
Hussein Nasser's Blog, page 10
April 1, 2017
Creating a button on ArcMap
In this video we discuss how to customize ArcMap to add our own button. When the button is clicked we will list all the layers in the active map.



March 30, 2017
ArcObjects - Creating Point Features
We show how two different methods to construct point geometries then we persist them as feature in a geodatabase.

March 26, 2017
Set up a Postgres Instance to work with ArcGIS [Windows]
We discuss how to set up a postgres instance from scratch, configure the instance to work with ArcGIS and then create an enterprise geodatabase from ArcGIS Desktop and finally we connect to the geodatabase.

March 23, 2017
Set up an ArcGIS Desktop Development Environment
In this video, we discuss how to setup an ArcGIS Desktop environment for development from scratch. We start with a clean 8.1 Windows machine and then we install the required software. These are the list of software required.
1. ArcGIS Desktop 10.4.1
2. Visual Studio Community 2015
3. ArcObjects SDK For Microsoft .NET Framework
Download ArcGIS for 60 days, details here:
http://www.husseinnasser.com/2016/04/...
Download Visual Studio 2015 Community
https://www.visualstudio.com/downloads/
Questions and comments are welcomed!
-Hussein Nasser

November 28, 2016
Multi-User Geodatabase Youtube Series
h1 a:hover {background-color:#888;color:#fff ! important;} div#emailbody table#itemcontentlist tr td div ul { list-style-type:square; padding-left:1em; } div#emailbody table#itemcontentlist tr td div blockquote { padding-left:6px; border-left: 6px solid #dadada; margin-left:1em; } div#emailbody table#itemcontentlist tr td div li { margin-bottom:1em; margin-left:1em; } table#itemcontentlist tr td a:link, table#itemcontentlist tr td a:visited, table#itemcontentlist tr td a:active, ul#summarylist li a { color:#000099; font-weight:bold; text-decoration:none; } img {border:none;}
After a long break, we are back to the channel with a new series. I always wanted to start recording episodes on Enterprise Geodatabase, after all this is what get used in real production shops!
We will tackle, as always, a real-life example of implementation of the multi-user geodatabase. Throw ]any questions you would like answered in this series
Hope you guys like it.

After a long break, we are back to the channel with a new series. I always wanted to start recording episodes on Enterprise Geodatabase, after all this is what get used in real production shops!
We will tackle, as always, a real-life example of implementation of the multi-user geodatabase. Throw ]any questions you would like answered in this series
Hope you guys like it.
August 7, 2016
ACID (Part 4)
In the previous post, we discussed the Read Committed Isolation level. That level solved 1 type of read phenomena, Dirty Read, which we used to get in the Read Uncommited isolation level, but we still got Repeatable and phantom read with that level. In this post we talk about repeatable read isolation level. A slightly more expensive level of implementation but can kill the non-repeatable read phenomena.
The final state of our Like table look like this from the previous post.
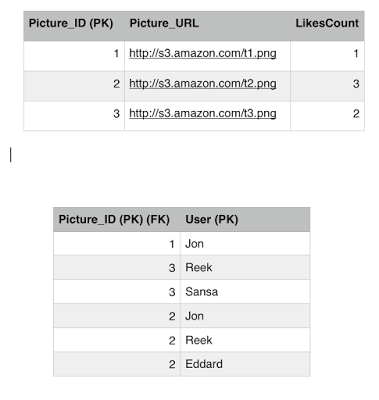
Here is the reference to all ACID posts that I authored:
ACID (Part 1) - Atomicity and Consistency
ACID (Part 2) - Isolation (Read Uncommitted)
ACID (Part 3) - Isolation (Read Committed)
ACID (Part 4) - Isolation (Repeatable Read)
Repeatable ReadWith a repeatable read isolation level, we not only read entries from committed transactions but we also read it from a previous timestamp. Usually it is the moment from we began our transaction, any other transactions that update entries after that moment will be overlooked by our transaction and it will attempt to retrieve an older "version" of the truth to make sure results are consistent. Lets jump to examples.
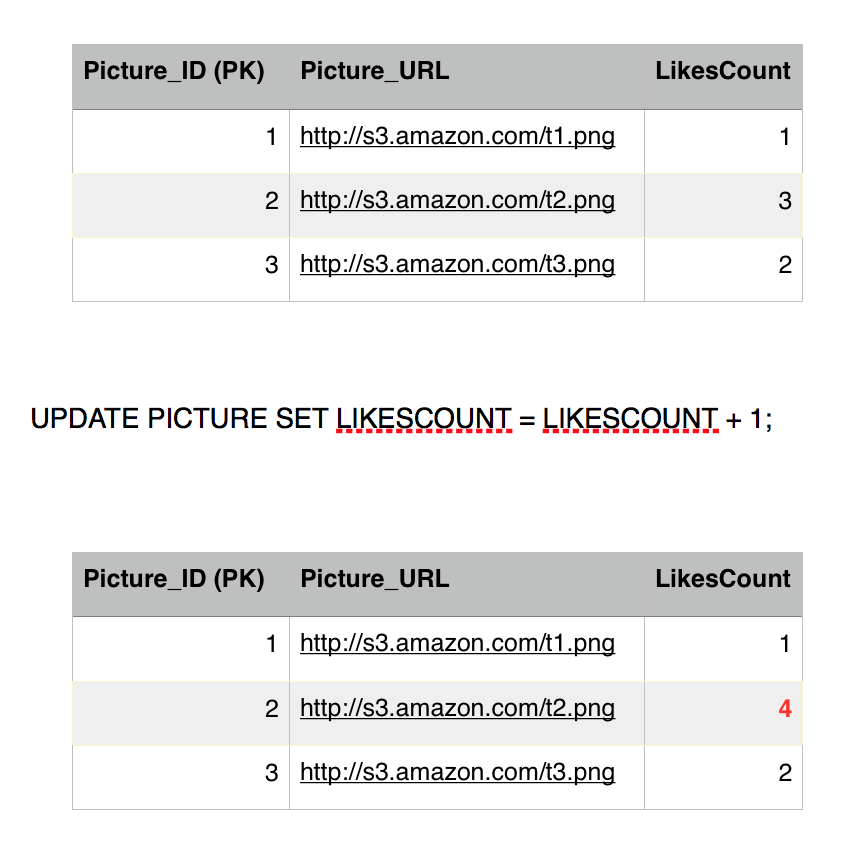
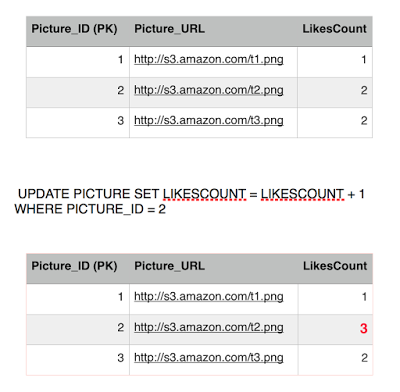
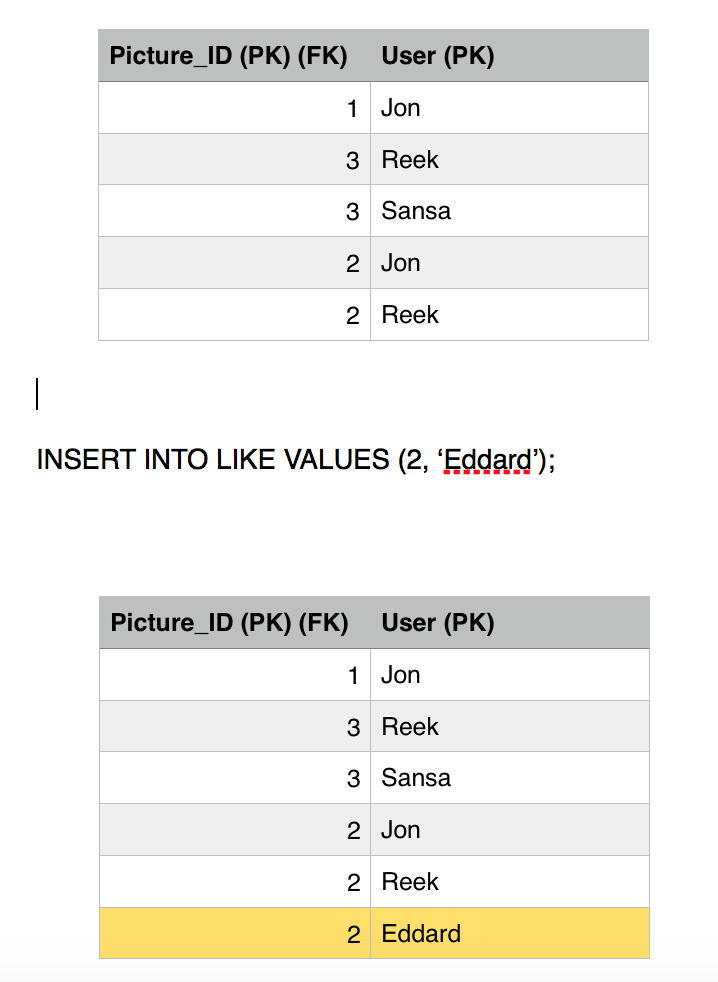
As we see, Eddard has already liked picture 2, he is attempting to fire another like to the same picture, we have atomicity and consistency that prevent him from doing so but lets see what happens. Eddard fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes and the list of users who liked it.
Eddard sends the like, first query executes successfully, incrementing the likes count.
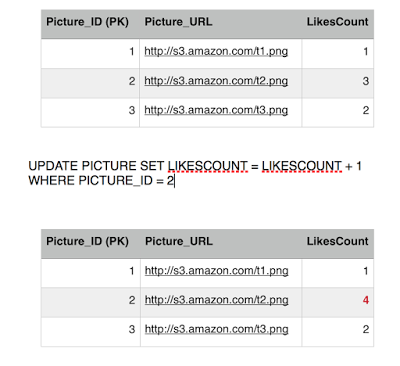
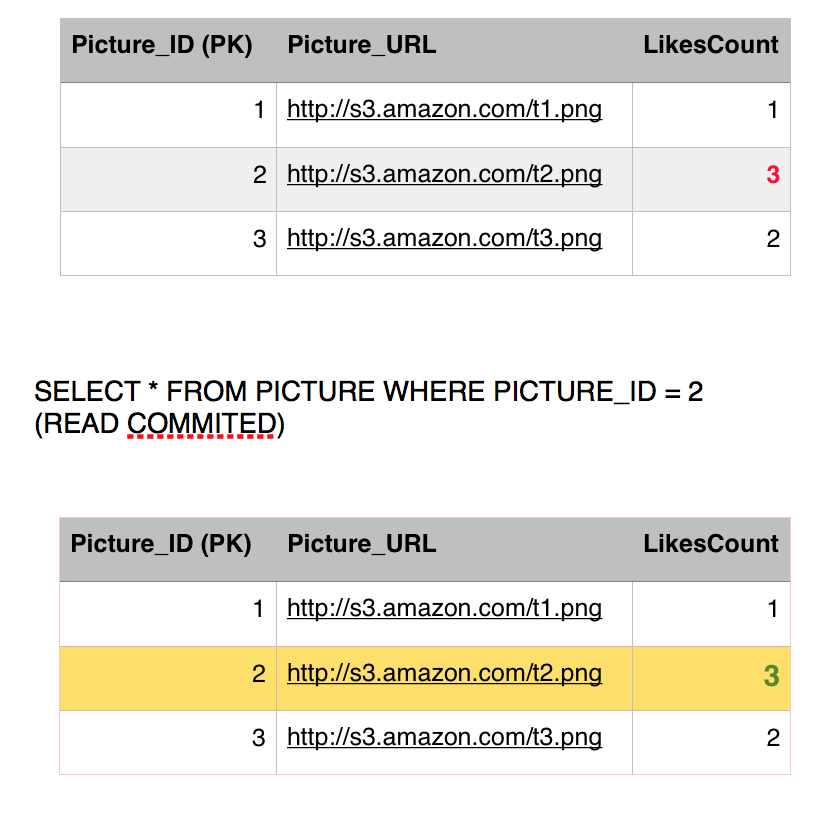
Before Eddard second query executes, Sansa's Select kicks in to read picture 2 row, she is going to get 3 likes instead of 4. This is because we are operating under the repeatable read isolation level, which only reads committed transactions, and since Eddard still did not commit (or rollback) his transaction, Sansa is getting the current commited value. So we have avoided a dirty read phenomena.
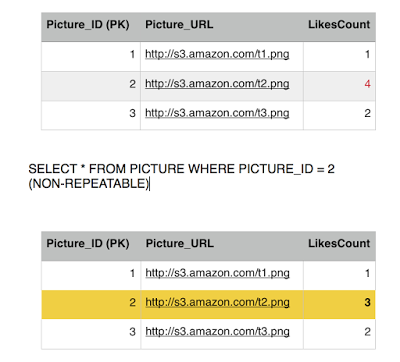
Sansa issues another read to the Like table to get all the users who likes picture 2, she gets three rows, Jon, Reek and Eddard. Consistent with the number of likes she got.

