
Eric S. Raymond's Blog, page 11
May 9, 2018
Embrace the SICK
There’s a very interesting article just out, C Is Not a Low-level Language;. in which David Chisnall punctures the comforting illusion that C is really a “close-to-the-metal” language and relates this illusion to the high costs of Spectre and other processor-level bugs.
Those of us who think seriously about language design have long been aware that C’s flat-address-space model is increasingly at odds with the real world of memory-caching hierarchies. Chisnall’s main contribution is to notice that speculative execution, the feature at the bottom of the Spectre and Meltdown bugs, is essentially a hack implemented to allow C programmers to maintain the illusion that they’re running on a really fast serial machine. But he has other interesting points as well.
I recommend reading Chisnall’s article before you go further with this post.
It’s no news to my regulars that I’ve been putting increasing investment into the Go language and now believe it a plausible candidate to replace C and C++ over most of C/C++’s range – that is, outside of kernels and hard realtime. So the question that immediately occurred to me upon reading the article was: Is Go necessarily productive of the same kind of kludge that Chisnall is calling out?
Because if it is – but something else isn’t – that could be a reason not to overcommit to Go. The twin pressures of demand for lower security defects and the increasing complexity costs of speculative execution are bound to toll heavily against Go if it does demand massive speculative execution and there’s any realistic alternative that does not. Do we need something much more divergent from C (Erlang? Ocaml? Even perhaps Haskell?) for systems programming to follow where the hardware is going?
So let’s walk through Chisnall’s discussion points, bounce Go off each one, and see what we can see. What we’ll find implies, I think, some more general conclusions about what will and won’t work in matching language design to real-world workloads and processor architectures.
On C requiring high “instruction-level parallelism”: So will Go if you write it like C. Sometimes this is not avoidable.
To write Go in a way that will keep a modern Intel processor’s instruction pipeline full you need, by Chisnall’s argument, to fruitfully decompose each serial algorithm into somewhere around 180 worker threads. Otherwise you need to do speculative execution to avoid having a significant chunk of your transistor budget simply behaving like a space heater.
Go, in itself, doesn’t solve this problem. Sure, it lowers the barriers – its implementation of CSP via channels and goroutines is quite elegant and a handier toolkit for writing massively concurrent code than I’ve ever seen before. But it’s only a toolkit; a naive translation of serial C code to Go is not going to use it and not going to solve your processor-utilization issue.
On the other hand, every other potential competitor to Go has the same problem. It might be the case that (say) Erlang or Rust or Haskell imply a better toolkit for massively concurrent programming, if one but knew how to use it. The problem is that the difficulty of moving any given chunk of production C code, or of writing a functional equivalent for it, rises in direct proportion to the ontological gap you have to jump to get from C to your new language.
The real cost of obsolescing speculative execution isn’t moving away from C, it’s what you have to do in your replacement language to go from a naive serial translation of your code to one that seriously jacks up the percentage of your processor clocks doing productive work by using concurrency in some appropriate way. And the real issue is that sometimes this isn’t possible at all.
This isn’t just a theoretical issue for me. I’m now scoping the job of moving reposurgeon from Python to Go in order to improve performance on large repositories and and it runs head-on into that wall. Python’s Global Interpreter Lock makes it C-equivalent for this discussion – yes it has a richer type ontology than C, and GC, but this turns out to help remarkably little with thread decomposition. It makes the trivial resource management issues a bit easier, but that just means you hit the question of how to write an algorithm that really exploits concurrency sooner.
Some of reposurgeon’s core operations can’t be factored into things done by a flock of threads at all, because for each commit you might want to vectorize over they do lookups unpredictably far back in time in the repository metadata. Some other operations could be because there are no time-order dependencies, but it’s going to require map-reduce-like partitioning of the metadata, with a high potential for bugs at the joins. Bad news: I think this is going to turn out to be a typical transition problem, not an unusually difficult one.
The implication is that the C-like requirement to look like a superfast serial machine (a) is not going away even partially without a lot of very hard work changing our algorithms, and (b) never going to go away entirely because there is an awkward residuum: some serial algorithms don’t have an equivalent that exploits concurrency. I dub these SICK algorithms, for “Serial Intrinsically; Cope, Kiddo!”
