
Gennaro Cuofano's Blog, page 10
September 23, 2025
AI Hallucination Detection Services: Third-Party Verification for AI Outputs

As artificial intelligence systems become increasingly integrated into critical decision-making processes, the phenomenon of AI hallucination—where models generate plausible-sounding but factually incorrect or entirely fabricated information—poses significant risks. AI Hallucination Detection Services emerge as essential third-party verification systems that validate AI outputs before they impact real-world decisions.
Understanding the Hallucination ChallengeAI hallucinations represent a fundamental challenge in modern machine learning systems. Unlike traditional software bugs that produce obvious errors, hallucinations often appear completely plausible. A language model might invent realistic-sounding scientific citations, a vision system might identify objects that aren’t present, or a predictive model might generate confident forecasts based on spurious patterns.
The subtlety of hallucinations makes them particularly dangerous. Users accustomed to AI systems providing accurate information may not question outputs that seem reasonable. This trust, combined with the authoritative tone many AI systems adopt, can lead to hallucinated information being accepted and acted upon without verification.
The causes of hallucination are rooted in how modern AI systems work. Neural networks learn patterns from training data and extrapolate to new situations. When faced with queries outside their training distribution or asked to connect disparate concepts, they may generate plausible-sounding but incorrect responses. The systems lack true understanding and instead perform sophisticated pattern matching.
Architecture of Detection ServicesHallucination detection services employ multiple techniques to identify potentially fabricated AI outputs. At the core, these systems use ensemble methods that compare outputs from multiple models. When different models produce conflicting information, it signals potential hallucination requiring further verification.
Knowledge graph validation forms another critical component. Detection services maintain comprehensive databases of verified facts and relationships. AI outputs are checked against these knowledge graphs to identify claims that contradict established information or introduce unsupported connections between concepts.
Uncertainty quantification provides probabilistic assessments of output reliability. By analyzing the confidence distributions within AI models and identifying cases where high confidence masks high uncertainty, detection services can flag outputs that warrant additional scrutiny.
Detection MethodologiesStatistical analysis of output patterns helps identify hallucinations. Detection services analyze factors like perplexity scores, attention patterns, and activation distributions to identify outputs that deviate from typical patterns. Unusual statistical signatures often indicate fabricated content.
Cross-reference checking validates factual claims against multiple independent sources. When an AI system makes specific claims about dates, statistics, or events, detection services automatically query trusted databases and information sources to verify accuracy. Discrepancies trigger deeper investigation.
Consistency analysis examines outputs for internal contradictions. Hallucinating AI systems often produce information that conflicts with other parts of their output. Detection services use logical reasoning engines to identify these inconsistencies and flag potentially unreliable content.
Industry-Specific ApplicationsIn healthcare, hallucination detection proves critical for AI-assisted diagnosis and treatment recommendations. Detection services specialized for medical applications maintain databases of verified medical knowledge, drug interactions, and treatment protocols. They can identify when AI systems suggest non-existent medications or propose contraindicated treatments.
Financial services require detection of hallucinated market analysis and predictions. Specialized services validate AI-generated financial advice against market data, regulatory requirements, and established financial principles. They can identify when AI systems invent non-existent financial instruments or misrepresent market conditions.
Legal applications demand extreme accuracy in AI-generated analysis. Detection services for legal AI verify case citations, check statutory references, and validate legal reasoning. They prevent AI systems from inventing precedents or misrepresenting legal principles in ways that could affect case outcomes.
Real-Time Detection CapabilitiesModern hallucination detection must operate at the speed of business. Real-time detection services integrate directly with AI systems through APIs, analyzing outputs as they’re generated. This enables immediate flagging of potential hallucinations before they can influence decisions or be disseminated to users.
Streaming analysis architectures process continuous AI outputs, maintaining context across extended interactions. This allows detection of hallucinations that develop over time or depend on conversational context. The systems can identify when AI models begin to fabricate information to maintain consistency with earlier hallucinated claims.
Edge deployment capabilities bring detection closer to AI systems, reducing latency and enabling offline verification. This proves particularly important for AI applications in environments with limited connectivity or where data privacy requirements prevent cloud-based verification.
Verification WorkflowsWhen potential hallucinations are detected, sophisticated workflows manage the verification process. Initial automated checks might escalate to specialist human reviewers with domain expertise. These experts can make nuanced judgments about whether flagged content represents genuine hallucination or acceptable extrapolation.
Graduated response systems provide different levels of intervention based on confidence in hallucination detection and potential impact. Low-risk situations might receive simple warnings, while high-stakes applications could trigger automatic blocking of AI outputs until human verification is complete.
Feedback loops ensure continuous improvement of detection capabilities. When human reviewers confirm or refute hallucination detection, this information trains the detection systems to better identify similar patterns in the future. Over time, the systems become more accurate at distinguishing genuine hallucinations from acceptable AI reasoning.
Integration with AI Development PipelinesHallucination detection services increasingly integrate with AI development workflows. During model training, they can identify architectures or training procedures that produce higher rates of hallucination. This allows developers to address hallucination tendencies before models are deployed to production.
Continuous integration and deployment pipelines incorporate hallucination testing alongside traditional performance metrics. Models must pass hallucination benchmarks before promotion to production environments. This shifts hallucination prevention from a post-deployment concern to a core development requirement.
A/B testing frameworks compare hallucination rates between different model versions or configurations. This enables data-driven decisions about model updates based on their impact on hallucination frequency and severity. Organizations can balance performance improvements against hallucination risks.
Economic Models and PricingHallucination detection services employ various pricing models to match different use cases and scales. Per-query pricing suits applications with variable or unpredictable usage patterns. Organizations pay only for the outputs they verify, making the service accessible to smaller deployments.
Subscription models provide unlimited verification within specified parameters. These work well for organizations with predictable AI usage patterns and offer budget certainty. Tiered subscriptions might offer different levels of verification depth or response time guarantees.
Enterprise agreements often include custom detection models trained on organization-specific data and requirements. These might include on-premise deployment options, dedicated support teams, and integration with internal knowledge bases. Pricing reflects the additional value of customization and dedicated resources.
Quality Metrics and StandardsMeasuring the effectiveness of hallucination detection requires sophisticated metrics beyond simple accuracy. Recall measures how many actual hallucinations the service catches, while precision indicates how many flagged outputs were genuine hallucinations. The balance between these metrics depends on application requirements.
Industry standards for hallucination detection are emerging through collaborative efforts between service providers, AI developers, and regulatory bodies. These standards define minimum detection capabilities, reporting requirements, and certification processes for detection services.
Benchmark datasets specifically designed to test hallucination detection capabilities help evaluate and compare services. These datasets include known hallucinations across various domains and difficulty levels. Regular benchmark updates ensure detection services keep pace with evolving AI capabilities.
Privacy and ConfidentialityHallucination detection services must handle sensitive information contained in AI outputs while performing verification. Privacy-preserving techniques like homomorphic encryption allow verification without exposing raw content. This enables detection services to operate on confidential business data, medical information, or legal documents.
Data retention policies balance the need for service improvement with privacy requirements. Detection services might retain anonymized patterns and statistics while deleting actual content after verification. Clear policies about data handling build trust with enterprise customers.
Audit trails document the verification process while protecting sensitive information. These trails prove valuable for compliance requirements and incident investigation while maintaining appropriate confidentiality. Cryptographic techniques ensure audit integrity without exposing verified content.
Regulatory Compliance IntegrationAs regulations increasingly require AI output verification, hallucination detection services help organizations demonstrate compliance. Services maintain detailed logs of verification activities, flag regulatory-relevant hallucinations, and generate compliance reports for auditors.
Industry-specific regulatory frameworks require specialized detection capabilities. Financial services regulations might require verification of specific types of financial advice, while healthcare regulations focus on medical accuracy. Detection services must understand and implement these domain-specific requirements.
International operations require detection services to navigate varying regulatory requirements across jurisdictions. Services must adapt their verification processes and reporting to meet local requirements while maintaining consistent quality standards globally.
Advanced Detection TechnologiesMachine learning models specifically trained to identify hallucinations show promising results. These models learn subtle patterns that distinguish hallucinated content from accurate information. Adversarial training helps these models identify increasingly sophisticated hallucinations.
Neurosymbolic approaches combine neural network pattern recognition with symbolic reasoning systems. This allows detection services to apply logical rules and domain knowledge to identify hallucinations that purely statistical methods might miss. The combination proves particularly effective for technical domains with well-defined rules.