Eddard transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 3.
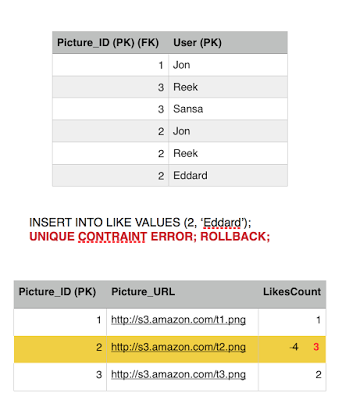
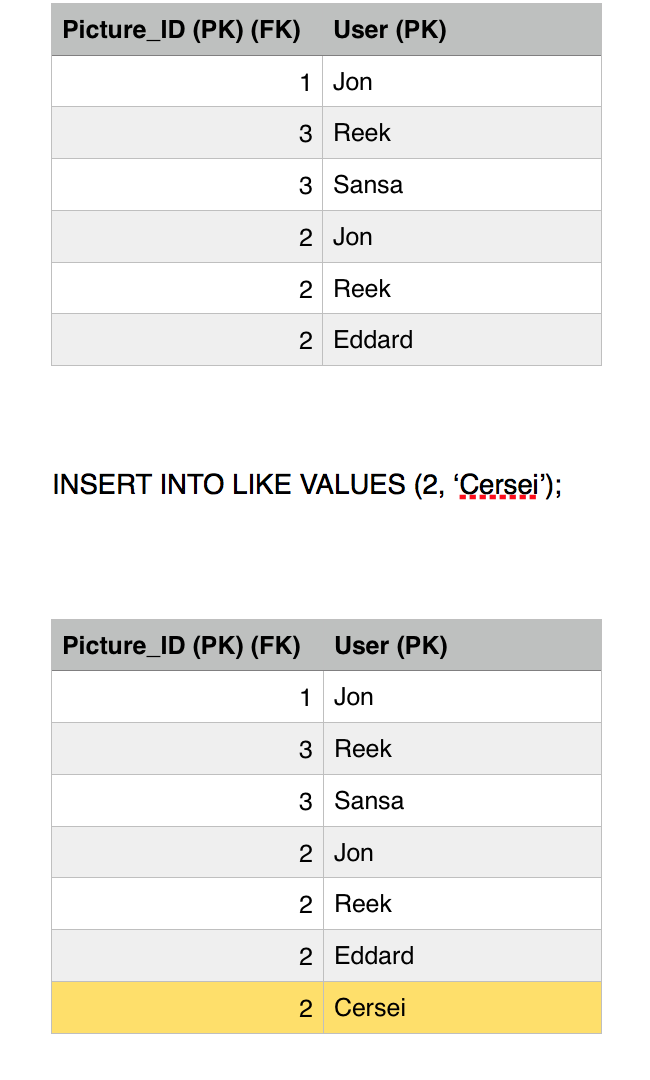
Eddard gives up, his transaction is finished and he failed to ruin our system consistent state, (we also chopped off his head). Meanwhile a new user comes in, Cersei and burns the database to the ground with wild fire. Not really, she likes picture 2, she is a brand new user who never liked picture 2 before so his transaction commits fine.
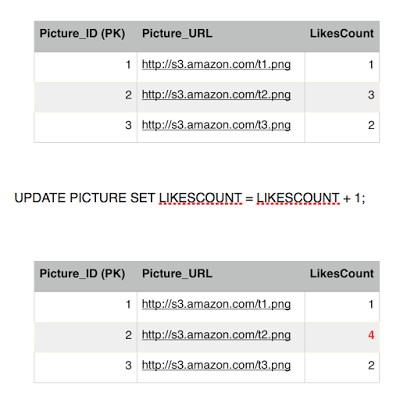
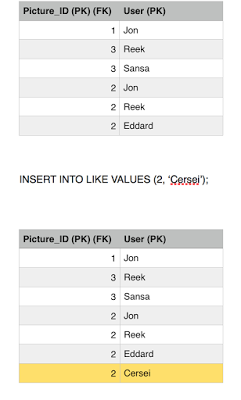
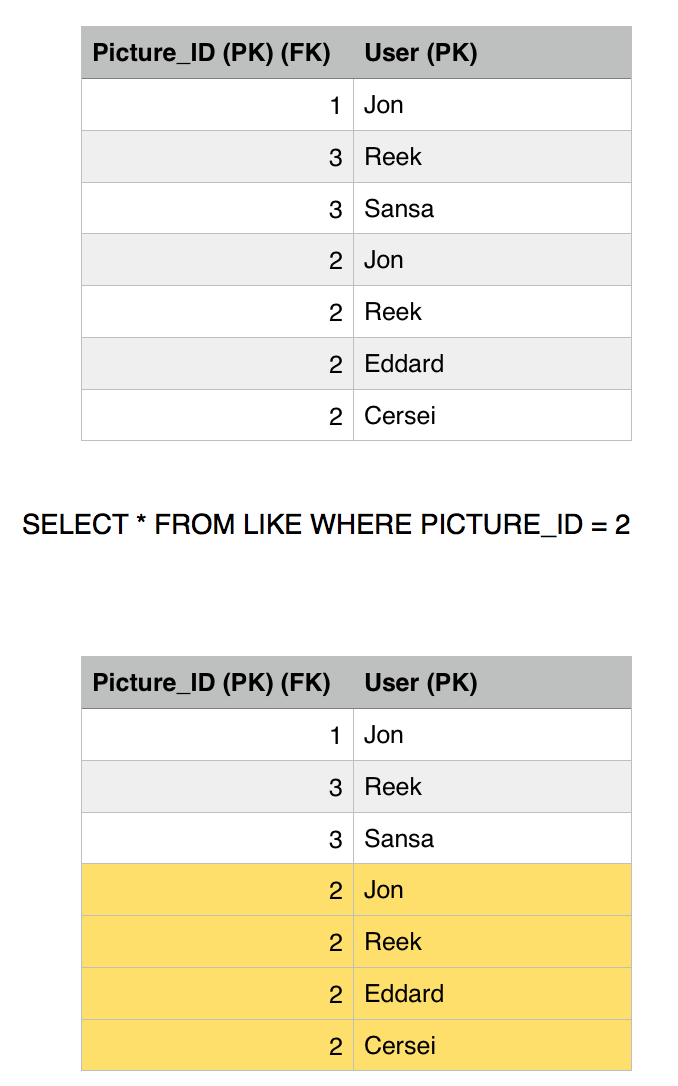
Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2 getting the likes count. Although the final committed value is 4, Sansa is going to get the original committed value when her transaction began which was 3. So we avoided getting the non-repeatable read phenamona with Repeatable read isolation level. It is slightly expensive since we have to keep history of versions of each committed values and go back searching for a previous value with a timestamp.

