
Jason Fried's Blog, page 4
April 28, 2020
Hiring programmers with a take-home test
There’s no perfect process for hiring great programmers, but there are plenty of terrible ways to screw it up. We’ve rejected the industry stables of grilling candidates in front of a whiteboard or needling them with brain teasers since the start at Basecamp. But you’re not getting around showing real code when applying for a job here.
In the early days of the company, we hired programmers almost exclusively from the open source community. I simply tapped people I’d been working with on the Ruby on Rails project, and I knew that their code would be good, because I’d seen so much of it! This is how we hired Jamis, Jeremy, Sam, Josh, Pratik, Matthew, and Eileen.
But if you only consider candidates from the open source community, you’re going to miss out on plenty of great programmers who just don’t have the time or the inclination to contribute code to open source.
And unfortunately, it’s rarely an option for candidates to submit code from a previous job with an application to a new job. Unlike design, which is at least somewhat out in the open, commercial code is often closely guarded. And even if it wasn’t, it’s often hard to tease out what someone was actually personally responsible for (which can also be a challenge with design!).
So what we’ve started to do instead at Basecamp is level the playing field by asking late-stage candidates to complete a small programming assignment as part of the final evaluation process. I’m going to show you two examples of these projects, and the submissions from the candidates that ended up being hired.
But first it’s important to recognize that we don’t ask applicants to do these assessments as part of their initial application. We simply get way too many applications for most openings to make that practical or fair. The last opening on the Research & Fidelity team got over 1,300 applications. Nobody can review that many code submissions!
So we whittle the group of candidates down aggressively first. This means judging their cover letter and, to a far lesser extent, their resume. For the opening we had on the Research & Fidelity team, we gave 40 people the take-home test, and even that proved to be too many. For the opening we had on the Security, Infrastructure & Performance team, we only gave 13 people the take-home test. That felt better. In the future, we’ll target fewer than 20 for sure.
Then there’s the assessment itself. I’ve heard many fair complaints that companies are asking candidates to complete massive projects that may take 20-30-40 hours of work, which is all unpaid, and which might be difficult for candidates to fit in with their existing job and life. Yeah, don’t do that. Asking someone for forty hours of work product, without pay, which might well go nowhere, is not what we do or advocate at Basecamp.
On the design side, we have asked candidates to complete more substantial projects, perhaps asking 10-20 hours of work, but then we pay them for the work. It’s like getting hired for a small freelance gig, even if you don’t get the job, and even if we’re never going to use the work.
But for programmers, we don’t need a project that large to get a good indication of someone’s programming skills or thought process. With both of the last two openings, we used assignment that were estimated to take 3-5 hours to complete.
That’s still a very substantial commitment! I wouldn’t ask anyone to submit such unpaid work without believing they were clearly in the running for the position. But when you look at our numbers, we usually don’t end up asking more than 1-3% of our applicants for such a commitment.
And it’s worth contrasting that against the work we’re not asking people to do. We don’t run candidates through some recruiter mill, where they have to do phone screening after phone screening. We don’t use any sort of automated tooling to scan resumes or whatever. We don’t even have people travel for interviews.
On our side, we often spend weeks perfecting the job opening itself. We put in an absolutely tremendous amount of work to conduct a fair, human, respectful, and thorough job search.
And the rules of the game are specified up front. You shouldn’t apply to a programming job at Basecamp unless you’re prepared to put in the work writing a considered, tailored cover letter, and then making the 3-5+ hours available to complete the programming assessment, if you make it into that top group of 1-3% of applicants.
The SIP assignment
Anyway, let’s take a look at these take-home assignments. The first is from our Security, Infrastructure & Performance team, and it was designed by Rosa. This was for a senior programmer opening. 13 applicants were asked to complete the assignment, and they were given a full week to do it (such that the estimated 3-5 hours could be spread out over several week nights or maybe the weekend).
It focused on a sliver of a real problem we’d been dealing with at Basecamp: Support for ban in rack-ratelimit. So it wasn’t some Tower of Hanoi abstract, computer-sciency test that you can look up a million solutions to, and which favor recent grads of CS algorithm courses. No, it was for implementing a feature in the same way you might well be asked to do on the job. There was a clear example of the API we wanted, and then candidates could solve it as they saw fit.
Jorge Manrubia, who we ended up hiring, submitted his solution as a full pull request –– complete with system tests and performance tests and documentation! It was a very comprehensive solution, but almost to a fault. I remember one of my concerns with Jorge’s submission was that it was borderline gold plated. We had several other submissions that were also wonderful, but far smaller, which could just as well had made for the final choice.
Jorge admitted to spending closer to 7-8 hours, in total, on his submission. We never policed this, because it really wasn’t a material part of the assessment. The solution would have been as compelling without all the extracurriculars, and several other candidates shone just as brightly with more modest submissions.
Which goes to a second point: Completing a programming assignment is required but insufficient to land a job at Basecamp. You can’t get hired without demonstrating a core competency in writing great code, but you also won’t get hired just because you can write great code alone.
The programming assessment simply unlocks the next step of the evaluation process. Out of the 13 candidates that received the programming assignment, 10 progressed to a first phone interview with Andrea (our head of people ops), then 6 progressed to interviews with the whole team, and finally 2 candidates got an extra interview to determine who we were going to hire.
The R&F assignment
For the programmer opening on our Research & Fidelity team, we followed a very similar process, but made the mistake of giving the programming assignment to too many people –– 40 in total. As discussed earlier, we should, and will in the future, cap that to 20 max.
This assignment was designed by Javan, and focused on another real-life sliver of the work we were doing on HEY: Enhance datalist autocomplete. The challenge came complete with the basic HTML form, and then directions on how to use JavaScript to enhance it to get us the universal autocomplete across the three major browsers.
Nabeelah Ali, who we ended up hiring here, submitted her solution with fewer flourishes than Jorge, but code no less impressive. Everything contained in a single page to make the solution work.
Like Jorge, Nabeelah also ended up spending more than the estimated 3-5 hours to complete the assignment. Somewhere around double there too. Much of that spent refactoring and polishing the solution. As a new mother with a 10-month old, just being back to work, and dealing with nightly wake-ups, this definitely wasn’t easy. But, as she said, “I would do that any day over a doing a live coding challenge”.
Which goes to the point that the alternative to a take-home programming assignment is rarely “nothing”. It’s often spending as much time, or more, traveling for a day of packed interviews. Some times traveling more than once! Dealing with the whiteboard assessments. Or going through abstract programming games or assessments that aren’t reflective of the work the team actually does.
There are of course other alternatives too. Some do half a day of pair programming together with candidates. Others ask for a code review, where the candidate comments on existing code. To me, the former often relies on an in-person meeting to work well (and that wasn’t going to happen, with Jorge hired from Spain, and Nabeelah hired from Norway), and the latter isn’t someone’s own code.
Hiring is hard. Applying is hard. Doing either with programmers without looking at actual code they wrote often risks leading down a path of bias (or, as we call it today, “fit”), credentialism, whiteboard puzzles, and brainteasers.
We’ll stick with the hard work.