Explainable AI techniques help detection services communicate why specific outputs were flagged as potential hallucinations. This transparency builds user trust and enables better decision-making about whether to accept or reject AI outputs. Clear explanations also help improve AI systems by identifying hallucination triggers.
Future DirectionsThe future of hallucination detection services will be shaped by advances in AI interpretability and verification technologies. As AI systems become more sophisticated, detection services must evolve correspondingly. This includes handling multimodal hallucinations where fabricated information spans text, images, and other media.
Integration with blockchain and distributed ledger technologies may provide immutable verification records. Smart contracts could automatically trigger verification for high-stakes AI decisions, creating transparent and auditable decision trails. This infrastructure would support both real-time verification and historical analysis.
Quantum computing may eventually enable more sophisticated verification algorithms that can process vast amounts of information to identify subtle hallucinations. The exponential speedup could allow real-time verification of complex AI reasoning chains that current systems cannot handle efficiently.
Building Trust in AI SystemsHallucination detection services play a crucial role in building and maintaining trust in AI systems. By providing independent verification, they give users confidence to rely on AI outputs for important decisions. This trust enables broader AI adoption while managing associated risks.
The presence of robust detection services encourages responsible AI development. Knowing that outputs will be verified incentivizes developers to create more reliable systems. The feedback from detection services helps identify and address systematic hallucination patterns in AI models.
Education about hallucination risks and detection capabilities helps users make informed decisions about AI reliance. Detection services often provide resources and training to help organizations understand hallucination risks and implement appropriate verification processes.
Conclusion: Essential Infrastructure for Reliable AIAI Hallucination Detection Services represent critical infrastructure for the responsible deployment of artificial intelligence. As AI systems take on increasingly important roles in business, healthcare, law, and other domains, the ability to verify their outputs becomes essential for managing risk and maintaining trust.
These services go beyond simple fact-checking to provide sophisticated analysis of AI reliability. By combining multiple detection methodologies, maintaining domain-specific knowledge bases, and continuously adapting to new hallucination patterns, they provide a crucial safety net for AI deployment.
The evolution of hallucination detection services will parallel the advancement of AI capabilities. As AI systems become more sophisticated and their applications more critical, the services that verify their outputs must match this progression. Organizations that implement robust hallucination detection position themselves to leverage AI’s benefits while managing its inherent risks, creating a foundation for sustainable and responsible AI adoption.
The post AI Hallucination Detection Services: Third-Party Verification for AI Outputs appeared first on FourWeekMBA.


AI Insurance Underwriting: New Insurance Products for AI Failures, Hallucinations, and Model Drift

The emergence of AI insurance underwriting represents a critical evolution in risk management as artificial intelligence systems become integral to business operations. This new category of insurance addresses unique risks associated with AI deployment, including model failures, hallucinations, biased decisions, and performance degradation over time.
Understanding AI-Specific RisksTraditional insurance models struggle to address the unique risk profile of artificial intelligence systems. Unlike physical assets or human errors, AI risks emerge from complex interactions between algorithms, data, and deployment environments. These risks can manifest suddenly and scale rapidly, potentially affecting millions of decisions before detection.
AI hallucinations—instances where models generate false or nonsensical outputs with high confidence—pose particular challenges. A language model might confidently assert fictional information, or a computer vision system might identify objects that don’t exist. These failures can lead to incorrect business decisions, reputational damage, or regulatory violations.
Model drift represents another critical risk. AI systems trained on historical data may become less accurate as real-world conditions change. This degradation can be gradual and difficult to detect, leading to slowly deteriorating performance that eventually crosses critical thresholds.
Categories of AI Insurance CoverageComprehensive AI insurance policies address multiple risk categories. Performance degradation coverage protects against losses when model accuracy falls below specified thresholds. This might cover revenue losses from recommendation systems that stop converting or increased costs from predictive maintenance systems that miss critical failures.
Hallucination and error coverage addresses direct losses from AI mistakes. This includes costs associated with incorrect decisions, false information dissemination, or actions taken based on hallucinated data. Coverage might extend to remediation costs, legal fees, and reputational damage control.
Bias and discrimination coverage protects against losses from AI systems that exhibit unfair treatment of protected groups. This includes legal defense costs, settlements, and remediation expenses when AI systems are found to discriminate in hiring, lending, or service delivery.
Underwriting Methodologies for AI RiskUnderwriting AI insurance requires novel approaches that differ from traditional actuarial methods. Insurers must assess the technical architecture of AI systems, the quality and representativeness of training data, and the robustness of testing and validation procedures.
Model documentation and interpretability play crucial roles in risk assessment. Insurers favor systems with clear documentation, explainable decisions, and comprehensive testing histories. Black box models that cannot explain their reasoning face higher premiums or may be uninsurable for certain applications.
The underwriting process includes technical audits that evaluate model architecture, training procedures, and deployment safeguards. Insurers may require access to model performance metrics, testing results, and incident histories. Some policies mandate ongoing monitoring and regular model updates as conditions of coverage.
Pricing Models and Premium StructuresAI insurance pricing reflects the unique risk dynamics of artificial intelligence systems. Base premiums consider factors like model complexity, application criticality, data volume processed, and potential impact of failures. High-stakes applications in healthcare, finance, or autonomous systems command higher premiums than low-risk recommendation engines.
Dynamic pricing models adjust premiums based on real-time performance metrics. Systems that maintain high accuracy and low error rates may qualify for premium reductions, while those showing signs of degradation face increased costs. This creates incentives for continuous model improvement and monitoring.
Usage-based pricing ties premiums to actual AI system utilization. Organizations pay more when AI systems make more decisions or process more data, reflecting the increased exposure to risk. This model aligns insurance costs with business value derived from AI systems.
Claims Processing and Loss AssessmentProcessing AI insurance claims requires specialized expertise to determine causation and assess damages. When failures occur, insurers must distinguish between model errors, data issues, implementation problems, and external factors. This often requires technical forensics and expert analysis.
Loss assessment in AI claims can be complex. Direct losses from incorrect decisions may be clear, but indirect impacts through customer churn, reputational damage, or regulatory penalties require careful evaluation. Some policies include business interruption coverage for periods when AI systems must be taken offline for remediation.
Rapid response teams help minimize losses when AI failures occur. These teams include technical experts who can diagnose problems, implement fixes, and prevent cascade failures. Some insurers offer incident response services as part of their coverage, helping organizations quickly address and remediate AI failures.
Risk Mitigation and Prevention ServicesLeading AI insurers offer risk mitigation services beyond simple coverage. These include model validation services that assess AI systems before deployment, ongoing monitoring platforms that detect performance degradation, and advisory services for AI governance and best practices.
Preventive maintenance programs help organizations avoid claims by identifying and addressing issues early. Regular model audits, bias testing, and performance benchmarking can catch problems before they cause significant losses. Some insurers require participation in these programs as a condition of coverage.
Training and certification programs help organizations build internal capabilities for AI risk management. These programs cover topics like responsible AI development, monitoring and maintenance procedures, and incident response protocols. Organizations with certified AI risk management programs may qualify for premium discounts.
Regulatory Compliance and StandardsAI insurance must navigate an evolving regulatory landscape. Different jurisdictions impose varying requirements for AI transparency, fairness, and accountability. Insurance policies must align with these regulations while providing meaningful coverage for compliance failures.
Standards bodies are developing frameworks for AI risk assessment and management. Insurers increasingly reference these standards in their underwriting criteria and policy terms. Organizations that adhere to recognized standards may find it easier to obtain coverage at favorable rates.
Documentation requirements for AI insurance claims often exceed regulatory minimums. Insurers may require detailed logs of model decisions, performance metrics, and system changes. This creates incentives for comprehensive AI governance and documentation practices.
Industry-Specific ConsiderationsDifferent industries face unique AI risks requiring specialized insurance products. Healthcare AI systems must address patient safety and medical malpractice concerns. Financial services AI must consider market manipulation and fair lending requirements. Autonomous vehicle AI involves complex liability questions around accident causation.
Cross-industry AI platforms pose particular challenges. A general-purpose language model might be used for customer service, content generation, and decision support across multiple industries. Insurers must assess risks across all potential applications and use cases.
Emerging applications create new insurance challenges. As AI moves into areas like drug discovery, climate modeling, and infrastructure management, insurers must develop expertise in these domains to properly assess and price risks.