SICK algorithms include but are not limited to: Dijkstra’s n-least-paths algorithm; cycle detection in directed graphs (with implications for 3-SAT solvers); depth first search; computing the nth term in a crypto hash chain; network-flow optimization…and lots of other problems in which you either have to compute sub-results in a strict time order or you have wickedly bad lookup locality in the working set (which can make the working set un-partitionable).
There’s actually another Go-specific implementation issue here, too. Theoretically Go could provide a programming model that exposes hardware-level threading in a tractable way. Whether it actually does so – how much heavier the runtime cost of actual Go threads is – is not clear to me. It depends on details of the Go runtime design that I don’t know.
This generalizes. To jack up processor utilization to a degree that makes speculative execution unnecessary, we actually need two preconditions. (1) We need a highly concurrent algorithm (not just 1 or 2 threads but in the neighborhood of 180), and (2) we need the target language’s threading overhead to be sufficiently low on the target architecture that it doesn’t swamp the gains.
While Go doesn’t solve the problem of SICK algorithms, it doesn’t worsen the problem either. The most we can say is that relative to its competitors it somewhat reduces the friction cost of implementing an algorithmically-concurrent translation of code if there is one to be found.
Chisnall also argues that C hides the cache memory hierarchy, making elaborate and sometimes unsuccessful hackery required to avoid triggering expensive cache misses. This is obviously correct once pointed out and I kind of kick myself for not noticing the contextual significance of cache-line optimization sooner.
Missing from Chisnall’s argument is any notion of how to do better here. Are we supposed to annotate our programs with cache-priority properties attached to each storage allocation? It’s easy to see how that could have perverse results. Seems like the only realistic alternative would be for the language to have a runtime that behaves like a virtual memory manager, doing its best to avoid cache misses at each level by aging out allocation blocks to the next lower level on an LRU or some similar scheme.
Again, Go doesn’t solve this problem, but no more do any of its let’s-replace-C competitors. You couldn’t even really tackle it without making every pointer in the language a double indirect through trampoline storage. (IIRC there was a language on the pre-Unix Mac that actually did this, long ago.)
We do get a little help here from the absence of pointer arithmetic in Go. And a little more from the way slices work; they are effectively trampoline storage pointing at elements that could be transparently relocated by a GC – or a VM embedded in the language runtime.
Combining those, though? I don’t think it’s been done yet, in Go or anywhere else – and excuse me, but I don’t want to be the poor bastard who has to debug a language runtime implementing that hot mess.
Next, Chisnall has some rather penetrating things to say about how the C language model impedes optimization. Here for he first time we get some serious help from Go that is already implemented – doesn’t depend on a hypothetical property of the runtime. The fact that for loops in Go naturally use a dedicated iterator construct rather than pointers is going to help a lot with loop-independence proofs in the typical slice or array case. (Rust makes the same call for the same benefit.)
Unlike C, Go does not guarantee properties that imply structure field order is fixed to source order. The existing Go implementations don’t reorder to optimize, but they could. There are no exposed pointer offsets, so a compiler is allowed to insert padding to speed up stride access. In general, the C features that Chisnall notes would impede vectorization and SROA have been carefully omitted from Go.
Chisnall then describes the problems with loop unswitching in C. I don’t see Go giving any additional optimization leverage here, unless you count the effects of uninitialized variables always being zeroed. That (as Chisnall points out) also guarantees that you can’t have program behavior that is randomly variable depending on the prior contents of memory.
Go sweeps away most of the issues under “understanding C”. Padding is never visible, bare pointers and pointer offsets are absent, pointers are strongly typed and cannot be interconverted with integer (well, trivially they can but the specification does not guarantee they will round-trip).
Integer overflow is the exception. To reduce the runtime overhead of arithmetic Go opts not to overflow-check each operation, the same choice as C’s. That choice could start a whole other argument about speed-vs-safety tradeoffs, but it’s an argument that would wander some distance from Chisnall’s principal concerns and mine, so I’m not going to pursue it.
Instead I want to return to the initial question about Go, and then consider in more detail what the existence of SICK algorithms means for processor design.
So, is Go a “low-level language” for modern processors? I think the answer is really “No, because there are very good reasons we’ll never have a ‘low-level’ language again.” While the ability to manage lots of concurrency fairly elegantly does pull Go in the direction of what goes on on a modern multi-core processor, CSP is a quite abstract and simplified interface to the reality of buzzing threads and lots of test-and-set instructions that has to be going on underneath. Naked, that reality is unmanageable by mere human brains – at least that’s what the defect statistics from the conventional mutex-and-mailbox approach to doing so say to me.