April 20, 2020
Seamless branch deploys with Kubernetes
Basecamp’s newest product HEY has lived on Kubernetes since development first began. While our applications are majestic monoliths, a product like HEY has numerous supporting services that run along-side the main app like our mail pipeline (Postfix and friends), Resque (and Resque Scheduler), and nginx, making Kubernetes a great orchestration option for us.
As you work on code changes or new feature additions for an application, you naturally want to test them somewhere — either in a unique environment or in production via feature flags. For our other applications like Basecamp 3, we make this happen via a series of numbered environments called betas (beta1 through betaX). A beta environment is essentially a mini production environment — it uses the production database but everything else (app services, Resque, Redis) is separate. In Basecamp 3’s case, we have a claim system via an internal chatbot that shows the status of each beta environment (here, none of them are claimed):
[image error](prior to starting work on HEY, we were running 8 beta environments for BC3)
Our existing beta setup is fine, but what if we can do something better with the new capabilities that we are afforded by relying on Kubernetes? Indeed we can! After reading about GitHub’s branch-lab setup, I was inspired to come up with a better solution for beta environments than our existing claims system. The result is what’s in-use today for HEY: a system that (almost) immediately deploys any branch to a branch-specific endpoint that you can access right away to test your changes without having to use the claims system or talk to anyone else (along with an independent job processing fleet and Redis instance to support the environment).
Let’s walk through the developer workflow
A dev is working on a feature addition to the app, aptly named new-feature.They make their changes in a branch (called new-feature) and push them to GitHub which automatically triggers a CI run in Buildkite:
[image error]
The first step in the CI pipeline builds the base Docker image for the app (all later steps depend on it). If the dev hasn’t made a change to Gemfile/Gemfile.lock, this step takes ~8 seconds. Once that’s complete, it’s off to the races for the remaining steps, but most importantly for this blog post: Beta Deploy.The “Beta Deploy” step runs bin/deploy within the built base image, creating a POST to GitHub’s Deployments API. In the repository settings for our app, we’ve configured a webhook that responds solely to deployment events — it’s connected to a separate Buildkite pipeline. When GitHub receives a new deployment request, it sends a webhook over to Buildkite causing another build to be queued that handles the actual deploy (known as the deploy build).The “deploy build” is responsible for building the remainder of the images needed to run the app (nginx, etc.) and actually carrying out the Helm upgrades to both the main app chart and the accompanying Redis chart (that supports Resque and other Redis needs of the branch deploy):
[image error]
From there, Kubernetes starts creating the deployments, statefulsets, services, and ingresses needed for the branch, a minute or two later the developer can access their beta at https://new-feature.corp.com. (If this isn’t the first time a branch is being deployed, there’s no initializing step and the deployment just changes the images running in the deployment).
What if a developer wants to manage the deploy from their local machine instead of having to check Buildkite? No problem, the same bin/deploy script that’s used in CI works just fine locally:
$ bin/deploy beta
[✔] Queueing deploy
[✔] Waiting for the deploy build to complete : https://buildkite.com/new-company/gre...
[✔] Kubernetes deploy complete, waiting for Pumas to restart
Deploy success! App URL: https://new-feature.corp.com
(bin/deploy also takes care of verifying that the base image has already been built for the commit being deployed. If it hasn’t it’ll wait for the initial CI build to make it past that step before continuing on to queueing the deploy.)
Remove the blanket!
Sweet, so the developer workflow is easy enough, but there’s got to be more going on below the covers, right? Yes, a lot. But first, story time.
HEY runs on Amazon EKS — AWS’ managed Kubernetes product. While we wanted to use Kubernetes, we don’t have enough bandwidth on the operations team to deal with running a bare-metal Kubernetes setup currently (or relying on something like Kops on AWS), so we’re more than happy to pay AWS a few dollars per month to handle managing our cluster masters for us.
While EKS is a managed service and relatively integrated with AWS, you still need a few other pieces installed to do things like create Application Load Balancers (what we use for the front-end of HEY) and touch Route53. For those two pieces, we have a reliance on the aws-alb-ingress-controller and external-dns projects.
Inside the app Helm chart we have two Ingress resources (one external, and one internal for cross-region traffic that stays within the AWS network) that have all of the right annotations to tell alb-ingress-controller to spin up an ALB with the proper settings (health-checks so that instances are marked healthy/unhealthy, HTTP→HTTPS redirection at the load balancer level, and the proper SSL certificate from AWS Certificate Manager) and also to let external-dns know that we need some DNS records created for this new ALB. Those annotations look something like this:
Annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/listen-ports: [{"HTTP": 80},{"HTTPS": 443}]
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-policy: ELBSecurityPolicy-TLS-1-2-2017-01
alb.ingress.kubernetes.io/actions.ssl... {"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}
alb.ingress.kubernetes.io/certificate... arn:aws:acm:us-east-1:############:certificate/########-####-####-####-############
external-dns.alpha.kubernetes.io/hostname: new-feature.us-east-1.corp.com.,new-feature.corp.com.
alb-ingress-controller and external-dns are both Kubernetes controllers and constantly watch cluster resources for annotations that they know how to handle. In this case, external-dns will know that it shouldn’t create a record for this Ingress resource until it has been issued an Address, which alb-ingress-controller will take care of in it’s own control loop. Once an ALB has been provisioned, alb-ingress-controller will tell the Kubernetes API that this Ingress has X Address and external-dns will carry on creating the appropriate records in the appropriate Route53 zones (in this case, external-dns will create an ALIAS record pointing to Ingress.Address and a TXT ownership record within the same Route53 zone (in the same AWS account as our EKS cluster that has been delegated from the main app domain just for these branch deploys).
These things cost money, right, what about the clean-up!?
Totally, and at the velocity that our developers are working on this app, it can rack up a small bill in EC2 spot instance and ALB costs if we have 20-30 of these branches deployed at once running all the time! We have two methods of cleaning up branch-deploys:
a GitHub Actions-triggered clean-up runa daily clean-up run
Both of these run the same code each time, but they’re targeting different things. The GitHub Actions-triggred run is going after deploys for branches that have just been deleted — it is triggered whenever a delete event occurs in the repository. The daily clean-up run is going after deploys that are more than five days old (we do this by comparing the current time with the last deployed time from Helm). We’ve experimented with different lifespans on branch deploys, but five works for us — three is too short, seven is too long, it’s a balance.
When a branch is found and marked for deletion, the clean-up build runs the appropriate helm delete commands against the main app release and the associated Redis release, causing a cascading effect of Kubernetes resources to be cleaned up and deleted, the ALBs to be de-provisioned, and external-dns to remove the records it created (we run external-dns in full-sync mode so that it can delete records that it owns).
Other bits
We’ve also run this setup using Jetstack’s cert-manager for issuing certs with Let’s Encrypt for each branch deploy, but dropped it in favor of wildcard certs managed in AWS Certificate Manager because hell hath no fury like me opening my inbox everyday to find 15 cert expiration emails in it. It also added several extra minutes to the deploy provisioning timeline for new branches — rather than just having to wait for the ALB to be provisioned and the new DNS records to propagate, you also had to wait for the certificate verification record to be created, propagate, Let’s Encrypt to issue your cert, etc etc etc.DNS propagation can take a while, even if you remove the costly certificate issuance step. This was particularly noticeable if you used bin/deploy locally because the last step of the script is to hit the endpoint for your deploy over and over again until it’s healthy. This meant that you could end up caching an empty DNS result since external-dns may not have created the record yet (likely, in-fact, for new branches). We help this by setting a low negative caching TTL on the Route53 zone that we use for these deploys.There’s a hard limit on the number of security groups that you can attach to an ENI and there’s only so much tweaking you can do with AWS support to maximize the number of ALBs that you can have attached to the nodes in an EKS cluster. For us this means limiting the number of branch deploys in a cluster to 30. HOWEVER, I have a stretch goal to fix this by writing a custom controller that will play off of alb-ingress-controller and create host-based routing rules on a single ALB that can serve all beta instances. This would increase the number of deploys per cluster up to 95ish (per ALB since an ALB has a limit on the number of rules attached), and reduce the cost of the entire setup significantly because each ALB costs a minimum of $16/month and each deploy has two ALBs (one external and one internal).We re-use the same Helm chart for production, beta, and staging — the only changes are the database endpoints (between production/beta and staging), some resource requests, and a few environmental variables. Each branch deploy is its own Helm release.We use this setup to run a full mail pipeline for each branch deploy, too. This makes it easy for devs to test their changes if they involve mail processing, allowing them to send mail to @new-feature.corp.com and have it appear in their account as if they sent it through the production mail pipeline. Relying on GitHub’s Deployments API means that we get nice touches in PRs like this:
[image error]complete with a direct link to the temporary deploy environment
If you’re interested in HEY, checkout hey.com and learn about our take on email.
Blake is Senior System Administrator on Basecamp’s Operations team who spends most of his time working with Kubernetes, and AWS, in some capacity. When he’s not deep in YAML, he’s out mountain biking. If you have questions, send them over on Twitter – @t3rabytes.

