
Robert E. Hoyt's Blog
September 23, 2018
National Health Interview Survey (NHIS)
This week I ran into the following article: Prevalence of diagnosed type 1 and type 2 diabetes among US adults in 2016 and 2017: population based study BMJ 2018; 362 doi: https://doi.org/10.1136/bmj.k1497(Published 04 September 2018) Cite this as: BMJ 2018;362:k1497.In spite of the article being published in the British Medical Journal the source of the data was the NHIS. Like NHANES, the NHIS it is part of the NCHS, which is under the CDC. This is a annual survey of "average" Americans and the questionnaires are handled by the Census Bureau. NCHS compiles statistical information to help guide public health and health policy decisions. Survey has been ongoing since 1960 and the results of the 2017 survey are available for download as several zip files, containing ASCII and CSV files. The questionnaires are organized around Family, Adult and Child. The major health categories are as follows:Physical and mental health statusChronic conditions, including asthma and diabetesAccess to and use of health care servicesHealth insurance coverage and type of coverageHealth-related behaviors, including smoking, alcohol use, and physical activityMeasures of functioning and activity limitationsImmunizationsThese datasets therefore promote research into many socio-behavioral issues. My review of the 2017 dataset shows that it has hundreds of variables on about 26000 subjects. Below is an image that reports compliance with recommended activity levels gleaned from NHIS data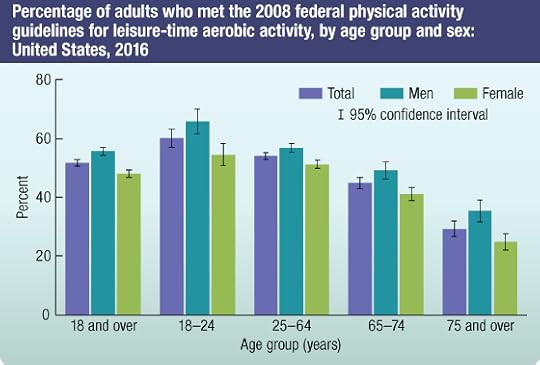


September 21, 2018
NHANES Data: a Treasure Trove for Biomedical Research
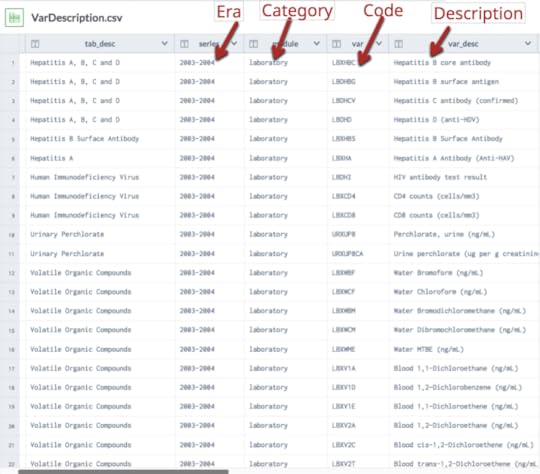
National Health & Nutrition Evaluation Survey (NHANES) is a program of the National Center for Health Statistics (NCHS), which is a a CDC program. The survey has existed since the 1960s and since 1999 has been continuous. About 5000 patients a year are surveyed and examined in detail and that includes extensive lab testing. The data and codebooks (data dictionaries) are free to access. This is important because obtaining real patient data at the patient level tends to be difficult due to HIPAA and is expensive to buy. There is a longitudinal project under way of 800 patients from the 2007-2014 cohorts that is not available yet, to the best of my knowledge.NHANES data is valuable for several reasons. It tends to represent a more “normal” US sample of patients. For example, more are college educated. NHANES data is frequently used for observational and benchmarking studies (compare another population and/or result with NHANES dataset). It is also good for hypothesis testing. NHANES data has been used for research for many years. For example, a Google Scholar search for NHANES in the title yielded more than 5,000 hits and a PubMed search turned up over 9,800 hits. Another advantage of NHANES data is that it is associated with extensive data dictionaries. These dictionaries explain exactly how the data was collected, what units, how many patients were examined and so forth. Importantly, the dictionaries also include the short hand name of the attribute which you must have to locate and analyze the data. For example, glycohemoglobin or A1c is coded LBXGH. A researcher would need to know that for a SQL query. NHANES data does have some limitations however:•Patient data is cross sectional and not longitudinal •Diagnoses is derived from patient questionnaires but in my experience, the results are very accurate. For example, 98% of patients who claimed they were diabetic had abnormal glucoses or glycohemoglobin or were on glucose lowering medications•Some lab tests are not done every year, so accessing multiple years is important• NHANES uses sampling weights that must be understood•Data files are available as SAS transport files; they need to be converted to csv filesThere is a new NHANES dataset that was created by Harvard University that combines 4 NHANES periods (1999-2006) so there is a single spreadsheet with 1191 attributes on 41,474 patients. The project was part of the i2B2 Initiative and is a public dataset. There is an article by CJ Patel et al. in Nature that explains how this was done and the significance of this initiative. This article introduces the concept of the exposome, in addition to phenotype. There is also an associated video. There are 3 ways you can access this large NHANES dataset:•Data Dryad(data repository) Files: Maintable (large spreadsheet), VarDescription (data dictionary)•Harvard Data Explorer•Data World. Project name = NHANES Compilation.Harvard Data Explorer Gallery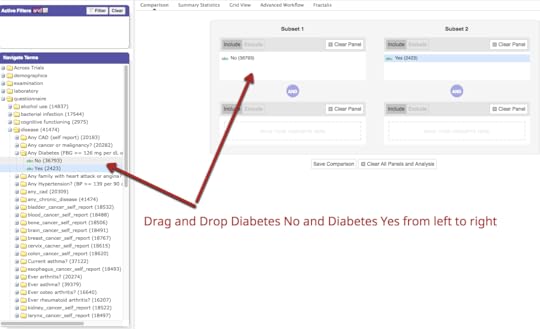
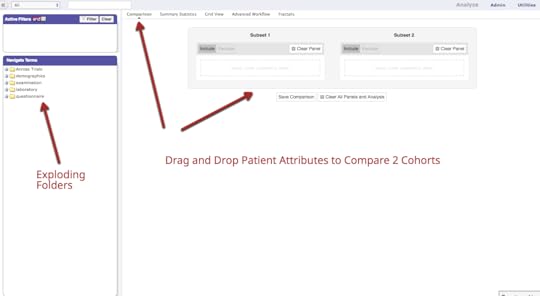
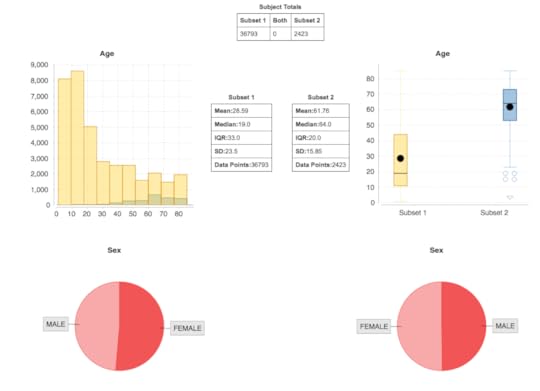

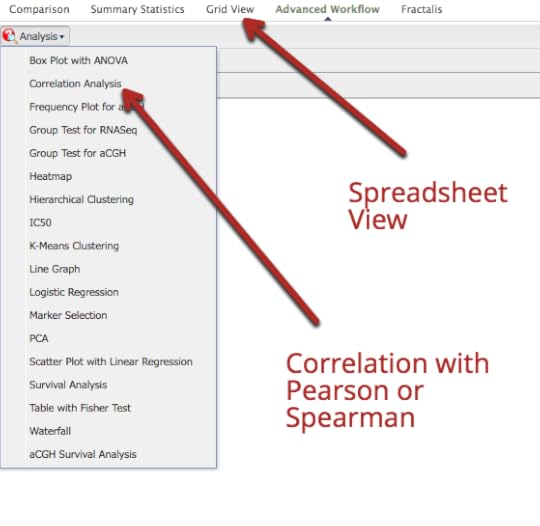
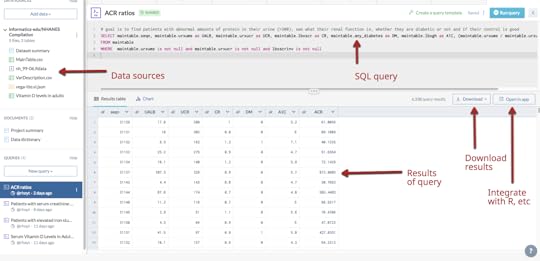
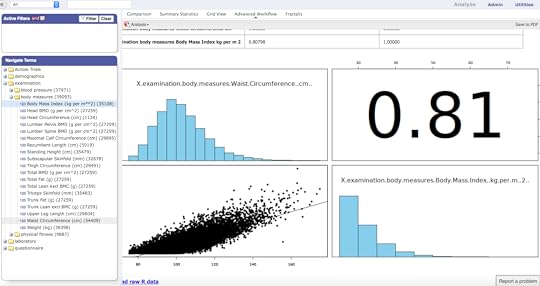 My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World Gallery
My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World Gallery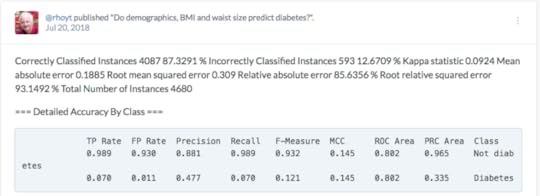
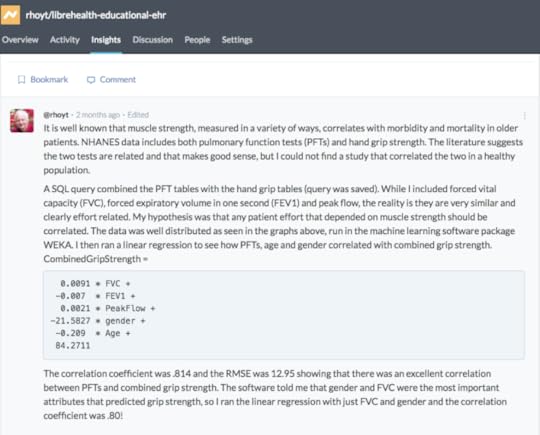
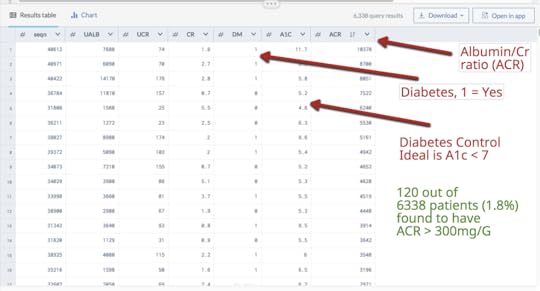 Conclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
Conclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World GalleryConclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
NHANES Data is a Treasure Trove for Biomedical Research
National Health & Nutrition Evaluation Survey (NHANES) is a program of the National Center for Health Statistics (NCHS), which is a a CDC program. The survey has existed since the 1960s and since 1999 has been continuous. About 5000 patients a year are surveyed and examined in detail and that includes extensive lab testing. The data and codebooks (data dictionaries) are free to access. This is important because obtaining real patient data at the patient level tends to be difficult due to HIPAA and is expensive to buy. There is a longitudinal project under way of 800 patients from the 2007-2014 cohorts that is not available yet, to the best of my knowledge.NHANES data is valuable for several reasons. It tends to represent a more “normal” US sample of patients. For example, more are college educated. NHANES data is frequently used for observational and benchmarking studies (compare another population and/or result with NHANES dataset). It is also good for hypothesis testing. NHANES data has been used for research for many years. For example, a Google Scholar search for NHANES in the title yielded more than 5,000 hits and a PubMed search turned up over 9,800 hits. Another advantage of NHANES data is that it is associated with extensive data dictionaries. These dictionaries explain exactly how the data was collected, what units, how many patients were examined and so forth. Importantly, the dictionaries also include the short hand name of the attribute which you must have to locate and analyze the data. For example, glycohemoglobin or A1c is coded LBXGH. A researcher would need to know that for a SQL query. NHANES data does have some limitations however:•Patient data is cross sectional and not longitudinal •Diagnoses is derived from patient questionnaires but in my experience, the results are very accurate. For example, 98% of patients who claimed they were diabetic had abnormal glucoses or glycohemoglobin or were on glucose lowering medications•Some lab tests are not done every year, so accessing multiple years is important• NHANES uses sampling weights that must be understood•Data files are available as SAS transport files; they need to be converted to csv filesThere is a new NHANES dataset that was created by Harvard University that combines 4 NHANES periods (1999-2006) so there is a single spreadsheet with 1191 attributes on 41,474 patients. The project was part of the i2B2 Initiative and is a public dataset. There is an article by CJ Patel et al. in Nature that explains how this was done and the significance of this initiative. This article introduces the concept of the exposome, in addition to phenotype. There is also an associated video. There are 3 ways you can access this large NHANES dataset:•Data Dryad(data repository) Files: Maintable (large spreadsheet), VarDescription (data dictionary)•Harvard Data Explorer•Data World. Project name = NHANES Compilation.Harvard Data Explorer Gallery My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World GalleryConclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World GalleryConclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
