
Hussein Nasser's Blog, page 11
July 12, 2016
ACID on Instagram (Part 1)
In the late 1970s, Jim Gray, the computer scientist who went missing in 2007 and never found, defined a set of properties for database transactions. These properties were Atomicity, Consistency, Isolation and Durability, thus ACID.
What are the ACID properties? How important are they? Can we trade these properties off for performance? Or should we architecture our software around those and make sure they all are met in all instances?
This blog post and the following posts will attempt to answer these questions and clarify each property with hopefully a relatable example. I will try to be consistent and use one example to explain all four properties. I picked Instagram.
Instagram is a popular photo sharing service that is available on mobile devices. You can post a picture, and people who follow you can like or comment on those pictures.
Note: We are going to make a lot of assumption about Instagram database model which may not necessary be the actual implementation. However, we will try to make assumptions that yield highest performance.
Consider this database design, we have a Picture table, and Like table.
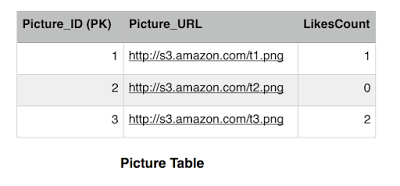
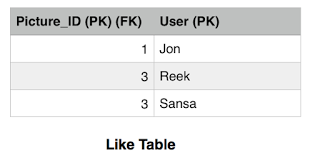
The picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has no likes. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
AtomicityAssume Jon, when he is not guarding the Wall, likes Picture 2. That is equivalent to one update query to the Picture table to increment the count of likes by 1 and one insert query to add a row in the Like table.
To achieve atomicity, those two queries should succeed together or they should fail together. They can't be one success and one fail or else we will end up in a inconsistent state where the likes rows do not match the count of the likes. Obviously its not a big deal if the like count did not match and here is where the trade off can happen. However, in some circumstances, like banking for instance, we can't tolerate such errors. The database solution should support atomic transactions where we can wrap those two queries in one transaction and then rollback in case one of them failed.
You might wonder, what could cause a query to fail? Network connectivity is one, hardware failure is another, but there are other constraints that we can put in place where the database can actually refuse to execute a query. Referential integrity and unique constraints for instance which brings us to the second property.
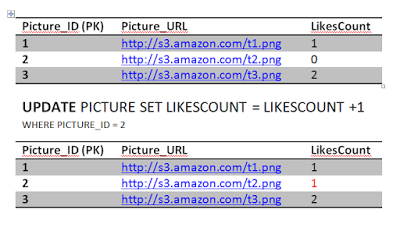

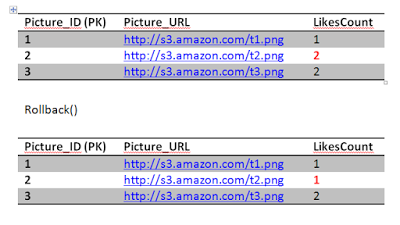
ConsistencyAssume this, Jon really likes picture 2 he double clicked it again sending another like. Obviously this is wrong, but we have a constraint in the system to prevent that thank fully.
The first statement will go through updating the likes count..
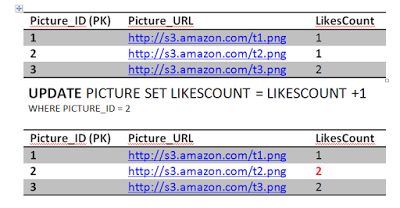
The second query will fail because of unique constraint that we have put in place (Jon and 2) unique key already exists. This will cause the transaction to rollback and undo the first update as well, restoring the system to a consistent state. The atomicity kicked in here and saved the day in order to achieve consistency. If we didn't have an atomic transaction, we will end up with wrong results. Again not the end of the world.

So there is a lot of room for discussions here right, we can implement this logic at the client side to prevent Jon from sending the second like. But that mean an additional cost for reading that Like table and making sure Jon has already liked that. However, leaving a database constraints will lead to a lot of unnecessary traffic to the database that could be prevented.You guys can chip in for a better design here.
Another point I guess I should mention is a consistent state is different than a correct state. I would like to quote C.J. Date on this.
I want to handle Isolation in another post since it is a long topic.