Chisnall begins the last section of his argument by suggesting “Perhaps it’s time to stop trying to make C code fast and instead think about what programming models would look like on a processor designed to be fast.” Here, where he passes from criticism to prescription, is where I think his argument gets in serious trouble. It trips over the fact that there are lots of important SICK algorithms.
His prescription for processor design is “Let’s make flocks of threads much faster”. Well, OK – but I think if you interpret that as a bargain you can make to eliminate speculative execution (which is what Chisnall wants to do, though he never quite says it) there’s a serious risk that you could wind up with an architecture badly matched to a of lot of actual job loads.
In fact, I think there is a strong case that this has already happened with the processors we have now. My hexacore Great Beast already has more concurrency capacity than reposurgeon’s graph-surgery language can use effectively (see ‘wickedly bad lookup locality’ above), and because some operations bottleneck on on SICK algorithms it is certain that getting out from under Python’s GIL won’t entirely fix the problem.
Underlying my specific problem is a general principle: you can reduce the demand for instruction-level parallelism to zero only if your job load never includes SICK algorithms. A GPU can pretty much guarantee that. A general Turing machine cannot.
Chisnall seems to me to be suffering from a bit of a streetlight effect here. He knows concurrency can make some things really fast, so he recommends making the streetlight brighter even though there are lots of SICK problems we can’t drag to where it shines. To be fair, he’s far from alone in this – I’ve noticed it in a lot of theoretically-oriented CS types.
He finishes by knocking down a strawman about parallel programming being hard for humans, when the real question is whether it can be applied to your job load at all.
There is, for some real problems, no substitute for plain old serial speed, and therefore we seem to be stuck with speculative execution. There’s nothing for it but to embrace that SICK.


May 5, 2018
Friends of Armed & Dangerous gathering 2018
The 2018 edition of the annual Friends of Armed & Dangerous FTF will be held in room 821 of the Southfield Westin in Southfield, MI between 9 p.m. and 12 p.m. this evening.
If you are at Penguicon, or in the neighborhood and can talk yourself yourself in, come join us for an evening of scintillating conversation and mildly exotic refreshments.
May 2, 2018
Review: The Mutineer’s Daughter
I greatly enjoyed Thomas Mays’s first novel, Atomic Rockets website and gained much thereby.
This is not a bad book; Mays gave it craftsmanlike attention. If you like things going boom in space, you will probably enjoy it even if you are ever so slightly irritated by the insert-plucky-girl-here plot. It proceeds from premise to conclusion with satisfactory amounts of tension and conflict along the way. As long as you don’t set your expectations much above “genre yard goods” it is an entertainment worth your money.
But I’m left thinking that not only can Mays do better on his own, but in fact already has. I want that sequel.
April 29, 2018
Flight of the reposturgeon!
I haven’t posted a reposurgeon release announcement in some time because there hasn’t been much that is very dramatic to report. But with 3.44 in the can and shipped, I do have an audacious goal for the next release, which may well be 4.0.
We (I and a couple of my closest collaborators) are going to try to move the reposurgeon code to Go.
I’ve been muttering about trying this for a while, because while Python is an excellent tool for a lot of things, speedy it is not. This is particular pain in he ass on really large repository moves; I’m still trying to get GCC over to git and am severely hampered by test cycles that take a minimium of nine hours or so.
Yes, I said nine hours, and that’s on the Great Beast’s semi-custom hardware specifically designed for the workload. I think there’s a realistic prospect that a Go implementation could cut an order of magnitude off that.
Still, until a couple days ago my speculations were wore wishes than plans. We’re talking 14KLOC of algorithmically sense Python, some of which came in from cometary contributors and I don’t necessarily understand very well myself. The labor load of hand translation – and worse, the expected defect rate – made the project impractical.
What changed everything is that Google has the same problem I do on a much larger scale – that is, piles and piles of underperforming Python needing to be moved to a language with compiled speed. Thus, the Go language (of which I am already a fan) and now…grumpy.
Yes, it’s a Python to Go source-code translator. It’s hedged around with warnings about a few unsupported features and many missing pieces of the Python standard libraries. Still…I think it’s a realistic path forward. If I have to write some of the missing library support myself, that’s not a big deal compared to moving a much larger block of deeply interwingled code by hand.