LibreHealth Educational EHR
One year ago LibreHealth EHR was populated with 9600 patients and their data from the 2011-2012 data collection period. It was beta-tested by three universities and the results were very favorable. Since then the reporting mechanism and student activity functionality have been enhanced. We are again offering the educational EHR to Health Informatics programs. While there is a charge for the installation and support of the software, I am offering (10) grants for $1000 each to support those schools that cannot afford the $150/month hosting fee. Further details are available in this document on Google Drive
May 17, 2017
New Open-Source EHR for Education, Training and Research
LibreHealth EHRis part of a 2016 initiative by former developers of OpenMRS and OpenEMR. The program consists of the EHR, a toolkit (API) and a Radiology platform. The EHR is open-source, web-based and free to download. The steering committee has long supported the notion that an open-source EHR would be a good platform for a variety of activities, such as education, training and research. This initiative received early assistance and support from the Indiana University-Purdue University Indianapolis (IUPUI) and the University of West Florida.It was everyone's vision that an open-source platform such as this could be used by a wide audience of students and instructors.Finding real patient data is always difficult so we settled on the National Health and Nutrition Examination Survey (NHANES) data set 2011-2012. While the patient names are fictitious, the patient data is real. Roughly 9600 patients were uploaded with associated diagnoses, medications, ICD-10 codes and vital signs. Lab work will be added shortly.The goal is to make this platform available free for universities and colleges who teach health informatics, health information management and the health sciences. We hope to host the EHR for a few universities in 2017, in order to gain valuable feedback.For those faculty who plan to use the "backend" of the program, we will offer a SQL dump file and CSV files for all tables, along with the data dictionaries and the SAS transport files. This should provide an opportunity for database management and predictive analytics.A demo has been created which we will make public once we have loaded the laboratory dataWe intend to also offer case studies and scenarios for EHR training and education for clinical and health science studentsFigure 1below shows a screen shot of an example patients "Problem Summary List"
and research. This initiative received early assistance and support from the Indiana University-Purdue University Indianapolis (IUPUI) and the University of West Florida.It was everyone's vision that an open-source platform such as this could be used by a wide audience of students and instructors.Finding real patient data is always difficult so we settled on the National Health and Nutrition Examination Survey (NHANES) data set 2011-2012. While the patient names are fictitious, the patient data is real. Roughly 9600 patients were uploaded with associated diagnoses, medications, ICD-10 codes and vital signs. Lab work will be added shortly.The goal is to make this platform available free for universities and colleges who teach health informatics, health information management and the health sciences. We hope to host the EHR for a few universities in 2017, in order to gain valuable feedback.For those faculty who plan to use the "backend" of the program, we will offer a SQL dump file and CSV files for all tables, along with the data dictionaries and the SAS transport files. This should provide an opportunity for database management and predictive analytics.A demo has been created which we will make public once we have loaded the laboratory dataWe intend to also offer case studies and scenarios for EHR training and education for clinical and health science studentsFigure 1below shows a screen shot of an example patients "Problem Summary List"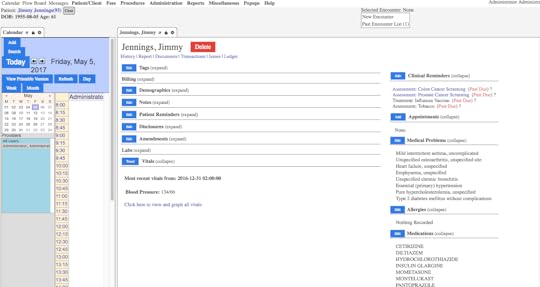 Figure 2shows a SQL query for frequency of diagnoses by ICD-10. The first number is the number of cases identified; such as 1882 patients were coded as essential hypertension
Figure 2shows a SQL query for frequency of diagnoses by ICD-10. The first number is the number of cases identified; such as 1882 patients were coded as essential hypertension Figure 3shows graphing of blood pressure trends
Figure 3shows graphing of blood pressure trends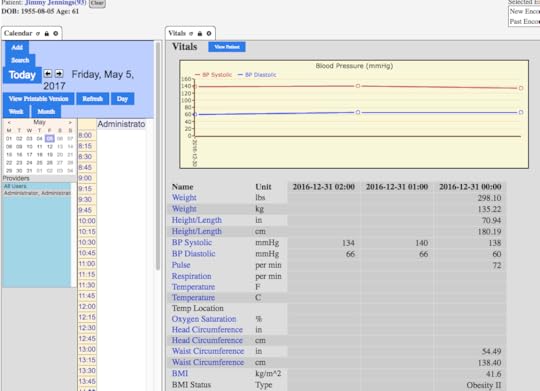
and research. This initiative received early assistance and support from the Indiana University-Purdue University Indianapolis (IUPUI) and the University of West Florida.It was everyone's vision that an open-source platform such as this could be used by a wide audience of students and instructors.Finding real patient data is always difficult so we settled on the National Health and Nutrition Examination Survey (NHANES) data set 2011-2012. While the patient names are fictitious, the patient data is real. Roughly 9600 patients were uploaded with associated diagnoses, medications, ICD-10 codes and vital signs. Lab work will be added shortly.The goal is to make this platform available free for universities and colleges who teach health informatics, health information management and the health sciences. We hope to host the EHR for a few universities in 2017, in order to gain valuable feedback.For those faculty who plan to use the "backend" of the program, we will offer a SQL dump file and CSV files for all tables, along with the data dictionaries and the SAS transport files. This should provide an opportunity for database management and predictive analytics.A demo has been created which we will make public once we have loaded the laboratory dataWe intend to also offer case studies and scenarios for EHR training and education for clinical and health science studentsFigure 1below shows a screen shot of an example patients "Problem Summary List"Figure 2shows a SQL query for frequency of diagnoses by ICD-10. The first number is the number of cases identified; such as 1882 patients were coded as essential hypertensionFigure 3shows graphing of blood pressure trends
September 20, 2016
Data Science Resources