What are the ACID properties? How important are they? Can we trade these properties off for performance? Or should we architecture our software around those and make sure they all are met in all instances?
This blog post and the following posts will attempt to answer these questions and clarify each property with hopefully a relatable example. I will try to be consistent and use one example to explain all four properties. I picked Instagram.
Instagram is a popular photo sharing service that is available on mobile devices. You can post a picture, and people who follow you can like or comment on those pictures.
Note: We are going to make a lot of assumption about Instagram database model which may not necessary be the actual implementation. However, we will try to make assumptions that yield highest performance.
Consider this database design, we have a Picture table, and Like table.
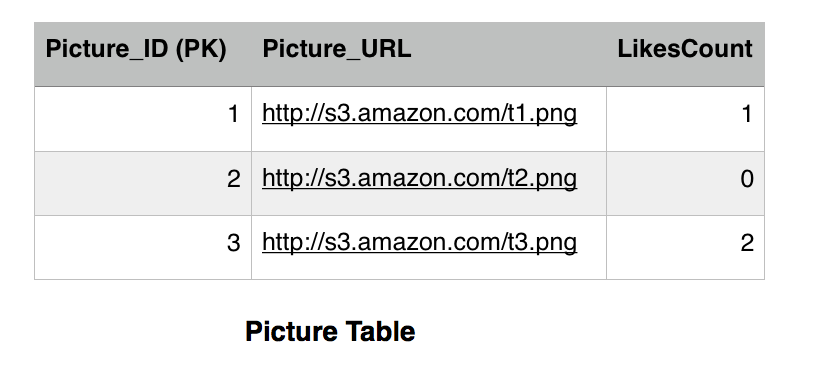
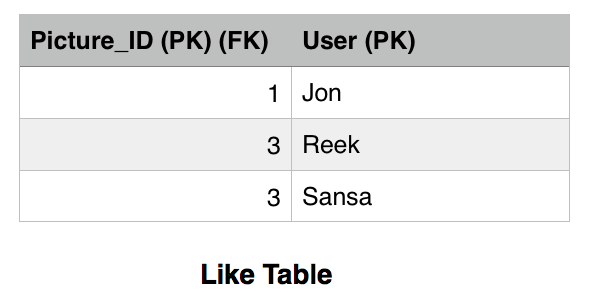
The picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has no likes. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
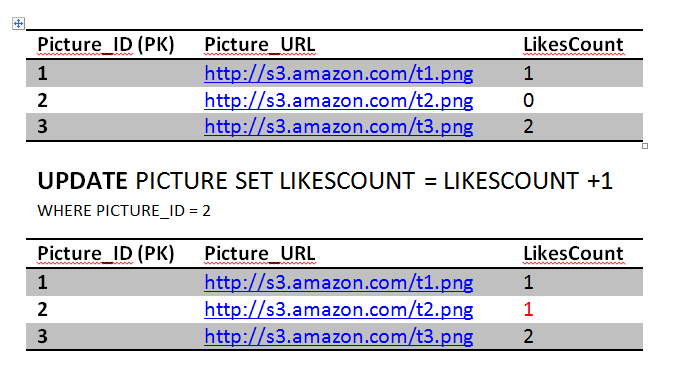
AtomicityAssume Jon, when he is not guarding the Wall, likes Picture 2. That is equivalent to one update query to the Picture table to increment the count of likes by 1 and one insert query to add a row in the Like table.
UPDATE PICTURE SET LIKESCOUNT = LIKESCOUNT +1 WHERE PICTURE_ID = 2;
INSERT INTO LIKE VALUES (2, 'Jon');
To achieve atomicity, those two queries should succeed together or they should fail together. They can't be one success and one fail or else we will end up in a inconsistent state where the likes rows do not match the count of the likes. Obviously its not a big deal if the like count did not match and here is where the trade off can happen. However, in some circumstances, like banking for instance, we can't tolerate such errors. The database solution should support atomic transactions where we can wrap those two queries in one transaction and then rollback in case one of them failed.
You might wonder, what could cause a query to fail? Network connectivity is one, hardware failure is another, but there are other constraints that we can put in place where the database can actually refuse to execute a query. Referential integrity and unique constraints for instance which brings us to the second property.