The Role of ReinsuranceThe potential for correlated AI failures across multiple organizations using similar models creates systemic risks. Reinsurance markets help spread these risks, enabling primary insurers to offer higher coverage limits and broader protection.
Catastrophic AI failure scenarios—where widely-used models fail simultaneously—require careful modeling and risk aggregation. Reinsurers develop scenarios for various failure modes and their potential market-wide impacts. This analysis informs both pricing and coverage limitations.
Parametric reinsurance products tied to specific AI performance metrics offer rapid payouts when triggering events occur. These products provide liquidity for insurers facing multiple simultaneous claims from correlated AI failures.
Technology Infrastructure for AI InsuranceAdministering AI insurance requires sophisticated technology infrastructure. Real-time monitoring systems track model performance across insured portfolios. Automated underwriting platforms assess technical documentation and assign risk scores. Claims processing systems must handle complex technical evidence and expert assessments.
Data sharing agreements between insurers and insured organizations enable continuous risk assessment. APIs provide secure access to model performance metrics, allowing insurers to detect deteriorating conditions early. Privacy-preserving techniques ensure sensitive business data remains protected.
Blockchain technology may play a role in creating transparent, tamper-proof records of model performance and claims history. Smart contracts could automate certain aspects of coverage, triggering payouts when predefined conditions are met.
Market Development and CompetitionThe AI insurance market is rapidly evolving with traditional insurers, InsurTech startups, and technology companies all developing offerings. Traditional insurers leverage their actuarial expertise and capital reserves but must build technical AI capabilities. InsurTech startups bring technical innovation but need to establish credibility and financial stability.
Technology companies entering the insurance market often focus on specific AI risks they understand deeply. Cloud providers might offer insurance for AI systems running on their platforms. AI model providers might bundle insurance with their services.
Competition drives innovation in coverage terms, pricing models, and risk mitigation services. As the market matures, we’re seeing standardization of common coverage elements while differentiation occurs through specialized expertise and value-added services.
Future Evolution of AI InsuranceThe future of AI insurance will be shaped by technological advances and emerging risks. Quantum computing threats to AI security, adversarial attacks on machine learning systems, and risks from artificial general intelligence will require new insurance products and underwriting approaches.
Integration with AI governance platforms will deepen, with insurance becoming part of comprehensive AI risk management ecosystems. Automated compliance checking, continuous validation, and predictive risk modeling will become standard features.
As AI becomes more autonomous, questions of liability and insurability will evolve. Insurance for AI systems that can modify their own code or objectives will require new conceptual frameworks. The industry must prepare for scenarios where AI systems themselves purchase and manage insurance coverage.
Best Practices for AI Insurance BuyersOrganizations seeking AI insurance should start with comprehensive risk assessment. Understanding your AI portfolio, use cases, and potential impact of failures helps determine appropriate coverage levels and types. Regular reviews ensure coverage keeps pace with AI deployment expansion.
Documentation and governance practices directly impact insurability and premiums. Organizations should maintain detailed records of model development, testing, deployment, and performance. Strong AI governance frameworks with clear accountability structures are viewed favorably by insurers.
Building relationships with insurers specializing in AI risk can provide value beyond simple coverage. These insurers often offer insights into emerging risks, best practices from across their portfolio, and early access to new coverage types as they develop.
Conclusion: Essential Protection for the AI EraAI insurance underwriting has evolved from a niche curiosity to an essential component of enterprise risk management. As organizations increasingly rely on AI for critical decisions and operations, the potential impact of AI failures grows correspondingly. Insurance provides both financial protection and incentives for responsible AI development and deployment.
The complexity of AI risks requires equally sophisticated insurance solutions. Modern AI insurance goes beyond simple financial coverage to include risk assessment, mitigation services, and incident response capabilities. This comprehensive approach helps organizations realize AI’s benefits while managing its unique risks.
As AI capabilities expand and new applications emerge, AI insurance will continue to evolve. Organizations that understand and proactively manage AI risks through appropriate insurance coverage position themselves for sustainable AI adoption. In an era where AI drives competitive advantage, AI insurance becomes not just a protective measure but a strategic enabler of innovation.
The post AI Insurance Underwriting: New Insurance Products for AI Failures, Hallucinations, and Model Drift appeared first on FourWeekMBA.
Your Strategic Prompting Playbook
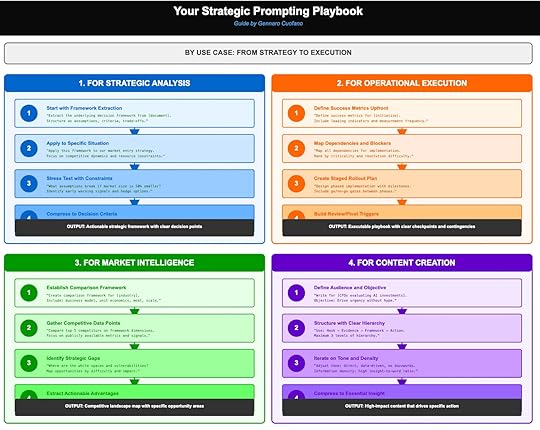
From Frameworks to Execution
AI isn’t just a tool for answering questions—it’s a system for structuring thought. But the value you extract depends entirely on the prompting strategy you deploy. Random questions yield random answers. Disciplined prompting yields actionable frameworks, decision clarity, and executable playbooks.
The Strategic Prompting Playbook lays out four core use cases: Strategic Analysis, Operational Execution, Market Intelligence, and Content Creation. Each follows a step-by-step prompting flow that transforms AI from a text generator into a structured thinking engine.
1. For Strategic AnalysisThe first use case is the backbone of executive decision-making: using AI to clarify frameworks, stress-test assumptions, and sharpen criteria for action.
Step 1: Framework Extraction
Instead of asking AI “What should we do?”, begin by extracting the decision structure from source materials—reports, case studies, or expert commentary. For example:
“Extract the underlying decision framework from this document. Structure as assumptions, criteria, and trade-offs.”
Step 2: Apply to Specific Situation
Next, force AI to adapt that framework to your context. If you’re exploring market entry:
“Apply this framework to our European expansion strategy. Focus on competitive dynamics and resource constraints.”
Step 3: Stress Test with Constraints
Frameworks look solid on paper until reality collides with assumptions. Stress test by shrinking market size, extending timelines, or tightening budgets. Ask:
“What assumptions break if market size is 50% smaller? Identify early warning signals and hedge options.”
Step 4: Compress to Decision Criteria
Finally, distill the analysis into clear, ranked decision points:
“Compress the framework into 3 prioritized decision criteria with trade-offs.”
Output: An actionable strategy framework, not generic advice—clear decision points, risk trade-offs, and contextualized application.
2. For Operational ExecutionAI excels at turning strategy into execution playbooks with checkpoints, contingencies, and monitoring systems. This prevents grand plans from stalling in implementation.
Step 1: Define Success Metrics Upfront
Force clarity by anchoring execution in measurable outcomes.
“Define success metrics for this initiative. Include leading indicators and measurement frequency.”
Step 2: Map Dependencies and Blockers
Ask AI to expose hidden friction points:
“Map all dependencies for implementation. Rank by criticality and resolution difficulty.”
Step 3: Create Staged Rollout Plan
Execution rarely works in a single leap. AI can design phased milestones with explicit go/no-go gates.
“Design a phased rollout plan with checkpoints. Include contingency triggers.”
Step 4: Build Review/Pivot Triggers
Plans without monitoring mechanisms collapse. AI can set thresholds for pivoting early.
“Define pivot triggers for budget overrun, adoption lag, or performance shortfall.”
Output: A clear operational playbook—timelines, triggers, dependencies—that reduces execution risk and builds accountability into rollout.
3. For Market IntelligenceInformation is abundant. What matters is comparative insight—understanding where you stand relative to competitors and where gaps can be exploited.
Step 1: Establish Comparison Framework
Start by defining the structure for analysis.
“Create comparison framework for SaaS players. Include business model, unit economics, moat, and scale.”
Step 2: Gather Competitive Data Points
Force AI to fill the framework with publicly available data.
“Compare top 5 competitors on the defined framework. Focus on metrics like pricing, retention, funding.”
Step 3: Identify Strategic Gaps
Ask AI to move beyond reporting and surface where competitors are vulnerable.
“Identify white spaces and vulnerabilities. Rank by difficulty to exploit and potential impact.”
Step 4: Extract Actionable Advantages
Finally, direct AI to synthesize recommendations:
“Extract 3 actionable opportunities for competitive advantage based on gaps identified.”