April 13, 2020
We’ve refreshed our policies
Spring is emerging in the US and as part of our company spring cleaning, we took a peek at our product policies, noticed some cobwebs, and got out the duster.
Besides rewriting sections to be more readable, we made four substantive changes:
1. We’ve consolidated our policies across all products owned and maintained by Basecamp, LLC.
That includes all versions of Basecamp, Highrise, Campfire, Backpack, and the upcoming HEY. This change mostly affects our legacy application customers, bringing their (stale) terms and privacy policies up-to-date.
2. We’ve added more details to our privacy policy.
Our customers deserve to be able to easily and clearly understand what data we collect and why. We’ve restructured and fleshed out our privacy policy to do just that, while also adding more details on your rights with regard to your information. Just as important are the things that haven’t changed: that we take the privacy of your data seriously; that we do not, have not, and never will sell your data; and that we take care to not collect sensitive data that aren’t necessary.
3. We’ve introduced a Use Restrictions policy. We are proud to help our customers do their best work. We also recognize that technology is an amplifier: it can enable the helpful and the harmful. There are some purposes we staunchly stand against. Our Use Restrictions policy fleshes out what used to be a fairly vague clause in our Terms of Service, clearly describing what we consider abusive usage of our products. In addition, we outline how we investigate and resolve abusive usage, including the principles of human oversight, balanced responsibilities, and focus on evidence that guide us in investigations.
4. We’ve adjusted how you can find out about policy changes.
In 2018, we open-sourced our policies by publishing them as a public repository on Github. One of the nice things about this repository is it tracks all the revisions we make in our policies so you can see what changed, when, and why. For instance, you can see every change we made to our policies in this refresh. You can also decide whether you want to get an email notification when changes are made by watching the repository. We’ll also be announcing any substantive changes here on SvN; if you prefer email updates, you can subscribe here.
As always, customers can always reach us at support@basecamp.com with questions or suggestions about our policies. You can also open an issue in our policies repository if you’d like to contribute!