ConsistencyAssume this, Jon really likes picture 2 he double clicked it again sending another like. Obviously this is wrong, but we have a constraint in the system to prevent that thank fully.
The first statement will go through updating the likes count..
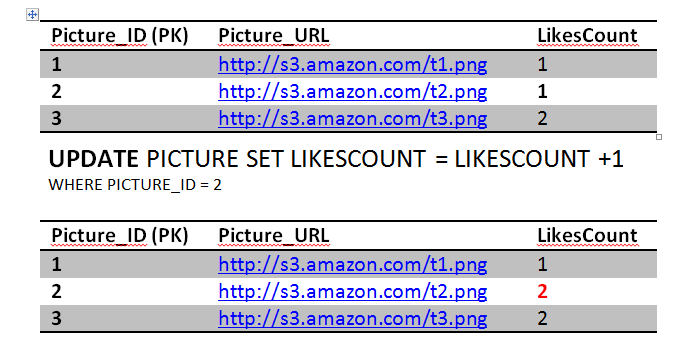
The second query will fail because of unique constraint that we have put in place (Jon and 2) unique key already exists. This will cause the transaction to rollback and undo the first update as well, restoring the system to a consistent state. The atomicity kicked in here and saved the day in order to achieve consistency. If we didn't have an atomic transaction, we will end up with wrong results. Again not the end of the world.


So there is a lot of room for discussions here right, we can implement this logic at the client side to prevent Jon from sending the second like. But that mean an additional cost for reading that Like table and making sure Jon has already liked that. However, leaving a database constraints will lead to a lot of unnecessary traffic to the database that could be prevented.You guys can chip in for a better design here.
Another point I guess I should mention is a consistent state is different than a correct state. I would like to quote C.J. Date on this.
Consistent mean "satisfying all known integrity constraints" Observe, therefore, that consistent does not necessarily mean correct; a correct state must necessarily be consistent, but a consistent state might still be incorrect, in the sense that it does not accurately reflect the true state of affairs in the real world. "Consistent" might be defined as "correct as far as the system is concerned". - An introduction to Database system.
I want to handle Isolation in another post since it is a long topic.


July 4, 2016
Persistent Connections
English is not my first language, so I have to remind myself of definitions from time to time. So mind me if you see me define a phrase before I elaborate on it. To persist something is to keep it existing. So what does a persistent connection refer to? and why this is something software engineers should know about?
TCP is the de-facto protocol of the network communication. When we want to send data between node A and node B we establish a TCP connection, be it a simple visit to google.com or an Oracle database connection, under the hood its all TCP.
Lots of things involve establishing the connection. Handshaking, acknowledgment, making sure the parties in the connection are in fact who they say they are etc. We don't need to discuss details of what exactly happens in this post, but one thing you should know, opening TCP connection is expensive.
So imagine this scenario. You visit http://www.nationalgeographic.com website, this uses the HTTP protocol which underneath open a TCP connection to the national geographic server. So lets take a time machine back in 1996, where HTTP/1.0 was just released. This would happen:
Open TCP Connection national geographic website (this has many steps remember)Read Index.html and send it back to the browserClose TCP ConnectionFor each Image in the page Open TCP Connection Read Image from the server disk, send back to browser Close TCP ConnectionNext image
Images are just an example of things we need to load, back then there were much more nastier resources.
So now imagine the overhead of opening and closing the connections. The network congestion from all acknowledgments being sent back and forth and the wasted processing cycles the server and client has to endure. That is why persistent connection became popular, open a connection, and leave it open while we send everything we have, once we are done we can close it. Here is a modern visit of nationalgeographic.com in 2016, HTTP 1.1
Open TCP Connection national geographic website Read Index.html and send it back to the browserFor each Image in the page Read Image from the server disk, send back to browserNext image... Do more ... Do moreClose TCP Connection
Now, I know this is very specific to browsers and web servers but the same story is true for database connections. In my years of experience as a programmer working with databases, I developed a habit, and am sure most of you did too, of opening a connection, sending a query and then closing a connection. That might be fine and barely noticeable if you have like 10 users on your application, but as you scale up, you will start noticing performance degradation.