Output: A competitive landscape map with explicit opportunity areas—not just data, but direction.
4. For Content CreationContent is often where strategy meets the market. AI can help ensure messaging isn’t just polished, but strategically aligned and action-oriented.
Step 1: Define Audience and Objective
Generic content fails because it isn’t audience-specific. AI fixes this by framing purpose.
“Write for CFOs evaluating AI investments. Objective: drive urgency without hype.”
Step 2: Structure with Clear Hierarchy
Force messaging into evidence-backed structure.
“Use 3-level hierarchy: Hook → Evidence → Framework → Action.”
Step 3: Iterate on Tone and Density
AI can flex tone (direct, data-driven, narrative) and adjust information density.
“Reframe in a high signal-to-noise ratio. Cut buzzwords, maximize data-to-argument ratio.”
Step 4: Compress to Essential Insight
Finally, produce an executive-ready distillation.
“Compress to one paragraph with clear call-to-action.”
Output: High-impact content that drives decisions, not just noise.
Why This Playbook WorksEach module follows a repeatable flow of analysis → application → stress test → compression. This structure turns AI outputs from brainstorming into deliverables executives can act on.
The Playbook also resolves the three biggest failures in AI adoption:
Lack of Clarity: Prompts are too vague, producing shallow answers.Lack of Context: Users forget to tie outputs to objectives and constraints.Lack of Conversion: Insights remain abstract instead of being operationalized.By forcing frameworks, decision criteria, and staged execution, the Playbook ensures AI delivers leverage, not trivia.
The Strategic AdvantageTeams using this Playbook build faster cycles of learning and execution.
Strategy becomes structured and testable.Operations scale with built-in safeguards.Market intelligence turns into exploitable gaps.Content shifts from noise to precision influence.In short, AI stops being a novelty tool and becomes an operating system for decision-making.
ConclusionThe Strategic Prompting Playbook transforms AI from a passive assistant into an active driver of organizational momentum.
For Strategy: clear frameworks with decision points.For Execution: phased playbooks with contingencies.For Intelligence: competitive maps with actionable gaps.For Content: targeted messaging that drives outcomes.The shift is subtle but profound. You’re no longer “asking AI for help.” You’re running structured protocols that turn language into leverage.
The takeaway is simple: If you want AI to think with you, not for you, use a Playbook.

The post Your Strategic Prompting Playbook appeared first on FourWeekMBA.
Advanced Prompting Techniques

The Power User Patterns for Extracting Strategic Intelligence
Most people use AI as if it were a search engine—throw in a question, get a quick answer. But power users know this is the least effective way to unlock value. The real leverage comes from systematic prompting patterns that structure how AI processes information, extracts insight, and builds knowledge over time.
The Advanced Prompting Techniques framework codifies six such patterns: Iterative Refinement, Multi-Perspective Simulation, Assumption Stress Testing, Cross-Domain Patterns, Reference-Build Method, and the Chain of Compression. These are not tricks—they are disciplined approaches that turn AI into a strategic partner rather than a shallow assistant.
1. Iterative Refinement LoopThe simplest but most overlooked pattern: don’t expect a single prompt to deliver a finished product. Instead, use progressive narrowing through structured iterations.
Round 1: Broad Scope — “Analyze this market.”Round 2: Segment Focus — “Focus on enterprise segments.”Round 3: Extract Specifics — “Extract pricing structures.”Round 4: Apply Comparison — “Compare to US benchmarks.”Each round sharpens the scope while retaining context from the previous step.
Key Benefits:
Maintains context across turns.Reduces ambiguity without overwhelming the system.Builds on prior knowledge with natural progression.This transforms AI from a vending machine into a thinking partner that “tightens the aperture” with you.
2. Multi-Perspective SimulationStrategy often fails because teams view issues through a single dominant lens—finance, operations, or product. The Multi-Perspective Simulation forces comprehensive analysis by simulating distinct stakeholder views.
Operator View: Execution feasibility, implementation details, lessons learned.Investor View: ROI, risk assessment, market potential.Customer View: Pain points, value focus, alternatives considered.Each perspective is capped at 100 words to enforce focus and avoid overlap.
Key Benefits:
Prevents blind spots by surfacing tensions.Creates balance between feasibility, profitability, and desirability.Forces prioritization of conflicting demands.This technique ensures that strategies aren’t one-dimensional.
3. Assumption Stress TestingEvery plan rests on hidden assumptions. When those fail, the entire system collapses. Assumption Stress Testing makes the implicit explicit by mapping dependencies.
The process:
List Core Assumptions — revenue growth rate, cost decline, adoption curve.Identify Break Points — what happens if assumption fails?Mark Warning Signs — early indicators of failure (lagging metrics, market signals).Propose Hedge Options — mitigation strategies like pilots, partnerships, insurance.Key Benefits:
Surfaces hidden risks before they scale.Enables proactive planning instead of reactive scrambling.Builds resilience and speeds pivoting.This turns AI into a risk radar—systematically probing what could go wrong and how to adapt.
4. Cross-Domain PatternsBreakthrough insights rarely come from within an industry. They emerge from pattern recognition across domains. This technique prompts AI to deliberately map lessons from one industry onto another.
Industry A: SaaS unit economics.Industry B: Pharma R&D cycles.Pattern Match: Both face long upfront investment with uncertain payoff.Focus Areas for Pattern Recognition:
Business model evolution.Market dynamics.Strategic mistakes.Disruption cycles.Key Benefits:
Surfaces analogies executives may miss.Accelerates strategic creativity.Identifies opportunities or risks earlier by learning from parallel domains.Cross-domain prompts shift the question from “What is happening here?” to “Where have we seen this movie before?”
5. Reference-Build MethodMost organizations treat AI outputs as disposable. The Reference-Build Method compounds knowledge instead of repeating cycles.
The sequence:
Extract Layer: Pull insights from source (“Key implementation steps…”).Build Layer: Add interpretation or application (“Building on our market analysis…”).Reference Phrase: Instruct AI to build on prior work rather than starting fresh (“Continue our earlier analysis…”).Key Benefits:
Maintains continuity across sessions.Reduces repetition and ensures depth.Creates compound insights instead of isolated fragments.This transforms AI into a knowledge stack—each layer builds on the last.
6. Chain of CompressionExecutives don’t need more information; they need sharper communication. The Chain of Compression trains AI to condense progressively without losing fidelity.
200 Words: Full context, details, complete argument.100 Words: Core points, key evidence, main conclusion.50 Words: Essential insights, proof included.1 Tweet: Pure essence.At each stage, supporting details are stripped while the insight remains intact.
Key Benefits:
Trains clarity through forced brevity.Surfaces the non-negotiable core message.Produces outputs tailored for different audiences—from analysts to boardrooms.This method ensures leaders get exactly the signal they need without noise.
Why These Patterns MatterThe difference between casual users and power users isn’t intelligence—it’s discipline. Power users deploy structured prompting techniques that:
Reduce Ambiguity: Each method narrows scope or defines structure.Force Rigor: Multi-perspective, stress testing, and cross-domain patterns create systematic checks.Compound Learning: Reference-building and iterative refinement turn AI into a cumulative intelligence engine.Accelerate Clarity: Compression ensures insights are delivered at the right altitude for decision-makers.Together, these patterns move prompting from asking questions to running protocols.
The Strategic PayoffOrganizations that master these techniques stop treating AI as a chatbot and start treating it as an executive partner.
Analysts gain structured workflows.Executives get clarity at the right resolution.Risk managers expose hidden fragilities.Strategists unlock cross-domain foresight.This shift matters because competitive advantage now depends less on access to AI—which is commoditizing—and more on how effectively you structure your interaction with it.
ConclusionThe Advanced Prompting Techniques framework provides six repeatable patterns to maximize AI’s strategic potential:
Iterative Refinement sharpens focus.Multi-Perspective Simulation balances competing priorities.Assumption Stress Testing mitigates hidden risks.Cross-Domain Patterns surface novel insights.Reference-Build Method compounds knowledge.Chain of Compression delivers clarity at speed.Each on its own is powerful. Together, they form a prompting arsenal that separates casual dabblers from disciplined operators.
The lesson is simple: stop improvising. Start running patterns.
The post Advanced Prompting Techniques appeared first on FourWeekMBA.