And if I end up improving the translator, where’s the downside?
April 23, 2018
The UPSide state diagram
I think this diagram is now stable enough to put on the record.
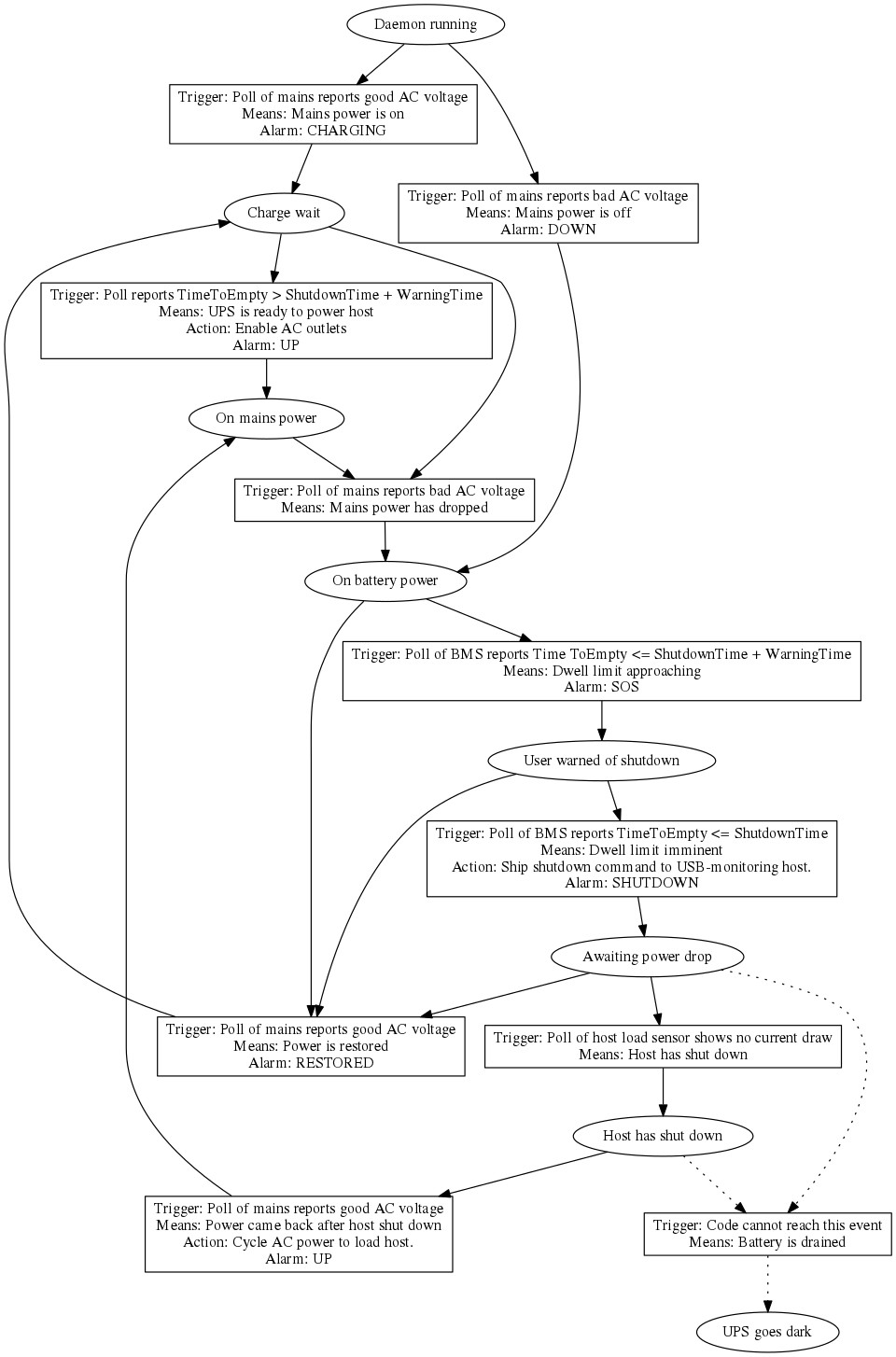
UPSide state diagram
Both this diagram and the Go code for the policy logic are generated from this pseudocode:
render.state("DaemonUp", "Daemon running")
render.action("DaemonUp", "ChargeWait", CHARGING)
render.state("ChargeWait", "Charge wait")
render.action("ChargeWait", "MainsUp", CHARGED)
render.action("ChargeWait", "OnBattery", MAINSDROP)
render.state("MainsUp", "On mains power")
render.action("DaemonUp", "OnBattery", MAINSOFF)
render.state("OnBattery", "On battery power")
render.action("MainsUp", "OnBattery", MAINSDROP)
render.action("OnBattery", "Overtime", DWELLWARNING)
render.state("Overtime", "User warned of shutdown")
render.action("Overtime", "PreShutdown", DWELLTIMEOUT)
render.state("PreShutdown", "Awaiting power drop")
render.action("PreShutdown", "ChargeWait", RESTORED)
render.state("UPSCrash", "UPS goes dark")
render.state("HostDown", "Host has shut down")
render.action("PreShutdown", "HostDown", HOSTDOWN)
render.action("PreShutdown", "UPSCrash", BATTERYDRAIN, unreachable=True)
render.action("OnBattery", "ChargeWait", RESTORED)
render.action("Overtime", "ChargeWait", RESTORED)
render.action("HostDown", "MainsUp", RESTORED_LATE)
render.action("HostDown", "UPSCrash", BATTERYDRAIN, unreachable=True)
To see the full context of this, clone git@gitlab.com:esr/upside.git and explore the docs/ directory.
April 22, 2018
UPSide progress report
The build-a-better-UPS project is progressing nicely. About a week ago we had first hardware lightup; I successfully threw messages over an I2C bus to the 20×4 LCD we plan to use as a status display. Hey, it’s not the power plane (yet) but it’s something.
Eric Baskin is making progress on the power plane. He has started ordering parts for a…not exactly breadboard rig, but something analogous that you do with higher-power electronics.
The control software is in very good shape. Having identified the kinds of sensors and switches we’ll need, I designed a file format that can describe sequences of events coming off the power plane. The daemon’s access to hardware is sealed off behind a Go class interface that has two implementations; the one that’s fully written interprets parsing those event files.
This means I can feed an event file to the daemon on standard input and see a log of its actions on standard output. Accordingly I don’t have to guess that the business logic is correct – I know it is. (And of course every such file is a stringent regression test, verifying everything but the low-level hardware interface.)