Another thing you gain of persistent connections is PUSH events. This is how WhatsApp is able to freak you out by instantly delivering your wife's message "Where are you!" to your phone the moment she hit the sent on hers. WhatsApp do that by having a live open connection to their server from your mobile (not exactly TCP though, a much more efficient protocol called XMPP, we can touch upon that on some other post).
Disadvantages?We mentioned the advantages of persistent connection, but are there any disadvantages? Yes, there is no free lunch apparently.
When using persistent connection, you keep the connection alive on both the client and server, so you start eating up more memory the more connections keep alive. So you have to be smart about closing those idle connections. Another problem came with persistent connections that is specifically for TCP. In a nut shell, now that we started to keep connections alive on the server, attackers came up with this idea, "Hey, what if we made the server run out of memory by establishing millions of connections and never replay back?" Thus DDOS attacks were born. Again we can touch more on this on another post.
-Hussein
TCP is the de-facto protocol of the network communication. When we want to send data between node A and node B we establish a TCP connection, be it a simple visit to google.com or an Oracle database connection, under the hood its all TCP.
Lots of things involve establishing the connection. Handshaking, acknowledgment, making sure the parties in the connection are in fact who they say they are etc. We don't need to discuss details of what exactly happens in this post, but one thing you should know, opening TCP connection is expensive.
So imagine this scenario. You visit http://www.nationalgeographic.com website, this uses the HTTP protocol which underneath open a TCP connection to the national geographic server. So lets take a time machine back in 1996, where HTTP/1.0 was just released. This would happen:
Open TCP Connection national geographic website (this has many steps remember)Read Index.html and send it back to the browserClose TCP ConnectionFor each Image in the page Open TCP Connection Read Image from the server disk, send back to browser Close TCP ConnectionNext image
Images are just an example of things we need to load, back then there were much more nastier resources.
So now imagine the overhead of opening and closing the connections. The network congestion from all acknowledgments being sent back and forth and the wasted processing cycles the server and client has to endure. That is why persistent connection became popular, open a connection, and leave it open while we send everything we have, once we are done we can close it. Here is a modern visit of nationalgeographic.com in 2016, HTTP 1.1
Open TCP Connection national geographic website Read Index.html and send it back to the browserFor each Image in the page Read Image from the server disk, send back to browserNext image... Do more ... Do moreClose TCP Connection
Now, I know this is very specific to browsers and web servers but the same story is true for database connections. In my years of experience as a programmer working with databases, I developed a habit, and am sure most of you did too, of opening a connection, sending a query and then closing a connection. That might be fine and barely noticeable if you have like 10 users on your application, but as you scale up, you will start noticing performance degradation.
Another thing you gain of persistent connections is PUSH events. This is how WhatsApp is able to freak you out by instantly delivering your wife's message "Where are you!" to your phone the moment she hit the sent on hers. WhatsApp do that by having a live open connection to their server from your mobile (not exactly TCP though, a much more efficient protocol called XMPP, we can touch upon that on some other post).
Disadvantages?We mentioned the advantages of persistent connection, but are there any disadvantages? Yes, there is no free lunch apparently.
When using persistent connection, you keep the connection alive on both the client and server, so you start eating up more memory the more connections keep alive. So you have to be smart about closing those idle connections. Another problem came with persistent connections that is specifically for TCP. In a nut shell, now that we started to keep connections alive on the server, attackers came up with this idea, "Hey, what if we made the server run out of memory by establishing millions of connections and never replay back?" Thus DDOS attacks were born. Again we can touch more on this on another post.
-Hussein
Persistant Connections
English is not my first language, so I have to remind myself of definitions from time to time. So mind me if you see me define a phrase before I elaborate on it. To persist something is to keep it existing. So what does a persistent connection refer to? and why this is something software engineers should know about?
TCP is the de-facto protocol of the network communication. When we want to send data between node A and node B we establish a TCP connection, be it a simple visit to google.com or an Oracle database connection, under the hood its all TCP.
Lots of things involve establishing the connection. Handshaking, acknowledgment, making sure the parties in the connection are in fact who they say they are etc. We don't need to discuss details of what exactly happens in this post, but one thing you should know, opening TCP connection is expensive.