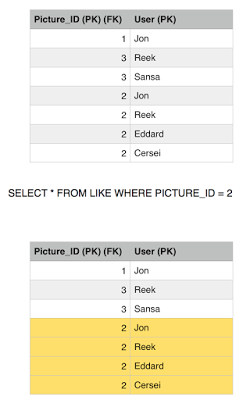
She issues a final read to the Like table to find out the list of users who liked picture 2, and surprise surprise, she got an extra record, hence Phantom read is still reproducible with repeatable read isolation level.
So we fix one problem with this isolation level but we introduce a cost of keeping history versions of previous committed values which we didn't have to with Read Committed level.
Next up, serializable isolation level.
-Hussein

The final state of our Like table look like this from the previous post.
Here is the reference to all ACID posts that I authored:
ACID (Part 1) - Atomicity and Consistency
ACID (Part 2) - Isolation (Read Uncommitted)
ACID (Part 3) - Isolation (Read Committed)
ACID (Part 4) - Isolation (Repeatable Read)
Repeatable ReadWith a repeatable read isolation level, we not only read entries from committed transactions but we also read it from a previous timestamp. Usually it is the moment from we began our transaction, any other transactions that update entries after that moment will be overlooked by our transaction and it will attempt to retrieve an older "version" of the truth to make sure results are consistent. Lets jump to examples.
As we see, Eddard has already liked picture 2, he is attempting to fire another like to the same picture, we have atomicity and consistency that prevent him from doing so but lets see what happens. Eddard fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes and the list of users who liked it.
Eddard sends the like, first query executes successfully, incrementing the likes count.
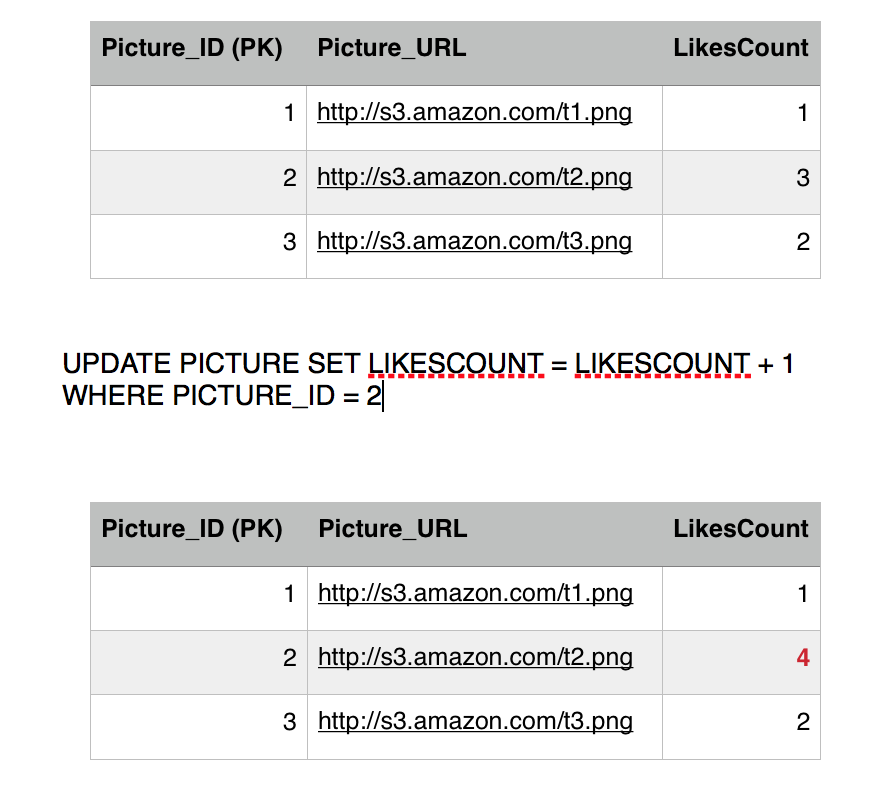
Before Eddard second query executes, Sansa's Select kicks in to read picture 2 row, she is going to get 3 likes instead of 4. This is because we are operating under the repeatable read isolation level, which only reads committed transactions, and since Eddard still did not commit (or rollback) his transaction, Sansa is getting the current commited value. So we have avoided a dirty read phenomena.
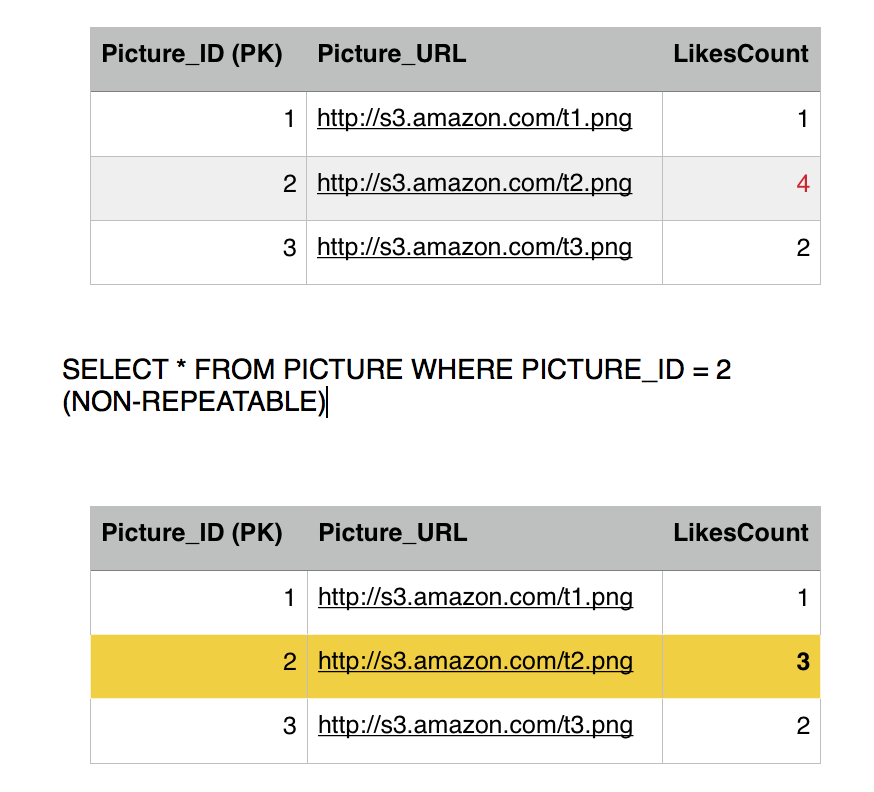
Sansa issues another read to the Like table to get all the users who likes picture 2, she gets three rows, Jon, Reek and Eddard. Consistent with the number of likes she got.
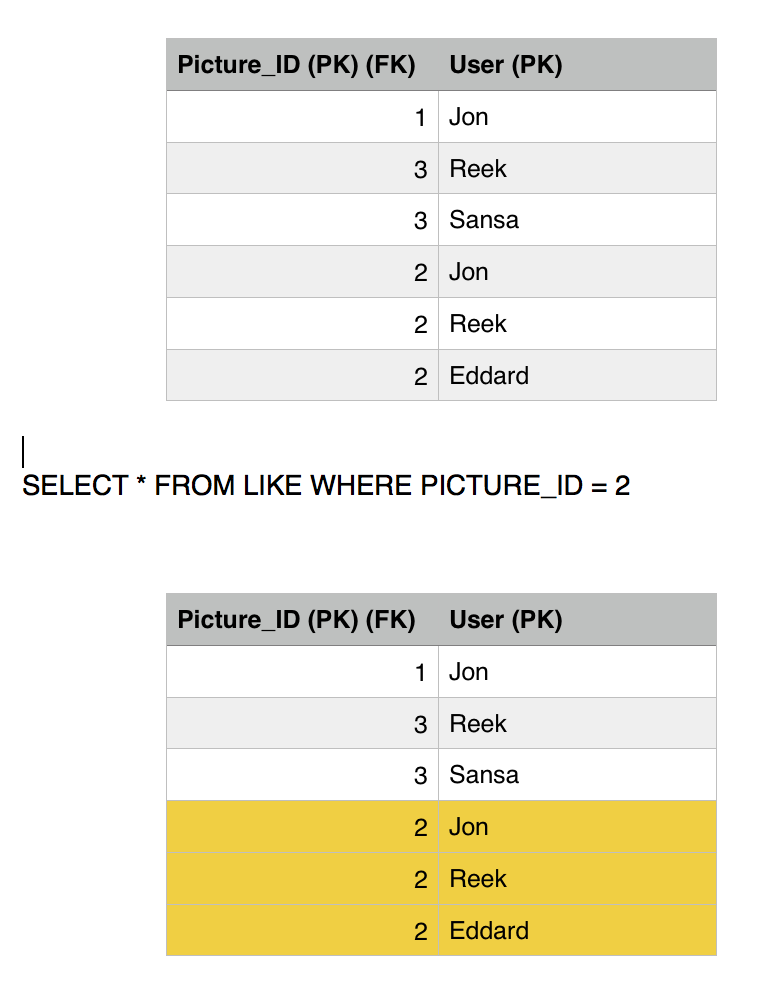
Eddard transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 3.
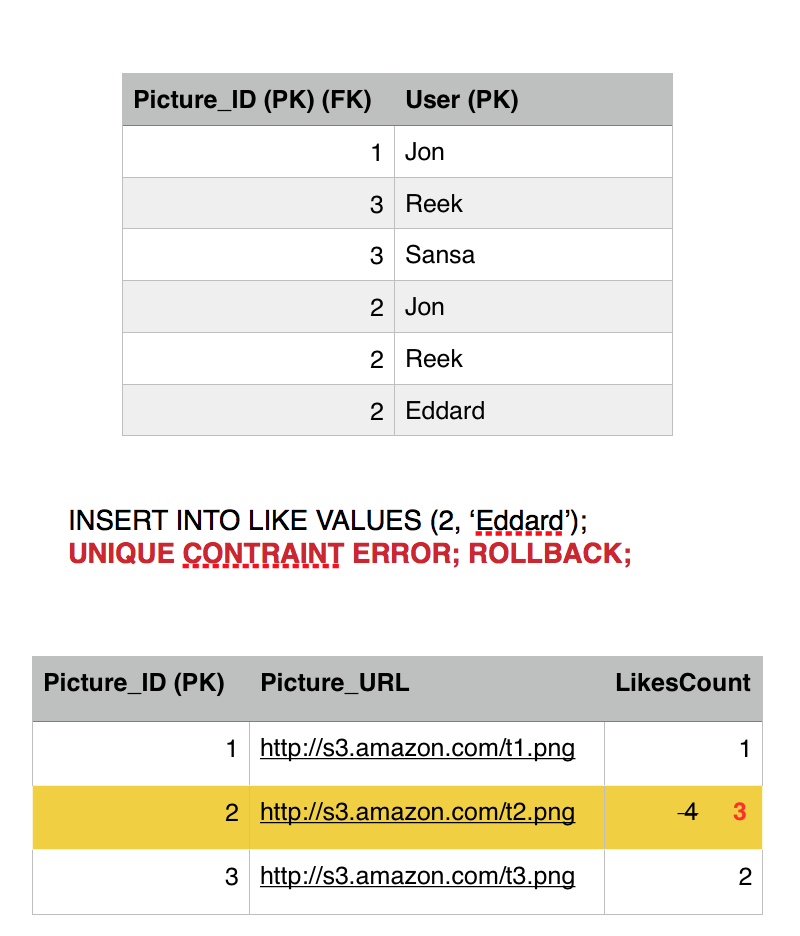
Eddard gives up, his transaction is finished and he failed to ruin our system consistent state, (we also chopped off his head). Meanwhile a new user comes in, Cersei and burns the database to the ground with wild fire. Not really, she likes picture 2, she is a brand new user who never liked picture 2 before so his transaction commits fine.
Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2 getting the likes count. Although the final committed value is 4, Sansa is going to get the original committed value when her transaction began which was 3. So we avoided getting the non-repeatable read phenamona with Repeatable read isolation level. It is slightly expensive since we have to keep history of versions of each committed values and go back searching for a previous value with a timestamp.