Core Prompt Templates (Battle-Tested)

From Random Requests to Repeatable Intelligence
Most teams approach AI as if every interaction were unique, improvising prompts as if they were one-off questions. This creates inconsistent outputs, wasted cycles, and no institutional learning. The solution is to stop treating prompts as disposable and start treating them as templates—battle-tested, reusable structures designed for strategic outcomes.
This framework organizes Core Prompt Templates into four domains—Analysis & Strategy, Enterprise & Operations, Content & Communication, and Research & Intelligence. Each template is optimized for a distinct function but shares a common DNA: clarity, context, constraints, and structure. Together, they turn prompting from an art into a repeatable operating system.
A. Analysis & StrategyStrategy lives and dies by framing. Without rigorous analysis, organizations fall into narrative confirmation bias—forcing data to fit the story they already want to tell. Templates in this domain discipline the process, ensuring structured decision inputs.
1. Framework ExtractionExtracts the decision logic embedded in documents, conversations, or datasets. The prompt demands a structured output—decision criteria, trade-offs, application rules.
Use Case: Deriving investment theses, strategic options, or decision playbooks from dense materials.
2. Reality Gap AnalysisCompares stated objectives vs actual outcomes. Forces systematic surfacing of misalignments—missed KPIs, resource gaps, execution drags.
Use Case: Post-mortems, board reviews, or diagnosing failing initiatives.
3. Constraint MappingMaps explicit and hidden operational constraints: budget, risk, dependency, scalability. Clarifies the boundaries that govern feasibility.
Use Case: Risk assessment, resource allocation, scenario planning.
4. Market Position AssessmentBenchmarks a company against peers: market share, unit economics, competitive strengths/weaknesses. Outputs comparative tables or 2×2 maps.
Use Case: Competitive strategy, M&A evaluation, investor decks.
These strategy templates replace fuzzy analysis with evidence-driven framing—essential for high-stakes decisions.
B. Enterprise & OperationsOperations are where AI usually under-delivers because outputs remain too generic. These templates force AI into the role of execution amplifier—supporting managers, operators, and executives with structured deliverables.
1. Stakeholder-Aligned MessagingGenerates communication tailored for specific roles: CTO, CFO, VP of Sales. Forces brevity (under 300 words) and vocabulary tuned to audience priorities.
Use Case: Executive updates, proposal framing, change-management memos.
2. Executive Briefing GeneratorProduces succinct briefings: top three insights, supporting data, clear next actions. Eliminates narrative fluff.
Use Case: CEO dashboards, board packets, investor reviews.
3. Deal ArchitectureStructures deals as pricing frameworks, value levers, common objections. Aligns commercial logic with negotiation strategy.
Use Case: Sales pitches, partnerships, procurement frameworks.
4. Operational PlaybookCreates execution checklists or SOPs with if/then conditions, success metrics, and operator-level clarity.
Use Case: QA protocols, onboarding flows, process design.
The value here is velocity: instead of reinventing messaging or SOPs, operators deploy templates that deliver 80% of the work instantly, then refine.
C. Content & CommunicationMost AI use cases start here—content. But unstructured prompting produces filler. The Compression Cascade template solves this by progressively condensing complex material into layered outputs.
Compression CascadeTransforms a dense report into structured layers: executive summary → key insights → messaging bullets → headline copy. Each layer reduces size while increasing clarity.
Use Case: Turning a 60-page analyst report into a three-slide investor deck, or a technical paper into a product blog.
The discipline is not “write something short.” It is **cascade transformation—**maintaining fidelity at every level while adapting to channel requirements.
D. Research & IntelligenceAI as an intelligence amplifier is powerful, but dangerous when prompts are loose. The Market Landscape Mapping template enforces structured capture.
Market Landscape MappingSurfaces key players, categories, and metrics. Requires table format with dimensions like market size, differentiation, funding, and momentum.
Use Case: Landscape scans for investment, competitive landscaping, market entry strategy.
Instead of a generic “tell me about competitors,” this template builds systematic maps that can feed into dashboards, reports, or investment memos.
Template Selection MatrixNot all templates serve the same purpose. The selection matrix aligns them with output format and time to value:
Matrix/Framework (immediate): Framework Extraction, Constraint Mapping.Checklist/Playbook (1–2 iterations): Operational Playbook, Deal Architecture.Brief/Summary (1–2 iterations): Executive Briefing Generator, Stakeholder Messaging.Table/Map (3–5 iterations): Market Position Assessment, Landscape Mapping.This prevents wasted cycles. Teams know whether they need a fast win, a structured framework, or a deeper research asset.
Why Templates WorkRepeatability: Prompts stop being one-offs and become reusable building blocks.Scalability: Teams across functions can deploy the same structures, ensuring consistency.Velocity: Pre-engineered templates cut iteration time from hours to minutes.Rigor: By forcing structure (frameworks, tables, cascades), outputs reach decision-grade quality faster.Templates turn AI into a process engine rather than a novelty tool.
Common Failure Without TemplatesGeneric outputs: “Summarize this report” produces bland text.Over-iteration: Teams waste cycles refining vague prompts.Lost learning: No compounding—each new analyst repeats the same mistakes.Low trust: Executives dismiss outputs as unreliable.The hidden cost isn’t poor content; it’s organizational disillusionment with AI.
The Strategic ShiftOrganizations that embrace Core Prompt Templates create a new layer of institutional knowledge:
Analysts standardize decision frameworks.Operators scale execution playbooks.Communicators repurpose insights across formats.Researchers capture landscapes systematically.This is how prompting evolves from improvisation to infrastructure.
ConclusionPrompts are not questions—they are programs. And like any program, they perform best when modularized, reusable, and tested under pressure.
The Core Prompt Templates (Battle-Tested) framework provides that foundation. From Framework Extraction to Market Mapping, Compression Cascades to Operational Playbooks, each template encodes a repeatable system for thought.
Organizations that adopt this discipline will stop treating AI as a vending machine for ideas and start wielding it as a scalable engine of strategy, execution, communication, and intelligence.
The message is simple: Don’t just prompt. Deploy templates.
The post Core Prompt Templates (Battle-Tested) appeared first on FourWeekMBA.
Principles of Effective Prompting

Turning AI into a senior analyst, not a conversational partner
Most organizations still misunderstand prompting. They see it as “asking questions nicely” rather than programming cognition with language. This mistake is costly: vague prompts lead to vague answers, creating the illusion of AI’s weakness when the real issue is user imprecision.
The Principles of Effective Prompting establish a disciplined framework: clarity, context, constraints, guardrails, and frameworks. Together they transform AI from a loose conversational tool into a structured thinking partner that operates with precision and reproducibility.
Core Philosophy: Direct Action Over DiscussionThe shift begins with mindset. Don’t treat AI as a brainstorming buddy or digital intern. Treat it as a senior analyst—a professional who thrives on clear instructions, crisp framing, and explicit goals.
The guiding rule: ambiguity in equals noise out. If the frame is sharp, the output will be sharp. If it’s vague, expect filler.
1. Clarity: Precision Beats PolitenessMost prompts fail because they are padded with conversational fluff. “Could you please help me with…” wastes tokens and dilutes intent. AI doesn’t respond to politeness; it responds to clarity.
Effective prompting starts with action verbs. Use analyze, create, rewrite, compare, extract. These signal intent and mode of reasoning.
Examples:
Weak: “Could you please help explain adoption?”Strong: “List adoption patterns.”Stronger: “Compare AI adoption costs in 2023 vs 2025.”By anchoring prompts in verbs, you orient the system toward structured action rather than open-ended speculation.
2. Context: Stacking the Who, What, and WhyAI doesn’t know why you’re asking unless you tell it. Context transforms generic answers into tailored insights.
The context stack ensures coverage:
Who: Target audience.What: Specific objective.Why: Purpose and urgency.When: Timeline or situational framing.Example:
Weak: “Analyze semiconductor disruptions.”Strong: “Analyze semiconductor disruptions for CTOs evaluating AI investments in 2025.”With context, the system orients outputs toward relevance and resonance. Without it, you get surface-level content.
3. Constraints: Cascading for PrecisionConstraints act like guardrails on a racetrack—they channel power into direction. Left unconstrained, AI sprawls. Well-structured constraints make outputs sharper, faster, and more consistent.
Apply the constraint cascade:
Scope: What to include, what to exclude.Style: Tone, format, voice.Format: Length, bullet points, or matrices.Example:
“Market analysis → B2B SaaS → financial metrics → 3 bullet max.”
Constraints don’t limit creativity; they filter noise and accelerate iteration.