 We are in the process of launching a supplement to the sixth edition of our textbook that will have new chapters on Introduction to Data Science, International Informatics and Clinical Decision Support. We thought it might be worthwhile to post the data science resources we uncovered in our research.Datasets:University of California, Irvine (UCI) Repository: 325 validated datasets covering many domains, different sizes and data types and different analytical methods. These data sets are commonly used for machine learning exercises. 1KDNuggets: under data sets tab they include 71 data sets available for free download, from various industries. 2The Datahub: Managed by the Open Knowledge Foundation, this site hosts more than 10,000 datasets from a variety of international contributors covering most industries. 3Kaggle: provides free, interesting datasets for various user interests, analysis. Datasets updated frequently. Examples of downloadable data include horse racing, basketball, and current trends, as well as health care emergency calls data. These datasets offer the introductory and advance user an opportunity to explore data science.4Healthcare data:HealthData.gov: can search by data category and format (.csv, .xls, zip, PDF, rdf, JSON, html, txt and API. 5Centers for Disease Control and Prevention: public use files (PUFs) from surveys from multiple branches and agencies within the government. 6Expert Health Data Programming: hosts the links to about 45 large data sets. 7Health Services Research Information Central: extensive health datasets, statistics, international data and data tools 8Vanderbilt Biostatistics Datasets. Multiple health related data sets are available to download as Excel, ASCII, R and S-Plus files. Also includes links to international data sets.9MIMIC III Critical Care database is a repository of more than 40,000 de-identified critical care patient-level data. 10CMS Data Navigator. Expedites the search for Medicare and Medicaid data. 11Free online statistics resources:Data science textbooks: An Introduction to Statistical Learning with Applications in R. 12The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd edition. 13Stat Trek. Online tutorials guide students through the introductory steps of statistics. There are brief quizzes and calculators to add interest and functionality 14Biostatistics. Open Learning Textbook. University of Florida.15OnlineStatBook. Excellent Introductory free online reference. The work was done primarily by David Lane from Rice University. There is also a free e-book for Mac or iOS devices “Introduction to Statistics: An Interactive e-Book. 16OpenIntro. Three free PDF download books. One book is associated with about 100 free datasets. 17Statistics How To. There is an online textbook as well as a companion e-book for sale. The web site includes calculators and stats tables.18Kaggle: There are forums for those just getting started in data science, as well as information about public data sets. Kaggle also provides job forums for those interested in careers in the data science field. If interested in learning how to run code, there is also an option to receive community feedback on your work. In addition, Kaggle hosts data science competitions for both health and non-health care data. Prizes/rewards are offered for meeting these challenges and getting the best prediction.4StatPages. A mega-site for essentially any free online statistical calculator you can think of.19Free online data science resourcesSchool of Data: Online course covers data fundamentals, data cleaning, exploring data, extracting data, mapping data and others.20Class Central: offers multiple free data science and big data-related courses 21Data Science Academy: aggregates courses from multiple universities 22Udacity: includes data science courses at beginner through advanced levels 23Oregon Health and Science University Free Healthcare Data Analytics Course. 24IBM Big Data University: offers multiple free courses related to data science and big data analytics for beginners and intermediate level learners 25Spreadsheet tutorialsUniversity of California at Berkeley. 26Google spreadsheets. 27R language tutorialsTutorials Point 28R Tutorial by Kelly Black 29Python language tutorialsThe Python Tutorial 30Tutorials Point 31SQL tutorialsSQLZoo 32Tutorials Point 33Web data extraction toolsImport .io 34Google Chrome extension scraper 35Geo-coding toolsGeonames 36QGIS (desktop GIS) 37Data science journalsData Mining and Knowledge Discovery. Six issues published by Springer each year. Available as open access and non-open access articles 38Data Science Journal. Peer-reviewed open-access journal 39Journal of Data Science. Publishes international research articles on data science. Online access is free 40KD Nuggets data science-related content 2TutorialsToolsAnalytical softwarePollsWebcastsReferences:UCI Machine Learning Repository.https://archive.ics.uci.edu/ml/datasets.htmlKD Nuggets.www.kdnuggets.comDataHubhttps://datahub.io/dataset Kaggle.www.kaggle.comHealthData. Gov.http://www.healthdata.gov/content/aboutCenters for Disease Control and Prevention. Public Use Data Files.http://www.cdc.gov/nchs/data_access/ftp_data.htmExpert Health Data Programming.http://www.ehdp.com/vitalnet/datasets.htm HSRIC.https://www.nlm.nih.gov/hsrinfo/datasites.html#488InternationalVanderbilt Biostatistics Datasets.http://biostat.mc.vanderbilt.edu/wiki/Main/DataSetsMIMIC Critical Care Database.https://mimic.physionet.orgCMS Data Navigatorhttps://dnav.cms.gov/Default.aspx An Introduction to Statistical Learning with Applications in R. Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani, Free download:http://www-bcf.usc.edu/~gareth/ISL/The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd edition. Hastie T, Tibshirani R, and Friedman J., Springer Series in Statistics 2009. ISBN 978-0-387-84858-7.http://www-stat.stanford.edu/~tibs/ElemStatLearn/Stat Trek.http://stattrek.com/tutorials/free-online-courses.aspx Biostatistics. University of Florida.http://bolt.mph.ufl.eduOnlineStatBook.http://onlinestatbook.com/2/index.htmland iTunes.apple.comOpenIntro Textbooks.www.OpenIntro.org Statistics How To.www.statisticshowto.comStat Pages.http://statpages.info/ School of Data.http://schoolofdata.org/courses/Class Centralhttps://www.class-central.com/subject/data-science Data Science Academyhttp://datascienceacademy.com/free-data-science-courses/ Udacityhttps://www.udacity.com/courses/data-science Oregon Health and Science University Free Healthcare Data Analytics Course.www.informaticsprofessor.blogspot.com.IBM Big Data University.https://bigdatauniversity.comUniversity of California, Berkeley Spreadsheet tutorials.http://multimedia.journalism.berkeley.edu/tutorials/spreadsheets/ Google Spreadsheets.https://sites.google.com/a/g.risd.org/training/RISD-Video-Tutorials/google-spreadsheet-tutorials R Language. Tutorials Point.http://www.tutorialspoint.com/r/index.htm R Tutorial by Kelly Blackhttp://www.cyclismo.org/tutorial/R/ The Python Tutorialhttps://docs.python.org/2/tutorial/ Tutorials Point. Python.http://www.tutorialspoint.com/python/ SQL Zoo.http://sqlzoo.net/wiki/SQL_Tutorial Tutorials Point. SQL.http://www.tutorialspoint.com/sql/ Import. Io.https://www.import.io/Google Chrome Extension Scraper.https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd?hl=enGeonames.QGIS.http://qgis.org/en/site/about/index.html Data Mining and Knowledge Discovery.http://www.springer.com/computer/database+management+%26+information+retrieval/journal/10618 Data Science Journal.http://datascience.codata.org/ Journal of Data Science.http://www.jds-online.com/