So imagine this scenario. You visit http://www.nationalgeographic.com website, this uses the HTTP protocol which underneath open a TCP connection to the national geographic server. So lets take a time machine back in 1996, where HTTP/1.0 was just released. This would happen:
Open TCP Connection national geographic website (this has many steps remember)Read Index.html and send it back to the browserClose TCP ConnectionFor each Image in the page Open TCP Connection Read Image from the server disk, send back to browser Close TCP ConnectionNext image
Images are just an example of things we need to load, back then there were much more nastier resources.
So now imagine the overhead of opening and closing the connections. The network congestion from all acknowledgments being sent back and forth and the wasted processing cycles the server and client has to endure. That is why persistent connection became popular, open a connection, and leave it open while we send everything we have, once we are done we can close it. Here is a modern visit of nationalgeographic.com in 2016, HTTP 1.1
Open TCP Connection national geographic website Read Index.html and send it back to the browserFor each Image in the page Read Image from the server disk, send back to browserNext image... Do more ... Do moreClose TCP Connection
Now, I know this is very specific to browsers and web servers but the same story is true for database connections. In my years of experience as a programmer working with databases, I developed a habit, and am sure most of you did too, of opening a connection, sending a query and then closing a connection. That might be fine and barely noticeable if you have like 10 users on your application, but as you scale up, you will start noticing performance degradation.
Another thing you gain of persistent connections is PUSH events. This is how WhatsApp is able to freak you out by instantly delivering your wife's message "Where are you!" to your phone the moment she hit the sent on hers. WhatsApp do that by having a live open connection to their server from your mobile (not exactly TCP though, a much more efficient protocol called XMPP, we can touch upon that on some other post).
Disadvantages?We mentioned the advantages of persistent connection, but are there any disadvantages? Yes, there is no free lunch apparently.
When using persistent connection, you keep the connection alive on both the client and server, so you start eating up more memory the more connections keep alive. So you have to be smart about closing those idle connections. Another problem came with persistent connections that is specifically for TCP. In a nut shell, now that we started to keep connections alive on the server, attackers came up with this idea, "Hey, what if we made the server run out of memory by establishing millions of connections and never replay back?" Thus DDOS attacks were born. Again we can touch more on this on another post.
-Hussein
TCP is the de-facto protocol of the network communication. When we want to send data between node A and node B we establish a TCP connection, be it a simple visit to google.com or an Oracle database connection, under the hood its all TCP.
Lots of things involve establishing the connection. Handshaking, acknowledgment, making sure the parties in the connection are in fact who they say they are etc. We don't need to discuss details of what exactly happens in this post, but one thing you should know, opening TCP connection is expensive.
So imagine this scenario. You visit http://www.nationalgeographic.com website, this uses the HTTP protocol which underneath open a TCP connection to the national geographic server. So lets take a time machine back in 1996, where HTTP/1.0 was just released. This would happen:
Open TCP Connection national geographic website (this has many steps remember)Read Index.html and send it back to the browserClose TCP ConnectionFor each Image in the page Open TCP Connection Read Image from the server disk, send back to browser Close TCP ConnectionNext image
Images are just an example of things we need to load, back then there were much more nastier resources.
So now imagine the overhead of opening and closing the connections. The network congestion from all acknowledgments being sent back and forth and the wasted processing cycles the server and client has to endure. That is why persistent connection became popular, open a connection, and leave it open while we send everything we have, once we are done we can close it. Here is a modern visit of nationalgeographic.com in 2016, HTTP 1.1
Open TCP Connection national geographic website Read Index.html and send it back to the browserFor each Image in the page Read Image from the server disk, send back to browserNext image... Do more ... Do moreClose TCP Connection
Now, I know this is very specific to browsers and web servers but the same story is true for database connections. In my years of experience as a programmer working with databases, I developed a habit, and am sure most of you did too, of opening a connection, sending a query and then closing a connection. That might be fine and barely noticeable if you have like 10 users on your application, but as you scale up, you will start noticing performance degradation.
Another thing you gain of persistent connections is PUSH events. This is how WhatsApp is able to freak you out by instantly delivering your wife's message "Where are you!" to your phone the moment she hit the sent on hers. WhatsApp do that by having a live open connection to their server from your mobile (not exactly TCP though, a much more efficient protocol called XMPP, we can touch upon that on some other post).