4. Guardrails: Blocking Bias and FluffGuardrails stop the system from wandering into bad habits. They explicitly state what not to do.
Common blocks:
No buzzwordsNo generic adviceNo hypotheticals without dataNo passive voiceNo fluff or paddingExample:
Weak: “Summarize this report.”Strong: “Summarize this report in 150 words. No fluff, no buzzwords, no filler.”Guardrails reduce variability. They push AI away from vague generalities and toward disciplined synthesis.
5. Frameworks: Structures Over AnswersThe real power of prompting is not getting answers but requesting reusable structures. Frameworks organize thinking in ways you can repeat, scale, and adapt.
Request specific formats:
Matrices (2×2, 3×3)Decision treesEvaluation criteriaProcess systemsExample:
“Extract decision framework. Structure as 2×2 matrix with trade-offs and criteria.”
This turns AI into a generator of mental models, not just content filler. Frameworks scale beyond one interaction; they become embedded assets in organizational playbooks.
Rule of ThumbThe sharper the frame, the sharper the output. Every principle—clarity, context, constraints, guardrails, frameworks—tightens the aperture. Ambiguity is the enemy.
The Professional Prompting FormulaAt its core, effective prompting can be expressed as a formula:
Action Verb + Context + Constraints + Structure = Effective Prompt
Start with the verb to define mode of reasoning.Load the context to align relevance.Add constraints to sharpen boundaries.Demand frameworks to enforce structure.Example:
“Compare adoption models for Fortune 500 CTOs (who) evaluating AI investments in 2025 (when/why). Limit to 200 words (constraint). Structure as 2×2 trade-off matrix (framework).”
The difference between a casual request and this formula is the difference between generic commentary and actionable strategy.
Why This MattersEffective prompting is not an academic exercise—it is an operational imperative.
Scalability: Structured prompts generate outputs that can be reused, not just consumed once.Reproducibility: Guardrails and constraints ensure consistency across multiple runs.Strategic Leverage: Frameworks enable organizations to encode decision logic, not just generate text.Cognitive Efficiency: By shifting from “ask and hope” to “program and extract,” teams unlock compounding value.Without discipline, AI becomes a novelty. With discipline, it becomes an enterprise-grade reasoning partner.
Pitfalls to AvoidOver-conversational tone: “Please write me…” dilutes signals.Vague objectives: “Tell me about AI trends” invites banality.Ignoring constraints: Long outputs with no format waste time.Failure to block noise: Without guardrails, AI reverts to clichés.Under-structuring: Asking for answers instead of systems loses scalability.Each pitfall stems from treating AI as an assistant instead of a programmable engine.
ConclusionThe Principles of Effective Prompting elevate prompting from improvisation to engineering.
Clarity makes intent explicit.Context grounds relevance.Constraints sharpen precision.Guardrails block noise.Frameworks enable scale.Together, they form a repeatable system that transforms AI into a structured collaborator.
Prompting, done right, is not asking—it is programming. The sharper the design, the sharper the output. Organizations that master this discipline will stop wasting cycles on filler and start compounding intelligence into enduring competitive advantage.
The post Principles of Effective Prompting appeared first on FourWeekMBA.
The Business Engineer’s Guide to Effective Prompting

Most people still treat AI as if it were a vending machine: input a vague request, hope for something useful, and complain if it disappoints. This mindset misses the point. AI is not a slot machine—it is a programmable reasoning engine. The quality of its output is not a matter of luck but of method.
The Business Engineer’s Guide to Effective Prompting reframes prompting as programming with language. Each prompt is not a casual question but a functional call, each conversation not idle chatter but an execution stack. The aim is not one-off answers but systematized thinking that scales.
This guide unfolds across six dimensions: core philosophy, templates, advanced techniques, pitfalls, strategic playbook, and infrastructure.
1. Core Philosophy: Direct Action Over DiscussionAt the center lies a simple shift: treat prompting as direct action. You’re not chatting with a machine; you’re programming its cognitive process.
Clarity: Precision beats eloquence. Strip prompts to their essentials: roles, verbs, constraints, and outputs.Context: Always load the “why” before the “what.” State background, purpose, audience, and scope.Constraints: Limit breeds quality. Explicit word counts, formats, and length guidelines anchor responses.Guardrails: Ban what you don’t want. Explicit exclusions prevent drift and noise.Frameworks: Structure beats style. Reusable patterns—comparisons, trade-offs, stepwise reasoning—transform prompts into repeatable assets.Prompting is not just about getting an answer—it’s about programming a decision-making engine that respects rules and reproduces results.
2. Core Prompt TemplatesTemplates are the scaffolding. They turn raw capability into reliable workflows.
Analysis & Strategy: Framework extraction, causal analysis, market positioning.Enterprise & Ops: Stakeholder mapping, operational diagnostics, organizational playbooks.Content & Comms: Strategic narratives, message distillation, document templates.Research & Intel: Competitive briefs, analytical mapping, pattern recognition.A strong template ensures consistency across use cases. For instance:
“Extract the underlying decision framework from [document/situation]. Structure as core assumptions, decision criteria, trade-offs, application rules. Keep operational, not theoretical. Format as 2×2 matrix, 150 words max.”
That is not a request—it’s a micro-program.
3. Advanced TechniquesThe next layer is sophistication—methods that push beyond simple Q&A.
Iterative Refinement Loop: Analyze, focus, extract, repeat. Chain prompts to progressively sharpen outcomes.Multi-Perspective Simulation: Rotate lenses—operator view, investor view, customer view. Contrast reveals blind spots.Assumption Stress Testing: Surface core assumptions, then probe for weak points.Cross-Domain Patterns: Borrow from analogies—apply lessons from industry A to industry B.Reference-Build Method: Layer context by referencing previous analyses, compounding knowledge depth over time.These techniques transform AI into a simulation partner, testing reality rather than parroting content.
4. Common PitfallsMost failures in prompting are predictable. Five stand out:
Prompt Bloat: Overloading the request with fluff.Open Ocean: Asking questions too broad to anchor (“Tell me about AI”).Single-Shot Fallacy: Expecting perfection in one pass instead of iterating.Context Amnesia: Restarting from scratch every time instead of threading conversations.Format Drift: Accepting unstructured outputs instead of demanding consistency.These traps reduce AI to trivia machine behavior. The fix is discipline: treat every interaction as programmable, not conversational.
5. Strategic PlaybookEffective prompting scales into business value only when embedded into a strategic playbook. Four core arenas dominate:
Strategic Analysis: Extract frameworks, compare options, identify trade-offs.Operational Execution: Diagnose processes, model decisions, and align organizational playbooks.Market Intelligence: Build competitor frameworks, simulate strategies, and identify defensible advantages.Content Creation: Distill narratives, synthesize research, and enforce clarity at scale.This is where prompting transcends individual productivity hacks and becomes a force multiplier for organizations.
6. Prompt InfrastructureScaling prompting requires infrastructure, not improvisation. Three layers are essential:
The Meta-FrameworkDefine who, what, why, how, when. Treat AI prompts like structured research protocols.
The Prompt Stack MethodFour levels of execution:
Foundation: Gather raw inputs.Pursuit: Apply frameworks.Analysis: Extract insights.Synthesis: Compose into action.Template LibraryCurate reusable prompt templates:
Market narrativesCompetitive briefsExecutive summariesFramework extractionsThe shift here is cultural. Prompting stops being personal artistry and becomes organizational process.
Core Principle: Systematized Thinking That ScalesPrompting isn’t asking—it’s programming with language. Each prompt is a function call. Each conversation is a program execution. Each framework is a reusable module.
The point is not cleverness but reproducibility. You’re not trying to “trick” the machine—you’re building a thinking system.
The organizations that master this approach will not just use AI—they will compound its effects. Instead of isolated wins, they’ll build repeatable playbooks for strategy, execution, intelligence, and communication.
AI then stops being a tool and becomes an operational partner.
ConclusionThe Business Engineer’s Guide reframes prompting as applied business engineering. It’s not about asking better questions—it’s about writing structured instructions that transform AI into a scalable decision engine.
Core philosophy teaches discipline.Templates provide scaffolding.Advanced techniques unlock depth.Avoiding pitfalls ensures consistency.The playbook turns individual prompts into enterprise value.Infrastructure ensures scale.The result: organizations stop gambling on AI outputs and start programming intelligence directly into their workflows.
The future will not belong to those who dabble in prompting—it will belong to those who engineer thinking systems that scale.