April 8, 2020
The Majestic Monolith can become The Citadel
The vast majority of web applications should start life as a Majestic Monolith: A single codebase that does everything the application needs to do. This is in contrast to a constellation of services, whether micro or macro, that tries to carve up the application into little islands each doing a piece of the overall work.
And the vast majority of web applications will continue to be served well by The Majestic Monolith for their entire lifespan. The limits upon which this pattern is constrained are high. Much higher than most people like to imagine when they fantasize about being capital-a Architects.
But. Even so, there may well come a day when The Majestic Monolith needs a little help. Maybe you’re dealing with very large teams that constantly have people tripping over each other (although, bear in mind that many very large organizations use the monorepo pattern!). Or you end up having performance or availability issues under extreme load that can’t be resolved easily within the confines of The Majestic Monolith’s technology choices. Your first instinct should be to improve the Majestic Monolith until it can cope, but, having done that and failed, you may look to the next step.
That next step is The Citadel, which keeps the Majestic Monolith at the center, but supports it with a set of Outposts, each extracting a small subset of application responsibilities. The Outposts are there to allow the Majestic Monolith to offload a particular slice of divergent behavior, either for organizational or performance or implementation reasons.
One example at Basecamp of this pattern was our old chat application Campfire. It was built back in 2005, when Ajax and other JavaScript techniques were still novel, so it was based on polling rather than the persistent connections modern chat apps use these days. That meant that every client connected to the system would trigger a request every three seconds asking “are there any new messages for me?”. The vast majority of these requests would reply “no, there’s not”, but to give that answer, you still had to authenticate the request, query the database, all that jazz.
This service had vastly different performance characteristics from the rest of the application. At any given time, it would be something like 99% of all requests. It was also a really simple system. In Ruby, it was barely 20 lines long, if I remember correctly. In other words, a perfect candidate for an Outpost!
So an Outpost we made. Over the years, it became a hobby to rewrite this Outpost in every high-performance programming language under the sun, because it could usually be done in a few hundred lines of code, regardless of the language. So we wrote it in C, C++, Go, Erlang, and I’m probably forgetting a few others.
But it was clearly an Outpost! The rest of the application continued as a Majestic Monolith built in Ruby on Rails. We didn’t try to carve the entire app up into little services, each written in a different language. No, we just extracted a single Outpost. That’s a Citadel setup.
As more and more people come to realize that the chase for microservices ended in a blind alley, the pendulum is going to swing back. The Majestic Monolith is here waiting for microservice refugees. And The Citadel is there to give peace of mind that the pattern will stretch, if they ever do hit that jackpot of becoming a mega-scale app.