Another thing I did towards correctness was avoiding hand-hacking. And thereby hangs a tale.
Before I wrote the first line of Go by hand I sat down and composed a state-transition diagram. The states are (for example) “mains power up” and “on battery dwell time, below threshold”. The events are sensor notifications like “good line voltage”. The transitions can include throwing control switches or repainting the LCD.
I first composed the diagram in DOT, the markup language of the graphviz toolkit. The raw DOT was repetitive and confusing, so I refactored it as a sequence of calls of two text macros – state() and transition() – that expand into DOT markup.
Then I had a thought: I have in this sequence of macros a complete description of of UPSide’s business logic. Wouldn’t it be smart to generate the code for the corresponding state machine from it? And that’s exactly what I did. The macro calls turned into method invocations in a little Python program that can implement them either by emitting DOT or by emitting state-machine code in Go.
Notice what this means. If the business logic needs to be modified, I can do almost the whole job by looking at, thinking about, and editing the state-transition diagram. Sure, I sometimes have to write hook functions to be fired on particular transitions – like “when you pass from ‘waiting for charge threshold’ to ‘mains power up’, enable all AC outlets”, but those hooks are almost trivial and easy to audit.
The defect attractor is not the hooks but the state machine that calls them – 8 states, 7 event types, 14 transitions. Not so much because it would be intrinsically complicated to write by hand, but because bugs and divergences from the state-transition diagram would be difficult to spot amidst all that boilerplate code. Any time you can compile this kind of thing from a higher-level declarative description, you win.
The choice of Go as an implementation language is looking like an excellent call. We haven’t yet really started to collect what I think the big long-term win will be – long-term reliability due to the language’s immunity to a large class of memory-management errors – but development on the daemon has definitely gone faster and smoother than it would have in C. The Go type system and compiler error messages are actually useful; who’d a thunk it?
The project does have one serious problem, though. We can’t find a COTS battery pack that meets our specs.