We are in the process of launching a supplement to the sixth edition of our textbook that will have new chapters on Introduction to Data Science, International Informatics and Clinical Decision Support. We thought it might be worthwhile to post the data science resources we uncovered in our research.Datasets:University of California, Irvine (UCI) Repository: 325 validated datasets covering many domains, different sizes and data types and different analytical methods. These data sets are commonly used for machine learning exercises. 1KDNuggets: under data sets tab they include 71 data sets available for free download, from various industries. 2The Datahub: Managed by the Open Knowledge Foundation, this site hosts more than 10,000 datasets from a variety of international contributors covering most industries. 3Kaggle: provides free, interesting datasets for various user interests, analysis. Datasets updated frequently. Examples of downloadable data include horse racing, basketball, and current trends, as well as health care emergency calls data. These datasets offer the introductory and advance user an opportunity to explore data science.4Healthcare data:HealthData.gov: can search by data category and format (.csv, .xls, zip, PDF, rdf, JSON, html, txt and API. 5Centers for Disease Control and Prevention: public use files (PUFs) from surveys from multiple branches and agencies within the government. 6Expert Health Data Programming: hosts the links to about 45 large data sets. 7Health Services Research Information Central: extensive health datasets, statistics, international data and data tools 8Vanderbilt Biostatistics Datasets. Multiple health related data sets are available to download as Excel, ASCII, R and S-Plus files. Also includes links to international data sets.9MIMIC III Critical Care database is a repository of more than 40,000 de-identified critical care patient-level data. 10CMS Data Navigator. Expedites the search for Medicare and Medicaid data. 11Free online statistics resources:Data science textbooks: An Introduction to Statistical Learning with Applications in R. 12The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd edition. 13Stat Trek. Online tutorials guide students through the introductory steps of statistics. There are brief quizzes and calculators to add interest and functionality 14Biostatistics. Open Learning Textbook. University of Florida.15OnlineStatBook. Excellent Introductory free online reference. The work was done primarily by David Lane from Rice University. There is also a free e-book for Mac or iOS devices “Introduction to Statistics: An Interactive e-Book. 16OpenIntro. Three free PDF download books. One book is associated with about 100 free datasets. 17Statistics How To. There is an online textbook as well as a companion e-book for sale. The web site includes calculators and stats tables.18Kaggle: There are forums for those just getting started in data science, as well as information about public data sets. Kaggle also provides job forums for those interested in careers in the data science field. If interested in learning how to run code, there is also an option to receive community feedback on your work. In addition, Kaggle hosts data science competitions for both health and non-health care data. Prizes/rewards are offered for meeting these challenges and getting the best prediction.4StatPages. A mega-site for essentially any free online statistical calculator you can think of.19Free online data science resourcesSchool of Data: Online course covers data fundamentals, data cleaning, exploring data, extracting data, mapping data and others.20Class Central: offers multiple free data science and big data-related courses 21Data Science Academy: aggregates courses from multiple universities 22Udacity: includes data science courses at beginner through advanced levels 23Oregon Health and Science University Free Healthcare Data Analytics Course. 24IBM Big Data University: offers multiple free courses related to data science and big data analytics for beginners and intermediate level learners 25Spreadsheet tutorialsUniversity of California at Berkeley. 26Google spreadsheets. 27R language tutorialsTutorials Point 28R Tutorial by Kelly Black 29Python language tutorialsThe Python Tutorial 30Tutorials Point 31SQL tutorialsSQLZoo 32Tutorials Point 33Web data extraction toolsImport .io 34Google Chrome extension scraper 35Geo-coding toolsGeonames 36QGIS (desktop GIS) 37Data science journalsData Mining and Knowledge Discovery. Six issues published by Springer each year. Available as open access and non-open access articles 38Data Science Journal. Peer-reviewed open-access journal 39Journal of Data Science. Publishes international research articles on data science. Online access is free 40KD Nuggets data science-related content 2TutorialsToolsAnalytical softwarePollsWebcastsReferences:UCI Machine Learning Repository.https://archive.ics.uci.edu/ml/datasets.htmlKD Nuggets.www.kdnuggets.comDataHubhttps://datahub.io/dataset Kaggle.www.kaggle.comHealthData. Gov.http://www.healthdata.gov/content/aboutCenters for Disease Control and Prevention. Public Use Data Files.http://www.cdc.gov/nchs/data_access/ftp_data.htmExpert Health Data Programming.http://www.ehdp.com/vitalnet/datasets.htm HSRIC.https://www.nlm.nih.gov/hsrinfo/datasites.html#488InternationalVanderbilt Biostatistics Datasets.http://biostat.mc.vanderbilt.edu/wiki/Main/DataSetsMIMIC Critical Care Database.https://mimic.physionet.orgCMS Data Navigatorhttps://dnav.cms.gov/Default.aspx An Introduction to Statistical Learning with Applications in R. Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani, Free download:http://www-bcf.usc.edu/~gareth/ISL/The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd edition. Hastie T, Tibshirani R, and Friedman J., Springer Series in Statistics 2009. ISBN 978-0-387-84858-7.http://www-stat.stanford.edu/~tibs/ElemStatLearn/Stat Trek.http://stattrek.com/tutorials/free-online-courses.aspx Biostatistics. University of Florida.http://bolt.mph.ufl.eduOnlineStatBook.http://onlinestatbook.com/2/index.htmland iTunes.apple.comOpenIntro Textbooks.www.OpenIntro.org Statistics How To.www.statisticshowto.comStat Pages.http://statpages.info/ School of Data.http://schoolofdata.org/courses/Class Centralhttps://www.class-central.com/subject/data-science Data Science Academyhttp://datascienceacademy.com/free-data-science-courses/ Udacityhttps://www.udacity.com/courses/data-science Oregon Health and Science University Free Healthcare Data Analytics Course.www.informaticsprofessor.blogspot.com.IBM Big Data University.https://bigdatauniversity.comUniversity of California, Berkeley Spreadsheet tutorials.http://multimedia.journalism.berkeley.edu/tutorials/spreadsheets/ Google Spreadsheets.https://sites.google.com/a/g.risd.org/training/RISD-Video-Tutorials/google-spreadsheet-tutorials R Language. Tutorials Point.http://www.tutorialspoint.com/r/index.htm R Tutorial by Kelly Blackhttp://www.cyclismo.org/tutorial/R/ The Python Tutorialhttps://docs.python.org/2/tutorial/ Tutorials Point. Python.http://www.tutorialspoint.com/python/ SQL Zoo.http://sqlzoo.net/wiki/SQL_Tutorial Tutorials Point. SQL.http://www.tutorialspoint.com/sql/ Import. Io.https://www.import.io/Google Chrome Extension Scraper.https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd?hl=enGeonames.QGIS.http://qgis.org/en/site/about/index.html Data Mining and Knowledge Discovery.http://www.springer.com/computer/database+management+%26+information+retrieval/journal/10618 Data Science Journal.http://datascience.codata.org/ Journal of Data Science.http://www.jds-online.com/
September 2, 2016
IBM Watson Analytics Academic Program