March 31, 2020
Why HEY had to wait
We had originally planned to release HEY, our new email service, in April. There was the final cycle to finish the features, there was a company meetup planned for the end of the month to celebrate together, we’d been capacity testing extensively, and the first step of a marketing campaign was already under way.
But then the world caught a virus. And suddenly it got pretty hard to stay excited about a brand new product. Not because that product wasn’t exciting, but because its significance was dwarfed by world events.
A lack of excitement, though, you could push through. The prospect of a stressful launch alongside the reality of a stressful life? No.
That’s not because we weren’t ready to work remotely. That we had to scramble to find new habits or tools to be productive. We’ve worked remotely for the past twenty years. We wrote a book on working remotely. Basecamp is a through and through remote company (and an all-in-one toolkit for remote work!).
But what’s going on right now is about more than just whether work can happen, but to which degree it should. We’re fortunate to work in software where the show doesn’t have to stop, like is the case in many other industries, but the show shouldn’t just carry on like nothing happened either.
About half the people who work at Basecamp have kids. They’re all at home now. Finding a new rhythm with remote learning, more cramped quarters, more tension from cooped-up siblings. You can’t put in 100% at work when life asks for 150%. Some things gotta give, and that something, for us, had to be HEY.
And it’s not like life is daisies even if you don’t have kids. This is a really stressful time, and it’s our obligation at Basecamp to help everyone get through that the best we can. Launching a new product in the midst of that just wasn’t the responsible thing to do, so we won’t.
Remember, almost all deadlines are made up. You can change your mind when the world changes around you.
HEY is going to launch when the world’s got a handle on this virus. When we either find a new normal, living within long-running restrictions, or we find a way to beat this thing. We’re not going to put a date on that, because nobody knows when that might be. And we’re not going to pretend that we do either.
In the meantime, we’ll keep making HEY better. We’re also going to put in time to level up Basecamp in a number of significant ways that have long been requested. The work doesn’t stop, it just bends.
If you wrote us an email to iwant@hey.com, you’re on the list, and we’ll let that list know as soon as we open up. If you think you might be interested in a better email experience when that’s something we all have the mental space to think about again, please do send us a story about how you feel about email to iwant@hey.com.
Stay home, stay safe!