Neither Eric B. nor I is an expert on battery state modeling, nor do we want to be. To avoid wandering into this swamp, we’ve made the same choice laptop designers do. We’re assuming that the battery will be sitting on the other side of a a fuel-gauge chip that does all that modeling itself and controls the battery’s trickle charger, so all we have to do is poll it frequently and let it tell us state of charge, state of battery, and expected dwell time.
So far, all the COTS batteries we’ve found that have an integrated fuel gauge chip are lithium-ion, designed for applications like flying drones where power-to-weight ratio is a big deal. Which is really annoying because explosion hazard.
What we want to do is use a variant of that technology called LiFePO – Lithium Iron Phosphate. This should greatly reduce the odds of kaboom (and lower costs) at the cost of less stored power per kilogram – but that downside would be OK because a UPS is a stationary application in which weight is much less important.
Alas, we have not yet found a product that is (a) commercial off the shelf (so we don’t have to fret about extra UL compliance issues beyond the power plane itself). (b) LiFePO, and (c) has the fuel gauge built in.
(Why not lead-acid? Well, they’re cheap, but we want better lifetime than you can get from those – besides, dumping lead and sulphuric acid into the waste stream is no favor to anyone. And we can’t find them with a built-in fuel gauge, either.)
We can evade this issue for a while. Eric B. can test the mains-conversion part of the design without a battery subsystem. Technology is moving fast; by the time the battery subsystem becomes critical-path, maybe there’ll be a COTS solution. If not, there are outfits that will do semi-custom battery packs to spec. That would be best avoided, though, as it would be certain to drive the unit cost way up.
April 11, 2018
How many Einsteins per Africa?
In 2008, Neil Turok, an eminent phycisist, gave a talk about trying to find the next Einstein in in sub-Saharan Africa. I was thinking about this a few days ago after his initiative re-surfaced in a minor news story,and wondered “what are his odds?”
Coincidentally, this morning I stumbled across the key figure needed to upper-bound them while researching something else.
So, how do you estimate something like that? Formally, what you’re looking for is an estimate of the frequency of Einstein-class brains in sub-Saharan Africa (“SSA” in the rest of this post). Or at least a statistical upper bound; that way we can make generous assumptions where we have a choice, insulating the calculation against various kinds of special pleading.
It may not be a sufficient condition for an African future Einstein to have Einstein’s IQ – he may have had some special creative spark not captured by testing – but tensor calculus is hard and depends on qualities about which there is no dispute that IQ captures well. (That is: both capacity for long chains of abstract logical reasoning, and spatial visualization.)
Therefore, we can upper-bound Turok’s number with an estimate of the number of people with Einstein-plus IQs in SSA. There are two problems with this project.
One is that Einstein never took an IQ test. There is, however, a mini-industry among psychometricians of estimating the IQs of historical figures from various proxies. If you do a little research you’ll find that the minimum IQ attributed to him is 160 (all figures Stanford-Binet).
I think this is low, myself; I’ve seen a median estimate of 175.
But since we’re looking for an upper bound, we’ll start with the low figure; this leaves statistical room for the maximum number of African Einsteins.
The other problem is that you need to know at least an IQ average for SSA. What I stumbled over this morning is just such a thing. The paper argues that previous estimates have erred by oversampling elite populations – and in African conditions that’s a pretty damn plausible argument. It marshals several lines of evidence for an average IQ of 68.
That’s almost all we need. I have a handy table of IQ percentages and rarities. Needs to be used with a bit of caution for two reasons. First, it’s based on a 100 average, so we need to slide our IQ target by 100-68=32 points to re-norm it. Second, it fails to account for the fact that black Africans probably have a slightly narrower IQ dispersion than the mostly Euro population the chart was based on.
I’m going to cheerfully ignore the dispersion issue (and avoid having to dig up cites for that claim) because, if anything, it will cause a slight overestimate of the fatness of the high-IQ tail in African populations. That is OK because (as with choosing a low estimate for Einstein’s IQ) it will make our upper-bound estimate err on the high side.
We also need one last piece of information: the population of SSA. This site says 1,050,135,841.
Time to crunch numbers. I didn’t actually do this calculation before I started writing this post, so I don’t know what the result will be. We’re targeting an IQ lower bound of 160 + 32 = 192 on the chart. That gives us a 16SD 1/X of 212343687. Dividing into population, we should expect 4.9 Einsteins per Africa.