She issues a final read to the Like table to find out the list of users who liked picture 2, and surprise surprise, she got an extra record, hence Phantom read is still reproducible with repeatable read isolation level.
So we fix one problem with this isolation level but we introduce a cost of keeping history versions of previous committed values which we didn't have to with Read Committed level.
Next up, serializable isolation level.
-Hussein
July 28, 2016
4 Software patches that could make Fitbit blaze smarter
Got the fitbit blaze two months ago. I'm not a watch person but I really like it. However, there are few improvements that can be achieved by software only and make the watch smarter.
1. Exercise TerminationSo when I start an exercise, for example biking, I go to Exercise -> Biking and then wait a for a moment for to establish a Bluetooth connection between the Blaze and the phone to pick up my GPS coordinate and other information from the smart phone. I then tap "Start" and bike. When I reach my destination, I manually tap "Finish" so it syncs my path, speed and all the data to the smart phone app.
I don't have a problem with manually stopping the exercise, but the problem is sometimes I start the biking exercise, and reach my destination and forget to tap "Finish", and if I don't do that the watch keeps running and gives false indication that I'm exercising when I'm actually not. One day it kept running for 8 hours (really 8 hours of continuous biking while I'm in the same location). And as I said I'm not a watch person so I'm not used to look at the watch often.
So there are many ways for fixing this. Fitbit could install a software patch for the watch that simply vibrate after a period of time (10 minutes or so) while in exercise mode. That will force me to look at the watch and manually stopping the exercise. There are more smart ways to solve this like checking the GPS coordinate, if I'm stationary for a while that means I'm not really biking and the exercise could terminate by it self. Although this might shorten the battery life as the watch will be forced to perform spatial calculation.
2. Offload Processing to PhoneUsing the Blaze processor is expensive and can drain battery, so that should be minimized as much as possible. While biking I noticed that the watch gets warmer and battery is quickly drained. The reason is the Blaze require the GPS coordinate to calculate the distance traveled, speed and other information. The GPS coordinate is acquired from the phone via the established Bluetooth connection. The Blaze then does all the processing on its processor, calculating the distance traveled, current speed. This could be optimized by offloading those extra processor cycles to the phone and periodically send the result to the blaze so it displays it.
Another option that could potentially optimize battery life is disable all those calculations while running the exercise. All the processing will be done on the phone and once the user terminate the exercise the result is sent to the watch and displayed. How may miles I biked (or walked), what was my average speed, maximum speed etc. This will optimize this even further for those (like me) who don't actually check their watch while biking and only check it once they reach their destination.
3. Power Saving ModeThere is a green beam light that detects whether the watch is on and I believe it also monitors the heart-beat as well. When I remove the watch, it still seem active and counts phantom steps and floors which wastes battery life. The blaze should switch to Power Saving mode or whatever you want to call it, which at that stage it shouldn't attempt to sync, count steps or floors. Charging this thing is the worst.
4. Alarm SyncAlthough I don't wear it to bed, but it seems natural that I would like to sync my smart phone (IPhone or Andriod) to the Blaze. Having different set of alarms seem redundant.
-Hussein