March 27, 2020
Working remotely builds organizational resiliency
For many, moving from everyone’s-working-from-the-office to everyone’s-working-at-home isn’t so much a transition as it is a scramble. A very how the fuck? moment.
That’s natural. And people need time to figure it out. So if you’re in a leadership position, bake in time. You can’t expect people to hit the ground running when everything’s different. Yes, the scheduled show must go on, but for now it’s live TV and it’s running long. Everything else is bumped out.
This also isn’t a time to try to simulate the office. Working from home is not working from the office. Working remotely is not working locally. Don’t try to make one the other. If you have meetings all day at the office, don’t simply simulate those meetings via video. This is an opportunity not to have those meetings. Write it up instead, disseminate the information that way. Let people absorb it on their own time. Protect their time and attention. Improve the way you communicate.
Ultimately this major upheaval is an opportunity. This is a chance for your company, your teams, and individuals to learn a new skill. Working remotely is a skill. When this is all over, everyone should have a new skill.
Being able to do the same work in a different way is a skill. Being able to take two paths instead of one builds resiliency. Resiliency is a super power. Being more adaptable is valuable.
This is a chance for companies to become more resilient. To build freedom from worry. Freedom from worry that without an office, without those daily meetings, without all that face-to-face that the show can’t go on. Or that it can’t work as well. Get remote right, build this new resiliency, and not only can remote work work, it’ll prove to work better than the way you worked before.