Well, that could have gone worse. Me, if I were looking for Einsteins, I’d try the obvious population first: Ashkenazic Jews. (Well, duh!) But at least it’s good to know Turok is not, statistically speaking, fishing in a completely dry hole.
…Or is he? Most of the plausible ways for the inputs to be wrong punch hell out of that number. In particular, a median 175 estimate for Einstein’s IQ drops it to….looking…less than 0.9%. Actually probably a lot less since my chart tops out at IQ 202 and the target would be 207. Even at 202 that’s less than one Einstein in 100 Africas.
OK, that’s not so good. At that level Turok’s odds look really bad unless there is some way to drastically elevate SSA’s IQ mean. The good news is that Africa is the only place left in the world this might still be possible, and it leads to actionable advice for Turok’s plan.
Adult IQ is hard to increase. You can jack it up slightly and temporarily with drugs like DMSO and Modafinil, but there aren’t any known interventions (even in childhood) that are reliable and permanent. On the other hand, it is easily lowered by environmental insults in childhood. There’s a lot of indirect evidence that neurological growth can be stunted by poor early-childhood nutrition.
In most of the world poor childhood nutrition is largely a solved problem; this was not true as recently as the late 1960s and represents one of the great human achievements of the last half-century. Africa is the dolorous exception.
So this is my advice to Turok: if you want an Einstein in thirty years, start by improving the diet of young children in Africa now.
This isn’t guaranteed to work. To know how effective this would be we’d have to look at mean adult IQs in a representative sample of SSAs that have had good childhood nutrition…
…OK, as I was typing it occurs to me that that test may have been run already. Lynn & Meisenberg think that previous average-IQ estimates have been high due to oversampling elites, and they cite one of 80 that they criticize. In Africa, “elite” is pretty much defined by “you get to feed yourself and your kids decently”.
So, hm, what happens if we take 80 as an estimate of the average IQ of SSAs not subjected to severe childhood environmental insults? Let’s call this the “future SSA” estimate. One reason to think this estimate is plausible is that the average IQ of SSA-descended American blacks is about 85.
As before, I don’t know the answer yet; I’m calculating as I go. Target IQs on my chart is now either 160 or 175 + (100 – 80). That’s either 180 with a 16SD 1/X of 3483046 or 195 with a 16SD 1/X of 1009976678.
It turns out that these assumptions predict an upper bound of 301 Einsteins per future Africa and a most likely figure of almost exactly 1 Einstein per future Africa. That’s if Turok or others can prevent malnutrition and other insults from keeping Africa as a whole below the performance of their elites.
For comparison, the U.S’s population of 325,700,000 should include 10320 Einsteins at 160 IQ and 93 at 175. That makes 175 look much more plausible to me, which unfortunately implies that 1 Einstein per future Africa is probably an upper bound.
Of course, one Einstein can make a continent-sized difference. I wish Neil Turok the best of luck finding him or (though less likely) her.
April 3, 2018
Fthagn to you too
I learned something fascinating today.
There is a spot in the South Pacific called the “Oceanic pole of inaccessibility” or alternatively “Point Nemo” at 48°52.6?S 123°23.6?W. It’s the point on the Earth’s ocean’s most distant from any land – 2,688 km (1,670 mi) from the Easter Islands, the Pitcairn Islands, and Antarctica.
There are two interesting things about this spot. One is that it’s used as a satellite graveyard. It’s conventional, when you can do a controlled de-orbit on your bird, to drop it at Point Nemo. Tioangong-1, the Chinese sat that just crashed uncontrolled into a different section of the South Pacific, was supposed to be dropped there. So were the unmanned ISS resupply ships. A total of more than 263 spacecraft were disposed of in this area between 1971 and 2016.
It’s a just the place to dump toxic fuel remnants and radionuclides because, in addition to being as far as possible from humans, the ocean there is abyssal desert, surrounded by the South Pacific Gyre so it’s hard for nutrients to reach the place. There’s probably no local ecology to trash.
However…
According to the great author and visionary Howard Phillips Lovecraft, Point Nemo is the location of the sunken city of R’lyeh, where the Great Old One Cthulhu lies dreaming.
The conclusion is obvious. The world’s space programs are secretly run by a cabal of insane Cthulhu cultists who are dropping space junk on Cthulhu’s crib in an effort to wake him up. “When the stars are right”, hmmph.