Bob Hoyt MDDirector, Health Informatics ProgramUniversity of West FloridaDallas Snider PhDAssistant Professor of Computer ScienceUniversity of West FloridaMost people are familiar with the story about IBM Watson's victory playing Jeopardy in 2011, but may not be aware that there are different versions. Watson Health Cloud is an open source cloud-based cognitive computing platform that is well positioned for “big data” analytics; further enhanced by the acquisition of the analytics vendors Explorys and Phytel in 2015. [1] They have also partnered with Apple, Johnson & Johnson and Medtronic, to analyze burgeoning data generated by personal fitness and implantable devices. With this approach, data available in Apple HealthKit and ResearchKit can be mined. [2]Other versions of IBM Watson include Watson Discovery Advisor (hypotheses explorer); Watson Engagement Advisor (end-user interactions); Watson for Wealth Management (financial advice) and Watson for Oncology (cancer treatment recommendations). [3]The most recent addition to this suite of Watson tools is IBM Watson Analytics (IWA), which was released in late 2014 as a free personal version. [4] In May 2015 Watson Analytics Professional was launched. [5] This cloud-based program has four basic sections, Explore (descriptive), Predict (analytic), Assemble (data visualization) and Refine (data preparation). We began with evaluating the fremium version that accepts .csv and Microsoft Excel files from your computer or common data repositories such as DropBox. The user can also upload Twitter feeds from their web site that can be analyzed.We created an Excel spreadsheet based on the 2015 County Health Rankings for the state of Florida. [6] After pre-processing the data we retained the following standard health measures, (% obese, % physically inactive, % smokers, % excessive drinking, teen birth rate, % uninsured, graduation rate, % some college, % unemployed, % single parent households, % days feeling fair-poor, physically unhealthy days and mentally unhealthy days). The rows consisted of data from the 67 Florida counties. The first step in the Watson Analytics process is to upload and save the file for analysis. The user will receive a data quality score on the dataset. Our data score was 91, which was excellent, but the software pointed out several potential outliers and one skewed distribution.When the data was first analyzed using “Explore”, Watson Analytics automatically generated 10 questions based on the data, such as “What is the breakdown of % obese by county”. In seconds, a map of all Florida counties was generated with % obese noted for each county (figure 1).Figure 1 % Obese by County Using natural language processing, a user can enter other questions in a search window. We entered “what is the relationship between % physically inactive and % obese and a graph was automatically generated (figure 2). Mouse over any data point and the county is identified with the raw data. The user can filter the data and augment it with calculations, data groups and hierarchies. In addition to the map view, data can be represented in tree, grid, area, bar, bubble, line, pie and categorical charts. With the free account, you can email the results and with the paid account you can save and share data via a link, image, PowerPoint or PDF. Results can be saved and pinned for future use.Figure 2. The relationship between % physically inactive and % obese by County
Using natural language processing, a user can enter other questions in a search window. We entered “what is the relationship between % physically inactive and % obese and a graph was automatically generated (figure 2). Mouse over any data point and the county is identified with the raw data. The user can filter the data and augment it with calculations, data groups and hierarchies. In addition to the map view, data can be represented in tree, grid, area, bar, bubble, line, pie and categorical charts. With the free account, you can email the results and with the paid account you can save and share data via a link, image, PowerPoint or PDF. Results can be saved and pinned for future use.Figure 2. The relationship between % physically inactive and % obese by County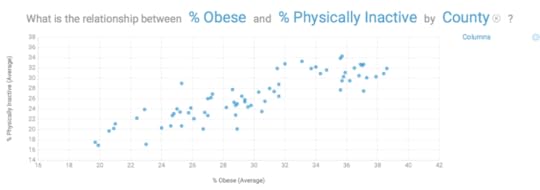 The next step was to upload the same dataset into “Predict”. We used % obese as the target and predictions automatically appeared. The top predictor was % physically inactive at 72% but the program interjected that the addition of “% uninsured” increased the predictive ability to 83%. At the top of the Predict window were 14 associations, automatically calculated by Watson Analytics. For example, there was a chart labeled “% obese and % fair-poor health are positively correlated”. Double click on the chart and the user can select the statistical details hyperlink and the results and the statistical methodology appears; e.g. (Pearson correlation, p Figure 3 Predict for factors related to % Obese
The next step was to upload the same dataset into “Predict”. We used % obese as the target and predictions automatically appeared. The top predictor was % physically inactive at 72% but the program interjected that the addition of “% uninsured” increased the predictive ability to 83%. At the top of the Predict window were 14 associations, automatically calculated by Watson Analytics. For example, there was a chart labeled “% obese and % fair-poor health are positively correlated”. Double click on the chart and the user can select the statistical details hyperlink and the results and the statistical methodology appears; e.g. (Pearson correlation, p Figure 3 Predict for factors related to % Obese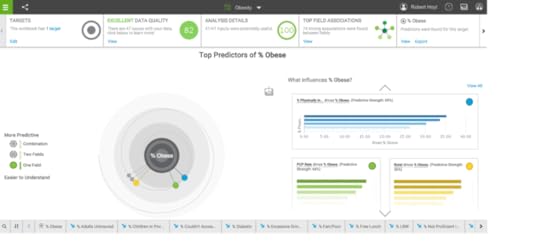 The third step is known as “Assemble” which provides the user with the opportunity to create dashboards and infographics by simply dragging and dropping data into the active panes. Again, multiple choices exist as to how the data can be represented/displayed. The display is actually interactive, in the sense when Counties is added with a scroll down list, changing the county changed all of the data displayed. (figure 4)Figure 4 Dashboard
The third step is known as “Assemble” which provides the user with the opportunity to create dashboards and infographics by simply dragging and dropping data into the active panes. Again, multiple choices exist as to how the data can be represented/displayed. The display is actually interactive, in the sense when Counties is added with a scroll down list, changing the county changed all of the data displayed. (figure 4)Figure 4 Dashboard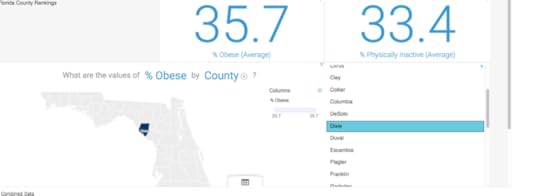 The four step is "Refine" where users can view and manipulate the raw data, as you would do in any spreadsheet.IBM Watson Analytics has a community page where problems can be shared and discussed, as well as useful hints posted. YouTube videos are available, as are webinars.The free version of Watson Analytics allows 1 user, 100,000 rows, 50 columns and 500MB of storage. The personal version is $30/month and permits 1 user, 1 million rows of data, 256 columns, 2 GB of storage and access to additional data. The professional version is $80/month and permits multiple users, 10 million rows, 500 columns, 100 GB of data storage, access to additional data (like Twitter feeds) and enhanced ability to share data sets.IBM offers the Professional version to universities free of charge for 12 months, if they plan to use Watson Analytics in their teaching programs. All faculty can access the program and up to 100 students can access the software. We are now in the process of evaluating Watson Analytics and comparing it with other data mining packages. The formalWatson academic program (WAP)launched in mid-July 2015.Where does IBM Watson Analytics fit in the overall scheme of data analytics/mining? It is probably too early to say for sure, but clearly IBM is attempting to make analytical tools available to a far wider audience than just data scientists. Traditionally, data scientists had to be mathematicians, statisticians, database experts and domain experts. According to Jeffrey Stanton there are 4 A’s of data: data architecture, data acquisition, data analysis and data archiving. [7] Watson Analytics provides a solution for the last three A’s. This platform is limited to Excel or .csv input and it does not perform clustering or unsupervised learning.In August 2015 IBM added more features: both the Personal and Professional versions support input from relational databases such as MS SQL Server and IBM DB2, as well as IBM Dash DB, IBM SQLDB for Bluemix, MySQL, IBM Cognos BI, .tsv and .sav files and cloud storage such as MS OneDrive, Box and DropBox. You will see these options when you select "Add" and then "upload