Disadvantages?We mentioned the advantages of persistent connection, but are there any disadvantages? Yes, there is no free lunch apparently.
When using persistent connection, you keep the connection alive on both the client and server, so you start eating up more memory the more connections keep alive. So you have to be smart about closing those idle connections. Another problem came with persistent connections that is specifically for TCP. In a nut shell, now that we started to keep connections alive on the server, attackers came up with this idea, "Hey, what if we made the server run out of memory by establishing millions of connections and never replay back?" Thus DDOS attacks were born. Again we can touch more on this on another post.
-Hussein
July 3, 2016
Process Isolation

You may have heard of this term in one of the conferences or tech talks. If you have worked with ArcGIS Server, you probably have seen the option to use High Process Isolation vs Low Process Isolation when configuring the GIS instances. So what does this mean and why does is it important to isolate processes?
So when we say "Isolate", we get a general idea of what that might be. To keep processes separate from each other. So you would think that one advantage of process isolation is to protect the process data from being accessed by other processes, and that is correct. But is that all?
Let's say you want to write a program to implement two functionalities (A and B). Functionality A is low intensive (perhaps its just printing the result or updating the UI) and B is high intensive (querying the database, processing, rendering etc..). So one approach is to write code to implement both A and B in one application. Both Code A and B will be running in one process.
Another approach is write the Code for A and the Code for B and use Process.Start() to execute code A in one process and code B in another process. Here is where the processes are isolated.
In the first approach if both A and B runs in the same process, you risk B eating on your memory. If anything goes wrong in code B and it crashes, the entire process will crash taking code A down with it and users will lose your application entirely. However in the second approach, if B crashes, A will still be running and it can easily relaunch B, resurrect it back to life.
-Hussein

April 29, 2016
ArcObjects SDK available for download !
After years finally users can freely download and work with the ArcObjects SDK for both .NET and Java! Previously this was only available to partners and customers who request the bundle DVD.
Here are the steps.
1. Go to Arcgis.com
2. Register a trial 60 days account
3. Sign in and on the right you can have the link.
 Now that you have ArcObjects SDK, go build cool solutions.
Now that you have ArcObjects SDK, go build cool solutions.
Don't forget we have two Youtube series on IGeometry discussing how to get started with ArcObjects. One with VB.NET and another with C# , more than 30+ hours of content.
Enjoy
Extending ArcObjects (VB,NET)
https://www.youtube.com/watch?v=XrZs1...
ArcGIS Add-incs (C#)
https://www.youtube.com/watch?v=nn4mt...

Here are the steps.
1. Go to Arcgis.com
2. Register a trial 60 days account
3. Sign in and on the right you can have the link.
 Now that you have ArcObjects SDK, go build cool solutions.
Now that you have ArcObjects SDK, go build cool solutions.Don't forget we have two Youtube series on IGeometry discussing how to get started with ArcObjects. One with VB.NET and another with C# , more than 30+ hours of content.
Enjoy
Extending ArcObjects (VB,NET)
https://www.youtube.com/watch?v=XrZs1...
ArcGIS Add-incs (C#)
https://www.youtube.com/watch?v=nn4mt...
April 26, 2016
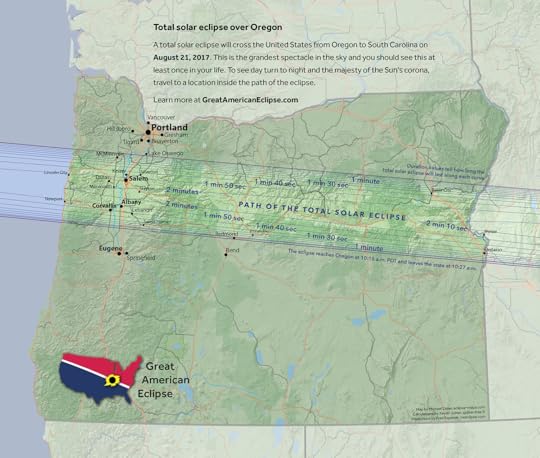
See the Great American Eclipse of August 21, 2017
My colleague Mike Zeiler is fascinated with Maps. What is astonishing is how he is able to author to serve his hobby. Solar Eclipses.