March 25, 2020
Live Q&A on remote working, working from home, and running a business remotely
In this livesteam, David and I answer audience questions about how to work remotely. At Basecamp we’ve been working remotely for nearly 20 years, so we have a lot of experience to share. This nearly 2-hour video goes into great detail on a wide variety of topics. Highly recommended if you’re trying to figure out how to work remotely.

A live tour of how Basecamp uses Basecamp to run Basecamp
David and I spent nearly 2-hours giving a livestream tour of our very own Basecamp account. We wanted to show you how Basecamp uses Basecamp to run projects, communicate internally, share announcements, know what everyone’s working on, build software, keep up socially, and a whole bunch more. Our entire company runs on Basecamp, and this video shows you how.

March 20, 2020
Remote Working: The home office desks of Basecamp
People are always curious about work-from-home (WFH), remote working setups. So, I posted a Basecamp message asking our employees to share a photo of their home office, desk, table, whatever. Here’s what came in.
First, the ask:
[image error]
And the answers, in the order they came in:
Andy Didorosi, Marketing
[image error]
Justin White, Programmer

Jonas Downey, Designer

Troy Toman, DevOps

Blake Stoddard, DevOps

Dan Kim, Programmer
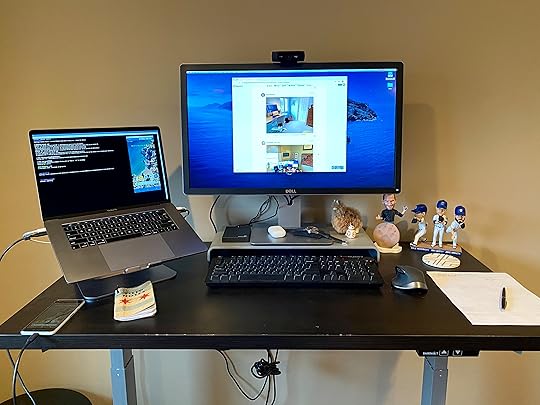
Elizabeth Gramm, Customer Support

Nathan Anderson, DevOps

Jane Yang, Data Analyst

George Claghorn, Programmer
[image error]
Ryan Singer, Strategy

Adam Stoddard, Designer

Willow Moline, Customer Support
[image error]
Jay Ohms, Programmer

Lexi Kent-Monning, Customer Support
[image error]
Zach Waugh, Programmer

Joan Stewart, Customer Support
[image error]
Pratik Naik, Programmer
[image error]
Kristin Aardsma, Customer Support

Flora Saramago, Programmer
[image error]
Conor Muirhead, Designer
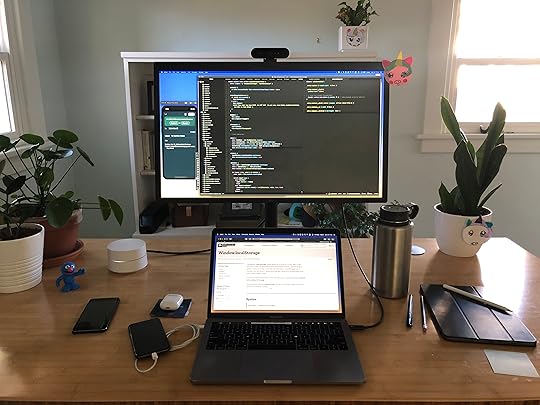
Tony Giang, Customer Support

Rosa Gutiérrez, Programmer

Dylan Ginsburg, Programmer
[image error]
Eron Nicholson, DevOps

John Williams, DevOps

Wailin Wong, REWORK Podcast

Merissa Dawson, Customer Support

Sam Stephenson, Programmer

Jeffrey Hardy, Programmer

Michael Berger, QA

Scott Upton, Designer

Jason Zimdars, Designer

Shaun Hildner, REWORK Podcast

David Heinemeier Hansson, Show-off CTO

Jason Fried, CEO
[image error]