1. Exercise TerminationSo when I start an exercise, for example biking, I go to Exercise -> Biking and then wait a for a moment for to establish a Bluetooth connection between the Blaze and the phone to pick up my GPS coordinate and other information from the smart phone. I then tap "Start" and bike. When I reach my destination, I manually tap "Finish" so it syncs my path, speed and all the data to the smart phone app.
I don't have a problem with manually stopping the exercise, but the problem is sometimes I start the biking exercise, and reach my destination and forget to tap "Finish", and if I don't do that the watch keeps running and gives false indication that I'm exercising when I'm actually not. One day it kept running for 8 hours (really 8 hours of continuous biking while I'm in the same location). And as I said I'm not a watch person so I'm not used to look at the watch often.
So there are many ways for fixing this. Fitbit could install a software patch for the watch that simply vibrate after a period of time (10 minutes or so) while in exercise mode. That will force me to look at the watch and manually stopping the exercise. There are more smart ways to solve this like checking the GPS coordinate, if I'm stationary for a while that means I'm not really biking and the exercise could terminate by it self. Although this might shorten the battery life as the watch will be forced to perform spatial calculation.
2. Offload Processing to PhoneUsing the Blaze processor is expensive and can drain battery, so that should be minimized as much as possible. While biking I noticed that the watch gets warmer and battery is quickly drained. The reason is the Blaze require the GPS coordinate to calculate the distance traveled, speed and other information. The GPS coordinate is acquired from the phone via the established Bluetooth connection. The Blaze then does all the processing on its processor, calculating the distance traveled, current speed. This could be optimized by offloading those extra processor cycles to the phone and periodically send the result to the blaze so it displays it.
Another option that could potentially optimize battery life is disable all those calculations while running the exercise. All the processing will be done on the phone and once the user terminate the exercise the result is sent to the watch and displayed. How may miles I biked (or walked), what was my average speed, maximum speed etc. This will optimize this even further for those (like me) who don't actually check their watch while biking and only check it once they reach their destination.
3. Power Saving ModeThere is a green beam light that detects whether the watch is on and I believe it also monitors the heart-beat as well. When I remove the watch, it still seem active and counts phantom steps and floors which wastes battery life. The blaze should switch to Power Saving mode or whatever you want to call it, which at that stage it shouldn't attempt to sync, count steps or floors. Charging this thing is the worst.
4. Alarm SyncAlthough I don't wear it to bed, but it seems natural that I would like to sync my smart phone (IPhone or Andriod) to the Blaze. Having different set of alarms seem redundant.
-Hussein
July 25, 2016
ACID (Part 3)
So in the last post we discussed Isolation (the third letter from ACID). We managed to cover the 1st isolation level which was the Read Uncommitted. That level of isolation in fact offers no isolation at all (thus poor consistency), but yield excellent performance because we don't have to jump to previous "versions" of the record being read. The three phenomenas are reproducible with the read uncommitted. The next level of isolation we want to talk about is Read Committed.
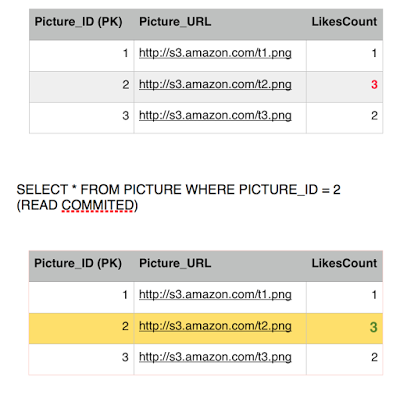
Read CommittedThis isolation level offers isolation against uncommitted reads. A transaction will only read entries that has been committed by other transacations. So from this definition we know that dirty reads phenomena cannot appear in this isolation level. But again, we need a good example that illustrates this. Lets do our Instagram example again.
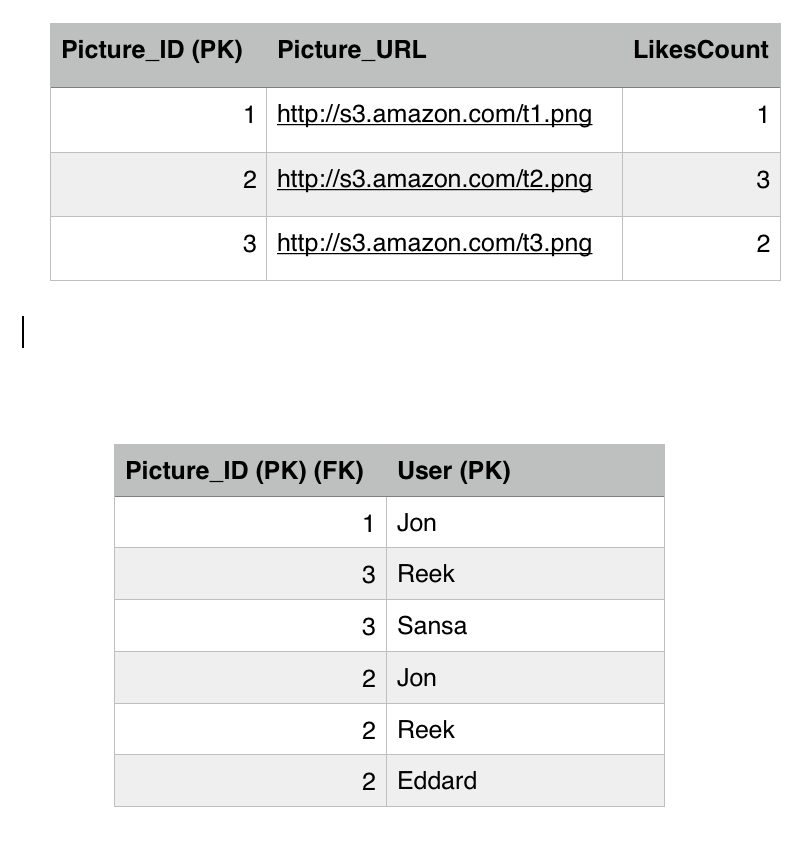
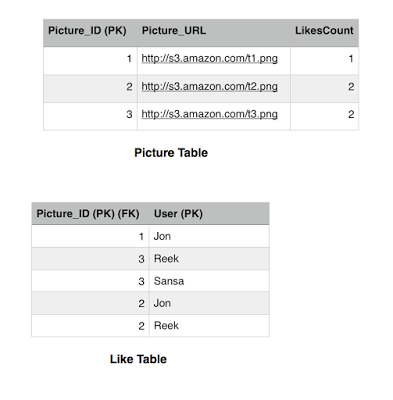
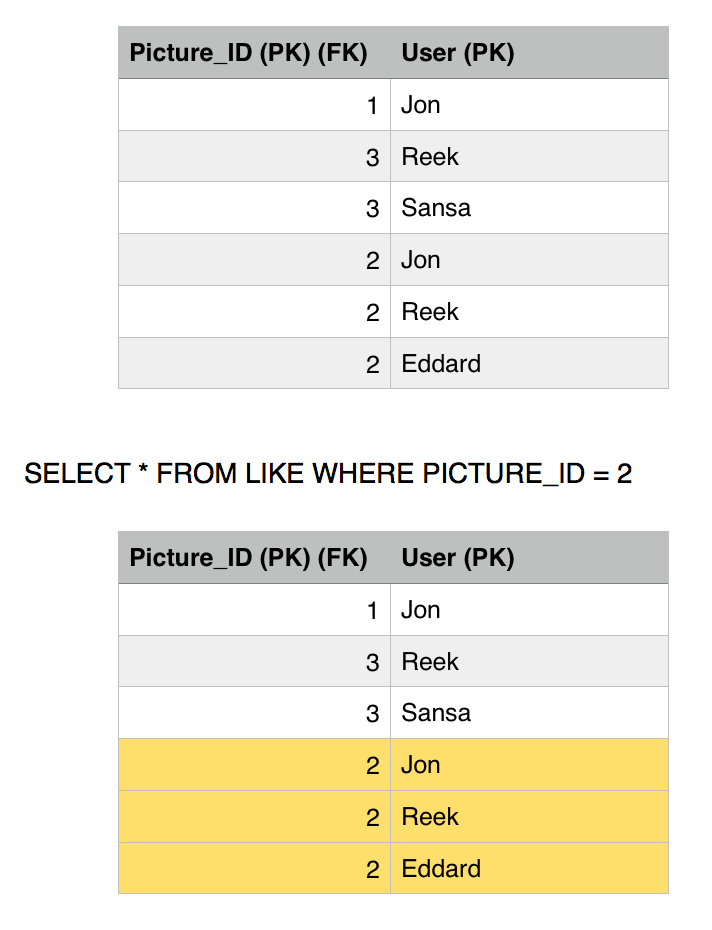
Brief recap, the Picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has 2 likes by Jon and Reek. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
Jon has already liked picture 2, but he is insisting in liking it again, we have nice atomicity and consistency that prevent him from doing so but lets see what happens. Jon fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes.
Jon sends the like, first query executes successfully, incrementing the likes count.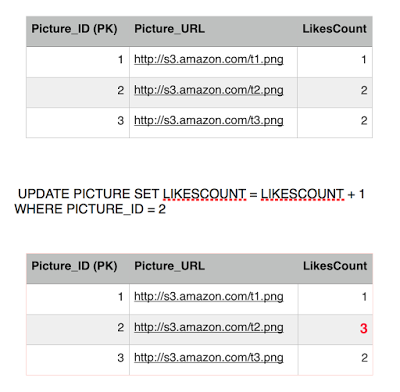
Before Jon second query executes, Sansa's Select kicks in to read picture 2 row, she is going to get 2 likes instead of 3. This is because we are operating under the Read Committed isolation level, and since Jon still did not commit his transaction, Sansa is getting whatever the previous committed value was. So we have avoided a dirty read phenomena.
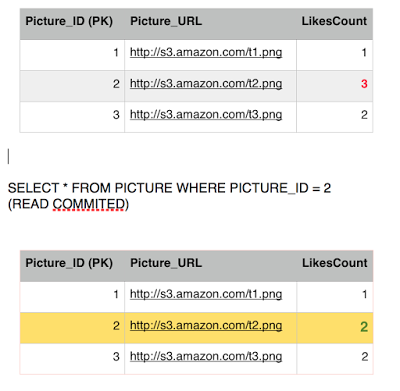
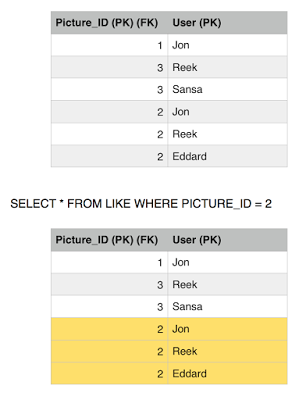
Sansa issues another read to the Like table to get all the users who likes picture 2, she gets two rows, Jon and Reek. Consistent with the number of likes she got.

Jon transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 2.
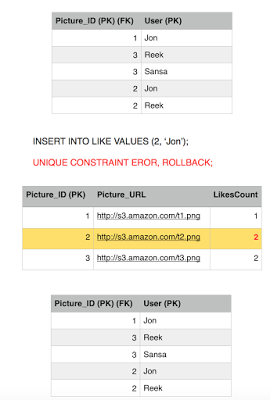
Jon gives up, his transaction is finished and he failed to ruin our system consistent state. But meanwhile a new user comes in, Eddard, likes picture 2, he is a brand new user who never liked picture 2 before so his transaction commits fine.

Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2 getting the likes count. She is getting a different result although she executed the same query twice in the same transaction. So we still get non-repeatable read phenamona with read committed isolation level.
She issues a final read to the Like table to find out the list of users who liked picture 2, and surprise surprise, she got an extra record this time, hence Phantom read is also reproducible with read committed.
So this isolation level did save us from a dirty read but still we getting phantoms and non-repeatable reads.
Next up, Repeatable Read
-Hussein

Read CommittedThis isolation level offers isolation against uncommitted reads. A transaction will only read entries that has been committed by other transacations. So from this definition we know that dirty reads phenomena cannot appear in this isolation level. But again, we need a good example that illustrates this. Lets do our Instagram example again.
Brief recap, the Picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has 2 likes by Jon and Reek. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
Jon has already liked picture 2, but he is insisting in liking it again, we have nice atomicity and consistency that prevent him from doing so but lets see what happens. Jon fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes.
Jon sends the like, first query executes successfully, incrementing the likes count.
Before Jon second query executes, Sansa's Select kicks in to read picture 2 row, she is going to get 2 likes instead of 3. This is because we are operating under the Read Committed isolation level, and since Jon still did not commit his transaction, Sansa is getting whatever the previous committed value was. So we have avoided a dirty read phenomena.

Sansa issues another read to the Like table to get all the users who likes picture 2, she gets two rows, Jon and Reek. Consistent with the number of likes she got.