data". You can upload sample data sets from the same Add area.Watson Analytic's approach is clearly streamlined, but their results must be validated by other approaches. It does provide a very rapid way to look at preliminary data for a variety of knowledge workers. If trends are detected, further exploration can be achieved with other statistical packages and consultation with data scientists.Dr. Hoyt plans to use Watson Analytics to teach his graduate students in Health Informatics more about data analytics and population health. He is unaware of another similar programs that will easily upload a data file, explore relationships, make predictions and create customizable data visualizations. It is his goal to create a healthcare data analytics course in the next year and use Watson Analytics as one of the analytical tools.Dr. Snider plans to have his computer science students manipulate visualizations of the associations and patterns in their data sets that are used in class projects. Furthermore, Watson Analytics' natural language processing will assist the students with comprehending the machine learning concepts discussed in the classroomReferences:1. Mearian L. IBM launches Watson Health global analytics cloud. ComputerWorld April 14 2015. Accessed May 24 2015.2. Campbell M. Apple partners with IBM Watson Health Cloud to bring secure cloud, data analytics to HealthKit and Research Kit. Apple Insider. April 13, 2015. Accessed May 23, 2015.3. Clements D, Myers M. Get the facts on IBM Watson Analytics. Ibmbigdatahub.com Accessed May 25, 2015.4. IBM Watson Analytics http://www.ibm.com/analytics/watson-a... Accessed May 20, 20155. Taft DK. IBM launches Watson Analytics Pro. eWeek. May 11, 2015. Accessed May 25, 20156. County Health Rankings http://www.countyhealthrankings.org/r... Accessed May 20, 20157. Stanton J. Introduction to Data Science. Rutgers University. 2012. https://ischool.syr.edu/media/documen... Accessed May 20, 2015
The four step is "Refine" where users can view and manipulate the raw data, as you would do in any spreadsheet.IBM Watson Analytics has a community page where problems can be shared and discussed, as well as useful hints posted. YouTube videos are available, as are webinars.The free version of Watson Analytics allows 1 user, 100,000 rows, 50 columns and 500MB of storage. The personal version is $30/month and permits 1 user, 1 million rows of data, 256 columns, 2 GB of storage and access to additional data. The professional version is $80/month and permits multiple users, 10 million rows, 500 columns, 100 GB of data storage, access to additional data (like Twitter feeds) and enhanced ability to share data sets.IBM offers the Professional version to universities free of charge for 12 months, if they plan to use Watson Analytics in their teaching programs. All faculty can access the program and up to 100 students can access the software. We are now in the process of evaluating Watson Analytics and comparing it with other data mining packages. The formalWatson academic program (WAP)launched in mid-July 2015.Where does IBM Watson Analytics fit in the overall scheme of data analytics/mining? It is probably too early to say for sure, but clearly IBM is attempting to make analytical tools available to a far wider audience than just data scientists. Traditionally, data scientists had to be mathematicians, statisticians, database experts and domain experts. According to Jeffrey Stanton there are 4 A’s of data: data architecture, data acquisition, data analysis and data archiving. [7] Watson Analytics provides a solution for the last three A’s. This platform is limited to Excel or .csv input and it does not perform clustering or unsupervised learning.In August 2015 IBM added more features: both the Personal and Professional versions support input from relational databases such as MS SQL Server and IBM DB2, as well as IBM Dash DB, IBM SQLDB for Bluemix, MySQL, IBM Cognos BI, .tsv and .sav files and cloud storage such as MS OneDrive, Box and DropBox. You will see these options when you select "Add" and then "upload data". You can upload sample data sets from the same Add area.Watson Analytic's approach is clearly streamlined, but their results must be validated by other approaches. It does provide a very rapid way to look at preliminary data for a variety of knowledge workers. If trends are detected, further exploration can be achieved with other statistical packages and consultation with data scientists.Dr. Hoyt plans to use Watson Analytics to teach his graduate students in Health Informatics more about data analytics and population health. He is unaware of another similar programs that will easily upload a data file, explore relationships, make predictions and create customizable data visualizations. It is his goal to create a healthcare data analytics course in the next year and use Watson Analytics as one of the analytical tools.Dr. Snider plans to have his computer science students manipulate visualizations of the associations and patterns in their data sets that are used in class projects. Furthermore, Watson Analytics' natural language processing will assist the students with comprehending the machine learning concepts discussed in the classroomReferences:1. Mearian L. IBM launches Watson Health global analytics cloud. ComputerWorld April 14 2015. Accessed May 24 2015.2. Campbell M. Apple partners with IBM Watson Health Cloud to bring secure cloud, data analytics to HealthKit and Research Kit. Apple Insider. April 13, 2015. Accessed May 23, 2015.3. Clements D, Myers M. Get the facts on IBM Watson Analytics. Ibmbigdatahub.com Accessed May 25, 2015.4. IBM Watson Analytics http://www.ibm.com/analytics/watson-a... Accessed May 20, 20155. Taft DK. IBM launches Watson Analytics Pro. eWeek. May 11, 2015. Accessed May 25, 20156. County Health Rankings http://www.countyhealthrankings.org/r... Accessed May 20, 20157. Stanton J. Introduction to Data Science. Rutgers University. 2012. https://ischool.syr.edu/media/documen... Accessed May 20, 2015
Using natural language processing, a user can enter other questions in a search window. We entered “what is the relationship between % physically inactive and % obese and a graph was automatically generated (figure 2). Mouse over any data point and the county is identified with the raw data. The user can filter the data and augment it with calculations, data groups and hierarchies. In addition to the map view, data can be represented in tree, grid, area, bar, bubble, line, pie and categorical charts. With the free account, you can email the results and with the paid account you can save and share data via a link, image, PowerPoint or PDF. Results can be saved and pinned for future use.Figure 2. The relationship between % physically inactive and % obese by CountyThe next step was to upload the same dataset into “Predict”. We used % obese as the target and predictions automatically appeared. The top predictor was % physically inactive at 72% but the program interjected that the addition of “% uninsured” increased the predictive ability to 83%. At the top of the Predict window were 14 associations, automatically calculated by Watson Analytics. For example, there was a chart labeled “% obese and % fair-poor health are positively correlated”. Double click on the chart and the user can select the statistical details hyperlink and the results and the statistical methodology appears; e.g. (Pearson correlation, p Figure 3 Predict for factors related to % ObeseThe third step is known as “Assemble” which provides the user with the opportunity to create dashboards and infographics by simply dragging and dropping data into the active panes. Again, multiple choices exist as to how the data can be represented/displayed. The