The post The Business Engineer’s Guide to Effective Prompting appeared first on FourWeekMBA.
September 22, 2025
The Three Types of Organizations: Accelerators, The Awakening, and The Obsolete

AI transformation is not evenly distributed. While some organizations sprint ahead and restructure entire industries, others remain trapped in denial or hesitation. The Three Types of Organizations framework explains this divergence: Accelerators, The Awakening, and The Obsolete. Where an organization falls on this spectrum is not random—it is directly correlated with its FRED score and its willingness to act with urgency.
The future does not wait for laggards. Within twelve months, the distribution of winners and losers shifts dramatically. Accelerators double their market share, the Awakening struggles to survive, and the Obsolete fade into permanent irrelevance.
1. The Accelerators (FRED Score: 10–12 | Top 20%)Accelerators are the organizations that didn’t wait for permission or proof. They recognized the paradigm shift early, moved decisively, and began embedding AI-first principles across the business. While competitors hesitated, they compounded advantages in data, talent, and execution.
Who They Are:AI embedded into every core process, not just side projects.Employees augmented rather than replaced, creating exponential productivity gains.Customer relationships redefined around continuous personalization and real-time intelligence.Efficiency breakthroughs at scale, making cost structures unmatchable.Their Playbook:Accelerators treat AI as foundational, not experimental. Instead of running pilots to prove value, they rebuild entire workflows and business models around AI-native assumptions. For them, AI is not a feature—it is the operating system of the organization.
Result: Accelerators pull away quickly. Compounding gains mean they cannot be caught by slower peers. Over twelve months, they double their market share as advantages in speed, learning loops, and customer acquisition snowball.
2. The Awakening (FRED Score: 4–9 | Middle 30%)The Awakening organizations sit in a precarious middle ground. They see the wave coming, they are scrambling to respond, but they are running against time. Their problem is not ignorance—it is hesitation.
Who They Are:Pilot programs are underway, but still small in scope.Leadership buy-in is emerging, yet not absolute.Skills gaps are acknowledged but only partially addressed.AI is treated as a project rather than a wholesale transformation.Their Playbook:The Awakening often believes it still has months or years to act. In reality, every day of delay costs unrecoverable ground. Competitors in the Accelerator camp are not waiting—they are already embedding AI into product design, marketing, customer service, and supply chains.
The Awakening faces a window rapidly closing. If they do not accelerate, they become irrelevant by default—not because they failed to act, but because they acted too slowly.
Result: Within twelve months, most of the Awakening shrinks to survivors. Some graduate into Accelerators if leadership acts decisively. But the majority get squeezed—losing customers, margins, and relevance.
3. The Obsolete (FRED Score: 0–3 | Bottom 50%)At the bottom of the distribution are the Obsolete. These organizations are still debating whether AI is “real” or “relevant.” They cling to legacy business models, dismiss AI as hype, and default to defensive postures.
Who They Are:Still in “wait and see” mode.Treat AI as overblown hype or irrelevant to their industry.Invest in protecting old business models rather than rethinking them.Daily erosion of relevance as customers leave and costs rise.Their Playbook:The Obsolete don’t have a playbook—they have a defense mechanism. Their strategy is denial, rationalization, and delay. They believe they are preserving stability, but in reality, they are guaranteeing decline.
By the time the Obsolete recognize reality, it is too late. The compounding gap created by Accelerators makes recovery impossible.
Result: Within twelve months, the Obsolete become permanently irrelevant. They do not just lose market share—they lose the ability to compete at all.
The 12-Month Market ProjectionThe framework’s power lies in its time compression. Unlike past transformations that unfolded over decades, AI adoption moves in twelve-month cycles.
Today: Market distribution sits roughly at 20% Accelerators, 30% Awakening, and 50% Obsolete.In 12 months: The split shifts to 40% Accelerators, 10% Awakening, and 50% Obsolete.This shift is not hypothetical—it is structural. Accelerators grow by compounding. The Awakening is squeezed by indecision. The Obsolete calcify into irrelevance.
The lesson: Your category today is not destiny—but time to change is running out.
Key Reality: Why Accelerators WinThe difference between Accelerators and everyone else is not technology—it is mindset and execution speed.
Accelerators embed AI into every process, creating irreversible efficiency gains.They see employees not as replaceable but as augmentable, unlocking exponential productivity.They redesign customer relationships around intelligence, not transactions.They treat AI as the foundation of the business, not as an experiment.The compound effect is decisive: once Accelerators pull ahead, others cannot catch up.
Strategic TakeawaysFor Accelerators:Keep pushing—complacency is the only real threat.Institutionalize paranoia: today’s edge can vanish if you assume permanence.Reinforce learning loops to sustain compound advantage.For The Awakening:Collapse timelines. Treat months like weeks.Scale pilots into production—stop waiting for perfect conditions.Accelerate skill-building and leadership alignment.Accept that hesitation is existential.For The Obsolete:There is no recovery strategy once irrelevance sets in.The only option is radical reinvention—disrupt yourself before the market finishes the job.The odds are low, but not impossible. The choice is binary: transform now or die.ConclusionThe Three Types of Organizations framework is not just descriptive—it is predictive. Where you are today determines your survival odds in twelve months.
Accelerators double their market share.The Awakening faces a closing window.The Obsolete fade permanently.The brutal reality: time is the scarcest resource in AI transformation. Every day compounds advantage or accelerates irrelevance.
Your category is not fixed—but hesitation guarantees failure. The question every leader must answer is simple: will you accelerate, awaken, or become obsolete?
The post The Three Types of Organizations: Accelerators, The Awakening, and The Obsolete appeared first on FourWeekMBA.
The FRED Paradox: Why the Blind Stay Blind, and the Aware Pull Ahead

The FRED Test is not just a diagnostic—it exposes a structural paradox at the heart of AI transformation. Those who most need to pass the test are the least likely to take it seriously, while those who already score high obsessively monitor and reinforce their lead. This creates a compounding gap that becomes insurmountable over time.
The paradox divides organizations into two camps: The Blind (FRED Score 0–6) and The Aware (FRED Score 7–12). The behaviors, mindsets, and trajectories of these two groups are not just different—they are inverted.
The Blind (FRED Score 0–6)Organizations in the Blind category operate with a dangerous mindset. They dismiss AI as hype, insist their industry is “different,” or rationalize delay with phrases like “let’s wait and see.”
Characteristics of the Blind:Complacency disguised as caution. They feel they have plenty of time.Dismissal of urgency. They treat frameworks like FRED as “just another report.”Committees over action. They default to endless deliberation rather than execution.False comfort. Scoring low does not trigger alarm—it triggers rationalization.The Blind are comfortable in their ignorance. They return to business as usual even after clear warnings. Their refusal to act does not stabilize their position; it accelerates their decline. By the time they recognize urgency, competitors have already consolidated advantage.
Trajectory: Within months, they begin to lag behind. Within a year, the gap is insurmountable.
The Aware (FRED Score 7–12)On the other end are the Aware. These organizations embody a winning mindset, one that is uncomfortably urgent about progress and perpetually paranoid about losing ground.
Characteristics of the Aware:Obsessive monitoring. They track their FRED score monthly, sometimes weekly.Constant adaptation. Strategy shifts continuously as they learn.Paranoia as discipline. They act on any weakness immediately.Daily iteration. Testing, learning, and compounding advantage.Edge-conscious. They know leadership is fragile and must be defended.The Aware treat AI not as a project but as an operating system. Their paranoia becomes a competitive advantage: every sign of weakness is met with immediate correction. The result is compounding returns—network effects, learning loops, and scale advantages that widen the gap against the Blind.
Trajectory: Within months, they pull ahead. Within a year, they are uncatchable leaders.
The Accelerating GapThe graphic illustrates the reality: the gap is not linear, it is exponential.
Today: Blind and Aware may look superficially close.+3 months: Blind organizations are already falling behind as competitors adopt at speed.+6 months: The divergence is visible in the market—Aware firms are learning faster, capturing customers, and compounding data advantages.+1 year: The gap is insurmountable. Blind firms cannot catch up without radical disruption, and most never do.This is why the FRED Test is not just a snapshot. It is a time horizon predictor. Where you score today is less important than what that score signals about your trajectory.
The Three Paradoxical TruthsAt the core of the FRED Paradox are three structural inversions that explain why organizations fail even when the urgency is obvious.