Jon transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 2.
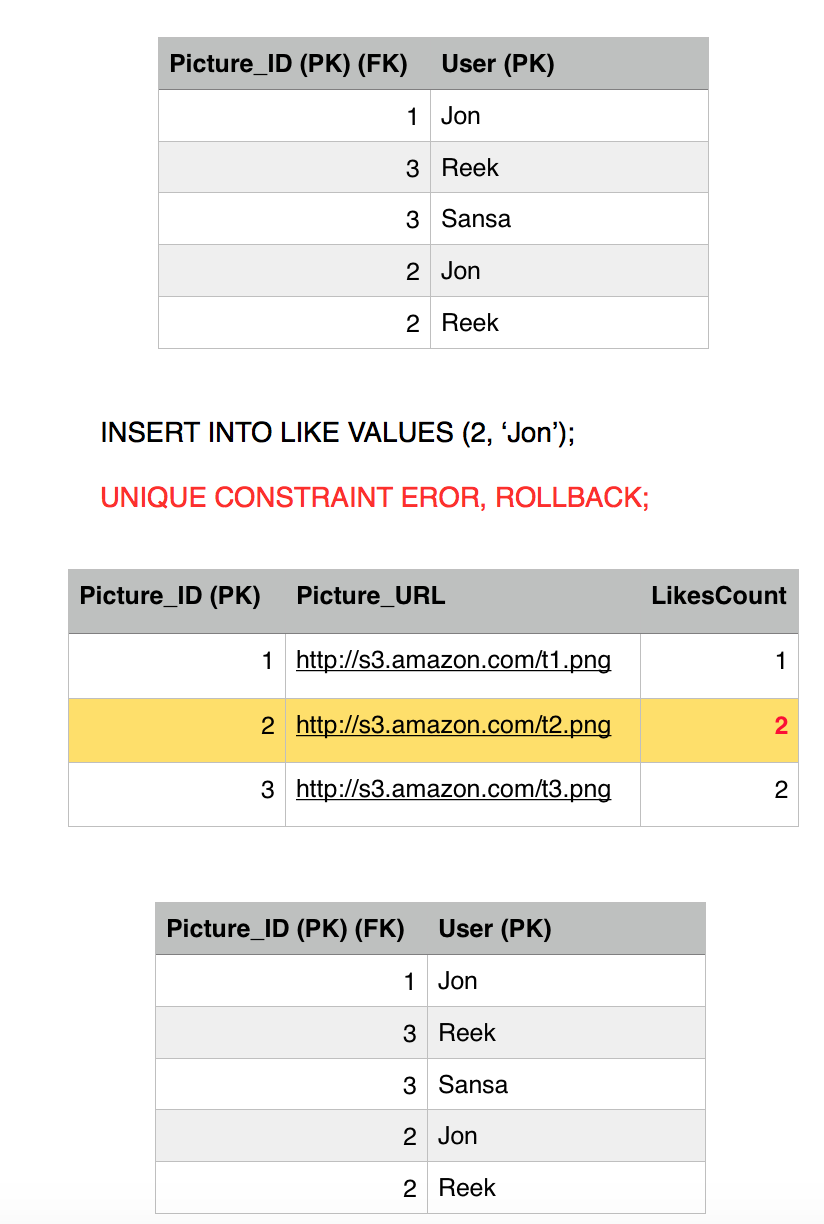
Jon gives up, his transaction is finished and he failed to ruin our system consistent state. But meanwhile a new user comes in, Eddard, likes picture 2, he is a brand new user who never liked picture 2 before so his transaction commits fine.
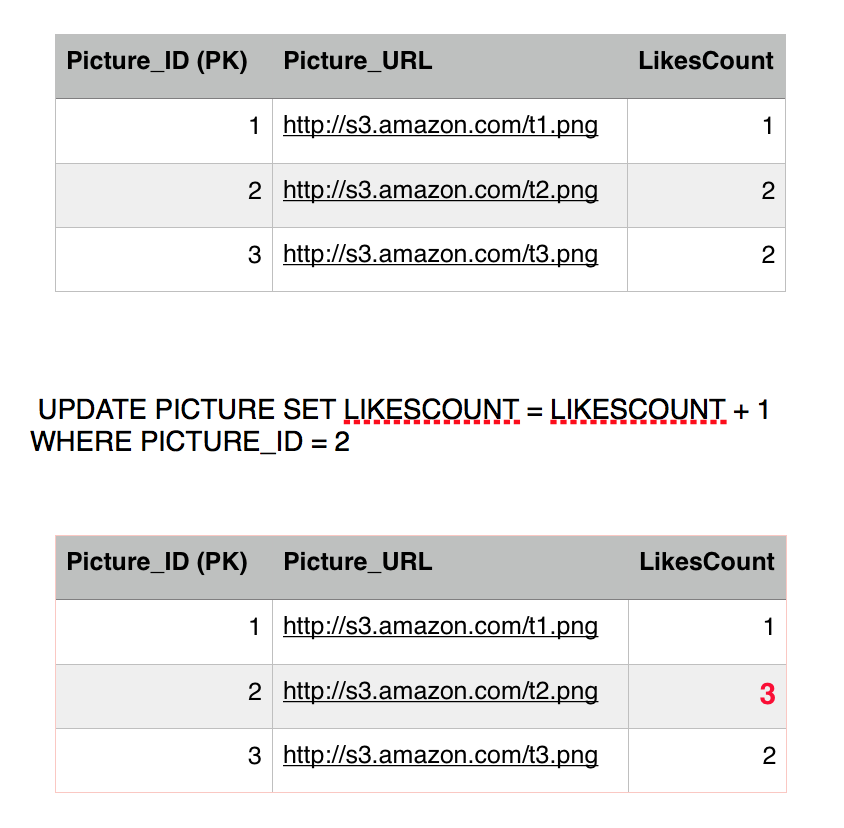
Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2 getting the likes count. She is getting a different result although she executed the same query twice in the same transaction. So we still get non-repeatable read phenamona with read committed isolation level.
She issues a final read to the Like table to find out the list of users who liked picture 2, and surprise surprise, she got an extra record this time, hence Phantom read is also reproducible with read committed.
So this isolation level did save us from a dirty read but still we getting phantoms and non-repeatable reads.
Next up, Repeatable Read
-Hussein
July 15, 2016
ACID (Part 2)
In the previous post, we discussed the two properties of ACID, Atomocity and Consistency.
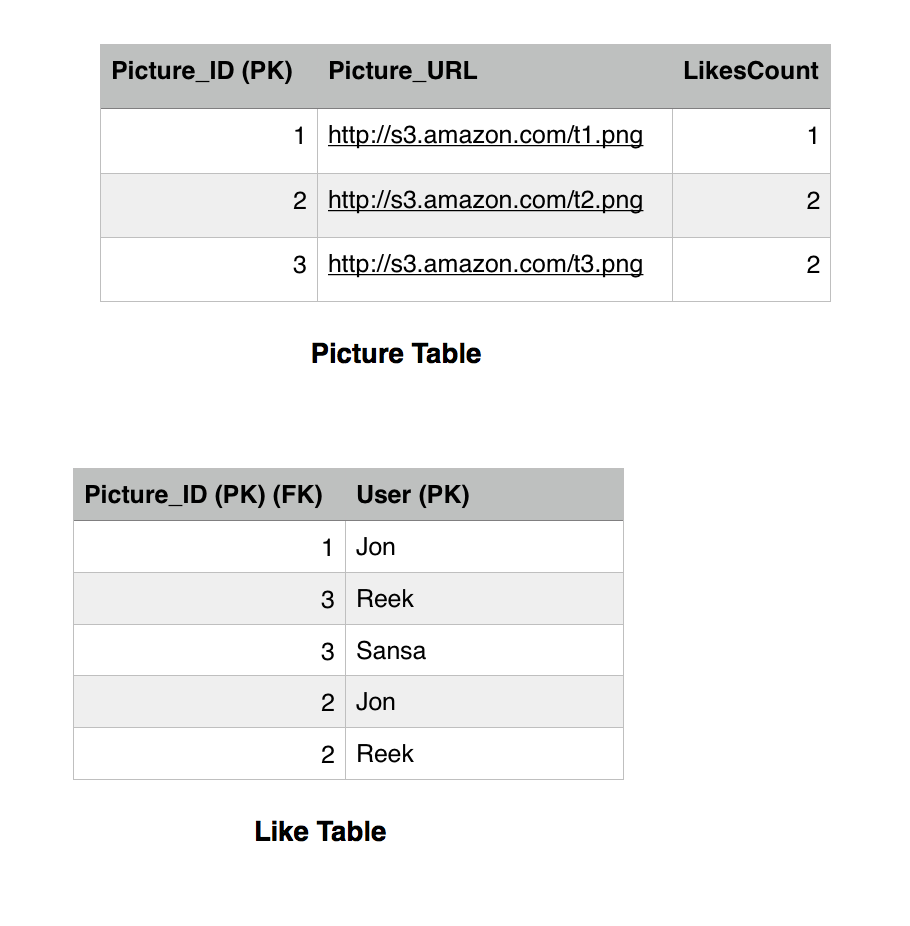
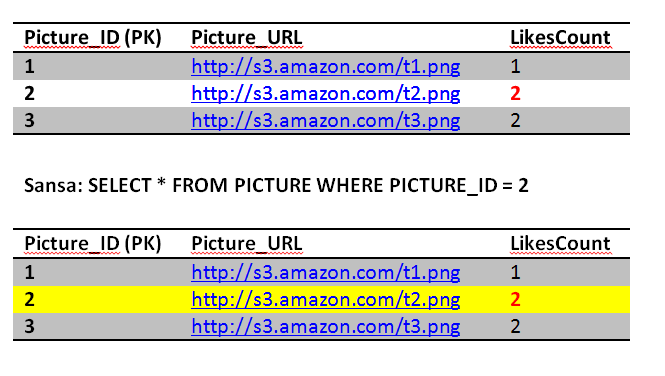
Brief recap, the Picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has 1 like by Jon. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
This is how our tables look like after the last post.

IsolationObviously Jon is not the only user here, otherwise he would have ruled the Iron throne already, there are other users that concurrently liking pictures and updating the database. The question remain, how can we control what goes in first? should we go maximum isolation, stop everyone and use a first come first served approach so users don't step on each other's toes? or we should allow multiple users to update similar entries in parallel and deal with results? its our call really. First approach is slow but gives you consistent results, second approach much faster but might return incorrect results.
There are four types of isolation levels that we will try to cover.
Read UncommittedHere there is no isolation at all; Anything that is written, whether committed or not, is available to be read. Let us see how this performs in our Instagram scenario.
Jon has already liked picture 2, but he is insisting in liking it again, we have nice atomicity and consistency that prevent him from doing so but lets see what happens. Jon fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes.
Jon sends the like, first query executes successfully, incrementing the likes count.