He travels around the world to see every eclipse, he is among the few who actually does that. Next year the eclipse will be in United States - Oregon, so he doesn't have to travel too far this time.
This is his website, go check out the cool maps he built and pay attention to the count down timer to the next eclipse.
http://www.greatamericaneclipse.com/
Enjoy
He travels around the world to see every eclipse, he is among the few who actually does that. Next year the eclipse will be in United States - Oregon, so he doesn't have to travel too far this time.
This is his website, go check out the cool maps he built and pay attention to the count down timer to the next eclipse.
http://www.greatamericaneclipse.com/
Enjoy
April 25, 2016
ArcGIS for Server Architecture Explained
h1 a:hover {background-color:#888;color:#fff ! important;} div#emailbody table#itemcontentlist tr td div ul { list-style-type:square; padding-left:1em; } div#emailbody table#itemcontentlist tr td div blockquote { padding-left:6px; border-left: 6px solid #dadada; margin-left:1em; } div#emailbody table#itemcontentlist tr td div li { margin-bottom:1em; margin-left:1em; } table#itemcontentlist tr td a:link, table#itemcontentlist tr td a:visited, table#itemcontentlist tr td a:active, ul#summarylist li a { color:#000099; font-weight:bold; text-decoration:none; } img {border:none;}
A youtube episode (part of docker series) where we discuss the ArcGIS for Server architecture. We talk about web servers (web adaptors) GIS Servers, config stores and how each component play a role in the ArcGIS server architecture.Enjoy

A youtube episode (part of docker series) where we discuss the ArcGIS for Server architecture. We talk about web servers (web adaptors) GIS Servers, config stores and how each component play a role in the ArcGIS server architecture.Enjoy
IGeometry
h1 a:hover {background-color:#888;color:#fff ! important;} div#emailbody table#itemcontentlist tr td div ul { list-style-type:square; padding-left:1em; } div#emailbody table#itemcontentlist tr td div blockquote { padding-left:6px; border-left: 6px solid #dadada; margin-left:1em; } div#emailbody table#itemcontentlist tr td div li { margin-bottom:1em; margin-left:1em; } table#itemcontentlist tr td a:link, table#itemcontentlist tr td a:visited, table#itemcontentlist tr td a:active, ul#summarylist li a { color:#000099; font-weight:bold; text-decoration:none; } img {border:none;} IGeometry
To stop receiving these emails, you may unsubscribe now. Email delivery powered by Google Google Inc., 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States
April 4, 2016
IGeometry
h1 a:hover {background-color:#888;color:#fff ! important;} div#emailbody table#itemcontentlist tr td div ul { list-style-type:square; padding-left:1em; } div#emailbody table#itemcontentlist tr td div blockquote { padding-left:6px; border-left: 6px solid #dadada; margin-left:1em; } div#emailbody table#itemcontentlist tr td div li { margin-bottom:1em; margin-left:1em; } table#itemcontentlist tr td a:link, table#itemcontentlist tr td a:visited, table#itemcontentlist tr td a:active, ul#summarylist li a { color:#000099; font-weight:bold; text-decoration:none; } img {border:none;} IGeometry
To stop receiving these emails, you may unsubscribe now. Email delivery powered by Google Google Inc., 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States 
April 1, 2016
Docker and ArcGIS- 02 - File, Client-Server, Services and WebGIS
This episode was really exciting for me to record.
First we talk about file geodatabases, then we discuss how Docker can fit in to swiftly deploy containers of ArcObjects for Linux clients with File geodatabases. Then we went ahead and talked about Client Server with enterprise geodatabase, which evolved into the ArcGIS for Server, to the mother of all weapons, the WebGIS. The Cloud.
Enjoy!
twitter @hnasr
First we talk about file geodatabases, then we discuss how Docker can fit in to swiftly deploy containers of ArcObjects for Linux clients with File geodatabases. Then we went ahead and talked about Client Server with enterprise geodatabase, which evolved into the ArcGIS for Server, to the mother of all weapons, the WebGIS. The Cloud.
Enjoy!
twitter @hnasr