1. Confidence InversionThe less you know about AI, the more confident you feel.
Blind organizations dismiss urgency because they lack understanding. Their ignorance creates false confidence, insulating them from the fear that should drive transformation. Meanwhile, the Aware—those who know the most—are paranoid about losing ground.
Those who most need to act urgently feel the least urgency.
Blind organizations rationalize delay because they underestimate risk. They think they can “wait until AI matures.” By the time urgency becomes undeniable, it is too late. The Aware, who are already ahead, act as if every day counts—because it does.
Winners act before ready; losers wait for perfection.
Aware organizations launch before conditions are perfect. They test, learn, and iterate their way into leadership. Blind organizations wait for certainty—for perfect ROI models, regulatory clarity, or market consensus. That wait guarantees obsolescence.
The FRED Paradox explains why AI transformation is producing a winner-take-most dynamic. It is not simply about technology; it is about mindset.
Blind organizations delay, rationalize, and eventually collapse.Aware organizations act, adapt, and compound advantage until they dominate.This asymmetry is why AI leadership consolidates so quickly. Unlike previous transformations, where laggards could catch up over years, AI’s compounding effects mean the window for competitive repositioning is measured in months.
Breaking the CycleFor organizations trapped in the Blind mindset, survival requires breaking the paradox:
Acknowledge ignorance. Replace false confidence with humility. Accept that the less you know, the more danger you are in.Invert urgency. Treat every delay as existential. Move timelines from years to months, from months to weeks.Adopt imperfect action. Stop waiting for clarity. Launch small, iterate fast, and build momentum.The paradox is only broken when Blind organizations behave like the Aware—obsessive, paranoid, and action-oriented. Anything less guarantees decline.
ConclusionThe FRED Paradox is the sharpest lens for understanding why AI is consolidating winners and erasing laggards. It is not just about readiness scores—it is about the mindset inversion between Blind and Aware organizations.
The Blind are confident, complacent, and slow—the exact qualities that ensure failure.The Aware are paranoid, urgent, and restless—the exact qualities that secure leadership.The accelerating gap is not a metaphor. Within a year, it becomes mathematically insurmountable. The lesson is clear: inaction compounds disadvantage, while obsession compounds advantage.
In the age of AI, leadership is not earned by being prepared when the time comes. Leadership belongs to those who move before they feel ready.
The post The FRED Paradox: Why the Blind Stay Blind, and the Aware Pull Ahead appeared first on FourWeekMBA.
Scoring the FRED Test: Where Your AI Readiness Really Stands

The FRED Test—Fast Adoption, Recognize Shift, Early Advantage, Decide Now—was designed to expose the brutal reality of AI readiness. But taking the test is only the beginning. The true insight emerges when you score your answers and place your organization within one of the four readiness zones: Danger, Caution, Ready, or Leader.
The scoring framework does not sugarcoat. It translates vague conversations about “digital transformation” into a sharp diagnostic. Every organization, whether Fortune 500 or startup, lands somewhere on the spectrum. And the score is not just descriptive—it is prescriptive, defining the urgency, type, and magnitude of action required.
Zone 1: Danger (Score 0–3)Organizations in the Danger Zone are in critical condition. They are effectively sleepwalking into obsolescence while competitors accelerate. With a score of 0–3, these companies have failed across multiple dimensions of FRED.
They are not adopting AI with urgency.They do not recognize the paradigm shift reshaping markets.They have no compounding early advantage.They are deferring decisions until it is too late.The language here is not metaphorical—it is clinical. Companies in this zone are not just behind; they are being erased in real time. Waiting has already become costly, and every day compounds the disadvantage.
Action requirement: Emergency intervention today. Danger Zone companies cannot afford committees, pilots, or incremental planning. They require immediate executive-level mandates to adopt AI at speed, shift perspective, and build foundational advantage. Delay is not measured in quarters—it is fatal.
Zone 2: Caution (Score 4–6)The Caution Zone represents organizations that are at least aware of the tsunami approaching—but awareness has not yet translated into decisive action. These firms recognize the paradigm shift but are still caught in hesitation. They see the need, but they move in weeks or months, not days.
At this stage, the problem is not ignorance but inertia. Organizations in Caution are risk-aware but not risk-resilient. They may already be experimenting with AI, but scale, speed, and urgency are missing.
Action requirement: Immediate action this week. The mandate is acceleration. These organizations must convert awareness into rapid execution. The danger is that while they deliberate, competitors in the Ready and Leader zones compound advantage daily.
The paradox of Caution is that leaders here often believe they are safe because they “see the shift.” But recognition without execution is indistinguishable from denial.
Zone 3: Ready (Score 7–9)The Ready Zone is where organizations begin to move with intent. These firms are prepared, experimenting, and in some cases scaling. They understand the transformation and have started building systems that integrate AI into core operations.
But readiness is not leadership. Companies in this zone are prepared but not leading. They are still at risk of losing momentum if they fail to scale aggressively. Being in Ready is not a permanent advantage—it is a fragile position that can collapse backward into Caution if execution stalls.
Action requirement: Strategic action this month. Ready Zone companies must focus on acceleration and scale. The key is to convert proof-of-concept experiments into enterprise-wide integration. Success requires moving from scattered pilots to repeatable, system-level adoption with measurable ROI.
The Ready Zone can feel comfortable, but it is dangerous to linger here. Competitors in the Leader Zone are compounding their advantage with every interaction.
Zone 4: Leader (Score 10–12)At the top sits the Leader Zone. These are organizations shaping the future, not reacting to it. They are AI-native or rapidly becoming so, embedding intelligence into every layer of operations, customer experience, and decision-making.
Scoring 10–12 signals not just readiness but leadership. These firms move fast, recognize shifts early, secure competitive moats, and make bold decisions without hesitation. Their challenge is not survival but sustainability: how to maintain leadership as others catch up.
Action requirement: Innovative action to push boundaries. Leaders must avoid complacency. The focus shifts to continuous innovation, expanding moats, and shaping industry standards. In the AI era, leadership today does not guarantee leadership tomorrow. The only way to preserve advantage is to constantly redefine it.
The FRED ParadoxThe scoring model also reveals a paradox. The organizations that most need to take the FRED Test—the Danger Zone—are often the least likely to. They dismiss urgency, delay adoption, and rationalize inaction. Meanwhile, the highest scorers in the Leader Zone, who are already ahead, obsessively monitor their readiness and continue pushing forward.
This paradox accelerates the gap. The weak fall further behind precisely because they underestimate the urgency, while the strong compound advantage because they continually reinforce their lead.
The result is an accelerating divergence: leaders accelerate into dominance, while laggards slide into irrelevance.
Market DistributionCurrent data highlights the severity of the gap. Based on observed adoption patterns:
60% of organizations sit in the Danger Zone, sleepwalking into obsolescence.20% are in Caution, aware but moving too slowly.15% are in Ready, building momentum but still at risk.Only 5% are true Leaders, shaping markets and defining the next wave.The implication is stark: the majority of firms are not just unprepared—they are structurally incapable of surviving without radical acceleration. The AI transformation is not evenly distributed; it is consolidating power in the hands of a small minority of leaders.
The Roadmap for Each ZoneThe scoring framework is not just diagnostic; it prescribes a roadmap.
Danger Zone: Execute emergency adoption measures immediately. Mandate top-down change and move from paralysis to speed.Caution Zone: Convert awareness into execution. Commit resources this week and accelerate timelines aggressively.Ready Zone: Scale aggressively. Build infrastructure, integrate AI enterprise-wide, and measure ROI systematically.Leader Zone: Innovate beyond the frontier. Expand moats, shape ecosystems, and ensure that today’s advantage does not become tomorrow’s complacency.Each zone requires different actions, but the underlying principle is the same: waiting accelerates disadvantage.
ConclusionScoring the FRED Test is not an academic exercise. It is a strategic reckoning. Every organization fits somewhere on the spectrum, and the score determines both urgency and survival odds.
The insight is sharp: most companies are in critical or cautionary states, while only a handful are shaping the future. The danger is that those in the lower zones rarely realize how dire their situation is, while those in the upper zones double down on their lead.
AI transformation is not a balanced race—it is an accelerating divergence. Leaders compound advantage. Laggards compound disadvantage.
The FRED Test forces leaders to confront their reality. Whether you are in Danger, Caution, Ready, or Leader, one truth holds: inaction is not neutral—it is irreversible decline.
The post Scoring the FRED Test: Where Your AI Readiness Really Stands appeared first on FourWeekMBA.