Before Jon second query executes, Sansa's Select kicks in to read picture 2, she is going to get (2 likes). This phenomena is called a dirty read , although Jon still didn't finish his transaction, we allowed Sansa to read a dirty uncommitted entry.
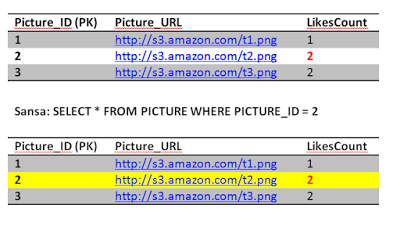
Sansa issues another read to the Like table to get all the users who likes picture 2, she gets one row, which is Jon. Inconsistent with the number of likes she gets hmmm.

Jon transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 1.

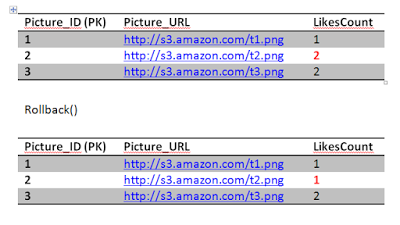
Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2. She is getting a different result although she executed the same query twice in the same transaction, she got different results from each one. This phenomena is called Non-Repeatable read.

While Sansa still executing her transaction, Reek likes picture 2, its his first like so the transaction commits fine.
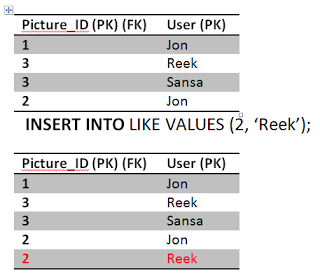
Finally Sansa completes her transaction by reading the likes of picture 2 again, this time she gets an extra record! what a mess. She got different set of rows running the same query. This phenomena is called Phantoms read
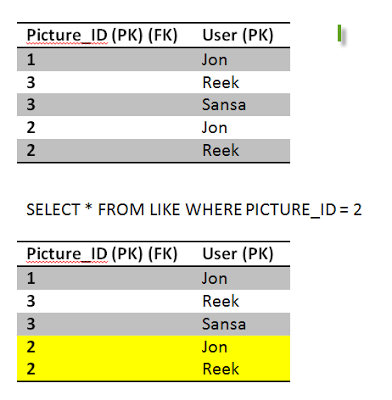
With read uncommitted isolation level we got all three phenomenas. The question is how important isolation for us, can we tolerate these problems?
Next post Read Committed.
-Hussein

Brief recap, the Picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has 1 like by Jon. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
This is how our tables look like after the last post.

IsolationObviously Jon is not the only user here, otherwise he would have ruled the Iron throne already, there are other users that concurrently liking pictures and updating the database. The question remain, how can we control what goes in first? should we go maximum isolation, stop everyone and use a first come first served approach so users don't step on each other's toes? or we should allow multiple users to update similar entries in parallel and deal with results? its our call really. First approach is slow but gives you consistent results, second approach much faster but might return incorrect results.
There are four types of isolation levels that we will try to cover.
Read UncommittedHere there is no isolation at all; Anything that is written, whether committed or not, is available to be read. Let us see how this performs in our Instagram scenario.
Jon has already liked picture 2, but he is insisting in liking it again, we have nice atomicity and consistency that prevent him from doing so but lets see what happens. Jon fires up a like on picture 2, and fraction of a second later Sansa loads up picture 2, this will retrieve the number of likes.
Jon sends the like, first query executes successfully, incrementing the likes count.

Before Jon second query executes, Sansa's Select kicks in to read picture 2, she is going to get (2 likes). This phenomena is called a dirty read , although Jon still didn't finish his transaction, we allowed Sansa to read a dirty uncommitted entry.
Sansa issues another read to the Like table to get all the users who likes picture 2, she gets one row, which is Jon. Inconsistent with the number of likes she gets hmmm.

Jon transaction moves on and executes the second query which fails because of the constraint we have in place. Rolling back the entry for likes back to 1.


Sansa's transaction is still running she is querying other tables, doing some stuff, updating the view count perhaps, and then finally, she comes back for a final read of picture 2. She is getting a different result although she executed the same query twice in the same transaction, she got different results from each one. This phenomena is called Non-Repeatable read.

While Sansa still executing her transaction, Reek likes picture 2, its his first like so the transaction commits fine.
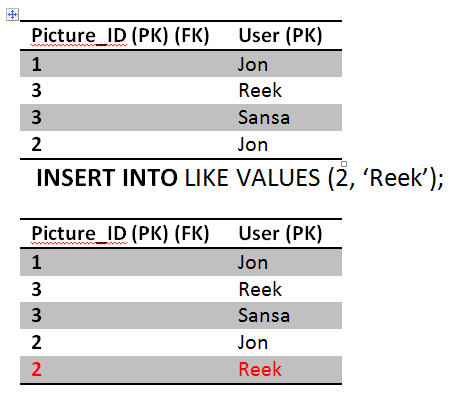
Finally Sansa completes her transaction by reading the likes of picture 2 again, this time she gets an extra record! what a mess. She got different set of rows running the same query. This phenomena is called Phantoms read
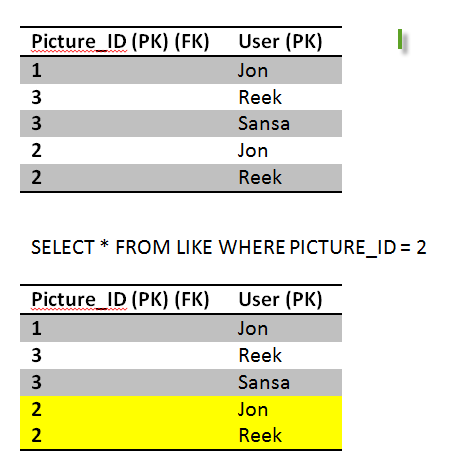
With read uncommitted isolation level we got all three phenomenas. The question is how important isolation for us, can we tolerate these problems?
Next post Read Committed.
-Hussein
July 12, 2016
ACID (Part 1)
In the late 1970s, Jim Gray, the computer scientist who went missing in 2007 and never found, defined a set of properties for database transactions. These properties were Atomicity, Consistency, Isolation and Durability, thus ACID.
What are the ACID properties? How important are they? Can we trade these properties off for performance? Or should we architecture our software around those and make sure they all are met in all instances?
This blog post and the following posts will attempt to answer these questions and clarify each property with hopefully a relatable example. I will try to be consistent and use one example to explain all four properties. I picked Instagram.
Instagram is a popular photo sharing service that is available on mobile devices. You can post a picture, and people who follow you can like or comment on those pictures.
Note: We are going to make a lot of assumption about Instagram database model which may not necessary be the actual implementation. However, we will try to make assumptions that yield highest performance.
Consider this database design, we have a Picture table, and Like table.
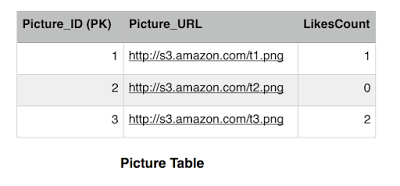
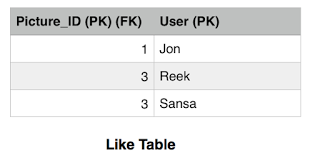
The picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has no likes. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
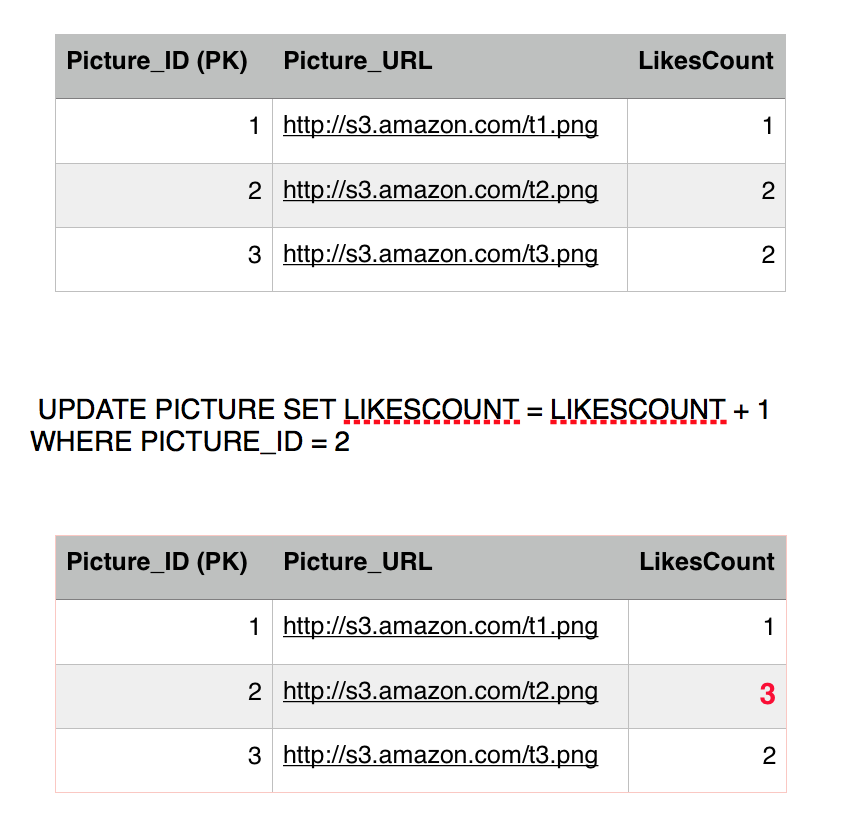
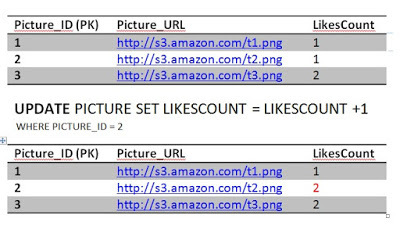
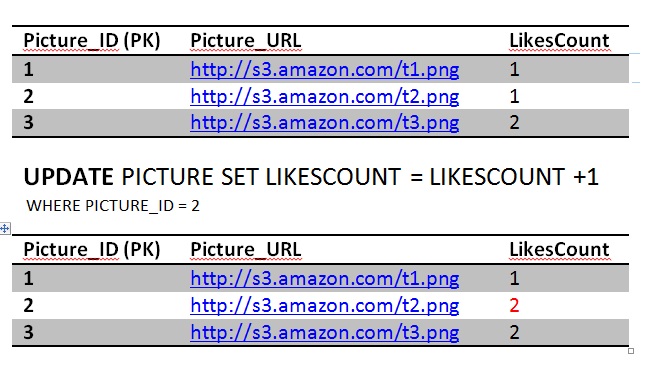
AtomicityAssume Jon, when he is not guarding the Wall, likes Picture 2. That is equivalent to one update query to the Picture table to increment the count of likes by 1 and one insert query to add a row in the Like table.
To achieve atomicity, those two queries should succeed together or they should fail together. They can't be one success and one fail or else we will end up in a inconsistent state where the likes rows do not match the count of the likes. Obviously its not a big deal if the like count did not match and here is where the trade off can happen. However, in some circumstances, like banking for instance, we can't tolerate such errors. The database solution should support atomic transactions where we can wrap those two queries in one transaction and then rollback in case one of them failed.
You might wonder, what could cause a query to fail? Network connectivity is one, hardware failure is another, but there are other constraints that we can put in place where the database can actually refuse to execute a query. Referential integrity and unique constraints for instance which brings us to the second property.
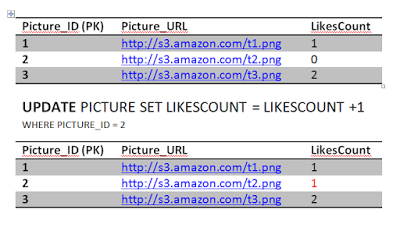