EDIT: I was misled by an error in Wikipedia that claims Tiangong-1 was deliberately dropped there, and jumped to a conclusion. Now corrected.
March 29, 2018
Progress in UPSide, and a change of plans.
Much has changed in UPSide over the last week. Ground has been broken on the software; one key piece of the control daemon, the policy state machine, now exists.
The big news, though, is that I found Gobot, a Go service library for writing IoT-like stuff and robotics. It’s kind of a hardware abstraction layer that gives you access via Go to things like GPIO pins and two-wire buses without C or assembler glue code. Supports three dozen different platforms, so (it plausibly claims) you get to port your code across them with relatively small changes like the names of the GPIO pins.
This is a big deal. Not having to write and test that glue code will probably cut UPSide’s development time by a good 50%. But even more importantly, it will largely decouple our software from the idiosyncracies of whatever SBC we first develop it on. If it turns out we have to change hardware horses in midstream this greatly reduces the chances of that being a disruptive setback for the software.
Recently I wrote on buying options as a hedge against uncertainty. Using GoBot is a cheap buy that looks like a really effective hedge.
There is only one real drawback. The LIME2 SBC I have is not on their support list. But I had a BeagleBone Black, gifted to me by a hacker at a Penguicon one or two years back, lying around unused. And it has the USB gadget port we need. So I’ve said goodbye to the LIME2 – free to good home – and adopted the BBB.
This has had fast results. This afternoon I got Go+Gobot to blink an LED on the BBB, exercising the GPIO pins. The thread across the chasm – and the whole procedure to set up your BBB and cross-build environment to make that happen is documented.
This is already so much less painful than C/C++ would have been that I feel like grinning like a fool.
There is, however, one purely physical problem with the BB that’s going to be a huge pain in the ass when we fabricate, and may force us to a different SBC in the final design. It’s the placement of the ports. (Good thing “different SBC in the final design” is now thinkable without stark terror, eh?)
The Ethernet, USB gadget port, an power plug are on one short edge of the board. The host port and the micro-DVI are on the opposite edge. Which is OK if you’re just using it in a hobby case – but we’re planning to build it into a larger enclosure, and for that kind of deployment this is crazy. You really want all your external ports on one side where they can be presented through a cutout, the way PC cases do it.
The fact that the power jack points forward is especially irritating. It should have been swapped with the USB host port. (This at least is a mistake the RPi designers didn’t make.) And those LEDs are not important enough to take up scarce edge space – that should be where the micro-DVI comes out.
(The LIME2 had similar though less severe port-placement problems, including the forward-facing power port.)
Oh well. It’s good enough for breadboarding, and if I have to I can imagine a strangely shaped 3D-printed shroud that exposes the Ethernet port while leaving just enough room for a right-angled barrel plug inside it.
Wanted: Linux SBC with one host USB port, one gadget USB port, one Ethernet port, and a mini-DVI all one one edge, with the power jack and SD card slot on a different edge. Grumble…
March 16, 2018
UPSide needs a battery technologist
The design of UPSide is coming together very nicely. We don’t have a full parts list yet, but we do have a functional diagram of the high-power subsystem most of which can be expanded into a schematic in a pretty straightforward way.
If you want to see what we have, clone the repo, cd to design-docs, make transactions.html, and view that in a browser. Note that the bus message inventory is out of date; don’t pay a lot of attention to it, one of the design premises has changed but I haven’t had time to rewrite that section yet.
We’ve got Eric Baskin, a very experienced power and signals EE, to do the high-power electronics. We’ve got me to do software and systems integration. We’ve got a lot of smart kibitzers to critique and improve the system design, spotting problems the two Eric’s might have missed. It’s all going well and smoothly – except in one key area.
UPSide needs a battery technologist – somebody who really understands all the tradeoffs among battery chemistries, how to spec battery types for different applications, and especially the ins and outs of battery management systems.
Eric Baskin and I are presently a bit out of our depth in this. Given time we could educate ourselves up to the required level, but the fact that that portion of the design is lagging the rest tells me that we ought to recruit somebody who already knows the territory.
Any takers? No money in it, but you get to maybe disrupt the whole UPS market and and certainly work with a bunch of interesting people.
Eric S. Raymond's Blog

- Eric S. Raymond's profile
- 141 followers