display is actually interactive, in the sense when Counties is added with a scroll down list, changing the county changed all of the data displayed. (figure 4)Figure 4 DashboardThe four step is "Refine" where users can view and manipulate the raw data, as you would do in any spreadsheet.IBM Watson Analytics has a community page where problems can be shared and discussed, as well as useful hints posted. YouTube videos are available, as are webinars.The free version of Watson Analytics allows 1 user, 100,000 rows, 50 columns and 500MB of storage. The personal version is $30/month and permits 1 user, 1 million rows of data, 256 columns, 2 GB of storage and access to additional data. The professional version is $80/month and permits multiple users, 10 million rows, 500 columns, 100 GB of data storage, access to additional data (like Twitter feeds) and enhanced ability to share data sets.IBM offers the Professional version to universities free of charge for 12 months, if they plan to use Watson Analytics in their teaching programs. All faculty can access the program and up to 100 students can access the software. We are now in the process of evaluating Watson Analytics and comparing it with other data mining packages. The formalWatson academic program (WAP)launched in mid-July 2015.Where does IBM Watson Analytics fit in the overall scheme of data analytics/mining? It is probably too early to say for sure, but clearly IBM is attempting to make analytical tools available to a far wider audience than just data scientists. Traditionally, data scientists had to be mathematicians, statisticians, database experts and domain experts. According to Jeffrey Stanton there are 4 A’s of data: data architecture, data acquisition, data analysis and data archiving. [7] Watson Analytics provides a solution for the last three A’s. This platform is limited to Excel or .csv input and it does not perform clustering or unsupervised learning.In August 2015 IBM added more features: both the Personal and Professional versions support input from relational databases such as MS SQL Server and IBM DB2, as well as IBM Dash DB, IBM SQLDB for Bluemix, MySQL, IBM Cognos BI, .tsv and .sav files and cloud storage such as MS OneDrive, Box and DropBox. You will see these options when you select "Add" and then "upload data". You can upload sample data sets from the same Add area.Watson Analytic's approach is clearly streamlined, but their results must be validated by other approaches. It does provide a very rapid way to look at preliminary data for a variety of knowledge workers. If trends are detected, further exploration can be achieved with other statistical packages and consultation with data scientists.Dr. Hoyt plans to use Watson Analytics to teach his graduate students in Health Informatics more about data analytics and population health. He is unaware of another similar programs that will easily upload a data file, explore relationships, make predictions and create customizable data visualizations. It is his goal to create a healthcare data analytics course in the next year and use Watson Analytics as one of the analytical tools.Dr. Snider plans to have his computer science students manipulate visualizations of the associations and patterns in their data sets that are used in class projects. Furthermore, Watson Analytics' natural language processing will assist the students with comprehending the machine learning concepts discussed in the classroomReferences:1. Mearian L. IBM launches Watson Health global analytics cloud. ComputerWorld April 14 2015. Accessed May 24 2015.2. Campbell M. Apple partners with IBM Watson Health Cloud to bring secure cloud, data analytics to HealthKit and Research Kit. Apple Insider. April 13, 2015. Accessed May 23, 2015.3. Clements D, Myers M. Get the facts on IBM Watson Analytics. Ibmbigdatahub.com Accessed May 25, 2015.4. IBM Watson Analytics http://www.ibm.com/analytics/watson-a... Accessed May 20, 20155. Taft DK. IBM launches Watson Analytics Pro. eWeek. May 11, 2015. Accessed May 25, 20156. County Health Rankings http://www.countyhealthrankings.org/r... Accessed May 20, 20157. Stanton J. Introduction to Data Science. Rutgers University. 2012. https://ischool.syr.edu/media/documen... Accessed May 20, 2015
Machine Learning 101
The demand for data scientists is very clear in all industries, to include healthcare. While statistics has been the backbone of data analytics it is not the only approach to predictive modeling. Not only can a data scientist use the programming languages R and Python they can rely on machine learning (ML), traditionally the tool of computer scientists.The purpose of this blog is to point out that machine learning tools can now be in the domain of almost anyone. Users can choose from commercial products such as Microsoft SQL Server Analysis Services (SSAS) or IBM SPSS Modeler, but they can also opt to use free open-source applications. The following is a list of some of these open-source choices: RapidMiner, KNIME, Pentaho, Orange and WEKA. Many of these choices require dragging a widget (operator) onto a field and connecting the input with output, in order to perform a function. The exception to that is WEKA that was developed at the University of Waikato in New Zealand. Not only is their software widely used, it is complemented by a textbook, an online self paced course and multiple YouTube instructional videos.For those reasons I would like to focus on WEKA in this blog. The software is available for multiple operating systems and the installation is simple. The input must be either a .csv file or an .arff file. Under tools there is an .arff viewer that can view either file type and convert an .arff file to .csv, if needed. I commonly use a .csv file to run the data in both IBM Watson Analytics for the statistical approach and WEKA for the machine learning approach.Machine learning performs many functions, but the three most commonly used are classification, regression and clustering. Classification is used for predictions when the outcome is categorical data, such as lived or died (binary). Regression is used for scenarios where the outcome (or dependent variable) is continuous or numerical, such as healthcare cost in dollars. Clearly, one of the challenges here is the fact that computer scientists often use terms that are different from statisticians, but mean the same (column = features = attributes) (outcome = class = target = dependent variable). Once you can get by the terminology, the approach gets much simpler. WEKA comes with multiple sample data sets, the user can train on that are classic validated data sets. More data sets can be found on the UC Irvine Machine Learning Repository. Below is a screenshot of WEKA explorer (figure 1)Figure 1 If the user wants to try out classification, they must first upload the file (.csv or .arff) under the "preprocess" tab. There they can perform "exploratory data analysis or EDA" by viewing the rows (instances) and features (attributes). This will provide an idea if the data is normally distributed or skewed. There is also a filter option, where data can be "normalized" or "standardized" and then analyzed. This can be important if your attributes are on very different scales. (figure 2)Figure 2