ConsistencyAssume this, Jon really likes picture 2 he double clicked it again sending another like. Obviously this is wrong, but we have a constraint in the system to prevent that thank fully.
The first statement will go through updating the likes count..
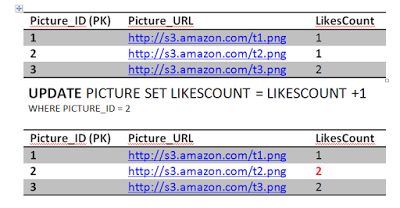
The second query will fail because of unique constraint that we have put in place (Jon and 2) unique key already exists. This will cause the transaction to rollback and undo the first update as well, restoring the system to a consistent state. The atomicity kicked in here and saved the day in order to achieve consistency. If we didn't have an atomic transaction, we will end up with wrong results. Again not the end of the world.
So there is a lot of room for discussions here right, we can implement this logic at the client side to prevent Jon from sending the second like. But that mean an additional cost for reading that Like table and making sure Jon has already liked that. However, leaving a database constraints will lead to a lot of unnecessary traffic to the database that could be prevented.You guys can chip in for a better design here.
Another point I guess I should mention is a consistent state is different than a correct state. I would like to quote C.J. Date on this.
I want to handle Isolation in another post since it is a long topic.

What are the ACID properties? How important are they? Can we trade these properties off for performance? Or should we architecture our software around those and make sure they all are met in all instances?
This blog post and the following posts will attempt to answer these questions and clarify each property with hopefully a relatable example. I will try to be consistent and use one example to explain all four properties. I picked Instagram.
Instagram is a popular photo sharing service that is available on mobile devices. You can post a picture, and people who follow you can like or comment on those pictures.
Note: We are going to make a lot of assumption about Instagram database model which may not necessary be the actual implementation. However, we will try to make assumptions that yield highest performance.
Consider this database design, we have a Picture table, and Like table.
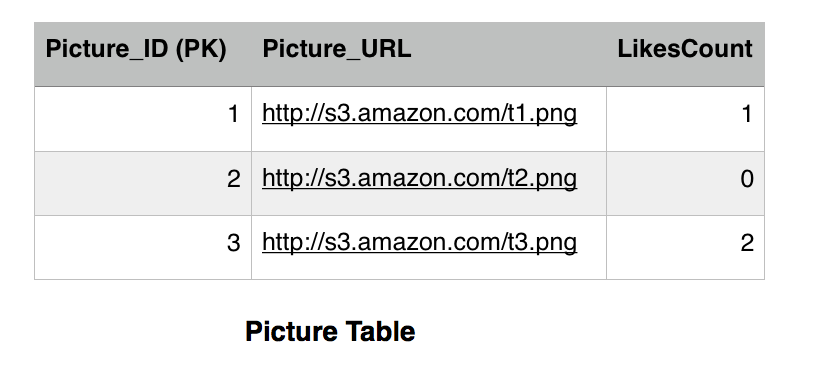
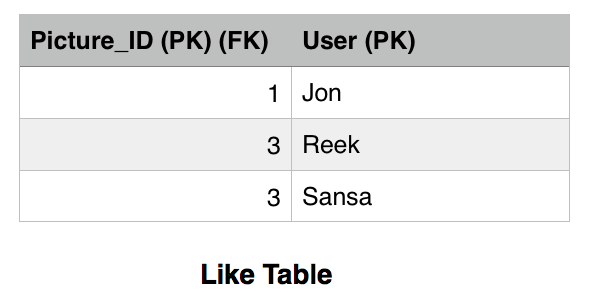
The picture table has the LikesCount field which keeps track of how many likes a picture got. This is a performance tweak in order to avoid querying the Like table every time we want to get the likes count for a picture. We notice that picture 1 has 1 like only by Jon and picture 3 has two likes by Reek and Sansa. Picture 2 has no likes. The Picture_ID is the primary key in the Picture table, while both the Picture_ID and the User constitute the primary key for the Like table. There are many fields that we can add but for simplicity we are sticking with these now.
AtomicityAssume Jon, when he is not guarding the Wall, likes Picture 2. That is equivalent to one update query to the Picture table to increment the count of likes by 1 and one insert query to add a row in the Like table.
UPDATE PICTURE SET LIKESCOUNT = LIKESCOUNT +1 WHERE PICTURE_ID = 2;
INSERT INTO LIKE VALUES (2, 'Jon');
To achieve atomicity, those two queries should succeed together or they should fail together. They can't be one success and one fail or else we will end up in a inconsistent state where the likes rows do not match the count of the likes. Obviously its not a big deal if the like count did not match and here is where the trade off can happen. However, in some circumstances, like banking for instance, we can't tolerate such errors. The database solution should support atomic transactions where we can wrap those two queries in one transaction and then rollback in case one of them failed.
You might wonder, what could cause a query to fail? Network connectivity is one, hardware failure is another, but there are other constraints that we can put in place where the database can actually refuse to execute a query. Referential integrity and unique constraints for instance which brings us to the second property.
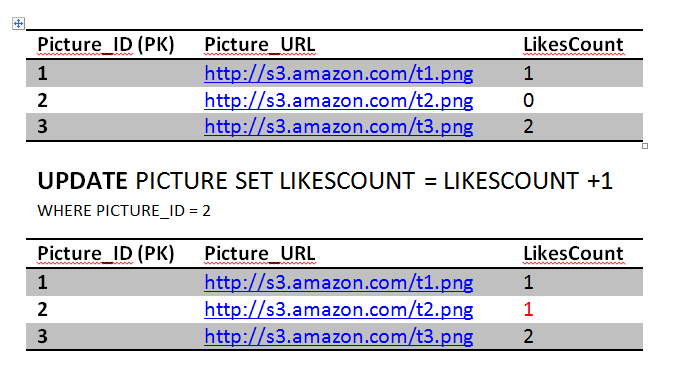

ConsistencyAssume this, Jon really likes picture 2 he double clicked it again sending another like. Obviously this is wrong, but we have a constraint in the system to prevent that thank fully.
The first statement will go through updating the likes count..
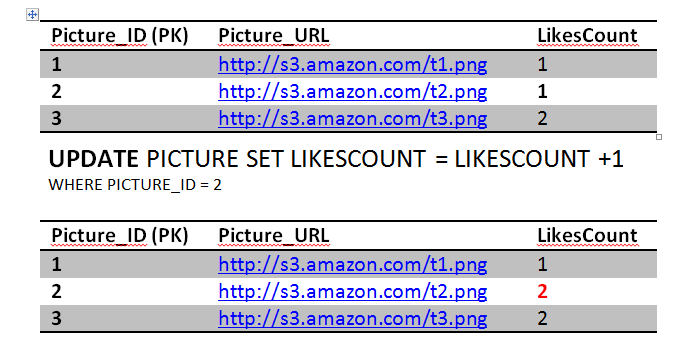
The second query will fail because of unique constraint that we have put in place (Jon and 2) unique key already exists. This will cause the transaction to rollback and undo the first update as well, restoring the system to a consistent state. The atomicity kicked in here and saved the day in order to achieve consistency. If we didn't have an atomic transaction, we will end up with wrong results. Again not the end of the world.
So there is a lot of room for discussions here right, we can implement this logic at the client side to prevent Jon from sending the second like. But that mean an additional cost for reading that Like table and making sure Jon has already liked that. However, leaving a database constraints will lead to a lot of unnecessary traffic to the database that could be prevented.You guys can chip in for a better design here.
Another point I guess I should mention is a consistent state is different than a correct state. I would like to quote C.J. Date on this.
Consistent mean "satisfying all known integrity constraints" Observe, therefore, that consistent does not necessarily mean correct; a correct state must necessarily be consistent, but a consistent state might still be incorrect, in the sense that it does not accurately reflect the true state of affairs in the real world. "Consistent" might be defined as "correct as far as the system is concerned". - An introduction to Database system.Consistency as you see is expensive to maintain, so some systems now especially distributed systems prefer a different consistency model called Eventual Consistency. Which we will touch upon on another topic.
I want to handle Isolation in another post since it is a long topic.