March 6, 2020
How we acquired HEY.com
Back on June 9, 2018, I cold emailed help@hey.com:
Hey there–
Curious… Would you entertain an offer to sell hey.com? I'd like to use it for something I'm working on, and willing to make you a strong offer.
Let me know. Thanks!
-Jason
And that’s where it all began.
For the 25+ years I’ve been emailing, I’d say close to 95% of those email began with some variation of “Hey [Name]”. So when it came time to think about a name for a new email system we’d be building, HEY was a natural.
Further, the “Hey!” menu in Basecamp 3 holds your notifications for new messages, chats, to-do assignments, automatic check-in prompts, boost summaries, and the like. So we already had some prior art on Hey being a place for communication.
But hey.com – that would be an amazing email address, and, we rightly assumed, hard to get. But what the hell – if you don’t ask you don’t get, so I sent the email, crossed my fingers, and waited.
The same day I emailed, June 9, 2018, he replied. Turns out we’d actually talked before on This Week in Tech, way back when. This was his first email back to me:
Hi Jason:
Thanks for reaching out, I've always respected your business accomplishments and your writing. You may not remember but we spoke briefly a couple of times when I was at TWiT.
As you might imagine, I've gotten a number of offers and inquiries about HEY.com over the years. Usually I ignore them, but very happy to chat with you about this or any other topic. I'm on cell at ###-###-####.
Thanks!
Dane
So we set up a call and had a nice chat. Really nice guy. A few days later, I made an offer.
He said no.
So I countered.
He said no.
We were clearly way off. And the momentum went cold. He decided he wasn’t ready to sell. I thanked him for the opportunity and said let’s stay in touch.
Then on August 19, 2019, well over a year after my initial outreach, he wrote me back.
Hi Jason:
Not sure if you're still interested in Hey.com, but I'm in the process of vetting what appears to be a serious inquiry to buy it. The numbers being discussed are notably higher than what you mentioned previously. Given your previous offer I'm thinking you probably won't be interested, but I appreciated your approach and also what you've done for the industry, so I thought I'd let you know as a courtesy.
We caught up via Zoom a few days later, discussed again, and I made another offer. This time significantly higher than our original offer. It was a nervous amount of money.
Things were beginning to heat up, but there was no deal yet. I completely understood – he owned this domain for a long time, and he wasn’t a squatter. Dane used hey.com for his business. It was part of his identity. It was a valuable asset. He needed time to think it through.
We traded a number of other emails, and then I upped the offer a little bit more on September 18, 2019.
A few days later we’d verbally agreed to move forward on an all-cash deal with a number of stipulations, conditions, etc. All were perfectly reasonable, so we asked him to prepare a contract.
There were a few small back and forths, but we essentially accepted his contract and terms as is. We wired the money into escrow, we waited for some Google mail transfer stuff to finish up, and on November 20th, 2019 the domain was officially transferred over into our ownership. Funds were released to escrow, and the deal was done.
This was a long 18 month process, and there was uncertainty at every step. We’d never bought a domain like this, he’d never sold a domain like this. There’s a lot of trust required on all sides. And more than money, hey.com was important to him. And who he sold it to was important to him as well.
But it was truly a pleasure to work with him. Dane was fair, thoughtful, patient, and accommodating. And for that we’re grateful. Business deals like this can get messy, but this one was clean and straightforward. Kudos to him and his lawyer for their diligence and clear communication.
All in we traded 60+ emails over the course of the deal. Toss in a few zoom calls as well.
So that’s the story of how we acquired hey.com. One cold email to kick it off, no domain brokers or middlemen, and a lot of patience and understanding on both sides.
Wait how much was it? I know everyone wants to know, but we can’t say. Both sides are bound by a non-disclosure around the final purchase price. You’ll just have to guess.
As for Dane, he relaunched his brand under a new name. You can check him out at VidiUp.tv.
As for us, this April we’ll be launching our brand new email serviced called HEY at hey.com.
Note: This post was cleared with Dane prior to publishing, so he’s cool with me sharing his name, the story, and the name of his new company.

Jason Fried's Blog

- Jason Fried's profile
- 1429 followers