If the user wants to try out classification, they must first upload the file (.csv or .arff) under the "preprocess" tab. There they can perform "exploratory data analysis or EDA" by viewing the rows (instances) and features (attributes). This will provide an idea if the data is normally distributed or skewed. There is also a filter option, where data can be "normalized" or "standardized" and then analyzed. This can be important if your attributes are on very different scales. (figure 2)Figure 2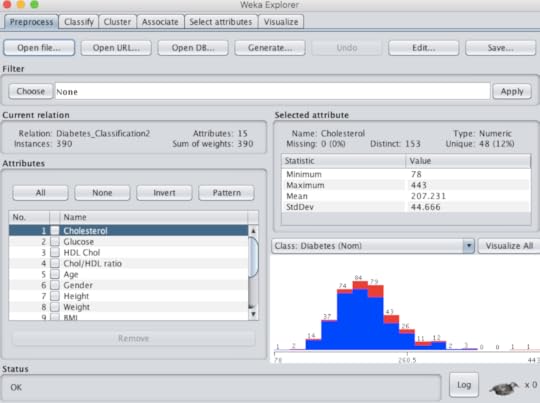 The "classify" tab is where the fun begins. Selecting the "Choose" option reveals an entire tree of algorithm choices. Those inappropriate for classification are greyed out. Unlike statistics, where normally one approach only is chosen, users routinely run several algorithms (like recipes) to see what approach or model provides the best results. For example, for most classification exercises I run a decision tree, Naive Bayes, logistic regression, K-nearest neighbor and support vector machine. Each run only takes one second or less. The results are very useful because it includes: classification accuracy, precision, recall (sensitivity), confusion matrix and area under the curve (AUC). Most healthcare workers are used to seeing results, in terms of sensitivity and specificity. If the results are similar they can be compared in another tab of WEKA called "experimenter" to determine if there is any statistical difference. Furthermore, there is another tab called "select attribute" where the user can determine which attributes really contribute to the outcome, as frequently only a few are really contribute to the outcome. Each algorithm can be further customized to see if the change affects the results. Below is the result of classification to determine what predicts type 2 diabetes in adults. We started with 14 predictors but ended with the best 4. (TP = true positive, FP = false positive) (table 1)Table 1
The "classify" tab is where the fun begins. Selecting the "Choose" option reveals an entire tree of algorithm choices. Those inappropriate for classification are greyed out. Unlike statistics, where normally one approach only is chosen, users routinely run several algorithms (like recipes) to see what approach or model provides the best results. For example, for most classification exercises I run a decision tree, Naive Bayes, logistic regression, K-nearest neighbor and support vector machine. Each run only takes one second or less. The results are very useful because it includes: classification accuracy, precision, recall (sensitivity), confusion matrix and area under the curve (AUC). Most healthcare workers are used to seeing results, in terms of sensitivity and specificity. If the results are similar they can be compared in another tab of WEKA called "experimenter" to determine if there is any statistical difference. Furthermore, there is another tab called "select attribute" where the user can determine which attributes really contribute to the outcome, as frequently only a few are really contribute to the outcome. Each algorithm can be further customized to see if the change affects the results. Below is the result of classification to determine what predicts type 2 diabetes in adults. We started with 14 predictors but ended with the best 4. (TP = true positive, FP = false positive) (table 1)Table 1 For regression, users select the "classify" tab and choose linear regression and for clustering they use the "cluster" tab. Clustering is unsupervised learning where you don't know the classes or attributes so you run clustering to see if there are groups hidden in the data that are worth further exploration. There is also a "select attributes" tab that determines which attributes are most important.I encourage healthcare workers in the data analytics realm to become familiar with WEKA or a similar program, as I believe they will find the programs useful and not that difficult to use.It is true that you must have some background information and most do not want to read an extensive textbook to gain this information. I highly recommend a 2016 ebook (248 page PDF) from Jason Brownlee that teaches basic machine learning and uses WEKA as the software application. It is written simply and clearly and doesn't involve coding or formulas! The cost is only $27 and is well worth it.
For regression, users select the "classify" tab and choose linear regression and for clustering they use the "cluster" tab. Clustering is unsupervised learning where you don't know the classes or attributes so you run clustering to see if there are groups hidden in the data that are worth further exploration. There is also a "select attributes" tab that determines which attributes are most important.I encourage healthcare workers in the data analytics realm to become familiar with WEKA or a similar program, as I believe they will find the programs useful and not that difficult to use.It is true that you must have some background information and most do not want to read an extensive textbook to gain this information. I highly recommend a 2016 ebook (248 page PDF) from Jason Brownlee that teaches basic machine learning and uses WEKA as the software application. It is written simply and clearly and doesn't involve coding or formulas! The cost is only $27 and is well worth it.
If the user wants to try out classification, they must first upload the file (.csv or .arff) under the "preprocess" tab. There they can perform "exploratory data analysis or EDA" by viewing the rows (instances) and features (attributes). This will provide an idea if the data is normally distributed or skewed. There is also a filter option, where data can be "normalized" or "standardized" and then analyzed. This can be important if your attributes are on very different scales. (figure 2)Figure 2The "classify" tab is where the fun begins. Selecting the "Choose" option reveals an entire tree of algorithm choices. Those inappropriate for classification are greyed out. Unlike statistics, where normally one approach only is chosen, users routinely run several algorithms (like recipes) to see what approach or model provides the best results. For example, for most classification exercises I run a decision tree, Naive Bayes, logistic regression, K-nearest neighbor and support vector machine. Each run only takes one second or less. The results are very useful because it includes: classification accuracy, precision, recall (sensitivity), confusion matrix and area under the curve (AUC). Most healthcare workers are used to seeing results, in terms of sensitivity and specificity. If the results are similar they can be compared in another tab of WEKA called "experimenter" to determine if there is any statistical difference. Furthermore, there is another tab called "select attribute" where the user can determine which attributes really contribute to the outcome, as frequently only a few are really contribute to the outcome. Each algorithm can be further customized to see if the change affects the results. Below is the result of classification to determine what predicts type 2 diabetes in adults. We started with 14 predictors but ended with the best 4. (TP = true positive, FP = false positive) (table 1)Table 1For regression, users select the "classify" tab and choose linear regression and for clustering they use the "cluster" tab. Clustering is unsupervised learning where you don't know the classes or attributes so you run clustering to see if there are groups hidden in the data that are worth further exploration. There is also a "select attributes" tab that determines which attributes are most important.I encourage healthcare workers in the data analytics realm to become familiar with WEKA or a similar program, as I believe they will find the programs useful and not that difficult to use.It is true that you must have some background information and most do not want to read an extensive textbook to gain this information. I highly recommend a 2016 ebook (248 page PDF) from Jason Brownlee that teaches basic machine learning and uses WEKA as the software application. It is written simply and clearly and doesn't involve coding or formulas! The cost is only $27 and is well worth it.


