ingredients and preparation times right on the search results page makes this an easy sell.
The second level this appeals to me on is the way it is implemented. Writing these SearchMonkey plugins becomes much simpler if the site you are writing the plugin for uses microformats of some sort. hCard, hCalendar, hReview, hAtom, xfn or generic structured eRDF or RDFa tags. The data can also be collected via a separate XML feed that can then be converted via XSLT in the SearchMonkey developer tool. The microformat data is collected and indexed and when you go to write a plugin and specify the url pattern you are writing the plugin for, it will find whatever indexed metadata it has for that url. If it doesn't have what you are looking for, you can still write a custom data scraper to get it, but that gets a bit more involved. I really like that the easy path is to add some sort of semantic markup to the pages. Yes, as Micah points out, this is not the (uppercase) Semantic Web, but it is still a push towards semantic markup. Having such a tangible and visible result of adding semantic tags is going to encourage people other than microformat geeks to do so. The more semantic markup we get, the better off the Web is.
The third part that appeals to me is the way the plugins are written. You write a little snippet of PHP. It is actually a method in a class you can't see, but its job is to return an associative array of data such as the title to display, the summary, extra links to show and whatever other key/value pairs you might want in the output. Because you have a full-featured scripting language available, you can write quite complicated logic in one of these plugins and pull whatever data you want from the site the plugin is written for.
You can also write an add-on to your plugin which is called an Infobar. It is a little bar that is shown below the plugin and from an Infobar you can access arbitrary external services. This example shows it well:
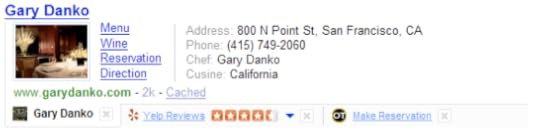
This one shows an OpenTable reservation link and a Yelp review, but almost anything can go there as long as you can squeeze it into the limited space you have.
The SearchMonkey is still in its infancy. It needs developer support. If you are in Silicon Valley, please come to the Developer Launch Party next week on Thursday May 15. See the link for details. If you aren't in the area, or even if you are, sign up for a developer account at http://developer.yahoo.com/searchmonkey/preview.html and help encourage the Web to become more semantic.
Rasmus Lerdorf's Blog

- Rasmus Lerdorf's profile
- 11 followers
Rasmus Lerdorf isn't a Goodreads Author
(yet),
but they
do have a blog,
so here are some recent posts imported from
their feed.

